Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorAndrea MartinMax Planck Institute for Psycholinguistics, Nijmegen, Netherlands
- Senior EditorYanchao BiPeking University, Beijing, China
Reviewer #1 (Public review):
Summary:
This paper presents three experiments. Experiments 1 and 3 use a target detection paradigm to investigate the speed of statistical learning. The first experiment is a replication of Batterink, 2017, in which participants are presented with streams of uniform-length, trisyllabic nonsense words and asked to detect a target syllable. The results replicate previous findings, showing that learning (in the form of response time facilitation to later-occurring syllables within a nonsense word) occurs after a single exposure to a word. In the second experiment, participants are presented with streams of variable length nonsense words (two trisyllabic words and two disyllabic words), and perform the same task. A similar facilitation effect was observed as in Experiment 1. In Experiment 3 (newly added in the Revised manuscript), an adult version of the study by Johnson and Tyler is included. Participants were exposed to streams of words of either uniform length (all disyllabic) or mixed length (two disyllabic, two trisyllabic) and then asked to perform a familiarity judgment on a 1-5 scale on two words from the stream and two part-words. Performance was better in the uniform length condition.
The authors interpret these findings as evidence that target detection requires mechanisms different from segmentation. They present results of a computational model to simulate results from the target detection task, and find that a bigram model can produce facilitation effects similar to the ones observed by human participants in Experiments 1 and 2 (though this model was not directly applied to test whether human-like effects were also produced to account for the data in Experiment 3). PARSER was also tested and produced differing results from those observed by humans across all three experiments. The authors conclude that the mechanisms involved in the target detection task are different from those involved in the word segmentation task.
Strengths:
The paper presents multiple experiments that provide internal replication of a key experimental finding, in which response times are facilitated after a single exposure to an embedded pseudoword. Both experimental data and results from a computational model are presented, providing converging approaches for understanding and interpreting the main results. The data are analyzed very thoroughly using mixed effects models with multiple explanatory factors. The addition of Experiment 3 provides direct evidence that the profile of performance for familiarity ratings and target detection differ as a function of word length variability.
Weaknesses:
(1) The concept of segmentation is still not quite clear. The authors seem to treat the testing procedure of Experiment 3 as synonymous with segmentation. But the ability to more strongly endorse words from the stream versus part-words as familiar does not necessarily mean that they have been successfully "segmented", as I elaborated on in my earlier review. In my view, it would be clearer to refer to segmentation as the mechanism or conceptual construct of segmenting continuous speech into discrete words. This ability to accurately segment component words could support familiarity judgments but is not necessary for above-chance familiarity or recognition judgments, which could be supported by more general memory signals. In other words, segmentation as an underlying ability is sufficient but not necessary for above-chance performance on familiarity-driven measures such as the one used in experiment 3.
(2) The addition of experiment 3 is an added strength of the revised paper and provides more direct evidence of dissociations as a function of word length on the two tasks (target detection and familiarity ratings), compared to the prior strategy of just relying on previous work for this claim. However, it is not clear why the authors chose not to use the same stimuli as used in experiment 1 and 2, which would have allowed for more direct comparisons to be made. It should also be specified whether test items in the UWL and MWL were matched for overall frequency during exposure. Currently, the text does not specify whether test words in the UWL condition were taken from the high frequency or low frequency group; if they were taken from the high frequency group this would of course be a confound when comparing to the MWL condition. Finally, the definition of part-words should also be clarified,
(3) The framing and argument for a prediction/anticipation mechanism was dropped in the Revised manuscript, but there are still a few instances where this framing and interpretation remain. E.g. Abstract - "we found that a prediction mechanism, rather than clustering, could explain the data from target detection." Discussion page 43 "Together, these results suggest that a simple prediction-based mechanism can explain the results from the target detection task, and clustering-based approaches such as PARSER cannot, contrary to previous claims."
Minor (4) It was a bit unclear as to why a conceptual replication of Batterink 2017 was conducted, given that the target syllables at the beginning and end of the streams were immediately dropped from further analysis. Why include syllable targets within these positions in the design if they are not analyzed?
(5) Figures 3 and 4 are plotted on different scales, which makes it difficult to visually compare the effects between word length conditions.
Reviewer #2 (Public review):
Summary:
The valuable study investigates how statistical learning may facilitate a target detection task and whether the facilitation effect is related to statistical learning of word boundaries. Solid evidence is provided that target detection and word segmentation rely on different statistical learning mechanisms.
Strengths:
The study is well designed, using the contrast between the learning of words of uniform length and words of variable length to dissociate general statistical learning effects and effects related to word segmentation.
Weaknesses:
The study relies on the contrast between word length effects on target detection and word learning. However, the study only tested the target detection condition and did not attempt to replicate the word segmentation effect. It is true that the word segmentation effect has been replicated before but it is still worth reviewing the effect size of previous studies.
The paper seems to distinguish prediction, anticipation, and statistical learning, but it is not entirely clear what each terms refers to.
Comments on revisions:
The authors did not address my concerns...they only replied to reviewer 1.
Author response:
The following is the authors’ response to the original reviews.
Reviewer #1 (Public review):
Summary:
This paper presents two experiments, both of which use a target detection paradigm to investigate the speed of statistical learning. The first experiment is a replication of Batterink, 2017, in which participants are presented with streams of uniform-length, trisyllabic nonsense words and asked to detect a target syllable. The results replicate previous findings, showing that learning (in the form of response time facilitation to later-occurring syllables within a nonsense word) occurs after a single exposure to a word. In the second experiment, participants are presented with streams of variable-length nonsense words (two trisyllabic words and two disyllabic words) and perform the same task. A similar facilitation effect was observed as in Experiment 1. The authors interpret these findings as evidence that target detection requires mechanisms different from segmentation. They present results of a computational model to simulate results from the target detection task and find that an "anticipation mechanism" can produce facilitation effects, without performing segmentation. The authors conclude that the mechanisms involved in the target detection task are different from those involved in the word segmentation task.
Strengths:
The paper presents multiple experiments that provide internal replication of a key experimental finding, in which response times are facilitated after a single exposure to an embedded pseudoword. Both experimental data and results from a computational model are presented, providing converging approaches for understanding and interpreting the main results. The data are analyzed very thoroughly using mixed effects models with multiple explanatory factors.
Weaknesses:
In my view, the main weaknesses of this study relate to the theoretical interpretation of the results.
(1) The key conclusion from these findings is that the facilitation effect observed in the target detection paradigm is driven by a different mechanism (or mechanisms) than those involved in word segmentation. The argument here I think is somewhat unclear and weak, for several reasons:
First, there appears to be some blurring in what exactly is meant by the term "segmentation" with some confusion between segmentation as a concept and segmentation as a paradigm.
Conceptually, segmentation refers to the segmenting of continuous speech into words. However, this conceptual understanding of segmentation (as a theoretical mechanism) is not necessarily what is directly measured by "traditional" studies of statistical learning, which typically (at least in adults) involve exposure to a continuous speech stream followed by a forced-choice recognition task of words versus recombined foil items (part-words or nonwords). To take the example provided by the authors, a participant presented with the sequence GHIABCDEFABCGHI may endorse ABC as being more familiar than BCG, because ABC is presented more frequently together and the learned association between A and B is stronger than between C and G. However, endorsement of ABC over BCG does not necessarily mean that the participant has "segmented" ABC from the speech stream, just as faster reaction times in responding to syllable C versus A do not necessarily indicate successful segmentation. As the authors argue on page 7, "an encounter to a sequence in which two elements co-occur (say, AB) would theoretically allow the learner to use the predictive relationship during a subsequent encounter (that A predicts B)." By the same logic, encoding the relationship between A and B could also allow for the above-chance endorsement of items that contain AB over items containing a weaker relationship.
Both recognition performance and facilitation through target detection reflect different outcomes of statistical learning. While they may reflect different aspects of the learning process and/or dissociable forms of memory, they may best be viewed as measures of statistical learning, rather than mechanisms in and of themselves.
Thanks for this nuanced discussion, and this is an important point that R2 also raised. We agree that segmentation can refer to both an experimental paradigm and a mechanism that accounts for learning in the experimental paradigm. In the experimental paradigm, participants are asked to identify which words they believe to be (whole) words from the continuous syllable stream. In the target-detection experimental paradigm, participants are not asked to identify words from continuous streams, and instead, they respond to the occurrences of a certain syllable. It’s possible that learners employ one mechanism in these two tasks, or that they employ separate mechanisms. It’s also the case that, if all we have is positive evidence for both experimental paradigms, i.e., learners can succeed in segmentation tasks as well as in target detection tasks with different types of sequences, we would have no way of talking about different mechanisms, as you correctly suggested that evidence for segmenting AB and processing B faster following A, is not evidence for different mechanisms.
However, that is not the case. When the syllable sequences contain same-length subsequences (i.e., words), learning is indeed successful in both segmentation and target detection tasks. However, in studies such as Hoch et al. (2013), findings suggest that words from mixed-length sequences are harder to segment than words from uniform-length sequences. This finding exists in adult work (e.g., Hoch et al. 2013) as well as infant work (Johnson & Tyler, 2010), and replicated here in the newly included Experiment 3, which stands in contrast to the positive findings of the facilitation effect with mixed-length sequences in the target detection paradigm (one of our main findings in the paper). Thus, it seems to be difficult to explain, if the learning mechanisms were to be the same, why humans can succeed in mixed-length sequences in target detection (as shown in Experiment 2) but fail in uniform-length sequences (as shown in Hoch et al. and Experiment 3).
In our paper, we have clarified these points describe the separate mechanisms in more detail, in both the Introduction and General Discussion sections.
(2) The key manipulation between experiments 1 and 2 is the length of the words in the syllable sequences, with words either constant in length (experiment 1) or mixed in length (experiment 2). The authors show that similar facilitation levels are observed across this manipulation in the current experiments. By contrast, they argue that previous findings have found that performance is impaired for mixed-length conditions compared to fixed-length conditions. Thus, a central aspect of the theoretical interpretation of the results rests on prior evidence suggesting that statistical learning is impaired in mixed-length conditions. However, it is not clear how strong this prior evidence is. There is only one published paper cited by the authors - the paper by Hoch and colleagues - that supports this conclusion in adults (other mentioned studies are all in infants, which use very different measures of learning). Other papers not cited by the authors do suggest that statistical learning can occur to stimuli of mixed lengths (Thiessen et al., 2005, using infant-directed speech; Frank et al., 2010 in adults). I think this theoretical argument would be much stronger if the dissociation between recognition and facilitation through RTs as a function of word length variability was demonstrated within the same experiment and ideally within the same group of participants.
To summarize the evidence of learning uniform-length and mixed-length sequences (which we discussed in the Introduction section), “even though infants and adults alike have shown success segmenting syllable sequences consisting of words that were uniform in length (i.e., all words were either disyllabic; Graf Estes et al., 2007; or trisyllabic, Aslin et al., 1998), both infants and adults have shown difficulty with syllable sequences consisting of words of mixed length (Johnson & Tyler, 2010; Johnson & Jusczyk, 2003a; 2003b; Hoch et al., 2013).” The newly added Experiment 3 also provided evidence for the difference in uniform-length and mixed-length sequences. Notably, we do not agree with the idea that infant work should be disregarded as evidence just because infants were tested with habituation methods; not only were the original findings (Saffran et al. 1996) based on infant work, so were many other studies on statistical learning.
There are other segmentation studies in the literature that have used mixed-length sequences, which are worth discussing. In short, these studies differ from the Saffran et al. (1996) studies in many important ways, and in our view, these differences explain why the learning was successful. Of interest, Thiessen et al. (2005) that you mentioned was based on infant work with infant methods, and demonstrated the very point we argued for: In their study, infants failed to learn when mixed-length sequences were pronounced as adult-directed speech, and succeeded in learning given infant-directed speech, which contained prosodic cues that were much more pronounced. The fact that infants failed to segment mixed-length sequences without certain prosodic cues is consistent with our claim that mixed-length sequences are difficult to segment in a segmentation paradigm. Another such study is Frank et al. (2010), where continuous sequences were presented in “sentences”. Different numbers of words were concatenated into sentences where a 500ms break was present between each sentence in the training sequence. One sentence contained only one word, or two words, and in the longest sentence, there were 24 words. The results showed that participants are sensitive to the effect of sentence boundaries, which coincide with word boundaries. In the extreme, the one-word-per-sentence condition simply presents learners with segmented word forms. In the 24-word-per-sentence condition, there are nevertheless sentence boundaries that are word boundaries, and knowing these word boundaries alone should allow learners to perform above chance in the test phase. Thus, in our view, this demonstrates that learners can use sentence boundaries to infer word boundaries, which is an interesting finding in its own right, but this does not show that a continuous syllable sequence with mixed word lengths is learnable without additional information. In summary, to our knowledge, syllable sequences containing mixed word lengths are better learned when additional cues to word boundaries are present, and there is strong evidence that syllable sequences containing uniform-word lengths are learned better than mixed-length ones.
Frank, M. C., Goldwater, S., Griffiths, T. L., & Tenenbaum, J. B. (2010). Modeling human performance in statistical word segmentation. Cognition, 117(2), 107-125.
To address your proposal of running more experiments to provide stronger evidence for our theory, we were planning to run another study to have the same group of participants do both the segmentation and target detection paradigm as suggested, but we were unable to do so as we encountered difficulties to run English-speaking participants. Instead, we have included an experiment (now Experiment 3), showing the difference between the learning of uniform-length and mixed-length sequences with the segmentation paradigm that we have never published previously. This experiment provides further evidence for adults’ difficulties in segmenting mixed-length sequences.
(3) The authors argue for an "anticipation" mechanism in explaining the facilitation effect observed in the experiments. The term anticipation would generally be understood to imply some kind of active prediction process, related to generating the representation of an upcoming stimulus prior to its occurrence. However, the computational model proposed by the authors (page 24) does not encode anything related to anticipation per se. While it demonstrates facilitation based on prior occurrences of a stimulus, that facilitation does not necessarily depend on active anticipation of the stimulus. It is not clear that it is necessary to invoke the concept of anticipation to explain the results, or indeed that there is any evidence in the current study for anticipation, as opposed to just general facilitation due to associative learning.
Thanks for raising this point. Indeed, the anticipation effect we reported is indistinguishable from the facilitation effect that we reported in the reported experiments. We have dropped this framing.
In addition, related to the model, given that only bigrams are stored in the model, could the authors clarify how the model is able to account for the additional facilitation at the 3rd position of a trigram compared to the 2nd position?
Thanks for the question. We believe it is an empirical question whether there is an additional facilitation at the 3rd position of a trigram compared to the 2nd position. To investigate this issue, we conducted the following analysis with data from Experiment 1. First, we combined the data from two conditions (exact/conceptual) from Experiment 1 so as to have better statistical power. Next, we ran a mixed effect regression with data from syllable positions 2 and 3 only (i.e., data from syllable position 1 were not included). The fixed effect included the two-way interaction between syllable position and presentation, as well as stream position, and the random effect was a by-subject random intercept and stream position as the random slope. This interaction was significant (χ2(3) =11.73, p=0.008), suggesting that there is additional facilitation to the 3rd position compared to the 2nd position.
For the model, here is an explanation of why the model assumes an additional facilitation to the 3rd position. In our model, we proposed a simple recursive relation between the RT of a syllable occurring for the nth time and the n+1th time, which is:
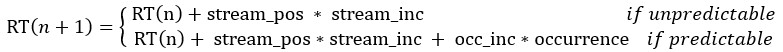
and
RT(1) = RT0 + stream_pos * stream_inc, where the n in RT(n) represents the RT for the nth presentation of the target syllable, stream_pos is the position (3-46) in the stream, and occurrence is the number of occurrences that the syllable has occurred so far in the stream.
What this means is that the model basically provides an RT value for every syllable in the stream. Thus, for a target at syllable position 1, there is a RT value as an unpredictable target, and for targets at syllable position 2, there is a facilitation effect. For targets at syllable position 3, it is facilitated the same amount. As such, there is an additional facilitation effect for syllable position 3 because effects of predication are recursive.
(4) In the discussion of transitional probabilities (page 31), the authors suggest that "a single exposure does provide information about the transitions within the single exposure, and the probability of B given A can indeed be calculated from a single occurrence of AB." Although this may be technically true in that a calculation for a single exposure is possible from this formula, it is not consistent with the conceptual framework for calculating transitional probabilities, as first introduced by Saffran and colleagues. For example, Saffran et al. (1996, Science) describe that "over a corpus of speech there are measurable statistical regularities that distinguish recurring sound sequences that comprise words from the more accidental sound sequences that occur across word boundaries. Within a language, the transitional probability from one sound to the next will generally be highest when the two sounds follow one another within a word, whereas transitional probabilities spanning a word boundary will be relatively low." This makes it clear that the computation of transitional probabilities (i.e., Y | X) is conceptualized to reflect the frequency of XY / frequency of X, over a given language inventory, not just a single pair. Phrased another way, a single exposure to pair AB would not provide a reliable estimate of the raw frequencies with which A and AB occur across a given sample of language.
Thanks for the discussion. We understand your argument, but we respectively disagree that computing transitional probabilities must be conducted under a certain theoretical framework. In our humble opinion, computing transitional probabilities is a mathematical operation, and as such, it is possible to do so with the least amount of data possible that enables the mathematical operation, which concretely is a single exposure during learning. While it is true that a single exposure may not provide a reliable estimate of frequencies or probabilities, it does provide information with which the learner can make decisions.
This is particularly true for topics under discussion regarding the minimal amount of exposure that can enable learning. It is important to distinguish the following two questions: whether learners can learn from a short exposure period (from a single exposure, in fact) and how long of an exposure period does the learner require for it to be considered to produce a reliable estimate of frequencies. Incidentally, given the fact that learners can learn from a single exposure based on Batterink (2017) and the current study, it does not appear that learners require a long exposure period to learn about transitional probabilities.
(5) In experiment 2, the authors argue that there is robust facilitation for trisyllabic and disyllabic words alike. I am not sure about the strength of the evidence for this claim, as it appears that there are some conflicting results relevant to this conclusion. Notably, in the regression model for disyllabic words, the omnibus interaction between word presentation and syllable position did not reach significance (p= 0.089). At face value, this result indicates that there was no significant facilitation for disyllabic words. The additional pairwise comparisons are thus not justified given the lack of omnibus interaction. The finding that there is no significant interaction between word presentation, word position, and word length is taken to support the idea that there is no difference between the two types of words, but could also be due to a lack of power, especially given the p-value (p = 0.010).
Thanks for the comment. Firstly, we believe there is a typo in your comment, where in the last sentence, we believe you were referring to the p-value of 0.103 (source: “The interaction was not significant (χ2(3) = 6.19, p= 0.103”). Yes, a null result with a frequentist approach cannot support a null claim, but Bayesian analyses could potentially provide evidence for the null.
To this end, we conducted a Bayes factor analysis using the approach outlined in Harms and Lakens (2018), which generates a Bayes factor by computing a Bayesian information criterion for a null model and an alternative model. The alternative model contained a three-way interaction of word length, word presentation, and word position, whereas the null model contained a two-way interaction between word presentation and word position as well as a main effect of word length. Thus, the two models only differ in terms of whether there is a three-way interaction. The Bayes factor is then computed as exp[(BICalt − BICnull)/2]. This analysis showed that there is strong evidence for the null, where the Bayes Factor was found to be exp(25.65) which is more than 1011. Thus, there is no power issue here, and there is strong evidence for the null claim that word length did not interact with other factors in Experiment 2.
There is another issue that you mentioned, of whether we should conduct pairwise comparisons if the omnibus interaction did not reach significance. This would be true given the original analysis plan, but we believe that a revised analysis plan makes more sense. In the revised analysis plan for Experiment 2, we start with the three-way interaction (as just described in the last paragraph). The three-way interaction was not significant, and after dropping the third interaction terms, the two-way interaction and the main effect of word length are both significant, and we use this as the overall model. Testing the significance of the omnibus interaction between presentation and syllable position, we found that this was significant (χ2(3) =49.77, p<0.001). This represents that, in one model, that the interaction between presentation and syllable position using data from both disyllabic and trisyllabic words. This was in addition to a significant fixed effect of word length (β=0.018, z=6.19, p<0.001). This should motivate the rest of the planned analysis, which regards pairwise comparisons in different word length conditions.
(6) The results plotted in Figure 2 seem to suggest that RTs to the first syllable of a trisyllabic item slow down with additional word presentations, while RTs to the final position speed up. If anything, in this figure, the magnitude of the effect seems to be greater for 1st syllable positions (e.g., the RT difference between presentation 1 and 4 for syllable position 1 seems to be numerically larger than for syllable position 3, Figure 2D). Thus, it was quite surprising to see in the results (p. 16) that RTs for syllable position 1 were not significantly different for presentation 1 vs. the later presentations (but that they were significant for positions 2 and 3 given the same comparison). Is this possibly a power issue? Would there be a significant slowdown to 1st syllables if results from both the exact replication and conceptual replication conditions were combined in the same analysis?
Thanks for the suggestion and your careful visual inspection of the data. After combining the data, the slowdown to 1st syllables is indeed significant. We have reported this in the results of Experiment 1 (with an acknowledgement to this review):
Results showed that later presentations took significantly longer to respond to compared to the first presentation (χ2(3) = 10.70, p=0.014), where the effect grew larger with each presentation (second presentation: β=0.011, z=1.82, p=0.069; third presentation: β=0.019, z=2.40, p=0.016; fourth presentation: β=0.034, z=3.23, p=0.001).
(7) It is difficult to evaluate the description of the PARSER simulation on page 36. Perhaps this simulation should be introduced earlier in the methods and results rather than in the discussion only.
Thanks for the suggestions. We have added two separate simulations in the paper, which should describe the PARSER simulations sufficiently, as well as provide further information on the correspondence between the simulations and the experiments. Thanks again for the great review! We believe our paper has improved significantly as a result.



