The technology is available for researchers to create a reproducible manuscript whereby calculations and graphs are generated computationally – thereby saving researcher time and avoiding human error. We are exploring ways to support life and biomedical scientists who wish to communicate their research in this way. In this post, Chris Hartgerink, a metascience researcher at Tilburg University, the Netherlands, describes how he composes a reproducible manuscript using R Markdown. If you would be interested in submitting your manuscript to eLife in R Markdown, or a similar format, please let us know by email to innovation@elifesciences.org.
Blog post by Chris Hartgerink, Tilburg University
This week, a paper that was almost three years in the making finally got published (Hartgerink et al., 2017). I feel confident about the paper and the results in it, not because it took three years to write, but because it's the output of a dynamic document that I produced using R Markdown.
A dynamic document? This means that I no longer had to manually enter all results from the data into tables or the text – the computer did it for me. All I had to do was point it in the right direction. Figures? The same! It saved me tons of time after I made the initial investment to learn how to use it. (Something else that saved me time was git version control, but that’s for another time.)
Why is this important? We are all human, and we make mistakes. And that’s okay! What matters is how we try to remedy those mistakes if they do occur. Even more importantly, if we can change the way we work in order to prevent some of them, that can help us tremendously. I think dynamic documents like R Markdown help us do so.
Markdown is a simple document language, which you can create in any text editor, including Windows Notepad and Notes for Mac. Markdown is supported in multiple tools designed to make life and work easier, including Reddit, Hypothes.is, Github and several blogging and commenting tools. The purpose of Markdown is simply to define the document structure and formatting. For example, the writer can define header levels using hash signs, and easily format text.
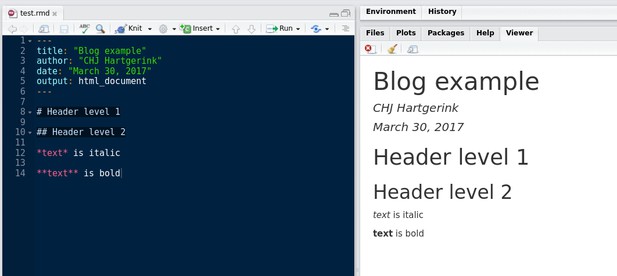
Basic syntax of Markdown.
This makes formatting as you write quick – no more buttons or keyboard shortcuts. Subsequently, the text file can be exported in multiple file formats, including PDF, html and even as a Word file to satisfy co-authors who prefer to use Word's track-changes function.
R Markdown is a flavour of Markdown: it allows you to include R code either as a code chunk between paragraphs of text, or as code within the text. This code is executable. As such, you can do analyses, make figures and format results automatically.
One problem I've worked on previously is checking the accuracy of p-values in the literature. My colleagues and I found that p-values can be mistyped or miscalculated, leading to inaccurate reporting of results, however unintentionally, in half of all papers, and leading to potential changes in the conclusions in one out of eight papers (in psychology; Nuijten et al. 2015). Enabling researchers to insert p-values via direct computation instead of manually copying results from statistical programmes will resolve this issue, for a start.
R Markdown is simple and easy to learn and use. I will show just one exciting aspect here. More extensive step-by-step guides are available. If you want to follow along, you will need to follow the steps described below.
| Step 1 | Install R from https://cran.r-project.org/ and Rstudio from https://www.rstudio.com/products/rstudio/download/ |
|---|---|
| Step 2 | In RStudio, install the R Markdown package by typing in the console: > install.packages('R Markdown') You will need to select a CRAN local to you, from which the package will be downloaded. |
| Step 3 | Once R Markdown is installed, go to File > New File > R Markdown file. This loads a new .Rmd file with a basic template already set out for you. |
Usually, we tend to type results in the running text ourselves, as depicted below. By clicking “Knit”, R Markdown creates a document (right) from a simple plain-text file (left). This is the basic function of Markdown and its associated flavours.
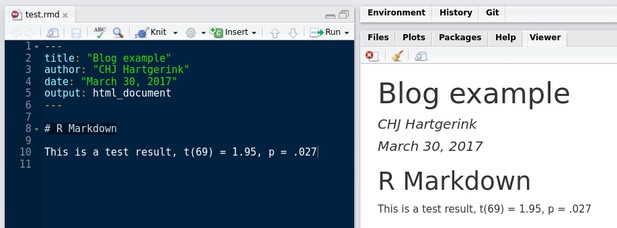
Using R Markdown to write a document.
However, in this text, we have a p-value that is calculated based on a t-value and the number of degrees of freedom. Let’s make this dynamic to ensure we have the rounding correct.
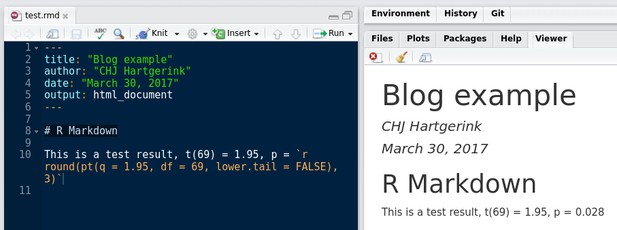
Using R Markdown to generate a document with dynamic results, to ensure accuracy of reporting and reproducibility of results.
As we see, the original contained a mistake (p = 0.027 has become p = 0.028) – using R Markdown allowed us to catch that error by using R code to generate and properly round them p-value (i.e., round(pt(q = 1.95, df = 69, lower.tail = FALSE), 3) calculates the p-value and rounds the result to three decimal places). So, there are no more mistakes, and we can be confident in our reporting. Disclaimer: of course, you can still input wrong code – garbage in, garbage out.
Further, you can generate plots from your research data within your dynamic document, demonstrated below using an example dataset pre-loaded in R (you can find more example datasets by typing data() into the console).
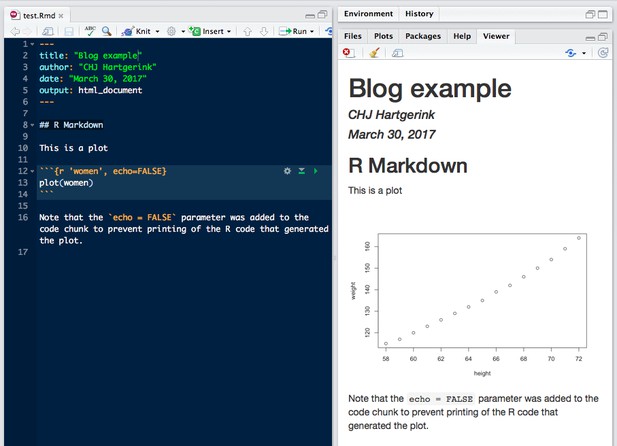
Using R Markdown to dynamically generate plots within a document.
Finally, you can even use citations and alter the citation style throughout the whole document without any problem; my experience is that it’s easier with R Markdown than with EndNote or Mendeley.
These are just simple examples. You can write entire manuscripts in this way. That’s what I did for our Collabra manuscript: you can view the raw manuscript at https://github.com/chartgerink/2014tgtbf/blob/master/submission/manuscript.Rnw. (Note: I preferred LaTeX for that project and used Sweave, which is R Markdown for LaTeX.)
Using R Markdown presents the opportunity to link results and graphs in the article directly to the data and code that produce them. All it takes is some initial time investment to learn how to work with it (Markdown can be learned in five minutes) and change your workflow to accommodate this modern approach to writing manuscripts.
A downside to working this way is that raw R Markdown files are not currently supported as a submission format by journals, meaning that we need to export our manuscripts to traditional Word or PDF formats before submitting – stripping out that rich, reproducible layer of information R Markdown facilitates. I hope dynamic documents will become more and more widespread in the future, both in how often they’re used by the authors and how publishers support this type of document, to truly innovate how scholarly information is communicated and consumed. Imagine interacting with a statistical result or graph in a research article and being presented with the underlying code – this would allow you to more directly evaluate the methods in a paper and empower you as a reader to be critical of what you are presented with.
References:
Hartgerink, C.H.J., Wicherts, J.M. and van Assen, M.A.L.M., (2017). Too Good to be False: Nonsignificant Results Revisited.Collabra: Psychology. 3(1), p.9. https://doi.org/10.1525/collabra.71
Nuijten, M. B., Hartgerink, C. H. J., van Assen, M. A. L. M., Epskamp, S., and Wicherts, J. M. (2015). The prevalence of statistical reporting errors in psychology (1985–2013).Behavior Research Methods, 48(4), pp.1205–1226. https://doi.org/10.3758/s13428-015-0664-2
This blog post is adapted from a post published by Chris Hartgerink at https://onsnetwork.org/chartgerink/2017/03/30/reproducible-manuscripts-are-the-future/.
For more R news and tutorials, please visit https://www.r-bloggers.com/.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



