Finding structure during incremental speech comprehension
- Changping Laboratory, China
- Centre for Speech, Language and the Brain, Department of Psychology, University of Cambridge, United Kingdom
Figures
Figure 1

Example spoken sentence stimuli and plausible structured interpretations.
The two target sentences in each set differ only in the transitivity of the first verb (Verb1). Each sentence has two possible structured interpretations before the actual main verb is presented: an active interpretation, where the subject noun (SN) performs the action, and a passive interpretation, where the SN is the recipient of the action. The interpretative preference hinges on the likelihood of the SN acting as an agent or a patient (i.e. its thematic role) in conjunction with the transitivity of Verb1. As the sentence progresses to the prepositional phrase, a combination of higher SN agenthood and greater Verb1 intransitivity (i.e. a higher active index) generally favours an active interpretation. Conversely, increased SN patienthood coupled with higher Verb1 transitivity (i.e. a higher passive index) may lead to a passive interpretation. Note that while the SN is the same for the two target sentences within the same set, it varies across different sentence sets. All images were generated using Midjourney for illustrative purposes.
Figure 2

Human incremental structural interpretations derived from continuation pre-tests.
(A) An example set of target sentences differing only in the transitivity of Verb1, HiTrans: high transitivity; LoTrans: low transitivity. Det: determiner; SN: subject noun; V1: Verb1; PP1–PP3: prepositional phrase; MV: main verb; END: the last word in the sentence. (B) Probability of a direct object (left) and a prepositional phrase (right) continuation after Verb1. (C) Probability of a main verb in the continuations after Verb1, which indicates an active interpretation. (D) Correlations between corpus-based lexical constraints and probabilistic interpretations in the two pre-tests (Spearman rank correlation, black dots indicate significance determined by 10,000 permutations, PFDR<0.05 corrected).
Figure 3 with 3 supplements

Incremental interpretation of sentential structure by BERT.
(A) Context-free dependency parse trees of two plausible structural interpretations. Left: passive interpretation where V1 is the head of a reduced relative clause. Right:aActive interpretation where V1 is the main verb. (B) Incremental input to BERT structural probing model, with the lightness of dots encoding different positions in the target sentences. Det: determiner; SN: subject noun; V1: Verb1; PP1–PP3: prepositional phrase; MV: main verb; END: the last word in the sentence. (C) BERT structural probing model is trained to output a parse depth vector, representing the parse depths of all the words in the sentence input. The BERT parse depth for a specific word is updated incrementally as the sentence unfolds word-by-word. In this example, the parse depth of ‘found’ increases with the presence of the prepositional phrase, indicating an increased preference for the passive interpretation according to the context-free parse depths in (A). (D) Incremental interpretation of the dependency between SN and V1 in the model space consisting of the parse depth of Det, SN, and V1. Upper: Each coloured circle represents the parse depth vector up to V1 derived at a certain position in the sentence (with the same colour scheme as in B). The hollow triangle and circle represent the context-free dependency parse vectors for passive and active interpretations in (A). Lower: incremental interpretation of the two target sentence types represented by the trajectories of median parse depth. (E) Distance from passive and active landmarks in the model space as the sentence unfolds (between each coloured circle and the two landmarks in the upper panel of D) (two-tailed two-sample t-test, *p<0.05, **p<0.001, n = 60 for both HiTrans and LoTrans sentences, error bars represent SEM).
Figure 3—figure supplement 1
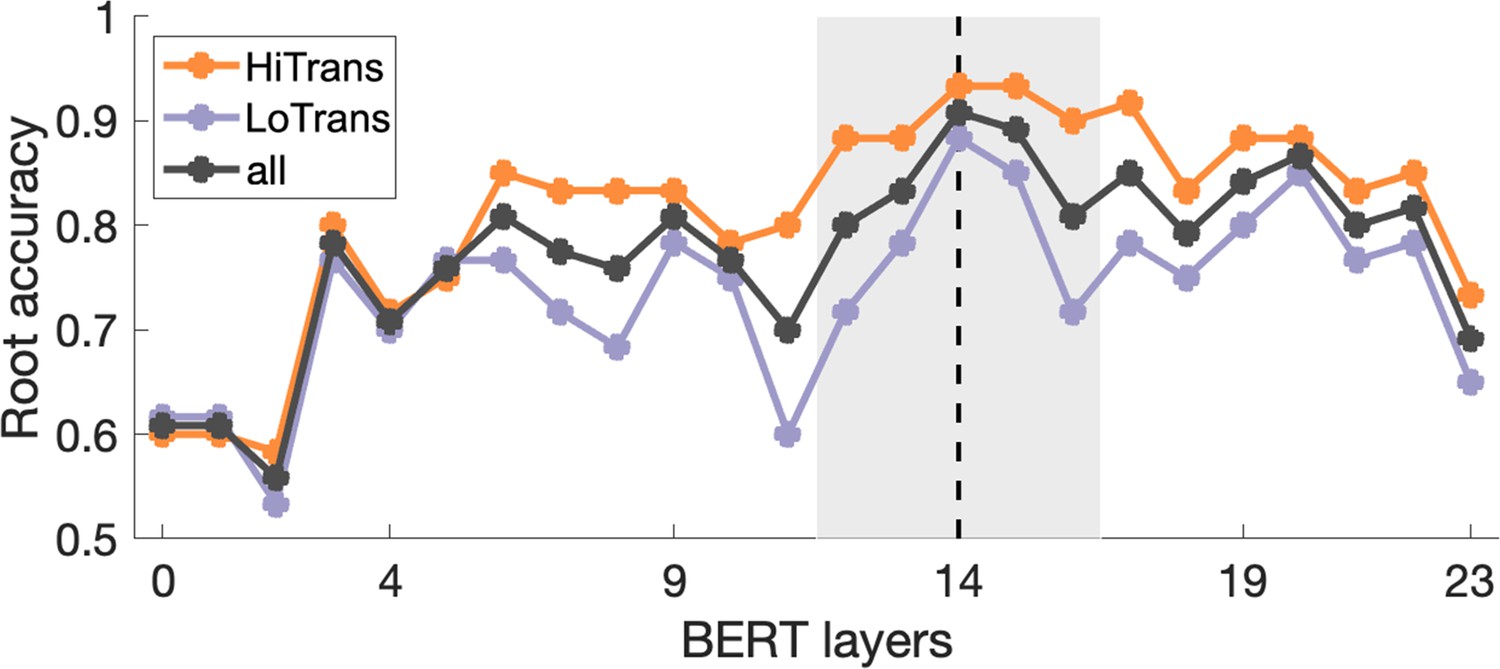
Performance of structural probing models trained on different BERT layers.
Structural probing models were trained to reconstruct a sentence’s structure by estimating each word’s dependency parse depth based on the word embeddings from BERT hidden states in this layer. The performance of structural probing models was evaluated by root accuracy (i.e. the percentage of the sentences in which the smallest parse depth is assigned to the main verb, i.e. the root of the dependency parse tree which is 0 in the context-free dependency parse tree) when the whole sentence is input to the model. Structural probing models derived from BERT layer 14 showed the best overall performance. However, additional structural probing models derived from its neighbouring layers (i.e. layers 12–13, 15–16 in the grey shade) were also included in further analyses to cover potentially useful downstream and upstream information. HiTrans: high Verb1 transitivity sentences (n = 60); LoTrans: low Verb1 transitivity sentences (n = 60); all: HiTrans and LoTrans sentences (n = 120).
Figure 3—figure supplement 2
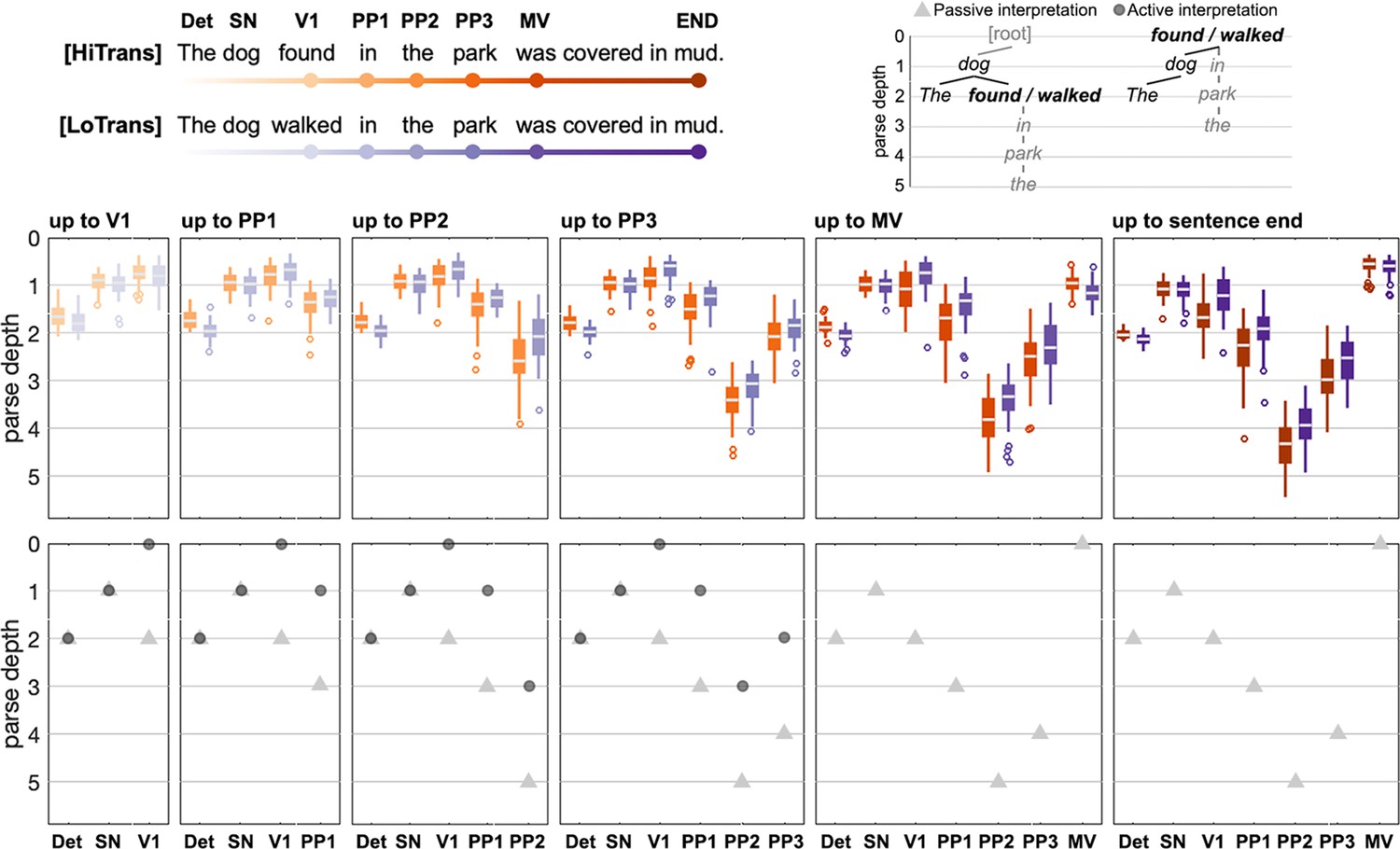
BERT structural representations of incremental sentence inputs.
Each sentence was input word-by-word to the BERT structural probing model, which returned the estimated parse depth of each word given the specific contents in the incremental sentence input. BERT parse depth of words at the same position formed a distribution in both HiTrans and LoTrans sentences (i.e. the boxplots), ranging around the corresponding context-free parse depths in either passive or active interpretations denoted by the triangle and circle markers separately, which might reflect probabilistic interpretations given the specific contents in a sentence. Moreover, the BERT parse depth of earlier words in the sentence was updated with each incoming later word, capturing the incrementality of speech comprehension. The results in this figure were obtained from the structural probing model trained on BERT layer 14. Det: determiner; SN: subject noun; V1: Verb1; PP1–PP3: prepositional phrase; MV: main verb; END: end of the sentence.
Figure 3—figure supplement 3
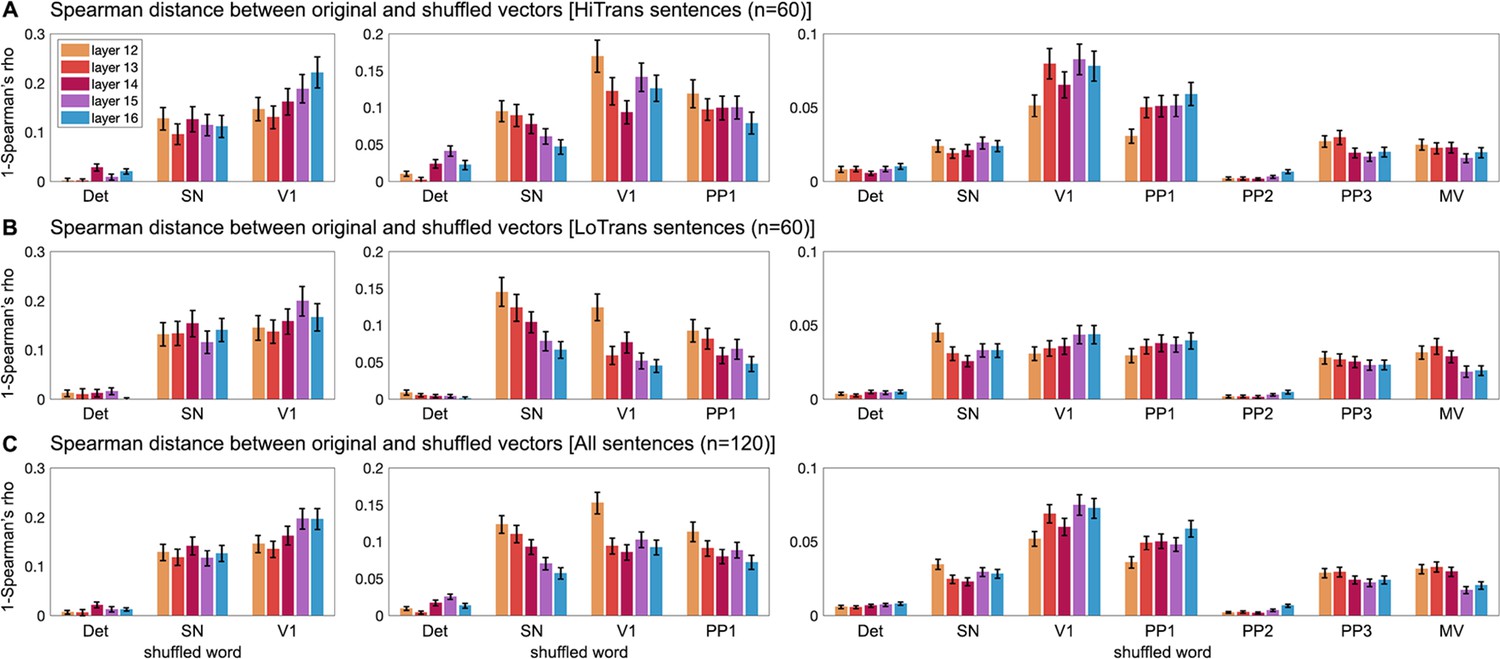
Contribution of words at different positions in BERT parse depth vectors.
Given the incremental BERT parse depth vectors up to Verb1 (V1) (left), PP1 (middle), and MV (left), we separately shuffled the parse depths of words at a particular position at a time across (A) HiTrans sentences, (B) LoTrans sentences, or (C) both types of sentences, and meanwhile kept the parse depths of the other words unchanged. Then we calculated the Spearman distance (i.e. 1-Spearman’s rho) between the original and the shuffled BERT parse depth vectors. The larger this distance, the more the word at this position contributed to the BERT parse depth vector. In general, content words contributed more than function words (i.e. the two determiners, one at the beginning of the sentence [e.g. “The dog …”), the other in the prepositional phrase – PP2 e.g. “ … in the park …”]. In fact, function words contributed the least to the overall variance of BERT structural representations. This analysis was conducted for the BERT parse depth obtained from layers 12–16. BERT parse depth at each position was shuffled 10,000 times, error bars represent 1 SD. HiTrans: high Verb1 transitivity; LoTrans: low Verb1 transitivity; Det: determiner; SN: subject noun; PP1–PP3: prepositional phrase; MV: main verb.
Figure 4 with 3 supplements

Correlation between incremental BERT structural measures and explanatory variables.
BERT structural measures include (A, B) BERT interpretative mismatch represented by each sentence’s distance from the two landmarks in model space (Figure 3D); (C, D) dynamic updates of BERT interpretative mismatch represented by each sentence’s movement to the two landmarks; (E, F) overall structural representations captured by the first two principal components (i.e. PC1 and PC2) of BERT parse depth vectors; (G, H) BERT Verb1 (V1) parse depth and its dynamic updates. Explanatory variables include lexical constraints derived from massive corpora and the main verb probability derived from the continuation pre-test (Spearman correlation, permutation test, PFDR<0.05, multiple comparisons corrected for all BERT layers, results shown here are based on layer 14, see Figure 4—figure supplements 1–3 for the results of all layers, see Figure 7—figure supplement 1 for the dynamic change of Verb1 parse depth); PP1–PP3: prepositional phrase; MV: main verb; END: the last word in the sentence.
Figure 4—figure supplement 1
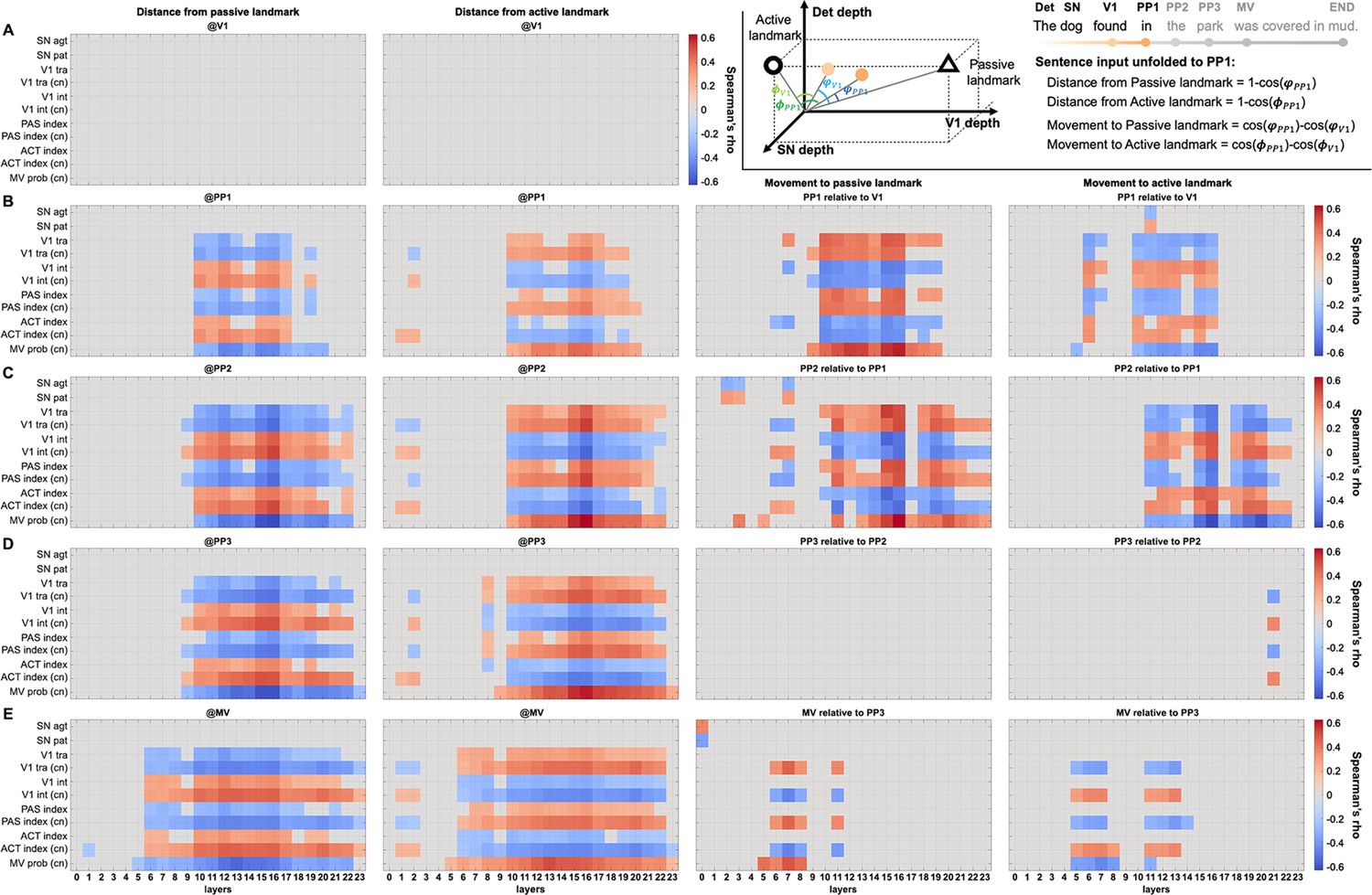
Correlation between BERT structural interpretations and explanatory variables.
The dynamic interpretation of the structural dependency between the subject noun (SN) and the Verb1 (V1) by BERT can be captured by each sentence’s trajectory in BERT model space (see Figure 3D), with the passive/active landmarks as references. The cosine distance between each sentence and the passive/active landmark was calculated as the sentence unfolded word-by-word. The change of the cosine distance from a landmark between two consecutive words (i.e. incremental movement relative to a certain landmark) was also calculated (see an example for a sentence unfolding from V1 to PP1 at the top-right corner). The distance and the incremental movement relative to the two landmarks in the model space were correlated with explanatory variables derived from corpus and human continuation pre-tests, correlation results with respect to incremental sentence inputs up to (A) V1, (B) PP1, (C) PP2, (D) PP3, and (E) MV are separately shown above (Spearman correlation, significance was determined by 10,000 permutations, PFDR<0.05, multiple comparisons corrected for all BERT layers). Note that only significant results are plotted, grey colour indicates non-significant results, which also applies to Figure 4—figure supplements 2 and 3. SN agt/pat: subject noun agenthood/patienthood; V1 tra/int: Verb1 transitivity/intransitivity; PAS/ACT index: passive/active index; MV prob: probability of a main verb in the continuations after PP derived from the continuation pre-test. Explanatory variables based on human continuations are indicated by ‘cn’ in parentheses. Det: determiner; PP1–PP3: prepositional phrase; MV: main verb.
Figure 4—figure supplement 2
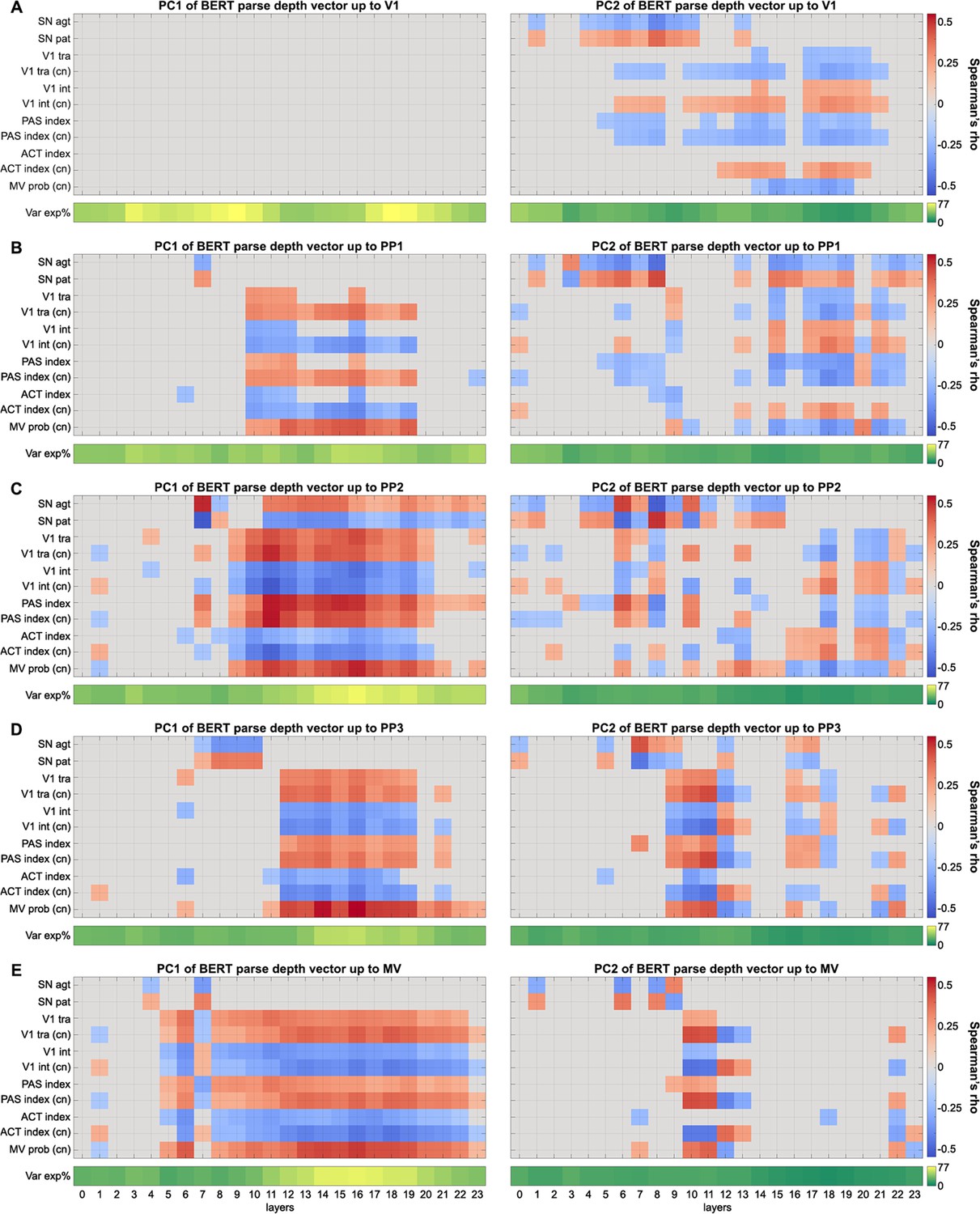
Correlation between the principal components (PCs) of BERT parse depth vectors and explanatory variables.
PCs of the incremental BERT parse depth vectors were derived to represent the overall information encoded in them. The first two PCs of BERT parse depth vectors for incremental sentence inputs up to (A) Verb1 (V1), (B) PP1, (C) PP2, (D) PP3, and (E) MV were separately correlated with explanatory variables derived from corpus and human continuation pre-tests (Spearman correlation, significance was determined by 10,000 permutations, PFDR<0.05, multiple comparisons corrected for all BERT layers). The variance explained (Var exp%) by each PC of each BERT layer is shown at the bottom of each panel. Det: determiner; SN: subject noun; PP1–PP3: prepositional phrase; MV: main verb.
Figure 4—figure supplement 3
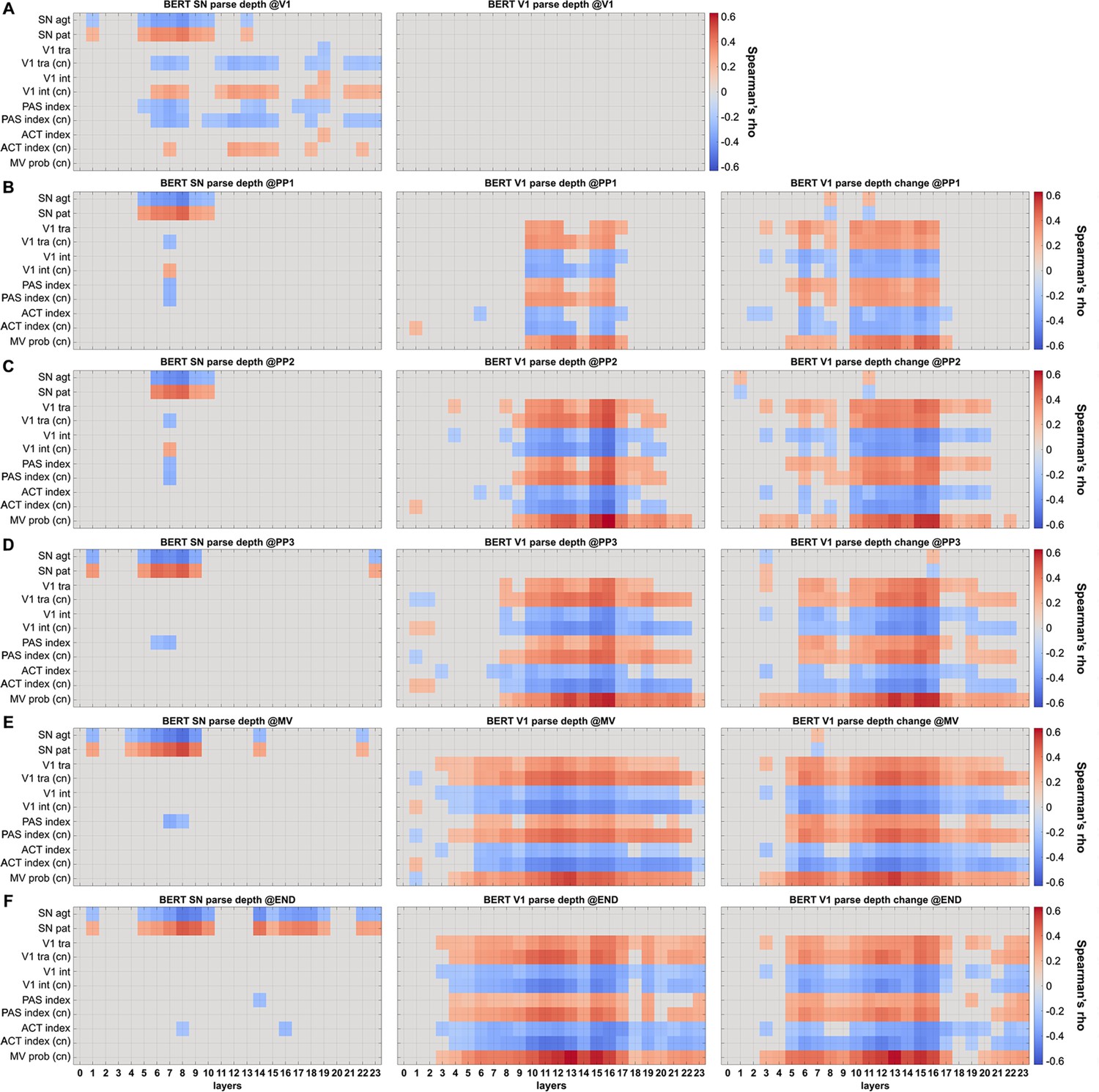
Correlation between BERT parse depth of individual words and explanatory variables.
BERT parse depth of SN (left), Verb1 (V1) (middle), and BERT Verb1 parse depth change relative to its first appearance (right) obtained from incremental sentence inputs up to (A) V1, (B) PP1, (C) PP2, (D) PP3, (E) MV, and (F) the end of the sentence were separately correlated with explanatory variables derived from corpus and human continuation pre-tests (Spearman correlation, significance was determined by 10,000 permutations, PFDR<0.05, multiple comparisons corrected for all BERT layers). Det: determiner; SN: subject noun; PP1–PP3: prepositional phrase; MV: main verb; END: end of the sentence.
Figure 5
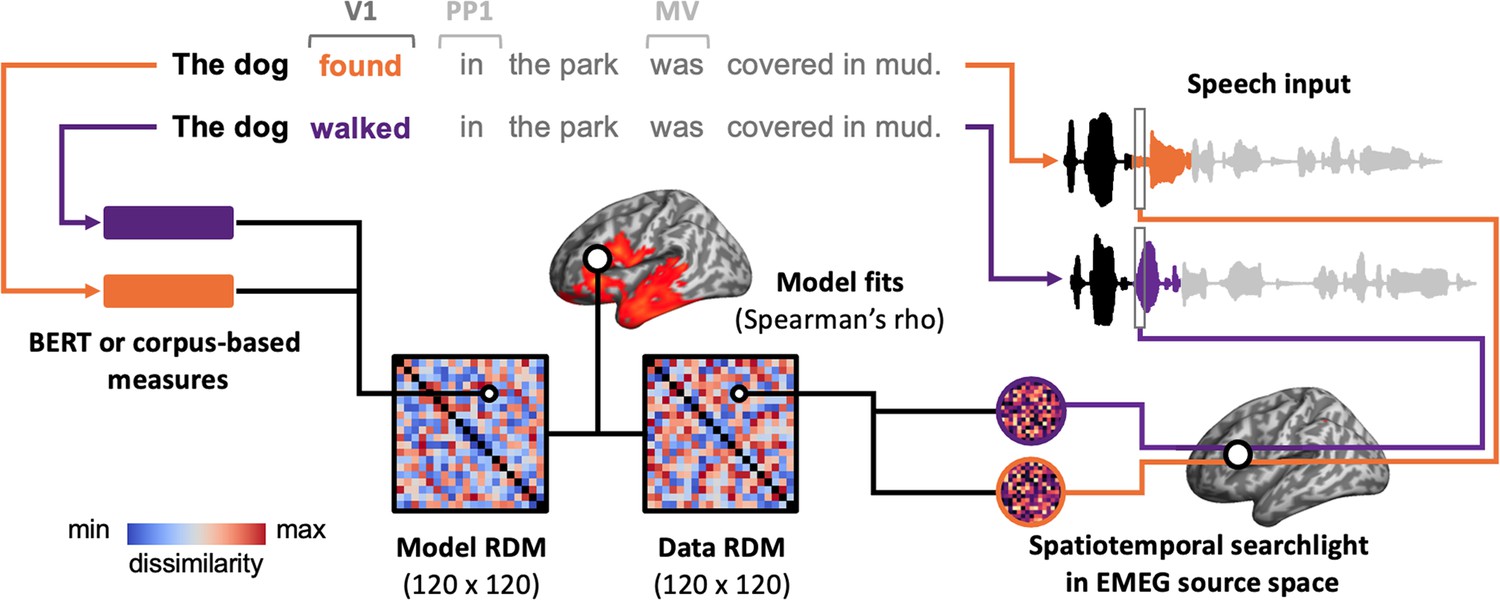
Illustration of the pipeline for spatiotemporal searchlight representational similarity analysis (ssRSA).
For each pair of sentences, we extract their BERT or corpus-based measures and calculate the dissimilarity between these measures, resulting in a model representational dissimilarity matrix (RDM). Meanwhile, we also extract the neural activity recorded while participants are listening to these sentences and calculate their dissimilarity to create a data RDM. Specifically, we use a spatiotemporal searchlight in EMEG source space, which moves across the brain and captures the neural activity within a 10-mm-radius sphere over a 60 ms sliding time window. By correlating the model RDM with data RDMs from all spatiotemporal searchlights, we can identify whether, and if so, when and where the brain represents the information captured by the model RDM. The ssRSA is conducted in V1, PP1, and MV epochs, respectively, with HiTrans and LoTrans sentences combined as one group (i.e. 120 sentences in total).
Figure 6 with 6 supplements
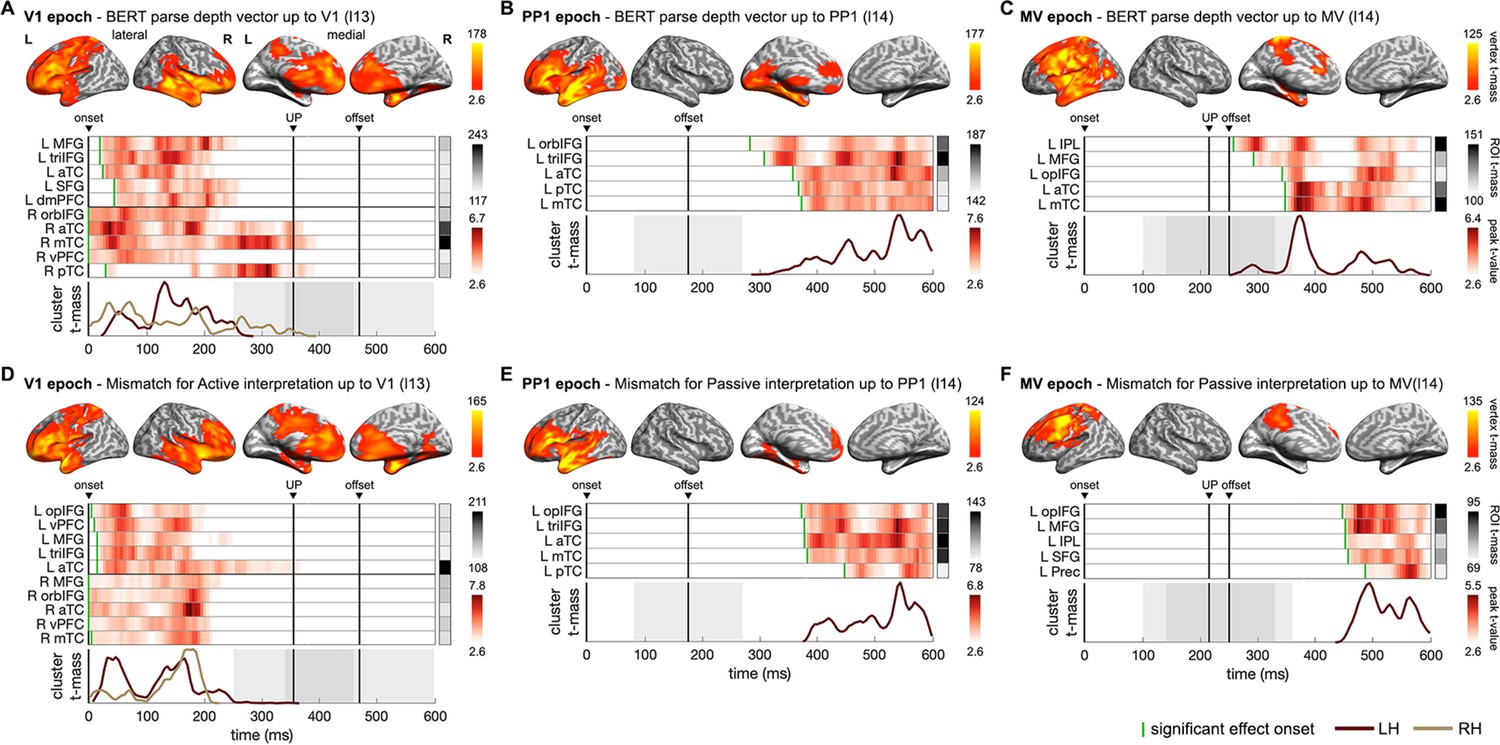
Neural dynamics underpinning the emerging structure and interpretation of an unfolding sentence.
(A–C) Spatiotemporal searchlight representational similarity analysis (ssRSA) results of BERT parse depth vector up to Verb1 (V1), the preposition (PP1), and the main verb (MV) in epochs separately time-locked to their onsets. (D–F) ssRSA results of the mismatch for the preferred structural interpretation (the specific BERT layer from which BERT structural measures were derived is denoted in parentheses). From top to bottom in each panel: vertex t-mass (each vertex’s summed t-value during its significant period); heatmap of time series of region of interest (ROI) peak t-value (the highest t-value in an ROI at each time point) with a green bar indicating effect onset and ROI t-mass (each ROI’s summed mean t-value during its significant period); cluster t-mass time series (summed t-value of all the significant vertices of a cluster at each time point) (cluster-based permutation test, vertex-wise p<0.01, cluster-wise p<0.05 in A–E; marginal significance in F with cluster-wise p=0.06). Solid vertical lines indicate the timings of onset, average uniqueness point (UP), and average offset of the word time-locked in the epoch with grey shades indicating the range of 1 SD. LH/RH: left/right hemisphere. See Supplementary file 2 for full anatomical labels. See Figure 6—figure supplement 1 for Spearman’s rho time series of ROIs in individual participants, and Figure 6—figure supplement 2 for the significant results of other BERT layers in the MV epoch.
Figure 6—figure supplement 1
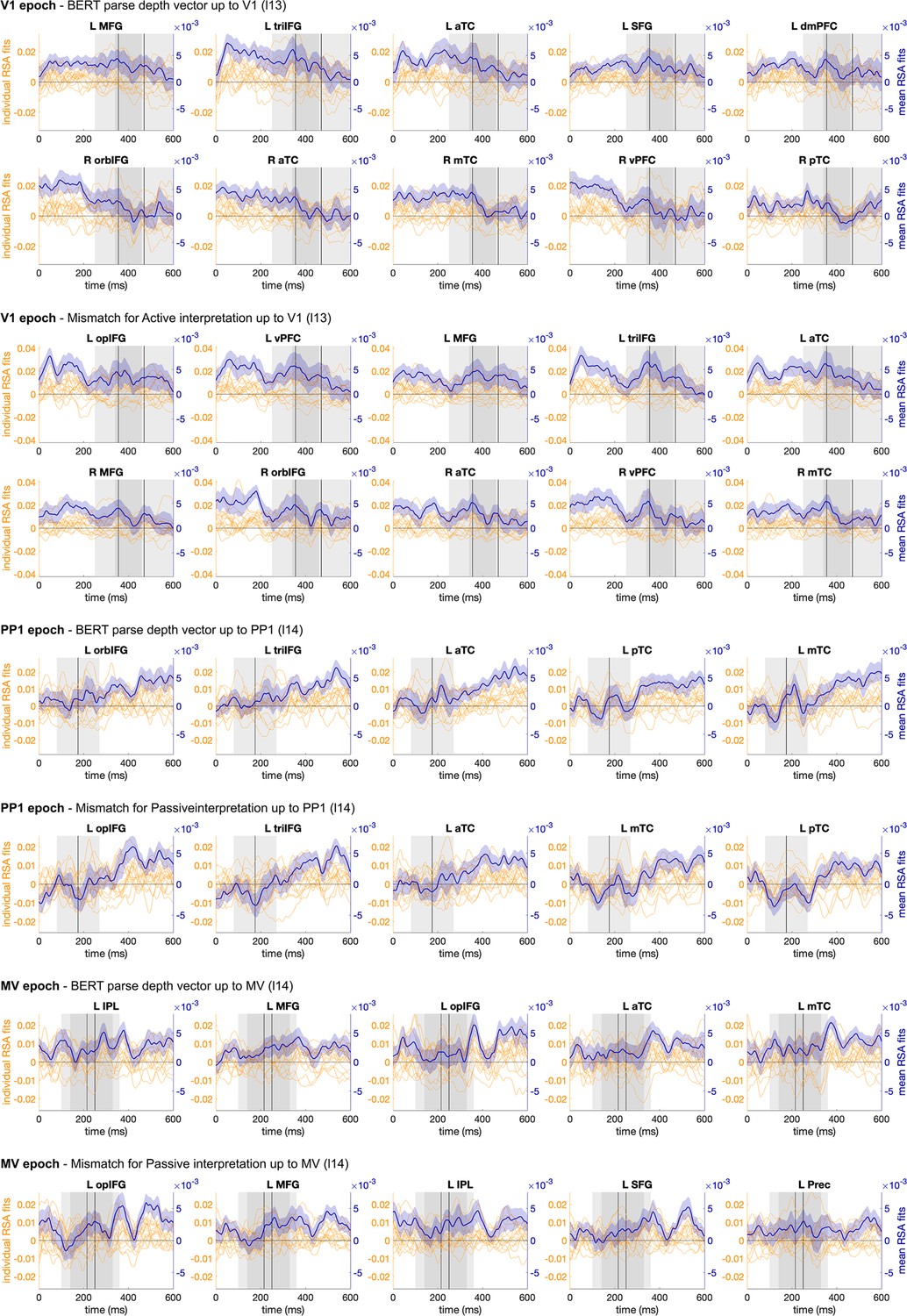
Spearman’s rho time series of ROIs across individual participants and their mean (with SEM) for BERT parse depth vector and its mismatch for active and passive interpretations in V1, PP1 and MV epochs.
V1: Verb1; PP1: preposition; MV: main verb.
Figure 6—figure supplement 2
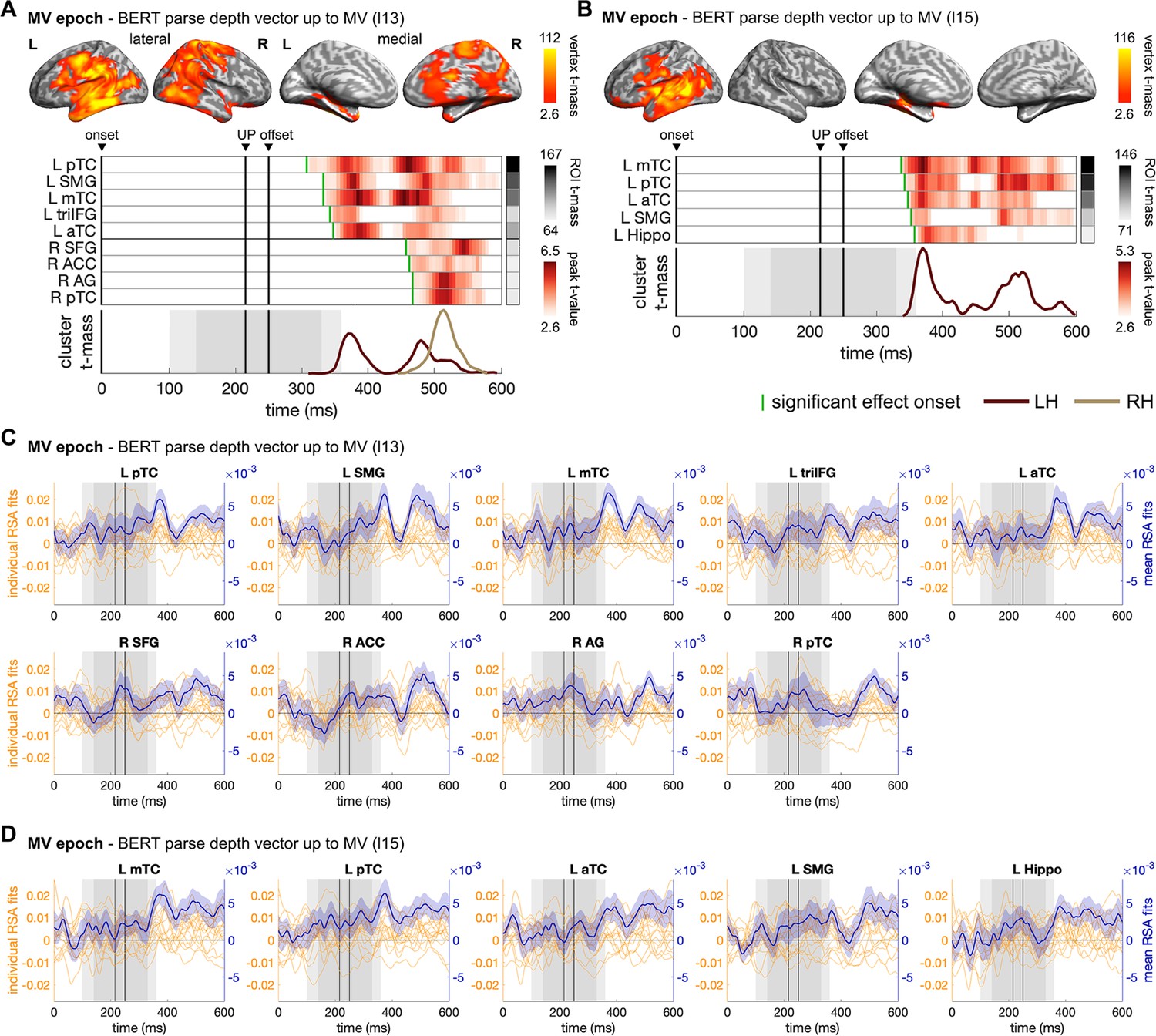
Spatiotemporal searchlight representational similarity analysis (ssRSA) results of BERT structural measures in the main verb (MV) epoch.
ssRSA results of BERT parse depth vector up to MV derived from (A) BERT layer 13 and (B) BERT layer 15 in MV epoch (cluster-based permutation test, vertex-wise p<0.01, cluster-wise p<0.05). The Spearman’s rho time series of ROIs across individual participants and their mean (with SEM) are shown in (C) and (D), respectively.
Figure 6—figure supplement 3
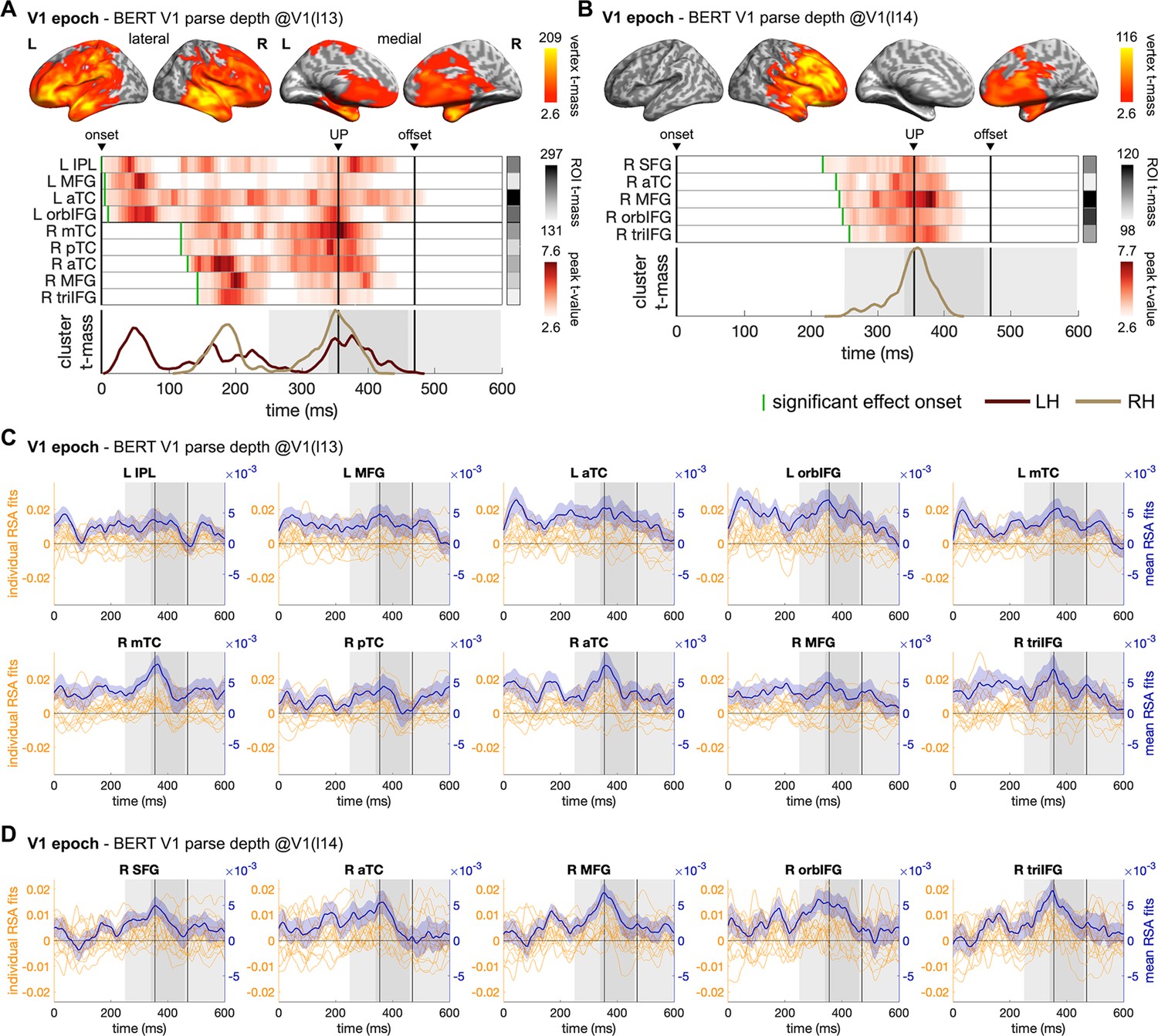
Spatiotemporal searchlight representational similarity analysis (ssRSA) results of BERT structural measures in the Verb1 (V1) epoch.
ssRSA results of BERT Verb1 parse depth derived from (A) BERT layer 13 and (B) BERT layer 14 in V1 epoch (cluster-based permutation test, vertex-wise p<0.01, cluster-wise p<0.05). From top to bottom in each panel: vertex t-mass (each vertex’s summed t-value during its significant period); time series of ROI peak t-value (the highest t-value in an ROI at each time point with a green bar indicating effect onset) and ROI t-mass (each ROI’s summed mean t-value during its significant period); cluster t-mass time series (summed t-value of all the significant vertices of a cluster at each time point). Solid vertical lines indicate the timings of onset, average uniqueness point (UP), and average offset of the word time-locked in the epoch with grey shades indicating the range of 1 SD. LH/RH: left/right hemisphere. The Spearman’s rho time series of ROIs across individual participants and their mean (with SEM) are shown in (C) and (D), respectively.
Figure 6—figure supplement 4
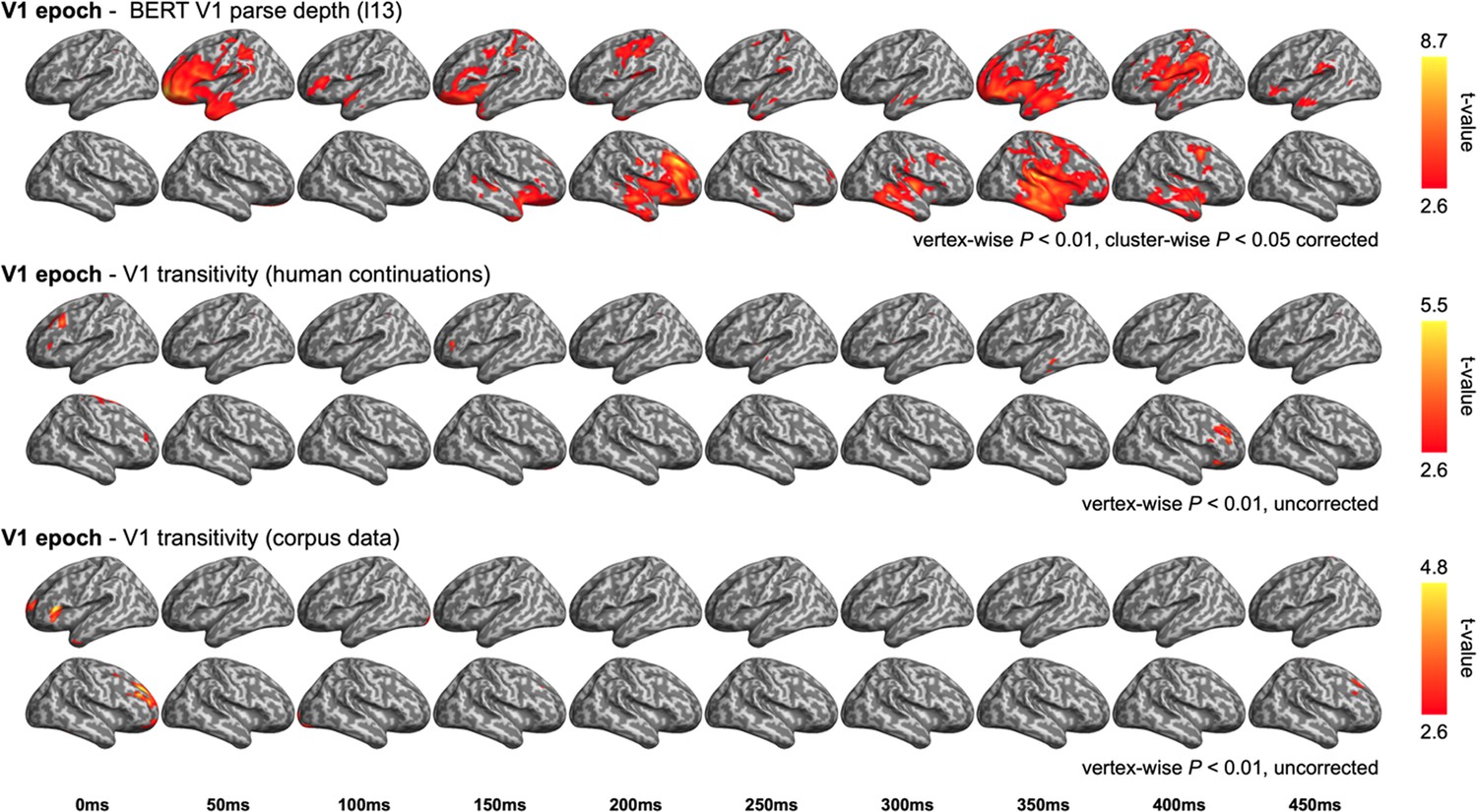
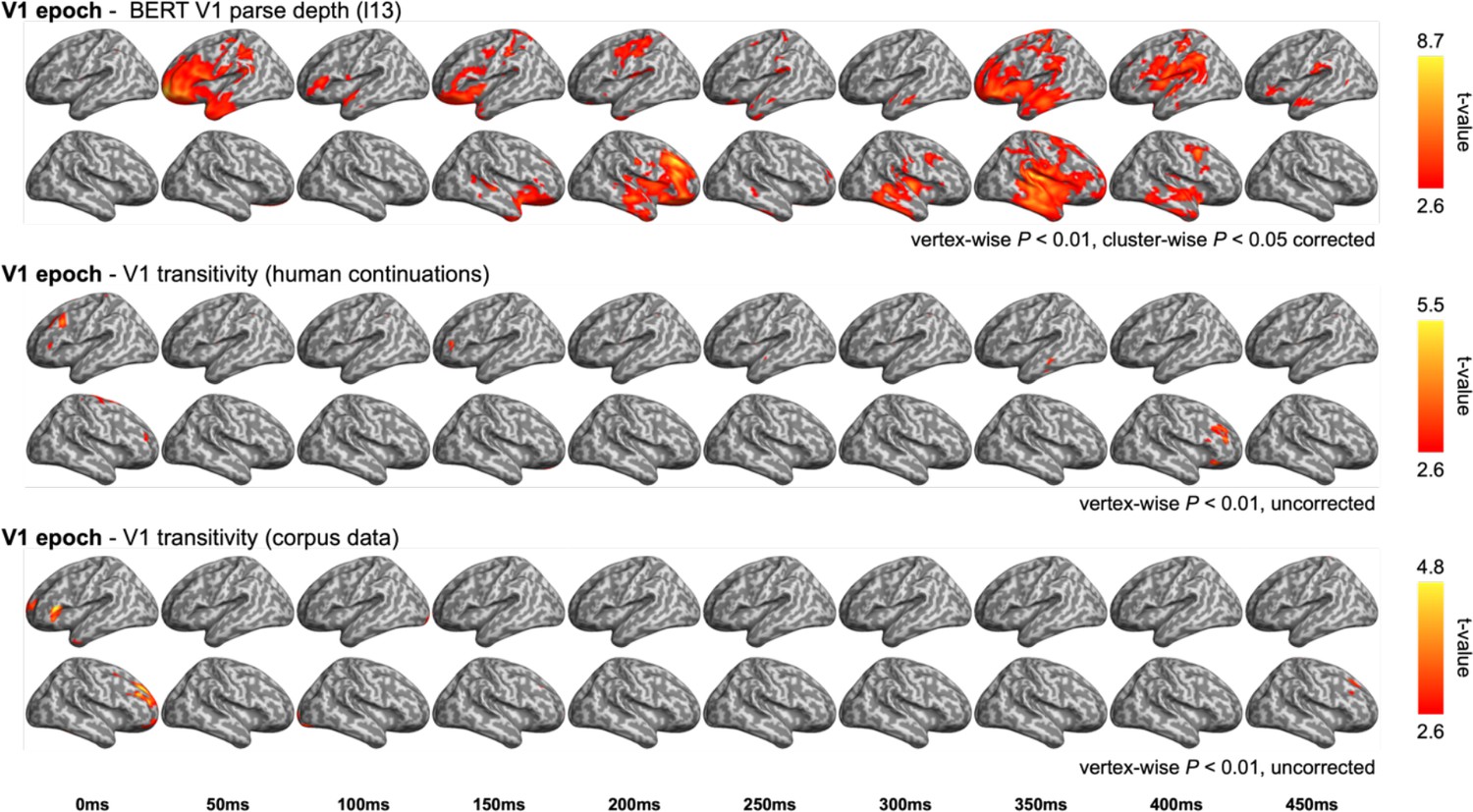
Comparison between the representational similarity analysis (RSA) model fits of BERT structural metrics and behaviour-/ corpus-based metrics in the Verb1 (V1) epoch.
Upper: model fits of BERT Verb1 parse depth (relevant to Figure 6—figure supplement 3A); middle: model fits of the first verb transitivity based on the continuation pre-rest conducted by the end of V1 (e.g. complete “The dog found …”); bottom: model fits of the Verb1 transitivity based on the same corpus data described in ‘Materials and methods’.
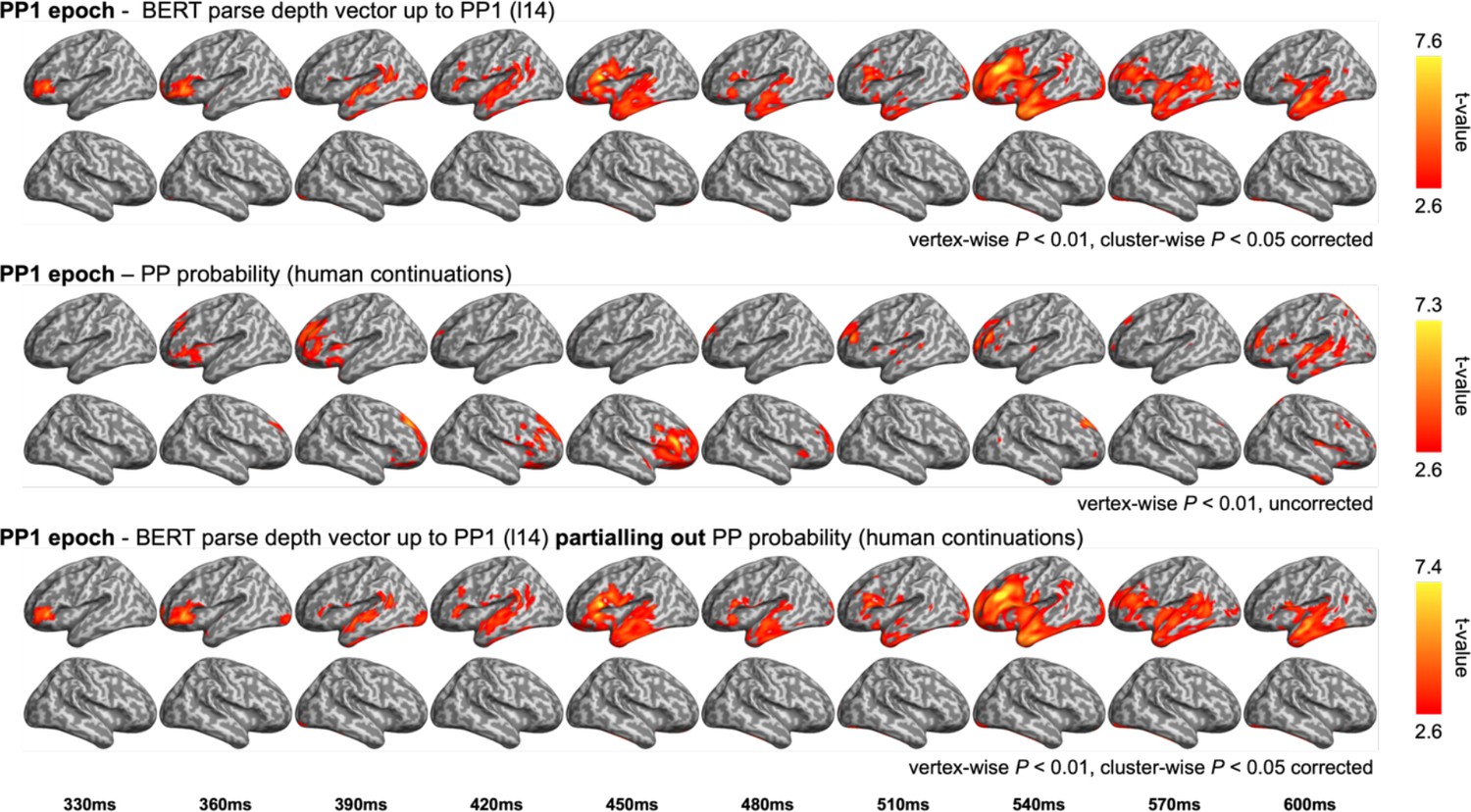
Figure 6—figure supplement 5
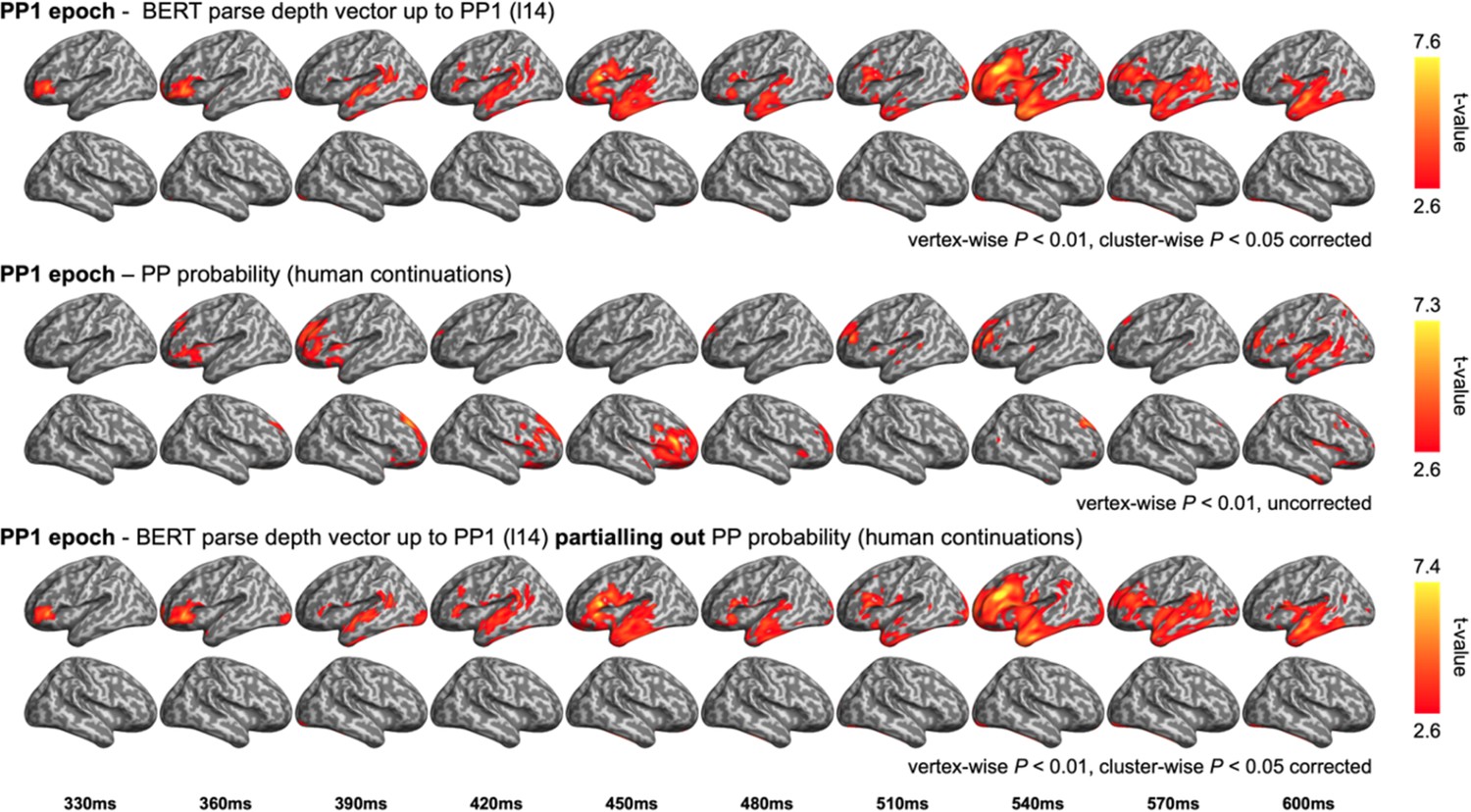
Comparison between the representational similarity analysis (RSA) model fits of BERT structural metrics and behaviour-/corpus-based metrics in the preposition (PP1) epoch.
Upper: model fits of BERT parse depth vector up to PP1; middle: model fits of the probability of a prepositional phrase (PP) continuation in the pre-rest conducted by the end of the first verb (e.g. complete “The dog found …”); bottom: model fits of BERT parse depth vector up to PP1 while partialling out the variance explained by PP probability.
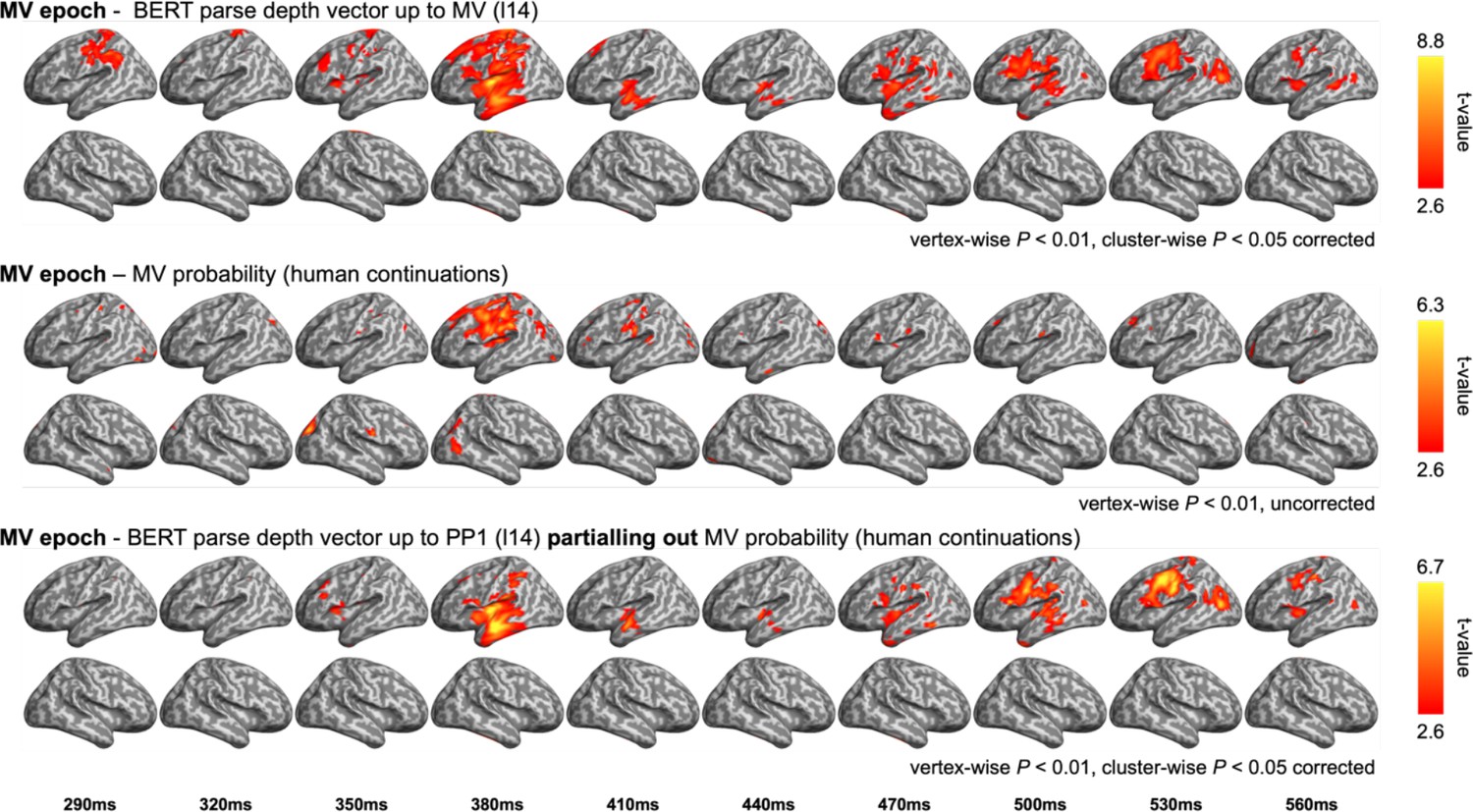
Figure 6—figure supplement 6
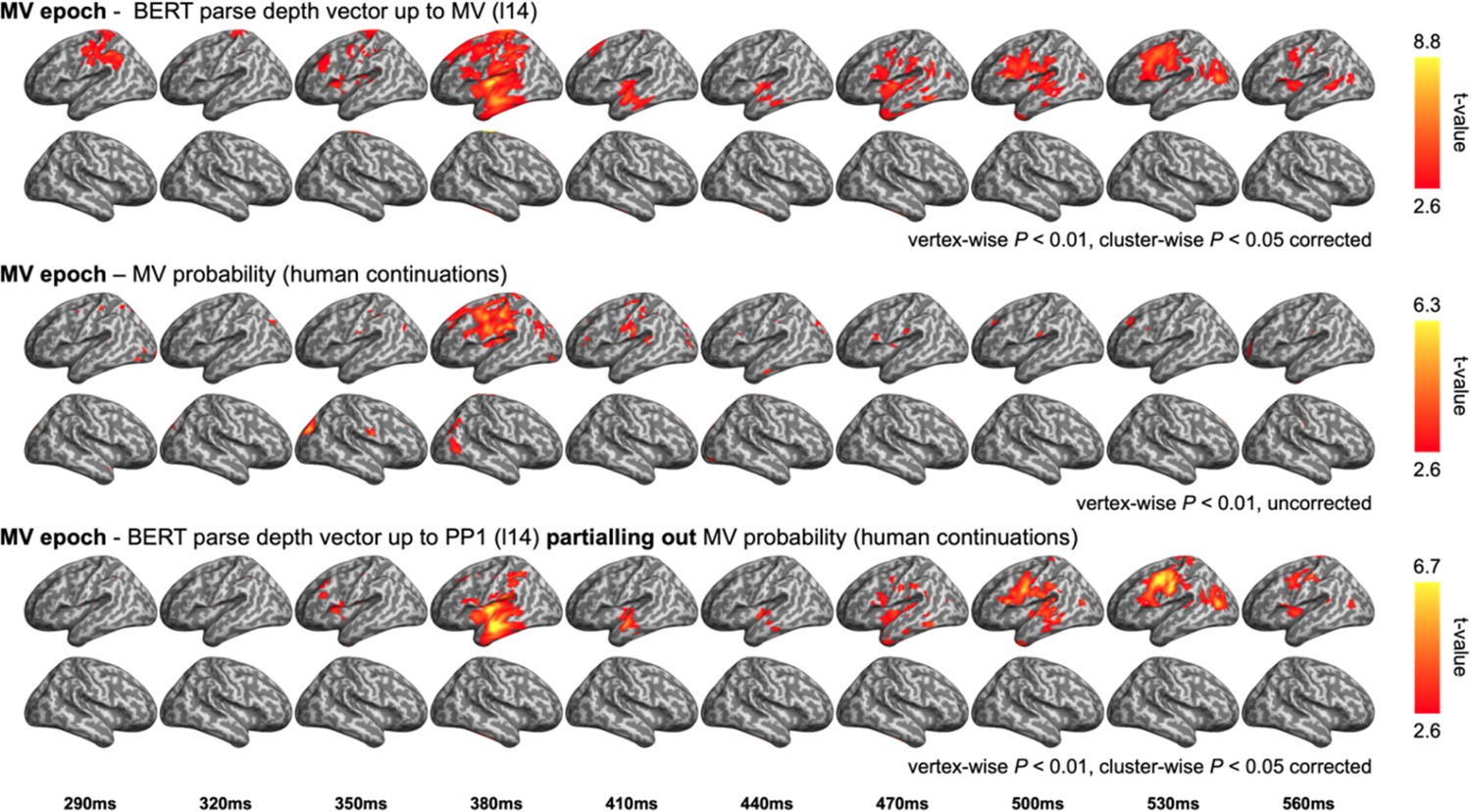
Comparison between the representational similarity analysis (RSA) model fits of BERT structural metrics and behaviour-/ corpus-based metrics in the main verb (MV) epoch.
Upper: model fits of BERT parse depth vector up to MV; middle: model fits of the probability of an MV continuation in the pre-rest conducted by the end of the prepositional phrase (e.g. “The dog found in the park …”); bottom: model fits of BERT parse depth vector up to MV while partialling out the variance explained by MV probability.
Figure 7 with 2 supplements

Neural dynamics updating the incremental structural interpretation.
(A) Spatiotemporal searchlight representational similarity analysis (ssRSA) results of BERT Verb1 (V1) parse depth change at the main verb (MV) relative to the parse depth of V1 when it is first encountered. (B) ssRSA results of the updated BERT V1 parse depth when the input sentence reaches the MV. (C) Spatiotemporal overlap between the effects in (A) and (B). (cluster-based permutation test, vertex-wise p<0.01, cluster-wise p<0.05). See Figure 7—figure supplement 2 for Spearman’s rho time series of ROIs in individual participants.
Figure 7—figure supplement 1
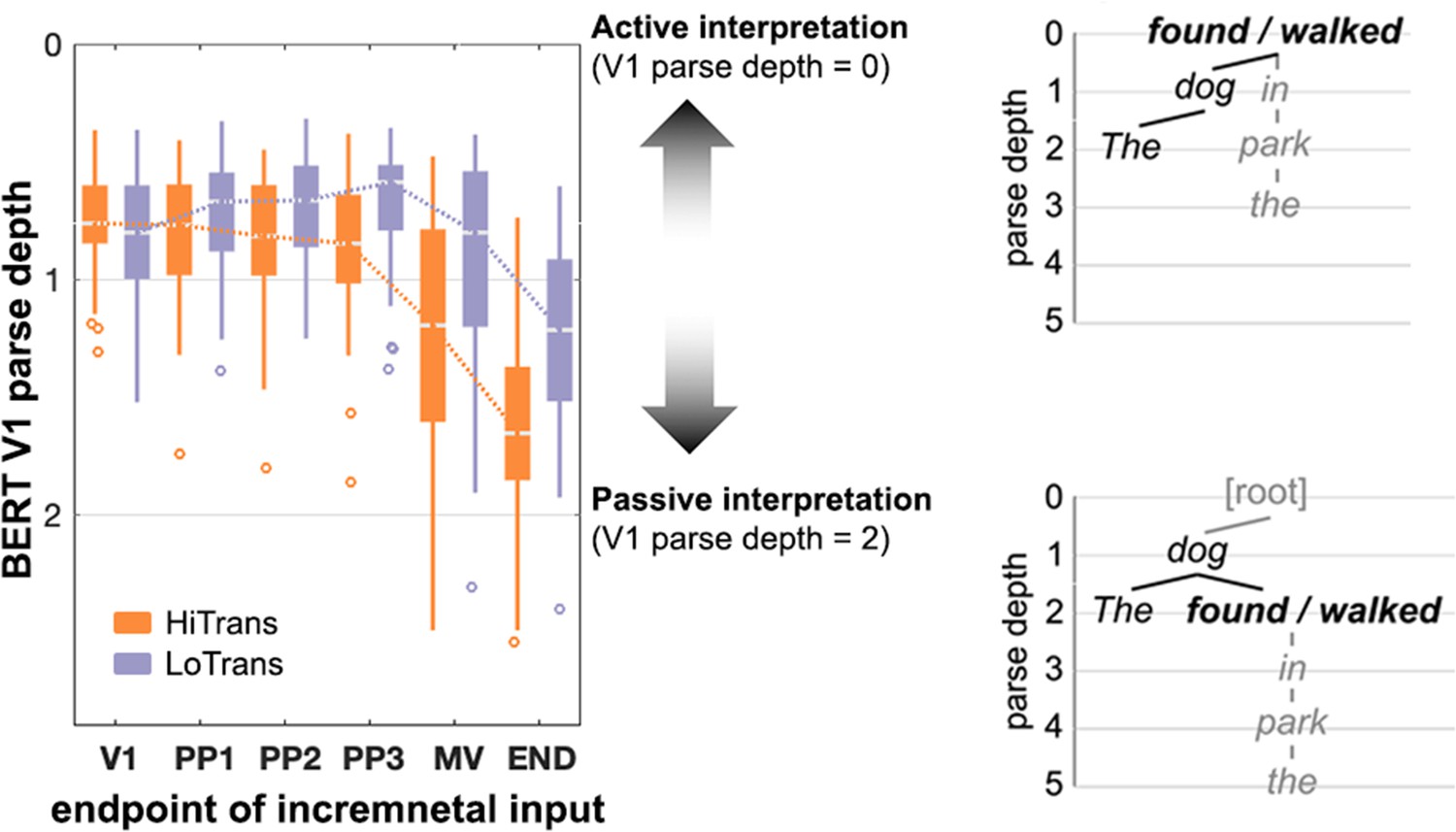
The dynamic change of BERT Verb1 (V1) parse depth in unfolding sentences.
BERT parse depth of Verb1 was updated every time an incoming later word was added in the incremental sentence input. In the context-free dependency parse tree (right panel), Verb1 parse depth is 2 for a passive interpretation and is 0 for an active interpretation. Therefore, the dynamically increasing or decreasing BERT Verb1 parse depth in an unfolding sentence reflected the preference biased towards a passive or an active interpretation separately (left panel). In terms of the group-level effect indicated the median value, BERT Verb1 parse depth in HiTrans sentences unidirectionally increased towards the passive interpretation after Verb1 (i.e. a parse depth of 2), whereas that in LoTrans sentences initially tended to decrease and approached a depth of 0 but increased with the appearance of the actual main verb, suggesting a reorientated preference for the passive interpretation instead of the initial active interpretation. The results above were obtained from the structural probing model trained on BERT layer 14. HiTrans: high Verb1 transitivity sentences; LoTrans: low Verb1 transitivity sentences; Det: determiner; SN: subject noun; PP1–PP3: prepositional phrase; MV: main verb; END: end of the sentence.
Figure 7—figure supplement 2
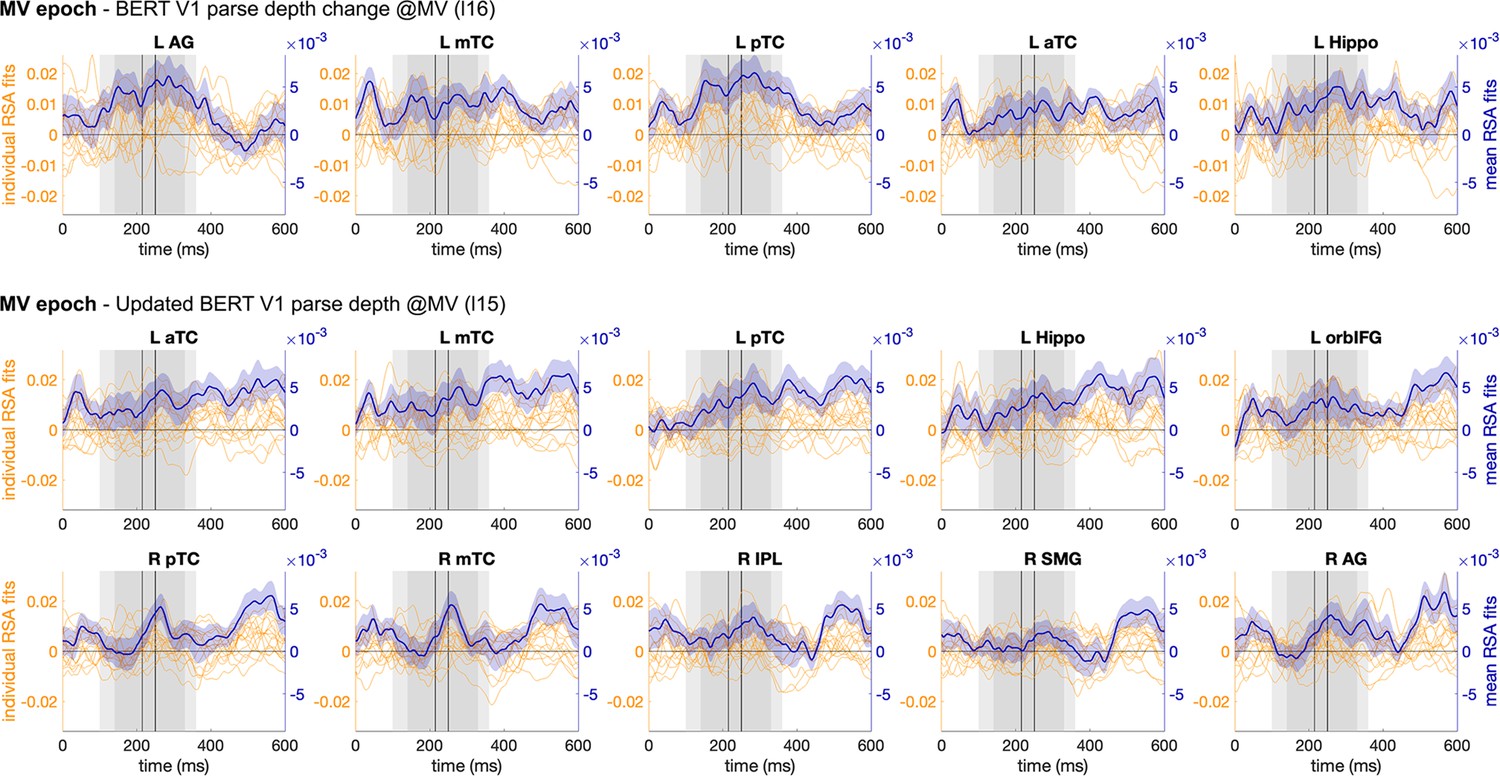
Spearman’s rho time series of ROIs across individual participants and their mean (with SEM) for BERT V1 parse depth change and the updated BERT V1 parse depth in the MV epoch.
V1: Verb1; MV: main verb.
Figure 8 with 3 supplements
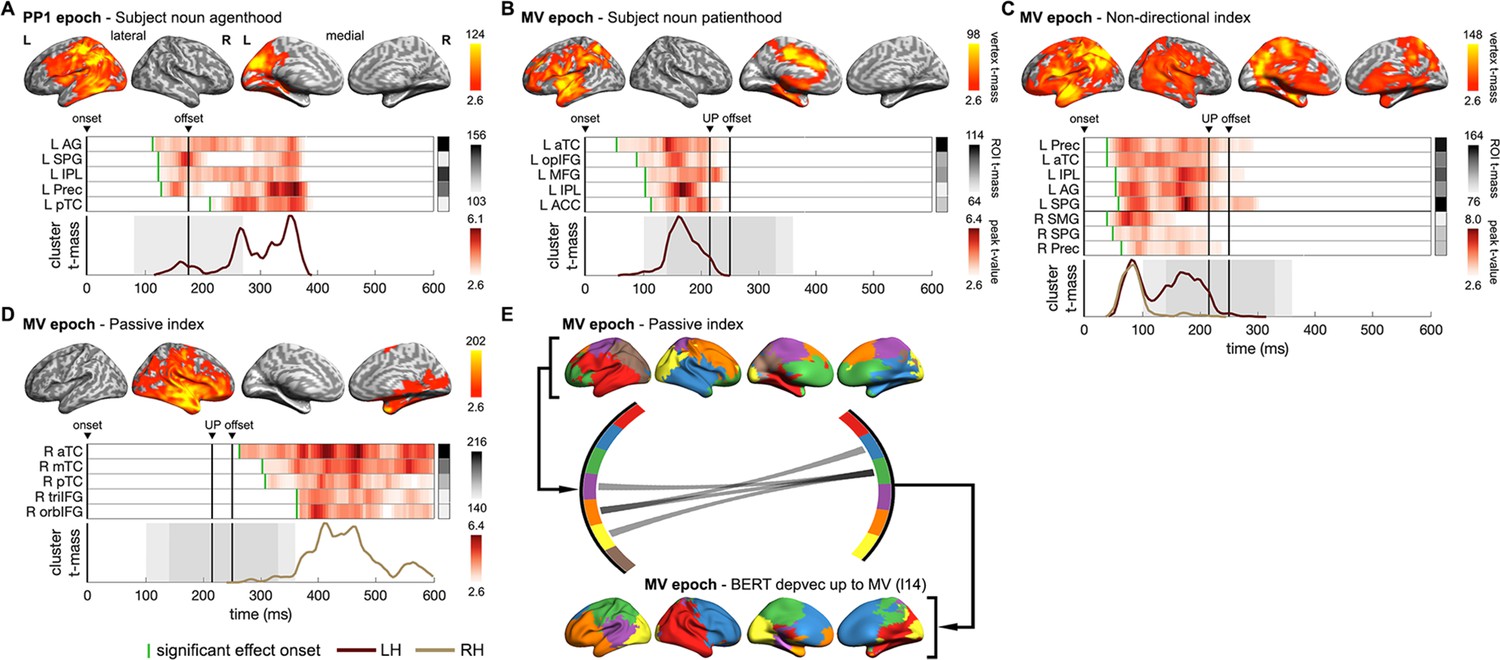
Neural dynamics of multifaceted probabilistic constraints underpinning incremental structural interpretations.
(A, B) Spatiotemporal searchlight representational similarity analysis (ssRSA) results of subject noun (SN) agenthood and SN patienthood (i.e. plausibility of SN being the agent or the patient of Verb1 [V1]) in PP1 and main verb (MV) epochs separately. (C) ssRSA results of non-directional index (i.e. interpretative coherence between SN and V1 regardless of the structure preferred) in MV epoch. (D) ssRSA results of passive index (i.e. interpretative coherence for the passive interpretation) in MV epoch. (E) Influence of the passive interpretative coherence on the emerging sentential structure in MV epoch revealed by the Granger causal analysis (GCA) based on the non-negative matrix factorization (NMF) components of whole-brain ssRSA results (see Figure 8—figure supplement 1 for more details). (A–D) Cluster-based permutation test, vertex-wise p<0.01, cluster-wise p<0.05; (E) permutation test PFDR<0.05. See Figure 8—figure supplement 2 for Spearman’s rho time series of ROIs in individual participants.
Figure 8—figure supplement 1
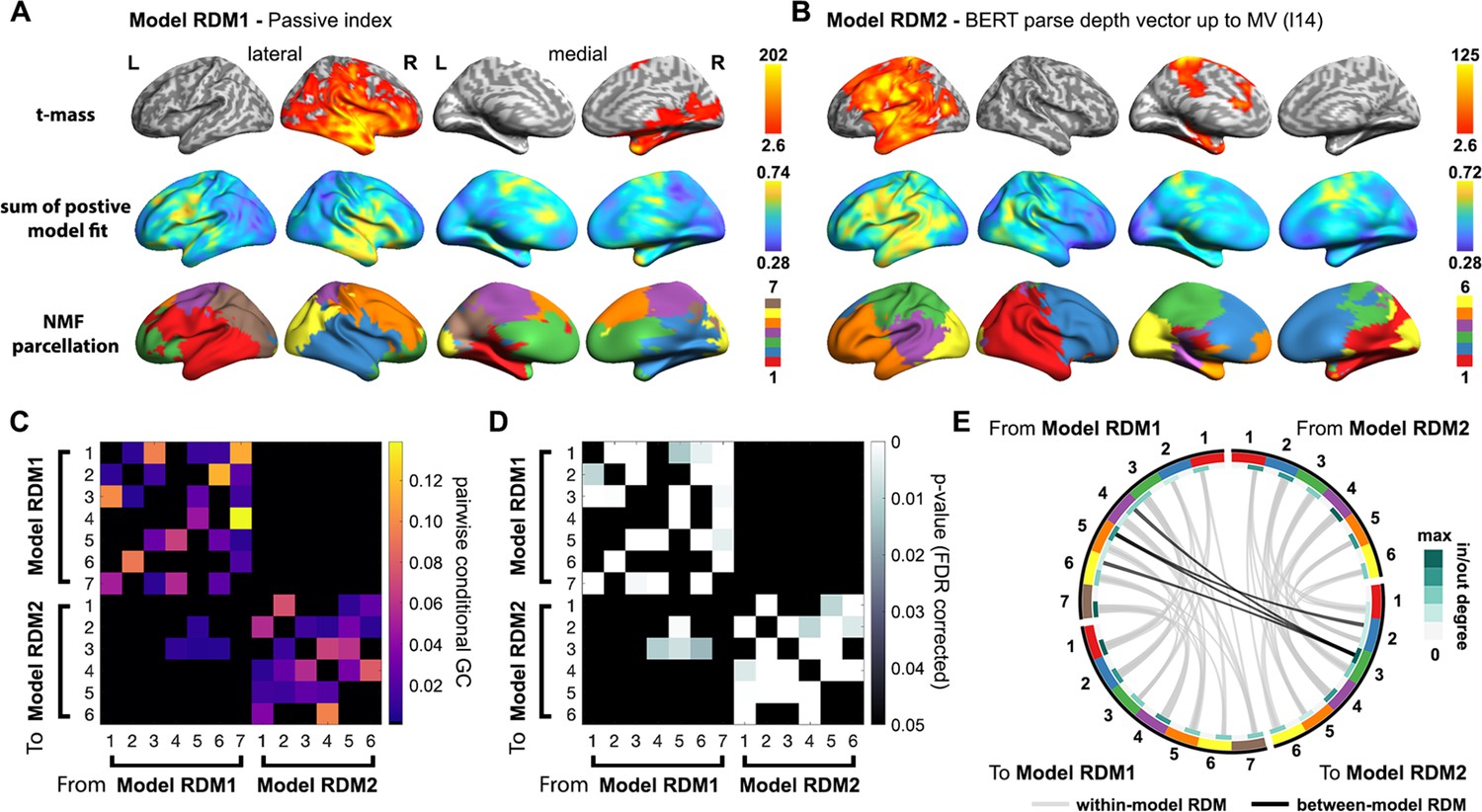
Directional relationship between multifaceted constraints and structured interpretation in the brain.
Non-negative matrix factorization (NMF) was applied to the whole-brain spatiotemporal searchlight representational similarity analysis (ssRSA) models fits of passive index and BERT parse depth vector up to the main verb (MV) from layer 14 in the MV epoch separately. Multivariate Granger causality analysis (GCA) was conducted based on time series of the NMF factors of the two model representational dissimilarity matrices (RDMs). Vertex-wise results of ssRSA and NMF parcellation of (A) passive index and (B) BERT parse depth vector up to MV: (from top to bottom) each vertex’s summed t-value during its significant period, sum of uncorrected positive model fit averaged across participants, NMF parcellation results illustrated by assigning each vertex to the NMF factor with the highest loading value. (C) Pair-wise conditional GC and (D) corresponding p-values obtained from multivariate GCA based on the two sets of NMF factors (FDR-corrected p<0.05). (E) Circos plot of significant GC connections between model RDMs in (C) and (D).
Figure 8—figure supplement 2
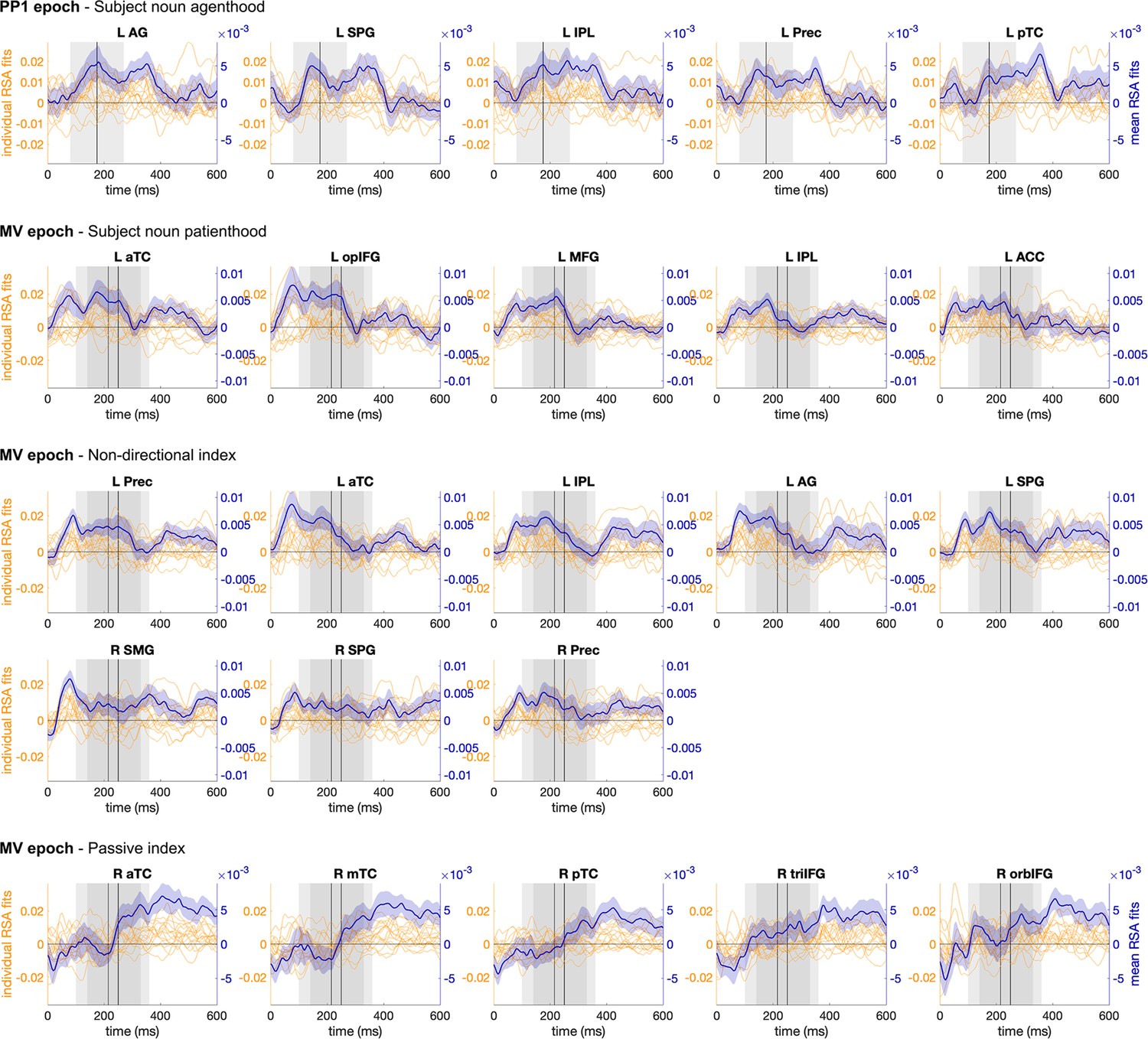
Spearman’s rho time-series of ROIs across individual participants and their mean (with SEM) for corpus-based measures in PP1 and MV epochs.
PP1: preposition, MV: main verb.
Figure 8—figure supplement 3
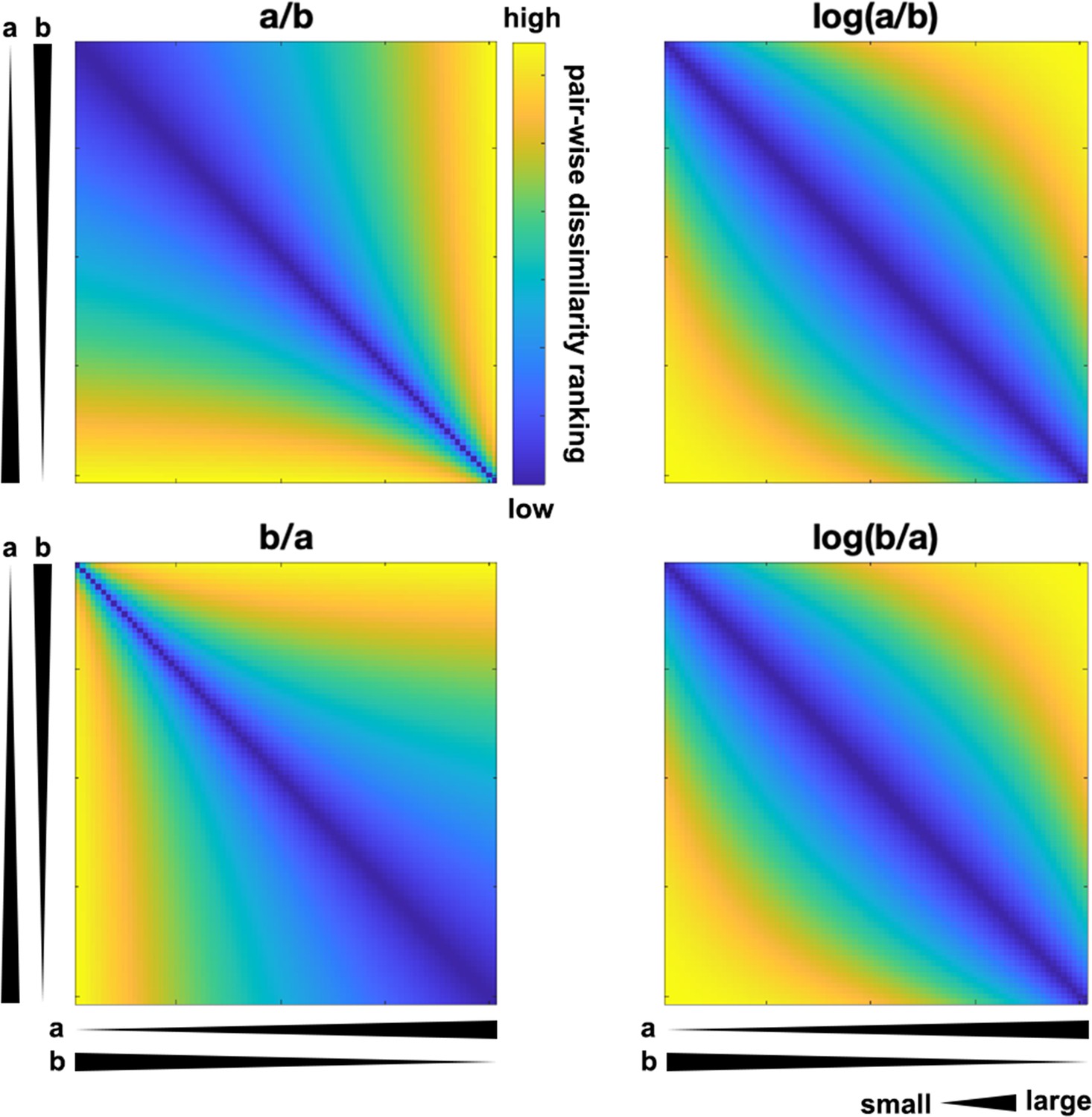
Illustration of directionality of dissimilarity geometry in the representational dissimilarity matrix (RDM) based on a ratio measure.
Suppose that variable a ranges from 0.1 to 0.9, and there are 81 items evenly sampled with an increment of 0.01 from a, while variable b equals 1 - a. Items are sorted by their values as indicated by the black wedges corresponding to a and b (ascending order for a, descending for b from top to bottom, from left to right). RDMs are built by calculating the absolute pair-wise difference of a/b, b/a (left) and their logarithmic transformation counterparts log(a/b) and log(b/a) (right). RDMs of a/b or b/a are directional in the sense that they distinguish items with large values for the numerator from the other items in the dissimilarity geometry (i.e. the contrast between the bright yellow [larger dissimilarity] and dark blue [smaller dissimilarity] areas in the RDM). However, such directionality is removed once the logarithmic transformation is applied, given that |log(a) - log(b)| is the same as |log(b) - log(a)|.
Author response image 1
Author response image 2
Author response image 3
Tables
Author response table 1
| HiTrans sentences | LoTrans sentences | |
|---|---|---|
| DO | 0.89±0.16 | 0.33±0.34 |
| PP | 0.04±0.08 | 0.39±0.29 |
| INTRANS | 0.02±0.05 | 0.21±0.24 |
| INF | 0.01±0.04 | 0.02±0.06 |
| SC | SC 0.00±0.01 | 0.00±0.02 |
| OTHER | 0.04±0.08 | 0.06±0.12 |
Author response table 2
| HiTrans sentences | LoTrans sentences | |
|---|---|---|
| MV | 0.66±0.19 | 0.12±0.15 |
| END | 0.05±0.07 | 0.26±0.11 |
| PP | 0.04±0.05 | 0.19±0.12 |
| INF | 0.01±0.03 | 0.07±0.11 |
| CONJ | 0.03±0.05 | 0.12±0.10 |
| ADV | 0.01±0.03 | 0.08±0.10 |
| OTHER | 0.20±0.13 | 0.16±0.09 |
Author response table 3
| Adjusted r2(corpora) | Adjusted r2(BERT) | F-statistic for model comparison | |
|---|---|---|---|
| DO probability | 0.28 | 0.06 | F(1,115)=35.68, P=2.66 x 10–8 |
| PP probability | 0.18 | –0.01 | F(1,115)=28.62, P=4.54 x 10–7 |
| MV probability | 0.12 | 0.44 | F(2,113)=33.21, P=4.51 x 10–12 |
Additional files
-
MDAR checklist
- https://cdn.elifesciences.org/articles/89311/elife-89311-mdarchecklist1-v1.pdf
-
Supplementary file 1
Summary of all quantitative measures used to create model RDMs.
- https://cdn.elifesciences.org/articles/89311/elife-89311-supp1-v1.xlsx
-
Supplementary file 2
Full anatomical labels of ROI abbreviations in ssRSA results.
- https://cdn.elifesciences.org/articles/89311/elife-89311-supp2-v1.xlsx
-
Supplementary file 3
Example stimuli sentence set presented to both BERT and human listeners.
- https://cdn.elifesciences.org/articles/89311/elife-89311-supp3-v1.xlsx
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Finding structure during incremental speech comprehension
eLife 12:RP89311.
https://doi.org/10.7554/eLife.89311.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}