On May 10 and 11, we hosted the eLife Innovation Sprint 2018, a two-day gathering of 62 researchers, designers, developers, technologists, science communicators and more, with the goal of developing prototypes of innovations that bring cutting-edge technology to open research communication. Together, the participants worked on 13 projects, from plug-ins and web-based tools to make researchers’ lives easier, to designing conceptual shifts in the way we share, review and endorse research. We summarise these projects below, and invite your comments and contributions to each.
Plaudit.pub
A team of six publishers, technologists and researchers aimed to address the obsession with prestige journals by creating an alternative way to evaluate research objects and people. They designed Plaudit.pub – “a simple, lightweight mechanism for an individual with an ORCID to recommend an object with a DOI”. The recommender lends their authority to the endorsement of the object, and the author of the object benefits from the endorsement. The project will link with open infrastructure such as Crossref Event Data, and has already garnered interest from potential integrators.
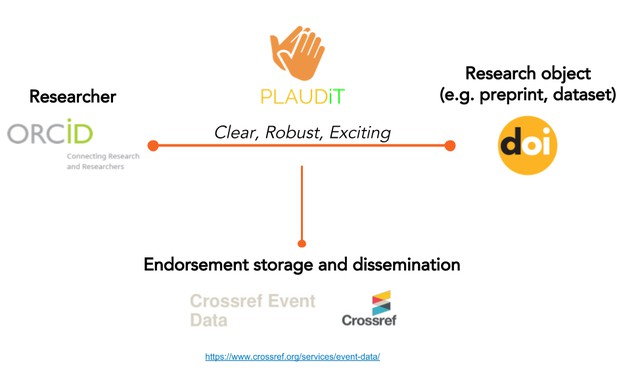
Concept diagram for Plaudit. Plaudit team members.
The code for this project is available on GitLab (previously on GitHub).
The team members were:
- Vincent Tunru, Software Engineer, Flockademic
- Sara Bosshart, Open Access Publisher, IWA Publishing
- Mattias Björnmalm, Research Fellow, Imperial College London
- Joe Wass, Principal R&D Engineer, Crossref
- Mark Patterson, Executive Director, eLife
- Alf Eaton, Developer, Atypon
Jupyter + Stencila
Jupyter notebooks are widely used to produce and document scientific results, combining text, code and data analysis and visualisation results in one document. Binder is an online service for running Jupyter Notebooks and other environments. Stencila is an open office suite for reproducible research documents, which are stored in the new Dar format. At the Sprint, Min Ragan-Kelley, Postdoctoral Fellow, Simula Research Laboratory, who develops for Project Jupyter, teamed up with Daniel Nüst, a researcher from the Institute for Geoinformatics, University of Münster, who is interested in improving the persistence of computational research using containerisation technologies. They connected these tools and formats so that users can edit reproducible documents (Dar files) as part of a Binder project, bringing us closer to interactive and reproducible research publications that are easy to share and reuse.
The code for this work is available on Github. Since the Sprint, the duo have continued to work on providing compatibility for Stencila within Jupyter servers, such that a Stencila document can now be shared as a Binder project. Try a working example or watch the demo below.
Project Trackbook
Project Trackbook is “an open lab notebook that gives researchers an interface to securely share and version control files in a decentralized network”. This project addresses the problem that many researchers face when they are unable to share work using centralised services, such as Dropbox and Google Drive, due to privacy and intellectual property concerns amongst other challenges. The notebook is designed to prompt users to employ best practises – including providing sufficient metadata and maintaining up-to-date records – and is built using Dat, enabling the sharing of large datasets and files.
Try the alpha-stage tool today by visiting dat://trackbook.hashbase.io/ in Beaker Browser.
The code is available on Github and continues to be developed.
The Project Trackbook team were:
- Joe Hand, Co-Executive Director, Code for Science and Society
- Bruno Vieira, Bioinformatics Scientist, Repositive
- Danielle Robinson, PhD, Co-Executive Director, Code for Science and Society
- Kirstie Whitaker, Research Fellow, Alan Turing Institute
- Marek Kultys, Information Designer, Science Practice
- Ruben Paz, Backend Developer, Repositive
- Vilim Štih, PhD Student, Max Planck Institute of Neurobiology

The Project Trackbook team at work. From left to right: Ruben Paz, Vilim Štih, Danielle Robinson, Joe Hand, Kirstie Whitaker, Bruno Vieira. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
PREreview 2.0
Launched at last year’s Mozilla Global Sprint, PREreview seeks to “diversify peer review in the academic community by crowdsourcing pre-publication feedback to improve the quality of published scientific output, and to train early-career researchers (ECRs) in how to review others' scientific work”. The project leads, Daniela Saderi and Samantha Hindle, are now looking to grow the initiative and develop a product that best serves the community’s needs.
At the eLife Sprint, Daniela was joined by product, UX and design experts as well as prospective users (researchers), and together they designed a new platform for PREreview by formulating user stories, designing wireframes, and exploring a potential minimal platform using existing open source technology. Elsewhere, and as part of the Mozilla Global Sprint, PREreview co-founder Samantha Hindle and team member Monica Granados hosted the first online live preprint journal club using PREreview resources.
The outputs from the eLife Sprint, notably the design capital and the code behind a prototype platform, are available on GitHub. Meanwhile, the PREreview team are working to build resources and capacity to enable ongoing growth and development of the project.
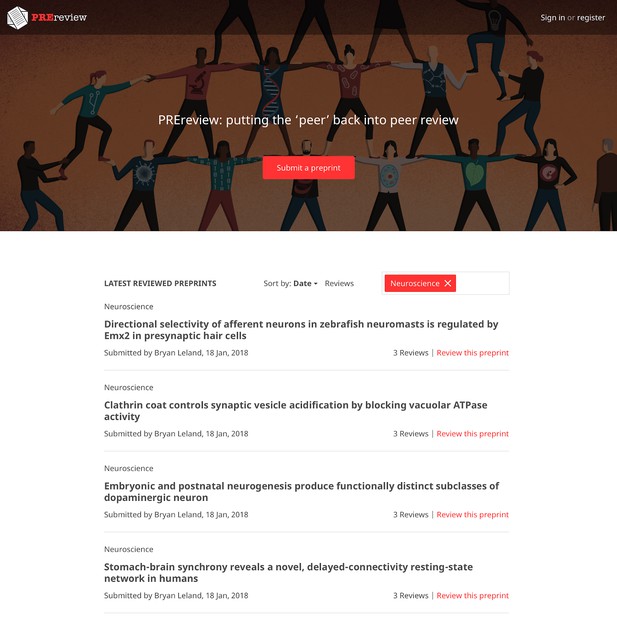
A mock-up of the potential PREreview website. Nick Duffield and Giuliano Maciocci.
The team were:
- Daniela Saderi, PhD Candidate, Oregon Health and Science University, and co-founder of PREreview
- André Marques-Smith, Postdoctoral Researcher, University College London
- Giuliano Maciocci, Head of Product, eLife
- Nick Duffield, UX Designer, eLife
- Daniel Ecer, Data Scientist, eLife
- Felix Hoffmann, PhD Student, Frankfurt Institute for Advanced Studies
- Joe McArthur, Assistant Director of the Right to Research Coalition, SPARC

Joe McArthur and Daniela Saderi consider how to build a community behind PREreview. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Appstract
Led by Anisha Keshavan, and building on her previous work to encourage community contributions to science (see Braindr), the Appstract team built “a mobile-friendly tapping game that allows players to annotate sample sizes from scientific abstracts”. Curating these data could enable researchers to identify and filter biomedical literature based on sample size, which is an important factor when assessing the validity of a claim or result. It also provides data for metascience researchers interested in sample sizes, for example investigating change in sample size over time, and the data could be used to train a machine learning algorithm to extract these data automatically in the future. The team are continuing to develop the tool, and encourage others to play online. The code is available on GitHub.

Appstract uses natural language processing (NLP) to identify numerical data and text within scientific abstracts. These elements are highlighted and the user taps to identify those that contribute to the study’s sample size. Appstract team.
The team were:
- Anisha Keshavan, Postdoctoral Fellow, University of Washington
- Charlotte (Charlie) Whicher, Product Manager, Repositive
- Peter Murray-Rust, Founder, ContentMine
- Jen Spencer, Software Engineer, YLD
- Sam Galson, Software Engineer, YLD
- Andreea Hrincu, UX Designer, Springer Nature
- Nuno Job, CEO, YLD

Charlie Whicher, Anisha Keshavan and Peter Murray-Rust work on Appstract. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Abstract Babel
Research articles in international journals are written in English. In order to improve the accessibility of science to the public, Luc Henry, Scientific Advisor, École Polytechnique Fédérale de Lausanne (EPFL), and Nathan Lisgo, Senior Drupal Developer, eLife, worked on a prototype web browser plug-in that translates scientific abstracts into the reader’s native language using open source automated translation tools. With the accuracy of automated translation tools improving, the duo are hopeful that this idea could become a reality.
Try the working demo (just click 'Translate'). The code is available on GitHub.

Wireframe of the translation tool. Luc Henry and Nathan Lisgo.
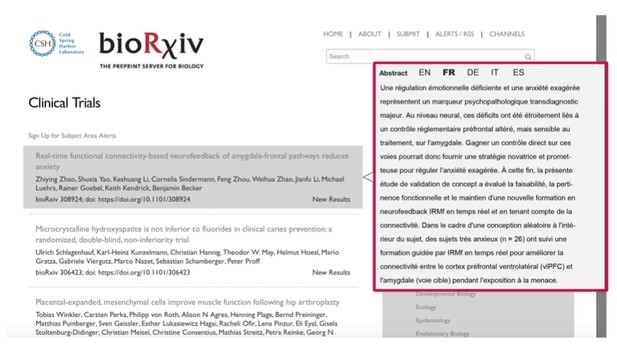
An example use case: an illustration of how translated abstracts might be made available on third-party platforms such as bioRxiv. Luc Henry and Nathan Lisgo.
WikiCiteVis
Items such as articles and books are cited in Wikipedia articles. Wikipedia has the data that captures all these citations, which this team used to prototype a search and visualisation tool for browsing Wikipedia citations. By the end of the Sprint, the team managed to build a working back end and front end, and now they plan to integrate these to deliver a working demo of a web-based tool for others to try. The code is available on GitHub.
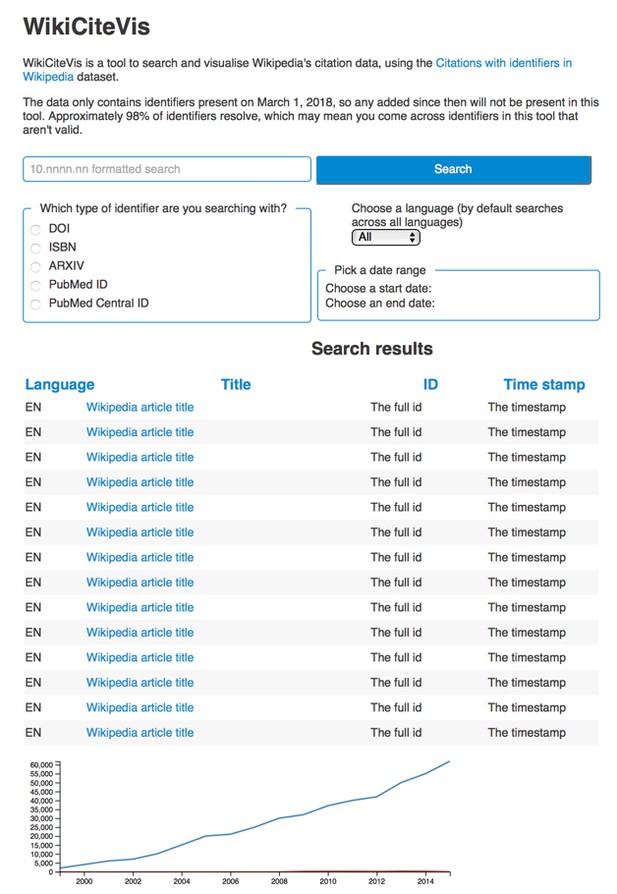
The front-end design of the WikiCiteVis tool. David Moulton.
The team were:
- Sam Walton, Partnerships Coordinator, Wikimedia Foundation
- Sean Wiseman, Senior Developer, eLife
- David Moulton, Senior Front-End Developer, eLife
- Chris Wilkinson, Senior Systems Developer, eLife
- Ian Mulvany, Head of Product Innovation, SAGE Publishing

Chris Wilkinson, Sean Wiseman and Sam Walton collaborate to build WikiCiteVis. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Of note, Ross Mounce, Open Access Grants Manager, Arcadia Fund, also worked on the Wikipedia citations dataset at the Sprint and identified the most-cited items across all Wikipedia pages. His work was mentioned in a recent Nature News & Comment article and is openly available on GitHub.
Reproducible Computational Research – a case study
Ivo Jimenez, PhD candidate, University of California, Santa Cruz, and Felix Z. Hoffmann, PhD Student, Frankfurt Institute for Advanced Studies, are both interested in reproducible research. Ivo is part of the team developing Popper, a convention that “allows researchers to automate the re-execution and validation of experimentation (computational and analysis) pipelines”, while Felix has previously contributed to Sumatra, a tool that automatically tracks and documents computational research. Together, this duo created an example project to demonstrate how to share computational research openly and reproducibly using both Popper and Sumatra. Real-life examples of reproducible research are important for testing, validating and refining tools. The case study can be found online on GitHub.

Source: Twitter.
Octopus
The largest project group tackled an equally large problem: “what would we want science to look like if we started again?” From this, they prototyped Octopus, “a system that breaks the traditional paper format into its component pieces, vertically and horizontally linked [with] commenting, flagging and rating as a replacement for peer review [and] automatic language translation, and all saving to a distributed database”. Follow the project online and explore more documentation on GitHub. The code for the prototype tool is also available on GitHub. The team plan to continue developing their ideas and designs into a testable prototype research communication platform.
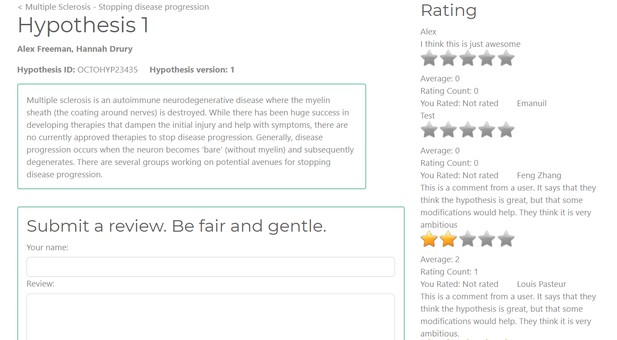
A mock-up of a user submitting a review of a hypothesis shared with Octopus. The Octopus team.
The team were:
- Alex Freeman, Executive Director, Winton Centre for Risk and Evidence Communication at the University of Cambridge
- Alessandra Dillenburg, PhD Student, University of Edinburgh
- Delwen Franzen, Researcher in Neurobiology, Previously the Ludwig-Maximilians-Universität München
- Simon Hazelwood-Smith, Researcher and Designer, Science Practice
- Rosario Villajos, UX Designer, Springer Nature
- Melissa Harrison, Head of Production Operations, eLife
- Kai Segrud, Software Engineer, Addgene
- Hannah Drury, Product Manager, eLife
- Ian Bruno, Director, Strategic Partnerships, Cambridge Crystallographic Data Centre
- Emanuil Tolev, Software Development Consultant, Cottage Labs LLP
- Martin John Hadley, Technical Lead (Interactive Data Network), University of Oxford

Alex Freeman, Ian Bruno, Simon Hazelwood-Smith, Emanuil Tolev, Rosario Villajos and Hannah Drury consider how to design Octopus. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Zotero Insights
When using literature management tools, researchers can highlight and annotate the texts in their library. These annotations and highlights provide a rich source of knowledge and information for subsequent work, and can be interrogated with proprietary tools. Unable to find a free and open source (FOSS) tool that allows a user to run quantitative text analyses on these annotations and highlights, Asura Enkhbayar, Data Scientist/PhD Student, Simon Fraser University, was motivated to build one. Together with Achintya Rao, Doctoral Student (UWE Bristol) and Science Communicator (CERN), and Rik Smith-Unna, Scientist and Software Developer, ScienceFair, this team ultimately found an existing open source tool that works on Zotero collections and worked to improve on it. Their work is available online on GitHub. Next, they aim to finalise the Zotero plug-in and to create a template notebook (or ‘cookbook’) for others to use for their own quantitative text analyses.
Citation Gecko
Doing literature reviews can be slow and, with so much being published, relevant papers may be missed. To aid literature discovery, Barney Walker, PhD Student, Imperial College London, is developing Citation Gecko, a tool that “uses open citation data and the citation network to suggest relevant papers based on a set of ‘seed papers’”. At the Sprint, Barney worked with Fábio Madeira, PhD in Computational Biology, Software Engineer, EMBL-EBI, and Vot Zardzewialy, Development Team Lead, Cambridge University Press, to extend Citation Gecko with a proof-of-concept widget that connects to Zotero (a popular literature-management tool) and retrieves the folder structure of a user’s collections. The team also worked on integrating open citations data into the database, to complement the existing data from Microsoft Academic Graph. Their next step is to implement user login for the Zotero widget.
Try Citation Gecko. The code is available on GitHub.
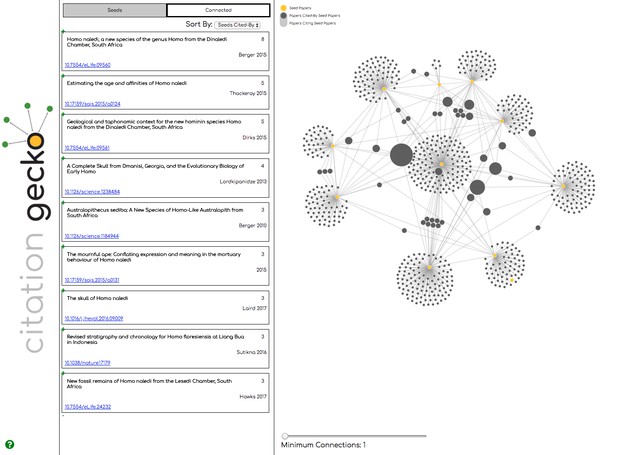
Visualising the citation network around ‘seed’ papers related to Homo naledi research.

Fábio Madeira, Barney Walker and Vot Zardzewialy extend Citation Gecko. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Funda
Project lead Oarabile Mudongo seeks to bring web literacy and access to knowledge to marginalised communities, specifically townships in Cape Town, South Africa. To bridge the digital divide, Oarabile has initiated a project to engage, educate and empower next-generation leaders to create lasting change in their own community. Initially named #Rethink Web Literacy, the project was rebranded at the eLife Sprint as Funda (which is Zulu for “to learn”). Oarabile worked with Nick Duffield, UX designer, eLife, to design a logo, and with Joe McArthur, Assistant Director of the Right to Research Coalition, SPARC, to consider community building around the initiative. Oarabile plans to continue developing the project with the aim of sharing it with the broader digital inclusion community at MozFest, Mozilla’s annual festival, in October. The project canvas is available online.
The new Funda logo. Nick Duffield.

Oarabile Mudongo works to improve web literacy in marginalised communities. Orquidea Real Photobook – Julieta Sarmiento Photography. Source: Flickr.
Reagents.io
One barrier to reproducibility in science is the lack of clarity on the lab reagents used in an experiment. Currently, the system relies on written methods without a formalised or machine-readable structure. Led by Julien Colomb, Reagents.io is a project to create standards that describe and report lab reagents, and create an application to merge different standards into one unique format. At the Sprint, Julien worked with Melissa Harrison, Head of Production Operations, eLife, to consider ways to make this information open and accessible. Contribute to the project via GitHub.
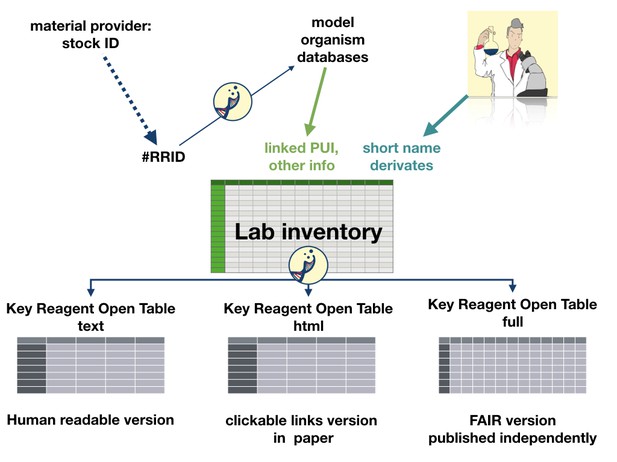
The principle behind Reagents.io. Julien Colomb.
To learn more about the eLife Innovation Sprint itself, read our summary on Inside eLife.
We welcome comments, questions and feedback. Please annotate publicly on the article or contact us at innovation [at] elifesciences [dot] org.
Do you have an idea or innovation to share? Send a short outline for a Labs blogpost to innovation [at] elifesciences [dot] org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



