Note: This post focuses on how Binder can be used in research to improve reproducibility. For a more technical description of the changes to Binder, see this post on the Jupyter Blog.
By Project Jupyter contributors (detailed below).
Scientific results are based on computation: intricate statistical methods are used for inference on small datasets, visualization is used to make large datasets more understandable, and high-performance algorithms are making it possible to ask questions that were unheard of 10 years ago. However, computation requires context. To understand the outputs, and to reuse the methods, we need to know the requirements underlying the code, data and hardware.
Moreover, these pieces must be woven together in a comprehensible and intuitive form, whether in a narrative for humans, or instructions for a computer. Finally, we also need the computational resources required to reproduce the results. Together, these pieces make up the computational environment needed to showcase your work. Assembling them is hard, and requires manual steps and technical expertise. So, while many groups share research code and data online (for example on GitHub or the Open Science Framework (OSF)), there’s no easy way to interact with this material. Simply recreating the environment needed to run another researcher’s analyses can take days.
Binder allows researchers to quickly create the computational environment needed to interact with research code and data shared online. To interact with someone else’s work, you simply click a URL and are taken directly to a live environment where you can run the code in the cloud.
For example, the following figure is an analysis of an open dataset related to bicycle usage in Zurich, Switzerland:
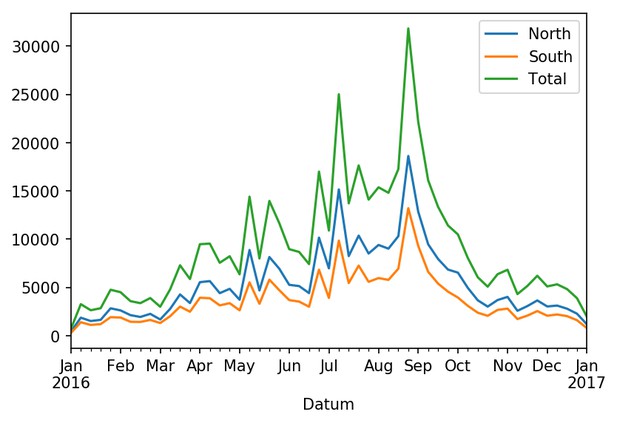
Total number of bikes per week traveling (by direction) past Mythenquai, Zurich. Data from City of Zurich; Notebook from Tim Head.
You can recreate and explore this result simply by clicking the text below. You’ll be taken to a live Jupyter Notebook running in the cloud. Go ahead, click it. We’ll wait.
Did you manage to generate the plot yourself? We want to make it simple for anyone to do the same for their work.
The Binder project has four main goals:
- Let anyone in the world with an internet connection easily run the code that is in public repositories.
- Empower authors of code or computational content to quickly create interactive versions of their work.
- Make it easy to create Binder services anywhere. One example of this is the public mybinder.org service, currently funded by the Gordon and Betty Moore Foundation. However, we envision a future where many Binder services coexist in harmony.
- Develop Binder as a 100% open source, community-driven project.
When Binder was first announced in May 2016, it connected GitHub repositories to computational environments that are universally accessible. Today, we are pleased to announce the Binder 2.0 service and BinderHub framework that are the foundation for a new phase of Binder’s usage and development. There are a lot of technical changes under the hood, and almost all of the back-end code has been rewritten, dramatically improving the reliability, scalability and ease of deployment. Here are the highlights:
- Binder is now powered by BinderHub, which uses JupyterHub technology to handle its services. This makes it more scalable, more stable and more flexible.
- Binder also uses an open-source tool called repo2docker to construct a computational environment from a code repository. Through this, Binder now supports more complex environments, including shell commands and Julia environments, and not just Python files.
- To this extent, Binder will be able to support many new scientific workflows, including new languages for data science such as R (via IRKernel) and Julia (via IJulia), as well as new user interfaces such as RStudio and JupyterLab.
- BinderHub is now easier to deploy on your own cloud instances or hardware, making it possible to create a network of Binder servers that serve your community.
- BinderHub URLs also support repositories in many different online locations, such as GitHub, GitLab and the OSF. If you have an idea for a new host for Git repositories, we’d love to support it with BinderHub.
For more technical details, please see our accompanying post on the Jupyter Blog. In the rest of this post, we’ll lay out some common use cases for Binder and share our vision for what we think this technology can do for the life sciences community.
How you can use Binder
- Share and publish scientific results — to the extent that academic research publications have accompanying code and data, Binder provides a simple way for researchers to share those resources in a fully reproducible and interactive manner. This complements several recent integrations of executable protocols and figures into journals, as well as efforts to formalise and share workflows between collaborators. For examples of Binder repositories being shared with published research, see this paper on tactile coding in mice or this review of machine learning in human intracranial neuroscience.
- Showcase research and analytics software features — several organizations, such as altair-viz, ipyvolume and xtensor, include Jupyter notebooks and a Binder badge with their open-source software packages to let users interact with and understand the functionality of their research and analytics tools.
- Enhance online content with interactive computation — Binder makes it easy for anyone with a bit of Python or R knowledge to create interactive online experiences. This is similar to the type of experience that Shiny has offered for the R community, but works across any programming language and user interface (including RStudio). For example, here’s a Jupyter-based calculator, here’s a repository that launches RStudio with an R kernel running and here’s a library for viewing 3D data with interactive widgets.
- Distribute interactive educational materials — in many online and in-person educational settings, students and teachers need quick access to materials that allow them to explore and practice computational examples. Binder opens the door for the rapid and scalable creation and deployment of interactive computational curricula, and it is already transforming education. For example, you can create interactive Jupyter presentations with RISE, or create interactive online textbooks for Binder.
Creating a binder-ready repository
With Binder, it is possible to quickly turn your computational material into a live, interactive online environment. To do this, users simply post their files in an online repository and include one or many ‘build’ files (such as ‘requirements.txt’) that describe the computational environment needed to run the code. For example, here’s the GitHub repository for the example above:
Tim Head’s GitHub repository containing code to explore open data from the city of Zurich, Switzerland.
See those files called ‘requirements.txt’ and ‘postBuild’? BinderHub will automatically use them as instructions for how to build the computational environment needed to run the code. To trigger this process, you can build a Binder via the BinderHub user interface (e.g. mybinder.org). Note that anybody can do this, even if they’re not the owner of a repository, so long as the proper build files are present (e.g., ‘requirements.txt’ or ‘environment.yml’).
BinderHub will then weave the material in your repository into a live computational environment and provide you access to that environment, running in the cloud. You can then share a link that automatically triggers this process for others. (If you have already built a repository, Binder will direct them straight to the interactive environment.)
Finally, it is also possible to deploy your own BinderHub service in the cloud (or on your own hardware). Binder has undergone an evolution in the technology and the community supporting this project. Under-the-hood, Binder is now powered by JupyterHub with Kubernetes, and is officially supported by the Jupyter project. This means that Binder is now more scalable and stable. It also means that it is much easier to deploy your own Binder service in the cloud. You can find instructions on how to do so in the BinderHub documentation (early stage; feedback welcome).
Our values
As we move forward, these are the guiding principles of the Binder community:
- Research and analytics should be interactive. We shouldn’t settle for a static snapshot of code and output.
- Interactive computation should be available to anybody, regardless of their location or hardware. The public mybinder.org will continue to serve as tech demonstration and public service, and we welcome others to set up their own BinderHub services for their purposes.
- Authors should be empowered to create interactive versions of their material without needing to learn lots of new tools. Our goal is to make pre-existing workflows Binder-ready, not force people to learn new ones.
- The technology powering these processes should be free, open source and community driven. Interactive computing online is too important to the future of scientific research to be controlled by a single entity. For this reason, the Binder project will always be an open-source project.
We are currently working on the formal community governance and organizational aspects of Binder, including running the public Binder service at mybinder.org. For now, the project is operating under the umbrella of Project Jupyter and NumFOCUS, and funded by the Gordon and Betty Moore Foundation. We’re actively exploring models for sustaining BinderHub development, as well as the mybinder.org service.
However, mybinder.org is not the only place where Binder servers can live. We envision a future in which there are multiple federated Binder services on the web. These might be run by university libraries to provide interactive computation for researchers, by publishers looking to provide easy interactive computing for paper replication, or by individuals who want to deploy a BinderHub service for their own purposes.
What's next?
We are excited to see what the next iteration of Binder brings. Whether it be new reproducible workflows, rich interactive computational documents, or new models for collaborative computational work, we hope that Binder continues to push the boundaries of computation and science. We invite the community to try out Binder, create Binder repos, contribute code and participate in our growing community.
To get started, see the following links:
- To try out the public Binder service and learn how to make your repository Binder-ready, see mybinder.org.
- For information on using and building Binders with a deployment, see mybinder.readthedocs.io.
- For community blog posts around Binder, see the pandas-cookbook blog and the Binder workshop blog post.
- To see the BinderHub technology behind a deployment, see the GitHub repository.
- For instructions on deploying your own BinderHub, see the BinderHub documentation.
- To join the conversation around Binder, see the Gitter channel.
- For simple examples of Binder-ready repositories, see the binder-examples GitHub page.
This is just the beginning of new features and improvements to Binder. We’re working hard to grow an open-source community around these tools, and we encourage issues, comments and pull requests on the BinderHub, repo2docker and JupyterHub repositories. We look forward to growing the Binder ecosystem, and we’re excited to see all of the Binders that people design.
Project Jupyter is an open-source project with too many contributors to list here. Key members of the JupyterHub and Binder project are listed alphabetically below.
C. Titus Brown (UC Davis), Matthias Bussonnier (UC Berkeley), Jessica Forde (UC Berkeley), Jeremy Freeman (CZI), Brian Granger (Cal Poly), Tim Head (Wild Tree Tech), Chris Holdgraf (UC Berkeley), M Pacer (UC Berkeley), Yuvi Panda (UC Berkeley), Fernando Perez (UC Berkeley), Min Ragan-Kelley (Simula Research Laboratory), and Carol Willing (Cal Poly)
Do you have an idea or innovation to share on eLife Labs? Please send a short outline to innovation [at] elifesciences.org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



