Blogpost by Steven Burgess, Editorial Community Manager, eLife, and Devang Mehta, Institute of Molecular Plant Biology, ETH Zurich
Who did what?
Scientific careers are built on recognition. It influences every stage of employment, from obtaining your first postdoc to landing an academic position or winning funding.
In most instances, achievement is measured in terms of scientific publications, including the number, quality and contribution made to each. This usually takes the form of a simple list of publications in an academic CV, in a bibliographic format, with a list of authors, the title, journal name and citation details. This approach has the advantage of being simple but suffers from a number of problems.
In modern times single author papers are rare, which has resulted in the widespread adoption of ordered author lists where names are ranked according to contribution. In biology, the first author tends to be the individual who has done most of the data collection, either via experimentation or theoretical approaches, and has written a first draft of the paper. The last author(s) are the Principal Investigators (PIs) involved, who often make top-level decisions about experimental approaches, secure funding and edit the manuscript prior to publication. However, deciding how to list names when the number of experimenters and PIs increases beyond two becomes increasingly arbitrary in a way that varies between disciplines.
This makes it difficult for hiring committees or funders to determine what an individual’s contribution has been to a piece of work, particularly if their name appears in the middle of a list. As a result, in life sciences research only the first and last authors tend to be recognised (since their roles appear to be most clearly defined) to the detriment of everyone else. In the worst cases, this formula can lead to unethical conduct.
One solution to this problem has been the introduction of author contribution statements, which are short freeform sentences where authors can state who did what. However, the usefulness of these statements has been hotly debated, with concerns raised over senior scientists pulling rank, lack of use and inaccuracy.
To address concerns over accuracy and use, in 2014 Liz Allen, who was working at the Wellcome Trust at the time, reported on a trial of a standardised taxonomy to recognise author contributions. These findings led to the development of the standardised Contributor Roles Taxonomy (CRediT), which divides author tasks into 14 categories and is currently used by several publishers, including eLife, Cell Press, PLOS and F1000Research.
This system has several advantages. Most notably, CRediT contributions are quantifiable and encapsulated within the machine-readable metadata about a publication. Thus, they provide a resource which can be utilised to develop a new system.
Do scientists care?
My foray into this started with a Twitter poll and blog piece exploring attitudes to ordered author lists, which uncovered significant interest in changing the system. This led to the suggestion of replacing the current linear display with a ‘film-credit’ model based around the 14 contributor roles.
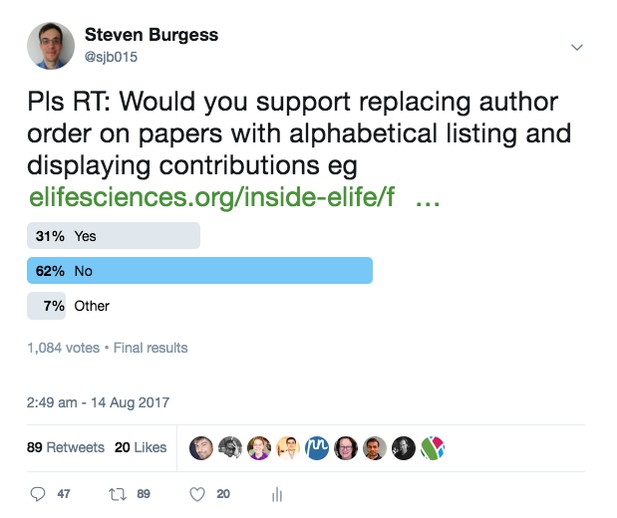
While Twitter can be useful for quickly getting feedback from a large number of people, we wanted to understand what was driving people’s responses and ran a follow-up survey. People were directed to the survey by email, Twitter and a blog post. We asked about career stage, publishing experiences, knowledge of CRediT and preferences for representing author contributions.
A few findings stand out. Most importantly over 95% of respondents said they would prefer to represent names on their papers using a system different to the conventional ordered author list. Intriguingly this was despite more than 70% stating that their contributions to papers had been properly recognised most or all of the time.
The ‘film-credit’ model was the most popular system, followed by ordered author lists with CRediT taxonomy.

Mock up of a ‘film-credit’ model for displaying author contributions. Names are grouped under contributions defined by CRediT taxonomy instead of the conventional author order list.
This held true irrespective of career stage:
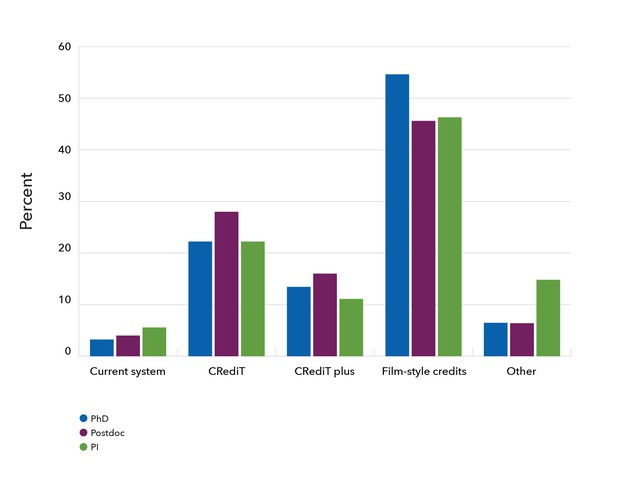
Preferences for displaying author lists by career stage, PhD + undergraduate (n=96), Postdoc (n=125), PI (n=54). ‘CRediT plus’ was the option of adding ‘major’ or ‘minor’ gradings to contributions made under CRediT taxonomy.
Finally it was clear much more could be done to raise awareness around standardised author taxonomies. Over three quarters of respondents had little or no idea about what CRediT is.
Creating a modern system for modern needs
The current system for author recognition evolved out of the historical limitations of publishing in a printed journal. As science moves online, we now have the opportunity to use digital technology to create new solutions to the challenges of scholarly communication.
The approach presented here is one of several aimed at providing appropriate recognition of contributions, such as percentage-based author contribution indexes (Boyer et al. 2017), badges and summary statements on CVs. Adoption of any new method will require a culture change, but it is encouraging to see recognition being widely discussed.
In moving towards a new system for recognition, there are a number of technical challenges that need to be addressed. CRediT is still only employed by a limited number of journals, but this includes eLife as well as titles under Cell Press, PLOS, GigaScience and Aries Systems. Moving forward we hope to work with CASRAI to support its efforts in encouraging adoption.
Currently eLife authors are asked to provide author contribution statements to accompany a manuscript. These are then listed at the end of an article along with affiliations. CRediT information is currently stored in the article XML at eLife. Over the next year we plan to investigate ways of utilising this data in a more useful way.
If it becomes possible for publishers to share this metadata with repositories such as Crossref, it could allow researchers to aggregate this information from publications in multiple journals and display it as part of an ORCiD profile, for example. If you would like to get involved in analysing or using the data, we would be glad to hear from you — please get in touch with Steven via innovation [at] elifesciences.org.
Thanks to Liz Allen for her input to this work so far. This blogpost builds on blogs previously posted on Medium by Steven Burgess and Devang Mehta.
Do you have an idea or innovation to share on eLife Labs? Please send a short outline to innovation [at] elifesciences.org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



