Robust and accurate prediction of residue–residue interactions across protein interfaces using evolutionary information
- Howard Hughes Medical Institute, University of Washington, United States
- University of Washington, United States
- Facebook Inc., United States
Abstract
Do the amino acid sequence identities of residues that make contact across protein interfaces covary during evolution? If so, such covariance could be used to predict contacts across interfaces and assemble models of biological complexes. We find that residue pairs identified using a pseudo-likelihood-based method to covary across protein–protein interfaces in the 50S ribosomal unit and 28 additional bacterial protein complexes with known structure are almost always in contact in the complex, provided that the number of aligned sequences is greater than the average length of the two proteins. We use this method to make subunit contact predictions for an additional 36 protein complexes with unknown structures, and present models based on these predictions for the tripartite ATP-independent periplasmic (TRAP) transporter, the tripartite efflux system, the pyruvate formate lyase-activating enzyme complex, and the methionine ABC transporter.
https://doi.org/10.7554/eLife.02030.001eLife digest
Proteins are considered the ‘workhorse molecules’ of life and they are involved in virtually everything that cells do. Proteins are strings of amino acids that have folded into a specific three-dimensional shape. Proteins must have the correct shape to function properly, as they often work by binding to other proteins or molecules—much like a key fitting into a lock. Working out the structure of a protein can, therefore, provide major insights into how the protein does its job.
Two or more proteins can bind together and form a complex to perform various tasks; and solving the structures of these complexes can be challenging, even if the structures of the protein subunits are known. Now, Ovchinnikov, Kamisetty, and Baker have developed a method for predicting which parts of the proteins make contact with each other in a two-protein complex.
Different species can have copies of the same proteins; but a copy from one species might have different amino acids at certain positions when compared to a related copy from another species. As such, when pairs of interacting proteins from different species are compared, there will be many positions in the two proteins that vary. However, if the amino acid at a position in one protein (let's call it ‘X’) varies, and the amino acid at, say, position ‘Y’ in the other protein also varies such that for any given amino acid at position Y there is often a specific amino acid at position X; positions X and Y are said to ‘co-vary’. Ovchinnikov et al. noticed that when a pair of amino acids (one from each protein in a two-protein complex) co-varied, these two amino acids tended to make contact with each other at the protein–protein interface.
Ovchinnikov et al. used the new method to make predictions about the protein–protein interfaces in 28 protein complexes found in bacteria, and also to make a prediction about the interface between protein subunits in the bacterial ribosome. When these predictions were checked against the actual structures, which were all known beforehand, they were found to be accurate if the number of copies of each protein being compared is greater than the average length of the two proteins.
Ovchinnikov et al. went on to predict the amino acids on the protein–protein interfaces for another 36 bacterial protein complexes with unknown structures, and to present models for four larger complexes. The next challenge is to extend the method to protein complexes that are found only in eukaryotes (i.e., not in bacteria). Since the number of related copies for eukaryotic proteins tends to be smaller, there are fewer proteins to compare and it is therefore harder to detect ‘covariation’ when it occurs.
https://doi.org/10.7554/eLife.02030.002Introduction
Recent work has demonstrated the accuracy of coevolution-based contact prediction for monomeric proteins using a global statistical model (Thomas et al., 2008) to distinguish between direct and indirect couplings (Marks et al., 2011; Morcos et al., 2011; Hopf et al., 2012; Nugent and Jones, 2012; Jones et al., 2012; Lapedes et al., 2012; Marks et al., 2012; Sułkowska et al., 2012; Kamisetty et al., 2013). While early approaches relied on estimating an inverse covariance matrix (Marks et al., 2011; Morcos et al., 2011; Jones et al., 2012), more recent studies have shown that a pseudo-likelihood-based approach (Balakrishnan et al., 2011) results in more accurate predictions (Ekeberg et al., 2013; Kamisetty et al., 2013) for a range of alignment sizes and protein lengths.
In contrast to this rich body of work for monomeric proteins, relatively little is known about the utility of such statistical models in predicting protein–protein interactions. The more general problem of predicting if two proteins interact with each other has been studied extensively using a wide variety of approaches (de Juan et al., 2013; Hosur et al., 2012; Zhang et al., 2012; Shoemaker and Panchenko, 2007, Valencia and Pazos, 2002, Ochoa and Pazos, 2010). Amino acid residue coevolution has been used to predict residue–residue interactions across interfaces with local statistical models (Pazos et al., 1997; Halperin et al., 2006). As noted above, the accuracy of these models is reduced by the confounding of direct and indirect correlations (Lapedes et al., 1999; Weigt et al., 2009); the application of global statistical models to coevolution-based contact prediction across interfaces has been limited to the case of the histidine-kinase/response-regulator two component system (Burger and van Nimwegen, 2008; Weigt et al., 2009; Schug et al., 2009; Dago et al., 2012).
In this study, we examine residue–residue covariation across protein–protein interfaces using a pseudo-likelihood-based statistical method. In a large set of complexes of known structure, we find that covarying pairs of positions are almost always in contact in the three-dimensional structure, provided there are sufficient aligned sequences. We find further that significant residue–residue covariance occurs frequently between physically interacting protein pairs but very rarely between non-interacting pairs, and hence should be useful for predicting whether two proteins interact. We use the pseudo-likelihood method to predict contacts across protein-interfaces for 36 evolutionarily conserved complexes of unknown structure and present structure models for four of the complexes particularly well constrained by these data.
Results
For a single protein family, it is straightforward to generate a multiple sequence alignment and subsequently identify covarying residue pairs. To identify covarying residue pairs between two proteins A and B is not as easy: only organisms that contain an ortholog of protein A and protein B contribute, and in generating the alignments the protein A and protein B sequences for each organism must be properly paired. To simplify the ortholog identification problem, we focus on pairs of genes with conserved chromosomal locations separated in the genome by fewer than 20 other annotated genes. We then build GREMLIN global statistical models for sequences in the paired protein families. The models have ‘one-body’ parameters for each amino acid at each position in the two proteins, and ‘two-body’ parameters for each pair of amino acids at each pair of positions in the two proteins. These parameters are obtained by maximizing the pseudo-likelihood of the observed sequence pairs, rather than their likelihood, which makes the quite formidable estimation tractable. In the following sections, we investigate the structural contexts of residue pairs with large values of these two-body coupling parameters
Residue–residue covariation in the bacterial 50S ribosomal unit
We began by studying residue–residue coupling parameters in the bacterial 50S ribosomal subunit—the largest evolutionarily conserved bacterial multiprotein complex with an atomic resolution structure. For each individual protein in the complex, we constructed multiple sequence alignments by querying the UniProt sequence database (Wu et al., 2006) for homologous sequences. For every pair of proteins in the complex, we then constructed a paired multiple sequence alignment (‘Materials and methods’). For each such paired alignment, we built a GREMLIN global statistical model, computed normalized coupling strengths from the two body coupling parameters, and ranked inter protein residue pairs based on these scores (‘Materials and methods’). A coupling strength larger than one indicates higher than average coupling between two residues.
We find that in the 50S ribosomal subunit only a small fraction of residue pairs coevolve, as indicated by coupling strengths (y axis of Figure 1A) greater than 1.5. Remarkably, the two residues in each of these pairs are almost all within 8 Å of each other in the 50S crystal structure (Figure 1A) and all are within 12 Å. The locations of the covarying residue pairs in the 50S structure (with the individual proteins pulled apart for clarity) are shown in Figure 1B; yellow lines indicate distances less than 8 Å and orange lines, distances less than 12 Å. For the 50S ribosome, the GREMLIN model was built using sequence data from ∼1500 non-redundant genomes; Figure 1D suggests that for complexes with such large numbers of aligned sequence, residue–residue interactions across interfaces can be predicted with quite high confidence based on amino acid sequence covariation.
Figure 1 with 1 supplement see all
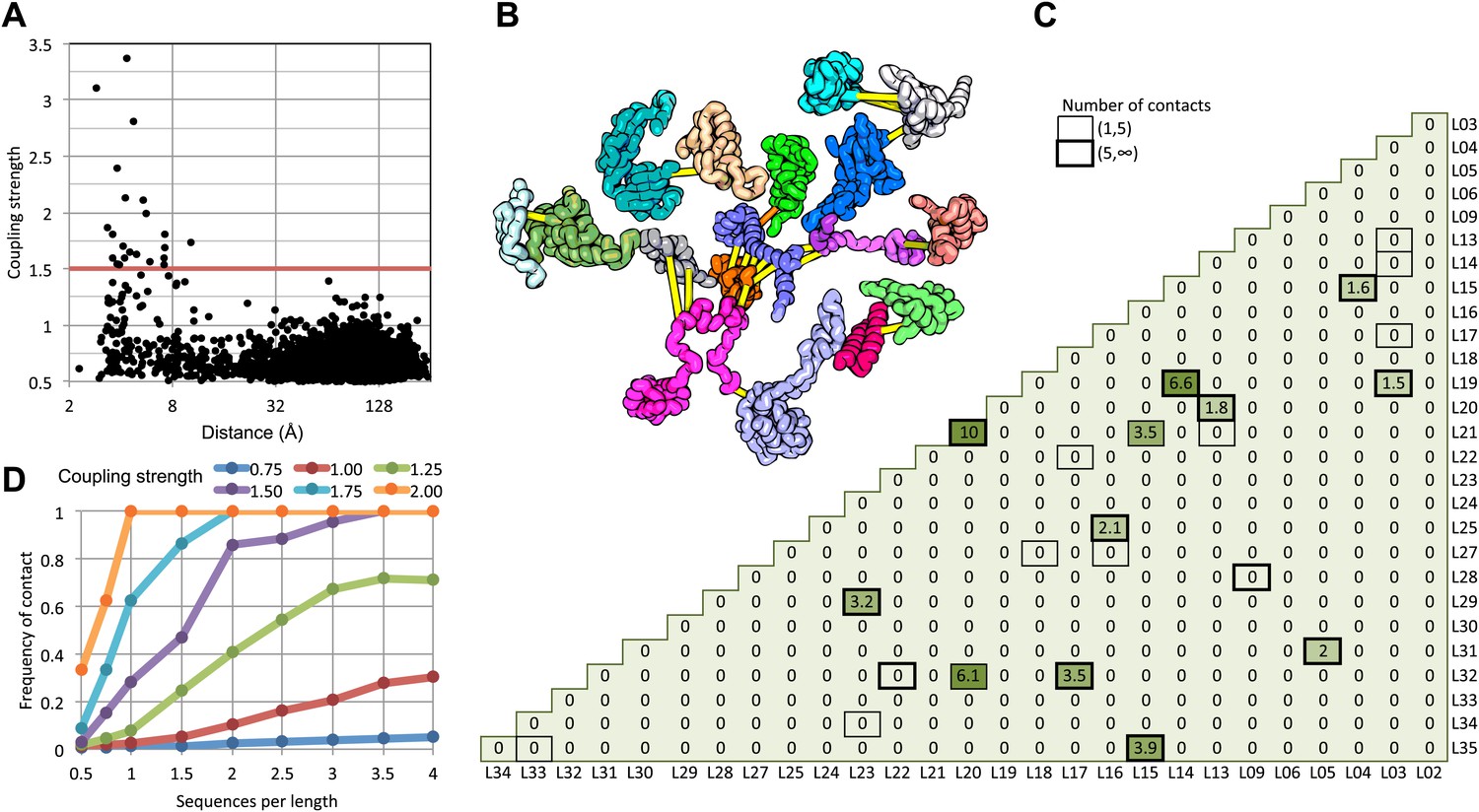
Residue pairs with high normalized coupling strengths are in contact in the 50S ribosomal subunit.
(A) Coupling strengths and inter-residue distances for each residue pair in the 50S subunit (black dots). Residue pairs with coupling strength greater than 1.5 are nearly always less than 8 Å apart. (B) Locations of coevolving (high coupling strength) residue pairs in the protein component of the 50S subunit. The monomers have been pulled apart slightly for clarity. Lines connect residue pairs with coupling strength greater than 1.5; yellow, distance less than 8 Å; orange, distance less than 12 Å. (C) Protein pairs with strong inter-residue covariation (colors) make contact in the three-dimensional structure (black boxes). For each protein pair, the sum of the coupling strength greater than 1.5 for each pair of 50S subunit proteins is indicated; black boxes indicate contacts in the crystal structure. (D) Dependence of contact prediction accuracy on coupling strength and the number of sequences in the alignments. For each of the indicated coupling strength cutoffs (colors), the frequency of contact in the 50S structure (y axis) was computed for sub alignments with different sequence depths (x axis).
For a large protein–protein complex, can the sum of the coupling strengths between pairs of proteins in the complex be used to distinguish directly interacting and non-interacting protein pairs? In the 50S subunit, every pair of proteins with summed coupling strengths (numbers in Figure 1C) greater than 1.5 interacts with each other (boxes in Figure 1C). There are, however, several instances of protein pairs that contact in the 50S subunit for which no covariance is observed; clearly not every interaction will be identified by the sum of the coupling strengths, for example between two proteins that are held together primarily by the ribosomal RNA.
How many aligned sequences are required for accurate contact prediction? To assess the dependence on alignment depth, we generated paired sub-alignments with varying numbers of sequences for every pair of 50S proteins and recomputed coupling strengths for each sub-alignment. For each alignment depth, we calculated the fraction of residue pairs within 12 Å for different ranges of coupling strengths. We find that the greater the number of aligned sequences, the lower the value of the coupling strength above which residue pairs are likely to be in contact in the structure (Figure 1D). For example, if the number of aligned sequences is greater than the sum of the lengths of the two proteins, residue–residue contact predictions are likely to be accurate if the coupling strength is 2 or greater (Figure 1D: orange dots), while if there are twice as many sequences, contact predictions are accurate above a coupling strength of 1.5 (the cutoff shown in Figure 1A). A sigmoidal function of the coupling strength and the number of sequences per position in the complex accurately fits the observed contact frequency data (‘Materials and methods’ and Figure 1—figure supplement 1); we refer to the fitted values as GREMLIN scores for the remainder of the paper.
Bacterial complex benchmark
We next generated paired-alignments for all E. coli gene-pairs that had conserved intergenic distances across genomes deposited in the UniProt (‘Materials and methods’). As the 50S results (Figure 1D) suggested that alignment depths greater than the average of the lengths of the two proteins were required for accurate prediction, we focused on paired alignments with at least this number of sequences—1126 gene pairs in total excluding the ribosomal proteins. For each of these 1126 pairs, we generated GREMLIN global statistical models and determined the coupling strength for each residue pair.
For 64 of the 1126 gene pairs, at least one pair of residues had GREMLIN score >0.85. For 28 of the 64 pairs three-dimensional structures have been determined experimentally, and the locations of the residue pairs with GREMLIN score >0.6 for several of these complexes are shown in Figure 2A (pairs within 8 Å are in yellow, between 8 Å and 12 Å in orange, and greater than 12 Å, in red). Almost all pairs with GREMLIN scores greater than 0.6 are in contact in the complex structures, with the notable exception of the NADH dehydrogenase subunits (Figure 2B). The complex is thought to undergo a cascade of conformational changes during electron transfer (Baradaran et al., 2013); the high GREMLIN score contacts not made in the solved structure may provide insight into the nature of these changes. As observed for the 50S complex (Figure 1C), the existence of one or more high GREMLIN scores between two proteins provides evidence that the proteins interact: 44% (28/64) of the protein pairs with high GREMLIN scores form a complex which has been solved crystallographically compared to 8% (78/1126) over the whole set.
Figure 2
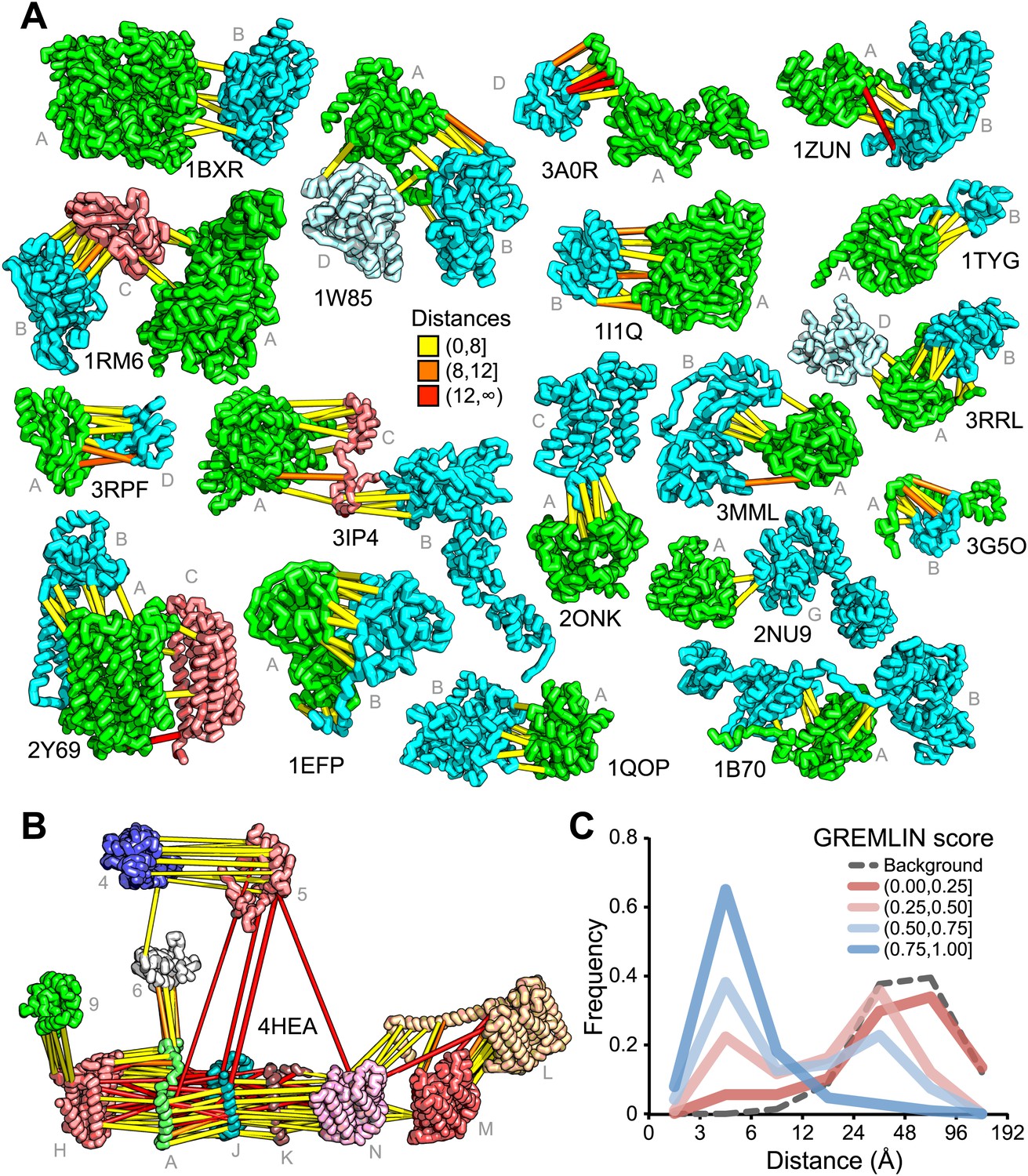
Residue covariation in complexes with known structures.
(A) Residue-pairs across protein chains with high GREMLIN scores almost always make contact across protein interfaces in experimentally determined complex structures. All contacts with GREMLIN scores greater than 0.6 are shown; the structures are pulled apart for clarity. Labels are according to chains in the PDB structure. (B) Complex I of the electron transport chain has an unusually large number of highly co-varying inter residue pairs not in contact in the crystal structure of 4HEA; these contacts may be formed in different state of the complex. Residue pairs within 8 Å are in yellow, between 8 Å and 12 Å in orange, and greater than 12 Å, in red. Distances are the minimal distances between any side chain heavy atom. Labels are according to chains in 4HEA. (C) Dependence of inter-residue distance distributions on GREMLIN score. All residue–residue pairs between subunits in the benchmark set were grouped into four bins based on their GREMLIN score (colors), and the distribution of residue–residue distances (x axis) within each bin computed from the three-dimensional structures. See Figure 2—source data 1 for the table of all the interfaces used in the calculation.
-
Figure 2—source data 1
PDB benchmark set.
The PDB id and chains in the benchmark set, with number of sequences per length (seq/len) in the multiple sequence alignment. For complexes involving more than one component, an all vs all analysis was performed.
- https://doi.org/10.7554/eLife.02030.006
Contact predictions for complexes of unknown structure
The results with the 50S ribosome and the protein pairs in the benchmark suggest that interactions can be accurately predicted across protein–protein interfaces given a sufficient number of aligned sequences. In Figure 3, we provide residue–residue contact predictions for the 36 of the 64 complexes with currently unknown structure (the E. coli gene sequences were clustered, and hence each complex may represent multiple E. coli gene pairs). These predictions should contribute to the determination of the structures of these biologically important complexes.
Figure 3

Predicted residue–residue interactions across protein interfaces of unknown structure.
Strongly co-evolving residue pairs for complexes without known structure that had at least one prediction with GREMLIN score greater than or equal to 0.85. Each row shows the residue pairs, their sequence identity and the GREMLIN score. Structure models for complexes highlighted in red are shown in Figure 5. Full dataset is provided with the deposited data.
From contacts to structural models
Are the predicted contacts useful in assembling models of the protein complex from models of each component? We evaluated this on a docking test set containing 18 protein complexes from the benchmark set where at least one component (or a close homolog) had a known structure in the apo form (‘Materials and methods’, docking test-set). We developed a docking protocol that used the predicted contacts as distance restraints and sampled the space of physically plausible structures to generate models of the protein–protein complex. The model with the best restraint score had an interface that was within 4 Å (in root mean square deviation) of the native interface in 14 of the 18 cases and had more than half the native contacts in 16 of the 18 cases (Figure 4A, Figure 4—figure supplement 1). Two of the cases in which the iRMSD (interface root-mean-square deviation) was the highest (bottom of table in A) are illustrated in Figure 4B–C: the high iRMSD is due to large changes in the conformation of one of the monomers upon binding; despite these changes the binding interface is reasonably accurately identified. Conformational changes that hinder the rigid-body docking protocol from sampling the bound conformation also occurred for thiazole synthase/sulfur carrier and phenylalanyl-tRNA synthase with iRMSD of 4.8A and 4.3A, respectively. In Figure 4D, a second energy minimum corresponds to a second interface in the complex with a different homo-oligomer subunit. In the absence of conformational changes, predicted contact guided docking is very accurate. The same protocol, on a positive control set of known bound structures of 41 protein-pairs (including 15 protein-pairs from the NADH electron transport complex), generated models that were within 2 Å of the native complex structure in 38 cases and within 4 Å in all but one case (Figure 4—source data 1, Figure 4—figure supplement 2).
Figure 4 with 2 supplements see all

Contact guided protein–protein docking on a benchmark set of 18 protein complexes.
(A) Structure models for each complex were generated by docking structures of its constituents, at least one of which (blue) was not from the structure of the complex guided by coevolution derived distance restraints. The interface C-alpha RMSD (iRMSD) of the structural model with the lowest energy to the experimentally determined structure and the fraction of native contacts are shown. Structure models for cases in red are shown in B and C and D. (B and C) Comparison between native and docked structure for the two largest failures in the benchmark: the large iRMSD is due to large conformational changes in the monomers upon docking but the interface is still modeled correctly in the region not involved in conformational change. (D) Multiple minima in the docking landscape (right) correspond to distinct interfaces in the complex (left).
-
Figure 4—source data 1
Bound set.
The iRMSD of the lowest energy structure and the fraction of native contacts in the positive control.
- https://doi.org/10.7554/eLife.02030.009
Taken together, these results suggest that in cases with small conformational change, the docking protocol can recover the entire interface to high accuracy and in cases where binding is accompanied by a large conformational change, the protocol recovers the largest intact and/or unobstructed interface.
Of the complexes with unknown structure listed in Figure 3, we selected four cases with two or more high GREMLIN score (≥0.6) contact predictions across the interface that had experimentally determined structures for most of the subunits (‘Materials and methods’) and generated structural models of the complexes. These models provide the basis for formulating hypotheses about the structure/function of the complex, but we emphasize they are not experimentally determined structures; in particular the assumption in the modeling procedure that there are not large backbone rearrangements could be incorrect—in such cases the overall organization of the complex is still likely to be correct but the details of the interfaces could be considerably in error.
The TRAP complex
The tripartite ATP-independent periplasmic (TRAP) transporters are composed of three proteins: two integral membrane proteins YIAM and YIAN, and one periplasmic protein YIAO (Mulligan et al., 2011). The structure of the periplasmic domain is known, but the membrane portion is unknown. To generate a model of the three-dimensional structure of the complex, we built YIAM models using Rosetta de novo structure prediction (Simons et al., 1999; Raman et al., 2009) guided by the intra-monomer predicted contacts, and models for YIAN and YIAO using RosettaCM comparative modeling. For YIAN the homologous structure of 4f35 (Mancusso et al., 2012) was used. The three monomer structure models were then assembled using PatchDock (Duhovny et al., 2002) and RosettaRelax (Conway et al., 2014) guided by the predicted intersubunit contacts (‘Materials and methods’). In the resultant model of the complex (Figure 5), YIAO interacts with both of the membrane components; this is supported by a number of intersubunit contacts (yellow lines).
Figure 5
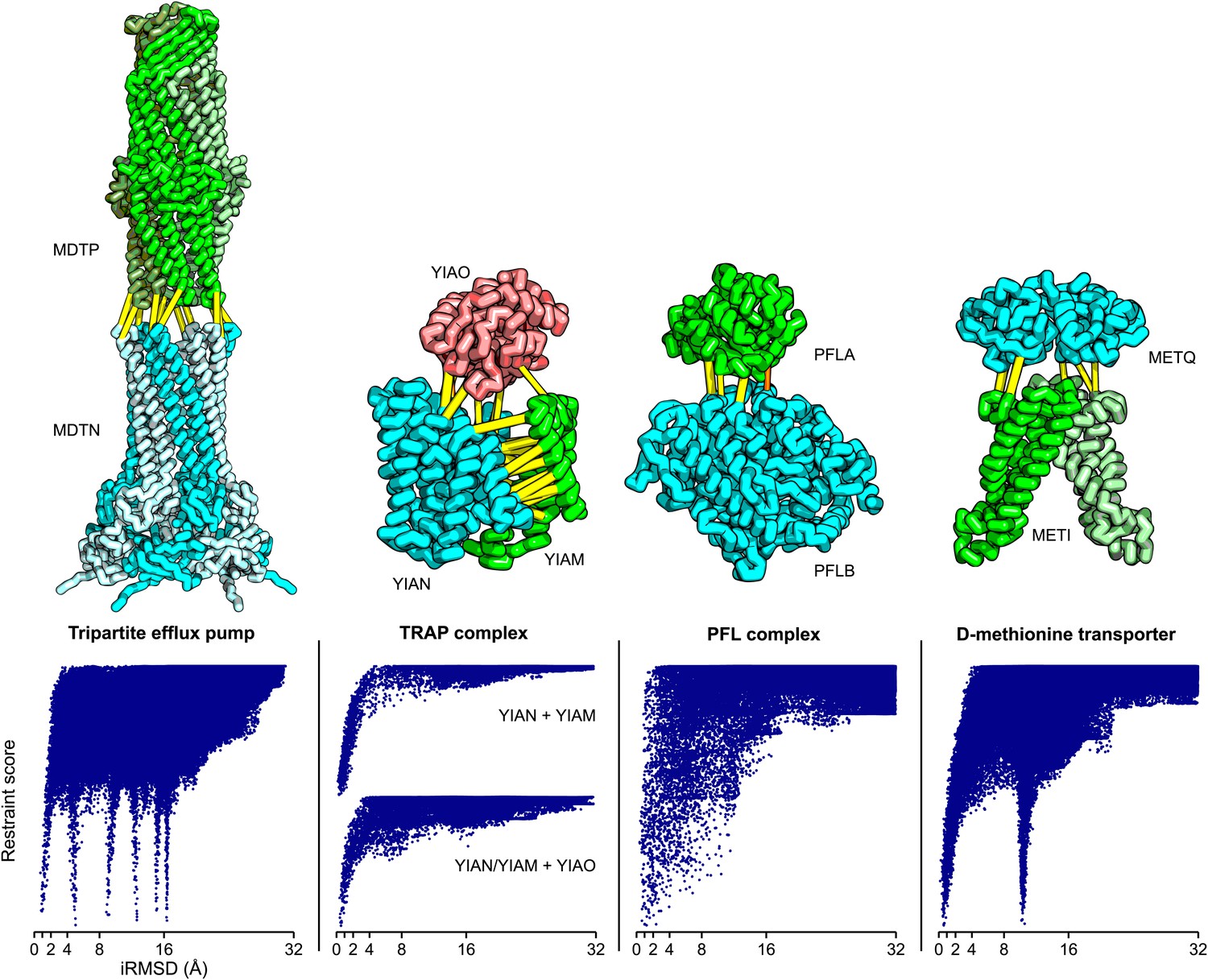
Structure models for complexes with unknown structures.
Residue pairs with GREMLIN scores ≥ 0.60 are connected by yellow bars; the structures are pulled apart for clarity. For METQ-METI and PFLA-PFLB GREMLIN scores ≥ 0.3 are shown. For each docking calculation the docking energy landscape is shown, with iRMSD to the selected model on the x-axis. The multiple minima correspond to permutations of the labels on the subunits of the homo-oligomer complex. Predicted structures of each complex are provided with the deposited data.
Tripartite efflux system
Tripartite efflux complexes span both the inner and outer membrane, and are widely used in bacteria to pump toxic compounds out of the cell. The mode of interactions between the outer membrane factor and the membrane fusion protein is unresolved, with reports suggesting either a tip-to-tip interaction, the insertion of one into the other, or a multistage interaction with an initial tip-to-tip interaction, followed by sliding one through the channel of the other (Long et al., 2012). We generated homology models for the subunits based on the alignments to 1yc9 (Federici et al., 2005) and 3fpp (Yum et al., 2009) and docked them to generate models of the multidrug resistance protein complex. The predicted residue–residue contacts for this family of complexes support the tip-to-tip interaction (Figure 4; yellow lines); the coevolution data did not provide any evidence to support the insertion model.
Pyruvate formate lyase-activating enzyme complex
Pyruvate formate-lyase (PFL) catalyzes the reaction of acetyl-CoA and formate from pyruvate and CoA in the Fermentation pathway. Formate acetyltransferase 1 or Pyruvate formate-lyase 1 (PFLB) is activated by Pyruvate formate-lyase 1-activating enzyme (PFLA). The structure of the complex is unknown, but the structures of the individual proteins have been solved (PDB ids: 3c8f [Becker and Kabsch, 2002] and 1h16 [Vey et al., 2008]). We carried out rigid body docking calculations with these two proteins guided by GREMLIN predictions. Interestingly, the region that undergoes conformational change in the activating enzyme upon substrate binding (3c8f -> 3cb8 [Becker and Kabsch, 2002]) is in the region we predict to be in contact with PFL.
D-methionine transport system
D-methionine transporter is an ATP-driven transport system that transports methionine. We docked the E. coli structure of METI (3tui, chain A and B, Johnson et al., 2012) with a RosettaCM model of METQ based on 3k2d (Yu et al., 2011). The resulting docked model is consistent with the top ranked GREMLIN predictions (Figure 5).
Discussion
Our results demonstrate unequivocally that there is strong selective pressure at protein–protein interfaces beyond simple residue conservation, and that co-evolving residue pairs are nearly always in contact in the protein complex. Not all contacting residues across protein interfaces likely co-evolve nor all protein–protein interfaces. Nevertheless, as illustrated in Figures 1 and 2, there is clearly sufficient coevolutionary signal to significantly constrain models of a large number of protein complexes.
There is a notable contrast in the utility of intra-monomer and intersubunit predicted contacts for structure modeling. We found previously (Kamisetty et al., 2013) that contacts could be predicted with high accuracy for monomeric proteins, provided there were sufficient aligned sequences, but in such cases there was almost always already a structure of a family member from which comparative models could be built, limiting the utility of the predicted contacts in structure prediction (Though predicted contacts can be useful in modeling allosteric changes in protein structures [Hopf et al., 2012; Morcos et al., 2013]). In contrast, here we find that more than half of the complexes for which the protein families of the constituent subunits are sufficiently large for accurate contact prediction do not currently have three-dimensional structures. Hence, while predicted contacts can be very accurate for both monomeric globular proteins and for protein–protein complexes, they are more useful for structure modeling for the latter due to the much poorer representation of protein complexes in the PDB.
While our approach of constructing a global statistical model from paired sequence alignments is generally applicable to any taxa, the current study focuses on prokaryotes and mitochondria. Doing so allows us to largely avoid the problem of distinguishing between paralogs by exploiting the operon architecture of bacterial genomes (Jacob et al., 2005). Constructing paired-sequence alignments for more complex genomic architectures is more involved and requires the ability to distinguish orthologs from paralogs, the subject of active research (Remm et al., 2001; Datta et al., 2009). Protocols for generating paired sequence alignments more generally are an important area for development in this area.
Materials and methods
Individual alignment generation
Request a detailed protocolMultiple sequence alignments were generated for each of the 4303 E. coli protein genes as identified by EcoGene 3.0 (Zhou et al., 2013) using HHblits (-n 8 -e 1E-20 -maxfilt ∞ -neffmax 20 -nodiff -realign_max ∞), and HHfilter (-id 100 -cov 75) in the HHsuite (version: 2.0.15, Remmert et al., 2011). To reduce redundancy, we constructed HMMs from each MSA and clustered genes based on the HHΔ (Kamisetty et al., 2013), a measure of HMM–HMM similarity: a pair of genes was assigned to the same cluster if the HHΔ is less than 0.5. This procedure resulted in 2340 non-redundant gene clusters.
For the benchmark set, a new alignment was generated using the sequence associated with each PDB. For the 50S ribosome and NADH dehydrogenase, we used Thermus thermophilus HB8 sequences from PDB structures 3uxr (Bulkley et al., 2012) and 4hea (Baradaran et al., 2013) respectively. For paralogous NADH dehydrogenase chains L, M, and N, we used an e-value of 1E-60 in the alignment generation protocol. In addition to complexes from the E. coli analysis, we also include the GatCAB amidotransferase complex in our benchmark set, using sequences from the PDB structure 3ip4 (Nakamura et al., 2010). For cases where the PDB sequence length was much longer than average coverage, we modified the coverage filter to 50% of query. The sequences were then realigned using clustal omega v1.2 (--iterations 2 --full-iter) (Sievers et al., 2011). Residues not present in the query sequence were dropped from subsequent analysis.
Paired alignment generation
Request a detailed protocolWe construct alignments of paired protein sequences [x1, x2, …, xp; xp+1, …, xp+q] from the same genome with positions 1:p and p+1:p+q corresponding to the first and second proteins respectively. We refer to such a multiple sequence alignment of paired sequences as a paired alignment.
For gene families with a single copy in each genome such as the ribosomal proteins, constructing paired alignments is straightforward as sequence pairs from the same genome can simply be concatenated. While the process of generating paired alignments in general is complicated in the presence of multiple paralogs of a gene in a single genome, in prokaryotes, co-regulated genes are often co-located on the genome into operons. We exploit this property to avoid paralogous genes when creating paired sequences by restricting to gene pairs that have small, conserved intergenic distances. A similar approach was used to construct a database of fusion proteins in prokaryotic genomes (Suhre and Claverie, 2004). Defining Δgene as the number of annotated genes between a gene pair, we only consider pairs with Δgene conserved in 60% of genomes and less than 20. To allow for ambiguity in annotation, if the second or third most common intergenic distance is within 1 of the mode, these gene-pairs are included in the conservation calculation. Given that most UniProt accession IDs are serially assigned in a genome (UniProt Accession), Δgene can be rapidly evaluated by looking at the difference in accession ids. The paired alignment is then filtered to reduce redundancy to 90% sequence identity and to remove positions that have more than 75% gaps.
Identification of protein complex structures
Request a detailed protocolTo identify protein pairs in the same complex structure, a HMM was constructed for each E. coli protein using hmmbuild from the already generated HHblits alignments. We then used hmmsearch to scan PDB sequences in the S2C database (Wang et al.; Both hmmbuild and hmmsearch are part of the HMMER v3.1b package [Eddy, 2009]). Only hits with e-value less than 1E-10 were considered. Protein pairs found in the same complex structure (PDB file) were considered to be in contact if a α atom in one structure was within 12 Angstroms of a α atom in the other.
Gremlin model construction from paired alignments
Request a detailed protocolGREMLIN constructs a global statistical model of the paired alignment, assigning a probability to every amino-acid sequence in the paired alignment:
where, the vi are vectors encoding position-specific amino-acid propensities and the wij are matrices encoding amino-acid coupling between positions i and j. These parameters are obtained from the aligned sequences by maximizing the regularized pseudo-likelihood (Balakrishnan et al., 2011) of the alignment as described in (Kamisetty et al., 2013):
where, each term in the summation is a conditional distribution capturing the probability of a particular amino-acid at a position in the context of the entire protein sequence and R(v,w) is a regularization term to prevent over-fitting.
Previous approaches (Morcos et al., 2011; Jones et al., 2012) estimated v, w using an approximate moment matching approach (Kamisetty et al., 2013) by inverting a generalized covariance matrix. These rely on a Gaussian-like approximation to the global partition function. Unlike these approaches, estimation via the pseudo-likelihood avoids this approximation relying instead on local partition functions (Balakrishnan et al., 2011; Ekeberg et al., 2013; Kamisetty et al., 2013). The resulting global optimization problem can be efficiently solved using standard convex optimization techniques and provides estimates for each vector vi and matrix wij (Kamisetty et al., 2013).
Ranking residue pairs with gremlin scores
Request a detailed protocolTo reduce the wij matrices to single values reflecting the strength of the coupling between positions i and j, we first compute sij, their vector 2-norm (the square root of the averages of the squares of the individual matrix elements). We correct for differences in sij due to sequence variability at different positions using the row and column averages of these values:
where brackets indicate averages taken over the indices outside the brackets in a manner similar to that of Average Product Correction (APC, Dunn et al., 2008). Unlike the APC, we account for differences in the rates of evolution in the two protein families by computing the averages only over the positions of the proteins corresponding to positions i and j: if i and j are both in the first (second) protein, the averages are computed over the positions in the first (second) protein; if i is in the first protein and j in the second, the column average is computed only over the positions of the first protein and the row average, only over the positions of the second protein. We then compute a normalized coupling strength, , by dividing the by the average of the top 3L/2 values across the two proteins (since there are roughly 3L/2 contacts for a protein of length L [Kamisetty et al., 2013; SI]).
As illustrated in Figure 1D, the relation between normalized coupling strength and contact frequency varies with the ratio of the number of aligned sequences to the length of the protein complex. We also observed that residues were more frequently in contact for a given coupling strength when the top score for that complex was high. To account for these dependencies, we constructed a model that estimates the probability of being in contact based on the bacterial 50S ribosomal complex:
where
and x is for the top scoring contact in each complex and scaled by the Gremlin score of the top contact in all other cases. The values of m, c, and σ (0.47, 0.96, and 9.77 respectively) were determined by a non-linear fit to the observed frequencies in the 50S ribosomal data from Figure 1D. This function accurately accounts for the observed contact frequencies (Figure 1—figure supplement 1).
Conversion of gremlin scores to distance restraints
Request a detailed protocolWe converted coupling strengths into residue-pair specific distance restraints and included them in the Rosetta structure prediction program. We use sigmoidal distance restraints of the form:
(1)
where, d is the distance between the constrained atoms and the weight is proportional to . The restraints were introduced between β atoms (α in the case of glycine) in the reduced-atom representation of Rosetta (centroid mode) and as ambiguous distance restraints (Lange et al., 2012) between side-chain heavy atoms (cutoff of 5.5 and slope of 4) in the full-atom stage of Rosetta. For the centroid mode, restraints used the amino acid pair specific β-β cutoff and slopes, as described in Kamisetty et al., 2013 SI Table III. These distance restraints supplement the Rosetta all atom energy; the combination ensures the sampling of physically realistic structures consistent with the contact predictions.
Comparative modeling
Request a detailed protocolComparative models were built using RosettaCM (Song et al., 2013) based on alignments to homologous structures generated using HHsearch (Remmert et al., 2011). For proteins that had missing density in regions predicted to be in contact, we used RosettaCM with co-evolution derived restraints to build the missing region before docking.
De Novo modeling
Request a detailed protocolThe Rosetta ab initio protocol consists of two stages: in the initial stage (‘centroid’) side-chains are represented by fixed center-of-mass atoms allowing for rapid generation and evaluation of various protein-like topologies; the second stage (‘full-atom’) builds in explicit side-chains and carries out all atom energy minimization (Simons et al., 1999; Raman et al., 2009). YIAM, a membrane protein, was modeled with the Rosetta membrane energy function (Yarov-Yarovoy et al., 2012, Barth et al., 2007). Strong repulsive interactions (Equation 1, weight: −100, cutoff: 35, slope: 2 and intercept: 100) were added between the center of the extracellular regions and the center of predicted intracellular regions, and strong attractive restraints (weight:100, cutoff:35, slope:2 and intercept: 0) within predicted intracellular regions and extracellular regions, effectively constructing a membrane-like sampling space. We used the consensus output of MESSA (Cong and Grishin, 2012) to predict transmembrane regions. 100,000 models were generated and 20 models that best fit the restraints converged to a single cluster.
Docking test set
Request a detailed protocolJackhammer (part of HMMER v3.1b package; Eddy, 2009) was used to identify a subset of 18 complexes in the benchmark set where at least one of the proteins or a close homolog had a solved structure of its apo form. In cases where the structure was of a homologous protein (e-value < 1E-20) and where most of the interface residues were present, we generated a structural model of the target protein using comparative modeling. We only considered cases where at least one of the structures was unbound as the bound–bound docking problem is not representative of real world docking challenges (Betts and Sternberg, 1999). The positive control shown in Figure 4—source data 1 was run on all protein-pairs from the benchmark set, where at least two predicted inter contacts had a high GREMLIN score (>0.6).
Complex assembly by protein–protein docking
Request a detailed protocolFor each inter restraint pair that is in the top 3/2L predictions, we used PatchDock v1.0, with clustering parameters (rmsd 0.5; discardClustersSmaller 0) (Duhovny et al., 2002) to generate an ensemble of conformations that were then scored using all the restraints. For tripartite efflux pump, the surface segmentation parameters were further modified (low_patch_thr 0; prune_thr 0.1; flat 1), to allow for more diverse interfaces. The top 5 models by restraint score were energy-minimized in cartesian space using both inter and intra restraints with cycles of minimization and side chain repacking using Rosetta as described in Conway et al. (2014). The best scoring model by restraint score was then selected.
For fraction of native contact (Fnat) and interface root-mean-squared deviation (iRMSD) calculation, the interface residue–residue contacts are those where the minimal distance between any heavy side-chain atom is less than 5 Å. The Fnat calculation is performed as described in Kamisetty et al. (2013) SI Table III.
All structural figures were drawn with PyMOL (The PyMOL Molecular Graphics System, Version 1.5.0.4 Schrödinger, LLC.).
Data Availability
Request a detailed protocolThe multiple sequence alignments used in the analysis and the full GREMLIN results for all the calculations described in the paper are provided at http://gremlin.bakerlab.org/complexes/ along with a web-server for paired-alignment generation, coevolution analysis and contact prediction/Rosetta restraint generation. The paired-alignments along with the PDB coordinates of the predicted structures are also available at Dryad: Ovchinnikov et al., 2014.
Data availability
-
Data from: Robust and accurate prediction of residue-residue interactions across protein interfaces using evolutionary informationAvailable at Dryad Digital Repository under a CC0 Public Domain Dedication.
-
PHENYLALANYL TRNA SYNTHETASE COMPLEXED WITH PHENYLALANINEID 1B70. Publicly available at the RCSB Protein Data Bank.
-
SOLUTION STRUCTURE OF THE EPSILON SUBUNIT OF THE F1-ATPSYNTHASE FROM ESCHERICHIA COLI AND ORIENTATION OF THE SUBUNIT RELATIVE TO THE BETA SUBUNITS OF THE COMPLEXID 1BSN. Publicly available at the RCSB Protein Data Bank.
-
STRUCTURE OF CARBAMOYL PHOSPHATE SYNTHETASE COMPLEXED WITH THE ATP ANALOG AMPPNPID 1BXR. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF THE ALDEHYDE OXIDOREDUCTASE FROM DESULFOVIBRIO DESULFURICANS ATCC 27774ID 1DGJ. Publicly available at the RCSB Protein Data Bank.
-
DIHYDROOROTATE DEHYDROGENASE A FROM LACTOCOCCUS LACTISID 1DOR. Publicly available at the RCSB Protein Data Bank.
-
ELECTRON TRANSFER FLAVOPROTEIN (ETF) FROM PARACOCCUS DENITRIFICANSID 1EFP. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF LACTOCOCCUS LACTIS DIHYDROOROTATE DEHYDROGENASE B. DATA COLLECTED UNDER CRYOGENIC CONDITIONSID 1EP3. Publicly available at the RCSB Protein Data Bank.
-
PYRUVATE FORMATE-LYASE (E.COLI) IN COMPLEX WITH PYRUVATE AND COAID 1H16. Publicly available at the RCSB Protein Data Bank.
-
STRUCTURE OF THE COOPERATIVE ALLOSTERIC ANTHRANILATE SYNTHASE FROM SALMONELLA TYPHIMURIUMID 1I1Q. Publicly available at the RCSB Protein Data Bank.
-
3D structure of the E1beta subunit of pyruvate dehydrogenase from the archeon Pyrobaculum aerophilumID 1IK6. Publicly available at the RCSB Protein Data Bank.
-
RuvA-RuvB complexID 1IXR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Sulfolobus solfataricus elongation factor 1 alpha in complex with GDPID 1JNY. Publicly available at the RCSB Protein Data Bank.
-
THE CRYSTAL STRUCTURE OF AMINODEOXYCHORISMATE SYNTHASE FROM FORMATE GROWN CRYSTALSID 1K0E. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF ACETATE COA-TRANSFERASE ALPHA SUBUNITID 1K6D. Publicly available at the RCSB Protein Data Bank.
-
THE CRYSTAL STRUCTURE OF SUCCINYL-COA SYNTHETASE ALPHA SUBUNIT FROM THERMUS THERMOPHILUSID 1OI7. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF WILD-TYPE TRYPTOPHAN SYNTHASE COMPLEXED WITH INDOLE PROPANOL PHOSPHATEID 1QOP. Publicly available at the RCSB Protein Data Bank.
-
Structure of 4-hydroxybenzoyl-CoA reductase from Thauera aromaticaID 1RM6. Publicly available at the RCSB Protein Data Bank.
-
Structure of the thiazole synthase/ThiS complexID 1TYG. Publicly available at the RCSB Protein Data Bank.
-
X-ray crystal structure of the Tryptophan Synthase b2 Subunit from Hyperthermophile, Pyrococcus furiosusID 1V8Z. Publicly available at the RCSB Protein Data Bank.
-
THE CRYSTAL STRUCTURE OF PYRUVATE DEHYDROGENASE E1 BOUND TO THE PERIPHERAL SUBUNIT BINDING DOMAIN OF E2ID 1W85. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Northeast Structural Genomics Target SR156ID 1XM3. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the outer membrane protein VceC from the bacterial pathogen Vibrio cholerae at 1.8 resolutionID 1YC9. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of a GTP-Regulated ATP Sulfurylase Heterodimer from Pseudomonas syringaeID 1ZUN. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF DHAL FROM E. COLIID 2BTD. Publicly available at the RCSB Protein Data Bank.
-
crystal structure of heterohexameric TusBCD proteins, which are crucial for the tRNA modificationID 2D1P. Publicly available at the RCSB Protein Data Bank.
-
Structural study of Project ID aq_1548 from Aquifex aeolicus VF5ID 2EKC. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Glutamyl-tRNA(Gln) amidotransferase subunit A (tm1272) from THERMOTOGA MARITIMA at 1.80 A resolutionID 2GI3. Publicly available at the RCSB Protein Data Bank.
-
Structure of PH0203 protein from Pyrococcus horikoshiiID 2IT1. Publicly available at the RCSB Protein Data Bank.
-
C123aT Mutant of E. coli Succinyl-CoA Synthetase Orthorhombic Crystal FormID 2NU9. Publicly available at the RCSB Protein Data Bank.
-
ABC transporter ModBC in complex with its binding protein ModAID 2ONK. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of conserved uncharacterized protein PH0987 from Pyrococcus horikoshiiID 2PHC. Publicly available at the RCSB Protein Data Bank.
-
POLYSULFIDE REDUCTASE NATIVE STRUCTUREID 2VPZ. Publicly available at the RCSB Protein Data Bank.
-
E. COLI SUCCINATE: QUINONE OXIDOREDUCTASE (SQR) WITH CARBOXIN BOUNDID 2WDQ. Publicly available at the RCSB Protein Data Bank.
-
Bovine heart cytochrome c oxidase re-refined with molecular oxygenID 2Y69. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of histidine kinase ThkA (TM1359) in complex with response regulator protein TrrA (TM1360)ID 3A0R. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of response regulator protein TrrA (TM1360) from Thermotoga maritima in complex with Mg(2+)-BeF (SeMet, L89M)ID 3A10. Publicly available at the RCSB Protein Data Bank.
-
4Fe-4S-Pyruvate formate-lyase Activating Enzyme with partially disordered AdoMetID 3C8F. Publicly available at the RCSB Protein Data Bank.
-
Catalytic core subunits (I and II) of cytochrome c oxidase from Rhodobacter sphaeroides complexed with deoxycholic acidID 3DTU. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of E.coli MacAID 3FPP. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the toxin-antitoxin complex RelBE2 (Rv2865-2866) from Mycobacterium tuberculosisID 3G5O. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the hydrophilic domain of respiratory complex I from Thermus thermophilus, oxidized, 4 mol/ASU, re-refined to 3.15 angstrom resolutionID 3IAS. Publicly available at the RCSB Protein Data Bank.
-
The high resolution structure of GatCABID 3IP4. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Immunogenic lipoprotein A from Vibrio vulnificusID 3K2D. Publicly available at the RCSB Protein Data Bank.
-
Allophanate Hydrolase Complex from Mycobacterium smegmatis, Msmeg0435-Msmeg0436ID 3MML. Publicly available at the RCSB Protein Data Bank.
-
Structure of the E.coli F1-ATP synthase inhibited by subunit EpsilonID 3OAA. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of E.coli Dha kinase DhaKID 3PNK. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of E.coli Dha kinase DhaK-DhaL complexID 3PNL. Publicly available at the RCSB Protein Data Bank.
-
Protein-protein complex of subunit 1 and 2 of Molybdopterin-converting factor from Helicobacter pylori 26695ID 3RPF. Publicly available at the RCSB Protein Data Bank.
-
Complex structure of 3-oxoadipate coA-transferase subunit A and B from Helicobacter pylori 26695ID 3RRL. Publicly available at the RCSB Protein Data Bank.
-
Inward facing conformations of the MetNI methionine ABC transporter: CY5 native crystal formID 3TUI. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of human mitochondrial PheRS complexed with tRNAPhe in the active open stateID 3TUP. Publicly available at the RCSB Protein Data Bank.
-
The structure of thermorubin in complex with the 70S ribosome from Thermus thermophilus. This file contains the 50S subunit of one 70S ribosome. The entire crystal structure contains two 70S ribosomesID 3UXR. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of a bacterial dicarboxylate/sodium symporterID 4F35. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the entire respiratory complex I from Thermus thermophilusID 4HEA. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Biotin Carboxyl Carrier Protein-Biotin Carboxylase Complex from E.coliID 4HR7. Publicly available at the RCSB Protein Data Bank.
References
-
Learning generative models for protein fold familiesProteins: structure, Function, and Bioinformatics 79:1061–1078.https://doi.org/10.1002/prot.22934
-
Toward high-resolution prediction and design of transmembrane helical protein structuresProceedings of the National Academy of Sciences of the United States of America 104:15682–15687.https://doi.org/10.1073/pnas.0702515104
-
X-ray structure of pyruvate formate-lyase in complex with pyruvate and CoA. How the enzyme uses the Cys-418 thiyl radical for pyruvate cleavageJournal of Biological Chemistry 277:40036–40042.https://doi.org/10.1074/jbc.M205821200
-
The antibiotic thermorubin inhibits protein synthesis by binding to inter-subunit bridge B2a of the ribosomeJournal of Molecular Biology 416:571–578.https://doi.org/10.1016/j.jmb.2011.12.055
-
Structural basis of histidine kinase autophosphorylation deduced by integrating genomics, molecular dynamics, and mutagenesisProceedings of the National Academy of Sciences of the United States of America 109:E1733–E1742.https://doi.org/10.1073/pnas.1201301109
-
Berkeley PHOG: PhyloFacts orthology group prediction web serverNucleic Acids Research 37:W84–W89.https://doi.org/10.1093/nar/gkp373
-
Emerging methods in protein co-evolutionNature Reviews Genetics 14:249–261.https://doi.org/10.1038/nrg3414
-
BookEfficient unbound docking of rigid moleculesIn: Berlin, editors. Algorithms in bioinformatics. Heidelberg: Springer. pp. 185–200.https://doi.org/10.1007/3-540-45784-4_14
-
A new generation of homology search tools based on probabilistic inferenceGenome Informatics 23:205–211.
-
The crystal structure of the outer membrane protein VceC from the bacterial pathogen Vibrio cholerae at 1.8 Å resolutionJournal of Biological Chemistry 280:15307–15314.https://doi.org/10.1074/jbc.M500401200
-
Protein–protein docking with simultaneous optimization of rigid-body displacement and side-chain conformationsJournal of Molecular Biology 331:281–299.https://doi.org/10.1016/S0022-2836(03)00670-3
-
Correlated mutations: Advances and limitations. A study on fusion proteins and on the Cohesin-Dockerin familiesProteins: structure, Function, and Bioinformatics 63:832–845.https://doi.org/10.1002/prot.20933
-
Sequence co-evolution gives 3D contacts and structures of protein complexes. bioRxiv10.1101/004762.
-
Assessing the utility of coevolution-based residue–residue contact predictions in a sequence-and structure-rich eraProceedings of the National Academy of Sciences of the United States of America 110:15674–15679.https://doi.org/10.1073/pnas.1319550110
-
Determination of solution structures of proteins up to 40 kDa using CS-Rosetta with sparse NMR data from deuterated samplesProceedings of the National Academy of Sciences of the United States of America 109:10873–10878.https://doi.org/10.1073/pnas.1203013109
-
Using sequence alignments to predict protein structure and stability with high accuracyhttp://arxiv.org/abs/1207.2484.
-
Correlated mutations in models of protein sequences: phylogenetic and structural effectsLecture Notes-Monograph Series 33:236–256.https://doi.org/10.1214/lnms/1215455556
-
Structure and mechanism of the tripartite CusCBA heavy-metal efflux complexPhilosophical Transactions of the Royal Society B: Biological Sciences 367:1047–1058.https://doi.org/10.1098/rstb.2011.0203
-
Protein structure prediction from sequence variationNature Biotechnology 30:1072–1080.https://doi.org/10.1038/nbt.2419
-
Coevolutionary signals across protein lineages help capture multiple protein conformationsProceedings of the National Academy of Sciences of the United States of America 110:20533–20538.https://doi.org/10.1073/pnas.1315625110
-
Direct-coupling analysis of residue coevolution captures native contacts across many protein familiesProceedings of the National Academy of Sciences of the United States of America 108:E1293–E1301.https://doi.org/10.1073/pnas.1111471108
-
Tripartite ATP-independent periplasmic (TRAP) transporters in bacteria and archaeaFEMS Microbiology Reviews 35:68–86.https://doi.org/10.1111/j.1574-6976.2010.00236.x
-
Two distinct regions in Staphylococcus aureus GatCAB guarantee accurate tRNA recognitionNucleic Acids Research 38:672–682.https://doi.org/10.1093/nar/gkp955
-
Accurate de novo structure prediction of large transmembrane protein domains using fragment-assembly and correlated mutation analysisProceedings of the National Academy of Sciences of the United States of America 109:E1540–E1547.https://doi.org/10.1073/pnas.1120036109
-
Correlated mutations contain information about protein-protein interactionJournal of Molecular Biology 271:511–523.https://doi.org/10.1006/jmbi.1997.1198
-
Structure prediction for CASP8 with all‐atom refinement using RosettaProteins: structure, Function, and Bioinformatics 77:89–99.https://doi.org/10.1002/prot.22540
-
Automatic clustering of orthologs and in-paralogs from pairwise species comparisonsJournal of Molecular Biology 314:1041–1052.https://doi.org/10.1006/jmbi.2000.5197
-
High-resolution protein complexes from integrating genomic information with molecular simulationProceedings of the National Academy of Sciences of the United States of America 106:22124–22129.https://doi.org/10.1073/pnas.0912100106
-
Improved recognition of native-like protein structures using a combination of sequence‐dependent and sequence‐independent features of proteinsProteins: structure, Function, and Bioinformatics 34:82–95.https://doi.org/10.1002/(SICI)1097-0134(19990101)34:1<82::AID-PROT7>3.0.CO;2-A
-
FusionDB: a database for in-depth analysis of prokaryotic gene fusion eventsNucleic Acids Research 32:D273–D276.https://doi.org/10.1093/nar/gkh053
-
Genomics-aided structure predictionProceedings of the National Academy of Sciences of the United States of America 109:10340–10345.https://doi.org/10.1073/pnas.1207864109
-
Integrated strategy reveals the protein interface between cancer targets Bcl-2 and NAF-1Proceedings of the National Academy of Sciences of the United States of America 111:5177–5182.https://doi.org/10.1073/pnas.1403770111
-
Graphical models of residue coupling in protein familiesIEEE/ACM Transactions on Computational Biology and Bioinformatics (TCBB) 5:183–197.https://doi.org/10.1109/TCBB.2007.70225
-
UniProt User manualhttp://www.uniprot.org/manual/accession_numbers, . accessed September 9, 2013.
-
Computational methods for the prediction of protein interactionsCurrent Opinion in Structural Biology 12:368–373.https://doi.org/10.1016/S0959-440X(02)00333-0
-
Structural basis for glycyl radical formation by pyruvate formate-lyase activating enzymeProceedings of the National Academy of Sciences of the United States of America 105:16137–16141.https://doi.org/10.1073/pnas.0806640105
-
S2C: a database correlating sequence and atomic coordinate residue numbering in the Protein Data BankDunbrack Lab. http://dunbrack.fccc.edu/s2c/. Accessed October 12, 2013.
-
Identification of direct residue contacts in protein–protein interaction by message passingProceedings of the National Academy of Sciences of the United States of America 106:67–72.https://doi.org/10.1073/pnas.0805923106
-
The Universal Protein Resource (UniProt): an expanding universe of protein informationNucleic Acids Research 34:D187–D191.https://doi.org/10.1093/nar/gkj161
-
Structural basis for gating charge movement in the voltage sensor of a sodium channelProceedings of the National Academy of Sciences of the United States of America 109:E93–E102.https://doi.org/10.1073/pnas.1118434109
-
Crystal structure of toll-like receptor 2-activating lipoprotein IIpA from Vibrio vulnificusProteins: structure, Function, and Bioinformatics 79:1020–1025.https://doi.org/10.1002/prot.22929
-
Crystal structure of the periplasmic component of a tripartite macrolide-specific efflux pumpJournal of Molecular Biology 387:1286–1297.https://doi.org/10.1016/j.jmb.2009.02.048
Article and author information
Author details
Funding
National Institutes of Health (1R01GM092802-04)
- Sergey Ovchinnikov
- Hetunandan Kamisetty
- David Baker
National Institutes of Health (National Institute of General Medical Studies, P41 GM103533)
- David Baker
Defense Threat Reduction Agency (DTRA) (N00024-10-D-6318/0024-02)
- Sergey Ovchinnikov
- David Baker
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Lei Shi and David La for their comments and helpful suggestions, and Rosetta@home participants for donating their computer time.
Note added in proof
Two other studies of protein-coevolution using global statistical models have recently appeared: Tamir et al., 2014, and Hopf et al., 2014. These studies provide independent validation of the robustness of global statistical methods for prediction of protein–protein contacts.
Copyright
© 2014, Ovchinnikov et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 18,422
- views
-
- 2,676
- downloads
-
- 624
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 624
- citations for umbrella DOI https://doi.org/10.7554/eLife.02030
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Robust and accurate prediction of residue–residue interactions across protein interfaces using evolutionary information
eLife 3:e02030.
https://doi.org/10.7554/eLife.02030




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}