Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorRoberto BottiniUniversity of Trento, Trento, Italy
- Senior EditorBarbara Shinn-CunninghamCarnegie Mellon University, Pittsburgh, United States of America
Reviewer #1 (Public review):
Summary:
This study aimed at replicating two previous findings that showed (1) a link between prediction tendencies and neural speech tracking, and (2) that eye movements track speech. The main findings were replicated which supports the robustness of these results. The authors also investigated interactions between prediction tendencies and ocular speech tracking, but the data did not reveal clear relationships. The authors propose a framework that integrates the findings of the study and proposes how eye movements and prediction tendencies shape perception.
Strengths:
This is a well-written paper that addresses interesting research questions, bringing together two subfields that are usually studied in separation: auditory speech and eye movements. The authors aimed at replicating findings from two of their previous studies, which was overall successful and speaks for the robustness of the findings. The overall approach is convincing, methods and analyses appear to be thorough, and results are compelling.
Weaknesses:
Eye movement behavior could have presented in more detail and the authors could have attempted to understand whether there is a particular component in eye movement behavior (e.g., blinks, microsaccades) that drives the observed effects.
Reviewer #2 (Public review):
Summary
Schubert et al. recorded MEG and eye tracking activity while participants were listening to stories in single-speaker or multi-speaker speech. In a separate task, MEG was recorded while the same participants were listening to four types of pure tones in either structured (75% predictable) or random (25%) sequences. The MEG data from this task was used to quantify individual 'prediction tendency': the amount by which the neural signal is modulated by whether or not a repeated tone was (un)predictable, given the context. In a replication of earlier work, this prediction tendency was found to correlate with 'neural speech tracking' during the main task. Neural speech tracking is quantified as the multivariate relationship between MEG activity and speech amplitude envelope. Prediction tendency did not correlate with 'ocular speech tracking' during the main task. Neural speech tracking was further modulated by local semantic violations in the speech material and by whether or not a distracting speaker was present. The authors suggest that part of the neural speech tracking is mediated by ocular speech tracking. Story comprehension was negatively related with ocular speech tracking.
Strengths
This is an ambitious study, and the authors' attempt to integrate the many reported findings related to prediction and attention in one framework is laudable. The data acquisition and analyses appear to be done with great attention to methodological detail. Furthermore, the experimental paradigm used is more naturalistic than was previously done in similar setups (i.e.: stories instead of sentences).
Weaknesses
While the analysis pipeline is outlined in much detail, some analysis choices appear ad-hoc and could have been more uniform and/or better motivated (other than: this is what was done before).
Reviewer #3 (Public review):
I thank the authors for their extensive revision of this paper, and I found some elements greatly improved.
In particular, the authors do embrace a somewhat more speculative tone in the current version, which I think is fitting for this work, as the data seem (to me) to be not fully conclusive. The data set collected here is clearly valuable and unique (and I would encourage the authors to make it publicly available!), however, my overall impression is that the specific analyses reported here might not fully
Despite the revised description of methods, results and figures, I still have trouble understanding many of the results and the authors conclusive interpretation of them. These are my main reservations:
(1) Regarding "individual prediction tendency" - thank you for adding clarifying methodological details and showing the data in a new Figure (#2). Honestly, however, I still can't say that I fully understand the result. For example, why is there also a significant response in the random condition as well? And how do you interpret the interesting time-course (with a peak ~200ms prior to the stimulus, and a reduction overtime from there?
Also (I may have missed this, but..) what neural data was used to train the classifier and derive the "prediction tendency" index? Was it just the broadband neural response? Is there a way to know which sensors contributed to this metric (e.g., are they predominantly auditory? Frontal?)? And is there a way to establish the statistical significance of this metric (e.g., how good the decoder actually was in predicting behavioral sensitivity?). I don't see any statistics in the results section describing the individual prediction tendency.
(2) Regarding the TRF analysis - Thanks for clarifying the approach used to obtain 2-second long "segments" of speech tracking. This is an interesting approach, however I think quite new(?) , and for me it raises a whole new set of questions, as well as additional controls and data that I would have liked to see, to be convinced that results are significant. I will elaborate:
- Do I understand correctly that you segment the real and predicted neural response into 2-second long segments and then calculate the Pearsons' correlation between them to assess the goodness of the model? This is very unclear, since in the methods section you state only that "the same" analysis was performed as for the full data - but what exactly? Clearly, values will be very different when using such short segments. I feel that additional details are still required (and perhaps data shown) to fully understand the "semantic violation" analysis of TRFs.
- I would like to reiterate my previous comment regarding the use of permutation tests to verify the validity of TRF-based measures derived. This would be especially important when using new approaches (such as the segmentation used here). The authors argue that this is not needed since this was not done in their previously published study. However, this sounds a bit like "two wrongs make a right" argument... why not just do it, and let us know that this 2-second segmentation approach allows estimating reliable speech tracking?
- Following up on my previous comment that defining "clusters" as at least two neighboring channels (Figure 3) - the fact that this is a default in Fieldtrip is by no means sufficient justification!. This seems quite liberal to me, especially given the many comparisons performed. Here too, permutations can help to determine the necessary data-driven threshold for corrections. This is of course critical for interpreting the result shown in Figures 3E&G that are critical "take home messages" of the paper - i.e., that the prediction-index from the first part of the experiment is related to speech tracking in the second part of the experiment. To my eyes, this does not look extremely convincing, but perhaps the authors can show more conclusive data to support this (e.g., scatter plots of the betas across participant?).
- A similar point can be made for the effect of semantic violations (though here the scalp-level result is somewhat more clustered). The authors point out that the semantic effect is a "replication" of their result reported in Schubert et al. 2023, but if I am not mistaken the results there were somewhat different (as was the manipulation). It would be nice to explicitly discuss the similarity/difference between these effects.
(3) Regarding the ocular-TRFs -
- Maybe this is just me, but I believe that effects that are robust should be clearly visible in the data, without the need for fancy "black-box" statistical models. In the case of the ocular TRFs, it is hard for me to see how these time-courses are not just noise (and, again, a permutation test would have helped to convince me..). The inconsistent results for horizontal and vertical eye-movements vis a vis the experimental conditions (single vs. multi-speaker conditions) don't help either, despite the authors argument that these are "independent" - but why should this be the case, especially if there is nothing really to look at in this task?
- I remain with this scepticism for the mediation-portion of the analysis as well... But perhaps replications from other groups or making the data public will help shed further light on this in the future.
Minor
- Thanks for adding information about the creation of semantic-violation stimuli. Since the violations and lexical-controls were taken from different audio recordings, it would have been nice to verify that differences between neural responses cannot be attributed to differences in articulations (e.g., by comparing their spectro-temporal properties).
Author response:
The following is the authors’ response to the original reviews
Reviewer #1 (Public review):
Summary:
This study aimed at replicating two previous findings that showed (1) a link between prediction tendencies and neural speech tracking, and (2) that eye movements track speech. The main findings were replicated which supports the robustness of these results. The authors also investigated interactions between prediction tendencies and ocular speech tracking, but the data did not reveal clear relationships. The authors propose a framework that integrates the findings of the study and proposes how eye movements and prediction tendencies shape perception.
Strengths:
This is a well-written paper that addresses interesting research questions, bringing together two subfields that are usually studied in separation: auditory speech and eye movements. The authors aimed at replicating findings from two of their previous studies, which was overall successful and speaks for the robustness of the findings. The overall approach is convincing, methods and analyses appear to be thorough, and results are compelling.
Weaknesses:
Linking the new to the previous studies could have been done in more detail, and the extent to which results were replicated could have been discussed more thoroughly.
Eye movement behavior could have been presented in more detail and the authors could have attempted to understand whether there is a particular component in eye movement behavior (e.g., microsaccades) that drives the observed effects.
We would like to thank you for your time and effort in reviewing our work and we appreciate the positive comments!
We extended our manuscript, now providing intermediate results on individual prediction tendency, which can be compared to our results from Schubert et al., (2023).
Furthermore, we expanded our discussion now detailing the extent to which our results (do not) replicate the previous findings (e.g. differences in horizontal vs. vertical ocular speech tracking, lack of distractor tracking, link between ocular speech tracking and behavioral outcomes).
While we agree with the reviewer that it is an important and most interesting question, to what extent individual features of gaze behavior (such as microsaccades, blinks etc.) contribute to the ocular speech tracking effect, it is beyond the scope of the current manuscript. It will be methodologically and conceptually challenging to distinguish these features from one another and to relate them to diverse cognitive processes. We believe that a separate manuscript is needed to give these difficult questions sufficient space for new methodological approaches and control analyses. The primary goal of this manuscript was to replicate the findings of Gehmacher et al. (2024) using similar methods and to relate them to prediction tendencies, attention, and neural speech tracking.
Reviewer #2 (Public review):
Summary
Schubert et al. recorded MEG and eye-tracking activity while participants were listening to stories in single-speaker or multi-speaker speech. In a separate task, MEG was recorded while the same participants were listening to four types of pure tones in either structured (75% predictable) or random (25%) sequences. The MEG data from this task was used to quantify individual 'prediction tendency': the amount by which the neural signal is modulated by whether or not a repeated tone was (un)predictable, given the context. In a replication of earlier work, this prediction tendency was found to correlate with 'neural speech tracking' during the main task. Neural speech tracking is quantified as the multivariate relationship between MEG activity and speech amplitude envelope. Prediction tendency did not correlate with 'ocular speech tracking' during the main task. Neural speech tracking was further modulated by local semantic violations in the speech material, and by whether or not a distracting speaker was present. The authors suggest that part of the neural speech tracking is mediated by ocular speech tracking. Story comprehension was negatively related to ocular speech tracking.
Strengths
This is an ambitious study, and the authors' attempt to integrate the many reported findings related to prediction and attention in one framework is laudable. The data acquisition and analyses appear to be done with great attention to methodological detail (perhaps even with too much focus on detail-see below). Furthermore, the experimental paradigm used is more naturalistic than was previously done in similar setups (i.e. stories instead of sentences).
Weaknesses
For many of the key variables and analysis choices (e.g. neural/ocular speech tracking, prediction tendency, mediation) it is not directly clear how these relate to the theoretical entities under study, and why they were quantified in this particular way. Relatedly, while the analysis pipeline is outlined in much detail, an overarching rationale and important intermediate results are often missing, which makes it difficult to judge the strength of the evidence presented. Furthermore, some analysis choices appear rather ad-hoc and should be made uniform and/or better motivated.
We would like to thank you very much for supporting our paper and your thoughtful feedback!
To address your concerns, that our theoretical entities as well as some of our analytical choices lack transparency, we expanded our manuscript in several ways:
(1) We now provide the intermediate results of our prediction tendency analysis (see new Figure 2 of our manuscript). These results are comparable to our findings from Schubert et al. (2023), demonstrating that on a group level there is a tendency to pre-activate auditory stimuli of high probability and illustrating the distribution of this tendency value in our subject population.
(2) We expanded our methods section in order to explain our analytical choices (e.g. why this particular entropy modulation paradigm was used to measure individual prediction tendency).
(3) We now provide an operationalisation of the terms “neural speech tracking” and “ocular speech tracking” at their first mention, to make these metrics more transparent to the reader.
(4) We are summarizing important methodological information ahead of each results section, in order to provide the reader with a comprehensible background, without the necessity to read through the detailed methods section.
(5) We expanded our discussion section, with a special emphasis on relating the key variables of the current investigation to theoretical entities.
Reviewer #3 (Public review):
Summary:
In this paper, the authors measured neural activity (using MEG) and eye gaze while individuals listened to speech from either one or two speakers, which sometimes contained semantic incongruencies.
The stated aim is to replicate two previous findings by this group: (1) that there is "ocular speech tracking" (that eye-movements track the audio of the speech), (2) that individual differences in neural response to tones that are predictable vs. not-predictable in their pitch is linked to neural response to speech. In addition, here they try to link the above two effects to each other, and to link "attention, prediction, and active sensing".
Strengths:
This is an ambitious project, that tackles an important issue and combines different sources of data (neural data, eye-movements, individual differences in another task) in order to obtain a comprehensive "model" of the involvement of eye-movements in sensory processing.
The authors use many adequate methods and sophisticated data-analysis tools (including MEG source analysis and multivariate statistical models) in order to achieve this.
Weaknesses:
Although I sympathize with the goal of the paper and agree that this is an interesting and important theoretical avenue to pursue, I am unfortunately not convinced by the results and find that many of the claims are very weakly substantiated in the actual data.
Since most of the analyses presented here are derivations of statistical models and very little actual data is presented, I found it very difficult to assess the reliability and validity of the results, as they currently stand. I would be happy to see a thoroughly revised version, where much more of the data is presented, as well as control analyses and rigorous and well-documented statistical testing (including addressing multiple comparisons).
We thank you for your thoughtful feedback. We appreciate your concerns and will address them below in greater detail.
These are the main points of concern that I have regarding the paper, in its current format.
(1) Prediction tendencies - assessed by listening to sequences of rhythmic tones, where the pitch was either "predictable" (i.e., followed a fixed pattern, with 25% repetition) or "unpredictable" (no particular order to the sounds). This is a very specific type of prediction, which is a general term that can operate along many different dimensions. Why was this specific design selected? Is there theoretical reason to believe that this type of prediction is also relevant to "semantic" predictions or other predictive aspects of speech processing?
Theoretical assumptions and limitations of our quantification of individual prediction tendency are now shortly summarized in the first paragraph of our discussion section. With this paradigm we focus on anticipatory “top-down” predictions, whilst controlling for possibly confounding “bottom-up” processes. Since this study aimed to replicated our previous work we chose the same entropy-modulation paradigm as in other studies from our group (e.g. Demarchi et al. 2019, Schubert et al. 2023;2024, Reisinger et al. 2024), which has proven to give reproducible findings of feature-specific preactivations of sounds in a context of low entropy. One advantage of this design is that it gives us the opportunity to directly compare the processing of “predictable” and “unpredictable” sounds of the same frequency in a time-resolved manner (this argument is now also included in the Methods section).
Regarding the question to what extent this type of prediction might also be relevant to “semantic” predictions we would like to refer to our previous study (Schubert et al., 2023), where we explicitly looked at the interaction between individual prediction tendency and encoding of semantic violations in the cortex. (In short, there we found a spatially dissociable interaction effect, indicating an increased encoding of semantic violations that scales with prediction tendency in the left hemisphere, as well as a disrupted encoding of semantic violations for individuals with stronger prediction tendency in the right hemisphere.) We did not aim to replicate all our findings in the current study, but instead we focused on merging the most important results from two independent phenomena in the domain of speech processing and bringing them into a common framework. However, as now stated in our discussion, we believe that “predictions are directly linked to the interpretation of sensory information. This interpretation is likely to occur at different levels along the cognitive (and anatomical) hierarchy…” and that “this type of prediction is relevant for acoustic processing such as speech and music, whose predictability unfolds over time.”
(2) On the same point - I was disappointed that the results of "prediction tendencies" were not reported in full, but only used later on to assess correlations with other metrics. Even though this is a "replication" of previous work, one would like to fully understand the results from this independent study. On that note, I would also appreciate a more detailed explanation of the method used to derive the "prediction tendency" metric (e.g, what portion of the MEG signal is used? Why use a pre-stimulus and not a post-stimulus time window? How is the response affected by the 3Hz steady-state response that it is riding on? How are signals integrated across channels? Can we get a sense of what this "tendency" looks like in the actual neural signal, rather than just a single number derived per participant (an illustration is provided in Figure 1, but it would be nice to see the actual data)? How is this measure verified statistically? What is its distribution across the sample? Ideally, we would want enough information for others to be able to replicate this finding).
We now included a new figure (similar to Schubert et al. 2023) showing the interim results of the “prediction tendency” effect as well as individual prediction tendency values of all subjects.
Furthermore we expanded the description of the “prediction tendency” metric in the Methods section, where we explain our analytical choices in more detail. In particular we used a pre-stimulus time window in order to capture “anticipatory predictions”. The temporally predictably design gives us the opportunity to capture this type of predictions. The integration across channels is handled by the multivariate pattern analysis (MVPA), which inherently integrates multidimensional data (as mentioned in the methods section we used data from 102 magnetometers) and links it to (in this case) categorical information.
(3) Semantic violations - half the nouns ending sentences were replaced to create incongruent endings. Can you provide more detail about this - e.g., how were the words selected? How were the recordings matched (e.g., could they be detected due to audio editing?)? What are the "lexically identical controls that are mentioned"? Also, is there any behavioral data to know how this affected listeners? Having so many incongruent sentences might be annoying/change the nature of listening. Were they told in advance about these?
We expanded the Methods section and included the missing information:
“We randomly selected half of the nouns that ended a sentence (N = 79) and replaced them with the other half to induce unexpected semantic violations. The swap of nouns happened in the written script before the audio material was recorded in order to avoid any effects of audio clipping. Narrators were aware of the semantic violations and had been instructed to read out the words as normal. Consequently all target words occurred twice in the text, once in a natural context (serving as lexical controls) and once in a mismatched context (serving as semantic violations) within each trial, resulting in two sets of lexically identical words that differed greatly in their contextual probabilities (see Figure 1F for an example). Participants were unaware of these semantic violations.” Since we only replaced 79 words with semantic violations in a total of ~ 24 minutes of audio material we believe that natural listening was not impaired. In fact none of the participants mentioned to have noticed the semantic violations during debriefing (even though they had an effect on speech tracking in the brain).
(4) TRF in multi-speaker condition: was a univariate or multivariate model used? Since the single-speaker condition only contains one speech stimulus - can we know if univariate and multivariate models are directly comparable (in terms of variance explained)? Was any comparison to permutations done for this analysis to assess noise/chance levels?
For mTRF models it depends on the direction (“encoding” vs. “decoding”) whether or not the model is comparable to a univariate model. In our case of an encoding model the TRFs are fitted to each MEG channel independently. This gives us the possibility to explore the effect over different areas (whereas a multivariate “decoding” model would result in only one speech reconstruction value).
In both conditions (single and multi speaker) a single input feature (the envelope of the attended speech stream) was used. Of course it would be possible to fit the model to use a multivariate encoding model, predicting the brain’s response to the total input of sounds. This would, however, target a slightly different question than ours as we aimed to investigate how much of the attended speech is tracked.
Regarding your suggestion of a comparison to permutations to assess noise levels we would like to point out that we chose the same methodological approach as in our previous studies, that we aimed to replicate here. Indeed in these original studies no permuted versions (with exception of the mediation analysis where comparing a model with an additional input predictor to a single predictor model would not result in a fair comparison) have been used. We conducted the mTRF approach considering the guidelines of Crosse et al. (2016) to the best of our knowledge and in accordance with similar studies in this field.
Crosse, M. J., Di Liberto, G. M., Bednar, A., & Lalor, E. C. (2016). The multivariate temporal response function (mTRF) toolbox: a MATLAB toolbox for relating neural signals to continuous stimuli. Frontiers in human neuroscience, 10, 604.
(5) TRF analysis at the word level: from my experience, 2-second segments are insufficient for deriving meaningful TRFs (see for example the recent work by Mesik & Wojtczak). Can you please give further details about how the analysis of the response to semantic violations was conducted? What was the model trained on (the full speech or just the 2-second long segments?) Is there a particular advantage to TRFs here, relative - say - to ERPs (one would expect a relatively nice N400 response, not)? In general, it would be nice to see the TRF results on their own (and not just the modulation effects).
We fully agree with the reviewers statement that 2-second segments would have been too short to derive meaningful TRFs. To investigate the effect of semantic violations, we used the same TRFs trained on the whole dataset (with 4-fold cross validation). The resulting true as well as the predicted data was segmented into single word epochs of 2 seconds. We selected semantic violations as well as their lexically identical controls and correlated true with predicted responses for every word. Thus, we conducted the same analysis as for the overall encoding effect, focusing on only part of the data. We have reformulated the Methods section accordingly to clear up this misunderstanding. Since the TRFs are identical to the standard TRFs from the overall neural speech tracking, they are not informative to the semantic violation effect. However, since the mTRF approach is the key method throughout the manuscript (and our main focus is not on the investigations of brain responses to semantic violations) we have favoured this approach over the classical ERF analysis.
(6) Another related point that I did not quite understand - is the dependent measure used for the regression model "neural speech envelope tracking" the r-value derived just from the 2sec-long epochs? Or from the entire speech stimulus? The text mentions the "effect of neural speech tracking" - but it's not clear if this refers to the single-speaker vs. twospeaker conditions or to the prediction manipulation. Or is it different in the different analyses? Please spell out exactly what metric was used in each analysis.
As suggested we now provide a clear definition of each dependent metric for each analysis.
“Neural speech tracking” refers to the correlation coefficients between predicted and true brain responses from the aforementioned encoding model, trained and tested on the whole audio material within condition (single vs. multi-speaker).
Recommendations for the authors:
Reviewing Editor Comments:
The reviewers have provided a number of recommendations to improve the manuscript, particularly requesting that more data be reported, with an emphasis on the measurements themselves (eye movements and TRFs) rather than just the numerical outputs of mathematical models.
We appreciate all the reviewers' and editor’s comments and effort to improve our manuscript. In the revised version we provide interim findings and missing data, updated figures that include an intuitive illustration of the metrics (such as TRFs), and a thoroughly revised discussion section where we focus on the relationship between our observed quantities and theoretical entities. We now offer operationalized definitions of the relevant concepts (“prediction tendency”, “active ocular sensing” and “selective attention”) and suggest how these entities might be related in the context of speech processing, based on the current findings. We are confident that this revision has improved the quality of our paper a lot and we are grateful for all the feedback and suggestions.
Reviewer #1 (Recommendations for the authors):
(1) Participants had to fixate throughout the tasks. How did the authors deal with large eye movements that violated the instructed fixation?
As described in the Methods section: “Participants were instructed to look at a black fixation cross at the center of a grey screen.” This instruction was not intended to enforce strict fixation but rather to provide a general reference point, encouraging participants to keep their gaze on the grey screen and avoid freely scanning the room or closing their eyes. Unlike trial-based designs, where strict fixation is feasible due to shorter trial durations, this approach did not impose rigid fixation requirements. Consequently, the threshold for "instruction violation" was inherently more flexible, and no additional preprocessing was applied to the gaze vectors.
Fixating for such an extended period of time (1.5 hours?) is hard. Did fixation behavior change over time? Could (fixation) fatigue affect the correlations between eye movements and speech tracking? For example, fatigued participants had to correct their fixation more often and this drives, in part, the negative correlation with comprehension?
Yes, participants spent approximately 2 hours in the MEG, including preparation time (~30 minutes). However, participants were given opportunities to rest their eyes between different parts and blocks of the experiment (e.g., resting state, passive listening, and audiobook blocks), which should help mitigate fatigue to some extent.
That said, we agree that it is an intriguing idea that fatigue could drive the ocular speech tracking effect, with participants potentially needing to correct their gaze more as the experiment progresses. However, our analysis suggests this is unlikely for several reasons:
(1) Cross-validation in encoding models: Ocular speech tracking effects were calculated using a 4-fold cross-validation approach (this detail has now been added to the Methods section; please see our response to public review #3). This approach reduces the influence of potential increases in gaze corrections over time, as the models are trained and validated on independent data splits. Moreover, if there were substantial differences in underlying response magnitudes between folds - for instance, between the first and fourth fold - this would likely compromise the TRF's ability to produce valid response functions for predicting the left-out data. Such a scenario would not result in significant tracking, further supporting the robustness of the observed effects.
(2) TRF time-course stability: If fatigue were driving increased gaze corrections, we would expect this to be reflected in a general offset (capturing the mean difference between folds) in the TRF time-courses shown in Figure 4 (right panel). However, no such trend / offset is evident.
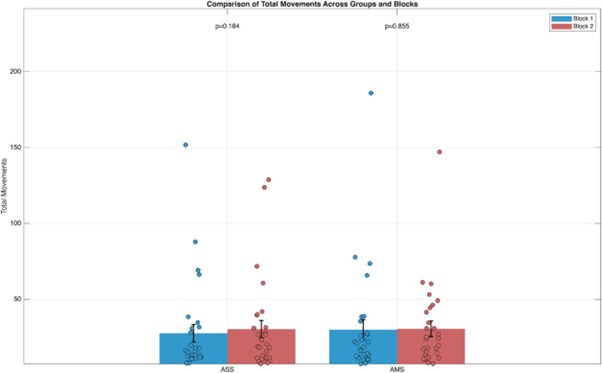
(3) Comparison of eye movement data: To directly investigate this possibility, we compared the amount of total eye movements between the first and last blocks for both the single and multi-speaker conditions. Total movement was calculated by first calculating the differences in pixel values between consecutive eye positions on both the x- and y-axes. The Euclidean distance was then computed for each difference, providing a measure of movement between successive time points. Summing these distances yielded the total movement for each block. Statistical analysis was performed separately for the single speaker (ASS) and multi-speaker (AMS) conditions. For each condition, paired comparisons were made between the first and last blocks (we resorted to non-parametric tests, if assumptions of normality were violated):
For the single speaker condition (ASS), the normality assumption was not satisfied (p≤0.05p, Kolmogorov-Smirnov test). Consequently, a Wilcoxon signedrank test was conducted, which revealed no significant difference in total movements between the first and last blocks (z=−1.330, p=0.184). For the multi-speaker condition (AMS), the data met the normality assumption (p>0.05), allowing the use of a paired t-test. The results showed no significant difference in total movements between the first and last blocks (t=−0.184, p=0.855).
The results are visualized in a bar plot (see below), where individual data points are displayed alongside the mean and standard error for each block. Statistical annotations indicate that neither condition demonstrated significant differences between the blocks. These findings suggest that total eye movements remained stable across the experimental conditions, regardless of whether participants were exposed to a single or multiple speakers.
Author response image 1.
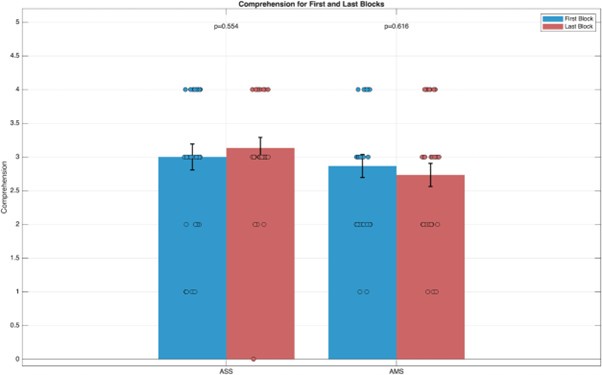
(4) Behavioral responses: Participants’ behavioral responses did not indicate any decrease in comprehensibility for later blocks compared to earlier ones. Specifically, a comparison of comprehension scores between the first and last blocks revealed no significant difference in either the single-speaker condition (ASS; Wilcoxon signed-rank test Z=−0.5911, p=0.5545) or the multi-speaker condition (AMS; Wilcoxon signed-rank test: Z=0.5018, p=0.6158). These findings suggest that participants maintained consistent levels of comprehension throughout the experiment, regardless of the condition or block order. The results are visualized in a bar plot (see below), where individual data points are displayed alongside the mean and standard error for each block. Statistical annotations indicate that neither condition demonstrated significant differences between the blocks.
Author response image 2.
Together, these factors suggest that fatigue is unlikely to be a significant driver of the ocular speech tracking effects observed in this study.
(2) The authors should provide descriptive statistics of fixation behavior /fixational eye movements. What was the frequency and mean direction of microsaccades, do they follow the main sequence, etc., quantify drift and tremor?
Thank you for their suggestion regarding descriptive statistics. To address this, we computed the rates of microsaccades (which were extracted using the microsaccade detection algorithm as proposed in Liu, B., Nobre, A. C. & van Ede, F. Functional but not obligatory link between microsaccades and neural modulation by covert spatial attention. Nat. Commun. 13, 3503 (2022)) and fixations as these metrics are directly relevant to our study and the requests above.
Microsaccade Rates:
- Single speaker Condition: Mean = 2.306 Hz, SD = 0.363 Hz. ○ Multi speaker: Mean = 2.268 Hz, SD = 0.355 Hz.
Fixation Rates:
- Single speaker Condition: Mean = 2.858 Hz, SD = 1.617 Hz. ○ Multi speaker Condition: Mean = 2.897 Hz, SD = 1.542 Hz.
These values fall within the expected ranges reported in the literature (fixation rates: 2– 4 Hz, microsaccade rates: ~0.5–2.5 Hz) and serve as a sanity check, confirming the plausibility of our eye-tracking data. Regarding the reviewer’s request for additional metrics (e.g., microsaccade direction, main sequence analysis, drift, and tremor), extracting these features would require advanced algorithms and analyses not supported by our current preprocessing pipeline or dataset. We hope that the provided metrics, which were the main focus of this study, serve as a sufficient sanity check and highlight the robustness of our data.
Related to this, I am wondering whether microsaccades are the feature that drives speech tracking.
This is an important and pressing question that we aim to address in future publications. Currently, our understanding - and the reason microsaccades and blinks are not analysed in this manuscript - is limited by methodological constraints. Specifically, microsaccades are binary response vectors, which are not compatible with TRF analyses. Addressing this would require adapting future models to handle timecontinuous binary response data or exploring alternative approaches, such as regression-based ERFs (for example as in Heilbron et al. 2022). As the primary goal of this manuscript was to replicate the findings of Gehmacher et al. (2024) using similar methods and to integrate these findings into an initial unified framework, we did not investigate additional eye movement features here. However, we agree that microsaccades (and also blinks, see below) likely contribute, at least in part, to the observed ocular speech tracking effects, and we now suggest this in the Discussion:
“Relatedly, it remains an open question whether microsaccades are a key feature driving ocular speech tracking. However, our current study does not analyze microsaccades due to methodological constraints: microsaccades are binary response vectors, which are incompatible with TRF analyses used here. Addressing this would require adapting models to handle time-continuous binary response data or potentially exploring alternative approaches, such as regression-based ERFs (e.g., as in Heilbron et al., 2022). While these limitations preclude microsaccade analysis in the current study, we hypothesize that they could enhance temporal precision and selectively amplify relevant sensory input, supporting auditory perception. Future studies should explore this possibility to uncover the specific contributions of microsaccades to speech tracking.”
(3) Can the authors make sure that interpolated blinks did not drive any of the effects? Can interpolated blink trials be excluded?
Using continuous audiobooks as stimuli meant that we could not exclude blink periods from the analysis without introducing substantial continuation artifacts in the TRF analysis. Importantly, the concept of covert motor routines and active sensing suggests that participants engage more strongly in motor routines - including ocular behaviors such as microsaccades and blinks - during tasks like speech tracking. These motor routines are inherently tied to individual gaze patterns, making microsaccades and blinks correlated with other ocular behaviors. This complicates efforts to disentangle their individual contributions to the observed ocular speech tracking effects.
Engagement in these motor routines, as posited by active sensing, would naturally load onto various viewing behaviors, further intertwining their roles.
Even if we were to examine correlations, such as the amount of blinks with the ocular speech tracking effect, it is unlikely to provide a clearer understanding due to these inherent overlaps. The methodological and conceptual challenge lies in distinguishing these features from one another and understanding their respective roles in driving the observed effects.
However, the aim of this manuscript was not to dissect the ocular speech tracking effect in greater detail, but rather to relate it - based on similar analytical choices as in Gehmacher et al - to prediction tendencies, attention, and neural speech tracking. While it will be crucial in future work to differentiate these patterns and their connections to diverse cognitive processes, it is beyond the scope of this study to address all these questions comprehensively.
We acknowledge that eye movements, including microsaccades and blinks (however, see challenges for this in response 2), remain underexplored in many experimental paradigms. Their interplay with cognitive processes - such as attention, prediction, and sensory integration - will undoubtedly be an important focus for future studies.
(4) Could the authors provide more details on how time shuffling was done for the eyemovement predictor, and include a circularly shifted version (or a version that does not destroy temporal contiguity) in their model comparisons? Some types of shuffling can result in unrealistic time series, which would end up in an unfair comparison with the model that has the real eye movement traces as predictors.
We thank the reviewer for their insightful question regarding the time-shuffling procedure for the eye-movement predictor and for suggesting the inclusion of a circularly shifted version in our model comparisons. Below, we provide further details about our approach and the rationale behind it:
(1) Random Shuffling: In our analysis, the eye-movement predictor was randomly shuffled over time, meaning that individual samples were randomly replaced. This method completely disrupts the temporal structure of the signal, providing a null model that directly tests whether the temporal mediation observed is due to the specific temporal relationship between ocular movements and envelope tracking.
(2) Circular Shifting: While circular shifting maintains temporal contiguity, it introduces certain challenges in the context of TRF analysis. Specifically:
- Adaptation to Shifts: The TRF model could adapt to the introduced shift, potentially reducing the validity of the null comparison.
- Similarity due to Repetition: The broadband envelope exhibits strong repetitive patterns over time, such as rhythms inherent to speech. Circular shifting can therefore produce predictors that are very similar to the original signal. As a result, this similarity may lead to null distributions that do not adequately disrupt the temporal mediation we aim to test, making it less robust as a control.
(3) Rationale for Random Shuffling: The primary goal of our mediation analysis is to determine whether there is a temporal mediation of envelope tracking by ocular movements. By deliberately destroying the temporal structure through random shuffling, we ensure that the null model tests for the specific temporal relationship that is central to our hypothesis. Circularly shifted predictors, on the other hand, may partially preserve temporal dependencies, making them less suitable for this purpose.
In summary, while circular shifting is a valuable approach in other contexts, it is less appropriate for the specific goals of this study. We hope this explanation clarifies our methodological choices and demonstrates their alignment with the aims of our analysis.
(5) Replication: I want to point out that it is great that the previous findings were in principle replicated. However, I would like to suggest a more nuanced evaluation of the replication:
a) Instead of a (direct) replication, the present study should be called a 'conceptual replication', since modifications in design and procedure were made.
Thank you very much for this suggestion! We now use the term ‘conceptual replication’ throughout the manuscript.
b) Not all the findings from the Gehmacher et al., 2024 study were replicated to a full extent:
Did the authors find indications of a vertical vs. horizontal tracking difference in the Gehmacher 2024 data? Could they check this in the Gehmacher 2024 data?
The findings for horizontal and vertical gaze tracking in Gehmacher et al. (2024) are detailed in the supplementary material of that publication. Both single-speaker and multi-speaker target conditions showed significant speech tracking effects in both horizontal and vertical directions. However, there was a slightly stronger tracking effect for the single-speaker condition in the vertical direction. Due to the highly predictable structure of words in Gehmacher et al. effects here were probably overall boosted as compared to continuous audiobook listening, likely leading to the differentiation of horizontal and vertical gaze. See figures in Gehmacher et al. supplementary file for reference.
c) Another difference between their previous and this study is the non-existent tracking of the multi-speaker distractor in this study. The authors should point this out clearly in the discussion and potentially provide an explanation.
Thank you for highlighting this point! We now address this in the discussion:
“Importantly, in contrast to Gehmacher et al. (2024), we did not observe ocular tracking of the multi-speaker distractor in this study. This difference is likely attributable to the simplistic single-trial, 5-word task structure in Gehmacher et al., which resulted in high temporal overlap between the target and distractor speech streams and likely drove the significant distractor-tracking effects observed in that study. The absence of such an effect during continuous listening in our study suggests that ocular tracking is indeed more specific to selective attention.”
Minor:
(1) I was a little surprised to not see an indication of eyes/eye movements in Figure 6. The intention of the authors might have been to create a general schematic illustration, but I find this a bit misleading. This paper provides nice evidence for a specific ocular effect in speech tracking. There is, to my knowledge, no indication that speech would be influenced by different kinds of active sensing (if there are, please include them in the discussion). Given that the visuomotor system is quite dominant in humans, it might actually be the case that the speech tracking the authors describe is specifically ocular.
Taking into account all the reviewers' remarks on the findings and interpretations, we have updated this figure (now Fig. 7) in the manuscript to make it more specific and aligned with the revised discussion section. Throughout the manuscript, we now explicitly refer to active ocular sensing in relation to speech processing and have avoided the broader term 'active sensing' in this context. We hope these revisions address the concerns raised.
(2) I find the part in the discussion (page 2, last paragraph) on cognitive processes hard to follow. I don't agree that 'cognitive processes' are easily separable from any of the measured responses (eye and brain). Referring to the example they provide, there is evidence that eye movements are correlated with brain activity that is correlated with memory performance. How, and more importantly, why would one separate those?
Thank you for raising this important point. We have carefully considered your comments, particularly regarding the interplay between cognitive processes and measured responses (eye and brain), as well as the challenge of conceptually separating them. Additionally, we have incorporated Reviewer #2's query (13) into a unified and complementary reasoning. In response, we have rewritten the relevant paragraph in the discussion to provide a clearer and more detailed explanation of how ocular and neural responses contribute to speech processing in an interdependent manner. We hope this revision addresses your concerns and offers a more precise and coherent discussion on this topic:
“Despite the finding that eye movements mediate neural speech tracking, the behavioural relevance for semantic comprehension appears to differ between ocular and neural speech tracking. Specifically, we found a negative association between ocular speech tracking and comprehension, indicating that participants with lower comprehension performance exhibited increased ocular speech tracking. Interestingly, no significant relationship was observed between neural tracking and comprehension.
In this context, the negative association between ocular tracking and comprehension might reflect individual differences in how participants allocate cognitive resources. Participants with lower comprehension may rely more heavily on attentional mechanisms to process acoustic features, as evidenced by increased ocular tracking. This reliance could represent a compensatory strategy when higher-order processes, such as semantic integration or memory retrieval, are less effective. Importantly, our comprehension questions (see Experimental Procedure) targeted a broad range of processes, including intelligibility and memory, suggesting that this relationship reflects a trade-off in resource allocation between low-level acoustic focus and integrative cognitive tasks.
Rather than separating eye and brain responses conceptually, our analysis highlights their complementary contributions. Eye movements may enhance neural processing by increasing sensitivity to acoustic properties of speech, while neural activity builds on this foundation to integrate information and support comprehension. Together, these systems form an interdependent mechanism, with eye and brain responses working in tandem to facilitate different aspects of speech processing.
This interpretation is consistent with the absence of a difference in ocular tracking for semantic violations (e.g., words with high surprisal versus lexically matched controls), reinforcing the view that ocular tracking primarily reflects attentional engagement with acoustic features rather than direct involvement in semantic processing. This aligns with previous findings that attention modulates auditory responses to acoustic features (e.g., Forte et al., 2017), further supporting the idea that ocular tracking reflects mechanisms of selective attention rather than representations of linguistic content.
Future research should investigate how these systems interact and explore how ocular tracking mediates neural responses to linguistic features, such as lexical or semantic processing, to better understand their joint contributions to comprehension.”.
(3) Attention vs. predictive coding. I think the authors end up with an elegant description of the observed effects, "as an "active sensing" mechanism that implements the attentional optimization of sensory precision." However, I feel the paragraph starts with the ill-posed question "whether ocular speech tracking is modulated not by predictive, but other (for example attentional) processes". If ocular tracking is the implementation of a process (optimization of sensory precision, aka attention), how could it be at the same time modulated by that process? In my opinion, adding the notion that there is a modulation by a vague cognitive concept like attention on top of what the paper shows does not improve our understanding of how speech tracking in humans works.
Thank you for raising this point. We agree that it is critical to clarify the relationship between ocular speech tracking, attention, and predictive processes, and we appreciate the opportunity to refine this discussion.
To avoid the potential confusion that active ocular sensing represents on the one hand an implementation of selective attention on the other it seems to be modulated by it, we now use the formulation “ocular speech tracking reflects attentional mechanisms rather than predictive processes.”
To address your concern that the conceptualization of attention seems rather vague, we have revised the whole paragraph in order to redefine the theoretical entities in question (including selective attention) and to provide a clearer and more precise picture (see also our revised version of Fig. 6, now Fig. 7). We now focus on highlighting the distinct yet interdependent roles of selective attention and individual prediction tendencies for speech tracking.:
“With this speculative framework we attempt to describe and relate three important phenomena with respect to their relevance for speech processing: 1) “Anticipatory predictions” that are created in absence of attentional demands and contain probabilistic information about stimulus features (here, inferred from frequency-specific pre-activations during passive listening to sound sequences). 2) “Selective attention” that allocates resources towards relevant (whilst suppressing distracting) information (which was manipulated by the presence or absence of a distractor speaker). And finally 3) “active ocular sensing”, which refers to gaze behavior that is temporally aligned to attended (but not unattended) acoustic speech input (inferred from the discovered phenomenon of ocular speech tracking). We propose that auditory inflow is, at a basic level, temporally modulated via active ocular sensing, which “opens the gates” in the sensory periphery at relevant timepoints. How exactly this mechanism is guided (for example where the information about crucial timepoints comes from, if not from prediction, and whether it requires habituation to a speechstream etc.) is yet unclear. Unlike predictive tendencies, active ocular sensing appears to reflect selective attention, manifesting as a mechanism that optimizes sensory precision. Individual differences with respect to anticipatory predictions on the other hand, seem to be independent from the other two entities, but nevertheless relevant for speech processing. We therefore support the notion that representational content is interpreted based on prior probabilistic assumptions. If we consider the idea that “a percept” of an (auditory) object is actually temporally and spatially distributed (across representational spacetime - see Fig. 7), the content of information depends on where and when it is probed (see for example Dennett, 1991 for similar ideas on consciousness). Having to select from multiple interpretations across space and time requires a careful balance between the weighting of internal models and the allocation of resources based on current goals. We suggest that in the case of speech processing, this challenge results in an independent adaptation of feature-based precision-weighting by predictions on the one hand and temporal precision-weighting by selective attention on the other.”
Reviewer #2 (Recommendations for the authors):
My main recommendation is outlined in the Weaknesses above: the overarching rationale for many analysis choices should be made explicit, and intermediate results should be shown where appropriate, so the reader can follow what is being quantified and what the results truly mean. Specifically, I recommend to pay attention to the following (in no particular order):
(1) Define 'neural speech tracking' early on. (e.g.: 'The amount of information in the MEG signal that can multivariately be explained by the speech amplitude envelope.' (is that correct?))
Thank you for pointing out that this important definition is missing. It is now defined at the first mention in the Introduction as follows: “Here (and in the following) “neural speech tracking” refers to a correlation coefficient between actual brain responses and responses predicted from an encoding model based solely on the speech envelope”.
(2) Same for 'ocular speech tracking'. Here even reading the Methods does not make it unambiguous how this term is used.
It is now defined at the first mention in the Introduction as follows: “Ocular speech tracking” (similarly to “neural speech tracking” refers to the correlation coefficient between actual eye movements and movements predicted from an encoding model based on the speech envelope”.
In addition also define both (neural and ocular speech tracking) metrics in the Methods Section.
(3) Related to this: for ocular speech tracking, are simply the horizontal and vertical eye traces compared to the speech envelope? If so, this appears somewhat strange: why should the eyes move more rightward/upward with a larger envelope? And the direction here depends on the (arbitrary) sign of right = positive, etc. (It would make more sense to quantify 'amount of movement' in some way, but if this is done, I missed it in Methods.)
Thank you for your insightful comments. You are correct that the horizontal and vertical traces were used for ocular speech tracking, and no additional details were included in the Methods. While we agree that the observed rightward/upward movement may seem unusual, this pattern is consistent with previous findings, including those reported in Gehmacher et al. (2024). In that study, we discussed how ocular speech tracking could reflect a broader engagement of the motor system during speech perception. For example, we observed a general right-lateralized gaze bias when participants attended to auditory speech, which we hypothesized might resemble eye movements during text reading, with a similar temporal alignment (~200 ms). We also speculated that this pattern might differ in cultures that read text from right to left.
We appreciate your suggestion to explore alternative methods for quantifying gaze patterns, such as the "amount of movement" or microsaccades. While these approaches hold promise for future studies, our primary aim here was to replicate previous findings using the same signal and analysis methods to establish a basis for further exploration.
(4) In the Introduction, specifically blink-related ocular activity is mentioned as being related to speech tracking (for which a reference is, incidentally, missing), while here, any blink-related activity is excluded from the analysis. This should be motivated, as it appears in direct contradiction.
Thank you for pointing this out. The mention of blink-related ocular activity in the Introduction refers to findings by Jin et al. (2018), where such activity was shown to align with higher-order syntactic structures in artificial speech. We have now included the appropriate reference for clarity.
While Jin et al. focused on blink-related activity, in the present study, we focused on gaze patterns to investigate ocular speech tracking, replicating findings from
Gehmacher et al. (2024). This approach was motivated by our goal to validate previous results using the same methodology. Importantly to this point, the exclusion of blinks in our analysis was due to methodological constraints of TRF analysis, which requires a continuous response signal; blinks, being discrete and artifact-prone, are incompatible with this approach.
To address your concern, we revised the Introduction to clarify this distinction and provide explicit motivation for focusing on gaze patterns. It now reads:
“Along these lines, It has been shown that covert, mostly blink related eye activity aligns with higher-order syntactic structures of temporally predictable, artificial speech (i.e. monosyllabic words; Jin et al, 2018). In support of ideas that the motor system is actively engaged in speech perception (Galantucci et al., 2006; Liberman & Mattingly, 1985), the authors suggest a global entrainment across sensory and (oculo)motor areas which implements temporal attention.
In another recent study from our lab (Gehmacher et al., 2024), we showed that eye movements continuously track intensity fluctuations of attended natural speech, a phenomenon we termed ocular speech tracking. In the present study, we focused on gaze patterns rather than blink-related activity, both to replicate findings from
Gehmacher et al. (2024) and because blink activity is unsuitable for TRF analysis due to its discrete and artifact-prone nature. Hence, “Ocular speech tracking” (similarly to “neural speech tracking” refers to the correlation coefficient between actual eye movements and movements predicted from an encoding model based on the speech envelope.”
Jin, P., Zou, J., Zhou, T., & Ding, N. (2018). Eye activity tracks task-relevant structures during speech and auditory sequence perception. Nature communications, 9(1), 5374.
(5) The rationale for the mediation analysis is questionable. Let speech envelope = A, brain activity = B, eye movements = C. The authors wish to claim that A -> C -> B. But it is equally possible that A -> B -> C. They reflect on this somewhat in Discussion, but throughout the rest of the paper, the mediation analysis is presented as specifically testing whether A -> B is mediated by C, which is potentially misleading.
Indeed we share your concern regarding the directionality of the relationships in the mediation analysis. Our choice of ocular movements as a mediator was motivated by the fact that the relationship between acoustic speech and neural activity is well established, as well as previous results indicating that oculomotor activity contributes to cognitive effects in auditory attention (Popov et al., 2022).
Indeed, here we treat both interpretations (“ocular movements contribute to neural speech tracking” versus “neural activity contributes to ocular speech tracking”) as equal. We now emphasise this point in our discussion quite thoroughly:
“It is important to note that our current findings do not allow for inference on directionality. Our choice of ocular movements as a mediator was motivated by the fact that the relationship between acoustic speech and neural activity is well established, as well as previous results indicating that oculomotor activity contributes to cognitive effects in auditory attention (Popov et al., 2022). However, an alternative model may suggest that neural activity mediates the effect of ocular speech tracking. Hence, it is possible that ocular mediation of speech tracking may reflect a) active (ocular) sensing for information driven by (top-down) selective attention or b) improved neural representations as a consequence of temporally aligned increase of sensory gain or c) (not unlikely) both. In fact, when rejecting the notion of a single bottom-up flow of information and replacing it with a model of distributed parallel and dynamic processing, it seems only reasonable to assume that the direction of communication (between our eyes and our brain) will depend on where (within the brain) as well as when we look at the effect. Thus, the regions and time-windows reported here should be taken as an illustration of oculo-neural communication during speech processing rather than an attempt to "explain" neural speech processing by ocular movements.”
(6) The mediation analysis can be improved by a proper quantification of the effect (sizes or variance explained). E.g. how much % of B is explained by A total, and how much of that can in turn be explained by C being involved? For drawing directional conclusions perhaps Granger causality could be used.
In Figure 4 (now Figure 5) of our manuscript we use standardized betas (which correspond to effect sizes) to illustrate the mediation effect. With the current mTRF approach it is however not possible (or insightful) to compare the variance explained. It is reasonable to assume that variance in neural activity will be explained better when including oculomotor behavior as a second predictor along with acoustic simulation. However this increase gives no indication to what extent this oculomotor behavior was task relevant or irrelevant (since all kinds of “arbitrary” movements will be captured with brain activity and therefore lead to an increase in variance explained). For this reason we chose to pursue the widely accepted framework of mediation (Baron & Kenny, 1986). This (correlational) approach is indeed limited in its interpretations (see prev. response), however the goal of the current study was to replicate and illustrate the triad relationship of acoustic speech input, neural activity and ocular movements with no particular hypotheses on directionality.
(7) Both prediction tendency and neural speech tracking depend on MEG data, and thus on MEG signal-to-noise ratio (SNR). It is possible some participants may have higher SNR recordings in both tasks, which may result in both higher (estimated) prediction tendency and higher (estimated) speech tracking. This would result in a positive correlation, as the authors observe. This trivial explanation should be ruled out, by quantifying the relative SNR and testing for the absence of a mediation here.
We agree that for both approaches (MVPA and mTRF models) individual MEG SNR plays an important role. This concern has been raised previously and addressed in our previous manuscript (Schubert et al., 2023). First, it should be noted that our prediction tendency value is the result of a condition contrast (rather than simple decoding accuracy) which compensates for the influence of subject specific signal-to-noise ratio (as no vacuous difference in SNR is to be expected between conditions). Second, in our previous study we also used frequency decoding accuracy as a control variable to correlate with speech tracking variables of interest and found no significant effect.
(8) Much of the analysis pipeline features temporal response functions (TRFs). These should be shown in a time-resolved manner as a key intermediate step.
We now included the Neural Speech tracking TRFs into the Figure (now Figure 3).
(9) Figure 2 shows much-condensed results from different steps in the pipeline. If I understand correctly, 2A shows raw TRF weights (averaged over some time window?), while 2B-F shows standardized mean posterior regressor weights after Bayesian stats? It would be very helpful to make much more explicit what is being shown here, in addition to showing the related TRFs.
Thank you for pointing this out! The figure description so far has been indeed not very insightful on this issue. We now adapted the caption and hope this clarifies the confusion: “ Neural speech tracking is related to prediction tendency and word surprisal, independent of selective attention. A) Envelope (x) - response (y) relationships are estimated using deconvolution (Boosting). The TRF (filter kernel, h) models how the brain processes the envelope over time. This filter is used to predict neural responses via convolution. Predicted responses are correlated with actual neural activity to evaluate model fit and the TRF's ability to capture response dynamics. Correlation coefficients from these models are then used as dependent variables in Bayesian regression models. (Panel adapted from Gehmacher et al., 2024b). B) Temporal response functions (TRFs) depict the time-resolved neural tracking of the speech envelope for the single speaker and multi speaker target condition, shown here as absolute values averaged across channels. Solid lines represent the group average. Shaded areas represent 95% Confidence Intervals. C–H) The beta weights shown in the sensor plots are derived from Bayesian regression models in A). For Panel C, this statistical model is based on correlation coefficients computed from the TRF models (further details can be found in the Methods Section). C) In a single speaker condition, neural tracking of the speech envelope was significant for widespread areas, most pronounced over auditory processing regions. D) The condition effect indicates a decrease in neural speech tracking with increasing noise (1 distractor). E) Stronger prediction tendency was associated with increased neural speech tracking over left frontal areas. F) However, there was no interaction between prediction tendency and conditions of selective attention. G) Increased neural tracking of semantic violations was observed over left temporal areas. H) There was no interaction between word surprisal and speaker condition, suggesting a representation of surprising words independent of background noise. Marked sensors indicate ‘significant’ clusters, defined as at least two neighboring channels showing a significant result. N = 29.”
Gehmacher, Q., Schubert, J., Kaltenmaier, A., Weisz, N., & Press, C. (2024b). The "Ocular Response Function" for encoding and decoding oculomotor related neural activity. bioRxiv, 2024-11.
(10) Bayesian hypothesis testing is not done consistently. Some parts test for inclusion of 0 in 94% HDI, while some parts adopt a ROPE approach. The same approach should be taken throughout. Additionally, Bayes factors would be very helpful (I appreciate these depend on the choice of priors, but the default Bambi priors should be fine).
Our primary aim in this study was to replicate two recent findings: (1) the relationship between individual prediction tendencies and neural speech tracking, and (2) the tracking of the speech envelope by eye movements. To maintain methodological consistency with the original studies, we did not apply a ROPE approach when analyzing these replication effects. Instead, we followed the same procedures as the original work, focusing on the inclusion of 0 in the HDI for the neural effects and using the same methods for the ocular effects. Additionally, we were not specifically interested in potential null effects in these replication analyses, as our primary goal was to test whether we could reproduce the previously reported findings.
For the mediation analysis, however, we chose to extend the original approach by not only performing the analysis in a time-resolved manner but also applying a ROPE approach. This decision was motivated by our interest in gaining more comprehensive insights — beyond the replication goals — by also testing for potential null effects, which can provide valuable information about the presence or absence of mediation effects.
We appreciate your thoughtful feedback and hope this clarifies our rationale for the differing approaches in our Bayesian hypothesis testing.
Regarding Bayes Factors,
We understand that some researchers find Bayes Factors appealing, as they offer a seemingly simple and straightforward way to evaluate the evidence in favor of/ or against H0 in relation to H1 (e.g. BF10 > 102 = Decisive; according to the Jeffreys Scale). However, in practice Bayes Factors are often misunderstood e.g. by interpreting Bayes Factor as posterior odds or not acknowledging the notion of relative evidence in the Bayes Factor (see Wong et al. 2022). Instead of using Bayes Factors, we prefer to rely on estimating and reporting the posterior distribution of parameters given the data, prior and model assumptions (in form of the 94% HDI). This allows for a continuous evaluation of evidence for a given hypothesis that is in our eyes easier to interpret as a Bayes Factor.
Jeffreys, Harold (1998) [1961]. The Theory of Probability (3rd ed.). Oxford, England. p. 432. ISBN 9780191589676.
Wong, T. K., Kiers, H., & Tendeiro, J. (2022). On the Potential Mismatch Between the Function of the Bayes Factor and Researchers’ Expectations. Collabra: Psychology, 8(1), 36357. https://doi.org/10.1525/collabra.36357
(11) It would be helpful if Results could be appreciated without a detailed read of Methods. I would recommend a recap of each key methodological step before introducing the relevant Result. (This may also help in making the rationale explicit.)
In addition to the short recaps of methods that were already present, and information on quantifications of neural and ocular tracking and bayes statistics (see responses 1, 2, 9), we now added the following parts below to the results sections. Please refer to them in the context of the manuscript where they should now complement a key recap of methodological steps necessary to readily understand each analysis and rational that led to the results:
Individual prediction tendency is related to neural speech tracking:
“Thus, this measure is a single value per subject, which comprises a) differences between two contextual probabilities (i.e. ordered vs. random) in b) feature-specific tone representations c) in advance of their observation (summed over a time-window of -0.3 - 0 s). Importantly, this prediction tendency was assessed in an independent entropy modulation paradigm (see Fig. 1). On a group level we found an increased tendency to pre-activate a stimulus of high probability (i.e. forward transition) in an ordered context compared to a random context (see Fig, 2A). This effect replicates results from our previous work (Schubert et al., 2023, 2024). Using the summed difference between entropy levels (ordered - random) across pre-stimulus time, one value was extracted per subject (Fig. 2B). This value was used as a proxy for “individual prediction tendency” and correlated with encoding of clear speech across different MEG sensors. [...]
Neural speech tracking, quantified as the correlation coefficients between predicted and observed MEG responses to the speech envelope, was used as the dependent variable in Bayesian regression models. These models included condition (single vs. multi-speaker) as a fixed effect, with either prediction tendency or word surprisal as an additional predictor, and random effects for participants.”
Eye movements track acoustic speech in selective attention:
“For this, we separately predicted horizontal and vertical eye movements from the acoustic speech envelope using temporal response functions (TRFs). The resulting model fit (i.e. correlation between true and predicted eye movements) is commonly referred to as “speech tracking”. Bayesian regression models were applied to evaluate tracking effects under different conditions of selective attention (single speaker, attended multi-speaker, unattended multi-speaker). Furthermore, we assessed whether individual prediction tendency or semantic word surprisal influenced ocular speech tracking.”
Neural speech tracking is mediated by eye movements:
“This model evaluates to what extent gaze behaviour functions as a mediator between acoustic speech input and brain activity.”
Neural and ocular speech tracking are differently related to comprehension: “Bayesian regression models were used to investigate relationships between neural/ocular speech tracking and comprehension or difficulty. Ocular speech tracking was analyzed separately for horizontal and vertical eye movements.”
(12) The research questions in the Introduction should be sharpened up, to make explicit when a question concerns a theoretical entity, and when it concerns something concretely measured/measurable.
We sharpened them up:
“Taking into account the aforementioned study by Schubert and colleagues (2023), the two recently uncovered predictors of neural tracking (individual prediction tendency and ocular tracking) raise several empirical questions regarding the relationship between predictive processes, selective attention, and active ocular sensing in speech processing:
(1) Are predictive processes related to active ocular sensing in the same way they are to neural speech tracking? Specifically, do individuals with a stronger tendency to anticipate predictable auditory features, as quantified through prestimulus neural representations in an independent tone paradigm, show increased or even decreased ocular speech tracking, measured as the correlation between predicted and actual eye movements? Or is there no relationship at all?
(2) To what extent does selective attention influence the relationship between prediction tendency, neural speech tracking, and ocular speech tracking? For example, does the effect of prediction tendency or ocular speech tracking on neural tracking differ between a single-speaker and multi-speaker listening condition?
(3) Are individual prediction tendency and ocular speech tracking related to behavioral outcomes, such as comprehension and perceived task difficulty? Speech comprehension is assessed through accuracy on comprehension questions, and task difficulty is measured through subjective ratings.
Although predictive processes, selective attention, and active sensing have been shown to contribute to successful listening, their potential interactions and specific roles in naturalistic speech perception remain unclear. Addressing these questions will help disentangle their contributions and establish an integrated framework for understanding how neural and ocular speech tracking support speech processing.”
(13) The negative relationship between story comprehension and ocular speech tracking appears to go against the authors' preferred interpretation, but the reflection on this in the Discussion is very brief and somewhat vague.
Thank you for pointing this out. We have taken your comments into careful consideration and also incorporated Reviewer #1's query (Minor point 2) into a unified and complementary reasoning. We have rewritten the relevant paragraph in the discussion to provide a clearer and more detailed explanation. We hope this revision offers a more precise and less vague discussion on this important point.
“Despite the finding that eye movements mediate neural speech tracking, the behavioural relevance for semantic comprehension appears to differ between ocular and neural speech tracking. Specifically, we found a negative association between ocular speech tracking and comprehension, indicating that participants with lower comprehension performance exhibited increased ocular speech tracking. Interestingly, no significant relationship was observed between neural tracking and comprehension.
In this context, the negative association between ocular tracking and comprehension might reflect individual differences in how participants allocate cognitive resources. Participants with lower comprehension may rely more heavily on attentional mechanisms to process acoustic features, as evidenced by increased ocular tracking. This reliance could represent a compensatory strategy when higher-order processes, such as semantic integration or memory retrieval, are less effective. Importantly, our comprehension questions (see Experimental Procedure) targeted a broad range of processes, including intelligibility and memory, suggesting that this relationship reflects a trade-off in resource allocation between low-level acoustic focus and integrative cognitive tasks.
Rather than separating eye and brain responses conceptually, our analysis highlights their complementary contributions. Eye movements may enhance neural processing by increasing sensitivity to acoustic properties of speech, while neural activity builds on this foundation to integrate information and support comprehension. Together, these systems form an interdependent mechanism, with eye and brain responses working in tandem to facilitate different aspects of speech processing.
This interpretation is consistent with the absence of a difference in ocular tracking for semantic violations (e.g., words with high surprisal versus lexically matched controls), reinforcing the view that ocular tracking primarily reflects attentional engagement with acoustic features rather than direct involvement in semantic processing. This aligns with previous findings that attention modulates auditory responses to acoustic features (e.g., Forte et al., 2017), further supporting the idea that ocular tracking reflects mechanisms of selective attention rather than representations of linguistic content.
Future research should investigate how these systems interact and explore how ocular tracking mediates neural responses to linguistic features, such as lexical or semantic processing, to better understand their joint contributions to comprehension.”.
(14) Page numbers would be helpful.
We added the page numbers.
Reviewer #3 (Recommendations for the authors):
Results
(1) Figure 2 - statistical results are reported in this figure, but they are not fully explained in the text, nor are statistical values provided for any of the analyses (as far as I can tell).
Also, how were multiple comparisons dealt with (the choice of two neighboring channels seems quite arbitrary)? Perhaps for this reason, the main result - namely the effect of "prediction tendency" and "semantic violations" - is quite sparse and might not survive more a rigorous statistical criterion. I would feel more comfortable with these results if the reporting of the statistical analysis had been more thorough (ideally, including comparison to control models).
We would like to thank you again for your detailed queries, comments, and questions on our work. We first of all adapted this figure (now Figure 3 in the manuscript, please see responses 8 and 9 to Reviewer #2) to help readers understand the metrics and values within each statistical analysis. In addition, we indeed did not include the detailed statistics in the text! We now added the missing statistic reports calculated as averages over ‘clusters’:
“Replicating previous findings (Schubert et al., 2023), we found widespread encoding of clear speech (average over cluster: β = 0.035, 94%HDI = [0.024, 0.046]), predominantly over auditory processing regions (Fig. 3C), that was decreased (β = -0.018, 94%HDI = [0.029, -0.006]) in a multi-speaker condition (Fig. 3D). Furthermore, a stronger prediction tendency was associated with increased neural speech tracking (β = 0.014, 94%HDI = [0.004, 0.025]) over left frontal sensors (see Fig. 3E). We found no interaction between prediction tendency and condition (see Fig. 3F).” [...] “In a direct comparison with lexically identical controls, we found an increased neural tracking of semantic violations (β = 0.039, 94%HDI = [0.007, 0.071]) over left temporal areas (see Fig. 3G). Furthermore, we found no interaction between word surprisal and speaker condition (see Fig. 3H).”
Regarding the "prediction tendency" effect, it is important to note that this finding replicates a result from Schubert et al. (2023). The left frontal location of this effect is also consistent over studies, which convinces us of the robustness of the finding. Furthermore, testing this relationship properly requires a mixed-effects model in order to account for the variability across subjects that is not explained by fixed effects and the repeated measures design. For this reason a random Intercept had to be fitted for each subject (1|subject in the respective model formula). This statistical requirement motivated our decision to use bayesian statistics as (at least to our knowledge) there is no implementation of a cluster-based permutation mixed effects model (yet). In order to provide a more conservative criterion (as bayesian statistics don’t require a multiple comparison correction) we chose to impose in addition the requirement of a “clustered” effect.
The choice of using two neighboring channels is consistent with the default parameter settings in FieldTrip’s cluster-based permutation testing (cfg.minnbchan = 2). This parameter specifies the minimum number of neighboring channels required for a sample to be included in the clustering algorithm, ensuring spatial consistency in the identified clusters. This alignment ensures that our methodology is comparable to numerous prior studies in the field, where such thresholds are standard. While it is true that all statistical analyses involve some degree of arbitrariness in parameter selection (e.g., alpha levels or clustering thresholds), our approach reflects established conventions and ensures comparability with previous findings.
While the original study utilized source space analyses, we replicated this effect using only 102 magnetometers. This choice was made for computational simplicity, demonstrating that the effect is robust even without source-level modeling. Similarly, the "semantic violation" effect, while perceived as sparse, is based solely on magnetometer data and - in our opinion - should not be viewed as overly sparse given the methods employed. This effect aligns with the two-neighbor clustering approach, ensuring spatial consistency across magnetometers. The results reflect the robustness of the effects within the constraints of magnetometer-level analyses.
Overall, the methodological choices, including the choice of a bayesian linear mixed effects model, the use of two neighboring channels and the reliance on magnetometers, are grounded in established practices and methodological considerations. While stricter thresholds or alternative approaches might yield different results, our methods align with best practices in the field and ensure the robustness, comparability, and replicability of our findings.
(2) Figure 3 - the difference between horizontal and vertical eye-movements. This result is quite confusing and although the authors do suggest a possible interpretation for this in the discussion, I do wonder how robust this difference is or whether the ocular signal (in either direction) is simply too noisy or the effect too small to be detected consistently across conditions. Also, the ocular-TRFs themselves are not entirely convincing in suggesting reliable response/tracking of the audio - despite the small-but-significant increase in prediction accuracy.
The horizontal versus vertical comparison was conducted to explore potential differences in how these dimensions contribute to ocular tracking of auditory stimuli (please also see our response to Reviewer #1, Response 5b, that includes the vertical vs. horizontal effects of Gehmacher at al. 2024). It would indeed be interesting to develop a measure that combines the two directions into a more natural representation of 'viewing,' such as a combined vector. However, this approach would require the use of complex numbers to represent both magnitude and direction simultaneously, hence the development of novel TRF algorithms capable of modeling this multidimensional signal. While beyond the scope of the current study, this presents an exciting avenue for future research and would allow us to move closer to understanding ocular speech tracking and the robustness of these effects, above and beyond the already successful replication.
It is also important to emphasize that ocular-TRFs are derived from (viewing) behavioral data rather than neural signals, and are thus inherently subject to greater variability across participants and time. This higher variability does not necessarily indicate a small or unreliable effect but reflects the dynamic and task-dependent nature of eye movement behavior. The TRFs with shaded error margins represent this variability, highlighting how eye movements are influenced by both individual differences and moment-to-moment changes in task engagement.
Despite this inherent variability, the significant prediction accuracy improvements confirm that ocular-TRFs reliably capture meaningful relationships between eye movements and auditory stimuli. The observed differences between horizontal and vertical TRFs further support the hypothesis that these dimensions are differentially involved in the task, possibly driven by the specific roles they play in sensorimotor coupling.
(3) Figure 4 - this figure shows source distribution of 3 PCA components, derived from the results of the mediation effect of eye movements on the speech-tracking. Here too I am having difficulty in interpreting what the results actually are. For one, all three components are quite widespread and somewhat overlapping, so although they are statistically "independent" it is hard to learn much from them about the brain regions involved and whether they truly represent separable contributions. Similarly difficult to interpret are the time courses, which share some similarities with the known TRFs to speech (especially PC3). I would have expected to find a cleaner "auditory" response, and clearer separation between sensory regions and regions involved in the control of eye movements. I also wonder why the authors chose not to show the sourcelocalization of the neural and ocular speech-tracking responses alone - this could have helped us between understand what "mediation" of the neural response might look like.
We appreciate the reviewer’s interest in better understanding the source distribution and time courses of the PCA components. While we acknowledge that the widespread and overlapping nature of the components may make a more fine grained interpretation challenging, it is important to emphasize that our analysis simply reflects the data, hence we can only present and interpret what the analysis revealed.
Regarding your suggestion to show the source localization of ocular speech tracking and neural speech tracking alone, we would like to point out that ocular tracking is represented by only one channel for vertical and one channel for horizontal eye movements. Thus, in this case the estimated source of the effect are the eyes themselves. We believe that the source localization of neural speech tracking has been a thoroughly studied topic in research so far (locating it to perisylvian, auditory areas with a stronger preference for the left hemisphere) and can also be seen in Schubert et al., (2023). Nevertheless, we believe the observed PCA components still provide valuable, and most importantly novel insights into the interplay between eye movements and neural responses in speech tracking.
Discussion/interpretation
(1) Although I appreciate the authors' attempt to propose a "unified" theoretical model linking predictions about low-level features to higher features, and the potential involvement of eye movements in 'active sensing' I honestly think that this model is overambitious, given the data presented in the current study. Moreover, there is very little discussion of past literature and existing models of active sensing and hierarchical processing of speech, that could have helped ground the discussion in a broader theoretical context. The entire discussion contains fewer than 20 citations (some of which are by these authors) and needs to be substantially enriched in order to provide context for the authors' claims.
Thank you very much for your thoughtful feedback and for appreciating our approach. We hope that the revised manuscript addresses your concerns. Specifically, we now emphasize that our proposal is a conceptual framework, with the main goal to operationale “prediction tendency”, “active ocular sensing”, and “selective attention” and to “organise these entities according to their assumed function for speech processing and to describe their relationship with each other.” We did this by thoroughly revising our discussion section with a clear emphasis on the definition of terms, for example:
“With this speculative framework we attempt to describe and relate three important phenomena with respect to their relevance for speech processing: 1) “Anticipatory predictions” that are created in absence of attentional demands and contain probabilistic information about stimulus features (here, inferred from frequency-specific pre-activations during passive listening to sound sequences). 2) “Selective attention” that allocates resources towards relevant (whilst suppressing distracting) information (which was manipulated by the presence or absence of a distractor speaker). And finally 3) “active ocular sensing”, which refers to gaze behavior that is temporally aligned to attended (but not unattended) acoustic speech input (inferred from the discovered phenomenon of ocular speech tracking).”
Our theoretical proposals are now followed by a recap of our results that support the respective idea, for example:
“...these predictions are formed in parallel and carry high feature-specificity but low temporal precision (as they are anticipatory in nature). This idea is supported by our finding that pure-tone anticipation is visible over a widespread prestimulus interval, instead of being locked to sound onset”
“....we suggest that active (ocular) sensing does not necessarily convey feature- or content-specific information, it is merely used to boost (and conversely filter) sensory input at specific timescales (similar to neural oscillations). This assumption is supported by our finding that semantic violations are not differentially encoded in gaze behaviour than lexical controls.”
And we put a strong focus on highlighting the boundaries of these ideas, in order to avoid theoretical confusion, misunderstandings or implicit theoretical assumption that are not grounded in data, in particular:
“In fact, when rejecting the notion of a single bottom-up flow of information and replacing it with a model of distributed parallel and dynamic processing, it seems only reasonable to assume that the direction of communication (between our eyes and our brain) will depend on where (within the brain) as well as when we look at the effect. Thus, the regions and time-windows reported here should be taken as an illustration of oculo-neural communication during speech processing rather than an attempt to "explain" neural speech processing by ocular movements.”
“Even though the terminology [“hierarchy”] is suggestive of a fixed sequence (similar to a multi storey building) with levels that must be traversed one after each other (and even the more spurious idea of a rooftop, where the final perceptual experience is formed and stored into memory), we distance ourselves from these (possibly unwarranted) ideas. Our usage of “higher” or “lower” simply refers to the observation that the probability of a feature at a higher (as in more associative) level affects the interpretation (and thus the representation and prediction) of a feature at lower (as in more segregated) levels (Caucheteux et al., 2023).”
Additionally, we have made substantial efforts to present complementary results (see response to Reviewer #2, point 8) to further substantiate our interpretation. Importantly, we have updated the illustration of the model (see response to Reviewer #, minor point 1) and refined both our interpretations and the conceptual language in the Discussion. Furthermore, we have included additional citations where appropriate to strengthen our argument.
We would also like to briefly note that this section of the Discussion aimed to highlight existing literature that bridges the gap our model seeks to address. However, as this is a relatively underexplored area, the references available are necessarily limited.
(2) Given my many reservations about the data, as presented in the current version of the manuscript, I find much of the discussion to be an over-interpretation of the results. This might change if the authors are able to present more robust results, as per some of my earlier comments.
We sincerely hope that our comprehensive revisions have addressed your concerns and improved the manuscript to your satisfaction.



