Elucidating the selection mechanisms in context-dependent computation through low-rank neural network modeling
- School of Data Science, Fudan University, China
- Lingang Laboratory, China
- Institute of Science and Technology for Brain-Inspired Intelligence, Fudan University, China
- Key Laboratory of Computational Neuroscience and Brain-Inspired Intelligence, Fudan University, China
eLife Assessment
This study provides an important set of analyses and theoretical derivations to understand the mechanisms used by recurrent neural networks (RNNs) to perform context-dependent accumulation of evidence. The results regarding the dimensionality and neural dynamical signatures of RNNs are convincing and provide new avenues to study the mechanisms underlying context-dependent computations. This manuscript will be of interest to a broad audience in systems and computational neuroscience.
https://doi.org/10.7554/eLife.103636.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Convincing: Appropriate and validated methodology in line with current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
Humans and animals exhibit a remarkable ability to selectively filter out irrelevant information based on context. However, the neural mechanisms underlying this context-dependent selection process remain elusive. Recently, the issue of discriminating between two prevalent selection mechanisms—input modulation versus selection vector modulation—with neural activity data has been highlighted as one of the major challenges in the study of individual variability underlying context-dependent decision-making (CDM). Here, we investigated these selection mechanisms through low-rank neural network modeling of the CDM task. We first showed that only input modulation was allowed in rank-one neural networks and additional dimensions of network connectivity were required to endow neural networks with selection vector modulation. Through rigorous information flow analysis, we gained a mechanistic understanding of why additional dimensions are required for selection vector modulation and how additional dimensions specifically contribute to selection vector modulation. This new understanding then led to the identification of novel neural dynamical signatures for selection vector modulation at both single neuron and population levels. Together, our results provide a rigorous theoretical framework linking network connectivity, neural dynamics, and selection mechanisms, paving the way towards elucidating the circuit mechanisms when studying individual variability in context-dependent computation.
Introduction
Imagine you are playing a card game. Your strategy depends not only on the cards you have but also on what your opponents are doing. As the game progresses, you adjust your moves based on their actions to increase your chances of winning. This example illustrates how much of our decision-making, both in everyday life and in more complex tasks, is influenced by the context in which we are acting (Miller and Cohen, 2001; Roy et al., 2010; Mante et al., 2013; Saez et al., 2015; Siegel et al., 2015; Bernardi et al., 2020; Takagi et al., 2021; Flesch et al., 2022; Barbosa et al., 2023). However, how the brain performs such context-dependent computation remains elusive (Fusi et al., 2016; Cohen, 2017; Badre et al., 2021; Okazawa and Kiani, 2023).
Using a monkey CDM behavioral paradigm, a recent work uncovered a novel mechanism in the brain that helps adjust decisions based on context (Mante et al., 2013). This mechanism, called ‘selection vector modulation,’ is distinct from the early sensory input modulation counterpart (Desimone and Duncan, 1995; Noudoost et al., 2010). More recently, building on this work, new research with rats supported a novel theoretical framework regarding how the brain makes context-dependent decisions and revealed how this process may vary between individuals (Pagan et al., 2025). Critically, this theoretical framework pointed out that current neurophysiological data fell short of distinguishing between selection vector modulation and sensory input modulation, calling for rethinking what kind of evidence is required for differentiating different selection mechanisms.
Here, we aim to address this challenge by using the low-rank recurrent neural network (RNN) modeling approach (Landau and Sompolinsky, 2018; Mastrogiuseppe and Ostojic, 2018; Kadmon et al., 2020; Schuessler et al., 2020; Beiran et al., 2021; Beiran et al., 2023; Dubreuil et al., 2022; Valente et al., 2022; Ostojic and Fusi, 2024). This approach allowed us to simulate and better understand the neural processes behind context-dependent computation. More importantly, endowed by the low-rank RNN theory (Beiran et al., 2021; Dubreuil et al., 2022), this approach allowed us to develop a set of analyses and derivations uncovering a previously unknown link between connectivity dimensionality, neural dynamics, and selection mechanisms. This link then led to the identification of novel neural dynamical signatures for selection vector modulation at both the single neuron and population levels. Together, our work provides a neural circuit basis for different selection mechanisms, shedding new light on the study of individual variability in neural computation underlying the ubiquitous context-dependent behaviors.
Results
Task paradigm, key concept, and modeling approach
The task paradigm we focused on is the pulse-based CDM task (Pagan et al., 2022), a novel rat-version CDM paradigm inspired by the previous monkey CDM work (Mante et al., 2013). In this paradigm, rats were presented with sequences of randomly-timed auditory pulses that varied in both location and frequency (Figure 1A). In alternating blocks of trials, rats were cued by an external context signal to determine the prevalent location (in the ‘LOC’ context) or frequency (in the ‘FRQ’ context). Note that compared to the continuous sensory input setting in previous works (e.g. Mante et al., 2013), this pulse-based sensory input setting allowed the experimenters to better characterize both behavioral and neural responses (Pagan et al., 2022). We will also demonstrate the unique advantage of this pulse-based input setting later in the present study (e.g. Figure 7).
Figure 1
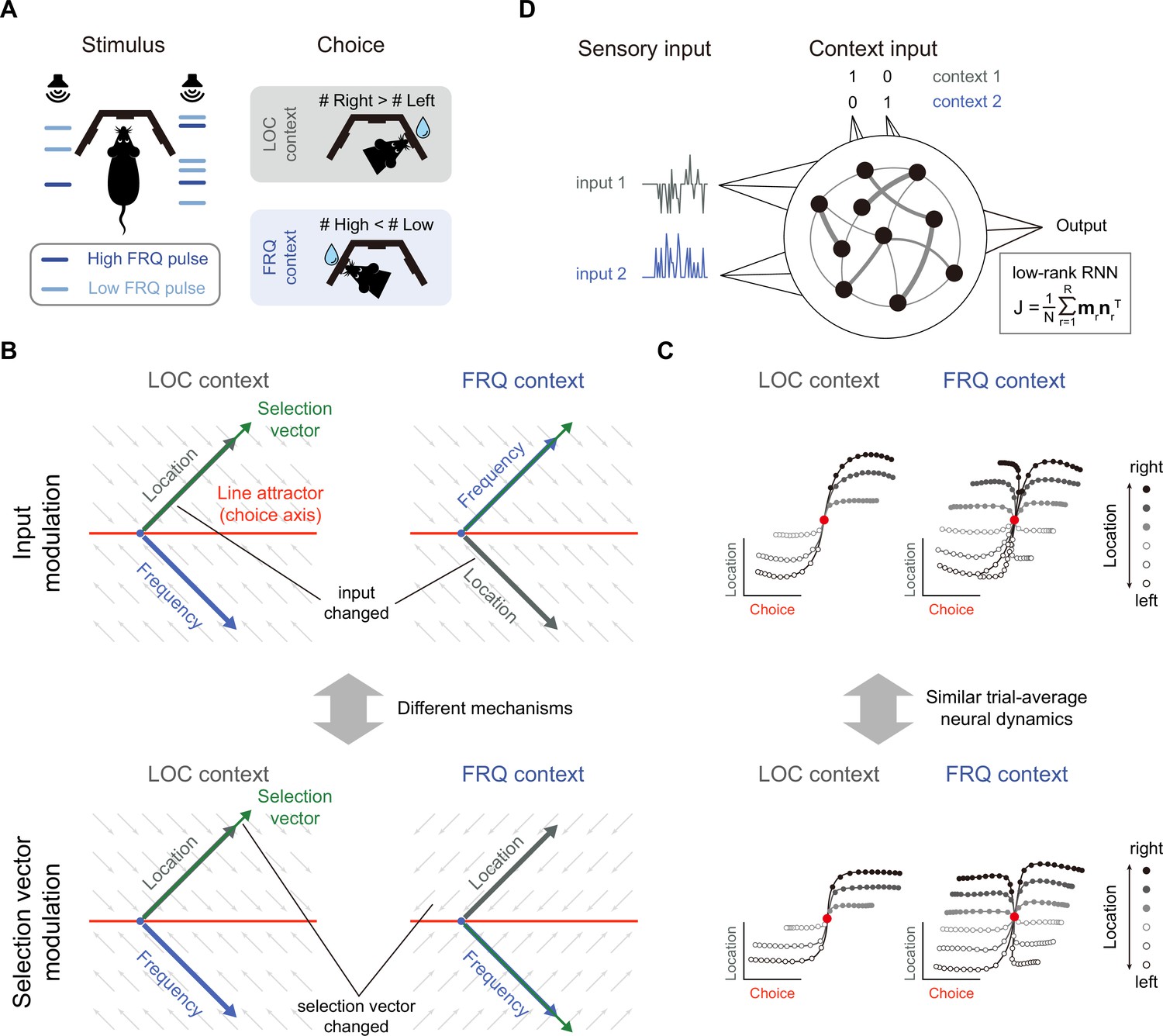
Prevalent candidate selection mechanisms in context-dependent decision-making (CDM) cannot be dissociated by classical neural dynamics analysis.
(A) A pulse-based context-dependent decision-making task (adapted from Pagan et al., 2022). In each trial, rats were first cued by sound to indicate whether the current context was the location (LOC) context or the frequency (FRQ) context. Subsequently, rats were presented with a sequence of randomly timed auditory pulses. Each pulse could come from either the left speaker or right speaker and could be of low frequency (6.5 kHz, light blue) or high frequency (14 kHz, dark blue). In the LOC context, rats were trained to turn right (left) if more pulses are emitted from the right (left) speaker. In the FRQ context, rats were trained to turn right (left) if there are more (fewer) high-frequency pulses compared to low-frequency pulses. (B) Two prevalent candidate mechanisms for context-dependent decision-making. Top: The input modulation mechanism. In this scenario, while the selection vector remains invariant across contexts, the stimulus input representation is altered in a way such that only the relevant stimulus input representation (i.e. the location input in the LOC context and the frequency input in the FRQ context) is well aligned with the selection vector, thereby fulfilling the requirement of context-dependent computation. Bottom: The selection vector modulation mechanism. In this scenario, although the stimulus input representation remains constant across different contexts, the selection vector itself is altered by the context input to align with the relevant sensory input. Red line: line attractor (choice axis). Green arrow: selection vector. Thick gray and blue arrows stand for the projections of the location and frequency input representation directions on the space spanned by the line attractor and selection vector, respectively. The small gray arrows stand for direction of relaxing dynamics. (C) Networks with distinct selection mechanisms may lead to similar trial-averaged neural dynamics (adapted from Pagan et al., 2022). In a model with pure input modulation, the irrelevant sensory input can still be represented by the network in a direction orthogonal to the selection vector. Therefore, using the classical targeted dimensionality reduction method (Mante et al., 2013), both the input modulation model (top) and the selection vector modulation model (bottom) would exhibit similar trial-averaged neural dynamics as shown in Pagan et al., 2022. (D) The setting of low-rank RNN modeling for the CDM task. The network has four input channels. Input 1 and input 2 represent two sensory inputs, while the other two channels indicate the context. The connectivity matrix is constrained to be low-rank, expressed as , where is the number of neurons, is the matrix’s rank, and is a rank-1 matrix formed by the outer product of two N-dimensional connectivity vectors and .
To solve this task, rats had to select the relevant information for the downstream evidence accumulation process based upon the context. There were at least two different mechanisms capable of performing this selection operation, i.e., selection vector modulation and input modulation (Mante et al., 2013; Pagan et al., 2022). To better introduce these mechanisms, we first reviewed the classical linearized dynamical systems analysis and the concept of selection vector (Figure 1B; Mante et al., 2013; Sussillo and Barak, 2013; Maheswaranathan et al., 2019; Maheswaranathan and Sussillo, 2020; Nair et al., 2023). In the linearized dynamical systems analysis, the neural dynamics around the choice axis (Figure 1B, red line) is approximated by a line attractor model. Specifically, the dynamics in the absence of external input can be approximated by the following linear equation , where M is a matrix with one eigenvalue being equal to 0 and all other eigenvalues having a negative real part. For brevity, let us denote the left eigenvector of the 0 eigenvalue as . In this linear dynamical system, the effect of any given perturbation can be decomposed along the directions of different eigenvectors: the projection onto the direction will remain constant while the projections onto all other eigenvectors will exponentially decay to zero. Thus, for any given input , only the component projecting onto the direction (i.e. ) can be integrated along the line attractor (see Methods for more details). In other words, serves as a vector selecting the input information, which is known as the ‘selection vector’ in the literature (Mante et al., 2013).
Two distinct selection mechanisms can then be introduced based upon the concept of selection vector (Pagan et al., 2022). Specifically, to perform the CDM task, the stimulus input (LOC input, for example) must have a larger impact on evidence accumulation in the relevant context (LOC context) than in the irrelevant context (FRQ context). That is, must be larger in the relevant context than in the irrelevant context. The difference between these two can be decomposed into two components:
(1)
where the symbol denotes difference across two contexts (relevant – irrelevant) and the bar symbol denotes average across two contexts (see Methods for more details). The first component is called input modulation in which the change of input information across different contexts is emphasized (Figure 1B, top). In contrast, the second component is called selection vector modulation in which the change of selection vector across contexts is instead highlighted (Figure 1B, bottom).
While these two selection mechanisms were clearly defined, recent work showed that it is actually challenging to differentiate them through neural dynamics (Pagan et al., 2022). For example, both input modulation and selection vector modulation can lead to similar trial-averaged neural dynamics through targeted dimensionality reduction (Figure 1C; Pagan et al., 2022). Take the input modulation as an example (Figure 1C, top). One noticeable aspect we can observe is that the input information (e.g. location information) is preserved in both relevant (LOC context) and irrelevant contexts (FRQ context), which seems contradictory to the definition of input modulation. What is the mechanism underlying this counterintuitive result? As Pagan et al. pointed out earlier, input modulation is not the input change () per se. Rather, it means the change of input multiplied by selection vector (i.e. ). Therefore, for the input modulation, while input information indeed is modulated by context along the selection vector direction, input information can still be preserved across contexts along other directions orthogonal to the selection vector, which explains the counterintuitive result and highlights the challenge of distinguishing input modulation from selection vector modulation in experiments (Pagan et al., 2022).
In this study, we sought to address this challenge using the low-rank RNN modeling approach. In contrast to the ‘black-box’ vanilla RNN approach (e.g. Mante et al., 2013), the low-rank RNN approach features both well-controlled model complexity and mechanistic transparency, potentially providing a fresh view into the mechanisms underlying the intriguing selection process. Specifically, the low-rank RNNs we studied here implemented an input-output task structure similar to the classical RNN modeling work of CDM (Figure 1D; Mante et al., 2013). More concretely, the hidden state of a low-rank RNN with neurons evolves over time according to
(2)
where is a low-rank matrix with output vectors and R input-selection vectors , is the time constant of single neurons, is the nonlinear activation function, embedded into the network through mimic the location and frequency click inputs, and embedded through indicate whether the current context is location or frequency. The output of the network is a linear projection of neural activity (see Methods for more model details). Under this general architectural setting, on one hand, through controlling the rank of the matrix during backpropagation training, we can determine the minimal rank required for performing the CDM task and reverse-engineer the underlying mechanism, which will be demonstrated in Figure 2. On the other hand, recent theoretical progress of low-rank RNNs (Beiran et al., 2021; Beiran et al., 2021; Dubreuil et al., 2022) enabled us to explicitly construct neural network models with mechanistic transparency, complementing the reverse-engineering analysis (Mante et al., 2013; Sussillo and Barak, 2013), which will be shown in Figure 3.
Figure 2 with 1 supplement see all
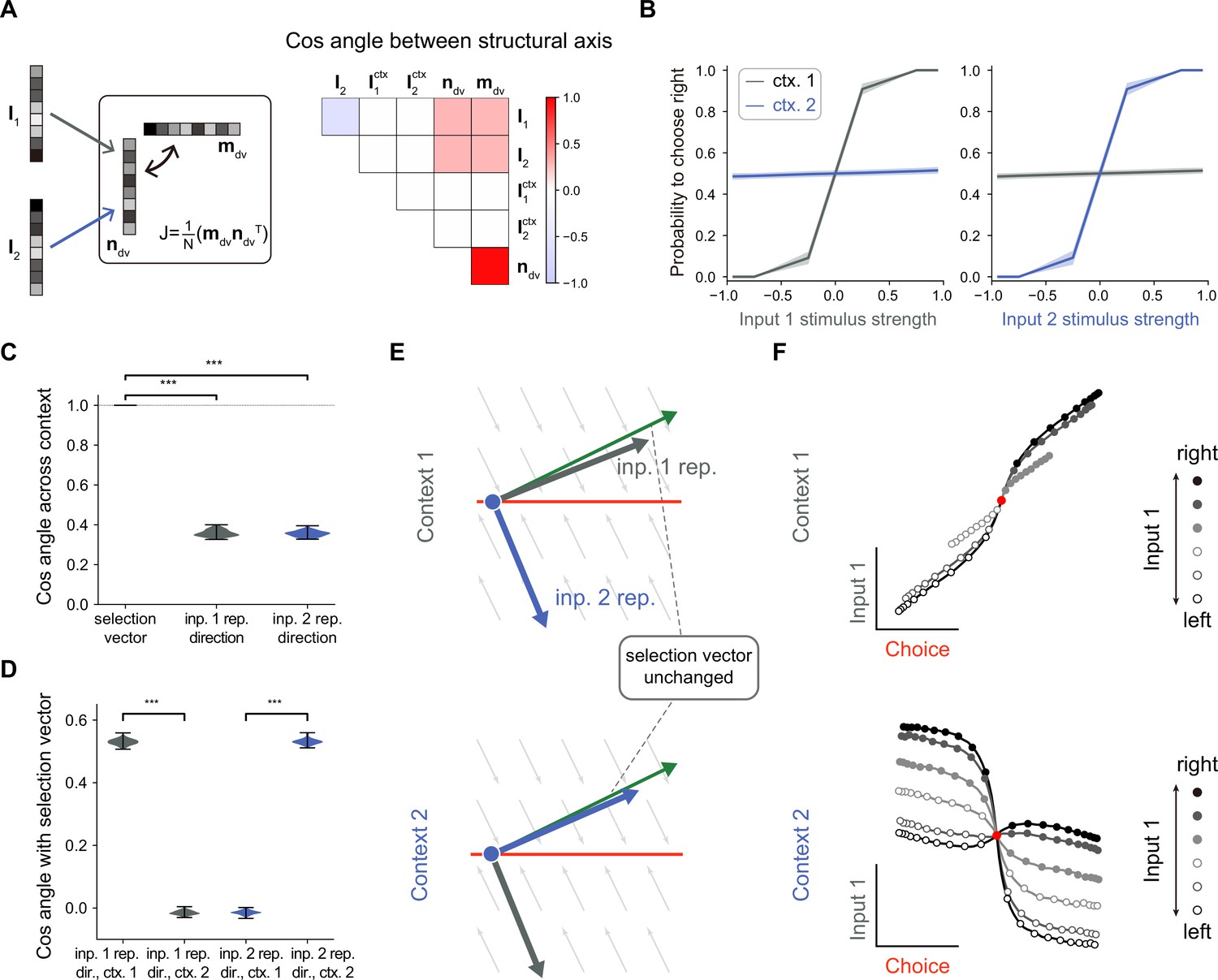
No selection vector modulation in rank-1 neural network models.
(A) Illustration of rank-1 connectivity matrix structure. Left: a rank-1 matrix can be represented as the outer product of an output vector and an input-selection vector , of which the input-selection vector played the role of selecting the input information through its overlap with the input embedding vectors and . The context signals are fed forward to the network with embedding vectors and . Since the overlap between the context embedding vectors and input-selection vector are close to 0, for simplicity, we omitted the context embedding vectors here. Right: an example of the trained rank-1 connectivity structure characterized by the cosine angle between every pair of connectivity vectors (see Figure 2—figure supplement 1 and Methods for details). (B) The psychometric curve of the trained rank-1 recurrent neural networks (RNNs). In context 1, input 1 strongly affects the choice, while input 2 has little impact on the choice. In context 2, the effect of input 1 and input 2 on the choice is exchanged. The shaded area indicates the standard deviation. Ctx. 1, context 1. Ctx. 2, context 2. (C) Characterizing the change of selection vector as well as input representation direction across contexts using cosine angle. The selection vector in each context is computed using linearized dynamical system analysis. The input representation direction is defined as the elementwise multiplication between the single neuron gain vector and the input embedding vector (see Methods for details). ***p<0.001, one-way ANOVA test, n=100. Inp., input. Rep., representation. (D) Characterizing the overlap between the input representation direction and the selection vector. ***p<0.001, one-way ANOVA test, n=100. Dir., direction. (E) The state space analysis, for example, trained rank-1 RNN. The space is spanned by the line attractor axis (red line) and the selection vector (green arrow). (F) Trial-averaged dynamics for example rank-1 RNN. We applied targeted dimensionality reduction (TDR) to identify the choice, input 1, and input 2 axes. The neuron activities were averaged according to input 1 strength, choice and context, and then projected onto the choice and input 1 axes to obtain the trial-averaged population dynamics (see Methods for details).
Figure 3 with 1 supplement see all
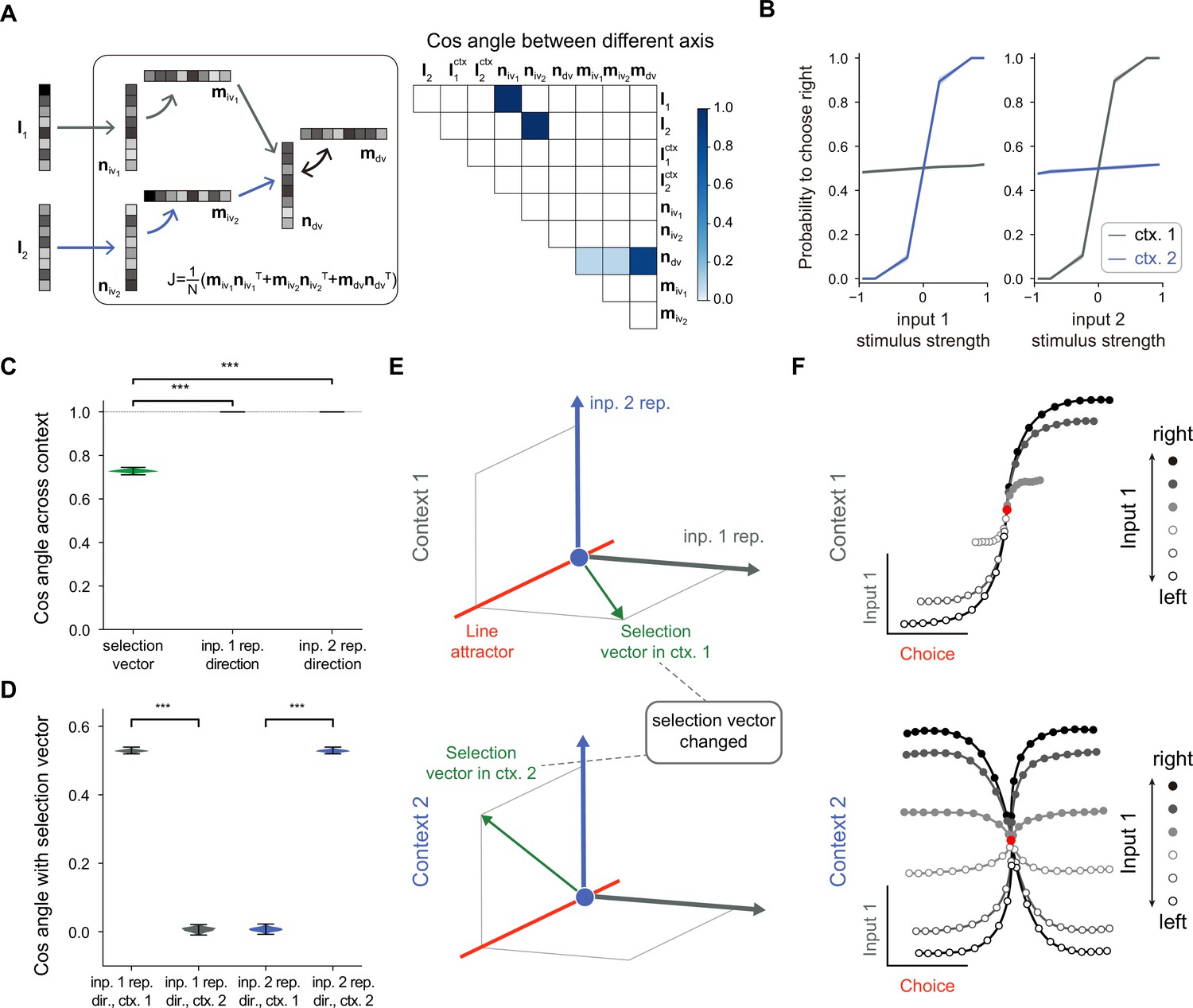
A rank-3 neural network model with pure selection vector modulation.
(A) Illustration of the utilized rank-3 connectivity matrix structure. Left: the rank-3 matrix can be represented as the summation of three outer products, including the one with the output vector and the input-selection vector , the one with the output vector and the input-selection vector , and the one with the output vector and the input-selection vector , of which the input-selection vectors and played the role of selecting the input information from and , respectively. Right: the connectivity structure of the handcrafted RNN model characterized by the cosine angle between every pair of connectivity vectors (see Figure 3—figure supplement 1 and Methods for more details). (B) The psychometric curve of the handcrafted rank-3 recurrent neural network (RNN) model. (C) Characterizing the change of selection vector as well as input representation direction across contexts using cosine angle. The selection vector in each context is computed using linearized dynamical system analysis. The input representation direction is defined as the elementwise multiplication between the single neuron gain vector and the input embedding vector (see Methods for details). ***p<0.001, one-way ANOVA test, n=100. (D) Characterizing the overlap between the input representation direction and the selection vector. ***p<0.001, one-way ANOVA test, n=100. (E) The state space analysis for example rank-3 RNN. The space is spanned by the line attractor axis (red line, invariant across contexts), selection vector in context 1 (green arrow, top panel), and selection vector in context 2 (green arrow, bottom panel). (F) Trial-averaged dynamics for example rank-3 RNN.
No selection vector modulation in rank-one models
In the literature, it was found that rank-one RNN models suffice to solve the CDM task (Dubreuil et al., 2022). Here, we further asked whether selection vector modulation can occur in rank-one RNN models. To this end, we trained many rank-1 models (see Methods for details) and found that indeed having rank-1 connectivity (e.g. with the overlap structure listed in Figure 2A; for the detailed connectivity structure, see Figure 2—figure supplement 1) is sufficient to perform the CDM task, consistent with the earlier work. As shown in Figure 2B, in context 1, the decision was made based on input-1 evidence, ignoring input-2 evidence, indicating that the network can effectively filter out irrelevant information. To answer what kind of selection mechanisms underlie this context-dependent computation, we computed the selection vector in two contexts through linearized dynamical systems analysis (Sussillo and Barak, 2013). Cosine angle analysis revealed that selection vectors kept invariant across different contexts (Figure 2C, left), indicating no selection vector modulation. This result was preserved across different hyperparameter settings (such as different regularization coefficients or activation functions). Note that this result actually can be mathematically proved (Pagan et al., 2023; Pagan et al., 2025). Therefore, our modeling result reconfirmed the limitation of rank-one models on selection vector modulation.
While the selection vector was not altered by contexts, the direction of input representations changed significantly across different contexts (Figure 2C, left; see Methods for the definition of input representation direction). Further analysis revealed that the overlap between the input representation direction and the unchanged selection vector is large in the relevant context and small in the irrelevant context, supporting the input modulation mechanism (Figure 2D). These results indicate that while a rank-1 network can perform the task, it can only achieve flexible computation through input modulation (Figure 2E). Importantly, when applying a similar targeted dimensionality reduction method to this rank-1 model, we found that the irrelevant sensory input information was indeed well-represented in neural activity state space (Figure 2F), supporting the conclusion made in the Pagan et al. paper that the presence of irrelevant sensory input in neural state space cannot be used as a reliable indicator for the absence of input modulation (Figure 1C).
In summary, we conclude that to study the mechanism of selection vector modulation, instead of limiting to the simplest model of CDM task, it is necessary to explore network models with higher ranks.
A low-rank model with pure selection vector modulation
To study the mechanism of selection vector modulation, we designed a rank-3 neural network model, with one additional rank for each sensory input feature (i.e. for input 1 and for input 2; Figure 3A, left). Specifically, we ensured that has a positive overlap with and zero overlap with , while has a positive overlap with (Figure 3A, right; see Figure 3—figure supplement 1 and Methods for more details). Moreover, our rank-3 network relies on a multi-population structure, consistent with the notion that higher-rank networks still require a multi-population structure to perform flexible computations (Dubreuil et al., 2022). This configuration implies that the stimulus input 1 (2) is first selected by , represented by , and subsequently selected by before being integrated by the accumulator. In principle, this sequential selection process enables more sophisticated contextual modulations.
We confirmed that a model with such a connectivity structure can perform the task (Figure 3B) and then conducted an analysis similar to that performed for rank-1 models. Unlike the rank-1 model, the selection vector for this rank-3 model changes across contexts while the input representation direction remains invariant (Figure 3C). Further analysis revealed that the overlap between the selection vector and the unchanged input representation direction is large in the relevant context and small in the irrelevant context (Figure 3D), supporting a pure selection vector modulation mechanism (Figure 3E) distinct from the input modulation counterpart shown in Figure 2D. When applying a similar targeted dimensionality reduction method to this rank-3 model, as what we expected, we found that both relevant and irrelevant sensory input information was indeed well-represented in neural activity state space (Figure 3F), which was indistinguishable from the input modulation counterpart (Figure 2F).
Together, through investigating these two extreme cases—one with pure input modulation and the other with pure selection vector modulation, we not only reconfirm the challenge of distinguishing input modulation from selection modulation based on neural activity data (Pagan et al., 2022) but also point out the previously unknown link between selection vector modulation and network connectivity dimensionality.
Understanding context-dependent modulation in Figs. 2 and 3 through pathway-based information flow analysis
What is the machinery underlying this link between selection vector modulation and network connectivity dimensionality? One possible way to address this issue is through linearized dynamical systems analysis: first computing the selection vector and the sensory input representation direction through reverse-engineering (Sussillo and Barak, 2013) and then calculating both selection vector modulation and input modulation according to Equation 1. However, the connection between the network connectivity dimensionality and the selection vector obtained through reverse-engineering is implicit and in general non-trivial (Pagan et al., 2023), hindering further investigation of the underlying machinery. Here, by combining recent theoretical progress in low-rank RNNs (Mastrogiuseppe and Ostojic, 2018; Dubreuil et al., 2022) and linearized dynamical systems analysis (Sussillo and Barak, 2013), we introduced a novel pathway-based information flow analysis approach, providing an explicit link between network connectivity, neural dynamics, and selection mechanisms.
To start with, the low-rank RNN dynamics (i.e. Equation 2) can be described by an information flow graph, with each task variable as a node and each effective coupling between task variables as an edge (Mastrogiuseppe and Ostojic, 2018; Dubreuil et al., 2022). Take the rank-1 RNN in Figure 2 as an example. A graph with three nodes, including two input variables and one decision variable , suffices (Figure 4A; see Methods for more details). In this graph, the dynamical evolution of the task variable can be expressed as:
(3)
where the effective coupling from the input variable to the decision variable is equal to the overlap between the input representation direction (each element is defined by ) and the input-selection vector . More precisely, , where is defined as for two length- vectors. Since the input representation direction depends on the single neuron gain and the context input can modulate this gain, the effective coupling is context-dependent. Indeed, as shown in Figure 4A, Figure 4—figure supplement 1A, exhibited a large value in context 1 but was negligible in context 2, while exhibited a large value in context 2 but was negligible in context 1. In other words, information from the input variable can arrive at the decision variable only in the relevant context, which exactly is the computation required by the CDM task.
Figure 4 with 2 supplements see all
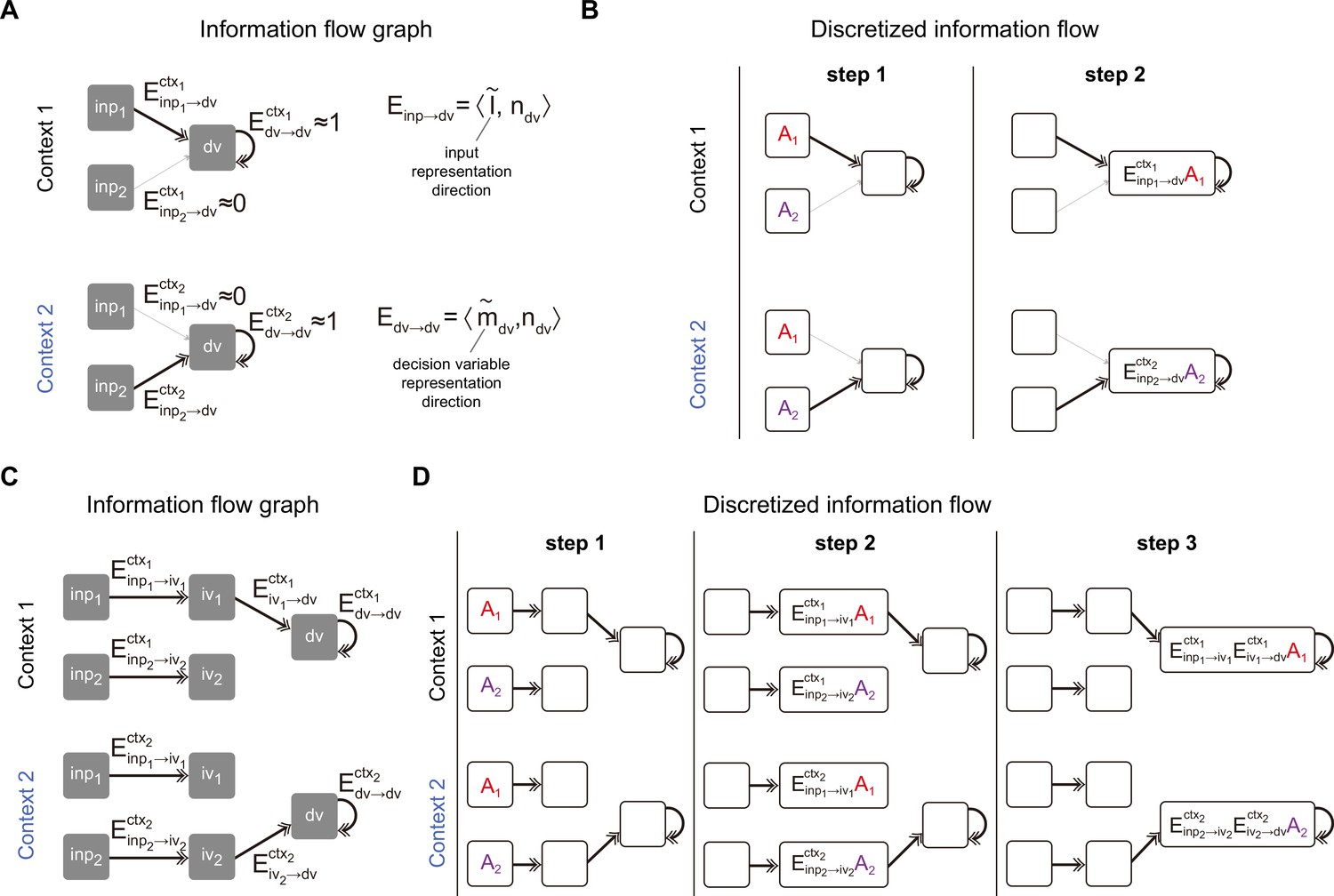
Pathway-based information flow analysis.
(A) The information flow graph of the rank-1 model presented in Figure 2. In this graph, nodes represented task variables communicating with each other through directed connections (denoted as ) between them. Note that is the overlap between the representation direction of the sender variable (e.g. the representation directions of input variable and decision variable and ) and the input-selection vector of the receiver variable (e.g. the input-selection vector of decision variable ). As such, naturally inherits the context dependency from the representation direction of task variable: while exhibited a large value and was negligible in context 1, the values of these two exchanged in context 2. (B) Illustration of information flow dynamics in (A) through discretized steps. At step 1, sensory information and were placed in and slots, respectively. Depending on the context, different information contents (i.e. in context 1 and in context 2) entered into the slot at step 2 and were maintained by recurrent connections in the following steps, which is desirable for the context-dependent decision-making task. (C) The information flow graph of the rank-3 model presented in Figure 3. Different from (A), here to arrive at the slot, the input information has to first go through an intermediate slot (e.g. the pathway in context 1 and the pathway in context 2). (D) Illustration of information flow dynamics in (C) through discretized steps.
To get a more intuitive understanding of the underlying information flow process, we discretized the equation and followed the information flow step by step. Specifically, by discretizing Equation 3 using Euler’s method with a time step equal to the time constant of the system, we get
(4)
Take context 1 as an example (Figure 4B, top panel). Initially, there is no information in the system. In step 1, pulse inputs of size and are placed in the and slots, respectively. The information from these slots, after being multiplied by the corresponding effective coupling, then flows to the slot. In context 1, , meaning only the content from the slot can arrive at the slot. Consequently, in step 2, the information content in the slot would be . The following steps will replicate step 2 due to the recurrent connectivity of the slot. The scenario in context 2 is similar to context 1, except that only the content from the slot arrives at the slot (Figure 4B, bottom panel). The continuous dynamics for each task variable given pulse input is displayed in Figure 4—figure supplement 2A–C.
The same pathway-based information flow analysis can also be applied to the rank-3 model (Figure 4C and D). In this model, similar to the rank-1 models, there are input variables ( and ) and decision variable . Additionally, it includes intermediate variables ( and ) corresponding to the activity along the and axes. In this scenario, instead of flowing directly from the input to the decision variable, the information flows first to the intermediate variables and then to the decision variable. These intermediate variables act as intermediate nodes. Introducing these nodes does more than simply increase the steps from the input variable to the decision variable. In the rank-1 case, the context signals can only modulate the pathway from the input to the decision variable. However, in the rank-3 case, context signals can modulate the system in two ways: from the input to the intermediate variables and from the intermediate variables to the decision variable.
Take the rank-3 model introduced in Figure 3 as an example. Context signals did not alter the representation of input signals, leading to constant effective couplings (i.e. constant and ) from input to intermediate variables across contexts. Instead, it changed the effective coupling from the intermediate variables to the decision variable (i.e. large in context 1 and near zero in context 2; Figure 4C, Figure 4—figure supplement 1B). Consider the context 1 scenario in the discrete case. In step 1, pulse inputs of size and are placed in the and slots, respectively. In step 2, information flows to the intermediate slots, with in the slot and in the slot. In step 3, only the information in the slot flows to the slot, with the information content being (Figure 4D, top panel). The scenario in context 2 is similar to context 1, except that only the content from the slot reaches the slot in the third step, with the content being (Figure 4D, bottom panel). The continuous dynamics for each task variable given pulse input is displayed in Figure 4—figure supplement 2D, E.
Together, this pathway-based information flow analysis provides an in-depth understanding of how the input information can be routed to the accumulator depending on the context, laying the foundation for a novel pathway-based information flow definition of selection vector and input contextual modulations.
Information flow-based definition of selection vector modulation and selection vector for more general cases
Based on the understanding gained from the pathway-based information flow analysis, we now provide a novel definition of input modulation and selection vector modulation distinct from the one in Equation 1. To begin with, we first considered a model with mixed input and selection vector modulation (Figure 5, left), instead of studying extreme cases (i.e. one with pure input modulation in Figure 2 and the other with pure selection vector modulation in Figure 3). In this more general model, input information can either go directly to the decision variable (with effective coupling ) or first pass through the intermediate variables before reaching the decision variable (with effective coupling and respectively). Applying the same information flow analysis, we see that a pulse input of unit size will ultimately reach the slot with a magnitude of (Figure 5A, right; see Methods for more details). In other words, the total effective coupling from the input to the decision variable is equal to . Now, it is straightforward to decompose the context-dependent modulation of in terms of input or selection vector change:
(5)
in which the first component stands for the change of input representation (termed as input modulation) and the second component is the one without changing the stimulus input representation (termed as selection vector modulation).
Figure 5
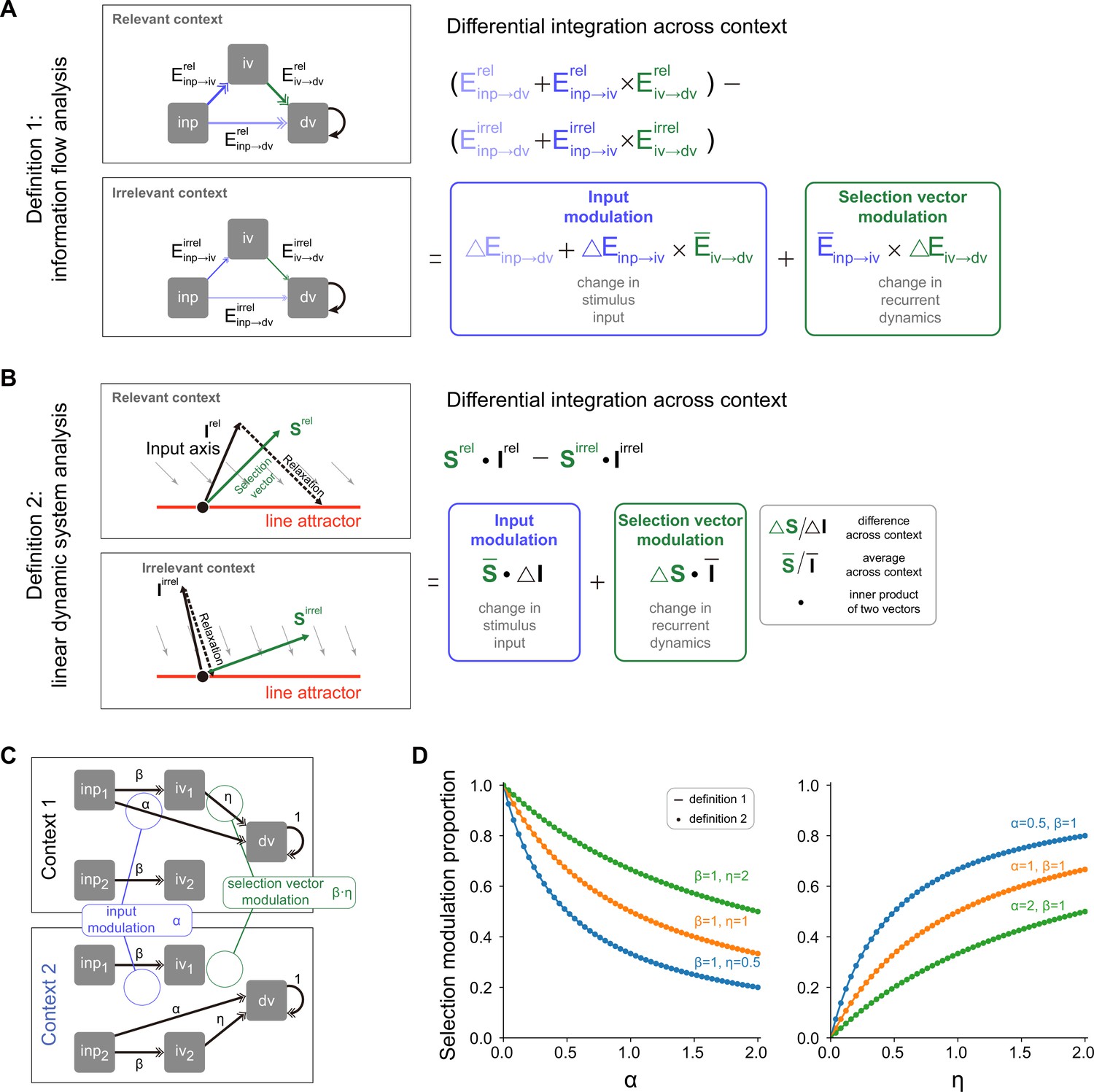
A novel pathway-based definition of selection vector modulation.
(A) A pathway-based decomposition of contextual modulation in a model with both input and selection vector modulations. This definition is based on an explicit formula of the effective connection from the input variable to the decision variable in the model (i.e. ; see Method for details). The input modulation component is then defined as the modulation induced by the change of the input representation direction across contexts. The remaining component is then defined as the selection vector modulation one. (B) Illustration of contextual modulation decomposition introduced in Pagan et al., 2022. In this definition, the selection vector has to be first reverse-engineered through linearized dynamical systems analysis. The input modulation component is then defined as the modulation induced by the change of input representation direction across contexts, while the selection vector modulation component is defined as the one induced by the change of the selection vector across contexts. (C) A family of handcrafted recurrent neural networks (RNNs) with both input and selection vector modulations. , and represent the associated effective coupling between task variables. In this model family, the pathway, susceptible to the input modulation, is parameterized by while the pathway, susceptible to the selection vector modulation, is parameterized by and . As such, the ratio of the input modulation to the selection vector modulation can be conveniently controlled by adjusting , and . (D) Comparison of pathway-based definition in (A) with the classical definition in (B) using the model family introduced in (C).
We then asked if this pathway-based definition is equivalent to the one in Equation 1 based on linearized dynamical system analysis (Figure 5; Pagan et al., 2022). To answer this question, we numerically compared these two definitions using a family of models with both input and selection vector modulations (Figure 5C; see Methods for model details) and found that these two definitions produced the same proportion of selection vector modulation across a wide range of parameter regimes (Figure 5D). Together with theoretical derivation of equivalence (see Methods), this consistency confirmed the validity of our pathway-based definition of contextual modulation decomposition.
Having elucidated the pathway-based definitions of input and selection vector modulation, we next provide a novel pathway-based definition of selection vector. For the network depicted in Figure 5A, the total effective coupling can be rewritten as , where is the input representation direction and . This reformulation aligns with the insight that the amount of input information that can be integrated by the accumulator is determined by the dot product between the input representation direction and the selection vector. Thus, is the selection vector of the circuit in Figure 5A.
To better understand why selection vector has such a formula, we visualized the information propagation from input to the choice axis using a low-rank matrix (Figure 6A). Specifically, it comprises two components, each corresponding to a distinct pathway. For the first component, input information is directly selected by . For the second component, input information is sent first to the intermediate variable and then to the decision variable. This pathway involves two steps: in the first step, the input representation vector is selected by , and in the second step, to arrive at the choice axis, the selected information has to be multiplied by the effective coupling . By concatenating these two steps, information propagation from the input to the choice axis in this pathway can be effectively viewed as a selection process mediated by the vector (termed as the second-order selection vector component). Therefore, provides a novel pathway-based definition of selection vector in the network. We further verified the equivalence between this pathway-based definition and the linearized-dynamical-systems-based classical definition (Mante et al., 2013) in our simple circuit through theoretical derivation (see Methods) and numerical comparison (Figure 6B).
Figure 6
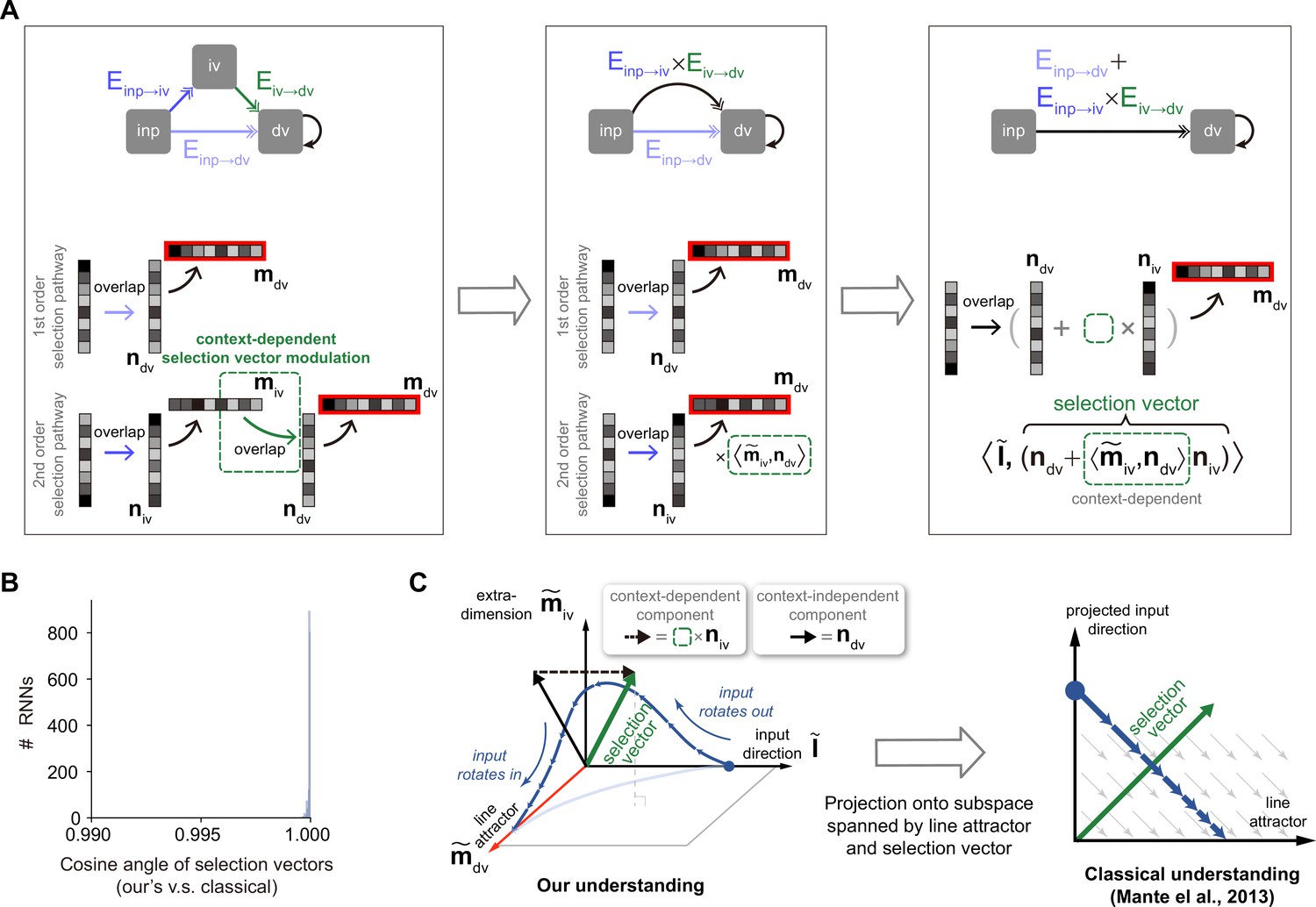
An explicit pathway-based formula of selection vector.
(A) Illustration of how an explicit pathway-based formula of selection vector is derived. In a model with both the first-order selection pathway (i.e. ) and the second-order selection pathway (i.e. ), the second-order pathway can be reduced to a pathway with the effective selection vector that exhibited the contextual dependency missing in rank-1 models. (B) Comparison between this pathway-based selection vector and the classical one (Mante et al., 2013) using 1000 recurrent neural networks (RNNs) (see Methods for details). (C) The connection between our understanding and the classical understanding in neural state space. Based upon the explicit formula of selection vector in (A), the selection vector modulation has to rely on the contextual modulation of additional representation direction (i.e. ) orthogonal to both the input representation direction () and decision variable representation direction (, line attractor). Therefore, it requires at least three dimensions (i.e. , , and ) to account for the selection vector modulation in neural state space.
To visualize the pathway-based selection vector in neural activity state space, we found that a minimum of three dimensions is required, including the input representation direction, the decision variable representation direction, and the intermediate variable representation direction (Figure 6C, left). This geometric visualization highlighted the role of extra dimensions beyond the classical two-dimensional neural activity space spanned by the line attractor and selection vector (Figure 6C, right) in accounting for the selection vector modulation. This is simply because only the second-order selection vector component, which depends on the existence of the intermediate variable, is subject to contextual modulation. In other words, without extra dimensions to support intermediate variable encoding, there will be no selection modulation.
Together, this set of analyses provided a parsimonious pathway-based understanding for both selection vector and its contextual modulation.
Model prediction verification with vanilla RNN models
The new insights obtained from our new framework enable us to generate testable predictions for better differentiating selection vector modulation from input modulation, a major challenge unresolved in the field (Pagan et al., 2022).
First, we predict that it is more likely to have a large proportion of selection vector modulation for a neural network with high-dimensional connectivity. To better explain the underlying rationale, we can simply compare the number of potential connections contributing to the input modulation with those contributing to the selection vector modulation for a given neural network model. For example, in the network presented in Figure 5, there are three connections (including light blue, dark blue, and green ones) while only one connection (i.e. the green one) supporting selection vector modulation. For a circuit with many higher-order pathways (e.g. Figure 7A), only those connections with the input as the sender is able to support input modulation. In other words, there exist far more connections potentially eligible to support the selection vector modulation (Figure 7B), thereby leading to a large selection vector modulation proportion. We then tested this prediction on vanilla RNNs trained through backpropagation (Figure 7C; Mante et al., 2013; Song et al., 2016; Yang and Wang, 2020). Using effective dimension (see Methods for a formal definition; Rudelson and Vershynin, 2007; Sanyal et al., 2020) to quantify the dimensionality of the connectivity matrix, we found a strong positive correlation between the effective dimension of connectivity matrix and the selection vector modulation (Figure 7D, left panel and Figure 7—figure supplement 1A, see Method for details).
Figure 7 with 4 supplements see all
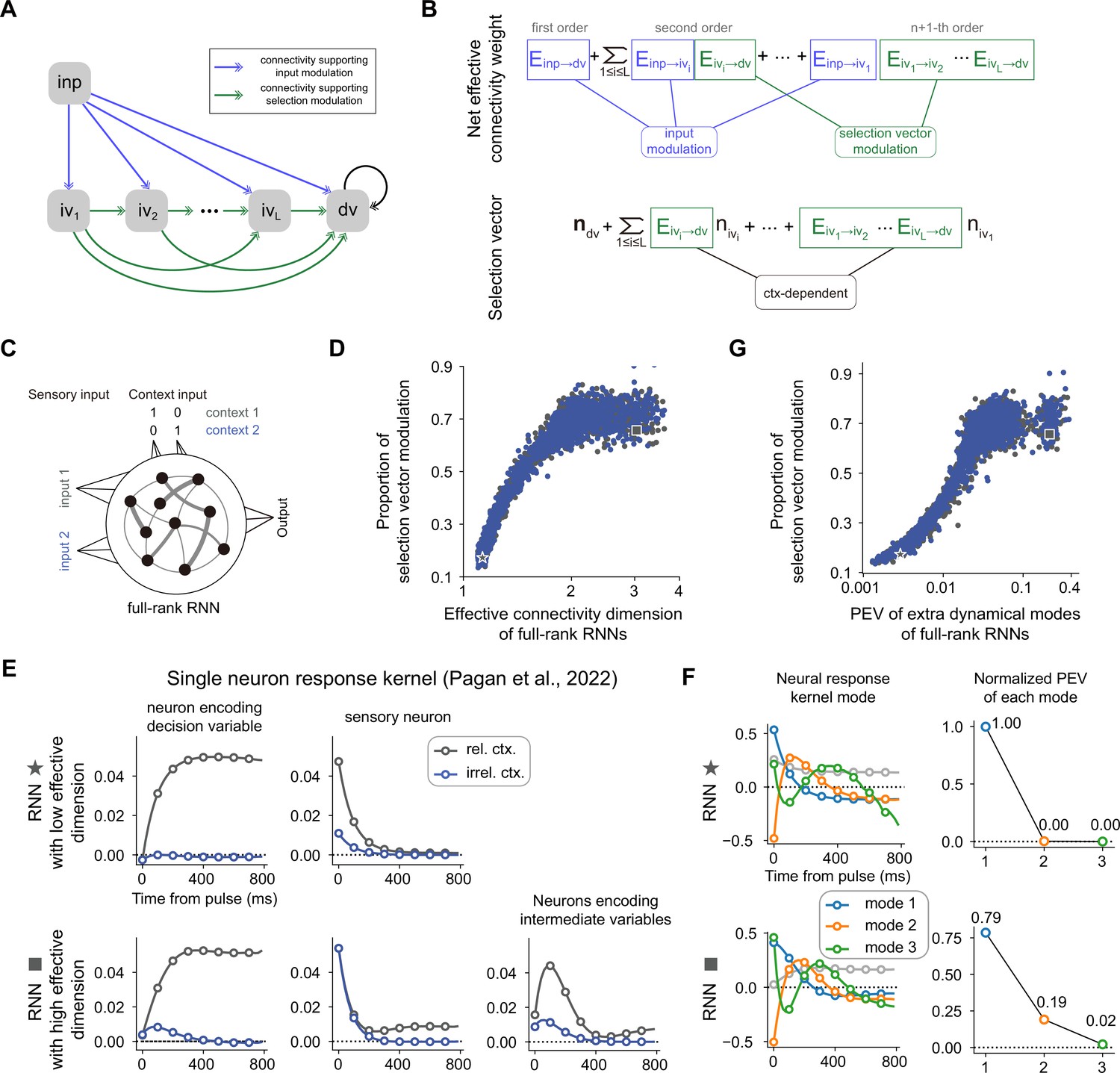
The correlation between the dimensionality of neural dynamics and the proportion of selection vector modulation is confirmed in vanilla recurrent neural networks (RNNs).
(A) A general neural circuit model of context-dependent decision-making (CDM). In this model, there are multiple pathways capable of propagating the input information to the decision variable slot, of which the blue connections are susceptible to the input modulation while the green connections are susceptible to the selection vector modulation (see Methods for details). (B) The explicit formula of both the effective connection from the input variable to the decision variable and the effective selection vector for the model in (A). (C) The setting of vanilla RNNs trained to perform the CDM task. See Methods for more details. (D) Positive correlation between effective connectivity dimension and proportion of selection vector modulation. Given a trained RNN with matrix J, the effective connectivity dimension, defined by where are singular values of J, is used to quantify the connectivity dimensionality. Spearman’s rank correlation, r=0.919, p<1e-3, n=3892. The x-axis is displayed in log scale. (E) Single neuron response kernels for two example RNNs. The neuron response kernels were calculated using a regression method (Pagan et al., 2022; see Methods for details). For simplicity, only response kernels for input 1 are displayed. Top: Response kernels for two example neurons in the RNN with low effective dimension (indicated by a star marker in panel D). Two typical response kernels, including the decision variable profile (left) and the sensory input profile (right), are displayed. Bottom: Response kernels for three example neurons in the RNN with high effective dimension (indicated by a square marker in panel D). In addition to the decision variable profile (left) and sensory input profile (middle), there are neurons whose response kernels initially increase and then decrease (right). Gray lines, response kernels in context 1 (i.e. rel. ctx.). Blue lines, response kernels in context 2 (i.e. irrel. Ctx.). (F) Principal dynamical modes for response kernels in the population level extracted by singular value decomposition. Left: Shared dynamical modes, including one persistent choice mode (gray) and three transient modes (blue, orange, green) are identified across both RNNs. Right: For the -th transient mode, the normalized percentage of explained variance (PEV) is given by , where are singular values for each transient mode (see Methods for details). (G) Positive correlation between response-kernel-based index and proportion of selection vector modulation. For a given RNN, percentage of explained variance (PEV) of extra dynamical modes is defined as the accumulated normalized PEV of the second and subsequent transient dynamical modes (see Methods for details). Spearman’s rank correlation, r=0.902, p<1e-3, n=3892. The x-axis is displayed in log scale.
We then asked if we could generate predictions to quantify the proportion of selection vector modulation purely based on neural activities. To this end, as what has been performed in Pagan et al., we took advantage of the pulse-based sensory input setting to calculate the single neuron response kernel (see Methods for details). For a given neuron, the associated response kernel is defined to characterize the influence of a pulse input on its firing rate in later times. For example, for a neuron encoding the decision variable, the response kernel should exhibit a profile accumulating evidence over time (Figure 7E, top left). In contrast, for a neuron encoding the sensory input, the response kernel should exhibit an exponential decay profile with time constant (Figure 7E, top right). For each RNN trained through backpropagation, we then examined the associated single neuron response kernels. We found that for the model with low effective dimension (denoted by a star marker in Figure 7D), there were mainly two types of response kernels, including sensory input profile and decision variable profile (Figure 7E, top). In contrast, for the model with the highest effective dimension (denoted by a square marker in Figure 7D), aside from the sensory input and decision variable profiles, richer response kernel profiles were exhibited (Figure 7E, bottom). In particular, there was a set of single neuron response kernels with peak amplitudes occurring between the pulse input onset and the choice onset (Figure 7E, bottom right). These response kernels cannot be explained by the combination of sensory input and decision variables. Instead, the existence of these response kernels signifies neural dynamics in extra dimensions beyond the subspaces spanned by the input and decision variable, the genuine neural dynamical signature of the existence of selection vector modulation (Figure 6C).
While single neuron response kernels are illustrative in highlighting the model difference, they lack explanatory power at the population level. Therefore, we employed the singular value decomposition method to extract the principal dynamical modes of response kernels at the population level (see Methods for details). We found that similar dynamical modes, including one persistent choice mode (gray) and three transient modes (blue, orange, green), were shared across both the low and high effective dimension models (Figure 7F, left). The key difference between these two models lies in the percentage of explained variance (PEV) of the second transient mode (orange): while there is near-zero PEV in the low effective dimension model (Figure 7F, top right), there is substantial PEV in the high effective dimension model (Figure 7F, bottom right), consistent with the single neuron picture shown in Figure 7E. This result led us to use the PEV of extra dynamical modes (including the orange and green ones; see Methods for details) as a simple index to quantify the amount of selection vector modulation in these models. As expected, we found that the PEV of extra dynamical modes can serve as a reliable index reflecting the proportion of selection vector modulation in these models (Figure 7G, right panel and Figure 7—figure supplement 1B and C). Similar results for vanilla RNNs trained with different hyperparameter settings are displayed in Figure 7—figure supplement 2.
Together, we identified novel neural dynamical signatures of section vector modulation at both the single neuron and population level, suggesting the potential great utility of these neural dynamical signatures in distinguishing the contribution of selection vector modulation from input modulation in experimental data.
Discussion
Using low-rank RNNs, we provided a rigorous theoretical framework linking network connectivity, neural dynamics, and selection mechanisms, and gained an in-depth algebraic and geometric understanding of both input and selection vector modulation mechanisms, and accordingly uncovered a previously unknown link between selection vector modulation and extra dimensions in neural state space. This gained understanding enabled us to generate novel predictions linking novel neural dynamic modes with the proportion of selection vector modulation, paving the way towards addressing the intricacy of neural variability across subjects in context-dependent computation.
A pathway-based definition of selection vector modulation
In their seminal work, Mante, Sussillo, and their collaborators developed a numerical approach to compute the selection vector for trained RNN models (Mante et al., 2013). Based on this concept of selection vector, recently, Pagan et al. proposed a new theoretical framework to decompose the solution space of context-dependent decision-making, in which input modulation and selection vector modulation were explicitly defined (i.e. Equation 1). Here, taking the theoretical advantage of low-rank RNNs (Mastrogiuseppe and Ostojic, 2018; Dubreuil et al., 2022), we went beyond numerical reverse-engineering and provided a complementary pathway-based definition of both selection vector and selection vector modulation (i.e. Equation 5). This new definition gained us a novel geometric understanding of selection vector modulation, revealed a previously unknown link between extra dimensions and selection vector modulation (Figure 6C), and eventually provided us with experimentally identifiable neural dynamical signature of selection vector modulation at both the single neuron and population levels (Figure 7, E-G).
Individual neural variability in higher cognition
One hallmark of higher cognition is individual variability, as the same higher cognition problem can be solved equally well with different strategies. Therefore, studying the neural computations underlying individual variability is no doubt of great importance (Hariri, 2009; Parasuraman and Jiang, 2012; Keung et al., 2020; Nelli et al., 2023). Recent experimental advances enabled researchers to investigate this important issue in a systematic manner using delicate behavioral paradigms and large-scale recordings (Pagan et al., 2022). However, the computation underlying higher cognition is largely internal, requiring discovering novel neural activity patterns as internal indicators to differentiate distinct circuit mechanisms. In the example of context-dependent decision-making studied here, to differentiate selection vector modulation from input modulation, we found the PEV in extra dynamical modes is a reliable index for a wide variety of RNNs (Figure 7D, Figure 7—figure supplement 2). However, cautions have to be made here as we can conveniently construct counter-examples deviating from the picture depicted by this index. For instance, manually introducing additional dimensions that do not directly contribute to the computation can disrupt the index (Figure 7—figure supplement 4A and B). In the extreme scenario, we can construct two models with distinct circuit mechanisms (selection vector modulation and input modulation, respectively) but having the same neural activities (Figure 7—figure supplement 3), suggesting that any activity-based index alone would fail to make this differentiation. Then, why did the proposed index work for the trained vanilla RNNs shown in Figure 7D? Our lesion analysis suggests that the underlying reason is that the major variance in neural activity of vanilla RNNs learned through backpropagation is task-relevant (Figure 7—figure supplement 4C, see Methods for details). However, it is highly likely that task-irrelevant neural activity variance exists in higher brain regions, meaning the proposed index may not perform well in neural recordings. Therefore, our modeling work suggests that, to address the intricacy of individual variability of neural computations underlying higher cognition, integrative efforts incorporating not only large-scale neural activity recordings but also activity perturbations, neuronal connectivity knowledge, and computational modeling may be inevitably required.
Beyond context-dependent decision-making
While we mainly focused on context-dependent decision-making tasks in this study, the issue of whether input or selection vector modulation prevails is not limited to the domain of decision-making. For instance, recent work by Chen et al., 2024 demonstrated that during sequence working memory control (Botvinick and Watanabe, 2007; Xie et al., 2022), sensory inputs presented at different ordinal ranks first entered into a common sensory subspace and then were routed to the corresponding rank-specific working memory subspaces in monkey frontal cortex. Here, similar to the decision-making case (Figure 1C), the same issue arises: where is the input information selected by the context (here, the ordinal rank)? Can the presence of a common sensory subspace (similar to the presence of location information in both relevant and irrelevant contexts in Figure 1C) preclude the input modulation? The pathway-based understanding of input and selection vector modulation gained from CDM in this study may be transferable to address these similar issues.
The role of transient dynamics in extra dimensions in context-dependent computation
In this study, we linked the selection vector modulation with transient dynamics (Aoi et al., 2020; Soldado-Magraner et al., 2023) in extra dimensions. While the transient dynamics in extra dimensions are not necessary in context-dependent decision-making here (Dubreuil et al., 2022; Figure 2), more complex context-dependent computation may require its presence. For example, recent work by Tian et al., 2024 found that transient dynamics in extra subspaces is required to perform the switch operation (i.e. exchanging information in subspace 1 with information in subspace 2). Understanding how transient dynamics in extra dimensions contribute to complex context-dependent computation warrants further systematic investigation.
In summary, through low-rank neural network modeling, our work provided a parsimonious mechanistic account for how information can be selected along different pathways, making significant contributions towards understanding the intriguing selection mechanisms in context-dependent computation.
Materials and methods
Key resources table
| Reagent type (species) or resource | Designation | Source or reference | Identifiers | Additional information |
|---|---|---|---|---|
| Software, algorithm | Python | https://www.python.org/ | RRID:SCR_008394 | version: 3.9 |
The general form of RNNs
Request a detailed protocolWe investigated networks of neurons with input channels, described by the following temporal evolution equation
(6)
In this equation, represents the activation of neuron at time , denotes the characteristic time constant of a single neuron, and is a nonlinear activation function. Unless otherwise specified, we use the tanh function as the activation function. The coefficient represents the connectivity weight from neuron to neuron . The input corresponds to the -th input channel at time , with feedforward weight to neuron , and represents white noise at time . The network’s output is obtained from the neuron’s activity through a linear projection:
(7)
The connectivity matrix , specified as , can be a low-rank or a full-rank matrix. In the low-rank case, is restricted to a low-rank matrix , in which is the -th output vector, and is the -th input-selection vector, with each element of and considered an independent parameter (Dubreuil et al., 2022). In this paper, we set the time constant to be 100 ms, and use Euler’s method to discretize the evolution equation with a time step .
Task setting
Request a detailed protocolWe modeled the click-version CDM task recently investigated by Pagan et al., 2022. The task involves four input channels , , , and , where and are stimulus inputs and and are context inputs. Initially, there is a fixation period lasting for . This is followed by a stimulus period of and then a decision period of .
For trial , at each time step, the total number of pulse inputs (#pulse) is sampled from a Poisson distribution with a mean value of . Each pulse has two properties: location and frequency. Location can be either left or right, and frequency can be either high or low. We randomly sample a pulse to be right with probability (hence left with probability ) and to be high with probability (hence low with probability ). The values of and are independently chosen from the set {39/40, 35/40, 25/40, 15/40, 5/40, 1/40}. The stimulus strength for the location input at trial is defined as , and for the frequency input, it is defined as . The input represents location evidence, calculated as 0.1 times the difference between the number of right pulses and the number of left pulses (#right-#left) at time step . The input represents frequency evidence, calculated as 0.1 times the difference between the number of high-frequency pulses and the number of low-frequency pulses (#high-#low) at time step .
The context is randomly chosen to be either the location context or the frequency context. In the location context, and throughout the entire period. The target output is defined as the sign of the location stimulus strength (1 if , otherwise –1). Thus, in this context, the target output is independent of the frequency stimulus input. Conversely, in the frequency context, and . The target output is defined as the sign of the frequency stimulus strength (1 if , otherwise –1). Thus, in this context, the target output is independent of the location stimulus input.
Linearized dynamical system analysis (Figure 1 and Figure 7)
Request a detailed protocolTo uncover the computational mechanism enabling each RNN to perform context-dependent evidence accumulation, we utilize linearized dynamical system analysis to ‘open the black box’ (Mante et al., 2013). The dynamical evolution of an RNN in context is given by:
(8)
where is the neuron activity. First, we identify the slow point of each RNN in each context using an optimization method (Mante et al., 2013). Let be the discovered slow point, i.e., where . We define a diagonal matrix , with the -th diagonal element representing the sensitivity of the -th neuron at the slow point. Near the slow point, we have . Then, we can derive:
(9)
Thus, the dynamics of neuron activity around the slow point can be approximated by a linear dynamical system:
(10)
(11)
where is the identity matrix, denotes the state transition matrix of the dynamical system, and are stimulus input representation directions. Similar to previous work (Mante et al., 2013), we find that for every network, the linear dynamical system near the slow point in each context is roughly a linear attractor. Specifically, the transition matrix has a single eigenvalue close to zero, while all other eigenvalues have negative real parts. The right eigenvector of associated with the eigenvalue close to zero defines the stable direction of the dynamical system, forming the line attractor (unit norm). The left eigenvector of associated with that eigenvalue defines the direction of the selection vector . The norm of selection vector is chosen such that . Previous work (Mante et al., 2013) has shown that a perturbation from the line attractor will eventually converge to the line attractor, with the distance from the starting point being .
Based on linearized dynamical systems analysis, Pagan et al. recently defined input modulation and selection vector modulation (Pagan et al., 2022) as:
(12)
(13)
Specifically, the input modulation and selection vector modulation for stimulus input 1 are defined as and , respectively. Similarly, the input modulation and selection vector modulation for stimulus input 2 are defined as and , respectively. Proportion for selection vector modulation (Figure 7D and G) is defined as .
Training of rank-1 RNNs using backpropagation (Figure 2)
Request a detailed protocolThe rank-1 RNNs in Figure 2 are trained using backpropagation-through-time with the PyTorch framework. These networks are trained to minimize a loss function defined as:
(14)
Here, is the target output, is the network output, and the indices and represent time and trial, respectively. is a temporal mask with value {0, 1}, where is 1 only during the decision period. is the L2 regularization loss. For full-rank RNNs (Figure 7), and for low-rank RNNs, . The loss function is minimized by computing gradients with respect to all trainable parameters. We use the Adam optimizer in PyTorch with the decay rates for the first and second moments set to 0.9 and 0.99, respectively, and a learning rate of . Each RNN is trained for 5000 steps with a batch size of 256 trials.
For Figure 2, we trained 100 RNNs of neurons with the same training hyperparameters. The rank of the connectivity matrix is constrained to be rank-1, represented as . We trained the elements of the input vectors , connectivity vector , and the readout vector . All trainable parameters were initialized with random independent Gaussian weights with a mean of 0 and a variance of . The regularization coefficient is set to .
Trial-averaged analyses (Figures 2F and 3F)
Request a detailed protocolFor the trial-averaged analyses shown in Figures 2f and 3f, we followed a procedure similar to Mante et al., 2013. Specifically, at each time point and for each neuron , we fit the following linear regression model to characterize how different task variables contribute to that neuron’s activity:
(15)
Here, , , , and represent the values of the corresponding variables on trial k. Next, for each regressor (choice, input 1, input 2, context), we pooled the resulting regression coefficients across neurons to get the time-vary regression vectors . For regressor , we identified the time when the regression vector has maximum norm, and got the time-independent regression vectors:
(16)
(17)
Next, we assembled these vectors into a matrix and used QR decomposition to get the orthogonalized regression basis . Finally, we averaged neuronal activity across trials sharing the same condition (choice, context, input 1), and then projected this average activity onto the choice and input 1 axes. This process resulted in the trial-averaged population dynamics illustrated in Figures 2F and 3F.
Proof of no selection vector modulation in rank-1 RNNs (Figure 2)
Request a detailed protocolThe transition matrix of neuron activity in the rank-1 RNN is given by:
(18)
Multiplying on the right by , we obtain
(19)
where the symbol is defined as for two vectors of length-. The requirement for the linear attractor approximation, , is met by all our trained and handcrafted RNNs (Figure 4—figure supplement 1). This demonstrates that is the left eigenvector of the transition matrix, and hence is the selection vector in each context. Therefore, the direction of the selection vector is invariant across different contexts for the rank-1 model, indicating no selection vector modulation and this is consistent with the training results shown in Figure 2.
Handcrafting rank-3 RNNs with pure selection vector modulation (Figure 3)
Request a detailed protocolFirst, we provide the implementation details of the rank-3 RNNs used in Figure 3. The network consists of 30,000 neurons divided into three populations, each with 10,000 neurons. The first population (neurons 1–10,000) receives stimulus input, accounting for both the information flow from the stimulus input to the intermediate variables and the recurrent connection of the decision variable. The second (neurons 10,001–20,000) and third populations (neurons 20,001–30,000) handle the information flow from the intermediate variables to the decision variable and are modulated by the context signal. To achieve this, we generate three Gaussian random matrices of shape 10,000×3. Let denote the -th column of matrix . The stimulus input is given by the concatenation of three length-10,000 vectors , 0 where denotes a length-10,000 zero vector. The stimulus input is given by . The context input is given by . The context input is given by . The connectivity vectors and are given by , and , respectively. The input-selection vectors and are given by , , and , respectively, where represents the average gain of the second population in context 1 or the third population in context 2. The readout vector is given by . We generate 100 RNNs based on this method to ensure that the conclusions in Figure 3 do not depend on the specific realization of random matrices. Linearized dynamical system analysis reveals that all these RNNs perform flexible computation through pure selection vector modulation. Please see the section ‘The construction of rank-3 RNN models’ for a mean-field-theory-based understanding.
Pathway-based information flow graph analysis of low-rank RNNs (Figure 4)
Request a detailed protocolThe dynamical evolution equation for low-rank RNN with ranks and input channels in context c is given by
(20)
Assuming at , the dynamics of are always constrained in the subspace spanned by and {. Therefore, can be expressed as a linear combination of these vectors: leading to the following evolving dynamics of task variables:
(21)
(22)
where denotes activation along the -th input vector, termed the input task variable and denotes activation along the -th output vector, termed the internal task variable.
The rank-1 RNN case
Request a detailed protocolTherefore, for rank-1 RNNs, the latent dynamics of decision variable (internal task variable associated with ) in context is given by
(23)
Similar to the linearized dynamical systems analysis introduced earlier, we linearized Equation 15 around , obtaining the following linearized equation:
(24)
where (termed as the decision variable representation direction) and (termed as the input representation direction), with equal to . By denoting and as and , respectively, together with the fact that is close to zero for all trained rank-1 RNNs, we obtain
(25)
which is Equation 3 in the main text.
The rank-3 RNN case
Request a detailed protocolUsing a similar method, we can uncover the latent dynamics of rank-3 RNNs, as shown in Figure 5. Note that the rank-3 RNN in Figure 3 is a special case of this more general form. The latent dynamics for internal task variables in context can be written as:
(26)
(27)
By applying the same first-order Taylor expansion, we obtain the following equations:
(28)
(29)
We consider the case in which the intermediate variables (, internal task variables associated with , respectively) only receive information from the corresponding stimulus input, and the effective coupling of the recurrent connection is 1 in both contexts. Specifically, we assume:
(30)
(31)
(32)
Our construction methods for rank-3 RNNs in Figures 3 and 5 guarantee these conditions when the network is large enough (for example, in our setting). Under these conditions, Equations 20 and 21 can be simplified to:
(33)
(34)
Suppose at the network receives a pulse from input 1 with size and a pulse from input 2 with size , which correspond to , . Under this condition, the expression for is given by
(35)
From Equation 27, as , will converge to , providing a theoretical basis for the pathway-based information flow formula presented in Figures 4 and 5.
Building rank-3 RNNs with both input and selection vector modulations (Figure 5)
Understanding low-rank RNNs in the mean-field limit
Request a detailed protocolThe dynamics of task variables in low-rank RNNs can be mathematically analyzed under the mean-field limit () when each neuron’s connectivity component is randomly drawn from a multivariate Gaussian mixture model (GMM) (Beiran et al., 2021; Dubreuil et al., 2022). Specifically, we assume that, for the -th neuron, the connectivity component vector is drawn independently from a GMM with components. The weight for the -th component is , and this component is modeled as a Gaussian distribution with mean zero and covariance matrix . Let denote the upper-left submatrix of , which represents the covariance matrix of within the -th component. Let denote the covariance of and , where the -th neuron belongs to the -th component.
Given these assumptions, under the mean-field limit (), Equation 14 can be expressed as
(36)
(37)
(38)
where if , otherwise Under the condition of small task variables ( and ), is approximately equal to and the quantities are determined solely by the covariance of the context signal input within each population. Clearly, the effective coupling from the input task variable to the internal task variable is given by , and the effective coupling between the internal task variables and is given by .
Mean-field-theory-based model construction
Request a detailed protocolUtilizing this theory, we can construct RNNs tailored to any given ratio of input modulation to selection vector modulation by properly setting the connectivity vectors . The RNN we built consists of 30,000 neurons divided into three populations. The first population (neurons 1–10,000) receives the stimulus input, accounting for information flow from stimulus input to intermediate variables (the connection strength is controlled by ) and the recurrent connection of the decision variable. The second (neurons 10,001–20,000) and third populations (neurons 20,001–30,000) receive the stimulus input, accounting for the information flow from the stimulus input to the decision variable (the connection strength is controlled by ), and the information flow from the intermediate variables to the decision variable (the connection strength is controlled by ), and are modulated by contextual input. To achieve this, we generate three Gaussian random matrices of shape 10,000 × 3, 10,000 × 5 and 10,000 × 5, respectively. Let denote the -th column of matrix . The stimulus input is given by the concatenation of three length-10,000 vectors . The stimulus input is given by . The context input is given by . The context input is given by . The connectivity vectors and are given by , and , respectively. The input-selection vectors and are given by , , respectively. is given by , where is the average gain of the second population in context 1 or third population in context 2. The readout vector is given by .
For the network, in context 1, is only determined by the covariance of the context 1 signal. That is,
(39)
Our construction method guarantees that for , respectively. Hence, for , respectively. Then the effective coupling from input variable to in context 1 is given by
(40)
Similarly, we can get that:
(41)
(42)
(43)
Other unmentioned effective couplings are zero. Similarly, the effective couplings in context 2 are given by
(44)
(45)
(46)
Thus, for each input, the input modulation is and the selection vector modulation is . Therefore, any given ratio of input modulation to selection vector modulation can be achieved by varying the parameters and . The example in Figure 3 with pure selection vector modulation is a special case with and .
Pathway-based definition of selection vector (Figure 6)
Request a detailed protocolNext, we will consider the rank-3 RNN with latent dynamics depicted in Equations 18 and 19. The input representation produced by a pulse input in a certain context at is given by . We have proven that this pulse input will ultimately reach the slot with a magnitude of . This equation can be rewritten as
(47)
Therefore, we define as the pathway-based definition of the selection vector. Through calculations, we can prove that this pathway-based definition of the selection vector is equivalent to the classical definition based on linearized dynamical systems. In fact, the transition matrix of neuron activity in this rank-3 RNN is given by:
(48)
Multiplying on the right by , we obtain:
(49)
Moreover, under the condition that the choice axis is invariant across contexts, i.e., is invariant across contexts (Mante et al., 2013; Pagan et al., 2022),
(50)
This demonstrates that is indeed the left eigenvector of the transition matrix as well as the classical selection vector of the linearized dynamical systems.
The equivalence between two definitions of selection vector modulation (Figure 5)
Request a detailed protocolHere, we use the rank-3 RNN and input 1 as an example to explain why there is an equivalence between our definition of selection vector modulation and the classical one (Pagan et al., 2022). In the previous section, we have proven that the input representation direction and selection vector are given by and , respectively. According to the classical definition (Pagan et al., 2022), the input modulation and selection vector modulation are given by and , respectively. Since , and are invariant across different contexts, we have:
(51)
(52)
Substituting these into Equations 7 and 8 yields:
(53)
(54)
a result fully consistent with the pathway-based definition in Equation 5 of the main text.
Comparison between the pathway-based selection vector and the classical one (Figure 6)
Request a detailed protocolWe generate 1000 RNNs according to the procedure in Figure 5C (see Method ‘Mean-field-theory-based model construction’ for details), with each RNN defined by parameters , and independently sampled from a Uniform (0, 1) distribution. For each RNN, we computed the selection vector for the RNN in a given context (e.g. context 1 or 2) in two ways:
via linearized dynamical system analysis following Mante et al., 2013, producing the selection vector (classical in Figure 6B), using the theoretical derivation (‘our’s’ in Figure 6B).
We repeated this process 1000 times and measured the cosine angle between these two selection vectors and plotted the resulting distribution for context 1 (gray) and context 2 (blue) in Figure 6B.
Pathway-based analysis of higher order low-rank RNNs (Figure 7A and B)
Request a detailed protocolIn this section, we will consider RNNs with more intermediate variables (Figure 7A). Here, we consider only one stimulus modality for simplicity and use the same notation convention as in the previous sections. The network consists of one input variable , intermediate variables , and one decision variable . For simplicity, we let be an alias for the input variable and be an alias for the decision variable. We use the shorthand and to denote the effective coupling and , respectively. The dynamics of these task variables are given by
(55)
(56)
(57)
Consider the case when, at time , the network receives a pulse input with unit size (i.e. ). Then, we have
(58)
(59)
(60)
where . In Equation 52, stands for the incomplete Gamma function and . These expressions tell us that, as time goes to infinity, all intermediate task variables will decay to zero and the decision variable will converge to , which means that a pulse input of unit size will ultimately reach the slot with a magnitude of . Therefore, we define the total effective coupling from the input variable to the decision variable in this higher-order graph as
(61)
The difference of the total effective coupling between relevant context and irrelevant context can be decomposed into:
(62)
The first term, caused by changing a stimulus input representation, is defined as the input modulation. The second term, the one without changing the stimulus input representation, is defined as the selection vector modulation.
Using a similar method in rank-3 RNNs, the selection vector for RNNs of higher order is given by:
(63)
Training of full-rank vanilla RNNs using backpropagation (Figure 7)
For Figure 7, we trained full-rank RNNs of neurons. We trained the elements of the input vectors, the connectivity matrix, and the readout vector. We tested a large range of regularization coefficients ranging from 0 to 0.1. For each chosen from the set {0, 0.001, 0.002, 0.003, 0.004, 0.005, 0.006, 0.007, 0.008, 0.009, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1}, we trained 100 full-rank RNNs. A larger value results in a trained connectivity matrix with lower rank, making the network more similar to a rank-1 RNN. All trainable parameters were initialized with random independent Gaussian weights with a mean of 0 and variance of . Only trained RNNs with their largest eigenvalue of the activity transition matrix falling within the –0.05–0.05 range in both contexts were selected for subsequent analysis.
To ensure that the conclusions drawn from Figure 7 are robust and not dependent on specific hyperparameter settings, we conducted similar experiments under different model hyperparameter settings. First, we trained RNNs with the softplus activation function and regularization coefficients chosen from {0.1, 0.09, 0.08, 0.07, 0.06, 0.05, 0.04, 0.03, 0.02, 0.01, 0.008, 0.004, 0.002, 0.001} (Figure 7—figure supplement 2A). Unlike tanh, softplus does not saturate on the positive end. Additionally, we tested the initialization of trainable parameters with a variance of (Figure 7—figure supplement 2B). Together, these experiments confirmed that the main results do not depend on the specific model hyperparameter settings.
Estimating matrix dimension and extra dimension (Figure 7)
Request a detailed protocolEffective dimension of connectivity matrix (Figure 7D)
Request a detailed protocolLet be the singular values of the connectivity matrix. The matrix’s rank is the number of nonzero singular values. However, rank alone can overlook differences in how quickly those singular values decay. To capture this, we define the effective dimension as its stable rank (Sanyal et al., 2020):
(64)
Each term lies between 0 and 1, so the effective dimension satisfies . When all nonzero singular values are equal, equals the matrix rank. But if some singular values are much smaller than others, effective dimension will be closer to 1.
Single neuron response kernel for pulse input (Figure 7E)
Request a detailed protocolWe apply pulse-based linear regression (Pagan et al., 2022) to assess how pulse input affects neuron activity. The activity of neuron in trial at time step is given by:
(65)
where is the RNN’s choice on trial defined as the sign of its output during the decision period, is the context of trial (1 for context 1 and 0 for context 2), indicates signed input evidence as defined previously in Methods. The first three regression coefficients, , and , capture the influence of choice, context, and time on the neuron’s activity at each time step, each being a 40-dimension vector. The remaining coefficient, , , , and , reflect the impact of pulse input on the neuron activity in a specific context, each also a 40-dimension vector. The asterisk (*) indicates the convolution operation between the response kernel and input evidence, described by:
(66)
Therefore, there are a total of 280 regression coefficients for each neuron. We obtained these coefficients using ridge regression with 1000 trials for each RNN. The coefficient is termed the single neuron response kernel for input in context (Figure 7E).
Response kernel modes and normalized percentage of explained variance (PEV) (Figure 7F)
Request a detailed protocolFor each RNN, we construct a matrix with shape from neuron response kernels for input 1 (or input 2) across both contexts, where represents time steps and is the number of neurons, with each column as a neuron’s response kernel in a context. Then we apply singular value decomposition (SVD) to the matrix:
(67)
where is a diagonal square matrix of size , with diagonal element being the singular value of the matrix. The first column of U serves as a persistent mode (mode 0), while the second and following columns are transient modes (transient dynamical modes 1, 2, etc.). The normalized PEV of transient dynamical mode is defined as:
(68)
PEV of extra dynamical modes
Request a detailed protocolThe PEV of extra dynamical modes for input 1 (or 2) is defined based on the normalized PEV of transient dynamical mode:
(69)
The counterintuitive extreme example (Figure 7—figure supplement 3)
Request a detailed protocolWe can manually construct two models (RNN1 and RNN2) with distinct circuit mechanisms (input modulation versus selection vector modulation) but showing the same neural activities. Specifically, we generated three Gaussian random matrices () of shape 10,000 × 5, 10,000 × 5 and 10,000 × 1, respectively. Let denote the -th column of matrix . The two models have the same input vectors, output vectors, and input-selection vectors for intermediate task variables ( and ), given by:
(70)
(71)
(72)
(73)
where . The difference between these two RNNs lies in their input-selection vector for the decision variable. For RNN1, is given by
(74)
For RNN2, is given by:
(75)
In this construction, the information flow graphs from input 1 to the decision variable () in each context for the two RNNs are shown in Figure 7—figure supplement 3A.
Although the connectivity matrices of the two networks are different (Figure 7—figure supplement 3B), when provided with the same input, the neuron activity of the -th neuron in RNN1 is exactly the same as that of the -th neuron in RNN2 at the same time point (Figure 7—figure supplement 3C). The statistical results of similarity between all neuron pairs are given in Figure 7—figure supplement 3D.
Manually adding redundant structure and PEV of irrelevant activity (Figure 7—figure supplement 4)
Redundant RNN (Figure 7—figure supplement 4B and C)
Request a detailed protocolTo see if the currently proposed method can work when there is a significant amount of neural activity variance irrelevant to the task, we manually added irrelevant neural activity into the trained RNNs (termed as redundant RNNs). Specifically, we randomly choice trained vanilla RNNs (Figure 7D–G). To add irrelevant additional dimensions to the network without affecting the original function, for each RNN with N neurons, we build a larger RNN with neurons equally divided into two populations. The input embeddings, readout vector, and the connectivity strengths between neurons within the first population (the first to the -th neurons) are the same as the original RNN. As for the second population (the -th to the -th neurons), the input embeddings are sampled with Gaussian noise, with the standard deviation equal to that of the original RNN input embeddings and the readout vector is set to 0. The connectivity strengths within the second population are sampled with Gaussian noise, with the standard deviation chosen such that the average sum of square activity of the two populations is nearly equal. Moreover, there is no connectivity between the two populations. The resulting RNN, compared to the original network, introduces adding task-irrelevant neural activity (neural activity in the second population). At the same time, it performs the CDM task in the same way as the original network, with the identical selection vector modulation value.
PEV of irrelevant activity (Figure 7—figure supplement 4C)
Request a detailed protocolWe hypothesize that the proportion of explained variance (PEV) in extra dynamical modes performs reliably for trained RNNs (Figure 7G) because task-irrelevant neural activity is minimal in these networks. To test this possibility, we conducted in-silico lesion experiments for the trained RNNs. The main idea is that if an RNN contains a large portion of task-irrelevant variance, there will exist a subspace (termed as task-irrelevant subspace) that captures this part of variance and removing this task-irrelevant subspace will not affect the network’s behavior.
Based on this idea, we developed an optimization method to identify such a task-irrelevant subspace for any given RNN. The main idea is to find a lesion subspace such that removing all neural activity within this subspace does not affect the network’s behavior, while capturing as much variance in neural activity caused by pulse inputs as possible. Specifically, for any given RNN, we constructed a new RNN with its connectivity matrix defined as , where is the connectivity matrix of the original RNN, is the identity matrix, and is the orthogonal basis of the lesion subspace. Here, is of shape , where is the dimension of the subspace ( in Figure 7—figure supplement 4). For the new RNN, the matrix removes all components of neural activity within the lesion subspace. We try to find the best by minimizing:
(76)
where is the network’s output at the last time step for pulse input at the beginning, is the output without lesion, is a matrix, indicating the neuron activities caused by a pulse input for the RNN without lesion, is a hyperparameter balancing the two parts. We only consider input 1 under condition one for simplicity. The first part ensures that after removing neural activity in the subspace, the network’s output in response to unit pulse remains unchanged. The second part aims to maximize the variance of neuron activity captured by lesion subspace. The orthogonal basis is parameterized using the Cayley transform: . Matrix is optimized using gradient descent with the Adam optimizer with a learning rate of . The training process lasts for 2000 steps and the maximum of under the condition of is defined as the network’s PEV of irrelevant activity (Figure 7—figure supplement 4C).
Data availability
All code and models supporting the findings of this study have been deposited in GitHub (copy archived at Zhang, 2025). Additional materials are available from the corresponding author upon reasonable request.
References
-
Prefrontal cortex exhibits multidimensional dynamic encoding during decision-makingNature Neuroscience 23:1410–1420.https://doi.org/10.1038/s41593-020-0696-5
-
The dimensionality of neural representations for controlCurrent Opinion in Behavioral Sciences 38:20–28.https://doi.org/10.1016/j.cobeha.2020.07.002
-
Early selection of task-relevant features through population gatingNature Communications 14:6837.https://doi.org/10.1038/s41467-023-42519-5
-
Shaping dynamics with multiple populations in low-rank recurrent networksNeural Computation 33:1572–1615.https://doi.org/10.1162/neco_a_01381
-
From numerosity to ordinal rank: a gain-field model of serial order representation in cortical working memoryThe Journal of Neuroscience 27:8636–8642.https://doi.org/10.1523/JNEUROSCI.2110-07.2007
-
BookCognitive control: core constructs and current considerationsIn: Egner T, editors. The Wiley Handbook of Cognitive Control. Wiley. pp. 1–28.https://doi.org/10.1002/9781118920497
-
Neural mechanisms of selective visual attentionAnnual Review of Neuroscience 18:193–222.https://doi.org/10.1146/annurev.ne.18.030195.001205
-
The role of population structure in computations through neural dynamicsNature Neuroscience 25:783–794.https://doi.org/10.1038/s41593-022-01088-4
-
Why neurons mix: high dimensionality for higher cognitionCurrent Opinion in Neurobiology 37:66–74.https://doi.org/10.1016/j.conb.2016.01.010
-
The neurobiology of individual differences in complex behavioral traitsAnnual Review of Neuroscience 32:225–247.https://doi.org/10.1146/annurev.neuro.051508.135335
-
Coherent chaos in a recurrent neural network with structured connectivityPLOS Computational Biology 14:e1006309.https://doi.org/10.1371/journal.pcbi.1006309
-
ConferenceReverse engineering recurrent networks for sentiment classification reveals line attractor dynamicsAdvances in Neural Information Processing Systems. pp. 15696–15705.
-
ConferenceHow recurrent networks implement contextual processing in sentiment analysisProceedings of the 37th International Conference on Machine Learning. pp. 6608–6619.
-
An integrative theory of prefrontal cortex functionAnnual Review of Neuroscience 24:167–202.https://doi.org/10.1146/annurev.neuro.24.1.167
-
Top-down control of visual attentionCurrent Opinion in Neurobiology 20:183–190.https://doi.org/10.1016/j.conb.2010.02.003
-
Neural mechanisms that make perceptual decisions flexibleAnnual Review of Physiology 85:191–215.https://doi.org/10.1146/annurev-physiol-031722-024731
-
Computational role of structure in neural activity and connectivityTrends in Cognitive Sciences 28:677–690.https://doi.org/10.1016/j.tics.2024.03.003
-
Prefrontal cortex activity during flexible categorizationThe Journal of Neuroscience 30:8519–8528.https://doi.org/10.1523/JNEUROSCI.4837-09.2010
-
Dynamics of random recurrent networks with correlated low-rank structurePhysical Review Research 2:013111.https://doi.org/10.1103/PhysRevResearch.2.013111
-
SoftwareSelection_vector_modulation_lowrank_rnn, version swh:1:rev:3c3ff39df2d084f863a9d411c606a378011a3a3bSoftware Heritage.
Article and author information
Author details
Funding
Ministry of Science and Technology (China) (STI2030-Major Project, 2021ZD0204105)
- Bin Min
National Natural Science Foundation of China (32271149)
- Bin Min
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Gouki Okazawa and Xuexin Wei for valuable discussions and comments on earlier versions of the manuscript. This work was supported by the Ministry of Science and Technology of China (STI2030-Major Project, 2021ZD0204105) and the National Natural Science Foundation of China (32271149).
Version history
- Preprint posted:
- Sent for peer review:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.103636. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2024, Zhang et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,435
- views
-
- 104
- downloads
-
- 5
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 3
- citations for umbrella DOI https://doi.org/10.7554/eLife.103636
-
- 2
- citations for Version of Record https://doi.org/10.7554/eLife.103636.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Elucidating the selection mechanisms in context-dependent computation through low-rank neural network modeling
eLife 13:RP103636.
https://doi.org/10.7554/eLife.103636.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}