By Jay Jay Billings, Team Lead, Scientific Software Development, Oak Ridge National Laboratory, Tennessee, USA.
I often enjoy thinking about how much software has changed our lives, how much software exists in the world, and how much is being written. I also like to consider how quickly the rate at which we write software is changing and the implications that this has for society. This is especially important for science where publications tend to summarize work done from a specific perspective but the real record of the work may be the software itself. What do we really do today to preserve and, if you will, curate collections of software, especially scientific software and the business software that supports science?
About two years ago I was asked to join an effort by the US Department of Energy's (DOE) Office of Scientific and Technical Information (OSTI) that, in part, looked at this question. The effort was to develop a new software service and search platform for the DOE's vast – and I do mean vast – software collection, including both open and closed source projects. This effort came to be known as DOE CODE and the Alpha version of the platform was released in November 2017.
Curating thousands of software projects
DOE CODE is the latest in a long line of names for a software center that has supported the US scientific community since 1960. Started by Margaret Butler at Argonne National Laboratory as the Argonne Code Center, it later became the National Energy Software Center. In 1991, the center moved to OSTI headquarters (Oak Ridge, Tennessee) and was renamed the Energy Science and Technology Software Center (ESTSC), with the ESTSC website launched in 1997. The effort to develop DOE CODE as the new public-facing platform for the software center started in 2017. In the 58 years since Margaret’s Code Center, over 3,600 software products have been submitted to the collection by national laboratories and DOE grantees, many of which are still active. Each record includes all of the metadata about the software, as described by Announcement Notice 241.4, as well as the code, either in binary or source form.
Nearly 4,000 packages make up a truly vast collection of software. However, when we started the project, we noticed by searching around on GitHub that many projects supported by DOE funds were not catalogued. A GitHub search for "Department of Energy" returned over one million hits at the time. Assuming a file or class would be between 100 and 1,000 lines, we estimated that the number of DOE software packages on GitHub that were not in the existing catalog was between 1,000 and 10,000 packages. Further investigation by Ian Lee from Lawrence Livermore National Laboratory suggested that it was closer to the lower number. This does not include projects on other sites such as BitBucket or Sourceforge.net, but if we assume that there are roughly as many packages on those sites, then our estimate of the total number of DOE software packages in online and offline repositories is somewhere between 4,000 and 7,000 packages.
This collection of software includes some of the most well-known software packages in our space, including high-performance computing and math packages such as PETSc, [3]. The oldest packages in the repository date from 1966 and simulate particle penetration in various media. While we may never find all of the uncatalogued packages, it is clear that open source software is a very important part of the DOE's software development community – an important consideration during the redevelopment of the software services and search platform for this community.
It also became clear over the course of initial requirements-gathering exercises that the DOE needed a new software service and search platform that could simultaneously meet the needs of both open and closed source projects. Figuring out exactly how the DOE community worked with open source software would be a challenge on its own, but establishing a balance between the needs of both open and closed software projects required significantly more effort. This new effort and the new service it would spawn were distinct enough that a new name was warranted, thus the adoption of the much simpler "DOE CODE" over previous names.
DOE CODE: Curating code across the internet
DOE CODE needed to assist with OSTI's continuing mission to collect, preserve and disseminate software, which is considered by the DOE to be an invaluable part of our scientific and technical record. Therefore the platform acts as a single point of entry for those who need to discover, submit, or create projects. Instead of mandating that all DOE software exist in one place, DOE CODE embraces the reality that most projects exist somewhere on the internet and are generally accessible in one way or the other. DOE CODE reaches out to these repositories or, in the case of GitHub, BitBucket and Sourceforge.net, integrates directly with their programming interfaces. DOE CODE itself exposes a programming interface so it can be used the same way by libraries or similar services around the world. Users can provide their own repositories or use repositories hosted by OSTI through GitLab or through a dedicated DOE CODE GitHub community.
The platform can mint Digital Object Identifiers (DOIs) for software projects – a big request from the community early in development. To date, many of the projects which exist in OSTI's full catalog have been migrated to DOE CODE and many of these projects have been assigned DOIs as well.
The interface is streamlined and easy to use. Adding project metadata is often as simple as providing the repository address and letting DOE CODE do the rest to scrape it from the repository. This feature was highly requested by the requirements teams, and works best when the information is specified concretely in a special file: metadata.yml. However, even if this file doesn’t exist, many details can still be retrieved, including developer information, descriptions, licenses and other details based on both repository history and conventions such as LICENSE.txt and README.md files.
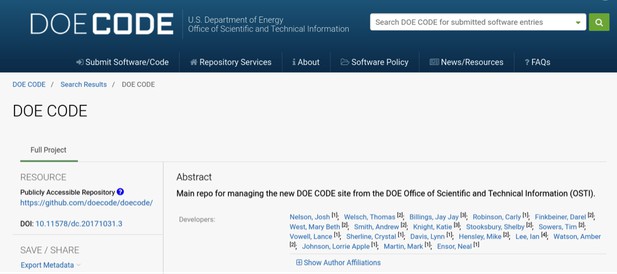
The DOE CODE entry for DOE CODE. Notice the repository and DOI information on the left, as well as the full manifest of authors on the right. It is, in the words of my nephew, "epically meta" to build a service like DOE CODE that can list itself as an open source project. In fact, throughout the development process we used the DOE CODE repo on GitHub as our primary test case for working with source code repositories.
Searching is as simple as using the search bar, but advanced options such as language and license are also available. Clicking on any given author will list the full set of software attributed to that author. A personal benefit of the platform is having a list of all the packages I’ve contributed to available in a single place, making it easier to share my outputs with funders and assessors.
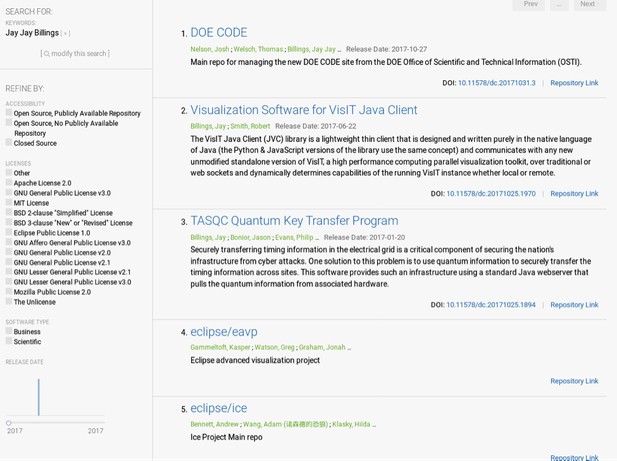
Some of the author’s projects found in DOE CODE by an author search. DOIs are attached to some projects and all of the projects have repository links.
These features combine to provide an experience that is focused on enabling social coding while simultaneously integrating software, publications, data and researcher details to create a holistic picture of DOE development activities. Part of this includes embracing social media and allowing users to share what they find through their favorite social media platform.
DOE CODE also centralizes information on software policy for the DOE and links to developer resources from, for example, the Better Scientific Software project.
The Alpha release of DOE CODE contained about 700 open source software packages and the total number of packages has been growing at an average rate of 10 a week since launch.
Custom deployments
My favourite feature of DOE CODE, as its lead architect, is that it is open source itself. This means that the code can be reused and that this level of software project curation can be adopted, modified and explored wherever it is needed.
OSTI's deployment of DOE CODE fits into its existing infrastructure as a plugin of sort. It feeds information to OSTI’s ELink service, which ingests the metadata and executes a number of data processing workflows in the background to process the information according to a number of DOE orders, policies, business rules and basic technical requirements. ELink then publishes this information to the main OSTI.GOV site and provides some additional metadata to DOE CODE.
It doesn't have to work that way though. Oak Ridge National Laboratory (ORNL) is in the process of deploying a DOE CODE clone, called ORNL Code, that leaves out the back-end processing, restyles the site and adds Single Sign-On (SSO) authentication to integrate with ORNL's other applications.
What we have found with the deployment of ORNL Code, which I am also leading, is that it is relatively straightforward to do custom deployments of DOE CODE. That was by design, but it is always good to verify it! We are also taking the next step at ORNL by putting ORNL Code in the cloud on Amazon Web Services. I remain hopeful that other organizations will try this too. (Interested readers should see “Getting Involved” below for who to email!)
Building with the community
The effort to build DOE CODE was one of the most vibrant and fast-paced projects I've worked on in my time in the National Laboratories. Yes, I have definitely worked on projects that were shorter than 16 months from conception to Alpha launch, but I have rarely worked on projects with such a large amount of engagement and scope that launched on time 16 months later. The key to this success, in my opinion, was that we engaged as many people from the DOE community as possible and we kept every possible line of communication open. Part of this included, as previously discussed, releasing DOE CODE itself as an open source project.
Early in our development process we established about 18 separate requirements teams that we used throughout our development process for guidance and testing. I stopped counting the number of people that we interviewed when it reached around 90 early in January 2017. These teams were composed of members from various communities of interest from within the US National Laboratories – usually a handful of people, one team grew to 27 in number, which was the phone call where I learned the consequences of saying "Sure, invite your friends!". We also had good community interactions on the GitHub site and Twitter, and at conferences, during the development cycle. I personally presented a talk on the project many times and sometimes multiple times in a single day. By the end of the year, we had presented 13 invited talks on DOE CODE.
To say that the DOE CODE team is grateful and indebted to the broader DOE community is an understatement, but it is a good start. We certainly could not have built the platform without their help and the many great people behind the scenes at OSTI and ORNL as well.
Next steps
There are a number of interesting opportunities for DOE CODE in the future. One of the most pressing things that must be investigated is how the large number of ‘restricted access’ DOE projects should be handled since they can not be generally released to the public, but need to appear in the catalog. Some of the other interesting possibilities include tighter integration with other online services and the broader catalog. What I would personally like to see, but is not currently planned, would be a number of advanced features that we discovered during requirements interviews, such as cloud provisioning and launch of software in the catalog and running various tools to mine data from the catalog, such as static analysis tools, performance tools, security vulnerability and sensitive information scanning.
Some in the community are already taking advantage of the open API to mine the catalog and learn more about historical software development in the DOE or to learn about the current connections between projects. I think this is a very interesting use of DOE CODE and I hope to see much more of it in the future, perhaps even some API enhancements to support it as well.
Get involved
If you are interested in getting involved or learning more, you should check out the DOE CODE site or the GitHub community. You can also reach out on Twitter: OSTI is @OSTIgov, and I am always available @jayjaybillings. For those who prefer email, doecode@osti.gov is the direct support list for DOE CODE.
Links
[1] DOE CODE – https://www.osti.gov/doecode
[2] DOE CODE GitHub Community – https://github.com/doecode
[3] PETSc – https://www.mcs.anl.gov/petsc/
Do you have an idea or innovation to share? Send a short outline for a Labs blogpost to innovation@elifesciences.org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



