By Titipat Achakulvisut1, Tulakan Ruangrong2 , Daniel Ernesto Acuna3, Brad Wyble4, Dan Goodman5, Konrad Kording1
1Department of Bioengineering, University of Pennsylvania, United States
2Department of Biomedical Engineering, Mahidol University, Thailand
3School of Information Studies, Syracuse University, United States
4Department of Psychology, Penn State University, United States
5Department of Electrical and Electronic Engineering, Imperial College London, United Kingdom
A successful collaboration in science occur when the right combination of people meet. Whether that happens is often a function of chance, either through casual interactions at conferences, grant panels, or more recently online social media platforms. This reliance on the serendipity of social interaction has a lot of drawbacks, being by definition hit-or-miss depending on the conference or meeting, and with its chances of success heavily biased by one’s academic status. For example, a graduate student might have less chance to meet with senior researchers than with peers at their own career stage.
In 2017, we started to think about a more systematic approach to scientific matchmaking. Key to this process is bringing people together that are interested in similar issues. We thus started neuromatching, which uses natural language processing to determine which neuroscientists have similar approaches to their work, or study similar problems. We used this algorithm successfully for the Cognitive Computational Neuroscience (CCN) conference to create a “mindmatch” coffee break in the 2018 and 2019 conferences. Our “mind-match session” lasted for 90 minutes, and we used machine learning to match attendees based on their interests. We found from our survey that scientists with relevant topics of interest tended to have higher satisfaction (Pearson; r = 0.52, p < 0.01). The session had very positive feedback from attendees (enjoyable and useful scores of 8.4 and 7.9 out of 10, respectively; 38% of mind-match participants filled out the survey). This component of the meeting is well-suited for an online format because attendees can be automatically paired up with other attendees at scale.
Having demonstrated the success of this in the format of legacy conferences, we next plan to try this in an online format sometime in 2020. However, the COVID-19 pandemic shut down all of the legacy conferences for at least 6 months, and so we decided to move quicker. As a result, the first neuromatch unconference was run in March 2020 (Achakulvisut et al., 2020), featuring both scientific matchmaking and traditional conference elements, such as talk sessions and live panel discussions. Since then, our matchmaking method has been expanded to include matchmaking for career hunters; we have also created the neuromatch academy, where students will be grouped into pods according to interest. Here we talk about the concepts, principles and objectives of bringing people together in online spaces.
Bringing the coffee break online
Neuromatching
To tackle the matching problem, we set it up as an optimization problem aimed at minimizing a global topical distance between matched attendees. We add constraints where each attendee has to meet exactly N other attendees. Here, we also ask the preference of the meeting, ranging from casual to collaborative (range of number 0 to 1). We slightly modify the distance matrix so that people with similar preference are more likely to be matched.
Algorithm details. Natural language processing (NLP) has a rich history of describing the content of scientific publications in topic spaces where distance approximates the difference in meaning (Kong et al., 2016; Lopes et al., 2010). For neuromatch we use a very simple standard approach, latent semantic analysis (LSA) along with linear programming (Achakulvisut et al., 2016; Taylor, 2008). We apply LSA on the document-terms matrix based on submitted abstracts of the matches. Then, we create a cosine distance matrix between pairs of attendees. A linear programming problem is formed to find an assignment matrix b that minimizes the total distance between pairs of attendees under given constraints such as the number of meetings (Achakulvisut et al., 2018). There is little doubt that matching could be improved by moving to more advanced methods. At the same time, the current algorithm works well and having some noise in the algorithm leads to more diverse meetings which participants may enjoy more.
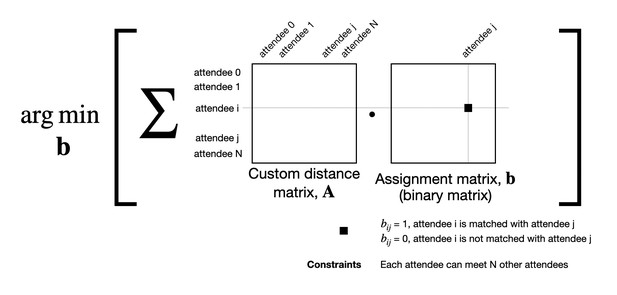
Schematic of matching algorithms. We formulate a matching problem as a linear programming problem. It aims to solve the binary assignment matrix (b) which minimize the global topic distance (A) between all attendees. bij indicates if attendee i is or is not matched with attendee j.
These neuromatch conversations were some of the highest quality I’ve had out of any conference, in-person or otherwise. I began to see how good collaborations emerge naturally from great, energetic conversations, if you can find them. Thanks to neuromatch for making that happen.
– Feedback from neuromatch attendee
Career matching
In legacy conferences, we typically have a job board for attendees to look at, which neuromatch also makes available in an online format. We have a public job board for the conference similar to how legacy conferences work. Furthermore, we are now experimenting with job matching. The algorithm is a variant of mind-matching algorithm, where we instead solve an optimal matching problem between job seekers and job posters. Using the text and keywords of a pool of position announcements, and also abstracts from papers published by a pool of job candidates, it is possible to define a shared topic space and match individuals to the jobs they are most appropriate for.
The way students find supervisors, and in general the way people move across labs, is today largely dominated by networks of personal acquaintances. Providing good academic matchmaking possibilities promises to reduce friction in the academic job market. For example, it should be easy for a student to shortlist potentially appropriate labs, and for labs to know who may be a good fit for a new position. There is a good opportunity to use neuromatch and similar technologies to make these processes more efficient and less biased.
Group discussion (coming in neuromatch 2.0)
Generally, legacy conferences provide a number of social hours where attendees can mingle and chat about specific topics. In this online format, we replace the coffee break or research over beer by running a clustering technique using hierarchical clustering to group people together. We apply hierarchical clustering where we minimize average distance between clusters while preserving the minimum distance by order. Here, we can group the attendees in a group of N people and then ask them to do a group discussion within a timeslot during the conference.
Future improvements
Optimising matching algorithms for scientific meetings
In the future, to improve the matching experience, the outcomes of mind-matching can be studied to understand the factors that make it enjoyable and useful in an online meeting format. This includes adjusting meeting lengths, acquiring additional information from attendees, e.g. from their Mendeley profile, and improving the algorithm itself (Bhagavatula et al., 2018). Furthermore, we can include location or time zone as an input for our optimisation problem if we want to constraints locations of the match by time zone.
Machine learning opportunities to improve online conferences
We believe that machine learning can be used to improve social components when we move online. Online conferences can facilitate meetings and collaborations between attendees. We find algorithms such as mind-matching can lower the barrier of how people can meet during the conference. We show here that machine learning can help us establish social components during the conference.
References
Kong, X., Jiang, H., Yang, Z., Xu, Z., Xia, F., & Tolba, A. (2016). Exploiting Publication Contents and Collaboration Networks for Collaborator Recommendation. PLOS ONE, 11(2), e0148492. https://doi.org/10.1371/journal.pone.0148492
Lopes, G. R., Moro, M. M., Wives, L. K., & de Oliveira, J. P. M. (2010). Collaboration Recommendation on Academic Social Networks (pp. 190–199). https://doi.org/10.1007/978-3-642-16385-2_24
Achakulvisut, T., Acuna, D. E., Ruangrong, T., & Kording, K. (2016). Science Concierge: A Fast Content-Based Recommendation System for Scientific Publications. PLOS ONE, 11(7), e0158423. https://doi.org/10.1371/journal.pone.0158423
Bhagavatula, C., Feldman, S., Power, R., & Ammar, W. (2018). Content-Based Citation Recommendation. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 238–251. https://doi.org/10.18653/v1/N18-1022
Achakulvisut, T., Ruangrong, T., Bilgin, I., Van Den Bossche, S., Wyble, B., Goodman, D. F., & Kording, K. P. (2020). Improving on legacy conferences by moving online. ELife, 9. https://doi.org/10.7554/eLife.57892
Achakulvisut, T., Acuna, D. E., & Kording, K. (2018). Paper-Reviewer Matcher. GitHub. https://github.com/titipata/paper-reviewer-matcher
Taylor, C. J. (2008). On the optimal assignment of conference papers to reviewers.
#
We welcome comments, questions and feedback. Please annotate publicly on the article or contact us at innovation [at] elifesciences [dot] org.
Do you have an idea or innovation to share? Send a short outline for a Labs blogpost to innovation [at] elifesciences [dot] org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



