Vocal development in a Waddington landscape
- Princeton University, United States
Abstract
Vocal development is the adaptive coordination of the vocal apparatus, muscles, the nervous system, and social interaction. Here, we use a quantitative framework based on optimal control theory and Waddington’s landscape metaphor to provide an integrated view of this process. With a biomechanical model of the marmoset monkey vocal apparatus and behavioral developmental data, we show that only the combination of the developing vocal tract, vocal apparatus muscles and nervous system can fully account for the patterns of vocal development. Together, these elements influence the shape of the monkeys’ vocal developmental landscape, tilting, rotating or shifting it in different ways. We can thus use this framework to make quantitative predictions regarding how interfering factors or experimental perturbations can change the landscape within a species, or to explain comparative differences in vocal development across species
https://doi.org/10.7554/eLife.20782.001eLife digest
As infants develop they learn new behaviors and refine existing ones. For example, human infants progress from crying to babbling to producing speech-like sounds. A complex sequence of changes in muscles, the nervous system and in patterns of interactions with other individuals all contribute to these emerging behaviors.
Despite this complexity, most studies of vocal development have only considered single factors in isolation. A study of speech development, for example, might examine how changes in the brain enable infants to imitate sounds. However, that same study will probably ignore how changes in the structure of the vocal cords, or in the behavior of the parents, also promote imitation.
Young marmoset monkeys, like human infants, gradually develop from producing immature cries to adult-like calls. Teramoto, Takahashi et al. built a computational model of this process and compared the model to data from real animals. The first version of the model focused solely on how the marmosets’ vocal cords grow, and did not fully reproduce how adult-like calls emerge in real marmosets. Teramoto, Takahashi et al. therefore added factors to the model that simulate improvements in muscle control, learning in the nervous system and in the behavior of other animals. These findings show that, to reflect how adult-like calls emerge in real marmosets, the model needs to include all of these factors.
The model developed by Teramoto, Takahashi et al. may also provide insights into why vocal learning and some other behaviors emerge in some species and not others. It may also be used to predict the consequences of disrupting individual processes in young animals at particular points in time and how such disruptions shape the way an animal develops on its way to adulthood.
https://doi.org/10.7554/eLife.20782.002Introduction
Understanding how behavior changes across development requires a system-level understanding of the interplay among an organism’s current behavioral capabilities, its changing body and changing nervous system (Byrge et al., 2014). Vocal behavior emerges, at a minimum, from the interactions of the vocal apparatus (the vocal folds, vocal tract and lungs) (Ghazanfar and Rendall, 2008), the muscles that control the vocal apparatus, and the nervous system and its interplay with social factors. Development of vocal behavior is the process of adapting a context-dependent stable configuration of these elements so that they work together to produce vocalizations typical of each developmental stage (Figure 1a). Yet, there is no theoretical or computational framework in which to understand how the elements of vocal systems come to assemble themselves in this manner during development.
Figure 1
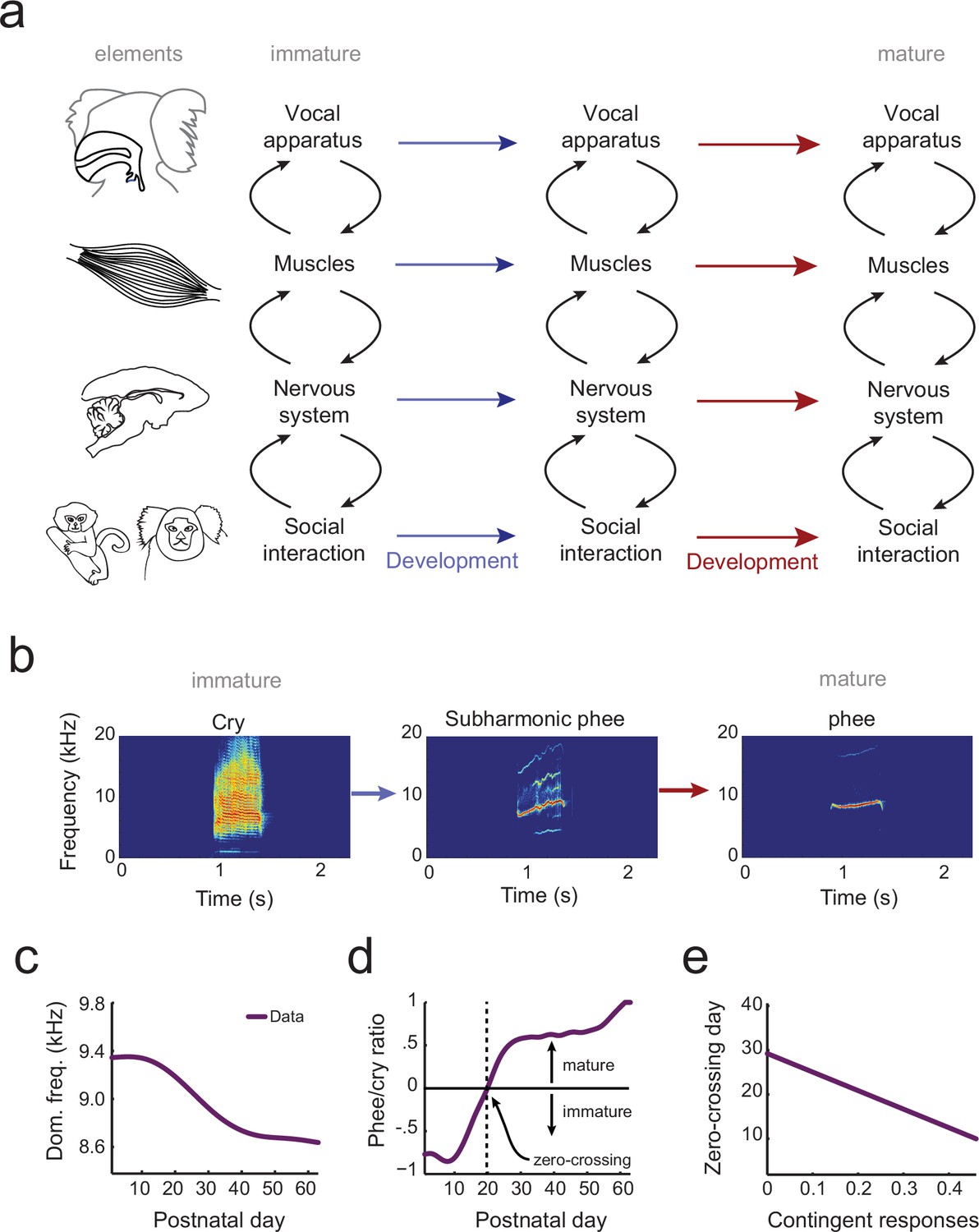
The elements of vocal development and their interactions.
(a) Vocal development is the result of changes in, and interactions among, the vocal apparatus, muscles, nervous system, and social context. (b) Infant marmosets produce mostly immature calls (cries and subharmonics) during early postnatal days which are replaced by more adult-like calls (phees) during development. (c) Changes in vocal acoustics during development include a lowering of the dominant frequency. Purple curve shows a cubic spline fit to the data. (d) Change in the proportion of mature calls compared to immature calls (the phee/cry ratio). Purple curve shows a cubic spline fit to the data. The zero-crossing day is the postnatal day in which the number of cries and phees are the same, marking the transition from mature to immature vocalization. (e) Relationship between the probability of parental contingent responses and the zero-crossing day. Purple line shows the linear regression fit to the data.
Studies of vocal development typically focus only on one or two of the above elements at any given time. For example, the vocal learning literature emphasizes the role played by imitation and the neural changes that may facilitate this behavior, particularly in songbirds and humans (Doupe and Kuhl, 1999). In such considerations, vocal development is not restricted by body structure or motor development, but rather by memory-related constraints and perceptual predispositions. Such a view is incomplete for a number of reasons (Tchernichovski and Marcus, 2014; Vihman, 2015). For example, young swamp sparrows cannot imitate artificially sped up versions of their species’ song, demonstrating muscular constraints on learning (Podos, 1996). Along similar lines, in human infants there is not only growth in the vocal apparatus (Fitch and Giedd, 1999; Vorperian et al., 2005), but developmental changes in vocalization-related motor control (Green et al., 2000) and respiration (Boliek et al., 1996). Moreover, in songbirds (West and King, 1988; Chen et al., 2016), bats (Prat et al., 2015), marmoset monkeys (Takahashi et al., 2015; Gultekin and Hage, 2017) and humans (Kuhl et al., 2003; Goldstein et al., 2003; Goldstein and Schwade, 2008), social responses by adults influence vocal development. Given that vocal development consists of a number of moving parts, how can we track and understand how these parts and their relationships change over time to produce mature-sounding vocalizations?
Similar questions, of course, plague all studies of development. Cells, for example, are dynamic entities whose phenotypes change over time. How can we understand the trajectory of a pluripotent stem cell differentiating into a fixed cell type (e.g., a neural stem cell differentiating into a neuron vs. a glial cell vs. remaining a stem cell)? Waddington (Waddington, 1957) envisioned this canalized pattern as a ball (the cell’s state) rolling down a surface with hills and valleys to seek the lowest points in an epigenetic landscape. At watersheds, the valleys branch so that the ball takes one of two available paths and thus establishes its identity at that particular time. Recently, this metaphor for cellular development was given a formal quantitative theoretical framework (Wang et al., 2011). Cells have states defined by the expression patterns of interacting genes. These states correspond to different basins of attraction in a probability landscape; cell differentiation proceeds as movement from one basin to another (Wang et al., 2011). All forms of biological development – including vocal development – are probabilistic like this cell fate example (Gottlieb, 2007). Vocalizations also go through different states as they transition from immature to mature forms (Kent and Murray, 1982; Tchernichovski et al., 2001; Scheiner et al., 2002; Lipkind et al., 2013; Takahashi et al., 2015; Zhang and Ghazanfar, 2016) (e.g., for marmoset monkeys, see Figure 1b). These states are defined by the probabilistic relationship between the vocal apparatus, muscle control, neural activity and social context (Figure 1a).
In the current study, our goal is to generate an integrated landscape framework for vocal development that incorporates these elements and their interactions over time. To do so, we will use marmoset monkey vocal development, which shares numerous parallels with human vocal development (Takahashi et al., 2015; Zhang and Ghazanfar, 2016; Takahashi et al., 2016; Ghazanfar and Zhang, 2016). First, infant marmoset monkey call acoustics change during development (Pistorio et al., 2006; Takahashi et al., 2015; Zhang and Ghazanfar, 2016) (Figure 1c). Second, these changes in acoustics reflect the transition from an initial mixture of immature and mature vocal sounds to adult-like vocalizations (Takahashi et al., 2015, 2016; Zhang and Ghazanfar, 2016) (Figure 1d). Third, as in humans (Goldstein et al., 2003; Kuhl et al., 2003; Goldstein and Schwade, 2008), the timing of this transition is influenced by contingent parental vocal feedback (Takahashi et al., 2015, 2016; Gultekin and Hage, 2017) (Figure 1e). Finally, after taking into account their rapid growth relative to humans (de Castro Leão et al., 2009), changes in the developmental trajectory of marmoset vocal behaviors occur at the same life history stages (Takahashi et al., 2015, 2016; Zhang and Ghazanfar, 2016; Ghazanfar and Zhang, 2016). Using an extensive longitudinal vocal behavioral dataset from marmoset infants (Takahashi et al., 2015, 2016; Zhang and Ghazanfar, 2016), collected under two controlled contexts (brief social isolation (undirected context) and vocal interactions with a parent (directed context)), we applied optimal control principles to formulate and test the predictions of a landscape framework for vocal development. This landscape shows how changes in the vocal apparatus, muscles, nervous system, and social interaction together shape the vocal developmental trajectory of an infant (Figure 1a).
Overview of approach
In our study, the specific vocal behavior under investigation is the production of mature contact (‘phee’) calls. Adult marmoset monkeys produce these vocalizations when alone and out of sight of others (undirected context) (Borjon et al., 2016). If another marmoset is within earshot, then the pair will begin taking turns exchanging these calls (directed context) (Takahashi et al., 2013). Very young infants are only gradually able to produce mature sounding contact calls (Takahashi et al., 2015; Zhang and Ghazanfar, 2016), and contingent vocal interactions with parents appears to accelerate this process (Takahashi et al., 2015, 2016). Here, we use optimal control theory to construct a Waddington-like developmental landscape to model this process.
Optimal control approaches have long been used in studies of motor behaviors and their application requires four specifications: (1) well-defined behaviors, (2) a biomechanical model of the system, (3) a cost function, and (4) an optimization criterion that describes the probabilities of those behaviors (Wolpert and Landy, 2012). The theory posits that the probability of producing a specific motor action can be calculated by knowing the cost that a given behavior demands (Wolpert and Landy, 2012). If the cost to produce an action is high, that action should be less probable than another whose cost is lower. In the current study, the four specifications are the following: (1) Immature and mature contact calls are the behaviors; (2) The biomechanical model is one established for songbird vocalizations (Amador and Mindlin, 2008; Perl et al., 2011; Amador et al., 2013) that we have shown is also appropriate for marmoset monkeys (Takahashi et al., 2015); (3) The cost function is the amount of effort required to produce contact calls; and (4) The optimization criterion is the maximum entropy principle. Maximizing the entropy allows us to identify the probability distribution that is most consistent with the cost function and makes the fewest assumptions. In essence, the goal of our study is to understand how each of the elements of vocal behavior – the vocal apparatus, muscles, nervous system, social interaction – modifies this cost function over postnatal days.
The overall pattern of vocal (contact call) development consists of a change in dominant frequency, a rapid transition from immature to mature calls, and a correlation between the amount of parental feedback and the rate of this transition (Figure 1c–e). We will use the optimal control approach to take the following inferential steps in order to explain this pattern of vocal development (Figure 2). First, we will use the biomechanical model to simulate growth of the vocal apparatus (specifically, the vocal tract length) (Figure 2a,b). We will then fit the model’s parameters so that it can reproduce the dominant frequency changes observed in marmoset monkey vocal development (Figures 1c and 2c). Second, we will test whether these changes in the vocal tract length can also account for the rapid transition from immature to mature contact calls (phee/cry ratio; Figure 1d). To do this, we combine the cost function (Figure 2d) with the optimization criterion which together generate a probability distribution for the production of immature and mature calls (Figure 2e). Third, the prediction is either falsified or supported by comparing the model-based phee/cry ratio with the real marmoset phee/cry ratio (Figure 2f). If the prediction is falsified, we add a new element to the cost function (e.g, change in muscle control) which changes it shape and thus changes the probability distribution of call types produced in the emerging landscape. We then repeat the inferential steps using the vocalization data, cost function, and optimal control theory (Figure 2g). To distinguish when a statement is about the model or about the real data, we will always indicate the corresponding model parameter when discussing the model. With the intent to make the main message of the article as clear as possible, we postpone most of the mathematical content to Materials and methods and the Appendix. The reader interested in the mathematical aspects of the modeling will find callouts in relevant places of the main text.
Figure 2
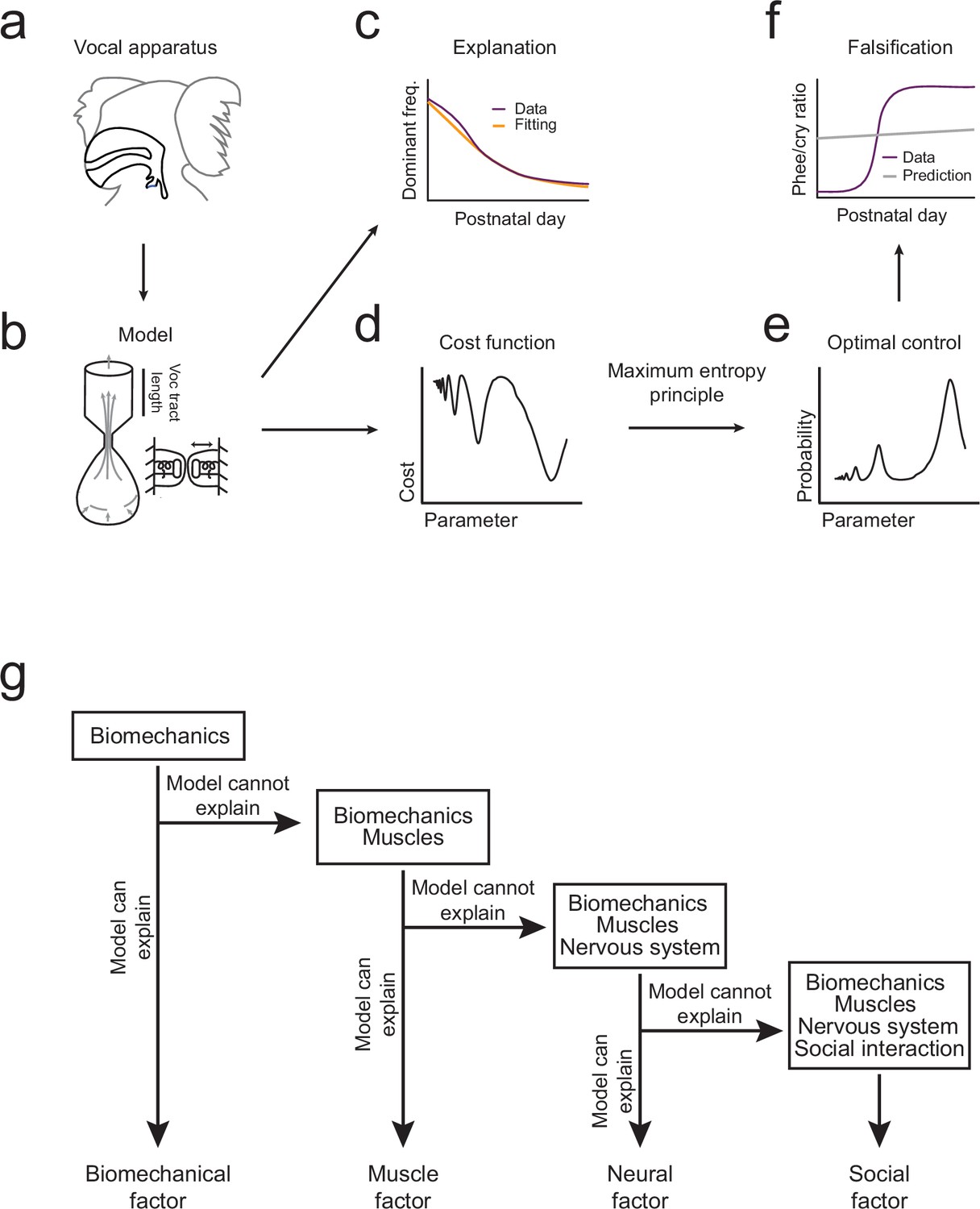
Illustration of the inferential process used in the study.
(a,b) A biomechanical model is made of the infant marmoset monkey vocal apparatus. (c) The model is used to simulate how the growth of the vocal tract lowers the dominant frequency of calls. Model data (yellow line) can be fitted to the real data (purple line). (d,e) Optimal control theory is used to generate a cost function for producing different call types and the maximum entropy principle is used to calculate a probability distribution. (f) Using the probability distribution, we can calculate the phee/cry ratios produced by the simulated vocal tract growth (gray line) and compare with the real marmoset phee/cry ratio data (purple line). (g) The contributions of other individual elements (see Figure 1a) are gradually added to the framework using a sequential inferential approach together with mathematical modeling.
In what follows, we first present the biomechanical model of the marmoset vocal apparatus as this serves as the foundation of our optimal control approach. We then present our findings related to the growth of the vocal tract and the successive additions of muscle, nervous system and social interaction to the developmental landscape.
Results
A biomechanical model of the marmoset monkey vocal apparatus
Establishing a biomechanical model for the vocalizations produced by developing marmoset monkeys is required for the optimal control approach. Briefly, we use a model that is a second order ordinary differential equation with two possible time-varying parameters: , representing the air pressure produced by the lungs and , representing vocal fold tension (Figure 3a). Different values of and generate different combinations of air pressure and laryngeal tension, resulting in distinct acoustic signals. The third parameter is a fixed inverse time scale that sets the upper frequency range of glottal (vocal fold) oscillations. The glottal air flow () is then filtered by the vocal tract to produce the final vocal output (). The vocal tract is modeled as a cylinder in which the filtering property depends on its length and reflection coefficient (Figure 3a). Details of the model are described in Materials and methods: The vocal fold model and From vocal vibrations to calls, Equations (14–17); parameter values are given in Table 1 and further mathematical details appear in the Appendix.
Figure 3
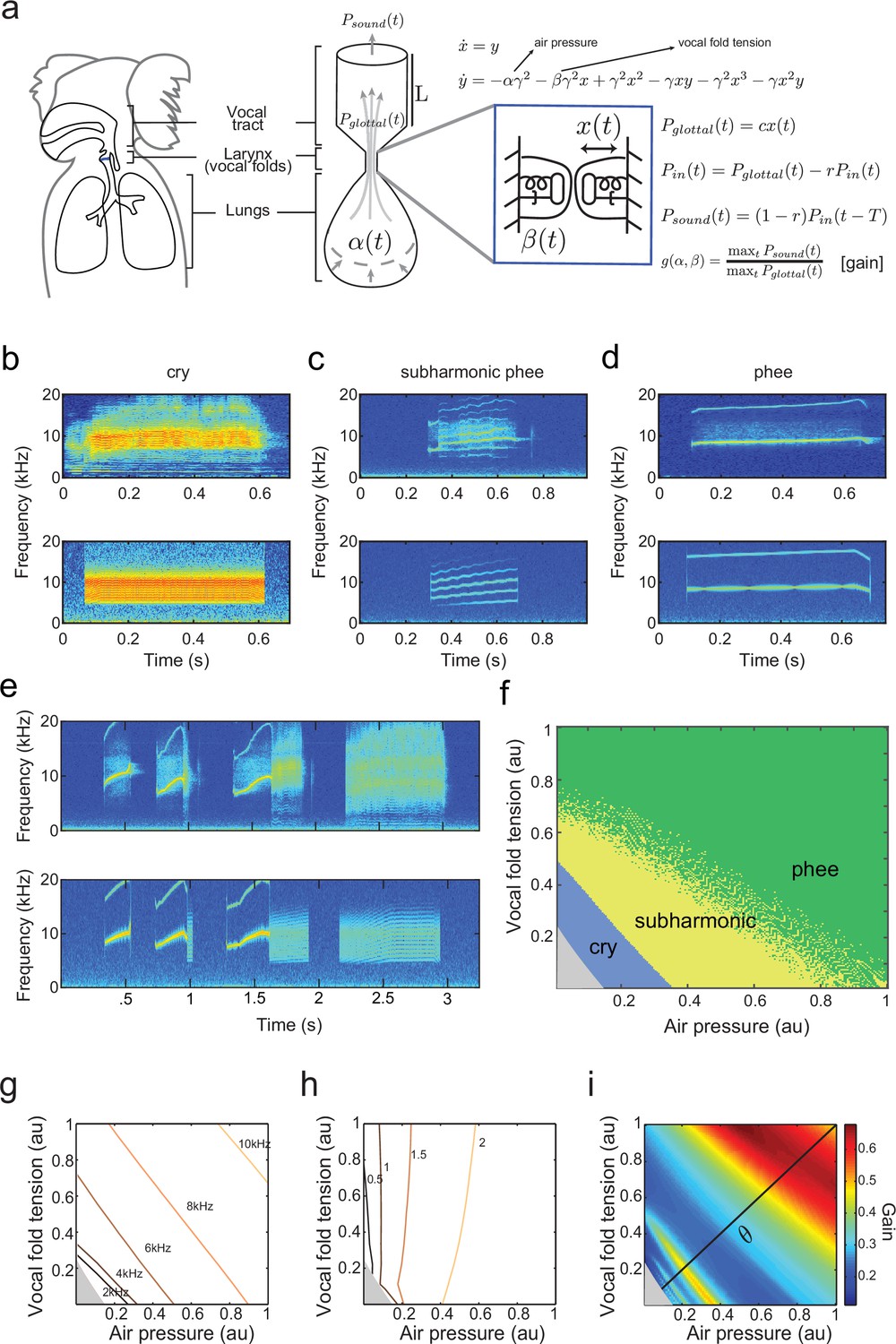
A biomechanical model of marmoset vocal apparatus.
(a) Representation of the biomechanical model of the vocal production apparatus. In our one-mass model are displacement and velocity of vocal folds; nondimensional lung air pressure, vocal fold tension and overall inverse timescale are represented by parameters and . Glottal exit air flow is filtered by the vocal tract, modeled as a cylinder of length with reflection coefficient at the mouth, to produce vocal output . is the one way travel time with sound speed . (b–d) Examples of real infant calls (top) and model simulation of the same calls (bottom). (e) Example of a sequence of infant calls (top) and model simulation (bottom). (f) Different values of air pressure and vocal fold tension produce distinct types of calls. Gray region represents parameter values that do not produce vocalization (i.e., self-sustained oscillation). (g) Isofrequency curves. Lines show air pressure and vocal fold tension values that produce glottal air flow that oscillates at the same frequencies; parameters in the gray region do not produce self-sustained oscillations. (h) Iso-amplitude curves. Lines show air pressure and vocal fold tension values that produce glottal air flow with same amplitudes. (i) Plot showing gains: the ratios between sound produced after the resonance (vocal output) and before the resonance (glottal air flow); warmer colors indicate higher ratios. The diagonal line () is parametrized by . au = arbitrary units.
By varying the air pressure and vocal fold tension , the model produces immature and mature contact calls (cries, subharmonic-phees and phees) with nearly identical acoustic features to those produced by infant marmosets (Figure 3b–d); it can also simulate sequences of calls (Figure 3e). Respiration and vocal fold tension can change in time to produce the different call types. To obtain the results in Figure 3b–e, and were varied as increasing and/or decreasing linear ramps. Figure 3f shows the parameter regions that result in each call type. Lower respiratory power and vocal fold tension produce cries, whereas higher values produce phees. When and are small (gray region, Figure 3f) there is no vocal production. Physiological respiratory data support the predictions of the model (Takahashi et al., 2015).
By varying the parameters, the fundamental frequencies and amplitude of vocal sounds can be changed. Higher fundamental frequencies are obtained when the air pressure and/or the laryngeal muscle tension increases (Monsen et al., 1978; Hollien, 2014). Consistent with this, Figure 3g shows that the model has isofrequency (same frequency) lines for glottal airflow that increase with higher air pressure and/or muscle tension . Vocal amplitude is mainly controlled by the air pressure (Sundberg et al., 1993), which the model expresses as nearly vertical iso-amplitude (same amplitude) curves in Figure 3h. The glottal air flow is then filtered by the resonant vocal tract. The gain is measured as the ratio between the amplitudes of vocal output (after vocal tract resonance) and of glottal air flow (before vocal tract resonance) (). Glottal air pressures that oscillate at the resonance frequencies produce higher gains than those that do not (Ghazanfar and Rendall, 2008). Figure 3i shows the effect on the gain produced by different values of air pressure and muscle tension. The highest gains are obtained for glottal airflow at approximately 9–10 kHz (Figure 3g,i).
Growth of the vocal tract contributes to lower dominant frequency
In humans and other primates, vocal development includes a lowering of the dominant frequency of calls (Hammerschmidt et al., 2000, 2001; Kent and Murray, 1982; Scheiner et al., 2002; Pistorio et al., 2006; Takahashi et al., 2015) (Figure 1c). Such changes in frequency in early vocal acoustics are typically associated with increases in the size of the vocal folds: as they get bigger they naturally oscillate more slowly, producing lower frequency sounds. Some early vocalizations are also noisy (see the cry in Figure 1b). Noisiness in vocal acoustic features in general are typically associated with instabilities in the vocal fold movements (Kent and Murray, 1982; Fitch et al., 2002; Tokuda et al., 2002). Our initial modeling study of the biomechanics of marmoset monkey vocal development revealed that, unexpectedly, the vocal tract may additionally play an important role in generating the acoustic features present in both immature and mature vocalizations (Takahashi et al., 2015). Thus, in this study, we explore the role of vocal tract growth on shaping the developmental landscape.
When an animal’s body size increases during development, so does the length of its vocal tract (Fitch and Giedd, 1999). Since longer vocal tracts have lower main and subharmonic resonance frequencies , etc., we expect the resonance frequency to decrease over development. To test this, we fitted the developmental change in dominant frequency observed in the undirected context data (Figure 4a) and estimated the developmental change in this feature due to the changing length of the vocal tract (Figure 4b). As expected, the increase in and the associated changes in resonance frequencies during development can explain the observed reduction in the dominant frequency of vocalizations. Thus, the change in dominant frequency is a developmental feature that can be associated with changes in vocal tract length. Having established that, we can now use optimal control theory to determine if vocal tract length can also explain other features of the infant marmoset vocal development. In particular, we will examine if the change in can explain the rapid transition from producing mostly immature vocalizations like cries and subharmonic-phees to mostly adult-like contact phee calls (Figure 1d) (Takahashi et al., 2015; Zhang and Ghazanfar, 2016). To do so, we will need to calculate the probability to produce immature and mature calls. Optimal control theory will allow us to do this, but first we must define an ethologically relevent 'cost' of producing vocalizations.
Figure 4
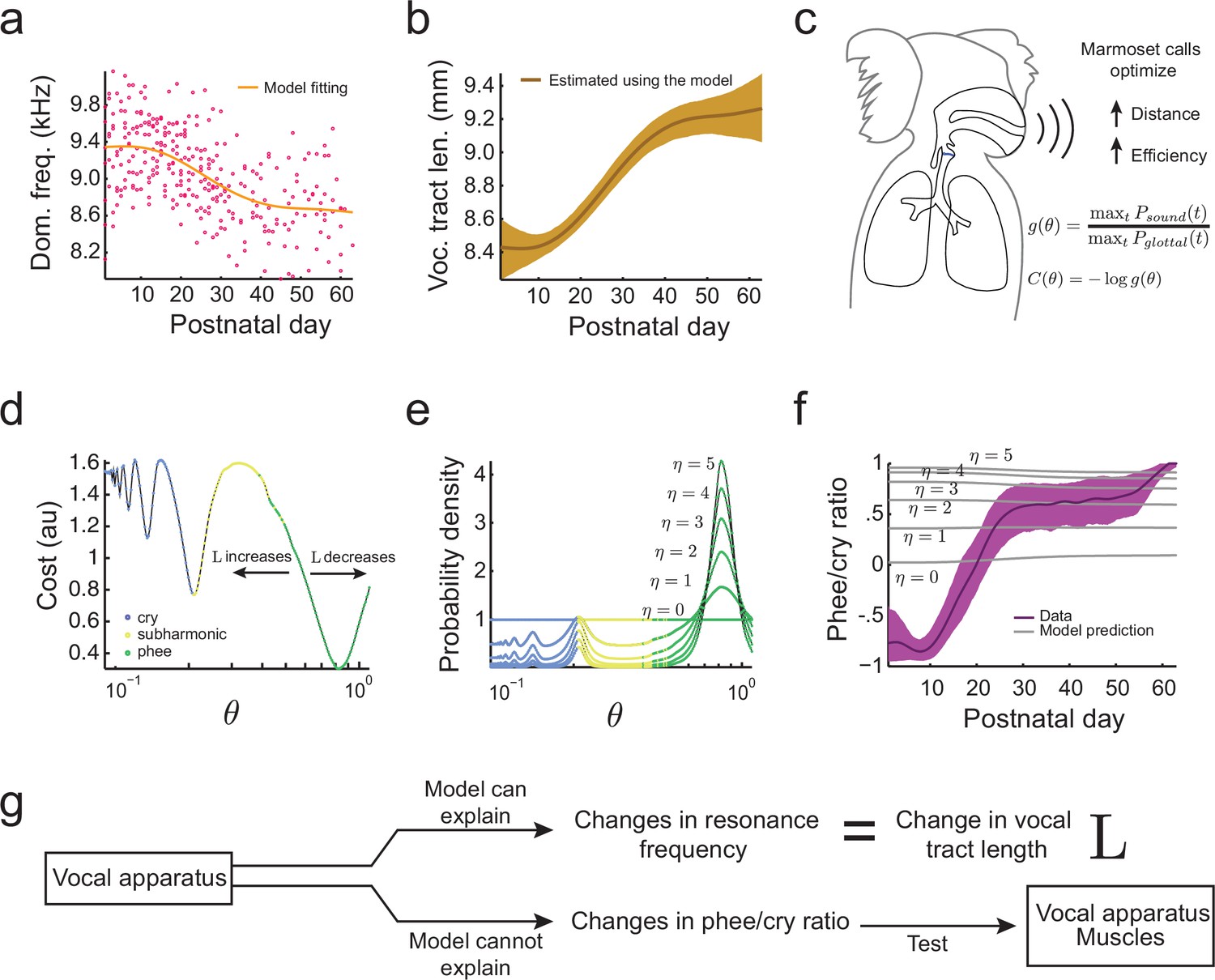
Growth of the vocal tract.
(a) Change in dominant frequency of infant marmoset calls during development. Yellow curve shows the value of resonant frequency fitted by the biomechanical model. Red dots are the mean dominant frequency of each postnatal day for all 10 infants ( sessions). (b) Vocal tract length estimated by the model assuming a closed-closed cylindrical tube (brown curve); shaded region indicates 95% confidence interval. (c) Infant marmosets produce calls that maximize distance and efficiency. Therefore, the cost of producing a call is inversely related to the gain . (d) Cost function to produce calls at different air pressure and vocal fold tension values (). Blue, yellow, and green dots indicate parameter regions for cry, subharmonic-phee, and phee production, respectively. Minimal cost is achieved for phees, which have glottal air flow oscillating at the natural frequency of the vocal cavity; -axis is in log-scale. (e) Probability density to produce calls at different values; color code is the same as in (d). Increasing concentrates probability in the parameter range that produces phees. (f) Population and model phee/cry ratios. Purple line is the population value of phee/cry ratio for the real marmoset infant data; shaded region indicates 95% confidence interval ( sessions). Gray lines indicate phee/cry ratios predicted by the model for different values of . (g) Growth (lengthening) of the vocal tract can explain the lowering of the dominant frequency, but not the transition from cries to phees.
Based on what we know about the ethology of infant marmoset monkeys, there are benefits to producing vocalizations with higher gains (i.e., vocalizations that are louder, longer and more tonal) (Figure 4c). Marmoset infant cries, subharmonic-phees, and phees are produced when they are separated from the parents (Takahashi et al., 2015). These vocalizations are louder compared to other infant calls and result in parents approaching the infant, and so are considered contact calls (Newman, 1985). However, infant marmoset calls that are more tonal (or 'phee' like; [Figure 1b, right panel]) are more likely to elicit parental responses (Takahashi et al., 2016). Hence, we model the cost of producing a call at different air pressure and vocal fold tension as inversely related to the gain . We can therefore write the cost to produce a vocalization with a given air pressure () and vocal fold tension () as
(1)
where , remain in the region of viable calls (see Figure 3f). The higher the gain for this function, the lower the cost. The logarithm is used to make the unit of gain proportional to decibels (dB).
To simplify our analysis and allow visualization, in what follows we will consider only the diagonal section of the parameter space, labeled , that passes through the region of cries, subharmonic-phees, and phees. Other choices of and that include these three calls yield similar results. The cost function Equation (1) becomes
(2)
where . Figure 4d illustrates our first ‘landscape’: the cost function with troughs indicating where glottal air pressure oscillates at the vocal tract’s resonance frequency and subharmonics , etc. This cost function describes one section of the developmental landscape related to respiration and vocal fold tension.
We can now describe the effect of developmental changes in vocal tract length on the shape of this landscape. An increase in causes a decrease in the location of the troughs with respect to , and vice-versa (Figure 4d). The different color regions indicate the different types of calls produced by the model for a given . Minimal cost is obtained when the infant produces mature contact phee calls because the frequency of glottal oscillations match . Given the cost function, we want to predict the probability that the infant will produce a call with a given air pressure and vocal fold tension. This is achieved by using the maximum entropy principle, via application of the softmax action selection rule (Jaynes, 1982; Wilson et al., 2014). This will give the probability of producing different calls that is consistent with the cost function and makes the fewest possible assumptions (see Materials and methods: Softmax action selection rule for details). This rule implies that the probability to produce a call with a given is proportional to the exponential of the negative of the cost:
(3)
Here is a non-negative parameter that controls the concentration of the probability distribution and that can be estimated from the data. is the normalizing constant such that the total probability is one. Figure 4e shows that increasing increases the probability to produce phees. When is zero, all parameter values are equally likely and we obtain the minimum possible proportion of phees.
Now we can ask a key question. Is a developmental landscape that only incorporates changes in vocal tract growth sufficient to explain not only lowering of the dominant frequency (Figure 1c), but also the other features of marmoset monkey vocal development? If so, then it should be able to explain the rapid transition from immature to mature calls during development (Figure 1d; [Takahashi et al., 2015]). To test this hypothesis, we calculated the phee/cry ratio, defined as
(4)
for the data and the model. Using the model, we can calculate the probability to produce a specific type of call by integrating the probability density for the air pressure and vocal fold tension that produce each type of call. Specifically, if is the set of parameters for which the model produces cries (Figure 4e, blue region), we have
(5)
Similarly, if is the set of parameters for which the model produces phees (Figure 4e, green region), we have
(6)
Figure 4f (gray lines) shows that during development, changes in vocal tract length have only a small influence on the phee/cry ratio and increasing only increases the probability of phees. But the phee/cry ratio in the marmoset data is negative for early postnatal days, showing more cries, and exhibiting a fast transition to mostly phee production after postnatal days. Therefore, there are no values of and that can fit the data and the cost function that includes only the change in vocal tract length cannot predict the cries-to-phees transition observed in development (Figure 4f,g). In other words, the changes in the position of troughs in the landscape due to vocal tract length increases are insufficient to explain other features of vocal development beyond lowering of the dominant frequency. Therefore, we will next consider the development of muscular control in the vocal apparatus.
Development of both vocal tract and muscle control accounts for the rapid transition from immature to mature vocalizations
Laryngeal and respiratory muscle size, strength, and dynamics significantly change through postnatal development in humans (Moore, 2004; Sasaki, 2006). We expect the control of respiratory and laryngeal muscles to change similarly during development in marmoset monkeys. Based on this assumption, one possibility is that the larger proportion of cries that occurs in the early postnatal period is due to very young infants having difficulty producing higher air pressures and vocal fold tensions required to generate mature (phee) calls (Figure 3f). Producing higher values requires stronger respiratory and laryngeal muscles and greater coordination (Takahashi et al., 2015). Our aim, therefore, is to estimate a new cost function and hence developmental landscape based on both vocal tract growth and the development of muscular control. We will model the cost of muscular control by modeling the required muscular effort as : a linear function of with a parameter whose values define how steep is the change in muscular effort for larger values of air pressure and vocal fold tension. Figure 5a shows the muscular effort for different values of and . In this second function, the total cost to produce a call for a given value of is the sum of the cost of the vocal tract change Equation (2) and muscular effort:
(7)
Figure 5
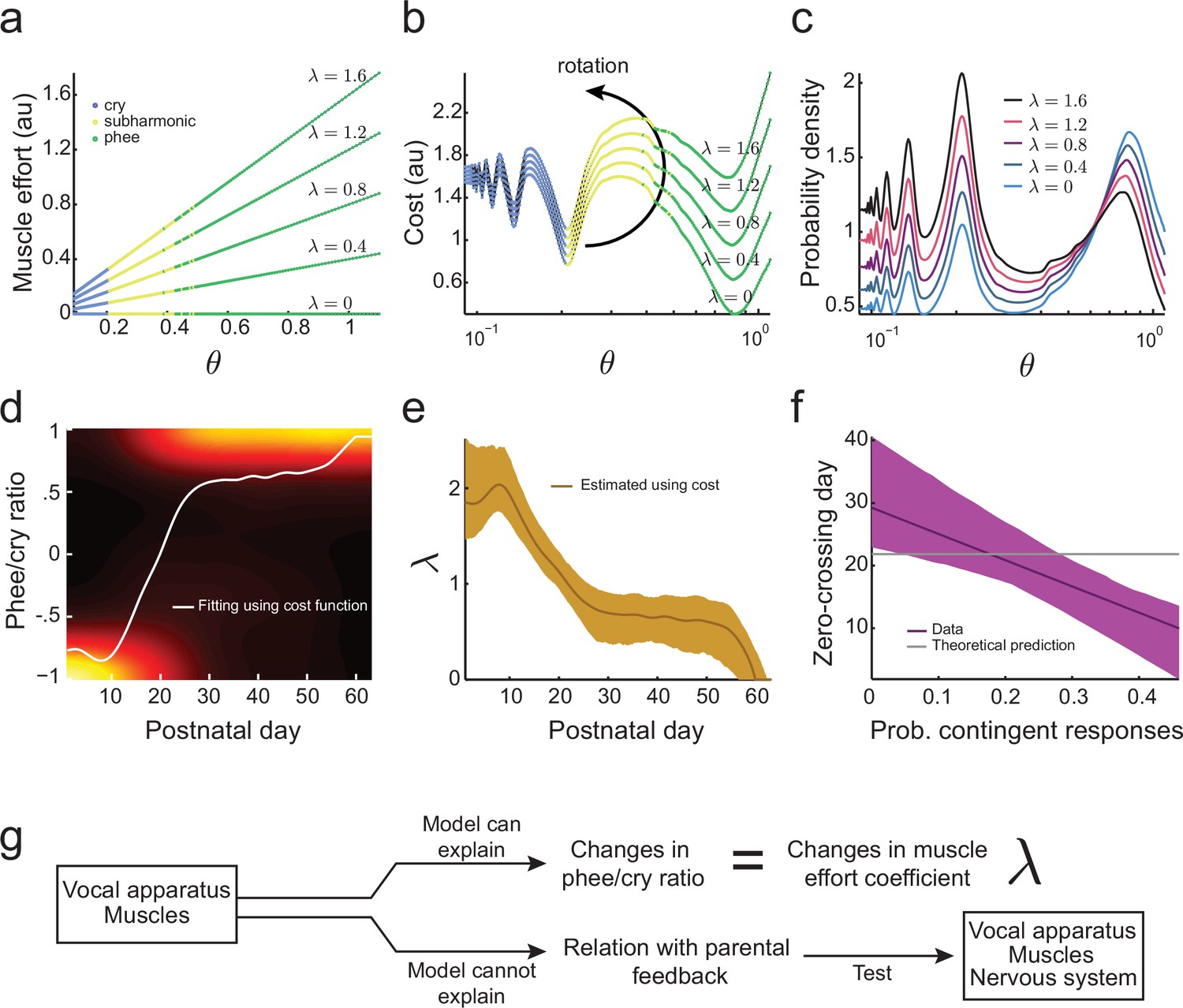
Development of muscular control in the vocal apparatus.
(a) Muscular control necessary to produce different air pressure and vocal fold tension; higher values of imply a greater effort to produce given air pressure and vocal fold tension. Blue, yellow, and green dots indicate parameter regions for cry, subharmonic-phee, and phee production, respectively. (b) Cost functions for different values of . (c) Probability to produce calls at different air pressure and vocal fold tension. For higher values of , probability to produce phee diminishes and the probability to produce cries increases. (d) Phee/cry ratio fitted by the model (white curve). Colors indicate the probability density of the phee/cry ratio for the marmoset population ( sessions); warmer colors indicate higher probability densities. (e) Estimated muscle effort coefficient () during development (brown curve); shaded region indicates confidence interval ( sessions). (f) Relationships between the probability of contingent parental responses and zero-crossing day for real data (purple line) and the model (gray line); shaded region indicates confidence interval ( infants). (g) Changes in muscular control can explain the population change in the phee/cry ratio, but not the social feedback-influenced the individual timing of this transition.
for . Figure 5b shows this cost function for different values of and . Higher values of increase the cost to produce phees (green) more rapidly than the cost to produce cries (blue). Therefore, the effect of adding to the cost function is to rotate the developmental landscape counter-clockwise, increasing the cost of producing phees.
Using the maximum entropy principle as before (softmax action selection rule Equation (3)), we can calculate the probability to produce calls for a given . As expected from the effect of on the cost function (Figure 5b), Figure 5c shows that higher values of imply a lower probability to produce phees and higher probability to produce cries. This indicates that the developmental transition from cries to phees can be a consequence of a decrease in (i.e., an increase in muscular control) during development. To test this possibility, we fitted the phee/cry ratio data using the cost function Equation (7) (Figure 5d). The fit follows the phee/cry ratio curve obtained from the directed context data obtained from infant marmosets (Figure 4f). Figure 5e shows the values of estimated by applying the model to these real data. As expected, we find that decreases during development (i.e., muscular control increases).
Thus, a two-element developmental landscape that includes vocal tract growth and the development of muscle control of the vocal apparatus can account for two key features of vocal development: lowering of the dominant frequency as calls become more mature and the rapid transition from early immature calls to mature ones. Our next question is whether this two-element landscape can also explain individual variability in the timing of the rapid transition. This timing is represented by the zero-crossing day (Figure 1d,e) when the number of immature and mature calls produced is equal (Takahashi et al., 2015). Our prior work demonstrated that the individual timing of the zero-crossing day appears to depend upon the number of contingent responses provided by parents when they hear the infant’s contact calls (Takahashi et al., 2015). Thus, to answer this question, we calculated the correlation between the zero-crossing day and the probability of contingent parental responses to infant calls (Takahashi et al., 2015). We observe that there are clear correlations between the amount of parental feedback and the rate of the cry-to-phee transition (Figure 5f, purple line) but these cannot be explained by the cost function that only includes the elements of vocal tract growth and muscular control improvements (Figure 5f, gray line). Therefore, an additional factor is needed, one that can control the vocal apparatus and is influenced by social feedback – the nervous system (Figure 5g).
Learning in the nervous system facilitated by social feedback accelerates the individual rate of vocal development
As in songbirds (West and King, 1988; Chen et al., 2016) and humans (Kuhl et al., 2003; Goldstein et al., 2003; Goldstein and Schwade, 2008), contingent parental responses appear to influence vocal development in marmoset monkeys (Takahashi et al., 2015, 2016). The timing of transition from a cry-dominated early developmental period to phee-dominated later period is correlated with the amount of contingent parental vocal feedback that each infant receives (Figure 1e) (Takahashi et al., 2015). Contingent parental responses are those that are produced within 5 s of an infant call. Infants that receive a higher proportion of contingent parental calls exhibit earlier transitions from cries to phees. This, of course, is social feedback-based reinforcement learning mediated by large-scale networks in the nervous system (Syal and Finlay, 2011). Given that increasing muscular control (i.e., decreasing ) increases the phee/cry ratio, we hypothesize that the change in the nervous system driven by social feedback affects the daily rate at which decreases during development. In light of this, the amount of change in would be proportional to the amount of parental feedback that the infant receives: a larger proportion of parental feedback will decrease by a larger amount. Therefore, we propose the following relationship between the value of as a function of time, , indexed by postnatal day, and the average proportion of contingent parental feedback, represented by :
(8)
Here is a parameter that models the effect of learning and can be calculated from the data. models the neuromuscular development that is independent of contingent parental calls. Like human infant babbling (Koopmans-van Beinum et al., 2001), infant marmosets will eventually produce adult-like calls with little or no parental feedback (Takahashi et al., 2015; Gultekin and Hage, 2017). Thus, the daily change in decomposes into two parts: one () that depends on parental feedback and another () that is independent of such feedback. Equation (8) implies that decreases linearly with :
(9)
where is the starting value at postnatal day 0. The new cost function for each postnatal day which includes vocal tract growth, muscular control and nervous system development is
(10)
where the subscript indicates dependence on time. Equation (10) derives from Equation (7) with replaced by from Equation (9).
Figure 6a shows the effect of different proportions of contingent parental calls on the development of as predicted by this cost function. If there is no parental vocal feedback (), e.g., the infant is deaf or raised in social isolation, still decreases, but at a slower rate determined by (black line). Figure 6b shows that the proportion of parental feedback is negatively correlated to the timing of transition from cries to phees. Therefore, learning in the developing nervous system facilitated by social feedback tilts the developmental landscape, so that the transition from cries to phees happens sooner and faster. Figure 6c (blue dots) shows the relationship between the proportion of contingent parental calls and the zero-crossing day in the data and the same relationship fitted using the cost function Equation (10) (yellow curve, see Materials and methods: The full cost function and more parameter choices for further details). The fitting shows that the relationship between the proportion of contingent parental responses and the rate of transition from cries to phees can be explained by the development of the nervous system facilitated by parental feedback. Nevertheless, this cost function does not explain why parents produce different amounts of contingent calls. Therefore, we have to consider how the social interaction with parents may depend on other variables of infant vocal development (Figure 6d).
Figure 6
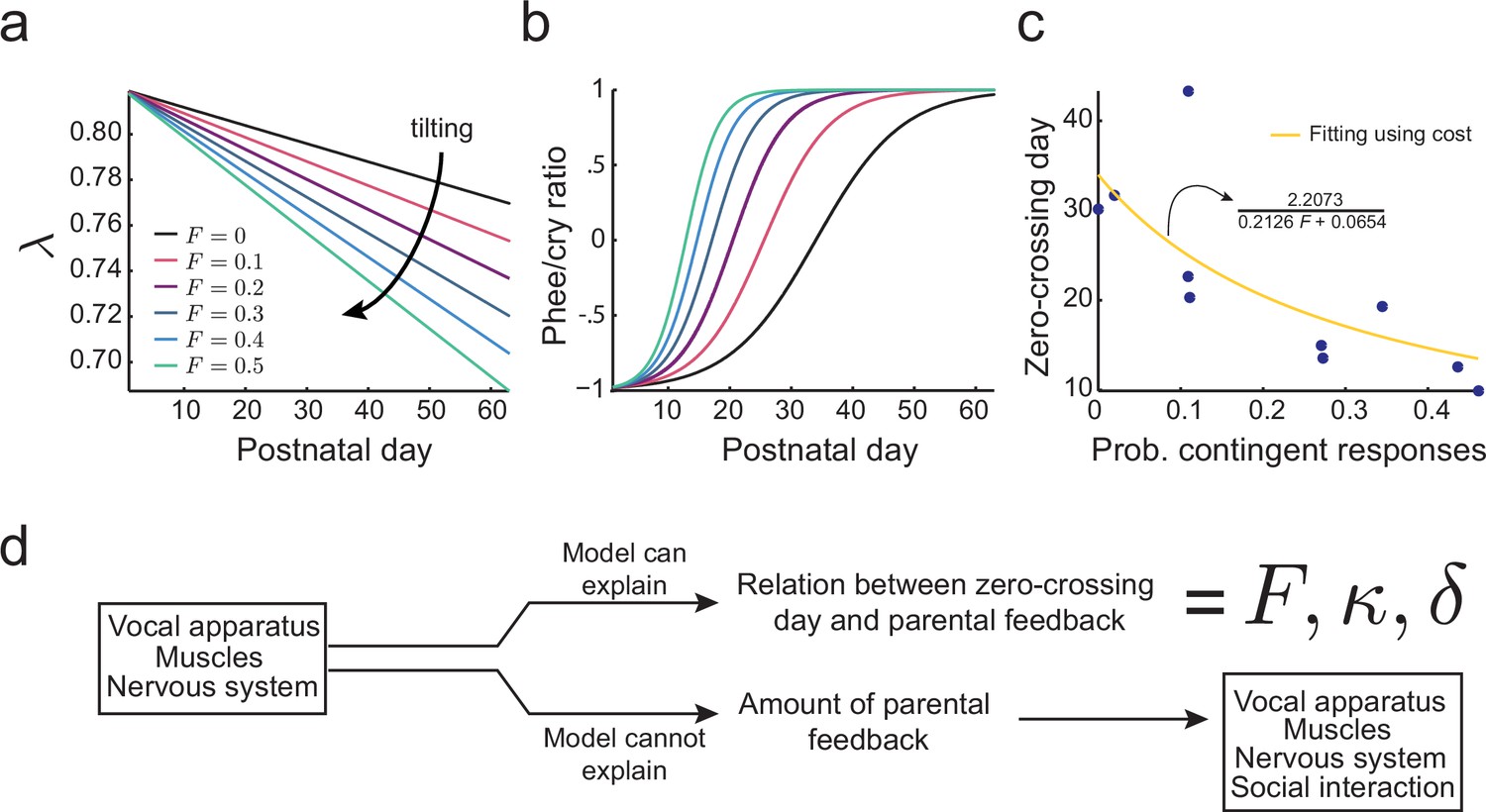
Learning in the developing nervous system.
(a) Developmental change of for different values of the probability of contingent parental response, , with constant learning parameter (see Materials and methods: The full cost function and more parameter choices). Higher values of parental feedback cause faster decay of . (b) Predicted phee/cry ratios for different values of the probability of contingent parental responses. Higher values of parental feedback cause earlier and faster transitions from cries to phees. Color code is the same as in (a). (c) Relationship between the probability of contingent parental response and zero-crossing day; blue dots represent real data ( infants) and yellow line is the model fit. (d) Changes in the nervous system can explain the relation between the rate of transition from cries to phees and the probability of contingent parental feedback, but not the amount of parental feedback.
Infant growth rate does not influence the probability of contingent responses from parents
The interactions between parents and an infant are predictive of overall health, quality of attachment and the subsequent communication skills of the child. Unhealthy infants who do not vocalize a lot tend to be fed and held less by mothers, and are slowed in their speech development and thus adversely affect the probability of interactions with parents (Zeskind, 2013; Lester, 1985). Differences in such vocal output can be related to differences in growth (Zeskind and Lester, 1981). Therefore, one hypothesis is that infant marmoset monkeys with faster growth rates call more and, as a result, receive more contingent feedback from parents which would accelerate the transition from immature to more mature calls. If this is true, then the higher frequency of parental feedback should be a consequence of parents responding to healthier, more vocal infants. If the hypothesis is falsified, it would suggest that the direct effect of parental feedback is to change the infant’s developing nervous system, thereby affecting the rate of this vocal transition independently of overall growth rates.
To model these relationships, let and respectively be the weight change over development (a measure of growth) and the call rate of the infant marmosets. We can write the frequency of parental feedback as a simple linear function:
(11)
where is noise independent of and , is the intercept, and , are coefficients relating and to . If or is different from zero, we have evidence of an indirect effect. To test this hypothesis, we fitted Equation (11) to the infant marmoset vocalization data collected in the directed context. We find that no coefficient is significantly different from zero (, , , , , ). We also tested whether and are separately correlated to (Figure 7a,b). Again, both correlations are not significantly different from zero (respectively, and ). This corroborates the alternative hypothesis that parental feedback has a direct effect on the infant nervous system that cannot be accounted for by the growth or call rates of infants.
Figure 7
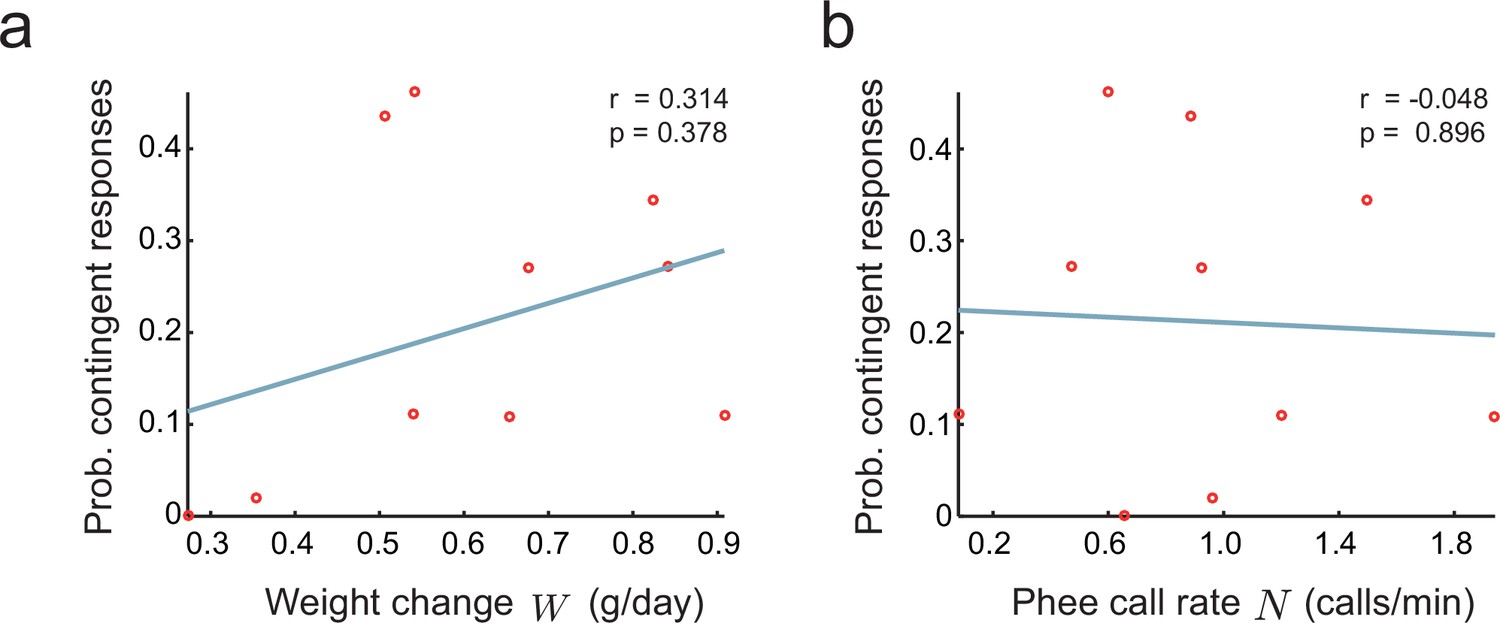
Relationship between parental feedback and infant growth.
(a) Relationship between rate of infant weight change and the probability of parental responses . Red circles represent data ( infants). Line indicates linear fit; Pearson correlation. (b) Relationship between rate of infant phee call production and probability of parental responses ; plot convention as in (a).
A dynamic and integrated Waddington landscape for vocal development
What makes an infant marmoset transition from immature to mature-sounding vocalizations? By combining the influences of the developing vocal tract, muscles of the vocal apparatus and the nervous system, we can now present an integrated landscape of vocal development in the manner envisioned by Waddington (Waddington, 1957). Figure 8a summarizes the relationships between these different elements of vocal production and the corresponding changes in vocal development. In our framework, these elements define the dynamics of the cost function, i.e., the shape of the developmental landscape. Figure 8b illustrates the landscape plotted over -space. Its interpretation is as follows: (1) Development of vocal tract length changes the resonance frequency by shifting the troughs/valleys of the landscape represented by the shape of (Figure 8c); (2) neuromuscular maturation increases the probability to produce phees by reducing the cost function by an amount per day, i.e. rotating the landscape from one postnatal day to the next (Figure 8d); and (3) nervous system development driven by social feedback further increases the probability to produce phees by tilting the entire landscape by an amount that is the product of the learning rate and the proportion of parental feedback (Figure 8e).
Figure 8
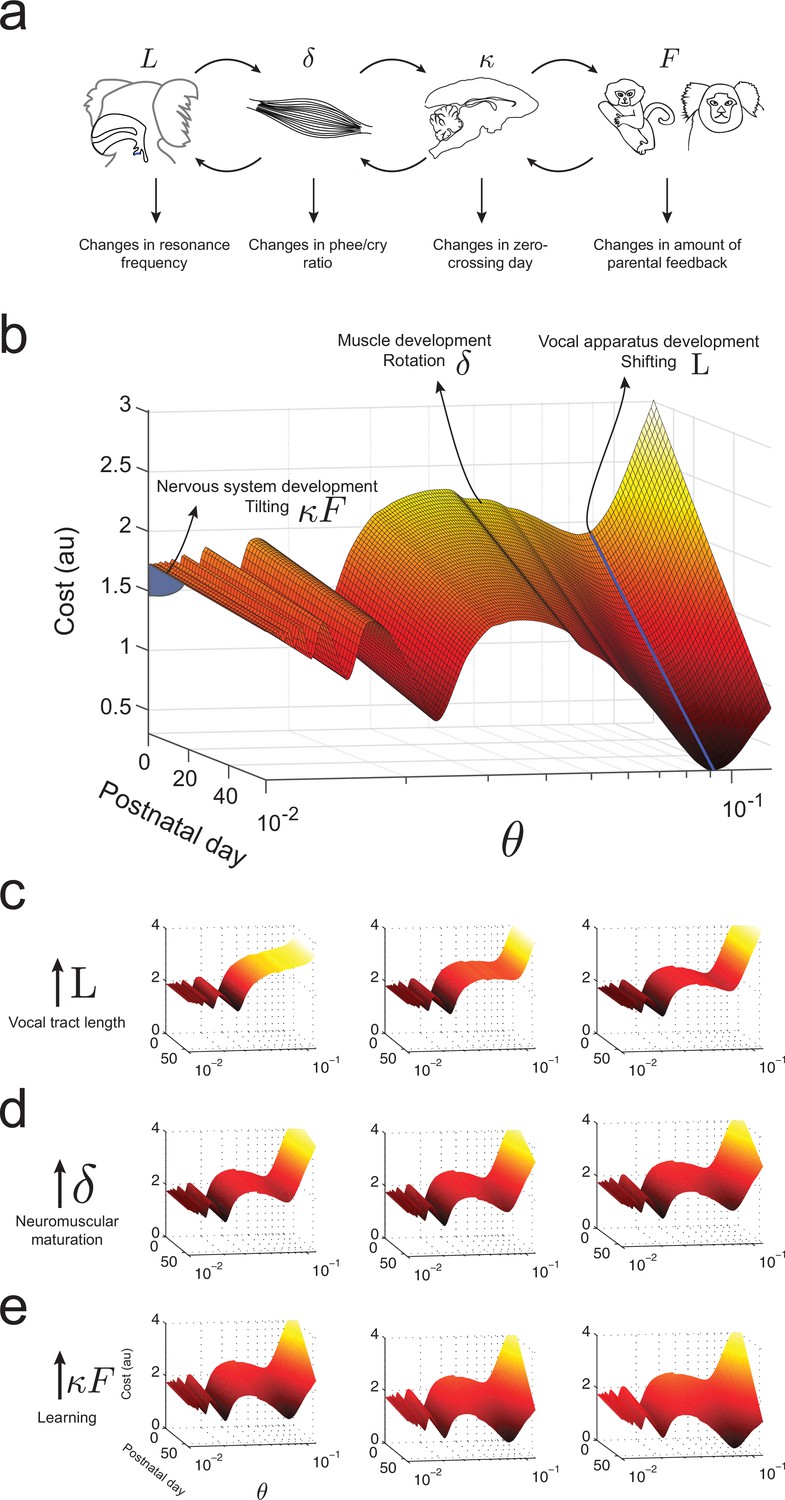
Waddington landscape for vocal development.
(a) Developmental changes associated with each vocal component: vocal tract length , neuromuscular maturation , learning rate , and parental feedback . (b) Different components of vocal behavior change distinct features of the developmental landscape. Similar colors indicate regions with the same cost values; darker colors indicate lower costs. The blue solid line shows the natural frequency of the vocal tract, which depends upon its length . Neuromuscular maturation parameter changes the shape of the landscape. The nervous system, influenced by parental feedback , changes the slope of the landscape, speeding up development as increases; -axis represents values in logarithmic scale. (c) Change in landscape as vocal tract length increases for fixed (left to right). (d) Change in landscape as neuromuscular maturation increases for fixed (left to right). (e) Change in landscape as learning rate times amount of parental feedback increases for fixed (left to right). See Table 2 for parameter values.
To better visualize the dynamics of the landscape as it applies to an individual marmoset infant’s vocal development, we can associate a diffusion process to it (Video 1). The video shows the states of a particle driven by the gradient of the cost function of Equation (10) and white noise, on 11 postnatal days separated by 6-day intervals. The position of the particle indicates the call types produced on that postnatal day and the amount of time spent producing each call. Much like the basins of attraction proposed for cell differentiation (Wang et al., 2011), the deeper the valley, the longer the diffusion process spends in it each day. As time elapses, the cost function deforms so that the probability of observing cries decreases and phees become more likely, with a zero crossing day in the third or fourth week, depending on the individual. See Materials and methods: Softmax action selection rule for more information.
Video 1
Animation showing a typical realization of a diffusion process with cost function as described in Materials and methods: Softmax action selection rule.
The particle travels through a developmental landscape that changes its shape due to changes in vocal apparatus, muscle strength, nervous system, and social interaction. The particle’s location represents the behavior of a marmoset infant. In early postnatal days, it stays mostly in the parameter region producing immature calls, whereas in later postnatal days, it stays mostly in the region producing more mature calls. Diffusion dynamics are shown at intervals of six days. Lower left panel shows the numbers of cries and phees produced in each simulated postanatal day; lower right panel shows the phee/cry ratio for the same postnatal days.
Discussion
Vocal development is a systems-level phenomenon. Its understanding requires the analysis of changes in the vocal apparatus, associated muscles, the nervous system and social interactions. Each of these elements modifies the others and itself over time (Thelen and Smith, 2006; Byrge et al., 2014). Using data from developing marmoset monkeys and optimal control theory, we generated a systematic and quantitative inferential framework based on Waddington’s developmental landscape metaphor (Waddington, 1957). We used it to account for three features of marmoset monkey contact call development: the lowering of the dominant frequency, the rapid transition from producing mostly immature to mostly mature calls, and the influence of social feedback on the timing of this transition (Takahashi et al., 2015).
We showed that the change in the dominant frequency of infant vocalizations can be explained by developmental increases in the length of the vocal tract. However, vocal tract growth could not account for the timing of the transition from immature vocalizations (cries), which are abundant in early postnatal days, to mature vocalizations (phee calls) which exemplify later periods. This transition can, however, be explained by including the development of muscular control. This suggests that immature respiratory and laryngeal muscles do not allow the infant marmoset to produce adult-like phees: calls that demand greater effort and/or coordination (Takahashi et al., 2015; Zhang and Ghazanfar, 2016). The development of the vocal tract and muscular control, however, could not explain how parental feedback influences the timing of the transition from immature to mature vocalizations. Including a learning component mediated by the nervous system allowed us to infer a relationship between contingent parental vocal responses and the rate of vocal maturation in individual infants. Thus, incorporating vocal tract growth, increased muscular control and learning-related changes in the nervous system into a single landscape allowed us to see how these elements interact over time and influence the trajectory of vocal development. This underscores the fact that neural networks do not function in isolation; they must typically process sensory data and communicate with muscles to create appropriate behaviors. The resulting coupling with physiological systems both enables and constrains the behaviors that such neural circuits can produce (Chiel and Beer, 1997; Tytell et al., 2011).
Vocal biomechanics of developing marmoset monkeys
The key to our optimal control-based elaboration of the vocal development landscape was the biomechanical model for vocal production. The model was originally developed to describe bird song production (Amador and Mindlin, 2008; Perl et al., 2011; Amador et al., 2013) and then adapted to model infant marmoset vocal production (Takahashi et al., 2015). The main advantage of the model is its ability to produce all infant marmoset calls by varying only two parameters: air pressure and vocal fold tension; continuous changes in these parameters can produce spectrally distinct cries, subharmonic-phees, and phees. These are sufficiently distinct that they were previously considered to be different types of calls (Pistorio et al., 2006; Bezerra and Souto, 2008).
The ability of our biomechanical model to generate such acoustic diversity contrasts with previous models. For example, the origin of cries in nonhuman primates has been attributed to turbulent or chaotic dynamics of the vocal folds (Fitch et al., 2002), perhaps as a consequence of vocal fold asymmetry (Herzel, 1993) and/or source-vocal tract interactions (Hatzikirou et al., 2006). Our model produces cries simply through a mismatch between the low frequency periodic glottal air flow and the higher frequency resonance of the infant’s upper vocal tract; no chaotic dynamics occurs. The primary difference between cries and phee calls is that the frequency of glottal oscillations is lower in the former (see Figure 9 (left)). This result provides direct biomechanical support for the hypothesis that cries are the scaffolding for vocal maturation in both marmosets (Takahashi et al., 2015) and humans (Kent and Murray, 1982).
Figure 9
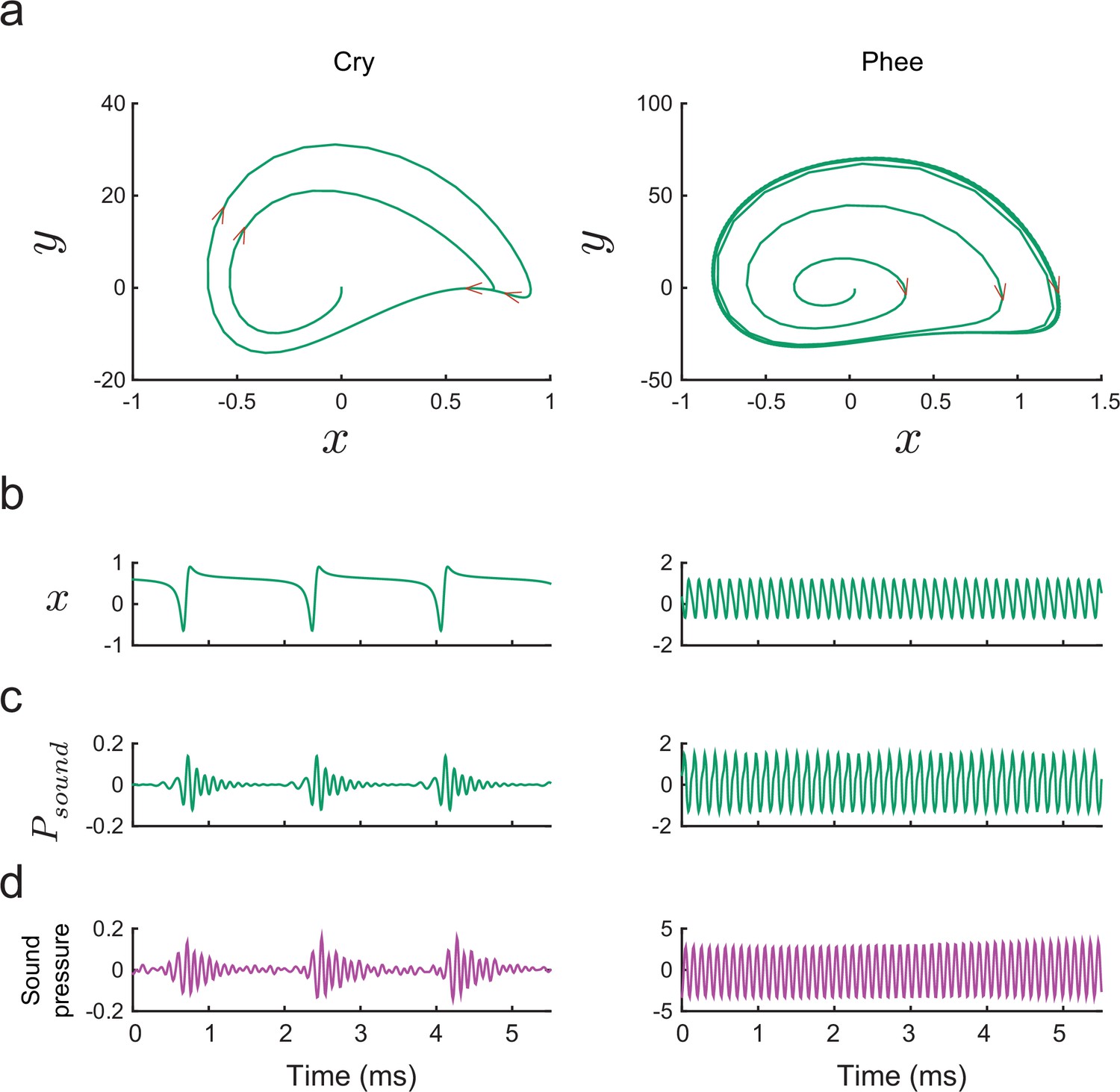
Producing marmoset cries and phees with the model.
(a) Trajectories of plotted vs. for Equation (14) for a cry (left) and a phee (right). Parameter values for cry and for phee respectively. (b) Glottal air flows produced by the model and (c) vocalizations produced after resonance in the vocal tract for a cry and a phee. (d) Cry and phee waveforms for calls recorded from infant marmosets; compare with model waveforms shown in (c). Note different vertical scales on left and right columns, indicating that phees are substantially louder than cries.
Vocal development as the transformation of a cost function
In our study, vocal development is understood as a transformation of the cost function through time as a consequence of changes in the vocal apparatus, muscles, nervous system, and social interaction. To calculate the probability that an infant marmoset produces cries, subharmonic-phees, or phees, we first defined the cost of producing a call with a given air pressure and vocal fold tension. We then calculated the probability of producing each type of call using the maximum entropy principle. The idea of a cost that changes in time to describe development goes back at least to Waddington’s epigenetic landscape metaphor (Waddington, 1957), but in Waddington’s formulation the metaphorical landscape is static and the paths that phenotypical differentiation might take are genetically determined. Modern perspectives using Waddington’s landscape metaphor (including the current study) think of development as probabilistic and allow the landscape to change shape over time (Thelen and Smith, 2006; Wang et al., 2011; Ferrell, 2012; Sasahara et al., 2015). For example, Sasahara et al. investigated the development of rhythmic structure in the songs of Bengalese finches using a landscape perspective. They showed that rhythm development exhibits branching and new trajectories along which early, simple vocalizations developed into diverse note types followed by specific silent gaps. The trajectory patterns differed considerably among individual birds, but rhythm proficiency progressed exponentially in all birds (Sasahara et al., 2015).
Some caveats: Selection of vocal elements, other behaviors, shape of trajectories and sequential order
In our probabilistic landscape, we inferred the role of vocal tract growth, muscular control and the influence of social feedback on nervous system development. This allowed us to explain – in an integrative manner – the role these elements together play in the transformation of immature to mature contact calls in developing marmosets. We used these somewhat generic elements to most clearly illustrate (in our view) the developmental phenomena, as there is no prior study of this kind. However, a more detailed landscape could certainly be generated by at least three means. First, more elements could be added. For example, lowering of the dominant frequency may also be due to growth-related increases in the size of the vocal folds (Hammerschmidt et al., 2000, 2001), but we only considered the vocal tract. Similarly, 'muscular control' and 'nervous system' in our landscape could be more specifically represented by separating the development of individual muscles and neural connections, respectively, related to vocal apparatus control.
Second, other infant behaviors may act as scaffolding or otherwise constrain or facilitate vocal development (Iverson, 2010). In the case of infant marmosets, the ability to self-monitor (and thus to take turns vocalizing with parents) matures in an experience-independent manner at the same time as they transform immature contact calls into mature versions (Takahashi et al., 2016). The current study did not incorporate how such changes in self-monitoring could also shape the developmental landscape for this vocal transformation.
Third, we made assumptions about the developmental trajectory of the elements. For example, we assumed that the development of muscular control and learning in the nervous system were linear processes. This simplification has the benefit of making clear the main phenomena in our framework, but more precise data on the developmental trajectories of muscles or learning-related neuronal activity would provide more accurate predictions. Our framework is general enough to incorporate such details for a deeper understanding. For example, if the linear functions can be replaced by more realistic, perhaps non-linear, functions relating air pressure, vocal fold tension and muscular control, they could be incorporated.
Finally, one part of our inferential sequence was that increased muscular control was due to learning-related changes in the nervous system via social reinforcement. An alternative inferential sequence could have been adopted. For example, improvements in muscular control independent of learning could have resulted in more mature-sounding infant calls and thereby increased the rate of parental vocal feedback. This would lead to a different explanation of the correlation between the rate of transition from cries to phees and the amount of parental feedback. We did not test this possibility in our inferential sequence because this hypothesis would be valid only if the change in social interaction were incorporated in the model before changes in the nervous system. The behavioral data do not support this alternative sequence of events: parental call rate, and strength of the dynamic interaction between infants and parents, remain constant throughout development (Takahashi et al., 2015, 2016). Thus, a change in social interaction driven by muscle development (before learning-related neural changes) cannot explain the relationship between parental feedback and rate of transition to more mature calls.
Applications of the vocal development landscape
An integrative understanding of vocal development is important for a variety of reasons, because while we know that many communication disorders originate in problems early in life, we lack any clear grasp of the initial problems. By the time a child is diagnosed with a disorder, the symptoms represent a build up of earlier developmental events. For example, the early vocalizations of infants elicit attention, care and vocal responses from parents (Lester, 1985; Zeskind, 2013). Infants who do not vocalize much tend to be fed and held less by mothers, and are slowed in their vocal development. The lack of adequate early vocal output by infants may be due to many factors, including abnormal growth of the vocal apparatus, weak laryngeal and respiratory muscles, and/or problems related to nervous system function, such as arousal dysregulation or deficits in motor control and learning.
Understanding the mechanisms for human communication, and how it may go awry, requires the use of model animals that naturally exhibit at least a subset of similar communicative behaviors. The early vocal development of marmosets shares a number of parallels with prelinguistic vocal development in humans (Ghazanfar and Zhang, 2016), perhaps due to convergent evolution of a cooperative breeding strategy (Borjon and Ghazanfar, 2014; Ghazanfar and Takahashi, 2017). Moreover, we are gaining knowledge of the genetics of this species (Harris et al., 2014) and, more specifically, the sensorimotor physiology related to its vocal production (Eliades and Wang, 2008; Miller et al., 2015; Zhang and Ghazanfar, 2016; Borjon et al., 2016; Roy et al., 2016). Recent innovations establishing genetically-modified marmosets (Sasaki et al., 2009; Okano et al., 2016) will allow for any number of experimental routes needed to gain novel insights into vocal development. The landscape framework in the current study could be used to make quantitative predictions on the effects of genetic or other types of experimental manipulations. For example, the landscape framework combined with genetic engineering could be used to make predictions regarding the influences of communication- or connectivity-related genes expressed during neuroembryological development in marmosets (Matsunaga et al., 2013; Kato et al., 2014).
Naturally, marmosets do not share with humans every aspect of postnatal vocal development. Songbirds, for example, are much better suited to investigate the shared mechanistic basis for more sophisticated forms of vocal learning (Lipkind et al., 2013), though such learning occurs at different life-history stages. The vocal development landscape may be used to illuminate why there are species differences in both the degree to which vocalizations can be learned and the life history-timing of such learning. For example, vocal development data from songbirds and humans could be used to generate landscapes for comparison with the marmoset landscape. Closely related species which differ radically in their vocal behavior could also be compared in this manner. For instance, the landscapes of New World squirrel monkeys, whose vocalizations change very little during development (Hammerschmidt et al., 2001), could be quantitatively compared to each other and with the marmoset landscape. Similarly, evolutionary insights could be gained by comparing vocal development landscapes of the white-rumped munia and its domesticated counterpart, the Bengalese finch, whose song behaviors and biologies differ considerably (Katahira et al., 2013; Suzuki et al., 2014). Moreover, as the evolution of a phenotype in essence defines its developmental trajectory, providing the developmental parameters for different species could illuminate how changes in their respective landscapes lead to similarities or differences in their adult vocal behaviors.
Overall, we believe that the integrated systems view provided by the vocal development landscape not only eschews the incorrect view that there are privileged levels of understanding behavior and its development (Noble, 2012; Krakauer et al., 2017), but also enables us to make predictions regarding how natural or experimental perturbations (e.g., changes in social feedback, weakening of muscles, disruptions of neural circuits, genetic engineering, etc.) will affect the development of vocal behavior, and why species differ in their capacity to learn communication signals.
Materials and methods
Subjects
All experiments were approved by the Princeton University Institutional Animal Care and Use Committee. The data analyzed in this work is a subset of the dataset that was previously published (Takahashi et al., 2015) and can be found at http://science.sciencemag.org/content/suppl/2015/08/13/349.6249.734.DC1. The subjects used in the study were 10 infants and six adults (three male-female pairs, 2 years old), captive common marmosets (Callithrix jacchus) housed at Princeton University. The colony room is maintained at a temperature of approximately 27°C and 50–60% relative humidity, with a 12L:12D light cycle. Marmosets live in family groups; all were born in captivity. They had ad libitum access to water and were fed daily with standard commercial chow supplemented with fruits and vegetables. Additional treats (peanuts, cereal, fruits and marshmallows) were used prior to each session to transfer the animals from their home-cage into a transfer cage.
Experimental procedures
Request a detailed protocolThe vocalizations of marmoset monkey infants were recorded starting on the first postnatal day in two different contexts: undirected (i.e., social isolation) and directed (with auditory, but not visual, contact with their mother or father). The details of the full experiments were described previously (Takahashi et al., 2015). Here, the experimental procedures are described in brief for the convenience of the reader. Early in life, infants are always carried by a parent. Thus, the parent carrying the infant(s) was first lured from the home cage into a transfer cage using treats. The infant marmoset was then gently separated from the adult and taken to the experiment room where it was placed in a second transfer cage on a flat piece of foam. The testing corner was counterbalanced across sessions. A speaker was placed at a third corner equidistant from both testing corners and pink noise (amplitude decaying inversely proportional to frequency) was broadcast at 45 dB (at 0.88 m from speaker) in order to mask occasional noises produced external to the testing room. An opaque curtain of black cloth divided the room to visually occlude the subject from the other corner. A digital recorder (ZOOM H4n Handy Recorder) was placed directly in front of the transfer cage at a distance of .76m. Audio signals were acquired at a sampling frequency of 96 kHz.
Every session typically consisted of two consecutive undirected experiments (one twin followed by the other) and one directed experiment (just one of the twins on a given day). Each session started with the undirected experiments lasting 5 min each. The order of the infants was counterbalanced. As soon as the undirected experiment was finished, one of the parents was brought to the experiment room and put into the opposing corner of the room. A second digital recorder (ZOOM H4n Handy Recorder) was placed directly in front of the parent at a distance of 0.76m from the transfer cage. During this setup procedure and throughout the directed experiment, the opaque curtain prevented the infant and the parent from having visual contact. The directed experiment lasted for min. The order of which parent participated in the interaction was counterbalanced. If the parent took more than 15 min to be lured for the directed calls experiment, the experiment was aborted to avoid any excessive separation stress on infants and parents. The number of undirected experiments with at least one call production was 40, 38, 38, 38, 37, 39, 19, 15, 16, 21 (10 infants, 301 sessions, 73,421 utterances). The number of directed experiments for each infant was 17, 13, 13, 18, 24, 24, 22, 21, 21, 22 (10 infants, 195 sessions). The number of subjects used in this study is based on a previous cross-sectional developmental study of marmoset vocalization that studied nine marmosets (Pistorio et al., 2006). A post hoc power analysis using G*Power 3.1 showed an achieved power of 0.818 for the correlation in Figure 5f (, Pearson’s , Type I error , ). All the experimental data used in this article is documented and can be found at http://science.sciencemag.org/content/suppl/2015/08/13/349.6249.734.DC1.
Detection of calls
Request a detailed protocolTo determine the onset and offset of a syllable, a custom made MATLAB routine automatically detected the onset and offset of any signal that differed from background noise over a specific frequency range. To detect the differences, the full recording signal was first bandpass filtered between 6 and 10 kHz. Second, the signal was resampled to a 1 kHz sampling rate, a Hilbert transform was applied and its absolute value was calculated to obtain the amplitude envelope of the signal. The amplitude envelope was further low pass filtered to 50 Hz. A segment of the recording without any call (silent) was chosen as a comparison baseline. The 99th percentile of the amplitude value in the silent period was used as the detection threshold. Sounds with an amplitude envelope higher than the threshold were considered as possible vocalizations. Finally, to ensure that sounds other than call syllables were excluded, a researcher verified whether each detected sound was a vocalization or not, based on the spectrogram.
Quantification of the dominant frequency
Request a detailed protocolAfter detecting the onset and offset of calls, a custom made MATLAB routine calculated the dominant frequency of each syllable. The dominant frequency of a syllable was calculated as the average frequency at which the spectrogram had maximum power. A cubic spline curve was fitted to the population data using the MATLAB csaps function.
Classification of type of call syllables
Request a detailed protocolEach automatically detected call was manually classified as phee, phee-cry, subharmonic-phee, cry, twitter, and trill, based on the spectro-temporal profile measured by the spectrogram. To ensure validity of our classification procedure, 10 sessions chosen at random were classified by two different individuals and compared. The classification matched in more than 99.9% of the call syllables. The six call types show very distinct spectro-temporal profiles and can be easily classified by eye (Pistorio et al., 2006; Bezerra and Souto, 2008).
Calculation of phee/cry ratio and zero-crossing day
Request a detailed protocolFor the directed calls experiments, a whole (i.e., multisyllabic) call was defined as any uninterrupted sequence of utterances of the same type (phee or cry) with previous offset to next onset separated by less than 500 ms (DiMattina and Wang, 2006; Takahashi et al., 2013). To quantify the developmental transition from cry to phee, for each session and subject, the ratio between the number of phees minus cries and the number of phees plus cries was calculated, i.e.,
(12)
A cubic spline curve was fitted to the phee/cry ratio data to obtain the phee/cry ratio curve. The zero-crossing day was defined as the first point at which the phee/cry ratio curve crossed zero, transitioning from a negative to a positive value. The zero-crossing day quantifies how quickly each infant transitioned from the cry-abundant initial period to phee-dominated later period.
Contingent/non-contingent responses vs. zero crossing day
Request a detailed protocolA parental call was classified as a contingent response to an infant call if the parental call onset was separated by less than 5 s from the infant call offset with no other call between them (Takahashi et al., 2015). To test if the contingent parental responses were related to how fast infants transition from cries to phees, we calculated the Pearson’s correlation and the linear regression between the proportion of infant phees to which the parents responded before the zero-crossing day (total number of contingent parental responses before the zero-crossing day divided by the total number of infant phees in the period) and the zero-crossing day. To calculate the correlation, only the proportion of contingent parental responses that occurred before the zero-crossing day were included to be consistent with the causal ordering in which the possible cause (contingent parental response) happens before the effect (zero-crossing day). We used MATLAB csaps function to calculate the correlation and significance test.
Biomechanical model of vocal apparatus
Request a detailed protocolTo investigate how nonlinearities in infant marmoset calls arise, and why they decline throughout development, we extended previous biomechanical models of the human speech production system. The resulting biomechanical model of the larynx and upper vocal tract is based on the one-mass model of Titze (Titze, 1988), which is simpler than earlier two-mass models (Ishizaka and Flanagan, 1972; Herzel, 1993; Lucero, 1993) and can produce a wide range of birdsong (Amador and Mindlin, 2008; Perl et al., 2011; Amador et al., 2013). In the next two sections we describe the model; further technical details are provided in the Appendix.
The vocal fold model
Request a detailed protocolTitze (1988) approximates vocal fold dynamics using two modes of vibration: lateral displacement of the tissues in the form of a mucosal wave, and a flapping motion due to out-of-phase oscillations at the entry and exit of the glottis (Perl et al., 2011). Titze’s model uses the body-cover hypothesis, which proposes that laryngeal vibrations are governed by muscles and cartilage that determine its geometry, and by its covering of soft tissue that allows waves to propagate in the direction of air flow. Bilateral symmetry in vocal fold oscillations is assumed, simplifying the system to a single degree of freedom oscillator of the form
(13)
where is the mass of the vocal folds and , and respectively their lateral displacement, velocity and acceleration; and are nonlinear damping and stiffness forces, is the driving force due to lung air pressure, and denotes time.
As we shall see, the functions and determine the kinds of dynamics produced, and they are typically written as power series. Even truncating these series at third order leaves many coefficients to be determined, and we therefore make a nonlinear change of coordinates that transforms Equation (13) to its normal form that appears in Figure 3a:
Here the number of coefficients or control parameters is reduced to 3. Normal forms preserve all qualitative aspects of the dynamics of the original system in the neighborhoods of critical parameter values where bifurcations (Guckenheimer and Holmes, 1983) occur and different dynamical behaviors appear. That this could be done for Equation (13) was first realized by Perl et al. (2011). In this case the parameters and (which may vary with time) represent lung air pressure and vocal fold tension, and is a time constant. Details on the derivations of Equations (13) and (14) are provided in the Appendix.
Figure 10
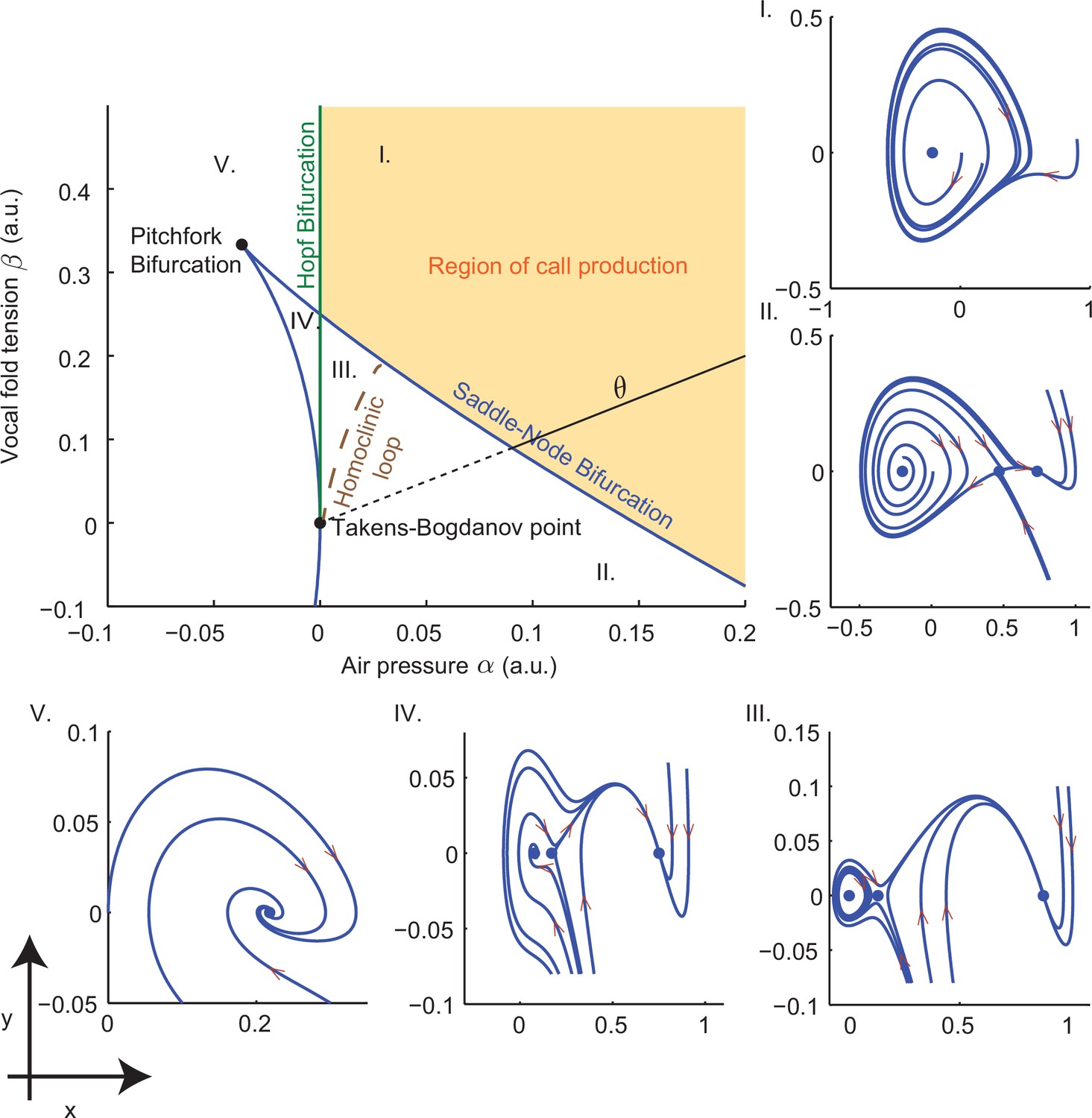
Bifurcation set and phase portraits of the model (Equation (14)).
Top left panel shows the bifurcation set in the parameter space spanned by air pressure and muscle tension . Solid curves indicate saddle-node bifurcations in which pairs of fixed points disappear leaving regions II, III and IV, and Hopf bifurcations in which a stable limit cycle appears entering region I from region V and region III from region IV. Phase portraits in -space illustrate vocal fold dynamics in regions I-V. Sustained oscillations surrounding a source produce calls in region I; a source, sink and saddle coexist with a small limit cycle in region III, but viable calls are not produced. A unique sink exists in region V, two sinks and a saddle in region IV, and a sink, saddle and source in region II; no sustained oscillations appear in these regions. Solid part of the line labeled starting at the Takens-Bogdanov point indicates the axis used in evaluating cost functions. Note that region of -parameter space is smaller than that in Figure 3f–i.
Models such as Equations (13) and (14) have been fitted to experimental data and model simulations have been compared with human vocalization and bird song (Mergell et al., 2000; Sitt et al., 2008; Zañartu et al., 2011; Amador et al., 2013). However, vocal production in marmosets has not been extensively studied and detailed measurements of lung pressure and muscle activity are lacking. As a proxy for this data, recordings of different marmoset calls were used to fit model parameters in the present work. The relative simplicity of the normal form (14) is helpful in this regard.
From vocal fold vibrations to calls
Request a detailed protocolEquipped with a simple model of laryngeal dynamics, we next derive the resulting sound pressure signals emitted from the mouth. Again seeking simplicity, we appeal to source-filter theory, which assumes that the vocal fold dynamics are independent of filtering within the upper vocal tract (Titze, 1994). The derivation of Titze (Titze, 1988), outlined in Appendix §§1.1.1-1.1.2, shows that the pressure at entry to the upper vocal tract is proportional to at the midpoint vocal fold position. Figure 9a shows phase space plots of and for air pressure and vocal fold tension corresponding to a cry (left) and a phee (right). Figure 9b shows the corresponding time histories of . The resulting pressure changes propagate through the upper vocal tract and mouth cavity, which we model as a uniform cylinder. At the exit from the cylinder, part of the wave is reflected back towards the entrance (glottis) and the rest is transmitted as sound. Letting be the time for sound to travel the length, , of the cylinder, the supraglottal pressure, , at the inlet to the upper vocal tract has the following form:
(15)
where is a function of (Appendix §1.1.2) and is the reflection coefficient. Near any given point the time-dependent function may be approximated by a Taylor series, and ignoring second and higher order terms we obtain
(16)
and is a nonnegative constant. In Takahashi et al. (2015) a third order approximation was used (see Appendix 1.1.2, Equation (34)), but given that the higher order terms are small and produce only minor effects, here we use only the first order term.
Note that the vocal fold dynamics determined by Equation (14) are independent of sound pressure in the vocal tract, but the incoming pressure is affected by the reflection . Finally, the emitted sound is the part not reflected back towards the vocal folds:
(17)
Figure 9c shows the signals which result from the effect of resonance on in Figure 9b for comparison with waveforms from examples of a cry and phee recorded from an infant marmoset in Figure 9d.
Unlike the zebra finch song model of Amador et al. (Amador et al., 2013), we do not model the mouth cavity separately; our model can reproduce typical marmoset calls well without this refinement, as shown in Figure 3b–e. Thus, the mathematical model is defined by Equations (14) and (16–17). The components of the model are summarized in Figure 3a in relation to those of the marmoset’s vocal apparatus in panel (a), and Table 1 lists parameter values and ranges used in simulations. To verify that the model could reproduce realistic marmoset calls, the parameters were fit manually to match the spectrotemporal data of calls as shown in Figure 3b–e.
Table 1
Parameter values used for simulations to fit marmoset calls. The notation means that values are chosen in the range 0 to 1.1.
| Parameter | Description | Value(s) |
|---|---|---|
| Time step size (s) | 5 | |
| Nondimensional pressure | ||
| Nondimensional muscle tension | ||
| Time constant (1/ms) | 45 | |
| Pressure coefficient | 1 | |
| Pressure reflection coefficient | 0.8 | |
| Time for one way sound travel in vocal tract (s) | 50 |
Numerical simulations
Request a detailed protocolNumerical simulations of Equations (14) and (16–17) were carried out using Euler’s method in custom written MATLAB codes. Parameter values are given in Table 1. To generate the simulated calls, we varied and within the range and matched the frequency spectra and temporal profiles of the simulated sound to the corresponding vocalizations. To improve the fit between the model and recordings, pink noise was added to the simulation to match its presence in the background of the exemplar vocalizations in Figure 3b–e, using the MATLAB pinknoise function (file exchange #42919 by Hristo Zhivomirov [Kasdin, 1995]). The parameter was held fixed for the cry, while was ramped up and down in a piecewise-linear manner; for the other calls, both and were ramped up and down to produce the varying fundamental and harmonic frequencies of calls such as those in Figure 3c–e. High pass filtering of was done using MATLAB eegfilt.
Below, we provide the MATLAB code used to solve Equations (14) and (16).
function [x, y, p_in] = funcamador(gamma, a, b, r, T, c, x1, y1, dt)
%FUNCAMADOR.M This function will use the Euler method to simulate the
%motion of the vocal folds.
% This simulation will run for 1 s with time step dt and with
% initial conditions x1 and y1.
%% Initializing system
t = 1000;
N = floor(t/dt);
x = zeros(1,N + 1);
y = zeros(1,N + 1);
x(1) = x1;
y(1) = y1;
p_in = zeros(1,N + 1);
%% Simulating using Euler
for n = 1:N
x(n + 1) = x(n) + dt*y(n);
y(n + 1) = y(n) + dt*(-a*gamma^2 - b*gamma^2*x(n) + gamma^2*x(n)^2 ...
- gamma*x(n)*y(n) - gamma^2*x(n)^3 - gamma*x(n)^2*y(n) );
if n < T + 1
p_in(n + 1) = c*x(n);
else
p_in(n + 1) = c*x(n)- r*p_in(n-T);
end
endDynamics of the biomechanical model
Request a detailed protocolCombination calls like that of Figure 3e suggest that infants can dynamically modulate their vocal output by relatively small muscular changes, since switches between the call types occur very rapidly (Zhang and Ghazanfar, 2016). We show that small changes in air pressure () and laryngeal muscle tension () can switch our model’s output from cries to phees.
Figure 10 illustrates the vocal fold dynamics produced by Equation (14) over a range of values of air pressure and muscle tension . The top left panel shows curves in -space on which bifurcations of fixed points (equilibria) of this equation occur. As parameter values cross these curves, equilibria appear or disappear, their stability types change, and limit cycles representing sustained periodic oscillations in can appear, as illustrated in the phase portraits corresponding to regions I-V. Appendix §1.1.4 details the calculations that yield the bifurcation curves.
Only in the shaded region I, lying above the upper saddle-node bifurcation curve and to the right of the Hopf bifurcation curve, do robust stable limit cycles and hence calls exist, to which almost all solutions converge. Each passage around the cycle corresponds to the vocal folds opening and closing once. Moreover, as approach the saddle-node bifurcation curve from above, the period of oscillations grows to infinity, so that small changes in these parameters can produce large changes in waveform and hence spectral content. In this region varies rapidly and slowly in different parts of the cycle, implying a broad frequency content (see Figure 9a,b (left) above). This extreme sensitivity is responsible for the rapid switches from cries to phees as lung pressure and/or vocal tension increases.
No other regions reliably yield calls. Values of cannot produce sustained oscillations, because in region V there is a single stable equilibrium and in region IV there two stable equilibria and a saddle point; in both cases all solutions converge on equilibria and no sound is produced, consistent with the biological intuition that low driving pressure produces no sound. In region II one stable and one unstable equilibrium coexist with a saddle, again without limit cycles, and all solutions approach equilibria. A small stable limit cycle surrounds the unstable equilibrium in region III, but random perturbations due to noise typically drive the system to the stable equilibrium, thus quenching the oscillations.
We therefore focus on parameter values in region I. Since Equation. (14) only captures the behavior of the original vocal fold model of Titze (1988) locally (Figure 11; see Materials and methods: The vocal fold model), we restrict the control parameters to and and use numerical simulations to fit values of , that produce the spectrograms and waveforms of calls of interest. The remaining parameters , , and were chosen to reproduce observed resonant frequencies and sound pressure levels, as described in Appendix §1.1.2, and were fixed at the values listed in Table 1, unless otherwise specified.
Figure 11
The larynx and glottis model.
The coordinate system is shown with fixed depth , lateral displacement at midpoint, cross sectional areas at larynx entry and exit, at midpoint, air pressures , and prephonatory widths at entry and exit. Adapted from Titze (1988).
Parameter dependence of the calls
Request a detailed protocolWithin the parameter ranges that stably produce calls, we investigated the relationship between parameter values and characteristics of the resulting model call. To obtain these, we iterated over many parameter values, recorded the natural frequency and amplitude of the calls produced, and computed their gains and , as shown in Figure 3i.
Fitting the resonance frequency and estimating the vocal tract length
Request a detailed protocolFor a closed-closed tube, the fundamental frequency is given by Hz (Kinsler and Frey, 1962), which provides the relationship . We used m/s. We then calculated the resonance frequencies of the biomechanical model for upper vocal tract lengths mm and interpolated the frequency over this range with a cubic spline curve, thus relating to the resonance frequencies . Using a second cubic spline curve fitted to the marmoset data and the relationship between and the resonance frequencies obtained previously, we calculated the corresponding vocal tract lengths . For the data we used the dominant (highest amplitude) frequencies as surrogates of resonance frequency. The 95% confidence interval for the resulting estimated vocal tract lengths were calculated from the dominant frequency data by resampling with replacement 1000 times and repeating the estimation method on each of the resampled data sets.
Classifying the type of call in the model
Request a detailed protocolInitially, the calls produced by the model were classified manually as had been done with the infant recordings (Takahashi et al., 2015). To facilitate analysis of the model, an automatic classifier was developed and manually validated on a smaller sample. For each pair (, ), the call was simulated for one second. The envelope was calculated using the Hilbert transform of the call lowpass filtered at 4 kHz. Then, the power spectrum of the modeled call and that of its envelope were calculated. Cries are generated by a combination of slow vocal fold vibrations and resonance (Figure 9 (left)). Therefore, we expect the power spectrum of the amplitude modulation to contain a peak for the cry but not for the subharmonics or phee. To differentiate between the latter we compared the relative power of the first and the second peak of the power spectrum of the call itself. For the phee, we expect the first peak to be , and hence the largest peak in the spectrum. In contrast, for subharmonics we expect peaks of the power spectrum to occur below the resonance frequency, so the largest peak will not be the first. As a result, if the first peak was larger than the second peak, then the call was classified as a phee and otherwise as a subharmonic.
Softmax action selection rule
Request a detailed protocolThe softmax action selection rule is obtained by applying the maximum entropy principle. We state the principle in a simplified form that suffices for this article. Let be a cost function which may also be called an ‘observable’ or ‘utility’ of the system. Assume that has expected value . Given a cost function , a natural question is to know what is the probability distribution that the animal will execute a specific action. In our case, knowing the cost of producing a vocalization, we ask what is the probability that a marmoset will produce a call with air pressure and laryngeal tension . The maximum entropy principle specifies that the probability density associated with the cost function should be the one that maximizes the entropy and satisfies the expectation constraint . In other words, the maximum entropy principle states that given a cost function and a constraint, we must choose a probability distribution that makes the fewest possible assumptions (because maximal ignorance equates to maximal entropy). Such a probability distribution is said to follow the softmax action selection rule and can be written as , where is a normalizing constant so that and is chosen to satisfy the constraint on the expected value of . Probabilities were computed using a right Riemann sum approximation.
A complementary way to understand the softmax action selection rule is to introduce gradient dynamics with a potential derived from the cost function (Video 1). More precisely, consider the diffusion equation
(18)
where is the gradient of and is a Wiener process. The equilibrium probability distribution for the dynamics of Equation (18) is given by Equation (3):
(19)
The resulting diffusion process therefore has an equilibrium measure given by the probability distribution predicted by the softmax action selection rule. If vocalizations are produced at periodic intervals (approximately once per second in infant marmosets [Zhang and Ghazanfar, 2016]), with the parameter defined by the stochastic process , then the probability of producing each call type is given by the time that spends in each valley of the cost function . This probability is found by integrating over the parameter region defining each call type, as in Equations (5) and (6).
To generate the simulations for Video 1, we approximated the diffusion process (18) by a random walk with a potential that is a discretization of . To allow rapid visualization of the typical diffusion dynamics, we arbitrarily sped up the timescale.
Calculating from the data in Figure 5
Request a detailed protocolThe cost function that only includes the contribution of vocal apparatus and muscle control is given by
(20)
To estimate the values of for each postnatal day, we first fitted a cubic spline curve to the marmosets' phee/cry ratio data. Then we calculated the value of that best approximated the phee/cry ratio curve for each postnatal day. The exact values of depend on the choice of , but the difference is only in the scaling factor and the result in Figure 5e is representative for any choice of . In Figure 5c,e we used . Larger values of have a similar effect, but since the probability densities are more concentrated on the peaks it is harder to display the effects of different ’s in analogues of Figure 5c,e.
The full cost function and more parameter choices
Request a detailed protocolThe final time-varying cost function with all its parameters can be written as
(21)
We can decompose as follows. The biomechanical contribution is represented by , where the dependency on time comes from the change in the vocal tract length or equivalently from the time for sound to traverse the cylinder. The change in muscle development is represented by , the change in the nervous system by , and represents the contribution of social feedback. To obtain the sharp transition from low to high phee/cry ratio, a good value was (Figure 6b). With this parameter, the zero-crossing day occurred when , implying that
(22)
We chose so Equation (22) yields (see Figure 6c). Any value of would give the same curve fitting as we need only to rescale and accordingly. is the only parameter that cannot be estimated from the data. Fitting the function to the data relating the amount of parental feedback () and zero-crossing day , we get and . Table 2 lists the parameters used to produce Figure 8b–e.
Correlating with and
Request a detailed protocolWe tested if the rate of weight change and the rate of infant phee production before the zero-crossing day could predict the frequency of parental feedback . To calculate the weight change we first calculated the difference between two consecutive weight measurements and divided by the number of days between them to obtain the local rate of weight change. The overall rate of weight change was calculated as the average of local rates of weight change before the zero-crossing day. If there were a linear relationship between the weight change and the frequency of parental feedback, we would expect a significant Pearson correlation () between these parameters. We also fitted a multiple linear regression between the explanatory variables and , and the dependent variable . We applied the two-sided t-test to verify the nullity of regression coefficients ( infants). We concluded that neither infant weight increases nor changes in phee call numbers could predict the frequency of parental feedback.
Appendix 1 Derivation of the biomechanical model
In this appendix we review background material on laryngeal dynamics and vocal production models, and provide details on the derivation of the biomechanical model and the normal form of the vocal fold equations used in this paper.
1.1 The biomechanical model
As in recent work on songbirds (Perl et al., 2011; Amador et al., 2013), we base our model on Titze’s work on human vocal fold dynamics and voice production (Titze, 1988). We briefy summarize conservation laws from fluid mechanics (e.g. Bird et al., 2007, Chap. 3), which are used in deriving the model, and then outline its simplification via coordinate transformations to obtain the normal form describing vocal fold dynamics (Equation (14) in the main text):
In the process we find that the usual procedure, using Taylor series expansion about a degenerate (codimension 2) fixed point with a double zero eigenvalue and assuming linear and cubic order stiffness and damping terms, yields the term instead of as in Perl et al. (2011), Amador et al. (2013), and we indicate a modification to the damping term in the original model of Titze (1988) that would produce Equation (23). We explain the reason for this difference and also derive explicit expressions in terms of the parameters for which bifurcations create steady and periodic states relevant for vocalizations.
1.1.1 Conservation laws for one-dimensional flows
Bernouilli’s law expresses the conservation of energy in a fluid flowing at velocity through a frictionless pipe:
(24)
where and denote fluid pressure and density, the acceleration due to gravity, and the height of the pipe. Variations of gravitational energy in the respiratory and vocal system are insignificant, and we need only consider the balance of potential and kinetic energy in the first and third terms of (24). The mass flow rate also remains constant but cross sectional areas can change. Across such a change from area to , these conservation laws imply that
(25)
where the subscripts denote values in the locations of areas and . In writing Equations (25) we have also assumed that changes in density are negligible ( constant). Titze, 1988, uses these equations to express pressure differences across the vocal folds.
1.1.2 Vocal fold dynamics and coupling to the upper vocal tract
We describe vocal fold dynamics in terms of two modes: displacement of tissue in the direction of airflow, and lateral flapping due to antiphase motions at the entry and exit of the larynx. The tissue displacement is approximated by a traveling mucosal surface wave of fixed shape, as in d’Alembert’s solution of the classical wave equation (Greenberg, 1978), that couples time and space dependence. This implies that the lateral displacements and at entry and exit of the larynx can be written in terms of the displacement and velocity at the midpoint of the vocal folds. Section IIA of Titze (1988) approximates the wave by a linear function, and letting denote the time taken for it to travel half the length of the glottis, obtains
(26)
The resulting cross-sectional areas at entry and exit of the glottis are therefore
where is the depth of the glottis and and are the prephonatory lateral positions of its lower and upper ends in the absence of airflow: see Figure 11. We do not model the flow in the trachea, assuming that it simply transmits lung pressure to the larynx (see below).
As indicated in Figure 11 (cf. Figure 3a), we assume bilateral symmetry and represent the vocal folds, moving in antiphase on left and right, by a mass supported by a spring, subject to dissipative forces and driven by the transglottal pressure. The second order ordinary differential equation (ODE) that describes the resulting dynamics therefore has the form
(28)
where the nonlinear terms and represent energy dissipation and spring stiffness, and the last term is the driving force due to the mean pressure averaged over the glottis from entry to exit, applied to the glottal area measured at the midpoint of the vocal folds. Using Equations (25) and several simplifying assumptions, (Titze, 1988), ( see § IIB-C, Figure 5 and Equation (21) of the reference) shows that, when subglottal pressure is equal to lung air pressure , vocal tract input pressure is atmospheric, and supraglottal area is large relative to , can be approximated as
(29)
where is a kinetic pressure coefficient representing losses in the entry and glottis and recovery in the supra-glottal expansion region.
Vocal fold dynamics
We follow Perl et al. (2011) in assuming third order nonlinearities in the stiffness and damping terms of Equation (28), and using Equation (29) and Equations (27a–27b), obtain the system
cf. Titze (1988), Equation (22) and Perl et al. (2011), Equations (1–3). Here the parameters and are positive and may take either sign. Note that some symbols differ from those of Perl et al. (2011) and that we have replaced the nonspecific damping term in Perl et al. (2011), Equation (1) by the linear damping term . Equation (30) contains 11 parameters, most of which are unknown, but our subsequent reduction to the normal form Equation (23) with an overall time scale and two nondimensional parameters analogous to and will allow us to fit fundamental call frequencies and explore the biophysical space of muscle tension and driving pressure. However, as shown below, to obtain this normal form, also given in Perl et al. (2011), Equation (8), may require inclusion of a quadratic damping term or an additional forcing term (Amador, 2009). Henceforth we assume that all parameters are held constant, because the normal form theory used here applies only to autonomous ODEs.
Coupling to the vocal tract
In Titze (1988), Equation (35) models the fluctuating input pressure to the vocal tract as , where is the flow rate at glottal exit and are the tract’s input resistance and inertance. The flow derivative is therefore , but for simplicity we assume quasi-steady flow . Thus, from Equation (27b), we obtain
(31)
and we may write the input pressure in terms of the vocal fold displacement as
(32)
Vocal tract dynamics
The supraglottal vocal tract and mouth cavity filter the input pressure . In the absence of details on marmosets, we model the entire supraglottal sytem as a cylinder supporting traveling plane waves, a fraction of which are reflected back from the exit at the mouth, and the remainder transmitted to produce the animal’s calls. Letting denote the time taken for waves to travel at speed to the exit and back and be the reflection coefficient, this adds a delayed and scaled copy of the input pressure to Equation (32):
(33)
Collecting the terms multiplying and yields the series approximation
(34)
which appears as Equation (16) in the main text. For further details see Titze and Alipour, (2006), Ch 7. The part of not reflected produces the transmitted sound pressure : Equation (17) in the main text. We note that the parameters used by Takahashi et al. (2015) prompted our neglect of and in Equation (16) in the main text.
1.1.3 Normal form transformation
Here we explain how the simplified normal form ODE may be derived from the version of Titze’s model of vocal fold dynamics adopted by Perl et al. (2011), Equations (30) above. For a general introduction to normal forms and analyses of relevant examples, see Guckenheimer and Holmes (Guckenheimer and Holmes, 1983, §3.3 and §7.3).
In studying linear ODEs of the form , where is an -vector and is an constant matrix, it is helpful to change coordinates via a similarity transformation , where is a matrix whose columns are eigenvectors of . In the -coordinates, the ODE becomes and is a diagonal matrix containing the eigenvalues of . The transformation decouples the variables, making analyses much simpler; it also effectively reduces possible matrix entries to the eigenvalues. In a similar manner, normal form theory allows one to simplify nonlinear ODEs , where the components of are polynomial functions.
We start by nondimensionalizing the displacement and velocity in Equation (30), letting and renaming parameter groups for convenience. to obtain:
Here is the glottal timescale from Equations (26), is an overall inverse timescale, velocity also has dimension time and the remaining parameters are dimensionless. Note that all the parameters excepting and are strictly positive; in particular coefficients of the terms and on the right hand side of Equation (35b) must be negative for global stability of the vocal fold dynamics.
Fixed points of Equations (35a–35b) lie at , where solves the quartic equation
(36)
and to obtain the normal form we will make a Taylor series expansion about a double root at which the Jacobian matrix of Equations (35) has a zero eigenvalue of multiplicity 2. For and there are three biophysically relevant roots and (the root corresponds to a closed glottis). For small and
(37)
a double root occurs at
(38)
If we additionally choose the dissipation parameters such that
(39)
the Jacobian matrix of Equation (35) linearized at the degenerate fixed point is
(40)
This linear part identifies a Takens-Bogdanov point (Guckenheimer and Holmes, 1983, §3.3,§7.3), see §1.1.4 below. Note that Equation (39) implies that and . Thus, at this point the nondimensional pressure , and dissipation parameters are all small and scaled in fractional powers of the linear stiffness , which is also small and negative.
We now expand the right hand side of Equation (35) in a Taylor series about that may be written in vector notation as
(41)
where denotes the deviation from and the are homogeneous polynomial functions of order . In general, all possible terms may occur in each of these functions: six in , eight in , etc. We next define a new variable via the near-identity transformation
(42)
where the functions are homogeneous polynomials in . Under this change of variables Equation (41) becomes
(43)
in which the functions can be significantly simplified by suitable choices of the ’s.
Specifically, differentiating Equation (42) with respect to time and using the chain rule, we obtain and thereby find that
(44)
where denotes the Jacobian matrix of first order derivatives of . As shown in Equation (43), the first order (linear) term in this ODE is (it is unchanged by the transformation ), but the quadratic order function is
(45)
We now seek to choose the six terms in the two components of the quadratic vector function to cancel as many of the analogous terms in as possible. The matrix determines the extent to which this can be done via the Lie Bracket operator ad, where denotes the linear part of Equation (41) and the Jacobian matrix of first partial derivatives of . In general ad is a homogeneous polynomial of order , so transformations of increasing order can successively remove terms in the ‘new’ nonlinear functions .
For the matrix (40) all quadratic terms except those of the forms
(46)
can be removed, and a similar computation using shows that all cubic terms except
(47)
can be removed (Guckenheimer and Holmes, 1983, §3.3). These are precisely the four nonlinear terms that remain in the normal form Equation (23) adopted by Amador et al. (2013) (similar pairs of terms would remain at each higher order power). However, in performing the transformation to remove terms of from , additional terms of and higher are introduced. Except for multiples of those in Equation (47), these can be removed by a subsequent transformation , but to obtain the correct ODE at cubic order terms of the forms (47) must be included. Since we will neglect all terms of , this analysis is strictly valid only for sufficiently small state variable values and in a neighborhood of the Takens-Bogdanov point, implying that the parameters and should also remain small.
We now describe the specific transformations employed to derive the normal form. As noted above we first change coordinates to shift the degenerate Takens-Bogdanov point occurring for the parameter values of Equations (37–39) to the origin. To avoid excessive notation, we retain the notation for the vocal fold displacement, now measured relative to :
where
There are similar expressions for the coefficients and but since they can be removed from the they are not needed here. At the term can be removed by the transformation
(50)
which, via the Lie Bracket operation, produces the additional terms
(51)
at . The second of these can be removed along with the terms and by a further transformation , but the first must be added to the term which which passes unchanged through the transformation from Equation (48b). This yields the ODE
(yj4]
Examining the parameter combinations that appear in the coefficients via Equations (49) and (35c), using the asymptotic expressions (37–38), continuing to assume that and remain small, and retaining only the leading order and terms, we deduce that , , and , consistent with global stability as noted following Equations (35). Setting and and letting denote departures in nondimensional pressure and linear stiffness (muscle tension) from the values corresponding to the Takens-Bogdanov point, we obtain the normal form (23) with the exception that the coefficient of is , in place of .
The factor is not crucial, but the fact that the quadratic damping term has the opposite sign to that of Equation (23) removes a key feature of the model, namely, the occurence of a saddle-node bifurcation on a limit cycle on the upper saddle-node bifurcation curve shown in Figure 10 and described in the next section. Without the long-period finite amplitude limit cycles that exist near this curve, the model does not produce infant cries with broad spectral content. This region in parameter space is also where all but one of the ‘gestures’ in zebra finch song are located (Amador et al., 2013, Figure 2d).
To obtain a negative sign for , it suffices to add a quadratic damping term, replacing in Equation (35b) by , which modifies the coefficient to . The left hand side of the dissipation balance (39) becomes and setting then yields the normal form (23) at leading order. We note that the term implies that the force is negative when (during vocal fold opening), but positive when (vocal fold closing), leading to a balance of energy dissipation and creation. Similar effects arise from terms of the form (Holmes, 1977). Also, the linear damping term could be omitted without affecting the normal form.
We note that in her PhD thesis (Amador, 2009) includes a constant term in Equation (30b) representing the force due to dorsal gating muscles [G.B. Mindlin, personal communication]. Adjusting this additional parameter allows one to locate the Takens-Bogdanov point more easily and also derive the normal form with a positive coefficient in the term, as used in Perl et al. (2011) and Amador et al. (2013).
1.1.4 Bifurcation sets and parameter dependence
We now derive the bifurcation set of the normal form ODEs Equation (23) and infer the qualitative structures of the phase portraits shown in Figure 10. For this analysis we take the pressure and muscle tension parameters as time-independent and seek steady solutions, specifically fixed points and limit cycles. For , fixed points of Equations (23) occur with satisfying the cubic equation
(53)
one, two or three fixed points can exist, depending on the value of .
Stability types of the fixed points are determined by the eigenvalues of the Jacobian matrix
which has trace , determinant , and eigenvalues .
Takens-Bogdanov point
Noting that has a double zero eigenvalue if , we deduce that this occurs for at the fixed point , about which the Taylor series expansion and normal form transformations of §1.1.3 are made. A nondegenerate sink also exists at .
Hopf bifurcations
When has purely imaginary eigenvalues, or more specifically when and , a Hopf bifurcation can occur. Since , implies or . The latter condition implies a closed glottis and so is biophysically irrelevant, and in the former case must be positive. This yields the Hopf bifurcation set : the vertical line emerging from the Takens-Bogdanov point in Figure 10. Crossing this set from left to right, the sink at becomes a source and a limit cycle appears or disappears.
The direction of bifucation and stability of the limit cycles can be determined by computing the coefficient of a third order term in the normal form of the Hopf bifurcation, as described by Guckenheimer and Holmes (1983), §3.4. At and the Jacobian (54) takes the form
(55)
with eigenvalues . Using the similarity transformation
(56)
Equation (23) becomes
(57)
and we may use Equation (3.4.10) of Guckenheimer and Holmes (1983) to determine that
(58)
implying that the limit cycles are stable and lie to the right of the bifurcation set , in region I or region III (depending on the value of ).
Saddle-node and pitchfork bifurcations
In 2-dimensional systems like Equation (23) a pair of fixed points, either a saddle and a source or a saddle and a sink, come together in a degenerate saddle-node bifurcation and disappear (or, crossing the bifurcation set in the opposite direction, appear and separate). A saddle node occurs when one of the eigenvalues of is zero and the other is not, i.e., for with . Alternatively, they may be located by seeking double roots of Equation (53), which occur when its first derivative also vanishes
(59)
Substituting the solution of (59) into Equation (53) and noting that , we obtain the two saddle-node bifurcation curves:
(60)
As shown in Figure 10, these curves meet in a cusp at the pitchfork bifurcation point , at which the unique fixed point is a triple root of Equation (53). Note that the Takens-Bogdanov point lies on the left hand curve, where the Hopf bifurcation line begins.
Homoclinic loop bifucations
Unfolding the Takens-Bogdanov normal form as in Guckenheimer and Holmes (1983), §7.3 shows that a third bifurcation curve emerges from the point to the right of and tangent to it at . On this curve, shown dashed in Figure 10, one of the separatrices emerging from the saddle point returns to it in a homoclinic loop. Approaching from above and to the left in region III the stable limit cycle grows until, for parameters on this homoclinic bifucation curve, it fuses with the saddle and disappears. Numerical solutions indicate that the curve crosses regions III and II, thereby dividing them, and ends on the upper saddle-node bifurcation curve. To the right of this meeting point, the saddle-node bifurcation occurs on a closed cycle, creating finite amplitude limit cycles whose periods rapidly decrease from infinity moving upward and rightward into region I. See (Perl et al., 2011, Figure 4), but note that a different parameterization is used in that paper. The extreme sensitivity of the period and waveform of these oscillations are largely responsible for the broad spectral content and ‘uncontrollable’ aspects of infant cries produced by the model.
No general methods exist for finding homoclinic bifurcation curves analytically, although they can be approximated in the neighborhood of multiply-degenerate fixed points such as the Takens-Bogdanov point. In fact a bifurcation set topologically equivalent to the present one has been found in a version of the forced van der Pol oscillator (Holmes and Rand, 1978), cf. Guckenheimer and Holmes (1983, §2.1).
References
-
Beyond harmonic sounds in a simple model for birdsong productionChaos: An Interdisciplinary Journal of Nonlinear Science 18:043123.https://doi.org/10.1063/1.3041023
-
Structure and usage of the vocal repertoire of callithrix jacchusInternational Journal of Primatology 29:671–701.https://doi.org/10.1007/s10764-008-9250-0
-
Convergent evolution of vocal cooperation without convergent evolution of brain sizeBrain, Behavior and Evolution 84:93–102.https://doi.org/10.1159/000365346
-
Arousal dynamics drive vocal production in marmoset monkeysJournal of Neurophysiology 116:753–764.https://doi.org/10.1152/jn.00136.2016
-
Developmental process emerges from extended brain-body-behavior networksTrends in Cognitive Sciences 18:395–403.https://doi.org/10.1016/j.tics.2014.04.010
-
Virtual vocalization stimuli for investigating neural representations of species-specific vocalizationsJournal of Neurophysiology 95:1244–1262.https://doi.org/10.1152/jn.00818.2005
-
Birdsong and human speech: common themes and mechanismsAnnual Review of Neuroscience 22:567–631.https://doi.org/10.1146/annurev.neuro.22.1.567
-
Bistability, bifurcations, and Waddington's epigenetic landscapeCurrent Biology 22:R458–R466.https://doi.org/10.1016/j.cub.2012.03.045
-
Morphology and development of the human vocal tract: a study using magnetic resonance imagingThe Journal of the Acoustical Society of America 106:1511–1522.https://doi.org/10.1121/1.427148
-
Evolution of human vocal productionCurrent Biology 18:R457–R460.https://doi.org/10.1016/j.cub.2008.03.030
-
BookThe evo-devo of vocal communication: insights from marmoset monkeysIn: Kaas J. H, Preuss T. M, editors. Evolution of Nervous Systems (2nd edn). Elsevier Press. pp. 317–324.https://doi.org/10.1016/B978-0-12-804042-3.00137-8
-
The autonomic nervous system is the engine for vocal development through social feedbackCurrent Opinion in Neurobiology 40:155–160.https://doi.org/10.1016/j.conb.2016.07.016
-
Social feedback to infants' babbling facilitates rapid phonological learningPsychological Science 19:515–523.https://doi.org/10.1111/j.1467-9280.2008.02117.x
-
Probabilistic epigenesisDevelopmental Science 10:1–11.https://doi.org/10.1111/j.1467-7687.2007.00556.x
-
The physiologic development of speech motor control: lip and jaw coordinationJournal of Speech Language and Hearing Research 43:239–255.https://doi.org/10.1044/jslhr.4301.239
-
BookNonlinear oscillations, dynamical systems and bifurcations of vector fields (Sixth Edition, 2002)New York: Springer.
-
Limiting parental feedback disrupts vocal development in marmoset monkeysNature Communications 8:14046.https://doi.org/10.1038/ncomms14046
-
Vocal development in squirrel monkeysBehaviour 138:1179–1204.https://doi.org/10.1163/156853901753287190
-
Voice instabilities due to source-tract interactionsActa Acustica united with Acustica 92:468–475.
-
Bifurcations and chaos in voice signalsApplied Mechanics Reviews 46:399–413.https://doi.org/10.1115/1.3120369
-
Vocal fold dynamics for frequency changeJournal of Voice 28:395–405.https://doi.org/10.1016/j.jvoice.2013.12.005
-
Bifurcations of the forced van der pol oscillatorQuarterly of Applied Mathematics 35:495–509.https://doi.org/10.1090/qam/492551
-
Behaviour of an oscillator with even non-linear dampingInternational Journal of Non-Linear Mechanics 12:323–326.https://doi.org/10.1016/0020-7462(77)90008-7
-
Synthesis of voiced sounds from a Two-Mass model of the vocal cordsBell System Technical Journal 51:1233–1268.https://doi.org/10.1002/j.1538-7305.1972.tb02651.x
-
On the rationale of maximum-entropy methodsProceedings of the IEEE 70:939–952.https://doi.org/10.1109/PROC.1982.12425
-
Discrete simulation of colored noise and stochastic processes and 1/f α power law noise generationProceedings of the IEEE 83:802–827.https://doi.org/10.1109/5.381848
-
Acoustic features of infant vocalic utterances at 3, 6, and 9 monthsThe Journal of the Acoustical Society of America 72:353–365.https://doi.org/10.1121/1.388089
-
Babbling and the lack of auditory speech perception: a matter of coordination?Developmental Science 4:61–70.https://doi.org/10.1111/1467-7687.00149
-
Infant Crying: Theoretical and Research Perspectives1–27, There’s more to crying than meets the ear, Infant Crying: Theoretical and Research Perspectives, New York, Plenum Publishing Corp.
-
Dynamics of the two‐mass model of the vocal folds: Equilibria, bifurcations, and oscillation regionThe Journal of the Acoustical Society of America 94:3104–3111.https://doi.org/10.1121/1.407216
-
Differential cadherin expression in the developing postnatal telencephalon of a New World monkeyJournal of Comparative Neurology 521:4027–4060.https://doi.org/10.1002/cne.23389
-
Irregular vocal-fold vibration--high-speed observation and modelingThe Journal of the Acoustical Society of America 108:2996–3002.https://doi.org/10.1121/1.1314398
-
Responses of primate frontal cortex neurons during natural vocal communicationJournal of Neurophysiology 114:1158–1171.https://doi.org/10.1152/jn.01003.2014
-
Indirect assessment of the contribution of subglottal air pressure and vocal-fold tension to changes of fundamental frequency in EnglishThe Journal of the Acoustical Society of America 64:65–80.https://doi.org/10.1121/1.381957
-
BookPhysiologic development of speech productionIn: Maasen B, Kent R. D, Peters H. F. M, van Lieshout P. H. H. M, Hulsijn W, editors. Speech Motor Control in Normal and Disordered Speech. Oxford, UK: Oxford University Press. pp. 191–209.
-
BookThe infant cry of primates: an evolutionary perspectiveIn: Lester BM, Boukydis CFZ, editors. Infant Crying: Theoretical and Research Perspectives. New York: Plenum Press. pp. 307–323.
-
Reconstruction of physiological instructions from zebra finch songPhysical Review E 84:051909.https://doi.org/10.1103/PhysRevE.84.051909
-
Acoustic analysis of vocal development in a new world primate, the common marmoset (Callithrix jacchus)The Journal of the Acoustical Society of America 120:1655–1670.https://doi.org/10.1121/1.2225899
-
Motor constraints on vocal development in a songbirdAnimal Behaviour 51:1061–1070.https://doi.org/10.1006/anbe.1996.0107
-
A rhythm landscape approach to the developmental dynamics of birdsongJournal of the Royal Society Interface 12:20150802.https://doi.org/10.1098/rsif.2015.0802
-
Dynamical origin of spectrally rich vocalizations in birdsongPhysical Review E 78:011905.https://doi.org/10.1103/PhysRevE.78.011905
-
Behavioral and neural trade-offs between song complexity and stress reaction in a wild and a domesticated finch strainNeuroscience & Biobehavioral Reviews 46:547–556.https://doi.org/10.1016/j.neubiorev.2014.07.011
-
Early development of turn-taking with parents shapes vocal acoustics in infant marmoset monkeysPhilosophical Transactions of the Royal Society B: Biological Sciences 371:20150370.https://doi.org/10.1098/rstb.2015.0370
-
Coupled oscillator dynamics of vocal turn-taking in monkeysCurrent Biology 23:2162–2168.https://doi.org/10.1016/j.cub.2013.09.005
-
Vocal learning beyond imitation: mechanisms of adaptive vocal development in songbirds and human infantsCurrent Opinion in Neurobiology 28:42–47.https://doi.org/10.1016/j.conb.2014.06.002
-
BookDynamic systems theoriesIn: Lerner R, editors. Handbook of Child Psychology (Sixth Edition). Wiley Online Library. pp. 258–312.
-
The myoelastic aerodynamic theory of phonation, Iowa City, IA, National Center for Voice and SpeechThe myoelastic aerodynamic theory of phonation, Iowa City, IA, National Center for Voice and Speech.
-
The physics of small-amplitude oscillation of the vocal foldsThe Journal of the Acoustical Society of America 83:1536–1552.https://doi.org/10.1121/1.395910
-
Nonlinear analysis of irregular animal vocalizationsThe Journal of the Acoustical Society of America 111:2908–2919.https://doi.org/10.1121/1.1474440
-
Spikes alone do not behavior make: why neuroscience needs biomechanicsCurrent Opinion in Neurobiology 21:816–822.https://doi.org/10.1016/j.conb.2011.05.017
-
The Handbook of Language Emergence437–457, Perception and production in phonological development, The Handbook of Language Emergence, 10.1002/9781118346136.ch20.
-
Development of vocal tract length during early childhood: a magnetic resonance imaging studyThe Journal of the Acoustical Society of America 117:338–350.https://doi.org/10.1121/1.1835958
-
Motor control is decision-makingCurrent Opinion in Neurobiology 22:996–1003.https://doi.org/10.1016/j.conb.2012.05.003
-
Observation and analysis of in vivo vocal fold tissue instabilities produced by nonlinear source-filter coupling: a case studyThe Journal of the Acoustical Society of America 129:326–339.https://doi.org/10.1121/1.3514536
-
Analysis of cry features in newborns with differential fetal growthChild Development 52:207–212.https://doi.org/10.2307/1129232
-
BookInfant crying and the synchrony of arousalIn: Altenmüller E, Schmidt S, Zimmermann E, editors. Evolution of emotional communication: from sounds in nonhuman mammals to speech and music in man. Oxford: Oxford University Press. pp. 155–172.https://doi.org/10.1093/acprof:oso/9780199583560.003.0010
Article and author information
Author details
Funding
National Science Foundation (DMS-1430077)
- Philip Holmes
National Institutes of Health (R01NS054898)
- Asif A Ghazanfar
James S. McDonnell Foundation (220020238)
- Asif A Ghazanfar
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Morgan Gustison, Talmo Pereira and Nicholas Roy for their constructive comments on earlier drafts of this paper. This work was supported by NSF-CRCNS DMS-1430077 (PH), a James S McDonnell Scholar Award (AAG), and NIH R01NS054898 (AAG).
Ethics
Animal experimentation: This study was performed in strict accordance with the recommendations in the Guide for the Care and Use of Laboratory Animals of the National Institutes of Health. All of the animals were handled according to approved institutional animal care and use committee (IACUC) protocols (#1908-15) of Princeton University.
Copyright
© 2017, Teramoto et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,831
- views
-
- 440
- downloads
-
- 26
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 26
- citations for umbrella DOI https://doi.org/10.7554/eLife.20782
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Vocal development in a Waddington landscape
eLife 6:e20782.
https://doi.org/10.7554/eLife.20782




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}