Human attention during goal-directed reading comprehension relies on task optimization
- Key Laboratory for Biomedical Engineering of Ministry of Education, College of Biomedical Engineering and Instrument Sciences, Zhejiang University, China
- Nanhu Brain-computer Interface Institute, China
- Division of Arts and Sciences, New York University Shanghai, China
Figures
Figure 1 with 2 supplements
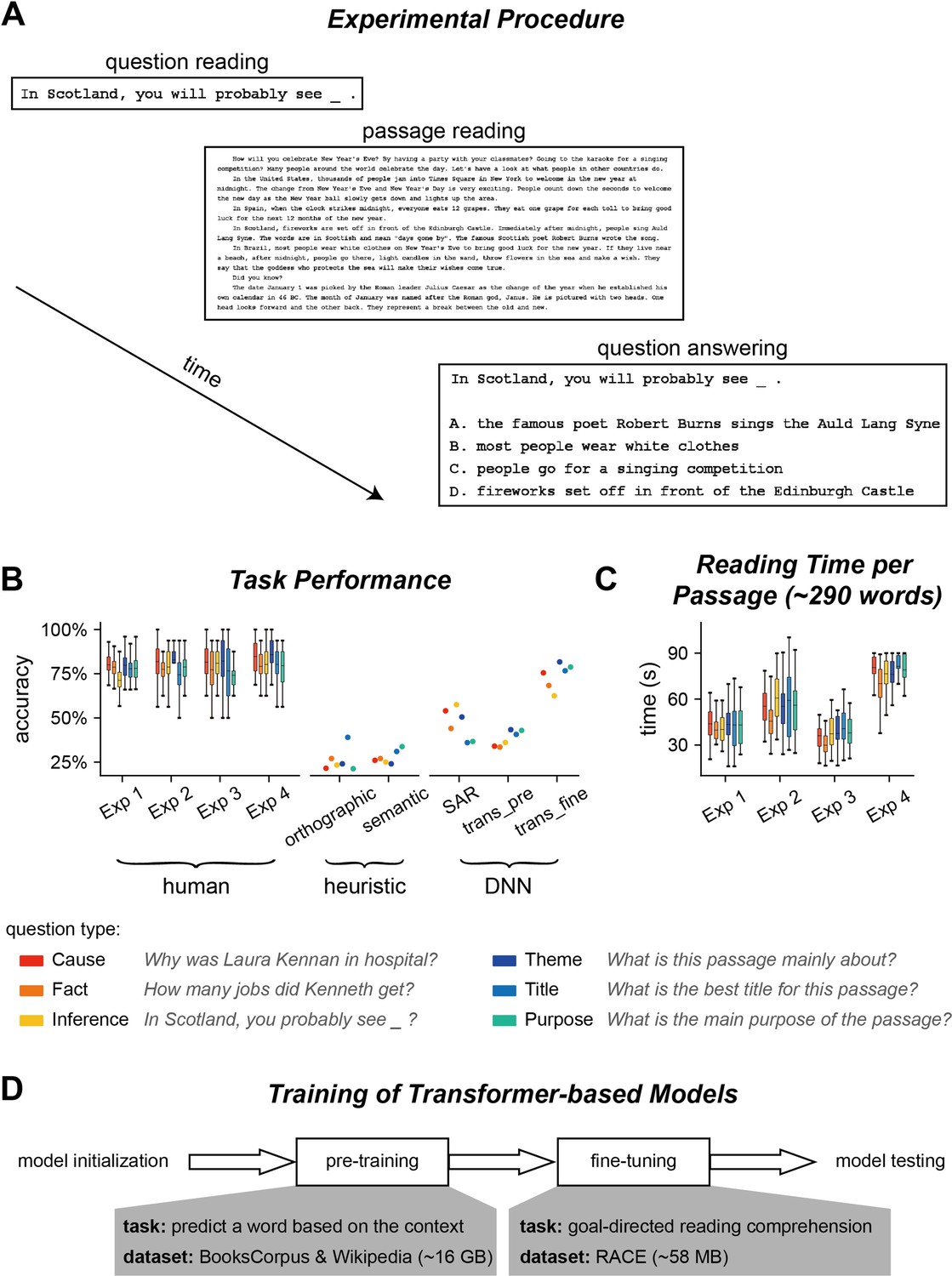
Experiment and performance.
(A) Experimental procedure for Experiments 1–3. In each trial, participants saw a question before reading a passage. After reading the passage, they chose the answer to the question from four options. (B) Accuracy of question answering for humans and computational models. The question type is color coded and an example question is shown for each type. trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (C) Time spent on reading each passage. The box plot shows the mean (horizontal lines inside the box), 25th and 75th percentiles (box boundaries), and 25th/75th percentiles ±1.5× interquartile range (whiskers) across participants (N = 25). (D) Illustration of the training process for transformer-based models. The pre-training process aims to learn general statistical regularities in a language based on large corpora, while the fine-tuning process trains models to perform the reading comprehension task.
Figure 1—figure supplement 1

Illustration of the word-level heuristic models and the recurrent neural network (RNN)-based Stanford Attentive Reader (SAR) model.
(A) The orthographic and semantic models calculate the word-wise similarities between all words in the integrated option and all words in the passage, forming a similarity matrix. The similarity measures used in the orthographic and semantic models are the edit distance and correlation between word embeddings, respectively. For each option, the similarity matrix is averaged across all rows and all columns to form a scalar decision score. The option with the largest decision score is chosen as the answer. (B) The SAR model uses bidirectional RNNs to encode contextual information. A vectorial representation for the passage is created using the weighted sum of the vectorial representation of each word, and the weight on each word, that is, the attention weight, is calculated based on its similarity to the vectorial representation of the question. The summarized passage representation and the option representation are used to form the decision score with a bilinear dot layer.
Figure 1—figure supplement 2
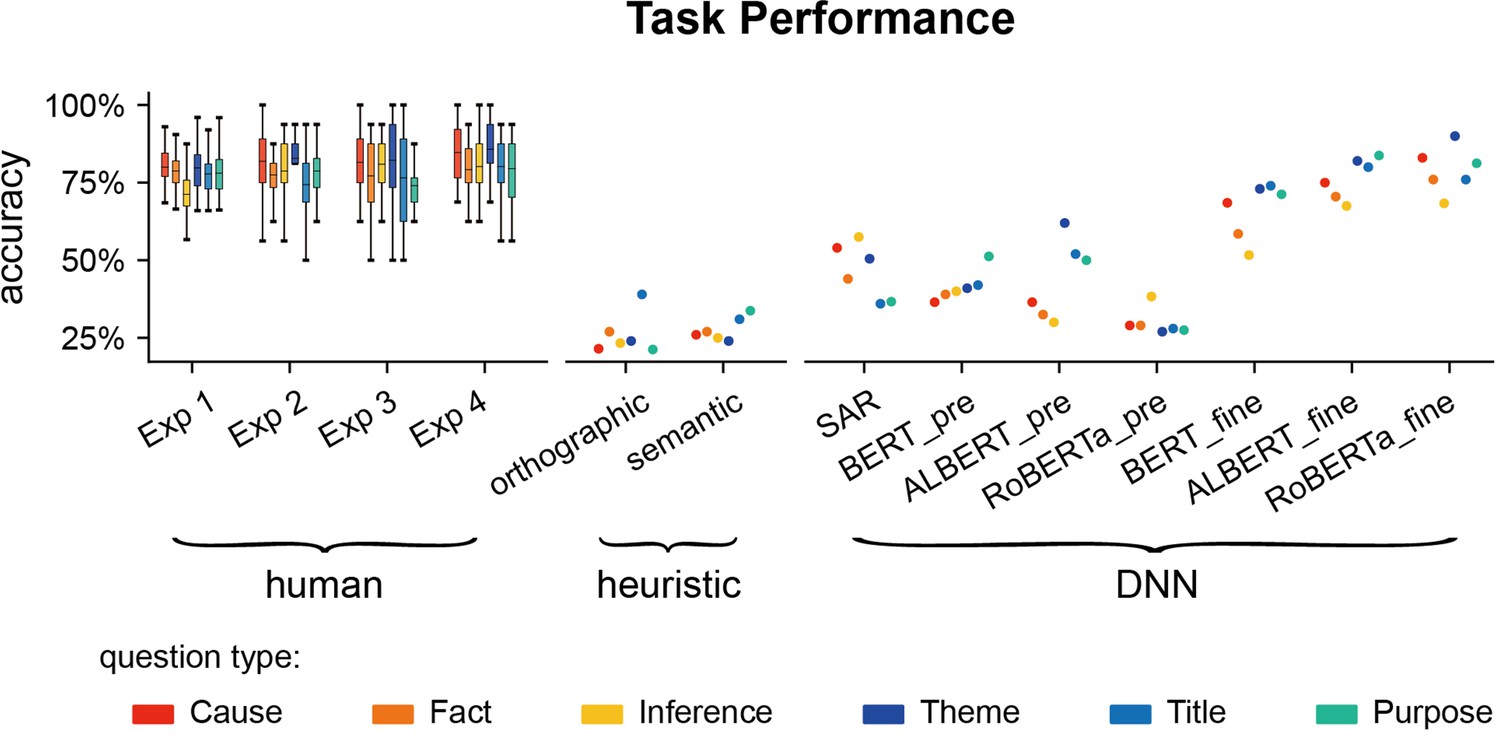
Question answering accuracy for individual transformer-based models.
Human results and other computational models are also plotted for comparison. *_pre: pre-trained transformer-based models; *_fine: transformer-based models fine-tuned on the goal-directed reading task.
Figure 2
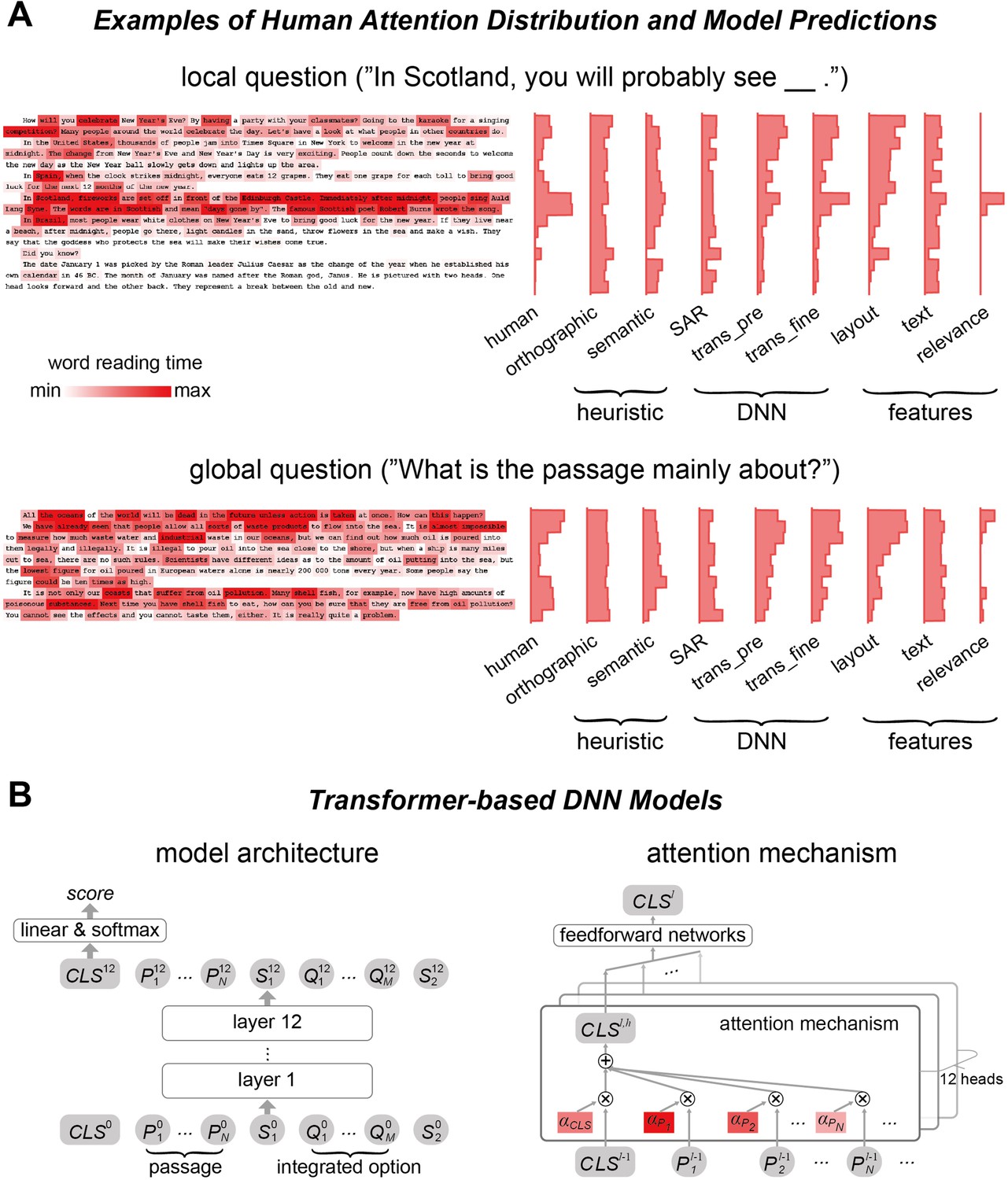
Human attention distribution and computational models.
(A) Examples of human attention distribution, quantified by the word reading time. The histograms on the right showed the mean reading time on each line for both human data and model predictions. trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (B) The general architecture of the 12-layer transformer-based models. The model input consists of all words in the passage and an integrated option. Output of the model relies on the node CLS (Legge et al., 2002), which is used to calculate a score reflecting how likely an option is the correct answer. The CLS node is a weighted sum of the vectorial representations of all words and tokens, and the attention weight for each word in the passage, that is, α, is the deep neural network (DNN) attention analyzed in this study.
Figure 3 with 3 supplements
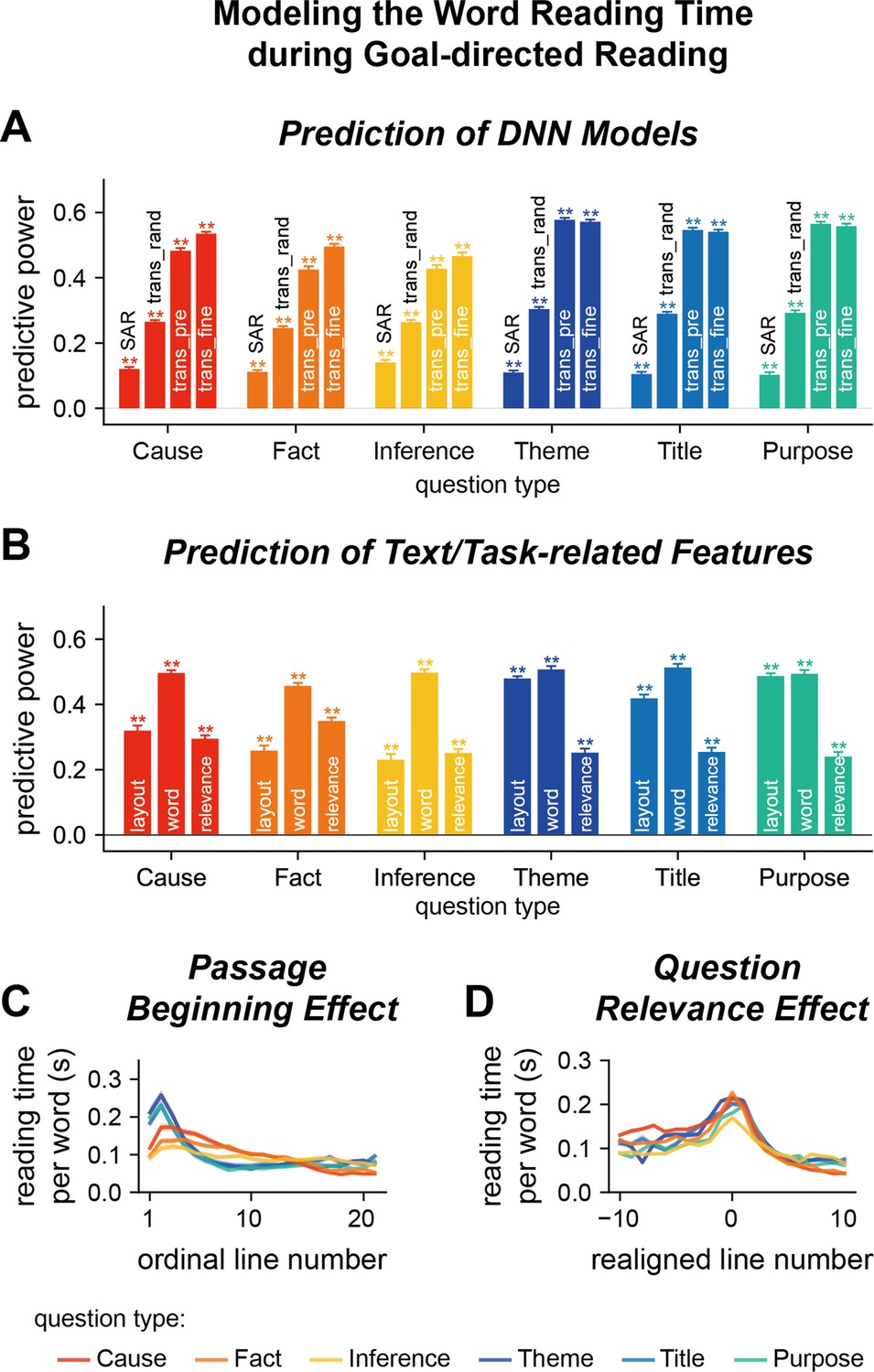
Model word reading time in Experiment 1.
(A, B) Predict the word reading time based on the attention weights of deep neural network (DNN) models, text features, or question relevance. The predictive power is the correlation coefficient between the predicted word reading time and the actual word reading time. Predictive power significantly higher than chance is denoted by stars on the top of each bar. **p<0.01. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (C) Relationship between the word reading time and line index. The word reading time is longer near the beginning of a passage and the effect is stronger for global questions than local questions. (D) Relationship between the word reading time and question relevance. Line 0 refers to the line with the highest question relevance. The word reading time is higher for the question-relevant line. Color indicates the question type. The shade area indicates 1 standard error of the mean (SEM) across participants (N = 25).
Figure 3—figure supplement 1
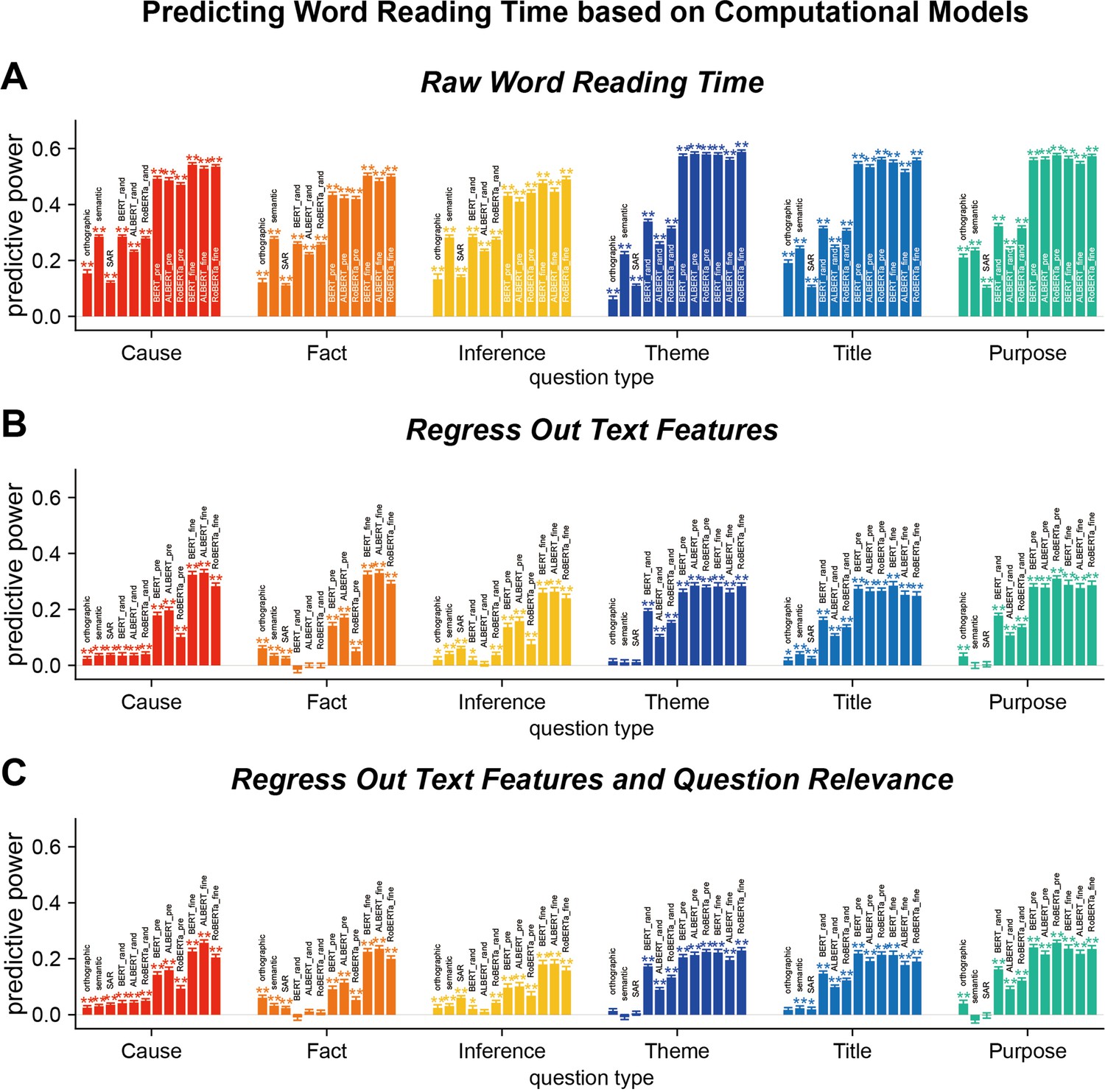
Transformer-based models can explain word reading time even when the influences of text features and question relevance are regressed out.
(A) Predict the raw word reading time using the attention weights of individual transformer-based models. Results from other computational models are also plotted for comparison. (B) Predict the residual word reading time when basic text features, that is, layout and word features, are regressed out. (C) Predict the residual word reading time when both basic text features and question relevance are regressed out. Predictive power significantly higher than chance is denoted by stars of the same color as the bar. *_rand: transformer-base models with randomized parameters; *_pre: pre-trained transformer-based models; *_fine: transformer-based models fine-tuned on the goal-directed reading task. *p<0.05; **p<0.01.
Figure 3—figure supplement 2

Weights on individual attention heads in the linear regression when predicting human word reading time.
The weights of the linear regression are normalized by their maximum value. The light-colored dots denote the weights on each head, and the dark-colored dots represent the mean weight within a layer. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task.
Figure 3—figure supplement 3
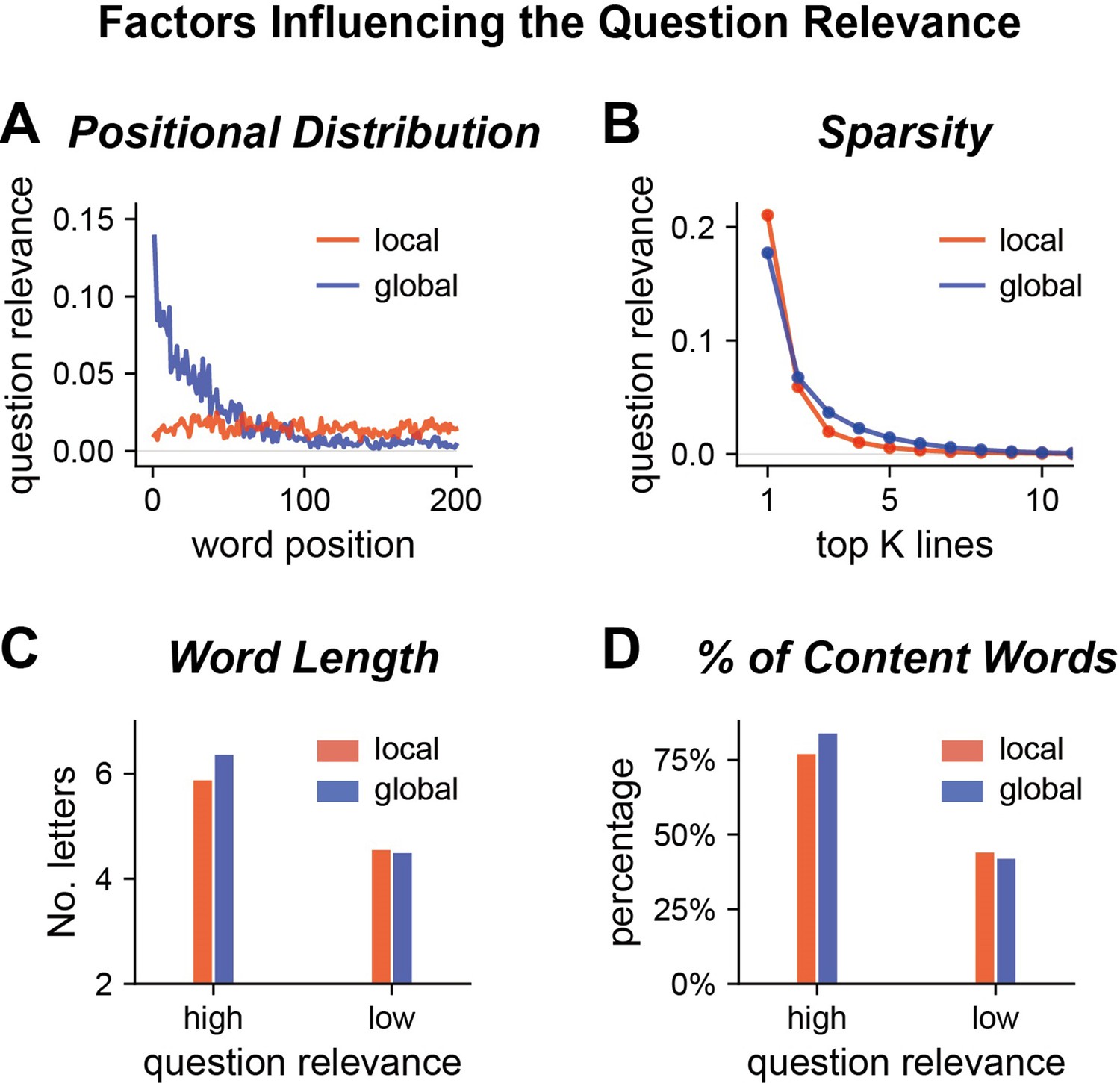
Properties of the question relevance of words.
(A) Question relevance as a function of the word position within a passage. For global but not local questions, question-relevant words concentrate near the beginning of a passage. (B) Decay of mean question relevance across lines. The question relevance is averaged within each line, and all lines in a passage are sorted based on the mean question relevance in descending order. Therefore, line 1 is the line with the highest question relevance, and line 2 is the line with the second highest question relevance. For both global and local questions, the mean question relevance sharply decreases over lines. (C) The mean word length, in terms of the number of letters, for words with the question relevance greater or smaller than 0.1. Words of higher relevance are generally longer. (D) Percentage of content words for words with higher or lower question relevance. Question-relevant words are more often content words.
Figure 4 with 3 supplements
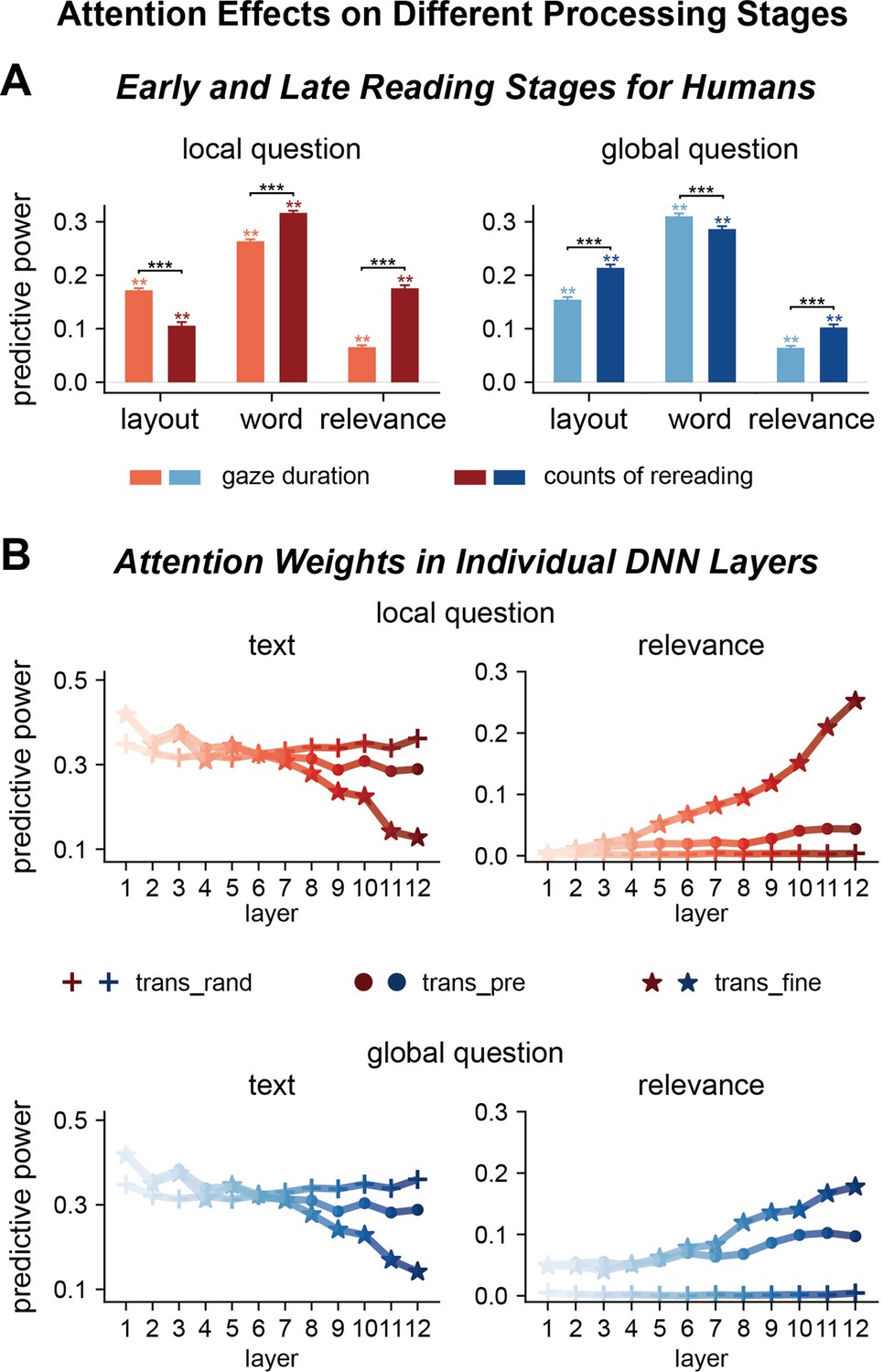
Factors influencing attention distribution in different processing stages for humans and deep neural networks (DNNs).
(A) Human attention in early and late reading stages is differentially modulated by text features and question relevance. The early and late stages are separately characterized by gaze duration, that is, duration for the first reading of a word, and counts of rereading, respectively. **p<0.01; ***p<0.001. (B) DNN attention weights in different layers are also differentially modulated by text features and question relevance. Each attention head is separately modeled and averaged within each layer, and the results are further averaged across the three transformer-based models. Shallow layers of both fine-tuned and pre-trained models are more sensitive to text features. Deep layers of fine-tuned models are sensitive to question relevance. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task.
Figure 4—figure supplement 1
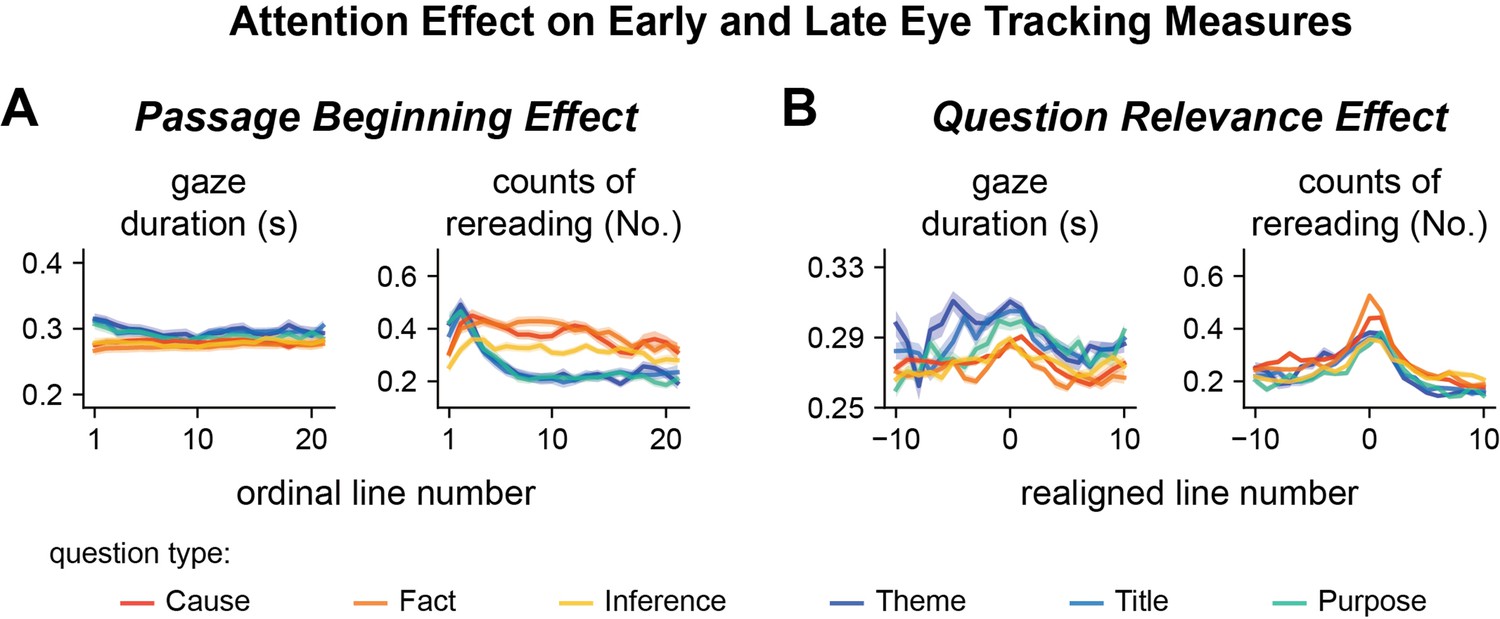
Passage beginning effects (A) and question relevance effects (B) in early and late reading stages.
The passage beginning effect differ between global and local questions mainly in the late reading stage reflected by the counts of rereading. The question relevance effect is also only reliably observed in the late reading stage.
Figure 4—figure supplement 2

Factors influencing attention weights in each layer of deep neural networks (DNNs) for local questions.
Similar results are observed for all three models: The sensitivity to text features decreases from shallow to deep layers, while the sensitivity to question relevance increases across layers. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task.
Figure 4—figure supplement 3

Factors influencing attention weights in each layer of deep neural networks (DNNs) for global questions.
Similar results are observed for all three models: The sensitivity to text features decreases from shallow to deep layers, while the sensitivity to question relevance increases across layers. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task.
Figure 5 with 2 supplements
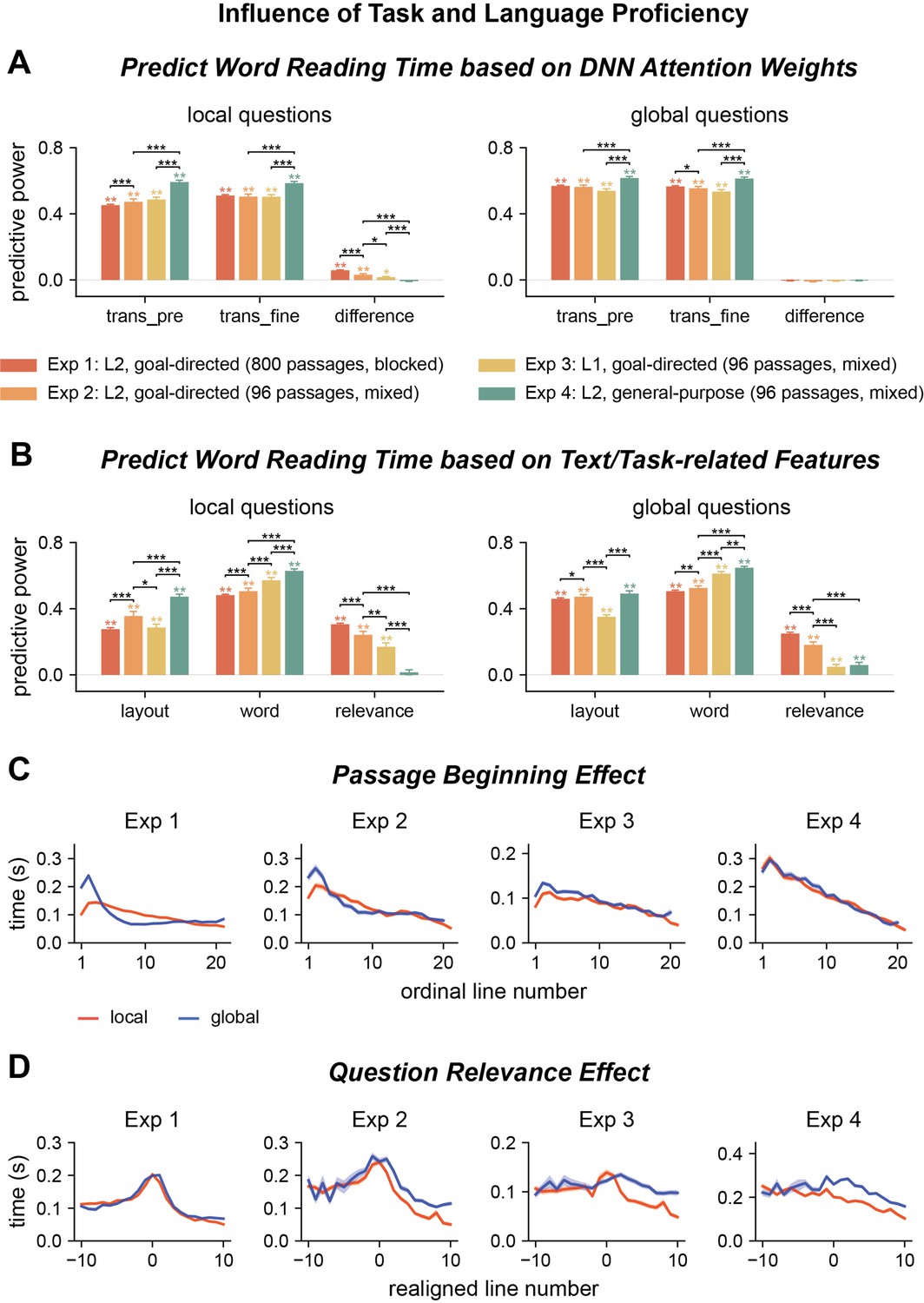
Influence of task and language proficiency on word reading time.
(A, B) Predict the word reading time using attention weights of deep neural network (DNN) models, text features, and question relevance for all four experiments. Predictive power significantly higher than chance is marked by stars of the same color as the bar. Significant differences between experiments are denoted by black stars. trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. *p<0.05; **p<0.01; ***p<0.001. (C, D) Passage beginning and question relevance effects for all four experiments. The shade area indicates 1 SEM across participants (N = 25 for Exp 1; N = 20 for Exps 2-4).
Figure 5—figure supplement 1

Factors influencing human reading in different processing stages in Experiment 2 (A), Experiment 3 (B), and Experiment 4 (C).
The early and late stages are separately characterized by gaze duration, that is, duration for the first reading of a word, and counts of rereading, respectively. *p<0.05; **p<0.01; ***p<0.001.
Figure 5—figure supplement 2
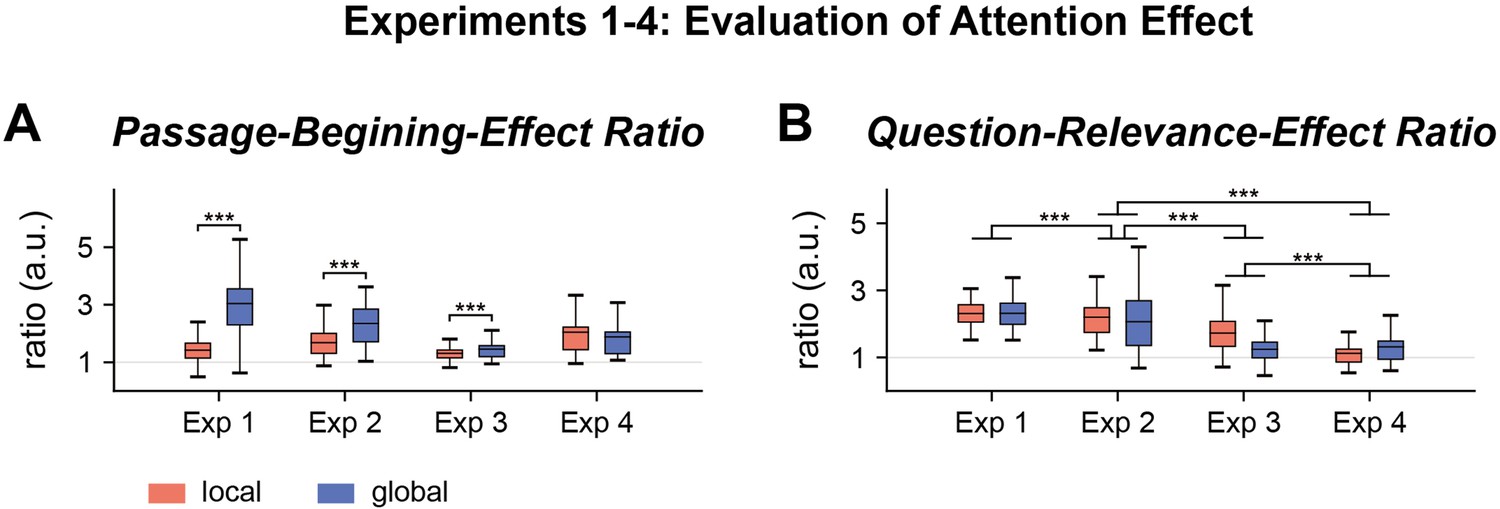
Passage beginning effects (A) and question relevance effects (B) in four experiments.
The passage beginning effect was quantified by the ratio between the mean word reading time on the first three lines of a passage and the mean word reading time on other lines. The question relevance effect was quantified by the ratio between mean word reading time on the line that was most relevant to the question and lines that were more than five lines away. See Figure 1 for the explanation for the box plots. **p<0.01; ***p<0.001.
Author response image 1

Fine-tuning based on local and global questions does not significantly modulate the prediction of human reading time.
Lighter-color symbols show the results for the 3 BERT-family models (i.e., BERT, ALBERT, and RoBERTa) and the darker-color symbols show the average over the 3 BERT-family models. trans_fine: model fine-tuned based on the RACE dataset; trans_local: models additionally fine-tuned using local questions; trans_global: models additionally fine-tuned using global questions.
Tables
Author response table 1
The hyperparameter for fine-tuning DNN models with specific question type.
| fold of cross- validation | training : validation : test | learning rate | training epochs | training batch size | weigh decay | early stopping patience |
|---|---|---|---|---|---|---|
| 10 | 70%:20%:10% | 1e-5 | 10 | 16 | 0.1 | 2 |
Additional files
-
Supplementary file 1
Supplementary tables.
(a) p-values for the model prediction of word reading time. trans_rand: transformer-base models with randomized parameters; trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (b) p-values for the prediction of word reading time using text or task-related features. (c) Linear mixed effects modeling of human word reading time. The question type is coded as 0 (local question) or 1 (global question), and other factors are continuous regressors. Given the substantial number of attention weights in BERT (i.e., 144), we present the 1st quartile and 3rd quartile values for b, SE, and t and report the ratio of attention weights that reach significant level. b: regression coefficient; SE: standard error of regression coefficient. (d) p-values for the prediction of early and late eye-tracking measures using text or task-related features. GD: gaze duration; CR: counts of rereading. (e) p-values for the prediction of word reading time for all four experiments. trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (f) p-values for the comparisons between experiments. trans_pre: pre-trained transformer-based models; trans_fine: transformer-based models fine-tuned on the goal-directed reading task. (g) Hyperparameters for DNN fine-tuning. We adapted these hyperparameters from references (Lan et al., 2020; Liu et al., 2019; Zhu et al., 2015; Wolf et al., 2020).
- https://cdn.elifesciences.org/articles/87197/elife-87197-supp1-v1.docx
-
MDAR checklist
- https://cdn.elifesciences.org/articles/87197/elife-87197-mdarchecklist1-v1.docx
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Human attention during goal-directed reading comprehension relies on task optimization
eLife 12:RP87197.
https://doi.org/10.7554/eLife.87197.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}