Blogpost by Giuliano Maciocci, Head of Product
The academic manuscript is evolving into a complex, deeply interconnected digital artefact. We need to consider a design strategy to accommodate the transition.
Progressive enhancement is a strategy for web design that emphasises core webpage content first. This strategy then progressively adds more nuanced and technically rigorous layers of presentation and features on top of the content as the end-user’s browser/internet connection allow. — Wikipedia
State of play
There has been, and there will continue to be, a lot of discussion within the academic publishing community as to how to divest from a longstanding print legacy and truly embrace new digital technologies for the dissemination of research output.
Yet the traditional manuscript format still rules supreme, considered by most the ultimate long-form narrative of a discovery. Composed mainly of text and static figures, the primary research artefact through which most researchers share new discoveries is still primarily consumed as a printable PDF: the digital equivalent of a printed page.
Complex datasets, and sometimes the code used to analyse them, are ultimately reduced to little more than PNG images.
At the same time online HTML versions of the research manuscript are increasingly becoming nexus artefacts. No longer self-contained entities, today’s online manuscripts link out to a growing variety of data, stored across a growing number of both general purpose (Dryad, Zenodo, figshare) and specialised (Proteopedia, Genbank) repositories.
Much of this data is typically linked to the manuscript via a simple URI, or is at most visualised within the context of the manuscript itself through a static figure representing a snapshot of whatever state of the data, or its analysis, the manuscript’s author deemed most relevant to the manuscript’s narrative. And so complex datasets, and sometimes the code used to analyse them, are ultimately reduced to little more than PNG images.
Moving forward
Things are changing however. Researchers and publishers have an increasing number of options at their disposal to integrate new types of rich content directly into their online manuscripts. Interactive figures, for example, can provide authors with more tools to present their findings, and readers with richer ways to interact with them. Today’s combination of browser technology and increasingly powerful cloud computation allow for the direct, and increasingly powerful visualisations of a manuscript’s data within the context of the manuscript itself, from 3D molecular visualisations to executable code.
What used to be the online equivalent of a printed page can now contain entire virtual machines.
Let’s take the latter example: until very recently, vetting or replicating a data analysis referred to in a research paper used to require finding the relevant GitHub repository for the algorithm, cloning it, replicating the author’s runtime environment and all its dependencies on a local machine, downloading the relevant data set, and running the code on top of it. Today, all of that can be embedded within the online version of the paper itself via services like Binder or CodeOcean, and executed with a single button press, enabling a whole new category of interactive figure.
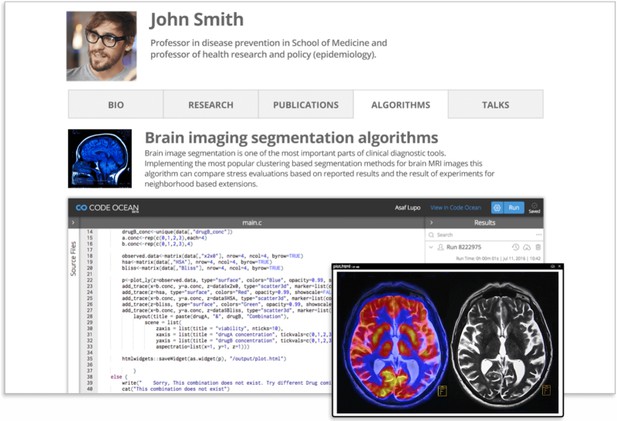
Example of an embedded Integrated Development Environment. Source: codeocean.com.
But while these tools offer new opportunities to enhance the discoverability of research output, their use within an online manuscript also brings considerable challenges. What used to be the online equivalent of a printed page can now contain entire virtual machines, requiring access to cloud computing resources and streaming massive datasets.
Such a manuscript is therefore no longer easily portable, is challenging to consume on anything but a desktop, and requires a live internet connection for some of its richer figures to display properly. The core content of the manuscript now also bears new dependencies to digital assets outside of the publisher’s purview.
Add to that the necessity of providing a (sadly still necessary) PDF copy to the paper without losing critical content, and you’re looking at something of production nightmare. By comparison, making the HTML version of a manuscript responsive so it can render on mobile devices (which incidentally many online publications are yet to do well) doesn’t seem like such a big deal.
Progressive engagement
We’ll take a brief look at how a progressive enhancement design philosophy can help overcome some of these challenges. But while we can apply progressive enhancement to account for device, dependency and connectivity issues with interactive figures, we should also consider how the same design philosophy addresses how users engage with research content online:
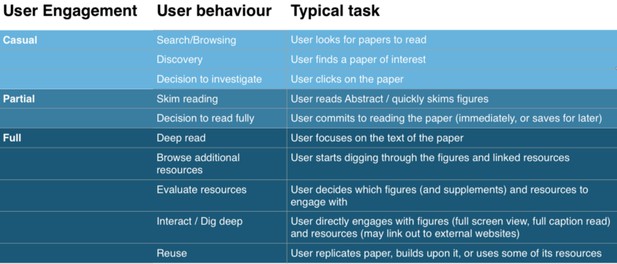
Progressive engagement with research artefacts. Giuliano Maciocci.
Let’s take the above user behaviour progression as a rough example. We can start to see how the way we present our manuscript and figures should afford different levels of interaction based not just on device and connectivity concerns, but on the user’s different stages of engagement with the content.
The ideal presentation of a research artefact should therefore coax the user into increasingly higher levels of engagement, with a particular focus on providing the user with the just right level of context to bridge the delicate transition from partial to full engagement.
Put simply, we don’t want to overwhelm the user with a rich interface presenting embedded code they must read and execute in order to see an output, when all they want is to know at an earlier level of engagement is whether that output is even relevant to them in the first place.
A research artefact should therefore coax the user into increasingly higher levels of engagement.
We also don’t want to assume the above behaviour progression is always true: a user could for instance be looking for a specific example of a method, figure or result across multiple papers, and may not be interested in each manuscript’s narrative as a whole.
And finally we must account for the platform from which the user may be engaging: while more casual interactions may well be catered for by a mobile device, tasks indicative of deeper levels of engagement would realistically only be carried out on a more capable desktop platform and its associated input and display methods.
Progressive enhancement
So what we need here is a graduated approach to handling these increasingly rich data types, levels of user engagement, and consumption platforms without losing the core benefits of today’s manuscript formats: easy consumption and portability. We can therefore take the PDF as the worst-case, legacy form of the core manuscript content, and build up from there.
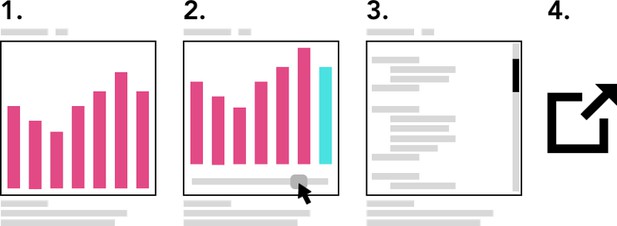
Progressive enhancement of a single figure: static, interactive, code, external resource. Giuliano Maciocci.
So going back to our embedded analysis code example, we can start thinking about an implementation that roughy follows this outline:
- Start with embedding a lightweight static figure (a snapshot) of the key output of the code. This should represent whatever state the author deems fit to best convey the key finding/narrative contribution of the code in question. This will only serve as the minimum viable experience for skimming purposes (Casual engagement), but also as a safe baseline for when the content is being accessed through less capable devices, as a printable/PDF compatible output, and as a valid snapshot of what state the data was in when it was peer-reviewed (where applicable).
- Allow the user to switch the static figure to an interactive output where supported, providing whatever level of UI is needed to appreciate the output in full.
- Where appropriate, allow the user to dig behind the output of the interactive figure and directly look at the code behind it. You may at this stage allow minor edits to the algorithm and the ability to run it again in-situ to view the output.
- If the user wants to engage further, for example intending to fork or modify the code, or do anything more complex, provide links to the most appropriate external resource where the user can benefit from a more appropriate environment or UI to do their work (e.g., the original GitHub and/or data repository, or an online IDE).
In the relatively simpler case of a 3D visualisation, we can use just steps 1.and 2. to ensure a baseline level of compatibility for a figure even as we provide the ability to directly interact with the 3D content.
In summary, we have effectively recast the classic figure viewer as an asset viewer, and populated the element with increasingly rich versions of the same asset as the user continues to engage with it.
(Note: In cases 2. and 3. we ideally want to embed a strictly versioned snapshot of the code locked at the stage of manuscript review, but that’s a discussion for a different day).
Lightweight implementation example
In order to fully leverage the advantages of progressive enhancement, it would also be helpful if all of a manuscript’s progressive levels of interaction were somehow encapsulated within a single canonical description of the manuscript and all of its core content.
For example, when dealing with figures a JATS XML based authoring toolset like Texture could introduce a source attribute to keep track of alternative forms of the same figure and their dependencies, while allowing for the addition of third-party embeds for code, 3D and other data.
At its simplest, using the Texture framework to link a static figure as an alternative to the dynamic output of a spreadsheet cell would look something like this:
<graphic texture:src=”Sheet1!C15" xlink:href=”fig1.png”/>The regular xlink:href would ensure a valid static snapshot of the data in the figure is always available.
(Thanks to Michael Aufreiter at Substance for this example.)
Compatible publishing platforms could then take that core JATS XML manuscript description and use it to render the right form in the right context: simple static figures when creating a PDF or rendering to mobile, or full embeds when delivering to a desktop browser.
Conclusion
In the context of research artefacts, the presentation of interactive figures in manuscripts is only one example of how a progressive enhancement design approach can be helpful in framing design and development decisions.
By taking into account varying levels of user engagement as well as various tiers of device capability, publishers and tool creators in the research space can ensure a smoother transition to new and richer ways of presenting research outputs.
It’s also important to note that progressive enhancement can and should also be applied to the manuscript as a whole. Increasing layers of semantic highlighting and its related interactions can for example be deployed incrementally as the user moves deeper down the text, so as not to overload the user experience when that user’s level of engagement is still low.
Finally, the same principles are applicable to the presentation of smaller, discrete research objects beyond the manuscript format, where the opportunities for more novel interactions can also benefit from a more granular handling of both user behaviours and platform constraints.
Thanks to CZI and Substance for inspiring this post. Stay tuned for an upcoming follow up by Substance with more detail on implementation strategies, and make sure to check out their piece on Reproducible Science for People Who Don’t Code.
This blogpost is cross-posted on Medium.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter. We welcome comments and questions, so please comment using Hypothes.is.



