Integrating prediction errors at two time scales permits rapid recalibration of speech sound categories
- Department of Basic Neuroscience, University of Geneva, Switzerland
Figures
Figure 1
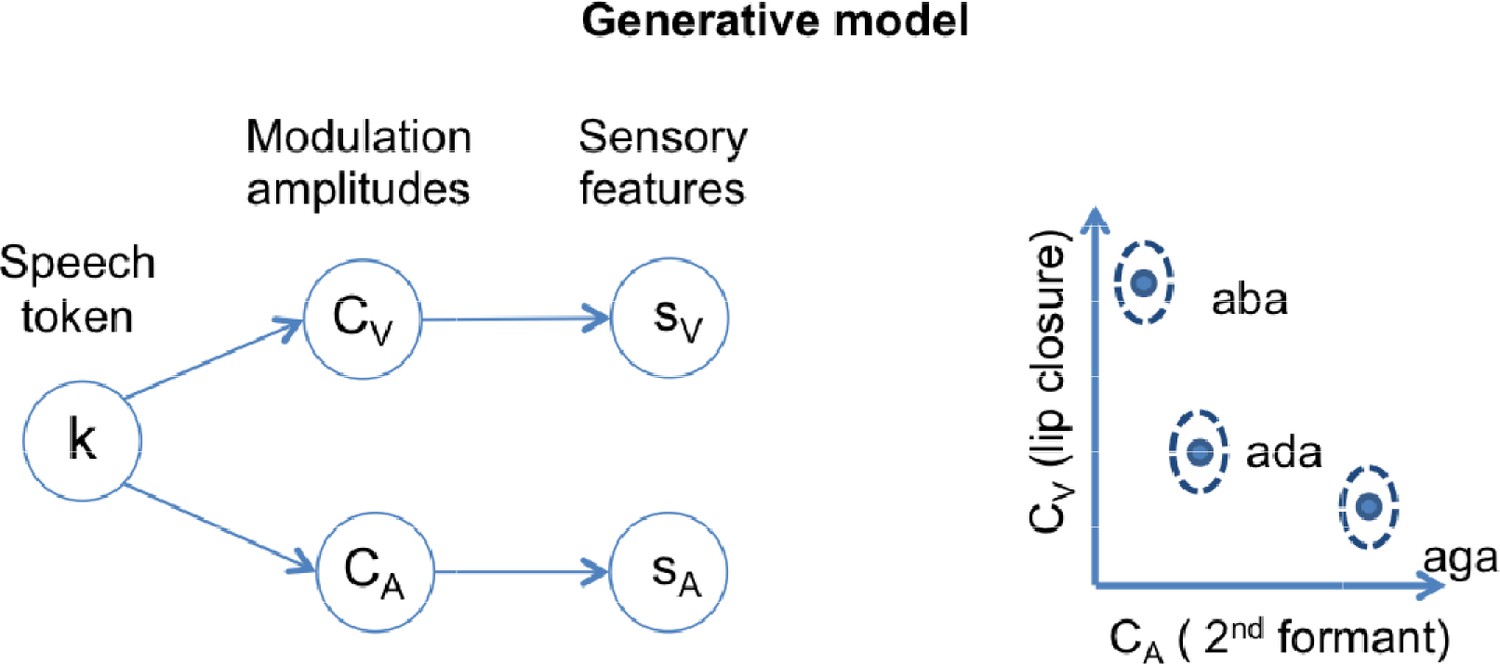
Schematics of the generative model.
In a given trial, a speech token ‘k’ determines the amplitudes of degree of lip closure (CV) and magnitude of second formant deflection (CA) by sampling from the appropriate Gaussian distribution. The distributions corresponding to each speech token ‘k’ are represented in the two-dimensional feature space on the right panel. The model also includes sensory noise to account for how these features appear at the sensory periphery (sV and sA).
Figure 2
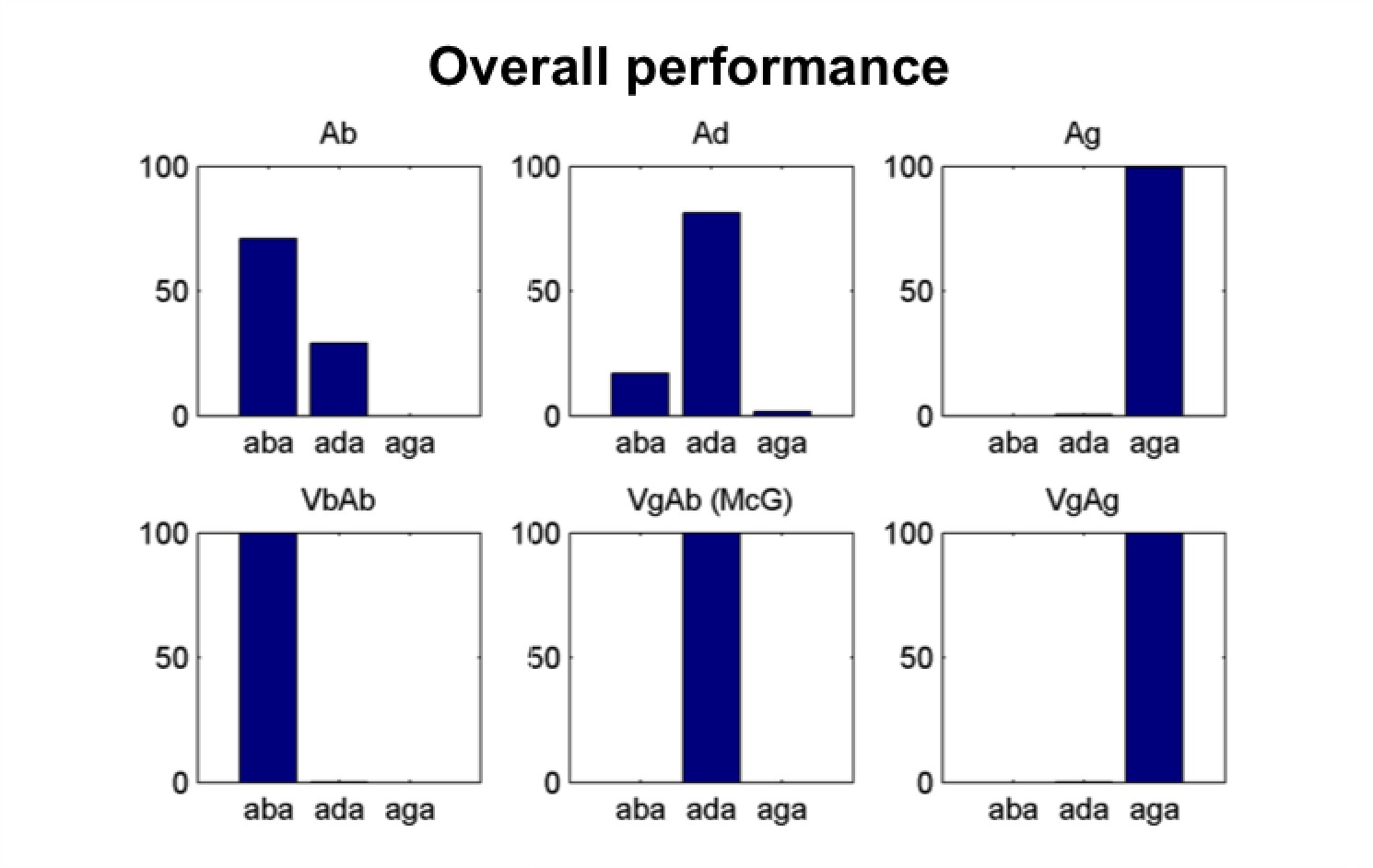
Model’s overall performance.
Simulation of the Lüttke et al. (2016a) experiment. Model classification across all trials. Each subpanel shows the percentage of /aba/, /ada/ and /aga/ percepts corresponding to each of the six conditions (Ab: acoustic only /aba/; Ad: acoustic only /ada/; Ag: acoustic only /aga/; VbAb: congruent audiovisual /aba/; VgAb incongruent McGurk stimuli with visual /aga/ and acoustic /aba/; VgAg: congruent /aga/). Congruent and acoustic only stimuli are categorized with a high degree of accuracy and McGurk trials are consistently fused, that is, perceived as /ada/. We reproduce the experimental paradigm consisting of six types of stimuli presented in pseudo-random order; three non-ambiguous acoustic only tokens:/aba/, /ada/ and /aga/, and three audiovisual stimuli: congruent /aba/, incongruent visual /aga/with acoustic /aba/(McGurk stimuli), and congruent /aga/.
Figure 3
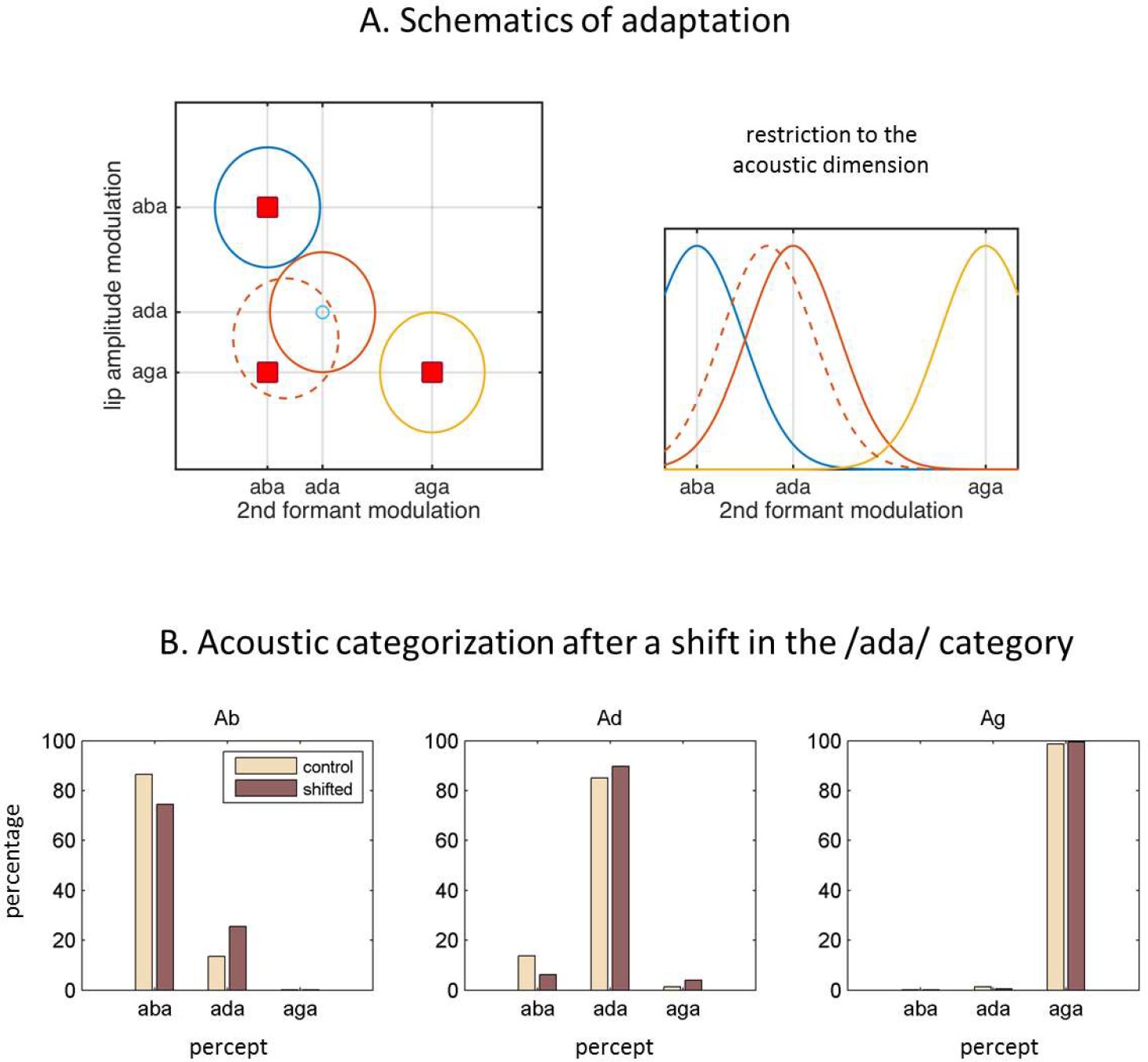
Internal model adaptation.
(A) Speech tokens are represented in a multimodal feature space here represented by two main dimensions. Each ellipse stands for the internal representation of each congruent category (‘aba’ in blue, ‘ada’ in red, ‘aga’ in yellow). The red squares show the location of the audiovisual stimuli in the 2D feature space. They represent congruent /aba/(top left), congruent /aga/(bottom right), and McGurk stimuli (bottom left). When McGurk stimuli are repeatedly perceived as /ada/, the /ada/ representation (in solid red) is modified in such a way that it ‘moves’ (dashed red) towards the presented McGurk stimulus (visual /aga/ with acoustic /aba/) and therefore should affect the processing of subsequent sensory input. The right panel illustrates how the acoustic representation for /ada/ has shifted towards that of /aba/. (B) The effects of the shift in the internal representation on the categorization of the purely acoustic /aba/(Ab), /ada/(Ad) and /aga/(Ag) sounds. Each panel shows the percentage of /aba/, /ada/ and /aga/ percepts for the ‘control’ representations (solid lines) and the representations with the recalibrated /ada/(dashed line). As in Lüttke et al. (2016a), the biggest effect is observed when categorizing the /aba/ sounds.
Figure 4

Cumulative and transient update rules.
‘ada’ percepts in response to acoustic /aba/ stimulation. We show two contrasts. The McGurk contrast compares the percentage of ‘ada’ responses when acoustic /aba/ is preceded by control stimuli (acoustic /aba/ and /aga/, congruent /aba/ and /aga/) versus by fused McGurk trials. The /ada/ contrast refers to acoustic /aba/ preceded by control stimuli (acoustic /aba/ and /aga/) versus acoustic trials correctly perceived as ‘ada’. The four panels show the simulation results for the parameters that led to the closest fit to the McGurk contrast reported by Lüttke et al. (2016a) for four different update rules as indicated in the insets: (A) control, no update, (B) the standard Bayesian updates, (C) the constant delta rule, and (D) Decay, the update rule that assumes that recalibration occurs at two time scales. Both the standard Bayes (B) and the constant delta rule (C) lead to changes in internal representations that are reflected in the overall increase in ‘ada’ percepts (with respect to the control, no update model on panel A) however, it did not translate into significant effects specific to the next trial. The model assuming two time scales does reproduce the effect of a fused McGurk on the next trial (McGurk contrast). Only the McGurk contrast for the two time scale recalibration model (D, left) was significant (**p=0.0003). All other p values were greater than 0.05, except (*, p=0.03, C right).
Figure 5

Category parameters across an experiment.
θ/aba/,A, θ/ada/,A and θ/aga/,A after each of the 414 trials (69 repetitions of 6 different stimuli) in a sample simulated experimental run. (A) For the standard Bayesian model, category parameter updates become smaller as the experiment progresses. (B) For the constant delta rule updates of similar size occur throughout the experiment but are constant across trials. (C) Updates for the hierarchical delta rule with decay don’t drift but decay to a long-term less volatile component.
Figure 6
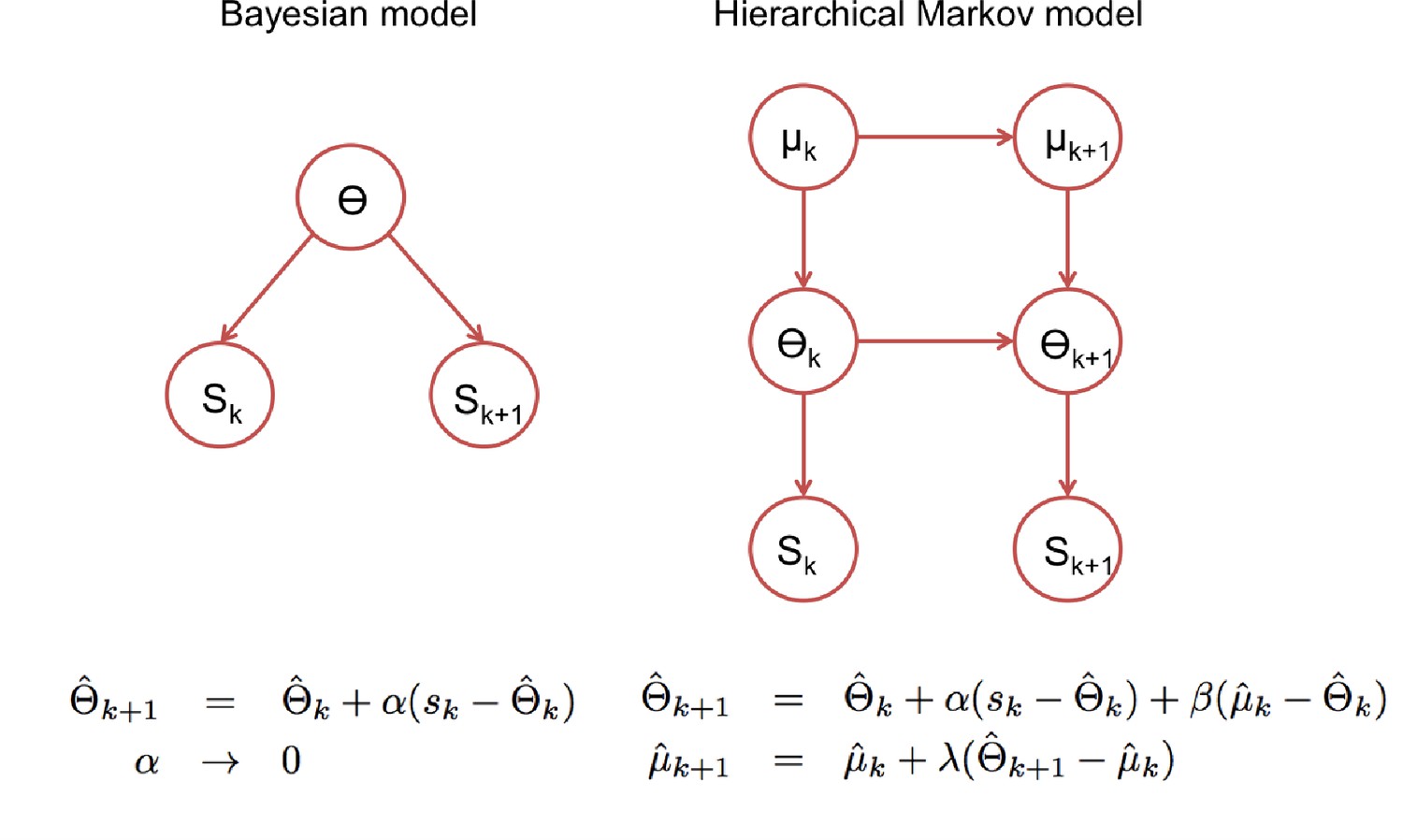
Statistical models underlying the two classes of update rules used in the paper.
Here Θ stands for the model parameters that determine the speech categories used by the perceptual model (See Figure 3) and ‘k’ for the trial index. On the standard Bayesian approach (left), model parameters are considered constant in time leading to update rules that give the same weight to all prediction errors, which in turn leads to a ‘learning rate’ αk that becomes smaller with the number of trials. On the right, we show a hierarchical Markov model implementation that would lead to the kind of update rules that we introduced empirically to accommodate the rapid recalibration effect. This alternative view implicitly assumes that model parameters can change in time and therefore lead to update rules with learning rates (α, β and λ) that under certain assumptions, settle to non-zero constant values.
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Integrating prediction errors at two time scales permits rapid recalibration of speech sound categories
eLife 9:e44516.
https://doi.org/10.7554/eLife.44516




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}