Modeling collective behavior in groups of mice housed under semi-naturalistic conditions
- Laboratoire de physique de l’École normale supérieure, CNRS, PSL University, Sorbonne Université, Université Paris Cité, France
- Center of Excellence for Neural Plasticity and Brain Disorders, BRAINCITY, a Nencki-EMBL Partnership, Nencki Institute of Experimental Biology of Polish Academy of Sciences, Poland
Figures
Figure 1 with 1 supplement
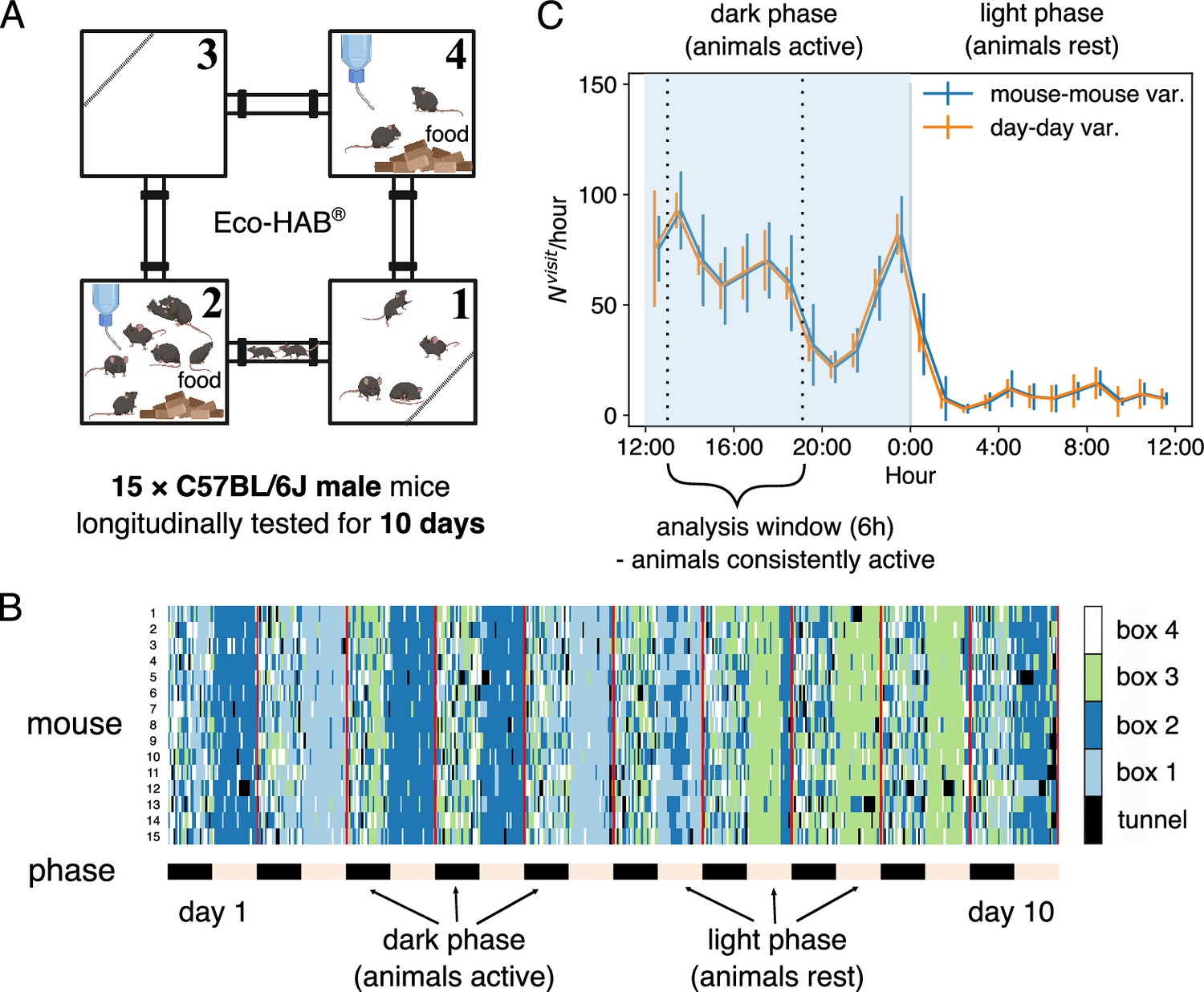
Mice were tested in Eco-HAB, a system for automated, ecologically relevant assessment of voluntary behavior in groups of mice.
Animals were tested for 10 days. (A) Schematic of the Eco-HAB system, where four compartments are connected with tunnels. Food and water are available ad libitum in compartments 2 and 4. (B) Time series of the location of 15 mice over 10 days, as aligned to the daylight cycle. (C) Circadian clock affects the activity of the mice, measured by the number of transitions in each hour averaged over the 15 mice and the 10 days. Error bars represent SD across all mice (mouse-mouse variability, in blue) or across all days for the mean activity level for all mice (day–day variability, in orange). The two curves are slightly shifted horizontally for clearer visualization. We focus the following analysis on the data collected during the first half of the dark phase, between 13:00 and 19:00 (shaded region).
Figure 1—figure supplement 1
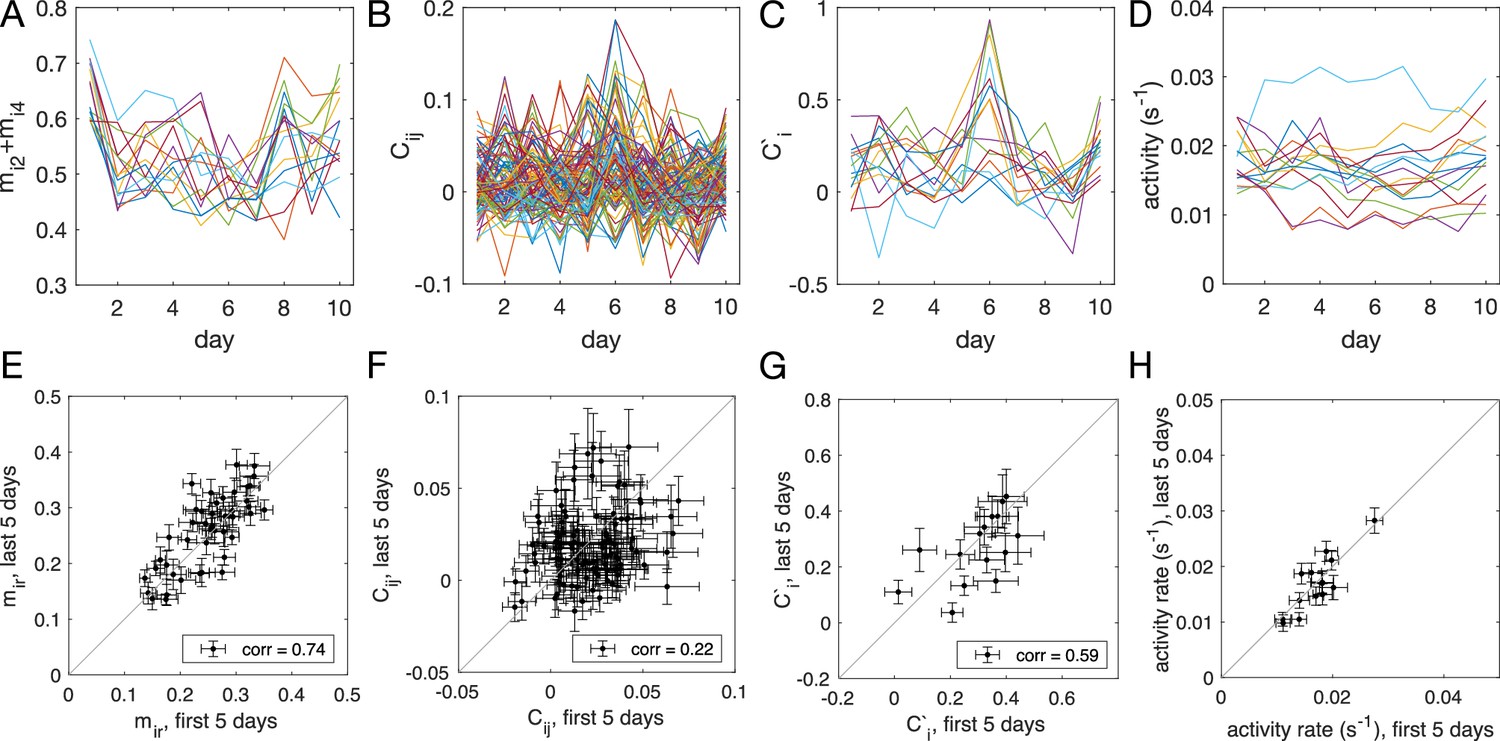
Stability of the data, given by the time evolution across 10 days of the experiment and the scatter plot between the observables measured using the first 5 days of the data versus the last 5 days of the data for cohort M1 ().
The observables plotted include (A, E) , probability of mouse being found in compartment , (B, F) , the (connected) pairwise correlation, or the in-cohort sociability, between mouse and mouse , (C, G) the sum of observed in-cohort sociability, which gives a proxy for how mouse is effected by the social interaction, and (D, H) the activity rate, measured by the number of transition event per second. The error bars in panels (E–H) are extrapolated from random halves of the data.
Figure 2 with 8 supplements
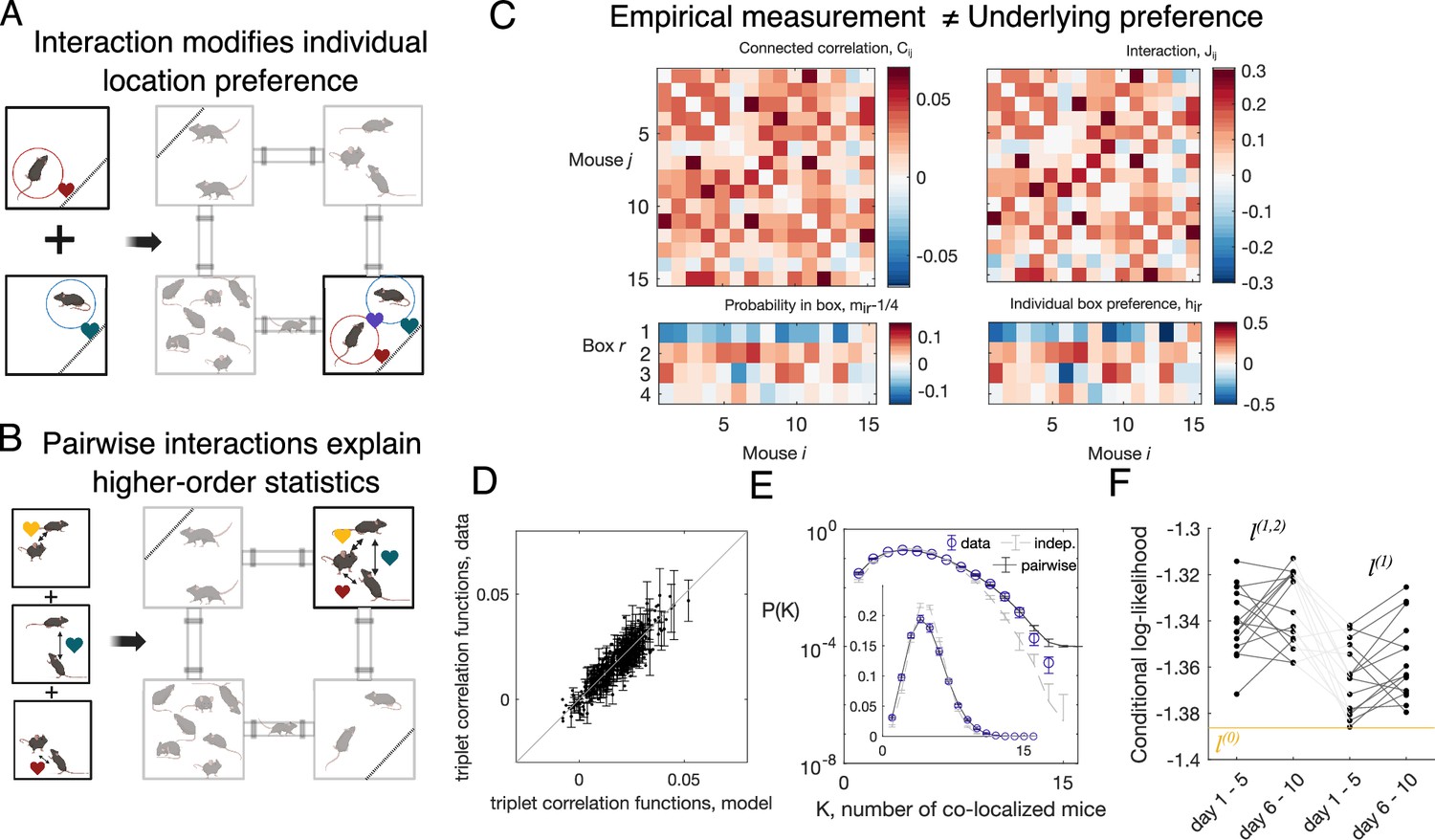
Mice in Eco-HAB interact pairwisely.
(A, B) The schematics showing pairwise interactions: two mice are more likely to be found in the same compartment than the sum of their individual preference implies (A); also, the probability for three mice being in the same compartment can be predicted from the pairwise interactions (B). (C) From pairwise correlation , defined as the probability for mouse and mouse being in the same compartment (subtracted by the prediction of the independent model), and the probability for mouse to be found in compartment (subtracted by the model where each mouse spends equal amount of time in each of the four compartments), , pairwise maximum entropy model learns the interaction strength between a pair of mice, , and the local field , which gives the tendency for each mouse in each compartment. The data shown is the aggregated 5-day data from day 1 to day 5 of the C57BL/6J males (cohort M1, ). The pairwise maximum entropy model can predict higher-order statistical structures of the data (schematics in B), such as the probability for triplets of mice being in the same compartment (subtracted by the prediction of the independent model, mathematically ) (D), and the probability of mice being found in the same compartment (E). Error bars in (D) and (E) are extrapolated from random halves of the data (see ‘Materials and methods’ for details). (F) Conditional log-likelihood of mouse locations, predicted by the pairwise model (), the independent model (), and the null model assuming no compartment preference or interactions (, the yellow line), for each mice.
Figure 2—figure supplement 1

The pairwise maximum entropy model reproduces the probability for each mouse in each compartment, , and the probability for pairs of mice in the same compartment, , as given by the data.
Error bars are extrapolated from random halves of the data.
Figure 2—figure supplement 2

Learned parameters in the pairwise interaction model versus the observed statistics, plotted for the 5-day aggregate data from the first 5 days of the experiment on male cohort M1 before TIMP-1 treatment.
(A) The inferred interaction versus the connected correlation ; (B) the inferred individual compartment preference versus the in-compartment probability for each mouse - 1/4.
Figure 2—figure supplement 3

The probability of mice found in the same compartment, predicted by the pairwise maximum entropy model, the independent model, and computed from the 5-day aggregate data for the first 5 days in male cohort M1 before TIMP-1 treatment ().
The subpanels are arranged in the same order as in the Eco-HAB setup. Error bars for the experiment are extrapolated from 50 random halves of the data, for the independent is generated by 50 random cyclic shuffling of the data, and for the pairwise model is from 50 random MCMC samplings (each with 54,000 realizations, the same number of data points as the data) for the pairwise model.
Figure 2—figure supplement 4
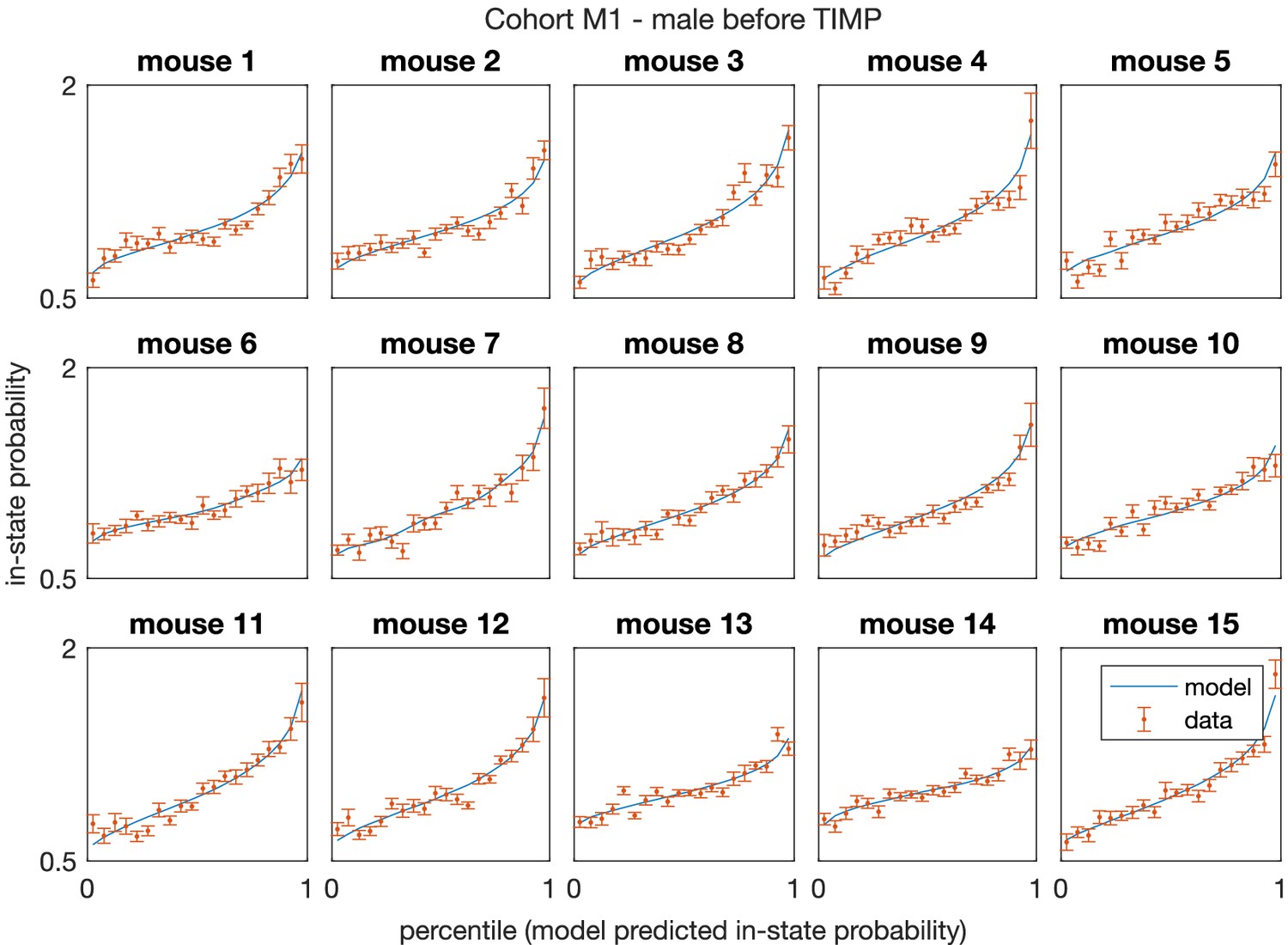
Model-predicted in-state probability matches data observation for the aggregate data of first 5 days of experiment in mice cohort M1 – C57BL/6J male mice (), which shows the prediction of the inferred pairwise model is unbiased.
Error bars are extrapolated from 20 draws of random halves of the data.
Figure 2—figure supplement 5

Cross-validation for maximum entropy models with triplet interactions and models with pairwise interactions on combined 10-day data (cohort M1, ).
For the triplet model, L2 regularization is applied only to the triplet interactions. For the pairwise model, L2 regularization is applied only to the pairwise interactions. Error bars are standard error from the mean across six different training-test set partitions, each containing 1 hour of data as test set and 5 hours of data as training set. The maximum of test-set log likelihood is achieved when the regularization strength is large in the triplet model, and when the regularization strength is small in the pairwise model, indicating that the triplet model overfits for the data pulled from all 10 days.
Figure 2—figure supplement 6
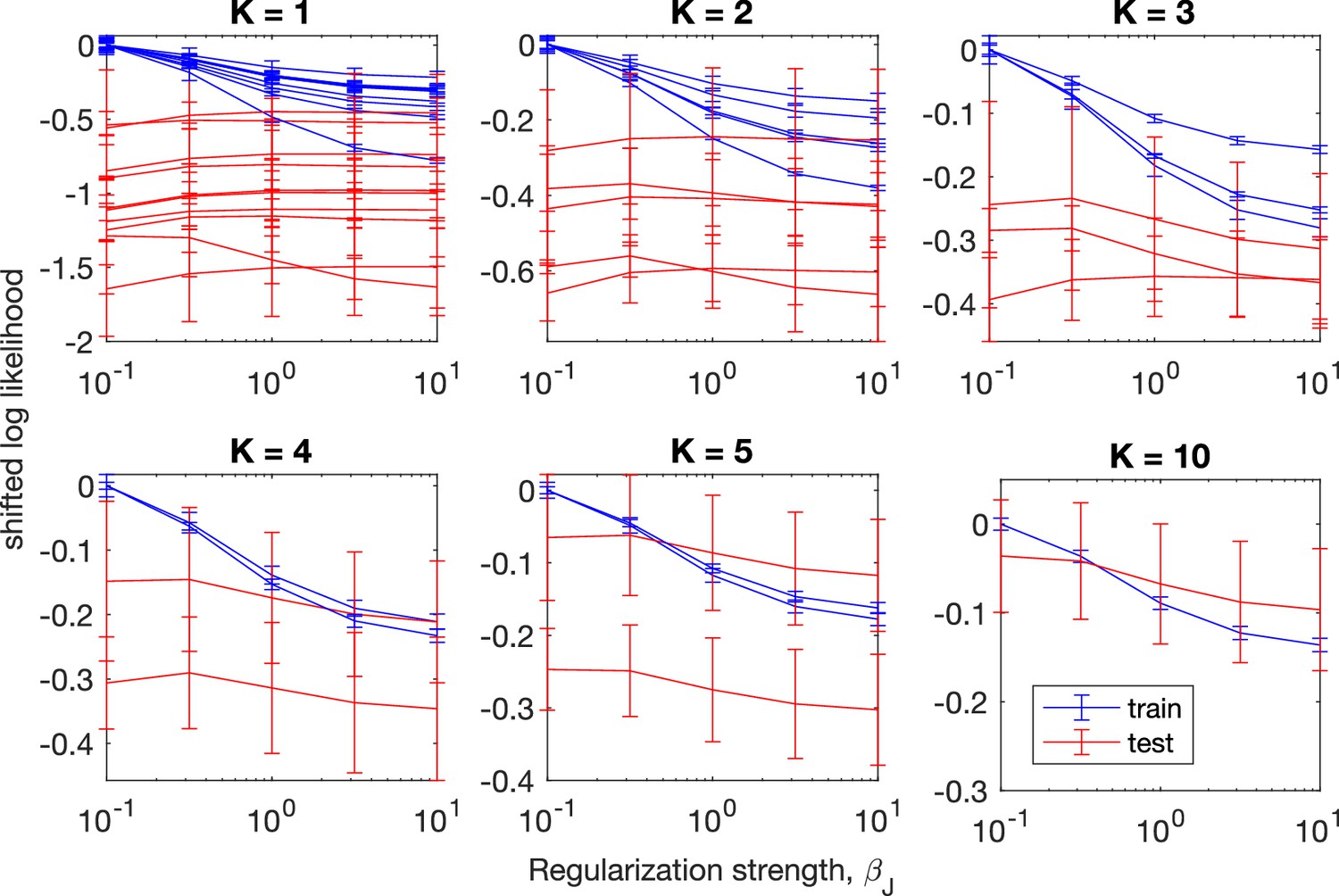
Cross-validation for maximum entropy models with pairwise interactions on combined data from a total of days (cohort M1, ).
The plotted log-likelihoods are shifted by the training-set log likelihood at L2 regularization strength . The L2 regularization strength is applied only to the pairwise interactions. Error bars are standard error from the mean across six different training-test set partitions, each containing 1 hour of data as test set and 5 hours of data as training set. For , the test-set likelihood increases as the regularization strength increases, indicating that the pairwise maximum entropy model overfits if we only consider data from each day; while for , the test-set likelihood decreases as the regularization parameter increases, indicating no overfitting.
Figure 2—figure supplement 7
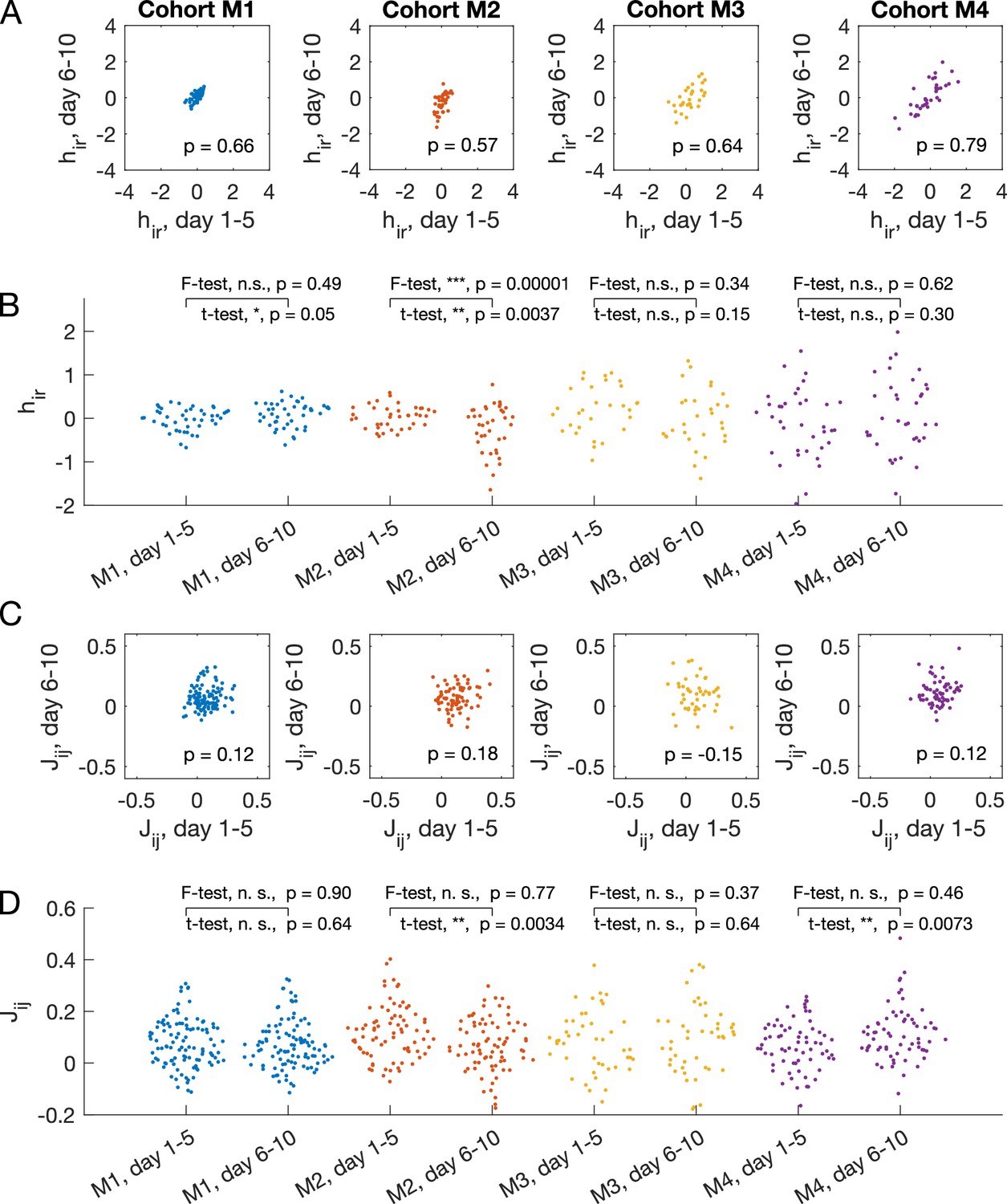
Temporal consistency of inferred parameters from 5-day accumulated data for mice cohorts M1 (), M2 (), M3 (), M4().
(A) Chamber preference for each mouse in each box, , between models learned from the accumulated data from days 1–5, compared to the model learned from accumulated data from days 6–10. The Pearson’s correlation coefficient is shown on the plot. (B) Swarm plot for inferred pairwise interactions for each cohort from the first 5 days and the last 5 days. Two-sided t-test for equal mean and two-sided F-test for equal variance are performed. The asterisks encode the following p-values: . (C) and (D) are the same as (A) and (B) for the pairwise interaction between mouse and mouse , .
Figure 2—figure supplement 8
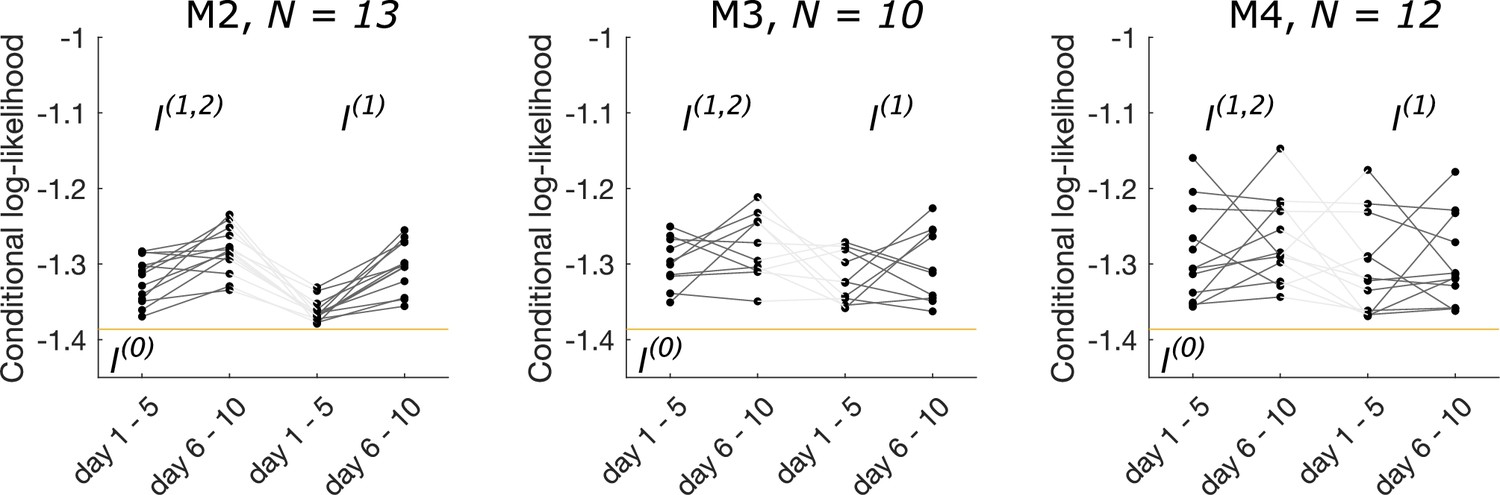
The conditional log likelihood is different for each cohort of C57BL/6J male mice in cohort M2, in cohort M3, and in cohort M4 (before BSA injection), exhibiting individuality.
Figure 3 with 2 supplements
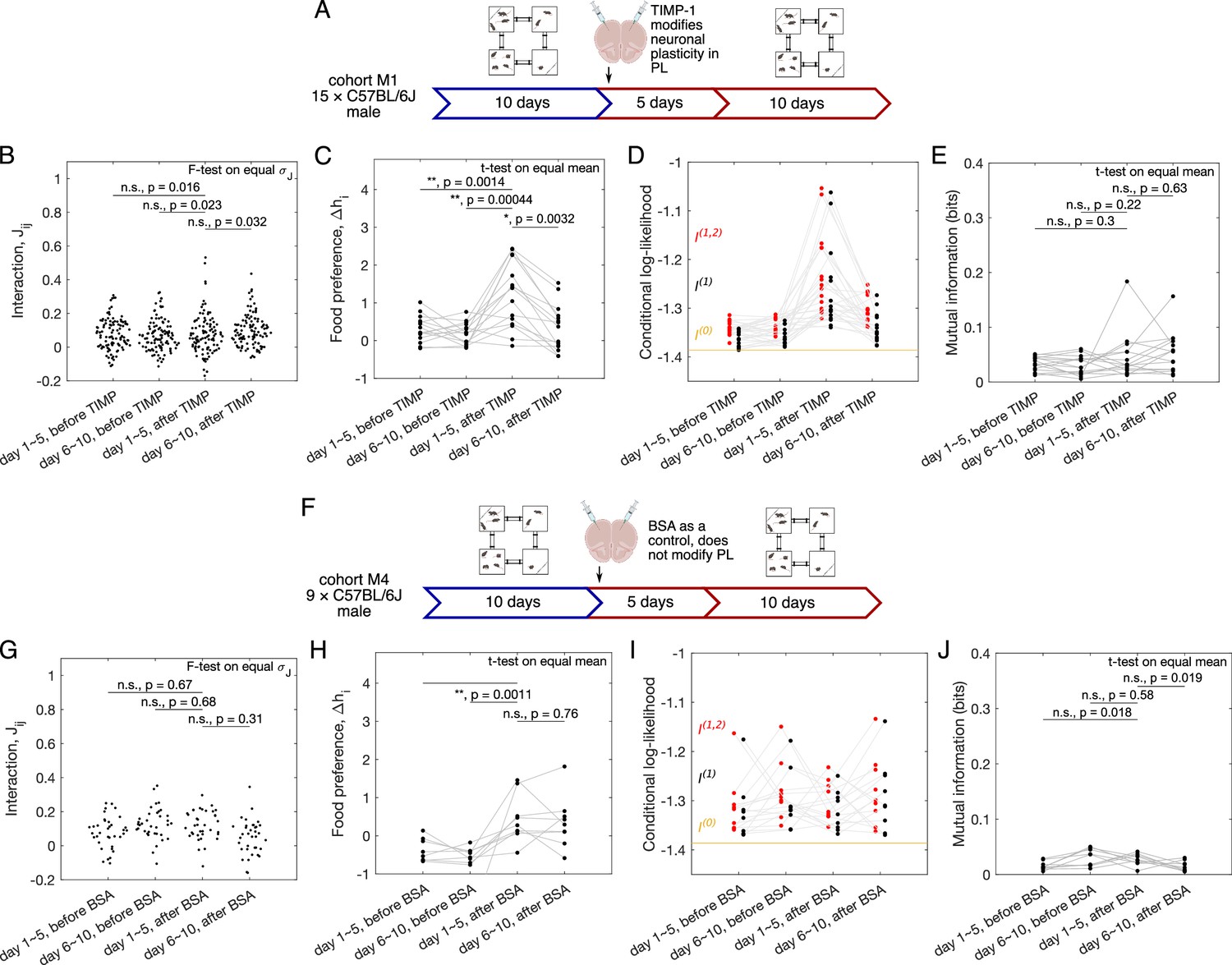
Quantification of sociability and the impact of the impaired neuronal plasticity in the prelimbic cortex (PL).
(A) Schematic of the experiment, in which neuronal plasticity in the PL of the tested subjects was impaired with TIMP-1 treatment. A cohort of C57BL/6J male mice () was tested in Eco-HAB for 10 days, and then removed from the cages for neuronal plasticity manipulation procedures. After a recovery period, they were placed back in Eco-HAB for another 10 days. For each of the 5-day aggregate of the experiment, both before and after TIMP-1 treatment, we plot (B) the model-inferred interactions , (C) preference for food compartments , (D) conditional log-likelihood for the pairwise model, , the independent model, , and the baseline null model, , and (E) mutual information between single mouse position and the rest of the network given by the inferred pairwise model. (F–J) Same as (A–E), now for male C57BL/6J mice subject to injection of BSA-infused nanoparticles, a control which does not impair neuronal plasticity in the PL (cohort M4, ).
Figure 3—figure supplement 1
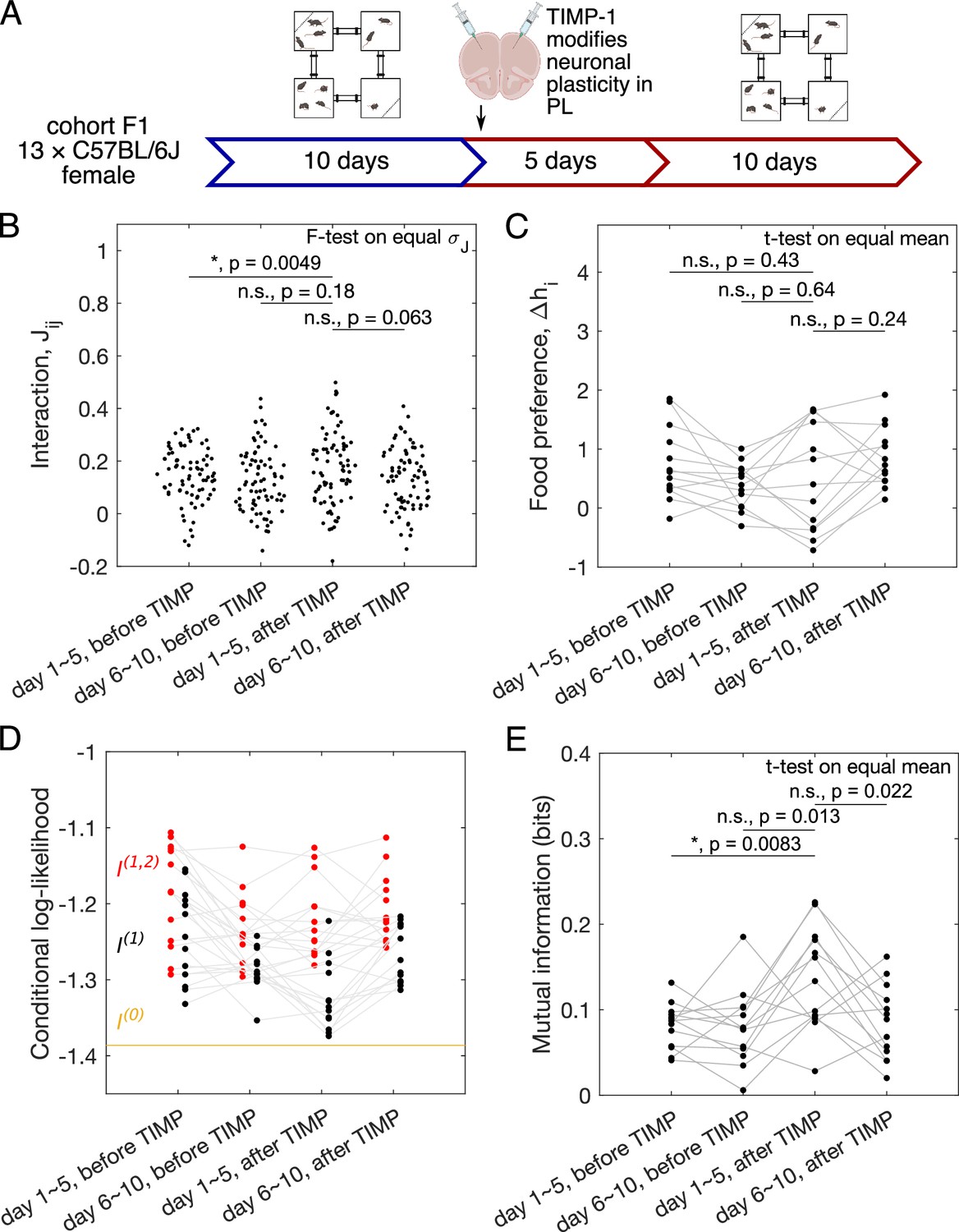
Same as Figure 3A–E, now for female C57BL/6J mice subject to injection of TIMP-1-infused nanoparticles (cohort F1, ).
Figure 3—figure supplement 2
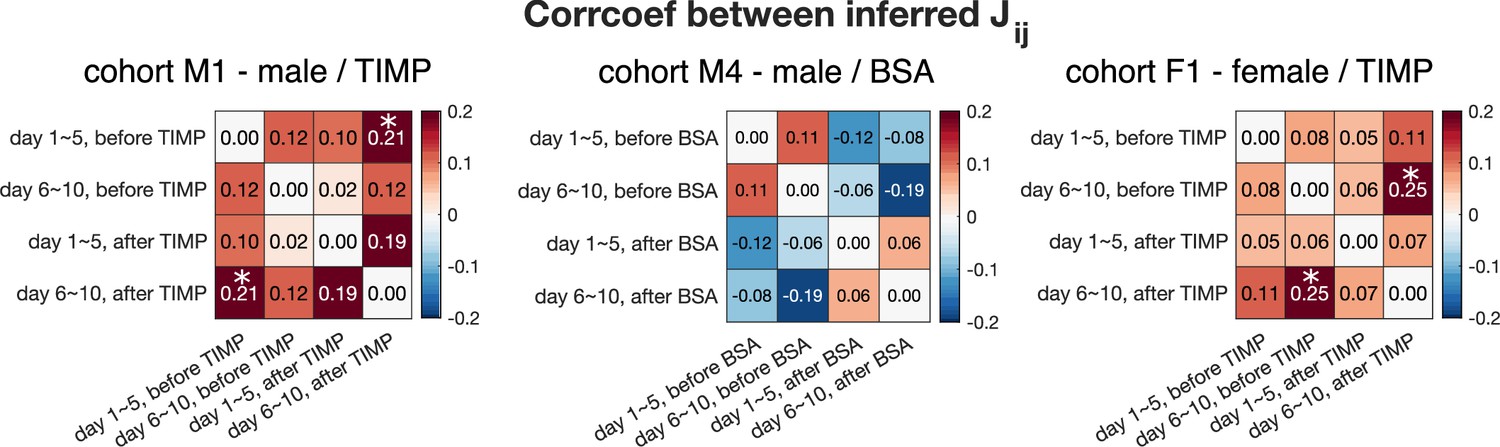
Pearson’s correlation coefficient between inferred interaction from different 5-day aggregated data, before and after drug injection, for cohorts M1 (N = 15), M4 (N = 9), and F1 (N = 13).
Asterisks indicate statistical significance. Almost no correlation is detected between the inferred . The only two comparisons that exhibit statistical significance are between the first and last 5 days after TIMP injection for cohort M1 (p-value=0.033), and between last 5 days before TIMP and last 5 days after TIMP injection for cohort F1 (p-value=0.028).
Figure 4 with 3 supplements

Effect of TIMP-1 on the structure of the interaction network.
(A) Schematics of how triplets of mice may enter a state of ‘dissatisfaction’ due to competitive pairwise interactions. Dissatisfaction reduces the space of preferable states due to competitive interactions. (B) The global dissatisfaction triplet index (DTI), , computed using inferred interaction from 5-day segments of the data shows that for both male and female mice treated with TIMP-1 the global DTI is significantly increased after drug treatment, for cohorts M1 (), M4 (), and F1 (). Two-sided Welch’s t-test is performed to test the significance of the difference of the global DTI between the first 5 days after drug injection against the other 5-day segments of the data. Error bars estimate the data variability, which is generated by taking random halves of the data (see ‘Materials and methods’ for details).
Figure 4—figure supplement 1
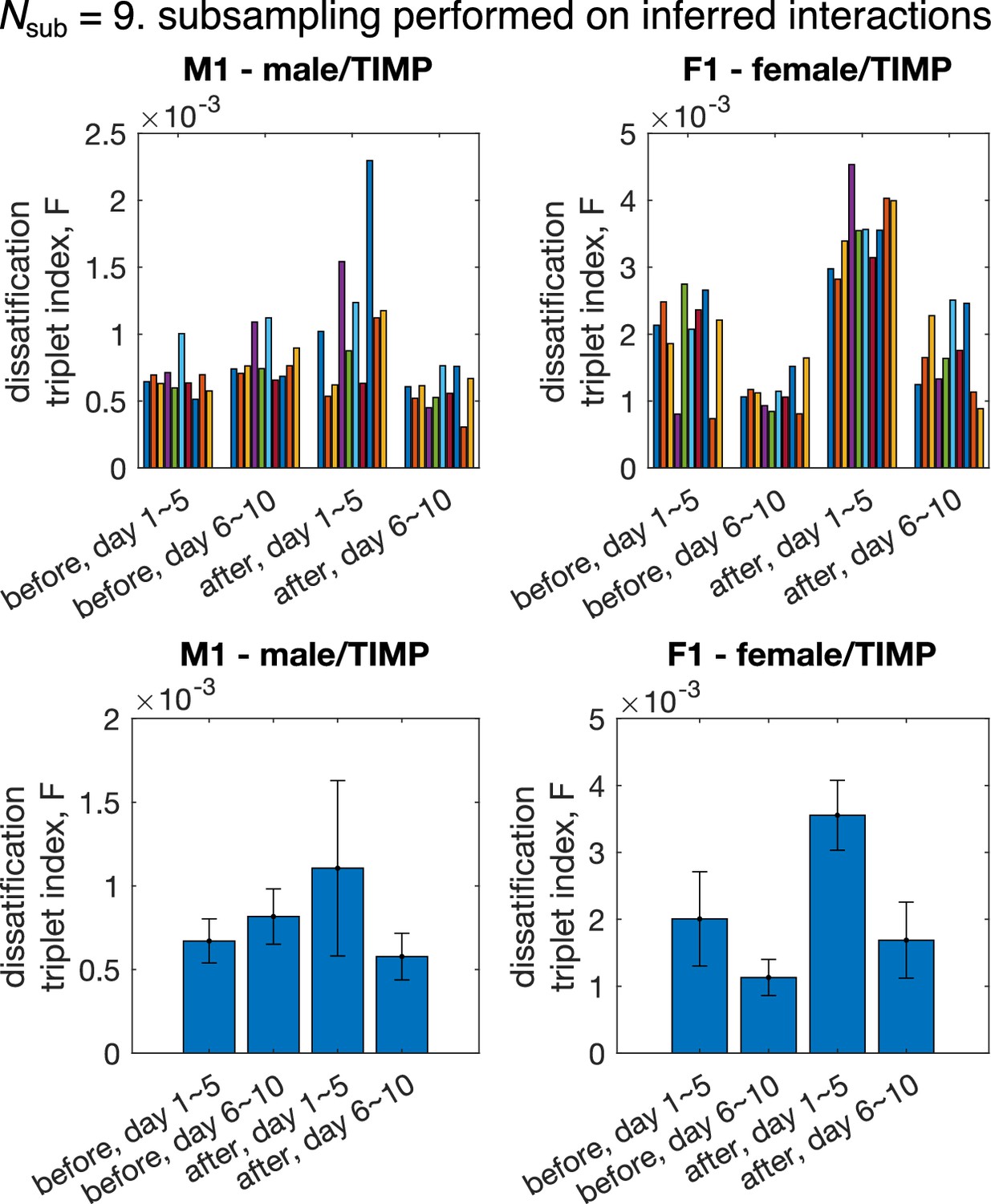
Dissatisfaction triplet index computed using subgroups of mice for cohorts M1 (, ) and F1 (, ).
Subsampling is performed at the level of inferred interactions, that is, interactions among all mice are inferred using the pairwise maximum entropy model, then, 10 random subgroups of mice are drawn. Top: each colored bar represent 1 realization of the subsampling. Bootstraps of random halves of the data were used in analysis to be consistent Figure 4. Bottom: average over subgroups of the bar plot in the top row. Error bar represents standard deviation across different realizations of subgroups.
Figure 4—figure supplement 2
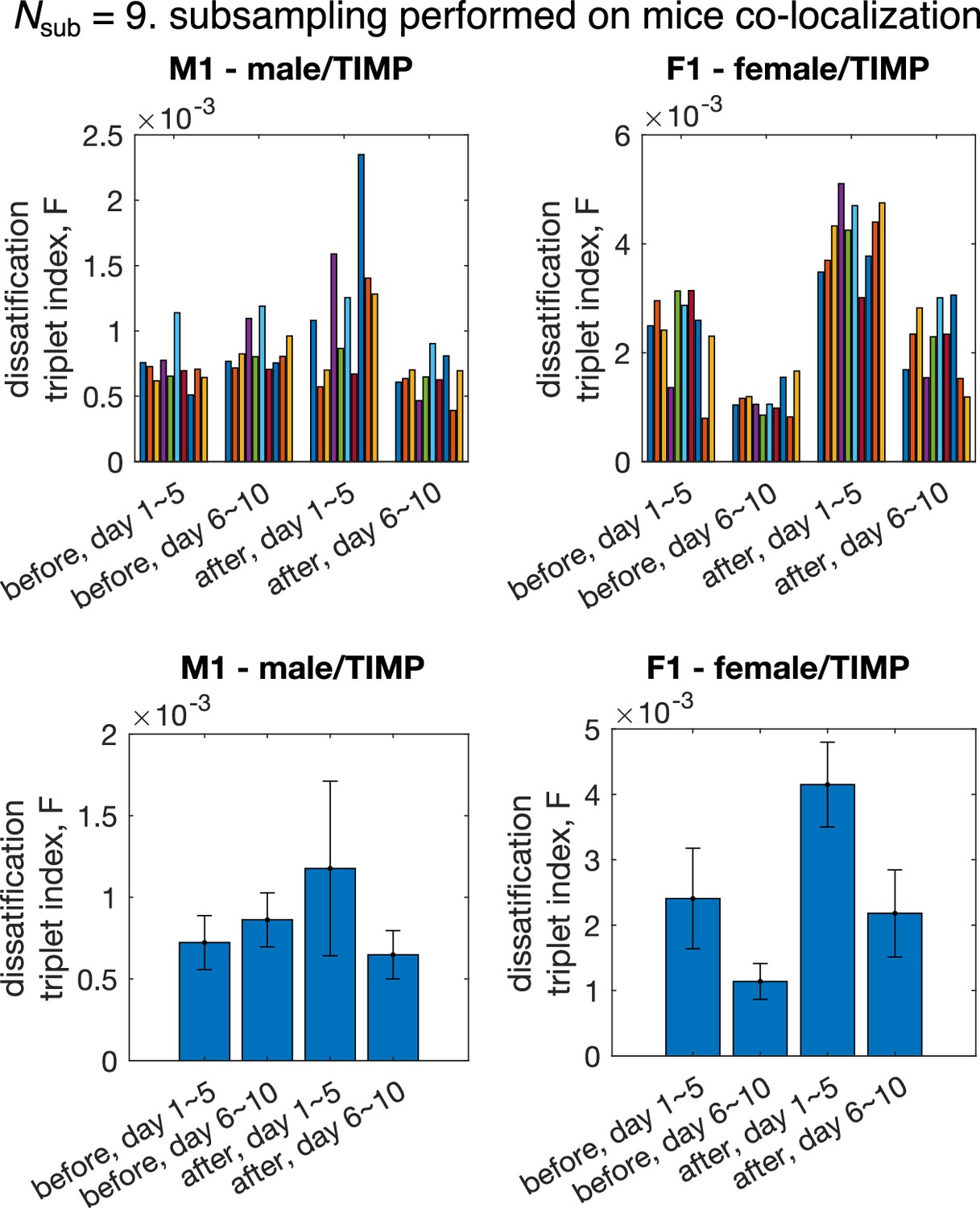
Dissatisfaction triplet index computed using subgroups of mice from cohorts M1 and F1.
Subsampling is performed at the data level, hat is, the co-localization patterns of randomly selected mice are used to infer the interaction strengths, which are then used to compute the dissatisfaction triplet index .
Figure 4—figure supplement 3
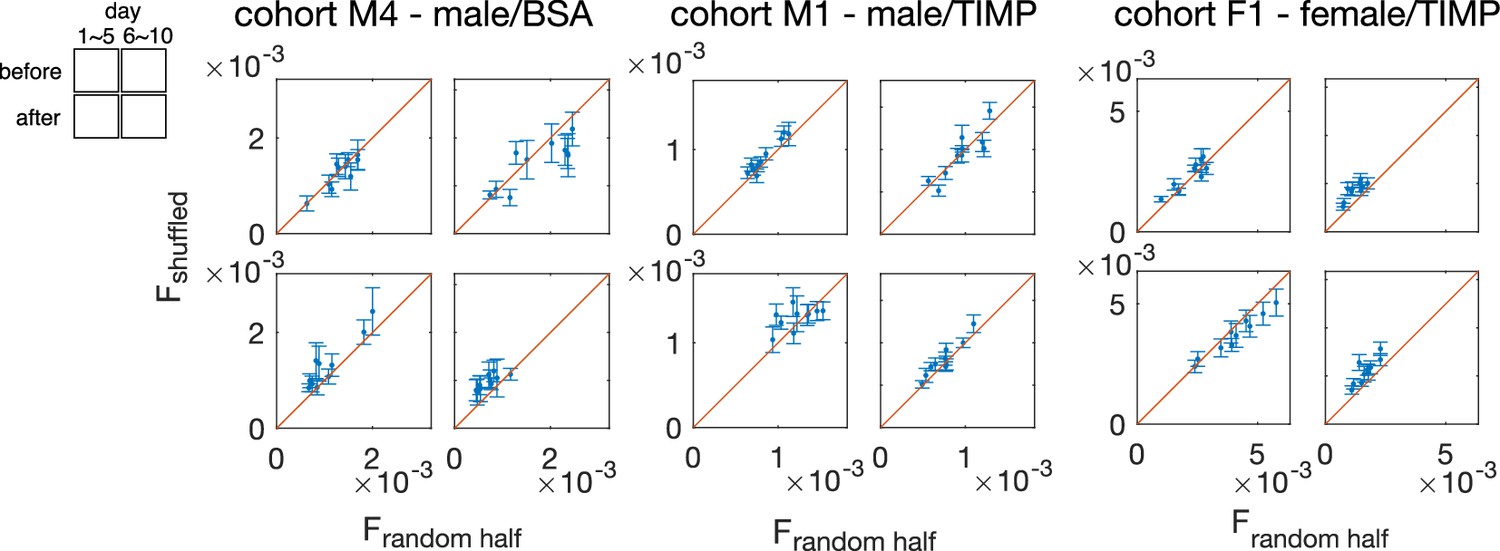
The global dissatisfaction triplet index (DTI) computed using shuffled interaction, versus the global DTI computed using the inferred interaction, , for cohorts M1 (), M4 (), and F1 ().
Each point corresponds to one random half of the data. The two sets of global DTI’s are equal within the range of the error bars, computed by standard deviation across 20 random shuffling of the inferred interaction , which shows the global DTI comes from the value of the inferred interaction, and that there is no additional network structure of the inferred interaction.
Tables
Table 1
Summary of experiments used in this study.
The column gives the number of mice in the cohort used for the analysis, with cohort M4 and F1 containing dead or inactive mice after injection. The original number of mice is included in the parenthesis, and the exclusion procedure is described in ‘Exclude inactive and dead mice from analysis’. The column ‘NP’ indicates the load of the injected nanoparticles. The column ‘Day 1’ indicates the first day of observation in each of the 10-day experiment.
| Cohort ID | Gender | Day 1, WT | NP | Day 1, NP | ||
|---|---|---|---|---|---|---|
| M1 | Male | 15 | 10×2 | 180,511 | TIMP-1 | 180,526 |
| M2 | Male | 13 | 10 | 181,012 | N/A | N/A |
| M3 | Male | 10 | 10 | 200,701 | N/A | N/A |
| M4 | Male | 9 (out of 12) | 10×2 | 200,713 | BSA | 200,727 |
| F1 | Female | 13 (out of 14) | 10×2 | 180,413 | TIMP-1 | 180,430 |
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Modeling collective behavior in groups of mice housed under semi-naturalistic conditions
eLife 13:RP94999.
https://doi.org/10.7554/eLife.94999.4




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}