Improving the accuracy of single-trial fMRI response estimates using GLMsingle
- Department of Psychology, Harvard University, United States
- Center for Human Brain Health, School of Psychology, University of Birmingham, United Kingdom
- cerebrUM, Département de Psychologie, Université de Montréal, Canada
- Department of Psychology, New York University, United States
- Center for Human Neuroscience, Department of Psychology, University of Washington, United States
- Department of Psychology, Neuroscience Institute, Carnegie Mellon University, United States
- Center for Magnetic Resonance Research (CMRR), Department of Radiology, University of Minnesota, United States
Figures
Figure 1

Overview of GLMsingle.
GLMsingle takes as input a design matrix (where each column indicates the onset times for a given condition) and fMRI time-series in either volumetric or surface space, and returns as output an estimate of single-trial BOLD response amplitudes (beta weights). GLMsingle incorporates three techniques designed to optimize the quality of beta estimates: first, the use of a library of hemodynamic response functions (HRFs), where the best-fitting HRF from the library is chosen for each voxel; second, an adaptation of GLMdenoise (Kay et al., 2013) to the single-trial GLM framework, where data-derived nuisance regressors are identified and used to remove noise from beta estimates; and third, an efficient re-parameterization of ridge regression (Rokem and Kay, 2020) as a method for dampening the noise inflation caused by correlated single-trial GLM predictors.
Figure 2 with 1 supplement
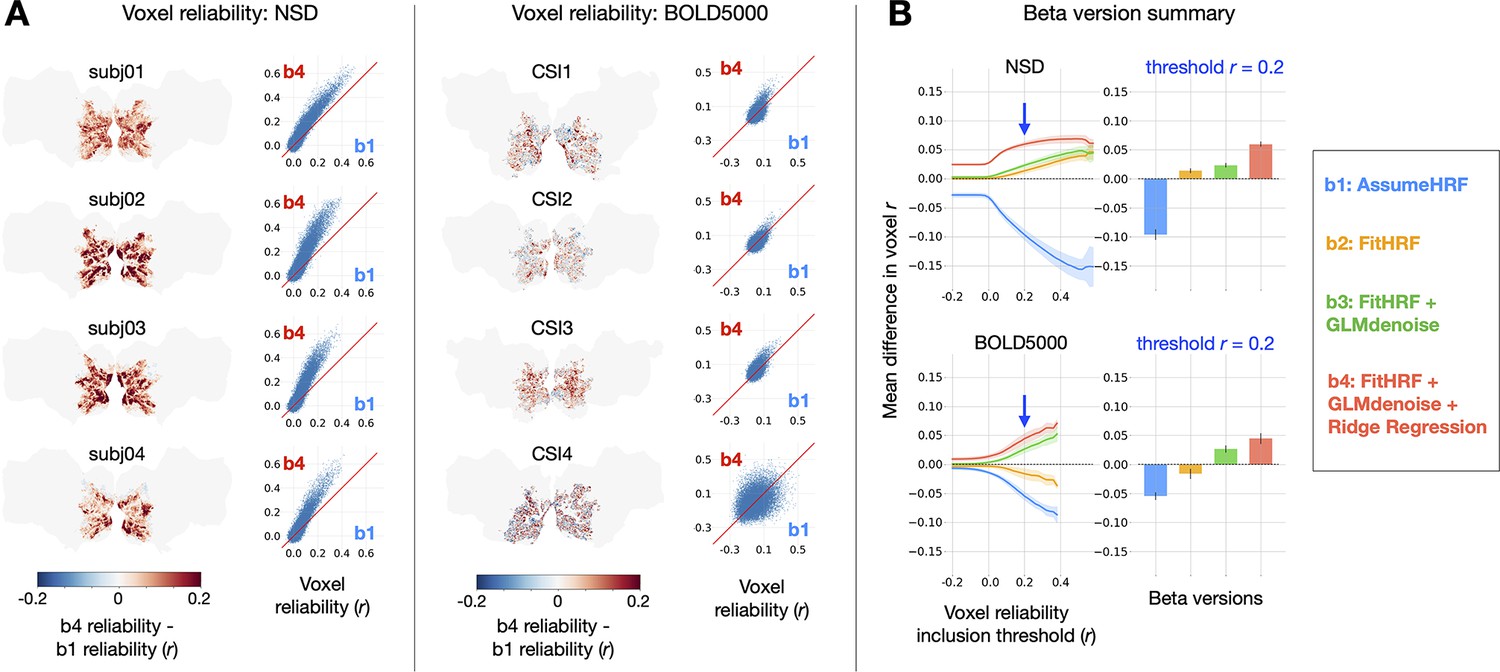
Impact of GLMsingle on voxel test-retest reliability. To compute reliability for a given voxel, we measure the test-retest Pearson correlation of GLM beta profiles over repeated presentations of the same stimuli (see Materials and methods).
(A) Differences in reliability between (derived from a baseline GLM) and (the final output of GLMsingle) are plotted within a liberal mask of visual cortex (nsdgeneral ROI). Scatter plots show reliability values for individual voxels. (B) Relative differences in mean reliability within the nsdgeneral ROI. For each voxel, we computed the mean reliability value over all beta versions being considered (-), and then used this as the basis for thresholding voxels (from Pearson –0.2 – 0.6). At each threshold level, for each beta version, we compute the voxel-wise difference between the reliability of that specific beta version and the mean reliability value, and then average these difference values across voxels within the nsdgeneral ROI. The traces in the first column indicate the mean (+/- SEM) across subjects within each dataset (N = 4 for both NSD and BOLD5000). The bars in the second column indicate subject-averaged differences in reliability at threshold 0.2. The relative improvement in reliability due to GLMsingle ( vs. ) tends to increase when examining voxels with higher reliability, and each optimization stage within GLMsingle (HRF fitting, GLMdenoise, ridge regression) confers added benefit to voxel reliability.
Figure 2—figure supplement 1
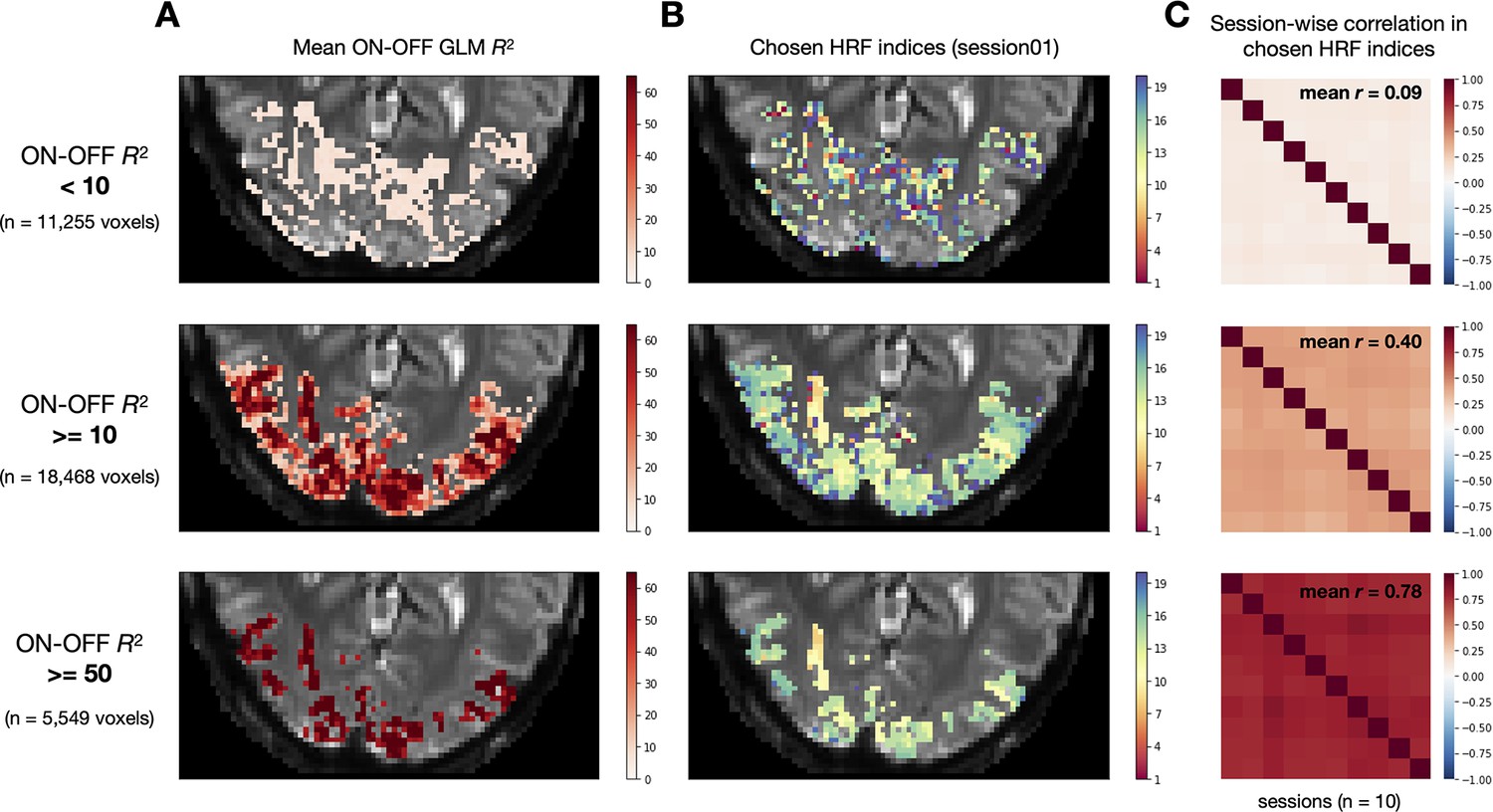
Inspection of HRF structure across space and time. Here we examine the optimal HRF indices chosen by GLMsingle within a liberal mask of visual cortex (nsdgeneral ROI) from an example subject (NSD subj01).
(A) Maps of values from an ON-OFF GLM, where all conditions are collapsed into a single predictor (see Materials and methods). ON-OFF values are output by GLMsingle for each of the subject’s 10 experimental sessions, and plotted here are the average values. Voxels are thresholded at three different levels: (top row), reflecting relatively inactive voxels, including those outside of gray matter; (middle row), reflecting voxels that are active in response to experimental stimuli; and (bottom row), reflecting voxels that are highly active in response to experimental stimuli. (B) Chosen HRF indices from the first scan session. In active voxels (middle and bottom rows), optimal HRF indices exhibit structure in the form of a low-frequency spatial gradient. (C) Stability of chosen HRF indices across sessions at different ON-OFF thresholds. The optimal HRF indices within the nsdgeneral ROI are extracted for each session, thresholded at different ON-OFF levels, and correlated between each pair of sessions. The inset indicates the average over the lower triangular portion of each matrix. Optimal HRF indices identified using GLMsingle are stable over different experimental sessions in voxels that are active in response to experimental stimuli.
Figure 3
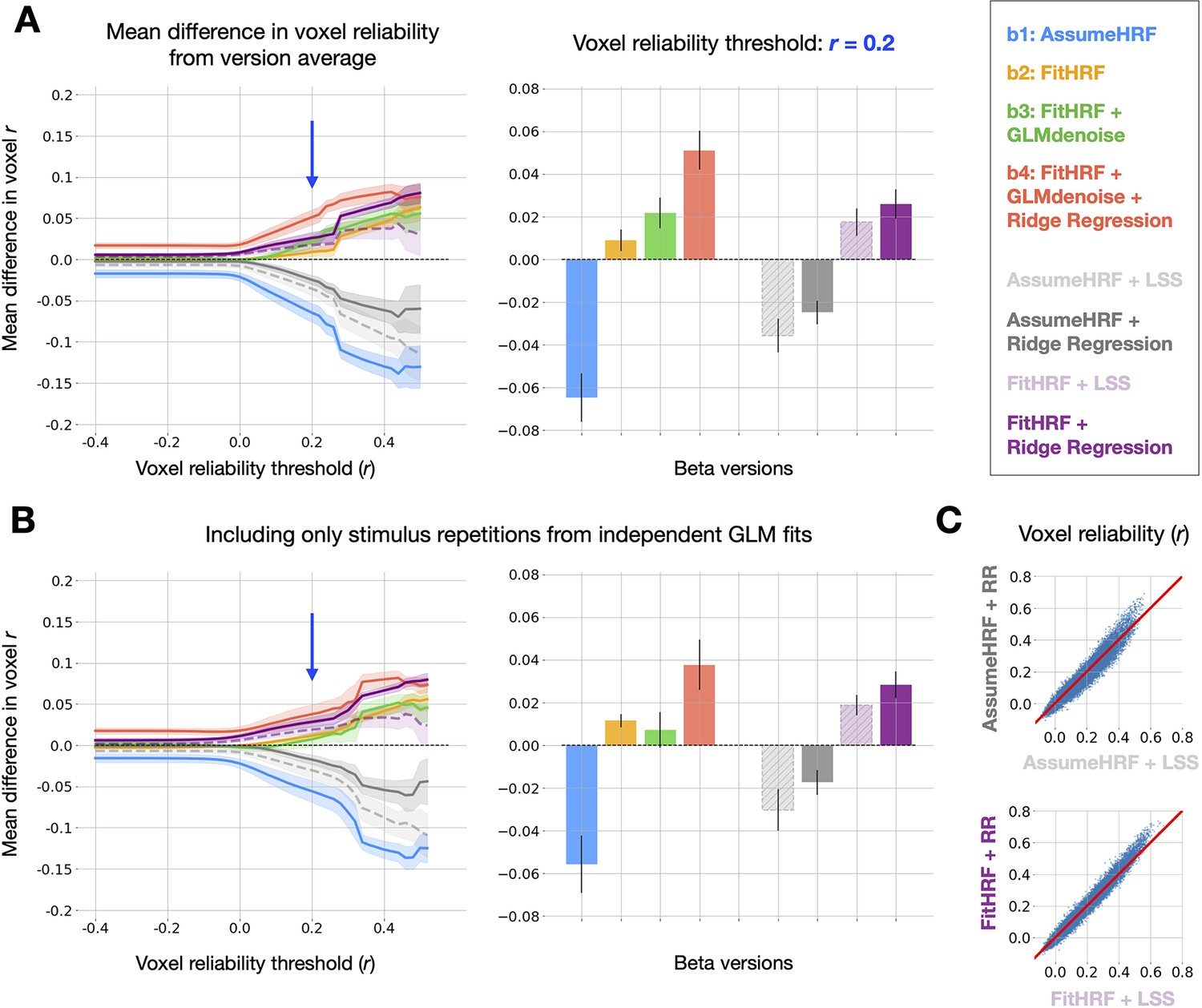
Relative quality of GLMsingle and LSS beta versions. (A) Left panel: relative differences in mean reliability between beta versions.
8 beta versions are compared: -, and the 4 auxiliary beta versions used to compare GLMsingle and Least-Squares Separate (LSS). LSS betas (dashed traces) are compared to those estimated using fractional ridge regression (RR, solid traces), when using a canonical HRF (LSS, light gray vs. RR, dark gray) and when performing HRF optimization (LSS, light purple vs. RR, dark purple). Right panel: summary of performance at threshold level 0.2. Error bars reflect the standard error of the mean, computed over the 8 subjects analyzed from NSD and BOLD5000. Fractional ridge regression yields more reliable signal estimates than LSS across voxel reliability levels. (B) Same as Panel (A), except that reliability computations occur only between image repetitions processed in independent partitions of fMRI data. Qualitative patterns are unchanged. (C) Scatter plots comparing voxel reliability between corresponding LSS and GLMsingle beta versions (top: AssumeHRF; bottom: FitHRF). Plotted are results for an example subject (NSD subj01, nsdgeneral ROI). The advantage of ridge regression over LSS is most apparent in the most reliable voxels.
Figure 4
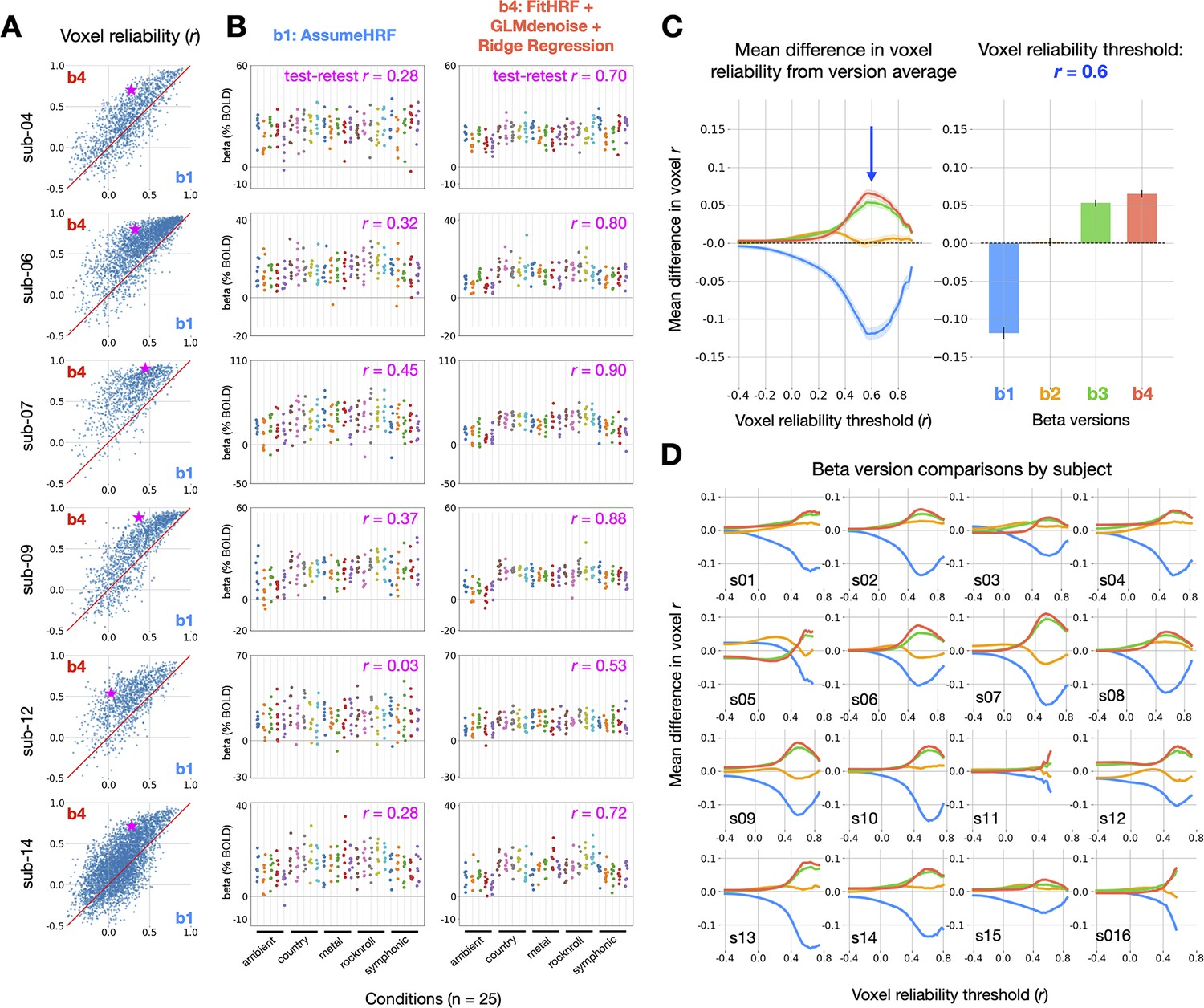
Impact of GLMsingle on reliability in the StudyForrest music-listening task. (A) Differences in voxel test-retest reliability (Pearson ) between (a baseline GLM) and (the final output of GLMsingle) are plotted for individual voxels.
Only voxels that are active in response to experimental stimuli (ON-OFF ) are plotted. (B) Estimated beta values (% BOLD change) for and in a hand-selected auditory cortex voxel from 6 representative subjects. Chosen voxels are indicated with pink stars in panel A. Each column represents one of 25 experimental conditions, with each condition presented 8 times. Test-retest reliability values reflect the split-half correlation between groups of 4 trial repetitions, averaged over all possible splits of the available repetitions (70 unique splits). (C) Relative differences in mean reliability between beta versions - , computed using the same procedure as used for NSD and BOLD5000 (see Figure 2). Traces indicate the mean (+/- SEM) across subjects (N = 16). The bar graph (right) indicates the subject-averaged differences in reliability at threshold . (D) Relative differences in mean reliability over different reliability inclusion thresholds are plotted for each subject.
Figure 5
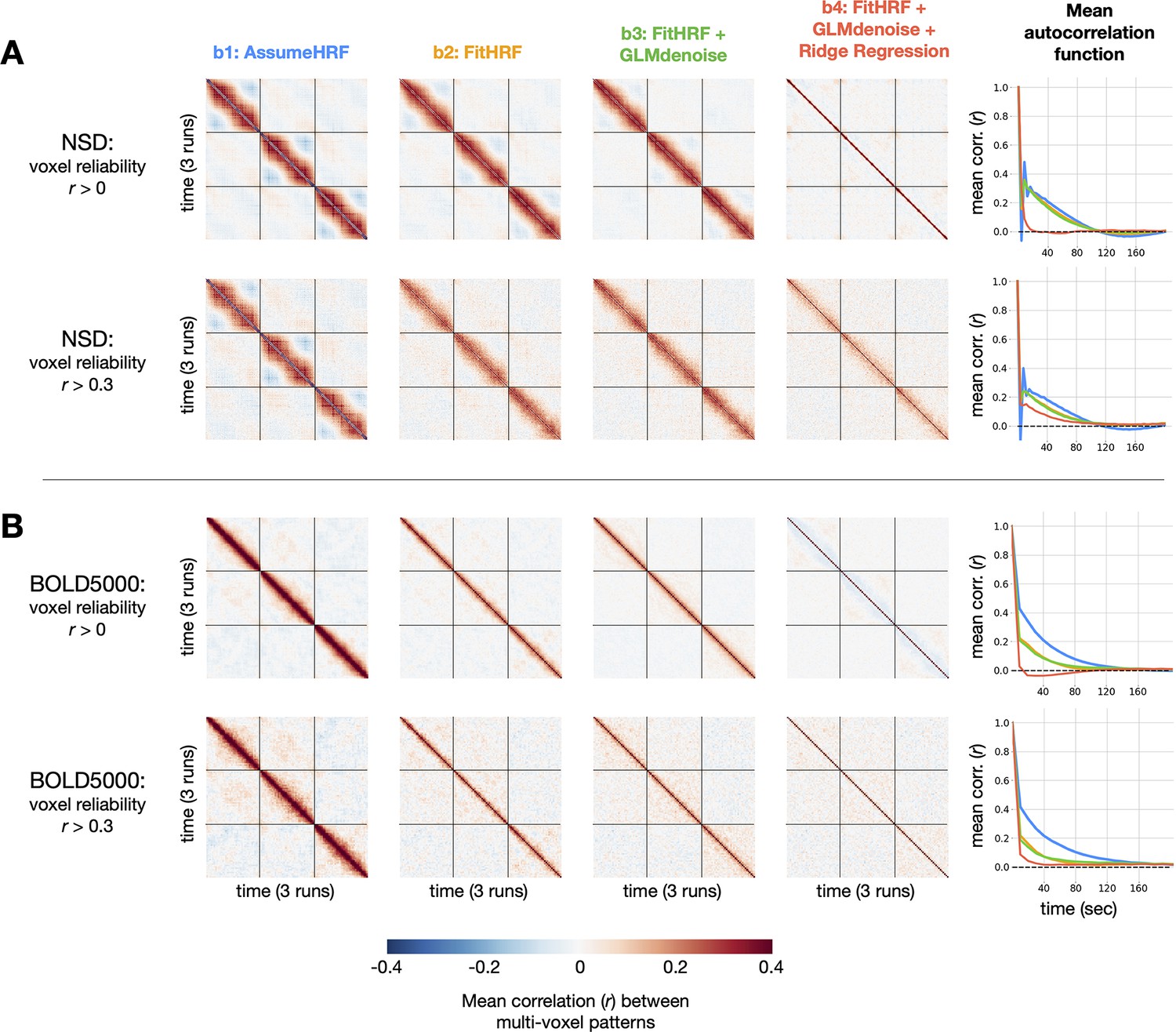
Impact of GLMsingle on temporal autocorrelation. For each dataset, we compute the degree of temporal autocorrelation in each beta version by averaging session-wise representational similarity matrices over subjects.
We plot results arising from analysis of voxels at two different reliability thresholds ( 0 and 0.3) for NSD (A) and BOLD5000 (B). Assuming that ground-truth neural responses to consecutive trials should be uncorrelated on average, positive (or negative) Pearson values off the diagonal imply suboptimal estimation of BOLD responses. In the right-most column, we plot mean autocorrelation between all pairs of timepoints. Applying GLMsingle () results in a substantial decrease in temporal autocorrelation compared to a baseline GLM approach ().
Figure 6
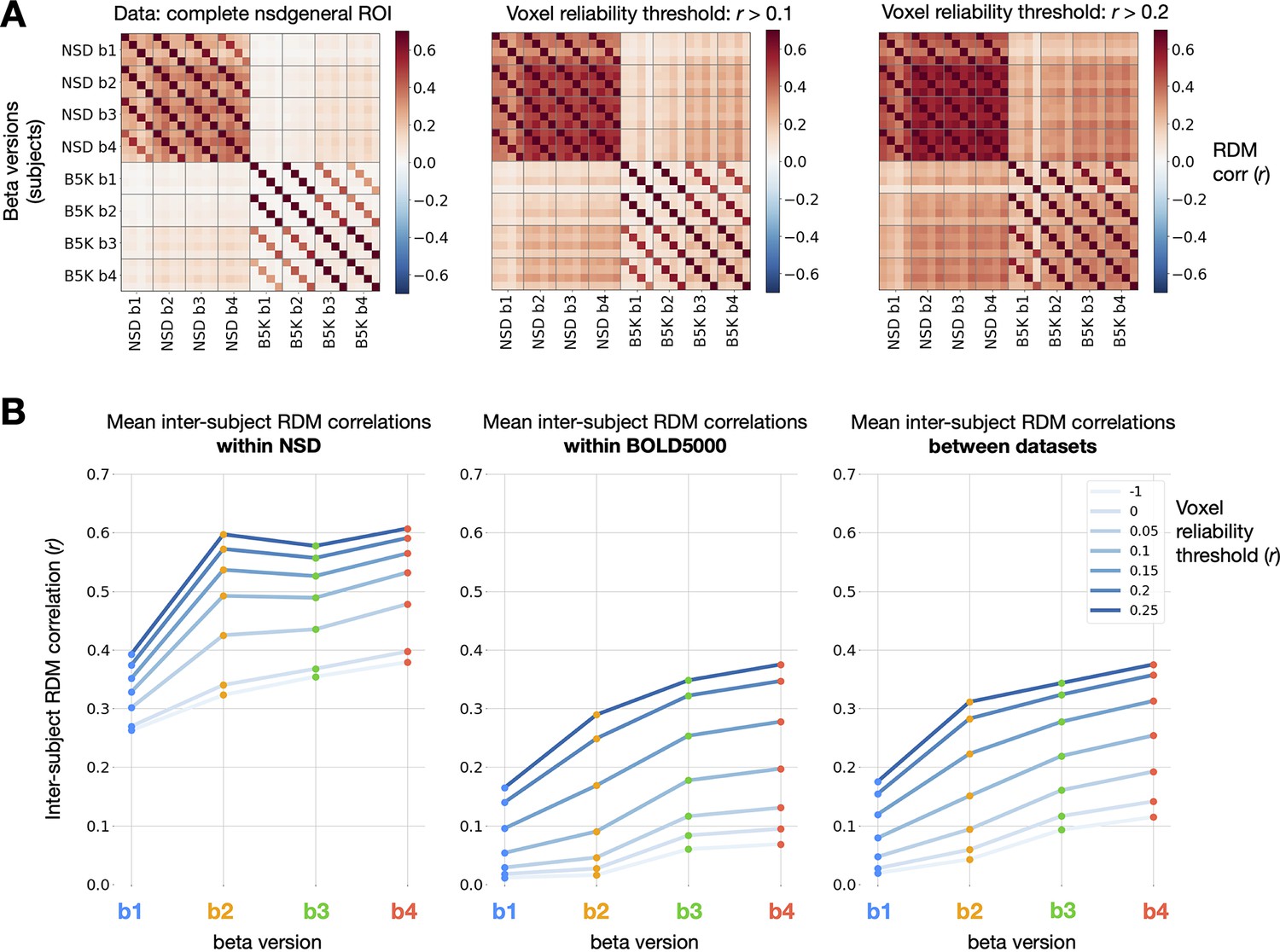
Impact of GLMsingle on inter-subject RDM correlations.
(A) Correlations of RDMs across all pairs of subjects and beta versions, at 3 different voxel reliability thresholds. We compute RDMs for each subject and beta version using Pearson dissimilarity (1 - ) over repetition-averaged betas within the nsdgeneral ROI. Grid lines separate beta versions from one another, an individual cell reflects the RDM correlation between one pair of subjects, and cross-dataset comparisons occupy the top-right and bottom-left quadrants of the matrices. (B) Mean inter-subject RDMs correlations within NSD (N = 4; left), within BOLD5000 (N = 4; center), and between the two datasets (N = 16 subject pairs; right). GLMsingle () yields a considerable strengthening of RDM correspondence for each subject pair being considered, within and between datasets.
Figure 7

Impact of GLMsingle on image-level MVPA decoding accuracy.
(A) Image-level linear SVM decoding accuracy by beta version. At each reliability threshold, we compute the mean decoding accuracy over subjects within each dataset, as well as the standard error of the mean (N = 4 for NSD; N = 3 for BOLD5000). Classifiers are trained on available image repetitions, and tested on the held-out repetition, with accuracy averaged over cross-validation folds. Applying GLMsingle () yields dramatic increases in image decodability compared to a baseline GLM (). (B) The effect of GLMsingle on animacy representation is shown in an example NSD subject (subj01) using multidimensional scaling. GLMsingle clarifies the division in representational space between stimuli containing animate and inanimate objects.
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Improving the accuracy of single-trial fMRI response estimates using GLMsingle
eLife 11:e77599.
https://doi.org/10.7554/eLife.77599




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}