Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorMaria ChaitUniversity College London, London, United Kingdom
- Senior EditorMichael FrankBrown University, Providence, United States of America
Reviewer #1 (Public Review):
Summary:
This paper presents a compelling and comprehensive study of decision-making under uncertainty. It addresses a fundamental distinction between belief-based (cognitive neuroscience) formulations of choice behavior with reward-based (behavioral psychology) accounts. Specifically, it asks whether active inference provides a better account of planning and decision making, relative to reinforcement learning. To do this, the authors use a simple but elegant paradigm that includes choices about whether to seek both information and rewards. They then assess the evidence for active inference and reinforcement learning models of choice behavior, respectively. After demonstrating that active inference provides a better explanation of behavioral responses, the neuronal correlates of epistemic and instrumental value (under an optimized active inference model) are characterized using EEG. Significant neuronal correlates of both kinds of value were found in sensor and source space. The source space correlates are then discussed sensibly, in relation to the existing literature on the functional anatomy of perceptual and instrumental decision-making under uncertainty.
Reviewer #2 (Public Review):
Summary:
Zhang and colleagues use a combination of behavioral, neural, and computational analyses to test an active inference model of exploration in a novel reinforcement learning task.
Strengths:
The paper addresses an important question (validation of active inference models of exploration). The combination of behavior, neuroimaging, and modeling is potentially powerful for answering this question.
I appreciate the addition of details about model fitting, comparison, and recovery, as well as the change in some of the methods.
Weaknesses:
The authors do not cite what is probably the most relevant contextual bandit study, by Collins & Frank (2018, PNAS), which uses EEG.
The authors cite Collins & Molinaro as a form of contextual bandit, but that's not the case (what they call "context" is just the choice set). They should look at the earlier work from Collins, starting with Collins & Frank (2012, EJN).
Placing statistical information in a GitHub repository is not appropriate. This needs to be in the main text of the paper. I don't understand why the authors refer to space limitations; there are none for eLife, as far as I'm aware.
In answer to my question about multiple comparisons, the authors have added the following: "Note that we did not attempt to correct for multiple comparisons; largely, because the correlations observed were sustained over considerable time periods, which would be almost impossible under the null hypothesis of no correlations." I'm sorry, but this does not make sense. Either the authors are doing multiple comparisons, in which case multiple comparison correction is relevant, or they are doing a single test on the extended timeseries, in which case they need to report that. There exist tools for this kind of analysis (e.g., Gershman et al., 2014, NeuroImage). I'm not suggesting that the authors should necessarily do this, only that their statistical approach should be coherent. As a reference point, the authors might look at the aforementioned Collins & Frank (2018) study.
I asked the authors to show more descriptive comparison between the model and the data. Their response was that this is not possible, which I find odd given that they are able to use the model to define a probability distribution on choices. All I'm asking about here is to show predictive checks which build confidence in the model fit. The additional simulations do not address this. The authors refer to figures 3 and 4, but these do not show any direct comparison between human data and the model beyond model comparison metrics.
Reviewer #3 (Public Review):
Summary:
This paper aims to investigate how the human brain represents different forms of value and uncertainty that participate in active inference within a free-energy framework, in a two-stage decision task involving contextual information sampling, and choices between safe and risky rewards, which promotes shifting between exploration and exploitation. They examine neural correlates by recording EEG and comparing activity in the first vs second half of trials and between trials in which subjects did and did not sample contextual information, and perform a regression with free-energy-related regressors against data "mapped to source space."
Strengths:
This two-stage paradigm is cleverly designed to incorporate several important processes of learning, exploration/exploitation and information sampling that pertain to active inference. Although scalp/brain regions showing sensitivity to the active-inference related quantities do not necessary suggest what role they play, they are illuminating and useful as candidate regions for further investigation. The aims are ambitious, and the methodologies impressive. The paper lays out an extensive introduction to the free energy principle and active inference to make the findings accessible to a broad readership.
Weaknesses:
In its revised form the paper is complete in providing the important details. Though not a serious weakness, it is important to note that the high lower-cutoff of 1 Hz in the bandpass filter, included to reduce the impact of EEG noise, would remove from the EEG any sustained, iteratively updated representation that evolves with learning across trials, or choice-related processes that unfold slowly over the course of the 2-second task windows.
Author response:
The following is the authors’ response to the original reviews.
Public Reviews:
Reviewer #1 (Public Review):
Summary:
This paper presents a compelling and comprehensive study of decision-making under uncertainty. It addresses a fundamental distinction between belief-based (cognitive neuroscience) formulations of choice behaviour with reward-based (behavioural psychology) accounts. Specifically, it asks whether active inference provides a better account of planning and decision-making, relative to reinforcement learning. To do this, the authors use a simple but elegant paradigm that includes choices about whether to seek both information and rewards. They then assess the evidence for active inference and reinforcement learning models of choice behaviour, respectively. After demonstrating that active inference provides a better explanation of behavioural responses, the neuronal correlates of epistemic and instrumental value (under an optimised active inference model) are characterised using EEG. Significant neuronal correlates of both kinds of value were found in sensor and source space. The source space correlates are then discussed sensibly, in relation to the existing literature on the functional anatomy of perceptual and instrumental decision-making under uncertainty.
Strengths:
The strengths of this work rest upon the theoretical underpinnings and careful deconstruction of the various determinants of choice behaviour using active inference. A particular strength here is that the experimental paradigm is designed carefully to elicit both information-seeking and reward-seeking behaviour; where the information-seeking is itself separated into resolving uncertainty about the context (i.e., latent states) and the contingencies (i.e., latent parameters), under which choices are made. In other words, the paradigm - and its subsequent modelling - addresses both inference and learning as necessary belief and knowledge-updating processes that underwrite decisions.
The authors were then able to model belief updating using active inference and then look for the neuronal correlates of the implicit planning or policy selection. This speaks to a further strength of this study; it provides some construct validity for the modelling of belief updating and decision-making; in terms of the functional anatomy as revealed by EEG. Empirically, the source space analysis of the neuronal correlates licences some discussion of functional specialisation and integration at various stages in the choices and decision-making.
In short, the strengths of this work rest upon a (first) principles account of decision-making under uncertainty in terms of belief updating that allows them to model or fit choice behaviour in terms of Bayesian belief updating - and then use relatively state-of-the-art source reconstruction to examine the neuronal correlates of the implicit cognitive processing.
Response: We are deeply grateful for your careful review of our work and for the thoughtful feedback you have provided. Your dedication to ensuring the quality and clarity of the work is truly admirable. Your comments have been invaluable in guiding us towards improving the paper, and We appreciate your time and effort in not just offering suggestions but also providing specific revisions that I can implement. Your insights have helped us identify areas where I can strengthen the arguments and clarify the methodology.
Comment 1:
The main weaknesses of this report lies in the communication of the ideas and procedures. Although the language is generally excellent, there are some grammatical lapses that make the text difficult to read. More importantly, the authors are not consistent in their use of some terms; for example, uncertainty and information gain are sometimes conflated in a way that might confuse readers. Furthermore, the descriptions of the modelling and data analysis are incomplete. These shortcomings could be addressed in the following way.
First, it would be useful to unpack the various interpretations of information and goal-seeking offered in the (active inference) framework examined in this study. For example, it will be good to include the following paragraph:
"In contrast to behaviourist approaches to planning and decision-making, active inference formulates the requisite cognitive processing in terms of belief updating in which choices are made based upon their expected free energy. Expected free energy can be regarded as a universal objective function, specifying the relative likelihood of alternative choices. In brief, expected free energy can be regarded as the surprise expected following some action, where the expected surprise comes in two flavours. First, the expected surprise is uncertainty, which means that policies with a low expected free energy resolve uncertainty and promote information seeking. However, one can also minimise expected surprise by avoiding surprising, aversive outcomes. This leads to goal-seeking behaviour, where the goals can be regarded as prior preferences or rewarding outcomes.
Technically, expected free energy can be expressed in terms of risk plus ambiguity - or rearranged to be expressed in terms of expected information gain plus expected value, where value corresponds to (log) prior preferences. We will refer to both decompositions in what follows; noting that both decompositions accommodate information and goal-seeking imperatives. That is, resolving ambiguity and maximising information gain have epistemic value, while minimising risk or maximising expected value have pragmatic or instrumental value. These two kinds of values are sometimes referred to in terms of intrinsic and extrinsic value, respectively [1-4]."
Response 1: We deeply thank you for your comments and corresponding suggestions about our interpretations of active inference. In response to your identified weaknesses and suggestions, we have added corresponding paragraphs in the Methods section (The free energy principle and active inference, line 95-106):
“Active inference formulates the necessary cognitive processing as a process of belief updating, where choices depend on agents' expected free energy. Expected free energy serves as a universal objective function, guiding both perception and action. In brief, expected free energy can be seen as the expected surprise following some policies. The expected surprise can be reduced by resolving uncertainty, and one can select policies with lower expected free energy which can encourage information-seeking and resolve uncertainty. Additionally, one can minimize expected surprise by avoiding surprising or aversive outcomes (oudeyer et al., 2007; Schmidhuber et al., 2010). This leads to goal-seeking behavior, where goals can be viewed as prior preferences or rewarding outcomes.
Technically, expected free energy can also be expressed as expected information gain plus expected value, where the value corresponds to (log) prior preferences. We will refer to both formulations in what follows. Resolving ambiguity, minimizing risk, and maximizing information gain has epistemic value while maximizing expected value have pragmatic or instrumental value. These two types of values can be referred to in terms of intrinsic and extrinsic value, respectively (Barto et al., 2013; Schwartenbeck et al., 2019).”
Oudeyer, P. Y., & Kaplan, F. (2007). What is intrinsic motivation? A typology of computational approaches. Frontiers in neurorobotics, 1, 108.
Schmidhuber, J. (2010). Formal theory of creativity, fun, and intrinsic motivation (1990–2010). IEEE transactions on autonomous mental development, 2(3), 230-247.
Barto, A., Mirolli, M., & Baldassarre, G. (2013). Novelty or surprise?. Frontiers in psychology, 4, 61898.
Schwartenbeck, P., Passecker, J., Hauser, T. U., FitzGerald, T. H., Kronbichler, M., & Friston, K. J. (2019). Computational mechanisms of curiosity and goal-directed exploration. elife, 8, e41703.
Comment 2:
The description of the modelling of choice behaviour needs to be unpacked and motivated more carefully. Perhaps along the following lines:
"To assess the evidence for active inference over reinforcement learning, we fit active inference and reinforcement learning models to the choice behaviour of each subject. Effectively, this involved optimising the free parameters of active inference and reinforcement learning models to maximise the likelihood of empirical choices. The resulting (marginal) likelihood was then used as the evidence for each model. The free parameters for the active inference model scaled the contribution of the three terms that constitute the expected free energy (in Equation 6). These coefficients can be regarded as precisions that characterise each subjects' prior beliefs about contingencies and rewards. For example, increasing the precision or the epistemic value associated with model parameters means the subject would update her beliefs about reward contingencies more quickly than a subject who has precise prior beliefs about reward distributions. Similarly, subjects with a high precision over prior preferences or extrinsic value can be read as having more precise beliefs that she will be rewarded. The free parameters for the reinforcement learning model included..."
Response 2: We deeply thank you for your comments and corresponding suggestions about our description of the behavioral modelling. In response to your identified weaknesses and suggestions, we have added corresponding content in the Results section (Behavioral results, line 279-293):
“To assess the evidence for active inference over reinforcement learning, we fit active inference (Eq.9), model-free reinforcement learning, and model-based reinforcement learning models to the behavioral data of each participant. This involved optimizing the free parameters of active inference and reinforcement learning models. The resulting likelihood was used to calculate the Bayesian Information Criterion (BIC) (Vrieze 2012) as the evidence for each model. The free parameters for the active inference model (AL, AI, EX, prior, and α) scaled the contribution of the three terms that constitute the expected free energy in Eq.9. These coefficients can be regarded as precisions that characterize each participant's prior beliefs about contingencies and rewards. For example, increasing α means participants would update their beliefs about reward contingencies more quickly, increasing AL means participants would like to reduce ambiguity more, and increasing AI means participants would like to learn the hidden state of the environment and avoid risk more. The free parameters for the model-free reinforcement learning model are the learning rate α and the temperature parameter γ and the free parameters for the model-based are the learning rate α, the temperature parameter γ and prior (the details for the model-free reinforcement learning model can be seen in Eq.S1-11 and the details for the model-based reinforcement learning model can be seen Eq.S12-23 in the Supplementary Method). The parameter fitting for these three models was conducted using the `BayesianOptimization' package in Python (Frazire 2018), first randomly sampling 1000 times and then iterating for an additional 1000 times.”
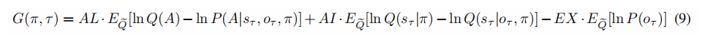
Vrieze, S. I. (2012). Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychological methods, 17(2), 228.
Frazier, P. I. (2018). A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.
Comment 3:
In terms of the time-dependent correlations with expected free energy - and its constituent terms - I think the report would benefit from overviewing these analyses with something like the following:
"In the final analysis of the neuronal correlates of belief updating - as quantified by the epistemic and intrinsic values of expected free energy - we present a series of analyses in source space. These analyses tested for correlations between constituent terms in expected free energy and neuronal responses in source space. These correlations were over trials (and subjects). Because we were dealing with two-second timeseries, we were able to identify the periods of time during decision-making when the correlates were expressed.
In these analyses, we focused on the induced power of neuronal activity at each point in time, at each brain source. To illustrate the functional specialisation of these neuronal correlates, we present whole-brain maps of correlation coefficients and pick out the most significant correlation for reporting fluctuations in selected correlations over two-second periods. These analyses are presented in a descriptive fashion to highlight the nature and variety of the neuronal correlates, which we unpack in relation to the existing EEG literature in the discussion. Note that we did not attempt to correct for multiple comparisons; largely, because the correlations observed were sustained over considerable time periods, which would be almost impossible under the null hypothesis of no correlations."
Response 3: We deeply thank you for your comments and corresponding suggestions about our description of the regression analysis in the source space. In response to your suggestions, we have added corresponding content in the Results section (EEG results at source level, line 331-347):
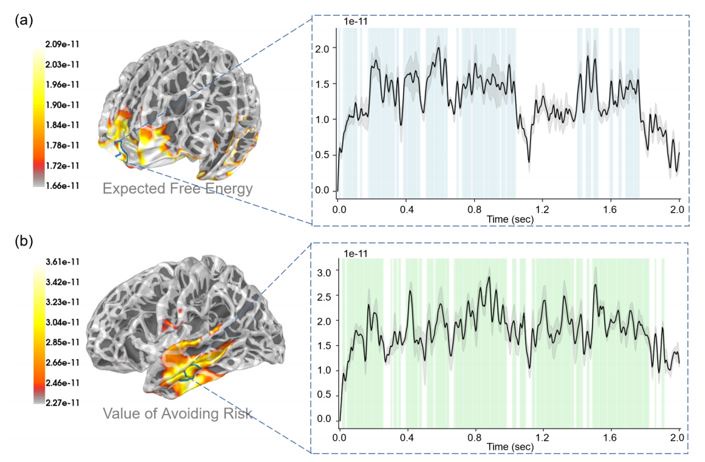
“In the final analysis of the neural correlates of the decision-making process, as quantified by the epistemic and intrinsic values of expected free energy, we presented a series of linear regressions in source space. These analyses tested for correlations over trials between constituent terms in expected free energy (the value of avoiding risk, the value of reducing ambiguity, extrinsic value, and expected free energy itself) and neural responses in source space. Additionally, we also investigated the neural correlate of (the degree of) risk, (the degree of) ambiguity, and prediction error. Because we were dealing with a two-second time series, we were able to identify the periods of time during decision-making when the correlates were expressed. The linear regression was run by the "mne.stats.linear regression" function in the MNE package (Activity ~ Regressor + Intercept). Activity is the activity amplitude of the EEG signal in the source space and regressor is one of the regressors that we mentioned (e.g., expected free energy, the value of reducing ambiguity, etc.).
In these analyses, we focused on the induced power of neural activity at each time point, in the brain source space. To illustrate the functional specialization of these neural correlates, we presented whole-brain maps of correlation coefficients and picked out the brain region with the most significant correlation for reporting fluctuations in selected correlations over two-second periods. These analyses were presented in a descriptive fashion to highlight the nature and variety of the neural correlates, which we unpacked in relation to the existing EEG literature in the discussion. Note that we did not attempt to correct for multiple comparisons; largely, because the correlations observed were sustained over considerable time periods, which would be almost impossible under the null hypothesis of no correlations.”
Comment 4:
There was a slight misdirection in the discussion of priors in the active inference framework. The notion that active inference requires a pre-specification of priors is a common misconception. Furthermore, it misses the point that the utility of Bayesian modelling is to identify the priors that each subject brings to the table. This could be easily addressed with something like the following in the discussion:
"It is a common misconception that Bayesian approaches to choice behaviour (including active inference) are limited by a particular choice of priors. As illustrated in our fitting of choice behaviour above, priors are a strength of Bayesian approaches in the following sense: under the complete class theorem [5, 6], any pair of choice behaviours and reward functions can be described in terms of ideal Bayesian decision-making with particular priors. In other words, there always exists a description of choice behaviour in terms of some priors. This means that one can, in principle, characterise any given behaviour in terms of the priors that explain that behaviour. In our example, these were effectively priors over the precision of various preferences or beliefs about contingencies that underwrite expected free energy."
Response 4: We deeply thank you for your comments and corresponding suggestions about the prior of Bayesian methods. In response to your suggestions, we have added corresponding content in the Discussion section (The strength of the active inference framework in decision-making, line 447-453):
“However, it may be the opposite. As illustrated in our fitting results, priors can be a strength of Bayesian approaches. Under the complete class theorem (Wald 1947; Brown 1981), any pair of behavioral data and reward functions can be described in terms of ideal Bayesian decision-making with particular priors. In other words, there always exists a description of behavioral data in terms of some priors. This means that one can, in principle, characterize any given behavioral data in terms of the priors that explain that behavior. In our example, these were effectively priors over the precision of various preferences or beliefs about contingencies that underwrite expected free energy.”
Wald, A. (1947). An essentially complete class of admissible decision functions. The Annals of Mathematical Statistics, 549-555.
Brown, L. D. (1981). A complete class theorem for statistical problems with finite sample spaces. The Annals of Statistics, 1289-1300.
Reviewer #2 (Public Review):
Summary:
Zhang and colleagues use a combination of behavioral, neural, and computational analyses to test an active inference model of exploration in a novel reinforcement learning task.
Strengths:
The paper addresses an important question (validation of active inference models of exploration). The combination of behavior, neuroimaging, and modeling is potentially powerful for answering this question.
Response: We want to express our sincere gratitude for your thorough review of our work and for the valuable comments you have provided. Your attention to detail and dedication to improving the quality of the work are truly commendable. Your feedback has been invaluable in guiding us towards revisions that will strengthen the work. We have made targeted modifications based on most of the comments. However, due to factors such as time and energy constraints, we have not added corresponding analyses for several comments.
Comment 1:
The paper does not discuss relevant work on contextual bandits by Schulz, Collins, and others. It also does not mention the neuroimaging study of Tomov et al. (2020) using a risky/safe bandit task.
Response 1:
We deeply thank you for your suggestions about the relevant work. We now discussion and cite these representative papers in the Introduction section (line 42-55):
“The decision-making process frequently involves grappling with varying forms of uncertainty, such as ambiguity - the kind of uncertainty that can be reduced through sampling, and risk - the inherent uncertainty (variance) presented by a stable environment. Studies have investigated these different forms of uncertainty in decision-making, focusing on their neural correlates (Daw et al., 2006; Badre et al., 2012; Cavanagh et al., 2012).
These studies utilized different forms of multi-armed bandit tasks, e.g the restless multi-armed bandit tasks (Daw et al., 2006; Guha et al., 2010), risky/safe bandit tasks (Tomov et al., 2020; Fan et al., 2022; Payzan et al., 2013), contextual multi-armed bandit tasks (Schulz et al., 2015; Schulz et al., 2015; Molinaro et al., 2023). However, these tasks either separate risk from ambiguity in uncertainty, or separate action from state (perception). In our work, we develop a contextual multi-armed bandit task to enable participants to actively reduce ambiguity, avoid risk, and maximize rewards using various policies (see Section 2.2) and Figure 4(a)). Our task makes it possible to study whether the brain represents these different types of uncertainty distinctly (Levy et al., 2010) and whether the brain represents both the value of reducing uncertainty and the degree of uncertainty. The active inference framework presents a theoretical approach to investigate these questions. Within this framework, uncertainties can be reduced to ambiguity and risk. Ambiguity is represented by the uncertainty about model parameters associated with choosing a particular action, while risk is signified by the variance of the environment's hidden states. The value of reducing ambiguity, the value of avoiding risk, and extrinsic value together constitute expected free energy (see Section 2.1).”
Daw, N. D., O'doherty, J. P., Dayan, P., Seymour, B., & Dolan, R. J. (2006). Cortical substrates for exploratory decisions in humans. Nature, 441(7095), 876-879.
Badre, D., Doll, B. B., Long, N. M., & Frank, M. J. (2012). Rostrolateral prefrontal cortex and individual differences in uncertainty-driven exploration. Neuron, 73(3), 595-607.
Cavanagh, J. F., Figueroa, C. M., Cohen, M. X., & Frank, M. J. (2012). Frontal theta reflects uncertainty and unexpectedness during exploration and exploitation. Cerebral cortex, 22(11), 2575-2586.
Guha, S., Munagala, K., & Shi, P. (2010). Approximation algorithms for restless bandit problems. Journal of the ACM (JACM), 58(1), 1-50.
Tomov, M. S., Truong, V. Q., Hundia, R. A., & Gershman, S. J. (2020). Dissociable neural correlates of uncertainty underlie different exploration strategies. Nature communications, 11(1), 2371.
Fan, H., Gershman, S. J., & Phelps, E. A. (2023). Trait somatic anxiety is associated with reduced directed exploration and underestimation of uncertainty. Nature Human Behaviour, 7(1), 102-113.
Payzan-LeNestour, E., Dunne, S., Bossaerts, P., & O’Doherty, J. P. (2013). The neural representation of unexpected uncertainty during value-based decision making. Neuron, 79(1), 191-201.
Schulz, E., Konstantinidis, E., & Speekenbrink, M. (2015, April). Exploration-exploitation in a contextual multi-armed bandit task. In International conference on cognitive modeling (pp. 118-123).
Schulz, E., Konstantinidis, E., & Speekenbrink, M. (2015, November). Learning and decisions in contextual multi-armed bandit tasks. In CogSci.
Molinaro, G., & Collins, A. G. (2023). Intrinsic rewards explain context-sensitive valuation in reinforcement learning. PLoS Biology, 21(7), e3002201.
Levy, I., Snell, J., Nelson, A. J., Rustichini, A., & Glimcher, P. W. (2010). Neural representation of subjective value under risk and ambiguity. Journal of neurophysiology, 103(2), 1036-1047.
Comment 2:
The statistical reporting is inadequate. In most cases, only p-values are reported, not the relevant statistics, degrees of freedom, etc. It was also not clear if any corrections for multiple comparisons were applied. Many of the EEG results are described as "strong" or "robust" with significance levels of p<0.05; I am skeptical in the absence of more details, particularly given the fact that the corresponding plots do not seem particularly strong to me.
Response 2: We deeply thank you for your comments about our statistical reporting. We have optimized the fitting model and rerun all the statistical analyses. As can be seen (Figure 6, 7, 8, S3, S4, S5), the new regression results are significantly improved compared to the previous ones. Due to the limitation of space, we place the other relevant statistical results, including t-values, std err, etc., on our GitHub (https://github.com/andlab-um/FreeEnergyEEG). Currently, we have not conducted multiple comparison corrections based on Reviewer 1’s comments (Comments 3) “Note that we did not attempt to correct for multiple comparisons; largely, because the correlations observed were sustained over considerable time periods, which would be almost impossible under the null hypothesis of no correlations”.
Author response image 1.
Comment 3:
The authors compare their active inference model to a "model-free RL" model. This model is not described anywhere, as far as I can tell. Thus, I have no idea how it was fit, how many parameters it has, etc. The active inference model fitting is also not described anywhere. Moreover, you cannot compare models based on log-likelihood, unless you are talking about held-out data. You need to penalize for model complexity. Finally, even if active inference outperforms a model-free RL model (doubtful given the error bars in Fig. 4c), I don't see how this is strong evidence for active inference per se. I would want to see a much more extensive model comparison, including model-based RL algorithms which are not based on active inference, as well as model recovery analyses confirming that the models can actually be distinguished on the basis of the experimental data.
Response 3: We deeply thank you for your comments about the model comparison details. We previously omitted some information about the comparison model, as classical reinforcement learning is not the focus of our work, so we put the specific details in the supplementary materials. Now we have placed relevant information in the main text (see the part we have highlighted in yellow). We have now added the relevant information regarding the model comparison in the Results section (Behavioral results, line 279-293):
“To assess the evidence for active inference over reinforcement learning, we fit active inference (Eq.9), model-free reinforcement learning, and model-based reinforcement learning models to the behavioral data of each participant. This involved optimizing the free parameters of active inference and reinforcement learning models. The resulting likelihood was used to calculate the Bayesian Information Criterion (BIC) as the evidence for each model. The free parameters for the active inference model (AL, AI, EX, prior, and α) scaled the contribution of the three terms that constitute the expected free energy in Eq.9. These coefficients can be regarded as precisions that characterize each participant's prior beliefs about contingencies and rewards. For example, increasing α means participants would update their beliefs about reward contingencies more quickly, increasing AL means participants would like to reduce ambiguity more, and increasing AI means participants would like to learn the hidden state of the environment and avoid risk more. The free parameters for the model-free reinforcement learning model are the learning rate α and the temperature parameter γ and the free parameters for the model-based are the learning rate α, the temperature parameter γ and prior (the details for the model-free reinforcement learning model can be found in Eq.S1-11 and the details for the model-based reinforcement learning model can be found in Eq.S12-23 in the Supplementary Method). The parameter fitting for these three models was conducted using the `BayesianOptimization' package in Python, first randomly sampling 1000 times and then iterating for an additional 1000 times.”
We have now incorporated model-based reinforcement learning into our comparison models and placed the descriptions of both model-free and model-based reinforcement learning algorithms in the supplementary materials. We have also changed the criterion for model comparison to Bayesian Information Criterion. As indicated by the results, the performance of the active inference model significantly outperforms both comparison models.
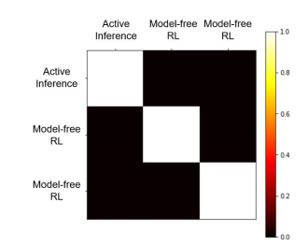
Sorry, we didn't do model recovery before, but now we have placed the relevant results in the supplementary materials. From the result figures, we can see that each model fits its own generated simulated data well:
“To demonstrate how reliable our models are (the active inference model, model-free reinforcement learning model, and model-based reinforcement learning model), we run some simulation experiments for model recovery. We use these three models, with their own fitting parameters, to generate some simulated data. Then we will fit all three sets of data using these three models.
The model recovery results are shown in Fig.S6. This is the confusion matrix of models: the percentage of all subjects simulated based on a certain model that is fitted best by a certain model. The goodness-of-fit was compared using the Bayesian Information Criterion. We can see that the result of model recovery is very good, and the simulated data generated by a model can be best explained by this model.”
Author response image 2.
Comment 4:
Another aspect of the behavioral modeling that's missing is a direct descriptive comparison between model and human behavior, beyond just plotting log-likelihoods (which are a very impoverished measure of what's going on).
Response 4: We deeply thank you for your comments about the comparison between the model and human behavior. Due to the slight differences between our simulation experiments and real behavioral experiments (the "you can ask" stage), we cannot directly compare the model and participants' behaviors. However, we can observe that in the main text's simulation experiment (Figure 3), the active inference agent's behavior is highly consistent with humans (Figure 4), exhibiting an effective exploration strategy and a desire to reduce uncertainty. Moreover, we have included two additional simulation experiments in the supplementary materials, which demonstrate that active inference may potentially fit a wide range of participants' behavioral strategies.
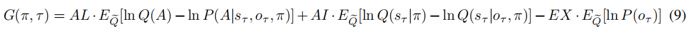
Author response image 3.
(An active inference agent with AL=AI=EX=0. It can accomplish tasks efficiently like a human being, reducing the uncertainty of the environment and maximizing the reward.)
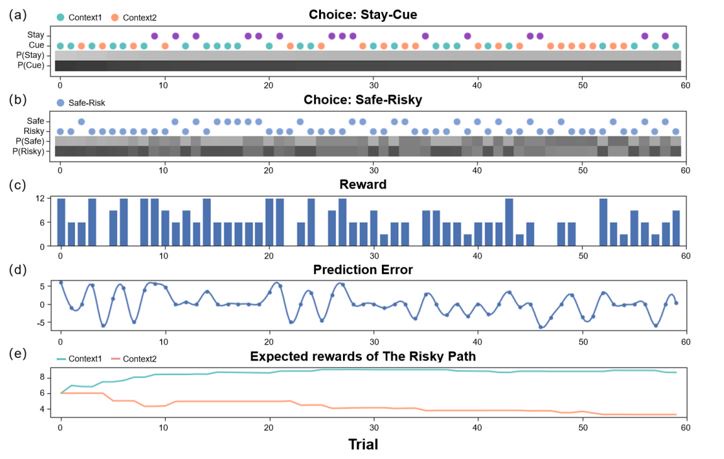
Author response image 4.
(An active inference agent with AL=AI=0, EX=10. It will only pursue immediate rewards (not choosing the "Cue" option due to additional costs), but it can also gradually optimize its strategy due to random effects.)
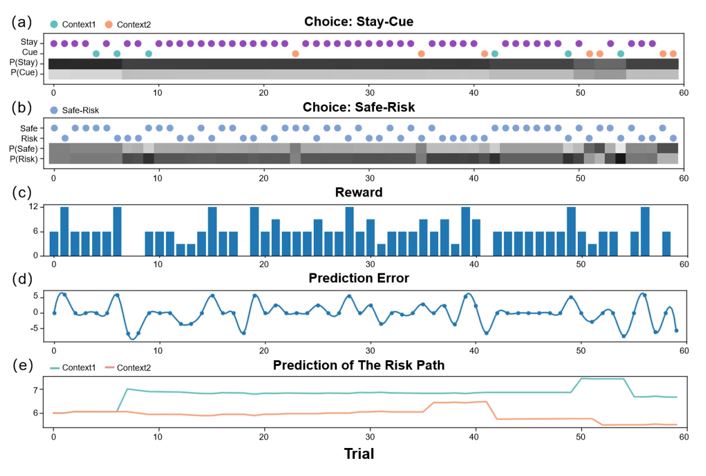
Author response image 5.
(An active inference agent with EX=0, AI=AL=10. It will only pursue environmental information to reduce the uncertainty of the environment. Even in "Context 2" where immediate rewards are scarce, it will continue to explore.) (a) shows the decision-making of active inference agents in the Stay-Cue choice. Blue corresponds to agents choosing the "Cue" option and acquiring "Context 1"; orange corresponds to agents choosing the "Cue" option and acquiring "Context 2"; purple corresponds to agents choosing the "Stay" option and not knowing the information about the hidden state of the environment. The shaded areas below correspond to the probability of the agents making the respective choices. (b) shows the decision-making of active inference agents in the Stay-Cue choice. The shaded areas below correspond to the probability of the agents making the respective choices. (c) shows the rewards obtained by active inference agents. (d) shows the reward prediction errors of active inference agents. (e) shows the reward predictions of active inference agents for the "Risky" path in "Context 1" and "Context 2".
Comment 5:
The EEG results are intriguing, but it wasn't clear that these provide strong evidence specifically for the active inference model. No alternative models of the EEG data are evaluated.
Overall, the central claim in the Discussion ("we demonstrated that the active inference model framework effectively describes real-world decision-making") remains unvalidated in my opinion.
Response 5: We deeply thank you for your comments. We applied the active inference model to analyze EEG results because it best fit the participants' behavioral data among our models, including the new added results. Further, our EEG results serve only to verify that the active inference model can be used to analyze the neural mechanisms of decision-making in uncertain environments (if possible, we could certainly design a more excellent reinforcement learning model with a similar exploration strategy). We aim to emphasize the consistency between active inference and human decision-making in uncertain environments, as we have discussed in the article. Active inference emphasizes both perception and action, which is also what we wish to highlight: during the decision-making process, participants not only passively receive information, but also actively adopt different strategies to reduce uncertainty and maximize rewards.
Reviewer #3 (Public Review):
Summary:
This paper aims to investigate how the human brain represents different forms of value and uncertainty that participate in active inference within a free-energy framework, in a two-stage decision task involving contextual information sampling, and choices between safe and risky rewards, which promotes a shift from exploration to exploitation. They examine neural correlates by recording EEG and comparing activity in the first vs second half of trials and between trials in which subjects did and did not sample contextual information, and perform a regression with free-energy-related regressors against data "mapped to source space." Their results show effects in various regions, which they take to indicate that the brain does perform this task through the theorised active inference scheme.
Strengths:
This is an interesting two-stage paradigm that incorporates several interesting processes of learning, exploration/exploitation, and information sampling. Although scalp/brain regions showing sensitivity to the active-inference-related quantities do not necessarily suggest what role they play, it can be illuminating and useful to search for such effects as candidates for further investigation. The aims are ambitious, and methodologically it is impressive to include extensive free-energy theory, behavioural modelling, and EEG source-level analysis in one paper.
Response: We would like to express our heartfelt thanks to you for carefully reviewing our work and offering insightful feedback. Your attention to detail and commitment to enhancing the overall quality of our work are deeply admirable. Your input has been extremely helpful in guiding us through the necessary revisions to enhance the work. We have implemented focused changes based on a majority of your comments. Nevertheless, owing to limitations such as time and resources, we have not included corresponding analyses for a few comments.
Comment 1:
Though I could surmise the above general aims, I could not follow the important details of what quantities were being distinguished and sought in the EEG and why. Some of this is down to theoretical complexity - the dizzying array of constructs and terms with complex interrelationships, which may simply be part and parcel of free-energy-based theories of active inference - but much of it is down to missing or ambiguous details.
Response 1: We deeply thank you for your comments about our work’s readability. We have significantly revised the descriptions of active inference, models, research questions, etc. Focusing on active inference and the free energy principle, we have added relevant basic descriptions and unified the terminology. We have added information related to model comparison in the main text and supplementary materials. We presented our regression results in clearer language. Our research focused on the brain's representation of decision-making in uncertain environments, including expected free energy, the value of reducing ambiguity, the value of avoiding risk, extrinsic value, ambiguity, and risk.
Comment 2:
In general, an insufficient effort has been made to make the paper accessible to readers not steeped in the free energy principle and active inference. There are critical inconsistencies in key terminology; for example, the introduction states that aim 1 is to distinguish the EEG correlates of three different types of uncertainty: ambiguity, risk, and unexpected uncertainty. But the abstract instead highlights distinctions in EEG correlates between "uncertainty... and... risk" and between "expected free energy .. and ... uncertainty." There are also inconsistencies in mathematical labelling (e.g. in one place 'p(s|o)' and 'q(s)' swap their meanings from one sentence to the very next).
Response 2: We deeply thank you for your comments about the problem of inconsistent terminology. First, we have unified the symbols and letters (P, Q, s, o, etc.) that appeared in the article and described their respective meanings more clearly. We have also revised the relevant expressions of "uncertainty" throughout the text. In our work, uncertainty refers to ambiguity and risk. Ambiguity can be reduced through continuous sampling and is referred to as uncertainty about model parameters in our work. Risk, on the other hand, is the inherent variance of the environment and cannot be reduced through sampling, which is referred to as uncertainty about hidden states in our work. In the analysis of the results, we focused on how the brain encodes the value of reducing ambiguity (Figure 8), the value of avoiding risk (Figure 6), and (the degree of) ambiguity (Figure S5) during action selection. We also analyzed how the brain encodes reducing ambiguity and avoiding risk during belief update (Figure 7).
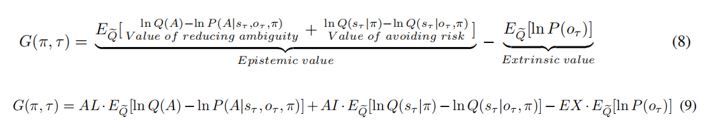
Comment 3:
Some basic but important task information is missing, and makes a huge difference to how decision quantities can be decoded from EEG. For example:
- How do the subjects press the left/right buttons - with different hands or different fingers on the same hand?
Response 3: We deeply thank you for your comments about the missing task information. We have added the relevant content in the Methods section (Contextual two-armed bandit task and Data collection, line 251-253):
“Each stage was separated by a jitter ranging from 0.6 to 1.0 seconds. The entire experiment consists of a single block with a total of 120 trials. The participants are required to use any two fingers of one hand to press the buttons (left arrow and right arrow on the keyboard).”
Comment 4:
- Was the presentation of the Stay/cue and safe/risky options on the left/right sides counterbalanced? If not, decisions can be formed well in advance especially once a policy is in place.
Response 4: The presentation of the Stay/cue and safe/risky options on the left/right sides was not counterbalanced. It is true that participants may have made decisions ahead of time. However, to better study the state of participants during decision-making, our choice stages consist of two parts. In the first two seconds, we ask participants to consider which option they would choose, and after these two seconds, participants are allowed to make their choice (by pressing the button).
We also updated the figure of the experiment procedure as below (We circled the time that the participants spent on making decisions).
Author response image 6.
Comment 5:
- What were the actual reward distributions ("magnitude X with probability p, magnitude y with probability 1-p") in the risky option?
Response 5: We deeply thank you for your comments about the missing task information. We have placed the relevant content in the Methods section (Contextual two-armed bandit task and Data collection, line 188-191):
“The actual reward distribution of the risky path in "Context 1" was [+12 (55%), +9 (25%), +6 (10%), +3 (5%), +0 (5%)] and the actual reward distribution of the risky path in "Context 2" was [+12 (5%), +9 (5%), +6 (10%), +3 (25%), +0 (55%)].”
Comment 6:
The EEG analysis is not sufficiently detailed and motivated.
For example,
- why the high lower-filter cutoff of 1 Hz, and shouldn't it be acknowledged that this removes from the EEG any sustained, iteratively updated representation that evolves with learning across trials?
Response 6: We deeply thank you for your comments about our EEG analysis. The 1Hz high-pass filter may indeed filter out some useful information. We chose a 1Hz high-pass filter to filter out most of the noise and prevent the noise from affecting our results analysis. Additionally, there are also many decision-related works that have applied 1Hz high-pass filtering in EEG data preprocessing (Yau et al., 2021; Cortes et al., 2021; Wischnewski et al., 2022; Schutte et al., 2017; Mennella et al., 2020; Giustiniani et al., 2020).
Yau, Y., Hinault, T., Taylor, M., Cisek, P., Fellows, L. K., & Dagher, A. (2021). Evidence and urgency related EEG signals during dynamic decision-making in humans. Journal of Neuroscience, 41(26), 5711-5722.
Cortes, P. M., García-Hernández, J. P., Iribe-Burgos, F. A., Hernández-González, M., Sotelo-Tapia, C., & Guevara, M. A. (2021). Temporal division of the decision-making process: An EEG study. Brain Research, 1769, 147592.
Wischnewski, M., & Compen, B. (2022). Effects of theta transcranial alternating current stimulation (tACS) on exploration and exploitation during uncertain decision-making. Behavioural Brain Research, 426, 113840.
Schutte, I., Kenemans, J. L., & Schutter, D. J. (2017). Resting-state theta/beta EEG ratio is associated with reward-and punishment-related reversal learning. Cognitive, Affective, & Behavioral Neuroscience, 17, 754-763.
Mennella, R., Vilarem, E., & Grèzes, J. (2020). Rapid approach-avoidance responses to emotional displays reflect value-based decisions: Neural evidence from an EEG study. NeuroImage, 222, 117253.
Giustiniani, J., Nicolier, M., Teti Mayer, J., Chabin, T., Masse, C., Galmès, N., ... & Gabriel, D. (2020). Behavioral and neural arguments of motivational influence on decision making during uncertainty. Frontiers in Neuroscience, 14, 583.
Comment 7:
- Since the EEG analysis was done using an array of free-energy-related variables in a regression, was multicollinearity checked between these variables?
Response 7: We deeply thank you for your comments about our regression. Indeed, we didn't specify our regression formula in the main text. We conducted regression on one variable each time, so there was no need for a multicollinearity check. We have now added the relevant content in the Results section (“EEG results at source level” section, line 337-340):
“The linear regression was run by the "mne.stats.linear regression" function in the MNE package (Activity ~ Regressor + Intercept). Activity is the activity amplitude of the EEG signal in the source space and regressor is one of the regressors that we mentioned (e.g., expected free energy, the value of reducing ambiguity, etc.).”
Comment 8:
- In the initial comparison of the first/second half, why just 5 clusters of electrodes, and why these particular clusters?
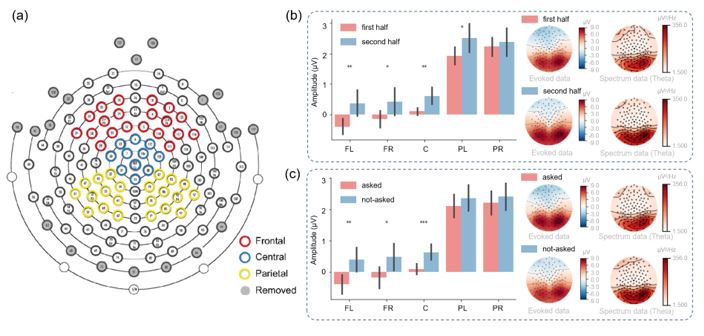
Response 8: We deeply thank you for your comments about our sensor-level analysis. These five clusters are relatively common scalp EEG regions to analyze (left frontal, right frontal, central, left parietal, and right parietal), and we referred previous work analyzed these five clusters of electrodes (Laufs et al., 2006; Ray et al., 1985; Cole et al., 1985). In addition, our work pays more attention to the analysis in source space, exploring the corresponding functions of specific brain regions based on active inference models.
Laufs, H., Holt, J. L., Elfont, R., Krams, M., Paul, J. S., Krakow, K., & Kleinschmidt, A. (2006). Where the BOLD signal goes when alpha EEG leaves. Neuroimage, 31(4), 1408-1418.
Ray, W. J., & Cole, H. W. (1985). EEG activity during cognitive processing: influence of attentional factors. International Journal of Psychophysiology, 3(1), 43-48.
Cole, H. W., & Ray, W. J. (1985). EEG correlates of emotional tasks related to attentional demands. International Journal of Psychophysiology, 3(1), 33-41.
Comment 9:
How many different variables are systematically different in the first vs second half, and how do you rule out less interesting time-on-task effects such as engagement or alertness? In what time windows are these amplitudes being measured?
Response 9 (and the Response for Weaknesses 11): There were no systematic differences between the first half and the second half of the trials, with the only difference being the participants' experience. In the second half, participants had a better understanding of the reward distribution of the task (less ambiguity). The simulation results can well describe these.
Author response image 7.
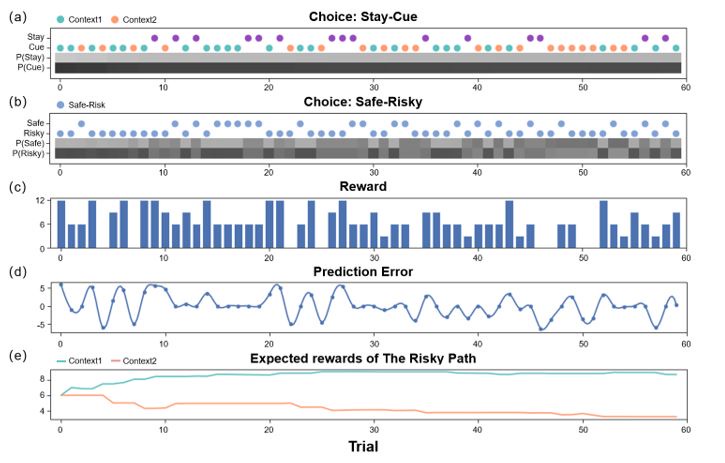
As shown in Figure (a), agents can only learn about the hidden state of the environment ("Context 1" (green) or "Context 2" (orange)) by choosing the "Cue" option. If agents choose the "Stay" option, they will not be able to know the hidden state of the environment (purple). The risk of agents is only related to wh
ether they choose the "Cue" option, not the number of rounds. Figure (b) shows the Safe-Risky choices of agents, and Figure (e) is the reward prediction of agents for the "Risky" path in "Context 1" and "Context 2". We can see that agents update the expected reward and reduce ambiguity by sampling the "Risky" path. The ambiguity of agents is not related to the "Cue" option, but to the number of times they sample the "Risky" path (rounds).
In our choosing stages, participants were required to think about their choices for the first two seconds (during which they could not press buttons). Then, they were asked to make their choices (press buttons) within the next two seconds. This setup effectively kept participants' attention focused on the task. And the two second during the “Second choice” stage when participants decide which option to choose (they cannot press buttons) are measured for the analysis of the sensor-level results.
Comment 10:
In the comparison of asked and not-asked trials, what trial stage and time window is being measured?
Response 10: We have added relevant descriptions in the main text. The two second during the “Second choice” stage when participants decide which option to choose (they cannot press buttons) are measured for the analysis of the sensor-level results.
Author response image 8.
Comment 11:
Again, how many different variables, of the many estimated per trial in the active inference model, are different in the asked and not-asked trials, and how can you know which of these differences is the one reflected in the EEG effects?
Response 11: The difference between asked trials and not-asked trials lies only in whether participants know the specific context of the risky path (the level of risk for the participants). A simple comparison indeed cannot tell us which of these differences is reflected in the EEG effects. Therefore, we subsequently conducted model-based regression analysis in the source space.
Comment 12:
The authors choose to interpret that on not-asked trials the subjects are more uncertain because the cue doesn't give them the context, but you could equally argue that they don't ask because they are more certain of the possible hidden states.
Response 12: Our task design involves randomly varying the context of the risky path. Only by choosing to inquire can participants learn about the context. Participants can only become increasingly certain about the reward distribution of different contexts of the risky path, but cannot determine which specific context it is. Here are the instructions for the task that we will tell the participants (line 226-231).
"You are on a quest for apples in a forest, beginning with 5 apples. You encounter two paths: 1) The left path offers a fixed yield of 6 apples per excursion. 2) The right path offers a probabilistic reward of 0/3/6/9/12 apples, and it has two distinct contexts, labeled "Context 1" and "Context 2," each with a different reward distribution. Note that the context associated with the right path will randomly change in each trial. Before selecting a path, a ranger will provide information about the context of the right path ("Context 1" or "Context 2") in exchange for an apple. The more apples you collect, the greater your monetary reward will be."
Comment 13:
- The EEG regressors are not fully explained. For example, an "active learning" regressor is listed as one of the 4 at the beginning of section 3.3, but it is the first mention of this term in the paper and the term does not arise once in the methods.
Response 13: We have accordingly revised the relevant content in the main text (as in Eq.8). Our regressors now include expected free energy, the value of reducing ambiguity, the value of avoiding risk, extrinsic value, prediction error, (the degree of) ambiguity, reducing ambiguity, and avoiding risk.
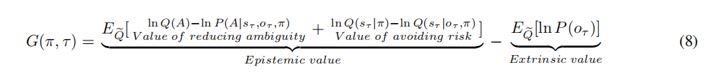
Comment 14:
- In general, it is not clear how one can know that the EEG results reflect that the brain is purposefully encoding these very parameters while implementing this very mechanism, and not other, possibly simpler, factors that correlate with them since there is no engagement with such potential confounds or alternative models. For example, a model-free reinforcement learning model is fit to behaviour for comparison. Why not the EEG?
Response 14: We deeply thank you for your comments. Due to factors such as time and effort, and because the active inference model best fits the behavioral data of the participants, we did not use other models to analyze the EEG data. At both the sensor and source level, we observed the EEG signal and brain regions that can encode different levels of uncertainties (risk and ambiguity). The brain's uncertainty driven exploration mechanism cannot be explained solely by a simple model-free reinforcement learning approach.
Recommendations for the authors:
Response: We have made point-to-point revisions according to the reviewer's recommendations, and as these revisions are relatively minor, we have only responded to the longer recommendations here.
Reviewer #1 (Recommendations For The Authors)
I enjoyed reading this sophisticated study of decision-making. I thought your implementation of active inference and the subsequent fitting to choice behaviour - and study of the neuronal (EEG) correlates - was impressive. As noted in my comments on strengths and weaknesses, some parts of your manuscript with difficult to read because of slight collapses in grammar and an inconsistent use of terms when referring to the mathematical quantities. In addition to the paragraphs I have suggested, I would recommend the following minor revisions to your text. In addition, you will have to fill in some of the details that were missing from the current version of the manuscript. For example:
Recommendation 1:
Which RL model did you use to fit the behavioural data? What were its free parameters?
Response 1: We have now added information related to the comparison models in the behavioral results and supplementary materials. We applied both simple model-free reinforcement learning and model-based reinforcement learning. The free parameters for the model-free reinforcement learning model are the learning rate α and the temperature parameter γ, while the free parameters for the model-based approach are the learning rate α, the temperature parameter γ, and the prior.
Recommendation 2:
When you talk about neuronal activity in the final analyses (of time-dependent correlations) what was used to measure the neuronal activity? Was this global power over frequencies? Was it at a particular frequency band? Was it the maximum amplitude within some small window et cetera? In other words, you need to provide the details of your analysis that would enable somebody to reproduce your study at a certain level of detail.
Response 2: In the final analyses, we used the activity amplitude at each point in the source space for our analysis. Previously, we had planned to make our data and models available on GitHub to facilitate easier replication of our work.
Reviewer #3 (Recommendations For The Authors)
Recommendation 1:
It might help to explain the complex concepts up front, to use the concrete example of the task itself - presumably, it was designed so that the crucial elements of the active inference framework come to the fore. One could use hypothetical choice patterns in this task to exemplify different factors such as expected free energy and unexpected uncertainty at work. It would also be illuminating to explain why behaviour on this task is fit better by the active inference model than a model-free reinforcement learning model.
Response 1: Thank you for your suggestions. We have given clearer explanations to the three terms in the active inference formula: the value of reducing ambiguity, the value of avoiding risk, and the extrinsic value (Eq.8), which makes it easier for readers to understand active inference.
In addition, we can simply view active inference as a computational model similar to model-based reinforcement learning, where the expected free energy represents a subjective value, without needing to understand its underlying computational principles or neurobiological background. In our discussion, we have argued why the active inference model fits the participants' behavior better than our reinforcement learning model, as the active inference model has an inherent exploration mechanism that is consistent with humans, who instinctively want to reduce environmental uncertainty (line 435-442).
“Active inference offers a superior exploration mechanism compared with basic model-free reinforcement learning (Figure 4 (c)). Since traditional reinforcement learning models determine their policies solely on the state, this setting leads to difficulty in extracting temporal information (Laskin et al., 2020) and increases the likelihood of entrapment within local minima. In contrast, the policies in active inference are determined by both time and state. This dependence on time (Wang et al., 2016) enables policies to adapt efficiently, such as emphasizing exploration in the initial stages and exploitation later on. Moreover, this mechanism prompts more exploratory behavior in instances of state ambiguity. A further advantage of active inference lies in its adaptability to different task environments (Friston et al., 2017). It can configure different generative models to address distinct tasks, and compute varied forms of free energy and expected free energy.”
Laskin, M., Lee, K., Stooke, A., Pinto, L., Abbeel, P., & Srinivas, A. (2020). Reinforcement learning with augmented data. Advances in neural information processing systems, 33, 19884-19895.
Wang, J. X., Kurth-Nelson, Z., Tirumala, D., Soyer, H., Leibo, J. Z., Munos, R., ... & Botvinick, M. (2016). Learning to reinforcement learn. arXiv preprint arXiv:1611.05763.
Friston, K., FitzGerald, T., Rigoli, F., Schwartenbeck, P., & Pezzulo, G. (2017). Active inference: a process theory. Neural computation, 29(1), 1-49.
Recommendation 2:
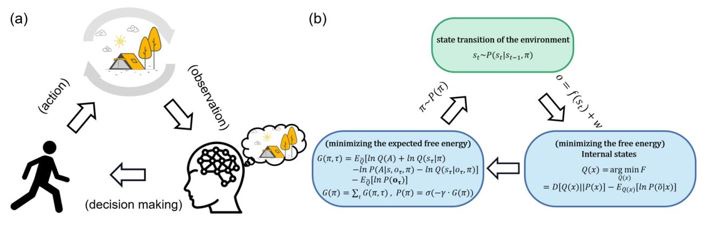
Figure 1A provides a key example of the lack of effort to help the reader understand. It suggests the possibility of a concrete example but falls short of providing one. From the caption and text, applied to the figure, I gather that by choosing either to run or to raise one's arms, one can control whether it is daytime or nighttime. This is clearly wrong but it is what I am led to think by the paper.
Response 2: Thank you for your suggestion, which we had not considered before. In this figure, we aim to illustrate that "the agent receives observations and optimizes his cognitive model by minimizing variational free energy → the agent makes the optimal action by minimizing expected free energy → the action changes the environment → the environment generates new observations for the agent." We have now modified the image to be simpler to prevent any possible confusion for readers. Correspondingly, we removed the figure of a person raising their hand and the shadowed house in Figure a.
Author response image 9.
Recommendation 3:
I recommend an overhaul in the labelling and methodological explanations for consistency and full reporting. For example, line 73 says sensory input is 's' and the cognitive model is 'q(s),' and the cause of the sensory input is 'p(s|o)' but on the very next line, the cognitive model is 'p(s|o)' and the causes of sensory input are 'q(s).' How this sensory input s relates to 'observations' or 'o' is unclear, and meanwhile, capital S is the set of environmental states. P seems to refer to the generative distribution, but it also means probability.
Response 3: Thank you for your advice. Now we have revised the corresponding labeling and methodological explanations in our work to make them consistent. However, we are not sure how to make a good modification to P here. In many works, P can refer to a certain probability distribution or some specific probabilities.
Recommendation 4:
Even the conception of a "policy" is unclear (Figure 2B). They list 4 possible policies, which are simply the 4 possible sequences of steps, stay-safe, cue-risky, etc, but with no contingencies in them. Surely a complete policy that lists 'cue' as the first step would entail a specification of how they would choose the safe or risky option BASED on the information in that cue
Response 4: Thank you for your suggestion. In active inference, a policy actually corresponds to a sequence of actions. The policy of "first choosing 'Cue' and then making the next decision based on specific information" differs from the meaning of policy in active inference.
Recommendation 5:
I assume that the heavy high pass filtering of the EEG (1 Hz) is to avoid having to baseline-correct the epochs (of which there is no mention), but the authors should directly acknowledge that this eradicates any component of decision formation that may evolve in any way gradually within or across the stages of the trial. To take an extreme example, as Figure 3E shows, the expected rewards for the risky path evolve slowly over the course of 60 trials. The filter would eliminate this.
Response 5: Thank you for your suggestion. The heavy high pass filtering of the EEG (1 Hz) is to minimize the noise in the EEG data as much as possible.
Recommendation 6:
There is no mention of the regression itself in the Methods section - the section is incomplete.
Response 6: Thank you for your suggestion. We have now added the relevant content in the Results section (EEG results at source level, line 337-340):
“The linear regression was run by the "mne.stats.linear regression" function in the MNE package (Activity ∼ Regressor + Intercept, Activity is the activity amplitude of the EEG signal in the source space and regressor is one of the regressors that we mentioned).”
Recommendation 7:
On Lines 260-270 the same results are given twice.
Response 7: Thank you for your suggestion. We have now deleted redundant content.
Recommendation 8:
Frequency bands are displayed in Figure 5 but there is no mention of those in the Methods. In Figure 5b Theta in the 2nd half is compared to Delta in the 1st half- is this an error?
Response 8: Thank you for your suggestion. It indeed was an error (they should all be Theta) and now we have corrected it.
Author response image 10.