Gene Expression: Bursting through the cell cycle
- Weizmann Institute of Science, Israel
Imagine trying to maintain a constant speed while driving a car. Sounds simple enough, but what if you’re only allowed to press the accelerator pedal intermittently. As strange as this driving technique seems, cells often behave in a comparable manner when transcribing genes to produce messenger RNA (mRNA) molecules. The mRNA molecules are produced when a region of the gene called the promoter is open: since these promoters randomly switch between open and closed states, the mRNA molecules are produced in bursts. Cells also degrade mRNA, just as friction from the road reduces the speed of a car. As a result, mRNA levels will rise and fall over time (Raj and van Oudenaarden, 2008).
Now let’s go back to our car analogy and add another complication. What if a second driver miraculously appears from time to time, controlling their accelerator independently of yours? How could you possibly avoid breaking the speed limit now? With double the acceleration you would have to compensate by either reducing how often or how hard you pressed the accelerator pedal.
Cells face a similar challenge when they replicate (Figure 1). During some phases of the cell cycle, the cell contains twice as many copies of each gene as usual, which could double the amount of mRNA that is produced. How do replicating cells compensate for this so that mRNA levels remain constant? Now, in eLife, Ido Golding and colleagues – including Samuel Skinner as first author – present an elegant framework that can be used to address this question (Skinner et al., 2016).
Figure 1
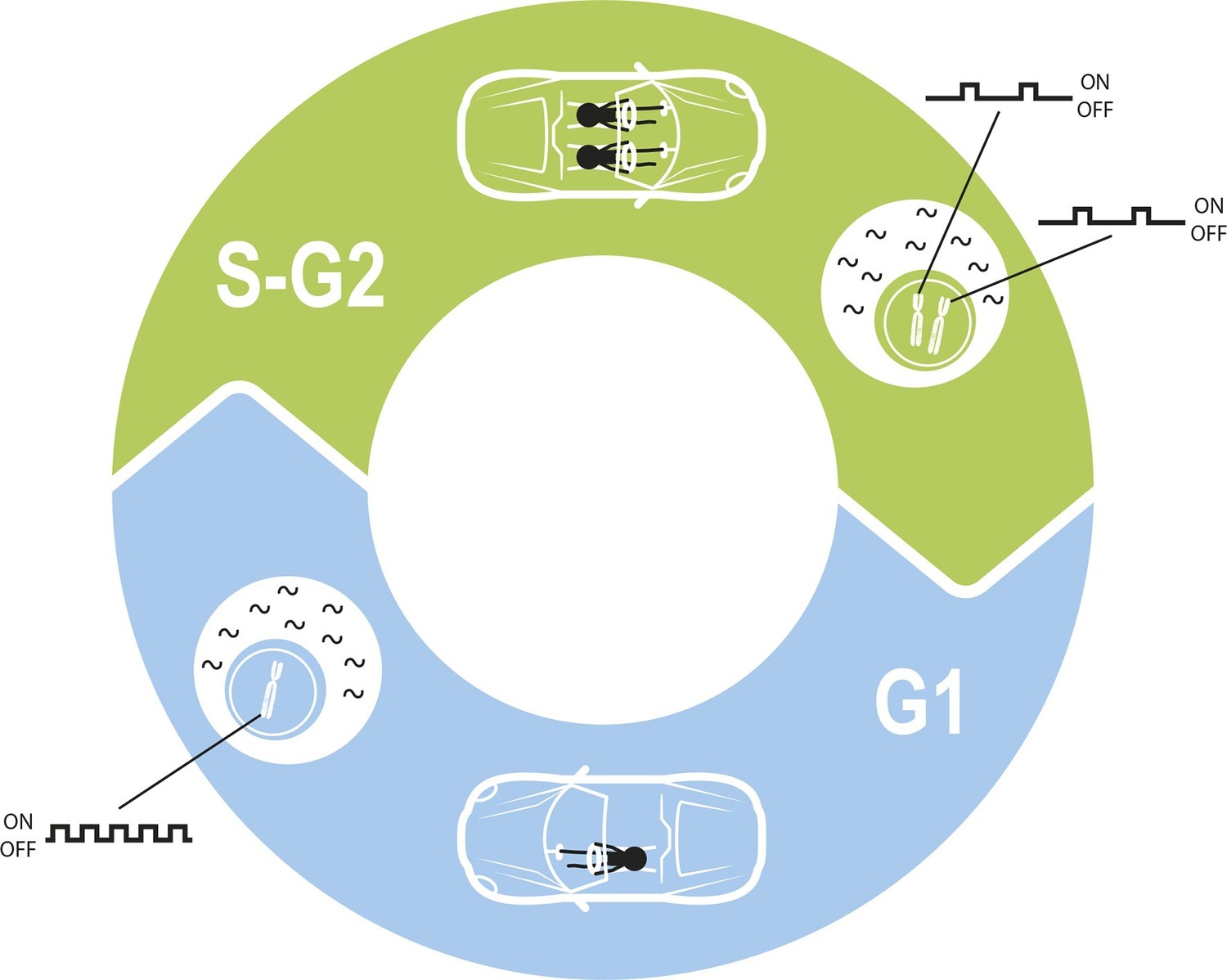
Maintaining constant levels of mRNA throughout the cell cycle.
During the G1 phase of the cell cycle (blue), the promoter for a given gene opens and closes to produce mRNA molecules (black waves) in bursts. However, during the S phase and G2 phase of the cell cycle (green), the cell contains twice as many copies of each gene as a result of replication. Cells must therefore compensate for these extra copies in order to maintain constant mRNA levels throughout the cell cycle. Skinner et al. found that this compensation is achieved by reducing the number of times per hour that the promoter is open. The challenge of maintaining a constant level of mRNA is similar to the challenge of maintaining a constant speed in a car in which a second driver periodically appears.
Using a technique called single-molecule mRNA fluorescence in-situ hybridization, Skinner et al. – who are based at Baylor College of Medicine, Rice University, the University of Illinois at Urbana-Champaign and the Icahn School of Medicine at Mount Sinai – quantified the levels of mature and newly transcribed mRNA molecules in individual mouse embryonic stem cells. They also measured how much DNA each cell contained and used this to work out which phase of the cell cycle the cell was in. These measurements allowed the activity of each copy of a particular gene to be analyzed before and after gene replication.
Skinner et al. found that two genes that are important in embryonic stem cells, Nanog and Oct4, are transcribed in a “bursty” manner. Furthermore, this activity reduces after DNA replication to compensate for the extra DNA in the cell, thus equalizing mRNA levels over the cell cycle. A similar "dosage compensation" mechanism for altering the rate of transcription following DNA replication has been documented in other biological systems (Fraser and Nurse, 1978; Padovan-Merhar et al., 2015; Voichek et al., 2016; Yunger et al., 2010).
There are three parameters that could be reduced to achieve dosage compensation: how often a given promoter opens per hour (the burst frequency); how long it remains open for; and the rate at which mRNA is produced from an open promoter (burst size). To identify which of these parameters are relevant in mouse stem cells, Skinner et al. developed a model that accounts for the fact that the number of copies of a gene changes during the cell cycle.
A simplified model in which the burst frequency was the only parameter that changed during the cell cycle resulted in an excellent fit to the experimental data. This means that cells seem to compensate for gene replication by having each copy switch to an open state less often, rather than by reducing how many mRNAs they produce when open. Skinner et al. also found that the burst frequency was the parameter that differed most between their two studied genes, Oct4 and Nanog. These results reinforce the findings of other recent studies in mammalian cells, which identified the importance of regulating transcription rate through changes in burst frequency. This regulation can occur throughout the cell cycle (Padovan-Merhar et al., 2015), in response to transcription factor levels (Senecal et al., 2014) or in liver genes in response to metabolic stimuli (Bahar Halpern et al., 2015).
The cell cycle poses additional challenges for cells. For one, cell division immediately halves mRNA production, and so mRNA levels must increase in preparation for this event. This is achieved through a mechanism that monitors the volume of the cell and increases burst size accordingly (Padovan-Merhar et al., 2015). In addition, mRNA degradation rates vary greatly between genes, posing different constraints on burst parameters and their compensation mechanisms. Again there are parallels with driving: it is much more difficult to maintain a constant speed on a dirt track than on a major highway.
Finally, there are cases where cells amplify variability in mRNA levels to generate differences between cells. An example is the bacterial stress response, where variable mRNA levels of key genes can help to vary the response (Eldar and Elowitz, 2010). Stem cell differentiation strategies may also change depending on the stage of the cell cycle that has been reached (Pauklin and Vallier, 2013). Skinner et al. now provide the tools to identify the burst parameters that vary throughout the cell cycle for any gene and biological system of interest.
References
-
Bursty gene expression in the intact mammalian liverMolecular Cell 58:147–156.https://doi.org/10.1016/j.molcel.2015.01.027
-
Expression homeostasis during DNA replicationScience 351:1087–1090.https://doi.org/10.1126/science.aad1162
Article and author information
Author details
Publication history
- Version of Record published: March 7, 2016 (version 1)
Copyright
© 2016, Ben-Moshe et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 4,722
- views
-
- 420
- downloads
-
- 5
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Gene Expression: Bursting through the cell cycle
eLife 5:e14953.
https://doi.org/10.7554/eLife.14953
Further reading
-
- Computational and Systems Biology
- Genetics and Genomics
We propose a new framework for human genetic association studies: at each locus, a deep learning model (in this study, Sei) is used to calculate the functional genomic activity score for two haplotypes per individual. This score, defined as the Haplotype Function Score (HFS), replaces the original genotype in association studies. Applying the HFS framework to 14 complex traits in the UK Biobank, we identified 3619 independent HFS–trait associations with a significance of p < 5 × 10−8. Fine-mapping revealed 2699 causal associations, corresponding to a median increase of 63 causal findings per trait compared with single-nucleotide polymorphism (SNP)-based analysis. HFS-based enrichment analysis uncovered 727 pathway–trait associations and 153 tissue–trait associations with strong biological interpretability, including ‘circadian pathway-chronotype’ and ‘arachidonic acid-intelligence’. Lastly, we applied least absolute shrinkage and selection operator (LASSO) regression to integrate HFS prediction score with SNP-based polygenic risk scores, which showed an improvement of 16.1–39.8% in cross-ancestry polygenic prediction. We concluded that HFS is a promising strategy for understanding the genetic basis of human complex traits.
-
- Computational and Systems Biology
Revealing protein binding sites with other molecules, such as nucleic acids, peptides, or small ligands, sheds light on disease mechanism elucidation and novel drug design. With the explosive growth of proteins in sequence databases, how to accurately and efficiently identify these binding sites from sequences becomes essential. However, current methods mostly rely on expensive multiple sequence alignments or experimental protein structures, limiting their genome-scale applications. Besides, these methods haven’t fully explored the geometry of the protein structures. Here, we propose GPSite, a multi-task network for simultaneously predicting binding residues of DNA, RNA, peptide, protein, ATP, HEM, and metal ions on proteins. GPSite was trained on informative sequence embeddings and predicted structures from protein language models, while comprehensively extracting residual and relational geometric contexts in an end-to-end manner. Experiments demonstrate that GPSite substantially surpasses state-of-the-art sequence-based and structure-based approaches on various benchmark datasets, even when the structures are not well-predicted. The low computational cost of GPSite enables rapid genome-scale binding residue annotations for over 568,000 sequences, providing opportunities to unveil unexplored associations of binding sites with molecular functions, biological processes, and genetic variants. The GPSite webserver and annotation database can be freely accessed at https://bio-web1.nscc-gz.cn/app/GPSite.




{kind=link}