Allosteric conformational ensembles have unlimited capacity for integrating information
- Department of Systems Biology, Harvard Medical School, United States
- Institute for Medical Engineering and Science, Department of Biological Engineering, Massachusetts Institute of Technology, United States
- Infectious Disease and Microbiome Program, Broad Institute of MIT and Harvard, United States
Abstract
Integration of binding information by macromolecular entities is fundamental to cellular functionality. Recent work has shown that such integration cannot be explained by pairwise cooperativities, in which binding is modulated by binding at another site. Higher-order cooperativities (HOCs), in which binding is collectively modulated by multiple other binding events, appear to be necessary but an appropriate mechanism has been lacking. We show here that HOCs arise through allostery, in which effective cooperativity emerges indirectly from an ensemble of dynamically interchanging conformations. Conformational ensembles play important roles in many cellular processes but their integrative capabilities remain poorly understood. We show that sufficiently complex ensembles can implement any form of information integration achievable without energy expenditure, including all patterns of HOCs. Our results provide a rigorous biophysical foundation for analysing the integration of binding information through allostery. We discuss the implications for eukaryotic gene regulation, where complex conformational dynamics accompanies widespread information integration.
Introduction
Cells receive information in different ways, of which molecular binding is the most diverse and widespread. Binding events influence downstream biological functions. In the biophysical treatment that we present here, biological functions, such as the output of a gene or the oxygen-carrying capacity of haemoglobin, are quantified as averages over the probabilities of microscopic states. We will be concerned with how binding events collectively determine these probability distributions and will refer to this process as the integration of binding information.
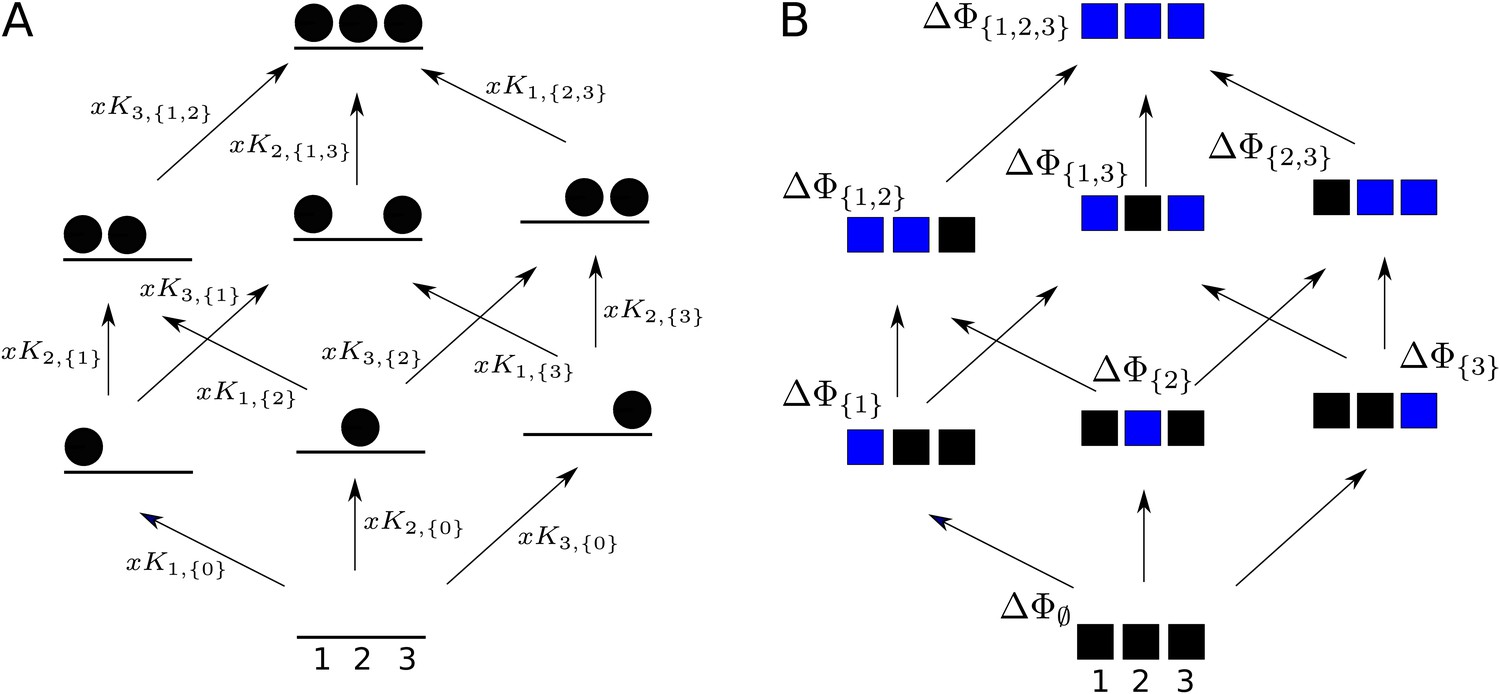
The most proximal form of such integration is pairwise cooperativity, in which binding at one site modulates binding at another site. This can arise through direct interaction, where one binding event creates a molecular surface, which either stabilises or destabilises the other binding event. This situation is illustrated in Figure 1A, which shows the binding of ligand to sites on a target molecule. (In considering the target of binding, we use ‘molecule’ for simplicity to denote any molecular entity, from a single polypeptide to a macromolecular aggregate such as an oligomer or complex with multiple components.) We use the notation for the association constant—on-rate divided by off-rate, with dimensions of (concentration)−1—where denotes the binding site and denotes the set of sites which are already bound. This notation was introduced in previous work (Estrada et al., 2016) and is explained further in the Materials and methods. It allows binding to be analysed while keeping track of the context in which binding occurs, which is essential for making sense of how binding information is integrated.
Figure 1
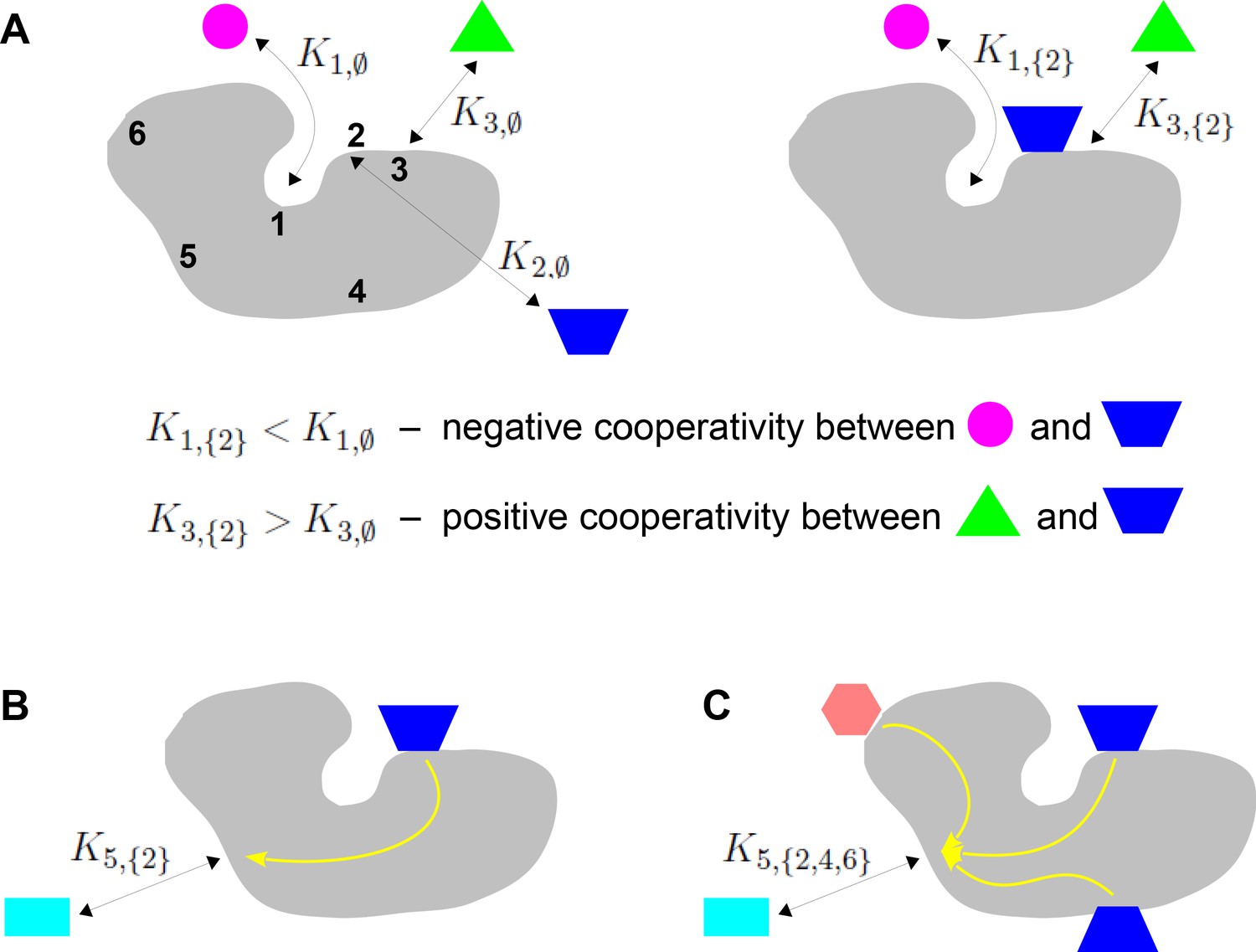
Binding cooperativity.
(A) Pairwise cooperativity by direct interaction on a target molecule (grey). As discussed in the text, the target could be any molecular entity. Left: target molecule with no ligands bound; numbers denote the binding sites. Right: target molecule after binding of blue ligand to site 2. (B) Indirect long-distance pairwise cooperativity, which can arise ‘effectively’ through allostery. (C) Higher-order cooperativity, in which multiple bound sites, 2, 4 and 6, affect binding at site 5.
Oxygen binding to haemoglobin is a classical example of integration of binding information, for which Linus Pauling gave the first biophysical definition of cooperativity (Pauling, 1935). At a time when the mechanistic details of haemoglobin were largely unknown, Pauling assumed that cooperativity arose from direct interactions between the four haem groups. He defined the pairwise cooperativity for binding to site , given that site is already bound, as the fold change in the association constant compared to when site is not bound. In other words, the pairwise cooperativity is given by , where denotes the empty set. (Pauling considered non-pairwise effects but deemed them unnecessary to account for the available data.) It is conventional to say that the cooperativity is ‘positive’ if this ratio is greater than 1 and ‘negative’ if this ratio is less than 1; the sites are said to be ‘independent’ if the cooperativity is exactly 1, in which case binding to site has no influence on binding to site . This terminology reflects the underlying free energy (Equation 1). Association constants and cooperativities may be thought of as an alternative way of describing the free-energy landscape, as we will explain in more detail in the Results. Figure 1A depicts the situation in which there is negative cooperativity for binding to site 1 and positive cooperativity for binding to site 3, given that site 2 is bound.
Studies of feedback inhibition in metabolic pathways revealed that information to modulate binding could also be conveyed over long distances on a target molecule, beyond the reach of direct interactions (Changeux, 1961; Gerhart, 2014; Figure 1B). Monod and Jacob coined the term ‘allostery’ for this form of indirect cooperativity (Monod and Jacob, 1961). Monod, Wyman and Changeux (MWC) and, independently, Koshland, Némethy and Filmer (KNF) put forward equilibrium thermodynamic models, which showed how effective cooperativity could arise from the interplay between ligand binding and conformational change (Koshland et al., 1966; Monod et al., 1965). In the two-conformation MWC model (Figure 2B), there is no ‘intrinsic’ cooperativity—the binding sites are independent in each conformation—and ‘effective’ cooperativity arises as an emergent property of the dynamically interchanging ensemble of conformations.
Figure 2
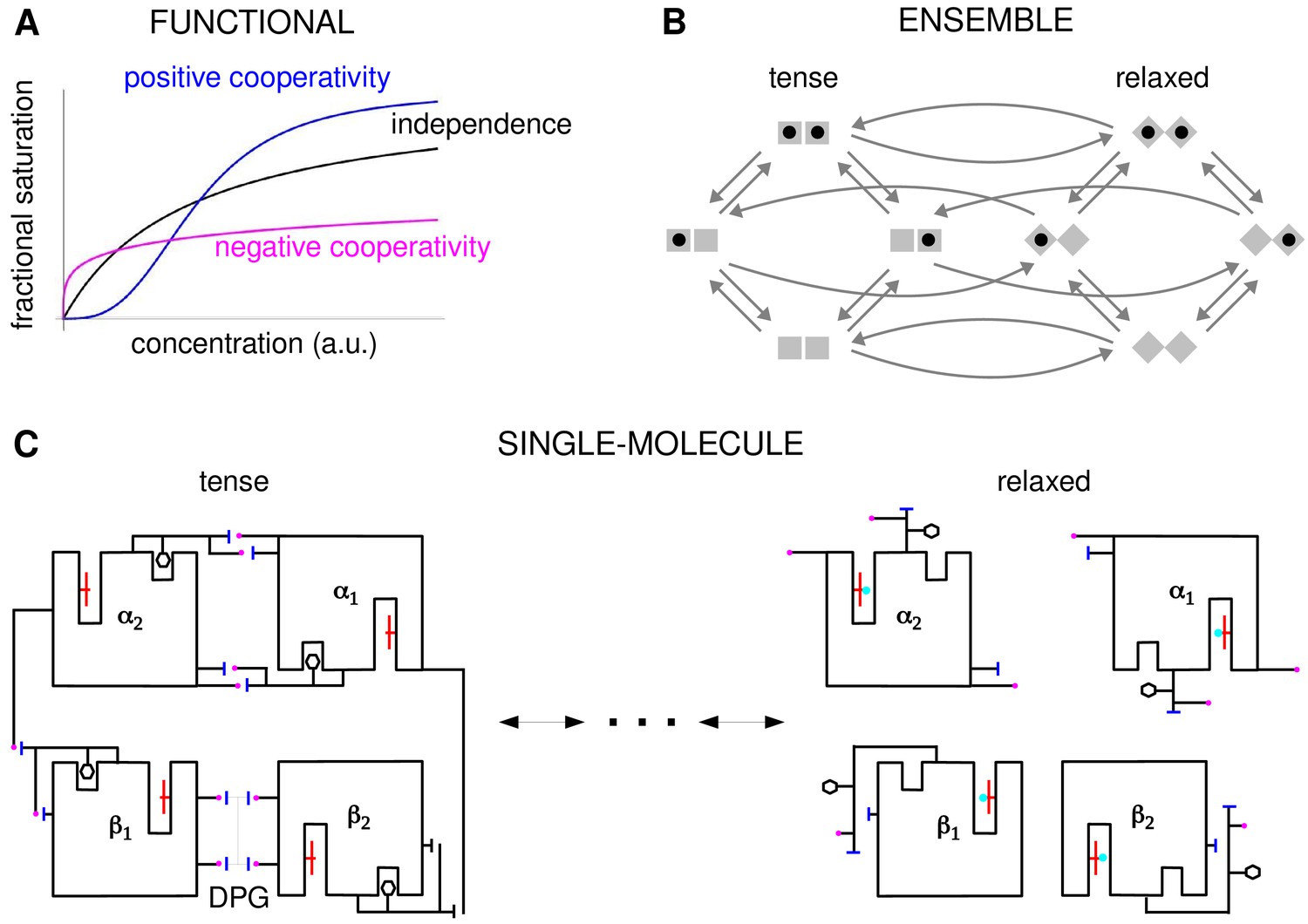
Cooperativity and allostery from three perspectives.
(A) Plots of the binding function, whose shape reflects the interactions between binding sites, as described in the text. (B) The Monod, Wyman and Changeux (MWC) model with a population of dimers in two quaternary conformations, with each monomer having one binding site and ligand binding shown by a solid black disc. The two monomers are considered to be distinguishable, leading to four microstates. Directed arrows show transitions between microstates. This picture anticipates the graph-theoretic representation used later in this paper. (C) Schematic of the end points of the allosteric pathway between the tense, fully deoxygenated and the relaxed, fully oxygenated conformations of a single haemoglobin tetramer, , showing the tertiary and quaternary changes, based on Figure 4 of Perutz, 1970. Haem group (red); oxygen (cyan disc); salt bridge (positive, magenta disc; negative, blue bar); DPG is 2–3-diphosphoglycerate.
In these studies, the effective cooperativity between sites was not quantitatively determined. Instead, the presence of cooperativity was inferred from the shape of the binding function, which is the average fraction of bound sites, or fractional saturation, as a function of ligand concentration (Figure 2A). The famous MWC formula is an expression for this binding function (Monod et al., 1965). If the sites are effectively independent, the binding function has a hyperbolic shape, similar to that of a Michaelis–Menten curve. A sigmoidal curve, which flattens first and then rises more steeply, indicates positive cooperativity, while a curve which rises steeply first and then flattens indicates negative cooperativity. Surprisingly, despite decades of study, the effective cooperativity of allostery is still largely assessed in this way, through the shape of the binding function, which is sometimes quantified in terms of a sensitivity or Hill coefficient. However, the shape of the binding function, and any associated Hill coefficient, are measures which aggregate over conformations and binding states, and they give little insight into how binding information is being integrated. To put it another way, the underlying free-energy landscape cannot be inferred from the shape of the binding function: as we will see below, different free-energy landscapes can give rise to indistinguishable binding functions. One of the contributions of this paper is to show how effective cooperativities can be quantified, providing thereby a set of parameters which collectively describe the allosteric free-energy landscape and placing allosteric information integration on a similar biophysical foundation to that provided by Pauling for direct interactions between two sites.
The MWC and KNF models are phenomenological: effective cooperativity arises as an emergent property of a conformational ensemble. This leaves open the question of how information is propagated between distant binding sites across a single molecule. This question was particularly relevant to haemoglobin, for which it had become clear that the haem groups were sufficiently far apart that direct interactions were implausible. Perutz’s X-ray crystallography studies of haemoglobin revealed a pathway of structural transitions during cooperative oxygen binding which linked one conformation to another (Figure 2C), thereby relating the single-molecule viewpoint to the ensemble viewpoint (Perutz, 1970). These pioneering studies provided important justification for key aspects of the MWC model, which has endured as one of the most successful mathematical models in biology (Changeux, 2013; Marzen et al., 2013).
Allostery was initially thought to be limited to certain symmetric protein oligomers like haemoglobin and to involve only a few, usually two, conformations. But Cooper and Dryden's theoretical demonstration that information could be conveyed by fluctuations around a dominant conformation anticipated the emergence of a more dynamical perspective (Cooper and Dryden, 1984; Henzler-Wildman and Kern, 2007). At the single-molecule level, it has been found that binding information can be conveyed over long distances by complex atomic networks, of which Perutz’s linear pathway (Figure 2C) is only a simple example (Schueler-Furman and Wodak, 2016; Kornev and Taylor, 2015; Knoverek et al., 2019; Wodak et al., 2019). These atomic networks may in turn underpin complex ensembles of conformations in many kinds of target molecules and allosteric regulation is now seen to be common to most cellular processes (Nussinov et al., 2013; Changeux and Christopoulos, 2016; Motlagh et al., 2014; Lorimer et al., 2018; Wodak et al., 2019; Ganser et al., 2019). The unexpected finding of widespread intrinsic disorder in proteins has been particularly influential in prompting a reassessment of the classical structure-function relationship, with conformations which may only be fleetingly present providing plasticity of binding to many partners (Wrabl et al., 2011; Wright and Dyson, 2015; Berlow et al., 2018).
However, while ensembles have grown greatly in complexity from MWC’s two conformations and new theoretical frameworks for studying them have been introduced (Wodak et al., 2019), the quantitative analysis of information integration has barely changed beyond pairwise cooperativity. In the present paper, we will be particularly concerned with higher-order cooperativities (HOCs) in which multiple binding events collectively modulate another binding site (Figure 1C). Such higher-order effects can be quantified by association constants, , where the set has more than one bound site. The size of , denoted by , is the order of cooperativity, so that pairwise cooperativity may be considered as HOC of order 1. For the example in Figure 1C, the ratio, , defines the non-dimensional HOC of order 3 for binding to site 5, given that sites 2, 4 and 6 are already bound. The notation used here is essential to express such higher-order concepts.
Higher-order effects have been discussed in previous studies (Dodd et al., 2004; Peeters et al., 2013; Martini, 2017; Gruber and Horovitz, 2018) and treated systematically in the mutant-cycle strategy developed in Horovitz and Fersht, 1990 and recently reviewed (Carter, 2017). The latter approach relies on perturbing residues or modules to unravel networks of energetic couplings within a macromolecule. It focusses on the single-molecule scale in contrast to the ensemble scale of the present paper (Figure 2). Mutant-cycle studies have confirmed the presence of substantial higher-order interactions underlying information propagation in proteins (Jain and Ranganathan, 2004; Sadovsky and Yifrach, 2007; Carter et al., 2017). The two approaches may be seen as different ways of analysing the free-energy landscape, as we explain in the Results.
HOCs were introduced in Estrada et al., 2016, where it was shown that experimental data on the sharpness of gene expression could not be accounted for purely in terms of pairwise cooperativities (Park et al., 2019a). In this context, the target molecule is the chromatin structure containing the relevant transcription factor (TF) binding sites and the analogue of the binding function is the steady-state probability of RNA polymerase being recruited, considered as a function of TF concentration (Estrada et al., 2016; Park et al., 2019a). The Hunchback gene considered in Estrada et al., 2016, Park et al., 2019a, which is thought to have six binding sites for the TF Bicoid, requires HOCs up to order 5 to account for the data, under the assumption that the regulatory machinery is operating without energy expenditure at thermodynamic equilibrium. An important problem emerging from this previous work, and one of the starting points for the present paper, is to identify a molecular mechanism capable of implementing such HOCs.
In the present paper, we show that allosteric conformational ensembles can implement any pattern of effective HOCs. Accordingly, they can implement any form of information integration that is achievable at thermodynamic equilibrium. We work at the ensemble level (Figure 2B) using a graph-based representation of Markov processes developed previously (below). We introduce a systematic method of ‘coarse graining’, which is likely to be broadly useful for other studies. This allows us to define the effective HOCs arising from any allosteric ensemble, no matter how complex. These effective HOCs provide a quantitative language in which the integrative capabilities of any ensemble can be specified. We show, in particular, that allosteric ensembles can account for the experimental data on Hunchback mentioned above, which was the problem that prompted the present study. It is straightforward to determine the binding function from the effective HOCs, and we derive a generalised MWC formula for an arbitrary ensemble, which recovers the functional perspective. Our results subsume and generalise previous findings and clarify issues which have been present since the concept of allostery was introduced. Our graph-based approach further enables general theorems to be rigorously proved for any ensemble (below), in contrast to calculation of specific models which has been the norm up to now.
Our analysis raises questions about how effective HOCs are implemented at the level of single molecules, similar to those answered by Perutz for haemoglobin and the MWC model (Figure 2C). This important problem lies outside the scope of the present paper and requires different methods (Wodak et al., 2019), such as the mutant-cycle approach mentioned above (Carter, 2017). Our analysis is also restricted to ensembles which are at thermodynamic equilibrium without expenditure of energy, as is generally assumed in studies of allostery. Energy expenditure may be present in maintaining a conformational ensemble, for example, through post-translational modification, but the significance of this has not been widely appreciated in the literature. Thermodynamic equilibrium sets fundamental physical limits on information processing in the form of ‘Hopfield barriers’ (Estrada et al., 2016; Biddle et al., 2019; Wong and Gunawardena, 2020). Energy expenditure can bypass these barriers and substantially enhance equilibrium capabilities. However, the study of non-equilibrium systems is more challenging and we must defer analysis of this interesting problem to subsequent work (Discussion).
The integration of binding information through cooperativities leads to the integration of biological functions. Haemoglobin offers a vivid example of how allostery implements this relationship. This one target molecule integrates two distinct functions, of taking up oxygen in the lungs and delivering oxygen to the tissues, by having two distinct conformations, each adapted to one of the functions, and dynamically interchanging between them. In the lungs, with a higher oxygen partial pressure, binding cooperativity causes the relaxed conformation to be dominant in the molecular population, which thereby takes up oxygen; in the tissues, with a lower oxygen pressure, binding cooperativity causes the tense conformation to be dominant in the population, which thereby gives up oxygen. Evolution may have used this integrative strategy more widely than just to transport oxygen, and we review in the Discussion some of the evidence for an analogy between functional integration by haemoglobin and by gene regulation.
Results
Construction of the allostery graph
Our approach uses the linear framework for timescale separation (Gunawardena, 2012), details of which are provided in the 'Materials and methods' along with further references. We briefly outline the approach here.
In the linear framework, a suitable biochemical system is described by a finite directed graph with labelled edges. In our context, graph vertices represent microstates of the target molecule and graph edges represent transitions between microstates, for which the edge labels are the instantaneous transition rates. A linear framework graph specifies a finite-state, continuous-time Markov process, and any reasonable such Markov process can be described by such a graph. We will be concerned with the probabilities of microstates at steady state. These probabilities can be interpreted in two ways, which reflect the ensemble and single-molecule viewpoints of Figure 2. From the ensemble perspective, the probability is the proportion of target molecules which are in the specified microstate, once the molecular population has reached steady state, considered in the limit of an infinite population. From the single-molecule perspective, the probability is the proportion of time spent in the specified microstate, in the limit of infinite time. The equivalence of these definitions comes from the ergodic theorem for Markov processes (Stroock, 2014). These different interpretations may be helpful when dealing with different biological contexts: a population of haemoglobin molecules may be considered from the ensemble viewpoint, while an individual gene may be considered from the single-molecule viewpoint. As far as the determination of probabilities is concerned, the two viewpoints are equivalent.
The graph representation may also be seen as a discrete approximation of a continuous energy landscape, as in Figure 3, in which the target molecule is moving deterministically on a high-dimensional landscape in response to a potential, while being buffeted stochastically through interactions with the surrounding thermal bath (Frauenfelder et al., 1991). In mathematics, this approximation goes back to the work of Wentzell and Freidlin on large deviation theory for stochastic differential equations in the low noise limit (Ventsel' and Freidlin, 1970; Freidlin and Wentzell, 2012). It has been exploited more recently to sample energy landscapes in chemical physics (Wales, 2006) and in the form of Markov State Models arising from molecular dynamics simulations (Noé and Fischer, 2008; Sengupta and Strodel, 2018). In this approximation, the vertices correspond to the minima of the free energy up to some energy cut-off, the edges correspond to appropriate limiting barrier crossings and the labels correspond to transition rates over the barrier.
Figure 3
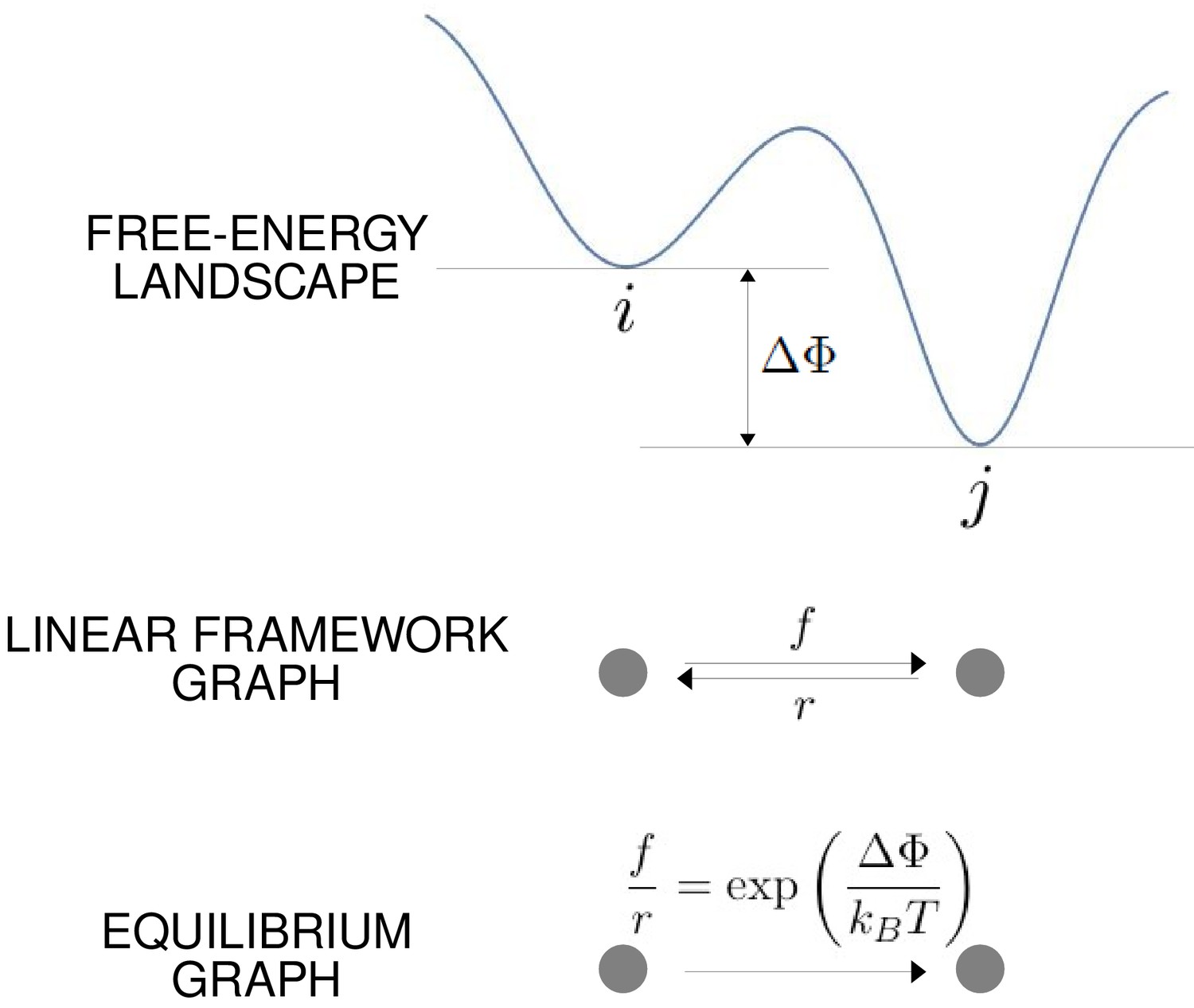
The free-energy landscape and corresponding graphs.
From the top, a hypothetical one-dimensional free-energy landscape, showing two graph vertices, and , as local minima of the free energy; the corresponding linear framework graph showing the edges between and with respective transition rates; the corresponding equilibrium graph whose edge label is the ratio of the transition rates, which is determined by the free-energy difference between the vertices (Equation 1).
The linear framework graph, or the accompanying Markov process, describes the time-dependent behaviour of the system. Our concern in the present paper is with systems which have reached a steady state of thermodynamic equilibrium, so that detailed balance, or microscopic reversibility, is satisfied. The assumption of thermodynamic equilibrium has been standard since allostery was introduced (Koshland et al., 1966; Monod et al., 1965) but has significant implications, as pointed out in the Introduction, and we will return to this issue in the Discussion. At thermodynamic equilibrium, we can dispense with dynamical information and work with what we call ‘equilibrium graphs’ (Figure 3). These are also directed graphs with labelled edges but the edge labels no longer contain dynamical information in the form of rates but rather ratios of forward to reverse rates. These ratios are determined by the minima of the free-energy landscape, with the equilibrium label on the edge from vertex to vertex being given by the formula in Figure 3 . Free energy is often expressed relative to a reference level, as we will do below, so it will be convenient to write the equilibrium label from to as
(1)
where is the relative free-energy of vertex , is Boltzmann’s constant and is the absolute temperature (Figure 3). Note that if the edge in question involves components from outside the graph itself, such as a ligand which binds to to yield , then the chemical potential of the ligand will contribute to the free energy. This contribution will manifest itself in the presence of a ligand concentration term in the edge label, as seen in Figure 4. The equilibrium edge labels are the only parameters needed at thermodynamic equilibrium and the free energies of the vertices can be recovered from them, up to an additive constant. From now on, in the main text, when we say ‘graph’, we will mean ‘equilibrium graph’.
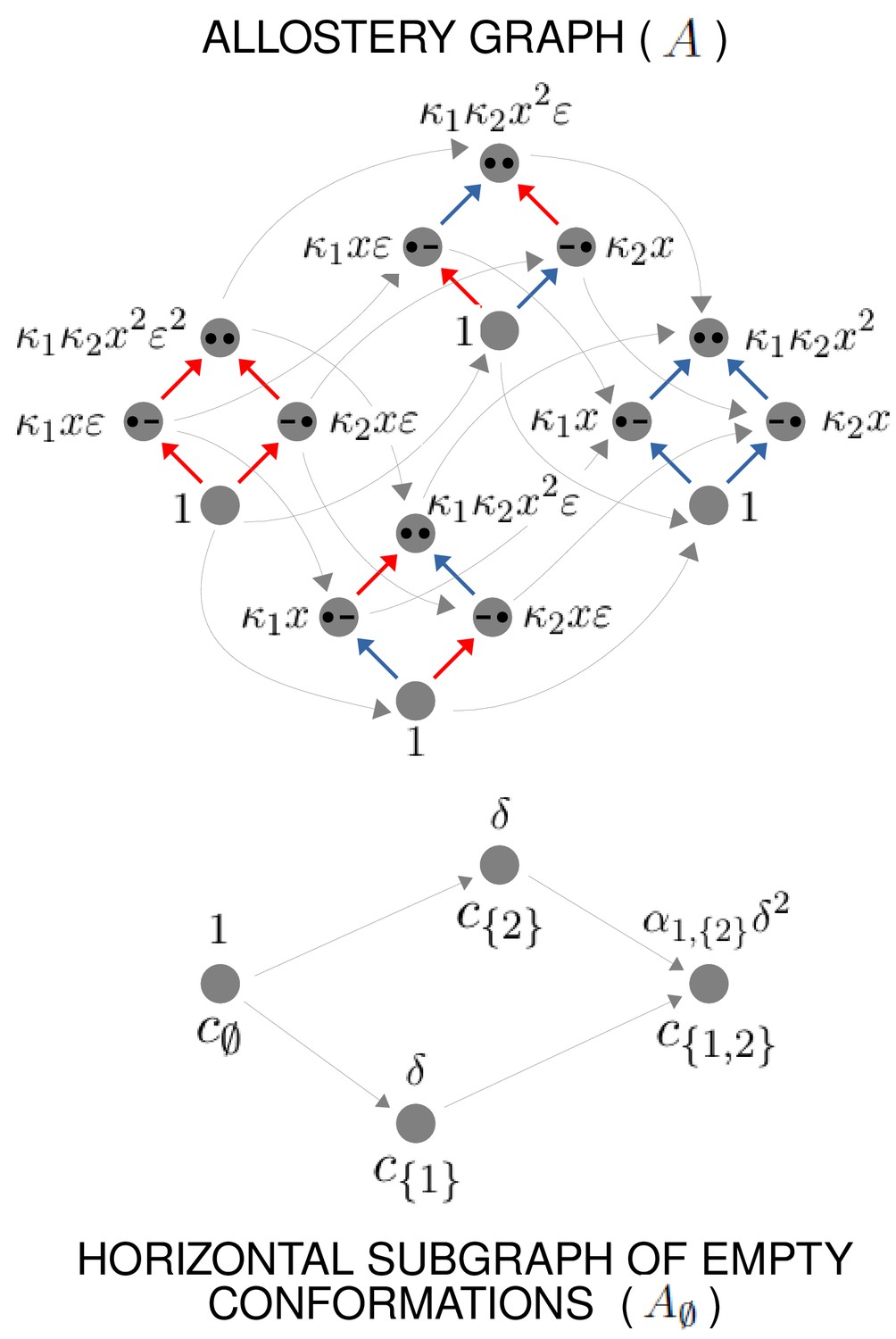
Figure 4
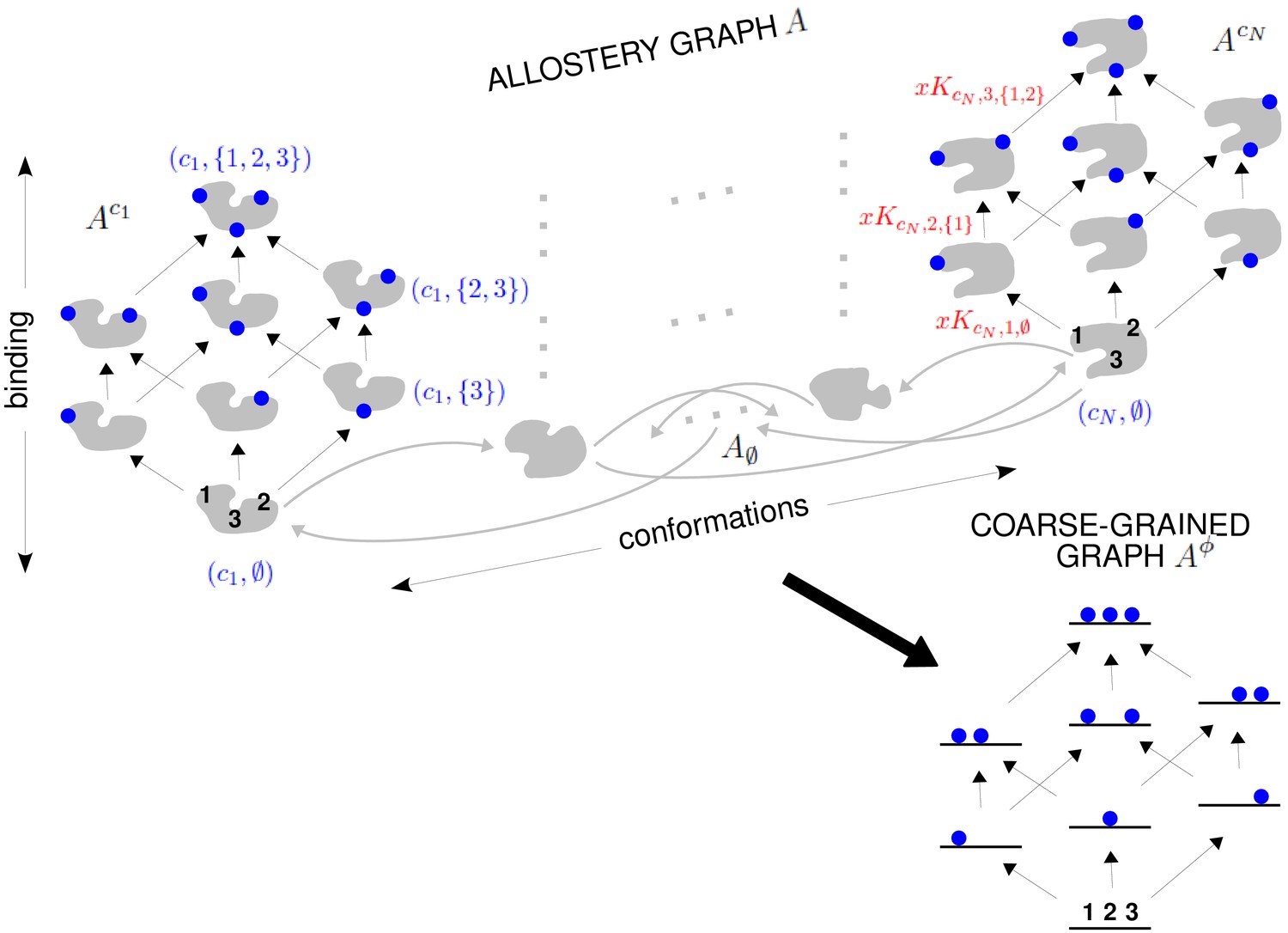
The allostery graph and coarse graining.
A hypothetical allostery graph (top) with three binding sites for a single ligand (blue discs) and conformations, , shown as distinct grey shapes. Binding edges (‘vertical’ in the text) are black and edges for conformational transitions (‘horizontal’) are grey. Similar binding and conformational edges occur at each vertex but are suppressed for clarity. Note that edges are shown in only one direction but are always reversible. All vertical subgraphs, , have the same structure, as seen for the vertical subgraphs, (left) and (right), and all horizontal subgraphs, , also have the same structure, shown schematically for the horizontal subgraph of empty conformation, , at the base. Example notation is given for vertices (blue font) and edge labels (red font), with denoting ligand concentration and sites numbered as shown for vertices and . The coarse-graining procedure coalesces each horizontal subgraph, , into a new vertex and yields the coarse-grained graph, (bottom right), which has the same structure as for any . Further details in the text and the Materials and methods.
We explain such graphs using our main example. Figure 4 shows the graph, , for an allosteric ensemble, with multiple conformations and multiple sites, , for binding of a single ligand ( in the example). The graph vertices represent abstract conformations with patterns of ligand binding, denoted , where the index designates the conformation with , and is the subset of bound sites. Directed edges represent transitions arising either from binding without change of conformation (‘vertical’ edges), where , which occur for all conformations ck, or from conformational change without binding (‘horizontal’ edges), where , which occur for all binding subsets . Edges are shown in only one direction for clarity—when binding or unbinding is present, we use the direction of binding—but edges are always reversible, in accordance with thermodynamic equilibrium. Ignoring labels and thinking only in terms of vertices and edges, or ‘structure’, has a product form: the vertical subgraphs, , consisting of those vertices with conformation ck and all edges between them, all have the same structure and the horizontal subgraphs, , consisting of those vertices with binding subset and all edges between them, also all have the same structure (Figure 4). Structurally speaking, we can think of as the graph product (Ahsendorf et al., 2014) of the vertical subgraph and the horizontal subgraph (Figure 4).
In an allostery graph, ‘conformation’ is meant abstractly as any state for which binding association constants can be defined. It does not imply any particular atomic configuration of a target molecule nor make any commitments as to how the pattern of binding changes.
The product-form structure of the allostery graph reflects the ‘conformational selection’ viewpoint of MWC, in which conformations exist prior to ligand binding, rather than the ‘induced fit’ viewpoint of KNF, in which binding can induce new conformations. Considerable evidence now exists for conformational selection, in the form of transient, rarely populated conformations which exist prior to binding (Tzeng and Kalodimos, 2011). Induced fit may be incorporated within our graph-based approach by treating new conformations as always present but at extremely low probability. One of the original justifications for induced fit was that it enabled negative cooperativities, in contrast to conformational selection (Koshland and Hamadani, 2002), but we will show below that induced fit is not necessary for this and that negative HOCs arise naturally in our approach. Accordingly, the product-form structure of our allostery graphs is both convenient and powerful.
The edge labels are the non-dimensional ratios of the forward transition rate to the reverse transition rate; accordingly, the label for the reverse edge is the reciprocal of the label for the forward edge (Materials and methods). Labels may include the influence of components outside the graph, such as a binding ligand. For instance, the label for the binding edge is , where is the ligand concentration and is the association constant (Figure 1A), with dimensions of (concentration)−1, as described in the Introduction. Horizontal edge labels are not individually annotated and need only be specified for the horizontal subgraph of empty conformations, , since all other labels are determined by detailed balance (Materials and methods).
The graph structure allows HOCs between binding events to be calculated, as suggested in the Introduction. We will define this first for the ‘intrinsic’ HOCs which arise in a given conformation and explain in the next section how ‘effective’ HOCs are defined for the ensemble. In conformation ck, the intrinsic HOC for binding to site , given that the sites in are already bound, denoted , is defined by normalising the corresponding association constant to that for binding to site when nothing else is bound (Estrada et al., 2016),
(2)
HOCs are non-dimensional quantities. If has only a single site, say , then the intrinsic HOC of order 1, , is the classical pairwise cooperativity between sites and . There is positive or negative intrinsic HOC if or , respectively, and independence if (Figure 1A).
For any graph , the steady-state probabilities of the vertices can be calculated from the edge labels. For each vertex, , in , the probability, , is proportional to the quantity, , obtained by multiplying the edge labels along any directed path of edges from a fixed reference vertex to . It is a consequence of detailed balance that does not depend on the choice of path in . This implies algebraic relationships among the edge labels. These can be fully determined from and independent sets of parameters can be chosen (Materials and methods). For the allostery graph, a convenient choice vertically is those association constants with less than all the sites in , denoted ; horizontal choices are discussed in the Materials and methods but are not needed for the main text.
Since probabilities must add up to 1, it follows that
(3)
Equation 3 yields the same result as equilibrium statistical mechanics, with the denominator being the partition function for the thermodynamic grand canonical ensemble. Equilibrium statistical mechanics typically focusses only on vertices and uses their free energies as the fundamental parameters. Directed graphs of the form considered here were previously used in Hill, 1966 and Schnakenberg, 1976 to study systems away from thermodynamic equilibrium, where the graph edges become essential to represent entropy production (Wong and Gunawardena, 2020). We find that the graph remains just as useful at thermodynamic equilibrium because binding and unbinding are the fundamental mechanisms through which information is integrated and these mechanisms must be represented by graph edges. Indeed, as the next section shows, graphs are invaluable for formulating higher-order concepts.
Our specification of an allostery graph allows for arbitrary conformational complexity and arbitrary interacting ligands (we consider only one ligand here for simplicity), with the independent association constants in each conformation being arbitrary and with arbitrary changes in these parameters between conformations. Moreover, the abstract nature of ‘conformation’, as described above, permits substantial generality. Allostery graphs can be formulated to encompass the two conformations of MWC (Marzen et al., 2013), nested models (Robert et al., 1987), the fluctuations of Cooper and Dryden, 1984 and more recent views of dynamical allostery (Tzeng and Kalodimos, 2011), the multiple domains of the Ensemble Allosteric Model developed by Hilser and colleagues (Hilser et al., 2012) and applied also to intrinsically disordered proteins (Motlagh et al., 2012), other ensemble models (LeVine and Weinstein, 2015; Tsai and Nussinov, 2014) and Markov State Models arising from molecular dynamics simulations (Noé and Fischer, 2008).
Relationships between higher-order measures
As mentioned in the Introduction, a systematic approach to higher-order effects using mutant-cycle analysis was developed in Horovitz and Fersht, 1990 and Horovitz and Fersht, 1992 and widely used subsequently (Carter, 2017). The HOCs presented above were introduced in our previous work (Estrada et al., 2016), and the present paper is concerned not with HOCs per se, but with effective HOCs that arise from an allosteric ensemble, as will be described below. Nevertheless, it may still be helpful to explain the relationship between our HOCs and the higher-order couplings arising from mutant-cycle analysis. We are grateful to an anonymous reviewer for making this point to us. The material which follows may be of particular interest to those familiar with the relevant literature but is not required for the main results of the paper.
Both HOCs and higher-order couplings can be seen as different ways of analysing the underlying free-energy landscape. Both approaches make essential use of directed graphs to organise this landscape. Figure 5A shows the labelled equilibrium graph for ligand binding to three sites in a single conformation, while Figure 5B shows a directed graph of the kind used in Horovitz and Fersht, 1990 for defining higher-order couplings for perturbations to three sites. The latter graphs are sometimes called ‘boxes’ (Horovitz and Fersht, 1990). We use ‘sites’ here for either individual residues or the modules described in Carter, 2017. Perturbations are typically mutations, such as replacement of an asparagine residue by alanine. The choice of replacement can make a difference to the results, but this is not usually depicted in graph representations like Figure 5B. The directed edges have rather different interpretations in the two examples in Figure 5: for the equilibrium graph in Figure 5A, a directed edge represents the biochemical process of ligand binding; for the coupling graph in Figure 5B, a directed edge represents an experimental perturbation. In both cases, the vertices have an associated free energy, denoted , where is either the subset of bound sites in the equilibrium graph (Figure 5A) or the subset of perturbed sites in the coupling graph (Figure 5B). The notation is conventionally used in the literature to signify a free-energy difference (Equation 1) or free energy relative to a chosen zero level. A frequent choice of zero is the free energy of empty binding or of the unperturbed state, in which case , but we have not assumed this here. Note that the free energies of the equilibrium graph have a contribution from the ligand, which manifests itself in the dependence of the edge labels on the ligand concentration, , while the free energies of the coupling graph do not. Despite this difference, the free energies provide in both cases the fundamental independent thermodynamic parameters, of which there are for sites, in terms of which both HOCs and higher-order couplings can be rigorously defined.
Figure 5
Graphs for defining higher-order measures.
(A) Equilibrium graph, similar to those in Figure 4, for binding of a ligand to three sites on a single conformation, ordered as shown at the base, and annotated with edge labels. The single conformation has been omitted from subscripts for clarity. (B) Directed graph used to define higher-order couplings, for a macromolecule with three sites or modules (solid squares), ordered as shown at the base, with perturbations indicated by blue colour in place of black. Vertices are annotated with the corresponding free energy.
The definition is easiest for HOCs. Equation 1 tells us that the edge label, , is given by
(4)
We omit the single conformation from subscripts for clarity. It follows from Equation 2 that HOCs can be written in terms of free energies as follows:
(5)
HOCs are non-dimensional quantities associated to graph edges. As noted above, there are algebraic relationships among them arising from detailed balance at thermodynamic equilibrium. An independent set of parameters is formed by restricting to those for which , of which there are . Taken together with the ‘bare’ association constants for initial ligand binding, , they form a complete set of independent parameters for the free-energy landscape. It follows from Equations 4 and 5 that these parameters can be used to recover the fundamental free energies, so that the two sets of parameters are mathematically equivalent.
Mutant-cycle studies often refer to both Horovitz and Fersht, 1990 and Horovitz and Fersht, 1992, which present apparently different measures of higher-order coupling. The second of these papers introduces what we will refer to as the ‘residual free energy’ of a vertex and denote . This is the free energy remaining at vertex after accounting for the contributions from all proper subsets of . The residual free energy may be concisely defined recursively, starting from , by
(6)
We see from Equation 6 that and that . may be calculated directly from but, as the previous example suggests, overlapping contributions of the actual free energies must be cancelled out (Horovitz and Fersht, 1992, Equation 4),
(7)
To see why Equation 7 is a consequence of Equation 6, note first that Equation 7 gives the correct result for . It may then be recursively checked by assuming it holds for and substituting into Equation 6 to check that it holds for . Each subset contributes a term arising from for each that satisfies . The sign of coming from Equation 7 is . These terms almost completely cancel each other out because, letting ,
Taking into account the additional sign coming from Equation 6, we recover Equation 7 for . This proves recursively that Equation 7 is the solution of Equation 6 in terms of free energies.
We can go further to show how is expressed in terms of HOCs. For this, we must assume that . When , ligand binding contributes to , but when that is no longer the case, as we will see. Choose any site . The summation in Equation 7 involves terms . It can be reorganised into a sum of terms of the form , where . The sign of these terms is given by the sign of coming from Equation 7 and is therefore . It is easy to see that, because , there must be equal numbers of +1 and −1 signs. It follows from Equation 4 that
where the double exponent just means that the right-hand side is a ratio in which those terms for which is odd go in the numerator and those terms for which is even go in the denominator. Using Equation 2, we can rewrite as . Since there are equal numbers of each sign, we can cancel each occurrence of between numerator and denominator to yield a formula for residual free energies in terms of HOCs when :
(8)
The choice of in Equation 8 is arbitrary. As an illustration of Equation 8, recalling from Equation 5 that , we see that
(9)
Equations 8 and 9 show how the residual free energy is built up from binding at any given site to the hierarchy of subsets of the remaining sites.
Residual free energies can be thought of as a measure of collective synergy between sites (Horovitz and Fersht, 1992). They are associated to graph vertices and constitute independent parameters, with no algebraic relationships between them. It follows from Equations 6 and 7 that they are mathematically equivalent to the fundamental free energies. Residual free energies have also been independently described for other purposes in Equation 4 of Martini, 2017.
The higher-order couplings introduced in Horovitz and Fersht, 1990 appear at first sight to be quite different from the residual free energies introduced in Horovitz and Fersht, 1992. The couplings are described by examples for low orders, as are typically encountered in practice (Horovitz and Fersht, 1990). We provide a general definition here by introducing a slightly more complex version. A coupling is associated to a pair, consisting of, first, a vertex, , and, second, an ordered sequence of distinct sites, , none of which are in , so that . The vertex should be thought of as an ‘offset’ within the coupling graph and the sites, as specifying an ordered sequence of perturbations undertaken around . Higher-order couplings are conventionally used in the literature only for , but this more complex version is needed for the definition in Equation 11 below. Associated to such a pair is a th order coupling, which we will denote by . We start by defining the first-order coupling, , for any satisfying the restriction above, in terms of the free energy,
(10)
With that in hand, we can define for , again for any satisfying the restriction
(11)
where it is clear that must be disjoint from , so that the right-hand side of Equation 11 is recursively well defined. Unravelling Equations 11 and 10, we see that
(12)
which corresponds when to Equation 1 of Horovitz and Fersht, 1990. With some more work, it can be seen that Equation 11 reproduces the and examples in Horovitz and Fersht, 1990. Equation 12 expresses the intuition behind higher-order coupling, that it measures the effect of a perturbation relative to the unperturbed state, hierarchically for a sequence of perturbations.
It can be seen quite easily from Equations 5 and 12 that
(13)
We note from Equation 13 that ‘order’ is counted differently between HOCs and conventional higher-order couplings: when , Equation 13 relates a higher-order coupling with to a HOC of order 1. Substituting Equation 13 into Equation 11 and continuing the recursion, we find that
at which point the similarity with Equation 9 becomes evident and the pattern emerges. It can be shown by direct substitution in Equation 11 that the following general formula holds, which expresses higher-order couplings in terms of HOCs for any :
(14)
Comparing Equation 14 with Equation 8 we see that, despite their very different definitions in Equations 11 and 6, conventional higher-order couplings are the same as residual free energies. Indeed, for ,
(15)
Equation 15 may seem strange because a higher-order coupling is defined in terms of an ordered sequence of perturbations, , while a residual free energy depends only on the subset of sites, , without respect to the order of sites. It is a consequence of detailed balance at thermodynamic equilibrium that the order in which the perturbations are undertaken does not matter. For example, it is clear from Equation 12 that . More generally, if ρ is any permutation of the perturbed sites, so that ρ is a bijective function, , then it can be shown that
(16)
Note that Equation 16 follows from Equation 15 when . This property of invariance under permutation is referred to as ‘symmetry’ in Horovitz and Fersht, 1990 and is similar to the algebraic relations which give rise to the independent HOCs, with , as described previously.
The equality between the higher-order couplings introduced in Horovitz and Fersht, 1990 and the residual free energies introduced in Horovitz and Fersht, 1992, as described in Equation 15, is presumably well known to those in the field. It seems to be implicitly assumed in Horovitz and Fersht, 1992, but we have not found a clear statement of it in the literature. It would be difficult to formulate one in the absence of a general definition of higher-order coupling, as we have given in Equation 11. The formulas above may therefore be of some value in offering a rigorous treatment.
Each of the measures we have discussed, HOCs, residual free energies and higher-order couplings, offers a different way of analysing the free-energy landscape using the graphs in Figure 5. HOCs are associated to graph edges; residual free energies are associated to graph vertices; and higher-order couplings are associated to sequences of sites, at least when symmetries are ignored. As we have seen above, the three measures are mathematically equivalent. However, they are useful for different purposes. HOCs tell us about the integration of binding information; residual free energies capture the collective synergy between sets of sites; and higher-order couplings show how these same synergies can be extracted from a sequence of experimental perturbations. One advantage of HOCs is that they are non-dimensional quantities in terms of which it is straightforward to calculate the other measures. By doing so, we were able to show rigorously that higher-order couplings are also residual free energies (Equation 15).
Having explained how various higher-order measures are related to each other, we return to the question of how effective cooperativity arises from allosteric ensembles with multiple conformations. For this problem, HOCs are much easier to use than either residual free energies or higher-order couplings. With Equations 8 and 14 now available, effective residual free energies or effective higher-order couplings may be calculated from the effective HOCs that we construct below, but we will not exploit this capability in the present paper.
Coarse graining yields effective HOCs
As MWC showed, even if there is no intrinsic cooperativity in any conformation, an effective cooperativity can arise from the ensemble. This is usually detected in the shape of the binding function (Figure 2A). Here, we introduce a method of coarse graining through which effective cooperativities can be rigorously defined. We illustrate this for the allostery graph, , and explain the general coarse-graining method in the Materials and methods. For allostery, the idea is to treat the horizontal subgraphs, , as the vertices of a new coarse-grained graph, , (Figure 4, bottom right). There is an edge between two vertices in , if, and only if, there is an edge in between the corresponding horizontal subgraphs. It is not hard to see that is identical in structure to any of the vertical subgraphs . We can think of as if it represents a single effective conformation to which ligand is binding, and we can index each vertex of by the corresponding subset of bound sites, . The key point, as explained in detail in the Materials and methods, is that it is possible to assign labels to the edges in so that
(17)
with being at thermodynamic equilibrium under these label assignments. According to Equation 17, the probability of being in a coarse-grained vertex of is identical to the overall probability of being in any of the corresponding vertices of . This is exactly the property a coarse graining should satisfy at steady state. It is not difficult to see why a procedure like this should work. The coarse-graining formula in Equation 17 tells us the expected probability distribution on the coarse-grained graph, . Equation 3 can then be used to back out the equilibrium labels on the edges of which give rise to this probability distribution. We provide a more direct way of achieving the same result in Equation 40. This assignment of labels to is the only way to ensure Equation 17 at equilibrium, so that the coarse graining is both systematic and unique. The Materials and methods gives a more careful treatment for coarse graining any linear framework graph, which may not itself be at thermodynamic equilibrium.
Our coarse-graining procedure offers a general method for calculating how effective behaviour emerges, at thermodynamic equilibrium, from a more detailed underlying mechanism. This procedure is likely to be broadly useful for other studies. We note that it applies only to the steady state. It does not provide a coarse graining of the underlying dynamics, which is a much harder problem.
Because resembles the graph for ligand binding at a single conformation, we can calculate HOCs for —equivalently, effective HOCs for —just as we did above, by normalising the effective association constants. Once the dust of calculation has settled (Materials and methods), we find that has effective association constants and effective HOCs:
(18)
The quantity is calculated by multiplying labels over paths, as above, within the vertical subgraph . The terms within angle brackets, of the form , where is some function over conformations ck, denote averages over the steady-state probability distribution of the horizontal subgraph: . The right-hand formula in Equation 18 for the effective HOCs has a suggestive structure: it is an average of a product divided by the product of the averages. The effective parameters in Equation 18 provide a biophysical language in which the integrative capabilities of any ensemble can be rigorously specified.
Effective HOCs for MWC-like ensembles
The functional viewpoint is readily recovered from the ensemble. A generalised MWC formula can be given in terms of effective HOCs, from which the classical two-conformation MWC formula is easily derived (Materials and methods). Some expected properties of effective HOCs are also easily checked (Materials and methods). First, is independent of ligand concentration, . Second, there is no effective HOC for binding to an empty conformation, so that . Third, if there is only one conformation c1, then the effective HOC reduces to the intrinsic HOC, so that .
More illuminating are the effective HOCs for the MWC model. We consider any conformational ensemble which is MWC-like: there is no intrinsic HOC in any conformation, so that and ; and the bare association constants are identical at all sites, so that we can set . There may, however, be any number of conformations, not just the two conformations of the classical MWC model. It then follows that depends only on the size of , so that we can write as , where is the order of cooperativity. Equation 18 then simplifies to (Materials and methods)
(19)
We see that, although there is no intrinsic HOC in any conformation, effective HOC of each order arises from the moments of over the probability distribution on . In particular, Equation 19 shows that the effective pairwise cooperativity is .
In studies of G-protein coupled receptor (GPCR) allostery, Ehlert relates ‘empirical’ to ‘ultimate’ levels of explanation by a procedure similar to our coarse graining, but with only two conformations, and calculates a ‘cooperativity constant’ which is the same as (Ehlert, 2016). Gruber and Horovitz calculate ‘successive ligand binding constants’ for the two-conformation MWC model which are the same as effective association constants, , (Gruber and Horovitz, 2018) (Materials and methods). To our knowledge, these are the only other calculations of effective allosteric quantities. We note that Equation 19 applies to all HOCs, not just pairwise, and to any MWC-like ensemble, not just those with two conformations.
The classical MWC model yields only positive cooperativity (Koshland and Hamadani, 2002; Monod et al., 1965), as measured in the functional perspective (Figure 2A). We find that MWC-like ensembles yield positive effective HOCs of all orders. Strikingly, these effective HOCs increase with increasing order of cooperativity: provided is not constant over conformations (Materials and methods),
(20)
This shows that ensembles with independent and identical sites, including the two-conformation MWC model, can effectively implement high orders and high levels of positive cooperativity. Equation 20 is very informative, and we return to it in the Discussion.
It is often suggested that negative cooperativity requires a different kind of ensemble to those considered here, such as one allowing KNF-style induced fit (Koshland and Hamadani, 2002). However, if two sites are independent but not identical, so that , then, with just two conformations, the effective pairwise cooperativity can become negative. Indeed, , if, and only if, the values of the association constants are not in the same relative order in the two conformations (Materials and methods). Negative effective cooperativity can arise from non-identical sites and does not need a special kind of ensemble.
Integrative flexibility of ensembles
Equation 18 shows that effective HOCs of any order can arise for a conformational ensemble but does not reveal what values they can attain. Can they vary arbitrarily? The question can be rigorously posed as follows. Suppose that we are considering binding sites and that numbers , for , and , for , are chosen at will. Does there exist a conformational ensemble such that the bare effective association constants satisfy , and the independent effective HOCs satisfy ?
To address this question, we assume that there is no intrinsic HOC, so as not to introduce cryptically what we want to generate. It follows that the sites cannot be identical, for otherwise Equation 20 shows that integrative flexibility is impossible. Accordingly, the bare association constants, for , can be treated as free parameters in each conformation ck. If there are conformations in the ensemble, then there are free parameters coming from the horizontal edges (Materials and methods). Dimensional considerations imply that the effective HOCs cannot take arbitrary values if . Conversely, we prove the following flexibility theorem: any pattern of values can be realised by an allosteric ensemble with no intrinsic cooperativity, to any required degree of accuracy, provided there are enough conformations with the right probability distribution and the right patterns of bare association constants.
To see why this is possible, we outline the argument here and give rigorous details in Theorem 1 in the Materials and methods. Other arguments may of course be possible and the details presented here should not be thought of as the only way for the results to hold. We will use an allostery graph whose conformations are indexed by subsets and denoted . Both binding subsets and conformations will then be indexed by subsets of . To avoid confusion, we will use to label binding subsets and to label conformations, so that a vertex of will be . The allostery graph for the case is shown in Figure 6. We will focus on the horizontal subgraph of empty conformations, , because that is what is needed for calculating effective HOCs using Equation 18. We will take the reference vertex of to be . Recall from what was explained previously that the product of the equilibrium labels along any path in from the reference vertex to the vertex is the quantity , in terms of which the steady-state probabilities of are given by Equation 3. Let . These quantities are free parameters whose values we are going to assign. They are more convenient for our purposes than an independent set of equilibrium labels for . By Equation 3,
(21)
Figure 6
Example allostery graph for the flexibility theorem.
There are sites and conformations, giving a 16-vertex allostery graph (top). Vertices indicate a bound site with a solid black dot and an unbound site with a black dash. Sites are indexed in increasing order, , from left to right. The red vertical binding edges carry a factor of ε in their equilibrium labels; the blue vertical binding edges do not, as specified in the text and Equation 60. The vertices of the allostery graph are annotated with the values of , as specified in the text and Equation 61. The horizontal subgraph of empty conformations is shown at the bottom, with conformations indexed below each vertex by subsets of and annotated above each vertex with the corresponding value of , as specified by Equation 24.
The other free parameters that we need are quantities, , to which we will subsequently assign values, in terms of which we will define the intrinsic association constants. We will assume that the sites are independent in each conformation, so that all intrinsic HOCs of are 1. It follows that . We then set if , and if . Here, ε is a small positive quantity which can be chosen to determine the degree of accuracy to which the and are approximated. In the calculations which follow, we will only be interested in terms which do not involve ε as a factor. Because the sites are independent in each conformation, it follows that, in the vertical subgraph, , at any conformation , , whenever . However, if , then acquires factors of ε and so , where ≈ means simply that the related quantities become equal as ε becomes very small. In this case, for our purposes, is negligible whenever . Figure 6 illustrates how this plays out in the allostery graph for .
To calculate the effective association constants, the left-hand formula in Equation 18 shows that we must evaluate the averages and . Using Equation 21,
The only terms in the sum which do not involve ε as a factor are those for which . Furthermore, the definition of given above shows that these terms do not depend on . Similarly, using Equation 21 again,
and the only terms in the sum which do not involve ε as a factor are those for which . These terms also do not depend on . It follows from Equation 18 that
(22)
where we have ignored all terms involving ε as a factor.
Equation 22 tells us two things. First, that the effective association constants are approximately proportional to the corresponding κ’s. Hence, if the proportionality constants, which depend only on the , are determined, we can choose the so as to make the bare effective association constants approximately equal to . Second, Equation 22 tells us that the effective HOCs, , are independent of the and depend only on the ,
(23)
It remains for us to assign values to the so that the effective HOCs become approximately equal to the α’s.
To do this, assume that, for the conformation , the subset is written as , where the indices are in increasing order, . Because of this ordering, the quantities are given to us by hypothesis. Hence, we can define
(24)
Here, δ is another small positive quantity, similar to ε, which can be chosen to set the degree of accuracy to which the β’s and α’s are approximated. As with ε, we will treat as negligible terms in which δ is a factor. Figure 6 illustrates Equation 24 for the case .
It can be seen from Equation 24 that , where has a factor of δ and is therefore negligible as δ becomes very small, . It then follows from Equation 23 that
(25)
where we have used as a generic symbol for quantities which are negligible as δ becomes very small. By Equation 24, , so that
(26)
This establishes part of what is required. For the other part, we can return to Equation 22 and set
from which it follows from Equation 22 that
(27)
Equations 26 and 27 show that the effective association constants and effective HOCs can take arbitrary positive values to any desired degree of accuracy, as determined by ε and δ. This establishes the flexibility theorem. The Materials and methods provides a more careful treatment in Theorem 1, which rigorously establishes the approximation as ε and δ become very small.
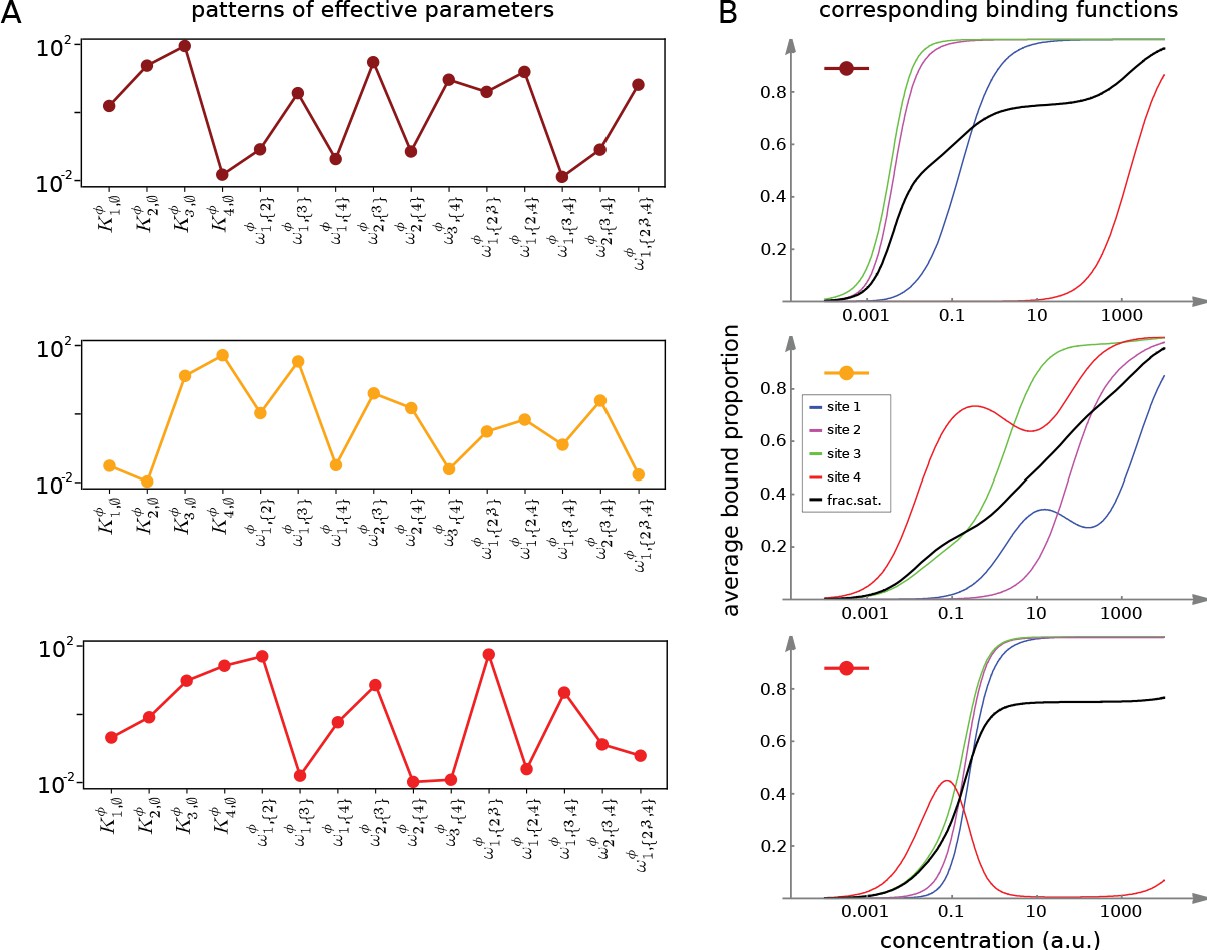
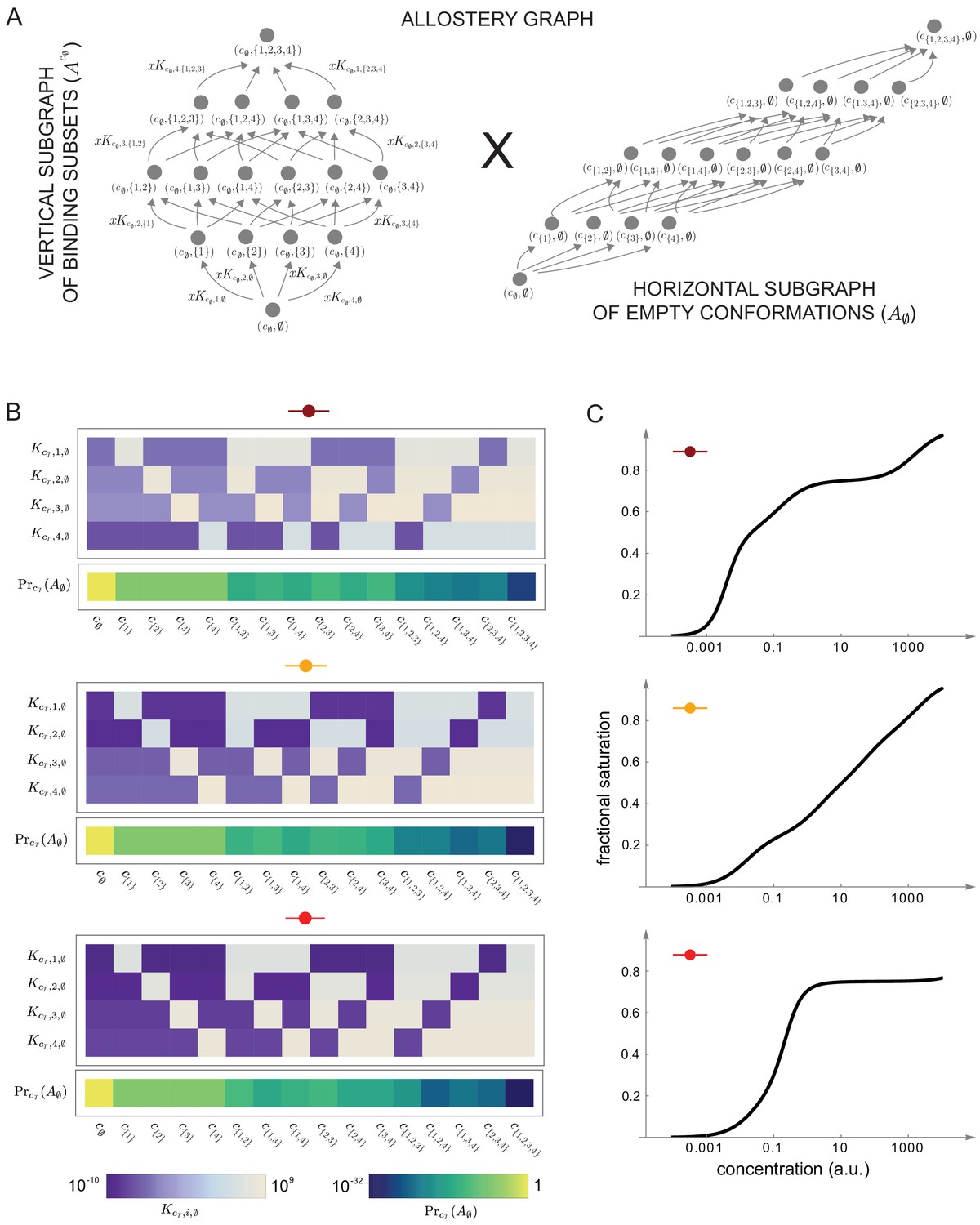
Figures 7 and 8 together illustrate the flexibility theorem. Figure 7A shows three arbitrarily chosen patterns of effective parameters for a target molecule with four ligand binding sites. Figure 7B shows the corresponding overall binding functions (black curves) together with the individual site-specific binding functions (coloured curves). As a matter of thermodynamics, the overall binding function is always an increasing function of ligand concentration. In contrast, the site-specific binding functions may increase or decrease depending on the combinations of positive and negative effective HOCs in Figure 7A, and thereby show more clearly the complexity arising from those different combinations. The implementation of the effective parameters by an allosteric ensemble, as specified by the flexibility theorem, is illustrated in Figure 8. Figure 8A shows the allosteric ensemble for sites as a product graph with 16 binding patterns and 16 conformations. Figure 8B shows the intrinsic association constants in each conformation coming from the proof of the flexibility theorem, to an accuracy of 0.01. Figure 8C confirms that this allosteric ensemble exactly reproduces the overall binding functions in Figure 7B.
Figure 7
Integrative flexibility of allostery I.
(A) Three choices of effective bare association constants, , in arbitrary units of (concentration)−1, and independent effective higher-order cooperativities , , for , in non-dimensional units, for ligand binding to four sites. Each example is coded by a colour (maroon, orange, red) and exhibits a different pattern of positive and negative effective HOCs. (B) Corresponding plots of average bound proportion at each site (colour coded as in middle inset) and the overall binding function, or fractional saturation, (black), calculated directly from the effective parameters. Note that the latter is always increasing; see the text for more details.
Figure 8
Integrative flexibility of allostery II.
(A) The allostery graph, , which implements the choices of effective higher-order cooperativities (HOCs) in Figure 7, shown as the product of the vertical subgraph of binding patterns at conformation , , and the horizontal subgraph of empty conformations, . As required in the proof of the flexibility theorem, both conformations and binding subsets are indexed by subsets of , where is the number of binding sites. Since for the effective HOCs in Figure 7, there are 16 binding subsets and 16 conformations, . (B) Intrinsic bare association constants, , in each conformation, in arbitrary units of (concentration)−1, and the probability distribution on the subgraph of empty conformations, , for the allostery graph in (A), giving the three choices of effective parameters in Figure 7A to an accuracy of 0.01 (Materials and methods), colour coded on a log scale as shown in the respective legends below. (C) Overall binding functions for the three parameterised ensembles in (B) (black curves), overlaid on the overall binding functions from Figure 7B (red curves), which were calculated from the effective parameters. The match is too close for the red curves to be visible. Numerical values are given in the Materials and methods. Calculations were undertaken in a Mathematica notebook, available on request.
In respect of the dimensional argument made previously, the allostery graph used in the proof above has free parameters for and the are a further free parameters, giving free parameters in total. This is more than the minimal required number of but not by much. It remains an interesting open question whether a conformational ensemble can be constructed, perhaps with more free parameters, which gives the effective HOCs exactly, rather than only approximately. One consequence of the definitions of and of in Equation 24 is that the parameters of the allosteric ensemble become exponentially small, as is evident for the examples in Figure 8B. Another interesting question is whether alternative constructions can be found which do not exhibit such a broad range of parameter values. Irrespective of these questions, the proof given above confirms that there is no fundamental biophysical limitation to achieving any pattern of values to any desired degree of accuracy. Accordingly, a central result of the present paper is that sufficiently complex allosteric ensembles can implement any form of information integration that is achievable without energy expenditure.
Allosteric ensembles for Hill functions
As mentioned in the Introduction, the starting point for the present paper was to account for experimental data on gene expression. Studies in Drosophila have shown that the Hunchback gene, in response to the maternal TF Bicoid, is sharply expressed in a way that is well fitted, after appropriate normalisation, to a Hill function, . This sharp expression underlies the initial patterning of anterior-posterior stripes in the early Drosophila embryo. Estimated values for the Hill coefficient, , vary depending on the experimental construct and time of measurement but are typically in the range during early nuclear cycle 14 (Tran et al., 2018). The relevant promoter is believed to have Bicoid binding sites, and the mechanistic basis for the sharpness is the subject of considerable interest. We showed in previous work that, if the promoter was assumed to have six Bicoid binding sites and to be operating at thermodynamic equilibrium, then the highest Hill coefficient that could be achieved of , at the so-called Hopfield barrier, required HOCs for Bicoid binding of order up to 5 (Estrada et al., 2016). In particular, pairwise cooperativities, which had previously been invoked to account for the sharpness (Gregor et al., 2007), are not sufficient to explain the data. Left open by this previous work was a molecular mechanism which could create the high-order HOCs required for Hill functions. We have seen above that allosteric ensembles can create any pattern of HOCs, so it is natural to ask if there are allosteric ensembles which yield good approximations to Hill functions.
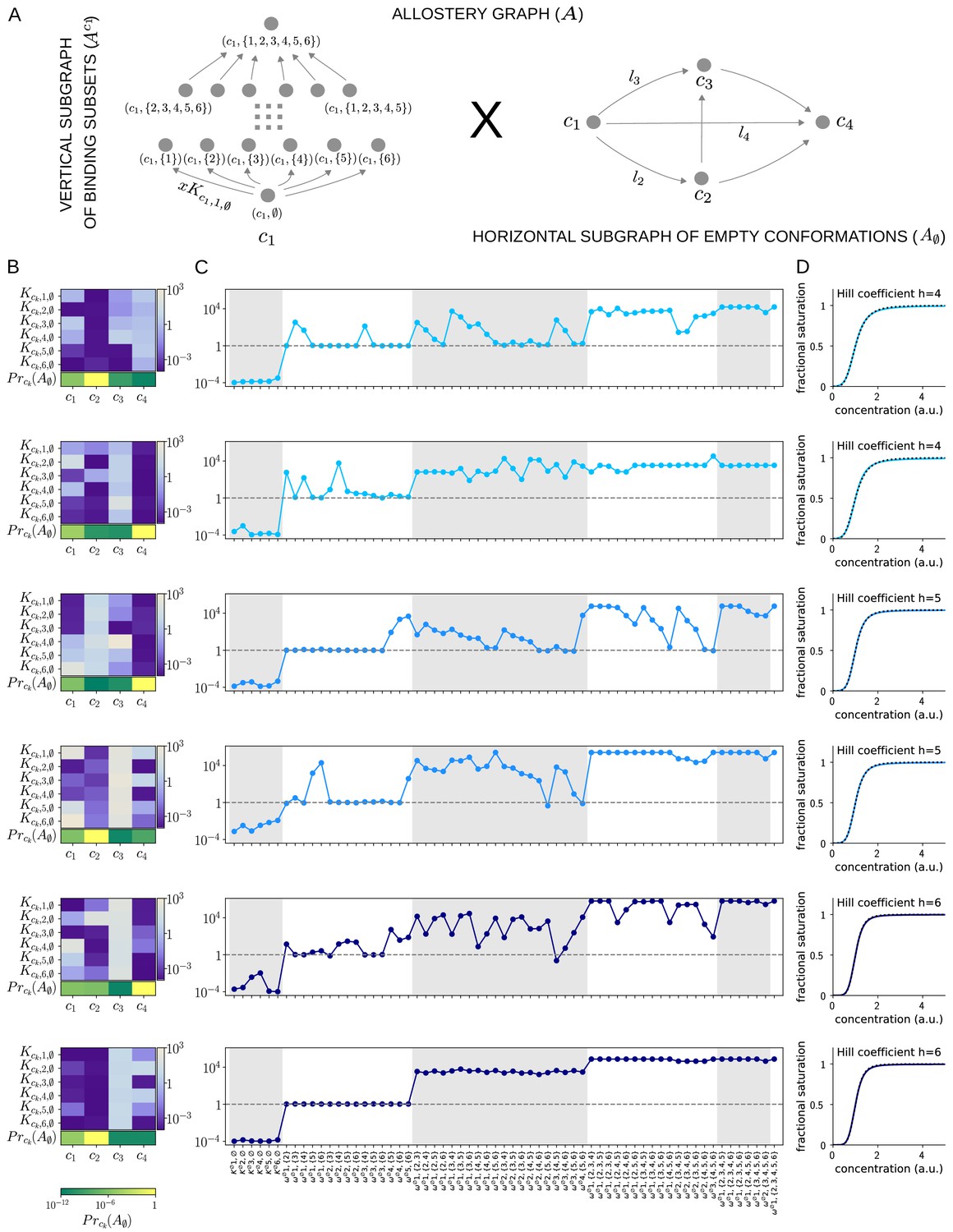
We implemented a numerical optimisation algorithm to find binding functions which approximated Hill functions (Materials and methods). Hill functions are naturally normalised so that , so we followed the procedure introduced previously (Estrada et al., 2016) of normalising concentration to its value at half-maximum: if the normalised binding function is denoted , then . Figure 9 shows results for an allosteric ensemble with four conformations for ligand binding to six sites. The ensemble has no intrinsic cooperativity in any conformation, so that for any binding subset , while the bare association constants, , differ between the conformations (Figure 9B). This gives free parameters together with an additional three free parameters for the independent equilibrium labels on the horizontal subgraph (Figure 9A). We limited the parameter ranges so that the were in the range and the equilibrium labels of were in the range . With these settings, it was not difficult to find normalised binding functions which are very well fitted by the Hill function, , for Hill coefficients , 5 and 6 (Figure 9D).
Figure 9
Allosteric ensembles for Hill functions.
(A) Allostery graph, , for representing Hill functions with six binding sites and four conformations, shown as the product of the vertical subgraph of binding subsets and the horizontal subgraph of empty conformations. Some vertices are annotated and some edges are labelled; the edge labels, and , on the horizontal subgraph are the independent labels coming from a spanning tree used in the algorithm described in the text. (B) Intrinsic bare association constants in each conformation, in arbitrary units of (concentration)−1 colour coded in the vertical bar on the right, and the probability distribution on the subgraph of empty conformations, colour coded in the horizontal bar at the bottom. (C) Corresponding effective association constants in arbitrary units of (concentration)−1 and the non-dimensional independent effective higher-order cooperativities arising from the ensemble. (D) Corresponding binding functions (blue curves) overlaid on the Hill function (black dashes) with the indicated Hill coefficient, . Two sets of parameter values are shown, with the same shade of blue, for each Hill coefficient , 5 and 6.
We were able to find multiple sets of parameters which yielded excellent fits; Figure 9 shows two representative examples for each Hill coefficient. It is evident that very different numerical ensembles (Figure 9B) can give almost identical binding functions (Figure 9D). This reinforces the point made in the Introduction that the binding function, or some associated measure of its shape, such as a Hill coefficient, are aggregate measures which give little insight into how binding information is being integrated. For this, the patterns of effective parameters provide more detailed information. As can be seen from Figure 9C, effective HOCs of all orders up to 5 are needed for each Hill function, as suggested previously (Estrada et al., 2016), with predominantly positive effective HOCs, , and varying amounts of independence, .
It is interesting to ask what role the size of the ensemble plays in approximating Hill functions. We cannot give a definitive answer but can make some observations. We were able to approximate with a two-conformation ensemble with six sites but only with much wider parametric ranges. It was also more difficult in terms of optimisation time to find a good fit, and we did not find multiple fits. This suggests that the larger the ensemble the easier it is to approximate Hill functions with limited parameter ranges. It is also conceivable that the size of the ensemble may have to increase with the number of binding sites to retain control over the parametric ranges. We must leave such issues to subsequent work. While our results are numerical, and therefore limited to the ensemble we have analysed, it seems clear that allosteric ensembles provide a molecular mechanism that can closely approximate Hill functions with the required high orders of effective cooperativity, thereby providing a solution to our original question. Since Hill functions are widely used to fit data, the potential for an underlying allosteric mechanism may be broadly useful.
Discussion
Jacques Monod famously described allostery as ‘the second secret of life’ (Ullmann, 2011). It is only relatively recently, however, that the prescience of his remark has been appreciated and the wealth of conformational ensembles present in most cellular processes has been revealed (Changeux and Christopoulos, 2016; Motlagh et al., 2014; Nussinov et al., 2013).
The present paper seeks to expand the existing allosteric perspective by providing a biophysical foundation for information integration by conformational ensembles. Equation 48 and Equation 49 in the Materials and methods (Equation 18 above) provide for the first time a rigorous definition of effective, higher-order quantities—the association constants, , and cooperativities, ,—arising from any ensemble. Since our methods are equivalent to those of equilibrium statistical mechanics (Material and methods), these definitions correctly aggregate the free-energy contributions which emerge in the ensemble from ligand binding to a conformation, intrinsic cooperativity within a conformation and conformational change. As noted above, our results encompass recent work on effective properties of the classical, two-conformation MWC ensemble—for pairwise cooperativity (Ehlert, 2016) and higher-order association constants (Gruber and Horovitz, 2018)—but they hold more generally for ensembles of arbitrary complexity with any number of conformations, including those with intrinsic cooperativities.
The effective quantities introduced here provide a language in which the integrative capabilities of an ensemble can be rigorously expressed. To begin with, the overall binding function can be determined in terms of the effective quantities through a generalised MWC formula (Materials and methods), thereby recovering the functional viewpoint (Figure 2A) from the ensemble viewpoint (Figure 2B). This generalised MWC formula reduces to the usual MWC formula for the classical two-conformation MWC model (Equation 55). We also clarify issues which had been difficult to understand in the absence of a quantitative definition of effective quantities. We find that the classical MWC model exhibits effective HOCs of any order and that these are always positive. In other words, binding always encourages further binding. Moreover, these effective HOCs increase strictly with increasing order (Equation 20), so that the more sites which are bound, the greater the encouragement to further binding. We see that HOC has always been present, even for oxygen binding to haemoglobin, albeit unrecognised for lack of an appropriate quantitative definition. Equation 20 confirms in a more precise way the long-standing realisation from the functional perspective that the MWC model exhibits only positive cooperativity; at the same time it succinctly expresses the rigidity and limitations of this model.
It is often stated in the allostery literature that negative cooperativity requires induced fit, in which binding induces conformations which are not present prior to binding. This view goes back to Koshland, who pointed to the emergence of negative cooperativity in the KNF model of allostery, which allows induced fit, and contrasted that to the positive cooperativity of the MWC model, which assumes conformational selection (Koshland and Hamadani, 2002). Our language of effective quantities permits a more discriminating analysis. It confirms, as just pointed out, that the classical MWC model exhibits only positive effective HOCs but also shows that induced fit is not required for negative effective HOC, which can arise just as readily from conformational selection (Materials and methods). What is required is not a different kind of ensemble but, rather, binding sites that are not identical.
Our main result, on the flexibility of conformational ensembles, shows that positive and negative HOCs of any value can occur in any pattern whatsoever, provided that the conformational ensemble is sufficiently complex, with enough conformations (Figure 8). Since the effective quantities provide a complete parameterisation of an ensemble at thermodynamic equilibrium, we see that conformational ensembles can implement any form of information integration that is achievable without external sources of energy. In particular, allosteric ensembles can be found whose binding functions closely approximate Hill functions (Figure 9), thereby answering the question which prompted this study, as to how such functions might arise in gene regulation.
Eukaryotic gene regulation is one of the most complex forms of cellular information processing (Wong and Gunawardena, 2020). Information from the binding of multiple TFs at many sites, often widely distributed across the genome in distal enhancer sequences, must be integrated to determine whether, and in what manner, a gene is expressed. The results of the present paper offer a way to think further about how such integration takes place (Tsai and Nussinov, 2011). We focus on gene regulation, but our results may also be useful for analysing other mechanisms of information integration, such as GPCRs (Thal et al., 2018).
As pointed out in the Introduction, haemoglobin solves the problem of integrating two quite different physiological functions—picking up oxygen in the lungs and delivering oxygen to the tissues—by having two conformations, each adapted to one of these functions, and dynamically inter-converting between them (Figure 10A). The effective cooperativity of oxygen binding ensures that the appropriate conformation dominates the ensemble in the distinct contexts of the lungs, where oxygen is abundant, and the tissues, where oxygen is scarce, so that oxygen is transferred from the former to the latter.
Figure 10
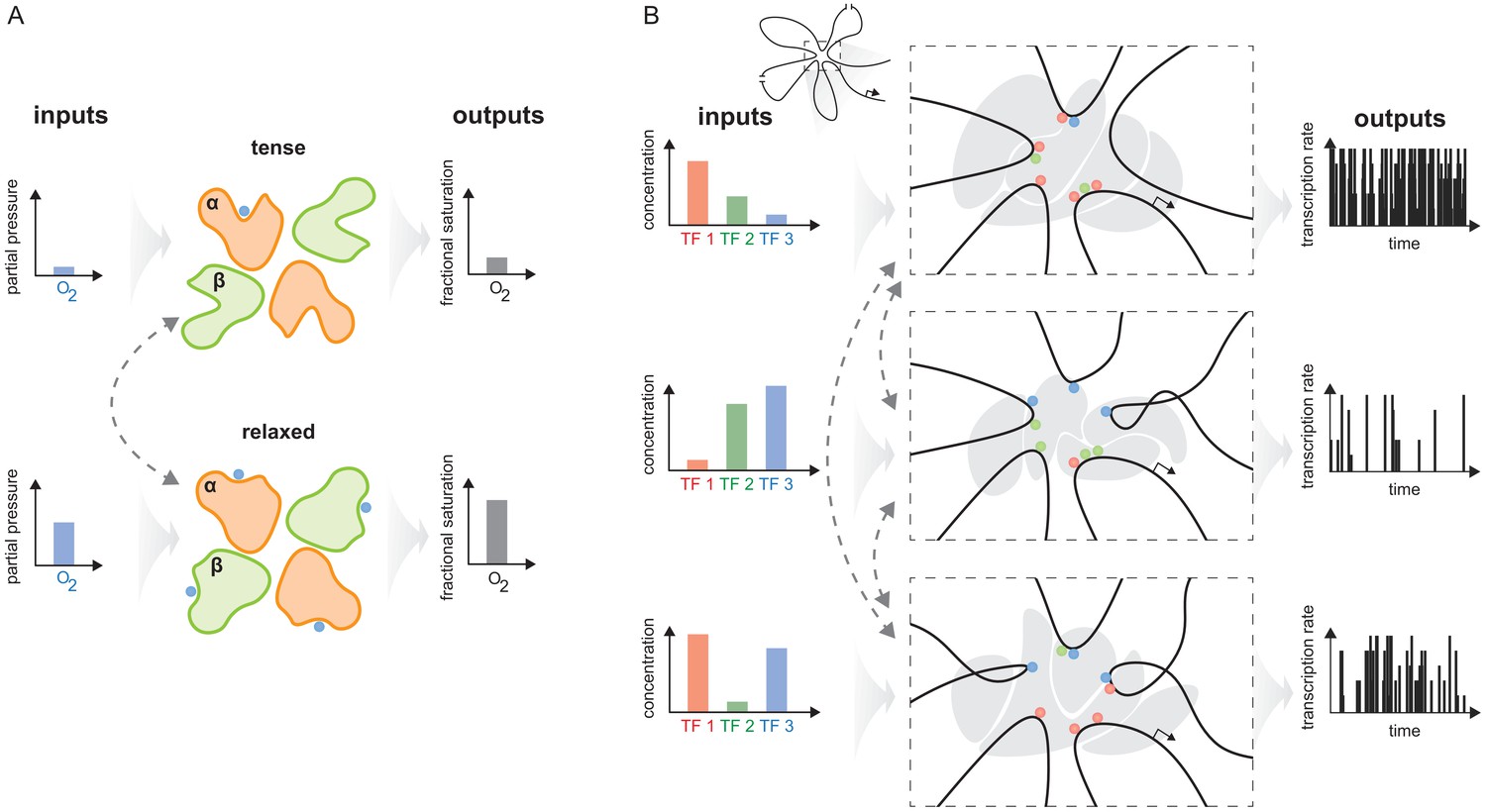
The haemoglobin analogy in gene regulation.
(A) The two conformations of haemoglobin are each adapted to one of the two input-output functions which haemoglobin integrates to solve the oxygen transport problem. These conformations dynamically interchange in the ensemble (grey dashed arrows). (B) The gene regulatory machinery couples input patterns of transcription factors (TFs) (left) to output patterns of stochastic expression of mRNA splice isoforms (right, showing bursting patterns of one isoform). Our results suggest that a sufficiently complex conformational ensemble, built out of chromatin, TFs, co-regulators and phase-separated condensates (centre, grey shapes in three distinct conformations), could integrate these functions at a single gene in an analogous way to haemoglobin. Chromatin is represented by the thick black curve, whose looped arrangement around the promoter is shown schematically (top).
Genes have to be regulated to achieve yet more elaborate forms of integration, with the same gene being expressed differently in different contexts. Such pleiotropy is particularly evident in developmental genes (Bolt and Duboule, 2020) but usually occurs in distinct cells within the developing organism. The same gene is present in these cells, but it may be difficult to know whether the corresponding regulatory machineries are also the same. More directly suitable examples for the present discussion arise in individual cells exposed to distinct stimuli (Molina et al., 2013; Kalo et al., 2015; Lin et al., 2015), which may be particularly the case for neurons or cells of the immune system (Marco et al., 2020; Smale et al., 2013).
Depending on the input pattern of TFs present in a given cellular context (Figure 10B, left), a gene may be expressed in a certain way, as a distribution of splice isoforms, each with an overall level of mRNA expression and a pattern of stochastic bursting (Lammers et al., 2020; Figure 10B, right). A different input pattern of TFs may elicit a different mRNA output. Our results suggest that one way in which these different input-output relationships could be integrated in the workings of a single gene is through allostery of the overall regulatory machinery. An allosteric analogy in gene regulation was previously made by Mirny, 2010, building upon observations of indirect cooperativity between TFs that were mediated by nucleosomes (Miller and Widom, 2003). In the allosteric analogy, TF binding to DNA takes place in one of two conformations—nucleosome present or absent—which dynamically interchange, leading to the classical MWC model. Here, we build upon Mirny’s idea to suggest that not only indirect cooperativity but also, more broadly, information integration may be accounted for by the conformational dynamics of the gene regulatory machinery. The latter comprises not just individual nucleosomes but whatever other molecular entities are implicated in conveying information from TF binding sites to RNA polymerase and the transcriptional machinery (Figure 10B, centre), as discussed below. If this hypothesis is correct, then the flexibility result tells us that the overall regulatory conformational ensemble must exhibit sufficient complexity to implement the integration of binding information.
Studies of individual regulatory components have revealed many levels of conformational complexity. DNA itself exhibits conformational changes in respect of TF binding (Kim et al., 2013). Nucleosomes are moved or evicted to alter chromatin conformation and DNA accessibility (Mirny, 2010; Voss and Hager, 2014). TFs, in particular, show high levels of intrinsic disorder compared to other classes of proteins (Liu et al., 2006), especially in their activation domains, and these disordered regions exhibit dynamic multivalent interactions characteristic of higher-order effects (Chong et al., 2018; Clark et al., 2018). Hub TFs like p53 exhibit high levels of conformational flexibility in the context of specific DNA binding (Demir et al., 2017). Transcriptional co-regulators, which do not directly bind DNA but are recruited there by TFs, exhibit substantial conformational complexity: CBP/p300 has multiple intrinsically disordered regions which facilitate higher-order cooperative interactions (Dyson and Wright, 2016), while the Mediator complex exhibits quite remarkable conformational changes upon binding to TFs (Allen and Taatjes, 2015). Transcription initiation sub-complexes such as TFIID, which help assemble the transcriptional machinery, show conformational plasticity (Nogales et al., 2017), while the C-terminal domain of RNA Pol II, which is repetitive and intrinsically disordered, shows surprising local structural heterogeneity (Portz et al., 2017). The significance of RNA conformational dynamics during transcription is becoming clearer (Ganser et al., 2019). Finally, transcription may also be regulated within larger-scale entities, such as transcription factories (Edelman and Fraser, 2012), phase-separated condensates (Sabari et al., 2018) and topological domains (Benabdallah and Bickmore, 2015). The role of such entities remains a matter of debate (Mir et al., 2019), but they may play a significant role in conveying information over long genomic distances between distal enhancers and target promoters (Furlong and Levine, 2018). From the perspective taken here, in view of their size and extent, they may exhibit conformational dynamics on longer timescales.
These various findings have emerged largely independently of each other. They indicate the presence of many conformations of components of the gene regulatory machinery, with these components dynamically interchanging on varying timescales. The collective effect of these coupled dynamics is difficult to predict but we can hazard some guesses. It has been suggested, for example, that multi-protein complexes like Mediator couple the conformational repertoires of their component proteins into complex allosteric networks for processing information (Lewis, 2010). From an ensemble viewpoint, if component has conformations and component has conformations, we might naively expect that the coupling of and in a complex yields roughly conformations. Following this multiplicative logic for the many components involved in eukaryotic gene regulation, from DNA itself to condensates and domains, suggests that the gene regulatory machinery has enormous conformational capacity with a deep hierarchy of timescales.
In making the analogy to haemoglobin, it is the conformational dynamics which implements the transfer of information from upstream TF inputs to downstream gene output. In any given cellular context, as determined by the input pattern of TFs, we may expect one, or perhaps a few, overall regulatory conformations which are well-adapted to generate the required mRNA output and these conformations will be the most frequently observed. The ensemble may exhibit complex patterns of positive and negative effective HOCs among the input TFs which will characterise the required output. In the light of our flexibility theorem, the occurrence of such HOCs, which appear to be necessary to account for data on gene regulation (Park et al., 2019a), may be seen as evidence for conformational complexity. When the cellular context changes, different conformations, adapted to produce the output required in the new context, may be present most often—although careful inspection may show them to have been more fleetingly present previously, as would be expected under conformational selection. More broadly, the complexity of the regulatory conformational ensemble and its dynamics reflects the complexity of functional integration which the gene has to undertake.
Furlong and Levine have suggested a ‘hub and condensate’ model for the overall gene regulatory machinery, which brings together aspects of earlier models to account for how remote enhancers communicate with target promoters (Furlong and Levine, 2018). The allosteric perspective taken here emphasises the significance of conformational dynamics for the functional integration undertaken by such ‘hubs’.
Testing these ideas on the scale of the regulatory machinery presents a daunting challenge, but recent developments point the way towards approaching them, including advances in cryo-EM (Lewis and Costa, 2020), single-molecule microscopy (Li et al., 2019; Bacic et al., 2020), NMR (Shi et al., 2020), synthetic biology (Park et al., 2019b) and the measurement of higher-order quantities (Gruber and Horovitz, 2018). Before experiments can be formulated, an appropriate conceptual picture needs to be described and that is what we have tried to formulate here. We now know a great deal about the molecular components involved in gene regulation, but the question of how these components collectively give rise to function has been harder to grasp. The allosteric analogy to haemoglobin, upon which we have built here, suggests a potential way to fill this gap.
In extending the haemoglobin analogy, we have sidestepped the issue of energy expenditure. This is not relevant for haemoglobin, but it can hardly be avoided in considering eukaryotic gene regulation, where reorganisation of chromatin and nucleosomes requires energy-dissipating motor proteins and post-translational modifications driven by chemical potential differences are found on all components of the regulatory machinery (Wong and Gunawardena, 2020). What impact such energy expenditure has on ensemble functional integration is a very interesting question. In a separate study that was stimulated by the present paper, we have confirmed that, if a conformational ensemble is maintained in steady state away from thermodynamic equilibrium, then it can exhibit greater functional capabilities than at equilibrium. We hope to report on these findings subsequently. The results presented here offer a rigorous starting point for thinking about how regulatory ensembles integrate binding information at thermodynamic equilibrium. If, indeed, regulatory energy expenditure is essential for gene expression function, as studies increasingly suggest (Park et al., 2019a; Grah et al., 2020; Wolff et al., 2021), new methods, both theoretical and experimental, will be required to understand its functional significance.
Materials and methods
The linear framework
Background and references
Request a detailed protocolThe graphs described in the main text, like those in Figure 4, are ‘equilibrium graphs’, which are convenient for describing systems at thermodynamic equilibrium. Equilibrium graphs are derived from linear framework graphs. The distinction between them is that the latter specifies a dynamics, while the former specifies an equilibrium steady state. We first explain the latter and then describe the former. Throughout this section we will use ‘graph’ to mean ‘linear framework graph’ and ‘equilibrium graph’ to mean the kind of graph used in the main text.
The linear framework was introduced in Gunawardena, 2012, developed in Mirzaev and Gunawardena, 2013, Mirzaev and Bortz, 2015, applied to various biological problems in Ahsendorf et al., 2014, Dasgupta et al., 2014, Estrada et al., 2016, Wong et al., 2018a, Wong et al., 2018b, Yordanov and Stelling, 2018, Biddle et al., 2019, Yordanov and Stelling, 2020 and reviewed in Gunawardena, 2014, Wong and Gunawardena, 2020. Technical details and proofs of the ideas described here can be found in Gunawardena, 2012, Mirzaev and Gunawardena, 2013, as well as in the Supplementary Information of Estrada et al., 2016, Wong et al., 2018b, Biddle et al., 2019.
The framework uses finite, directed graphs with labelled edges and no self-loops to analyse biochemical systems under timescale separation. In a typical timescale separation, the vertices represent ‘fast’ components or states, which are assumed to reach steady state; the edges represent reactions or transitions; and the edge labels represent rates with dimensions of (time)−1. The labels may include contributions from ‘slow’ components, which are not represented by vertices but which interact with them, such as binding ligands in the case of allostery.
Linear framework graphs and dynamics
Request a detailed protocolGraphs will always be connected, so that they cannot be separated into sub-graphs between which there are no edges. The set of vertices of a graph will be denoted by . For a general graph, the vertices will be indexed by numbers and vertex 1 will be taken to be the reference vertex. Particular kinds of graphs, such as the allostery graphs discussed in the paper, may use a different indexing. An edge from vertex to vertex will be denoted and the label on that edge by . A subscript, as in , may be used to specify which graph is under discussion. When discussing graphs, we used the word ‘structure’ to refer to properties that depend on vertices and edges only, ignoring the labels.
A graph gives rise to a dynamical system by assuming that each edge is a chemical reaction under mass-action kinetics with the label as the rate constant. Since each edge has only a single source vertex, the corresponding dynamics is linear and can be represented by a linear differential equation in matrix form:
(28)
Here, is the graph, is a vector of component concentrations and is the Laplacian matrix of . Since material is only moved between vertices, there is a conservation law, . By setting , can be treated as a vector of probabilities. In such a stochastic setting, Equation 28 is the master equation (Kolmogorov forward equation) of the underlying Markov process. This is a general representation: given any well-behaved Markov process on a finite state space, there is a graph, whose vertices are the states, for which Equation 28 is the master equation.
The linear dynamics in Equation 28 gives the linear framework its name and is common to all applications. The treatment of the external components, which appear in the edge labels and which introduce nonlinearities, depends on the application. For the case of allostery treated here, we make the same assumptions as in thermodynamics for the grand canonical ensemble, with each ligand being present in a reservoir from which binding and unbinding to graph vertices does not change its free concentration. In this case, the edge labels are effectively constant. The same assumptions are implicitly used in other studies of allostery.
Steady states and thermodynamic equilibrium
Request a detailed protocolThe dynamics in Equation 28 always tends to a steady state, at which , and, under the fundamental timescale separation, it is assumed to have reached a steady state. If the graph is strongly connected, it has a unique steady state up to a scalar multiple, so that . Strong connectivity means that, given any two distinct vertices, and , there is a path of directed edges from to , . Under strong connectivity, a representative steady state for the dynamics, , may be calculated in terms of the edge labels by the Matrix Tree Theorem. We omit the corresponding expression as it is not needed here, but it can be found in any of the references given above. This expression holds whether or not the steady state is one of thermodynamic equilibrium. However, at thermodynamic equilibrium, the description of the steady state simplifies considerably because detailed balance holds. This means that the graph is reversible, so that, if , then also , and each pair of such edges is independently in flux balance, so that
(29)
This ‘microscopic reversibility’ is a fundamental property of thermodynamic equilibrium. Note that a reversible, connected graph is necessarily strongly connected.
Take any path of reversible edges from the reference vertex 1 to some vertex , , and let be the product of the label ratios along the path:
(30)
It is straightforward to see from Equation 29 that does not depend on the chosen path and that . The vector is therefore a scalar multiple of and so also a steady state for the dynamics. The detailed balance formula in Equation 29 also holds for μ in place of ρ. At thermodynamic equilibrium, the only parameters needed to describe steady states are label ratios.
Equilibrium graphs and independent parameters
Request a detailed protocolThis observation about label ratios leads to the concept of an equilibrium graph. Suppose that is a linear framework graph which can reach thermodynamic equilibrium and is therefore reversible (above). gives rise to an equilibrium graph, , as follows. The vertices and edges of are the same as those of , but the edge labels in , which we will refer to as ‘equilibrium edge labels’ and denote , are the label ratios in . In other words,
(31)
Scheme 1 illustrates the relationship between the linear framework graph and the corresponding equilibrium graph. Note that the equilibrium edge labels of are non-dimensional and that . The equilibrium edge labels are the essential parameters for describing a state of thermodynamic equilibrium.
Scheme 1
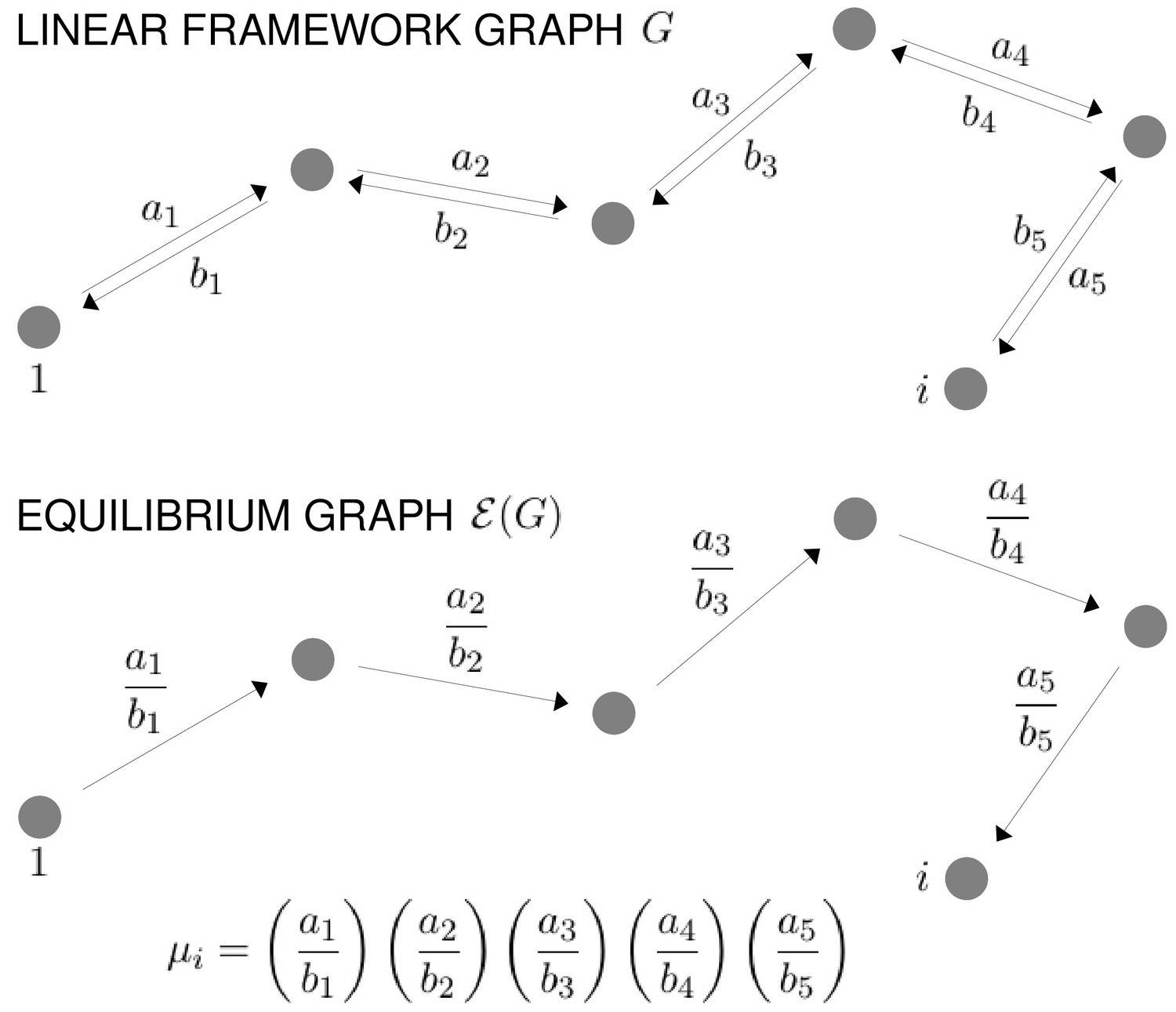
Graphs and equilibrium calculations.
At top, a path of reversible edges in a linear framework graph, , from the reference vertex, 1, to a vertex , with the edge labels shown. Below is the same path in the corresponding equilibrium graph, , showing the equilibrium labels, as given by Equation 31. The formula for the quantity , as specified in Equation 30, is shown at bottom. For μ to be well defined, must satisfy detailed balance (Equation 29) or, equivalently, the cycle condition (Equation 32) must hold in . Equilibrium probabilities are calculated from μ using Equation 33.
These parameters are not independent because Equation 29 implies algebraic relationships among them. Indeed, Equation 29 is equivalent to the following ‘cycle condition’, which we formulate for : given any cycle of edges, , the product of the equilibrium edge labels along the cycle is always 1:
(32)
This cycle condition is equivalent to the detailed balance condition in Equation 29 and either condition is equivalent to being at thermodynamic equilibrium.
There is a systematic procedure for choosing a set of equilibrium edge label parameters which are both independent, so that there are no algebraic relationships among them, and also complete, so that all other equilibrium edge labels can be algebraically calculated from them. Recall that a spanning tree of is a connected subgraph, , which contains each vertex of (spanning) and which has no cycles when edge directions are ignored (tree). Any strongly connected graph has a spanning tree and the number of edges in such a tree is one less than the number of vertices in the graph. Since and have the same vertices and edges, they have identical spanning trees. The equilibrium edge labels , taken over all edges of , form a complete and independent set of parameters at thermodynamic equilibrium. In particular, if has vertices, there are independent parameters at thermodynamic equilibrium.
In the main text, we defined an equilibrium allostery graph, (Figure 4), without specifying a corresponding linear framework graph, , for which . Because label ratios are used in an equilibrium graph, there is no unique linear framework graph corresponding to it. However, some choice of transition rates, and , can always be made such that their ratio is . Hence, some linear framework graph can always be defined such that . In some of the constructions below, we will work with the linear framework graph, , rather than with the equilibrium graph and will then show that the construction does not depend on the choice of .
Steady-state probabilities and equilibrium statistical mechanics
Request a detailed protocolThe steady-state probability of vertex , , can be calculated from the steady state of the dynamics by normalising, so that
(33)
where the first formula holds for any strongly connected graph and the second formula also holds if the graph is at thermodynamic equilibrium. In the latter case, Equation 29 holds and can be defined by Equation 30. The second formula in Equation 33 corresponds to Equation 3. If the graph is at thermodynamic equilibrium, the equilibrium edge labels may be interpreted thermodynamically, as illustrated in Figure 3 and discussed in the main text (Equation 1):
(34)
If Equation 34 is used to expand the second formula in Equation 33, it gives the specification of equilibrium statistical mechanics for the grand canonical ensemble, with the denominator being the partition function.
It will be helpful to let and denote the corresponding denominators in Equation 33, so that for any strongly connected graph and for a graph which is at thermodynamic equilibrium. We will refer to and as partition functions. It follows from Equation 33 that
(35)
depending on the context.
The allostery graph
Structure and labels
Request a detailed protocolAn allostery graph, , is an equilibrium graph which describes the interplay between conformational change and ligand binding, as illustrated in Figure 4. Its vertices are indexed by , where ck specifies a conformation with and specifies a subset of sites bound by a ligand whose concentration is . There is no difficulty in allowing multiple ligands and overlapping binding sites, but to keep the formalism simple, we describe here the case of a single ligand and distinct binding sites.
Recall from the main text that has vertical subgraphs, , consisting of vertices for all binding subsets, , together with all edges between them, with the vertices indexed by binding subsets, , and with being the reference vertex. has horizontal subgraphs, , consisting of vertices for all conformations ci, together with all edges between them, with the vertices labelled by conformations ci, and with c1 being the reference vertex. The product structure of is revealed by all vertical subgraphs having the same structure as each other and all horizontal subgraphs having the same structure as each other (Figure 4).
As for the labels, the vertical binding edges have equilibrium labels,
(36)
where is the concentration of the ligand and is the association constant for binding to site when the ligand is already bound at the sites in . The horizontal edges, which represent transitions between conformations, have equilibrium labels, , which are not individually annotated. However, it is only necessary to specify these equilibrium labels for a single horizontal subgraph, of which the subgraph of empty conformations, , is particularly convenient. To see this, let us calculate the quantity using Equation 30. Taking the reference vertex in to be , we can always find a path to any given vertex of by first moving horizontally within from to and then moving vertically within from to . According to Equation 30, the steady state is given by the product of the equilibrium labels along this path, so that
(37)
Now consider any horizontal edge in , . Since is at thermodynamic equilibrium, it follows from Equation 29, using μ in place of ρ, and Equation 37, that
Applying Equation 29 to , with μ in place of ρ, we see that
Hence, it follows that
(38)
Accordingly, all the labels in are determined by the vertical labels in Equation 36, from which and are determined, and the horizontal labels in the subgraph of empty conformations, . As can be seen from Scheme 2, Equation 38 amounts to exploiting the equilibrium cycle condition in Equation 32.
Scheme 2
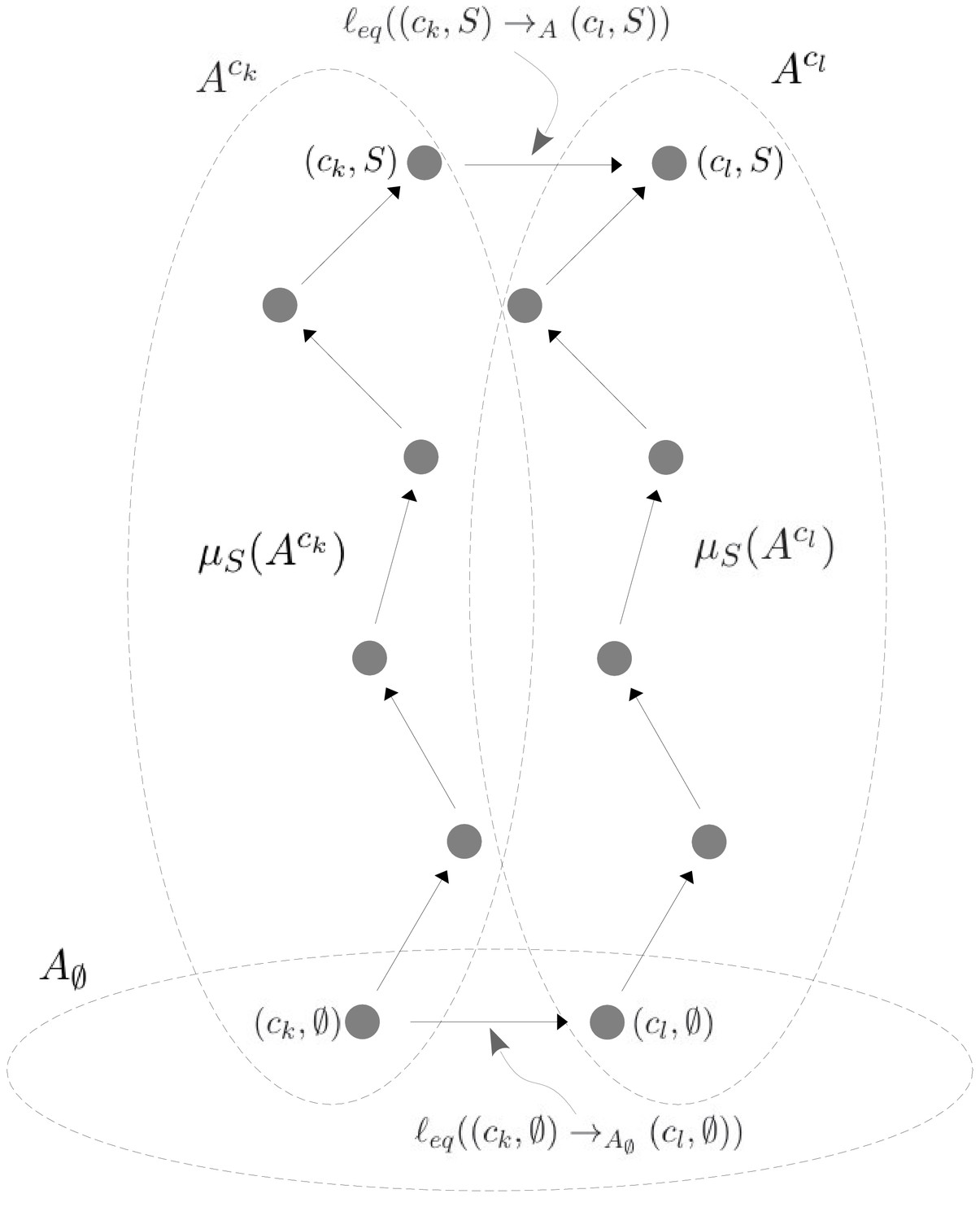
Illustration of Equation 38.
A hypothetical allostery graph shows how the label for the edge at the top, which links the vertical subgraphs at conformations ck and cl at the binding subset , can be calculated from the quantities and and the edge label at the bottom. The quantities come from paths to the vertices in question from the respective reference vertices in the vertical subgraphs, as specified in Equation 30 and Scheme 1. The edge label at the bottom comes from the horizontal subgraph of empty conformations, . The vertical subgraphs and have the same structure and the paths are shown as the same in each subgraph, but they could be arbitrary paths because of the cycle condition at thermodynamic equilibrium (Equation 32). Once appropriate directions are taken, the two paths and the edges at the top and bottom constitute a large cycle in the allostery graph and Equation 38 is simply a rewriting of Equation 32 applied to this cycle.
Independent parameters
Request a detailed protocolWe can choose any spanning tree in the horizontal subgraph of empty conformations, . As explained above, the equilibrium labels on the edges of this tree define a complete set of independent parameters for . As for the vertical subgraphs, , which all have the same structure, consider the subgraph of consisting of all edges, together with the corresponding source and target vertices, of the form, , where and is less than all the sites in (). It is not difficult to see that this subgraph is a spanning tree of (Estrada et al., 2016, SI, §3.2). Accordingly, the association constants, from Equation 36, with , form a complete set of independent parameters for . Because of the product structure of , adjoining the spanning trees in , for each conformation ck with , to the spanning tree in , yields a spanning tree in . Hence, the independent parameters for together with the independent parameters for are also collectively independent as parameters for . It follows from the description of labels above that these parameters are also complete for , so that any equilibrium label in can be expressed in terms of them.
A general method of coarse graining
Coarse graining a linear framework graph and Equation 17
Request a detailed protocolWe will describe the coarse-graining procedure for an arbitrary reversible linear framework graph, , and then explain how this can be adapted to an equilibrium graph, as described for the allostery graph in the main text.
We will say that a graph is in-uniform if, given any vertex , then for all edges , does not depend on the source vertex .
Lemma 1
Request a detailed protocolSuppose that is reversible and in-uniform. Then, is at thermodynamic equilibrium and the vector θ given by , which is well-defined by hypothesis, is a basis element in and a steady state for the dynamics.
Proof: If is any path of reversible edges in , then the product of the label ratios along the path satisfies
(39)
because the intermediate terms cancel out by the in-uniform hypothesis. If the path is a cycle, so that , then, again because of the in-uniform hypothesis, the right-hand side of Equation 39 is 1. Hence, satisfies the cycle condition in Equation 32 and is therefore at thermodynamic equilibrium. For the last statement, assume that i1 is the reference vertex 1 and that , for any vertex . Using Equation 30, we see that . Since is a scalar multiple, the last statement follows.
Now let be an arbitrary reversible graph, which need not satisfy detailed balance. Let be any partition of the vertices of , so that , and when . Let be the labelled directed graph with and let if, and only if, there exists and such that . Finally, let the edge labels of be given by
(40)
The quantity in Equation 40 is chosen arbitrarily so that the dimension of is (time)−1, as required for an edge label. This is necessary because, by the Matrix Tree Theorem, the dimension of is (time)1−N, where is the number of vertices in . However, plays no role in the analysis which follows because the coarse graining applies only to the steady state of , not its transient dynamics, and, as we will see, is always at thermodynamic equilibrium, so that disappears when equilibrium edge labels are considered.
Note that inherits reversibility from and that is in-uniform. Hence, by Lemma 1, is at thermodynamic equilibrium and
(41)
where λ is a scalar that does not depend on . Since is a partition of the vertices of , it follows from Equation 41 that
Equations 35 and 41 then show that both λ and cancel in the ratio for the steady-state probabilities, so that
(42)
Equation 42 is the coarse-graining equation, as given in Equation 17.
Coarse graining an equilibrium graph
Request a detailed protocolThe coarse-graining procedure described above can be applied to any reversible graph, which need not be at thermodynamic equilibrium. However, the coarse graining described in the paper was for an equilibrium graph. It is not difficult to see that the construction above can be undertaken consistently for any equilibrium graph. It is helpful to first establish a more general observation. The choice of edge labels for , as given in Equation 40, is not the only one for which Equation 42 holds, as the appearance of the factor indicates. However, the label ratios in are uniquely determined by the labels of .
Suppose that is a reversible graph with a vertex partition , as above. need not be at thermodynamic equilibrium. Suppose that is a graph which is isomorphic to as a directed graph (‘structurally isomorphic’), in the sense that it has identical vertices and edges but may have different edge labels. (Technically speaking, an ‘isomorphism’ allows for the vertices of to have an alternative indexing to those of as long as the two indexings can be inter-converted so as to preserve the edges. For simplicity of exposition, we assume that the indexing is, in fact, identical. No loss of generality arises from doing this.)
Lemma 2
Request a detailed protocolSuppose that is at thermodynamic equilibrium and the coarse-graining equation (Equation 42) holds for , so that . If is any reversible edge, then its equilibrium label depends only on ,
and and are isomorphic as equilibrium graphs, so that identical edges have identical equilibrium labels.
Proof: It follows from Equation 35 that and, since is at thermodynamic equilibrium, . Using the coarse-graining equation for , we see that
(43)
Since is at thermodynamic equilibrium, Equation 29, with μ in place of ρ, implies that
Substituting with Equation 43, the partition functions cancel out to give the formula above. Since satisfies the same assumptions as , it has the same equilibrium labels. Hence, and must be isomorphic as equilibrium graphs.
Corollary 1
Request a detailed protocolSuppose that is an equilibrium graph and that is any graph for which , as described above. If any coarse graining of is undertaken to yield the coarse-grained graph , which must be at thermodynamic equilibrium, then
and depends only on and not on the choice of .
Proof: acquires from the same coarse graining, with the partition of , where . By hypothesis, is at thermodynamic equilibrium, so that for some scalar multiple λ. Also, since , . Substituting in the formula in Lemma 2 yields the formula above. The equilibrium labels of therefore depend only on the equilibrium labels of , as required.
It follows from Corollary 1 that coarse graining can be carried out on an equilibrium graph, , by choosing any graph for which and carrying out the coarse-graining procedure described above on . This justifies the coarse-graining construction described in the main text.
Coarse graining the allostery graph
Proof of Equation 18
Request a detailed protocolAs described in the main text and Figure 4, the coarse-grained allostery graph, , is defined using the partition of by its horizontal subgraphs, , where runs through all binding subsets, . has the same structure of vertices and edges as any of the binding subgraphs, , and is indexed in the same way by the binding subsets, . Scheme 3 shows an example, which illustrates the calculations undertaken in this section.
Scheme 3

Coarse graining and effective association constants.
At top left is an example allostery graph, with binding of a single ligand to sites for conformations. Vertices indicate a bound site with a solid black dot and an unbound site with a black dash and binding subsets are colour coded: both sites unbound, black; only site 1 bound, magenta; only site 2 bound, cyan; both sites bound, blue. Some vertices are annotated and some edge labels are shown, with denoting ligand concentration. Note that the allostery graph has been oriented with its reference vertex at the top, in contrast to the graphs in the main text figures, in order to accommodate the formulas. Example calculations of based on Equation 30 are shown for the vertical subgraph . At bottom is the horizontal subgraph along with the calculation of its steady-state probability distribution in terms of the equilibrium labels, . and the quantities . At top right is the coarse-grained allostery graph, , with vertices colour coded as for the binding subsets of the allostery graph. Equation 48 for the effective association constants is illustrated below .
Consider the reversible edge in , , where . This reversible edge effectively arises from the binding and unbinding of ligand at site . According to Equation 36, its effective association constant, , should satisfy
(44)
Since is at thermodynamic equilibrium, we can make use of the formula in Corollary 1 to rewrite this as
Equations 30 and 36 tell us that , so that, after rearranging,
(45)
We can now appeal to Equations 35 and 37 to rewrite the term in brackets on the right as
(46)
At this point, it will be helpful to introduce the following notation. If is any equilibrium graph and is any real-valued function defined on the vertices of , let denote the average of over the steady-state probability distribution of ,
(47)
With this notation in hand, we can rewrite the denominator in Equation 46 as , where, from now on, averages will be taken over the steady-state probability distribution of the horizontal subgraph of empty conformations, (Scheme 3, bottom). Inserting this expression back into Equation 45 and rearranging, we obtain a formula for the effective association constant as a ratio of averages,
(48)
which gives the first formula in Equation 18. The ‘dot’ in Equation 48 signifies a product to make the formula easier to read. Scheme 3 demonstrates this calculation. Recall from the main text that HOCs are defined by normalising to the empty binding subset, so that . Furthermore, since the reference vertex of the vertical subgraphs, , is taken to be the empty binding subset, . It follows that the effective HOCs are given by
(49)
which gives the second formula in Equation 18.
Elementary properties of effective HOCs
Request a detailed protocolThe main text describes three elementary properties of effective HOCs which follow from Equation 49. The only quantity in Equation 49 which involves the ligand concentration, , is . It follows from Equation 30 that this quantity is a monomial in of the form , where does not involve and . In particular, does not depend on the conformation ck. It follows that can be extracted from the averages in Equation 49 and cancelled between the numerator and denominator. Hence, is independent of . If , then for all and it follows from Equation 49 that . Finally, if there is only one conformation c1, the averages in Equation 49 collapse and cancels above and below, so that , as required.
Generalised MWC formula
Request a detailed protocolThe original MWC formula calculates the binding curve, or fractional saturation, of the two-conformation model as a function of ligand concentration (Monod et al., 1965). Here, we do the same for an arbitrary allostery graph, . Let . The fractional saturation of is given by the average binding,
normalised to the number of binding sites, . By the coarse-graining formula in Equation 42, we can rewrite the fractional saturation as
(50)
The probability, , can be calculated using Equation 33, which requires the quantities . These can in turn be calculated by the path formula in Equation 30. We can choose the path in to use the independent parameters introduced above. Let , where . Making use of Equation 44, we see that
(51)
Equation 51 can be rewritten in terms of the non-dimensional effective HOCs, but it is simpler for our purposes to use instead the effective association constants, . The dependence on in Equation 51 shows that average binding is given by the logarithmic derivative of the partition function, , so the fractional saturation can be written as
(52)
With this in mind, Equation 51 shows that the partition function can be written as a polynomial in ,
Finally, the can be determined as averages over the horizontal subgraph of empty conformations using Equation 48. In this way, the fractional saturation in Equation 52 is ultimately determined by the independent parameters of , giving rise thereby to a generalised MWC formula that is valid for any allostery graph. We explain below how the classical MWC formula is recovered using this procedure.
Effective HOCs for MWC-like models
Proof of Equation 19 and related work
Request a detailed protocolLet be an allostery graph with ligand binding to sites which are independent and identical in each conformation. Because of independence, , so that does not depend on ; because the sites are identical, does not depend on . Hence, we may write and the labels on the binding edges of the vertical subgraph are all given by . It follows from Equation 30 that , where . Equation 49 then tells us that also depends only on , so that we can write it as , and Equation 49 simplifies to
(53)
which gives Equation 19.
If we consider the effective association constant instead of the effective HOC, then, with the same assumptions as above, Equation 48 tells us that
Suppose that only two conformations, and , are present. Let and write and as and , respectively. Then, for any random variable on conformations, , the average is given by . Hence,
(54)
which is the formula for the (s + 1)-th ‘intrinsic binding constant’ given by Gruber and Horovitz, 2018, Equation (2.10). In their analysis, the word ‘intrinsic’ corresponds to our ‘effective’.
We can use Equation 54 to work out what the generalised MWC formula derived above yields for the classical MWC model. Substituting Equation 54 in Equation 51, the intermediate terms in the product cancel out to leave,
in which the right-hand side depends only on . Collecting together subsets of the same size, the partition function of may be written as
It then follows from Equation 52 that the fractional saturation is given by
If we set and , this gives, for the fractional saturation,
(55)
which recovers the classical MWC formula in the notation of Monod et al., 1965, Equation 2.
Proof of Equation 20
Request a detailed protocolThe following result is unlikely not to be known in other contexts but we have not been able to find mention of it.
Lemma 3
Request a detailed protocolSuppose that is a positive random variable, , over a finite probability distribution. If , the following moment inequality holds,
with equality if, and only if, is constant over the distribution.
Proof: Suppose that the states of the probability space are indexed by and that pi denotes the probability of state . Then,
(56)
The quantity can then be written as
Collecting together terms in , we can rewrite this as
(57)
Note that the terms corresponding to yield and so do not contribute to Equation 57. Choose any pair and and let . Then, the coefficient of in Equation 57 becomes
Now, for , with equality if, and only if, . Since by hypothesis, , so the coefficient of is positive unless . Hence, unless whenever and , which means that is constant over the distribution. Of course, if is constant, then clearly for all . The result follows.
Corollary 2
Request a detailed protocolIf is an MWC-like allostery graph, its effective HOCs satisfy
(58)
with equality at any stage if, and only if, is constant over .
Proof: It follows from Equation 53 that we can rewrite the effective HOCs recursively as
(59)
Since , the result follows by recursively applying Lemma 3 to . Equation 58 gives Equation 20.
Negative effective cooperativity
Request a detailed protocolWe consider an allostery graph with two conformations and two sites, in which binding is independent but not identical, so that the association constants differ between sites. Let and , for . Since the sites are independent, , so that , for . It follows from Equation 30—see also Scheme 1—that
Let λ be the single equilibrium label in the horizontal subgraph of empty conformations,
It follows from Equations 30 and 33—see also the similar calculation in Scheme 3—that and . We know from Equation 49 that
and using the identifications above, we see that
Substituting and simplifying, we find that
The first and last terms are the same in the numerator and denominator, so it follows that if, and only if,
which is to say
The left-hand side factors to give
We see that negative cooperativity arises if, and only if, the sites have opposite patterns of association constants in the two conformations.
Flexibility of allostery
The integrative flexibility theorem
Request a detailed protocolWe provide here a complete version of the proof that was sketched in the main text, showing rigorously how the approximation is handled. Some preliminary notation is needed. Recall that if is a finite set—typically, a subset of —then will denote the number of elements in . If and are sets, then will denote the complement of in , . To control the approximation, we will use the ‘little o’ notation: will stand for any quantity which depends on and for which as . For instance, is but is if, and only if, . This notation allows concise expression of complicated expressions which vanish in the limit as . Note that as if, and only if, , which is a useful trick for simplifying .
Theorem 1
Request a detailed protocolSuppose and choose arbitrary positive numbers
Given any and , there exists an allosteric conformational ensemble, which has no intrinsic HOC in any conformation, such that
for all corresponding values of and .
Proof: Recall from the main text that we use an allostery graph whose conformations are indexed by subsets and denoted , as illustrated in Figure 6. The reference vertex of is . For the horizontal subgraph of empty conformations, , let . It follows from Equation 30, using μ in place of ρ, that the determine the equilibrium labels of . Keeping in mind that , the form a set of independent parameters for , as explained above. The steady-state probabilities are then given by (Equation 35).
Let be positive quantities whose values we will subsequently choose. We assume that all intrinsic HOCs are one and, for any binding microstate , we set
(60)
If is a conformation and is a binding microstate, it follows from Equation 60 that
(61)
After coarse graining, we can calculate effective association constants and effective HOCs using the formulas in Equations 48 and 49. Let be a binding microstate and . Using Equation 48 and Equations 60 and 61,
Letting , we can use the trick described above to rewrite this as
(62)
Equation 62 is the more rigorous version of Equation 22. It follows from Equation 62, using the same trick to reorganise the terms which are , that the effective HOCs are
(63)
Equation 63 is the more rigorous version of Equation 23. We see that the effective HOCs are independent of the quantities and depend only on the parameters, , of the horizontal subgraph .
We can now specify the . If , where , we set
(64)
where each of the α quantities is given by hypothesis. Note that the exponent of δ depends only on the size of and not on which elements contains. Equation 64 is illustrated in Figure 6.
It follows from Equation 64 that, given any ,
Using this, we see that the main term in Equation 63 has the form
(65)
It follows from Equation 64 that, when , , so using the trick above for reorganising the terms, we can rewrite Equation 65 as . Substituting back into Equation 63, we see that, when ,
(66)
Equation 66 is the more rigorous version of Equation 26.
With the choice of given by Equation 64, we can return to Equation 62 with and define
Substituting back into Equation 62 with , we see that
(67)
Equation 67 is the more rigorous version of Equation 27. The result follows from Equations 66, 67.
Construction of Figure 8
Request a detailed protocolWe implemented in a Mathematica notebook the proof strategy in Theorem 1 for any number of sites. The notebook takes as input parameters the and the for in the statement of the theorem, along with specified values for the quantities ε and δ. It produces as output the effective bare association constants, , and effective HOCs, for , as given by Theorem 1. The values of and δ can then be adjusted so that the calculated and are as close as required to the and . The notebook is available on request.
Figure 8 shows the results from using this notebook on three examples, chosen by hand to illustrate different patterns of effective bare association constants and effective HOCs. The actual numerical values are listed below.
The colour names used here refer to the colour code for the three examples in Figure 8. The maximum error was calculated as the larger of and . The quantities δ and ε were adjusted to make the maximum error less than 0.01.
The binding curves for each example (Figure 7B) show the dependence on concentration of average binding to site (coloured curves), which can be written in terms of the coarse-grained graph, , in the form
Here, is the indicator function for being in ,
Since the size of , which was denoted by above, is given by , we see from Equation 50 that the fractional saturation (Figure 7B, black curves) is the sum of the average bindings over all sites, normalised to the number of sites, .
| Maroon | Orange | Red | ||||
|---|---|---|---|---|---|---|
| 1 | 1.5777 | 1.5776 | 0.031353 | 0.031353 | 0.21257 | 0.21257 |
| 2 | 24.013 | 24.014 | 0.011104 | 0.011104 | 0.84301 | 0.84301 |
| 3 | 89.958 | 89.959 | 13.195 | 13.195 | 9.8514 | 9.8514 |
| 4 | 0.015685 | 0.015685 | 52.437 | 52.437 | 27.000 | 27.000 |
| 0.084815 | 0.0848456 | 1.0801 | 1.0801 | 50.455 | 50.454 | |
| 3.7432 | 3.7432 | 34.768 | 34.768 | 0.016359 | 0.016401 | |
| 0.044245 | 0.044264 | 0.032668 | 0.032669 | 0.60018 | 0.60018 | |
| 30.240 | 30.239 | 4.0683 | 4.0683 | 7.2944 | 7.2944 | |
| 0.074064 | 0.074083 | 1.5098 | 1.5098 | 0.010809 | 0.010809 | |
| 9.2687 | 9.2685 | 0.025183 | 0.025184 | 0.012613 | 0.012613 | |
| 4.0933 | 4.0933 | 0.31238 | 0.31238 | 57.783 | 57.783 | |
| 15.687 | 15.683 | 0.70016 | 0.70016 | 0.025618 | 0.025623 | |
| 0.013335 | 0.013349 | 0.13042 | 0.13056 | 4.4450 | 4.4450 | |
| 0.082851 | 0.082892 | 2.5235 | 2.5235 | 0.13584 | 0.13584 | |
| 6.5843 | 6.5825 | 0.017404 | 0.017407 | 0.063587 | 0.063833 | |
| Max. error | 0.00105 | 0.00105 | 0.00386 | |||
Allosteric ensembles for Hill functions
Construction of Figure 9
Request a detailed protocolAs described in the main text, we considered an allosteric ensemble with four conformations and six ligand binding sites with no intrinsic cooperativity in any conformation. Accordingly, the bare association constants, , constitute 6 free parameters for each conformation ck, , giving 24 free parameters. A further 3 free parameters arise for the independent equilibrium labels of the horizontal subgraph of empty conformations, , giving 27 free parameters in total. The association constants were restricted to lie in the range and the equilibrium labels in the range . To compare the binding function, , to the Hill functions , the concentration variable, , was normalised to its half-maximal value, u0.5, for which (Estrada et al., 2016). The normalised binding function, , then satisfies . We followed a two-step procedure to find binding functions which approximated Hill functions. The algorithm is publicly available on GitHub (github.com/rosamc/allostery-paper-2021; copy archived at swh:1:rev:386b23961732962e8ac8390322c9c6e6dfc39168), and we describe it here in general terms. For step 1, we used the measures of position, , and steepness, , of a normalised binding function, , introduced previously (Estrada et al., 2016). The steepness of is the maximum value of its derivative,
and the position of is the normalised concentration at which that maximum occurs,
The combination of these two measures provides an estimate of the shape of the binding function (Estrada et al., 2016). Starting with a seed for random number generation, we randomly sampled parameter values independently and logarithmically within the ranges specified above to find parameter sets for which and , which ensures that is not too far in position-steepness space from the Hill functions (Estrada et al., 2016, Supplementary Information, §6.1). This narrows down the search space substantially. Once such a parameter set has been found, step 2 of the procedure followed a Monte Carlo optimisation as follows. This algorithm was fine-tuned by hand, and full details are available with the source code on GitHub. The error between the selected binding function and the appropriate Hill function, , was measured as the average absolute difference between the functions at 1000 logarithmically spaced points between 0.0005 and 5,
where . Starting from the initial parameter set, , as selected in the first step, we randomly chose each parameter with probability and, for each chosen parameter, we randomly picked a new value v1 logarithmically in the range , where v0 is the existing parameter value. If the chosen value fell outside the appropriate parameter range, we took v1 to be the limit of the range. Having done this for each parameter to generate a new parameter set, , we chose for the next step of the iteration if and, if not, we chose with probability β; otherwise, we retained . The algorithm parameters , and were adjusted so that decreased and the range narrowed as the error decreased. Iterations were continued to an upper limit of , or until a parameter set was found for which . Step 1 and iterations of step 2 were undertaken with and 0.75 for each of 290 initial seeds for random number generation, and the examples shown in Figure 9 were selected from among those with the least error. For Hill coefficient , we had to relax the error bound slightly and the two examples shown in Figure 9 satisfy .
Data availability
No data has been generated or acquired for this study, which is purely theoretical.
References
-
The mediator complex: a central integrator of transcriptionNature Reviews Molecular Cell Biology 16:155–166.https://doi.org/10.1038/nrm3951
-
Recent advances in single-molecule fluorescence microscopy render structural biology dynamicCurrent Opinion in Structural Biology 65:61–68.https://doi.org/10.1016/j.sbi.2020.05.006
-
ConferenceRegulatory domains and their mechanismsCold Spring Harbor Symposia on Quantitative Biology. pp. 45–51.https://doi.org/10.1101/sqb.2015.80.027268
-
Expanding the paradigm: intrinsically disordered proteins and allosteric regulationJournal of Molecular Biology 430:2309–2320.https://doi.org/10.1016/j.jmb.2018.04.003
-
The regulatory landscapes of developmental genesDevelopment 147:dev171736.https://doi.org/10.1242/dev.171736
-
ConferenceThe feedback control mechanisms of biosynthetic L-threonine deaminase by L-isoleucineCold Spring Harbor Symposia on Quantitative Biology. pp. 313–318.https://doi.org/10.1101/SQB.1961.026.01.037
-
50 years of allosteric interactions: the twists and turns of the modelsNature Reviews Molecular Cell Biology 14:819–829.https://doi.org/10.1038/nrm3695
-
Allostery without conformational change. A plausible modelEuropean Biophysics Journal : EBJ 11:103–109.https://doi.org/10.1007/BF00276625
-
A fundamental trade-off in covalent switching and its circumvention by enzyme bifunctionality in glucose homeostasisJournal of Biological Chemistry 289:13010–13025.https://doi.org/10.1074/jbc.M113.546515
-
Cooperativity in long-range gene regulation by the lambda CI repressorGenes & Development 18:344–354.https://doi.org/10.1101/gad.1167904
-
Role of intrinsic protein disorder in the function and interactions of the transcriptional coactivators CREB-binding protein (CBP) and p300Journal of Biological Chemistry 291:6714–6722.https://doi.org/10.1074/jbc.R115.692020
-
Transcription factories: genetic programming in three dimensionsCurrent Opinion in Genetics & Development 22:110–114.https://doi.org/10.1016/j.gde.2012.01.010
-
Cooperativity has empirical and ultimate levels of explanationTrends in Pharmacological Sciences 37:620–623.https://doi.org/10.1016/j.tips.2016.06.001
-
The energy landscapes and motions of proteinsScience 254:1598–1603.https://doi.org/10.1126/science.1749933
-
BookRandom Perturbations of Dynamical SystemsHeidleberg, Germany: Springer.https://doi.org/10.1007/978-3-642-25847-3
-
The roles of structural dynamics in the cellular functions of RNAsNature Reviews Molecular Cell Biology 20:474–489.https://doi.org/10.1038/s41580-019-0136-0
-
Unpicking allosteric mechanisms of homo-oligomeric proteins by determining their successive ligand binding constantsPhilosophical Transactions of the Royal Society B: Biological Sciences 373:20170176.https://doi.org/10.1098/rstb.2017.0176
-
Studies in irreversible thermodynamics IV. diagrammatic representation of steady state fluxes for unimolecular systemsJournal of Theoretical Biology 10:442–459.https://doi.org/10.1016/0022-5193(66)90137-8
-
Structural and energetic basis of allosteryAnnual Review of Biophysics 41:585–609.https://doi.org/10.1146/annurev-biophys-050511-102319
-
Strategy for analysing the co-operativity of intramolecular interactions in peptides and proteinsJournal of Molecular Biology 214:613–617.https://doi.org/10.1016/0022-2836(90)90275-Q
-
Co-operative interactions during protein foldingJournal of Molecular Biology 224:733–740.https://doi.org/10.1016/0022-2836(92)90557-Z
-
Advanced methods for accessing protein Shape-Shifting present new therapeutic opportunitiesTrends in Biochemical Sciences 44:351–364.https://doi.org/10.1016/j.tibs.2018.11.007
-
Dynamics-Driven allostery in protein kinasesTrends in Biochemical Sciences 40:628–647.https://doi.org/10.1016/j.tibs.2015.09.002
-
Proteomics and models for enzyme cooperativityJournal of Biological Chemistry 277:46841–46844.https://doi.org/10.1074/jbc.R200014200
-
A matter of time: using dynamics and theory to uncover mechanisms of transcriptional burstingCurrent Opinion in Cell Biology 67:147–157.https://doi.org/10.1016/j.ceb.2020.08.001
-
Caught in the act: structural dynamics of replication origin activation and fork progressionBiochemical Society Transactions 48:1057–1066.https://doi.org/10.1042/BST20190998
-
Intrinsic disorder in transcription factorsBiochemistry 45:6873–6888.https://doi.org/10.1021/bi0602718
-
Allostery and molecular machinesPhilosophical Transactions of the Royal Society B: Biological Sciences 373:20170173.https://doi.org/10.1098/rstb.2017.0173
-
A measure to quantify the degree of cooperativity in overall titration curvesJournal of Theoretical Biology 432:33–37.https://doi.org/10.1016/j.jtbi.2017.08.010
-
Statistical mechanics of Monod-Wyman-Changeux (MWC) modelsJournal of Molecular Biology 425:1433–1460.https://doi.org/10.1016/j.jmb.2013.03.013
-
Collaborative competition mechanism for gene activation in vivoMolecular and Cellular Biology 23:1623–1632.https://doi.org/10.1128/MCB.23.5.1623-1632.2003
-
Laplacian dynamics with synthesis and degradationBulletin of Mathematical Biology 77:1013–1045.https://doi.org/10.1007/s11538-015-0075-7
-
Laplacian dynamics on general graphsBulletin of Mathematical Biology 75:2118–2149.https://doi.org/10.1007/s11538-013-9884-8
-
On the nature of allosteric transitions: a plausible modelJournal of Molecular Biology 12:88–118.https://doi.org/10.1016/S0022-2836(65)80285-6
-
ConferenceTeleonomic mechanisms in cellular metabolism, growth, and differentiationCold Spring Harbor Symposia on Quantitative Biology. pp. 389–401.https://doi.org/10.1101/SQB.1961.026.01.048
-
Interplay between allostery and intrinsic disorder in an ensembleBiochemical Society Transactions 40:975–980.https://doi.org/10.1042/BST20120163
-
Transition networks for modeling the kinetics of conformational change in macromoleculesCurrent Opinion in Structural Biology 18:154–162.https://doi.org/10.1016/j.sbi.2008.01.008
-
The underappreciated role of allostery in the cellular networkAnnual Review of Biophysics 42:169–189.https://doi.org/10.1146/annurev-biophys-083012-130257
-
Network theory of microscopic and macroscopic behavior of master equation systemsReviews of Modern Physics 48:571–585.https://doi.org/10.1103/RevModPhys.48.571
-
Computational approaches to investigating allosteryCurrent Opinion in Structural Biology 41:159–171.https://doi.org/10.1016/j.sbi.2016.06.017
-
Markov models for the elucidation of allosteric regulationPhilosophical Transactions of the Royal Society B: Biological Sciences 373:20170178.https://doi.org/10.1098/rstb.2017.0178
-
ConferenceToward an understanding of the gene-specific and global logic of inducible gene transcriptionCold Spring Harbor Symposia on Quantitative Biology. pp. 61–68.https://doi.org/10.1101/sqb.2013.78.020313
-
BookAn Introduction to Markov ProcessesIn: Vakil R, editors. Graduate Texts in Mathematics. Berlin, Germany: Springer-Verlag. pp. 1–203.https://doi.org/10.1007/978-3-642-40523-5
-
Precision in a rush: trade-offs between reproducibility and steepness of the hunchback expression patternPLOS Computational Biology 14:e1006513.https://doi.org/10.1371/journal.pcbi.1006513
-
Gene-specific transcription activation via long-range allosteric shape-shiftingBiochemical Journal 439:15–25.https://doi.org/10.1042/BJ20110972
-
A unified view of "how allostery works"PLOS Computational Biology 10:e1003394.https://doi.org/10.1371/journal.pcbi.1003394
-
Protein dynamics and allostery: an NMR viewCurrent Opinion in Structural Biology 21:62–67.https://doi.org/10.1016/j.sbi.2010.10.007
-
In memoriam: jacques Monod (1910-1976)Genome Biology and Evolution 3:1025–1033.https://doi.org/10.1093/gbe/evr024
-
On small random perturbations of dynamical systemsRussian Mathematical Surveys 25:1–55.https://doi.org/10.1070/RM1970v025n01ABEH001254
-
Dynamic regulation of transcriptional states by chromatin and transcription factorsNature Reviews Genetics 15:69–81.https://doi.org/10.1038/nrg3623
-
Energy landscapes: calculating pathways and ratesInternational Reviews in Physical Chemistry 25:237–282.https://doi.org/10.1080/01442350600676921
-
Gene regulation in and out of equilibriumAnnual Review of Biophysics 49:199–226.https://doi.org/10.1146/annurev-biophys-121219-081542
-
The role of protein conformational fluctuations in Allostery, function, and evolutionBiophysical Chemistry 159:129–141.https://doi.org/10.1016/j.bpc.2011.05.020
-
Intrinsically disordered proteins in cellular signalling and regulationNature Reviews Molecular Cell Biology 16:18–29.https://doi.org/10.1038/nrm3920
-
Steady-State differential dose response in biological systemsBiophysical Journal 114:723–736.https://doi.org/10.1016/j.bpj.2017.11.3780
-
Efficient manipulation and generation of kirchhoff polynomials for the analysis of non-equilibrium biochemical reaction networksJournal of the Royal Society Interface 17:20190828.https://doi.org/10.1098/rsif.2019.0828
Article and author information
Author details
Rosa Martinez-Corral

Jeremy Gunawardena
Funding
National Science Foundation (1462629)
- John W Biddle
- Jeremy Gunawardena
National Institutes of Health (GM122928)
- Rosa Martinez-Corral
European Molecular Biology Organization (ALTF683-2019)
- Rosa Martinez-Corral
National Science Foundation (DGE1144152)
- Felix Wong
James S. McDonnell Foundation
- Felix Wong
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We are indebted to Hernan Garcia and an anonymous reviewer for questions and suggestions which helped to improve this paper. JWB and JG were supported by US National Science Foundation (NSF) Award #1462629. RMC was supported by US National Institutes of Health award #GM122928 and EMBO Fellowship ALTF683-2019. FW was supported by the James S McDonnell Foundation and NSF Graduate Research Fellowship #DGE1144152.
Copyright
© 2021, Biddle et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,224
- views
-
- 329
- downloads
-
- 37
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 37
- citations for umbrella DOI https://doi.org/10.7554/eLife.65498
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Allosteric conformational ensembles have unlimited capacity for integrating information
eLife 10:e65498.
https://doi.org/10.7554/eLife.65498




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}