September 4 and 5 marked the second instance of the eLife Innovation Sprint, a global gathering of researchers, developers, designers, technologists, publishers and others to develop open-source prototypes to change the ways we discover, share, consume and evaluate research. A total of 60 participants worked on 14 projects, from web tools and interfaces to crowdsource research quality indicators, to machine learning tools for topical knowledge extraction.
You can find out more about these projects and related resources below – we would like to invite your feedback and contributions.
The Open Science Game
United by their love for games and teaching, this team of eight set out to design an engaging, educational and fun game to teach the benefits of open science and reusable research practices. They started by defining the goals, narrative and progression for the game, followed by the actual game mechanics. On Day 2, the group conducted a play test with other Sprint participants to refine the rules and design.
The prototype game is available here. Since the Sprint, the team has been polishing the design of the game cards, conducting more play tests and prototyping a deck builder that allows players to build custom decks.

Game testing in progress. Photo credit: Jess Brittain Photography.
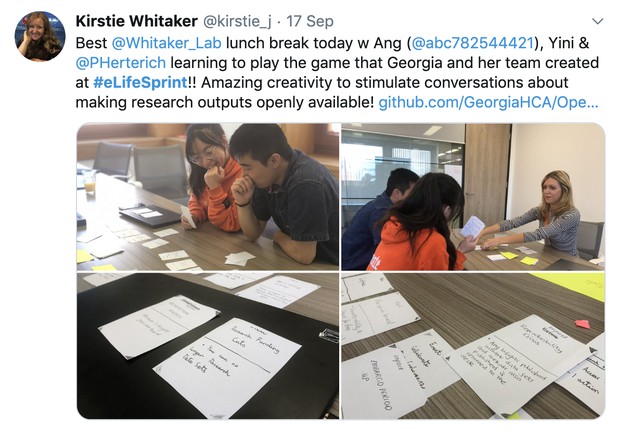
Source: Twitter.
The team members were:
- Barney Walker, Junior Front-End Developer, Labstep
- David Moulton, Senior Front-End Developer, eLife
- Georgia Aitkenhead, Research Associate, The Alan Turing Institute
- Joel Summerfield, Developer, eLife
- Lilly Winfree, Product Manager, Open Knowledge Foundation
- Susanna Richmond, Editorial Manager, eLife
- Veethika Mishra, Interaction Designer, Red Hat
HPC4Africa
Access to high-performance computing infrastructure in Africa is limited, and this poses limitations on research that involves big data analysis (geo/spatial mapping, bioinformatics, modelling, simulation, and so on). The idea behind HPC4Africa is to set up a cloud compute resource that will provide a platform for researchers for data analysis and open tool development.
At the Sprint, project lead Trust worked with fellow Sprinters skilled in this area to set up compute resources on AWS and was able to push some of the open bioinformatics tools he has developed. This will serve as a prototype to demonstrate the feasibility of having such a central cloud resource and a blueprint for future development.

Source: Twitter.
The team members were:
- Trust Odia, student, Stellenbosch University
- Ivo Jimenez, Research Scientist, UC Santa Cruz
- Aziz Khan, Postdoctoral Fellow, NCMM, University of Oslo, Norway
- Giorgio Sironi, Software Engineer – Tools & Infrastructure, eLife
- Nick Duffield, UX Designer, eLife
Inclusion in computational settings
Different computational tools are used by different communities globally, and computational training is offered to increasingly global and diverse audiences. This project aims to create a resource that crowdsources information and advice on these tools and resources in order to increase inclusivity in computational settings such as training. Over the two days of the Sprint, the team reformatted their original list of resources into a Wiki format to enhance readability and scalability, and interviewed other Sprint participants to gain first-hand insight and build diverse use cases.

Source: Twitter.
The resulting living GitHub Wiki can be accessed here, and the team invites all interested to stay updated using this Google form.

Sara and Offray presenting their project. Photo credit: Stuart King.
The team members were:
- Sara El-Gebali, Database Curator
- Offray Vladimir Luna Cárdenas, Researcher + Hacktivist, mutabiT / HackBo
Easy Binder + CODECHECK
Binder is an open service that can capture computational environments (software, versions and related dependencies) and allow them to be shared and used by other researchers. Currently, specific configuration files need to be created in order to run Binder. At the Sprint, the team set out to create Easy Binder, a user interface to ease the creation of these configuration files, with the aim of lowering the barrier for researchers to build containers and make their research more reproducible. The skeleton of the interface was shared with the Binder team.

A web interface for Easy Binder. Source: GitHub.
During the Sprint, the team also worked on advancing CODECHECK, a service that integrates with Binder to provide independent reproduction of computations in the context of research. The team discussed the development principles for CODECHECK and started building use cases for the service, including an exploration of how it could be integrated with research publishing and peer-review workflows.

Daniel and Ankit working on Easy Binder and CODECHECK. Photo credit: Jess Brittain Photography.
The team members were:
- Stephen Eglen, University Reader, University of Cambridge
- Daniel Nüst, Researcher, Institute for Geoinformatics, University of Münster
- Ankit Lohani, Software Developer & Architect, Standard Chartered Bank
reVal
Preprints allow authors to share their research output and invite early feedback prior to peer review and publication in a journal. This creates an opportunity for the development of an open toolstack that combines existing and future tools for preprint quality control and error detection, so that the manuscript can be improved prior to submission and publication. reVal is an extensible infrastructure in which both automated tools (e.g. Jetfighter for ensuring colour accessibility and Statcheck for detecting statistical reporting inconsistencies) and human-in-the-loop tools (e.g. SwipesForScience) can be plugged in for an integrated evaluation workflow.

Mapping the use cases for reVal. Source: the reVal team.
During the Sprint, the team mapped out how such an application would work and interact with a range of stakeholders, and distilled the workflow into technical requirements and the necessary software frameworks. Shyam also started to work on extending Jetfighter to fit into reVal. They invite creators of relevant tools to get in touch and contribute to the project.
You can read more about Jetfighter and access its GitHub repository to contribute.
The team members were:
- Shyam Saladi, PhD Student, California Institute of Technology
- Giuliano Maciocci, Head of Product and UX, eLife
InstruMinetal
In order to make the most out of the vast knowledge base of open literature, researchers need tools that can extract information from papers (semi-)automatically. During the Sprint, the InstruMinetal team focused on developing an example use case of searching and identifying scientific instruments in a corpus of research papers on phytochemistry.
The team developed SaWaMine, a method for automatically extracting candidates for scientific equipment terms from papers using word2vec and regular expressions, and a user interface to display the instrument candidates from a paragraph and allow users to identify the correct ones. They also added the newly extracted instrument data to Wikidata.

Source: the InstruMinetal team.
The team hopes to combine the SaWaMine and the new user interface to create ami dictionaries so that the extracted data can be searched.
The team members were:
- Sabine Weber, PhD student, University of Edinburgh
- Leonie Mueck, Division Editor, PLOS
- Michael Owonibi, Data Scientist, eLife
- Tiago Lubiana, graduate student in Computational Biology, University of São Paulo
- Peter Murray-Rust, Funder, ContentMine
- Sophia K. Cheng, Senior Software Engineer, Addgene
- Wambui Karuga, Linux System Engineer, BRCK
- Ambarish Kumar (remote)

The InstruMinetal team. Photo credit: Jess Brittain Photography.
OpenScore
A team of five set out to develop a system that would crowdsource research quality indicators and endorse good open science practices. The resulting platform, OpenScore, allows users to easily identify in what respect a certain paper follows good open science practices, and interact with papers by rating them.
The team created a demo and user interface prototypes during the Sprint. You can contribute to the project via its GitHub repository.
OpenScore prototype interface. Source: the OpenScore team.
The team members were:
- Cory Donkin, Developer, eLife
- Tanya Kuznetsova, UX/Product Designer, Digital Science
- Todd McGee, VP of Research and Development, HighWire Press
- Nicolás Alessandroni, Researcher / Editor, Universidad Autónoma de Madrid
- Theo Sanderson, Sir Henry Wellcome Fellow, Francis Crick Institute
OpenJournalGH
The OpenJournalGH team aimed to create an open journal publishing platform that is free, easy to setup and easy to use, such that publishers can focus on curation and peer review while helping researchers publish their work as smoothly and quickly as possible. Inspired by the co-creation processes facilitated by GitHub, the team created a GitHub repository template that can be used by research communities as a platform to publish open journals.
The team invites your feedback on the minimal template, which is accessible here.
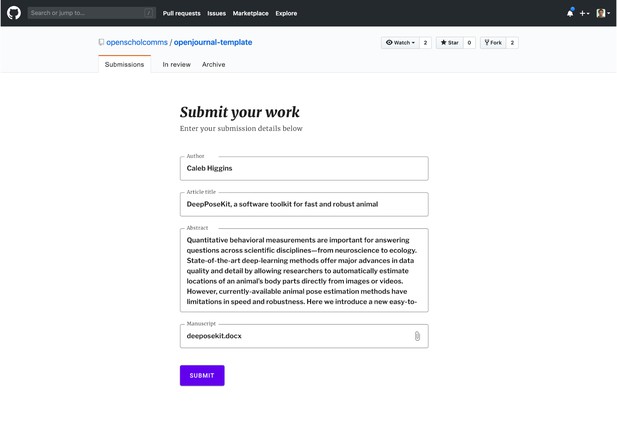
OpenJournalGH demo interface. Source: the OpenJournalGH team.
The team members were:
- Alf Eaton, Web Developer, Atypon
- Ivo Jimenez, Research Scientist, UC Santa Cruz
- Luigi Petrucco, graduate student, Max Planck Institute of Neurobiology
- Markus Konkol, Researcher, University of Münster, Institute for Geoinformatics
- Mauro Lepore, R Software Developer, 2 Degrees Investing Initiative
- Nick Duffield, UX Designer, eLife
- Nicolás Alessandroni, Researcher / Editor, Universidad Autónoma de Madrid

The OpenJournalGH team. Photo credit: Jess Brittain Photography.
BioJS
BioJS is a library of JavaScript components that enable users to visualise and process data using current web technologies. During the Sprint, one team upgraded two existing BioJS components – Protein Viewer (bio-pv) and Mecu Line – to web components and integrated them with the BioJS registry.
A screenshot from the updated bio-pv tool. Source: BioJS.

Sarthak and Nikhil presenting their work on BioJS. Photo credit: Jess Brittain Photography.
The team members were:
- Sarthak Sehgal, Frontend Engineer, Open Bioinformatics Foundation
- Nikhil Vats, Full Stack Developer, Open Bioinformatics Foundation
Study Design Reporting
Experimental designs are often captured in the methods section of a paper, and can often be difficult for researchers outside of the specific field to understand and reproduce. This team of four explored creating a tool for researchers and data managers to make describing experiments easier and less time-consuming. The tool, which is built on top of the ISA tools API, should generate visualisations for the experimental design to aid human understanding, as well as a Study Metadata Description File in ISA format to make the design machine-interoperable, and ultimately FAIR.
Beyond the Sprint, the team hopes to conduct further user testing and to create plug-ins that would integrate the tool into manuscript authoring tools such as Manuscripts and Stencila.
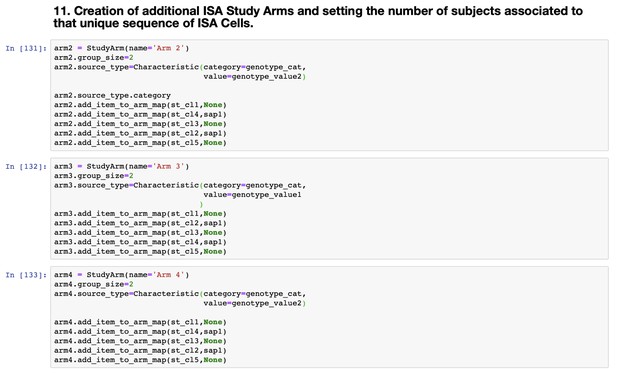
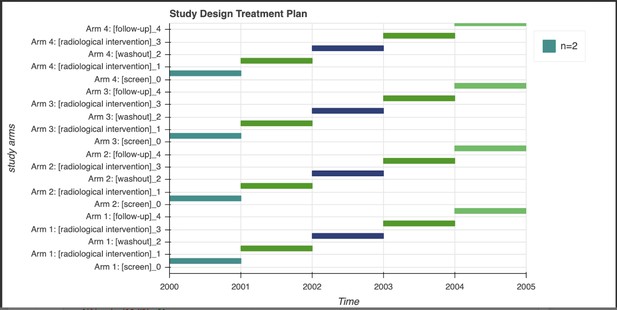
The study design reporting tool prototype. Source: the study design reporting team.
The team members were:
- Manuel Spitschan, Research Fellow, University of Oxford
- Galabina Yordanova, UX Designer, European Bioinformatics Institute
- Massimiliano Izzo, Research Software Engineer, University of Oxford
- Philippe Rocca-Serra, Senior Research Lecturer, University of Oxford

Phillippe and Massimiliano in discussion. Photo credit: Jess Brittain Photography.
Equitable Preprints
Over the past few years, the practice of preprinting in the life sciences has grown dramatically. There are now over 2,600 preprints deposited each month, which creates a need for methods to help researchers find relevant and interesting preprints to read. Unintentional biases in mainstream search algorithms can favour preprints with already high visibility, which can be associated with the ‘prestigiousness’ of the senior author and/or institution, geography, social network reach and so on.
At the Sprint, the Equitable Preprints team created Hidden Gems, a tool to shine a light on low-visibility preprints in biology. They came up with a ‘shadow index’ for visibility, based on the number of early views of a preprint’s abstract. Hidden Gem’s Django-based REST API serves data from the Rxivist database enhanced with the low-visibility shadow index, and a web user interface connects with that API and displays the preprints with the highest shadow index (hence lowest early visibility) by field.
The team also interviewed participants at the Sprint to build various use cases for Hidden Gems.
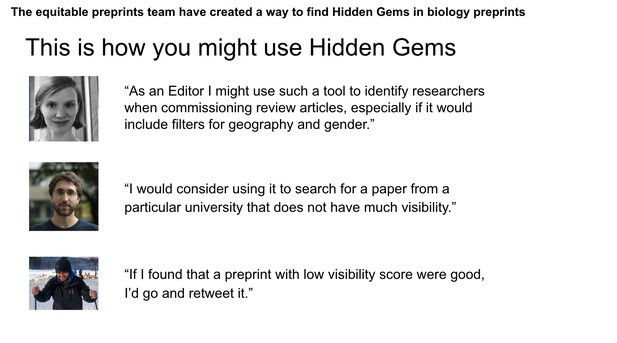
Use cases built for Hidden Gems through interviews during the Sprint. Source: the Equitable Preprints team.
Moving forward, the team would like to explore other metrics to sort for visibility, as well as more refined topic filters than fields. Read more about their design processes and discussions here, and contribute to the project via their GitHub repository.

Creating Hidden Gems. Photo credit: Jess Brittain Photography
The team members were:
- Dayane Araujo, Technical Outreach Officer, Europe PMC, EMBL-EBI
- Thomas Krichel, Founder and ведущий спесиалист
- Trust Odia, student, Stellenbosch University
- Mate Palfy, Community Manager for preLights, The Company of Biologists
- Michael Parkin, Data Scientist, EMBL-EBI
- Naomi Penfold, Associate Director, ASAPbio
- Daniela Saderi, Co-Founder and Project Lead, PREreview
- Dominika Tkaczyk, Principal R&D Developer, Crossref
- Hao Ye, Postdoc Researcher, University of Florida
- Vot Zardzewialy, Head of Platform Solutions, Cambridge University Press
- Rich Abdill (remote)
- Vincent Tunru (remote)
Software Citation
The use of software is extremely common in life sciences research, yet there is very little consensus as to how software should be cited in manuscripts. Software citations can assist researchers in assessing, understanding and reproducing the research methods and results by linking the work to relevant software version(s), and also help them to acknowledge the contributions of software developers and contributors in a traceable manner. This calls for better guidelines and tools for software developers to make their software citable, as well as for publishers and researchers to cite software correctly and easily.
At the start of the Sprint, this team explored different missing pieces that are necessary to monitor software citation using existing open science tools (e.g. Zenodo, Zotero and GitHub). They then mapped various user workflows and began building a web interface that would allow research software developers to generate a citation file and provide and edit rich metadata, which could be integrated into platforms such as Zenodo. The web interface will also allow publishers to request citation information and metadata.
Future workflows for the software citation tool. Source: the Software Citation team.
The team will continue to work on this project at the FORCE2019 Research Software Hackathon. Meanwhile, they invite you to contribute to the project's GitHub repository.

The Software Citation team at work. Photo credit: Jess Brittain Photography.
The team members were:
- Mateusz Kuzak, Research Software Community Manager, the Netherlands eScience Center
- Sarthak Sehgal, Frontend Engineer, Open Bioinformatics Foundation
- Jennifer Harrow, Tools Platform Coordinator, ELIXIR
- Melissa Harrison, Head of Production Operations, eLife
- Sarala Wimalaratne, Head of Infrastructure Services, DataCite
- Markus Konkol, Researcher, University of Münster, Institute for Geoinformatics
- Giuliano Maciocci, Head of Product and UX, eLife
- Giorgio Sironi, Software Engineer – Tools & Infrastructure, eLife
- Leonie Mueck, Division Editor, PLOS
Friendbot
The idea behind Friendbot is to build a chatbot for early detection of bullying. Bullying and associated mental health problems are common in academia and, while intervention and prevention rely on the incidents being detected and/or reported, bullying victims may be hesitant to confide in others. A conversational chatbot may be able to gain the user’s trust by providing privacy and anonymity, while the conversations can be analysed with AI and machine learning techniques to detect signs of bullying and/or mental health problems without compromising the user’s privacy.
At the Sprint, the team created a Facebook page that initiates a basic conversation powered by a Dialogflow back-end populated with curated questions. The next milestones for the project would be to collect more training data and build documentation for questions curation.
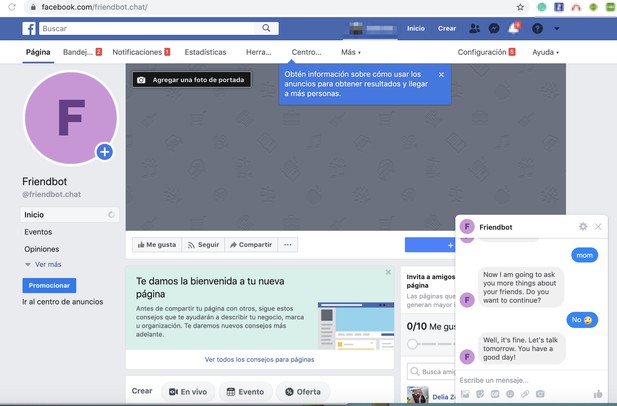
A prototype of Friendbot. Source: the Friendbot team.
The team welcomes your comments and feedback via Friendbot’s GitHub repository.
The team members were:
- Gabriela Gaona, Co-founder and COO, Codium
- Raoni Lourenço, PhD Candidate, New York University
- Wambui Karuga, Linux System Engineer, BRCK

Raoni and Gabriela working on Friendbot. Photo credit: Jess Brittain Photography.
Innovation Sprint Podcast
To capture the spirit and dynamics of the Sprint and highlight some of the work that happened, a team of three challenged themselves to record, edit and produce a podcast within the two days of the event. They brainstormed topics to explore and interviewed participants and organisers of the event, ultimately producing a podcast episode that projected many of the diverse voices, as well as serves as a lasting record of the Sprint.
The team members were:
- Jo Barratt, Producer / Delivery Manager, Open Knowledge Foundation
- Elsa Loissel, Assistant Features Editor, eLife
- Hannah Drury, Product Manager, eLife

Source: Twitter.
#
We welcome comments, questions and feedback. Please annotate publicly on the article or contact us at innovation [at] elifesciences [dot] org.
Do you have an idea or innovation to share? Send a short outline for a Labs blogpost to innovation [at] elifesciences [dot] org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



