Uncertainty alters the balance between incremental learning and episodic memory
- Department of Psychology, Columbia University, United States
- Mortimer B. Zuckerman Mind, Brain, Behavior Institute, Columbia University, United States
- Department of Psychology, Princeton University, United States
- Princeton Neuroscience Institute, Princeton University, United States
- The Kavli Institute for Brain Science, Columbia University, United States
Figures
Figure 1
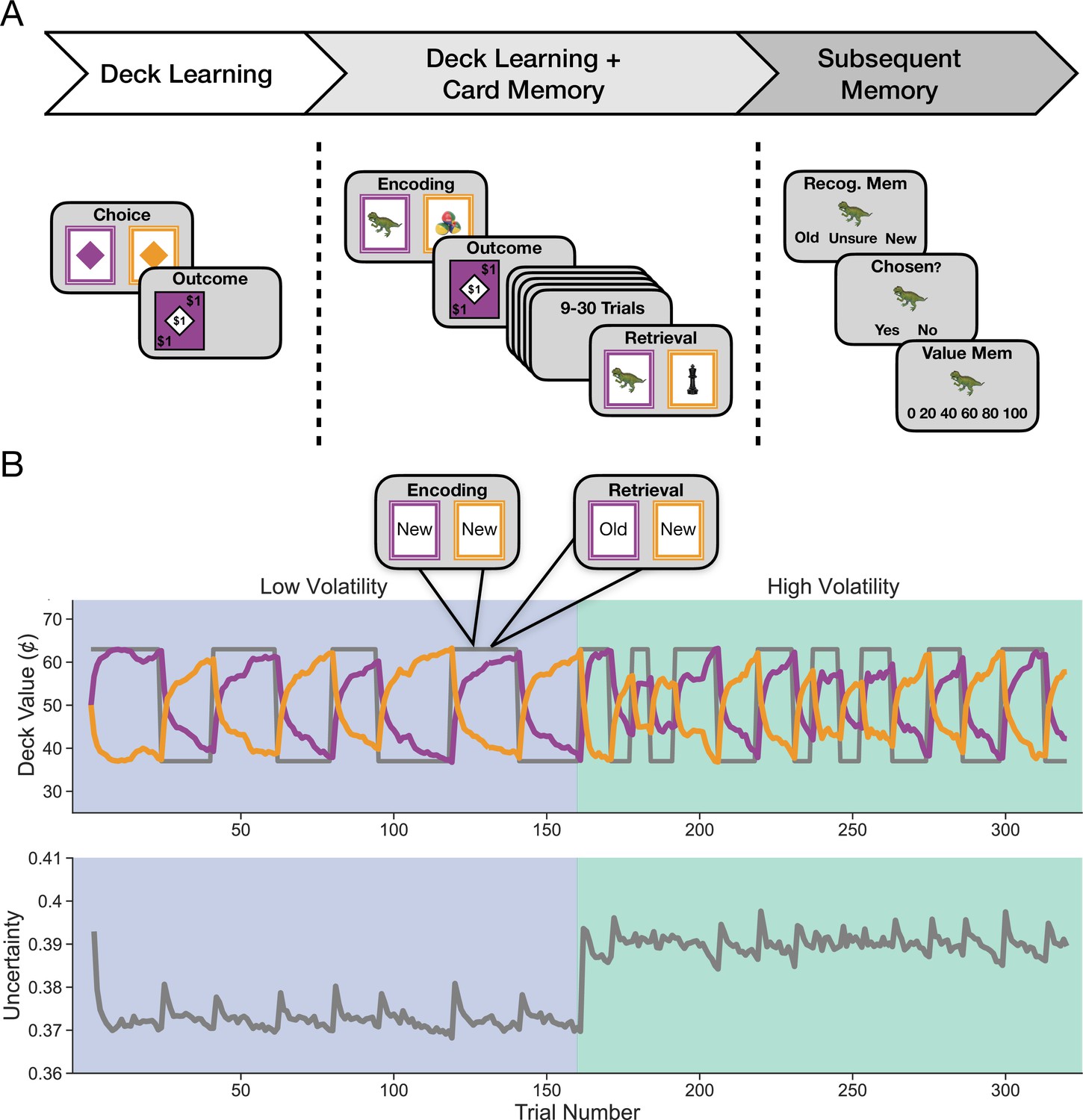
Study design and sample events.
(A) Participants completed three tasks in succession. The first was the deck learning task that consisted of choosing between two colored cards and receiving an outcome following each choice. One color was worth more on average at any given timepoint, and this mapping changed periodically. Second was the main task of interest, the deck learning and card memory task, which followed the same structure as the deck learning task but each card also displayed a trial-unique object. Cards that were chosen could appear a second time in the task after 9–30 trials and, if they reappeared, were worth the same amount, thereby allowing participants to use episodic memory for individual cards in addition to learning deck value from feedback. Outcomes ranged from $0 to $1 in increments of 20¢ in both of these tasks. Lastly, participants completed a subsequent memory task for objects that may have been seen in the deck learning and card memory task. Participants had to indicate whether they recognized an object and, if they did, whether they chose that object. If they responded that they had chosen the object, they were then asked if they remembered the value of that object. (B) Uncertainty manipulation within and across environments. Uncertainty was manipulated by varying the volatility of the relationship between cue and reward over time. Participants completed the task in two counterbalanced environments that differed in their relative volatility. The low-volatility environment featured half as many reversals in deck luckiness as the high-volatility environment. Top: the true value of the purple deck is drawn in gray for an example trial sequence. In purple and orange are estimated deck values from the reduced Bayesian model (Nassar et al., 2010). Trials featuring objects appeared only in the deck learning and card memory task. Bottom: uncertainty about deck value as estimated by the model is shown in gray. This plot shows relative uncertainty, which is the model’s imprecision in its estimate of deck value.
Figure 2 with 1 supplement
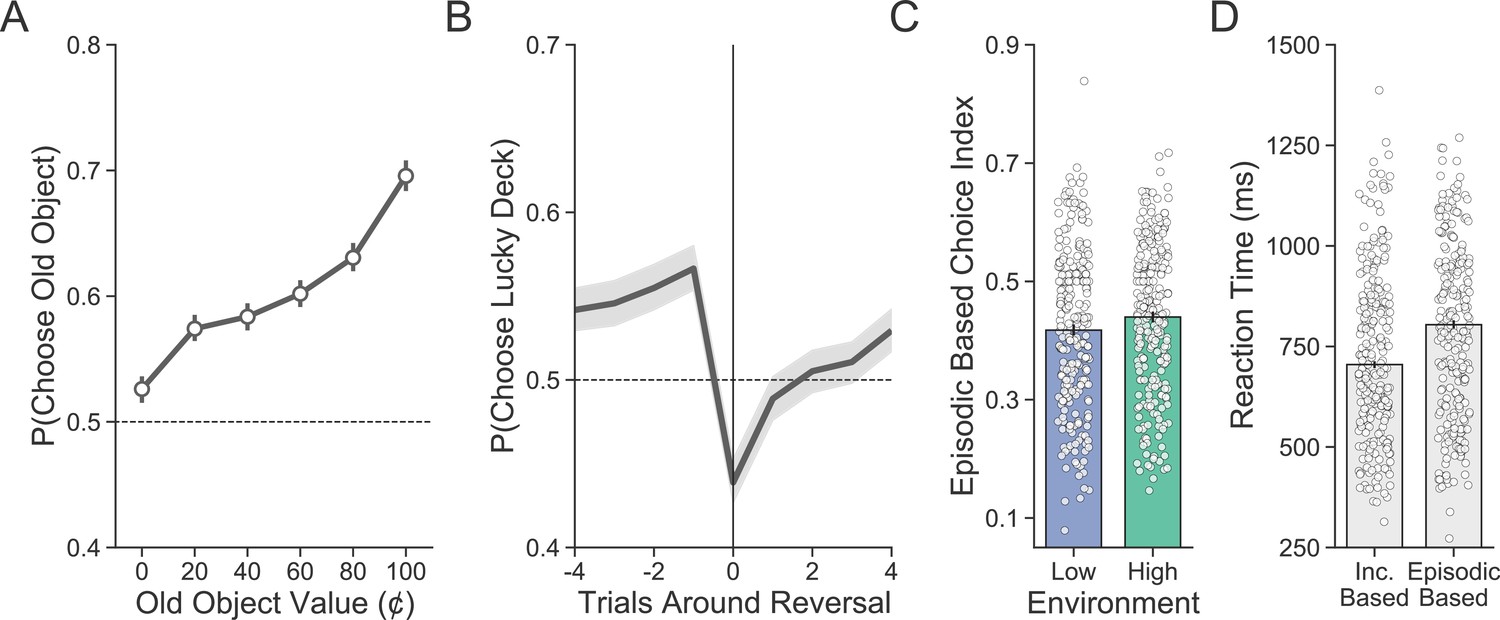
Evaluating the proportion of incremental and episodic choices.
(A) Participants’ (n = 254) choices demonstrate sensitivity to the value of old objects. Group-level averages are shown as points and lines represent 95% confidence intervals. (B) Reversals in deck luckiness altered choice such that the currently lucky deck was chosen less following a reversal. The line represents the group-level average, and the band represents the 95% confidence interval. (C) On incongruent trials, choices were more likely to be based on episodic memory (e.g., high-valued objects chosen and low-valued objects avoided) in the high- compared to the low-volatility environment. Averages for individual subjects are shown as points, and lines represent the group-level average with a 95% confidence interval. (D) Median reaction time was longer for incongruent choices based on episodic memory compared to those based on incremental learning.
Figure 2—figure supplement 1
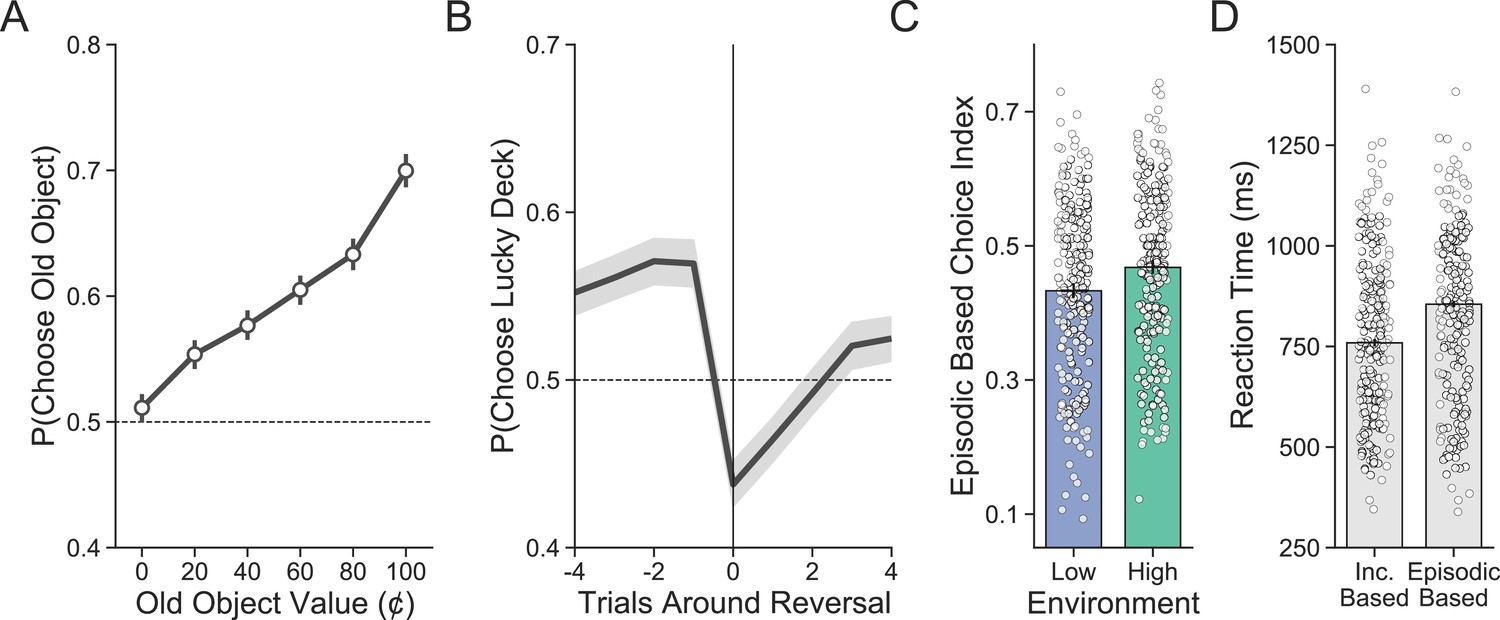
Recreation of Figure 2 in the main text using the replication dataset.
(A) Participants’ (n = 223) choices demonstrate sensitivity to the value of old objects. (B) Reversals in deck luckiness altered choice such that the currently lucky deck was chosen less following a reversal. (C) On incongruent trials, choices were more likely to be based on episodic memory in the high- compared to the low-volatility environment. (D) Reaction time was longer for incongruent choices based on episodic memory compared to those based on incremental learning.
Figure 3 with 1 supplement
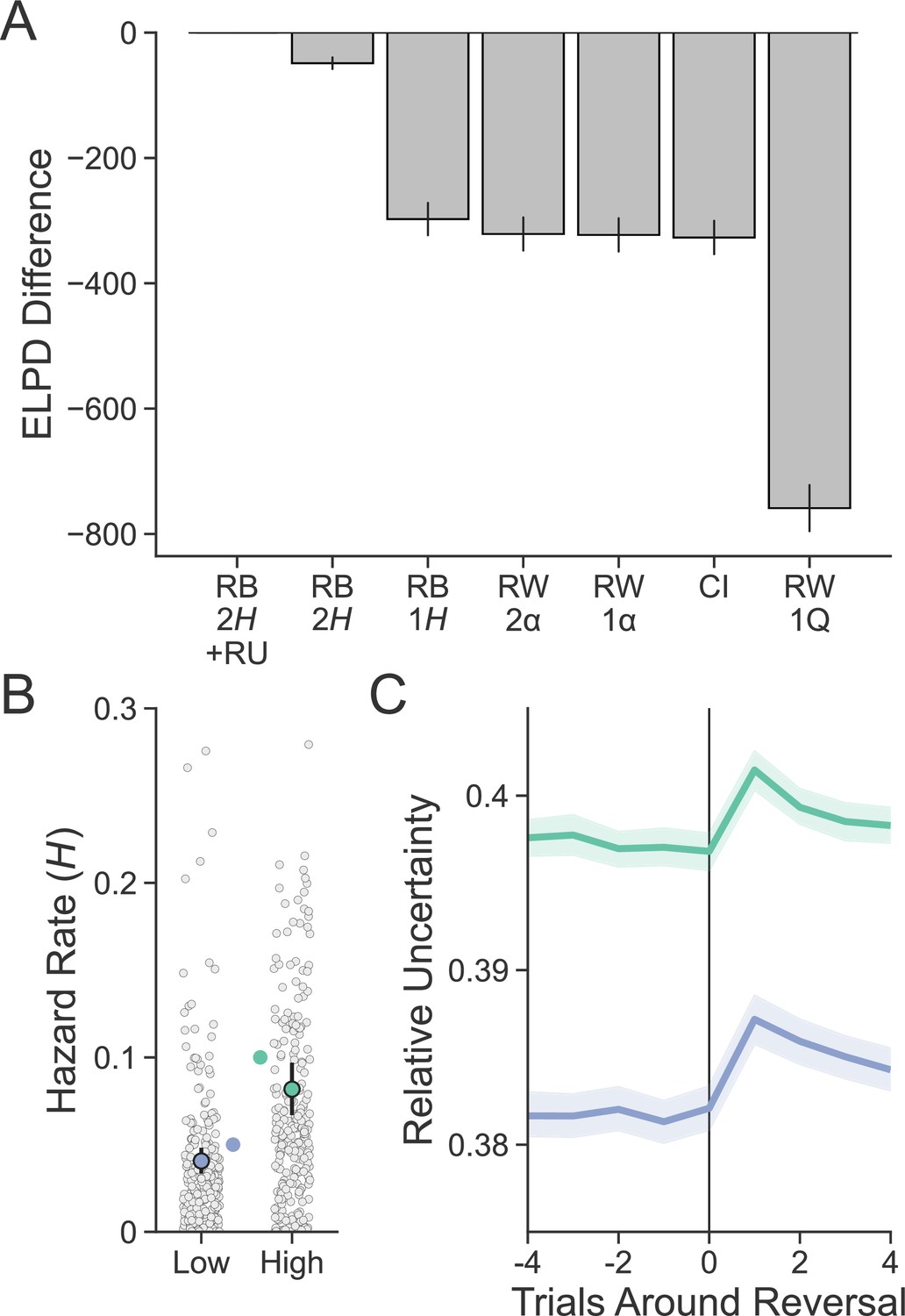
Evaluating model fit and sensitivity to volatility.
(A) Expected log pointwise predictive density (ELPD) from each model was calculated from a 20-fold leave-N-subjects-out cross-validation procedure and is shown here subtracted from the best-fitting model. The best-fitting model was the reduced Bayesian (RB) model with two hazard rates (2H) and sensitivity to the interaction between old object value and relative uncertainty (RU) in the choice function. Error bars represent standard error around ELPD estimates. (B) Participants (n = 254) were sensitive to the relative level of volatility in each environment as measured by the hazard rate. Group-level parameters are superimposed on individual subject parameters. Error bars represent 95% posterior intervals. The true hazard rate for each environment is shown on the interior of the plot. (C) RU peaks on the trial following a reversal and is greater in the high- compared to the low-volatility environment. Lines represent group means, and bands represent 95% confidence intervals.
Figure 3—figure supplement 1
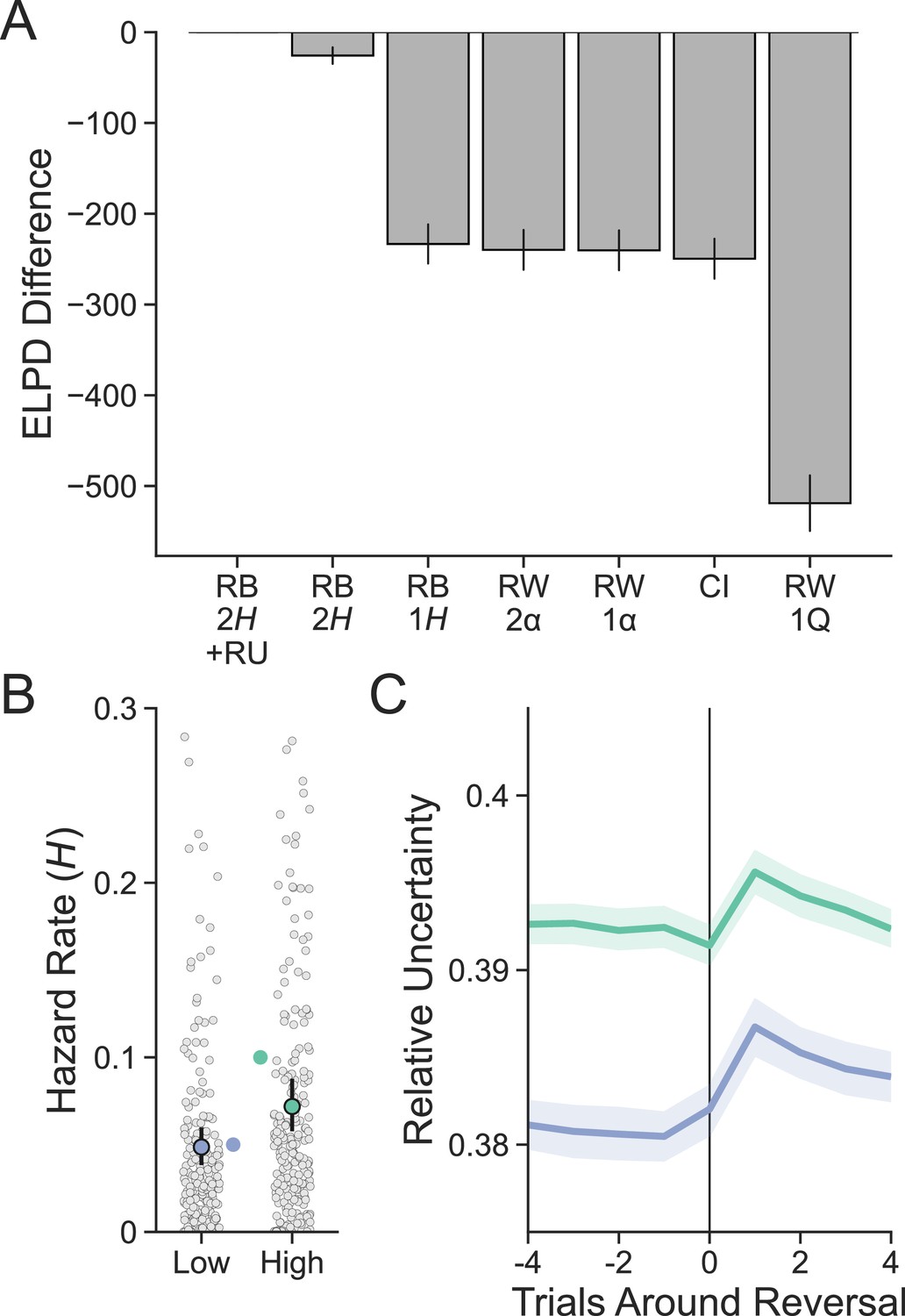
Recreation of Figure 3 in the main text using the replication dataset.
(A) The best-fitting model was again the reduced Bayesian (RB) model with two hazard rates (2H) and sensitivity to the interaction between old object value and relative uncertainty (RU) in the choice function. (B) Participants (n = 223) were affected by the relative level of volatility in each environment as measured by the hazard rate. Group-level parameters are superimposed on individual subject parameters. (C) RU peaks on the trial following a reversal and is greater in the high- compared to the low-volatility environment.
Figure 4 with 2 supplements
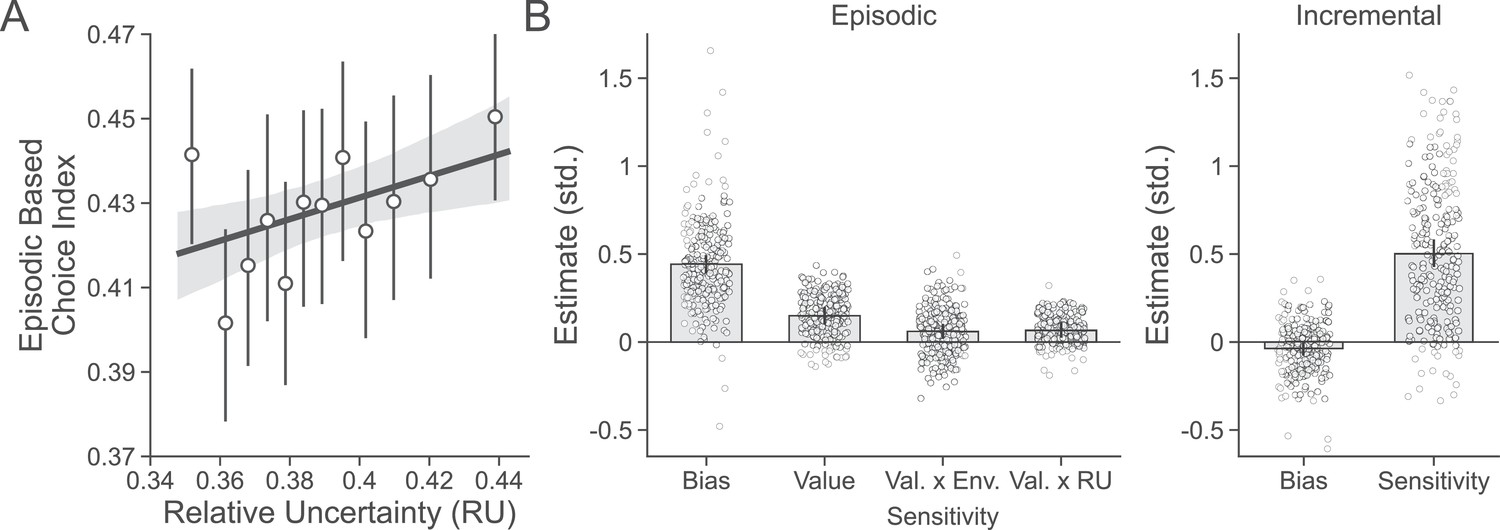
Evaluating effects of sensitivity to uncertainty on episodic choices.
(A) Participants’ (n = 254) degree of episodic-based choice increased with greater relative uncertainty (RU) as predicted by the combined choice model. Points are group means, and error bars are 95% confidence intervals. (B) Estimates from the combined choice model. Participants were biased to choose previously seen objects regardless of their value and were additionally sensitive to their value. As hypothesized, this sensitivity was increased when RU was higher, as well as in the high- compared to the low-volatility environment. There was no bias to choose one deck color over the other, and participants were highly sensitive to estimated deck value. Group-level parameters are superimposed as bars on individual subject parameters represented as points. Error bars represent 95% posterior intervals around group-level parameters. Estimates are shown in standard units.
Figure 4—figure supplement 1
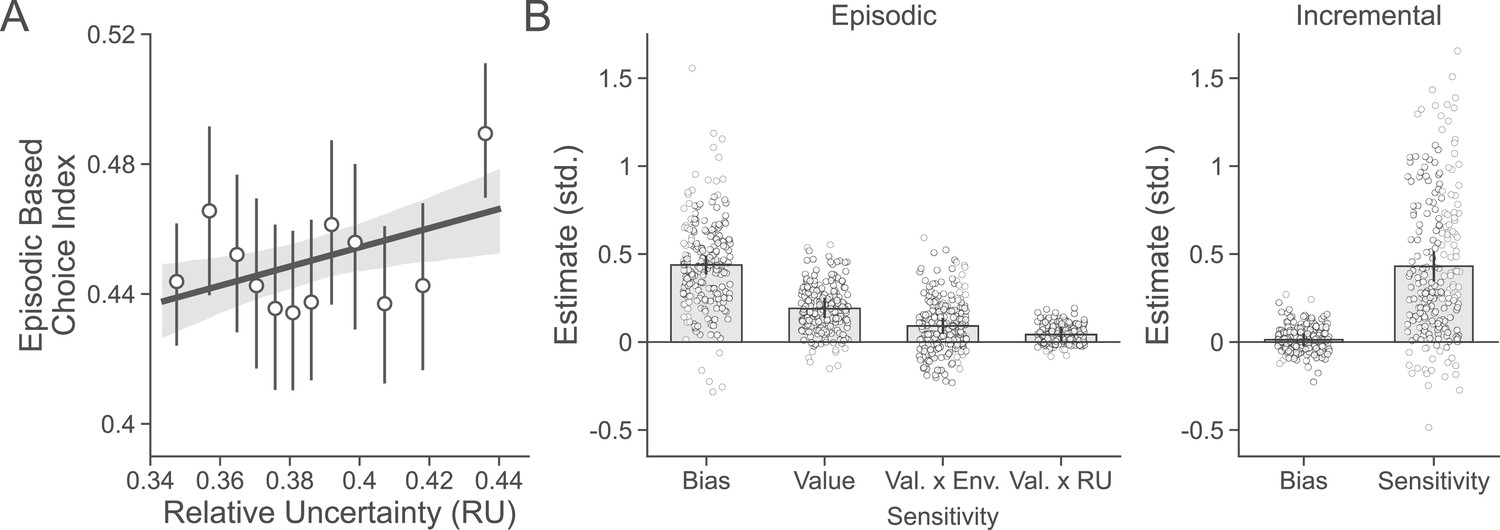
Recreation of Figure 4 in the main text using the replication dataset.
(A) Participants’ (n = 223) degree of episodic-based choice increases with greater relative uncertainty (RU). (B) Estimates from the combined choice model. Participants were biased to choose previously seen objects regardless of their value and were additionally sensitive to their value. As hypothesized, this sensitivity was increased when RU was higher as well as in the high- compared to the low-volatility environment. There was no bias to choose one deck color over the other, and participants were highly sensitive to estimated deck value.
Figure 4—figure supplement 2
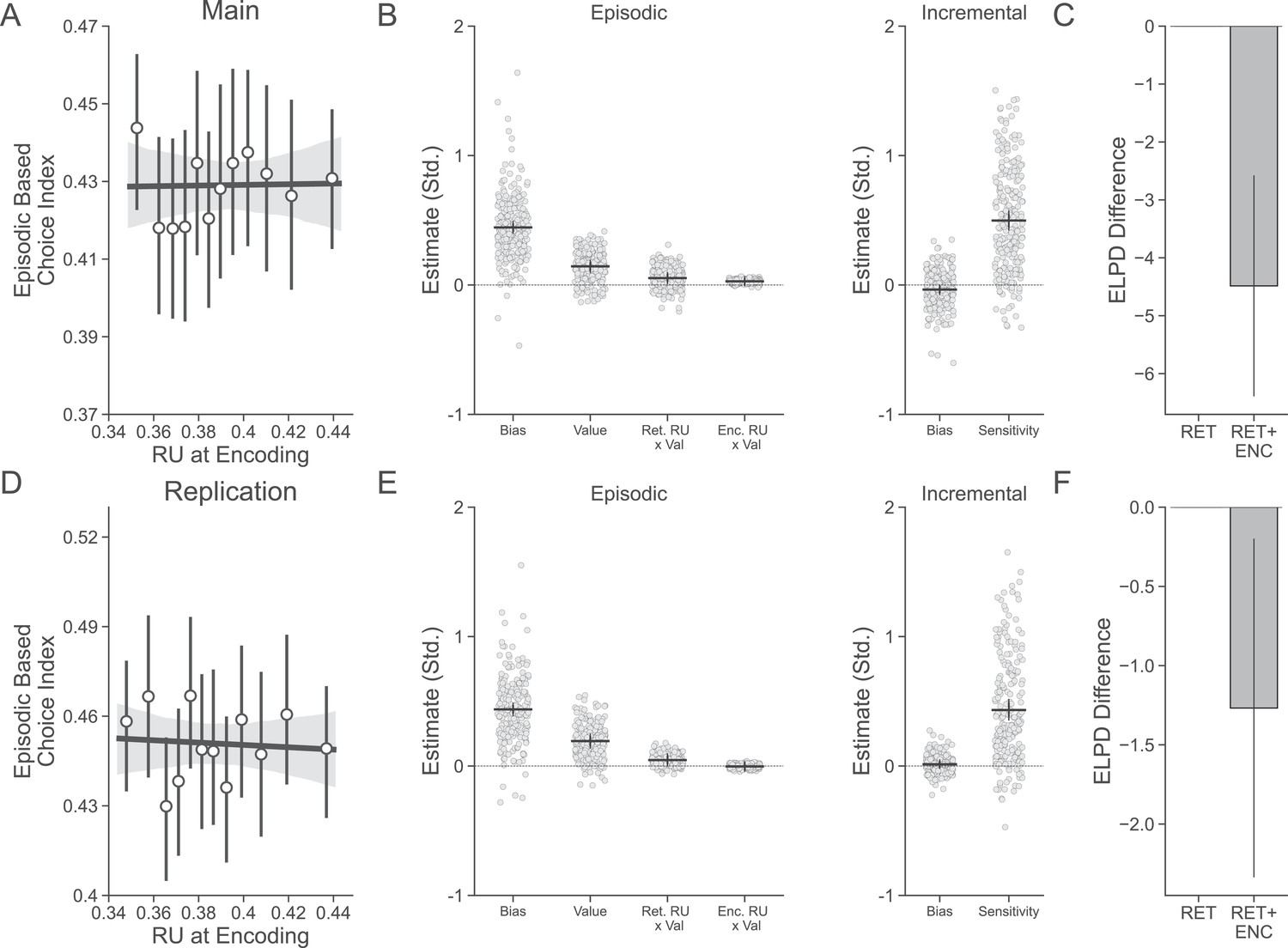
Results of relative uncertainty (RU) at encoding time on episodic-based choice in the main (A–C) and replication (D–F) sample.
(A) There was no relationship between RU at encoding and the degree to which participants (n = 254) based decisions on episodic value. (B) Estimates from the combined choice model including both effects of RU at retrieval time and RU at encoding time. Relative to the effect of the interaction between RU at retrieval time and old object value, the equivalent effect for RU at encoding time was small in the main sample. (C) Expected log pointwise predictive density for the combined choice model including only an effect of the interaction between RU at retrieval time and old object value (presented in the text) and the model also including the interaction between RU at encoding time and old object value. Including RU at encoding time did not improve model performance. (D) There was again no relationship between RU at encoding and episodic-based choice in the replication sample (n = 223). (E) In the replication sample, there was no effect of the interaction between RU at encoding and old object value on choice behavior. (F) Including RU at encoding time again did not improve model performance in the replication sample.
Figure 5 with 2 supplements
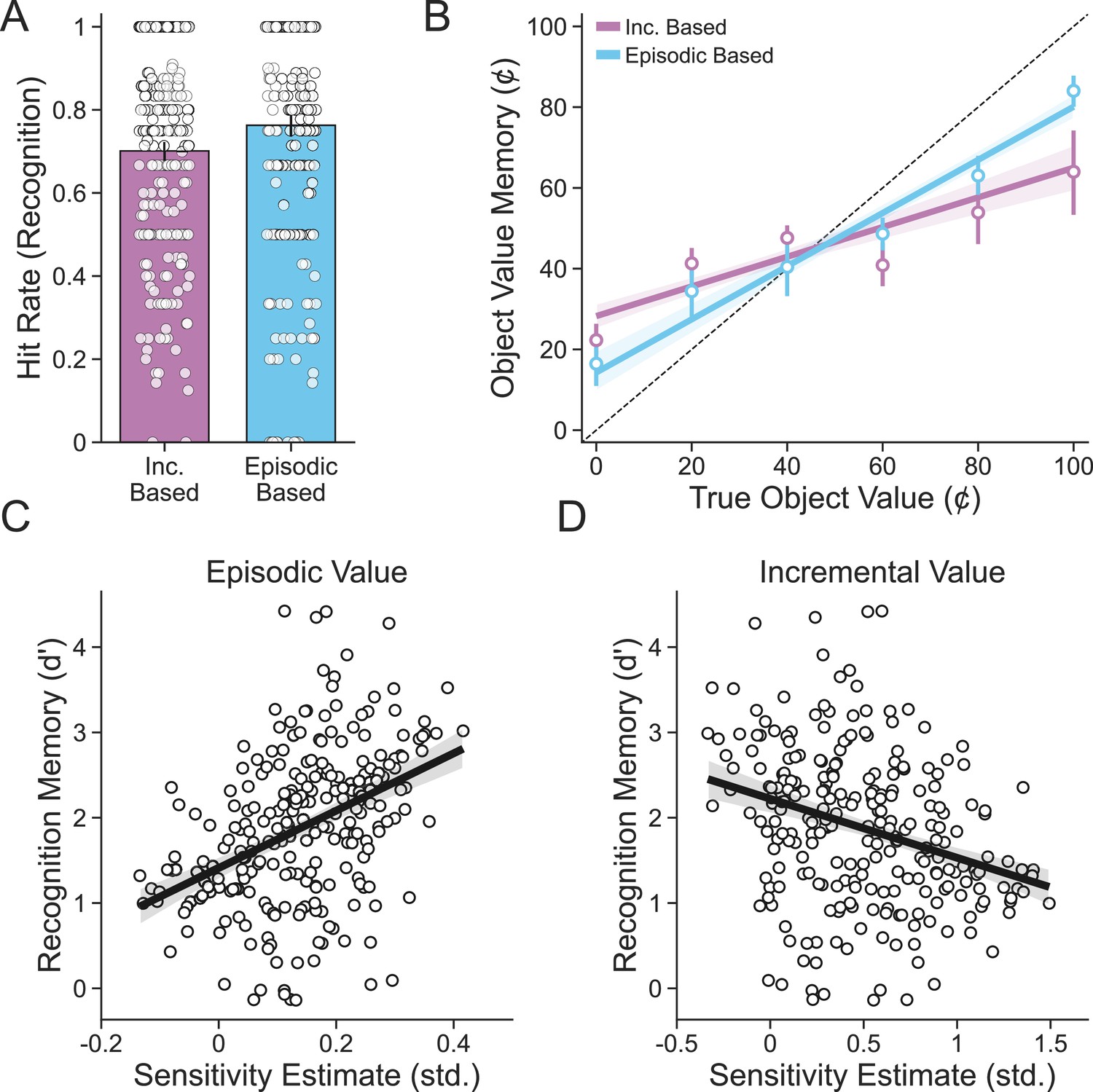
Relationship between choice type and subsequent memory.
(A) Objects originally seen during episodic-based choices were better remembered than objects seen during incremental-based choices. Average hit rates for individual subjects (n = 254) are shown as points, bars represent the group-level average, and lines represent 95% confidence intervals. (B) The value of objects originally seen during episodic-based choices was better recalled than objects seen during incremental-based choices. Points represent average value memory for each possible object value, and error bars represent 95% confidence intervals. Lines are linear fits, and bands are 95% confidence intervals. (C) Participants with greater sensitivity to episodic value as measured by random effects in the combined choice model tended to better remember objects seen originally in the card learning and deck memory task. (D) Participants with greater sensitivity to incremental value tended to have worse memory for objects from the card learning and deck memory task. Points represent individual participants, lines are linear fits, and bands are 95% confidence intervals.
Figure 5—figure supplement 1
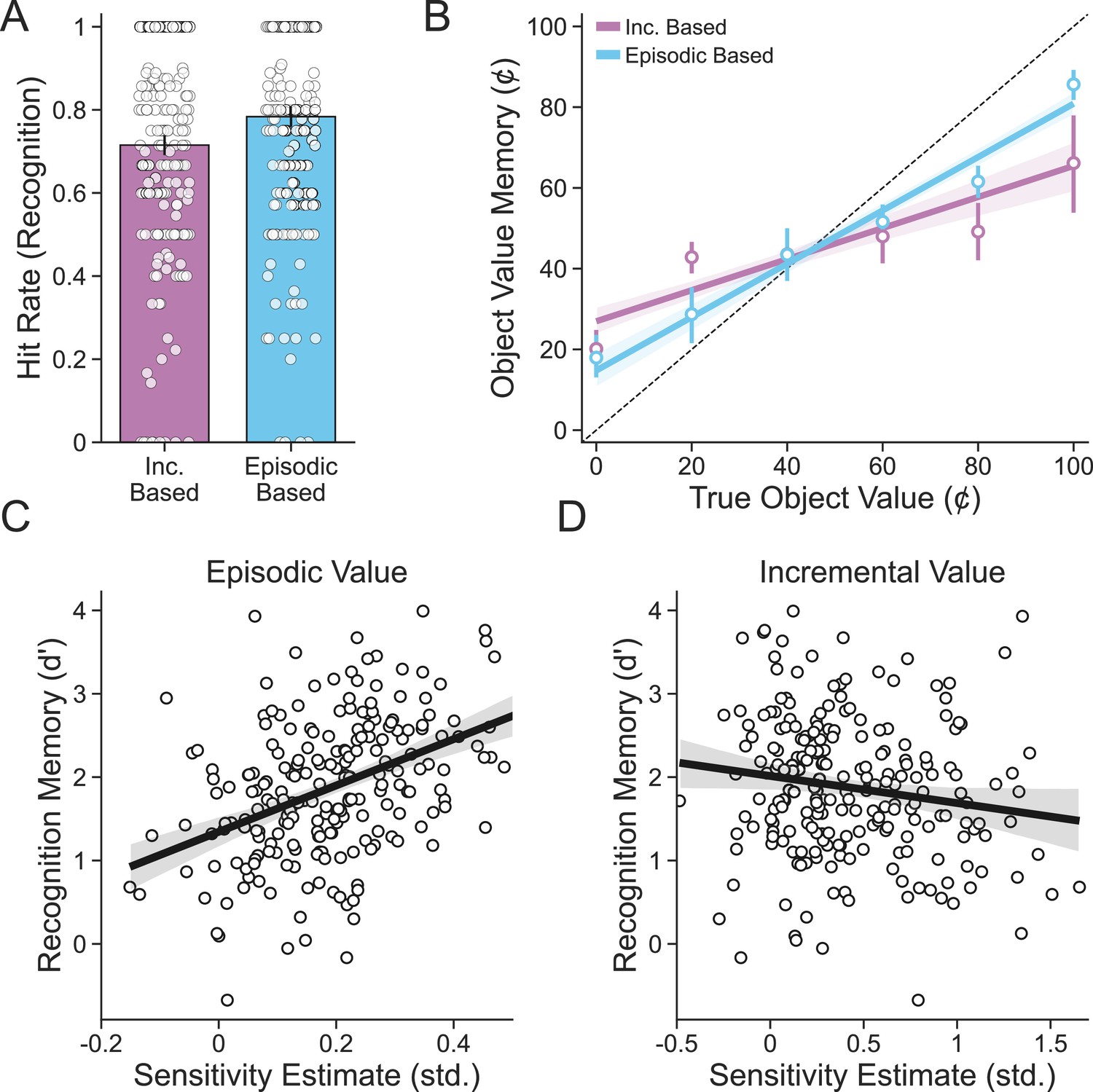
Recreation of Figure 5 in the main text using the replication dataset.
(A) Objects seen during episodic-based choices were better remembered than objects seen during incremental-based choices. (B) The value of objects originally seen during episodic-based choices was better recalled than objects seen during incremental-based choices. (C) Participants (n = 223) with greater sensitivity to episodic value tended to better remember objects from the deck learning and card memory task. (D) Participants with greater sensitivity to incremental value tended to have worse memory for objects from the card learning and deck memory task.
Figure 5—figure supplement 2
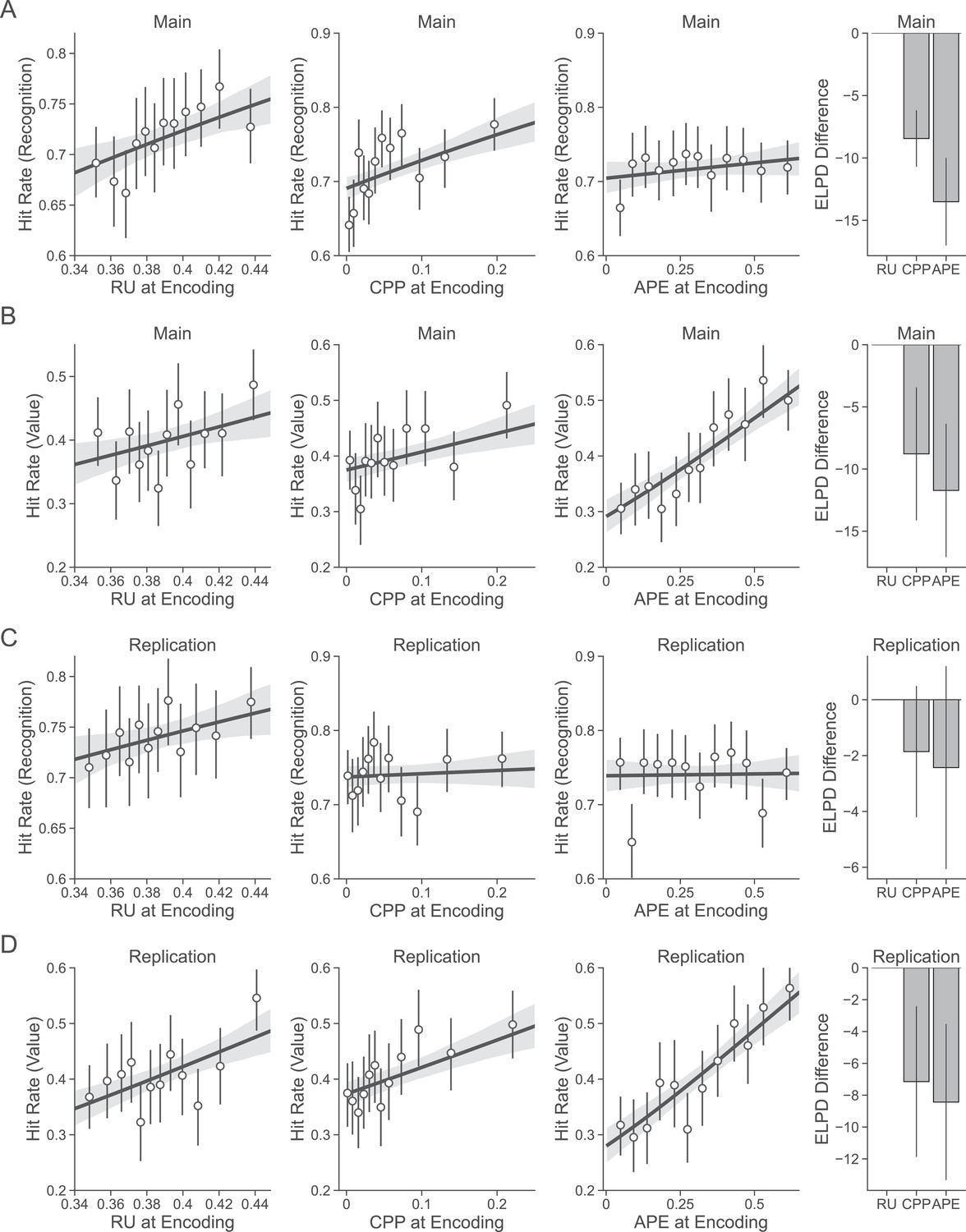
Effects of relative uncertainty (RU), changepoint probability (CPP), and absolute prediction error (APE) at encoding time on subsequent recognition and value memory in both the main and replication samples.
(A) Relationship between RU, CPP, and APE at encoding on recognition memory in the main sample (n = 254). RU outperformed both of these variables at predicting recognition memory (right). (B) Relationship between RU, CPP, and APE at encoding on value memory in the main sample. RU outperformed both of these variables at predicting value memory (right). (C) Relationship between RU, CPP, and APE at encoding on recognition memory in the replication sample (n = 223). Neither of these variables performed better than RU at predicting recognition memory (right). (D) Relationship between RU, CPP, and APE at encoding on value memory in the main sample. RU outperformed both of these variables at predicting value memory (right). Note that here value memory is visualized as a hit rate (where 1 is accurate value memory and 0 is inaccurate value memory) in order to show x-axis variables on a continuous scale, but analyses were conducted using the true value responses. Points are group means binned by x-axis variables at encoding, and error bars are 95% confidence intervals.
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Uncertainty alters the balance between incremental learning and episodic memory
eLife 11:e81679.
https://doi.org/10.7554/eLife.81679




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}