The geometry and dimensionality of brain-wide activity
- School of Data Science, University of Science and Technology of China, China
- Division of Life Science, The Hong Kong University of Science and Technology, China
- Hefei National Laboratory for Physical Sciences at the Microscale, Center for Integrative Imaging, University of Science and Technology of China, China
- Division of Life Sciences and Medicine, University of Science and Technology of China, China
- Department of Precision Machinery and Precision Instrumentation, University of Science and Technology of China, China
- Department of Mathematics, The Hong Kong University of Science and Technology, China
eLife Assessment
This important study shows a surprising scale-invariance of the covariance spectrum of large-scale recordings in the zebrafish brain in vivo. A convincing analysis demonstrates that a Euclidean random matrix model of the covariance matrix recapitulates these properties. The results provide several new and insightful approaches for probing large-scale neural recordings.
https://doi.org/10.7554/eLife.100666.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Convincing: Appropriate and validated methodology in line with current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
Understanding neural activity organization is vital for deciphering brain function. By recording whole-brain calcium activity in larval zebrafish during hunting and spontaneous behaviors, we find that the shape of the neural activity space, described by the neural covariance spectrum, is scale-invariant: a smaller, randomly sampled cell assembly resembles the entire brain. This phenomenon can be explained by Euclidean Random Matrix theory, where neurons are reorganized from anatomical to functional positions based on their correlations. Three factors contribute to the observed scale invariance: slow neural correlation decay, higher functional space dimension, and neural activity heterogeneity. In addition to matching data from zebrafish and mice, our theory and analysis demonstrate how the geometry of neural activity space evolves with population sizes and sampling methods, thus revealing an organizing principle of brain-wide activity.
Introduction
Geometric analysis of neuronal population activity has revealed the fundamental structures of neural representations and brain dynamics (Churchland et al., 2012; Zhang et al., 2023; Kriegeskorte and Wei, 2021; Chung and Abbott, 2021). Dimensionality reduction methods, which identify collective or latent variables in neural populations, simplify our view of high-dimensional neural data (Cunningham and Yu, 2014).Their applications to optical and multi-electrode recordings have begun to reveal important mechanisms by which neural cell assemblies process sensory information (Stringer et al., 2019a; Si et al., 2019), make decisions (Mante et al., 2013; Yang et al., 2022), maintain working memory (Xie et al., 2022) and generate motor behaviors (Churchland et al., 2012; Nguyen et al., 2016; Lindén et al., 2022; Urai et al., 2022).
In the past decade, the number of neurons that can be simultaneously recorded in vivo has grown exponentially (Buzsáki, 2004; Ahrens et al., 2012; Jun et al., 2017; Stevenson and Kording, 2011; Nguyen et al., 2016; Sofroniew et al., 2016; Lin et al., 2022; Meshulam et al., 2019; Demas et al., 2021). This increase spans various brain regions (Musall et al., 2019; Stringer et al., 2019a; Jun et al., 2017) and the entire mammalian brain (Stringer et al., 2019b; Kleinfeld et al., 2019). As more neurons are recorded, the multidimensional neural activity space, with each axis representing a neuron’s activity level (Figure 1A), becomes more complex. The changing size of observed cell assemblies raises a number of basic questions. How does this space’s geometry evolve and what structures remain invariant with increasing number of neurons recorded?
Figure 1
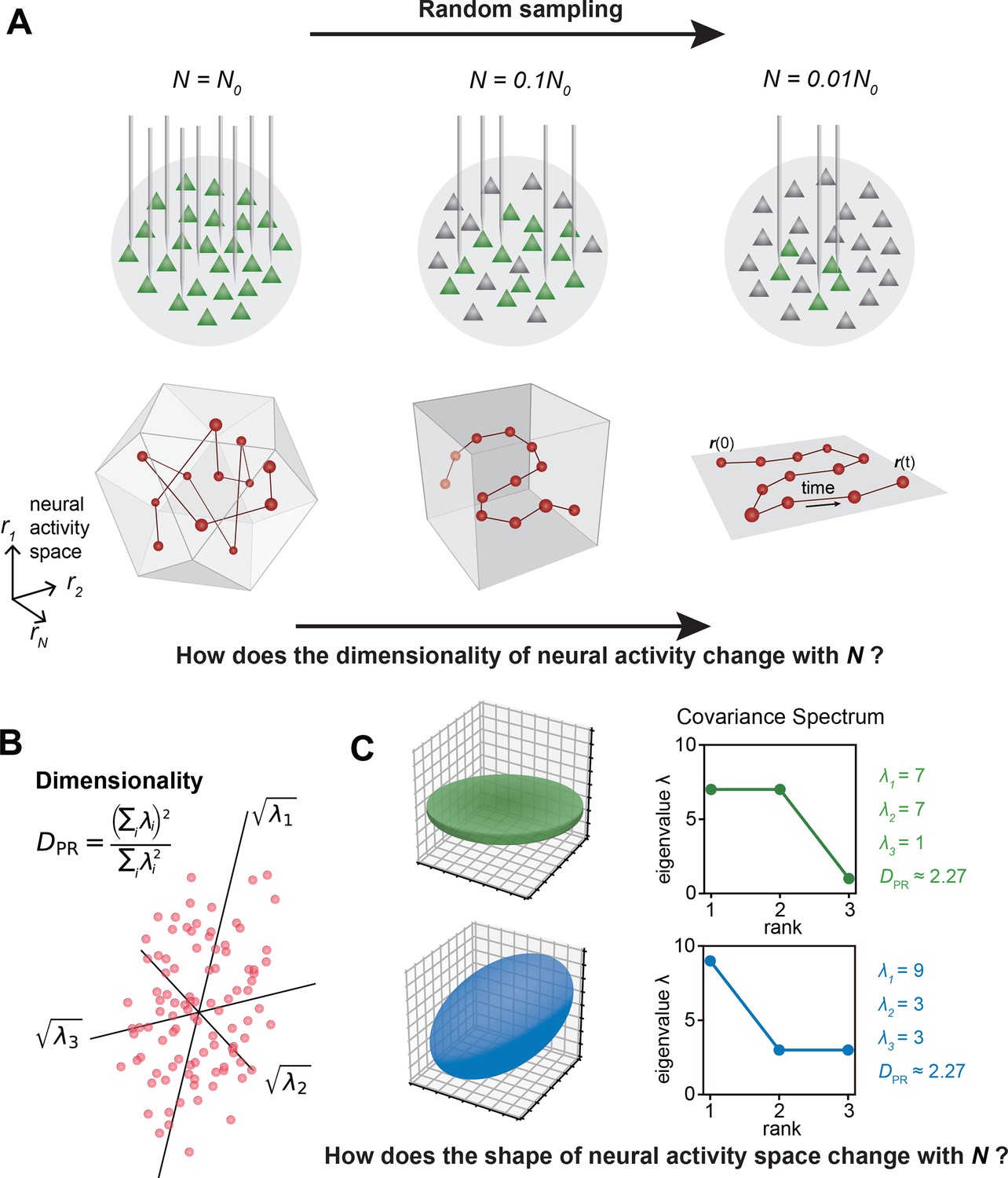
The relationship between the geometric properties of the neural activity space and the size of neural assemblies.
(A) Illustration of how dimensionality of neural activity () changes with the number of recorded neurons. (B) The eigenvalues of the neural covariance matrix dictate the geometrical configuration of the neural activity space with being the distribution width along a principal axis. (C) Examples of two neural populations with identical dimensionality () but different spatial configurations, as revealed by the eigenvalue spectrum (green: , blue: ).
A key measure, the effective dimension or participation ratio (denoted as , Figure 1B), captures a major part of variability in neural activity (Recanatesi et al., 2019; Litwin-Kumar et al., 2017; Gao et al., 2017 ; Clark et al., 2023; Dahmen et al., 2020). How does vary with the number of sampled neurons (Figure 1A)? Two scenarios are possible: grows continuously with more sampled neurons; saturates as the sample size increases. Which scenario fits the brain? Furthermore, even if two cell assemblies have the same , they can have different shapes (the geometric configuration of the neural activity space, as dictated by the eigenspectrum of the covariance matrix, Figure 1C). How does the shape vary with the number of neurons sampled? Lastly, are we going to observe the same picture of neural activity space when using different recording methods such as two-photon microscopy, which records all neurons in a brain region, versus Neuropixels (Jun et al., 2017), which conducts a broad random sampling of neurons?
Here, we aim to address these questions by analyzing brain-wide Ca2+ activity in larval zebrafish during hunting or spontaneous behavior (Figure 2A) recorded by Fourier light-field microscopy (Cong et al., 2017). The small size of this vertebrate brain, together with the volumetric imaging method, enables us to capture a significant amount of neural activity across the entire brain simultaneously. To characterize the geometry of neural activity beyond its dimensionality , we examine the eigenvalues or spectrum of neural covariance (Hu and Sompolinsky, 2022; Figure 1C). The covariance spectrum has been instrumental in offering mechanistic insights into neural circuit structure and function, such as the effective strength of local recurrent interactions and the depiction of network motifs (Hu and Sompolinsky, 2022; Morales et al., 2023; Dahmen et al., 2020). Intriguingly, we find that both the dimensionality and covariance spectrum remain invariant for cell assemblies that are randomly selected from various regions of the zebrafish brain. We also verify this observation in datasets recorded by different experimental methods, including light-sheet imaging of larval zebrafish (Chen et al., 2018), two-photon imaging of mouse visual cortex (Stringer et al., 2019b), and multi-area Neuropixels recording in the mouse (Stringer et al., 2019b). To explain the observed phenomenon, we model the covariance matrix of brain-wide activity by generalizing the Euclidean Random Matrix (ERM) (Mézard et al., 1999) such that neurons correspond to points distributed in a -dimensional functional or feature space, with pairwise correlation decaying with distance. The ERM theory, studied in theoretical physics (Mézard et al., 1999Goetschy and Skipetrov, 2013), provides extensive analytical tools for a deep understanding of the neural covariance matrix model, allowing us to unequivocally identify three crucial factors for the observed scale invariance.
Figure 2 with 4 supplements see all
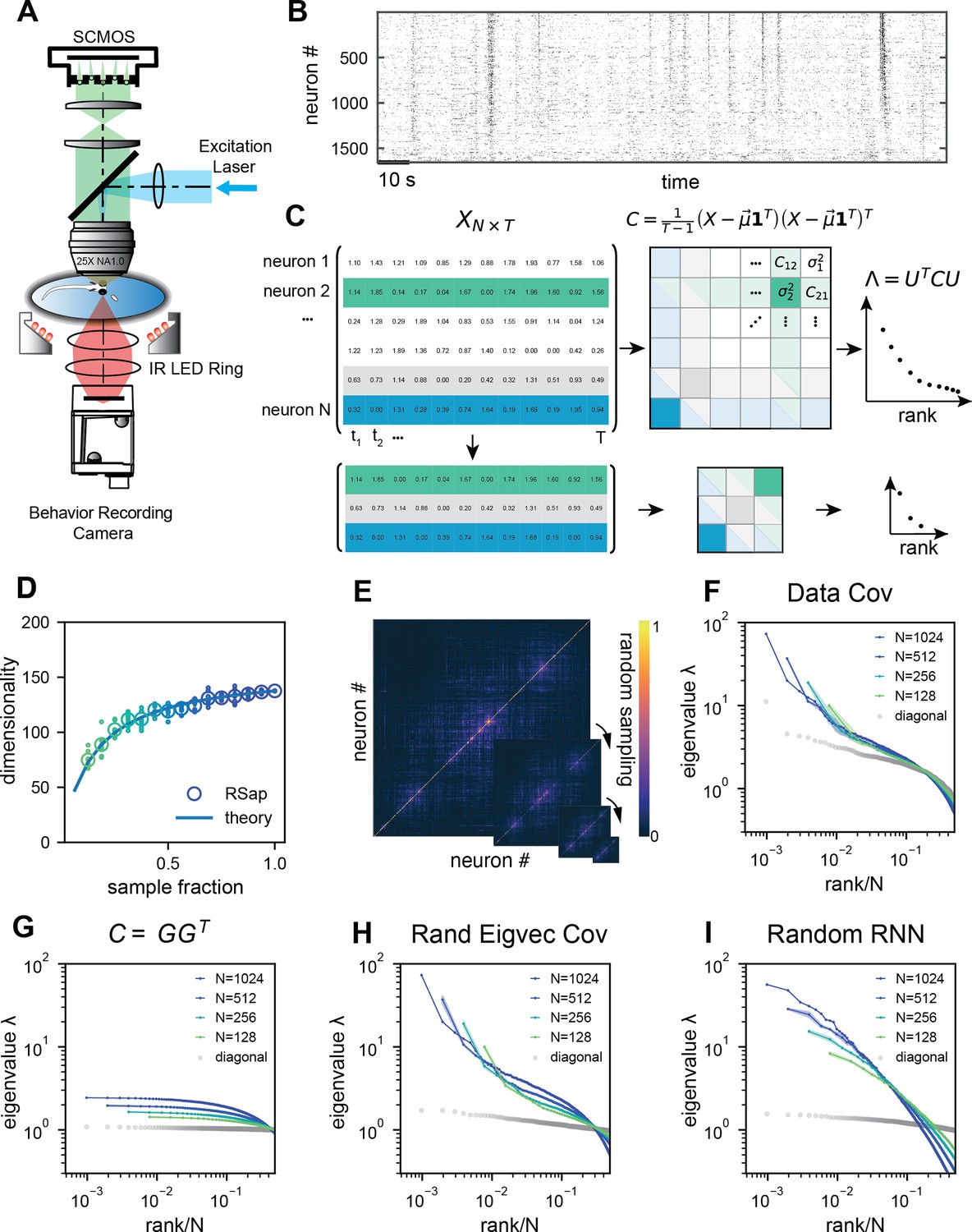
Whole-brain calcium imaging of zebrafish neural activity and the phenomenon of its scale-invariant covariance eigenspectrum.
(A) Rapid light-field Ca2+ imaging system for whole-brain neural activity in larval zebrafish. (B) Inferred firing rate activity from the brain-wide calcium imaging. The ROIs are sorted by their weights in the first principal component (Stringer et al., 2019b). (C) Procedure of calculating the covariance spectrum on the full and sampled neural activity matrices. (D) Dimensionality (circles, average across eight samplings (dots)), as a function of the sampling fraction. The curve is the predicted dimensionality using Equation 5. (E) Iteratively sampled covariance matrices. Neurons are sorted in each matrix to maximize values near the diagonal. (F) The covariance spectra, that is, eigenvalue versus rank/N, for randomly sampled neurons of different sizes (colors). The gray dots represent the sorted variances of all neurons. (G–I) Same as F but from three models of covariance (see details in Methods): (G) a Wishart random matrix calculated from a random activity matrix of the same size as the experimental data; (H) replacing the eigenvectors by a random orthogonal set; (I) covariance generated from a randomly connected recurrent network. The collapse index (CI), which quantifies the level of scale invariance in the eigenspectrum (see Methods), is: (G) CI = 0.214; (H) CI = 0.222; (I) CI = 0.139.
Building upon our theoretical results, we further explore the connection between the spatial arrangement of neurons and their locations in functional space, which allows us to distinguish among three sampling approaches: random sampling, anatomical sampling (akin to optical recording of all neurons within a specific region of the brain) and functional sampling (Meshulam et al., 2019). Our ERM theory makes distinct predictions regarding the scaling relationship between dimensionality and the size of cell assembly, as well as the shape of covariance eigenspectrum under various sampling methods. Taken together, our results offer a new perspective for interpreting brain-wide activity and unambiguously show its organizing principles, with unexplored consequences for neural computation.
Results
Geometry of neural activity across random cell assemblies in zebrafish brain
We recorded brain-wide Ca2+activity at a volume rate of 10 Hz in head-fixed larval zebrafish (Figure 2A) during hunting attempts (Methods) and spontaneous behavior using a Fourier light-field microscopy (Cong et al., 2017). Approximately 2000 ROIs (1977.3 ± 677.1, mean ± SD) with a diameter of 16.84 ± 8.51 µm were analyzed per fish based on voxel activity (Methods, Figure 2—figure supplement 1). These ROIs likely correspond to multiple nearby neurons with correlated activity. Henceforth, we refer to the ROIs as ‘neurons’ for simplicity.
We first investigate the dimensionality of neural activity (Figure 1B) in a randomly chosen cell assembly in zebrafish, similar to multi-area Neuropixels recording in a mammalian brain. We focus on how changes with a large sample size . We find that if the mean squared covariance remains finite instead of vanishing with , the dimensionality (Figure 1B) becomes sample size independent and depends only on the variance and the covariance between neurons and :
(1)
where denotes average across neurons (Methods and Dahmen et al., 2020). The finite mean squared covariance condition is supported by the observation that the neural activity covariance is positively biased and widely distributed with a long tail (Figure 2—figure supplement 2A). As predicted, the data dimensionality grows with sample size and reaches the maximum value specified by Equation 1 (Figure 2D).
Next, we investigate the shape of the neural activity space described by the eigenspectrum of the covariance matrix derived from the activity of randomly selected neurons (Figure 2C). When the eigenvalues are arranged in descending order and plotted against the normalized rank , where (we refer to it as the rank plot), this curve shows an approximate power law that spans 10 folds. Interestingly, as the size of the covariance matrices decreases ( decreases), the eigenspectrum curves nearly collapse over a wide range of eigenvalues. This pattern holds across diverse datasets and experimental techniques (Figure 2F, Figure 2—figure supplement 2E–L). The similarity of the covariance matrices of randomly sampled neural populations can be intuitively visualized (Figure 2E), after properly sorting the neurons (Methods).
The scale invariance in the neural covariance matrix – the collapse of the covariance eigenspectrum under random sampling – is non-trivial. The spectrum is not scale invariant in a common covariance matrix model based on independent noise (Figure 2G). It is absent when replacing the neural covariance matrix eigenvectors with random ones, keeping the eigenvalues identical (Figure 2H). A recurrent neural network with random connectivity (Hu and Sompolinsky, 2022) does not yield a scale-invariant covariance spectrum (Figure 2I). A recently developed latent variable model (Morrell et al., 2024; Appendix 1—figure 6), which is able to reproduce avalanche criticality, also fails to generate the scale-invariant covariance spectrum. Thus, a new model is needed for the covariance matrix of neural activity.
Modeling covariance by organizing neurons in functional space
Dimension reduction methods simplify and visualize complex neuron interactions by embedding them into a low-dimensional map, within which nearby neurons have similar activities. Inspired by these ideas, we use the ERM (Mézard et al., 1999) to model neural covariance. Imagine sprinkling neurons uniformly distributed on a -dimensional functional space of size (Figure 3A), where the distance between neurons and affects their correlation. Let represent the functional coordinate of the neuron . The distance-correlation dependency is described by kernel function with , indicating closer neurons have stronger correlations, and decreases as distance increases (Figure 3A and Methods). To model the covariance, we extend the ERM by incorporating heterogeneity of neuron activity levels (shown as the size of the neuron in the functional space in Figure 3A).
(2)
The variance of neural activity is drawn i.i.d. from a given distribution and is independent of neurons’ position.
Figure 3 with 2 supplements see all
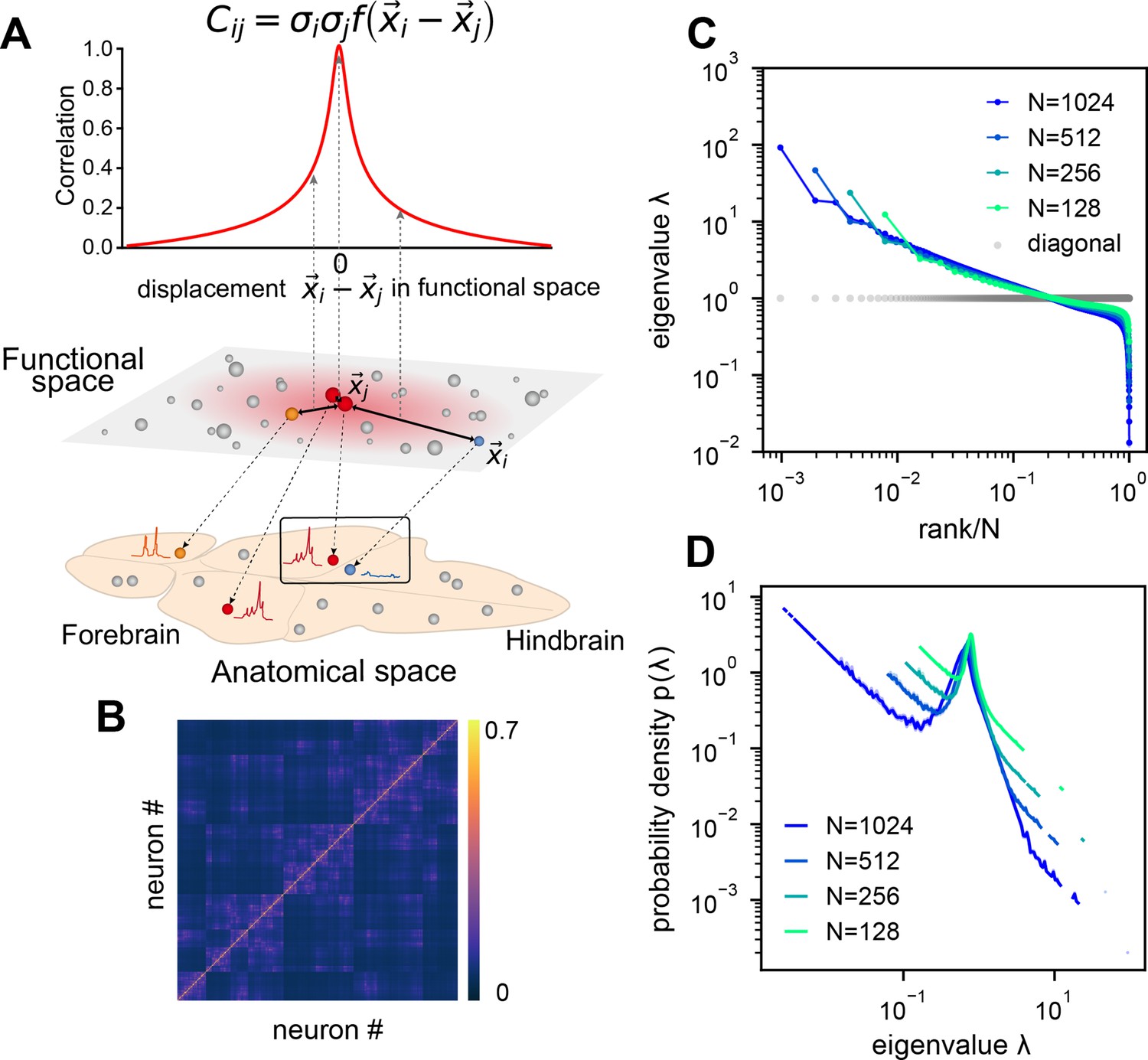
Euclidean Random Matrix (ERM) model of covariance and its eigenspectrum.
(A) Schematic of the ERM model, which reorganizes neurons (circles) from the anatomical space to the functional space (here is a two-dimensional box). The correlation between a pair of neurons decreases with their distance in the functional space according to a kernel function . This correlation is then scaled by neurons’ variance (circle size) to obtain the covariance . (B) An example ERM correlation matrix (i.e., when ). (C) Spectrum (same as Figure 2F) for the ERM correlation matrix in (B). The gray dots represent the sorted variances of all neurons (same as in Figure 2F). (D) Visualizing the distribution of the same ERM eigenvalues in C by plotting the probability density function (pdf).
This multidimensional functional space may represent attributes to which neurons are tuned, such as sensory features (e.g., visual orientation Hubel and Wiesel, 1959, auditory frequency) and movement characteristics (e.g., direction, speed Stefanini et al., 2020; Kropff et al., 2015). In sensory systems, it represents stimuli as neural activity patterns, with proximity indicating similarity in features. For motor control, it encodes movement parameters and trajectories. In the hippocampus, it represents the place field of a place cell, acting as a cognitive map of physical space (O’Keefe, 1976; Moser et al., 2008; Tingley and Buzsáki, 2018).
We first explore the ERM with various forms of and find that fast-decaying functions like Gaussian and exponential functions do not produce eigenspectra similar to the data and no scale invariance over random sampling (Figure 3—figure supplement 1A–H and Appendix 2). Thus, we turn to slow-decaying functions including the power law, which produce spectra similar to the data (Figure 3C, D; see also Figure 3—figure supplement 2). We adopt a particular kernel function because of its closed-form and analytical properties: (Methods). For large distance , it approximates a power law and smoothly transitions at small distance to satisfy the correlation requirement (Appendix 1—figure 3I, J).
Analytical theory on the conditions of scale invariance in ERM
To determine the conditions for scale invariance in ERM, we analytically calculate the eigenspectrum of covariance matrix (Equation 2) for large using the replica method (Mézard et al., 1999). A key order parameter emerging from this calculation is the neuron density . In the high-density regime , the covariance spectrum can be approximated in a closed form (Methods). For the slow-decaying kernel function defined above, the spectrum for large eigenvalues follows a power law (Appendix 2):
(3)
where r is the rank of the eigenvalues in descending order and is their probability density function. Equation 3 intuitively explains the scale invariance over random sampling. Sampling in the ERM reduces the neuron density ρ. The eigenspectrum is ρ-independent whenever . This indicates two factors contributing to the scale invariance of the eigenspectrum. First, a small exponent μ in the kernel function means that pairwise correlations slowly decay with functional distance and can be significantly positive across various functional modules and throughout the brain. For a given μ, an increase in dimension improves the scale invariance. The dimension could represent the number of independent features or latent variables describing neural activity or cognitive states.
We verify our theoretical predictions by comparing sampled eigenspectra in finite-size simulated ERMs across different and (Figure 4A). We first consider the case of homogeneous neurons ( in Equation 2, revisited later) in these simulations (Figures 3C, D, 4A), making ’s entries correlation coefficients. To quantitatively assess the level of scale invariance, we introduce a collapse index (CI, see Methods for a detailed definition). Motivated by Equation 3, the CI measures the shift of the eigenspectrum when the number of sampled neurons changes. The smaller CI values indicate higher scale invariance. Intuitively, it is defined as the area between spectrum curves from different sample sizes (Figure 4A, upper right). In the log–log scale rank plot, Equation 3 shows the spectrum shifts vertically with .
Figure 4 with 2 supplements see all
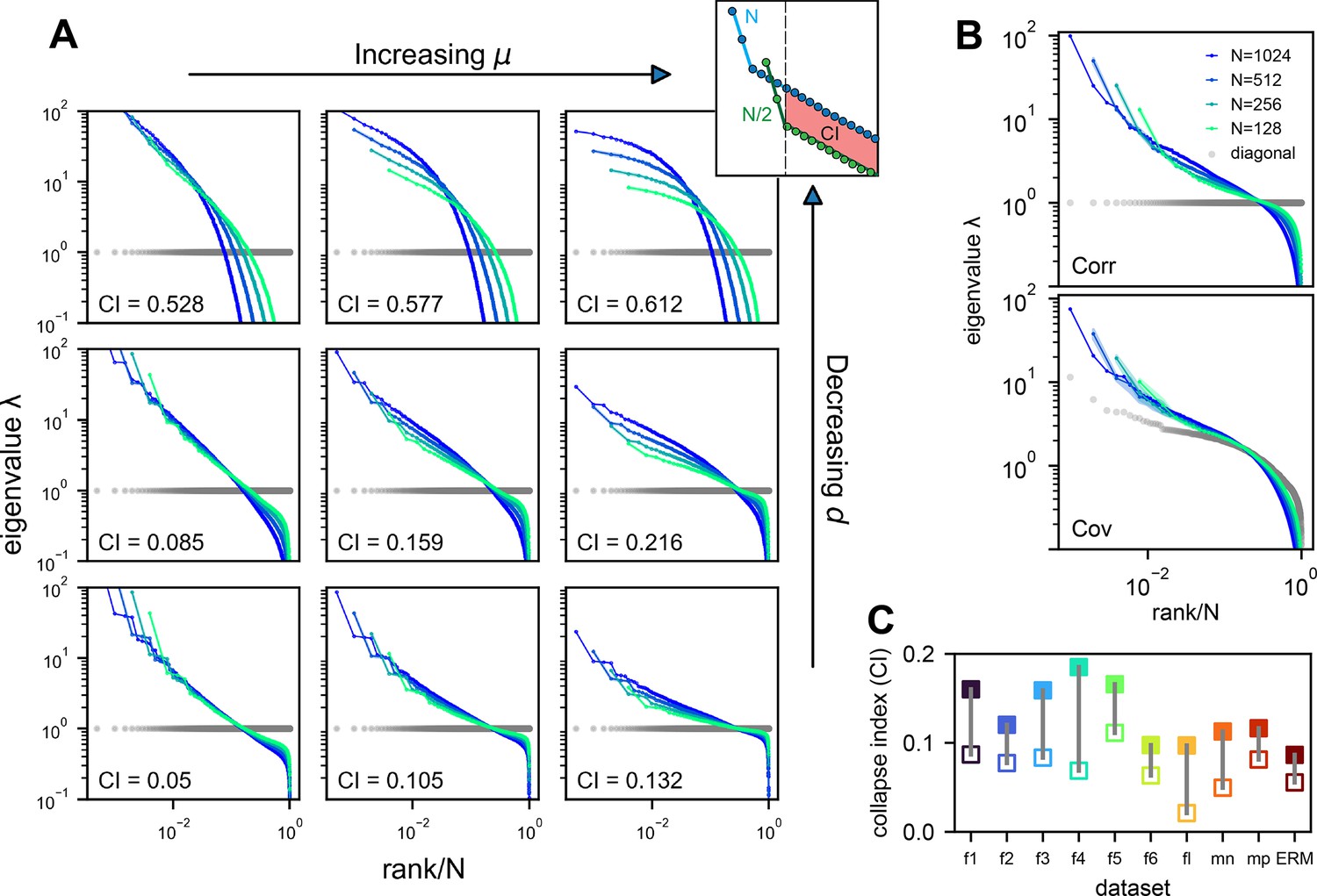
Three factors contributing to scale invariance.
(A) Impact of and (see text) on the scale invariance of Euclidean Random Matrix (ERM) spectrum (same plots as Figure 3C) with . The degree of scale invariance is quantified by the collapse index (CI), which essentially measures the area between different spectrum curves (upper right inset). For comparison, we fix the same coordinate range across panels hence some plots are cropped. The gray dots represent the sorted variances of all neurons (same as in Figure 2F). (B) Top: sampled correlation matrix spectrum in an example animal (fish 1). Bottom: same as top but for the covariance matrix that incorporates heterogeneous variances. The gray dots represent the sorted variances of all neurons (same as in Figure 2F). (C) The CI of the correlation matrix (filled squares) is found to be larger than that for the covariance matrix (opened squares) across different datasets: f1 to f6: six light-field zebrafish data (10 Hz per volume, this paper); fl: light-sheet zebrafish data (2 Hz per volume, Chen et al., 2018); mn: mouse Neuropixels data (downsampled to 10 Hz per volume); mp: mouse two-photon data (3 Hz per volume, Stringer et al., 2019b).
Thus, we define CI as this average displacement (Figure 4A, upper right, Methods), and a smaller CI means more scale invariant. Using CI, Figure 4A shows that scale invariance improves with slower correlation decay as decreases and the functional dimension increases. Conversely, with large and small , the covariance eigenspectrum varies significantly with scale (Figure 4A).
Next, we consider the general case of unequal neural activity levels and check for differences between the correlation (equivalent to ) and covariance matrix spectra. Using the collapsed index (CI), we compare the scale invariance of the two spectra in the experimental data. Intriguingly, the CI of the covariance matrix is consistently smaller (more scale-invariant) across all datasets (Figure 4C, Figure 4—figure supplement 2C, open vs. closed squares), indicating that the heterogeneity of neuronal activity variances significantly affects the eigenspectrum and the geometry of neural activity space (Tian et al., 2024). By extending our spectrum calculation to the intermediate density regime (Methods), we show that the ERM model can quantitatively explain the improved scale invariance in the covariance matrix compared to the correlation matrix (Figure 4—figure supplement 2B; Table 1).
Table 1
Table of notations.
| Notation | Description |
|---|---|
| Covariance matrix, Equation 2 | |
| Pairwise covariance between neuron i, j; entries of | |
| Participation ratio dimension, Equation 5 | |
| Anatomical sampling dimension, Equation 4 | |
| λ | Eigenvalue of a covariance matrix |
| Probability density function of covariance eigenvalues, Equation 8 | |
| r | Rank of an eigenvalue in descending order, Equation 3 |
| q | Fraction of eigenvalues up to λ and ; Equation 13 |
| Kernel function or distance-correlation function, Equation 11 | |
| Fourier transform of | |
| μ | Power-law exponent in , Equation 11 |
| ε | Resolution parameter in to smooth the singularity near 0, Equation 11 |
| Number of neurons | |
| The total number of neurons prior to sampling | |
| k | the fraction of sampled neurons |
| Linear box size of the functional space | |
| ρ | Density of neurons in the functional space, Equation 3 |
| Dimension of the functional space, Equation 3 | |
| Neural activity of neuron i at time t | |
| Temporal variance of neural activity, Equation 2 | |
| Cl | Collapse index for measuring scale invariance, Equation 13 |
| α | Power-law coefficient of eigenspectrum in the rank plot, see Discussion |
| Neuron i's coordinate in the functional and anatomical space, respectively | |
| The first canonical directions in the functional and anatomical space, respectively | |
| The first canonical correlation | |
| Correlation between anatomical and functional coordinates along ASap direction, Equation 4 |
Lastly, we examine factors that turn out to have minimal impact on the scale invariance of the covariance spectrum. First, the shape of the kernel function over a small distance (small distance means f(x) near x = 0 in the functional space, Appendix 1—figure 3) does not affect the distribution of large eigenvalues (Appendix 1—figure 3, Table 3, Appendix 1—figure 2, Appendix 1—figure 1A).
This supports our use of a specific to represent a class of slow-decaying kernels. Second, altering the spatial distribution of neurons in the functional space, whether using a Gaussian, uniform, or clustered distribution, does not affect large covariance eigenvalues, except possibly the leading ones (Appendix 1—figure 1B, Appendix 1). Third, different geometries of the functional space, such as a flat square, a sphere, or a hemisphere, result in eigenspectra similar to the original ERM model (Appendix 1—figure 1C). These findings indicate that our theory for the covariance spectrum’s scale invariance is robust to various modeling details.
Connection among random sampling, functional sampling, and anatomical sampling
So far, we have focused on random sampling of neurons, but how does the neural activity space change with different sampling methods? To this end, we consider three methods (Figure 5A1): random sampling (RSap), anatomical sampling (ASap) where neurons in a brain region are captured by optical imaging (Grewe and Helmchen, 2009; Gauthier and Tank, 2018; Stringer et al., 2019a), and functional sampling (FSap) where neurons are selected based on activity similarity (Meshulam et al., 2019). In ASap or FSap, sampling involves expanding regions of interest in anatomical space or functional space while measuring all neural activity within those regions (Appendix 1). The difference among sampling methods depends on the neuron organization throughout the brain. If anatomically localized neurons also cluster functionally (Figure 5A4), ASap ≈ FSap; if they are spread in the functional space (Figure 5A2), ASap ≈ RSap. Generally, the anatomical–functional relationship is in-between and can be quantified using the Canonical Correlation Analysis (CCA). This technique finds axes (CCA vectors and ) in anatomical and functional spaces such that the neurons’ projection along these axes has the maximum correlation, . The extreme scenarios described above correspond to and .
Figure 5 with 7 supplements see all
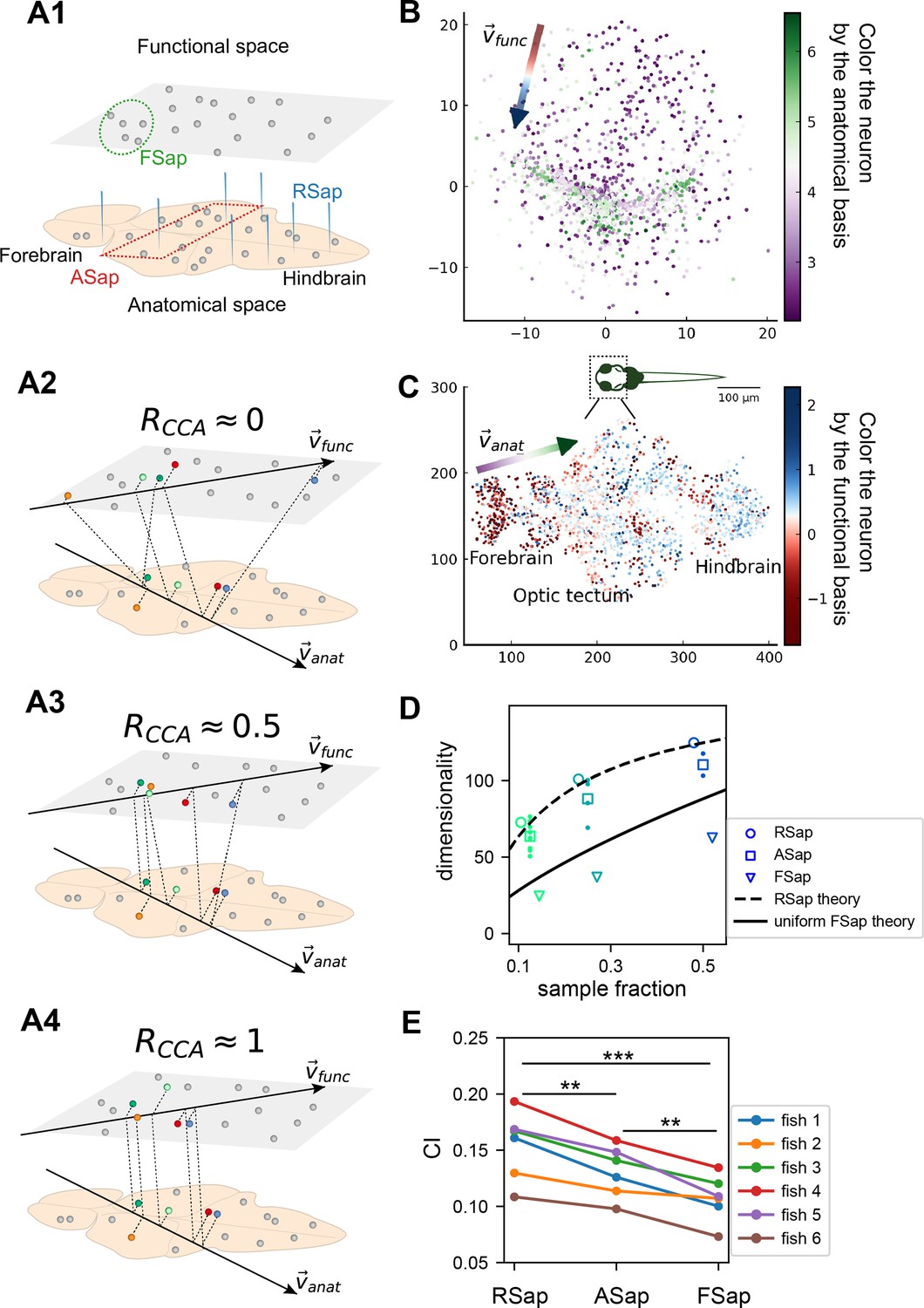
The relationship between the functional and anatomical space and theoretical predictions.
(A) Three sampling methods (A1) and (see text). When (A2), the anatomical sampling (ASap) resembles the random sampling (RSap), and while when (A4), ASap is similar to the functional sampling (FSap). (B) Distribution of neurons in the functional space inferred by MDS. Each neuron is color-coded by its projection along the first canonical direction in the anatomical space (see text). Data based on fish 6, same for (C-E). (C) Similar to (B) but plotting neurons in the anatomical space with color based on their projection along in the functional space (see text). (D) Dimensionality () across sampling methods: average under RSap (circles), average and individual brain region under ASap (squares and dots), and under FSap for the most correlated neuron cluster (triangles; Methods). Dashed and solid lines are theoretical predictions for under RSap and FSap, respectively (Methods). (E) The CI of correlation matrices under three sampling methods in six animals (colors). **p < 0.01; ***p < 0.001; one-sided paired t tests: RSap versus ASap, p = 0.0010; RSap versus FSap, p = 0.0004; ASap versus FSap, p = 0.0014.
To determine the anatomical–functional relationship in neural data, we infer the functional coordinates of each neuron by fitting the ERM using multidimensional scaling (MDS) (Cox and Cox, 2000) (Methods). For simplicity and better visualization, we use a low-dimensional functional space where . The fitted functional coordinates confirm the slow decay kernel function in ERM except for a small distance (Figure 5—figure supplement 3). The ERM with inferred coordinates also reproduces the experimental covariance matrix, including cluster structures (Figure 5—figure supplement 2) and its sampling eigenspectra (Figure 5—figure supplement 1).
Equipped with the functional and anatomical coordinates, we next use CCA to determine which scenarios illustrated in Figure 5A align better with the neural data. Figure 5B, C shows a representative fish with a significant (p-value = 0.0042, Anderson–Darling test). Notably, the CCA vector in the anatomical space, , aligns with the rostrocaudal axis. Coloring each neuron in the functional space by its projection along shows a correspondence between clustering and anatomical coordinates (Figure 5B). Similarly, coloring neurons in the anatomical space (Figure 5C) by their projection along reveals distinct localizations in regions like the forebrain and optic tectum. Across animals, functionally clustered neurons show anatomical segregation (Chen et al., 2018), with an average of 0.335 ± 0.054 (mean ± SD).
Next, we investigate the effects of different sampling methods (Figure 5A1) on the geometry of the neural activity space when there is a significant but moderate anatomical–functional correlation as in the experimental data. Interestingly, dimensionality in data under anatomical sampling consistently falls between random and functional sampling values (Figure 5D). This phenomenon can be intuitively explained by the ERM theory. Recall that for large , the key term in Equation 1 is . For a fixed number of sampled neurons, this average squared covariance is maximized when neurons are selected closely in the functional space (FSap) and minimized when distributed randomly (RSap). Thus, RSap and FSap set the upper and lower bounds of dimensionality, with ASap expected to fall in between. This reasoning can be precisely formulated to obtain quantitative predictions of the bounds (Methods). We predict the ASap dimension at large as
(4)
Here, is the dimensionality under RSap (Equation 1), represents the fraction of sampled neurons. is the correlation between anatomical and functional coordinates along the direction where the anatomical subregions are divided (Methods), and it is bounded by the canonical correlation . When , we get the upper bound (Figure 5D, dashed line). The lower bound is reached when (Figure 5A4), where Equation 4 shows a scaling relationship that depends on the sampling fraction (Figure 5D, solid line). This contrasts with the -independent dimensionality of RSap in Equation 1. Furthermore, if and its upper bound is not close to 1 (precisely for the ERM model in Figure 5D), align closer to the upper bound of RSap. This prediction agrees well with our observations in data across animals (Figure 5D, Figure 5—figure supplement 6, and Figure 5—figure supplement 7).
Beyond dimensionality, our theory predicts the difference in the covariance spectrum between sampling methods based on the neuronal density ρ in the functional space (Equation 3). This density ρ remains constant during FSap (Figure 5A1) and decreases under RSap; the average density across anatomical regions in ASap lies between those of FSap and RSap. Analogous to Equation 4, the relationship in ρ orders the spectra: ASap’s spectrum lies between those of FSap and RSap (Methods). This further implies that the level of scale invariance under ASap should fall between that of RSap and FSap, which is confirmed by our experimental data (Figure 5E).
Discussion
Impact of hunting behavior on scale invariance and functional space organization
How does task-related neural activity shape the covariance spectrum and brain-wide functional organization? We examine the hunting behavior in larval zebrafish, marked by eye convergence (both eyes move inward to focus on the central visual field) (Bianco et al., 2011). We find that scale invariance of the eigenspectra persists and is enhanced even after removing the hunting frames from the Ca2+ imaging data (Figure 4C, Appendix 1—figure 7A, B, Appendix 1). This is consistent with the scale-invariant spectrum found in other datasets during spontaneous behaviors (Figure 5—figure supplement 1F, Figure 2—figure supplement 2G, H), suggesting scale invariance is a general phenomenon.
Interestingly, in the inferred functional space, we observe reorganizations of neurons after removing hunting behavior (Appendix 1—figure 7C, D). Neurons in one cluster disperse from their center of mass (Appendix 1—figure 7D) and decreases the local neuronal density ρ (Appendix 1 and Appendix 1—figure 7E). The neurons in this dispersed cluster have a consistent anatomical distribution from the midbrain to the hindbrain in four out of five fish (Appendix 1—figure 9). During hunting, the cluster has robust activations that are widespread in the anatomical space but localized in the functional space (Appendix 1, Appendix 1—Video 1).
Our findings suggest that the functional space could be defined by latent variables that represent cognitive factors such as decision-making, memory, and attention. These variables set the space’s dimensions, with neural activity patterns reflecting cognitive state dynamics. Functionally related neurons – through sensory tuning, movement parameters, internal conditions, or cognitive factors – become closer in this space, leading to stronger activity correlations.
Criticality and power law
What drives brain dynamics with a slow-decaying distance–correlation function in functional space? Long-range connections and a slow decline in projection strength over distance (Kunst et al., 2019) may cause extensive correlations, enhancing global activity patterns. This behavior is also reminiscent of phase transitions in statistical mechanics (Kardar, 2007), where local interactions lead to expansive correlated behaviors. Studies suggest that critical brains optimize information processing (Beggs and Plenz, 2003; Dahmen et al., 2019). The link between neural correlation structures and neuronal connectivity topology is an exciting area for future exploration.
In the high-density regime of the ERM model, the rank plot (Equation 3) for large eigenvalues () follows a power law , with . The scale-invariant spectrum occurs when α is close to 1. Experimental data, however, align more closely with the model in the intermediate-density regime, where the power-law spectrum is an approximation and the decay is slower (for ERM model, Figure 4—figure supplement 1BC, and for data , mean ± SD, n =6 fish). Stringer et al., 2019a found an decay in the mouse visual cortex’s stimulus trial averaged covariance spectrum, and they argued that this decay optimizes visual code efficiency and smoothness. Our study differs in two fundamental ways. First, we recorded brain-wide activity during spontaneous or hunting behavior, calculating neural covariance from single-trial activity. Much of the neural activity was not driven by sensory stimulus and unrelated to specific tasks, requiring a different interpretation of the neural covariance spectrum. Second, without loss of generality, we normalized the mean variance of neural activity by scaling the covariance matrix so that its eigenvalues sum up to . This normalization imposes a constraint on the spectrum. In particular, large and small eigenvalues may have different behaviors and do not need to obey a single power law for all eigenvalues (Pospisil and Pillow, 2024) (Methods). Stringer et al., 2019a did not take this possibility into account, making their theory less applicable to our analysis.
We draw inspiration from the renormalization group (RG) approach to navigate neural covariance across scales, which has also been explored in the recent literature. Following Kadanoff’s block spin transformation (Kardar, 2007, Meshulam et al., 2019) formed size-dependent neuron clusters and their covariance matrices by iteratively pairing the most correlated neurons and placing them adjacent on a lattice. The groups expanded until the largest reached the system size. The RG process, akin to spatial sampling in functional space (FSap), maintains constant neuron density ρ. Thus, for any kernel function , including the power law and exponential, the covariance eigenspectrum remains invariant across scales (Appendix 1—figure 5A, B, D, E).
Morrell et al., 2024; Morrell et al., 2021 proposed a simple model in which a few time-varying latent factors impact the whole neural population. We evaluated if this model could account for the scale invariance seen in our data. Simulations showed that the resulting eigenspectra differed considerably from our findings (Appendix 1—figure 6). Although the Morrell model demonstrated a degree of scale invariance under functional sampling (or RG), it did not align with the scale-invariant features under random sampling, suggesting that this simple model might not capture all crucial features in our observations.
We emphasize that the covariance spectrum being a power law is distinct from the scale invariance we define in this study, namely the collapse of spectrum curves under random neuron sampling. The random RNN model in Figure 2I shows a power-law behavior, but lacks true scale invariance as spectrum curves for different sizes do not collapse. When connection strength approaches 1, the system exhibits a power-law spectrum of . Subsampling causes the spectrum to shift by , where is the sampling fraction (derived from Equation 24 in Hu and Sompolinsky, 2022).
Bounded dimensionality under random sampling
The saturation of the dimensionality at large sample sizes indicates a limit to neural assembly complexity, evidenced by the finite mean square covariance. This is in contrast with neural dynamics models such as the balanced excitatory–inhibitory (E–I) neural network (Renart et al., 2010), where resulting in an unbounded dimensionality (see Appendix 2). Our results suggest that the brain encodes experiences, sensations, and thoughts using a finite set of dimensions instead of an infinitely complex neural activity space.
We found that the relationship between dimensionality and the number of recorded neurons depends on the sampling method. For functional sampling, the dimensionality scales with the sampling fraction . This suggests that if anatomically sampled neurons are functionally clustered, as with cortical neurons forming functional maps, the increase in dimensionality with neuron number may seem unbounded. This offers new insights for interpreting large-scale neural activity data recorded under various techniques.
Manley et al., 2024 found that, unlike in our study, neural activity dimensionality in head-fixed, spontaneously behaving mice did not saturate. They used shared variance component analysis (SVCA) and noted that PCA-based estimates often show dimensionality saturation, which is consistent with our findings. We intentionally chose PCA in our study for several reasons. First, PCA is a trusted and widely used method in neuroscience, proven to uncover meaningful patterns in neural data. Second, its mathematical properties are well understood, making it particularly suitable for our theoretical analysis. Although newer methods such as SVCA might offer valuable insights, we believe PCA remains the most appropriate method for our research questions.
It is important to note that the scale invariance of dimensionality and covariance spectrum are distinct phenomena with different underlying requirements. Dimensionality invariance relies on finite mean square covariance, causing saturation at large sample sizes. In contrast, spectral invariance requires a slow-decaying correlation kernel (small ) and/or a high-dimensional functional space (large ). Although both features appear in our data, they result from distinct mechanisms. A neural system could show saturating dimensionality without spectral invariance if it has finite mean square covariance but rapidly decaying correlations with functional distance. Understanding these requirements clarifies how neural organization affects different scale-invariant properties.
Computational benefits of a scale-invariant covariance spectrum
Our findings are validated across multiple datasets obtained through various recording techniques and animal models, ranging from single-neuron calcium imaging in larval zebrafish to single-neuron multi-electrode recordings in the mouse brain (see Figure 2—figure supplement 2). The conclusion remains robust when the multi-electrode recording data are reanalyzed under different sampling rates (6–24 Hz, Figure 2—figure supplement 4). We also confirm that substituting a few negative covariances with zero retains the spectrum of the data covariance matrix (Figure 2—figure supplement 3 and Methods).
The scale invariance of neural activity across different neuron assembly sizes could support efficient multiscale information encoding and processing. This indicates that the neural code is robust and requires minimal adjustments despite changes in population size. One recent study shows that randomly sampled and coarse-grained macrovoxels can predict population neural activity (Hoffmann et al., 2023), reinforcing that a random neuron subset may capture overall activity patterns. This enables downstream circuits to readout and process information through random projections (Gao et al., 2017). A recent study demonstrates that a scale-invariant noise covariance spectrum with a specific slope enables neurons to convey unlimited stimulus information as the population size increases (Moosavi et al., 2024). The linear Fisher information, in this context, grows at least as .
Understanding how dimensionality and spectrum change with sample size also suggests the possibility of extrapolating from small samples to overcome experimental limitations. This is particularly feasible when , where the dimensionality and spectrum under anatomical, random, and functional sampling coincide (Equations 3 and 4). Developing extrapolation methods and exploring the benefits of scale-invariant neural code are promising future research directions.
Materials and methods
Key resources table
| Reagent type (species) or resource | Designation | Source or reference | Identifiers | Additional information |
|---|---|---|---|---|
| Strain, strain background (Danio rerio) | Tg(elavl3: H2B- GCaMP6f) | https://doi.org/10.7554/eLife.12741 | Jiu-Lin Du, Institute of Neuroscience, Chinese Academy of Sciences, Shanghai | |
| Software, algorithm | julia1.7 | https://julialang.org/ | ||
| Software, algorithm | MATLAB | https://ww2.mathworks.cn/ | ||
| Software, algorithm | Mathematica | https://www.wolfram.com/mathematica/ |
Experimental methods
The handling and care of the zebrafish complied with the guidelines and regulations of the Animal Resources Center of the University of Science and Technology of China (USTC). All larval zebrafish (huc:h2b -GCaMP6f Cong et al., 2017) were raised in E2 embryo medium (comprising 7.5 mM NaCl, 0.25 mM KCl, 0.5 mM MgSO4, 0.075 mM KH2PO4, 0.025 mM Na2HPO4, 0.5 mM CaCl2, and 0.35 mM NaHCO3; containing 0.5 mg/l methylene blue) at 28.5°C and with a 14-hr light and 10-hr dark cycle.
To induce hunting behavior (composed of motor sequences like eye convergence and J turn) in larval zebrafish, we fed them a large amount of paramecia over a period of 4–5 days post-fertilization (dpf). The animals were then subjected to a 24-hr starvation period, after which they were transferred to a specialized experimental chamber. The experimental chamber was 20 mm in diameter and 1 mm in depth, and the head of each zebrafish was immobilized by applying 2% low melting point agarose. The careful removal of the agarose from the eyes and tail of the fish ensured that these body regions remained free to move during hunting behavior. Thus, characteristic behavioral features such as J-turns and eye convergence could be observed and analyzed. Subsequently, the zebrafish were transferred to an incubator and stayed overnight. At 7 dpf, several paramecia were introduced in front of the previously immobilized animals, each of which was monitored by a stereomicroscope. Those displaying binocular convergence were selected for subsequent Ca2+ imaging experiments.
We developed a novel optomagnetic system that allows (1) precise control of the trajectory of the paramecium and (2) imaging brain-wide Ca2+ activity during the hunting behavior of zebrafish. To control the movement of the paramecium, we treated these microorganisms with a suspension of ferric tetroxide for 30 min and selected those that responded to its magnetic attraction. A magnetic paramecium was then placed in front of a selected larva, and its movement was controlled by changing the magnetic field generated by Helmholtz coils that were integrated into the imaging system. The real-time position of the paramecium, captured by an infrared camera, was identified by online image processing. The positional vector relative to a predetermined target position was calculated. The magnitude and direction of the current in the Helmholtz coils were adjusted accordingly, allowing for precise control of the magnetic field and hence the movement of the paramecium. Multiple target positions could be set to drive the paramecium back and forth between multiple locations.
The experimental setup consisted of head-fixed larval zebrafish undergoing two different types of behavior: induced hunting behavior by a moving paramecium in front of a fish (fish 1–5), and spontaneous behavior without any visual stimulus as a control (fish 6). Experiments were carried out at ambient temperature (ranging from 23 to 25°C). The behavior of the zebrafish was monitored by a high-speed infrared camera (Basler acA2000-165umNIR, 0.66×) behind a 4F optical system and recorded at 50 Hz. Brain-wide Ca2+ imaging was achieved using XLFM. Light-field images were acquired at 10 Hz, using customized LabVIEW software (National Instruments, USA) or Solis software (Oxford Instruments, UK), with the help of a high-speed data acquisition card (PCIe-6321, National Instruments, USA) to synchronize the fluorescence with behavioral imaging.
Behavior analysis
Request a detailed protocolThe background of each behavior video was removed using the clone stamp tool in Adobe Photoshop CS6. Individual images were then processed by an adaptive thresholding algorithm, and fish head and yolk were selected manually to determine the head orientation. The entire body centerline, extending from head to tail, was divided into 20 segments. The amplitude of a bending segment was defined as the angle between the segment and the head orientation. To identify the paramecium in a noisy environment, we subtracted a background image, averaged over a time window of 100 s, from all the frames. The major axis of the left or right eye was identified using DeepLabCut (Mathis et al., 2018). The eye orientation was defined as the angle between the rostrocaudal axis and the major axis of an eye. The convergence angle was defined as the angle between the major axes of the left and right eyes. An eye-convergence event was defined as a period of time where the angle between the long axis of the eyes stayed above 50° (Bianco et al., 2011).
Imaging data acquisition and processing
Request a detailed protocolWe used a fast eXtended light-field microscope (XLFM, with a volume rate of 10 Hz) to record Ca2+ activity throughout the brain of head-fixed larval zebrafish. Fish were ordered by the dates of experiments. As previously described (Cong et al., 2017), we adopted the Richardson–Lucy deconvolution method to iteratively reconstruct 3D fluorescence stacks (600 × 600 × 250) from the acquired 2D images (2048 × 2048). This algorithm requires an experimentally measured point spread function of the XLFM system. The entire recording for each fish is 15.3 ± 4.3 min (mean ± SD).
To perform image registration and segmentation, we first cropped and resized the original image stack to 400 × 308 × 210, which corresponded to the size of a standard zebrafish brain (zbb) atlas (Tabor et al., 2019). This step aimed to reduce substantial memory requirements and computational costs in subsequent operations. Next, we picked a typical volume frame and aligned it with the zbb atlas using a basic 3D affine transformation. This transformed frame was used as a template. We aligned each volume with the template using rigid 3D intensity-based registration (Studholme et al., 1997) and non-rigid pairwise registration (Rueckert et al., 1999) in the Computational Morphometry Toolkit (CMTK) (https://www.nitrc.org/projects/cmtk/). After voxel registration, we computed the pairwise correlation between nearby voxel intensities and performed the watershed algorithm on the correlation map to cluster and segment voxels into consistent ROIs across all volumes. We defined the diameter of each ROI using the maximum Feret diameter (the longest distance between any two voxels within a single ROI).
Finally, we adopted the ‘OASIS’ deconvolution method to denoise and infer neural activity from the fluorescence time sequence (Friedrich et al., 2017). The deconvolved of each ROI was used to infer firing rates for subsequent analysis.
Other experimental datasets analyzed
Request a detailed protocolTo validate our findings across different recording methods and animal models, we also analyzed three additional datasets (Table 2). We include a brief description below for completeness. Further details can be found in the respective reference. The first dataset includes whole-brain light-sheet Ca2+ imaging of immobilized larval zebrafish in the presence of visual stimuli as well as in a spontaneous state (Chen et al., 2018). Each volume of the brain was scanned through 2.11 ± 0.21 planes per second, providing a near-simultaneous readout of neuronal Ca2+ signals. We analyzed fish 8 (69,207 neurons × 7890 frames), 9 (79,704 neurons × 7720 frames), and 11 (101,729 neurons × 8528 frames), which are the first three fish data with more than 7200 frames. For simplicity, we labeled them l2, l3, and l1(fl). The second dataset consists of Neuropixels recordings from approximately ten different brain areas in mice during spontaneous behavior (Stringer et al., 2019b). Data from the three mice, Kerbs, Robbins, and Waksman, include the firing rate matrices of 1462 neurons × 39,053 frames, 2296 neurons × 66,409 frames, and 2688 neurons × 74,368 frames, respectively. The last dataset comprises two-photon Ca2+ imaging data (2–3 Hz) obtained from the visual cortex of mice during spontaneous behavior. While this dataset includes numerous animals, we focused on the first three animals that exhibited spontaneous behavior. While this dataset includes numerous animals, we focused on the first three animals that exhibited spontaneous behavior:spont_M150824_MP019_2016-04-05 (11,983 neurons × 21,055 frames), spont_M160825_MP027_2016-12-12 (11,624 neurons × 23,259 frames), and spont_M160907_MP028_2016-09-26 (9392 neurons × 10,301 frames) (Stringer et al., 2019b).
Table 2
Resources for additional experimental datasets.
| Dataset | Data reference |
|---|---|
| Light-sheet imaging of larval zebrafish (Chen et al., 2018) | https://janelia.figshare.com/articles/dataset/Whole-brain_light-sheet_imaging_data/7272617 |
| Neuropixels recordings in mice (Stringer et al., 2019b) | https://janelia.figshare.com/articles/dataset/Eight-probe_Neuropixels_recordings_during_spontaneous_behaviors/7739750 |
| Two-photon imaging in mice (Stringer et al., 2019b) | https://janelia.figshare.com/articles/dataset/Recordings_of_ten_thousand_neurons_in_visual_cortex_during_spontaneous_behaviors/6163622 |
Covariance matrix, eigenspectrum, and sampling procedures
Request a detailed protocolTo begin, we multiplied the inferred firing rate of each neuron (see Methods) by a constant such that in the resulting activity trace , the mean of over the nonzero time frames equaled one (Meshulam et al., 2019). Consistent with the literature (Meshulam et al., 2019), this step aimed to eliminate possible confounding factors in the raw activity traces, such as the heterogeneous expression level of the fluorescence protein within neurons and the nonlinear conversion of the electrical signal to Ca2+ concentration. Note that after this scaling, neurons could still have different activity levels characterized by the variance of over time, due to differences in the sparsity of activity (proportion of nonzero frames) and the distribution of nonzero values. Without normalization, the covariance matrix becomes nearly diagonal, causing significant underestimation of the covariance structures.
The three models of covariance in Figure 2G–I were constructed as follows. For model in Figure 2G, the entries of matrix (with dimensions ) were sampled from an i.i.d. Gaussian distribution with zero mean and standard deviation . In Figure 2H, we constructed the composite covariance matrix for fish 1 achieved by maintaining the eigenvalues from the fish 1 data covariance matrix and replacing the eigenvectors with a set of random orthonormal basis. Lastly, the covariance matrix in Figure 2I was generated from a randomly connected recurrent network of linear rate neurons. The entries in the synaptic weight matrix are normally distributed with , with a coupling strength (Hu and Sompolinsky, 2022; Morales et al., 2023). For consistency, we used the same number of time frames when comparing CI across all the datasets (Figures 4B, C, 5D, E, Figure 4—figure supplement 2C). For other cases, we analyzed the full length of the data (number of time frames: fish 1 – 7495, fish 2 – 9774, fish 3 – 13,904, fish 4 – 7318, fish 5 – 7200, and fish 6 – 9388). Next, the covariance matrix was calculated as , where is the mean of over time. Finally, to visualize covariance matrices on a common scale, we multiplied matrix C by a constant such that the average of its diagonal entries equaled one, that is, . This scaling did not alter the shape of covariance eigenvalue distribution, but set the mean at 1 (see also Equation 8).
To maintain consistency across datasets, we fixed the same initial number of neurons at . These neurons were randomly chosen once for each zebrafish dataset and then used throughout the subsequent analyses. We adopted this setting for all analyses except in two particular instances: (1) for comparisons among the three sampling methods (RSap, ASap, and FSap), we specifically chose 1024 neurons centered along the anterior–posterior axis, mainly from the midbrain to the anterior hindbrain regions (Figure 5DE, Figure 5—figure supplement 6). (2) When investigating the impact of hunting behavior on scale invariance, we included the entire neuronal population (Appendix 1).
We used an iterative procedure to sample the covariance matrix (calculated from data or as simulated ERMs). For RSap, in the first iteration, we randomly selected half of the neurons. The covariance matrix for these selected neurons was a diagonal block of . Similarly, the covariance matrix of the unselected neurons was another diagonal block of the same size. In the next iteration, we similarly created two new sampled blocks with half the number of neurons for each of the blocks we had. Repeating this process for iterations resulted in 2n blocks, each containing neurons. At each iteration, the eigenvalues of each block were calculated and averaged across the blocks after being sorted in descending order. Finally, the averaged eigenvalues were plotted against rank/ on a log–log scale.
In the case of ASap and FSap, the process of selecting neurons was different, although the remaining procedures followed the RSap protocol. In ASap, the selection of neurons was based on a spatial criterion: neurons close to the anterior end on the anterior–posterior axis were grouped to create a diagonal block of size , with the remaining neurons forming a separate block. FSap, on the other hand, used the RG framework (Meshulam et al., 2019) to define the blocks (details in Appendix 1). In each iteration, the cluster of neurons within a block that showed the highest average correlation () was identified and labeled as the most correlated cluster (refer to Figure 5D, Figure 5—figure supplement 6, and Figure 5—figure supplement 7).
In the ERM model, as part of implementing ASap, we generated anatomical and functional coordinates for neurons with a specified CCA properties as described in Methods. Mirroring the approach taken with our data, ASap segmented neurons into groups based on the first dimension of their anatomical coordinates, akin to the anterier–posterior axis. FSap employed the same RG procedures outlined earlier (Appendix 1).
To determine the overall power-law coefficient of the eigenspectra, α, throughout sampling, we fitted a straight line in the log–log rank plot to the large eigenvalues that combined the original and three iterations of sampled covariance matrices (selecting the top 10% eigenvalues for each matrix and excluding the first four largest ones for each matrix). We averaged the estimated α over 10 repetitions of the entire sampling procedure. of the power-law fit was computed in a similar way. To visualize the statistical structures of the original and sampled covariance matrices, the orders of the neurons (i.e., columns and rows) are determined by the following algorithm. We first construct a symmetric Toeplitz matrix , with entries and . The vector is equal to the mean covariance vector of each neuron calculated below. Let be a row vector of the data covariance matrix; we identify , where denotes a numerical ordering operator, namely rearranging the elements in a vector such that . The second step is to find a permutation matrix P such that is minimized, where denotes the Frobenius norm. This quadratic assignment problem is solved by simulated annealing. Note that after sampling, the smaller matrix will appear different from the larger one. We need to perform the above reordering algorithm for every sampled matrix so that matrices of different sizes become similar in Figure 2E.
The composite covariance matrix with substituted eigenvectors in Figure 2H was created as described in the following steps. First, we generated a random orthogonal matrix (based on the Haar measure) for the new eigenvectors. This was achieved by QR decomposition of a random matrix with i.i.d. entries . The composite covariance matrix was then defined as , where is a diagonal matrix that contains the eigenvalues of . Note that since all the eigenvalues are real and is orthogonal, the resulting is a real and symmetric matrix. By construction, and have the same eigenvalues, but their sampled eigenspectra can differ.
Dimensionality
Request a detailed protocolIn this section, we introduce the participation ratio () as a metric for effective dimensionality of a system, based on Recanatesi et al., 2019; Litwin-Kumar et al., 2017; Gao and Ganguli, 2015; Gao et al., 2017; Clark et al., 2023; Dahmen et al., 2020. is defined as:
(5)
Here, are the eigenvalues of the covariance matrix , representing variances of neural activities. denotes the trace of the matrix. The term denotes the expected value of the squared elements that lie off the main diagonal of . This represents the average squared covariance between the activities of distinct pairs of neurons.
With these definitions, we explore the asymptotic behavior of as the number of neurons approaches infinity:
This limit highlights the relationship between the PR dimension and the average squared covariance among different pairs of neurons. To predict how scales with the number of neurons (Figure 2D), we first estimated these statistical quantities (, , and ) using all available neurons, then applied Equation 5 for different values of . It is worth mentioning that a similar theoretical finding is established by Dahmen et al., 2020. The transition from increasing with to approaching the saturation point occurs when is significantly larger than .
ERM model
Request a detailed protocolWe consider the eigenvalue distribution or spectrum of the matrix at the limit of and . This spectrum can be analytically calculated in both high- and intermediate-density scenarios using the replica method (Mézard et al., 1999). The following sketch shows our approach, and detailed derivations can be found in Appendix 2. To calculate the probability density function of the eigenvalues (or eigendensity), we first compute the resolvent or Stieltjes transform , . Here, is the average across the realizations of (i.e., random ’ s and ’ s). The relationship between the resolvent and the eigendensity is given by the Sokhotski–Plemelj formula:
(6)
where means imaginary part.
Here we follow the field-theoretic approach (Mézard et al., 1999), which turns the problem of calculating the resolvent to a calculation of the partition function in statistical physics by using the replica method. In the limit , , ρ being finite, by performing a leading order expansion of the canonical partition function at large (Appendix 2), we find the resolvent is given by
(7)
In the high-density regime, the probability density function (pdf) of the covariance eigenvalues can be approximated and expressed from Equations 6 and 7 using the Fourier transform of the kernel function :
(8)
where is the Dirac delta function and is the expected value of the variances of neural activity. Intuitively, Equation 8 means that are distributed with a density proportional to the area of ’ level sets (i.e., isosurfaces).
In Results, we found that the covariance matrix consistently shows greater scale invariance compared to the correlation matrix across all datasets. This suggests that the variability in neuronal activity significantly influences the eigenspectrum. This finding, however, cannot be explained by the high-density theory, which predicts that the eigenspectrum of the covariance matrix is simply a rescaling of the correlation eigenspectrum by , the expected value of the variances of neural activity. Without loss of generality, we can always standardize the fluctuation level of neural activity by setting . This is equivalent to multiplying the covariance matrix by a constant such that , which in turn scales all the eigenvalues of by the same factor. Consequently, the heterogeneity of has no effect on the scale invariance of the eigenspectrum (see Equation 8). This theoretical prediction is indeed correct and is confirmed by direct numerical simulations and quantifying the scale invariance using the CI (Figure 4—figure supplement 2A).
Fortunately, the inconsistency between theory and experimental results can be resolved by focusing the ERM within the intermediate density regime , where neurons are positioned at a moderate distance from each other. As mentioned above, we set in our model and vary the diversity of activity fluctuations among neurons represented by . Consistent with the experimental observations, we find that the CI decreases with (see Figure 4—figure supplement 2B). This agreement indicates that the neural data are better explained by the ERM in the intermediate density regime.
To gain a deeper understanding of this behavior, we use the Gaussian variational method (Mézard et al., 1999) to calculate the eigenspectrum. Unlike the high-density theory where the eigendensity has an explicit expression, in the intermediate density the resolvent no longer has an explicit expression and is given by the following equation:
(9)
where computes the expectation value of the term within the bracket with respect to σ, namely . Here and in the following, we denote . The function is determined by a self-consistent equation,
(10)
We can solve from Equation 10 numerically and below is an outline, and the details are explained in Appendix 2. Let us define the integral . First, we substitute into Equation 10 and write . Equation 10 can thus be decomposed into its real part and imaginary part, and a set of nonlinear and integral equations, each of which involves both and . We solve these equations at the limit using a fixed-point iteration that alternates between updating and until convergence.
We find that the variational approximations exhibit excellent agreement with the numerical simulation for both large and intermediate ρ where the high-density theory starts to deviate significantly (for and , , Figure 4—figure supplement 1). Note that the departure of the leading eigenvalues in these plots is expected, since the power-law kernel function we use is not integrable (see Methods).
To elucidate the connection between the two different methods, we estimate the condition when the result of the high-density theory (Equation 8) matches that of the variational method (Equations 9 and 10; Appendix 2). The transition between these two density regimes can also be understood (see Equation 22 and Appendix 2).
Importantly, the scale invariance of the spectrum at previously derived using the high-density result (Equation 3) can be extended to the intermediate-density regime by proving the ρ-independence using the variational method (Appendix 2).
Finally, using the variational method and the integration limit estimated by simulation (see Methods), we show that the heterogeneity of the variance of neural activity, quantified by , indeed improves the collapse of the eigenspectra for intermediate ρ (Appendix 2). Our theoretical results agree excellently with the ERM simulation (Figure 4—figure supplement 2A, B).
Kernel function
Request a detailed protocolThroughout the paper, we have mainly considered a particular approximate power-law kernel function inspired by the Student’s t distribution
(11)
To understand how to choose and , see Methods. Variations of Equation 11 near have also been explored; see a summary in Table 3.
Table 3
Modifications of the shape of near used in Appendix 1—figures 1–3.
Flat: when , . Tangent: when , follows a tangent line of the exact power law ( and have a same first-order derivative when ). b and c are constants. Tent: when , follows a straight line while the slope is not the same as the tangent case. Parabola: when , follows a quadratic function ( and have same first-order derivative). t pdf: mimic the smoothing treatment like the t distribution. All the constant parameters are set such that .
| Definition | |
|---|---|
| Flat | |
| Tangent | |
| Tent | |
| Parabola | |
| t pdf |
It is worth mentioning that a power law is not the only slow-decaying function that can produce a scale-invariant covariance spectrum (Figure 3—figure supplement 2). We choose it for its analytical tractability in calculating the eigenspectrum. Importantly, we find numerically that the two contributing factors to scale invariance – namely, slow spatial decay and higher functional space – can be generalized to other nonpower-law functions. An example is the stretched exponential function with . When is small and is large, the covariance eigenspectra also display a similar collapse upon random sampling (Figure 3—figure supplement 2).
This approximate power-law has the advantage of having an analytical expression for its Fourier transform, which is crucial for the high-density theory (Equation 8),
(12)
Here, is the modified Bessel function of the second kind, and is the Gamma function. We calculated the above formulas analytically for with the assistance of Mathematica and conjectured the case for general dimension , which we confirmed numerically for .
We want to explain two technical points relevant to the interpretation of our numerical results and the choice of . Unlike the case in the usual ERM, here we allow to be non-integrable (over ), which is crucial to allow power law . The nonintegrability violates a condition in the classical convergence results of the ERM spectrum (Bordenave, 2008) as . We believe that this is exactly the reason for the departure of the first few eigenvalues from our theoretical spectrum (e.g., in Figure 3). Our hypothesis is also supported by ERM simulations with integrable (Figure 3—figure supplement 1), where the numerical eigenspectrum matches closely with our theoretical one, including the leading eigenvalues. For ERM to be a legitimate model for covariance matrices, we need to ensure that the resulting matrix is positive semidefinite. According to the Bochner theorem (Rudin, 1990), this is equivalent to the Fourier transform (FT) of the kernel function being nonnegative for all frequencies. For example, in 1D, a rectangle function does not meet the condition (its FT is ), but a tent function does (its FT is ). For the particular kernel function in Equation 11, this condition can be easily verified using the analytical expressions of its Fourier transform (Equation 12). The integral expression for , given as , shows that is positive for all . Likewise, the Gamma function . Therefore, the Fourier transform of Equation 11 is positive and the resulting matrix (of any size and values of ) is guaranteed to be positive definite.
Building upon the theory outlined above, numerical simulations further validated the empirical robustness of our ERM model, as showcased in Figures 3B–D–4A. In Figure 3B–D, the ERM was characterized by the parameters , , , , and and for . To numerically compute the eigenvalue probability density function, we generated the ERM 100 times, each sampled using the method described in Methods. The pdf was computed by calculating the pdf of each ERM realization and averaging these across the instances. The curves in Figure 3D showed the average of over 100 ERM simulations. The shaded area (most of which is smaller than the marker size) represented the SEM. For Figure 4A, the columns from left to right were corresponded to , and the rows from top to bottom were corresponded to . Other ERM simulation parameters: , , , , and . It should be noted that for Figure 4A, the presented data pertain to a single ERM realization.
Collapse index
We quantify the extent of scale invariance using CI defined as the area between two spectrum curves (Figure 4A, upper right), providing an intuitive measure of the shift of the eigenspectrum when varying the number of sampled neurons. We chose the CI over other measures of distance between distributions for several reasons. First, it directly quantifies the shift of the eigenspectrum, providing a clear and interpretable measure of scale invariance. Second, unlike methods that rely on estimating the full distribution, the CI avoids potential inaccuracies in estimating the probability of the top leading eigenvalues. Finally, the use of CI is motivated by theoretical considerations, namely the ERM in the high-density regime, which provides an analytical expression for the covariance spectrum (Equation 3) valid for large eigenvalues.
(13)
we set such that , which is the mean of the eigenvalues of a normalized covariance matrix. The other integration limit is set to 0.01 such that is the 1% largest eigenvalue.
Here, we provide numerical details on calculating CI for the ERM simulations and experimental data.
A calculation of CI for experimental datasets/ERM model
Request a detailed protocolTo calculate CI for a covariance matrix of size , we first computed its eigenvalues and those of the sampled block of size , denoted as (averaged over 20 times for the ERM simulation and 2000 times in experimental data). Next, we estimated using the eigenvalues of and at , . For the sampled , we simply had , its ith largest eigenvalue. For the original , was estimated by a linear interpolation, on the scale, using the value of in the nearest neighboring ’s (which again are simply ). Finally, the integral (Equation 13) was computed using the trapezoidal rule, discretized at ’s, using the finite difference , where denotes the difference between the original eigenvalues of and those of sampled .
Estimating CI using the variational method
Request a detailed protocolIn the definition of CI (Equation 13), calculating and directly using the variational method is difficult, but we can make use of an implicit differentiation
(14)
where is the complementary cdf (the inverse function of in Methods). Using this, the integral in CI (Equation 13) can be rewritten as
(15)
Since , we switch the order of the integration interval in the final expression of Equation 15.
First, we explain how to compute the complementary cdf numerically using the variational method. The key is to integrate the probability density function from λ to a finite rather than to infinity,
(16)
The integration limit cannot be calculated directly using the variational method. We thus used the value of (Methods) from simulations of the ERM with a large as an approximation. Furthermore, we employed a smoothing technique to reduce bias in the estimation of due to the leading zigzag eigenvalues (i.e., the largest eigenvalues) of the eigenspectrum. Specifically, we determined the nearest rank and then smoothed the eigenvalue on the log–log scale using the formula and , averaging over 100 ERM simulations.
Note that we can alternatively use the high-density theory (Appendix 2) to compute the integration limit instead of resorting to simulations. However, since the true value deviates from the derived from high-density theory, this approach introduces a constant bias (Figure 4—figure supplement 2) when computing the integral in Equation 16. Therefore we used the simulation value when producing Figure 4—figure supplement 2AB.
Next, we describe how each term within the integral of Equation 15 was numerically estimated. First, we calculated with a similar method described in Methods. Briefly, we calculated for density and for density , and then used the finite difference . Second, was evaluated at , where , and we used . Finally, we performed a cubic spline interpolation of the term , and obtained the theoretical CI by an integration of Equation 15. Figure 4—figure supplement 2A, B shows a comparison between theoretical CI and that obtained by numerical simulations of ERM (Methods).
Fitting ERM to data
Estimating the ERM parameters
Request a detailed protocolOur ERM model has four parameters: and dictate the kernel function , whereas the box size and the embedding dimension determine the neuronal density . In the following, we describe an approximate method to estimate these parameters from pairwise correlations measured experimentally . We proceed by deriving a relationship between the correlation probability density distribution and the pairwise distance probability density distribution in the functional space, from which the parameters of the ERM can be estimated.
Consider a distribution of neurons in the functional space with a coordinate distribution . The pairwise distance density function is related to the spatial point density by the following formula:
(17)
For ease of notation, we subsequently omit the region of integration, which is the same as here. In the case of a uniform distribution, . For other spatial distributions, Equation 17 cannot be explicitly evaluated. We therefore make a similar approximation by focusing on a small pairwise distance (i.e., large correlation):
(18)
By a change of variables:
Equation 17 can be rewritten as
(19)
where is the surface area of sphere with radius u. Note that the approximation of is not normalized to 1, as Equation 19 provides an approximation valid only for small pairwise distances (i.e., large correlation). Therefore, we believe this does not pose an issue.
With the approximate power-law kernel function , the probability density function of pairwise correlation is given by:
(20)
Taking the logarithm on both sides
(21)
Equation 21 is the key formula for ERM parameters estimation. In the case of a uniform spatial distribution, . For a given dimension , we can therefore estimate and separately by fitting on the log–log scale using the linear least squares. Lastly, we fit the distribution of (the diagonal entries of the covariance matrix ) to a log-normal distribution by estimating the maximum likelihood.
There is a redundancy between the unit of the functional space (using a rescaled ) and the unit of (using a rescaled ), thus and are a pair of redundant parameters: once ε is given, is also determined. We set throughout the article. In summary, for a given dimension and , of (Equation 11), the distribution of and (or equivalently ) can be fitted by comparing the distribution of pairwise correlations in experimental data and ERM. Furthermore, knowing enables us to determine a fundamental dimensionless parameter
(22)
which tells us whether the experimental data are better described by the high-density theory or the Gaussian variational method (Appendix 2). Indeed, the fitted is much smaller than 1, consistent with our earlier conclusion that neural data are better described by an ERM model in the intermediate-density regime.
Notably, we found that a smaller embedding dimension gave a better fit to the overall pairwise correlation distribution. The following is an empirical explanation. As grows, to best fit the slope of , will also grow. However, for very high dimensions , the y-intercept would become very negative, or equivalently, the fitted correlation would become extremely small. This can be verified by examining the leading order independent term in Equation 21, which can be approximated as . It becomes very negative for large since by construction. Throughout this article, we use when fitting the experimental data with our ERM model.
The above calculation can be extended to the cases where the coordinate distribution becomes dependent on other parameters. To estimate the parameters in coordinate distributions that can generate ERMs with a similar pairwise correlation distribution (Appendix 1—figure 1), we fixed the integral value . Consider, for example, a transformation of the uniform coordinate distribution to the normal distribution in . We imposed . For the log-normal distribution, a similar calculation led to . The numerical values for these parameters are shown in Appendix 1. However, note that due to the approximation we used (Equation 18), our estimate of the ERM parameters becomes less accurate if the density function changes rapidly over a short distance in the functional space. More sophisticated methods, such as grid search, may be needed to tackle such a scenario.
After determining the parameters of the ERM, we first examine the spectrum of the ERM with uniformly distributed random functional coordinates (Figure 5—figure supplement 1M–R). Second, we use to translate experimental pairwise correlations into pairwise distances for all neurons in the functional space (Figure 5—figure supplement 2, Figure 5—figure supplement 1G–L). The embedding coordinates in the functional space can then be solved through multidimensional scaling (MDS) by minimizing the Sammon error (Methods). The similarity between the spectra of the uniformly distributed coordinates (Figure 5—figure supplement 1M–R) and those of the embedding coordinates (Figure 5—figure supplement 1G–L) is also consistent with the notion that specific coordinate distributions in the functional space have little impact on the shape of the eigenspectrum (Appendix 1—figure 1).
Nonnegativity of data covariance
Request a detailed protocolTo use ERM to model the covariance matrix, the pairwise correlation is given by a non-negative kernel function that monotonically decreases with the distance between neurons in the functional space. This nonnegativeness brings about a potential issue when applied to experimental data, where, in fact, a small fraction of pairwise correlations/covariances are negative. We have verified that the spectrum of the data covariance matrix (Figure 2—figure supplement 3) remains virtually unchanged when replacing these negative covariances with zero (Figure 2—figure supplement 3). This confirms that the ERM remains a good model when the neural dynamics is in a regime where pairwise covariances are mostly positive Dahmen et al., 2019 (see also Figure 2—figure supplement 2B, Figure 2—figure supplement 2B–D).
Multidimensional scaling
Request a detailed protocolWith the estimated ERM parameters ( in and the box size for given and , see Methods), we performed MDS to infer neuronal coordinates in functional space. First, we computed a pairwise correlation from the data covariances. Next, we calculated the pairwise distance, denoted by , by computing the inverse function of with respect to the absolute value of , . We used the absolute value instead of as a small percentage of are negative (Figure 2—figure supplement 2A–D) where the distance is undefined. This substitution by the absolute value serves as a simple workaround for the issue and is only used here in the analysis to infer the neuronal coordinates by MDS. Finally, we estimated the embedding coordinates for each neuron by the SMACOF algorithm (Scaling by MAjorizing a COmplicated Function), which minimizes the Sammon error
(23)
where is the pairwise distance in the embedding space calculated above. To reduce errors at large distances (i.e., small correlations with , where is the estimated box size), we performed a soft cut-off at a large distance:
(24)
During the optimization process, we started at the embedding coordinates estimated by the classical MDS (Cox and Cox, 2000), with an initial sum of squares distance error that can be calculated directly, and ended with an error or its gradient smaller than 10−4.
The fitted ERM with the embedding coordinates reproduced the experimental covariance matrix including the cluster structures (Figure 5—figure supplement 2) and its sampling eigenspectra (Figure 5—figure supplement 1).
Canonical correlation analysis
Request a detailed protocolHere we briefly explain the CCA method (Knapp, 1978) for completeness. The basis vectors and , in functional and anatomical space, respectively, were found by maximizing the correlation . These basis vectors satisfy the condition that the projections of the neuron coordinates along them, and , are maximally correlated among all possible choices of and . Here, , represent the coordinates in functional and anatomical spaces, respectively. The resulting maximum correlation is . To check the significance of the canonical correlation, we shuffled the functional space coordinates across neurons’ identity and re-calculated the canonical correlation with the anatomical coordinates, as shown in Figure 5—figure supplement 4.
To study the effect of functional–anatomical relation described by in the ERM model, we generated three-dimensional anatomical coordinates and two-dimensional functional coordinates for each neuron which are jointly five-dimensional zero-mean multivariate Gaussian random variables. The coordinates are independent among each other, except for the first dimension of the functional coordinates and the first dimension , which are assigned to have a correlation coefficient equals to . The variances of the coordinates are , and for the numerics in Figure 5—figure supplement 7. Under this construction, the first canonical correlation between the anatomical and functional coordinates equals , and the first canonical direction in the anatomical space is and the first canonical direction in the functional space is .
Spectrum of three types of sampling procedures in ERM model
Request a detailed protocolIn Result, we have considered three types of sampling procedures: random sampling (RSap), spatial sampling in the anatomical space (ASap, e.g., recording neurons in a brain region), and spatial sampling in the functional space (FSap), namely spatial sampling in functional space by subdividing the space into smaller regions, is equivalent to the previously reported RG inspired process (Bradde and Bialek, 2017). Here, we consider the relationship between the spectrum of three types of sampling procedures.
We assume a uniform random distribution of neurons in a -dimensional functional space, . For RSap procedures, the resulting neuronal density is reduced to , with representing the sampling ratio () and being the initial density. In contrast, FSap maintains the original density, . This constancy in neuronal density under FSap ensures that the covariance eigenspectrum remains invariant across scales for any spatial correlation functions , such as power law and exponential, as shown in Appendix 1—figure 5A, B, D, E. In contrast, RSap reduces ρ, thus demanding more rigorous conditions to achieve a scale-invariant covariance spectrum (e.g., compare Appendix 1—figure 5A, C).
Under ASap, sampled neurons are not spread out evenly in functional space, whereas our theoretical framework assumes a uniform distribution. To reconcile this discrepancy, we employ a uniform approximation of the neural distribution. This approach involves introducing an effective density, , defined as the spatial average of the density function . This adjustment allows our theoretical model to accommodate non-uniform distributions encountered in anatomically spatial sampling.
(25)
where is the normalized density distribution (see Methods).
Using the Cauchy–Schwarz inequality, we have
(26)
thus .
According to the condition , we have , intuitively, sampling within a uniformly distributed neuron population does not increase the density.
So we have , that is, . Thus, the spectrum ASap should be between FSap and RSap.
Dimensions of three types of sampling procedures in ERM model
Scaling of dimensions through random sampling
Request a detailed protocolLet us revisit the definition of the participation ratio (PR) dimension as defined in Equation 5:
(27)
During the random sampling process, the expected values , , and remain constant. These constants allow for the estimation of the PR dimension across various scales using:
(28)
Here, represents a scaling factor (fraction) associated with sampling. The key question is to understand how the dimensionality changes with . Under random sampling, as increases, the dimensionality will quickly approaches a saturating point defined by Equation 1.
Scaling of dimensions through functional sampling
Request a detailed protocolIn this section, we leverage the uniform ERM model to estimate dimensions within the context of functional sampling, specifically focusing on the estimation of squared pairwise covariance and dimensionality. Adopting an approximation for a power-law kernel function allows us to express the expected value of the squared covariance as follows:
(29)
For a set subjected to functional sampling with a sampling fraction , this procedure adjusts the size of the functional space in the ERM model by a factor of . Consequently, the for the sampled fraction is given by:
(30)
Here, we assume that and are constant across the sampling process. This model enables the estimation of the ratio as detailed in the Methods.
(31)
In the large limit, we observe distinct behaviors in the evolution of dimensionality in both theory and data: it saturates in RSap (dashed line in Figure 5D), namely defined in Equation 1, whereas it follows a different scaling relationship in FSap (solid line in Figure 5D).
Comparative analysis of PR dimension across sampling techniques
Request a detailed protocolThis section examines the behavior of the PR dimension under three sampling techniques: anatomical sampling, random sampling, and functional sampling. We show that the average PR dimension following anatomical sampling occupies a middle ground between the extremes presented by random and functional sampling.
The PR dimension, denoted , reflects the sampling impact and depends on the distribution of the functional coordinates . Defining the sampling fraction as , the mean is represented as:
(32)
where the neuron set is segmented into clusters , each comprising neurons. The probability distribution corresponds to each cluster . The probability distribution for each cluster, , emerges naturally from the sampling process.
The equivalence of the mean probability density function across the sampled clusters to the original set’s probability density function leads us to the condition:
(33)
This condition is a direct consequence of the sampling process, ensuring that the aggregated probability density function of all sampled sets mirrors the overall density distribution of the neurons.
Applying the Lagrange multiplier method to optimize the mean :
(34)
Here, is the Lagrangian, is the Lagrange multiplier, we derive the optimal condition:
(35)
yielding:
(36)
At the optimal mean , each is equivalent, leading to (representative of random sampling). Hence, the mean post-random sampling sets the upper limit for the mean after anatomical sampling.
Let us investigate the lower bound of the mean PR dimension with the ERM model. For the minimization of mean , a key requirement is the functional spatial proximity of neurons within the same cluster, in other words, the neuron set should be distinctly separated in functional space. Consequently, achieving the minimum mean PR dimension necessitates a functional sampling strategy.
Derive upper bound of dimension from spectrum
Request a detailed protocolTo deduce from the spectrum, for simplicity, we focus on the high-density region, where we have an analytical expression for λ that is valid for large eigenvalues:
(37)
where is the size of the functional space, is the coefficient in Equation 3, which depends on , , and . Note that the eigenvalue decays rapidly after the threshold . Since we did not discuss small eigenvalues in this article, we represent them here as an unknown function :
(38)
As discussed in Methods, without changing the properties of the spectrum, we can always impose such that
(39)
We emphasize that this constraint requires that large and small eigenvalues behave differently because otherwise with would scale as , and is not proportional to .
Using the Cauchy–Schwarz inequality, we have an upper bound of :
(40)
On the other hand, is a lower bound of :
(41)
As a result, the dimensionality
is bounded as
(42)
Under random sampling, remains fixed. Thus, we must have a bounded dimensionality that is independent of for our ERM model. A tighter lower bound of is
(43)
A tighter upper bound of participation ratio can be written as:
(44)
However, in functional sampling, enlarging the region size with constant density ρ results in . Thus, the upper bound of should grow as , consistent with the previously derived result (Equation 31) in Methods.
Simulating CCA and anatomical sampling
Request a detailed protocolIn this section, we estimate the dimensions of the anatomically sampled neuron set. For simplicity, we assume that the functional coordinates of neurons, , and the anatomical coordinates of neurons, , both follow a multivariate Gaussian distribution. We define anatomical sampling, which involves sampling on , along a direction chosen arbitrarily and denote this direction as . Subsequently, we perform sampling on in the direction denoted by , which is determined to have the highest correlation with according to CCA. This process effectively mimics the scenario of functional sampling.
The key to calculating the PR dimension involves computing the expected value . In the ERM model, the distribution of can be estimated by the distribution of points in the functional space. This allows for the calculation of the PR dimension across anatomical sampling by comparing the distribution of after anatomical sampling with that after functional sampling. We can model the distribution of and as follows:
(45)
Here, we consider only the projection of the functional coordinate onto the direction , which exhibits the highest correlation, denoted by , with . Specifically, when selecting the anatomical direction as the first CCA direction, the correlation between and reaches its maximum, such that . In this case, anatomical sampling results in the minimization of the dimensionality.
Now, let us perform anatomical sampling on the neurons. The and denote the functional and anatomical coordinates of the neuron cluster after anatomical sampling, respectively.
To approximate, we need to calculate the functional coordinate probability distribution , which is the distribution of the neuron cluster after anatomical sampling. represents the selected direction in anatomical space, and denotes the quantile of , where is the sampled fraction. Note the following relationships and distributions:
(46)
(47)
The conditional probability distribution is equivalent to the distribution of the sum of and , where :
(48)
(49)
The computation of involves two technical challenges: (1) The distribution of is represented by a non-elementary function (Equation 49), which complicates the direct calculation of , which is the sum of and . To facilitate approximation, we model using a normal distribution with equivalent variance. (2) Calculating the variance of presents direct challenges, and the variance of differs across different neuron clusters i. Using a uniform distribution for simplifies this task (this assumption is only used to calculate the variance of ). Under this assumption, the variance of can be straightforwardly calculated as . Consequently, we approximate and as follows:
(50)
(51)
Calculating the PR dimension directly from the distribution of is difficult; thus, we approximate anatomical sampling with fraction as functional sampling with fraction , leading to:
(52)
Using the equation for functional sampling (Equation 30):
(53)
(54)
Appendix 1
Extensions of ERM and factors not affecting the scale invariance
In Appendix 1—figure 1, we considered five additional types of spatial density distributions (coordinate distributions) in functional space and two additional functional space geometries. We examined the points distributed according to the uniform distribution (), the normal distribution (), and the log-normal distribution (). We used the method described in Methods to adjust the parameters of the coordinate distributions based on the uniform distribution case, so that they all generate similar pairwise correlation distributions. The relationships between these parameters are described in Methods. In Appendix 1—figure 1B, we used the following parameters: for the uniform distribution; , for the normal distribution; and , for the log-normal distribution.
Second, we introduced multiple clusters of neurons in the functional space, with each cluster uniformly distributed in a box. We considered three arrangements: (1) two closely situated clusters (with a box size of , the distance between two cluster centers being ), and (2) two distantly situated clusters (with a box size of and the distance between clusters ), and three clusters arranged symmetrically in an equilateral triangle (with a box size of and the distance between clusters ).
Finally, we examined the scenario in which the points were uniformly distributed on the surface of a sphere (, being the radius of the sphere) or a hemisphere () embedded in (the pairwise distance is that in ). It should be noted that both cases have the same surface area as the 2D box.
Appendix 1—figure 1
Factors that do not affect the scale invariance.
(A) Rank plot of the covariance eigenspectrum for ERMs with different (see Table 3). Diagrams show different slow-decaying kernel functions along a 1D slice. (B) Same as A but for different coordinate distributions in the functional space (see text). The diagrams on the right illustrate uniform and clustered coordinate distributions. (C) Same as A but for different geometries of the functional space (see text). Diagrams illustrate spherical and hemispherical surfaces. (D) CI of the different ERMs considered in (A–C). The range on the y-axis is identical to Figure 4C. On the x-axis, 1: uniform distribution, 2: normal distribution, 3: log-normal distribution, 4: uniform two nearby clusters, 5: uniform two faraway clusters, 6: uniform 3-cluster, 7: spherical surface in , 8: hemispherical surface in . All ERM models in (B, C) are adjusted to have a similar distribution of pairwise correlations (Appendix 1).
Appendix 1—figure 2
Comparisons of large eigenvalues across different smoothing interval sizes, ε.
Rank plot (upper row) and pdf (lower row) of the covariance eigenspectrum for ERMs with different . (A) . (B) . (C) . (D) . Other ERM simulation parameters: , , , , , . The formulas for different ’s are listed in Table 3 in Methods.
Appendix 1—figure 3
Modifications of near .
The upper row illustrates the slow-decaying kernel function (blue solid line) and its power-law asymptote (red dashed line) along a 1D slice at various . The lower row is similar to A, but on the log–log scale. The formulas for different ’s are listed in Table 3 in Methods.
RG approach
Here we briefly summarize the RG approach used in Meshulam et al., 2019 and elucidate the adjustments required when applying the RG approach to ERM. The method consists of two stages: (i) iterative agglomerate clustering of neurons, and (ii) computing the spectrum of a block of the original covariance matrix corresponding to a cluster of the desired size based on the previous clustering result.
Stage (i): iterative clustering
We begin with neurons, where is assumed to be a power of 2. In the first iteration, we compute Pearson’s correlation coefficients for all neuron pairs. We then search greedily for the most correlated pairs and group the half pairs with the highest correlation into the first cluster; the remaining neurons form the second cluster. For each pair , we define a coarse-grained variable according to:
(S1)
where normalizes the average to ensure unit nonzero activity. This process reduces the number of neurons to . In subsequent iterations, we continue grouping the most correlated pairs of the coarse-grained neurons, iteratively reducing the number of neurons by half at each step. This process continues until the desired level of coarse-graining is achieved.
When applying the RG approach to ERM, instead of combining neural activity, we merge correlation matrices to traverse different scales. During the kth iteration, we compute the coarse-grained covariance as:
(S2)
and the variance as:
(S3)
Following these calculations, we normalize the coarse-grained covariance matrix to ensure that all variances are equal to one. Note that these coarse-grained covariances are only used in stage (i) and not used to calculate the spectrum.
Stage (ii): eigenspectrum calculation
The calculation of eigenspectra at different scales proceeds through three sequential steps. First, for each cluster identified in stage (i), we compute the covariance matrix using the original firing rates of neurons within that cluster (not the coarse-grained activities). Second, we calculate the eigenspectrum for each cluster. Finally, we average these eigenspectra across all clusters at a given iteration level to obtain the representative eigenspectrum for that scale.
In stage (ii), we calculate the eigenspectra of the sub-covariance matrices across different cluster sizes as described in Meshulam et al., 2019. Let be the original number of neurons. To reduce it to size , where is the kth reduction step, consider the coarse-grained neurons in step in stage (i). Each coarse-grained neuron is a cluster of neurons. We then calculate spectrum of the block of the original covariance matrix corresponding to neurons of each cluster (there are such blocks). Lastly, an average of these spectra is computed.
For example, when reducing from to neurons (), we would have two clusters of four neurons each. We calculate the eigenspectrum for each 4 × 4 block of the original covariance matrix, then average these two spectra together. To better understand this process through a concrete example, consider a hypothetical scenario where a set of eight neurons, labeled 1,2,3,...,7,8, are subjected to a two-step clustering procedure. In the first step, neurons are grouped based on their maximum correlation pairs, for example, resulting in the formation of four pairs: , and (see Appendix 1—figure 4). Subsequently, the neurons are further grouped into two clusters based on the results of the RG step mentioned above. Specifically, if the correlation between the coarse-grained variables of the pair and the pair is found to be the largest among all other pairs of coarse-grained variables, the first group consists of neurons , while the second group contains neurons . Next, take the size of the cluster for example. The eigenspectra of the covariance matrices of the four neurons within each cluster are computed. This results in two eigenspectra, one for each cluster. The correlation matrices used to compute the eigenspectra of different sizes do not involve coarse-grained neurons. It is the real neurons 1,2,3,...,7,8, but with expanding cluster sizes. Finally, the average of the eigenspectra of the two clusters is calculated.
Appendix 1—figure 4
Example of renormalization group (RG) approach for a set of eight neurons.
The figure is adapted from Meshulam et al., 2019. The diagram illustrates the iterative clustering process for eight neurons. In each iteration, neurons are paired based on maximum correlation, with their activities combined through summation and normalized to maintain unit mean for nonzero values. Each neuron can only be paired once per iteration, ensuring all neurons are grouped by the iteration’s end.
Appendix 1—figure 5
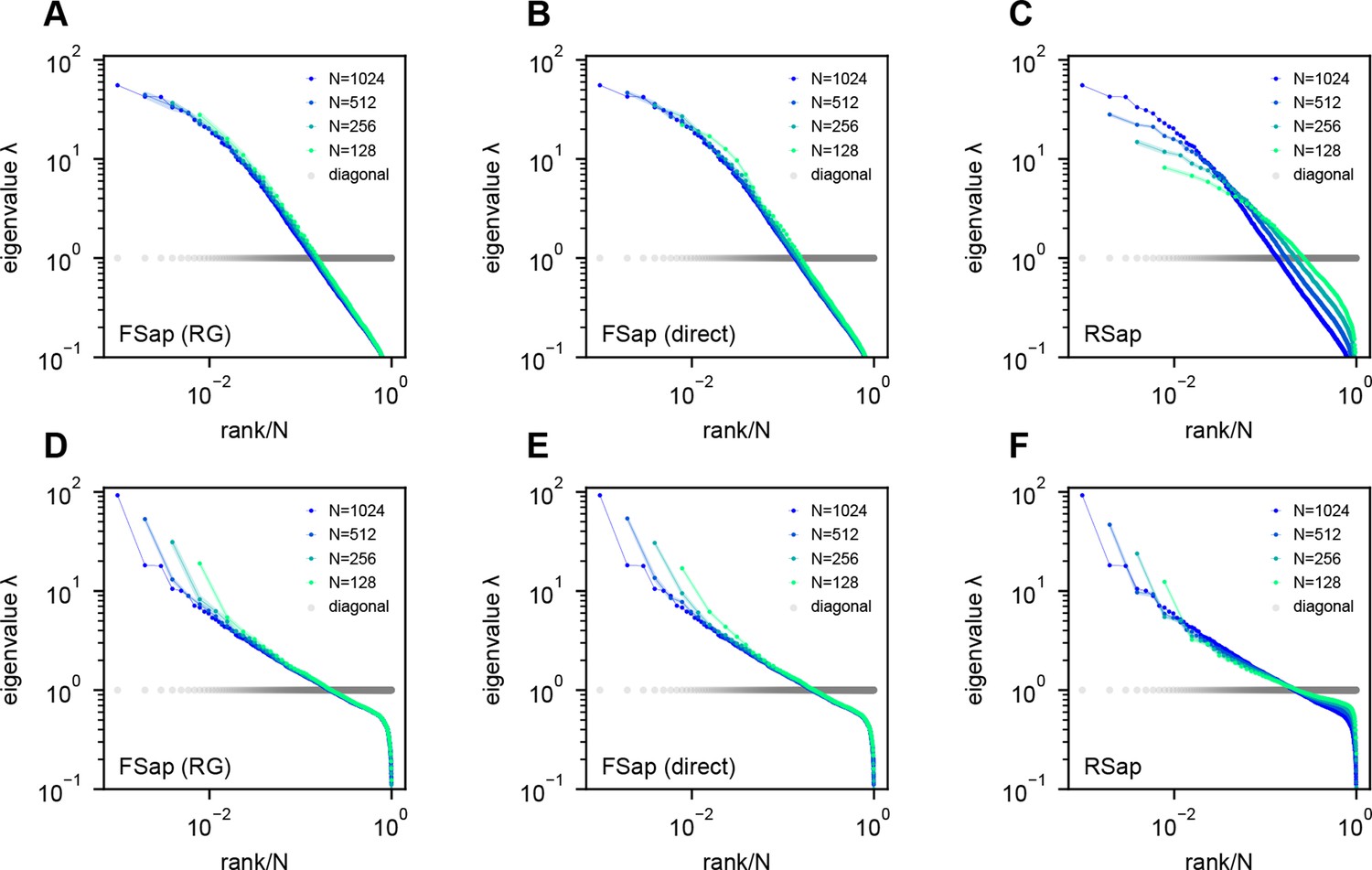
Eigenspectra of renormalization group (RG)-inspired clustering, direct functional region sampling (FSap), and random sampling (RSap) in ERM.
(A, D) RG clustered eigenspectra of ERM. The size of the cluster is denoted by , which is the number of neurons in each cluster. We adopt the RG approach (Meshulam et al., 2018; Meshulam et al., 2019), but with a specific modification (Appendix 1). (B, E) Direct spatial sampling in the functional space (FSap) and the corresponding ERM eigenspectra. We began our analysis with a set of neurons distributed in the functional space. Initially, we chose neurons that were located exclusively on one side of the x-axis of this space. We then proceeded to select neurons from 4 quadrants. This sampling process was repeated iteratively, generating successively smaller subsets of neurons. (C, F) Random sampled (RSap) eigenspectra of ERM. ERM parameters: (A–C) Exponential function where , and dimension . (D–F) Approximate power law Equation 11 with , and dimension . Other parameters are the same as Figure 3. The standard error of the mean (SEM) across the clusters is represented by the shaded area of each line.
Appendix 1—figure 6

Morrell et al.’s latent variable model.
(A–D) Functional sampled (FSap) eigenspectra of the Morrell et al. model. (E–H) Random sampled (RSap) eigenspectra of the same model. Briefly, in Morrell et al.’s latent variable model (Morrell et al., 2024; Morrell et al., 2021), neural activity is driven by latent fields and a place field. The latent fields are modeled as Ornstein–Uhlenbeck processes with a time constant τ. The parameters ε and η control the mean and variance of individual neurons’ firing rates, respectively. The following are the parameter values used. (A, E) Using the same parameters as in Morrell et al., 2021: , , , . Half of the cells are also coupled to the place field. (B–D, F–H) Using parameters from Morrell et al., 2024: , , . There is no place field. The time constant for (B, F, C, G) and (D, H), respectively.
Analyzing the effects of removing neural activity data during hunting
To identify and remove the time frames corresponding to putative hunting behaviors, the following procedure was used. The hunting interval was defined as 10 frames (1 s) preceding the onset of an eye convergence (see Methods) to 10 frames after the offset of this eye convergence. These frames were then excluded from the data before recalculating the covariance matrix (see Methods) and subsequently the sampled eigenspectra (Appendix 1—figure 7B, Appendix 1—figure 8B, D, F, H). As a control to the removal of the hunting frame, an equal number of time frames that are not within those hunting intervals were randomly selected and then removed and analyzed (Appendix 1—figure 7C, Appendix 1—figure 8A, C, E, G). The number of hunting interval frames and total recording frames for five fish exhibiting hunting behaviors are as follows: fish 1 – 268/7495, fish 2 – 565/9774, fish 3 – 2734/13,904, fish 4 – 843/7318, and fish 5 – 1066/7200. Fish 6 (number of time frames: 9388) was not exposed to a prey stimulus and, therefore, was excluded from the analysis.
To assess the impact of hunting removal on CI, we calculated the CI of the covariance matrix using all neurons recorded in each fish (without sampling to 1024 neurons). For the control case, we repeated the removal of the nonhunting frame 10 times to generate 10 covariance matrices and computed their CIs. We used a one-sample t-test to determine the level of statistical significance between the control CIs and the CI obtained after removal of the hunting frame.
Using fitted ERM parameters by full data, we performed a MDS on the control data and hunting-removed data to infer the functional coordinates. Note that the functional coordinates inferred by MDS are not unique: rotations and translations give equivalent solutions. For visualization purposes (not needed for analysis), we first used the Umeyama algorithm to optimally align the functional coordinates of control and hunting-removed data.
To identify distinct clusters within the functional coordinates, we fit Gaussian Mixture Models (GMMs) using the ‘GaussianMixtures’ package in Julia. We chose the number of clusters based on giving the smallest Bayesian information criterion score. After fitting the GMMs, a list of probabilities , was given for each neuron i specifying the probability of the neuron belonging to the cluster . The mean and covariance parameters were estimated for each Gaussian distributed cluster. For visualization (but not for analysis), a neuron was colored according to cluster where .
We used the following method to measure the size of the cluster and its fold change. For a 2D (recall in our ERM) Gaussian distributed cluster, let us consider an ellipse centered on its mean, and its axes are aligned with the eigenvectors of its covariance matrix . Let the eigenvalues of be . Then we set the length of the half-axis of the ellipse to be , respectively. Here, is a constant determined below. Note that the ellipse axes correspond to linear combinations of 2D Gaussian random variables that are independent and ’s are the variance of these linear combinations. From this fact, it is straightforward to show that the probability that a sample from the Gaussian cluster lies in the above ellipse depends only on , that is, , and not on the shape of the cluster. So, the ellipse represents a region that covers a fixed proportion of neurons for any cluster, and its area can be used as a measure for the size of the Gaussian cluster. Note that the area of the ellipse is . In Appendix 1—figure 9, we plot the ellipses to help visualize the clusters and their changes. We choose such that the ellipse covers 95% of the probability (i.e., the fraction of neurons belonging to the cluster).
In the control functional map where we fit the GMMs, we directly calculated the size measure from the estimated covariance for each Gaussian cluster. In the hunting-removed functional map, we needed to estimate the covariance for neurons belonging to a cluster under the new coordinates (we assume that the new distribution can still be approximated by a Gaussian distribution). We performed this estimation in a probabilistic manner to avoid issues of highly overlapping clusters where the cluster membership could be ambiguous for some neurons. First, we estimated the center/mean of the new Gaussian distribution by
Here, the summation goes over all the neurons in the functional space and is the membership probability defined above, and is the coordinate of neuron in the hunting-removed map. Similarly, we can use a weighted average to estimate the entries in the covariance matrix . For example,
Then we calculated the size of the cluster on the new map as . Finally, we computed the fold change in size as .
Appendix 1—figure 7
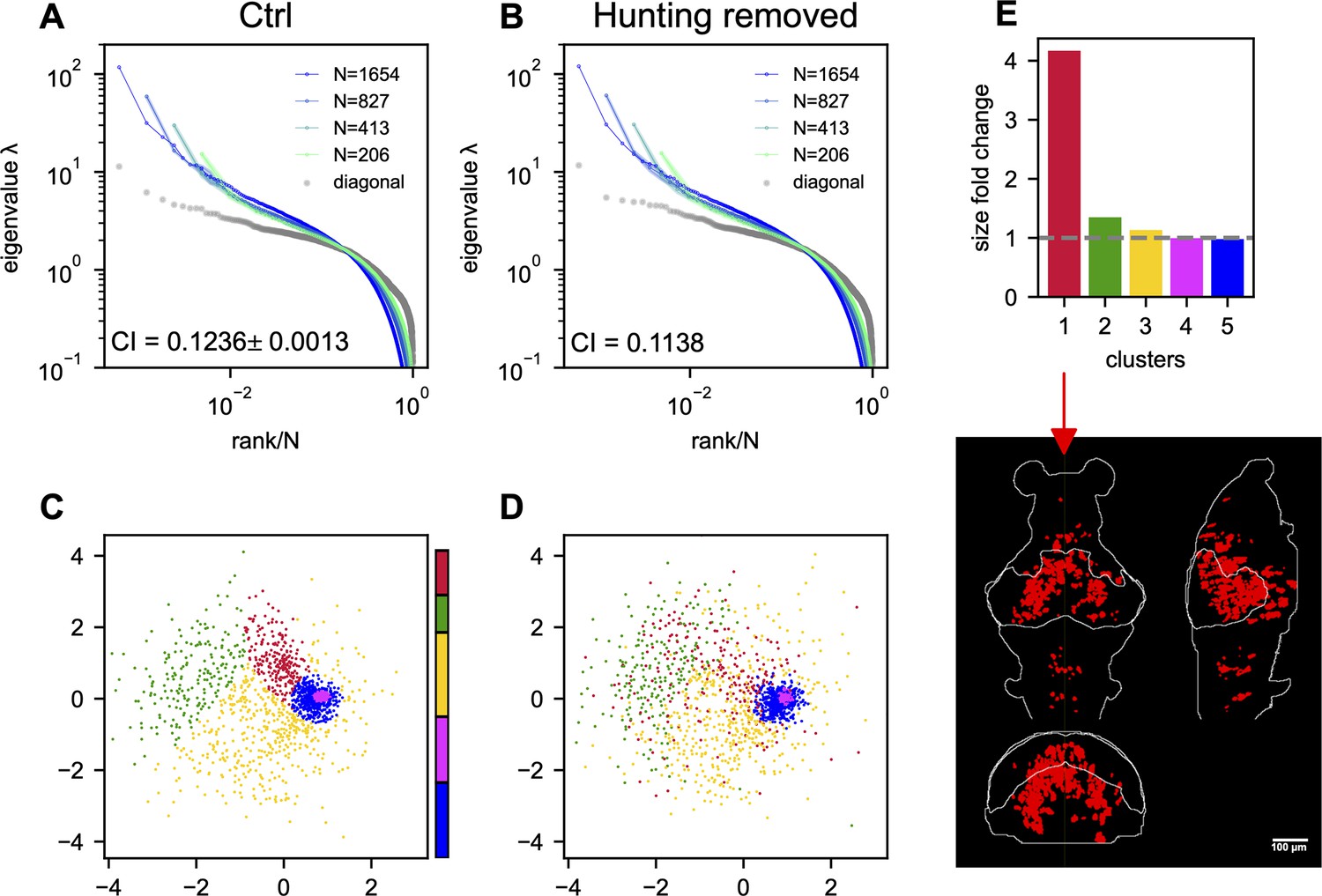
The effects of hunting behavior on scale invariance and functional space organization.
Sampled covariance eigenspectra of the data from fish 1 calculated from control (A) and hunting removed (B) data . Ctrl: We randomly remove the same number of non-hunting frames. This process is repeated 10 times, and the mean ± SD of the CI is shown in the plot. Hunting removed: The time frames corresponding to the eye-converged intervals (putative hunting state) are removed when calculating the covariance (Appendix 1). The CI for the hunting-removed data appears to be statistically smaller than in the control case (p-value = 1.5 × 10−9). (C) Functional space organization of control data. The neurons are clustered using the Gaussian Mixture Models (GMMs) and their cluster memberships are shown by the color. The color bar represents the proportion of neurons that belong to each cluster. (D) Similar to (C) but the functional coordinates are inferred from the hunting-removed data. The color code of each neuron is the same as that of the control data (C), which allows for a comparison of the changes to the clusters under the hunting-removed condition. See also the Movie S1. (E) Fold change in size/area (Appendix 1) for each cluster (top; the gray dashed line represents a fold change of 1, i.e., no change in size) and the anatomical distribution of the most dispersed cluster (bottom).
Appendix 1—figure 8
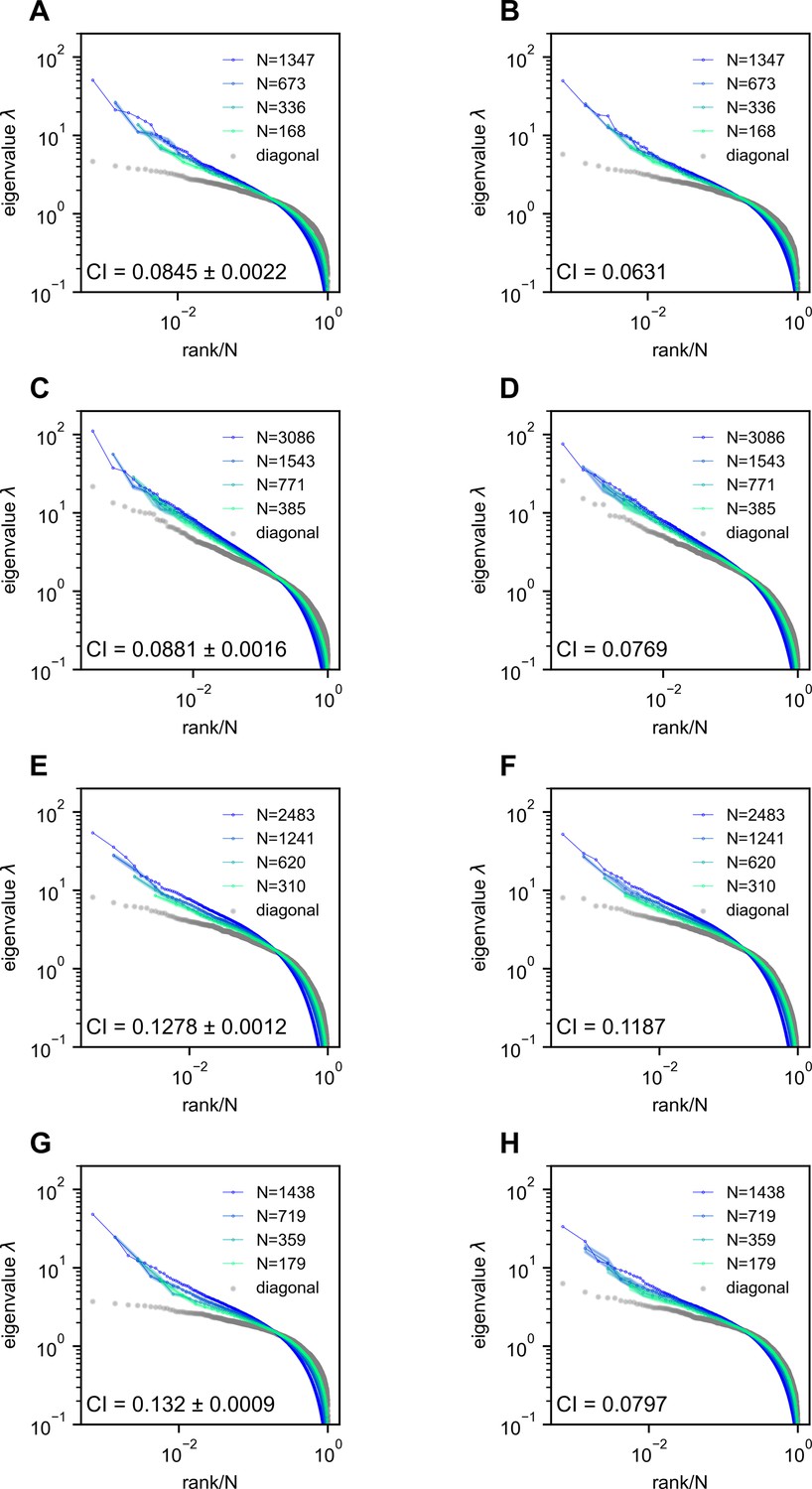
Removing the time segment of hunting behavior does not obliterate the scale-invariant eigenspectra.
Rows correspond to four light-field zebrafish data: fish 2 to fish 5 (results for fish 1 have been shown in Appendix 1—figure 7). (A, C, E, G) Ctrl: we randomly remove the same number of time frames that are not the putative hunting frames. We repeat this process 10 times to generate 10 control covariance matrices and the CI is represented by mean ± SD. (B, D, F, H) Hunting removed: data obtained by removing hunting frames from the full data (Appendix 1). The CI for the hunting removed data appears to be significantly smaller than that of the control case (one-sample t-test in fish 2, in fish 3, in fish 4, and in fish 5).
Appendix 1—figure 9
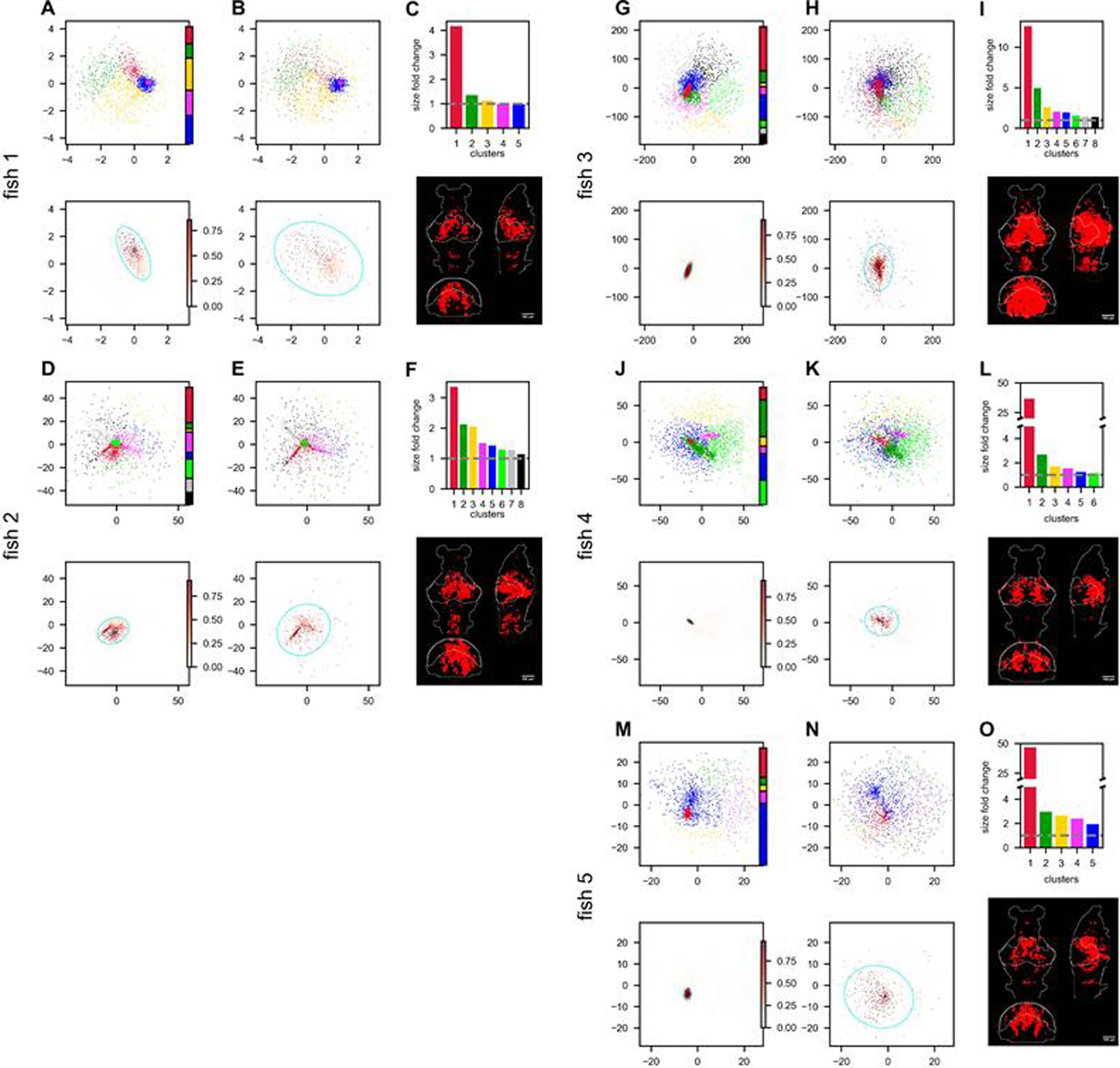
Hunting behavior reorganizes neurons in the functional space (continued on next page).
Rows correspond to five light-field recordings of zebrafish engaged in hunting behavior: fish 1 to fish 5. (A, D, G, J, M) (top) Functional space organization of the control data inferred by fitting the ERM and MDS (Result). Neurons are clustered using the Gaussian Mixture Models (GMMs) and their cluster memberships are shown by the color. The colorbar represents the proportion of neurons belonging to each cluster. (A, D, G, J, M) (bottom) The coordinate distribution of the cluster in control data which is most dispersed (i.e., largest fold change in size, see below) after hunting-removal. The transparency of the dots (colorbar) is proportional to the probability of the neurons belonging to this cluster (Appendix 1). The cyan ellipse serves as a visual aid for the cluster size: it encloses 95% of the neurons belonging to that cluster (Appendix 1). (B, E, H, K, N) (top) Similar to (A, D, G, J, M) (top) but the functional coordinates are inferred from the hunting-removed data. The color code of each neuron is the same as that in the control data, which allows for a comparison of the changes to the clusters under the hunting-removed condition. (B, E, H, K, N) (bottom) Similar to (A, D, G, J, M) (bottom) but the functional coordinates are inferred from the hunting-removed data. The transparency of each neuron is the same as in (A, D, G, J, M). (bottom), and it represents the probability (Appendix 1) of neurons belonging to the most dispersed cluster in the control data. Likewise, the cyan ellipse encloses 95% of the neurons belonging to that cluster (Appendix 1). (C, F, I, L, O) Top, size/area fold change (Appendix 1) for each cluster (the gray dashed line represents a fold change of 1, i.e., no change in size); bottom, the anatomical distribution of the neurons in the most dispersed cluster.
Appendix 1—video 1
Neural activity patterns in anatomical and functional space during hunting (click here).
Single-trial examples of fish 1 and fish 3. (A) Inferred firing rate activity in anatomical space. Scale bar, 100 µm. (B) Inferred firing rate activity in functional space. Functional space organization of the control data inferred by fitting the ERM and MDS in Result. The cyan ellipse serves as a visual aid for the cluster size: it encloses 95% of the neurons belonging to that cluster (Appendix 1). The inset illustrates the functional space organization, similar to that shown in Appendix 1—figure 7C. The colorbars in panels A and B depict the inferred activity magnitude of individual neurons. (C) Simultaneous behavior recording alongside the neural activity. Time, seconds.
Appendix 2
In this appendix, we elaborate upon the sketch introduced in the Methods, and present a full derivation of the covariance eigenspectrum of our ERM model. This section is organized as follows. First, we will briefly introduce the relationship between the eigenvalue probability density distribution and the resolvent. Second, we will turn the problem of calculating the resolvent to a calculation of the partition function using a field-theoretic representation and proceed to manipulate the partition function using the replica method. Third, we will introduce two approximate methods for calculating the partition function, leading to the high-density theory and the Gaussian variational method. We will discuss the implications and predictions of each method. Finally, we will discuss the relationship between the two methods and identify the parameter regime where the high-density theory agrees with the numerical simulation. Notation table: Appendix 2—table 1.
Resolvent
The eigenvalues of a Hermitian matrix are real. Their probability density function or eigendensity is formally given by
(S4)
where represents an average across different realizations of . The eigendensity is connected with the resolvent (Mézard et al., 1999; Goetschy and Skipetrov, 2013),
(S5)
we therefore compute the eigendensity using the standard inverse formula of Stieltjes tranform:
(S6)
Field representation
In this section, we discuss a field-theoretical representation of the resolvent . First, we rewrite Equation S5 as
(S7)
The determinant can be represented as a Gaussian integral
(S8)
where , and .
(S9)
We thus establish a relationship between the resolvent and
(S10)
Note that the constant term in Equation S9 can be killed by and we will ignore it in the sequel. Equation S10 is the central formula in this note. is also called the partition function in statistical physics. We endeavor to find a way to compute the average of .
Recall that in our ERM model (Result Equation S2 and Figure 3A), the covariance between neuron i and neuron j is determined by the distance kernel function and their neural activity variances:
(S11)
where are sampled from a uniform coordinate distribution are i.i.d. chosen from a probability density distribution and are independent of the neuron coordinates . The in Equation S10 is therefore an average over all possible and . In order to compute , we apply the replica method based on a smart use of the identity
Equation S10 now becomes
(S12)
The idea is to compute the right-hand side for finite and integer and then perform the analytic continuation to .
Now we seek to determine the value of . It contains copies (replicas) of the original system
(S13)
Writing it down explicitly, we have
(S14)
In order to proceed further, we introduce the following auxiliary fields:
(S15)
Equation S15 can be represented as a following functional integral
(S16)
(S17)
or we can combine Equations S16 and S17 as
(S18)
Using Equation S15, we can write the term in Equation S14 as
(S19)
We insert the relation Equations S18 and S19 into Equation S14,
(S20)
Integrating the last term in Equation S20
(S21)
so that from Equation S14 can be written as
(S22)
(S23)
(S24)
Integrating out the in Equations S22 and S24
(S25)
Here, is the inverse kernel satisfying:
(S26)
so that can be written as
(S27)
(S28)
The constant term of can be ignored because we should compute Equation S10 in the end.
To ensure the mathematical rigor in Equation S45, we next apply the Wick rotation (Appendix 2).
(S29)
(S30)
(S31)
High-density expansion
In this section, we directly calculate the canonical partition function in the limit by approximating the term (Equation S30) to a quadratic action, from which the partition function (Equation S29) would become a Gaussian integral.
Let us first calculate the in limit
(S32)
(S33)
Now let us calculate (Equation S29–S31) by letting
(S34)
where the high-density quadratic action
(S35)
where . Next, by integrating out the field, we find
(S36)
Using Equation S12 that connects the partition function with the resolvent, we have
(S37)
where is the Fourier transform of .
Finally, the eigendensity (Equation S6) is given by
(S38)
Derivation of power-law eigenspectrum in high-density limit
Here we calculate the eigendensity of our model, with the kernel function (Table 3). The Equation S38 (set as in Result) can be written as:
(S39)
where is the surface area of dimensional sphere. Here, we consider the approximation , whose Fourier transform and its derivative are , and . The constants are given by , ,
(S40)
Derivation of eigenspectrum with exponential kernel function in high-density limit
Here we consider the exponential kernel function , whose Fourier transform and its derivative are , and , , where
(S41)
It is straightforward to see that this spectrum is not scale invariant. For example, when , the above expression reduces to a perfect power-law spectrum , which changes with scale over sampling.
Variational approximation
To find a general approximation for the eigenspectrum that goes beyond the high-density limit, we use Gaussian variational approximation in the field representation, namely by looking for the best quadratic action ,
(S42)
to approximate the action in the partition function (Equations S29–S31). This enables us to represent the partition function by a Gaussian integral, which can be evaluated analytically. We find the best quadratic action by minimizing the difference between and , which is defined as KL divergence between two distributions that are proportional to and .
In this section, we will proceed by using the grand canonical ensemble formulation, namely the average in Equation S4, instead of using a fixed covariance matrix size , which is now carried out across all different sizes. If follows a Poisson distribution, it is easy to show (Appendix 2) that the grand canonical partition function is given by Equation S116:
where . As a result, the new action becomes
(S43)
Here and below, should be viewed as the average matrix size. The resolvent in Equation S12 can be similarly generalized to Equation S117,
As in statistical physics, we define the free energy as
(S44)
We shall define the variational free energy such that it would approximate the true free energy by minimizing ,
(S45)
where
(S46)
(S47)
The KL divergence is always nonnegative and the free energy is independent of the quadratic action . Therefore, we need to minimize the variational free energy . Let us now examine the variational free energy
(S48)
Here is the normalization factor
(S49)
Since we want to minimize , the constant term
(S50)
can beignored, and Equation S48 is reduced to
(S51)
To simplify the formula, let us introduce
(S52)
and rewrite Equation S51 as
(S53)
Next, we will compute each term in the variational free energy First, we calculate the third term in Equation S53 by Equations S42 and S49
(S54)
Second, we calculate the first term in Equation S53
(S55)
Third, we calculate the second term in Equation S53, recall the term (Equation S31)
(S56)
where
(S57)
(S58)
(S59)
In sum, the variational free energy is equal to
(S60)
Now let us find the best quadratic action that minimizes the variational free energy
(S61)
The solution of Equation S61 is given by
(S62)
(S63)
where . By using Equation S117, we finally obtain
(S64)
Scale invariance of the covariance spectrum in the Gaussian variational Model
In Result, we point to two factors that contribute to the scale invariance of eigenspectrum using the high-density theory. In this section, we show that the same conclusion can be drawn by using the Gaussian variational method. Furthermore, we examine how the heterogeneity of neural activity influences the eigendensity calculated by the Gaussian variational model. We show that , which characterizes the change of eigendensity due to sampling in the functional space, decreases with the heterogeneity of neural activity described by higher-order moment of neural activity variance, for example, .
Let us rewrite Equation S63 as
(S65)
To present a formal expression for the eigendensity, let us define , . From Equations S6 and S64, we find
(S66)
where .
A direct computation of Equation S66, however, remains difficult: the complication arises from the complex function in Equation S65, which in turn is an integral function of . To streamline the calculation, let us further define , . Writing it down explicitly, we have
(S67)
(S68)
The real and imaginary part of can now be expressed as functions of a and b. Integrating Equation S65 in the spherical coordinates, we have
(S69)
where for clarity, we have abused the notation a bit by defining is the surface area of unit -ball in the momentum space. In order to evaluate the integrals analytically, we introduce an ultraviolet cutoff . Numerically, whether integrating up to or greater than this bound shows little difference.
Numerical solution of the Gaussian variational method
With Equations S66–S69, we numerically calculate the eigendensity iteratively from the following steps:
Step 1: set the initial values of a and b as ,
Step 2: solve for a in Equation S67 with fixed b
Step 3: solve for b in Equation S68 with fixed a
Step 4: iterate Steps 2 and 3 10 times
Step 5: calculate using Equation S66
Note that we plug Equation S69 into Equations S67 and S68 in step 2–3.
Two contributing factors on the scale invariance
We next derive an analytical expression for Equation S69 by considering the approximate power law kernel function , from which the high-density theory results on the scale invariance can be extended.
By a change of variable , and let , , we have
(S70)
where ∼ indicates that all constant numerical factors (e.g., π and ) are ignored. To compute Equation S70, we perform a branch cut at , and perform a contour integral on the complex plane following the path in , Appendix 2—figure 1A. When , the integral on the large circle and the small circle goes to zero as , leaving only two simple poles (zeros of the function in the denominator) in the complex plane. By applying the residue theorem, we find an expression for in the limit
(S71)
The analytical expression for is a bit more involving.
(S72)
It has two terms, the second term is similar to Equation S70; the first term, however, diverges as . Thus, the radius of the small circle in Appendix 2—figure 1 cannot shrink to zero: this is precisely the requirement of an ultraviolet cutoff in the wave vector . The contour integral on the large circle , on the other hand, goes to zero as . Thus, the integral on contributes to the final result. By considering leading order term of for finite but small , we find
(S73)
Recall , and we find that the first term in is proportional to , independent of ε.
Appendix 2—figure 1
Calculate and .
(A) The path of the contour integral for , (Equation S70). The heatmap of and with respect to λ and ρ, in (B, C) are calculated by the numerical method (Methods). The parameters are , , , , , is i.i.d. sampled from a log-normal distribution with zero mean and a standard deviation of 0.5 in the natural logarithm of the values; we also normalize .
According to Equation S71 and S73, one can immediately see that as , the ρ-dependence relationship vanishes for and . We therefore conclude that a slower power-law decay in the kernel function and/or a higher dimension of the functional space are two contributing factors for the scale invariance of the covariance spectrum.
Heterogeneity of neural activity across neurons enhances scale invariance
Next, we take a more close look at how the eigendensity changes with ρ for finite but small and when . Using Equation S66, we have
(S74)
From numerical calculation, we find that typically , so one can use the approximation
(S75)
Recall Equation S66
(S76)
Since is very small for large λ, a more appropriate measure is to examine
(S77)
Considering the large eigenvalue case (the numerical value of is on the order of 1), we perform Taylor expansion and arrive at
(S78)
(S79)
Note is normalized to 1.
(S80)
By examining Equations S71 and S73, we find that when , , , decays weakly with ρ while increases weakly with ρ (also confirmed by numerical calculation, Figure 1B, C)
It is therefore straightforward to see from 80 that the higher-order moment (e.g., ) in the activity variance contributes to reducing the -dependence in the eigendensity function.
The relationship between CI and eigendensity
In this section, we show how the CI introduced in Methods is related to Equation S80, namely how the eigendensity changes with the neuronal density in the functional space. Recall the definition of CI in Equation S13:
where
we used implicit differentiation to compute . For clarity, we write the function explicitly involving λ and ρ as in Equations S81–S83.
(S81)
(S82)
(S83)
Now we can write CI as
(S84)
from which we arrive at Equation S15 in Methods:
(S85)
Finally, we can rewrite CI as a function of using a double integral:
(S86)
Compare high-density theory and Gaussian variational method
This section aims to determine the conditions under which the high-density approximation aligns with the simulation results. To this end, we begin by comparing the kernel operator in the high-density quadratic action and in the variational approximation. We identify the condition when high-density theory would agree with the variational method as well as the numerical simulation, namely . Secondly, we give a precise re-derivation of the high-density result by incorporating this condition into the variational approximation. Finally, we substitute with and estimate the parameter regime where the high-density theory would agree with numerical simulation. This analysis yields a deeper understanding of the relationship between high-density theory and variational method, and how they relate to simulation results.
A simple comparison of the two methods
For the sake of simplicity, we consider the correlation matrix with in this section. Returning to the explicit result Equation S29–S31 ,
(S87)
In the high-density approximation (Equation S35)
(S88)
Here, we introduce as the kernel operator in the high-density quadratic action.
(S89)
Fourier transform of leads to
(S90)
In the variational method Equation S63, we have
(S91)
where we introduce as the kernel operator in the variational quadratic action. Clearly, the condition that approaches is given by
The function is defined as:
As approaches 0, becomes identical to . Note that is difficult to compute; instead, we can compute and analyze (see Appendix 2)
(S92)
A re-derivation of the high-density result using the grand canonical ensemble
In this section, we re-derive the high-density result from the grand canonical ensemble and the variational method. The derivation also allows us to reproduce the approximation condition discussed in the previous section.
Let us recall the calculation of the free energy (Equation S60) in the variational approximation with
(S93)
(S94)
Following Equations S61 and S63:
(S95)
(S96)
(S97)
We can perform the same calculation in the high-density theory by considering the limit :
(S98)
Therefore, we can define the free energy in the high-density theory as
(S99)
then
(S100)
(S101)
This is precisely Equation S90 derived in the previous section.
(S102)
which is the resolvent of high-density approximation (Equation S37).
Explicit expression for the integral
In this section, we provide an explicit expression for the integral instead of , which is implicit and can not be calculated analytically. Like the derivation in Appendix 1—figure 9, we consider the lower and upper limits of integration for as . We then approximate the Fourier transform as a power-law function. To ensure that the singularity of falls within the integration range of , we introduce a simple correction to :
(103)
where , are all constants depending on the parameters , , and . Then we compute the contour integral (Appendix 2—figure 1A) by Taylor expansion. As a result, we have
(S104)
where .
Now let us take a close look at the behavior of the function Equation S92, plotted in Appendix 2—figure 2A,B . For small z, this function is negative. It then crosses zero and has a peak. As , the approaches zero. This is because Equation S104 approaches a positive constant, which is given by
where . For , we find the leading order expansion at already gives an accurate approximation (Appendix 2—figure 2A,B).
(S105)
Estimate the parameter condition when the high-density theory best agrees with numerical simulation
By analyzing the properties of the function , we think the high-density theory provides an accurate approximation when the zero-crossing of is near (the peak of low-density result Mézard et al., 1999) The root of the integral is given by
(S106)
It is easy to see that is a function of (or ) from Equation S104. We can rewrite Equation S106 as
(S107)
Here, we can also see that can be expressed as:
Using this expression for and letting , we can derive the following equation for , a dimensionless parameter that determines the condition when the high-density theory is an accurate approximation of our ERM model:
(S108)
Appendix 2—figure 2C shows how changes as a function for a small and fixed . For example, when , , , we find
This estimate is also consistent with our numerical simulation (Figure 4—figure supplement 1).
Wick rotation
To ensure mathematical rigor in Appendix 2, we should make sure that the action in Equation S46 is a real number. Here, we use Wick rotation to transform Equations S28–S30. The Gaussian integral Equation S29 can be divergent when is not positive definite, To address this issue, we can always write the partition function as a Gaussian integral by choosing the appropriate axes with Wick rotation.
(S109)
We can now change the integration variables by diagonalizing to via ,where is Fourier base
(S110)
(S111)
by letting . Note that is analytic. Thus if
and the convergence rate is faster than , we can apply the Wick rotation : instead of computing the integral on the real axis , we now rotate the integral line 45 degree clockwise to in the complex plane:
(S112)
On the other hand, if
and the convergence rate is faster than , we can apply the Wick rotation , namely to rotate the integral line 45 degree counterclockwise to :
(S113)
As a simple example, consider a one-dimensional Gaussian integral
When , we can use the Wick rotation
When , we can use the Wick rotation
Without loss of generality, we rotate in Appendix 2 for subsequent calculations.
Grand canonical ensemble
When using the Gaussian variational Approximation, we consider a critical extension from the canonical ensemble to the grand canonical ensemble when computing the partition function (Equation S9). We would like to justify this approximation in this section. Recall that the resolvent is given by
where can be viewed as the canonical partition function, the is the average over all random matrices for a given . Let us now generalize (Equation S9) into grand canonical ensemble, namely
(S114)
where indicates that we need to average over all possible random matrices and across all possible , with the probability to have a matrix size given by the Poisson distribution , where . When is large, has a very sharp peak at , and Equation S114 can be approximated as
(S115)
Using the replica trick, we recall Equation S12
Let us now define the grand canonical partition function as
(S116)
Likewise, the resolvent in Equation S12 is generalized to
(S117)
To see whether this definition makes sense, we write
(S118)
where the second equality uses the identity
and the last equality is indeed Equation S115 discussed earlier. Returning back to the explicit form of the grand canonical partition function in our ERM model (Equations S29–S31), we have
(S119)
Here, is the auxiliary fields (Equation S15), and are terms defined in Equation S119, Equations S29–S31 is used in Appendix 2 to compute the free energy.
E-I balanced asynchronized model summary
In this section, we discuss the E-I balanced asynchronized model (Renart et al., 2010), which predicts a different scaling D N under random sampling, since the variance scales as 1/N and diminishes as N approaches large limit.
Model
The simulation of binary networks involves updating neuron states within a network architecture identical to analytical studies. The update rule is probabilistic, with neuron activities set based on synaptic currents and a firing threshold. The dynamics resolution improves with network size, with neuron time constants effectively representing changes in firing activity. Parameters for simulations include connection probabilities, mean rates, thresholds, and synaptic strengths, scaled appropriately for network size.
Update rule:
Dynamics resolution:
In the simulation of binary networks, the model’s dynamics are governed by a set of parameters, each with a specific role: : This represents the state of neuron i in population α at the next time step . The state is binary, where 1 indicates the neuron is active (firing) and 0 indicates it is inactive.
: The Heaviside step function used in the update rule. It determines the neuron’s next state by comparing the net input to the neuron against its firing threshold. If the net input exceeds the threshold, the neuron’s state is set to active; otherwise, it remains or becomes inactive.
: This sum represents the total synaptic input to neuron i from all neurons j in population β at time t . is the synaptic weight from neuron j in population β to neuron i in population α, and is the state of neuron j at time t.
: The firing threshold of neuron i in population α. It is the value against which the net synaptic input is compared to determine whether neuron i will fire (transition to state 1) or not (remain in state 0).
, : Represents a specific population of neurons within the network. E: excitatory neurons, I: inhibitory neurons, or X: external source of neurons that provide inputs to the network but are not influenced by the network’s internal dynamics.
Firing Rate Correlation
The mean firing rate correlation scales inversely with the network size , specifically, . The standard deviation of decays only as (Renart et al., 2010).
Given that the variance of , denoted as , is , and the expected value of , denoted as , is , where is the sample size, and a and b are constants, we aim to calculate , the expected value of the square of the correlation coefficient .
The term in PR dimension is given by:
(S120)
Substituting and into the equation, we get:
(S121)
Thus in PR dimension , the term and are of the same order, and the PR dimension will not reach the upper bound .
Appendix 2—figure 2
Relationship between and .
(A) , (B) . Blue line: calculated numerically. Red line: 100-order expansion of Equation S104, which perfectly overlaps with the blue line. Green line: expansion to the first order. Other parameter: , , . (C) Relationship between and dimension with fixed Equation S108.
Appendix 2—figure 3
Wick rotation in complex plane.
Appendix 2—table 1
Table of notations.
| Notation | Description |
|---|---|
| Resolvent Equation S5 | |
| The average across realizations of 𝐶 (i.e., random and ’s), Equation S4 | |
| Canonical partition function, Gaussian integral representation of the determinant , Equation S8 | |
| Intermediate variable for Gaussian integral representation , Equation S8 | |
| Density field of | |
| Respective Lagrange multiplier fields of | |
| The action in (by analogy with the path integral formulation of quantum mechanics) | |
| The action in the high-density approximation of | |
| The action in the variational approximation of | |
| Term in | |
| The operator inverse of , Equation S26 | |
| Quadratic kernel in the Gaussian integral approximation of | |
| The operator inverse of , same definition as | |
| The Fourier transform of |
Data availability
The source code in this work can be found at https://github.com/wzz1999/ERM-scale (copy archived at Mak and Wang, 2025). The fish data collected and analyzed in this work can be found at https://doi.org/10.6084/m9.figshare.28721477.
-
figshareEight-probe Neuropixels recordings during spontaneous behaviors.https://doi.org/10.25378/janelia.7739750
-
figshareRecordings of ten thousand neurons in visual cortex during spontaneous behaviors.https://doi.org/10.25378/janelia.6163622
References
-
Neuronal avalanches in neocortical circuitsThe Journal of Neuroscience 23:11167–11177.https://doi.org/10.1523/JNEUROSCI.23-35-11167.2003
-
Prey capture behavior evoked by simple visual stimuli in larval zebrafishFrontiers in Systems Neuroscience 5:101.https://doi.org/10.3389/fnsys.2011.00101
-
Eigenvalues of euclidean random matricesRandom Structures & Algorithms 33:515–532.https://doi.org/10.1002/rsa.20228
-
Large-scale recording of neuronal ensemblesNature Neuroscience 7:446–451.https://doi.org/10.1038/nn1233
-
Neural population geometry: An approach for understanding biological and artificial neural networksCurrent Opinion in Neurobiology 70:137–144.https://doi.org/10.1016/j.conb.2021.10.010
-
Dimension of activity in random neural networksPhysical Review Letters 131:118401.https://doi.org/10.1103/PhysRevLett.131.118401
-
Dimensionality reduction for large-scale neural recordingsNature Neuroscience 17:1500–1509.https://doi.org/10.1038/nn.3776
-
Fast online deconvolution of calcium imaging dataPLOS Computational Biology 13:e1005423.https://doi.org/10.1371/journal.pcbi.1005423
-
On simplicity and complexity in the brave new world of large-scale neuroscienceCurrent Opinion in Neurobiology 32:148–155.https://doi.org/10.1016/j.conb.2015.04.003
-
Optical probing of neuronal ensemble activityCurrent Opinion in Neurobiology 19:520–529.https://doi.org/10.1016/j.conb.2009.09.003
-
The spectrum of covariance matrices of randomly connected recurrent neuronal networks with linear dynamicsPLOS Computational Biology 18:e1010327.https://doi.org/10.1371/journal.pcbi.1010327
-
Receptive fields of single neurones in the cat’s striate cortexThe Journal of Physiology 148:574–591.https://doi.org/10.1113/jphysiol.1959.sp006308
-
BookStatistical Physics of FieldsCambridge University Press.https://doi.org/10.1017/CBO9780511815881
-
Canonical correlation analysis: A general parametric significance-testing systemPsychological Bulletin 85:410–416.https://doi.org/10.1037//0033-2909.85.2.410
-
Neural tuning and representational geometryNature Reviews. Neuroscience 22:703–718.https://doi.org/10.1038/s41583-021-00502-3
-
Imaging whole-brain activity to understand behaviorNature Reviews. Physics 4:292–305.https://doi.org/10.1038/s42254-022-00430-w
-
DeepLabCut: markerless pose estimation of user-defined body parts with deep learningNature Neuroscience 21:1281–1289.https://doi.org/10.1038/s41593-018-0209-y
-
Coarse graining, fixed points, and scaling in a large population of neuronsPhysical Review Letters 123:178103.https://doi.org/10.1103/PhysRevLett.123.178103
-
Spectra of euclidean random matricesNuclear Physics B 559:689–701.https://doi.org/10.1016/S0550-3213(99)00428-9
-
Place cells, grid cells, and the brain’s spatial representation systemAnnual Review of Neuroscience 31:69–89.https://doi.org/10.1146/annurev.neuro.31.061307.090723
-
Single-trial neural dynamics are dominated by richly varied movementsNature Neuroscience 22:1677–1686.https://doi.org/10.1038/s41593-019-0502-4
-
Place units in the hippocampus of the freely moving ratExperimental Neurology 51:78–109.https://doi.org/10.1016/0014-4886(76)90055-8
-
Dimensionality in recurrent spiking networks: Global trends in activity and local origins in connectivityPLOS Computational Biology 15:e1006446.https://doi.org/10.1371/journal.pcbi.1006446
-
Nonrigid registration using free-form deformations: application to breast MR imagesIEEE Transactions on Medical Imaging 18:712–721.https://doi.org/10.1109/42.796284
-
How advances in neural recording affect data analysisNature Neuroscience 14:139–142.https://doi.org/10.1038/nn.2731
-
Thalamus-driven functional populations in frontal cortex support decision-makingNature Neuroscience 25:1339–1352.https://doi.org/10.1038/s41593-022-01171-w
Article and author information
Author details
Funding
Ministry of Science and Technology of the People's Republic of China (2022ZD0211900)
- Zezhen Wang
- Yuming Chai
- Kexin Qi
- Guodong Tan
- Quan Wen
Research Grants Council, University Grants Committee (ECS-26303921)
- Weihao Mai
- Yu Hu
National Science Foundation of China (NSFC-32071008)
- Zezhen Wang
- Yuming Chai
- Kexin Qi
- Guodong Tan
The funders had no role in study design, data collection, and interpretation, or the decision to submit the work for publication.
Acknowledgements
We are grateful to Liqun Luo and Changsong Zhou for their helpful suggestions on our manuscript. QW thanks Hideaki Shimazaki for the suggestion that the functional space could be the feature space for sensory coding. QW thanks Jia Lou for improving the illustration in Figures 1 and 3. QW was supported by the STI2030-Major Projects 2022ZD0211900 and the NSFC-32071008 from the National Science Foundation of China. YH was supported by ECS-26303921 from the Research Grants Council of Hong Kong.
Version history
- Sent for peer review:
- Preprint posted:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.100666. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2025, Wang, Mai, Chai et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 4,417
- views
-
- 408
- downloads
-
- 13
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 3
- citations for umbrella DOI https://doi.org/10.7554/eLife.100666
-
- 1
- citation for Reviewed Preprint v1 https://doi.org/10.7554/eLife.100666.1
-
- 2
- citations for Reviewed Preprint v2 https://doi.org/10.7554/eLife.100666.2
-
- 7
- citations for Version of Record https://doi.org/10.7554/eLife.100666.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
The geometry and dimensionality of brain-wide activity
eLife 14:RP100666.
https://doi.org/10.7554/eLife.100666.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}