Dynamics of immune memory and learning in bacterial communities
- Department of Physics, University of Toronto, Canada
- Institute of Biomaterials & Biomedical Engineering, University of Toronto, Canada
Abstract
From bacteria to humans, adaptive immune systems provide learned memories of past infections. Despite their vast biological differences, adaptive immunity shares features from microbes to vertebrates such as emergent immune diversity, long-term coexistence of hosts and pathogens, and fitness pressures from evolving pathogens and adapting hosts, yet there is no conceptual model that addresses all of these together. To this end, we propose and solve a simple phenomenological model of CRISPR-based adaptive immunity in microbes. We show that in coexisting phage and bacteria populations, immune diversity in both populations is coupled and emerges spontaneously, that bacteria track phage evolution with a context-dependent lag, and that high levels of diversity are paradoxically linked to low overall CRISPR immunity. We define average immunity, an important summary parameter predicted by our model, and use it to perform synthetic time-shift analyses on available experimental data to reveal different modalities of coevolution. Finally, immune cross-reactivity in our model leads to qualitatively different states of evolutionary dynamics, including an influenza-like traveling wave regime that resembles a similar state in models of vertebrate adaptive immunity. Our results show that CRISPR immunity provides a tractable model, both theoretically and experimentally, to understand general features of adaptive immunity.
Editor's evaluation
In this important work, the authors develop a theory for the coevolutionary dynamics of bacteria and phages, where the major evolutionary pressure comes from CRISPR-Cas adaptive immunity in bacteria. Through extensive stochastic numerical simulations and analytical calculations, the article presents a compelling analysis of the emergent properties of immune interactions, in the regime of a single proto-spacer and a single spacer. Some of the trends highlighted by the model are recovered from experimental data. The main results concern how diversity in both phage and bacteria population is linked and is shaped by immunity, and should be of broad interest in immunology.
https://doi.org/10.7554/eLife.81692.sa0Introduction
Adaptive immunity equips organisms to survive changing pathogen attacks across their lifetime. Many diverse organisms from bacteria to humans possess adaptive immune systems, and their presence shapes the survival, diversity, and evolution of both hosts and pathogens. How adaptive immunity changes the landscape of host-pathogen coexistence, how immune diversity emerges and evolves, and how the pressures of evolving pathogens and adaptive immunity are coupled to produce unique evolutionary outcomes: all of these factors are of fundamental importance to understanding the role of adaptive immunity in populations.
These questions have naturally been explored in the vertebrate adaptive immune system, which protects humans and other vertebrates from evolving pathogens. In these organisms, a diverse repertoire of T cell and B cell receptors can rapidly recognize and respond to a wide range of threats. Immune specificity is determined by the unique genetic sequence of each cell’s receptor, and individuals may harbour millions to billions of unique sequences distributed across four or more orders of magnitude of abundance (Desponds et al., 2016; Mora and Walczak, 2019; de Greef et al., 2020). Quantitative frameworks to model immune diversity and clone abundance have revealed that simple low-level interactions can give rise to complex outcomes including broad distributions of clone abundance (Desponds et al., 2016; Mora and Walczak, 2019; de Greef et al., 2020; Mayer et al., 2015; Gaimann et al., 2020; Dessalles et al., 2022), long-lived biologically realistic transient states (Yan et al., 2019; Gaimann et al., 2020), and clonal restructuring following immune challenges (Childs et al., 2015; Puelma Touzel et al., 2020; Sachdeva et al., 2020; Molari et al., 2020; Gaimann et al., 2020). Phenomenological models of pathogen coevolution with the immune system have accelerated our understanding of how the fitness landscape generated by the immune system constrains pathogen evolution (Luksza and Lässig, 2014; Marchi et al., 2019; Yan et al., 2019; Schnaack and Nourmohammad, 2021; Chardès et al., 2022), how the adaptive immune system responds to rapid pathogen evolution (Wang et al., 2015; Nourmohammad et al., 2019; Schnaack and Nourmohammad, 2021; Chardès et al., 2022), and what drives pathogen extinction (Yan et al., 2019; Marchi et al., 2019 or the extinction of particular clonal cell lineages Nourmohammad et al., 2019; Sachdeva et al., 2020). These models have also explored trade-offs such as between immune receptor specificity and cross-reactivity (Mayer et al., 2015; Nourmohammad et al., 2016), between the specificity of host-pathogen discrimination and sensitivity to pathogens (Childs et al., 2015; Downie et al., 2021; Metcalf et al., 2017), between the speed of an immune response and the efficiency of that response (Schnaack and Nourmohammad, 2021), or between metabolic resource use and immune coverage (Chardès et al., 2022). All of these models have shown rich dynamics and qualitatively different states of diversity and evolution arising from simple rules. However, experiments in vertebrates are difficult: vertebrate immunity depends on a complex interplay of many cell types and experiments are time-consuming because of long generation times (Altan-Bonnet et al., 2020).
Adaptive immunity in microbes is realized through the CRISPR system, conceptually related to the vertebrate adaptive immune system. The CRISPR system is functionally simple, yet it is incredibly powerful, as indicated by its widespread presence in many diverse bacteria and archaea Koonin and Makarova, 2019 and its experimentally demonstrated ability to provide strong immunity against phages (Paez-Espino et al., 2013; Paez-Espino et al., 2015; van Houte et al., 2016; Bondy-Denomy et al., 2013). Attacking phages expose their DNA to bacteria, and bacteria with a CRISPR immune system acquire small segments of phage DNA, called spacers. They store spacers in their genome and use them to recognize and destroy matching phage sequences in future infections: spacers are transcribed into RNA and guide DNA-cleaving CRISPR-associated proteins to recognize and cut re-infecting phages. Spacers provide a highly specific immune memory of infecting phages, preventing recognized phages from reproducing. In turn, phages can acquire mutations in the protospacer regions of their genome that are targeted by spacers. These features of the CRISPR immune system mean that (a) phage genetic evolution occurs by selection for escape mutants, and (b) the network of CRISPR immune interactions between bacteria and phages can be inferred by sequencing the genomes of co-living bacteria and phages. Spacer acquisition and phage mutation are rare random events, and many such events must be observed in order to understand their impact on populations. Bacteria and phages have short life cycles and can reach large population size, making it possible to build a statistical picture of the impacts of adaptive immunity.
The kinetics and interactions of phages and bacteria with CRISPR systems have been the subject of numerous experiments (van Houte et al., 2016; Common et al., 2019; Common et al., 2020; Chabas et al., 2021; Dimitriu et al., 2022; Guillemet et al., 2021). Some themes have emerged from experimental studies of CRISPR immunity: (a) high spacer diversity relative to phage diversity increases the likelihood of phage extinction (van Houte et al., 2016; Common et al., 2020; Guillemet et al., 2021), (b) bacteria become more immune to phages over time (Laanto et al., 2017; Morley et al., 2017; Common et al., 2019; Pyenson and Marraffini, 2020), and (c) phages readily gain mutations (Weinberger et al., 2012a; Paez-Espino et al., 2013; Levin et al., 2013; Pyenson et al., 2017; Watson et al., 2019; Pyenson and Marraffini, 2020; Guillemet et al., 2021; Guerrero et al., 2021a) and sometimes genome rearrangements (Paez-Espino et al., 2015) to escape CRISPR targeting. Explorations of CRISPR immunity in natural environments have also documented ongoing spacer acquisition and phage escape mutations (Weinberger et al., 2012a; Guerrero et al., 2021a). Likewise, previous theoretical work has addressed the impact of parameters such as spacer acquisition rate and phage mutation rate on spacer diversity (Childs et al., 2012; Han et al., 2013; Han and Deem, 2017) and population survival and extinction (Weinberger et al., 2012b), how costs of CRISPR immunity impact bacteria-phage coexistence (Skanata and Kussell, 2021) and the maintenance of CRISPR immunity (Levin, 2010; Weinberger et al., 2012b; Westra et al., 2015; Gurney et al., 2019), how spacer diversity impacts population outcomes (He and Deem, 2010; Weinberger et al., 2012a; Childs et al., 2012; Haerter and Sneppen, 2012; Han et al., 2013; Childs et al., 2014; Bradde et al., 2017; Han and Deem, 2017), and how stochasticity and initial conditions impact population survival (Bradde et al., 2019; Chabas et al., 2018). Notably, foundational work by Childs et al., 2014; Childs et al., 2012 and Weinberger et al., 2012a; Weinberger et al., 2012b found through simulations that spacer diversity readily emerges in a population of CRISPR-competent bacteria interacting with mutating phages.
However, the majority of both experiments and theory are based on observations and models of transient phenomena and short-term dynamics, while it is at long timescales that natural microbial communities experience bacteria-phage coexistence. Some notable experiments have measured long-term coexistence (Paez-Espino et al., 2015; Wei et al., 2011), and long-term sequential sequencing data from natural populations is becoming more available (Gómez and Buckling, 2011; Burstein et al., 2016), but appropriate theories to understand steady-state coexistence, sequence evolution and turnover, and immune memory in microbial populations remain rare. Because the processes of growth, death, and immune interaction are inherently random, understanding population establishment and extinction requires a fully stochastic analysis, and theoretical models that explore long-term coexistence have been partially deterministic to date (Weinberger et al., 2012a; Weinberger et al., 2012b; Childs et al., 2012; Levin et al., 2013; Childs et al., 2014; Santos et al., 2014; Weissman et al., 2018; Gurney et al., 2019). These models do not accurately capture rare stochastic events, in particular mutation, establishment, and extinction. Notable fully stochastic simulations of CRISPR immunity, on the other hand, have lacked rigorous analytic results (Han et al., 2013; Han and Deem, 2017).
To understand the emergent properties of immune memory and diversity in microbial populations and how phages and bacteria coexist long-term, we developed a simple theoretical model of bacteria and phages interacting with adaptive immunity. We model a population of bacteria with CRISPR immune systems interacting with phages that can mutate to escape CRISPR targeting, building on our previous work that assumed a clonal population of phages with multiple protospacers in each phage (Bonsma-Fisher et al., 2018). We model phages with single protospacers in this work to efficiently track mutations in large populations over long timescales. We stochastically simulate thousands of bacteria-phage populations across a range of population sizes, spacer acquisition rates, spacer effectiveness rates, and phage mutation rates, and derive analytic expressions for the probability of establishment for new phage mutants, the time to extinction for phage and bacterial clones, and the dependence of bacterial spacer diversity on spacer acquisition rate, effectiveness, and phage mutation rate. Our simulations are fully stochastic and run for many thousands of generations to accurately capture the dynamics of establishment and extinction, yet the underlying model is simple enough to solve analytically. We show that even with the simplest assumptions of uniform spacer acquisition and effectiveness, complex dynamics and a wide range of outcomes of diversity and population structure are possible. We recover and reinterpret experimentally observed feaures: (a) we find that high diversity is not beneficial for bacteria when phage and bacterial diversity is strongly coupled, (b) we show that bacterial immunity can either track new phage mutations rapidly or keep a memory for a long time, but not both, and (c) we find emergent diversity resulting from selection for phage mutations that evade CRISPR targeting, linking diversity to the dynamical quantities of establishment and extinction. We compute bacterial average immunity in our simulations and in available experimental data and show that our model predicts qualitative trends that are visible in data. Finally, we show that adding immune cross-reactivity leads to qualitatively different states of evolutionary dynamics: (a) a traveling wave regime that resembles a similar state in models of vertebrate adaptive immunity (Yan et al., 2019; Marchi et al., 2019; Marchi et al., 2021) emerges when high cross-reactivity creates a fitness gradient for phage evolution, and (2) a regime of low turnover protected from new establishment by the reduced fitness of new phage mutants.
Results
Bacteria and phages dynamically coexist and coevolve
We model bacteria and phage interacting and coevolving in a well-mixed system (Figure 1A and ‘Model’). Bacteria divide by consuming nutrients and phages reproduce by creating a burst of new phages after successfully infecting a bacterium. Bacteria can contain a single CRISPR spacer that confers immunity against phages with a matching protospacer. Phages are labelled with a single protospacer type, a binary sequence of length that can mutate to a new type during a burst with probability , where is the per-base mutation rate per generation. All simulations begin with a single clonal phage population unless otherwise specified.
Figure 1 with 7 supplements see all
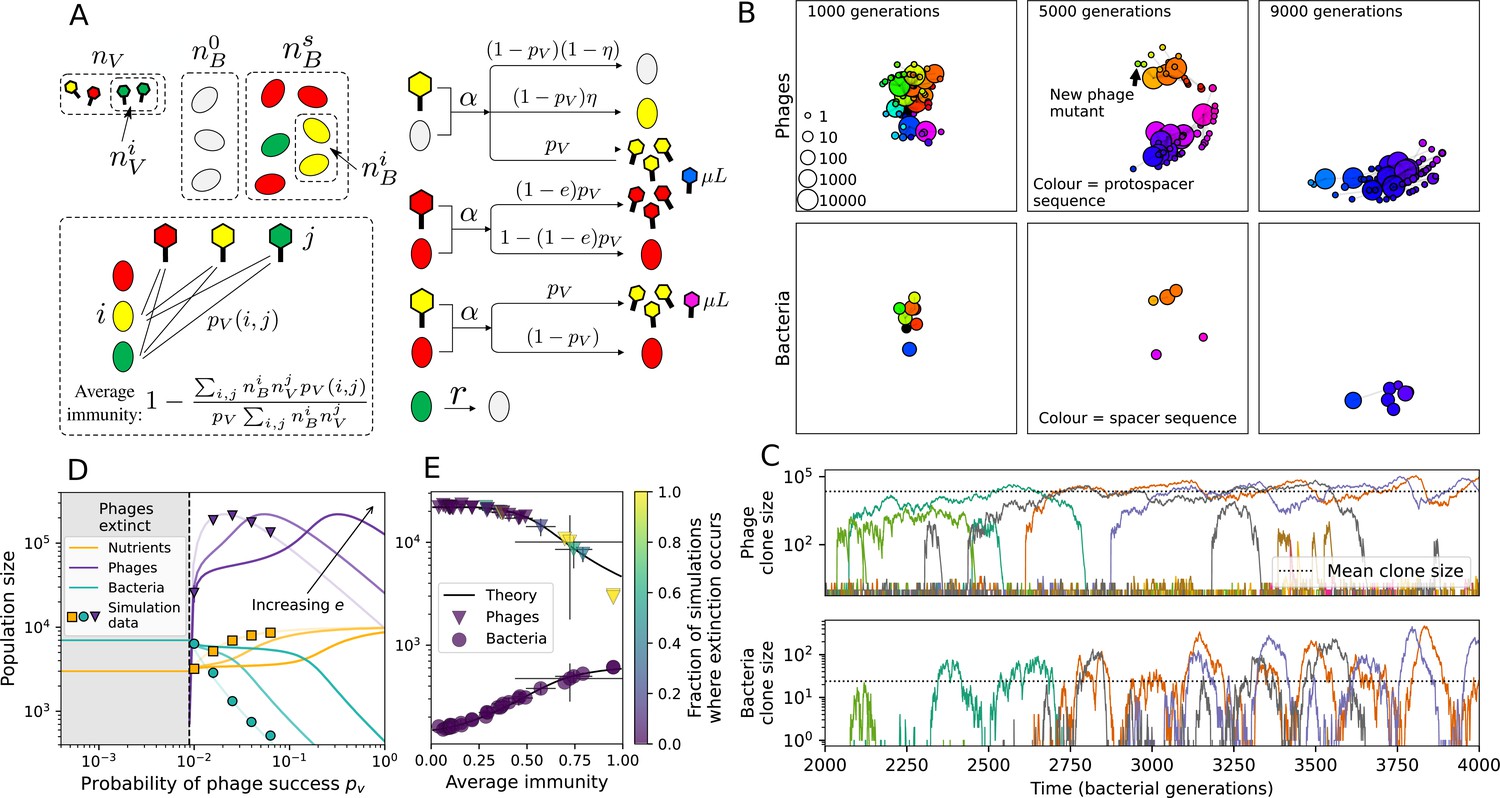
Model description.
(A) We model bacteria and phages interacting in a well-mixed vessel. We track nutrient concentration, phage population size (), and bacteria population size (). Bacteria can either have no spacer () or a spacer of type (, ), and phages can have a single protospacer of type (). With rate , a phage interacts with a bacterium. If the bacterium does not have a matching spacer, the phage kills with probability and produces a burst of new phages, while for bacteria with a matching spacer that probability is reduced to , . Bacteria without spacers that survive an attack have a chance to acquire a spacer with probability , and bacteria with spacers lose them at rate . Lower inset: average immunity is the weighted average pairwise immunity between spacer-containing bacteria and phages, given by . The probability of a phage with protospacer successfully infecting a bacterium with spacer is . (B) Three time points in a typical simulation with , , , and . Coloured circles represent unique protospacer or spacer sequences; shared sequences are shown with the same colour. The size of each circle is proportional to clone size, and new mutants are shown radially more distant from the centre. (C) Ten individual clone trajectories vs simulation time for phages (top) and bacteria (bottom). The mean clone size is shown with a horizontal dashed line. (D) Total phage, bacteria, and nutrient concentration as a function of phage success probability . Markers show an average over five independent simulations for different values of with , and . Solid lines show theoretical predictions for different constant values of effective . As decreases, phages go extinct at a critical value given by , where . (E) Total phage and bacteria population size as a function of average bacterial immunity to phages. Colours indicate the fraction of simulations in which phage or bacteria go extinct before a set endpoint. Solid lines show the mean-field prediction. Error bars are the standard deviation across three or more independent simulations.
Coexistence occurs across a wide range of parameters but is not guaranteed: below a certain success probability , phages are not able to reproduce often enough to overcome their base death rate due to outflow and adsorption and are driven extinct (grey area of Figure 1D; Bonsma-Fisher et al., 2018). In this expression, is the bacterial growth rate, is the phage burst size, is the phage adsorption rate, is a normalized outflow rate, and C0 is the inflow nutrient concentration. This is the same extinction threshold reported by Payne et al., 2018 as the cutoff for achieving herd immunity in a well-mixed bacterial population. To a first approximation, phages must successfully infect every bacteria they encounter, but if bacteria are growing quickly, then phages must do better to overcome bacterial growth, leading to the extra terms in this expression (see ‘Phage extinction threshold’). We write this extinction threshold as . Above the phage extinction threshold (), the phage population size increases with increasing but eventually decreases again as bacterial numbers are driven too low to support a large phage population (Bonsma-Fisher et al., 2018). A similar non-monotonicity as a function of the probability of naive bacterial resistance () was described in theoretical work by Weinberger et al., 2012b. In our model the position of the peak in phage population size as a function of infection success probability is determined by , the effectiveness of CRISPR spacers against phage; increasing pushes the peak to higher (Figure 1D). While is a constant parameter that determines the outcome of pairwise interactions between bacteria and phages, the bacterial population as a whole possesses an average immunity to phages that is a weighted average of all the possible pairwise interactions (Figure 1A inset). It is the overall average immunity that determines population outcomes, which we describe in detail in ‘Pathogen and host diversity must be considered together’.
To focus on regimes where bacteria and phages coexist, we select parameters within the deterministic coexistence regime to explore bacteria-phage coevolution. Even in this regime, stochastic extinction will eventually come for one or both populations in simulations (Figure 1E), though the timescale of extinction may be extremely long for large population sizes (Badali and Zilman, 2020). Phages are more susceptible to stochastic extinction than bacteria because of their large burst size which increases their overall population fluctuations (Appendix 3). The length of coexistence before stochastic extinction depends on population size as well as simulation parameters and initial conditions (see ‘Stochastic population extinction’): phage populations can be rescued from extinction by high mutation rate (Figure 1—figure supplement 3) or high initial protospacer diversity (Figure 1—figure supplement 6), but are more likely to go extinct if spacer effectiveness is high (Figure 1—figure supplement 1). Conversely, bacteria are more likely to go extinct if spacer effectiveness or spacer acquisition rate are low (Figure 1—figure supplement 4). Population survival and persistence in natural populations is impacted by additional factors we do not address in our model, including immigration (Volkov et al., 2003; Chabas et al., 2016, niche partitioning Simek et al., 2010; Weitz et al., 2013; Mills et al., 2013; Badali and Zilman, 2020; Voigt et al., 2021), environmental fluctuations (Abreu et al., 2020; Voigt et al., 2021), and spatial structure (Haerter et al., 2011; Haerter and Sneppen, 2012; Heilmann et al., 2010; Heilmann et al., 2012; Simmons et al., 2018; Skanata and Kussell, 2021).
Across a wide range of coexistence parameters, our simulations show continual phage evolution and bacterial CRISPR adaptation in response (Figure 1B). New phage protospacer clones arise from a single founding clone by mutation, and a small fraction of new mutants grow to a large size and become established. Once phage clones become large, bacteria acquire matching spacers and an immune bacterial subpopulation becomes established. The specific protospacer and spacer types present in the population continually change as old types go extinct and new types are created by phage mutation, but the average total diversity and average overlap between bacteria and phage remains constant at steady state (Figure 8). Both bacteria and phage clones stochastically go extinct, completing the life cycle of a clonal population (Figure 1C).
Phages drive stable emergent sequence diversity
New phage protospacer clones continually arise and go extinct in our simulations, generating turnover in clone identity in the population. Despite constant turnover, however, the total number of clones remains fixed at steady state. We use the mean number of bacterial clones at steady state, designated , as a measure of system diversity. This choice of diversity measurement is equivalent to the Hartley entropy of the clone size distribution, a special case of the Rényi entropy (Mora and Walczak, 2016; Altan-Bonnet et al., 2020). This definition weights all clones equally regardless of their abundance; such a measurement is not appropriate when clone size distributions are very broad and small clones may be unsampled, but is reasonable when clone size distributions are relatively narrow and all clones are sampled (Mora and Walczak, 2016). In our simulation results, both bacteria and phage populations exhibit relatively narrow clone size distributions across a range of parameters, with the exception of low values of spacer acquisition (Figure 2A, Figure 2—figure supplement 3, Figure 2—figure supplement 4). Even at low , however, clone size distributions are approximately exponential, indicating that they are not scale-invariant and that the mean clone size still captures important information about the full clone size distribution.
Figure 2 with 4 supplements see all
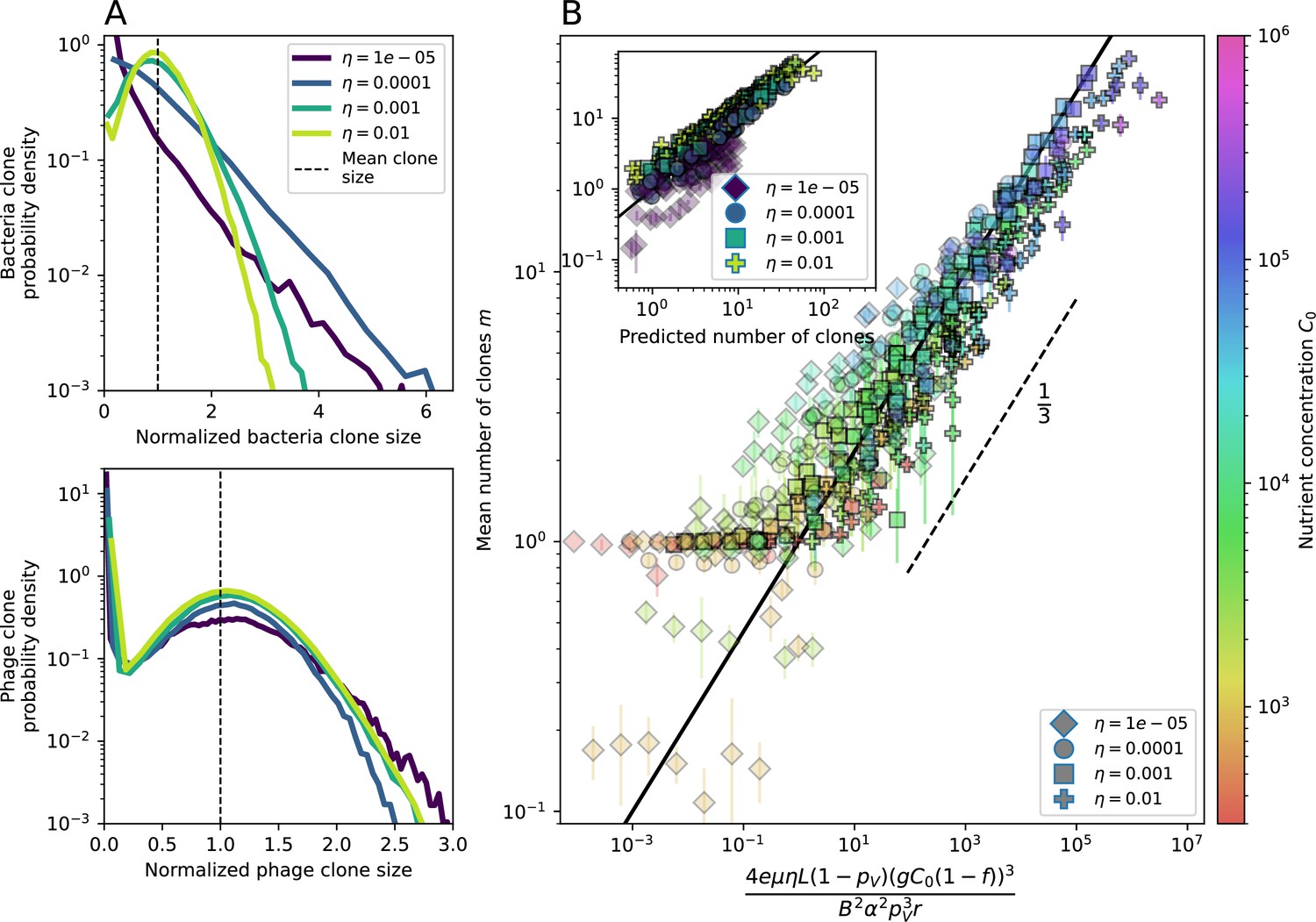
Diversity depends sub-linearly on parameters.
(A) Bacteria and phage clone size distributions normalized to the measured mean clone size for , , and . As increases, both clone size distributions become more sharply peaked. (B) The mean number of bacterial clones depends only on a combined parameter in the limit of small average immunity (generally coinciding with high C0). (Inset) The mean number of bacterial clones can be predicted by numerically solving Equation 1 for . The two lowest values of are shown with lighter shading. Error bars are the standard deviation across three or more independent simulations.
What determines clonal diversity? Many factors that correlate with transient diversity have been experimentally identified, such as phage extinction and slower phage evolution at high bacterial spacer diversity (van Houte et al., 2016; Common et al., 2020) and maintenance of a diverse bacterial population when exposed to diverse phages (Paez-Espino et al., 2015; Common et al., 2019; Guillemet et al., 2021; Lopatina et al., 2019), but a conceptual framework to understand emergent diversity has remained elusive. For instance, while initial high spacer diversity puts low-diversity phage populations under intense pressure to the point of driving them extinct (van Houte et al., 2016; Common et al., 2020), is the same true for emergent bacterial diversity after an extended period of coexistence? Is observed high bacterial spacer diversity indicative of successful bacterial escape from phage predation or an indicator of increased phage pressure? In our model, phage and bacterial diversity is tightly coupled: the number of large phage clones is approximately the same as the number of bacterial clones (Figure 22). This is also the case in experimental coevolution data from Paez-Espino et al., 2015: the number of phage protospacer types is on the same order of magnitude as the number of bacterial spacer types across most similarity thresholds (Figure 72). There is evidence that this coupling of diversity may also occur in the wild: a recent longitudinal study of Gordonia bacteria interacting with phage in a wastewater treatment plant identified 14 high-coverage phage genotypes and 11 high-coverage bacterial variants based on CRISPR spacer sequence (Guerrero et al., 2021a).
Using the tight correspondence between bacterial diversity and phage diversity in our model, we calculate the overall steady-state diversity by balancing the effective phage clone mutation rate , phage clone establishment probability , and the time to extinction for large phage clones (details in ‘Measuring diversity):
(1)
Equation 1 arises from the simple statement that the number of large clones must be equal to their establishment rate () multiplied by their average time to extinction (). This relationship successfully predicts the number of bacterial clones at steady state across a wide range of parameters and a wide range of diversity values (Figure 2B inset, Figure 2—figure supplement 1, and Figure 2—figure supplement 2). At the lowest value of the prediction tends to overestimate the number of clones – in this regime, low acquisition means that phage clones go extinct because of clonal interference before bacteria are able to acquire spacers (Figure 16, ‘Measuring diversity’).
Through approximations (‘Analytic approximations for diversity’), we find that diversity depends on a single combined parameter to the power (Figure 2B, Equation 2), and this parameter is proportional to spacer effectiveness , the probability of bacterial survival followed by spacer acquisition , and the phage mutation rate .
(2)
Each of these parameters intuitively increases diversity (e.g., a higher phage mutation rate means that phage diversity increases and bacterial diversity follows suit). What is surprising is that their combined effect on diversity is to a power much less than 1: this 1/3 exponent means that if the mutation rate increased tenfold, the diversity would only increase by about a factor of two (Appendix 2—figure 1). In contrast, a simple neutral model of cell division with mutations gives a linearly proportional increase in diversity for the same increase in mutation rate (Appendix 2—figure 2).
To understand where the dependence of diversity on these key parameters come from, we look more closely at each component expression. The effective phage mutation rate depends linearly on the parameter , while both the probability of establishment and the time to extinction depend inversely on diversity (Equation 5) and (Equation 173, Appendix 3). By comparison with Equation 1, we find that depends approximately linearly on mutation rate, resulting in the weak dependence on mutation rate.
The dependence of diversity on both and comes from the probability of phage establishment since depends only very weakly on these parameters through its dependence on total population sizes and depends explicitly on alone, not or . The phage probability of establishment is proportional to (Equation 5), and as before, this gives . Bacteria are more successful at high , which increases the phage establishment probability. Previous theoretical work has predicted that diversity increases as spacer acquisition rate increases (Childs et al., 2012); here, we provide a quantitative prediction for this dependence. In the following sections, we explore phage establishment in more detail.
What determines the fitness and establishment of new mutants?
We find that diversity emerges in our model from the balance of phage clone establishment and extinction. However, only some phage mutants escape initial stochastic extinction and survive long enough to become established. What determines the fate of a new phage mutant? In our model, a single phage mutation in a protospacer can completely overcome CRISPR targeting, which means that new phage mutants can infect all bacteria equally well and their initial growth rate s0 is independent of CRISPR: , where is the chemostat flow rate (a shared death rate for phages and bacteria). Surprisingly, however, even once bacteria start to acquire matching spacers, the probability of establishment for new phage mutants is still well-described by theory in which CRISPR targeting only influences total average population sizes (Figure 3C); that is, the specific interaction between a phage and its matching clone can be ignored. Intuitively, this is because phage clones must grow to a certain size before bacteria encounter them enough to begin to acquire spacers, and this size turns out to be large enough to avoid stochastic extinction (Figure 15). The probability of phage establishment is , where is the initial phage mutant death rate. Importantly, these rates are independent of the population size of matching CRISPR bacteria clones; the only dependence on bacteria is on the total bacterial population size (Appendix 3—figure 1), which is fairly stable at steady state.
Figure 3 with 3 supplements see all
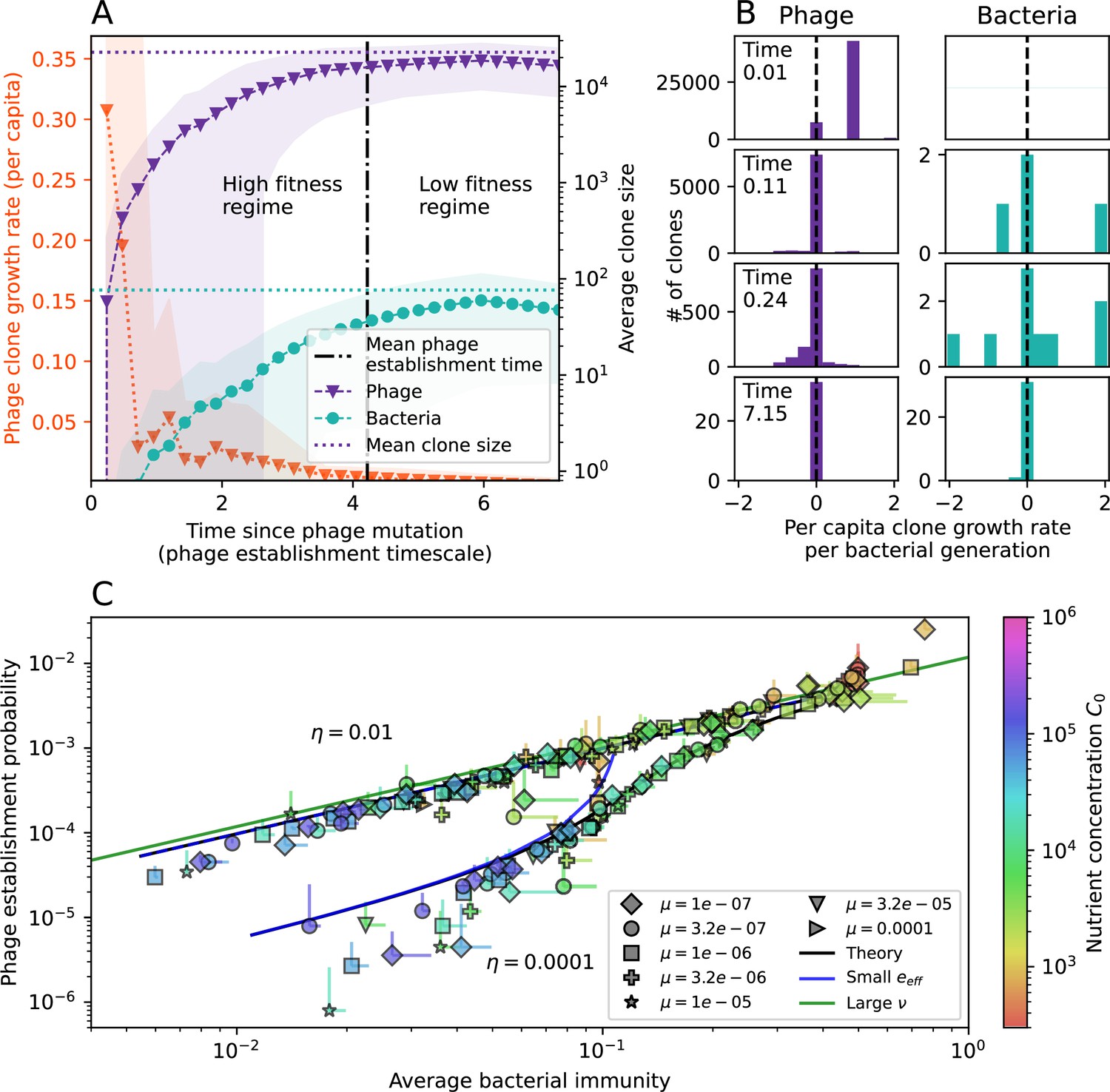
The fate of individual clones.
(A) Phage and bacteria coevolve in two timescale-separated regimes characterized by phage clone fitness. Average phage and bacteria clone size vs. time since phage mutation (right axis), and average clone growth rate vs. time since phage mutation (left axis). Markers show the average over all clone trajectories after steady state from six simulations with the same parameters. (B) Histograms of individual clone fitness grouped by time since phage mutation. Phage clones initially have fitness gt0, but rapidly most clones reach neutral growth (fitness ). Bacteria clones also follow suit, initially having fitness gt0 and rapidly reaching 0 fitness on average. Because spacer acquisition for a clone only happens after that clone is created by phage mutation, the top-right panel of (B) is empty at the earliest time point following phage mutation. Individual clone trajectories are highly variable. (C) Probability of phage clone establishment vs. average immunity. Clones are considered established in simulations when they reach the mean clone size. Equation 3 with is shown in green and with given by Equation 4 in blue. In (A, B), , , , and . Error bars are the standard deviation across three or more independent simulations.
Even though CRISPR targeting does not explicitly affect the establishment probability for new phage mutants, the probability of phage establishment increases as the average bacterial immunity increases (Figure 3C). Average immunity is a measure of the overall effectiveness of CRISPR immunity for the entire bacterial population; it is the average of all pairwise immunities between phage clones and bacterial clones weighted by their population sizes (Figure 1A inset). Because higher average immunity is beneficial for bacteria and leads to larger bacterial population sizes (Figure 3C), higher average immunity also means there is stronger selective advantage for new phage mutants that can escape CRISPR targeting (Figure 3C and Figure 5A).
For insight into the nature of this dependence, we approximated the probability of establishment at two extremes of average immunity (see ‘Dominant balance approximations for ’). The probability of establishment can also be written
(3)
where is the fraction of bacteria that have spacers and is the average number of bacterial clones at steady state. Low average immunity occurs when is small: in this limit, the fraction of bacteria with spacers is
(4)
where is the extinction threshold for phages ( for phage survival), and is the phage population size calculated with (Equation 52); this is the extreme limit of low average immunity where total population sizes approach their values in the absence of CRISPR immunity (Figure 26). The quantity can be understood as the ratio of the rate of spacer loss to the rate of spacer acquisition. If spacer loss is high and acquisition is low, the fraction of bacteria with spacers () decreases. This in turn correlates with a lower probability of phage establishment (Equation 3) since phages are less likely to establish when there is less pressure from bacteria defending against them with CRISPR. Equation 4 is plotted in Figure 3C in blue. At very high average immunity, on the other hand, becomes close to 1 regardless of (Figure 3—figure supplement 2), which is why the curves in Figure 3C overlap at high average immunity ( is plotted in green).
For more insight into the parameter dependence of , we apply the same approximation as for , expanding in and (‘Approximation for ’):
(5)
The probability of establishment increases with the probability of bacterial escape and spacer acquisition and with spacer effectiveness , but decreases with increasing mutation rate . This is consistent with the intuition that more successful bacteria increase the strength of selection for phage mutants (higher and ), but that higher mutation rate reduces the probability of establishment for any particular mutant.
Cross-reactivity leads to dynamically unique evolutionary states
We next asked how cross-reactivity between spacer and protospacer types impacts population dynamics and outcomes. Adding cross-reactivity was motivated by several experimental observations in CRISPR immunity: (a) In type I and type II CRISPR systems, single mutations in the PAM or protospacer seed regions (approximately 8 nucleotides at the start of a protospacer) can facilitate phage escape, whereas mutations elsewhere in the protospacer are tolerated by the CRISPR system (Deveau et al., 2008; Pyenson and Marraffini, 2020). Even when a phage manages to escape direct targeting, in type I and II systems an imperfect spacer match can facilitate priming: when Cas machinery binds to a protospacer match, even if unable to cleave the target, the likelihood of acquiring a nearby spacer is increased (Westra et al., 2015; Rao et al., 2017; Pyenson and Marraffini, 2020; Weissman et al., 2020). (b) Type III CRISPR targeting in Staphylococcus epidermidis has been shown to be completely tolerant to all single and even double mutations, meaning that these systems are naturally cross-reactive (Pyenson et al., 2017).
We simulated two types of cross-reactivity: one in which phages experience an exponential decrease in CRISPR effectiveness with mutational distance (Equation 7), and a step-function cross-reactivity where phages require additional mutations to perfectly escape CRISPR targeting (Equation 8). Phage success probability without cross-reactivity is given by Equation 6, a special case of 7 and 8 with .
(6)
(7)
(8)
The mutational distance is the number of mutations between a protospacer and spacer, and scales the radius of cross-reactivity, with larger meaning more mutations are required to achieve the same immune escape (Yan et al., 2019).
Exponential cross-reactivity has been modelled extensively in vertebrate adaptive immunity (Chao et al., 2005; Mayer et al., 2015; Marchi et al., 2019; Yan et al., 2019; Schnaack and Nourmohammad, 2021; Chardès et al., 2022), and our definition of exponential cross-reactivity as a function of mutational distance is the same as in Yan et al., 2019. Step-function cross-reactivity, on the other hand, is reminiscent of the type III CRISPR system in which multiple point mutations are required to escape CRISPR targeting (Pyenson et al., 2017) and was also modelled theoretically by Han et al., 2013.
We find that cross-reactivity results in strikingly different dynamics of clone establishment and persistence (Figure 4 and ‘Cross-reactivity’), including a travelling wave regime in which genetically neighbouring clones ‘pull’ each other along (Figure 4B–D), giving way to a regime in which new mutants have very low establishment rates in the case of step-function cross-reactivity (Figure 4C). When cross-reactivity is high and phages require multiple mutations to escape targeting, we expect new phage mutants to have a lower fitness on average because they may already be within the immunity range of existing bacterial clones. However, unlike without cross-reactivity, not all new mutant fitnesses are the same because fitness now depends on the distribution of matching spacers in the bacterial population. Cross-reactivity adds a ‘direction’ in the genetic landscape and a fitness gradient for new phage mutants, leading to a series of rapid establishments and a travelling-wave regime. We believe these rapid establishments also suppress instantaneous diversity; diversity emerges longitudinally instead of concurrently in this regime (Figure 4 and Figure 61). This is true for both types of cross-reactivity we studied, but we also observed striking qualitative differences between exponential and step-function cross-reactivity. In the former, all phage mutants are guaranteed a slight fitness advantage, and the travelling wave appears right at the start of simulations, with occasional lineage-splitting events (Figure 4B). In contrast, step-function cross-reactivity means that mutants within the cross-reactivity radius have no fitness advantage at all. In this case, there is some variable initial length of time required to establish the travelling wave pattern: at the start of a simulation, all mutants are within the cross-reactivity radius and evolve purely neutrally. At least new mutants must establish through neutral dynamics before the next mutant can escape CRISPR targeting and grow with high fitness; this leads to the travelling-wave regime appearing later for than for , and sometimes never appearing at all. Once the traveling wave appears, the dominant phage and bacteria clone types are exactly offset by : the most abundant phage clone will in general be mutations away from the most abundant concurrent bacteria clone. This is directly visible in the clone trajectories in Figure 4C–D inset and Figure 54: matching-colour bacteria and phage clones are offset in time. Another regime is also possible in the case of step-function cross-reactivity: if multiple large clones establish that are each outside of all the others’ cross-reactivity radii (Figure 63), then new mutants all have zero fitness and the travelling wave comes to an abrupt halt (around 7000 generations in Figure 4C). Establishment of new clones is once again extremely rare, and the existing large clones persist for a long time (Figures 53 and 62).
Figure 4 with 4 supplements see all
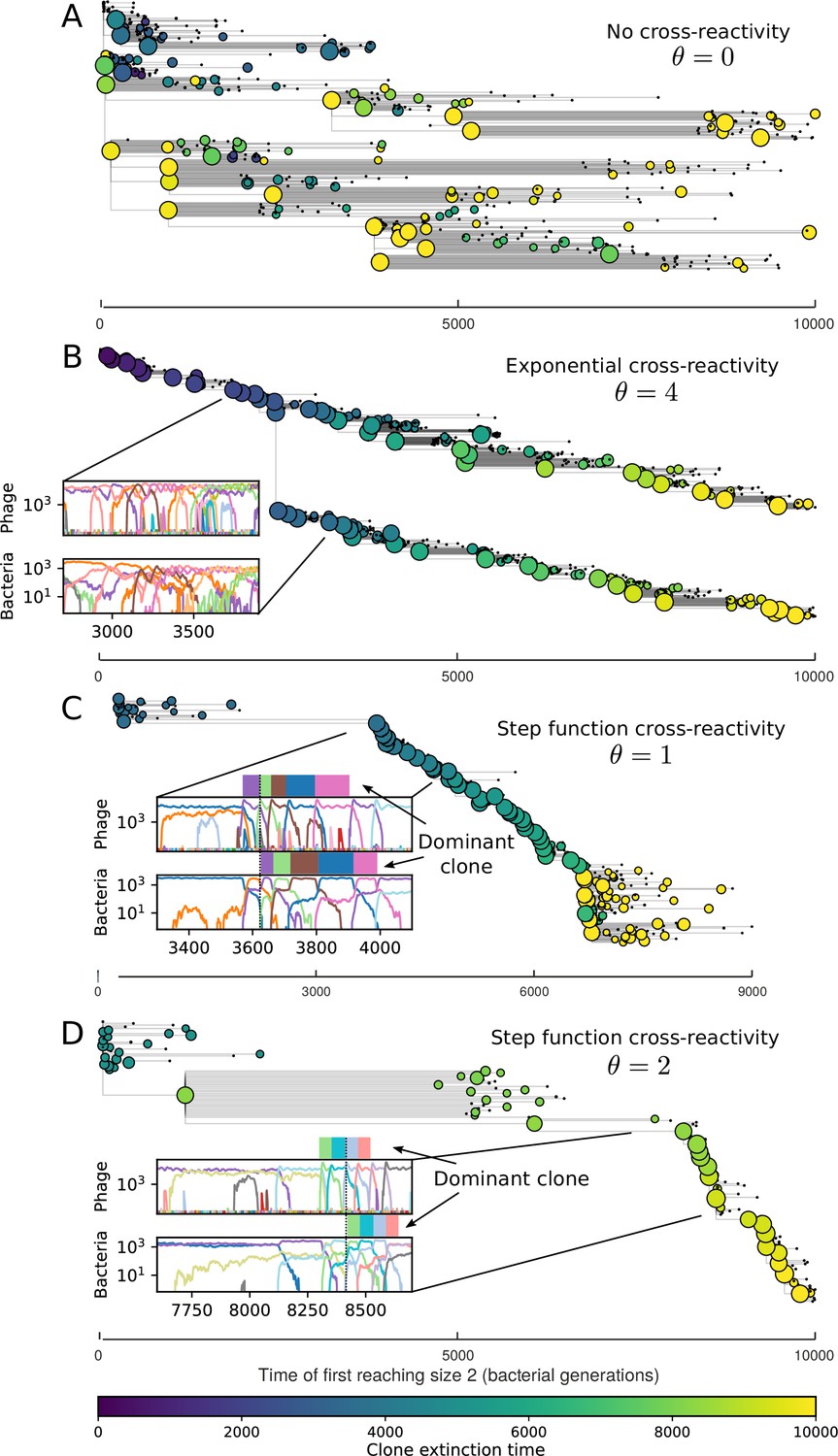
Cross-reactivity leads to ‘spindly’ phylogenies and regime switching.
Phage clone phylogenies for four simulations with different cross-reactivities: no cross-reactivity (A), exponential cross-reactivity with (B), and step-function cross-reactivity with (C) and (D). All simulations share all other parameters: . Phage clones are plotted at the first time they pass a population size of 2 to remove clutter from many new mutations destined for extinction, and the size of each circle is logarithmically proportional to the maximum size reached by that clone. Colours indicate the time of extinction of each clone. For each simulation with cross-reactivity, the left inset shows phage (top) and bacteria (bottom) clone sizes over time; colours indicate unique clone identities. Coloured rectangles above insets in (C) and (D) correspond to the dominant clone at each time. Dominant clone identities are offset by (vertical dashed line for visual aid).
Changes to the fitness landscape of individual clones caused by cross-reactivity also influence population-level outcomes such as diversity. In general, we find that for high cross-reactivity, average diversity is lower than predicted for simulations without cross-reactivity because the probability of phage establishment per mutant decreases (Figure 5A). A decrease in phage mutant fitness as the strength of cross-reactivity increases is in line with the dependence of fitness on cross-reactivity reported by Yan et al., 2019 and Rouzine and Rozhnova, 2018. Even with more complicated underlying dynamics, though, measuring average immunity alone is enough to reproduce total population sizes using our simple deterministic equations developed in the limit of no cross-reactivity (Figure 5C, 'Total population size'). This is because average immunity completely captures the population-level impact of CRISPR immunity, and we can replace the CRISPR effectiveness parameter with measured average immunity in Equations 13–17 to get very good agreement between measured and predicted population sizes even away from steady state (Figure 5—figure supplement 1). In contrast, inferring average immunity from the number of clones using the approximation that effective does not give good agreement with simulation results for simulations with cross-reactivity (Figure 5B).
Figure 5 with 1 supplement see all
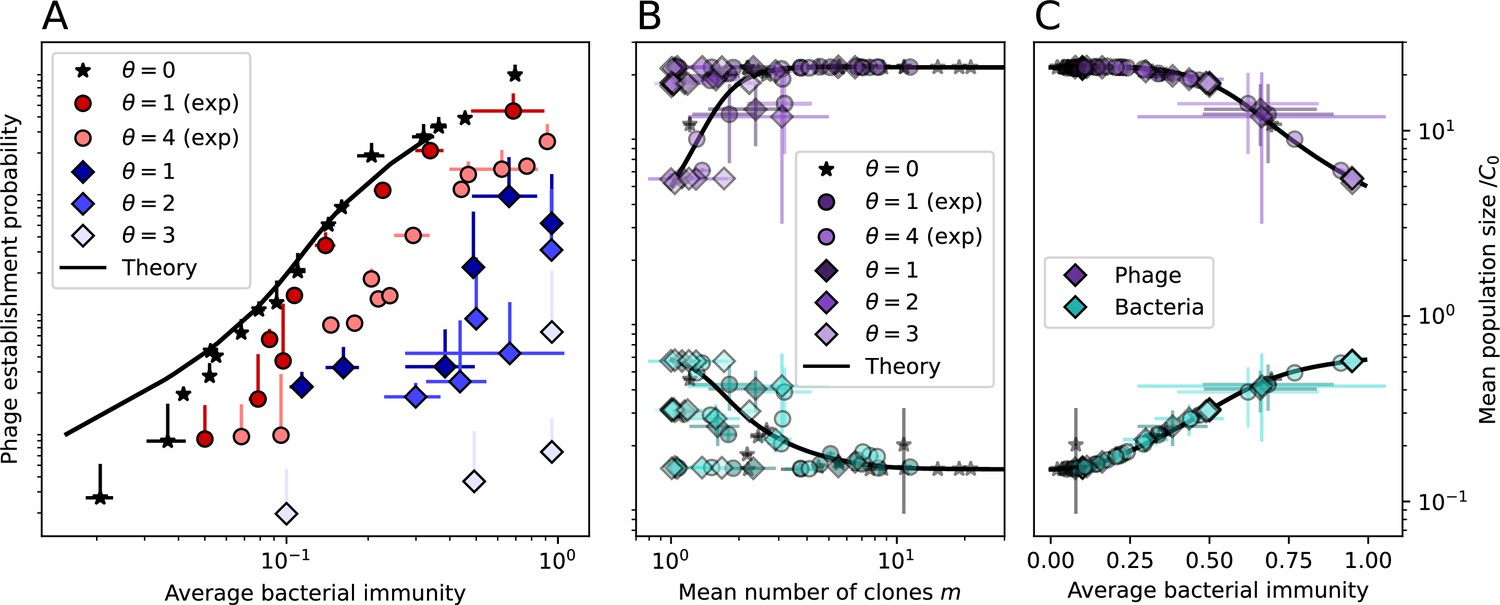
Average immunity underlies population outcomes.
(A) Probability of phage clone establishment vs. average immunity for different amounts and types of cross-reactivity. No cross-reactivity () is shown as black stars, exponential cross-reactivity in red, and step-function cross-reactivity in blue. Simulation averages are shown for and . Error bars are the standard deviation across three or more independent simulations and are shown in both x directions and the positive y direction. (B, C) Total phage (purple) and total bacteria (teal) average population sizes vs. the mean number of bacterial clones (B) and vs. average bacterial immunity (C) for . Each point is an average at steady state over three or more independent simulations with the same parameters; error bars are standard deviation. Total sizes are scaled by the initial nutrient concentration C0. Lighter colours indicate stronger cross-reactivity, marker shapes match legends in (A) and (B). Solid lines are the predicted total population size given by solving Equations 13–17 and using the approximation effective in (B) and the measured average immunity for effective in (C).
Figure 5B makes an additional subtle point: higher immune diversity promotes larger population sizes for phages but not for bacteria. This is counterintuitive and appears to conflict with several experimental results that show that more bacterial diversity increases the likelihood of phage extinction (van Houte et al., 2016; Common et al., 2020) and decreases the ability of phages to adapt (Morley et al., 2017). This discrepancy appears at first glance to be a consequence of limiting bacteria and phages to a single spacer and protospacer in our model, but we propose that it is actually because bacteria and phage diversity is decoupled in prior experiments. In the following section, we introduce a toy model to understand the conceptual impact of multiple protospacers and spacers when overall phage and bacterial diversity is coupled.
Pathogen and host diversity must be considered together
Our model restricts bacteria to a single spacer and phages to a single protospacer. This single-spacer assumption is a reasonable approximation for the experimental systems we consider: many liquid culture experiments find that most bacteria acquire a single spacer when exposed to phages, (Heler et al., 2015; Heler et al., 2019; Pyenson and Marraffini, 2020) even after up to 2 weeks (Paez-Espino et al., 2013; Common et al., 2019). Additionally, metagenomic results show that most spacer matches to viral sequences are located near the leader end of the CRISPR array Weinberger et al., 2012a. These results, combined with theory positing that recently acquired spacer provide more immune benefit than older spacers (Childs et al., 2012; Han et al., 2013), suggest that dynamics may be dominated by a very small number of spacers per bacterium.
Nevertheless, many bacteria possess tens to hundreds of spacers (Pavlova et al., 2021) and the question of multiple protospacers remains. Can we make inferences about how a more realistic multiple spacer or multiple protospacer scenario will change the relationship between diversity and average immunity in our model? First, we note that our model with exponential cross-reactivity is a good approximation for a realistic scenario where bacteria are limited to a single spacer but phages can have multiple protospacers. In this situation, multiple bacteria with unique spacers may target different protospacers in the same phage. A mutation in one protospacer will increase phage fitness but will not provide perfect immune escape, just as in the case of exponential cross-reactivity (Figure 4B). Even in this scenario, our qualitative results remain the same: bacteria and phage diversity is coupled and bacteria have higher average immunity at low diversity (Figure 5B and Figure 50).
We explored the consequences of both multiple spacers and multiple protospacers with a toy model. We generated synthetic sets of protospacers and spacers and varied the total diversity by changing the size of their pool and distributing their abundances exponentially to qualitatively match data (Bonsma-Fisher et al., 2018). We randomly assigned protospacers and spacers to individual phages and bacteria, then calculated average immunity. Importantly, we constrain phage and bacterial diversity to be coupled – overall spacer and protospacer diversity is the kept the same in all scenarios.
We find that across all combinations of array sizes and for two of three scenarios of protospacer diversity, average immunity is negatively correlated with diversity (Figure 69). Only when we limited phage diversity to a single mutating protospacer with all other protospacers conserved were bacteria with multiple spacers reliably able to target conserved protospacers regardless of the level of diversity in the variable protospacer position (Figure 69D). We compared our toy model to the experimental setup from Common et al., 2020. In their experiments, bacterial CRISPR spacer diversity was increased while phage diversity was kept constant with a single phage strain able to infect only one of the bacterial clones. This translated to an increasing initial average immunity as bacterial diversity increased and phages were able to infect a smaller proportion of the bacterial population (Figure 69A), which we think is not a realistic situation in a coevolving population of phages and bacteria.
Based on these results, we predict that in many realistic situations average immunity does not increase with diversity if phage and bacterial diversity are coupled. The intuition is this: if diversity of both bacteria and phages increase beyond the functional length of the CRISPR array, bacteria cannot be immune to all phage strains at once and average immunity must go down as diversity increases. The actual benefit of bacterial diversity depends very strongly on the characteristics of phage diversity (Figure 69) and manipulations of diversity should be understood in terms of their impact on average immunity. This has implications for understanding the so-called 'dilution effect' which is typically described as a decrease in the fraction of susceptible hosts as host diversity increases (Chabas et al., 2018; Common et al., 2020). Our model and analysis show that a dilution effect can only occur if host diversity increases out of proportion to pathogen diversity as in Common et al., 2020 (Figure 69A), whereas if both host and pathogen diversity increase in tandem, the dilution effect actually changes direction, decreasing the fraction of pathogens that a host may be immune to as pathogen diversity increases (Figure 69B–D). In the same vein, previous theoretical work has found that CRISPR with a fitness cost would be selected against when viral diversity is high for this reason (Weinberger et al., 2012b; Iranzo et al., 2013), notably with models that allowed for multiple spacers and protospacers. Our results, building on existing theory, show that phage and bacterial diversity must be explored in tandem and that CRISPR immunity may provide less benefit when phage diversity is high.
Dynamics are determined by diversity
How quickly does the phage population evolve? With explicitly modelled spacer and protospacer sequences of length , we quantify the speed of evolution as the ‘mutational distance’ per generation (Rouzine and Rozhnova, 2018): between two time points, how far in genome space has the phage population travelled, or how many mutations have occurred on average (Speed of evolution)?
The speed of evolution is both stable and repeatable between simulations at steady state and highly correlated between bacteria and phage (Figure 38). We find that the speed of evolution is inversely proportional to the time to extinction for large phage clones (Figure 6B, 'Measuring speed of evolution'). Intuitively, if phage clones turn over more quickly (small time to extinction), the population is able to move more quickly to a different genetic state, while if the time to extinction is large, new mutants are seeded close to parent populations that persist for a long time, limiting the mutational distance. Since the phage time to extinction has a simple relationship to bacterial diversity, we can also relate speed to diversity, and we find that the speed of evolution is proportional to diversity and proportional to the same parameter combination to the power 1/3 (Figure 6C). As in the case of diversity, increasing phage mutation rate increases the speed of evolution sublinearly, and like diversity, the prediction diverges from simulation results at low as described in 'Measuring diversity.
Figure 6 with 5 supplements see all
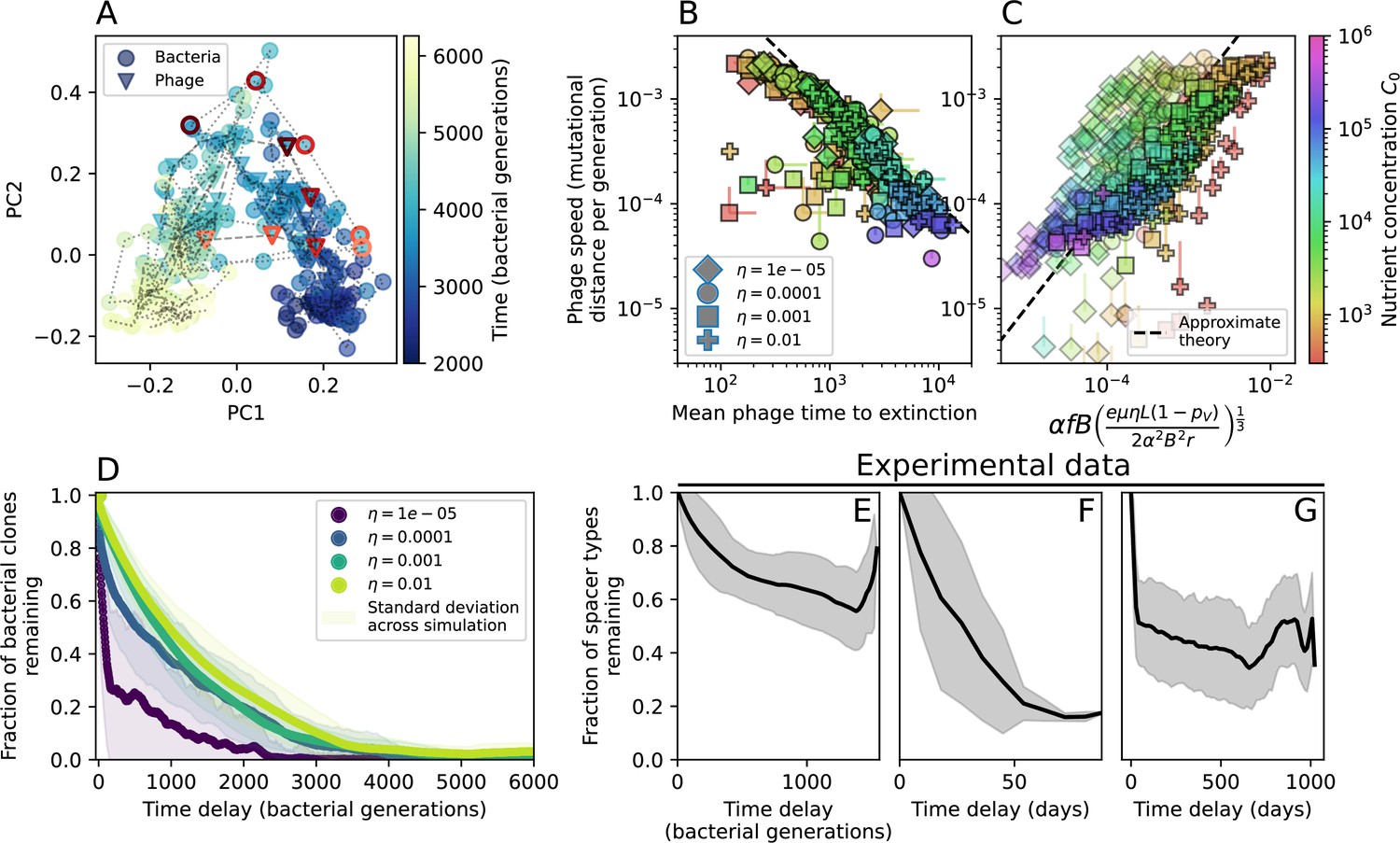
Phage evolution and spacer turnover.
(A) Principal Component Analysis (PCA) decomposition of phage and bacteria clone abundances for a simulation with , , , and . Clone abundances are normalized at each time point, then PCA is performed for the entire phage time series over generations (four times the mean extinction time for phage clones). Bacteria and phage clone abundances are transformed into the PCA coordinates; colours indicate simulation time. Five time points are highlighted in progressively lighter shades of red for emphasis. (B) Phage genomic speed of evolution vs. mean large phage clone time to extinction. The phage speed is the weighted average genomic distance between the phage population at the end of the simulation and the phage population at an earlier time, divided by the time interval. The dashed line is . (C) The speed of evolution increases as spacer effectiveness , spacer acquisition probability , and phage mutation rate increase. The dashed line shows an approximate theoretical calculation (assuming speed = 1/time to extinction) which captures the trend across a wide range of parameters. Error bars in (B) and (C) are the standard deviation across three or more independent simulations and are shown in the positive direction only. (D) Spacer turnover as a function of time delay for four simulations with , , and . The fraction of bacterial clones remaining is the fraction of clones that were present at time that are still present at time delay. Solid lines are an average across steady-state for each value of the time delay; shaded regions are the standard deviation. (E–G) Spacer-type turnover calculated as in (D) using experimental data from Paez-Espino et al., 2015 (E), metagenomic data sampled from groundwater from Burstein et al., 2016 (F), and metagenomic data sampled from a wastewater treatment plant from Guerrero et al., 2021a (G). Experimental time points are interpolated to the minimum sampling interval to allow averaging across the experiment.
Our simulations show continual spacer turnover at steady state (Figure 6D, Figure 6—figure supplement 3, Figure 6—figure supplement 4), a feature that we might also expect to see in actively evolving laboratory or natural populations of bacteria and phages. We analysed data from a long-term in vitro coevolution experiment with Streptococcus thermophilus bacteria and phage (Paez-Espino et al., 2015), data from a time-series sampling of a natural aquifer community of bacteria (Burstein et al., 2016), and data from a time-series sampling of a wastewater treatment plant (Guerrero et al., 2021a) (see 'Materials and methods') and calculated spacer turnover over time (Figure 6E–G). We found that spacer sequences experienced turnover in all cases, indicating ongoing change in the spacer content in these populations, though no experimental system sho wed complete turnover of all spacer types. Even if spacer loss is happening for non-selective reasons (e.g., mixing or flow in the aquifer system), turnover indicates that new spacers are being acquired as well and that CRISPR systems are active. Moreover, the timescale of early spacer turnover in the S. thermophilus experiment is similar to the timescale in our simulations — after 1000 generations, most simulations have between 40 and 60% of clones remaining (Figure 6D) and about 60% of clones remain after 1000 generations in the experimental data (Figure 6E). We modelled all simulation parameters on known parameters for S. thermophilus where possible.
Time-shifted average immunity calculated from data reveals distinctive patterns of turnover
Bacteria acquire spacers in response to phage clones becoming large. The spacer composition of the bacterial population tracks the phage protospacer composition with a lag: Figure 6A shows the first two components of a PCA decomposition of bacteria and phage abundances over time in a simulation, a visual illustration of bacterial tracking. Without cross-reactivity, trajectories in this lower-dimensional space do not travel in a straight line; they are reminiscent of the diffusive coevolutionary trajectories in antigenic space described in a theoretical model of vertebrate virus-host coevolution (Marchi et al., 2019). In the travelling wave regime with cross-reactivity, trajectories are much more ballistic (Figure 6—figure supplement 1). Can we quantify how well and how quickly can bacteria track the evolving phage population with CRISPR?
Average immunity is a simple metric that quantifies the overlap between bacteria and phages. In experiments with both microbes and vertebrates, time-shift infectivity analyses between host and pathogen populations typically show that hosts are more immune to pathogens from the past and less immune to pathogens from the future (Richman et al., 2003; Frost et al., 2005; Moore et al., 2009; Hall et al., 2011; Koskella, 2014; Betts et al., 2018; Common et al., 2019; Dewald-Wang et al., 2022). We conduct a time-shift analysis on our simulation data (Figure 7A and B, Figure 7—figure supplement 11, Figure 7—figure supplement 12) and find that the same pattern holds true, but only for a limited time window: bacteria are indeed more immune to phages from the past, but this past immunity has a peak and then decays as we look further into the past, eventually reaching 0 immunity (Figure 7B). The presence of a peak in past immunity reflects the timescale of spacer turnover: once the bacterial population has lost all spacers from a previous time point, it is no longer immune to contemporaneous phages and time-shifted average immunity falls to 0. In simulations, the position of this peak is dependent on parameters such as and (Figure 7E and F). As increases, the peak occurs further in the past since phage are now moving more quickly away from bacteria tracking, while as increases, the peak moves closer to the present since bacteria are responding more quickly to changes in the phage population. This suggests that there is a tradeoff between immune memory durability and responding quickly to immune threats: bacteria must choose between tracking the phage population closely or keeping past immunity for a long time.
Figure 7 with 12 supplements see all
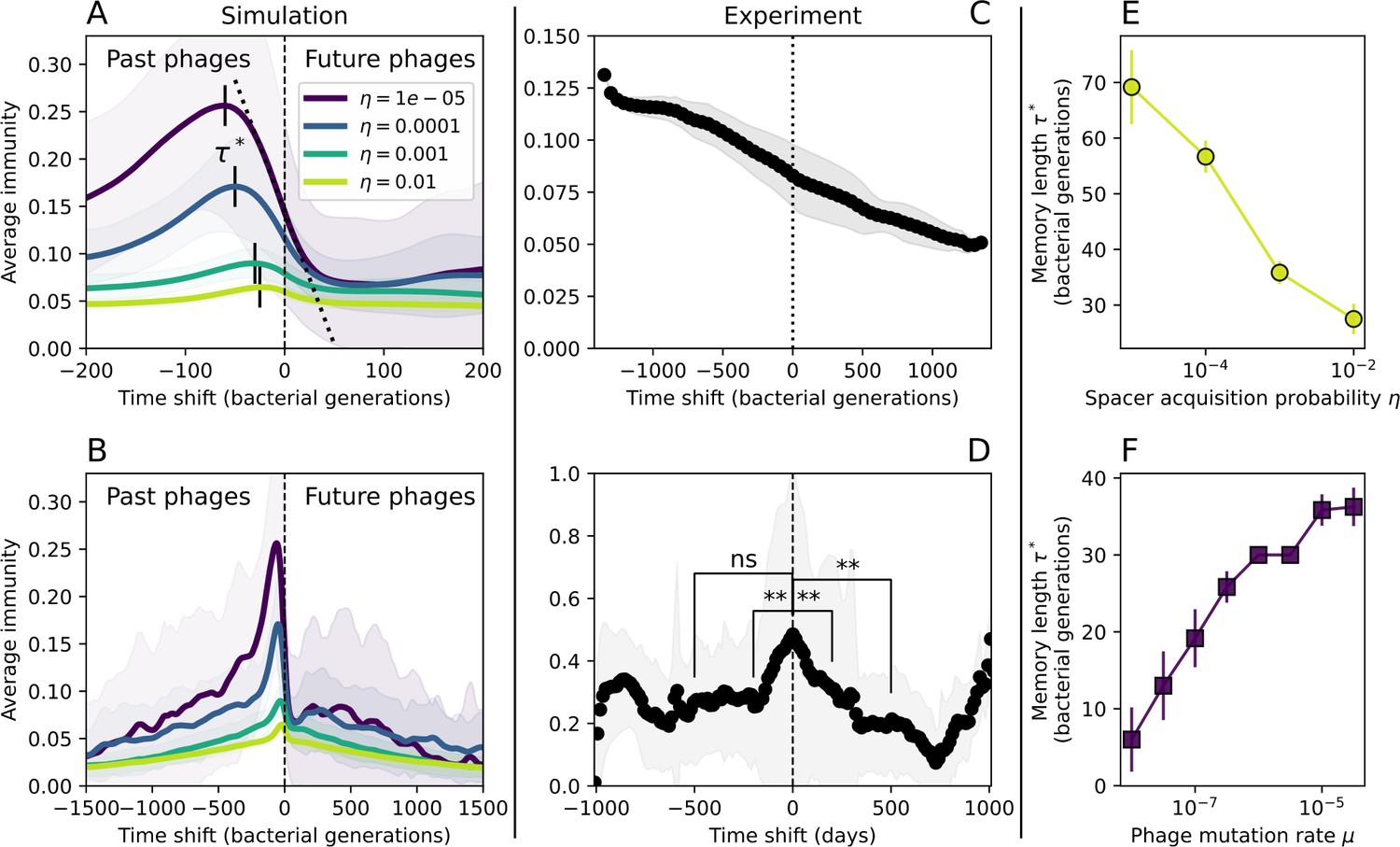
Quantifying immune memory in data.
(A, B) Average immunity of bacteria against phage for four simulations with different values of as a function of time shift. Solid lines are an average across steady state for each value of the time shift; shaded regions are the standard deviation. Average immunity peaks in the recent past (A, indicated by ) with a negative slope through zero delay (A, black dashed line) and decays to zero at long delays in the past or future (B). For all simulations , , and . (C, D) Average overlap between bacterial spacer and phage protospacer types using data from a lab experiment with S. thermophilus and phage from Paez-Espino et al., 2015 (C) and data from a wastewater treatment plant sampled over 3 years from Guerrero et al., 2021a (D). Spacer types are grouped by 85% similarity, and shaded region is standard deviation across averaged data. Base average immunity values were multiplied by the average number of protospacers corresponding to the S. thermophilus CRISPR system (C) and the Gordonia CRISPR systems (D) to account for multiple potential protospacer targets per phage. In (D), we compared two time shifts with zero delay average immunity using a Wilcoxon signed-rank test: for lower past immunity at 500 days, for lower past immunity at 200 days, for lower future immunity at 500 days, and for lower future immunity at 200 days. (E, F) The position of the peak in past immunity for simulated data vs. spacer acquisition probability (E) and phage mutation rate (F). The peak position is the time shift value for which the curves in (A) are largest, indicated by . Error bars are the standard deviation across three or more independent simulations.
Time-shift analyses are usually performed explicitly by directly combining stored samples from different time points (Betts et al., 2018; Common et al., 2019; Dewald-Wang et al., 2022). However, by sequencing CRISPR spacers and phage genomes, a pseudo-analysis can be done without any time-shifted competition experiments by calculating the overlap between bacterial spacers and phage protospacers at different times delays. We performed such an analysis for two published datasets: a long-term laboratory coevolution experiment with S. thermophilus and phage (Paez-Espino et al., 2015) and time series of metagenomic samples over 3 years from a wastewater treatment plant (Guerrero et al., 2021a). In both experiments, whole-genome shotgun sequencing was performed on bacteria and phage DNA, and CRISPR spacers and protospacers were recovered and reported. We re-analysed these datasets to detect CRISPR spacers by finding sequences adjacent to known CRISPR repeats in raw reads. We also detected protospacers by finding matches to our detected CRISPR spacers in reads that did not match the CRISPR repeats or the bacterial reference genome(s) (see ‘Laboratory coevolution experimental data’; ‘Experimental data from wastewater treatment plant’).
We grouped spacers with an 85% similarity threshold and interpolated counts between sequenced time points. We calculated the average overlap assuming (perfect immunity from matching spacers) as a function of time delay, averaging over all combinations of interpolated data with the same time delay (Figure 7C and D). We found two qualitatively different trends as a function of time delay. In the laboratory coevolution experiment, we found that bacteria are more immune to past phages and less immune to future phages (Figure 7C, Figure 7—figure supplement 1), consistent with what we see at short time delay in our model (Figure 7A, black dashed line). In contrast, in the wastewater treatment plant data, we found a peak in average immunity that is roughly centred at zero time delay: bacteria are most immune to phages from their same time point, and immunity rapidly decays in both the past and the future (Figure 7D), qualitatively similar to our simulation results on very long timescales (Figure 7B). These different trends may reflect different regimes of CRISPR immune memory: in the laboratory experiment data, we see no evidence of the decay of immune memory, while in the wastewater treatment data we see a suggestion of decay on the timescale of weeks. Bacteria appear to track the phage population closely in the wastewater data, while in the laboratory data bacteria lag behind the phage population.
Because the variability in average immunity between time points was very high in the wastewater treatment plant data, we performed a Wilcoxon signed-rank test between the average immunity at zero time delay and the average immunity at a time delay ±200 and ±500 (see ‘Calculating average immunity for details’). We found that past immunity after 200 days is significantly lower than present (Wilcoxon statistic p-value ), but that immunity after 500 days is not significantly lower than present (). For both time delays, we found that future immunity is significantly lower than present ( for 500 days and for 200 days). Interestingly, these significance values are not symmetric if we pose the question from the perspective of phage: the overlap between phage and future bacteria at 500 days is lower than the overlap for present phages (), and the overlap between phage and past bacteria is lower than the overlap at present (, Figure 88). This asymmetry, that bacteria are generally more immune to all past phages while phage are not more infective against all past bacteria, is qualitatively the same as that reported by Dewald-Wang et al. in an explicit time-shift study of bacteria and phage immunity and infectivity in chestnut trees (Dewald-Wang et al., 2022).
Discussion
Many bacteria and archaea possess CRISPR systems, and a significant fraction of these systems are likely to provide immunity against phages (Brodt et al., 2011; Shmakov et al., 2017; Pourcel et al., 2020). Given that bacteria and phages coexist in natural environments over extremely long timescales, the impact of CRISPR immunity in these steady-state conditions has remained underexplored. We constructed a phenomenological model of CRISPR immunity in a bacterial population interacting with phages to explore the impacts of adaptive immunity on population survival, fitness, and diversity. We found that both phage and bacterial genetic diversity emerged spontaneously with a minimal set of interactions, and we derived approximate analytic predictions for population outcomes. These rigorous analyses of our simple model lay a foundation for theoretical analysis of adaptive immunity in host-pathogen systems.
Our model is mechanistically simple, and we left out many known biological features and interactions by choice in order to gain a deep understanding of the factors that influenced our results. We modelled uniform spacer effectiveness, uniform spacer acquisition probability, and a constant phage mutation rate, all in a well-mixed system. This constitutes a null model of CRISPR immunity that provides a useful comparison point for both more accurate mechanistic models and experimental data. CRISPR is one of many other bacterial antiviral defence systems (Bernheim and Sorek, 2020), and within the CRISPR world, CRISPR systems are highly evolutionarily diverse and there are many known differences in function and effect between CRISPR systems of different bacterial species (Koonin et al., 2017; Hille et al., 2018; Makarova et al., 2020; Koonin and Makarova, 2022). Experiments typically study a particular CRISPR system, and it is unclear which revealed mechanisms are specific to that system or are a more general property of CRISPR systems. For example, the spacer acquisition rate has been demonstrated to vary across particular phage sequences in several experiments (Heler et al., 2019; Modell et al., 2017; Paez-Espino et al., 2013) and is the source of differences in spacer abundance in some experiments (Heler et al., 2019), but whether this is a general principle that causes broad abundance distributions is not known. Many theoretical works also include mechanistic details such as a lag between infection and burst (Levin et al., 2013; Santos et al., 2014), multiple protospacers and spacers (typically with a fixed upper bound) (Weinberger et al., 2012b; Iranzo et al., 2013; Bonsma-Fisher et al., 2018; Childs et al., 2014; Childs et al., 2012; Weissman et al., 2018, spatial structure Payne et al., 2018; Haerter et al., 2011, autoimmunity Weissman et al., 2018; Chabas et al., 2021, and fitness costs of immunity and/or escape mutations Weinberger et al., 2012b; Weissman et al., 2021). Many phages also contain anti-CRISPRs which impact phage evolution and CRISPR immunity (Bondy-Denomy et al., 2013; Hwang and Maxwell, 2019). These details are all biologically important, but stripping them away as we do provides great insight into which population features depend on these details and which may be more general properties of adaptive immunity.
Diversity and average immunity
Experimental manipulations of CRISPR diversity have focused on changing the number of bacterial spacers present in the population (van Houte et al., 2016; Morley et al., 2017; Common et al., 2020) while keeping phage diversity fixed (and low), with the exception of Guillemet et al., 2021 who also explored high vs. low phage diversity. In contrast, emergent phage and bacterial diversity are tightly coupled in our model (Figure 2B). At high diversity, bacteria must ‘choose’ which of many phage clones to gain immunity against, meaning that they are then immune to a smaller fraction of the total phage population compared to when diversity is low. This is not a result of limiting bacteria and phage to a single spacer or protospacer; this trend also holds when there are multiple spacers or protospacers provided phage and bacteria diversity are correlated, as we showed in ‘Pathogen and host diversity must be considered together’.
Our toy model described in ‘Pathogen and host diversity must be considered together’ shows that the framework of average immunity provides a conceptually intuitive way to understand the impacts of different types of diversity and modes of evolution. Future work to explicitly model the population dynamics of multiple spacers and protospacers with this lens will allow us to understand how and when these different evolutionary modes arise. For instance, it remains unknown how the linkage of different spacers and protospacers within genomes would affect individual clone dynamics. Our work effectively assumes that all spacers and protospacers evolve independently and are uncoupled, but in real genomes evolving with CRISPR, spacers and protospacers may hitchhike to prominence through selection acting on a different sequence in the same genome. Models of CRISPR locus spacer addition have shown that trailer-end clonality emerges from selective sweeps of newly added spacers (Weinberger et al., 2012a; Han et al., 2013), and hitchhiking will affect interpretations that can be drawn from the abundance of individual spacer clones. Exploring correlations between spacer abundances at different locus positions can be done in experimental data (such as Paez-Espino et al., 2013), and extending our simulation to explicitly include multiple protospacers and spacers per genome will provide further data.
Our results suggest that immune diversity itself may not be the most informative observable feature but that average immunity is what actually determines population outcomes. Indeed, when we introduced cross-reactivity between spacer sequences, we found that diversity decreased and that other processes such as establishment were impacted, but that average immunity still correctly predicted population sizes (Figure 5C). Average immunity completely summarizes the effect of CRISPR immunity and accurately predicts population outcomes. Experiments that manipulate bacterial diversity only change average immunity if they include a changing proportion of sensitive bacteria as in Common et al., 2020 (Figure 69A).
Our results showed complex outcomes and a wide range of overall spacer diversity despite limiting bacteria and phage to a single protospacer and spacer. We also observed rapid loss of previous spacer types as bacteria returned to the naive state before acquiring new spacers. In reality, bacteria can store multiple spacers in their CRISPR arrays (Pavlova et al., 2021; Pourcel et al., 2020) and phages can have several hundred to several thousand protospacer sequences which are determined by a particular protospacer-adjacent motif (PAM) in type I and II CRISPR systems (Leenay et al., 2016). In S. thermophilus phage 2972, for example, there are about 230 protospacers that can be acquired into the CRISPR1 locus of S. thermophilus (Paez-Espino et al., 2013) and 465 that can be acquired into the CRISPR3 locus. Similarly, many bacteria can store tens to hundreds of spacers in their CRISPR arrays (Pavlova et al., 2021; Chen et al., 2022; Bradde et al., 2020; Pourcel et al., 2020). Our single-spacer assumption is reasonable for the experimental systems we consider. In liquid culture experiments with staphylococci, most bacteria acquire a single spacer (Heler et al., 2015; Heler et al., 2019; Pyenson and Marraffini, 2020), and in short-term experiments with S. thermophilus, most bacteria acquired just one CRISPR spacer over 2 weeks (Paez-Espino et al., 2013 or one to three spacers over 9 days Common et al., 2019). In the experimental data we analysed here (a 200+ day experiment), the average number of newly acquired spacers hovered around 5 throughout the experiment (Paez-Espino et al., 2015). In a long-term study of metagenomic data, most spacer matches to extant viral sequences were located near the leader end of CRISPR loci; conserved trailer-end spacers had very few matches to sampled viruses (Weinberger et al., 2012a). All these results suggest that dynamics may be dominated by just a handful of spacers per bacterium. In addition, theoretical work has found that the most recently acquired spacer provides more immune benefit than older spacers (Childs et al., 2012; Han et al., 2013). Our single-protospacer assumption for phages had a more extreme impact, however: in our model, we assumed in the non-cross-reactive case that a single point mutation allowed phages to escape from all CRISPR targeting, when in reality a phage with hundreds of protospacers may need mutations in many different protospacers to fully escape from the bacterial population. Previous work on the impact of CRISPR diversity takes place in this context: that having more diverse bacterial spacers means phages need mutations in multiple protospacers to escape, and that a single mutation only escapes a single bacterial spacer at most, leaving other bacteria still resistant (Chabas et al., 2018; van Houte et al., 2016; Common et al., 2020). We approximated this scenario of gradually increasing phage fitness per protospacer mutation by adding cross-reactivity to our model and showed in ‘Cross-reactivity leads to dynamically unique evolutionary states’ that the relationship between diversity and average immunity does not qualitatively change. We also observed the same qualitative trend in a toy model exploring the effects of both multiple spacers and multiple protospacers (‘Pathogen and host diversity must be considered together’).
Our model makes quantitative predictions about the relationship of population size and population outcomes to average immunity that can be tested in data. We directly calculated average immunity in experimental data without the need to assemble phage genomes (Figure 7), and we found that average immunity is anticorrelated with phage population size in data in one experimental dataset, as predicted by our model (Figure 77). However, we did not find a correlation between average immunity and read count (a proxy for population size) in wastewater treatment plant data (Figure 90). When calculating average immunity using experimental data, one must make assumptions about the immune benefit of spacers. In our work, we assumed that spacer and protospacer sequences that belong to the same similarity group provide perfect immunity. Other more complex assumptions are possible, and there has been a great deal of work quantifying the efficiency of spacers based on the position of SNPs in the protospacer in vitro (see Sternberg et al., 2015 for an example) and in vivo (Soto-Perez et al., 2019). Additionally, phages regularly acquire mutations in PAMs, and these mutations strongly decrease the targeting efficiency of bacterial spacers (Leenay et al., 2016; Sun et al., 2013).
In certain limits, average immunity can be related to the Morisita–Horn similarity index Wolda, 1981 (see Appendix 1), where instead of comparing two populations from different timepoints or different regions, we compared bacteria and phage populations scaled by the immune benefit of CRISPR. By comparing our definition of average immunity to the Morisita–Horn index, we find that the Morisita overlap is constant across all parameters we study, which implies that the population diversity evolves to attain the highest possible overlap. Average immunity is also theoretically similar to the concept of distributed immunity introduced by Childs et al., 2014; Childs et al., 2012, the ‘immunity’ quantity calculated by Han et al., 2013, and the probability of an immune encounter used by Iranzo et al., 2013 to derive mean-field population predictions. The mathematical definition of average immunity is slightly different than these quantities, but the effect on populations is strikingly similar, and it is significant that several different models and different metrics find that a quantification of immunity is the important predictor for population-level outcomes.
In silico time-shift experiments yield qualitative trends
We calculated average immunity in two experimental datasets and performed synthetic time-shift experiments by calculating average immunity between time-shifted populations of bacteria and phage. This effectively replicates explicit time-shift experiments (Richman et al., 2003; Frost et al., 2005; Moore et al., 2009; Blanquart and Gandon, 2013; Koskella, 2014; Chabas et al., 2016; Pyenson and Marraffini, 2020; Laanto et al., 2017; Common et al., 2019; Dewald-Wang et al., 2022). A similar time-shift calculation using sequence data was performed by Guillemet et al., 2021; they approached the question from the phage perspective and found that phages are most infectious against bacteria from the past and least infectious against bacteria from the future. Our results show that powerful insights into the dynamical immune state of a population can be obtained from sequencing data without explicitly performing time-shift experiments. We applied the same simple method to two very different experimental populations, suggesting that this analysis may be feasible in other time-series datasets, including from other natural microbial populations.
Our model predicts that an immune-evolving population in true steady state must eventually experience declining past immunity. CRISPR arrays are not infinite, and spacers must eventually be lost, even though this may happen on very long timescales. This pattern of declining past immunity is also in line with the expectations of fluctuating selection dynamics in which more rare genotypes are more fit (Gaba and Ebert, 2009; Hall et al., 2011; Blanquart and Gandon, 2013; Dewald-Wang et al., 2022). Previous theoretical work applied to vertebrate adaptive immunity also supports the existence of a peak in adaptive benefit in the recent past (Blanquart and Gandon, 2013; Nourmohammad et al., 2016), and some experimental time-shift studies have reported a peak in adaptation for bacteria-phage interactions (Hall et al., 2011; Koskella, 2014; Dewald-Wang et al., 2022 and for HIV-immune system interactions Blanquart and Gandon, 2013; Nourmohammad et al., 2016). We saw two qualitatively different time-shift curves in the experimental data we analysed: in the long-term laboratory coevolution data, bacteria were more immune to all past phages and less immune to all future phages (Figure 7C), while in the wastewater treatment plant data, bacteria were most immune to phages in their present context and less immune to phages in both the past and the future (Figure 7D). The time-shift pattern of the laboratory coevolution data was consistent with experimental time-shift data that is typically said to be indicative of arms-race dynamics (Richman et al., 2003; Frost et al., 2005; Moore et al., 2009; Blanquart and Gandon, 2013; Betts et al., 2018; Common et al., 2019), while the wastewater data may be consistent with a ‘zoomed-out’ view of the eventual decline in immunity in both the distant past and distant future (Nourmohammad et al., 2016; Guillemet et al., 2021). Indeed, the distinction between arms-race dynamics and fluctuating selection dynamics in time-shift experiments may be a question of the timescale being investigated (Gaba and Ebert, 2009; Blanquart and Gandon, 2013; Dewald-Wang et al., 2022). Our simulation results may qualitatively match both of these regimes depending on the timescale observed, which suggests that measuring very long-term coexistence is an area for further work in host-parasite coexistence experiments. In general, we expect that the timescale of memory length is related to the size of CRISPR arrays: if overall rates of spacer gain and loss are balanced, then we expect an individual spacer’s lifetime in the population to be proportional to array length. The factors that affect the timescale of memory length is an interesting area for further work.
One reason why past immunity did not unambiguously decline in our analysis of the laboratory coevolution data may be that spacer loss was not observed in the original experiment (Paez-Espino et al., 2015. This is also true of several other similar experiments with S. thermophilus Paez-Espino et al., 2013; Weissman et al., 2018), though spacer loss was directly observed coincident with spacer acquisition in Deveau et al., 2008. Spacer loss has also been observed in other experimental systems (Jiang et al., 2013; Rao et al., 2017; Deecker and Ensminger, 2020; Garrett, 2021), and indirect evidence of spacer loss through sequence comparisons has been reported for S. thermophilus (Horvath et al., 2008 and metagenomic data Held et al., 2010; Weinberger et al., 2012a). Spacers may also be functionally lost despite remaining in the genome, either from stochastic decoupling of RNA polymerase (Zoephel and Randau, 2013; Martynov et al., 2017; Soto-Perez et al., 2019 or from a dilution effect of competition for limited Cas protein complexes Martynov et al., 2017; Bradde et al., 2020; Garrett, 2021). The ‘loss’ rate in our model could also be taken to be gain and loss of the entire CRISPR system, which is known to happen (Delaney et al., 2012; Rollie et al., 2020), although this would likely happen on much slower timescales than the acquisition and loss we model. The qualitative shape and timescale of time-shift curves like the ones we presented may indirectly contain information about the timescale of spacer loss.
We found in our simulations that memory length decreased as spacer acquisition probability increased and as phage mutation rate decreased: if bacteria followed phages more closely (higher ) or if phages evolved more slowly (lower ), the peak in past immunity was closer to the present and memory was more quickly lost (Figure 7A, E, and F). A similar correspondence was derived in a theoretical model of optimal immune memory formation in vertebrates: more frequent sampling of the pathogen landscape (corresponding to higher spacer acquisition in our model) led to faster memory loss (Mayer et al., 2019). Notably, that result is the optimal update scheme for an immune system wishing to minimize the costs of infection; there is no explicit optimization in our model, yet we find a pattern consistent with a potentially optimal solution.
Vertebrate adaptive immunity
CRISPR adaptive immunity is mechanistically very different from the vertebrate adaptive immune system, yet there are several striking conceptual similarities between them and in the way past theoretical works have modelled vertebrate immunity. For example, phenomenological models of binding affinity between antigens and the immune system have used the degree of similarity between strings as a metric for interaction strength (Detours and Perelson, 1999; Detours and Perelson, 2000; Chao et al., 2005; Wang et al., 2015; Nourmohammad et al., 2016; Sachdeva et al., 2020), and more abstract models of the change in immunity after a virus mutation have also used string similarity to track the strength of immune coverage (Luksza and Lässig, 2014; Rouzine and Rozhnova, 2018; Yan et al., 2019). This is a simplification of a complex protein-protein interaction in the case of the vertebrate immune system (Altan-Bonnet et al., 2020), but it is nearly identical to the actual mechanism of CRISPR immunity, suggesting that lessons from models of CRISPR immunity may in turn be applicable to other forms of adaptive immunity.
Pathogen evolution has been extensively explored in models of vertebrate immunity, and here too we can draw conceptual parallels. We found that the speed of phage evolution depended sublinearly on phage population size in our model (Figure 6C), analogous to the weak positive dependence on population size described by Marchi et al., 2021. Adding cross-reactivity between spacer types in our model changed overall population outcomes as well as population dynamics. We observed a traveling wave regime in which new phage mutants ‘pull’ existing bacterial clones along, even if their matching clone is small or extinct (Figure 54). This travelling wave regime is qualitatively similar to that observed in theoretical models of ‘ballistic’ pathogen evolution in effective low-dimensional antigenic space (Yan et al., 2019; Marchi et al., 2019; Marchi et al., 2021). Similar clone population dynamics were observed in a model of B cell activation and memory generation in which existing memory B cells are reactivated in response to infection with a mutated virus that remains within its cross-reactivity radius (Chardès et al., 2022). We also observed splitting of lineages into divergent subtypes in our model, a phenomenon that has been studied in vertebrate pathogen evolution as well (Marchi et al., 2019; Marchi et al., 2021). We found that the average number of distinct clans was proportional to overall diversity but that increasing cross-reactivity decreased the average clan size (‘Number and size of clone clans’). These qualitative similarities highlight the usefulness of CRISPR adaptive immunity to understand population dynamics that also occur in the vertebrate immune system.
Selection in the vertebrate immune system happens at many distinct stages within individuals, including T cell receptor selection in the thymus (Camaglia et al., 2022 and affinity maturation of B cells following an immune challenge Chardès et al., 2022; Nourmohammad et al., 2019; Nourmohammad et al., 2016; Molari et al., 2020). Selection also happens at the population level as pathogens and individuals coevolve over time (Marchi et al., 2019; Yan et al., 2019, for instance, in the evolution of influenza Luksza and Lässig, 2014; Yan et al., 2019). In contrast, within-host dynamics are much simpler in bacteria, and the possibilities for within-host coevolution are especially limited in the case of virulent phages that kill their hosts after a single infection. Similarly, in the vertebrate immune system, extremely high immune diversity is possible in a single individual, whereas in CRISPR immunity, total diversity per individual is many orders of magnitude lower: most bacteria contain tens of spacers with a very few examples of a few hundred spacers (Pavlova et al., 2021). This reintroduces the question of how to think about immunity in microbial populations, whether as playing out on the level of individuals or on the level of the entire population. Finally, unlike the vertebrate adaptive immune system, CRISPR immunity is heritable, and so the optimal immune strategy for bacteria takes place on a timescale potentially much longer than an individual’s lifetime as well as on the level of the entire population Mayer et al., 2016. We have highlighted several analogies between CRISPR adaptive immunity and vertebrate adaptive immunity. Overall, the mechanistic simplicity and experimental tractability of CRISPR immunity mean that abstract ideas from vertebrate immunity can be linked to measurable features of CRISPR immunity, and insights from CRISPR immunity may be useful in understanding vertebrate immunity as well.
Primed acquisition
In some CRISPR systems, an imprecise match between a spacer and protospacer results in a much higher spacer acquisition rate, a phenomenon called priming (Rao et al., 2017). Including cross-reactivity in our model is a way to explore the effect of primed acquisition. However, we modelled cross-reactivity as a change in phage infection success probability, whereas in primed acquisition it is the spacer acquisition rate that changes. Because bacteria must lose their spacer before gaining a new spacer in our model, including primed acquisition directly would require expanding bacterial arrays to at least two spacers. The acquisition probability could then become a function of protospacer-spacer similarity to directly model primed acquisition.
Selection patterns in CRISPR immunity
The mechanism of selection for immune variants in CRISPR adaptive immunity is a matter of debate. We observed several features that suggest the presence of negative frequency-dependent selection in our model: (a) decreased clone growth rates as clone size increased, (b) cyclic clone size dynamics as immune pairs oscillate in size, and (c) continual turnover in spacer types over time. This is consistent with recent experimental observations of negative frequency-dependent selection in host-pathogen systems (Betts et al., 2018; Guillemet et al., 2021). Our model also contains the base assumption that phages that can successfully infect dominant bacterial strains will experience positive selection, generating ‘kill-the-winner‘ dynamics that lead to negative frequency-dependent selection for bacteria (Weinberger et al., 2012a). Our model does not capture true host-pathogen coevolution because bacteria are not able to evolve beyond ‘following’ the mutational landscape of phages by acquiring spacers. In true coevolution, bacterial genomic mutations, apart from the ability to acquire spacers, are also drivers of evolution and sources of selection pressure on phages.
Phase transitions in immunity
We observed large population size fluctuations when average immunity reached a particular value of approximately 10% for the parameters we used (Figure 31). This critical value is determined by a balance of the rate of spacer acquisition and spacer loss that leads to exactly equal fitness for both bacteria with spacers and bacteria without spacers (see ‘Dominant balance approximations for ’). Despite the presence of spacers with non-zero effectiveness, near this critical point the population appears to behave as if there is no CRISPR immunity at all. This has two interesting results: first, the probability of phage establishment drops to zero for some simulations near this critical point (Figure 3—figure supplement 2), since if CRISPR has no influence then mutant phages do not experience strong positive selection. Second, population sizes become unstable near the transition: outcomes with quite different total bacteria population size and fraction of bacteria with spacers are possible (Figures 30 and 31). This critical point will be interesting to explore further as a possible phase transition.
Experimentally accessible parameters
We found that diversity in our model depended on spacer acquisition rate, spacer effectiveness, and spacer mutation rate. These parameters are all known to vary in natural systems, and some may also be experimentally manipulated. CRISPR systems display a range of spacer acquisition rates even within the same system (Heler et al., 2019), and both spacer acquisition rate and spacer effectiveness may be controlled by the level of expression of Cas proteins, which has been found to be connected to the quorum sensing pathway (Høyland-Kroghsbo et al., 2017). Additionally, recent work has found that spacer acquisition is more efficient at slow bacterial growth rate because phages also grow more slowly, giving bacteria more time to acquire spacers (Høyland-Kroghsbo et al., 2018; Dimitriu et al., 2022). This change in bacterial growth rate can be controlled by nutrient concentration (Dimitriu et al., 2022; Payne et al., 2018, temperature Høyland-Kroghsbo et al., 2018, or by bacteriostatic antibiotics which slow bacterial growth without killing Dimitriu et al., 2022). Phage mutations rates also vary and may be experimentally modified (Kysela and Turner, 2007). These findings all represent possible experimental manipulations of parameters relevant for CRISPR immunity; for example, given these findings we predict that a bacteria-phage population exposed to bacteriostatic antibiotics would evolve higher CRISPR spacer diversity than one without antibiotics.
Methods
Model
In this section, we describe the details of our phenomenological model of bacteria and phages, providing more detail for Figure 1A. Sections ‘Reactions’ and ‘Master equation’ list the stochastic interactions we simulate, and ‘Clone size master equation’ lists master equations that are used to derive mean-field equations for this dynamical system (Total population size) and clone size distributions for bacteria and phages (Appendix 2).
We model bacteria and phages interacting in a chemostat. The populations we track are nutrient concentration (), phages (), and bacteria (). Bacteria can either have no spacer () or a spacer of type (), and phages can have a single protospacer of type (). Nutrients flow in at concentration C0 with rate , and all species flow out with rate . The total number of bacteria with a spacer is and the total number of bacteria is . Bacteria grow at rate . With rate , a phage interacts with a bacterium. With probability , the phage will kill bacteria without a matching spacer and produce a burst of new phages with size , while for bacteria with a matching spacer that probability is reduced to (). Bacteria without spacers that survive an attack have a chance to acquire a spacer with probability . Bacteria with a spacer lose their spacer at rate . Phages are limited to a single protospacer, and phages can mutate to a new protospacer type with probability , where is the per-base mutation rate and is the protospacer length ( in all simulations). Parameter descriptions and default values are shown in Table 3. See refs Weissman et al., 2021; Gurney et al., 2019 for recent examples of other chemostat-based models.
Reactions
Table 1 lists all the interactions present in our model between individual bacteria (), phages (), and nutrients ().
Table 1
Model reactions.
| Bacterium divides | |
| Bacterium flows out | |
| Phage flows out | |
| Nutrients flow in | |
| Nutrients flow out | |
| Interaction, phage wins, | |
| probability of mutuant phages | |
| Interaction, bacterium survives | |
| Interaction, bacterium survives and acquires a spacer | |
| Interaction, phage wins, | |
| probability of mutant phages | |
| Interaction, bacterium survives | |
| Bacterium loses spacer |
In Table 1, is the probability of a phage with protospacer type killing a bacteria with spacer type .
in Table 1 is the probability of mutant phages in a burst, given by a binomial distribution:
(9)
where is the probability of no mutations for an individual phage. is the protospacer length and is the mutation probability per base per generation.
In this formulation of the mutation term, new mutants are assumed to be a new, not previously existent, phage type which increases by , the number of mutations (). In our simulations, phage mutations can happen to existing types, but these are rare events and we neglect them in our theoretical analysis.
Master equation
The reactions in Table 1 can be formulated as a master equation describing the probability of observing bacteria without spacers, the set of bacteria with spacers of type , the set of phages with protospacers of type , and a nutrient concentration of at time (Equation 10).
(10)
Each term is included only if all respective population quantities are ; for instance, the first term is only included if , since if then and the entire term is negative and non-physical. This is important to note especially in terms containing , which are only included if .
Clone size master equation
We can also write master equations for the total number of clones of size . These equations describe the population-level distribution of clone sizes instead of the size of a single typical clone as in Equations 123 and 147.
The master equation for bk, the number of bacteria clones of size , is:
(11)
The last term representing spacer acquisition is complicated: is the total number of phages which contain protospacers that match bacteria clones of size , multiplied by the probability of getting that protospacer if infected by that phage. In other words, these are the phages that bacteria clones of size could acquire spacers from to increase to size , multiplied by the probability of acquiring a particular spacer from those phages. In a model where phages are all identical with a large number of protospacers , , where is the total number of phages and is the probability of acquiring a particular spacer. If instead phages can only have a single protospacer, is not known in general, but approximations may be found; for instance, if there are phage types present and all phage clones are the same size, is again equal to .
The corresponding master equation for , the number of phage clones of size , is:
(12)
The phage master equation assumes that all new mutants are unique and that they are a type not currently present in the population.
is a binomial distribution giving the probability of mutant phages per burst (Equation 9).
is the probability of phage successfully infecting bacteria, and in general is an unknown function of both and . All details of immunity are contained in ; later we discuss certain choices of and their implications for the model and population dynamics. with no functional arguments is the probability of phage success against bacteria with no spacers, a constant.
Mean-field model results
Total population size
These mean-field equations for total bacteria, bacteria with spacers, phages, and nutrients are the backbone of our analytic model results. Throughout this work, we assume that clone dynamics take place in a background of total populations at steady state; these equations describe the model that we solve to find these steady-state quantities underlying results in ‘Bacteria and phages dynamically coexist and coevolve’, ‘Phages drive stable emergent sequence diversity’, ‘What determines the fitness and establishment of new mutants?’, ‘Cross-reactivity leads to dynamically unique evolutionary states’, and ‘Dynamics are determined by diversity’.
The total number of bacteria with spacers, , is equal to , and the total number of phages, , is and , and summing over and in Equations 11 and 12 gives mean-field equations:
(13)
(14)
We can also write mean-field equations for the total number of bacteria without spacers, , and the total nutrients, . The total number of bacteria is .
(15)
(16)
(17)
The probability of phage success against bacteria with spacers, averaged across the whole population, is given by .
is not known in general, but it can be simplified if certain assumptions are made about the population. In particular, we begin by assuming that immunity is all-or-nothing: if a bacterium has a matching spacer to a phage, the phage success probability is reduced to (where is the ‘spacer effectiveness’), but if a bacterium has a spacer that is not exactly matching, that spacer confers no immunity and the phage probability of success is , the same as against naive bacteria. This amounts to defining in terms of the spacer type and protospacer type as follows:
(18)
If each bacterium and phage can have only one spacer or protospacer, then the number of bacteria or phage with a particular spacer type is and , respectively, and
Equations 13–17 can be solved analytically at steady state if we further assume , where is the average number of bacterial clones at steady state. This assumption is described in detail in ‘Measuring diversity’. The solution is exactly the mean-field analytic solution described in Bonsma-Fisher et al., 2018 with the simple replacement of the parameter with .
Phage extinction threshold
This section relates to Figure 1E in ‘Bacteria and phages dynamically coexist and coevolve’.
We reported in our previous work (Bonsma-Fisher et al., 2018) that Equations 13–15–17 experience a change in fixed point at a critical threshold of the phage infection success probability : below , phages are driven extinct (Figure 1E). This is the same extinction threshold reported by Payne et al., 2018 as the cutoff for achieving herd immunity in a well-mixed bacterial population. To a first approximation, phages must successfully infect every bacteria they encounter, but if bacteria are growing quickly, then phage must do better to overcome bacterial growth. The correction gives as reported in Payne et al., 2018. To see this, we note that the bacterial birth rate in our model is when phage population sizes are small, and the phage birth rate in our model is since . When phage population sizes are small, the total number of bacteria is . Combining these expressions, we find as in our original expression.
Steady state
Simulation results are calculated and presented at steady state unless otherwise specified. We define steady state to be the simulation run-time divided by 5, choosing simulation run-times so that mean-field quantities have equilibrated by the steady-state time. We run large population simulations longer than small population simulations: these simulations have less frequent interactions on average because of decreased and take longer to equilibrate (Figure 8).
Figure 8
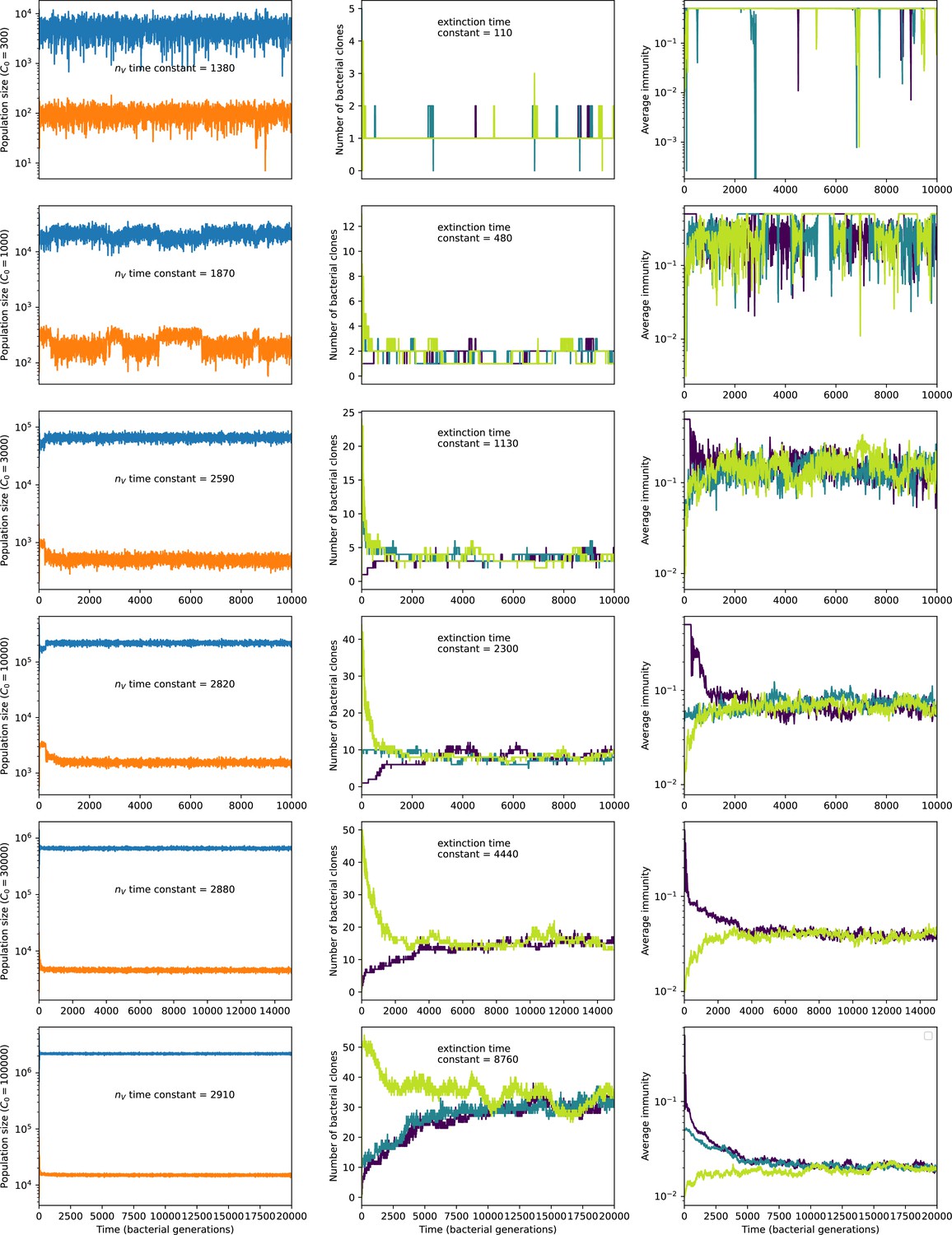
Total phage, total bacteria (left), and mean number of bacterial clones (right) vs. simulation time for five simulations with , , , and C0 ranging from 300 (top row) to 30,000 (bottom row).
Total population sizes equilibrate very quickly, but the total number of clones can take longer at large population sizes (high C0). The time constants inset are a measure of how quickly we expect each mean-field quantity to equilibrate: time constant is the inverse growth rate of the total phage population () and the extinction time constant is the mean time to extinction for large phage clones (Equation 171), a measure of the rate of turnover of the number of clones.
We set the total bacterial generations to be , rounded to the nearest thousand, with a minimum of 10,000 generations (see Table 2). The following table lists simulation length and assumed steady-state time for different values of C0.
Table 2
Simulation length.
| C0 | Simulation length (bacterial generations) | Steady-state start time () |
|---|---|---|
| 300 | 10,000 | 2000 |
| 1000 | 10,000 | 2000 |
| 3000 | 10,000 | 2000 |
| 10,000 | 10,000 | 2000 |
| 30,000 | 15,000 | 3000 |
| 100,000 | 20,000 | 4000 |
| 300,000 | 25,000 | 5000 |
| 1,000,000 | 30,000 | 6000 |
Figure 9 shows the mean number of bacterial clones () at steady state as a function of the initial number of phage clones. For most parameters, the steady-state is independent of the initial m. There is a slight dependence on initial at high C0.
Figure 9

Mean number of bacterial clones after bacterial generations vs. initial number of phage clones for , .
The mean is an average of 15 evenly spaced points from to bacterial generations. Error bars are the standard deviation across three or more independent simulations.
Single-clone mean-field dynamics
This section presents mean-field equations for the population size of single bacteria and phage clones. The steady-state bacteria and phage clone sizes (Equations 25 and 26) are, like the mean-field results in ‘Total population size’, used extensively in further analytic results. In particular, predicted mean clone sizes are used as a cutoff to measure the time to extinction for large clones (Appendix 3) and to calculate diversity in ‘Analytic approximations for diversity’ (main text ‘Phages drive stable emergent sequence diversity’). These expressions are also used to calculate the fitness of new phage mutants in Appendix 3.
We can write mean-field equations for individual clones and as well:
(19)
(20)
If is binary and all spacers are equally effective (Equation 18), and can be simplified:
(21)
(22)
In Equations 19 and 21, mutations that arise from phage decrease , which is captured in that becomes for type is effectively lower, since mutations go to different phage types.
The last term in Equations 19 and 21 is for mutations that happen in all other phages besides type that convert type to type . Any particular phage has a certain mutational distance from phage , , which means -specific mutations must happen to get from type to type . This happens with probability . Going forward we assume that this term is small, which is true if the overall mutation rate is sufficiently low and/or the space of protospacer types is sufficiently large so that mutations are almost always to new types not present in the population.
We solve the coupled time-dependent system given by Equations 21 and 22 numerically, assuming all other populations (, , , and ) are at their deterministic steady-state value and ignoring the last term of Equation 21. These solutions are plotted alongside mean clone sizes from a simulation in Figure 10 (‘Numerical deterministic prediction’). The deterministic solution matches the mean clone size well at early times but does not capture the effects of clone extinction at later times. By including only surviving clones in the simulation mean and normalizing the deterministic solution by the predicted fraction of surviving clones (‘Numerical deterministic prediction normalized to survival probability’), the theoretical prediction matches well at early times and can be piecewise-combined with the steady-state mean clone size to give good agreement at all times (see ‘Predicted clone size’ dashed lines in Figure 3—figure supplement 1). We estimate the predicted fraction of surviving phage clones by numerically solving Equation 153 which gives the phage clone probability of extinction in the absence of matching bacterial clones. The fraction of surviving clones is where is the probability of extinction. Normalizing by does not give good agreement at long times because goes to 1 as goes to infinity, causing the solution to diverge at long times. While individual trajectories do eventually go extinct, the mean clone size conditioned on survival reaches the deterministic steady state at long times.
Figure 10
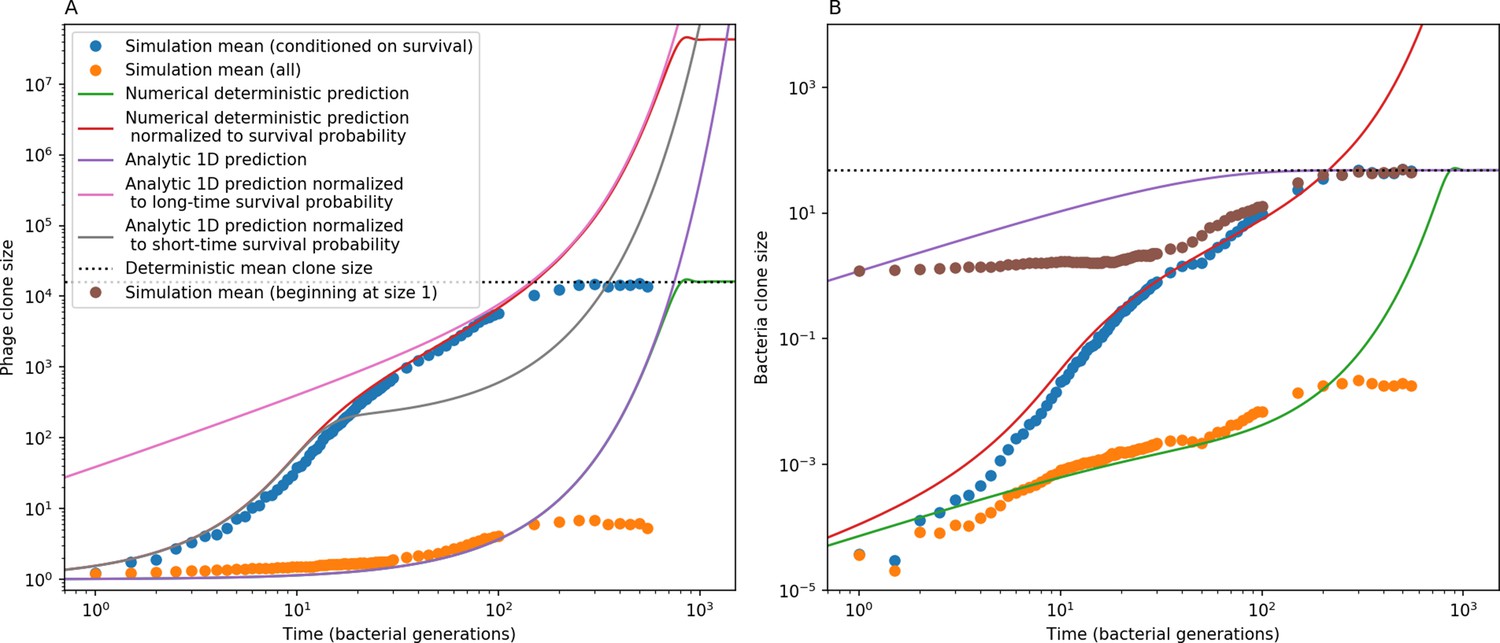
Phage (A) and bacteria (B) mean clone size in a simulation, either conditioned on survival (blue circles) or including extinct clones (orange circles).
Theoretical predictions are plotted as solid lines: the time-dependent numerical solution to Equations 21 and 22 in green, the same solution divided by the phage clone probability of survival in red, and a one-dimensional solution to Equation 21 in (A) and 22 in (B). Equations 25 and 26 are black dashed lines. An alternate simulation mean clone size is plotted for bacteria (brown circles) in which each clone trajectory is stacked based on the bacterial acquisition time and averaged across trajectories, conditioned on survival. Simulation parameters are , , , and .
We consider bacteria clones in the background of phage clones; that is, time 0 for a bacterial clone starts when the matching phage clone arises by mutation. This is the case in the numerical solution for the coupled bacteria-phage clone system given by Equations 21 and 22. For this reason, normalizing the bacterial clone size prediction by the phage clone probability of extinction also gives good agreement to the simulation mean conditioned on bacterial clone survival. (If a bacterial clone size is 0 but its corresponding phage clone has not yet gone extinct, that 0 will count in the mean clone size, but after the phage goes extinct, a 0 in the bacterial clone size will not be included.)
We can also solve Equations 21 and 22 analytically by assuming and are constant, respectively; this amounts to removing the dependence of phage clone dynamics on bacteria clone dynamics and vice versa.
If we assume , we get the following solution for :
(23)
where is the average growth rate of phage clones and is in minutes. This is the same growth rate as is in Equation 156 with a small correction: ; the burst of an individual phage clone is reduced by phages that mutate to a new type.
Likewise if we assume that is constant, we get the following solution for :
(24)
where is the average growth rate for bacterial clone and is the rate of spacer acquisition for that clone.
Equations 23 and 24 are plotted in Figure 10 (‘Analytic 1D prediction’). Equation 23 matches the phage clone size not conditioned on survival at early times, but continues to grow past the steady-state phage clone size without growing bacterial clones to reign it in. Equation 24 is not comparable to the simulation mean with time zero as the time of phage clone birth; rather it should be compared to bacterial clone growth independent of what the phages are doing. Using the steady-state mean phage clone size in Equation 24 (purple line), we obtain a rough correspondence with the simulation mean (brown circles). The prediction does not match at intermediate times, likely because this solution assumes that phage clones are at their mean size when in fact they are likely still smaller.
Equations 21 and 22 can be solved at steady state in terms of the total mean-field variables (ignoring the last term of Equation 21). These solutions (Equations 25 and 26) are indicated by horizontal dashed lines in Figure 10.
(25)
(26)
Simulation methods
This section describes how simulations were performed, shows basic simulation results, describes parameter choices (‘Parameter values’), and explores the parameter dependence of stochastic population extinction (‘Stochastic population extinction’) that relates to results in ‘Bacteria and phages dynamically coexist and coevolve’.
Simulations were written in Python and performed on the Béluga and Niagara supercomputers at the SciNet HPC Consortium (Ponce et al., 2019) and on a local server in our group. Our simulation code can be found at https://github.com/mbonsma/CRISPR-dynamics-model (copy archived at Bonsma-Fisher and Goyal, 2023). We used the tau-leaping method, a fast approximation for Gillespie simulation Cao et al., 2006 and compared with full Gillespie simulations for some cases. Gillespie and tau-leaping methods showed similar dynamics and good agreement for total population sizes (Figure 11), total spacer diversity (Figure 12), mean phage and bacteria clone sizes (Figure 13), and produced the same qualitative behaviour for individual spacer types (Figure 14).
Figure 11
Total phage () and total bacteria () as a function of time for a Gillespie simulation and a tau-leaping simulation with the same parameters.
Total phage is shown at early times (A) and late times (B), and total bacteria at early times (C) and late times (D). The simulation parameters are , , , and . Early time dynamics differ slightly in this example, but the long-time behaviour and steady-state values are similar.
Figure 12
Number of bacterial clones () vs. simulation time for three sets of simulations, each beginning with 1, 10, or 50 phage clones.
Gillespie simulations are dashed blue lines, and tau-leaping simulations are solid orange and red lines. The simulation parameters are , , , and .
Figure 13
Average population size of phage clones (solid lines) and bacterial clones (dashed lines) in a Gillespie and tau-leaping simulation with the same parameters.
The simulation parameters are , , , and .
Figure 14
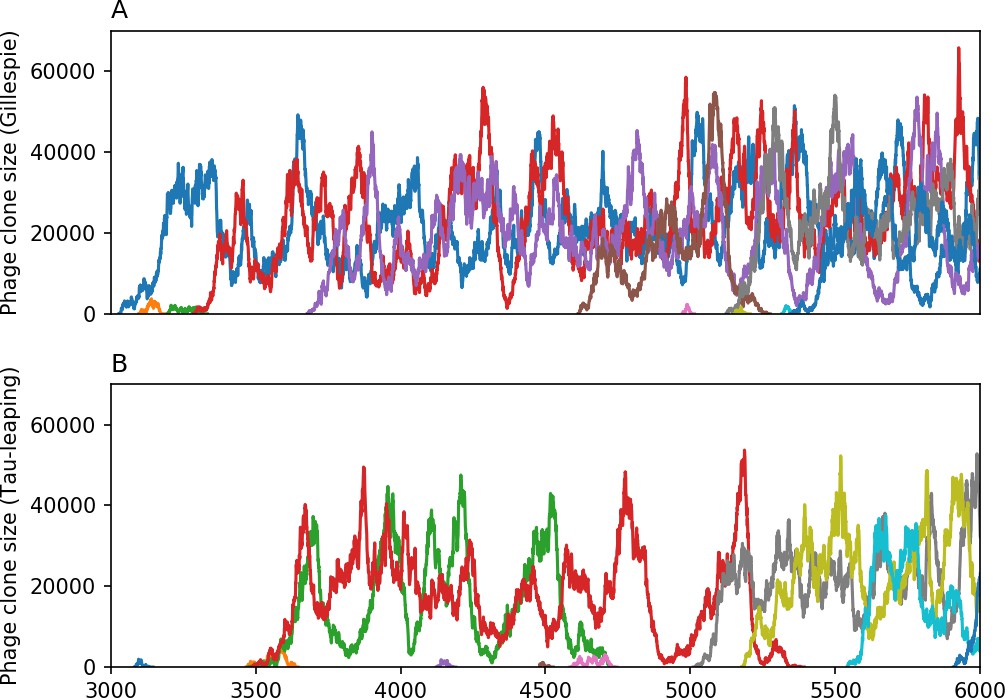
10 spacer trajectories for a Gillespie simulation (A) and tau-leaping simulation (B).
The first 10 trajectories that surpass are shown. The simulation parameters are , , , and .
We initialized five simulations for each parameter combination for a total of approximately 19,800 simulations, not including simulations with cross-reactivity. A small subset of simulation parameters were run six times instead of five. Not all simulations were successfully completed either due to errors while running or because their running time was exceedingly long. Of the initialized simulations, approximately 10,000 were completed and included in analysis. Simulations with very low tended to either have no phage establishments (at low C0) or very long running times (at high C0), and simulations with very high tended to have higher diversity and longer running times in general. Unless otherwise noted, plots with simulation averages are an average across three to six simulations with the same parameters. We set simulations to run for a fixed number of bacterial generations intended to be long enough to allow the system to reach steady state and remain there for a long time to generate statistics (‘Steady state’).
We model spacers and protospacers as a binary sequence of length as in Han et al., 2013; Han and Deem, 2017. When a phage reproduces and creates a burst of phages, we draw numbers from a binomial distribution with probability . Successes in this draw designate bits that will mutate (flip) in the newly created phages. It is possible but very rare for more than one mutation to happen in the same new phage: this occurs with probability whereas a single mutation occurs with probability . Multiple mutations occur approximately times as often as single mutations; for the largest value of we use, they represent 0.3% of events.
Our simulation code can be found on GitHub.
Parameter values
Parameter values are as above unless otherwise indicated. Representative values estimated for S. thermophilus bacteria in lab conditions.
Parameter descriptions and values are listed in Table 3. The burst size for phage that target S. thermophilus has been measured at between 140 and 200 (Lucchini, 1999) and 80 for phage 2972 (Levin et al., 2013). We use a burst size of 170. (Vaningelgem et al., 2004) measured the maximum growth rate of S. thermophilus in milk at 42°C to be . This corresponds to in our model; we choose based on C0 so that .
Table 3
Model parameters.
| Parameter | Description | Value |
|---|---|---|
| Bacterial doubling time | 41.7 min | |
| C0 | Inflow nutrient concentration in | 102 to 10-6 |
| Units of bacterial cell density | ||
| Phage adsorption rate | ||
| Phage burst size | 170 | |
| Chemostat flow rate | ||
| Probability of phage success | 0.02 | |
| for bacteria without spacers | ||
| Spacer effectiveness | 0.1 to 0.95 | |
| Rate of spacer loss | ||
| Probability of spacer acquisition | 10-5 to 10-2 | |
| Phage mutation rate per base per generation | 10-8 to 10-4 | |
| Phage protospacer length in nucleotides | 30 |
-
Parameter values are as above unless otherwise indicated. Representative values estimated for Streptococcus thermophilus bacteria in lab conditions.
The parameter in our model is the phage adsorption rate constant divided by the culture volume. The rate of adsorption for phage is of the order of ml Delbrück, 1940; this is similar to the values used in Levin et al., 2013 and Weissman et al., 2018. In order to explore regimes of different total population sizes, we decrease as we increase C0 in order to maintain stable coexistence between bacteria and phage; this is equivalent to decreasing the culture volume as C0 decreases. For example, if , we set , implying a culture volume of approximately .
Levin et al., 2013 estimated the frequency of phage mutants that escape CRISPR targeting by S. thermophilus to be between to . These measurements are the fractions of phages from lysate that can evade CRISPR targeting of different unique spacers. This is analogous to in our model, which is the probability of a mutation occurring in a newly burst phage. We use values of between 10-8 and 10-4 corresponding to between and to encompass the physiological range of phage mutation rates as well as unusually high mutation rates.
We generally fix the probability of successful phage infection against naive bacteria at (though is varied in Figure 1E and in Bonsma-Fisher et al., 2018). This is consistent with the value of 10-2 used in Doekes et al., 2021 and Berngruber et al., 2013. Several other models of CRISPR immunity have assumed phage success probability to be much higher, typically close to 1 (Childs et al., 2014; Childs et al., 2012; Weissman et al., 2018). Increasing does not qualitatively alter our results beyond changing the relative population sizes of phage and bacteria; at high values of bacteria population sizes are small and they become more likely to experience stochastic extinction (see Figure 1E). A low value of can be taken to reflect the presence or effectiveness of other anti-phage defence systems.
The rate of spacer loss in our model, , can be thought of as a phenomenological parameter since the true rate of spacer loss is not well understood (Weissman et al., 2018). For comparison, Jiang et al. estimate the rate of loss of function of the entire CRISPR system in S. epidermis at 10-4 to 10-3 per individual per generation (Jiang et al., 2013). We rescale the parameter as a function of bacterial growth rate, which means that the rescaled parameter is constant per bacterial generation. Our loss rate is an order of magnitude higher than the rate in Jiang et al., 2013.
We vary the parameters and to explore different 'strengths' of CRISPR immunity. The parameter is spacer effectiveness: when , spacers provide no immunity and bacteria with spacers are functionally no different from bacteria without spacers. When , a spacer-containing bacterium that encounters a phage with a matching protospacer is guaranteed to survive. We vary between 0.1 and 0.5 to explore different regimes of CRISPR effectiveness. The parameter is the probability that a naive bacterium will acquire a spacer if it is infected but not killed by a phage. Rates of naive spacer acquisition vary widely, and we vary between 10-5 and 10-2, with the value of constant within a simulation. For comparison with measured acquisition rates, Pyenson et al. measured naive acquisition in Staphylococcus aureus to be approximately 10-6 to 10-7 (Pyenson and Marraffini, 2020). Acquisition rates may hundreds of times higher in primed acquisition (Staals et al., 2016), and Heler et al. measured four orders of magnitude difference in spacer abundances shortly after infection, likely a result of differences in acquisition rate (Heler et al., 2019).
The flow rate was picked in order to get a stable fixed point where phage and bacteria coexist. Stability conditions approximately correspond to those derived in our previous work (Bonsma-Fisher et al., 2018).
Stochastic population extinction
This section relates to results in 'Bacteria and phages dynamically coexist and coevolve'.
Even when bacteria and phage are within the deterministic coexistence regime, populations may experience stochastic extinction (main text Figure 1F). Simulations are run for a fixed number of generations (see 'Steady state') or until bacteria or phage go extinct. Population extinction on the timescale of our simulation run-time is restricted to low values of C0 (no phage population extinctions happen for , and no bacteria extinctions happen for ). Phages are prone to population extinction at higher population sizes than bacteria because of their large burst size which makes their dynamics more noisy (see 'Long-time approximation for ').
Extinction probability is strongly related to total population size, with smaller populations being more likely to go extinct across all parameters (Figure 1—figure supplement 1 and Figure 1—figure supplement 2). However, there are differences that depend on parameters and initial conditions. First, high spacer effectiveness increases the likelihood of phage extinction and decreases the likelihood of bacterial extinction (Figure 1—figure supplement 1). High spacer effectiveness correspondingly increases the time to extinction for bacteria (Figure 1—figure supplement 4) and decreases the time to extinction for phages (Figure 1—figure supplement 3). Bacteria also appear to be less likely to go extinct at high values of (Figure 1—figure supplement 4). Phages have longer times to extinction and lower extinction probability at high values of (Figure 1—figure supplement 3). And finally, phages have a longer time to extinction if the initial number of phage clones () is high (Figure 1—figure supplement 6), but this effect disappears at low (Figure 1—figure supplement 5), perhaps because bacteria do not acquire spacers quickly enough for the initial phage diversity to make a difference before the number of clones equilibrates, which happens rapidly at low total population size (see upper rows of Figure 8).
Simulation results
Measuring diversity
This section describes in detail our method for measuring diversity in simulations, relating to results in 'Phages drive stable emergent sequence diversity'. It provides justification for matching the number of large phage clones to the number of bacteria clones and discusses the assumptions made and where they may break down.
A measure for the overall sequence diversity in the population is the total number of unique clones. In general, the bacterial diversity and phage diversity need not be the same, but it turns out that the number of bacterial clones (which we call ) closely tracks the number of 'large' phage clones across a wide range of parameters.
To measure the number of large phage clones in a simulation, we scale the observed phage clone size distribution by the probability of extinction for each clone size below a size cutoff given by Equation 115. We multiply each observed number of clones of size by the probability of extinction (Equation 159) to the power of the clone size (Equation 27): this gives a scaling factor for each clone size that predicts how many clones of that size will survive at long times (Equation 28). is plotted alongside the full normalized histogram of clone sizes for one simulation in Figure 15.
(27)
(28)
Figure 15
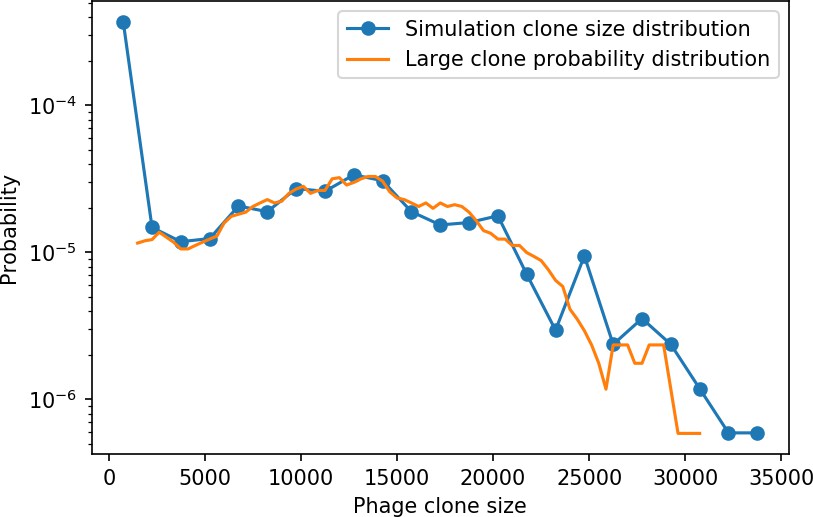
Phage clone size distribution from 15 combined time points for a simulation with the parameters , , , and .
The blue points are the values of the full normalized phage clone size histogram with a bin width of 1500. The orange line is given by in Equation 28 smoothed with a running average of window size 3000. Both distributions are scaled by the total number of phage clones.
We then calculate the number of large phage clones at steady state as , the total number of phage clones multiplied by the fraction of clones that survive for long times. Note that is not normalized; it is a quantity representing the proportion of the clone size distribution that corresponds to large clones. The predicted number of large phage clones is plotted against the observed mean number of bacterial clones in Figure 22. There is extremely good agreement at all parameters except the lowest value of , , where the estimated number of large phage clones tends to be larger than . In this regime, phage clones go extinct because of clonal interference before bacteria are able to acquire spacers (Figure 16 and Figure 17). At low and high , phage clone fitness declines more rapidly with less influence from bacterial spacer acquisition than at high and moderate : Figure 18 shows the ratio of phage clone initial fitness to phage clone fitness at the mean bacteria spacer acquisition time, measured from simulations, vs. . At most parameters, however, phage clone fitness has not changed much by the time bacteria are acquiring spacers.
Figure 16
Mean phage clone size at the time of first spacer acquisition vs. the deterministic mean phage clone size.
For each phage clone trajectory, the clone size at the time of first spacer acquisition is recorded and these are averaged across each simulation. Error bars are the standard deviation across three or more independent simulations.
Figure 17
Mean time to extinction for phage clones vs. the timescale of bacteria spacer acquisition given by where .
Points outlined in red are simulations where the ratio of large phage clones to bacterial clones exceeds 1.2. Phage clones experience clonal interference at low : they go extinct faster than bacteria acquire spacers.
Figure 18
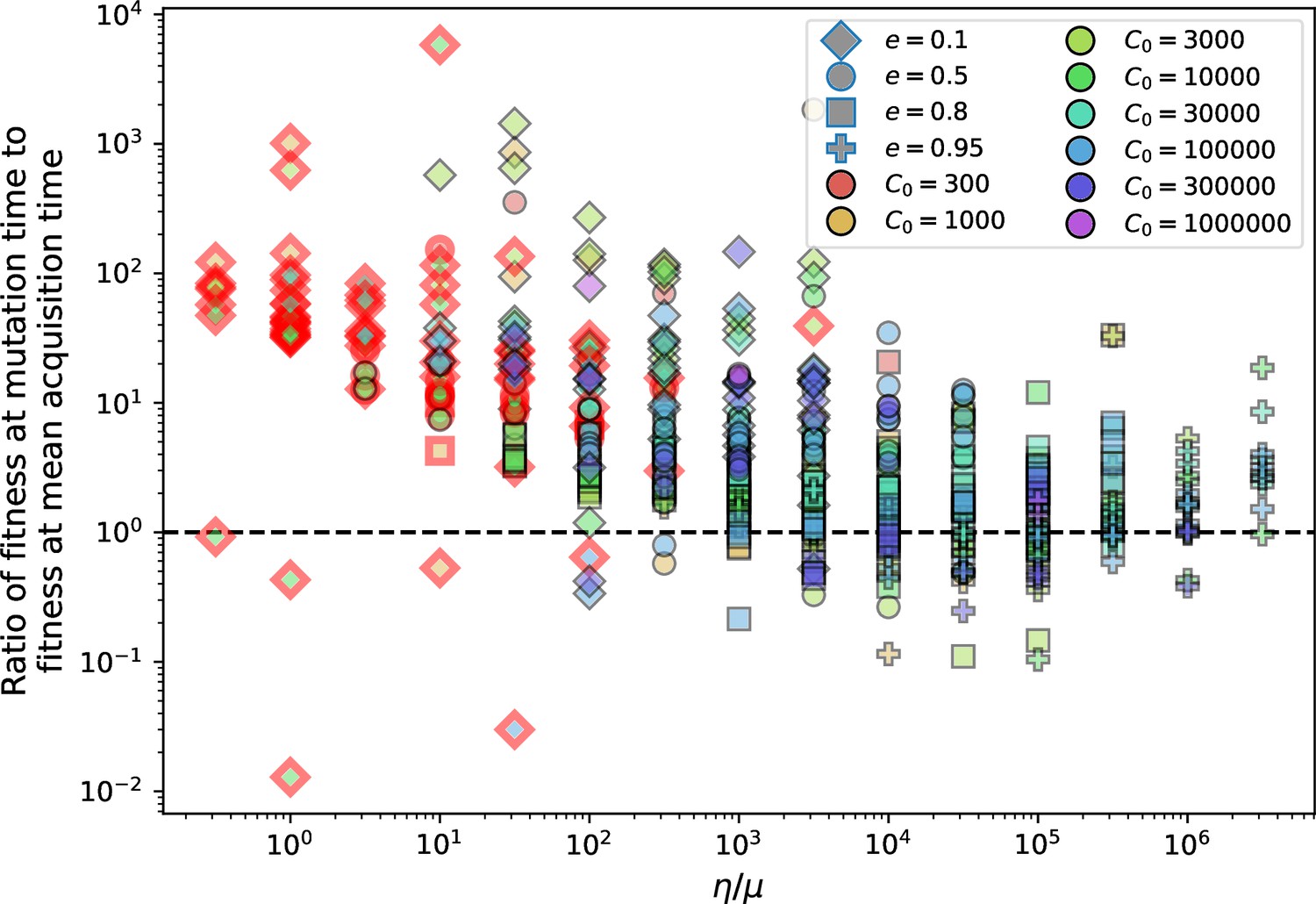
Ratio of average phage clone initial fitness to the average phage clone fitness at the mean bacterial spacer acquisition time vs .
Points outlined in red are simulations where the ratio of large phage clones to bacterial clones exceeds 1.2. The phage fitness is the average per capita growth rate of phage clones conditioned on survival. Phage clones experience clonal interference at low and high .
There is an -dependent ‘floor’ on the minimum size a phage clone must be before bacteria begin to acquire spacers (Figure 16). We can estimate the size of a phage clone at the time of first spacer acquisition by calculating the mean time of acquisition from an exponentially growing population. Let be the size of a phage clone relative to the time of mutation. We assume phage clones grow exponentially with rate s0 at early times, where is the average initial growth rate of phage clones: .
The probability that no acquisitions have happened by time is given by P0 in a Poisson process. Let be the rate of spacer acquisition (see Equation 15), then the probability of no acquisitions by time is . Now, the probability that an acquisition happens between time and is then
(29)
Equation 29 is shown as a function of for four simulations with different values of in Figure 19. The probability has a sharp peak: there is a particular time related to phage clone growth at which the first acquisition is most likely — intuitively, this is what leads to the appearance of a sharp floor in phage clone size at first acquisition. Interestingly, the mean time of first acquisition is non-monotonic in : the mean time is smallest for the lowest and highest values of .
Figure 19
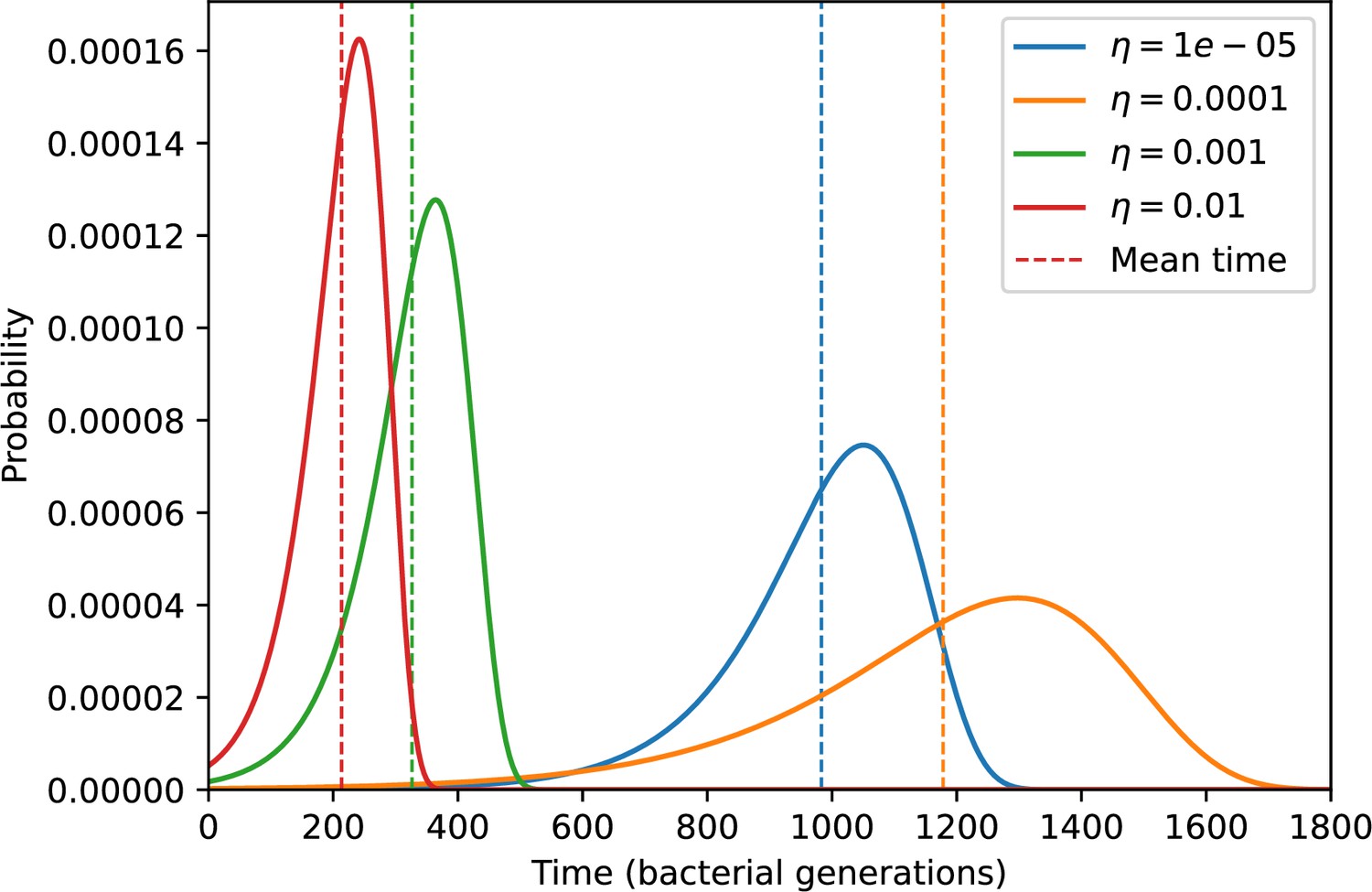
Probability of the first spacer acquisition happening at time for four simulations with different values of and , and .
The mean of each distribution is shown as a vertical dashed line.
We calculate the mean time from Equation 29:
(30)
(31)
where is the incomplete gamma function. We can plug this time into to estimate the mean phage clone size at first acquisition; the measured clone size is plotted as a function of this prediction in Figures 20 and 21. The clone size depends on the phage growth rate and bacterial acquisition rate, which are themselves primarily dependent on the total bacteria population size and the acquisition probability parameter . If (true for our parameters), then and , meaning that the time of first acquisition is larger than . ( for .) Since is the approximate time at which phages are safe from stochastic extinction due to drift (see ‘Clone fitness’), this means that phage clones are out of the stochastic extinction regime by the time bacteria begin to acquire spacers.
Figure 20

Mean phage clone size at time of first spacer acquisition for simulation data, the predicted with Equation 31, and the prediction with the mode of the distribution given by Equation 29 for four simulations with different values of and , and .
Figure 21
Measured mean phage clone size at the time of first spacer acquisition vs. the prediction given by of Equation 31.
Error bars are the standard deviation across three or more independent simulations.
The definition of large phage clones we just described depends on the measured simulation distribution of phage clone sizes. We can instead approximate the number of large phage clones as the product of the rate at which phage clones become established and the rate at which large phage clones go extinct. This statement is summarized in Equation 32. Numerically solving this equation for gives a prediction for the total number of bacterial clones and total number of large phage clones.
(32)
deterministic mean phage clone size at steady state
We now describe each of the three terms in Equation 32. The phage establishment rate is the phage mutation rate multiplied by the fraction of new phage mutants which become established. Derivation of the phage establishment fraction and phage time to extinction can be found in ‘Long-time approximation for ’ (Equation 158). Derivation of the mean time to extinction for large phage clones can be found in ‘Neutral time to extinction from backward master equation’ (Equation 171).
The phage mutation rate is the mean-field phage reproduction rate multiplied by the probability of one or more mutations per burst ().
We assume that , which is true if all clones are equal in size (i.e., and ) or if the deviations from equal size are uncorrelated between matching bacteria and phage clones. This assumption means that the average immunity in the population is approximately which is accurate across a wide range of parameters: Figure 22 and Figure 23 compare the full average immunity (Equation 33) with , where is the number of bacterial clones present at a given time point in a simulation. The assumption breaks down at low and high (points below the line in the upper right). Intuitively this happens when the sizes of matching clones become anti-correlated because bacteria acquire few spacers while phages acquire many mutations. The resulting matching pairs have more mismatched clone sizes than the mean number of bacterial clones would suggest. (In this particular case, phage clones are smaller than .) Conversely, at large population sizes and large spacer acquisition rates, matching clone sizes become correlated, leading to average immunity . Figure 24 shows clone size distributions for four simulations with increasing , showing that as increases the phage clone distribution becomes more narrow and the matching clone pairs become more correlated.
(33)
Figure 22
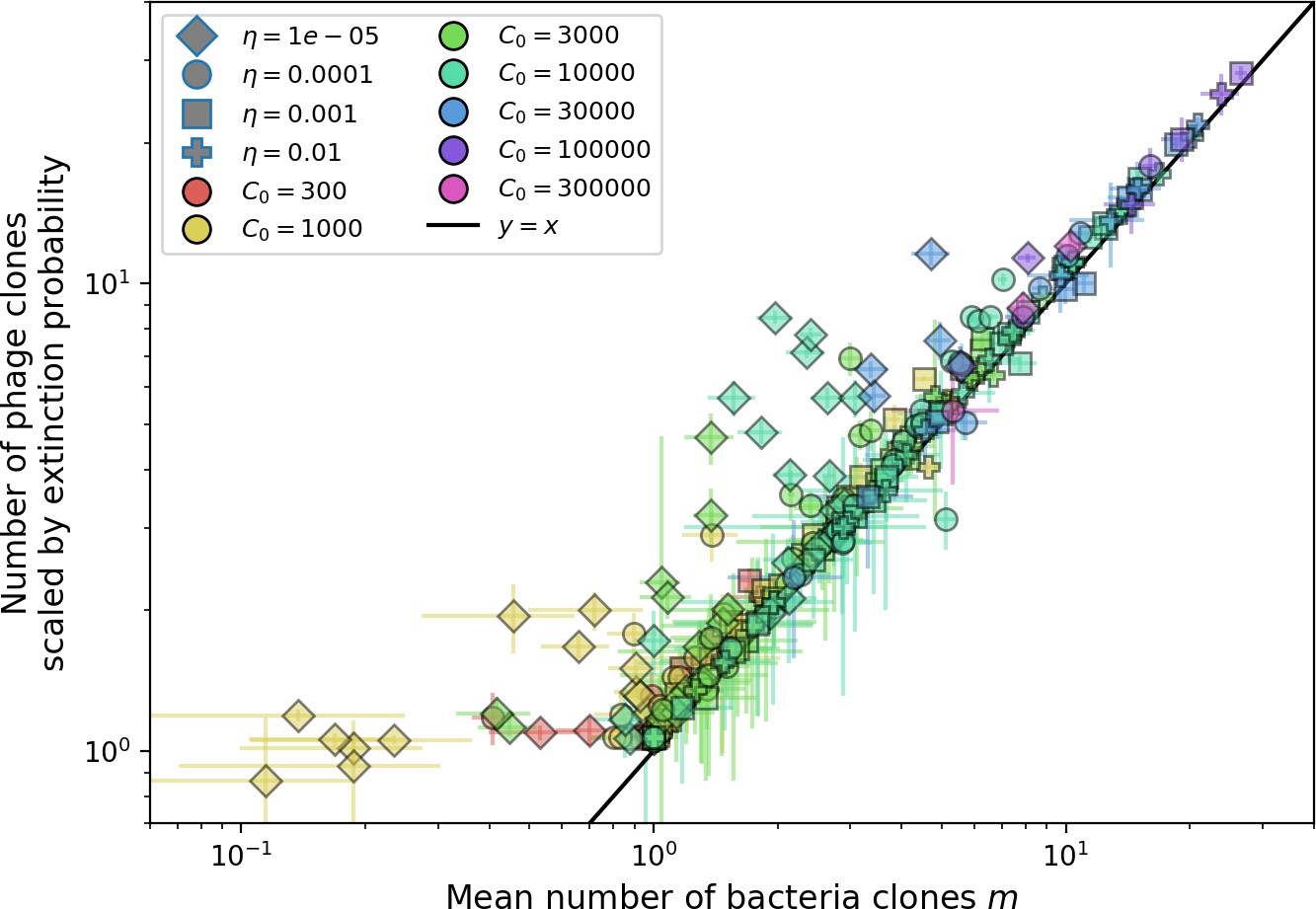
Mean number of large phage clones vs. mean number of bacterial clones in simulations.
For each simulation, we take a subset of 15 evenly spaced timepoints at steady state and calculate the size and number of phage clones present. We scale the observed clone sized distribution with Equation 28 and calculate the mean number of large phage clones by multiplying the total number of clones with the fraction of large phage clones given by . We use the simulation mean total population sizes to calculate s0 and in Equation 27. We obtain the mean number of bacterial clones by averaging the number of clones present at 15 evenly spaced timepoints at steady state. Error bars are the standard deviation across three or more independent simulations.
Figure 23
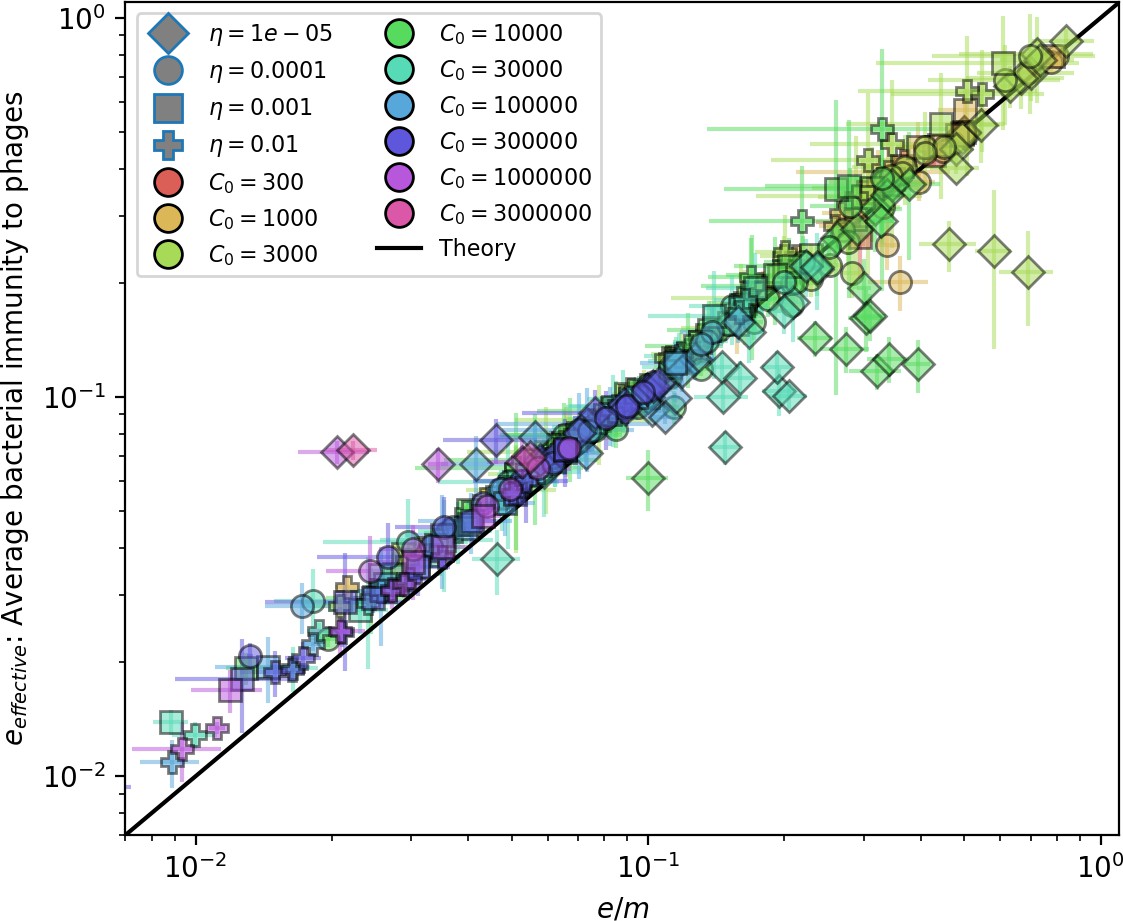
Effective vs across all simulations where on average.
Error bars are the standard deviation across three or more independent simulations. The solid black line is .
Figure 24
Four simulations with , , and .
From top to bottom, increases by a factor of 10 in each row, from in the top row to in the bottom row. The first two columns show clone size distributions combined from 15 time points between 2000 and 10,000 bacterial generations. Bacteria are in the left column and phages in the middle column. The third column shows the pairwise clone sizes of matching clones at the last sampled time point (9467 generations). The expected large phage clone size is the total phage population divided by the mean number of bacterial clones. The inverse overlap is , which we assume is as shown in Figure 23. The dashed line in the third column indicates the line that clone size pairs would fall on if they were perfectly correlated, and the red star indicates the mean large clone size for phages and the mean clone size for bacteria.
For several parameter combinations, there is no that satisfies Equation 32. This generally occurs for parameters resulting in small total population sizes. In these cases, no solution is found because the predicted mutation rate and/or the predicted establishment fraction and/or the predicted mean time to extinction for large clones are too low (Figure 25).
Figure 25
Measured simulation phage clone mutation rate, establishment fraction, and mean time to extinction as a function of the theoretical prediction for each.
Highlighted in grey are parameter combinations for which no theoretically predicted could be determined; the predicted quantity is instead calculated with the simulation mean . Error bar are the stnadard deviation across three or more independent simulations.
Analytic approximations for diversity
This section describes how we approximate our measurement of diversity to arrive at Equation 87, an analytic approximation for the number of bacterial clones at steady state. The first sections describe approximations for each of the components of diversity; the combination is summarized in ‘Approximation for ’. This is the mathematical background for results in ‘Phages drive stable emergent sequence diversity’.
We want to understand more intuitively how diversity depends on system parameters. Here we describe analytic approximations for diversity and its components. Equation 32 contains both explicitly and implicitly, so we approximate each of the three components to arrive at an analytic approximation for .
We can make some initial simplifications by cancelling terms (note that and ):
(34)
Now expanding s0 and the denominator and cancelling and collecting terms:
(35)
In theory, and . To see this, we start with the solutions for the deterministic mean bacteria and phage clone sizes (Equations 25 and 26, reprinted here):
(36)
(37)
From the deterministic mean-field equation for (Equation 14), we have that . Substituting this in Equation 36, we get
(38)
We can neglect P0, both because it is always close to 1 and because, at steady state, the effect of mutants leaving type is partially balanced by mutants entering type .
(39)
Similarly, from the deterministic mean-field equation for (Equation 13), we have . Substituting this in Equation 37, we get
(40)
Substituting and , we find .
Replacing and with and , respectively:
(41)
Now we want to solve Equation 41 for . This is difficult because the total population sizes , , , and also depend on . To find the dependence of , , , and , we note that we can approximate the steady-state solutions to Equations 13–17 as the corresponding solutions described in Bonsma-Fisher et al., 2018 with the simple replacement of the parameter with . This is because is a good approximation for the full average immunity at most parameters (Figure 23), and average immunity enters these equations in place of in the model without phage mutations. This is analogous to average adaptive immunity replacing the rate of innate immunity in the Lotka-Volterra system described by Iranzo et al., 2013.
We write the steady-state solutions for Equations 14 and 17 below, where we have defined as in Equation 18 and approximated average immunity as . For simplicity we rescale and by C0: and . Here . These steady-state solutions are shown in Figure 26.
Figure 26
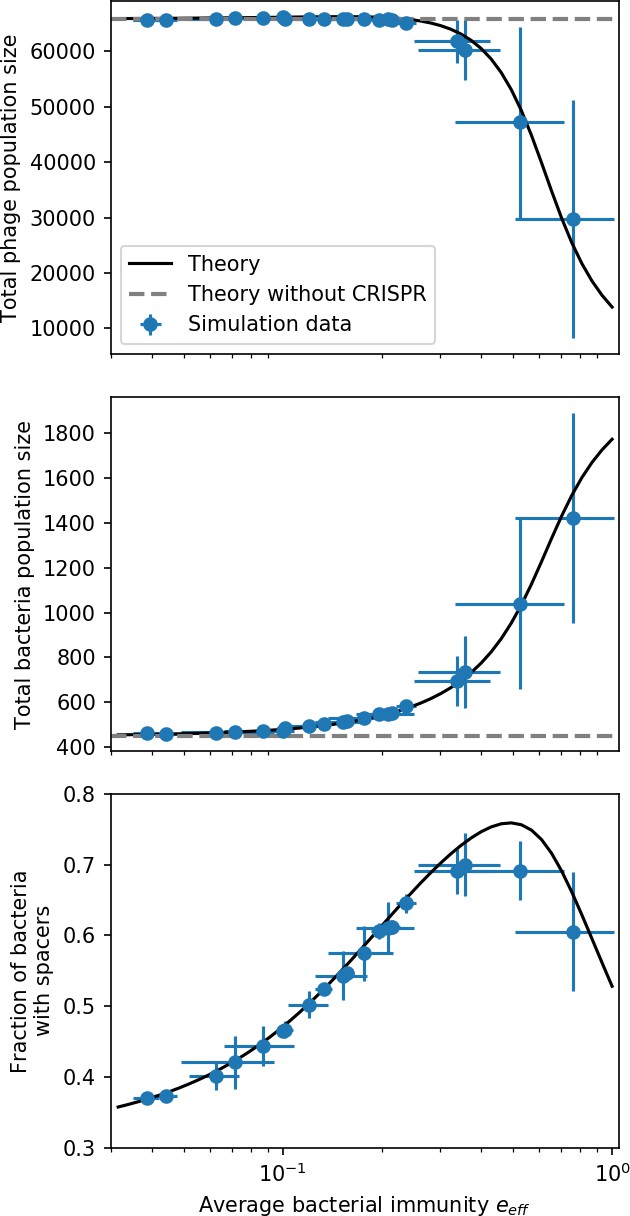
Total phage, total bacteria, and fraction of bacteria with spacers as a function of average immunity (effective ).
Blue points are simulation results. Error bars are standard deviation across three or more independent simulations. The solid black line is the solution given by Equations 42–44 (from Bonsma-Fisher et al., 2018) with the parameter replaced by effective . The horizontal grey dashed line corresponds to the no-CRISPR () mean-field solution (derived in Bonsma-Fisher et al., 2018).
At low average immunity (high diversity), the population behaves as if there were no CRISPR system at all. Figure 26 shows total phage, total bacteria, and the fraction of bacteria with spacers as a function of average immunity (effective ). At low average immunity, total population sizes are the same as in a population without CRISPR entirely. Interestingly, the effective no-CRISPR case does not necessarily correspond to no CRISPR spacers: even when effective for these parameters. This is because spacer acquisition and growth of that clone can still happen even if the spacer confers no fitness benefit.
(42)
(43)
We have defined and in terms of , which is given in the following implicit cubic equation, where :
(44)
This cubic equation is analytically solvable (ignoring the dependence of on ), but the full solutions in terms of all parameters are cumbersome.
Only one of the three solutions of Equation 44 is physical in the parameter range we use (real-valued and properly bounded):
(45)
where the coefficients are
(46)
(47)
(48)
(49)
Dominant balance approximations for
The cubic equation for given by Equation 44 can be simplified in certain parameter regimes using dominant balance. We write Equation 44 as with the coefficients as written above. Comparing the numerical values of the coefficients in different parameter regimes, we arrive at Table 4 which outlines three different approximations for obtained by dropping coefficients of the original cubic equation. Broadly speaking, at low and low , both the cubic and quadratic coefficients ( and ) are small, so , while at high and low the cubic coefficient () can be dropped, and at high and low the constant can be dropped. Figures 27—29 show total population sizes as a function of the three approximations in Table 4.
Table 4
approximations.
| ≤0.01 | 0.01 to 0.05 | 0.05 to 0.1 | 0.1 to 0.5 | 0.5 to 1 | |
|---|---|---|---|---|---|
| 10-5 to10-4 | |||||
| 10-4 to 10-2 | |||||
-
Note: the drop- solution also works for below for all values of (since ), but the solution is simpler and so preferred for the very low range.
Figure 27
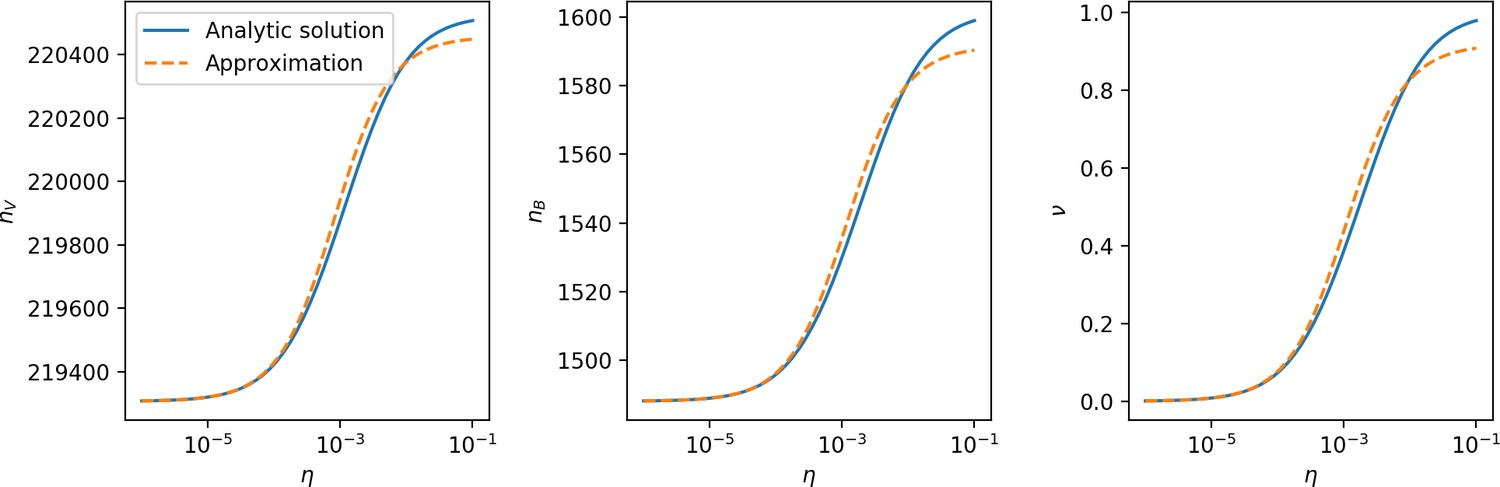
, , and vs. for , approximating .
Figure 28
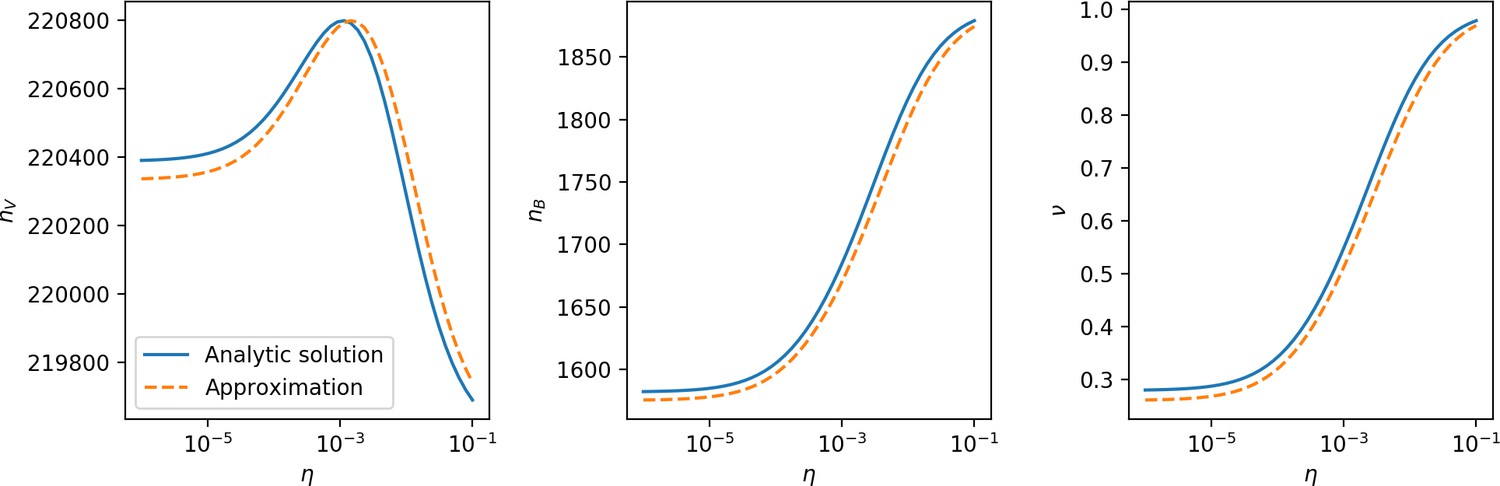
, , and vs for , approximating .
Figure 29
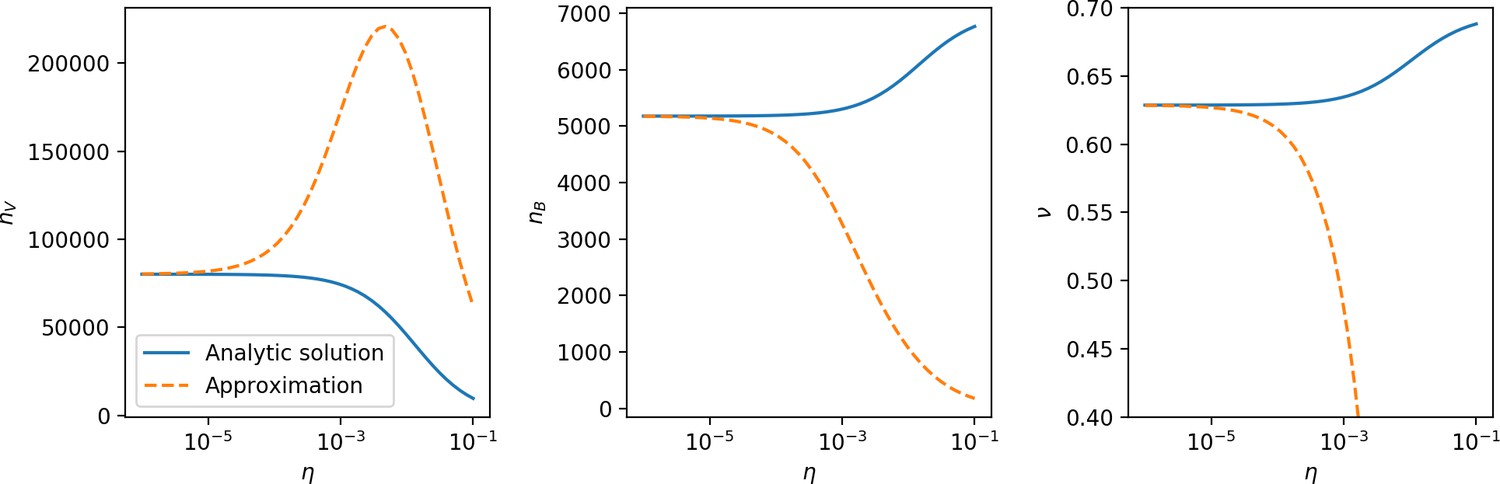
, , and vs. for , approximating .
For small effective and small , :
(50)
We define two combined parameters: , and . Each of these has an intuitive meaning: is the stability condition for phage existence, and is the probability of spacer acquisition following escape from naive phage predation, so it can be thought of as the overall spacer acquisition probability at the start of an infection. With these variable substitutions, we get
(51)
Now we notice that the deterministic total phage population size when is given by
(52)
We also include for for completeness:
(53)
We can replace some terms in with by comparison with Equation 52:
(54)
where is the spacer loss rate per minute. The second term in the denominator is the balance of spacer acquisition and spacer loss per naive bacterium: is the rate of spacer acquisition per naive bacterium in the low average immunity limit.
The third term in the denominator is negative for the parameters we use, but this is not necessarily true in general. It is negative if , which for the values of and we use (fixed across all simulations) is true for .
From this expression for we learn the following:
decreases if goes up. More spacer loss means a smaller fraction of bacteria with spacers.
increases if spacer acquisition goes up (provided is small).
increases if increases: higher CRISPR effectiveness means higher .
For , we define :
(55)
Equation 54 expression breaks down at high where the true value of is largely independent of . In this case, when both is small and is large, we can drop the third term in the denominator in Equation 54.
There is a discontinuity in Equation 54 at the value of where the denominator equals zero. This critical value of , , is given by Equation 56.
(56)
Taking a series expansion in and keeping the first two terms:
(57)
At high , the middle term dominates, and at small , the first two terms dominate (since the third term is and ). This transition governs the change between the low and high regimes; Equation 58 is plotted in Figure 3—figure supplement 2 and Figure 3—figure supplement 3.
(58)
If we substitute this critical value of into the mean-field equations and take to 0, we recover the no-CRISPR mean-field solutions for , , and . Since this also corresponds to , this seems to explain why several simulation values of the phage establishment probability go to 0 around effective for small and small C0 (Figure 30). Despite the presence of spacers with non-zero effectiveness, the population appears to behave as if there is no CRISPR near this point, which removes the fitness advantage of new phage mutants and lowers their establishment probability. We also see large fluctuations in total bacteria population size near this critical point (Figure 31).
Figure 30
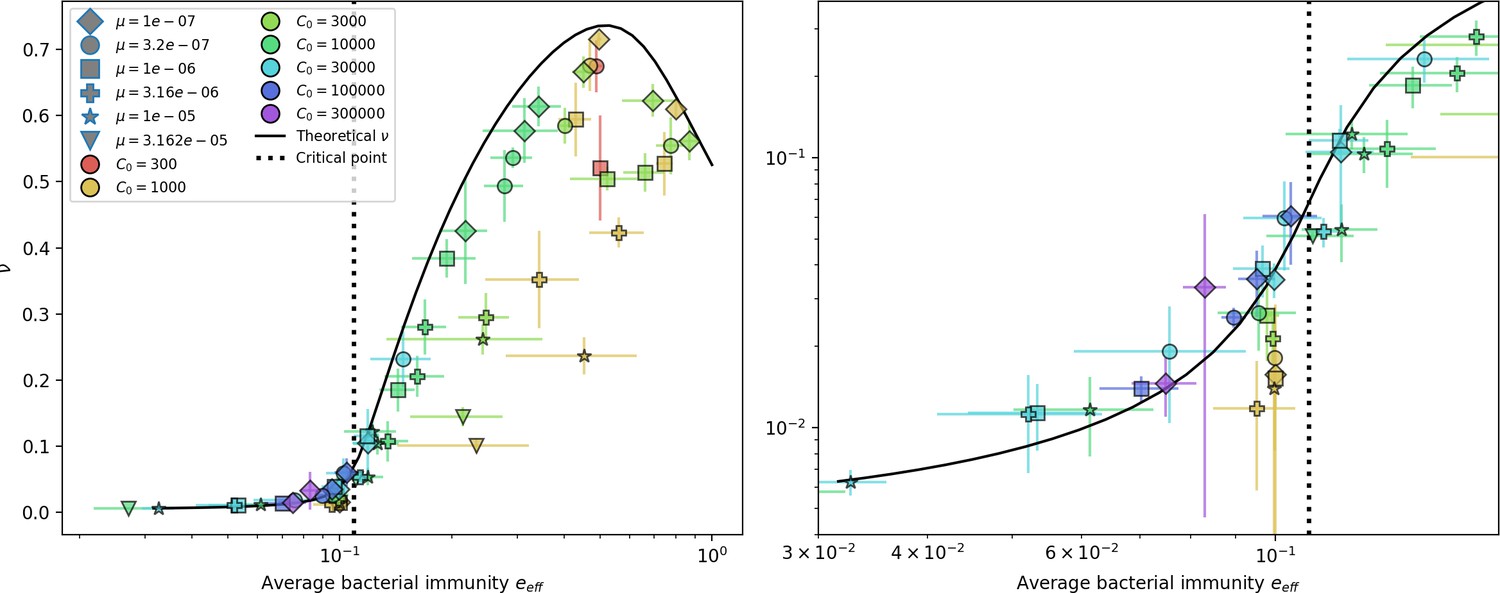
Fraction of bacteria with spacers vs. effective .
The solid line is the full numerical theoretical solution. The dashed black line is given by Equation 58. Error bars are the standard deviation across three or more independent simulations.
Figure 31
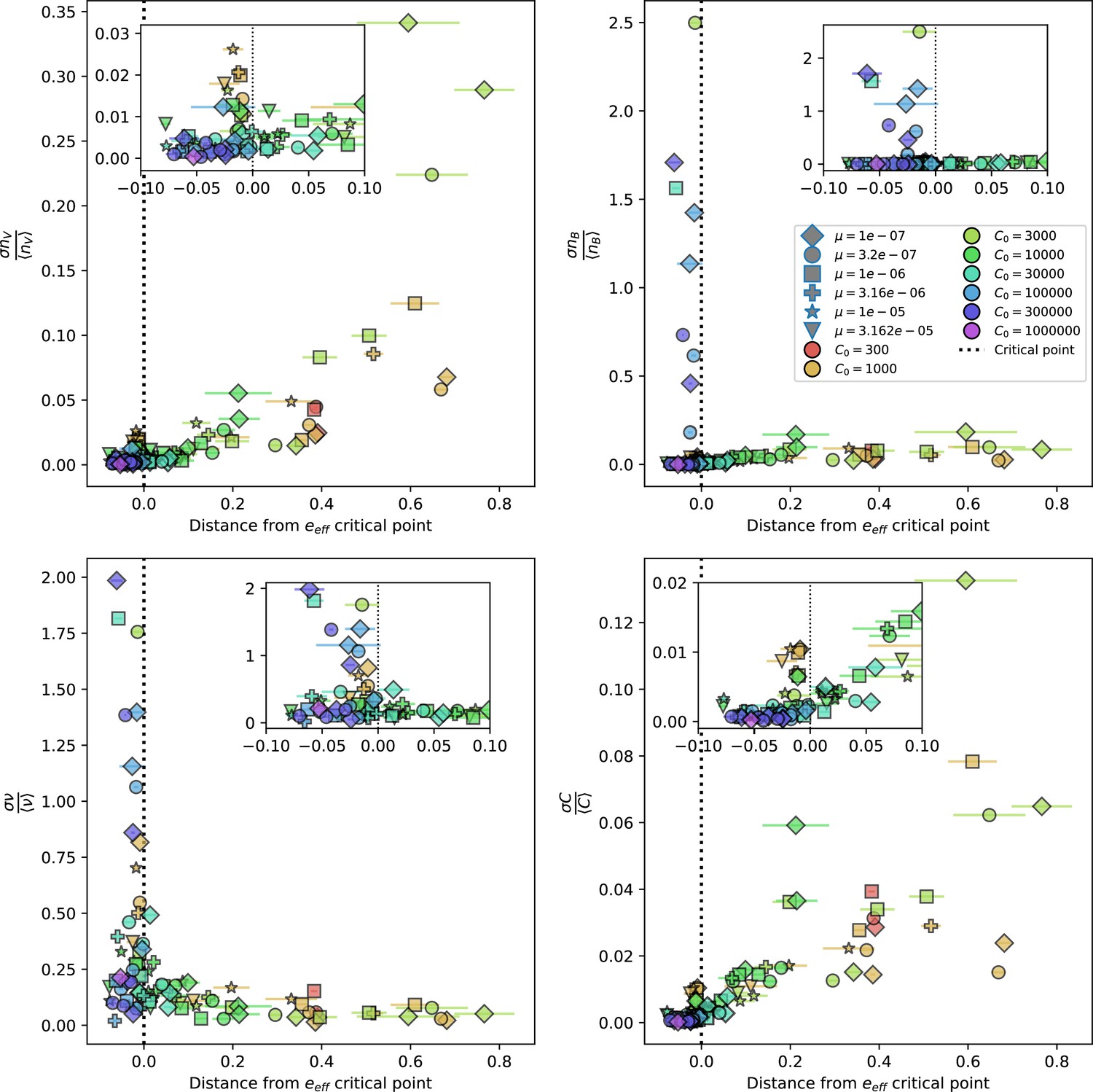
Population standard deviation divided by population mean as a function of the distance from the average immunity critical point given by Equation 58.
Insets show a smaller x-axis range for the same quantities. Total phage (top left), total bacteria (top right), fraction of bacteria with spacers (bottom left) and total nutrients (bottom right) are plotted. X error bars are the standard deviation across three or more independent simulations.
Another way to understand the critical point is to look at the difference in relative fitness between bacteria with and without spacers, and :
(59)
Now if effective is given by Equation 58:
(60)
Equation 60 indicates that at the critical value of effective , the fitness difference is exactly given by the balance of spacer acquisition and spacer loss. Below this critical point, there are additional constant negative terms, and for the same values of and , the relative fitness of spacer-containing bacteria is lower than naive bacteria; above this point, it is higher. At the critical point, the immunity boost from spacers exactly cancels out spacer loss. It is interesting that for the same reasons that many parameters collapse onto the same curves as a function of average immunity, the value of this critical point is largely independent of the parameters of CRISPR immunity and occurs at a value of effective regardless of , , or C0.
Large approximation for
In the limit of and small , we find the following approximate solution for by setting and taking a series expansion in .
(61)
Equation 61 is plotted in Figure 3—figure supplement 2 in red. The second term proportional to is tiny compared to the first for all values of we use.
Approximation for
If we evaluate the mean phage time to extinction (‘Neutral time to extinction from backward master equation’) at the deterministic mean phage clone size, we can approximate and as before:
(62)
We expand and in powers of :
(63)
(64)
Note that never appears without beside it in these expressions, so we will use the zeroth-order expression for (Equation 55) which still allows us to keep to first order elsewhere.
(65)
Substituting Equations 63–65 into :
(66)
The second term is order , which we drop, giving the following approximation for the mean phage time to extinction (plotted in Figure 32):
(67)
Figure 32

Approximate phage time to extinction vs. numerically calculated theoretical time to extinction, where the approximate time to extinction is given by (Koskella, 2014).
The full theoretical predicted value of is used in the approximate expression.
Here again we are using the phage population size independent of CRISPR (). Notably this is independent of and (except implicitly in ) but is still extremely close to the full theoretical quantity.
From Equation 67 we learn:
is insensitive to the changes in total phage population size caused by changing CRISPR immunity.
increases if the phage clone size increases.
is the effective burst size: for every phage adsorption, new phages emerge on average. This can be thought of as the phage growth rate. lies between 0 and 1; if is larger, is also larger.
The burst size also appears alone in the denominator (). A larger burst size means larger fluctuations: for larger , more deaths tend to happen between birth events at steady-state, so extinction happens sooner on average (shorter from in the denominator).
The normalized chemostat flow rate lies between 0 and 1 and is a death rate for phages; if is larger is smaller.
The term is more difficult to parse. A hand-wavy intuition is that while larger sometimes means smaller clone size and shorter extinction times (), it is also related to increased phage success in the population, and so the in the numerator softens the straight inverse dependence on through clone size.
Approximation for
Now we approximate the probability of phage clone establishment.
(68)
Recall that , , and . These all depend on , so plugging in Equation 42 for , we get
(69)
Equation 69 with given by Equation 54 is plotted in blue in Figure 3—figure supplement 2. The same expression with is plotted in green. There is a discontinuity in when the third term in the denominator becomes large, which is why the blue lines do not extend to large effective . These two approximations bound the full solution at low effective .
Approximation for phage mutation rate
The effective phage mutation rate (new phages per minute, ) is given by Equation 70. In general, depends both explicitly on and and implicitly through , , and . We do the same small approximation for as above, where we expand , , and in (, etc.). The zeroth order approximation () does not change much at all across the whole range of parameters we investigated (Equation 71 and Figure 33).
(70)
(71)
Figure 33
Approximate phage mutation rate for vs theoretical phage mutation rate.
Approximation for
Finally, we do the same approximation for the complete expression for , expanding all variables in powers of . The result turns out to be the same as if we combined the individual approximations shown above.
(72)
(73)
Let’s look at the first term by itself, neglecting and higher. Rearranging to collect terms:
(74)
Let us let the right-hand side of Equation 74 equal , a new parameter that is independent of . Now we are approximating:
(75)
Changing variables to
(76)
We solve this perturbatively. Let , then let where we assume is small. Now we are solving for the perturbation
(77)
We approximate for small . This gives
(78)
(79)
(80)
If is large, the leading order contribution to is .
(81)
Measured vs. is shown in Figure 34. To get more insight into the dependence of and on parameters, we make some approximations. First, since , we approximate . Then substituting in :
(82)
Figure 34
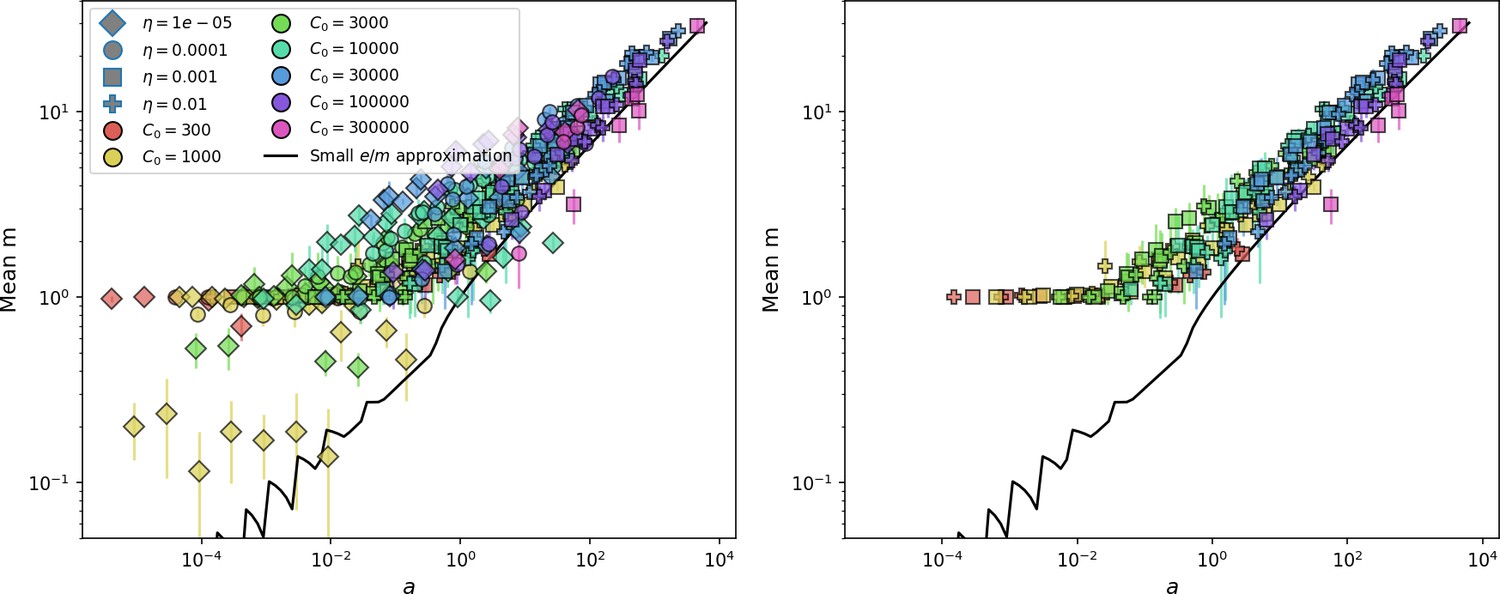
Measured mean in simulations vs. as given by Equation 81.
The solid line is vs. solved numerically using Equation 113. The right panel shows the same but with the two lowest values of removed. Error bars are the standard deviation across three or more independent simulations.
Substituting in :
(83)
(84)
Now we do an expansion assuming large burst size, . Expanding in :
(85)
Now if is small, specifically if , we can expand in . This assumption roughly amounts to assuming bacterial survival followed by spacer acquisition is rare compared to phage predation and spacer loss.
(86)
The 0th-order term captures the trend across a wide range of parameters and gives some insight into parameter dependence (Figure 2C). To summarize: For , and :
(87)
Equation 87 implies that goes like , a non-intuitive dependence.
increases as the overall phage mutation rate increases.
increases as increases.
increases for the same reasons that phage time to extinction increases, except that it depends on the total phage population size (instead of the phage clone size).
Speed of evolution
This section provides more detail on our calculation of the speed of phage evolution presented in ‘Dynamics are determined by diversity’.
The speed of evolution of a population is often taken as the rate at which its genetic structure changes over time. For example, Betts et al. measure the rate of evolution in a bacteria-phage coevolution experiment by calculating the Euclidean genetic distance between populations at different time points (Betts et al., 2018), and Rouzine and Rozhnova calculate the rate of substitution (Rouzine and Rozhnova, 2018). Speed of evolution is sometimes defined more functionally as the rate of change of a population’s fitness over time (see Desai and Fisher, 2007; Desai et al., 2007; Rouzine and Rozhnova, 2018).
In our context, the average population fitness does not change over time at steady state (more like a Red Queen scenario than an arms-race scenario) and so we use a measure of genetic distance to calculate the speed of evolution. Instead of Euclidean distance (L2 norm), we use Hamming distance or edit distance (L1 norm). This distance metric is more representative of the process involved in changing sequences since the sequence [1,1] is mutationally twice as far from [0,0] as [0,1]. Our sequence space has as many dimensions as the number of genetic sites, and a population’s 'centre of mass' can be calculated by weighting each sequence ('position') in this space by the frequency of each subpopulation with that sequence. Our effective space is dimension since each protospacer has 30 sites that can mutate. Each site can have the value 0 or 1 meaning there are 230 possible sequences, but a sequence can differ by at most 30 changes from another sequence. The maximum distance possible in our model using the L1 norm is 30.
For example: if and there are 20 phages with the sequence [0,1] and 10 phages with the sequence [1,1], then the centre of mass in the two-dimensional space is :
If the ancestor phage is [0,0], then the centre of mass distance is . If the ancestor sequence is at one of the corners (i.e. only values of 0 or 1), calculating the centre of mass in this manner is the same as calculating the population-weighted average distance from the ancestor: 20 phages are 1 mutation away, 10 are 2 mutations away, therefore the average distance is . However, if the ancestor sequence is not at a corner (i.e. if comparing two centres of mass), the sum of distances gives larger values than the difference of centres of mass. The sum of distances is a measure of the spread, while the change in centre of mass is a measure of the speed of evolution.
We can look at the distance of the phage and bacteria population in simulations from the ancestor sequence over time to get an idea of how the population moves through sequence space. Figures 35 and 36 show the mutational distance for phage and bacteria over time from either the ancestor phage sequence or a centre of mass starting point later in the simulation, for low (Figure 35) and high (Figure 36) values of .
Figure 35
Phage and bacteria centre of mass distance from the original phage and bacteria sequences.
The centre of mass distance is plotted in blue for phage (left) and bacteria (centre). Grey circles represent the size of clonal subpopulations at each distance from the ancestor sequence (arbitrary scale). The third panel shows the weighted average distance of the population from the centre of mass at that timepoint, a measure of the spread in sequences present at any time. In this simulation , , , , and mean .
Figure 36
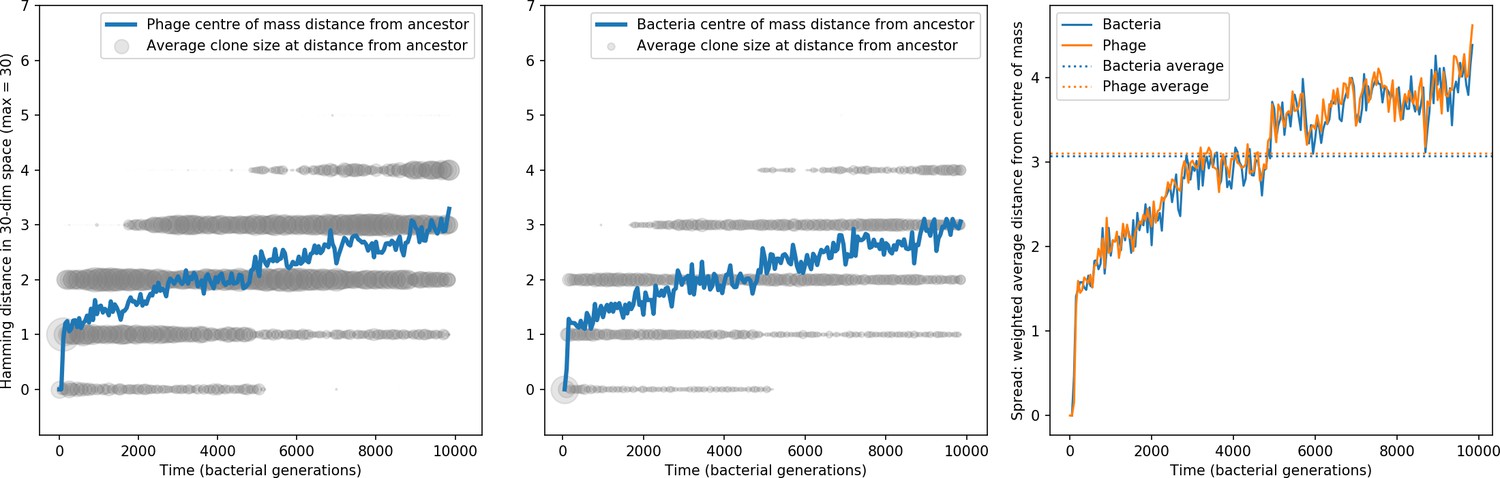
Phage and bacteria centre of mass distance from the original phage and bacteria sequences.
The centre of mass distance is plotted in blue for phage (left) and bacteria (centre). Grey circles represent the size of clonal subpopulations at each distance from the ancestor sequence (arbitrary scale). The third panel shows the weighted average distance of the population from the centre of mass at that timepoint, a measure of the spread in sequences present at any time. In this simulation , , , , and mean .
Since the maximum distance in our model is 30, there comes a point in distance where mutations back in the direction of the ancestor become likely. The fraction of available mutations fm that move away from the ancestor decreases as the distance increases: . For , this means that at a distance of 15 the population is equally likely to move towards or away from the ancestor. This is apparent in Figure 35 – the distance from the ancestor phage reaches 15 and then begins to decrease. In other simulations, the distance continues to increase and does not come close to 15 (Figure 36).
Measuring speed of evolution
The speed of evolution in this framework is the distance the population travels in spacer space in a certain amount of time. In principle, this is straightforward to calculate, but we find that the distance between populations does not increase linearly with the time interval used to calculate the distance (Figure 37 left panel). This means that measured speed will depend on the time interval used to calculate it (Figure 37 right panel), and there is no clear way to choose one particular time interval over another. We go to the long limit and measure the maximum distance from the ancestor reached by a population in a set number of bacterial generations. The maximum distance reached by bacteria and phage populations is highly correlated with each other within a simulation and is also repeatable across independent simulations (Figure 38). Speed in this definintion increases with phage mutant initial fitness (Figure 39).
Figure 37
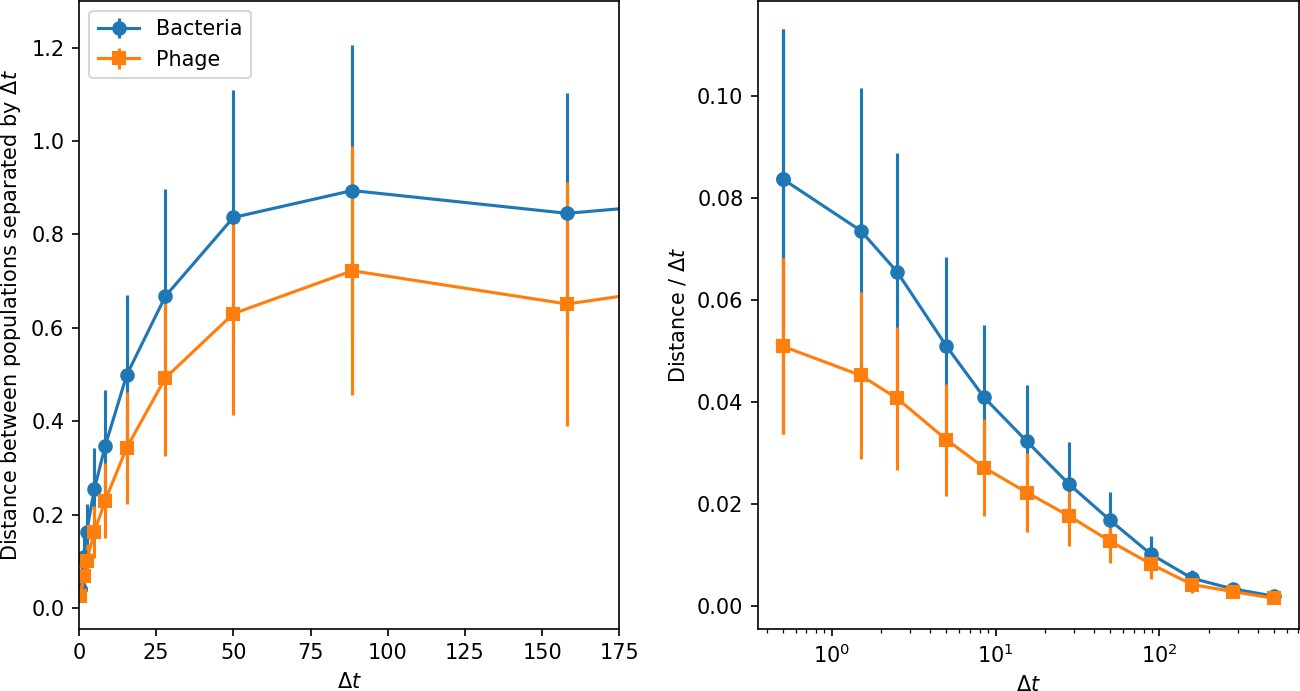
Phage and bacteria centre of mass distance from the centre of mass at time (left) and the distance divided by the time interval (right).
Distances are averaged over the entire simulation at steady state; error bars are standard deviation. Simulation parameters are , , , , and mean .
Figure 38

Maximum distance from ancestor population for bacteria vs. phage.
The maximum distance is highly correlated, indicating that the bacteria population tracks the phage population closely. Error bars are the standard deviation across three or more independent simulations.
Figure 39
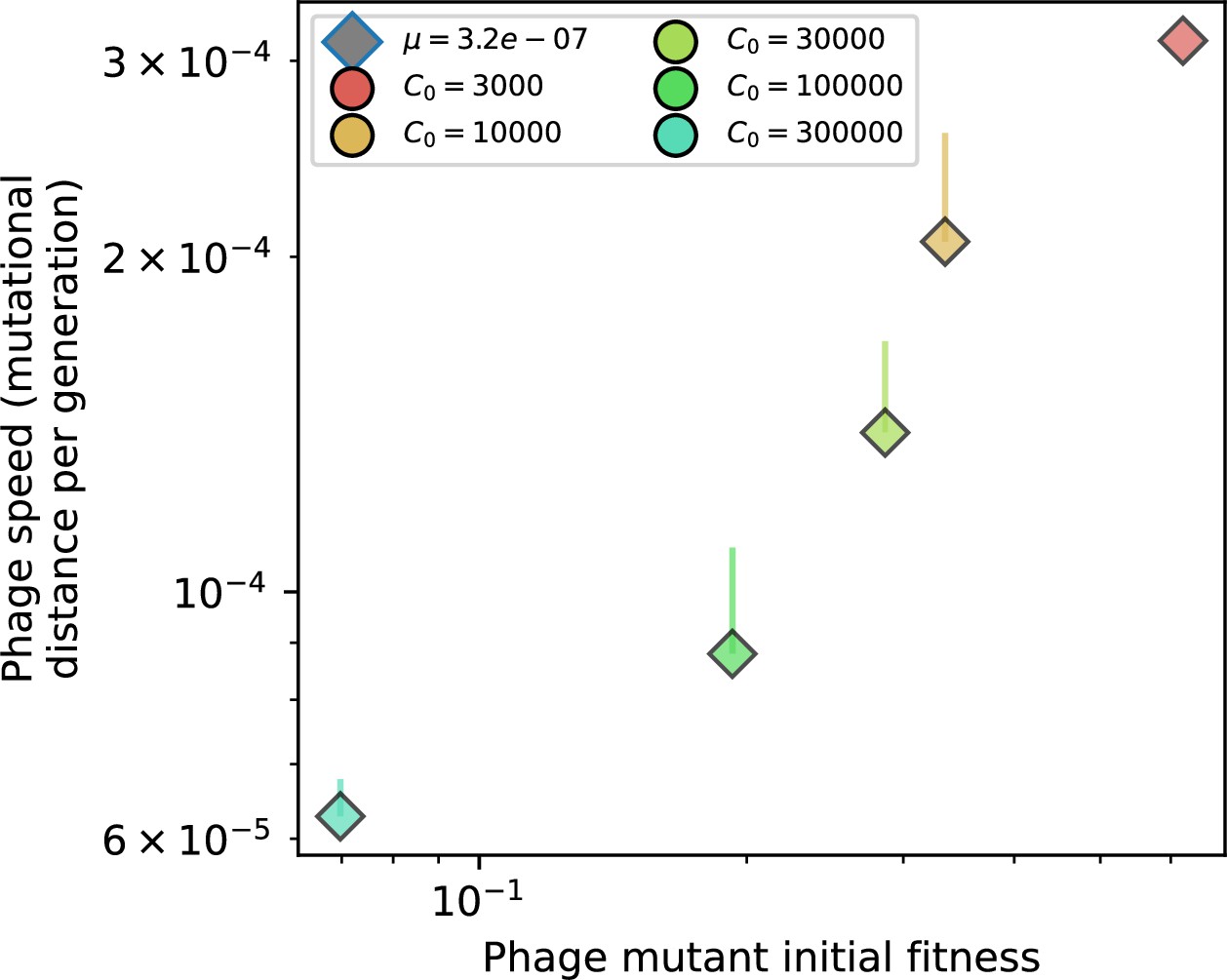
Phage mutational distance per generation vs. initial phage mutant fitness for simulations with , , and .
Error bars are the standard deviation across multiple independent simulations and are shown in the positive direction only.
The total number of phage establishments in a simulation determines the maximum distance that the population can move away from the ancestor, but if diversity is high, many of those establishments will not actually move the population further away. A simple approximate scaling for this process is that total distance is proportional to : if there are established clones and one of them is the furthest away from the ancestor, there is a probability that the next establishment will come from the furthest-away clone. This is similar to Childs et al., 2012 where if they have protospacers per phage (and one dominant bacterial species with a spacer), there is only a chance that a random mutation will actually be an escape mutation.
Since is a product of mutation rate, establishment probability, and extinction time, plotting distance per establishment vs. is equivalent to plotting speed vs. time to extinction (Equation 88). We have , where is the probability of establishment for a new phage clone, is the effective phage mutation rate, and is the mean time to extinction for large phage clones. Let the mutational distance from the ancestor be , where is the 'speed' and is a fixed time interval used to measure distance.
(88)
Figure 6—figure supplement 2 shows distance per establishment vs. and speed vs. . Relating distance and speed to the time to extinction gives further insight into the underlying parameter dependencies: we know from other approximations ('Analytic approximations for diversity') that , and for small we can substitute our approximation for , giving and . Applying the same approximation here as for above (Equation 87), with (Figure 6):
(89)
Spread in sequence space
We can ask how spread out the population is in sequence space – how far is the average clone from the centre of mass? When there are more clones (larger ), the population spread is larger (Figures 40 and 41). The spread also depends on initial conditions, at least on the timescale of our simulations: simulations that start with one phage clone (Figure 40) have lower spread than simulations that start with 50 phage clones (Figure 41). In principle, waiting for a very long time in simulations that begin with 1 clone should produce results in line with simulations that start with 50 clones as different clans diverge from each other over time. This suggests that there are multiple features with which we could define steady state, and they do not all reach true steady state at the same time. Total population size equilibrates fastest, followed by diversity (Figure 8), and then spread in sequence space.
Figure 40

Average population distance from the centre of mass at steady state for bacteria (left) and phages (right) vs. mean for simulations with one original phage clone ancestor.
The dashed line is , a purely phenomenological choice. Error bars are the standard deviation across three or more independent simulations.
Figure 41
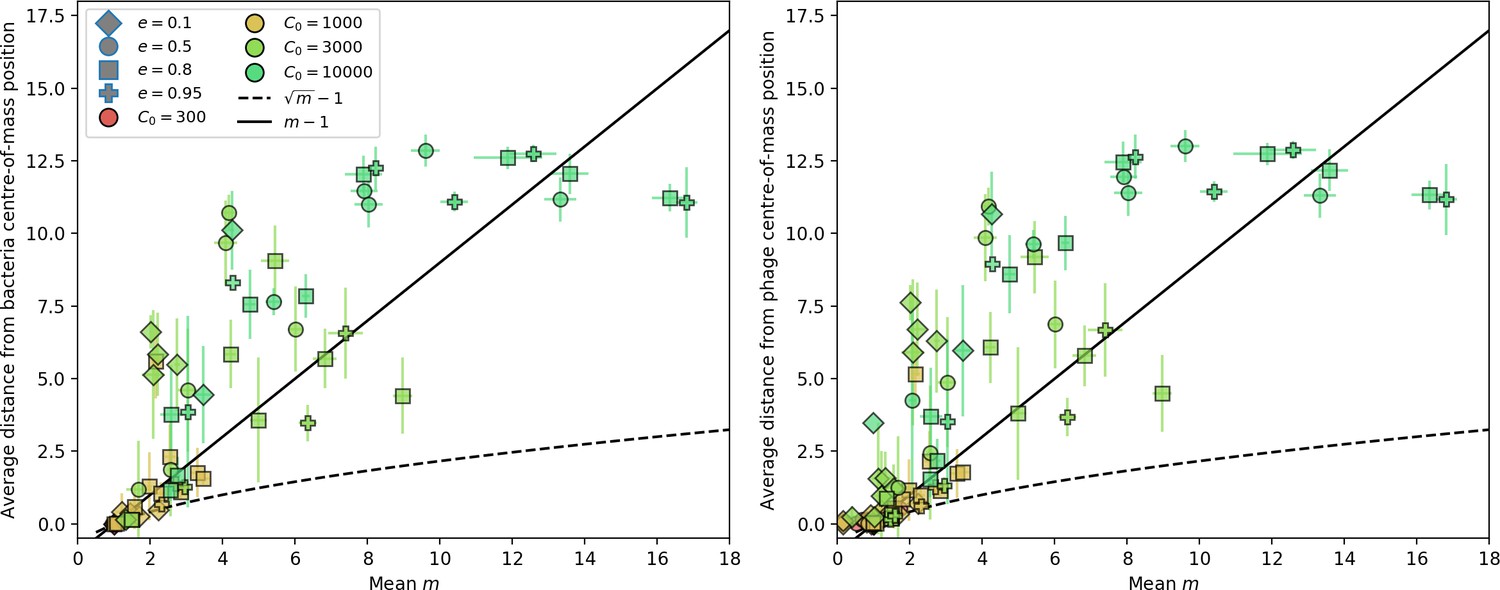
Average population distance from the centre of mass for bacteria (left) and phages (right) vs. mean for simulations with 50 original phage clones.
The dashed line is and the solid line is . Error bars are the standard deviation across three or more independent simulations.
Number and size of clone clans
Watching a simulation visualization of spacer and protospacer types, it is apparent that over time several different lineages may appear and become separated from each other in genome space (Figure 42). What determines how many separate 'clans' there are at steady state? What is the characteristic size of a clan? How does this depend on parameters? To address this question, we perform agglomerative clustering on protospacer and spacer sequences to identify separated groups of sequences. We use the L1 norm to define distance, which as described above is the most natural distance metric for sequence changes by mutation. Clusters are grouped using the ‘single’ linkage criterion in scikit-learn AgglomerativeClustering: the cluster distance is the minimum of the distances between all observations of the two sets. In other words, a collection of sequences that differ from any other sequence in the cluster by one mutation are all grouped together, even if some of the sequences differ by more than one from each other. This is a reasonable criterion for identifying groups of sequences that are related by descent and are actively feeding each other with mutations.
Figure 42

A frame from a simulation movie at 5000 generations with , , , , initial .
Phages are on the left, bacteria with spacers on the right.
Figures 43 and 44 show the resulting dendrogram from this clustering process for phages and bacteria at one time point for one initial phage clone and 10 initial phage clones. To determine the number of clusters, we use a distance threshold of 2. This separates groups that have no members closer than two mutations away. In reality, these groups may still be linked by descent more recently than other groups (apparent in the dendrograms), but a distance of 2 or more means these groups are likely to remain separate going forward in time since they lack a connecting clone that can be accessed by a single mutation.
Figure 43
Dendrogram resulting from agglomerative clustering with the L1 norm and linking clusters using the minimum distance between members.
The number of clusters is determined with a cutoff at a distance of 2. , , , , initial .
Figure 44
Dendrogram resulting from agglomerative clustering with the L1 norm and linking clusters using the minimum distance between members.
The number of clusters is determined with a cutoff at a distance of 2. , , , , initial .
Simulations with an initial number of clones greater than 1 converge to a steady-state number of clusters at a different rate than beginning with one clone since clones from a single ancestor remain more related on average than clones from multiple different ancestors (Figures 45 and 46).
Figure 45
Clan number and size over time in a simulation with , , , , initial .
Figure 46
Clan number and size over time in a simulation with , , , , initial .
We calculate the average number of clans at steady state and the average clan size for bacteria and phages across all simulations. The number of clans is proportional to ; at high mutation rates the number of clans is approximately . Low mutation rates mean that it takes a long time for the number of clans to equilibrate, which can be seen by contrasting the mutation rate dependence of 10 initial clones (Figure 47) with 1 initial clone (Figure 48).
Figure 47
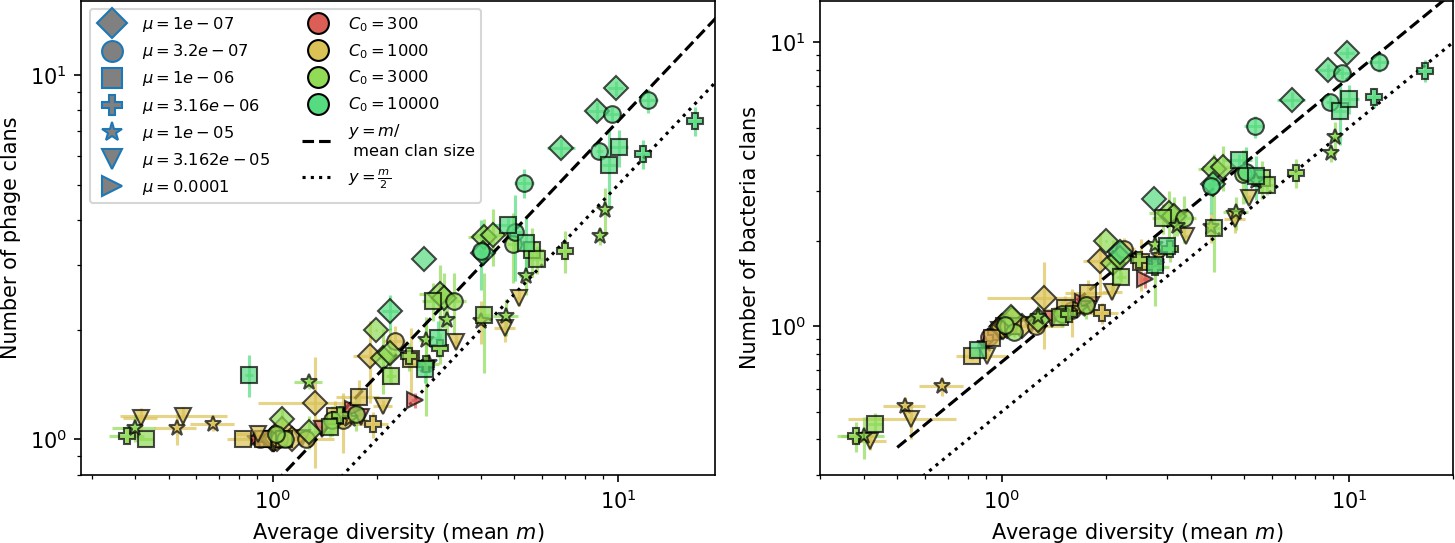
Average clan number vs. for all simulations that begin with 10 clones.
The dashed lines are divided by the mean bacterial clan size () and . Error bars are the standard deviation across three or more independent simulations.
Figure 48
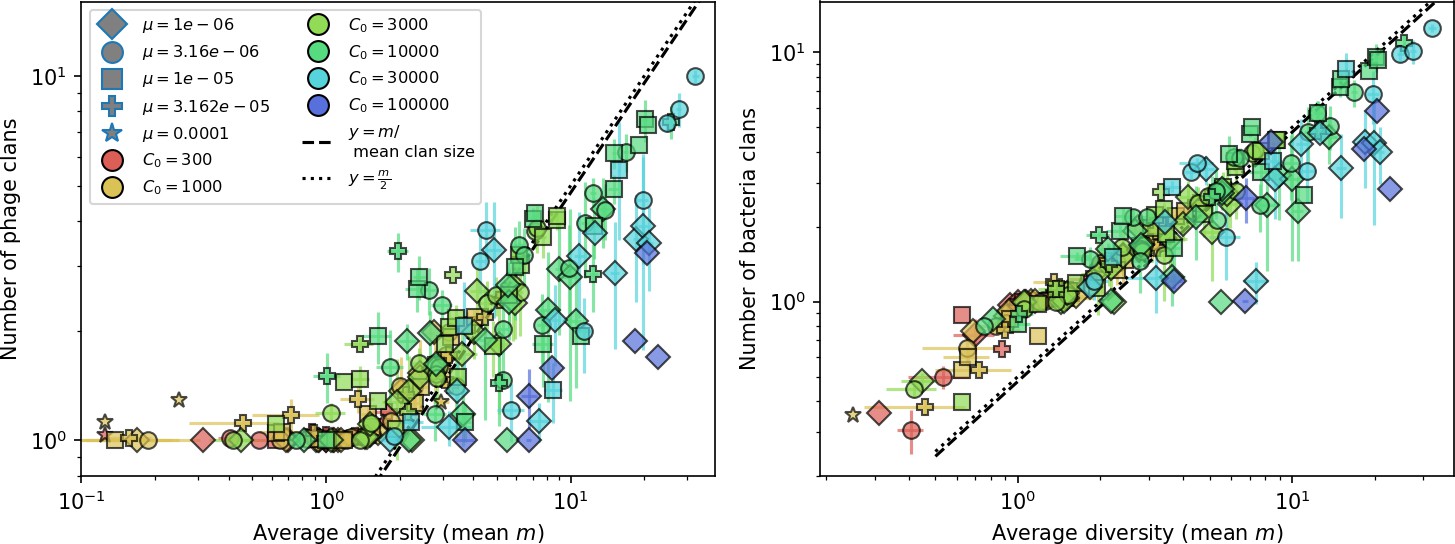
Average clan number vs. for all simulations that begin with one clone with .
The dashed lines are divided by the mean bacterial clan size and . Error bars are the standard deviation across three or more independent simulations.
The regimes of low and high clan number in our model are similar to regimes of virus-host coevolution identified in Marchi et al., 2019: at low virus mutation rates and low mutational jump distances, trajectories move in a straight line in antigenic space, while at higher jump distances, trajectories become more diffusive, the way ours look. At even higher mutation rates and jump sizes, trajectories split into multiple stable coexisting lineages, which is what we see at high diversity.
Based on their parameters and regimes, we expect that increasing cross-reactivity relative to mutation rate in our model should bring our results closer to the ballistic regime.
Cross-reactivity
In this section, we present additional methods and results for simulations with two types of cross-reactivity relating to results in 'Cross-reactivity leads to dynamically unique evolutionary states'.
In our standard simulations and theory, we assume that is binary (Equation 6): any mismatch between protospacers and spacers means bacteria no longer have any immune advantage against phage. Here, we discuss results of simulations where includes some cross-reactivity so that the more mutations a protospacer contains, the less immunity bacteria have against it.
We explore two types of cross-reactivity: one in which we define as an exponential function of the mutational distance between a spacer and protospacer (Equation 7), and one in which is a -function of mutational distance (Equation 8). The exponential definition of cross-reactivity is the same as that used in Marchi et al., 2019; Yan et al., 2019 to model viruses evolving in abstract antigen space (Marchi et al., 2019) and in genomic distance space (Yan et al., 2019). Note that our usual binary definition of is a special case of Equations 7 and 8 with . Figure 49 shows these different definitions of as a function of .
Figure 49
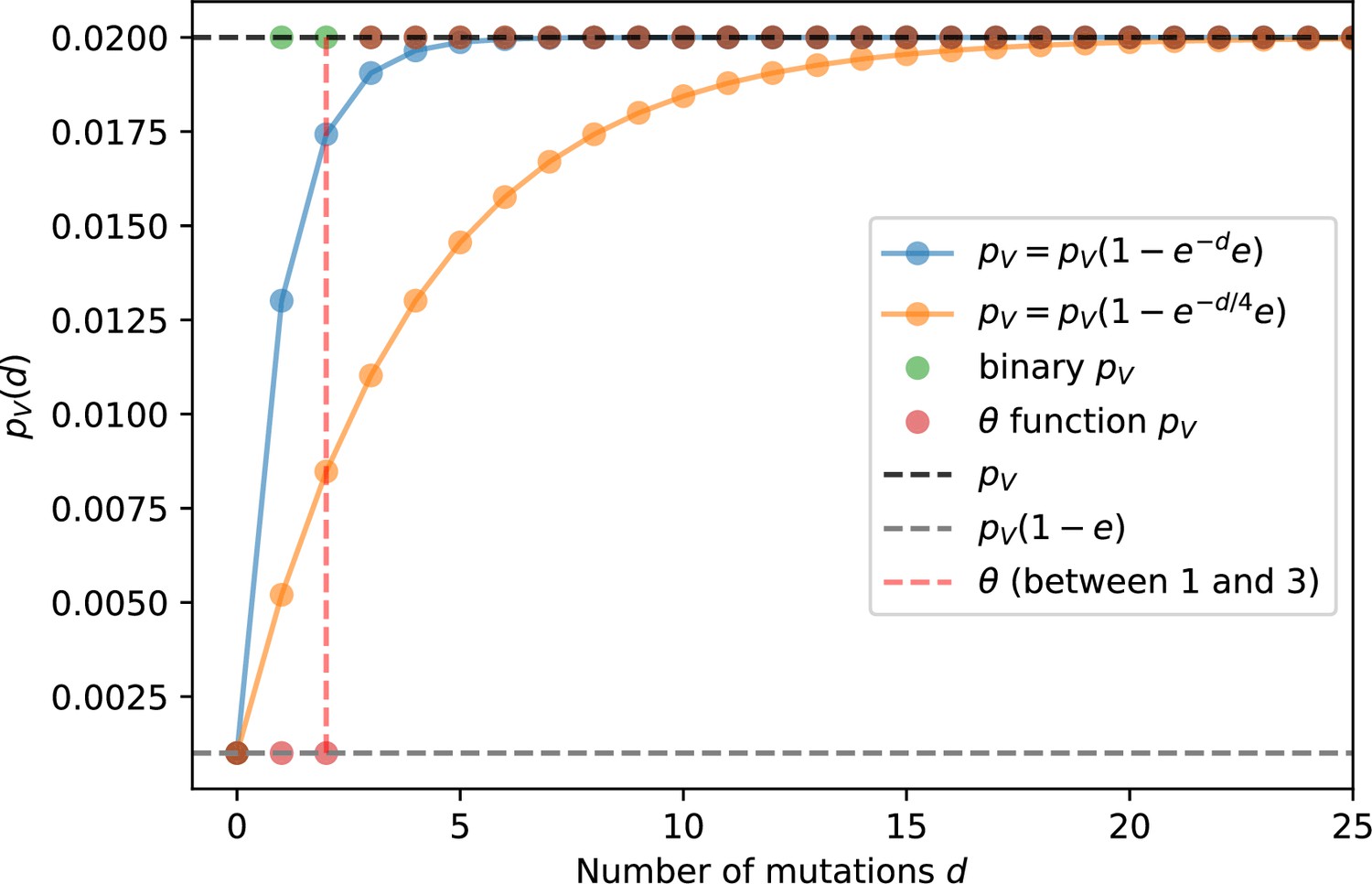
Phage infection success probability as a function of mutational distance between spacers and protospacers for different definitions and degrees of cross-reactivity.
Definitions are plotted for , .
Cross-reactivity leads to a higher average bacterial immunity against phages for the same parameters (Figures 50 and 51). This means that our assumption that effective , valid for nearly all parameters without cross-reactivity, breaks down when we introduce cross-reactivity. Importantly, this is a quasi-steady-state effect: if we start simulations with more initial clones, clone clans are genetically separated and both mean and average immunity converge to the binary case (Figure 50 right panel).
Figure 50
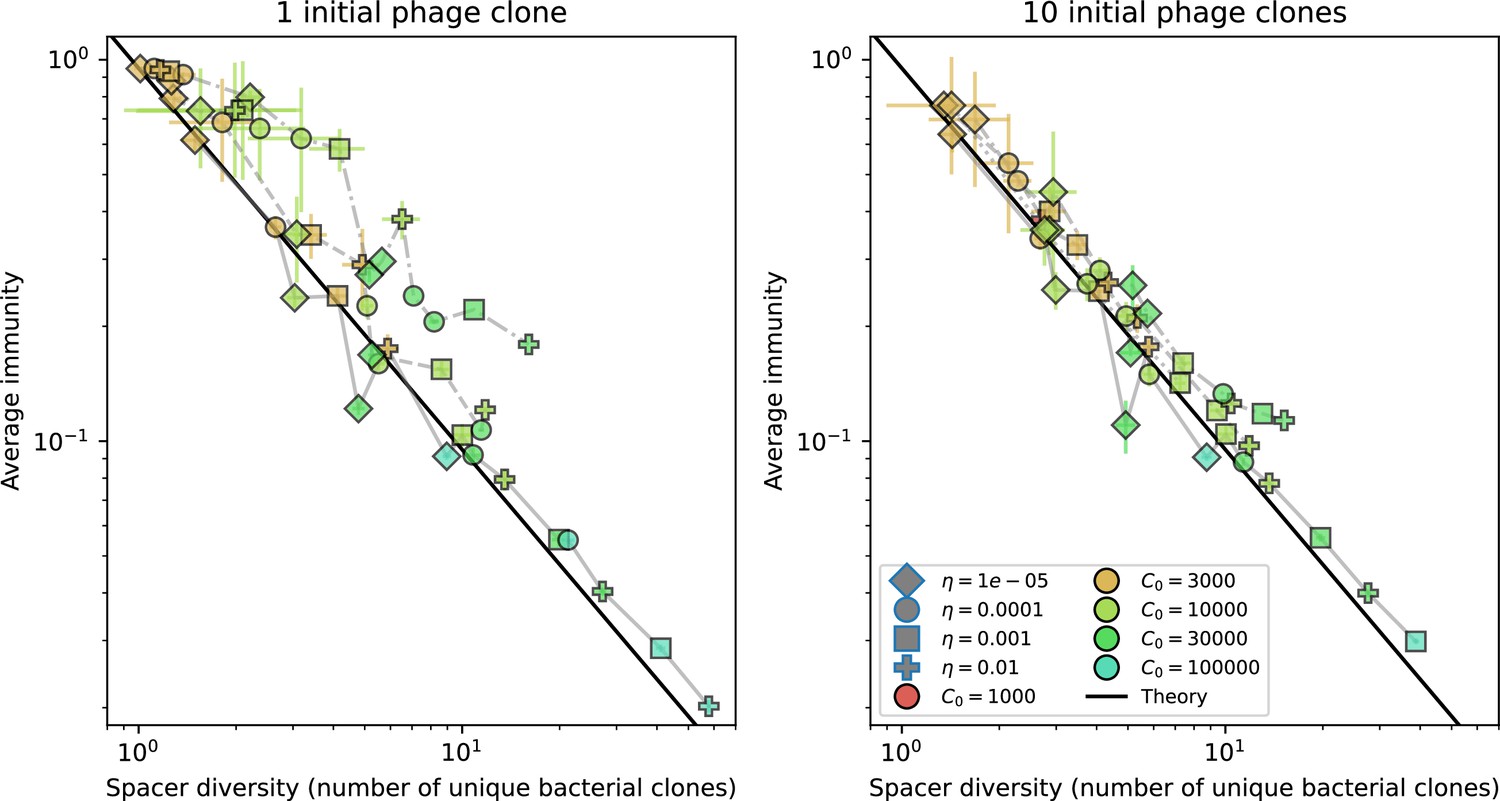
Average immunity vs. diversity with different degrees of cross-reactivity for simulations with , .
Dashed lines are simulations with cross-reactivity, solid line is simulations without cross-reactivity. Error bars are the standard deviation across three or more independent simulations.
Figure 51

Mean phage clone size (top) and mean bacteria clone size (bottom) relative to time of phage mutation for different definitions of .
These simulations begin with one initial phage clone and parameters , , , .
Phages are less likely to establish when there is cross-reactivity because phage escape mutations are incomplete (Figure 5A). However, the clones that do survive grow quicker: simulations with high cross-reactivity appear to have a faster mean growth rate for clones, regardless of conditioning on survival (Figure 51).
Adding cross-reactivity causes some unexpected dynamical behaviours (Figure 52, Figure 53). We observed a travelling wave regime in some simulations with large spikes in phage clone size (Figures 54 and 55). This happens because cross-reactivity creates a fitness gradient for new phage mutants such that some mutants are much more fit and establish much more quickly.
Figure 52
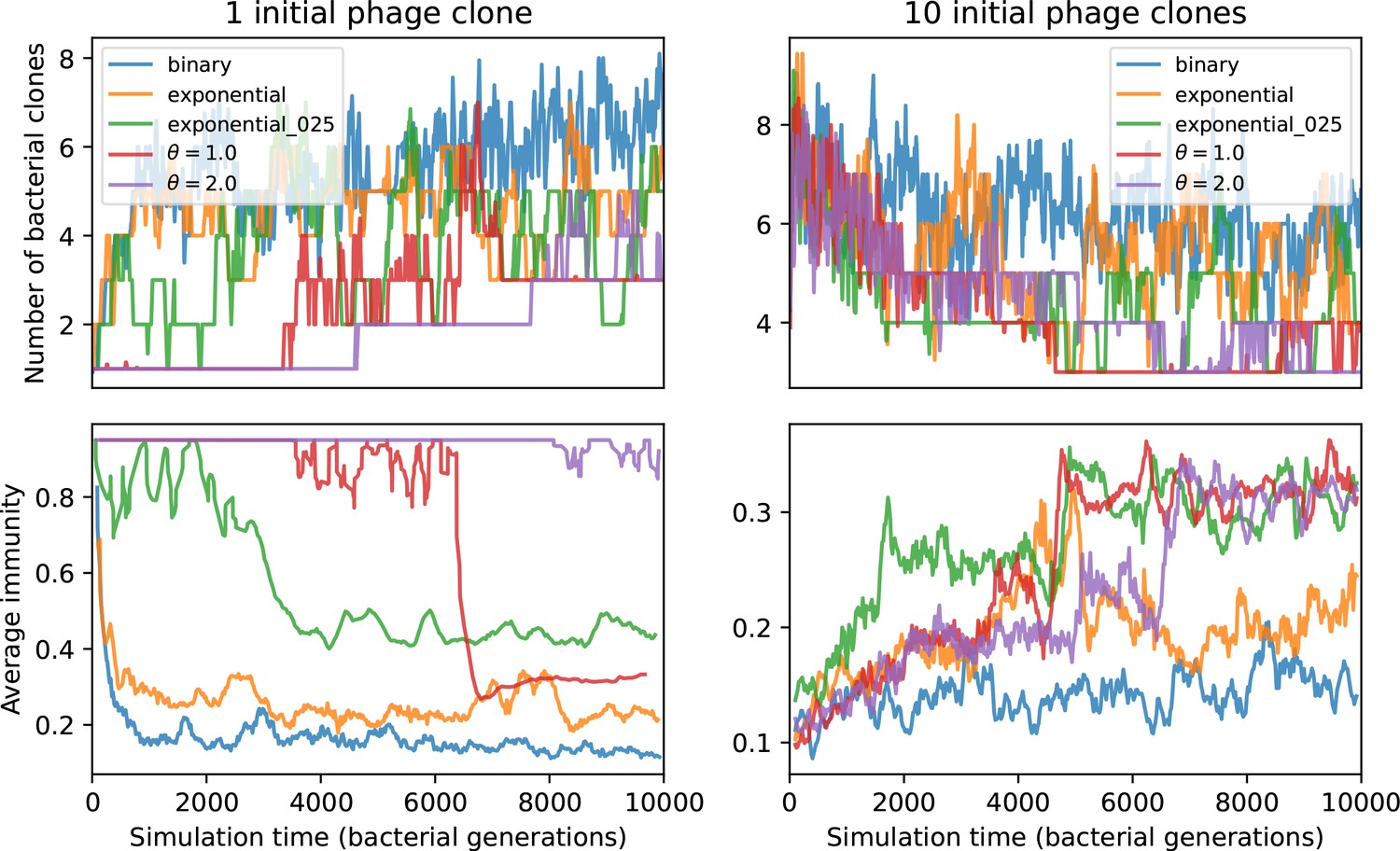
Number of bacterial clones (top) and average immunity (bottom) for simulations beginning with either 1 phage clone (left) or 10 phage clones (right).
These simulations have parameters , , , .
Figure 53
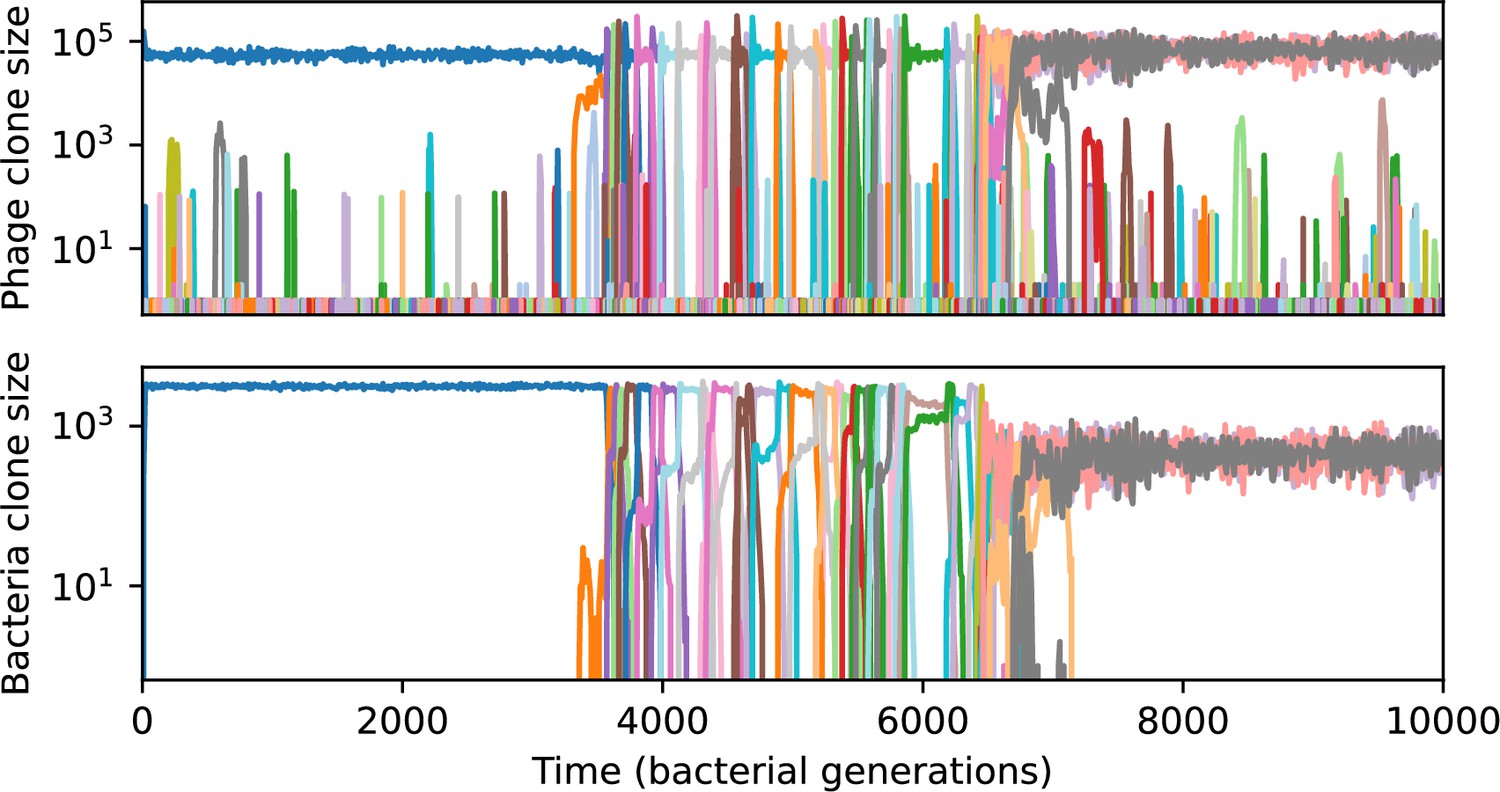
Phage clone size (top) and bacteria clone size (bottom) in a simulation with cross-reactivity (step function CRISPR effectiveness with ).
Figure 54
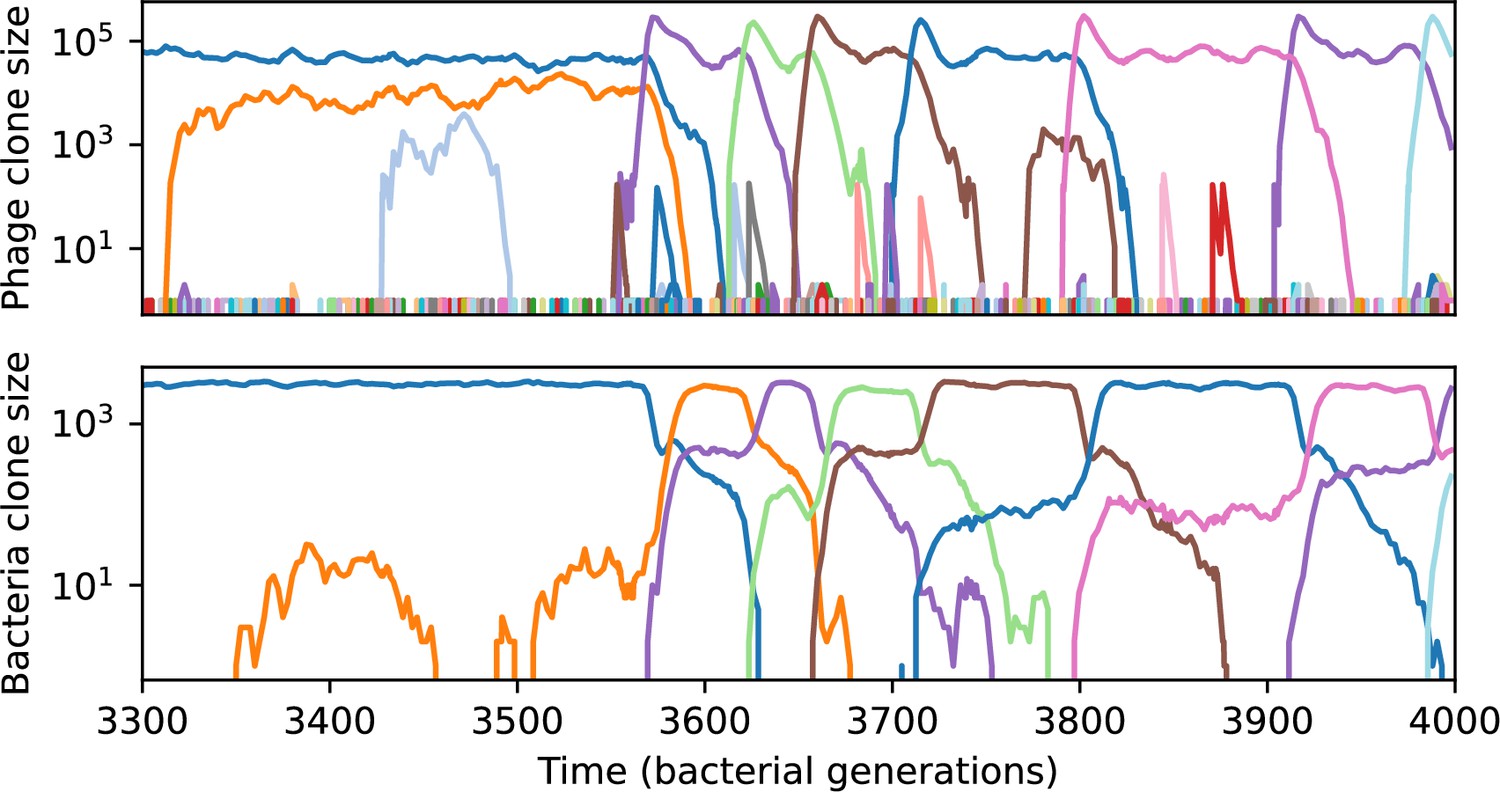
Phage clone size (top) and bacteria clone size (bottom) in a simulation with cross-reactivity (step function CRISPR effectiveness with ).
This simulation has one initial phage clone and parameters , , , and . Later times in this simulation are shown in Figure 55.
Figure 55
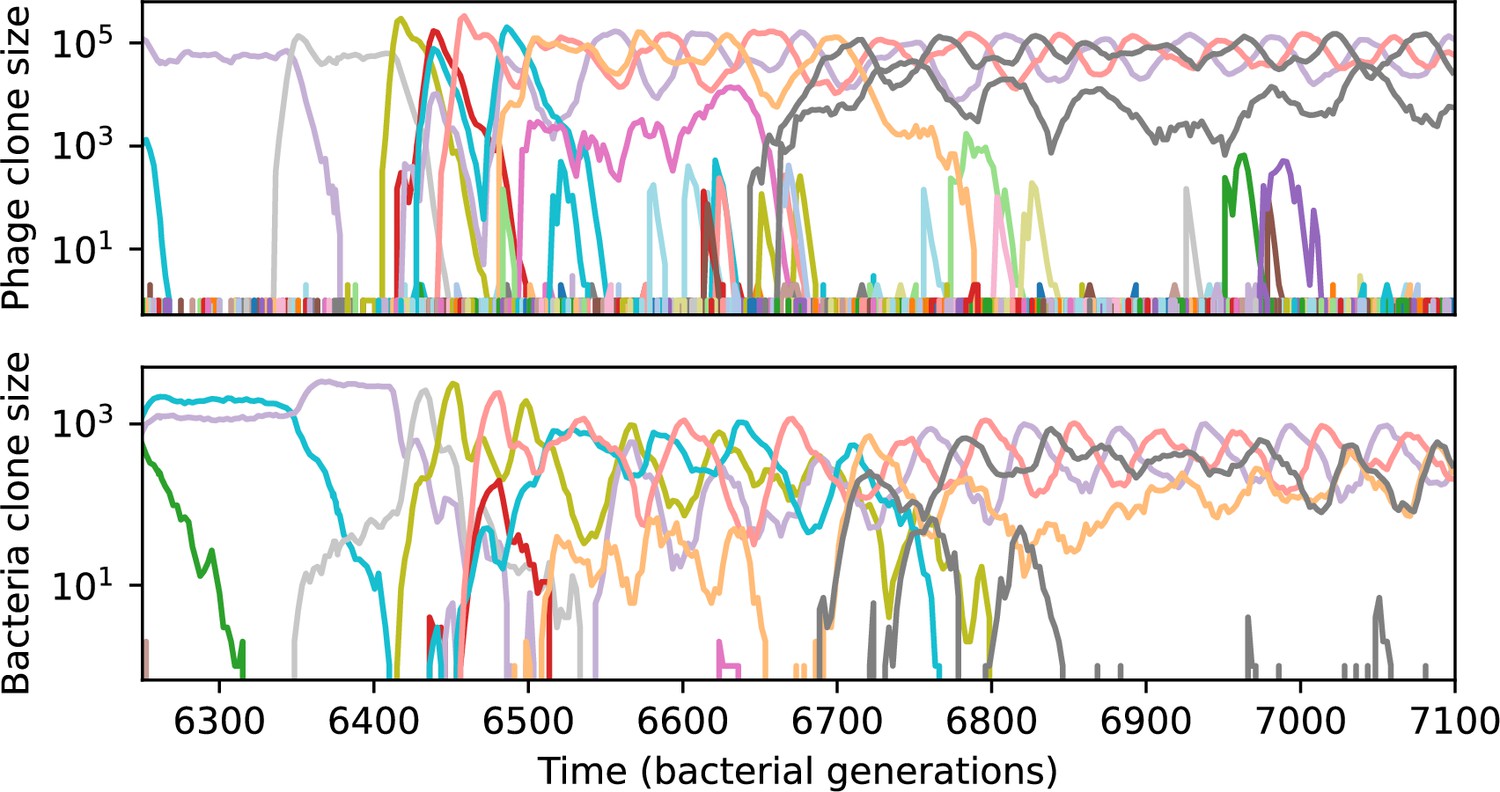
Phage clone size (top) and bacteria clone size (bottom) in a simulation with cross-reactivity (step function CRISPR effectiveness with ) showing the switch between a travelling wave and low turnover regime.
This simulation has one initial phage clone and parameters , , , and . Earlier times in this simulation are shown in Figure 54.
To see this happening, let us look closely at the simulation in Figure 54 at time 3565 (Figure 56). There are three large phage clones and two large bacteria clones (soon to be three). Phage clone 0 is the largest and phage clone 2 is the smallest. Phage clone 0 and phage clone 1 are both either 0 or 1 mutation away from bacteria clones 0 and 1 (Figure 57). Because , they are all equally fit; effectively they could be considered one large clone. Phage 2, however, is 1 mutation from bacteria clone 1 but 2 mutations from bacteria clone 0, so it now has a much higher fitness than the other two phage clones and grows quickly. But now bacteria clone 1 is also fit against this new mutant, so it too continues growing. This push-pull keeps going with new phage mutants experiencing runaway fitness for a while. This also leads to an asymmetry in clone identity between the populations: because a bacterial clone may be immune to a phage clone with a different but related sequence, we see bacteria clones becoming large after their matching phage clone has gone extinct because they are still resistant to an existing phage clone that is genetically related (Figures 58 and 59).
Figure 56
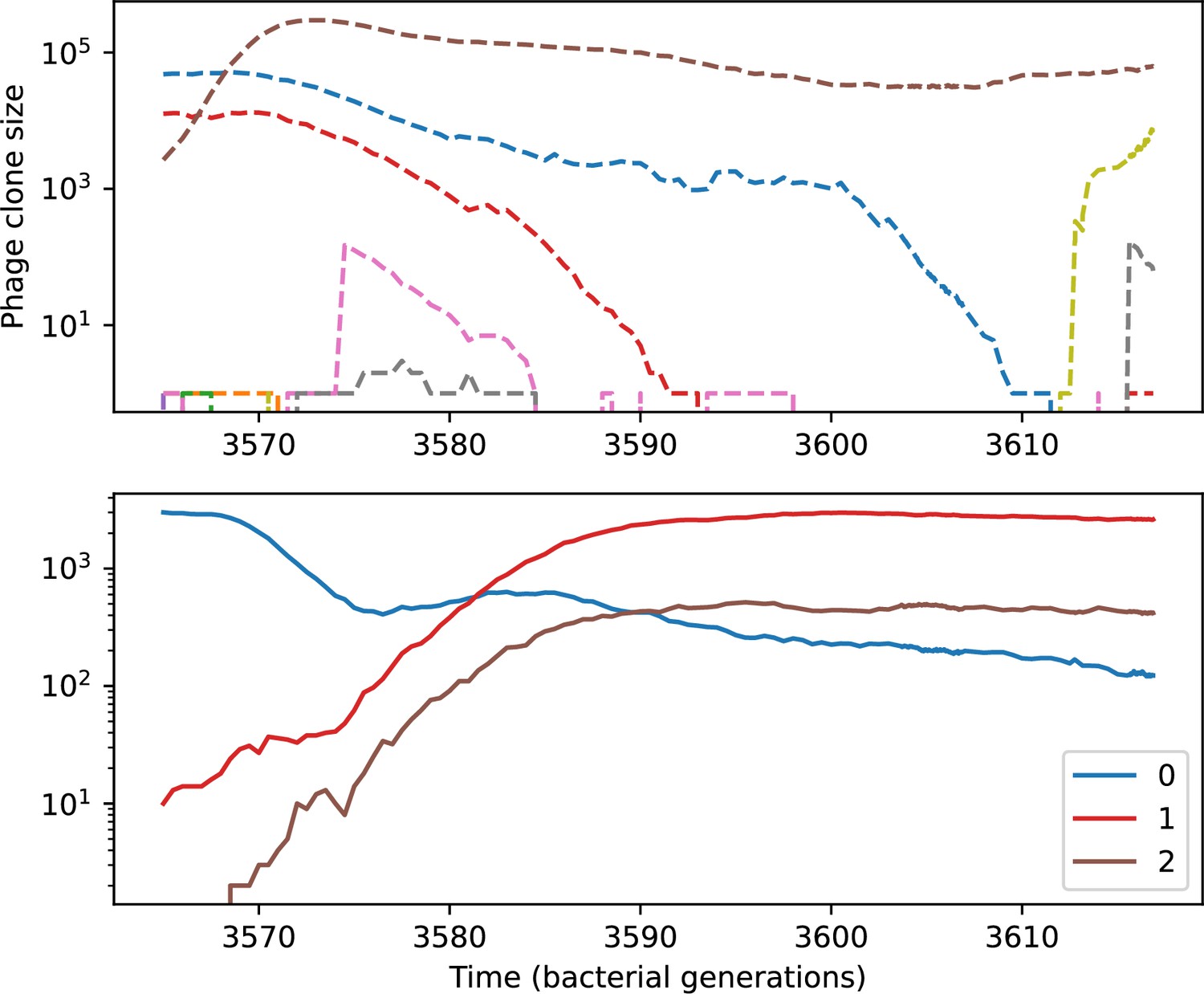
Phage clone size (top) and bacteria clone size (bottom) for a short time window of the simulation shown in Figure 54.
Large phage and bacteria clones are numbered in the legend; these numbers correspond to the numbers in Figure 57.
Figure 57
Phage infection success probability matrix for each clone shown in Figure 56.
Dark blue is low infection success, light blue is high infection success.
Figure 58

Mean phage clone size (top) and mean bacteria clone size (bottom) relative to the time of phage clone mutation, either normalized to surviving clones (left) or averaged over all trajectories (right) for the simulation shown in Figure 54 (, , ).
Clones in the travelling wave regime (4000–6200 generations, orange) grow much more quickly than clones in the initial low-turnover regime (1000–3200 generations, blue) or the final low turnover regime (7000–10,000 generations, green). The black dashed line is the mean clone size for a simulation with the same parameters but without cross-reactivity.
Figure 59
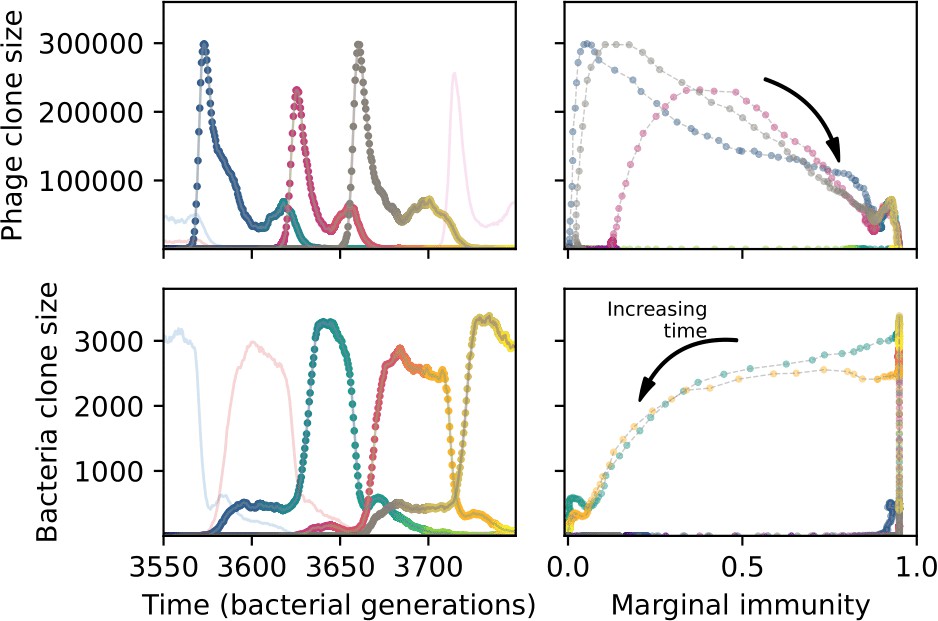
A slow-switching cross-reactivity regime for the simulation shown in Figure 54.
(Left) A subset of clone trajectories for phages (top) and bacteria (bottom) in a simulation with cross-reactivity (step function CRISPR effectiveness with ). Three trajectories are highlighted and coloured to show increasing time. The population is in a regime where matching clones are offset: because clones that are one mutation apart have the same complete immune overlap, the highlighted clones have large bacterial clone size well after the matching phage clone goes extinct. (Right) The clone size of the highlighted trajectories shown as a function of the bacterial marginal immunity against a particular phage clone (top) or the marginal immunity of a particular bacteria clone (bottom).
This fitness and growth pattern can be seen as a function of the marginal immunity of bacterial clones to the phage population and of the bacterial population to individual phage clones (Figure 59). Average immunity for individual clones, which we call marginal immunity in analogy with Nourmohammad et al., 2016, captures the fitness differences between individual clones that determine their dynamical behaviour. Without cross-reactivity, bacteria clones are only immune to at most one phage clone at a time, though their overall marginal immunity still changes smoothly as the matching phage clone changes size (Figure 60B). When cross-reactivity is added, bacteria may be immune or partially immune to multiple phage clones, and calculating marginal immunity summarizes all of these combined effects on the fitness of a particular clone. Bacteria clones grow larger once their marginal immunity is high, and phage clones grow large once bacterial marginal immunity against them is low. These opposing forces generate Lotka-Volterra oscillations even in the case with no cross-reactivity, though these oscillations are more rapid and persistent when cross-reactivity is added (Figure 60C and D). Phage clones grow quickly when bacteria have low marginal immunity to their sequence, while bacteria clones grow quickly when they have high marginal immunity.
Figure 60

Cross-reactivity leads to persistent oscillations.
(A) A subset of clone trajectories for phages (top) and bacteria (bottom) in a simulation with no cross-reactivity. Transient oscillations occur. One trajectory is highlighted and coloured to show increasing time. (B) The highlighted trajectory in (A) is shown as a function of the marginal immunity for phages (top) and bacteria (bottom). Clones experience an oscillating fitness that depends on their overlap from the other population. Arrows indicate the direction of increasing time in the oscillation. (C) A subset of clone trajectories for phages (top) and bacteria (bottom) in a simulation with cross-reactivity (step function CRISPR effectiveness with ). The population is in a regime where several clones experience persistent and rapid oscillations. One trajectory is highlighted and coloured to show increasing time. (D) The highlighted trajectory in (C) is shown as a function of the marginal immunity for phages (top) and bacteria (bottom). Clones experience an oscillating fitness that depends on their overlap from the other population. Arrows indicate the direction of increasing time in the oscillation. For all simulations , and .
Clones grow more quickly on average in the travelling wave regime than in other regimes in the same simulation (Figure 58).
In Figure 4, we show phylogenies of four simulations with different amounts and types of cross-reactivity. We used DendroPy Sukumaran and Holder, 2010 and Toytree Eaton and Matschiner, 2020 to construct and plot phylogenies for different simulations. Figure 61 shows simulations for the same parameters as in the main text but a tenfold higher phage mutation rate: most simulations have multiple coexisting lineages, and the travelling wave regime is less long-lived before periods of low turnover. In the low-turnover regime, a relatively small number of large clones that are all outside of each other’s cross-reactivity radius can coexist for a very long time, oscillating out of phase from each other (Figures 62 and 63).
Figure 61
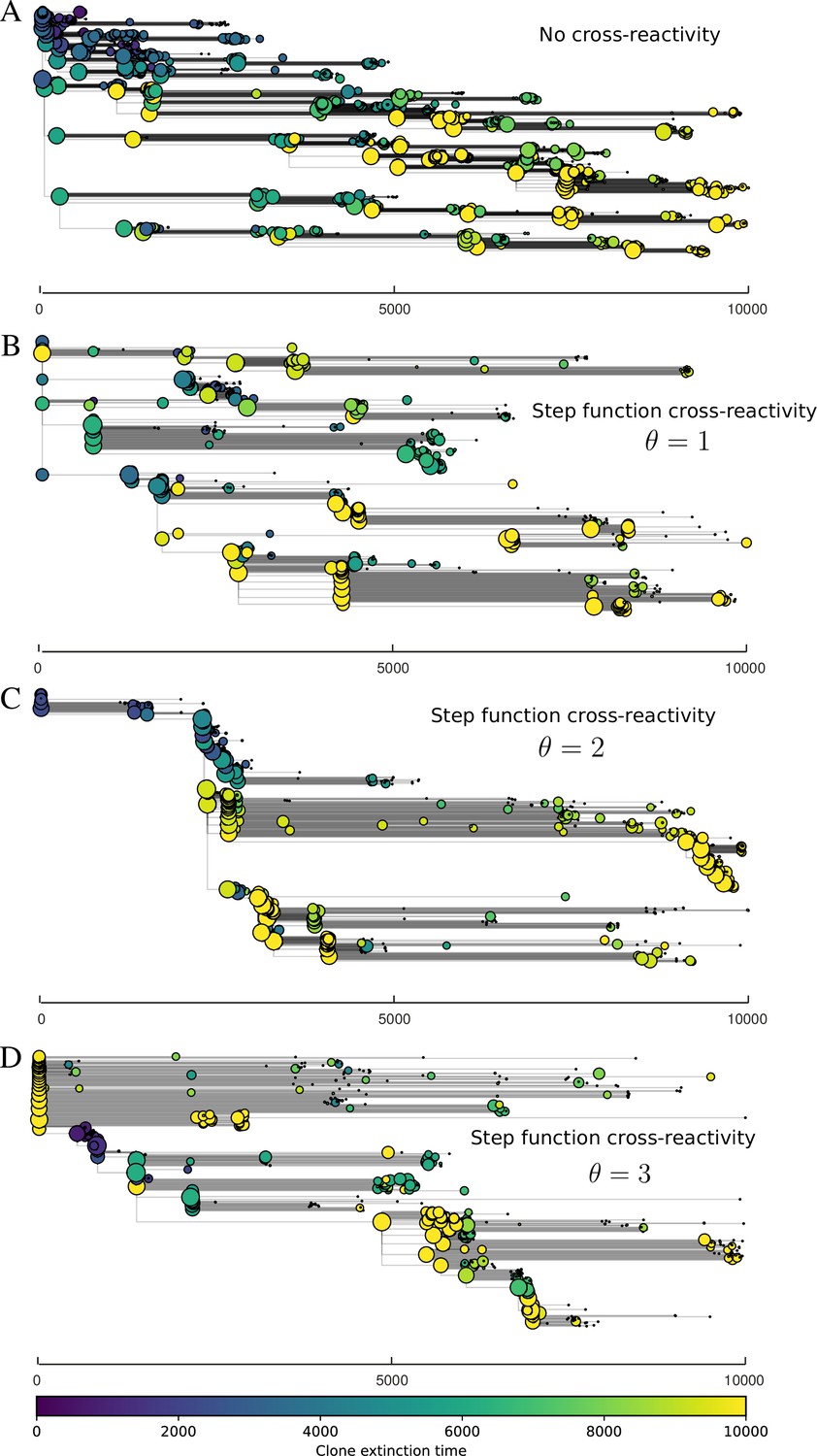
Phage clone phylogenies for four simulations with different cross-reactivities and a higher mutation rate than shown in main text Figure 4: no cross-reactivity (A) and step-function cross-reactivity with (B, ) (C), and (D).
All simulations share all other parameters: . Phage clones are plotted at the first time they pass a population size of 2 (to remove clutter from many new mutations destined for extinction), and the size of each circle is logarithmically proportional to the maximum size reached by that clone. Colours indicate the time of extinction of each clone. For each simulation with cross-reactivity, the left inset shows phage (top) and bacteria (bottom) clone sizes over time; colours indicate unique clone identities.
Figure 62
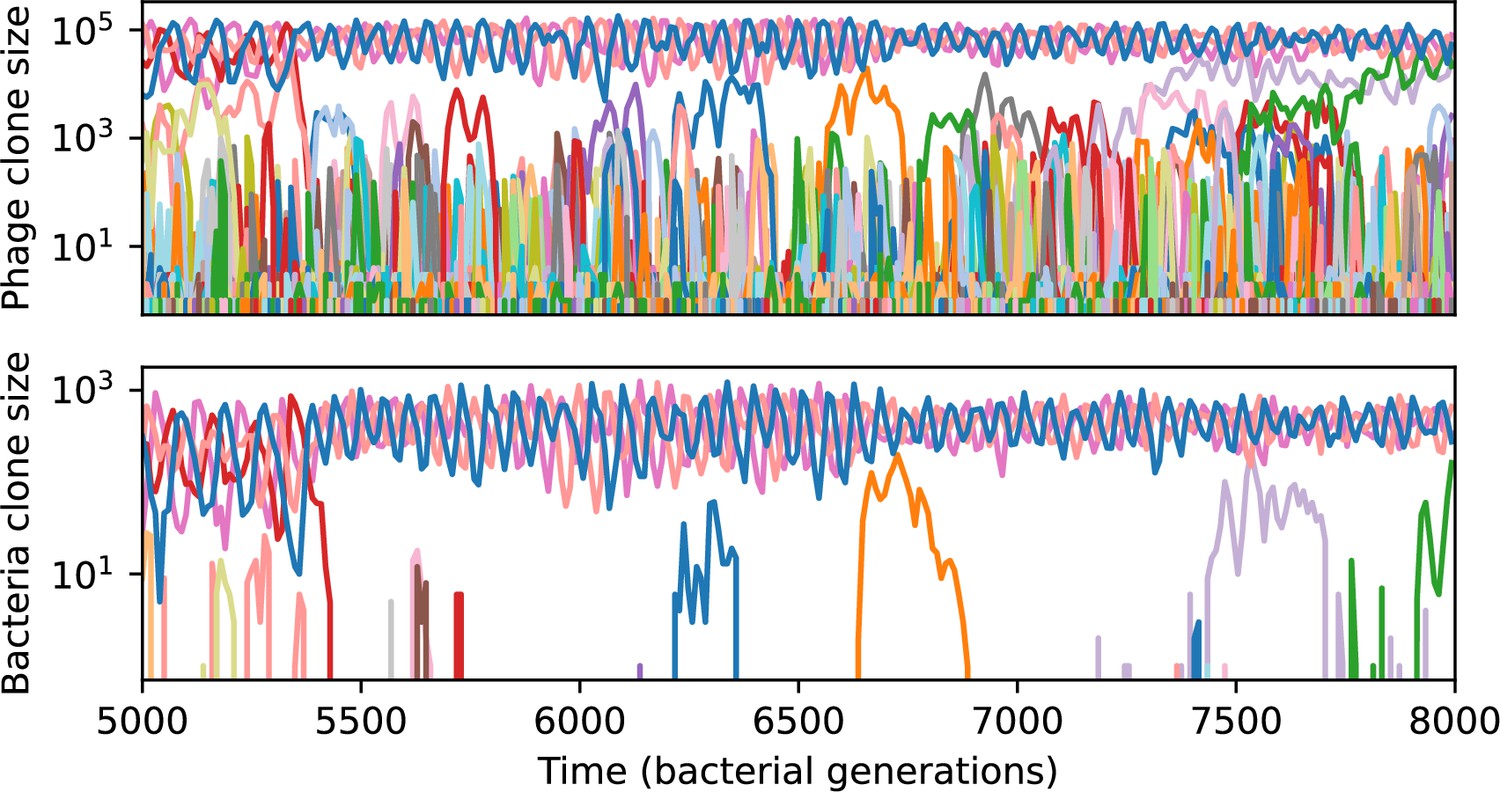
Phage clone size (top) and bacteria clone size (bottom) for a short time window of the simulation shown in Figure 61C.
Each of the large trajectories oscillating out of phase between 5000 and 7000 generations is at least three mutations away from all of the others; they are all outside each other’s cross-reactivity radius.
Figure 63

Matrix of mutational distance between each of the four largest phage clones shown in Figure 62; colours of those trajectories are labelled on the y axis.
Each clone is at least three mutations away from all other large clones.
The durability and turnover of immune memory is qualitatively different in the different regimes of the simulation with cross-reactivity shown in Figure 54. We calculated time-shifted average immunity for each of the three regimes (initial regime with no turnover, travelling wave regime, and persistent oscillation regime) and found that turnover was extremely low in all but the travelling wave regime, which had a rapid decay of immune memory to zero (Figure 64). In contrast, the immune memory for the same parameters without cross-reactivity had a much more gradual long-term decay towards zero immunity (Figure 65). In the travelling wave regime, different amounts of cross-reactivity result in different time-shifted immunity patterns. Turnover is slow but smooth with exponential cross-reactivity, while turnover is much more rapid with step-function cross-reactivity (Figure 66). The differences in rate of turnover can also be seen by comparing timescale of sequence change in Figure 4.
Figure 64
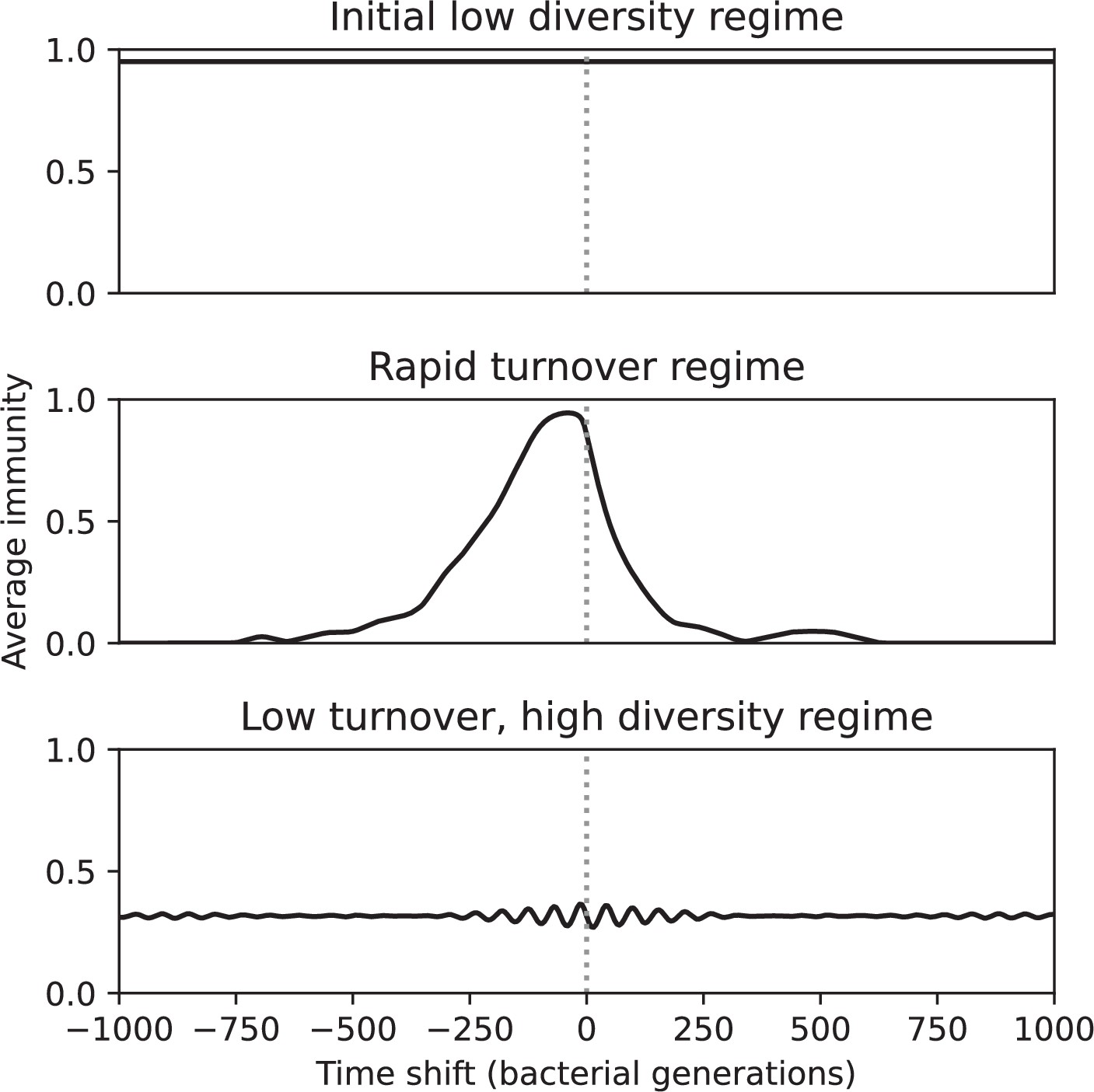
Time-shifted average immunity for three regimes of the simulation shown in Figure 54 (, , , and , step-function cross-reactivity with ).
The initial low-diversity regime (1000–3200 generations) and the low turnover, high diversity regime (7000–10,000 generations) had extremely low turnover, while the travelling wave regime (4000–6200 generations) had high average immunity near 0 delay that rapidly decayed to zero both in the past and future.
Figure 65
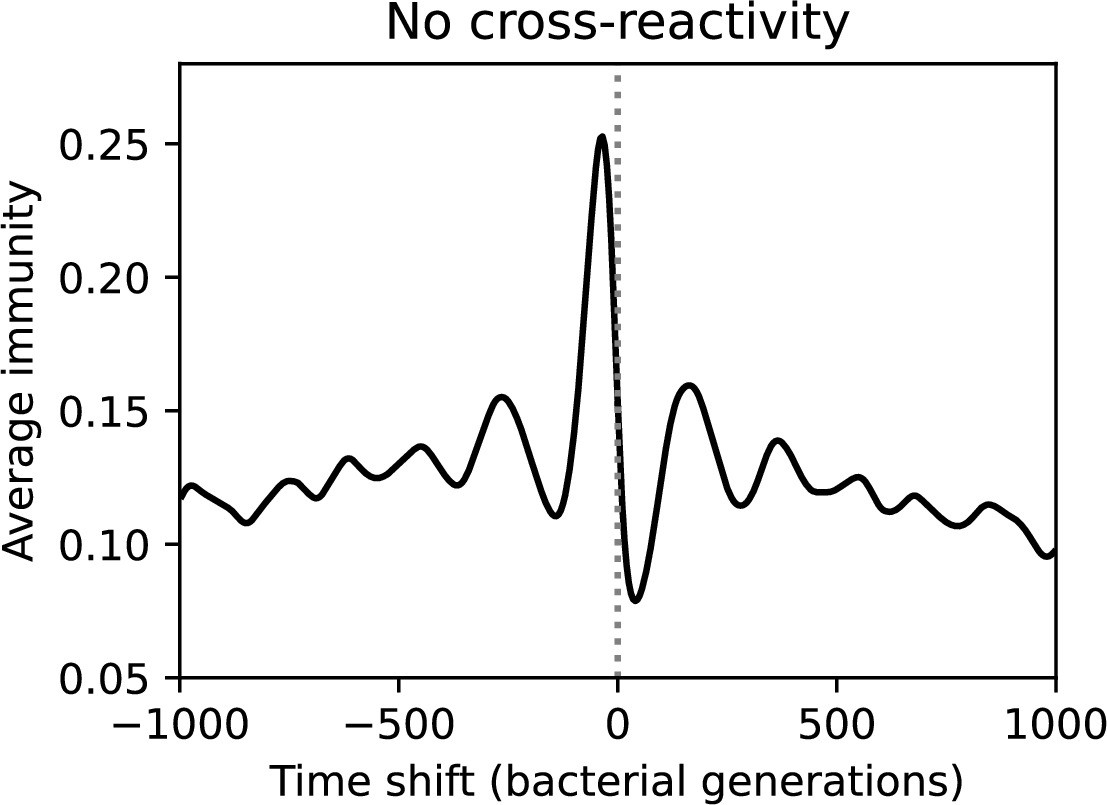
Time-shifted average immunity for the corresponding simulation to Figure 64 without cross-reactivity (, , , and ). Peak average immunity is low because of high diversity, and immunity decays very gradually to zero in both the past and future.
Figure 66
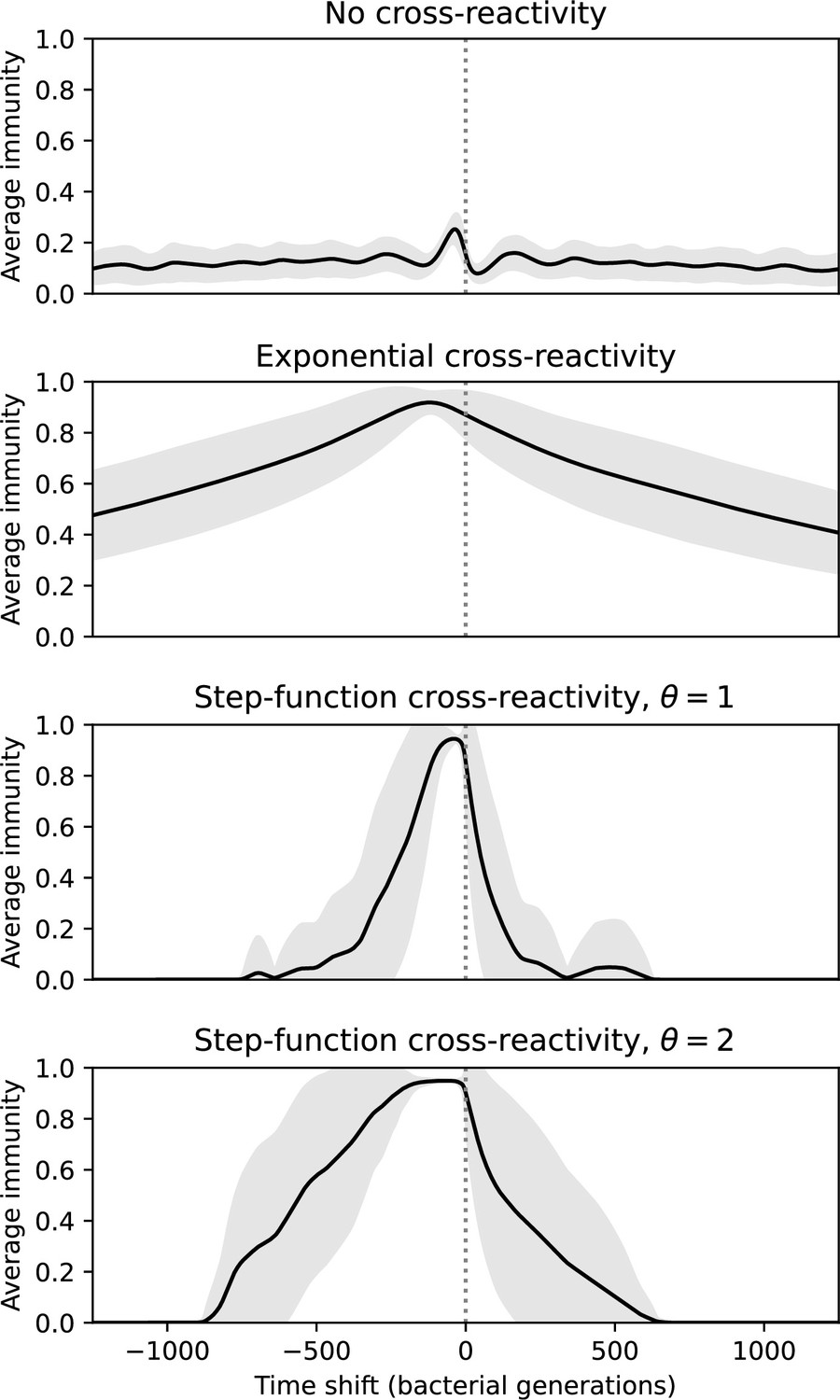
Time-shifted average immunity for four simulations with the same parameters but different types of cross-reactivity: no cross-reactivity (top), exponential cross-reactivity (middle top), step-function cross-reactivity with (middle bottom), and (bottom).
Shared parameters are , , , and . Only the travelling-wave regime of each simulation with cross-reactivity was used to compare turnover in this regime. The grey shaded region is the standard deviation across averaged data.
Adding cross-reactivity appears to slightly decrease average clan sizes (Figure 67). This is what we intuitively expect since cross-reactivity means phages are under pressure to get as far away from other clones as possible.
Figure 67
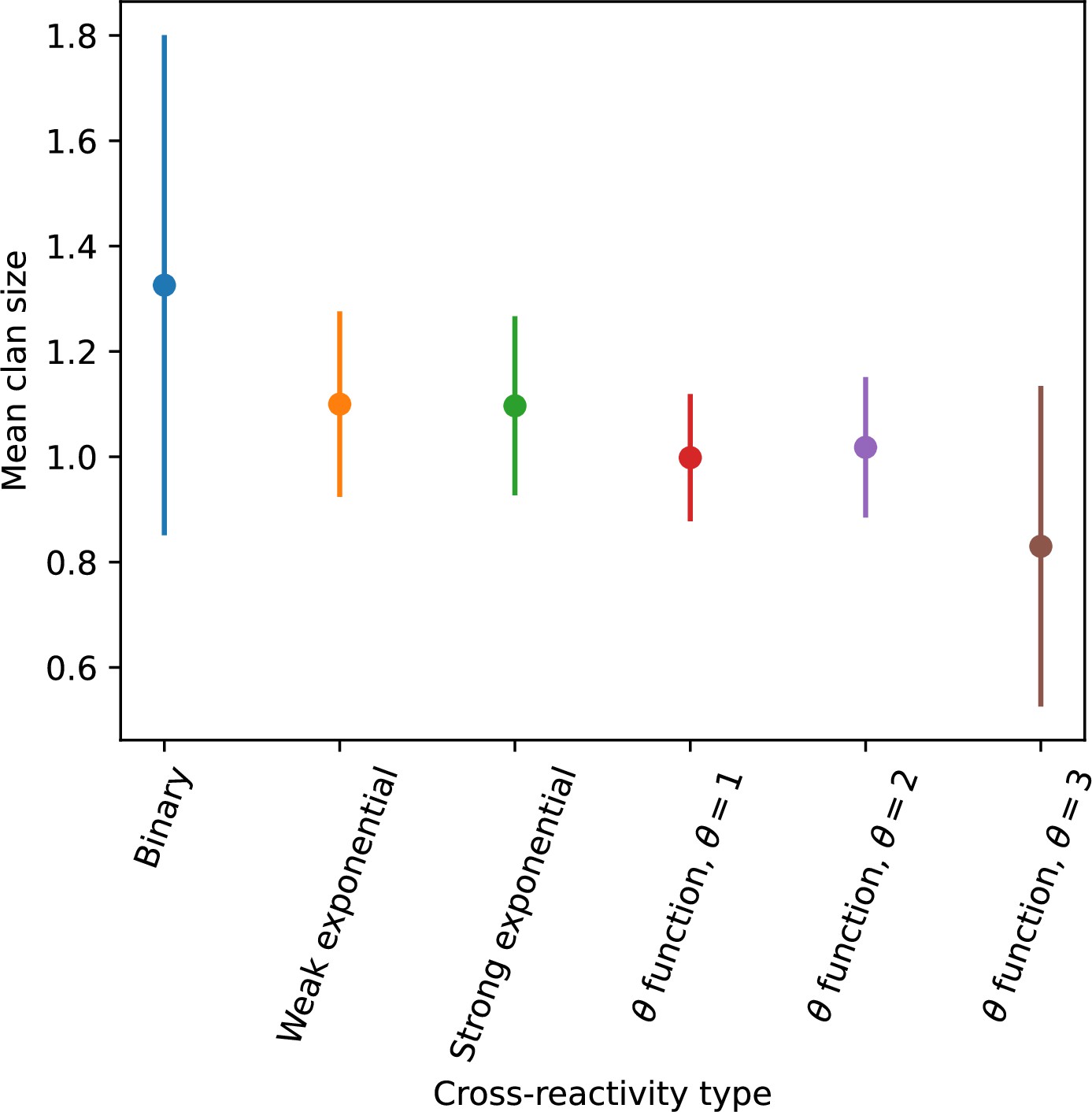
Average clan size across simulations with different parameters for different degrees of cross-reactivity with .
Error bars are the standard deviation across three or more independent simulations.
Data analysis
This section contains details of our methods for analysing sequencing data from three published papers – groundwater metagenome data used in calculating spacer turnover (Metagenomic CRISPR spacer analysis from Burstein et al., 2016), a laboratory long-term coevolution experiment used for spacer turnover and time-shifted average immunity (‘Laboratory coevolution experimental data’), and wastewater treatment plant metagenome data used for spacer turnover and time-shifted average immunity (‘Experimental data from wastewater treatment plant’). Methods and toy models relating to calculating average immunity in data are in ‘Theoretical considerations when calculating average immunity from data’.
Metagenomic CRISPR spacer analysis from Burstein et al., 2016
This dataset is the source for Figure 6F in ‘Dynamics are determined by diversity’.
We detected spacer sequences in metagenomic data from Burstein et al., 2016. We analysed the 0.1 filter dataset which contains metagenomic reads at six time points, found under accession PRJNA268031. We searched for matches to the CRISPR repeats identified in the study using blast; we accessed a list of repeats from the study’s Supplementary data 2. There were 144 unique repeat sequences. Reads are 150 bp long, and we kept only blast results where a repeat had two or more matches to a read in order to accurately detect spacers and to reduce spurious matches to repeats. To further ensure match quality, we kept only alignments that were at least 85% similar to repeat queries, unless another match to the same repeat was present on the read. This 85% threshold was chosen for consistency with previous spacer identification studies (Paez-Espino et al., 2013; Paez-Espino et al., 2015; Skennerton et al., 2013).
It is possible that multiple unique repeats match the same read. For each matched read, we kept the repeat match that had the highest alignment identity (fractional alignment length times percent identity). We detected spacers between repeats, then used the detected spacer length to extract spacers on either side of matched repeats. Because we required at least two repeat matches, at most three spacers could be detected from a read, and at minimum two spacers were detected. We detected a total of 37,963 spacers of which there were 17,491 unique sequences. The most abundant sequence was present 572 times. After grouping within each unique repeat by spacer sequence similarity with an 85% average similarity threshold, there were 12022 unique types with the largest type having an abundance of 616.
Theoretical considerations when calculating average immunity from data
The methods described here are used to scale the y-axis of Figure 7C, D in ‘Time-shifted average immunity calculated from data reveals distinctive patterns of turnover’.
In our simulations and model, we assume that each phage has a single protospacer and each bacterium has a single spacer. In reality, phages can have hundreds to thousands of possible protospacers, and bacteria can also acquire tens to hundreds of spacers (Pavlova et al., 2021). If we assume that average immunity plays out at the organism level; that is, if a bacterium that contains one or more spacers matching one or more phage protospacers is immune to that phage, then calculating average immunity in practice requires knowing something about the typical numbers of protospacers and spacers in organisms.
First, let us consider the effect of changing the number of protospacers while keeping spacer array length constant at 1. This is a reasonable model for experimental data at short timescales when most bacteria acquire only one new spacer. For a set of observed spacers and a set of observed protospacers with abundances ni and nj, if each spacer and protospacer are assumed to belong to one organism only, then the average immunity is given by Equation 90. We assume for simplicity that any matching spacer provides perfect immunity, that is, .
(90)
where denotes .
If instead the same set of protospacers is divided among fewer phages so that each phage has protospacers on average, then the total number of phages is . The numerator of average immunity remains the same since each bacterium still contains only a single spacer. Average immunity is exactly the same as before but multiplied by the average number of protospacers per phage (Equation 91).
(91)
This agrees with the intuition that more spacer targets per phage increases the immune potential of the CRISPR system.
In data from Paez-Espino et al., 2015, we find quantitative agreement between the range of average immunity values in their data and the types of values in our simulations once we apply this simple transformation with , since there are 231 possible CRISPR1 protospacers and 465 possible CRISPR3 protospacers in the phage genome (determined by searching for the canonical PAM for each CRISPR locus).
If bacteria contain multiple spacers and phages contain multiple protospacers, the combinatorics of average immunity gets more interesting. Now, if a bacterium contains multiple spacers that target the same phage, we assume this does not increase its immunity (although in reality there may be a benefit to multiple matching spacers).
We simulated sets of spacers and protospacers, randomly divided them into arrays of different sizes, and calculated the organism-level average immunity in each case. Figure 68 shows the average immunity values for several array lengths with different assumptions for how the set of spacer sequences and array lengths are distributed. We chose a set of spacer ‘sequences’ where each sequence is a letter of the alphabet, then constructed phage protospacer arrays by randomly drawing 5 unique letters 50 times to create 50 phages. We then sampled letters from the alphabet either uniformly or from an exponential distribution (where ‘A’ is the number 1, etc.). The exponential sampling captures the fact that in practice spacer abundance distributions are highly non-uniform. To create bacteria spacer arrays, we sampled from the set of spacers without replacement, either creating arrays of constant size or arrays with the same mean size but with their length either normally or exponentially distributed.
Figure 68

Average immunity vs. bacterial spacer array length for simulated distributions of protospacers and spacers.
We simulate 50 phages, each with 5 protospacers represented by letters from the alphabet, uniformly sampled. We simulate 420 bacterial spacers, drawn from the alphabet either uniformly (top row) or following an exponential distribution with mean 6 (bottom row). We construct arrays by sampling from the set of 420 spacers without replacement, either creating arrays of constant length (left column), or of variable length with a gaussian distribution (middle column) or exponential distribution (right column). Average immunity is calculated as in Equation 90 except the indices run over all arrays and not over individual sequences, and the presence of any matching pair gives perfect immunity. Blue points are average results over 50 simulations; error bars are standard deviation. The black dashed curve is given by .
We developed a simple theoretical model for the change in average immunity as array length increases. The baseline average immunity when bacteria are assumed to have single spacers we denote a1, and define a constant . Then as array length increases, the total number of bacteria decreases and the overlap increases, but by a smaller factor than the population size decrease: the remaining average immunity that could be gained is reduced with the same fraction as the original average immunity so that the average immunity for an array of length is . Plotting vs. on a log plot gives a straight line. Plugging in gives , plotted as a black dashed line in Figure 68. The theory agrees well with the simulated results except for when array length is exponentially distributed; in this case, we believe the presence of several very long and very short arrays means that short-array bacteria do not get the coverage of multiple spacers while the long-array bacteria have redundant spacers. This functional form for average immunity as a function of array length is very similar to a quantity derived by Iranzo et al., 2013 — they calculated that the probability that a random bacterium is immune to a random phage, each with a random set of spacers and protospacers is , where is the average bacterial array length, is the total number of unique protospacers, and is the number of protospacers per phage. The constant is a scaling factor that measures the degree of correlation between matching spacer and protospacer abundances. Their scaling is as a function of the phage array length instead of bacterial, but the same intuition applies.
An interesting result of this analysis is that the relative immune benefit from gaining a spacer decreases as immunity increases: a CRISPR array twice as long does not provide double the immunity. A similar diminishing-returns result has also been observed in theoretical models of vertebrate immunity where the relative decrease in immune susceptibility and increase in immune memory both decrease as the number of infections increases over an organism’s lifetime (Mayer et al., 2019). Long CRISPR arrays are also subject to a dilution effect: spacers compete to form complexes with limited Cas protein machinery, and if the number of spacers is high, there is a higher chance that the needed spacer is not available in high enough numbers during an infection (Martynov et al., 2017; Bradde et al., 2020).
Average immunity negatively correlates with diversity regardless of array size
This section describes the toy model we present in results ‘Pathogen and host diversity must be considered together.
In our simulations, we observed an inverse proportionality between average immunity and bacterial diversity (Figure 50). We wondered if this trend would hold for array sizes and numbers of protospacers larger than 1. Our intuition is that this trend should hold for any arrangement of spacers and protospacers into arrays, provided the following two statements are true: (a) bacteria and phage diversity is coupled; that is, phage protospacer diversity matches bacterial spacer diversity, and (b) diversity is larger than CRISPR array length.
We tested this with a toy model, described in ‘Pathogen and host diversity must be considered together’. Conceptually, there are two regimes of CRISPR immunity and phage evolution to consider. In an ‘evolutionarily late’ regime, bacteria are exposed to many diverse phages for which any one spacer may target only a few phage genotypes. In an ‘evolutionarily early’ regime, most phages are clonally similar and protospacer diversity is generated through escape mutations. In this scenario, we can imagine a set of phages that share most of their protospacers but have a small number of recently mutated protospacers. This regime can further be divided into a slow-mutation ‘successive sweeps’ regime in which each new mutation takes place in the background of the previous mutant and a fast-mutation ‘clonal interference’ regime in which many unique mutations coexist in the same background.
We explored these three scenarios by generating synthetic sets of protospacers and spacers and varying the total diversity by changing the size of the pool of available sequences, distributing sequences exponentially in abundance to qualitatively match data Bonsma-Fisher et al., 2018. We randomly assigned sequences to individual phages and bacteria, then calculated average immunity in three scenarios of protospacer origin. First, we divided protospacers randomly among 100 phages so that each phage had unique protospacers to mimic an evolutionarily diverse population. In the second scenario, we created a set of phages that mimic a population undergoing successive sweeps by changing the first protospacer, then the first and second, and so on. In the third scenario, the set of phages share the first protospacers and only the last protospacer is varied; this mimics an initially clonal population undergoing rapid mutations. In all scenarios, we sampled uniformly from the pool of protospacers to generate 1000 spacer sequences that were divided into bacterial arrays with either a constant array size (Figure 69B–D), or a Gaussian-distributed array size (Figure 70). We repeated the bacterial array assortment process 20 times for each total spacer diversity and combination of array sizes.
Figure 69
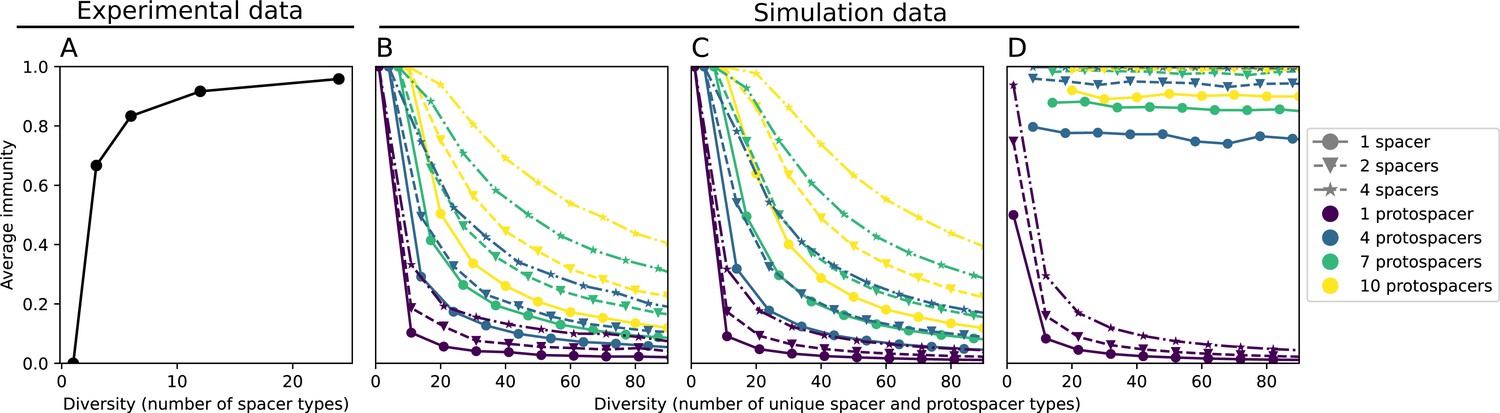
Average immunity decreases with coupled CRISPR diversity.
(A) Inferred initial average immunity as a function of diversity in the experiment of Common et al., 2020. Bacterial diversity was manipulated in the experiment by combining different numbers of bacterial clones defined by unique CRISPR spacers with a single phage strain that was able to infect only one of the clones. We calculated the expected initial average immunity based on the number of clones. (B–D) Results of a toy model of sorting a set of protospacers and spacers into arrays of variable length, either assigning protospacers fully randomly (B), as sequential mutations (C), or changing the last protospacer in the array only (D).
Figure 70

Average immunity vs. diversity (number of unique types) for simulated distributions of spacers and protospacers with different bacterial array sizes (increasing top to bottom) and different numbers of protospacers per phage (increasing left to right).
Bacterial array sizes are drawn from a Gaussian distribution with mean given by the array mean for each row and a standard deviation of 2. Points are averages across 50 independent runs.
We calculated average immunity in these synthetic scenarios, assuming for simplicity that any matching spacer provides perfect immunity, that is, , , or . For the set of bacteria and phages , the average immunity for the population is
(92)
where and . In our base model, bacteria and phages are each limited to a single spacer or protospacer, whereas now and label the full set of spacers or protospacers in an organism. is the number of bacteria with the same unique set of spacers and the Iverson bracket gives 1 if any of the spacers in matches any of the protospacers in and 0 if there is no overlap between sets and .
The 1-spacer 1-protospacer curve in Figure 69B represents the same situation as our simulations: one spacer and one protospacer (but with a random distribution of sequences), and the trend matches our simulations exactly with average immunity inversely proportional to diversity. This strict inverse dependence changes shape as the number of spacers and protospacers per organism changes.
We compared these toy model results to the experimental setup of Common et al., 2020. In their experiments, they combined equal proportions of bacterial strains with a different CRISPR spacer with one phage strain that is either targeted by all spacers or escaped from one of the spacers. There is then one susceptible bacterial strain per mixture when the escape phage is used. All experiments also contained one surface mutant bacterial strain that is always immune to the phage.
We can directly calculate the expected initial average immunity based on this setup. For bacterial CRISPR strains, one surface mutant strain, and one escape phage, total bacteria , total phage , each bacterial strain has abundance and .
We calculate average immunity assuming
We can include the surface mutant or not; it slightly shifts the total diversity but the trend is unaffected. For instance, for CRISPR clones, the phage is able to infect one of them, so average immunity is . If we included the surface mutant in equal proportions, we would get instead.
Laboratory coevolution experimental data
This dataset is the source for Figure 6E in ‘Dynamics are determined by diversity’ and Figure 7C in ‘Time-shifted average immunity calculated from data reveals distinctive patterns of turnover’.
We analysed experimental data from Paez-Espino et al., 2015. In this experiment, S. thermophilus bacteria were mixed with phage 2972 and allowed to coevolve until phage extinction, up to 232 days in one replicate. Bacteria and phage whole-genome shotgun sequencing was performed at irregular intervals (13 time points for series MOI-2B). This data is publicly available in the NCBI Sequence Read Archive under the accession PRJNA275232.
We analysed data from the MOI-2B series and detected spacers in the CRISPR1 and CRISPR3 loci by searching raw reads for matches to the S. thermophilus repeats (GTTTTTGTACTCTCAAGATTTAAGTAACTGTACAAC for CRISPR1 and GTTTTAGAGCTGTGTTGTTTCGAATGGTTCCAAAAC for CRISPR3) using BLAST.
The expected structure of the CRISPR locus is 36 nt repeats interspaced with 30 nt spacers. Reads are 100 nt long (Illumina), and so at most two complete spacers can be detected per read (one full repeat match near the centre of the read). To maximize the number of genuine spacers detected while removing low-quality matches, we kept only full-length alignments to the repeat (length 36), unless a shorter alignment was also present on the same read as a full-length alignment (for instance, if the repeat is partially present at the start or end of a read). If a single repeat match was present on a read, we extracted 30 nt on either side and labelled these spacers. We set a minimum spacer length to be 26 nt () and did not keep spacer sequences at the start or end of a read that were shorter than this. If two repeat matches were present, we extracted the spacer sequence between the matches.
To detect wild-type spacers, we searched for matches to the CRISPR repeats on the S. thermophilus DGCC7710 reference genome (accession NZ_CP025216) and extracted the sequences between repeat matches. We also searched raw reads from the day 1 data of the control replicate (no phages) for matches to the repeats and performed the same spacer extraction procedure.
We grouped all extracted spacers using the AgglomerativeClustering method from SciPy with an 85% similarity threshold and the ‘average’ linkage criterion. We performed this grouping separately for CRISPR1 and CRISPR3 spacers. Each spacer sequence was then labelled with a group type identifier. Figure 71 shows our detected spacer counts after grouping by 85% average similarity and eliminating single counts and matches to wild-type spacers, compared with the reported results from Paez-Espino et al., 2015; there is good agreement between our counts and the original authors’ counts.
Figure 71
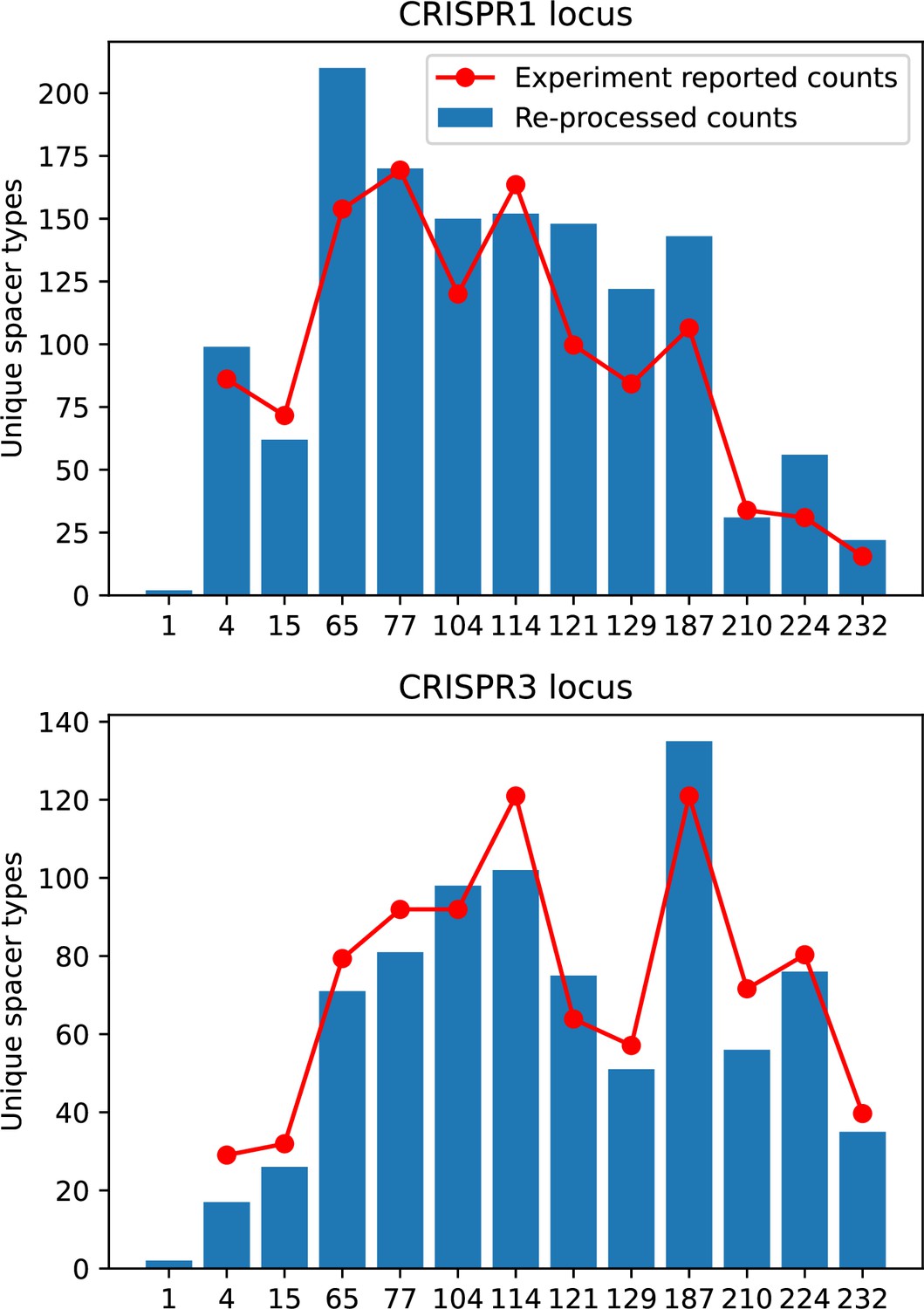
Unique spacer types detected in our analysis of data from Paez-Espino et al., 2015 after grouping by 85% average similarity and removing single spacer counts (blue bars).
Counts reported in Paez-Espino et al., 2015 are red points.
To detect protospacers, we first blasted all reads against the S. thermophilus DGCC7710 reference genome and the phage 2972 reference genome (accession NC_007019) (Figure 72). We next blasted all unique detected spacer sequences from the previous step against all the reads, removing any query sequences that are a perfect subset of another sequence and any sequences that were more than 30% N nucleotide. This detects both potential protospacer sequences and the original spacers themselves. To isolate protospacers, we kept only results that were on reads that did not match the bacterial genome and that did not match the CRISPR1 repeat (CRISPR3 repeats were not checked; however, they represent a very small number of additional reads, less than 0.1%). We kept only results that were 26 nt or larger. If there were multiple hits on a read from the same spacer type (but different sequences), we kept only the match with the lowest e-value. We extracted the matched sequence from the read and 10 nucleotides after it to check for a PAM sequence (all spacers were stored oriented in the same direction relative to the repeat to facilitate comparison and PAM detection). Since reads are paired-end, some reads will overlap, and some spacers may be double-counted in the overlap. We decremented the total spacer or protospacer count for a sequence by 1 if a spacer sequence was present on both ends of a paired read. We also removed sequences that contained long strings of 11 or more of the same nucleotide, assuming these to be sequencing errors. This removed around 1% of sequences.
Figure 72

Total reads per time point that match phage (blue) or bacteria (orange).
Top: total reads. Middle: total reads divided by phage and bacteria genome sizes. Bottom: fraction of total reads matching bacteria or phages.
We grouped all spacer and protospacer sequences together (separated by CRISPR locus) by several different similarity thresholds between 85 and 99% to assign type labels based on each similarity threshold.
We checked the 10 nt region downstream from each potential protospacer and removed any sequences that did not have a perfect match to the PAM: AGAAW for CRISPR1 (Paez-Espino et al., 2013; Paez-Espino et al., 2015; Shah et al., 2013; Garneau et al., 2010 and GGNG for CRISPR3 Paez-Espino et al., 2015; Shah et al., 2013). Since targeting is highly sensitive to PAM mutations (Shah et al., 2013), we assumed that any deviation from the perfect PAM meant that the protospacer would not be successfully targeted. There are cases where the PAM sequence is incomplete because of hitting the start or end of a read; these were also assumed to be imperfect PAMs (though some would be genuine). Changing this assumption to include partial PAMs that were subsets of perfect PAMs caused total average immunity numbers to increase and the slope of each curve to decrease. Results including incomplete PAMs were qualitatively similar to the results including all protospacer matches regardless of PAM, highlighting the importance of a perfect PAM match for functional immunity (Figure 7—figure supplement 2 and Figure 7—figure supplement 3; Figure 73).
Figure 73
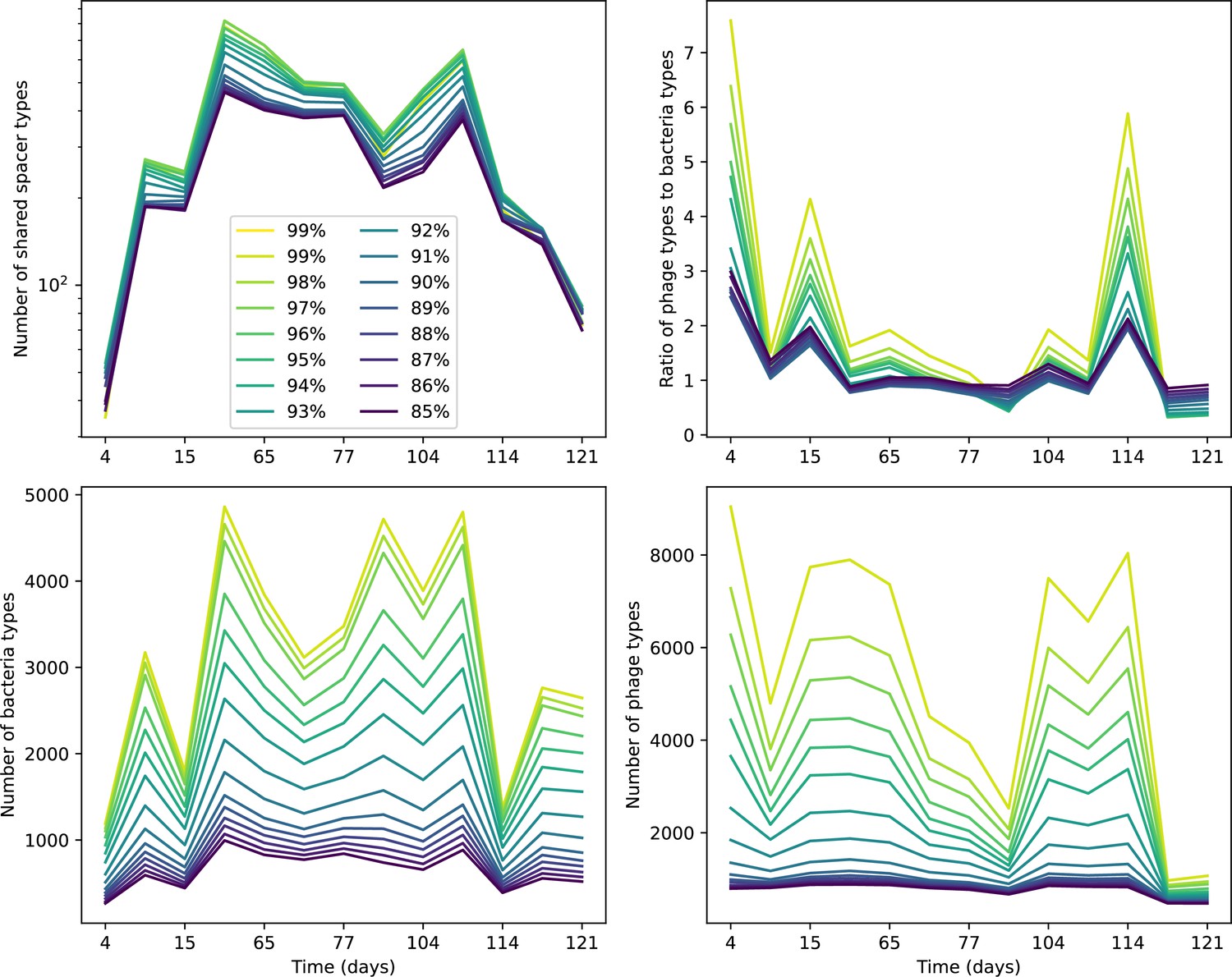
Number of shared spacer types between bacteria and phage (top left), ratio of the number of phage types to the number of bacteria types (top right), number of bacteria types (bottom left), and number of phage types (bottom right) as a function of the sampling date for data we analysed from Paez-Espino et al., 2015.
Colours indicate different similarity grouping thresholds. Spacer counts include wild-type spacers, and protospacers are included only if they possess a perfect PAM. Data is summed over CRISPR1 and CRISPR3. All sequences are included regardless of abundance.
Calculating average immunity
To calculate average immunity between bacteria and phage, we interpolated spacer and protospacer counts between sequenced time points using the shortest interval between experimental time points as the sampling frequency from the interpolated data. We removed the first time point and last two time points from the data because the first time point has low bacterial spacer counts and a very large phage population size, and at the last two time points, phage counts are very low because phages are about to go extinct (Figure 74 and Figure 73). Results including all time points are given in Figure 7—figure supplement 4; they are qualitatively similar except for large changes at the first and last time points where only the first and last phage population are included in the average, respectively.
Figure 74

Total phage and bacteria population size for the MOI2B experiment in Paez-Espino et al.Paez-Espino et al., 2015.
Circles are points digitized from Figure 1A in Paez-Espino et al., 2015; squares are the population size interpolated to match the sequencing dates in the experiment.
We calculated the time-shifted average overlap between bacteria and phage spacer types by comparing bacteria and phage types separated by a time delay and averaging over all points with the same time delay (Figure 7—figure supplement 4). As described in ‘Theoretical considerations when calculating average immunity from data’, we multiplied raw average immunity values by the total number of protospacers to account for multiple protospacers on each phage genome. The number of possible protospacers in phage 2972 for the CRISPR1 locus in S. thermophilus (AGAAW PAM) is 231 and the number for CRISPR3 is 465 (696 total). Note that because PAM mutations are common, the true number of protospacers may be less than this hypothetical amount, which would cause us to slightly overestimate average immunity. However, we are also assuming that each bacterium has one effective spacer, and this is likely an underestimate based on estimates of locus length from Paez-Espino et al., 2015.
As the similarity threshold increases, the overall overlap goes down slightly (Figure 7—figure supplement 4 and following) because there are more total types (Figure 72). Interestingly, the number of shared types across the whole dataset is very stable regardless of the clustering threshold: there is a tradeoff between the total number of types (which increases as the similarity threshold increases) and the likelihood that types are shared (which increases as the similarity threshold decreases). At high similarity thresholds, we expect that many spurious types will be created from sequencing errors in spacers, while at low similarity thresholds, genuine escape mutants will be grouped with spacers meaning that the immunity information contained in the overlap is not accurate. There are about 700 unique protospacer sequences in the wild-type phage genome, so we expect the number of unique types to be on the order of 700; they are for bacteria, but the number of phage types in our analysis can be quite a bit higher. For all similarity thresholds, we see that bacterial immunity is higher to phages from the past than phages from the future.
We experimented with different trimming thresholds for the data, removing time points from the beginning and end of the data. The early and late parts of the experiment experienced large fluctuations in population sizes, so if we are interested in steady-state behaviour, it makes sense to remove some time from the beginning and end. But, how much to remove? We can remove the points that look more different from the others either in terms of population size, total reads, or number of types: this could lead us to remove the first three and last three time points. Looking just at population size alone, it makes sense to remove the first time point and last two time points. Figure 7—figure supplement 4 shows results with different sets of points removed to compare the resulting overlap.
There were no protospacer matches to the reference genome wild-type spacers for CR1 and only a single protospacer match to CR3, even with a lenient 85% similarity threshold. This means the phage has effectively escaped all the wild-type spacers and only the new spacers matter. However, our results differ when wild-type spacers are removed since we also included spacer sequences from the control experiment as wild-type spacers. There are many sequence variants in the control experiment wild-type spacers that do cluster with other spacers, and there are protospacer sequences that cluster with supposed wild-type spacers at lenient grouping thresholds (Figure 75). This means that average immunity results with and without wild-type spacers are more similar at high similarity thresholds than at low thresholds.
Figure 75
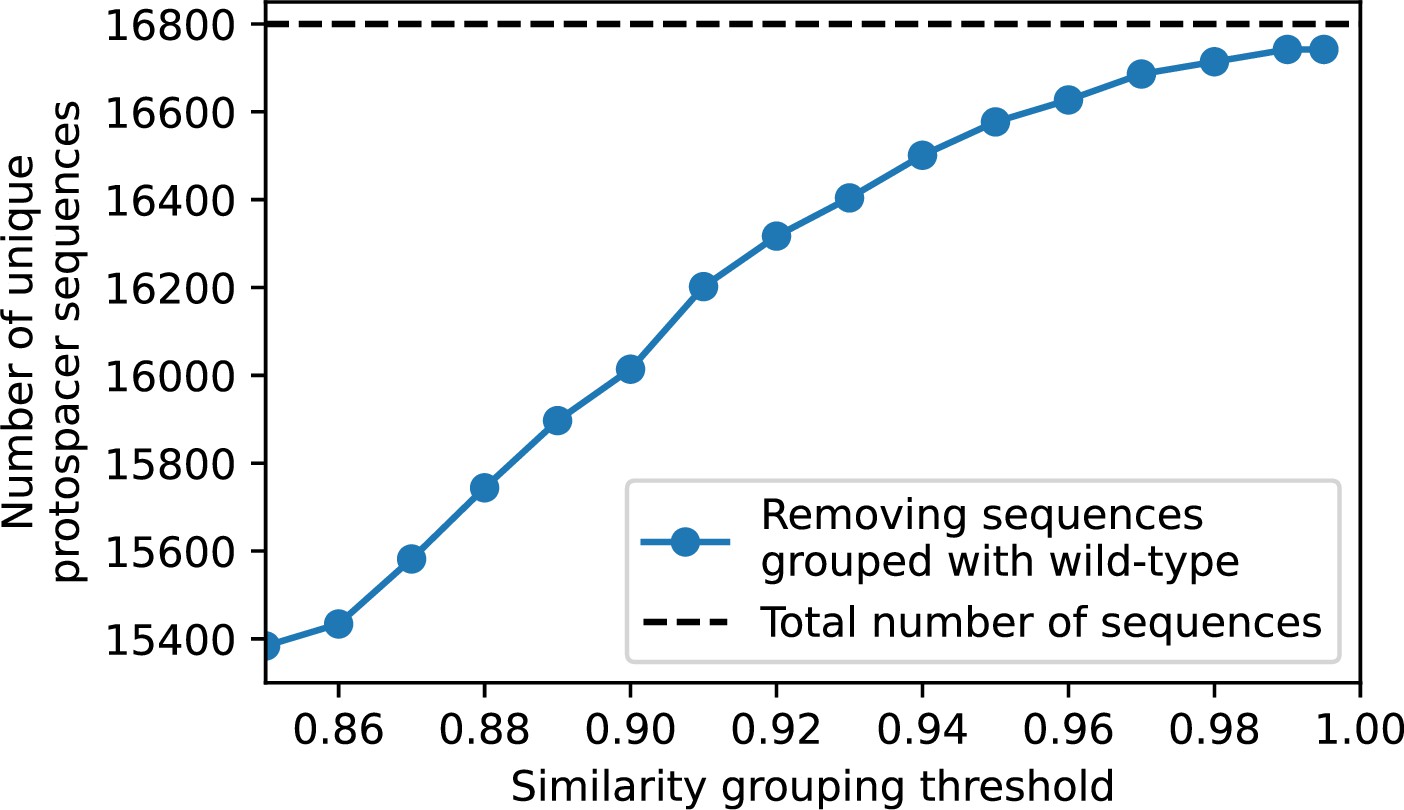
Total number of unique protospacer sequences after removing all sequences that cluster with wild-type sequences at different similarity thresholds.
Only protospacers with a perfect PAM are included.
Our model predicts that phage population sizes should decrease as average immunity increases and that bacterial population sizes should increase as average immunity increases. We calculated average immunity at each experimental time point and compared it to the reported phage and bacterial population size at each time point. Phage and bacteria population sizes were digitized from Figure 1A in Paez-Espino et al., 2015. We found that for all similarity groupings, the log-transformed phage population size was significantly negatively correlated with average immunity, while there was no significant correlation with bacterial population size (Figure 76). This suggests that the mechanism of phage extinction is increasing bacterial immunity over time, and indeed the average immunity just before phage extinction is very high (Figure 77).
Figure 76
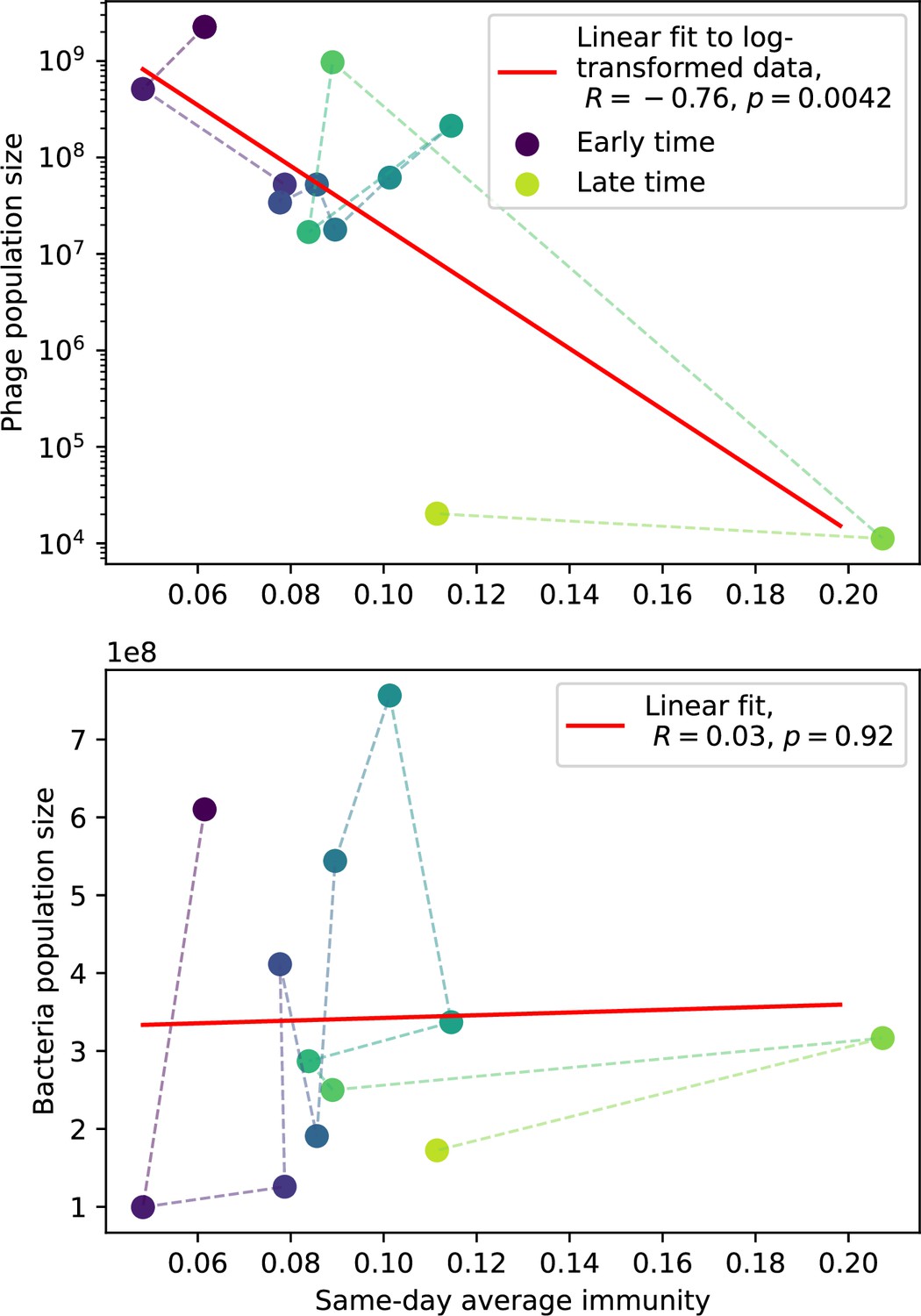
Phage (top) and bacteria (bottom) population size vs. average immunity calculated with data from Paez-Espino et al., 2015.
Protospacers are included if they have a perfect PAM, and all wild-type spacers are included. Spacers and protospacers are grouped with an 85% similarity threshold. Colours from blue to yellow indicate increasing time.
Figure 77
Average immunity vs time in the MOI-2B experiment.
Protospacers are included if they have a perfect PAM, and all wild-type spacers are included. Spacers and protospacers are grouped with an 85% similarity threshold.
Experimental data from wastewater treatment plant
This dataset is the source for Figure 6G in ‘Dynamics are determined by diversity’ and Figure 7D in ‘Time-shifted average immunity calculated from data’ reveals distinctive patterns of turnover.
We analysed metagenomic sequencing data from Guerrero et al., 2021a. This is a longitudinal study of a natural community of bacteria and phages in a wastewater treatment plant. Sixty samples were collected approximately biweekly over a 3-year period from a municipal sewage treatment plant, and whole-genome sequencing was performed on extracted DNA (Illumina platform, 250 bp paired-end reads). They focused on bacteria from the genus Gordonia, which is one of the most abundant taxa and was consistently present in samples. They detected CRISPR loci in Gordonia genome assemblies, then searched for matches to the two identified CRISPR repeats in all reads to detect other spacers. They constructed graphs of all the linked spacers based on spacer adjacency within reads. They searched for matches to spacers in the metagenomic data, then used matches to identify contigs that might be phages, resulting in two draft phage genomes (DC-56 and DS-92) that they followed over time. They searched for protospacers within these phage genomes using blast. They did not find matches between the Gordonia spacers and any other contigs from the dataset, suggesting that those two phages are the only two from which Gordonia is acquiring spacers. They used Crass and metaCRT to detect other possible CRISPR arrays within the unassembled data and other contigs; they did not find and/or do not discuss any other detected CRISPR loci. They found a broad fan-like network of CRISPR arrays within Gordonia that reflect new spacer acquisition, many of which matched the phage genomes. Older, conserved spacers largely did not match the phage genomes. They found that peaks in phage genome coverage (a proxy for abundance) over time were highly correlated with bacterial coverage, suggesting that their population dynamics are tightly coupled. They identified a PAM sequence, GTT (5’) for the CRISPR1 locus, but did not find that mutations occurred more frequently in the protospacer regions or PAM regions of the phage genomes than elsewhere in the genome.
Following the same analysis procedure we used for data from Paez-Espino et al., 2015 (‘Laboratory coevolution experimental data’), we used the two reported Gordonia CRISPR repeats (GTGCTCCCCGCGCGAGCGGGGATGATCCC for CRISPR1 (type I) and ATCAAGAGCCATGTCTCGCTGAACAGCGAATTGAAAC for CRISPR2 (type III)) to search for spacers in the raw read data using BLAST.
To detect wild-type spacers, we searched for matches to the CRISPR repeats on the Gordonia metagenome-assembled genome (MAG) provided on the study’s GitHub repository and extracted the sequences between repeat matches. We determined that spacers from the CRISPR1 locus had an average length of 32 nt and spacers from the CRISPR2 locus had an average length of 35 nt.
We detected spacers as sequences between or adjacent to repeat sequences. To maximize the number of genuine spacers detected while removing low-quality matches, we kept only full-length alignments to the repeat, unless a shorter alignment was also present on the same read as a full-length alignment (for instance, if the repeat is partially present at the start or end of a read). If a single repeat match was present on a read, we extracted 32 (CRISPR1) or 35 (CRISPR2) nt on either side and labelled these spacers. We set a minimum spacer length of 85% of the expected spacer length and did not keep spacer sequences at the start or end of a read that were shorter than this. If multiple repeat matches were present, we extracted intervening sequences as spacers.
We grouped all extracted spacers using the AgglomerativeClustering method from SciPy with an 85% similarity threshold and the ‘average’ linkage criterion. We performed this grouping separately for CRISPR1 and CRISPR2 spacers. Each spacer sequence was then labelled with a group type identifier.
To detect protospacers, we first blasted all reads against the Gordonia MAG and the two reported phage genomes (DC-56 and DS-92). We next blasted all unique detected spacer sequences from the previous step against all the reads, removing any query sequences that are a perfect subset of another sequence and any sequences that were more than 30% N nucleotide. This detects both potential protospacer sequences and the original spacers themselves. To isolate protospacers from spacers, we kept only results that were on reads that did not match the CRISPR1 or CRISPR2 repeat. Some reads matched both the bacterial genomes and the phage genomes; we removed matches for which the log-difference in e-value between phage genome match and bacteria genome match was less than 25, that is, the phage genome e-value must be lower than the bacteria e-value by a factor of 1025 to be considered not a bacteria match. Figure 78 shows the e-value differences for reads that matched both phage and bacteria for one time point.
Figure 78

Histogram of reads that matched both the Gordonia MAG and either phage reference genome vs the base-10 log difference in e-value between the matches for accession SRR9260993.
A positive value means the bacteria match has a lower e-value than the phage match. The vertical dashed line indicates the -25 cutoff; matches to the left were considered phage matches, matches to the right were considered bacteria matches.
We kept only potential protospacers that were 85% of the expected spacer length or larger. If there were multiple hits on a read from the same spacer type (but different sequences), we kept only the match with the lowest e-value. We extracted the matched sequence from the read and 10 nucleotides on either side to check for a PAM sequence (all spacers were stored oriented in the same direction relative to the repeat to facilitate comparison and PAM detection). Consistent with the PAM reported by Guerrero et al., we identified a GTT PAM at the 5’ end of protospacer sequences (Figure 79, reverse-complement).
Figure 79
Probability logo for the four nucleotides at the 5’ end of potential protospacer sequences, generated with WebLogo; the spacer sequence starts at the right edge of the logo meaning that the reverse-complement PAM is GTT.
Since reads are paired-end, some reads will overlap, and some spacers may be double-counted in the overlap. We decremented the total spacer or protospacer count for a sequence by 1 if a spacer sequence was present on both ends of a paired read.
We grouped all spacer and protospacer sequences together (separated by CRISPR locus) by several different similarity thresholds between 85 and 99% to assign type labels based on each similarity threshold.
We checked the 10 nt region upstream from each potential protospacer and removed any sequences that did not have a perfect match to the GTT PAM. Since targeting is highly sensitive to PAM mutations Shah et al., 2013, we assumed that any deviation from the perfect PAM meant that the protospacer would not be successfully targeted. There are cases where the PAM sequence is incomplete because of hitting the start or end of a read; these were also assumed to be imperfect PAMs (though some would be genuine). We detected 627,555 potential protospacers for the CRISPR1 locus and only 61 potential protospacers for the CRISPR2 locus. Since the CRISPR2 locus is a type III CRISPR system, we expect that there is no PAM for this system and so included all CRISPR2 protospacers; because there are so few, this choice does not affect results. After removing all CRISPR1 protospacers that did not have an adjacent match to the perfect PAM, we were left with 10,2761 protospacers in total representing 19,292 unique sequences and 537 unique types after grouping with an 85% similarity threshold. The total number of unique spacers detected from the CRISPR1 locus over the experiment was 5289 (2078 unique types at 85% similarity), while the total number from the CRISPR2 locus was an order of magnitude lower at 972 (357 unique types at 85% similarity). In total, 28,386 CRISPR1 spacers and 3353 CRISPR2 spacers were detected.
Our detection of reads that matched the Gordonia MAG and phage genomes is closely correlated with the reported coverage from the study (Figure 80).
Figure 80
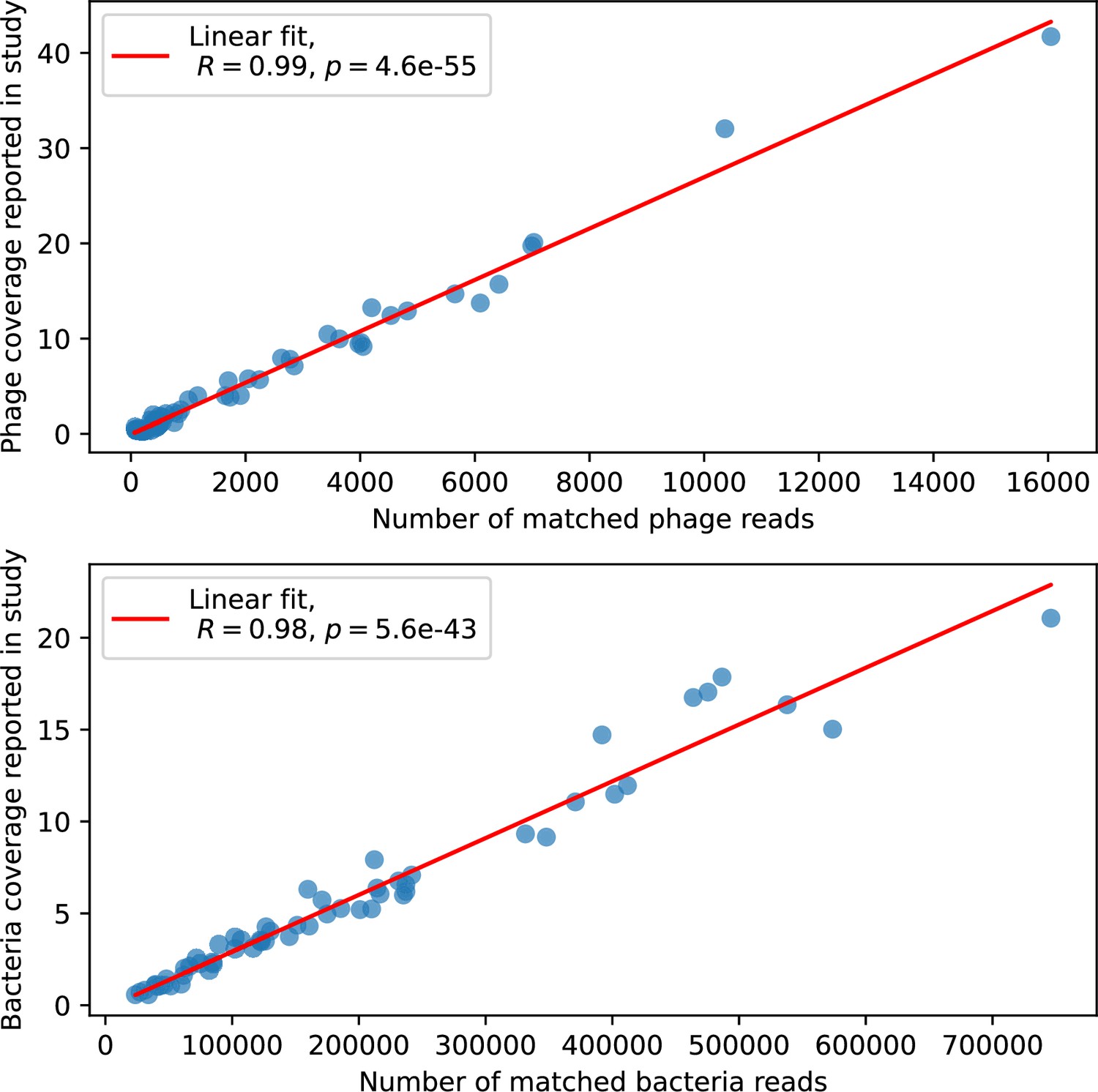
Phage genome (top) and bacteria genome (bottom) coverage, digitized from Figure 2D of Guerrero et al., 2021a vs. number of reads assigned to phage or bacteria from our analysis.
Each marker is a separate time point.
The number of unique protospacer and spacer types we detected fluctuated considerably over the course of the study (Figure 81, Figure 82). The number of shared types as well as the ratio of phage types to bacteria types also fluctuated considerably.
Figure 81
Abundance over time for the 20 largest bacteria clones (top) and phage clones (bottom) over time for data from Guerrero et al., 2021a.
The left panels show absolute counts, and the right panels show fractional abundance for the included types. None of the top types are shared between phage and bacteria.
Figure 82
Number of shared spacer types between bacteria and phage (top left), ratio of the number of phage types to the number of bacteria types (top right), number of bacteria types (bottom left), and number of phage types (bottom right) as a function of the sampling date for data we analysed from Guerrero et al., 2021a.
Colours indicate different similarity grouping thresholds. Spacer counts include wild-type spacers, and protospacers are included only if they possess a perfect PAM. Data is summed over CRISPR1 and CRISPR2.
About 40% of spacer and protospacer types remained throughout the time series without going extinct at an 85% similarity threshold (Figure 83). In data from Paez-Espino et al., 2015, about 20% of original types remained at the end of the experiment (Figure 6E); however, the fraction of types remaining decreases steadily in data from Paez-Espino et al., 2015 unlike in this dataset.
Figure 83
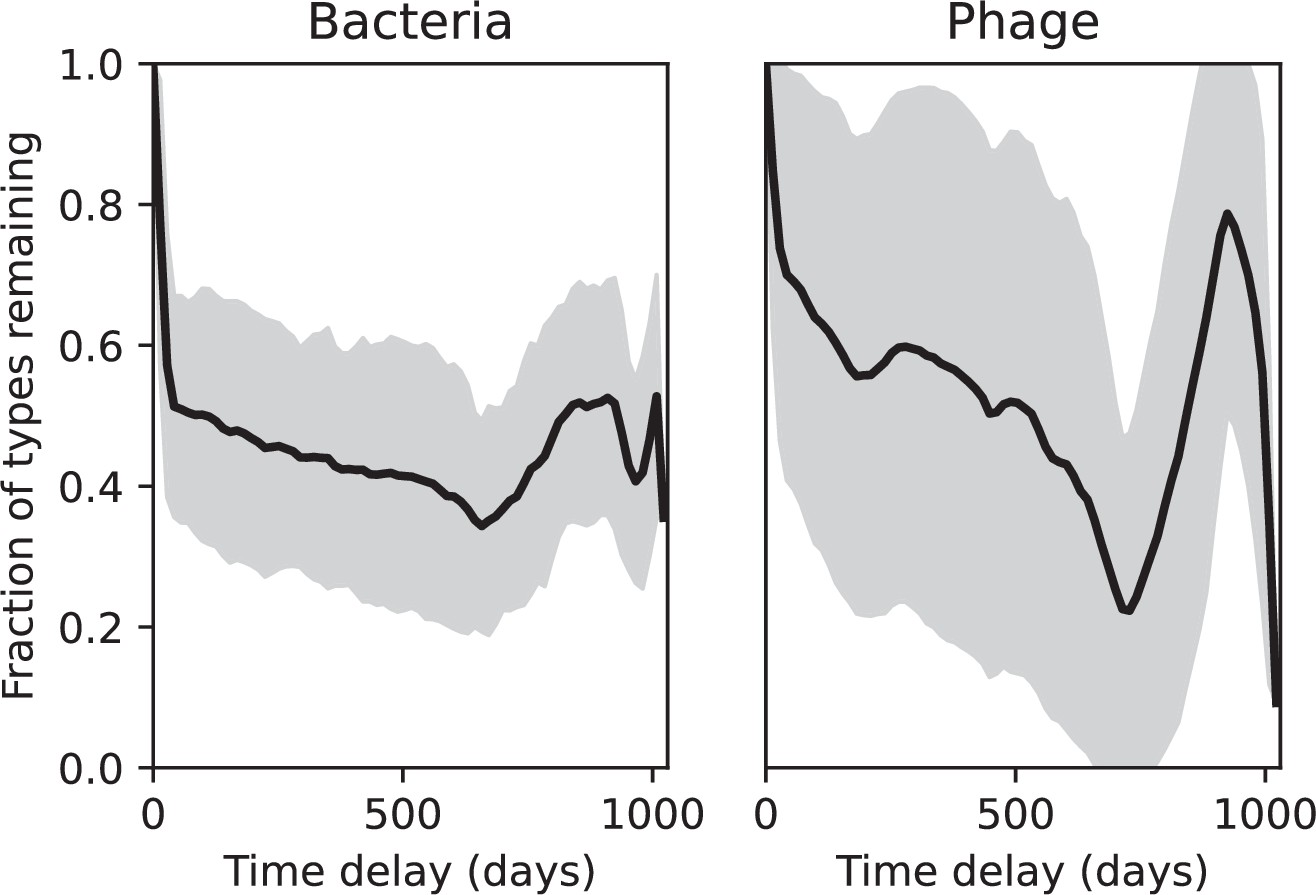
Fraction of spacer types (left) and protospacer types (right) remaining as a function of time delay, averaged over the entire time series from Guerrero et al., 2021a.
Types are grouped with an 85% similarity threshold. The grey shaded region is the standard deviation across averaged data.
Calculating average immunity
To calculate average immunity between bacteria and phage, we interpolated counts between sequenced time points using a 14-day spacing (the most common sampling interval in the data). We calculated the time-shifted average overlap between bacteria and phage spacer types by comparing bacteria and phage types separated by a time delay and averaging over all points with the same time delay (Figure 7—figure supplement 5). As described in ‘Theoretical considerations when calculating average immunity from data’, we multiplied raw average immunity values by the average number of protospacers with the GTT PAM from the phage DC-56 and DS-92 genomes (1956 protospacers) to account for multiple protospacers on each phage genome. Note that because PAM mutations are common, the true number of protospacers may be less than this hypothetical amount, which would cause us to slightly overestimate average immunity. However, we are also assuming that each bacterium has one effective spacer, and this is likely an underestimate. As the similarity threshold increases, the overall overlap goes down slightly because there are more total types. As in the data from Paez-Espino et al., 2015, the number of shared types across the whole dataset is insensitive to the clustering threshold: there is a tradeoff between the total number of types (which increases as the similarity threshold increases) and the likelihood that types are shared (which increases as the similarity threshold decreases) (Figure 82).
We experimented with different trimming thresholds for the data, removing time points from the beginning and end of the data series before calculating time-shifted average immunity (Figure 7—figure supplement 8, Figure 7—figure supplement 9 and Figure 7—figure supplement 10). For all similarity thresholds and most trimming choices, there is a peak in average immunity at zero time shift that decays in both the past and future directions (Figure 7—figure supplement 5). However, if enough data is trimmed from the beginning to remove the large spikes in average immunity between days 200 and 400 (Figure 84), the central peak is quite diminished or removed altogether (Figure 7—figure supplement 9 and Figure 7—figure supplement 10). The standard deviation of average immunity is large near the zero time shift (Figure 7—figure supplement 5), which is because average immunity is highly variable across the time series: there is a large spike in average immunity near the middle of the time series (Figure 84).
Figure 84
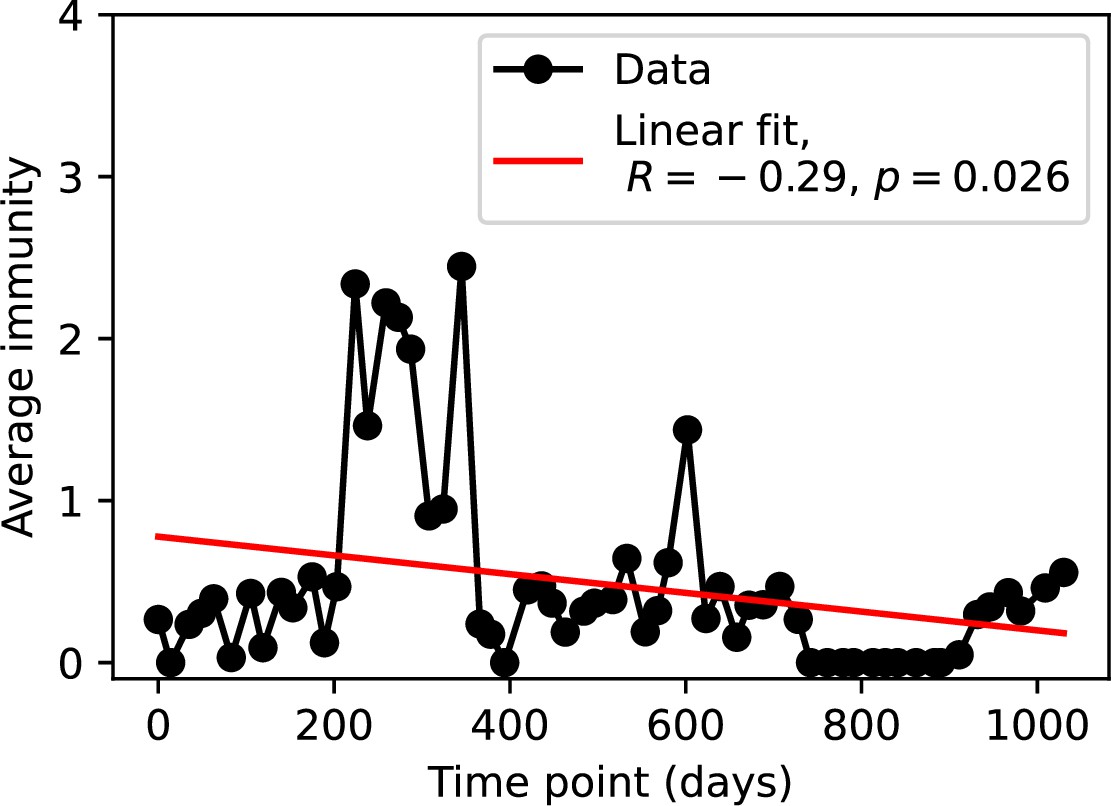
Average immunity at each time point in the time series.
Raw values cannot be larger than 1, but plotted values are multiplied by 1956, the average number of protospacers with the GTT PAM from the phage DC-56 and DS-92 genomes, yielding some values larger than 1.
Because the variability in average immunity between time points was very high, we performed a Wilcoxon signed-rank test between the average immunity at zero time delay and the average immunity at a time delay ±200 and ±500 (arbitrarily chosen). We paired each shifted time point with its corresponding average immunity at zero delay for each bacterial abundance (Figure 85). Using a paired test answers the following question for each time point: is the overlap between bacteria and past phages significantly lower than the overlap in the present, and is the overlap between bacteria and future phages significantly lower than the overlap in the present? The test returns a statistic that is the sum of the ranks of differences greater than zero; a larger number indicates more asymmetry between the two compared datasets. We found that past immunity after 200 days is significantly lower than present (Wilcoxon statistic , p-value ), but that immunity after 500 days is not significantly lower than present (). When comparing all time points with present, only a small range of past immunity values were significantly lower than present (Figure 86). For both time delays, we found that future immunity is significantly lower than present ( for 500 days and for 200 days). Interestingly, these significance values are not symmetric if we pose the question from the perspective of phage: the overlap between phage and future bacteria at 500 days is lower than the overlap for present phages (), and the overlap between phage and past bacteria is lower than the overlap at present (). This asymmetry, that bacteria are generally more immune to all past phages while phage are not more infective against all past bacteria, is qualitatively the same as that reported by Dewald-Wang et al. in an explicit time shift study of bacteria and phage immunity and infectivity in chestnut trees Dewald-Wang et al., 2022.
Figure 85
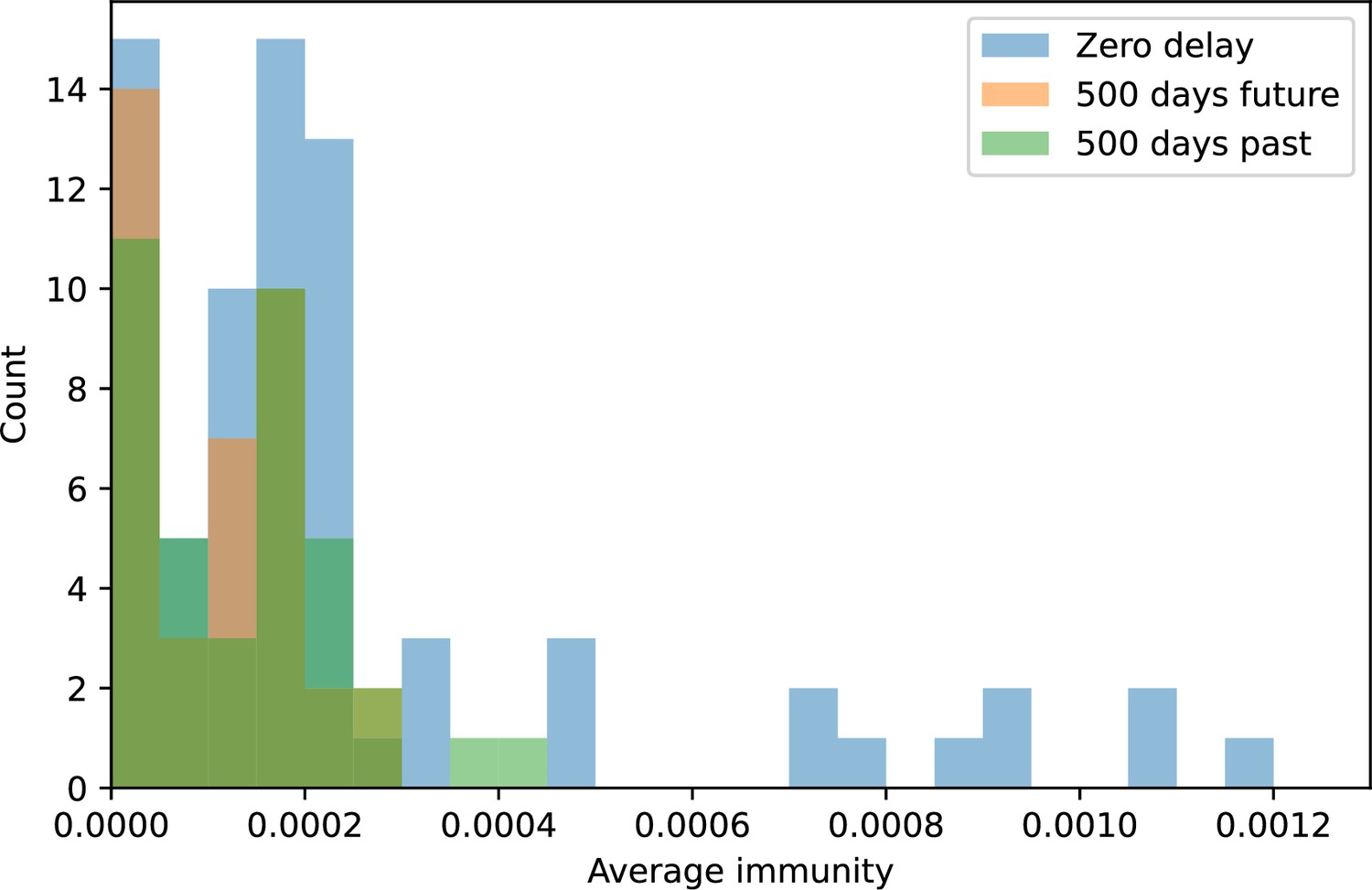
Distribution of average immunity values at zero time shift (blue) and at 500 days time shift for future phages (orange) and 500 days time shift for past phages (green).
Figure 86

p-values for the Wilcoxon signed-rank test comparing the average immunity at zero time shift with all other time shifts.
Bacteria immunity against past phages is generally not significantly lower than bacterial immunity against current phages (blue), while bacterial immunity against future phages is significantly lower than immunity against current phages for almost all time shifts (orange). The time shifts are not symmetric; bacterial overlap with past phages is not necessarily the same as phage overlap with future bacteria and vice versa. The number of points that are available to compare decreases as the time shifts get larger (black dashed line).
We confirmed that the past and future shifted average immunity becomes less correlated with the zero-shift average immunity as the time shift increases. Figure 87 shows the time-shifted average immunity as a function of the zero-shift average immunity for three time shift values, and we see that average immunity is highly correlated at small time shifts but becomes less correlated at larger shifts.
Figure 87
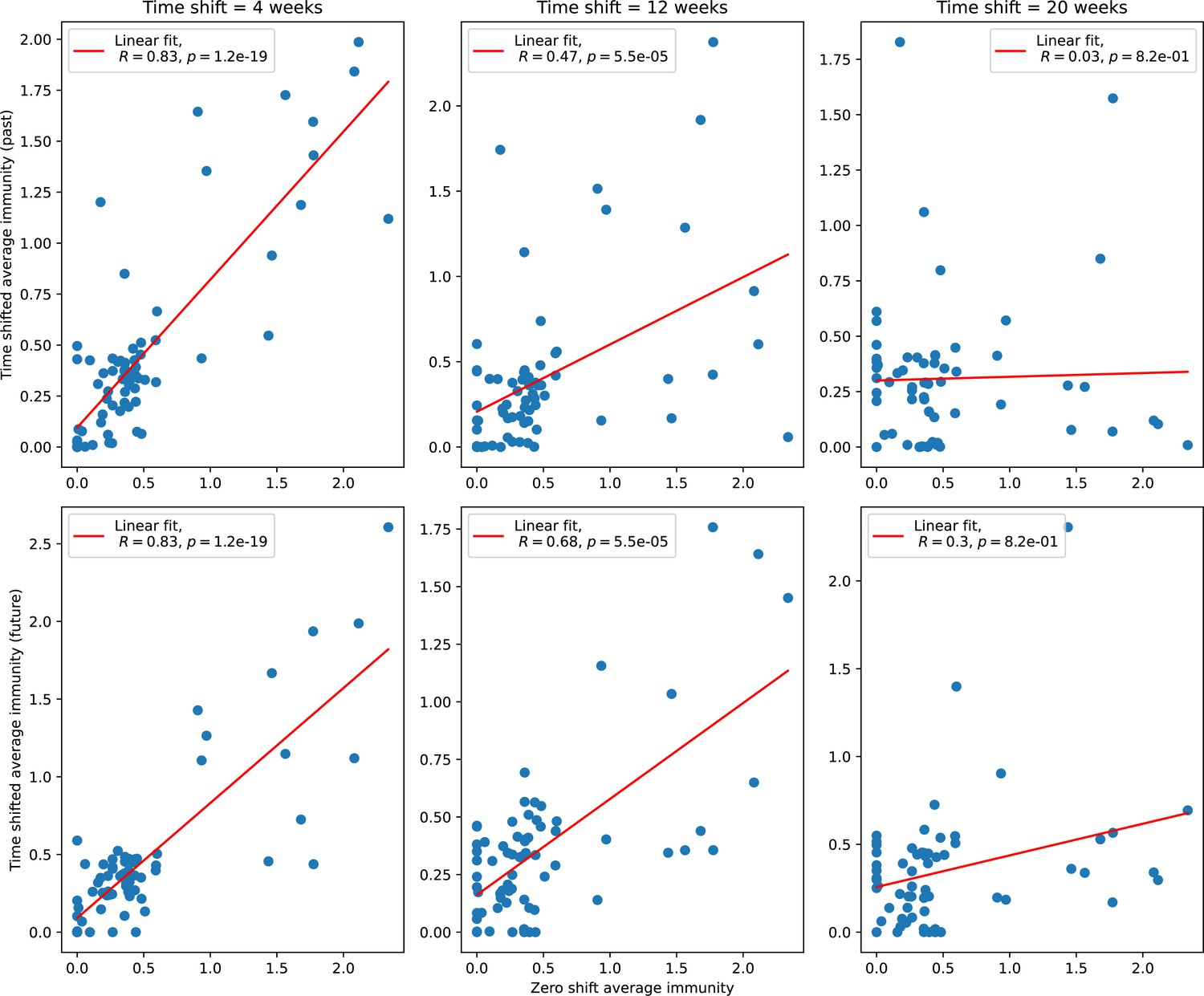
Time-shifted average immunity for each time point as a function of the zero-shift average immunity of that data point for shifts comparing past phages (top row) and future phages (bottom row).
We randomly shuffled time point labels for bacteria and phages separately (Figure 7—figure supplement 6) and together (Figure 7—figure supplement 7) and calculated average immunity with the bootstrapped data. The average immunity trend as a function of time shift disappears in the bootstrapped data even if bacteria and phage clone abundances remain matched at each time point.
Unlike in the data from Paez-Espino et al., 2015, we did not find a correlation between phage or bacteria coverage and average immunity (Figure 88), though Guerrero et al., 2021a did report that bacteria and phage coverage was correlated and that periods of high phage coverage coincided with higher abundance of Gordonia strains lacking matching spacers, suggesting that the expected negative correlation between phage abundance and bacterial immunity may be playing out at some level but may be confounded by generally higher detected average immunity when coverage is high.
Figure 88

Phage (top) and bacteria (bottom) population size vs. average immunity calculated with data from Guerrero et al., 2021a.
Protospacers are included if they have a perfect PAM, and all wild-type spacers are included. Spacers and protospacers are grouped with an 85% similarity threshold. Colours from blue to yellow indicate increasing time.
Spacer turnover
For all sets of experimentally observed spacers (Paez-Espino et al., 2015, Burstein et al., 2016, and Guerrero et al., 2021a), we calculated spacer turnover over time. We interpolated spacer abundances grouped by 85% similarity over time using the smallest time delay between samples, then calculated the average fraction of spacer types remaining as a function of time delay across the entire dataset.
Appendix 1
Relationship of average immunity to Morisita–Horn index
This appendix is presented to contextualize our work with the broader language of diversity in ecology.
In certain limits, average immunity can be related to the Morisita–Horn similarity index (Wolda, 1981; Childs et al., 2012), where instead of comparing two populations from different timepoints or different regions, we are comparing bacteria and phage populations scaled by the immune benefit of CRISPR. If we assume that a matching spacer provides perfect immunity () and there is no cross-reactivity, then and average immunity is given by
(93)
This is the Morisita overlap index between bacteria and phage without the factor of , where and are the Simpson’s diversity indices for bacteria with spacers and phages, respectively. In the limit that all phage and bacteria clones are equal sizes (, ), the factor , so we have . We found in most simulations that effective , which implies that the Morisita overlap between bacteria and phage is constant across all parameters we study. A constant Morisita overlap implies that the population diversity evolves to attain the highest possible overlap. The full average immunity includes pairwise comparisons between all species and may be quite different from the Morisita overlap index.
Appendix 2
A neutral model of non-coevolving bacteria
This section provides the mathematical background for the statement that neutral diversity depends linearly on mutation rate made in ‘Phages drive stable emergent sequence diversity’.
In our results for the diversity in a coevolving population of bacteria and phage, we find that diversity approximately scales like (Approximation for ). Intuitively this dependence seems quite weak, but we would like to know what to compare this to: what is the expectation for diversity in a population with mutations but without coevolution? An appropriate comparison point is a neutral model of a bacterial population that grows and dies; the birth and death rates are exactly matched to give a constant size at steady state. We also include the possibility of mutations: a bacterium may mutate to a new type with probability per division, and we assume that each mutation is to a new, never-before-seen type (infinite alleles model).
Let us consider a population of bacteria that divides with rate , dies with rate , and mutates with rate . We can write a master equation for the number of bacterial clones of size . New mutants enter at clone size 1, and we assume that the total population size is constant at . Mutations effectively lower the growth rate of a particular clone.
(94)
Generating function solution
The generating function for the probability distribution is . Let us replace the birth and death rates by and , respectively. , . Multiplying Equation 94 with and noting that , we get the following differential equation:
(95)
The term comes from the source term with .
Equation 95 can be solved with the method of characteristics (Van Kampen, 1981). We parameterize the function with a new variable . Applying the chain rule:
(96)
And by comparison with Equation 95, the characteristic equations are
(97)
(98)
(99)
From Equation 97 we see , so we can choose and replace with going forward.
Solving the characteristic equation for by integrating both sides gives Equation 100.
(100)
At , will pass through some point z0, so we have the initial condition . With z0 in Equation 100 at , we get Equation 101, where is given by Equation 100.
(101)
The variation of along this - curve is given by
(102)
which has the solution
(103)
The constant is a function of the characteristic - curve (Equation 100). To find the particular form of , we apply the initial condition , meaning we start with one clone of size at .
(104)
Let us use the temporary variable . Then , and the solution for is
(105)
Now we can write the full solution for , replacing with , where .
(106)
bk can be found by Taylor-expanding about . The full distribution is cumbersome for this initial condition, but the limit as , if , is independent of the initial condition:
(107)
Now we have required constant , which means
(108)
So to maintain constant population size, , as expected. The diversity is the total number of clones, defined as . We represent diversity as .
This gives the following result for steady-state diversity:
(109)
In our definition of the birth and death rates, it is implied that , and under that condition, the diversity is positive. If we let , we can write the diversity as
(110)
For small (i.e. mutation rate much smaller than division rate, usually true), . Equation 107 is equivalent to Fisher’s logseries with and . This is also equivalent to Hubbell’s unified neutral theory in the limit of large sample size. This result for diversity (Equation 110) is also approximately equivalent to the result obtained in Vallade et al., 2003 and also in He and Hu, 2005 when the mutation rate is within a few orders of magnitude of .
Comparison to coevolution model
In our bacteria-phage coevolution model, we find that diversity scales approximately like , where
(111)
For , and , the dependence of diversity on is given by Equation 112. Note that this expression correctly captures the fold change in diversity as a function of parameters, but the value itself is off by about a factor of 10.
(112)
Is this dependence quite different from what we get under neutral evolution without coevolution? Since we are measuring bacterial diversity in the coevolution model, the spacer acquisition probability is a good analog to bacterial mutation rate in the non-coevolving model. Let us look at the change in diversity for a given change in spacer acquisition probability.
In the coevolution model, a change in spacer acquisition probability gives approximately a change in diversity, while under the non-coevolution model, a change in mutation rate gives a change in diversity. For small , this is approximately . The change is dependent on the mutation rate, but if is not very large and , then a change in gives approximately a change in diversity. A similar correspondence can be reached with a different approximation. If is large, the leading order contribution to is , but a better approximation is given by Equation 113.
(113)
If is large, which it typically is, then the leading term is more accurately . This is directly comparable to the dependence of the non-coevolving model: diversity in the coevolution model goes like , and in the non-coevolving model it goes like . Either way, there’s a 1/3 power in the coevolution model that isn’t there in the simple model.
Appendix 2—figure 2 compares the predicted diversity and fold change in diversity in each model under the simple approximation assumptions here. Diversity increases more rapidly with mutation rate in the simple model than in the coevolution model.
Appendix 2—figure 1

Diversity vs. (left), (centre), and (right) for .
The dependence of diversity is not very well predicted even by the full numerical solution, but for mutation rate and spacer effectiveness the approximate solutions do pretty well in this regime. The simulation data increase in diversity as a function of spacer acquisition probability actually goes more like .
Appendix 2—figure 2

Approximate predictions for diversity in our coevolution model (blue) or a simple model with mutation but no coevolution (orange).
(A) Predicted diversity as a function of spacer acquisition probability in our coevolution model as given by Equation 111 for , , and (blue). Predicted diversity in the non-coevolving model as given by with (orange). The low- limit is . The high- limit is a series expansion in for giving . (B) Fold change in diversity as a function of fold change in mutation rate or spacer acquisition probability under the simple approximation that (blue) and (orange).
Appendix 2—figure 3
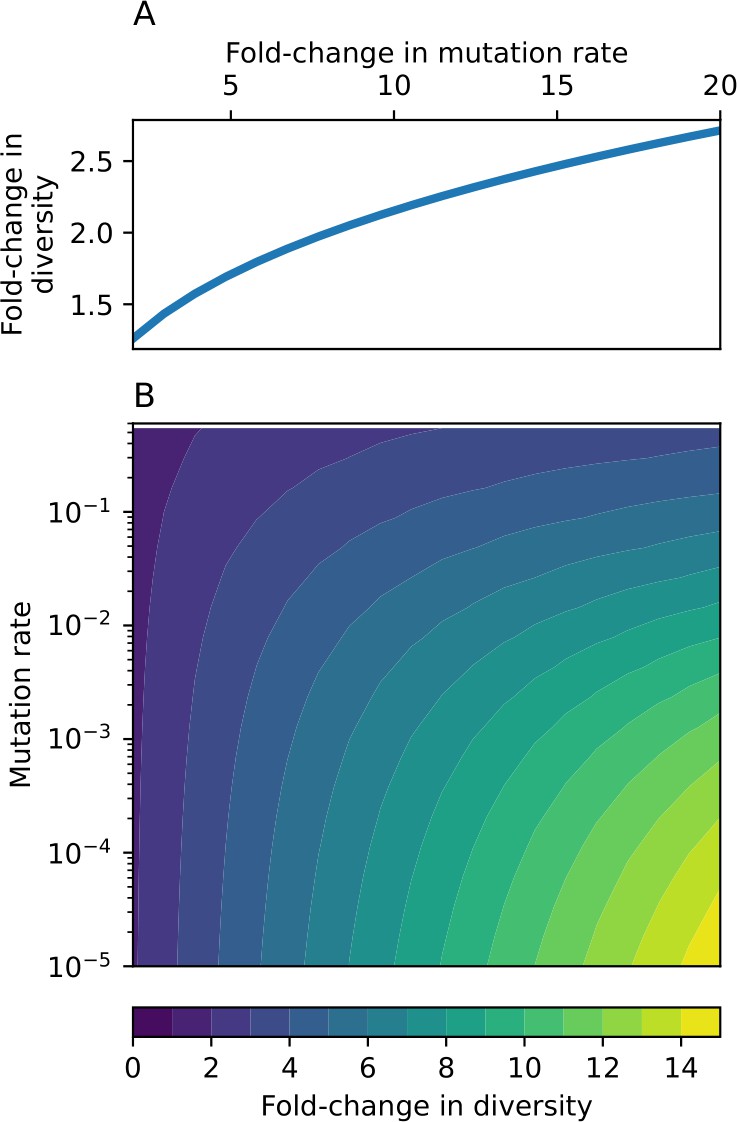
Fold change in diversity (number of species) as a function of mutation rate and , the fold change in mutation rate.
(A) Fold change in diversity as a function of fold change in mutation rate in the coevolution model: diversity increases by approximately a factor of , independent of mutation rate (solid line). (B) Fold change in diversity as a function of both mutation rate and fold change in mutation rate in the model without coevolution.
Appendix 3
Stochastic clone dynamics
In this appendix, we calculate clone size distributions for bacteria, the probability of extinction/establishment for phage clones, and the mean time to extinction for bacteria and phage clones. These results underlie our result for diversity; in particular the phage establishment probability is a core component of our calculation of diversity in ‘Phages drive stable emergent sequence diversity’. Phage establishment is also covered in ‘What determines the fitness and establishment of new mutants?’.
In this section we define as given by Equation 18.
Clone fitness
Here we use mean-field expressions for phage and bacteria clone size from ‘Single-clone mean-field dynamics to calculate the fitness of new phage mutants’. These results are used in ‘Measuring diversity to justify our assumptions about the timescale of spacer acquisition relative to phage establishment.
We investigated the fitness of new phage mutants to understand the effect of bacterial spacer acquisition on phage mutant growth. We define the fitness of phage clones to be their per-capita average growth rate: their average growth rate in bacterial generations divided by their average size. We calculate the fitness from simulation data by calculating the mean phage clone size conditioned on survival (as in Figure 10, ‘Single-clone mean-field dynamics’), then taking the time derivative, then dividing by the mean phage clone size. (In principle, this is equivalent to first taking the time derivative of each individual clone trajectory and then averaging across all trajectories, but we found that edge effects from trajectories that go extinct skewed the result, so we first average across all trajectories before taking a derivative.) Phage clone fitness over time in a single simulation is plotted in Figure 3—figure supplement 1 (orange markers).
We calculate the theoretical phage clone fitness by taking the time derivative of the predicted mean phage clone size and dividing by the predicted mean clone size. The predicted mean phage clone size is piecewise-defined at short times as the numerical solution of the system of Equations 21 and 22, and at long times as the numerical solution steady-state clone size (Equation 26). This prediction is plotted as a solid black line in Figure 3—figure supplement 1.
New phage mutants have a positive growth rate on average (initial fitness >0), and their growth rate drops to zero on average as bacteria acquire matching spacers and gain immunity to new mutants. We can define the time or size at which phage clones become ‘established’, after which they are safe from rapid stochastic extinction and behave like neutral clones (having a fitness that is close to 0). We define one minus the long-time limit of the probability of phage clone extinction (Equation 159) as the probability of establishment for new phage clones:
(114)
where is the average initial growth rate of phage clones and is the average initial death rate of phage clones (more in ‘Phage clone probability of extinction’). The establishment clone size can then be defined as the value of for which . Since is not necessarily small, we approximate as an exponential function and set as the scale of the exponent:
(115)
Equation 115 is the size at which phage clones become established on average (where ). This is plotted as a horizontal dashed line for one simulation in Figure 3—figure supplement 1. If (birth-death with no bursts and positive selection), then . This is the expected result for a simple birth-death process with selection as given in Desai and Fisher, 2007.
We can also find the time at which phage clones reach the establishment size. In the absence of matching bacterial spacers, new phage mutants grow deterministically as . We condition on survival by dividing by the probability of establishment; for this calculation we use the long-time probability of establishment given by Equation 156 with and . This curve does not match the measured growth at short times, but in the region of phages reaching their establishment size it agrees well (solid pink line in Figure 10).
With these assumptions, the growth curve for phage clones is
(116)
Replacing with the establishment clone size (115) and solving for , we find
(117)
Now , so the second logarithm can be approximated as .
(118)
We can further approximate by dropping the second term entirely since .
(119)
We get the same approximate value of if we take directly and assume . Equation 119 is also numerically close to the mean establishment time calculated by Desai and Fisher for positive selection, (where ) Desai and Fisher, 2007. This implies that the presence of a burst size does not dramatically change the dependence of the time to establishment on phage fitness. The phage growth rate s0 does still depend on , however. (Note that Desai and Fisher define establishment time differently than we do, so our cases are not directly comparable.) Equation 119 is plotted as a vertical dashed line in Figure 3—figure supplement 1.
The initial fitness f0 of a new phage mutant can be computed analytically by using a different early-time approximation for , this time conditioning on survival using the short-time approximation for given by Equation 163.
(120)
To estimate the initial fitness, we differentiate 120 with respect to , divide by to get the per-capita growth rate, and evaluate at :
(121)
Interestingly, if we had not conditioned on survival, the initial per-capita growth rate would simply be s0: conditioning on survival increases the apparent growth rate of phage clones by effectively ignoring their death rate.
We can evaluate in terms of our original parameters for insight. We replace with to capture the decrease in phage growth clone growth due to mutations away from a clone.
(122)
The initial fitness does not directly depend on characteristics of CRISPR immunity such as and because new phage mutants see the bacterial population as if it did not have any CRISPR immunity; f0 depends only on the total bacterial population size (Appendix 3—figure 1).
Appendix 3—figure 1
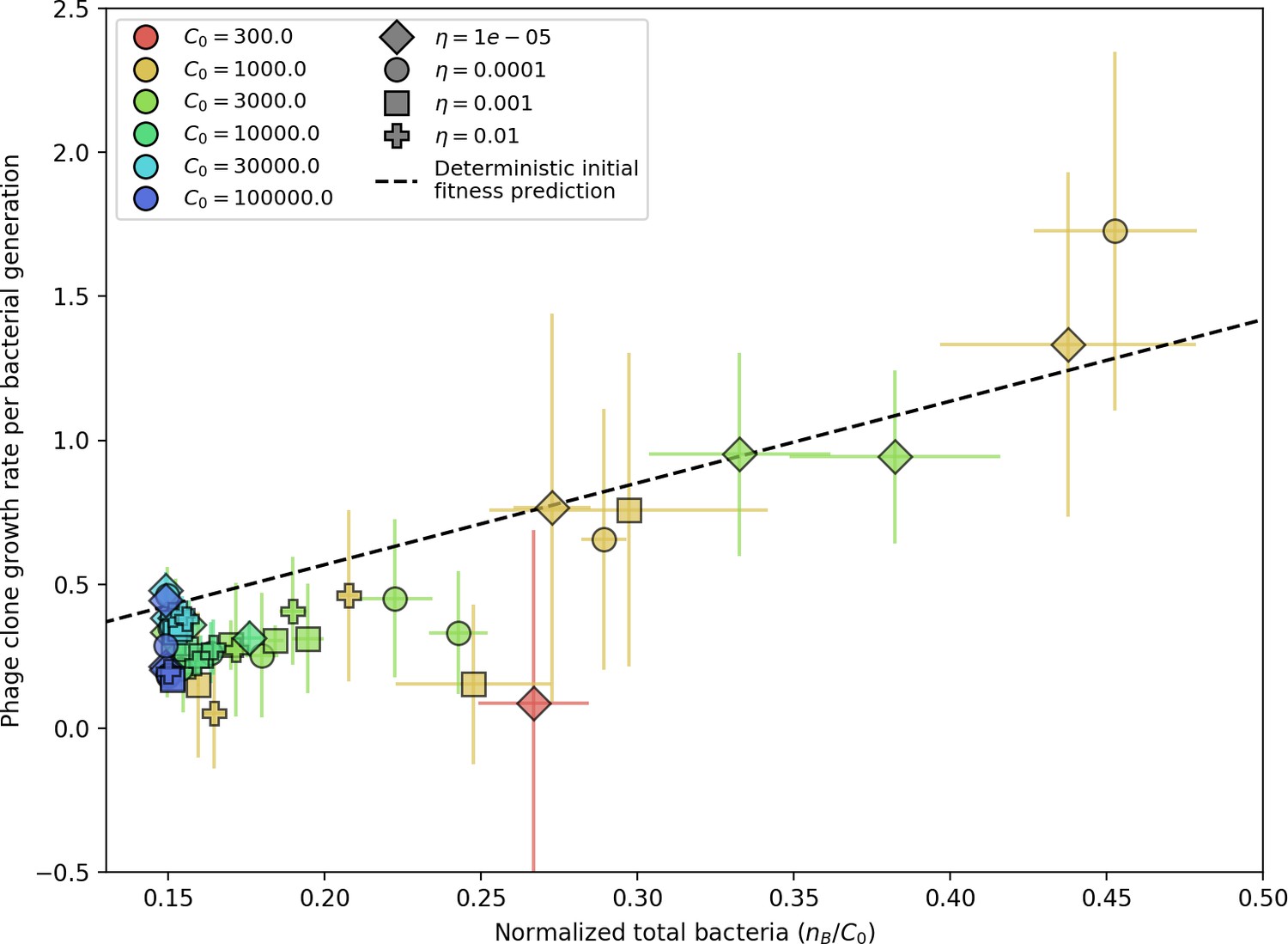
Phage clone initial growth rate vs. total bacteria normalized by the initial nutrient concentration C0.
Phage clone growth rate is as defined in Figure 3—figure supplement 1; for each simulation, the average phage clone growth rate is the derivative of the average phage clone size, averaged across all trajectories after steady state; plotted points and error bars are the average across three or more simulations. The phage initial fitness depends slightly on the phage mutation rate (mutants decrease the growth rate of a particular phage clone), but this dependence is slight enough that all mutation rates collapse onto the theoretical line. Here we plot data with . The phage clone initial growth rate also does not depend on or because new phage mutants see the bacteria population as if it did not have any CRISPR immunity. The theoretical initial phage clone growth rate is given by Equation 122. The effective lower bound of is set by the steady-state population size without CRISPR immunity: .
Bacteria clone dynamics
In this section, we calculate clone size distributions for bacteria and the time to extinction for bacterial clones. Clone size distributions from simulations are shown in Figure 2A.
To solve for the dynamics of individual bacteria clones, we write a one-dimensional master equation just for (Equation 123).
(123)
For brevity we write , the probability of having bacteria of type at time given N0 bacteria of type at .
Bacteria clone growth (), phage predation (), outflow (), and spacer loss () all depend on the number of bacteria , but spacer acquisition () adds new bacteria independent of the current size of the clone.
We assume that the total population is in steady state so that the total population sizes , , and are constant. In general, is time-dependent and varies for each clone , but we will assume that it is also constant at steady state.
This equation is very nearly identical in form to the bacteria clone size equation solved in our previous work Bonsma-Fisher et al., 2018 as well as the clone size equation described in Dessalles et al., 2022, and we repeat our derivation of the solution here in brief.
We solve Equation 123 using a generating function approach: . Multiplying Equation 123 by , we get the corresponding generating function partial differential equation:
(124)
Here and are the birth and death rates for bacterial clones: and . is the rate of spacer acquisition from naive bacteria: .
We solve Equation 124 using the method of characteristics Van Kampen, 1981. We parameterize the function with a new variable . Applying the chain rule:
(125)
Comparing Equation 124 with Equation 125 gives the following characteristic equations:
(126)
(127)
(128)
From Equation 126, we see , so we can choose and replace with going forward. Solving the characteristic equation for by integrating both sides gives Equation 129.
(129)
At , will pass through some point z0, so we have the initial condition . With z0 in Equation 129 at , we get Equation 130, where c2 is given by Equation 129.
(130)
The variation of along the curve is
(131)
Integrating both sides, we get
The constant is a function of the characteristic - curve (Equation 129). To find the particular form of , we apply the initial condition which gives , meaning that the clone starts at size N0 at time .
Let , therefore .
Solving for :
The full solution for can be written by replacing the constant with the expression for and replacing with , where is the time-dependent part of the curve.
Finally, replacing with , we get
, meaning that the total probability is conserved. Assuming , the limit as of is
The limit is independent of the initial clone size N0 as we expect. We can construct at steady state by taking successive derivatives of
(132)
This is a negative binomial distribution with parameters and . We can re-write this expression using Stirling’s approximation for to facilitate evaluation at large .
(133)
Equation 133 is an analytic expression describing the steady-state spacer abundance distribution that results from our simulations. To compare this prediction with our simulations, we assume that on average is equal to , where is the predicted total phage population size and is the number of large phage clones approximated by the predicted bacterial diversity.
Appendix 3—figure 2 compares the analytic distribution to the steady-state spacer clone size distribution from our simulations at several values of the spacer acquisition probability . The theoretical prediction captures the qualitative impact of increasing fairly well: as increases, the clone size distribution gains a more pronounced peak.
The discrepancy between the theoretical prediction and simulation data at high results in part from the predicted large phage clone size being larger than the measured large phage clone size in simulations. This can happen when the predicted number of clones is smaller than the simulation result. To assess whether this influenced our prediction, we also used maximum likelihood estimation to calculate the value of that gave the best fit between Equation 133 and the data; for the two largest values of , this does return a smaller value of and hence a distribution peak further to the left.
The previous two calculations assumed that the phage clone size is single-valued and constant in time. In reality, however, the phage clone size is both broadly distributed (Figure 24) and changing in time (Figure 3—figure supplement 1). We relax the first assumption by calculating an average bacterial distribution using the observed distribution of phage clones: we solve Equation 133 at each observed large phage clone size, then average across the distribution of clone sizes to calculate . (The large phage clone distribution is given by Equation 28.) This average distribution more accurately predicts the presence of small bacterial clones at high , but it actually behaves worse than the single- solution at small . This is related to the deviation of the number of large phage clones from the number of bacterial clones at small (Figure 22): at small , bacteria do not acquire spacers as readily and so phage clones experience clonal interference largely without bacterial influence. The average distribution then predicts more small bacterial clones than there are because the large phage clone distribution includes intermediate phage clone sizes that the bacteria do not end up acquiring spacers from. Essentially, the bacteria ‘see’ fewer phage clones than the theory predicts, so the observed bacteria clone size distribution has fewer smaller clones than predicted.
Equation 133 can be approximated for large as a gamma distribution:
(134)
Appendix 3—figure 2
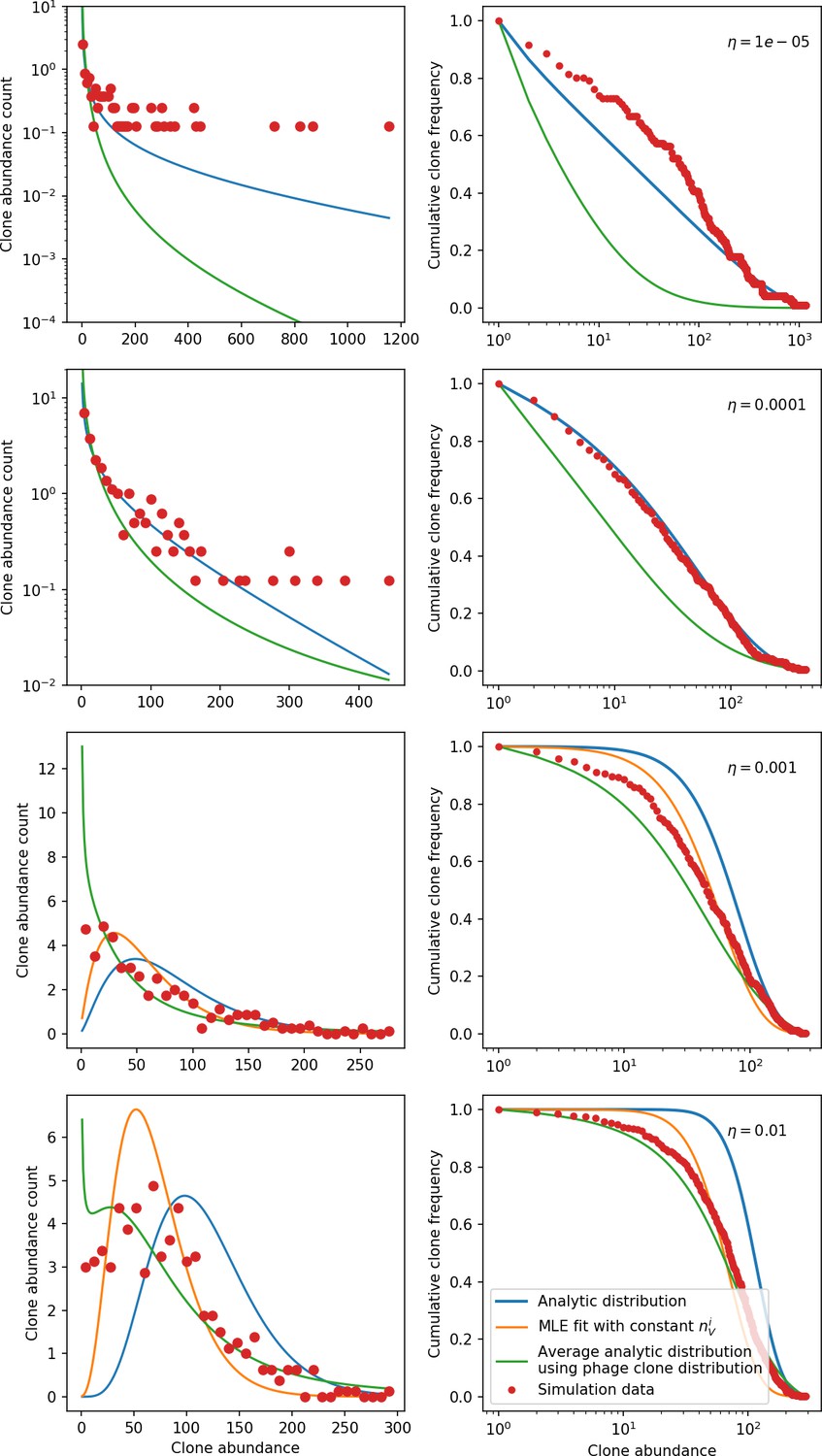
Clone size histograms (left) and cumulative distributions (right) for four different values of the spacer acquisition probability .
In all simulations, , , and . We sample 30 evenly spaced time points between 2000 and 10,000 bacterial generations and combine the clone sizes at each of the sampled points to create the clone size distributions plotted. Solid lines show three different theoretical solutions. The solid blue line is given by Equation 133 with all population quantities predicted from solving the system of Equations 13–17 with given by Equation 32 and . The solid orange line is given by Equation 133, with the value determined by maximum likelihood estimation (MLE) to give the best fit to the data. For the two largest values of , the value of returned by the MLE fit is smaller than the theoretical value of , while for the two smallest values of the MLE value of is larger. For large enough values of , the bacteria clone death rate is smaller than the birth rate which violates the assumptions used to derive Equation 133. This happens for the MLE fit at the two smallest values and hence no MLE solution is plotted. The solid green line is an average distribution calculated by solving Equation 133 at each observed large phage clone size and averaging across the distribution of clone sizes; i.e. . The large phage clone distribution is given by Equation 28.
This is a gamma distribution with shape parameter and rate parameter . Note that , consistent with the canonical form of the gamma distribution. The shape parameter describes the relative balance between spacer acquisition and growth: if , then spacer acquisition is the dominant means by which bacterial clones grow. This often also means that the clone size distribution has a peak at clone size gt1 (provided ). Specifically, the mode of the distribution is greater than 1 if . The rate parameter describes the decay constant of the exponential distribution resulting if the shape parameter equals 1.
Bacteria clone extinction
When a matching phage clone exists in the population, bacteria with a particular spacer have a fitness advantage if they encounter that phage. Once the matching phage goes extinct, bacteria tend to quickly go extinct as well; in fact, bacteria often go extinct before their matching phage clone (Appendix 3—figure 3). To understand why this might be, we derive a theoretical prediction for the mean time to extinction under the assumption that bacterial clones evolve neutrally once they become large. This prediction does describe the extinction time distribution well in some regimes, but it underestimates the time to extinction at large total population sizes. If the neutral assumption is valid, this means that bacterial clones go extinct stochastically and are not necessarily driven to extinction by the extinction of their matching phage clone. This is true at small-to-medium total population sizes (). On the other hand, when population sizes are large, bacteria clones go extinct more slowly than neutral theory would predict, likely because they are still being challenged by a matching phage and are also able to acquire spacers from that phage clone.
Appendix 3—figure 3
Bacteria and phage clone trajectories aligned to the time at which bacteria trajectories go extinct.
Bacteria trajectories are included if they reach size given by Equation 25 and all corresponding phage trajectories are plotted. In this simulation , , , and .
We calculate the time to extinction using the backward master equation corresponding to Equation 123. The backward equation is an equation for the time to extinction from a given state. Instead of working with frequencies, we write this in terms of the number of bacteria belonging to a clone, . Here , , and .
(135)
Notice that the rate terms in the backward equation depend only on , not on or like in the forward master equation. The forward equation is a sum of all the ways in which the system could end up at state at time from where it could have been at time , so those rates depend on the other states. The backward equation goes in the other direction, looking backwards: it is a sum of all the ways in which the system could have been in state at time now that time has elapsed.
Rearranging Equation 135, we arrive at Equation 136.
(136)
For boundary conditions, we have (time to extinction is 0 when already extinct) and (reflecting boundary at ). The reflecting boundary is harder to justify because in reality is a flexible upper limit on clone size, but in steady state when is approximately constant, it is true that no single clone will grow larger than .
To solve Equation 136, we expand about and keep terms up to 2nd order to get the Fokker–Planck equation:
(137)
To get an approximate solution, we drop the drift term, assuming that when clones are large their net growth rate is approximately zero so (this is the same as setting in Equation 22). This gives the following differential equation:
(138)
The solution to Equation 138 with the boundary conditions described above is
(139)
Equation 139 with is plotted in Appendix 3—figure 4, Appendix 3—figures 5–7 and Appendix 3—figure 10. We also solved the full Fokker–Planck equation numerically without assuming the drift term is 0 (Equation 137). In this numerical solution, we change the value of for different values of to reflect the fact that at small bacteria clone sizes phage clones also tend to be smaller; we use the numerical solutions for average and shown as dashed lines in Figure 3—figure supplement 1. This solution is shown in Appendix 3—figure 3.
Appendix 3—figure 4
Mean time to extinction for bacterial clones after reaching size as a function of for , , and .
The solid line is given by Equation 139 with , and the dashed line is given by numerically solving Equation 137.
Approximate time to extinction
Since we are interested in the time to extinction once bacterial clones reach a large size, we can substitute in Equation 139 to gain insight into the time to extinction for bacteria. The average clone size .
(140)
We can substitute values for using the steady-state deterministic solution for and assuming :
(141)
To approximate the extinction time expression, we decompose , , and into series expansions in , i.e. . We substitute these expressions into Equation 140 and perform an overall series expansion in . The zeroth-order term is shown here and plotted in Appendix 3—figure 3B, and the solution to first order is plotted in Appendix 3—figure 3A.
(142)
This expression remains unwieldy, so we also do a series expansion in and keep the zeroth-order term (equivalent to setting ). Spacer loss is not the dominant death rate for spacer-containing clones; the rate of spacer loss we use is an order of magnitude lower than the rate of cell death due to outflow (). This expression becomes very simple:
(143)
We can write Equation 143 in terms of total population sizes without CRISPR ( and ) to gain insight.
(144)
If average immunity is low, then (from the mean-field equation for ).
(145)
Equation 143 is compared to the measured time to extinction in Appendix 3—figure 3C. It is not a good approximation for low , but at the two highest values of it captures the trend reasonably well. The dependence of bacterial time to extinction on clone size (Equation 145, dropping the term) is shown in Appendix 3—figure 3.
Interestingly the dependence on in this approximate expression is identical to the dependence on in the phage extinction approximation (Equation 67). Furthermore, there is also a proportionality to the mean clone size in the form in the bacteria extinction equation (since if , which is why this approximation works best at high when is closer to 1). This is reasonable considering that the dynamics of bacteria and phage are ultimately matched to each other at steady state. This expression still depends on , which is an emergent quantity dependent on all other parameters as well. We apply the approximation for from 'Approximation for ' for more insight.
(146)
This simplified expression for time to extinction gives insight into the main drivers of extinction. Perhaps counterintuitively, the bacteria clone time to extinction decreases as the growth rate increases — a higher growth rate means faster dynamics overall and lower time to extinction. Note, however, that a higher growth rate (for instance, with larger C0) also leads to larger .
Bacteria extinction depends inversely on , , , , and , with the time to extinction decreasing with all parameters except the spacer loss rate . The bacteria time to extinction increases with increasing flow rate .
Phage clone dynamics
In this section, we calculate the probability of establishment for new phage mutants and the time to extinction for large phage clones. The phage establishment probability is a core component of our calculation of diversity in 'Phages drive stable emergent sequence diversity' and is explored on its own in 'What determines the fitness and establishment of new mutants?'. The phage time to extinction is also related to the speed of phage evolution in Figure 6, 'Dynamics are determined by diversity'.
To solve for the dynamics of individual phage clones, we can write a one-dimensional master equation just for (Equation 147). Here we neglect mutations; we assume that mutations are rare and a burst always contributes to the clonal population being tracked. This master equation is a birth-death master equation with bursts – it is in the form of a classic birth-death master equation except that the population grows with a jump of size . is the probability of having phages of type at time given N0 phages of type at .
(147)
Phage clone probability of extinction
Equation 159 is the basis for our prediction of phage establishment probability (Equation 114).
We can find the probability of extinction P0 for new phage mutants under the assumption that and are constant using Equation 147. We solve this equation using a generating function approach: . Multiplying Equation 147 by , we get the corresponding generating function partial differential equation:
(148)
Here where and are the birth and death rates for phage mutants: and . We distinguish two cases of constant , valid at early times after phage mutation, and , the deterministic steady-state value of given by Equation 25, valid at long times after phage mutation. When we are assuming , we use and .
We solve Equation 148 using the method of characteristics:
(149)
This gives the following characteristic equations:
(150)
(151)
Integrating these two equations, we get , and
(152)
The initial phage clone size is N0. The initial condition is
The last equality is from the method of characteristics: the solution for at the initial condition gives the full solution which is constant as parameterized by .
The probability of extinction is given by setting in .
where solves Equation 153, which we obtain by setting in Equation 152 and replacing with , since .
(153)
Long-time approximation for
To approximate at long times, we notice that since extinction probability becomes large at , then the large- limit corresponds to .
The denominator of Equation 153 will be smallest when is near 1, so the largest contribution to the integral will come from near 1. Expanding the denominator to second order with , where is small:
Changing back to the variable and substituting back into Equation 153, the integral becomes
(154)
which when evaluated gives
(155)
(156)
where is in units of minutes and we introduce the variable (and ). The parameter is the average growth rate of phage clones. When phage mutants first appear and , this corresponds to and we write . As , .
The limit of 155 is
(157)
The long-time limit of 156 is
(158)
For a phage clone that begins at size and for which there are no matching bacterial clones (), Equation 159 gives the probability of that clone going extinct.
(159)
If (a return to a simple birth-death equation where the population grows and dies by increments of 1), Equation 156 becomes
(160)
This is the expected probability of extinction for a simple birth-death process with selection given in Desai and Fisher, 2007. (Note that time can be rescaled so that .)
The long-time limit of 160 is
(161)
This is the expected limit for the extinction probability for a simple birth-death process with selection. As , the probability of extinction goes to 1.
Note that the probability of extinction for (Equation 158) is larger than for (Equation 161). Somewhat paradoxically, this implies that one effect of the burst size is to increase the probability of extinction for new phage mutants. This happens because bursts are infrequent events; on average, death events must occur for every one birth event, making death a more common stochastic outcome. The extinction probability for is times greater than for . Expanding in for large , this is .
Small-time approximation for
When is small, P0 will be close to 0, which means will be close to 0 and therefore we can approximate as being near 0.
The denominator simplifies to for small , and we get
(162)
(163)
Long-time approximation for with no selection
In the above derivations of the probability of phage clone extinction, we generally assumed that phages had a selective advantage because there were no bacteria with matching spacers at the time a phage clone arose by mutation. If instead a phage clone does not have a selective advantage, this corresponds to , or is exactly where is given by the mean-field steady state with no CRISPR; in other words, phage clones do not have a selective advantage if the population is in steady state and there is no CRISPR immunity to distinguish clones from each other.
Expanding the denominator with as before:
When , the first two terms cancel out. We get the integral
(164)
which gives
(165)
Equation 165 is equivalent to Equation 157, assuming . This is true when , since corresponds to .
Appendix 3—figure 5
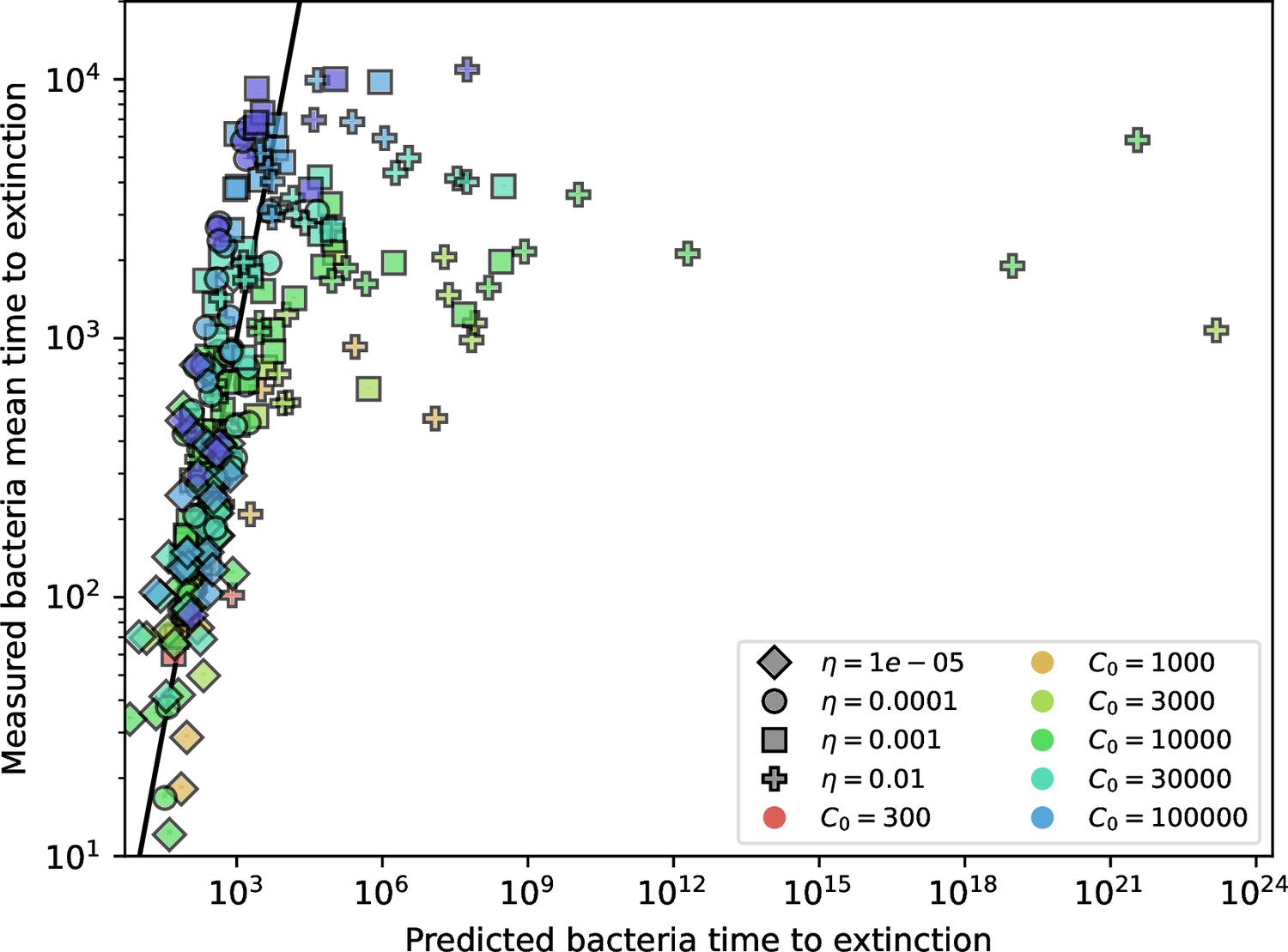
Predicted bacteria clone time to extinction with drift.
Measured vs. predicted mean time to extinction for bacterial clones after reaching size . The predicted time to extinction is the solution with drift, given by numerically solving Equation 167.
Neutral time to extinction from backward master equation
The phage time to extinction calculated here is compared to the speed of phage evolution in Figure 6, 'Dynamics are determined by diversity'.
We can calculate the time to extinction using the backward master equation corresponding to Equation 147. The backward equation is an equation for the time to extinction from a given state. Instead of working with frequencies, we write this in terms of the number of phages belonging to a clone, . Here and .
(166)
Rearranging Equation 166, we arrive at Equation 167.
(167)
For boundary conditions, we have (time to extinction is 0 when already extinct) and (reflecting boundary at ). As with bacteria clones, we assume here that the upper limit on phage clone size is constant at at steady state.
To solve Equation 167, we expand about and keep terms up to second order to get the Fokker–Planck equation:
(168)
At steady state and for large clones, , which means clones are approximately neutral and we can drop the drift term:
(169)
This is a straightforward second-order ordinary differential equation, which has the solution
(170)
Using the boundary condition , the constant . Using the second boundary condition, , and the full solution is
(171)
Once phage clones become large (by reaching size as given by Equation 26), they behave neutrally and Equation 171 agrees well with observed extinction times in simulations. We set and use the deterministic steady-state clone size for given by Equation 25 in and . Appendix 3—figure 9 compares observed large clone extinction times in a simulation (blue) to the prediction given by Equation 171 (orange dashed). Predicted and measured times to extinction for many simulations with Equation 171 are shown in Appendix 3—figure 10.
If , which it is at steady state, we can rewrite Equation 171 as:
(172)
Appendix 3—figure 6
Approximations for bacteria clone extinction.
Measured mean time to extinction for large bacterial clones vs. three successively more aggressive analytic approximations for the mean time to extinction. (A) The predicted time to extinction is given by taking a series expansion in and keeping terms to 1st order. (B) A series expansion in and keeping the 0th order term () only. (C) Series expansion in and and keeping the 0th order term only (Equation 143).
Appendix 3—figure 7
Approximations for bacteria clone extinction as a function of mean clone size.
Bacteria extinction time as a function of mean clone size. Large bacteria clone mean time to extinction as a function of , where is measured from simulations and is the total bacteria population size. This parameter combination describes the trend in both phage and bacteria extinction reasonably well at large values of (bottom panels). The solid line is given by Equation 145 without the $1 + \ln m$ term.
The factor comes from the integral of the second-order differential equation and from the reflecting boundary assumption, and interestingly it would happen even if (no burst): integrating the Fokker–Planck equation gives a factor of ; if we start from the steady-state value of , this becomes . Applying the reflecting boundary at cancels out the term. Very simply: the integral we are solving is , and this gives up to some constants. This simplified expression for time to extinction gives insight into the main drivers of extinction. The phage time to extinction decreases as the outflow rate increases — if phages die at a higher rate, they go extinct more quickly. Interestingly, a larger burst size decreases the time to extinction for large phage clones, consistent with an overall increase in the size of fluctuations as the burst size increases.
This expression still depends on , which is an emergent quantity dependent on all other parameters as well. We apply the approximation for from ‘Approximation for for more insight.
(173)
Comparing with Equation 146 for bacteria, both phage and bacteria extinction depend inversely on , , , , and , with the time to extinction decreasing with all parameters except the spacer loss rate . The bacteria time to extinction increases with increasing flow rate , while the phage time to extinction decreases with .
The clone size dependence of phage extinction is shown in Appendix 3—figure 11, comparing measured extinction times to the prediction of Equation 172 without the term. This captures the dominant trend in extinction time behaviour.
Appendix 3—figure 8
Phage clone extinction times and theoretical predictions for a simulation with parameters .
Time zero for each trajectory is the time at which that clone arose by mutation. All simulation trajectories are plotted in blue, and a subset of trajectories that do not reach a size of as given by Equation 26 are plotted in orange. Trajectories that do not become established by this definition go extinct more quickly than ones that do. All other curves are theoretical predictions for the extinction time. The green and red solid lines and purple and brown dashed lines show a numerical solution to Equation 153 with different values for . The remaining dashed lines are a small time approximation given by Equation 163, and a large time approximation given by Equation 156 with either or . All of these predictions agree with the simulation data in different regimes; none accurately captures the entire timecourse of extinctions.
Appendix 3—figure 9
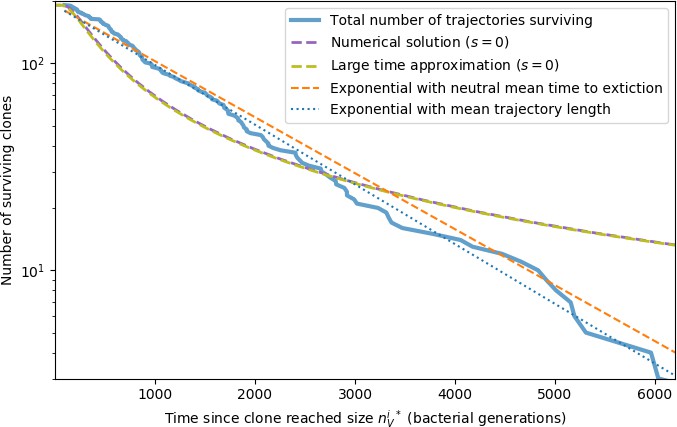
Large clone extinction times from a simulation with parameters .
Trajectories are counted as large if the phage clone size passes , the theoretical deterministic mean phage clone size for these parameters given by Equation 26. Once a trajectory reaches , we count that point as time zero to measure the extinction time of large clones. The numerical solution is given by solving Equation 153 with (). The large time approximation is given by Equation 157. The orange dashed line gives an exponential decay prediction with the mean time to extinction given by Equation 171 with .
Appendix 3—figure 10
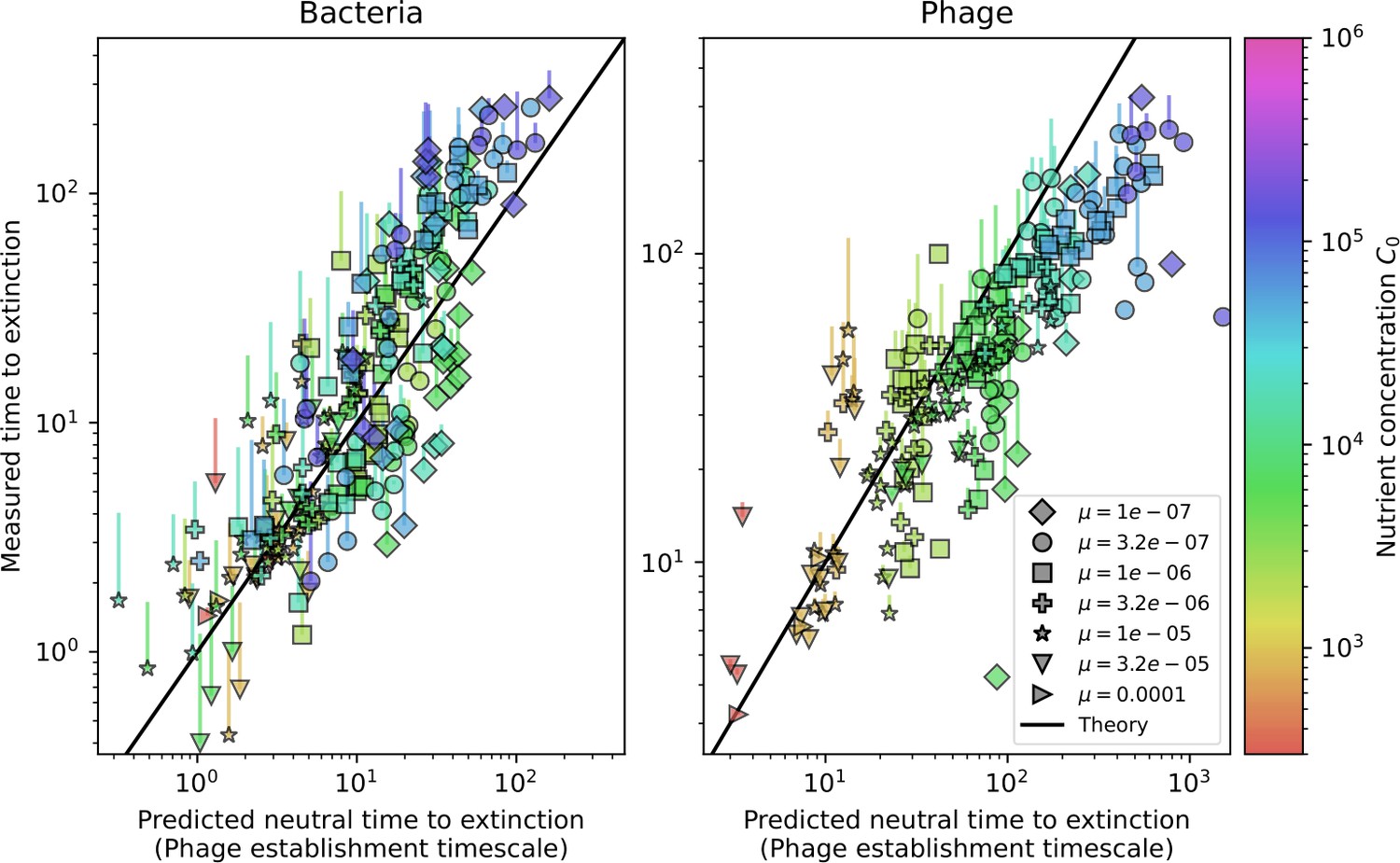
Mean time to extinction for large bacteria (left) and phage (right) clones as a function of the neutral fitness mean time to extinction prediction.
The solid black lines describe approximate analytic expressions for bacteria and phage time to extinction using a neutral fitness assumption. For bacteria, the black line solves Equation 139 using the mean bacteria and phage clone sizes. For phages, the black line solves Equation 171 using the mean phage clone size in place of .
Appendix 3—figure 11
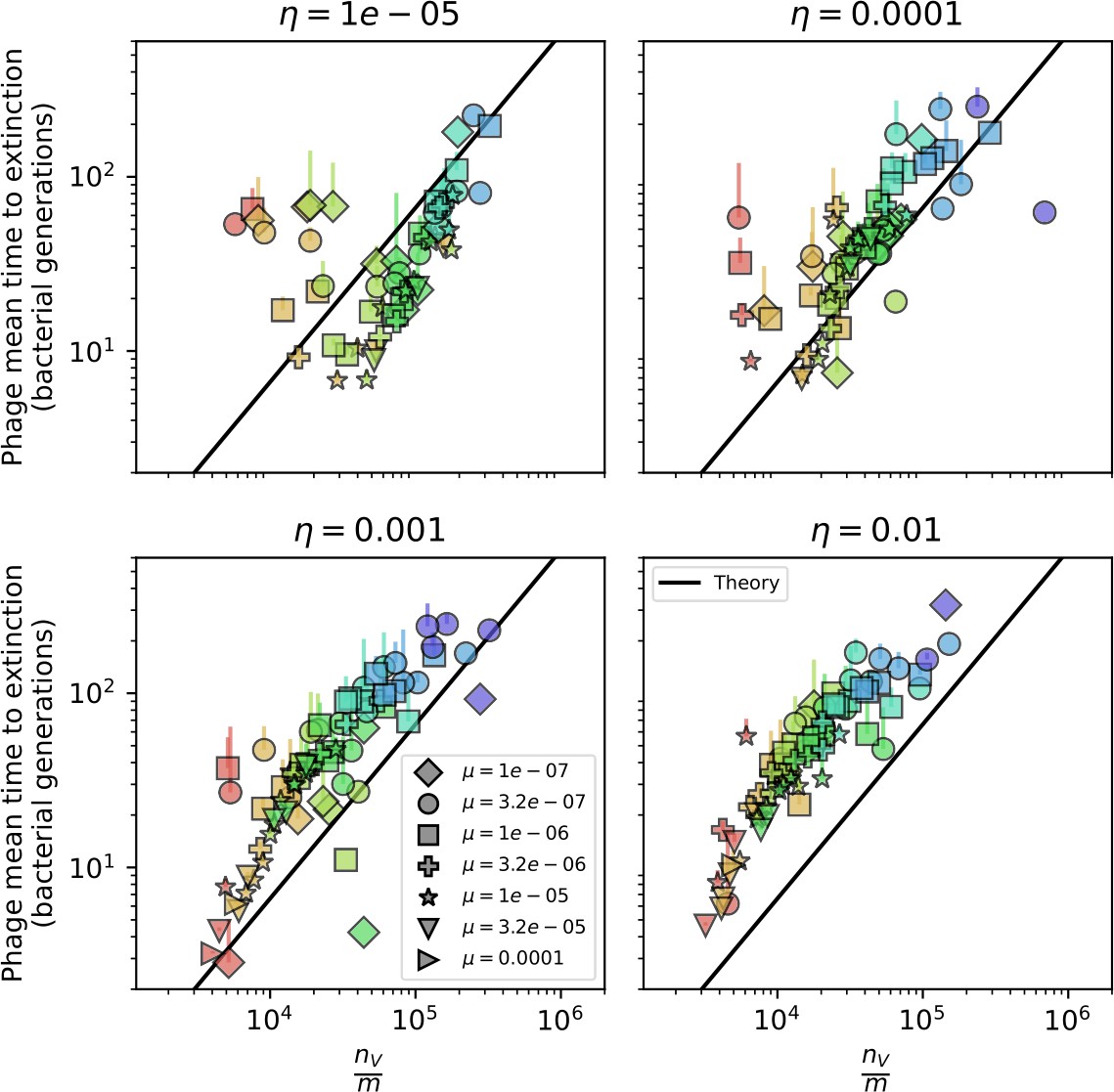
Phage extinction time as a function of mean clone size.
Large phage clone mean time to extinction as a function of , where is measured from simulations and is the total phage population size. The solid line is given by Equation 172 without the term.
Data availability
We analysed published genetic data from three sources: PRJNA268031 (Burstein et al., 2016), PRJNA275232 (Paez-Espino et al., 2015), and PRJNA484416 (Guerrero et al., 2021a). We also used phage genomes associated with Guerrero et al., 2021a available on GitHub at https://github.com/GuerreroCRISPR/Gordonia-CRISPR (Guerrero et al., 2021b). Processed spacer and protospacer sequences for all datasets, along with source code and data for all main text figures, is available on GitHub at https://github.com/mbonsma/CRISPR-dynamics-model (copy archived at Bonsma-Fisher and Goyal, 2023). Raw simulation data has been uploaded to Dryad: https://doi.org/10.5061/dryad.sn02v6x74.
-
Dryad Digital RepositorySimulation data from: Dynamics of immune memory and learning in bacterial communities.https://doi.org/10.5061/dryad.sn02v6x74
-
NCBI BioProjectID PRJNA268031. Rifle, CO metagenome from aquifer.
-
NCBI BioProjectID PRJNA275232. Streptococcus thermophilus infected with lytic phage 2972.
-
NCBI BioProjectID PRJNA484416. Time series genome centric analysis in activated sludge microbial communities.
References
-
Microbial communities display alternative stable states in a fluctuating environmentPLOS Computational Biology 16:e1007934.https://doi.org/10.1371/journal.pcbi.1007934
-
Quantitative immunology for physicistsPhysics Reports 849:1–83.https://doi.org/10.1016/j.physrep.2020.01.001
-
Effects of niche overlap on coexistence, fixation and invasion in a population of two interacting speciesRoyal Society Open Science 7:192181.https://doi.org/10.1098/rsos.192181
-
Evolution of virulence in emerging epidemicsPLOS Pathogens 9:e1003209.https://doi.org/10.1371/journal.ppat.1003209
-
The pan-immune system of bacteria: antiviral defence as a community resourceNature Reviews. Microbiology 18:113–119.https://doi.org/10.1038/s41579-019-0278-2
-
SoftwareCRISPR-dynamics-model, version swh:1:rev:af68da75b617e30d744318fb88f29db2888e3a97Software Heritage.
-
Dynamics of adaptive immunity against phage in bacterial populationsPLOS Computational Biology 13:e1005486.https://doi.org/10.1371/journal.pcbi.1005486
-
Cost and benefits of clustered regularly interspaced short palindromic repeats spacer acquisitionPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 374:20180095.https://doi.org/10.1098/rstb.2018.0095
-
Immigration of susceptible hosts triggers the evolution of alternative parasite defence strategiesProceedings. Biological Sciences 283:20160721.https://doi.org/10.1098/rspb.2016.0721
-
The effects of thymic selection on the range of T cell cross-reactivityEuropean Journal of Immunology 35:3452–3459.https://doi.org/10.1002/eji.200535098
-
Multiscale model of CRISPR-induced coevolutionary dynamics: diversification at the interface of Lamarck and DarwinEvolution; International Journal of Organic Evolution 66:2015–2029.https://doi.org/10.1111/j.1558-5646.2012.01595.x
-
Trade-Offs in antibody repertoires to complex antigensPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 370:1–10.https://doi.org/10.1098/rstb.2014.0245
-
Crispr-cas immunity leads to a coevolutionary arms race between streptococcus thermophilus and lytic phagePhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 374:20180098.https://doi.org/10.1098/rstb.2018.0098
-
Diversity in CRISPR-based immunity protects susceptible genotypes by restricting phage spread and evolutionJournal of Evolutionary Biology 33:1097–1108.https://doi.org/10.1111/jeb.13638
-
Type I-F CRISPR-cas distribution and array dynamics in legionella pneumophilaG3: Genes, Genomes, Genetics 10:1039–1050.https://doi.org/10.1534/g3.119.400813
-
Adsorption of bacteriophage under various physiological conditions of the hostThe Journal of General Physiology 23:631–642.https://doi.org/10.1085/jgp.23.5.631
-
Phage response to CRISPR-encoded resistance in Streptococcus thermophilusJournal of Bacteriology 190:1390–1400.https://doi.org/10.1128/JB.01412-07
-
Multiyear time-shift study of bacteria and phage dynamics in the phyllosphereThe American Naturalist 199:126–140.https://doi.org/10.1086/717181
-
Optimal immune specificity at the intersection of host life history and parasite epidemiologyPLOS Computational Biology 17:e1009714.https://doi.org/10.1371/journal.pcbi.1009714
-
Toytree: a minimalist tree visualization and manipulation library for pythonMethods in Ecology and Evolution 11:187–191.https://doi.org/10.1111/2041-210X.13313
-
Time-Shift experiments as a tool to study antagonistic coevolutionTrends in Ecology & Evolution 24:226–232.https://doi.org/10.1016/j.tree.2008.11.005
-
Pruning and tending immune memories: spacer dynamics in the CRISPR arrayFrontiers in Microbiology 12:664299.https://doi.org/10.3389/fmicb.2021.664299
-
Why put up with immunity when there is resistance: an excursion into the population and evolutionary dynamics of restriction–modification and CRISPR-casPhilosophical Transactions of the Royal Society B 374:20180096.https://doi.org/10.1098/rstb.2018.0096
-
Targeted bacterial immunity buffers phage diversityJournal of Virology 85:10554–10560.https://doi.org/10.1128/JVI.05222-11
-
Non-classical phase diagram for virus bacterial coevolution mediated by clustered regularly interspaced short palindromic repeatsJournal of the Royal Society, Interface 14:127.https://doi.org/10.1098/rsif.2016.0905
-
Sustainability of virulence in a phage-bacterial ecosystemJournal of Virology 84:3016–3022.https://doi.org/10.1128/JVI.02326-09
-
Diversity, activity, and evolution of CRISPR loci in Streptococcus thermophilusJournal of Bacteriology 190:1401–1412.https://doi.org/10.1128/JB.01415-07
-
Evolutionary dynamics of the prokaryotic adaptive immunity system CRISPR-Cas in an explicit ecological contextJournal of Bacteriology 195:3834–3844.https://doi.org/10.1128/JB.00412-13
-
Diversity, classification and evolution of CRISPR-Cas systemsCurrent Opinion in Microbiology 37:67–78.https://doi.org/10.1016/j.mib.2017.05.008
-
Origins and evolution of CRISPR-cas systemsPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 374:20180087.https://doi.org/10.1098/rstb.2018.0087
-
Optimal bacteriophage mutation rates for phage therapyJournal of Theoretical Biology 249:411–421.https://doi.org/10.1016/j.jtbi.2007.08.007
-
Natural diversity of CRISPR spacers of thermus: evidence of local spacer acquisition and global spacer exchangePhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 374:20180092.https://doi.org/10.1098/rstb.2018.0092
-
ThesisGenetic Diversity of Streptococcus thermophilusPhages and Development of PhD thesisSwiss Federal Institute of Technology Zurich.
-
Evolutionary classification of CRISPR-Cas systems: a burst of class 2 and derived variantsNature Reviews Microbiology 18:67–83.https://doi.org/10.1038/s41579-019-0299-x
-
Optimal number of spacers in CRISPR arraysPLOS Computational Biology 13:e1005891.https://doi.org/10.1371/journal.pcbi.1005891
-
Demographically framing trade-offs between sensitivity and specificity illuminates selection on immunityNature Ecology & Evolution 1:1766–1772.https://doi.org/10.1038/s41559-017-0315-3
-
How many different clonotypes do immune repertoires contain?Current Opinion in Systems Biology 18:104–110.https://doi.org/10.1016/j.coisb.2019.10.001
-
Host diversity limits the evolution of parasite local adaptationMolecular Ecology 26:1756–1763.https://doi.org/10.1111/mec.13917
-
Fierce selection and interference in B-cell repertoire response to chronic HIV-1Molecular Biology and Evolution 36:2184–2194.https://doi.org/10.1093/molbev/msz143
-
Strong bias in the bacterial CRISPR elements that confer immunity to phageNature Communications 4:1430.https://doi.org/10.1038/ncomms2440
-
Searching for fat tails in CRISPR-Cas systems: data analysis and mathematical modelingPLOS Computational Biology 17:e1008841.https://doi.org/10.1371/journal.pcbi.1008841
-
Inferring the immune response from repertoire sequencingPLOS Computational Biology 16:e1007873.https://doi.org/10.1371/journal.pcbi.1007873
-
Antigenic evolution of viruses in host populationsPLOS Pathogens 14:e1007291.https://doi.org/10.1371/journal.ppat.1007291
-
Assessing niche separation among coexisting Limnohabitans strains through interactions with a competitor, viruses, and a bacterivoreApplied and Environmental Microbiology 76:1406–1416.https://doi.org/10.1128/AEM.02517-09
-
Ecological memory preserves phage resistance mechanisms in bacteriaNature Communications 12:6817.https://doi.org/10.1038/s41467-021-26609-w
-
Crass: identification and reconstruction of CRISPR from unassembled metagenomic dataNucleic Acids Research 41:e105.https://doi.org/10.1093/nar/gkt183
-
DendroPy: a python library for phylogenetic computingBioinformatics 26:1569–1571.https://doi.org/10.1093/bioinformatics/btq228
-
Phage mutations in response to CRISPR diversification in a bacterial populationEnvironmental Microbiology 15:463–470.https://doi.org/10.1111/j.1462-2920.2012.02879.x
-
Analytical solution of a neutral model of biodiversityPhysical Review. E, Statistical, Nonlinear, and Soft Matter Physics 68:061902.https://doi.org/10.1103/PhysRevE.68.061902
-
Different genetic and morphological outcomes for phages targeted by single or multiple CRISPR-cas spacersPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 374:20180090.https://doi.org/10.1098/rstb.2018.0090
-
Persisting viral sequences shape microbial CRISPR-based immunityPLOS Computational Biology 8:e1002475.https://doi.org/10.1371/journal.pcbi.1002475
-
Immune loss as a driver of coexistence during host-phage coevolutionThe ISME Journal 12:585–597.https://doi.org/10.1038/ismej.2017.194
-
Avoidance of self during CRISPR immunizationTrends in Microbiology 28:543–553.https://doi.org/10.1016/j.tim.2020.02.005
-
Immune lag is a major cost of prokaryotic adaptive immunity during viral outbreaksProceedings of the Royal Society B. Biological Sciences 288:20211555.https://doi.org/10.1098/rspb.2021.1555
-
Phage-bacteria infection networksTrends in Microbiology 21:82–91.https://doi.org/10.1016/j.tim.2012.11.003
-
Similarity indices, sample size and diversityOecologia 50:296–302.https://doi.org/10.1007/BF00344966
-
Rna-Seq analyses reveal CRISPR RNA processing and regulation patternsBiochemical Society Transactions 41:1459–1463.https://doi.org/10.1042/BST20130129
Article and author information
Author details
Madeleine Bonsma-Fisher

Funding
Natural Sciences and Engineering Research Council of Canada (Vanier Canada Graduate Scholarship)
- Madeleine Bonsma-Fisher
Ministry of Colleges and Universities (Queen Elizabeth II Graduate Scholarship in Science & Technology)
- Madeleine Bonsma-Fisher
Walter C. Sumner Foundation (Walter C. Sumner Memorial Fellowship)
- Madeleine Bonsma-Fisher
Natural Sciences and Engineering Research Council of Canada (Discovery Grant RGPIN-2015)
- Sidhartha Goyal
Natural Sciences and Engineering Research Council of Canada (Discovery Grant and RGPIN-2021)
- Sidhartha Goyal
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We acknowledge helpful discussions and comments from all the members of the Goyal and Zilman groups. We thank Vijay Kumar for help with extinction probability of phage clones.
Version history
- Preprint posted: July 7, 2022 (view preprint)
- Received: July 7, 2022
- Accepted: January 15, 2023
- Accepted Manuscript published: January 16, 2023 (version 1)
- Version of Record published: April 20, 2023 (version 2)
Copyright
© 2023, Bonsma-Fisher and Goyal
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 773
- views
-
- 175
- downloads
-
- 1
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Dynamics of immune memory and learning in bacterial communities
eLife 12:e81692.
https://doi.org/10.7554/eLife.81692
Further reading
-
- Computational and Systems Biology
- Physics of Living Systems
Locomotion is a fundamental behavior of Caenorhabditis elegans (C. elegans). Previous works on kinetic simulations of animals helped researchers understand the physical mechanisms of locomotion and the muscle-controlling principles of neuronal circuits as an actuator part. It has yet to be understood how C. elegans utilizes the frictional forces caused by the tension of its muscles to perform sequenced locomotive behaviors. Here, we present a two-dimensional rigid body chain model for the locomotion of C. elegans by developing Newtonian equations of motion for each body segment of C. elegans. Having accounted for friction-coefficients of the surrounding environment, elastic constants of C. elegans, and its kymogram from experiments, our kinetic model (ElegansBot) reproduced various locomotion of C. elegans such as, but not limited to, forward-backward-(omega turn)-forward locomotion constituting escaping behavior and delta-turn navigation. Additionally, ElegansBot precisely quantified the forces acting on each body segment of C. elegans to allow investigation of the force distribution. This model will facilitate our understanding of the detailed mechanism of various locomotive behaviors at any given friction-coefficients of the surrounding environment. Furthermore, as the model ensures the performance of realistic behavior, it can be used to research actuator-controller interaction between muscles and neuronal circuits.
-
- Physics of Living Systems
Termites build complex nests which are an impressive example of self-organization. We know that the coordinated actions involved in the construction of these nests by multiple individuals are primarily mediated by signals and cues embedded in the structure of the nest itself. However, to date there is still no scientific consensus about the nature of the stimuli that guide termite construction, and how they are sensed by termites. In order to address these questions, we studied the early building behavior of Coptotermes gestroi termites in artificial arenas, decorated with topographic cues to stimulate construction. Pellet collections were evenly distributed across the experimental setup, compatible with a collection mechanism that is not affected by local topography, but only by the distribution of termite occupancy (termites pick pellets at the positions where they are). Conversely, pellet depositions were concentrated at locations of high surface curvature and at the boundaries between different types of substrate. The single feature shared by all pellet deposition regions was that they correspond to local maxima in the evaporation flux. We can show analytically and we confirm experimentally that evaporation flux is directly proportional to the local curvature of nest surfaces. Taken together, our results indicate that surface curvature is sufficient to organize termite building activity and that termites likely sense curvature indirectly through substrate evaporation. Our findings reconcile the apparently discordant results of previous studies.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}