Characterization of TSET, an ancient and widespread membrane trafficking complex
- University of Cambridge, United Kingdom
- University of Alberta, Canada
- MRC Laboratory of Molecular Biology, United Kingdom
Figures
Figure 1 with 5 supplements
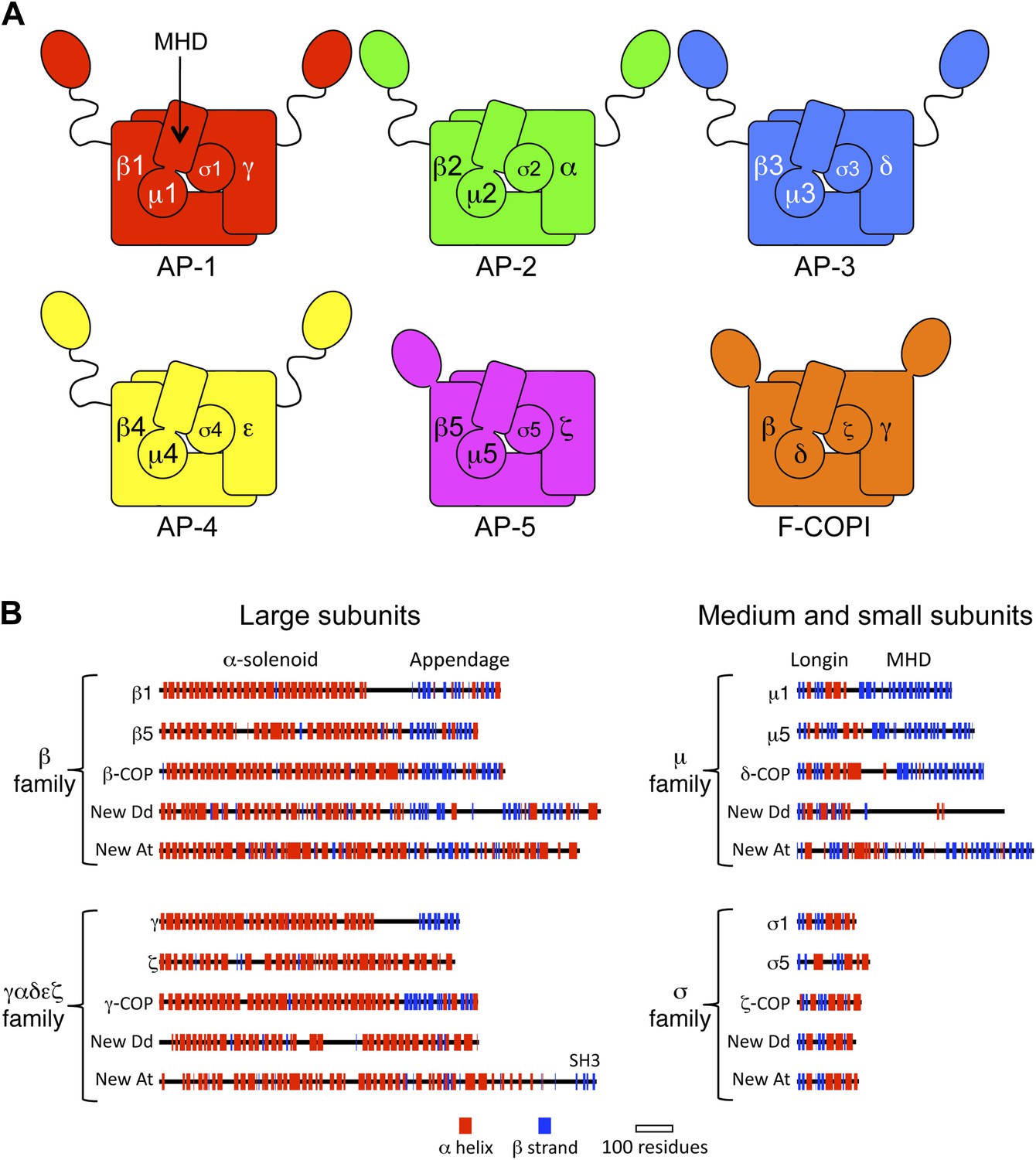
Diagrams of APs and F-COPI.
(A) Structures of the assembled complexes. All six complexes are heterotetramers; the individual subunits are called adaptins in the APs (e.g., γ-adaptin) and COPs in COPI (e.g., γ-COP). The two large subunits in each complex are structurally similar to each other. They are arranged with their N-terminal domains in the core of the complex, and these domains are usually (but not always) followed by a flexible linker and an appendage domain. The medium subunits consist of an N-terminal longin-related domain followed by a C-terminal μ homology domain (MHD). The small subunits consist of a longin-related domain only. (B) Jpred secondary structure predictions of some of the known subunits (all from Homo sapiens), together with new family members from Dictyostelium discoideum (Dd) and Arabidopsis thaliana (At). See also Figure 1—figure supplements 1–4, Figure 1—source data 1, 2.
-
Figure 1—source data 1
Large subunit homologues found by reverse HHpred in different organisms.
- https://doi.org/10.7554/eLife.02866.004
-
Figure 1—source data 2
Medium and small subunit homologues found by reverse HHpred in different organisms.
- https://doi.org/10.7554/eLife.02866.005
Figure 1—figure supplement 1
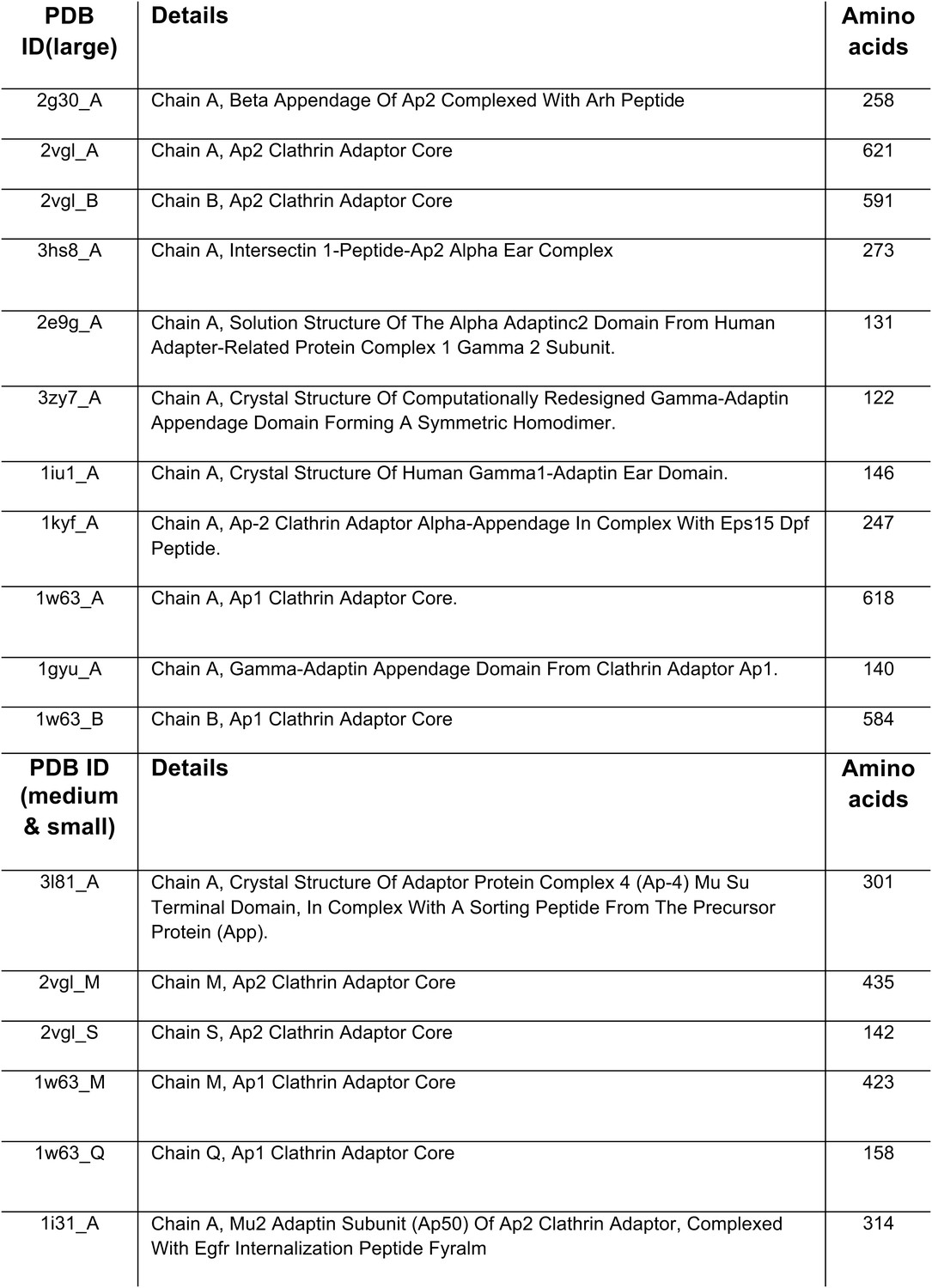
PDB entries used to search for adaptor-related proteins.
https://doi.org/10.7554/eLife.02866.006
Figure 1—figure supplement 2
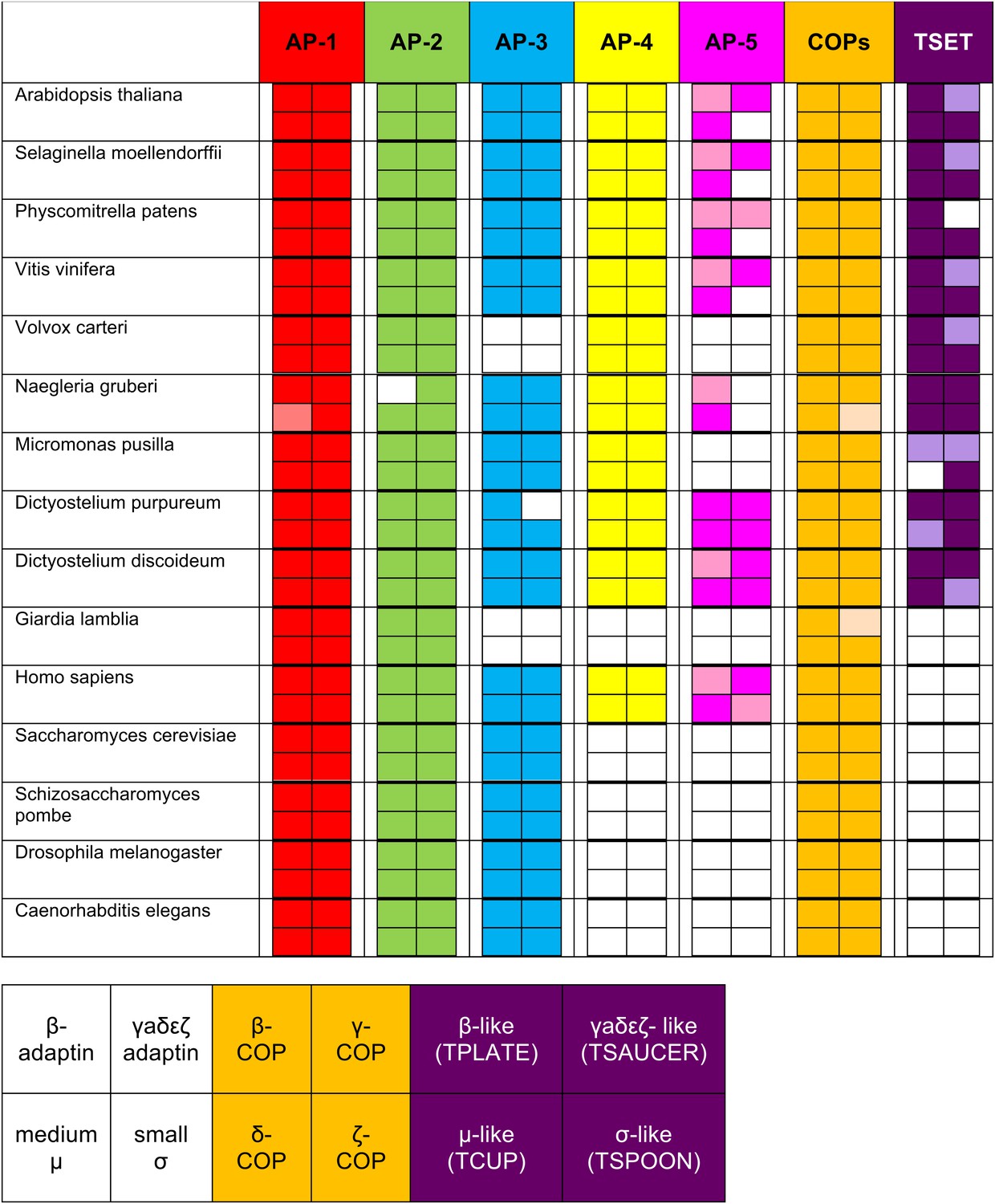
Summary table of all subunits identified using reverse HHpred.
The lighter shading indicates where an orthologue was found either below the arbitrary cut-off, by using NCBI BLAST (see Figure 1—figure supplement 3), or by searching a genomic database (e.g., AP-1 μ1 |Naegr1|35900|, JGI). The new complex is called ‘TSET’.
Figure 1—figure supplement 3
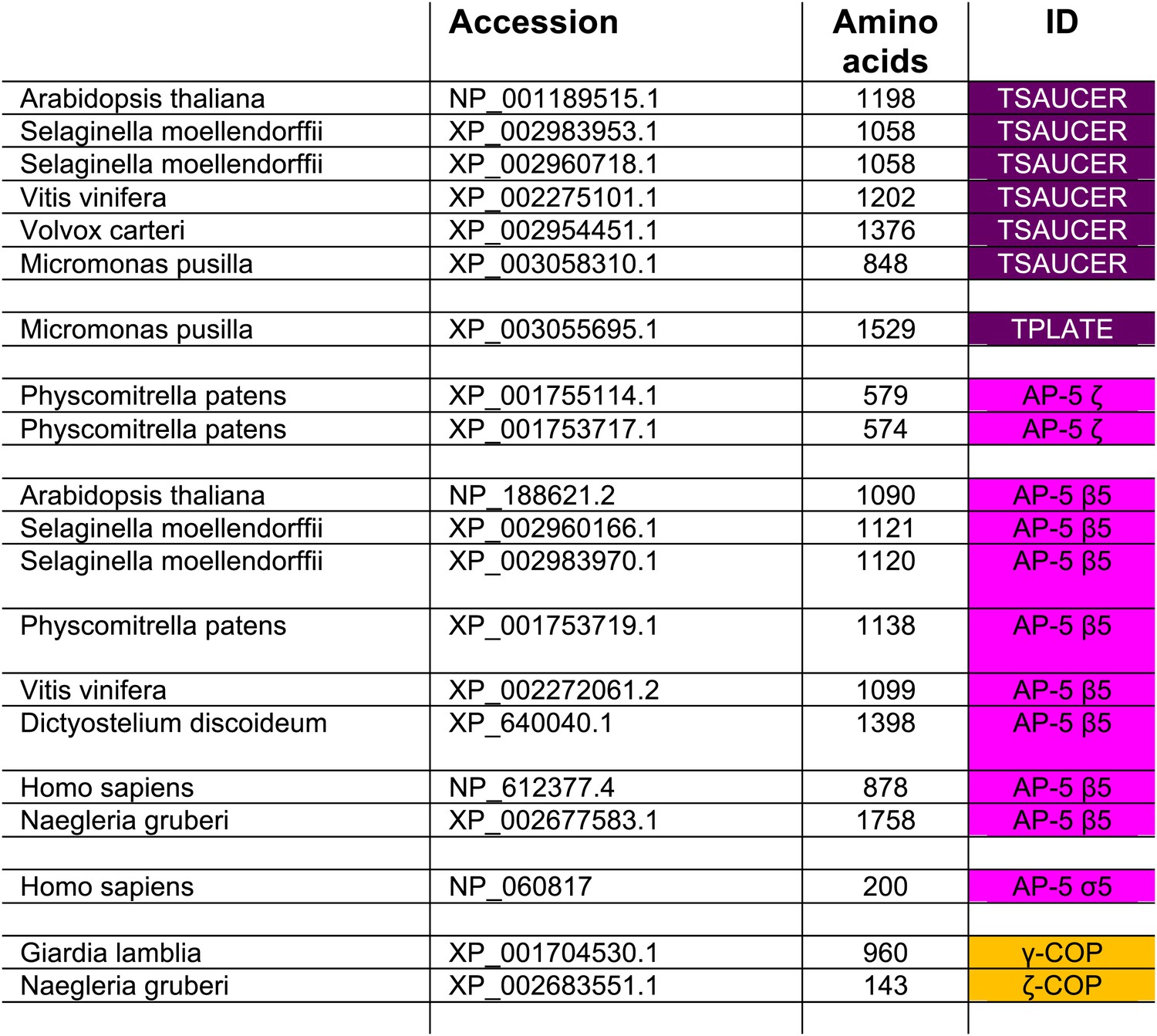
Subunits that failed to be identified using reverse HHpred, but were identified by homology searching using NCBI BLAST.
https://doi.org/10.7554/eLife.02866.008
Figure 1—figure supplement 4
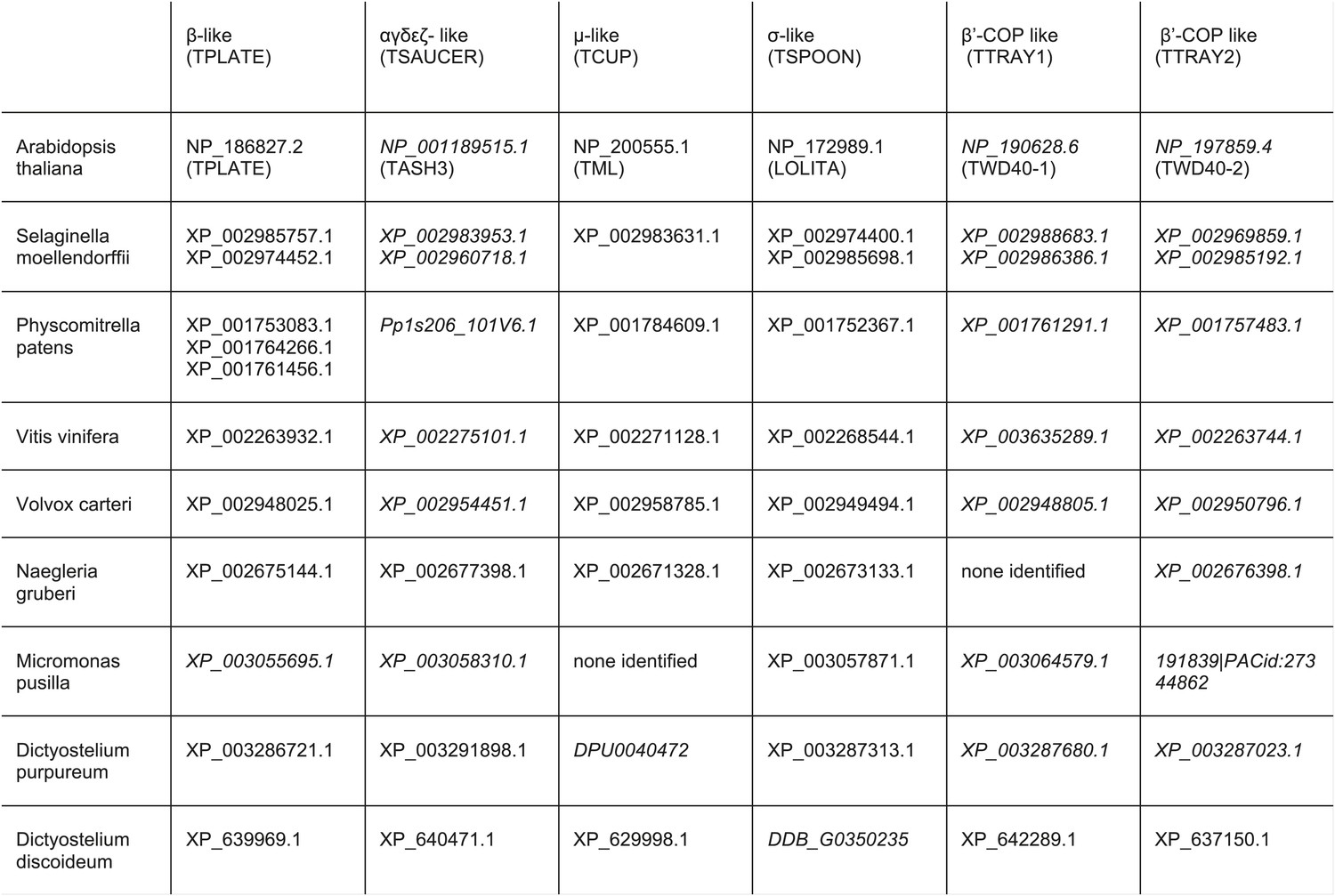
TSET orthologues in different species.
The orthologues were identified by reverse HHpred, except for those in italics, which were found by BLAST searching (NCBI) using closely related organisms. TTRAY1 and TTRAY2 were initially identified by proteomics in a complex with TSET, but could also have been predicted by reverse HHpred as closely related to β′-COP using the PDB structure, 3mkq_A. In all other organisms TTRAY1 and TTRAY2 were identified by NCBI BLAST (italics). Note that orthologues of TSAUCER in P. patens, and TTRAY 2 in M. pusilla were identified in Phytozome, which is a genomic database hosted by Joint Genome Institute (JGI). Note orthologues of TCUP in D. purpureum and TSPOON in D. discoideum were identified by searching genomic sequences using closely related sequences, and have been manually appended in DictyBase. In these cases corresponding sequences are not at present found at NCBI. Whilst S. moellendorffii and V. vinifera were included in the reverse HHpred database, they were not included in the Coulson plot.
Figure 1—figure supplement 5
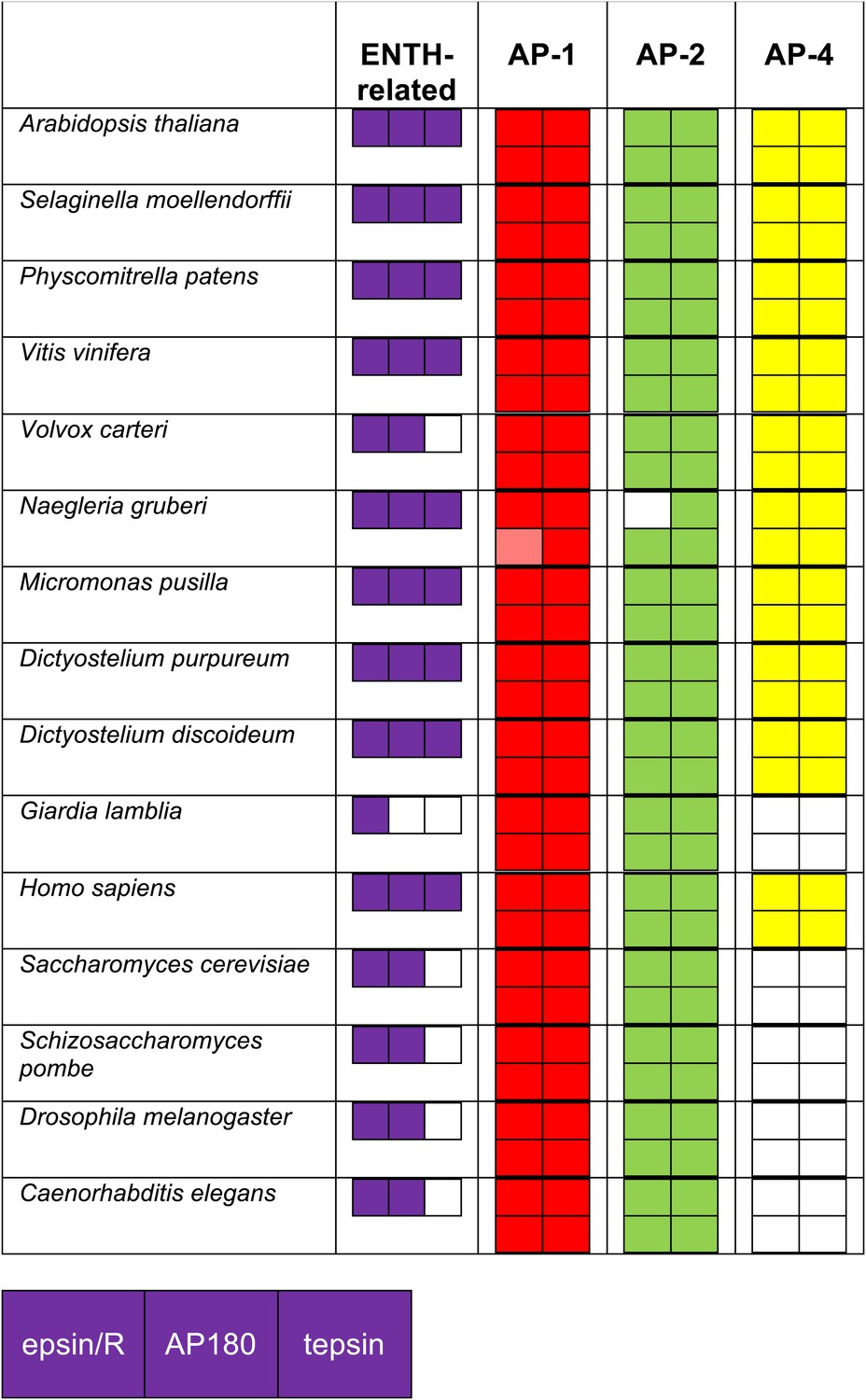
Identification of ENTH/ANTH domain proteins and the AP complexes with which they associate, using reverse HHpred.
Reverse HHpred searches were initiated using the key words ‘epsin’ or ‘ENTH’. The PDB structures used were: 1eyh_A (Chain A, Crystal Structure Of The Epsin N-Terminal Homology (Enth) Domain At 1.56 Angstrom Resolution); 1inz_A (Chain A, Solution Structure Of The Epsin N-Terminal Homology (Enth) Domain Of Human Epsin); 1xgw_A (Chain A, The Crystal Structure Of Human Enthoprotin N-Terminal Domain); 3onk_A (Chain A, Yeast Ent3_enth Domain), and the output was assimilated in Excel as described for the adaptors. The identity of the hits was determined using NCBI BLAST searching. Note that all of the organisms that have lost AP-4 have also lost its binding partner, tepsin.
Figure 2 with 3 supplements
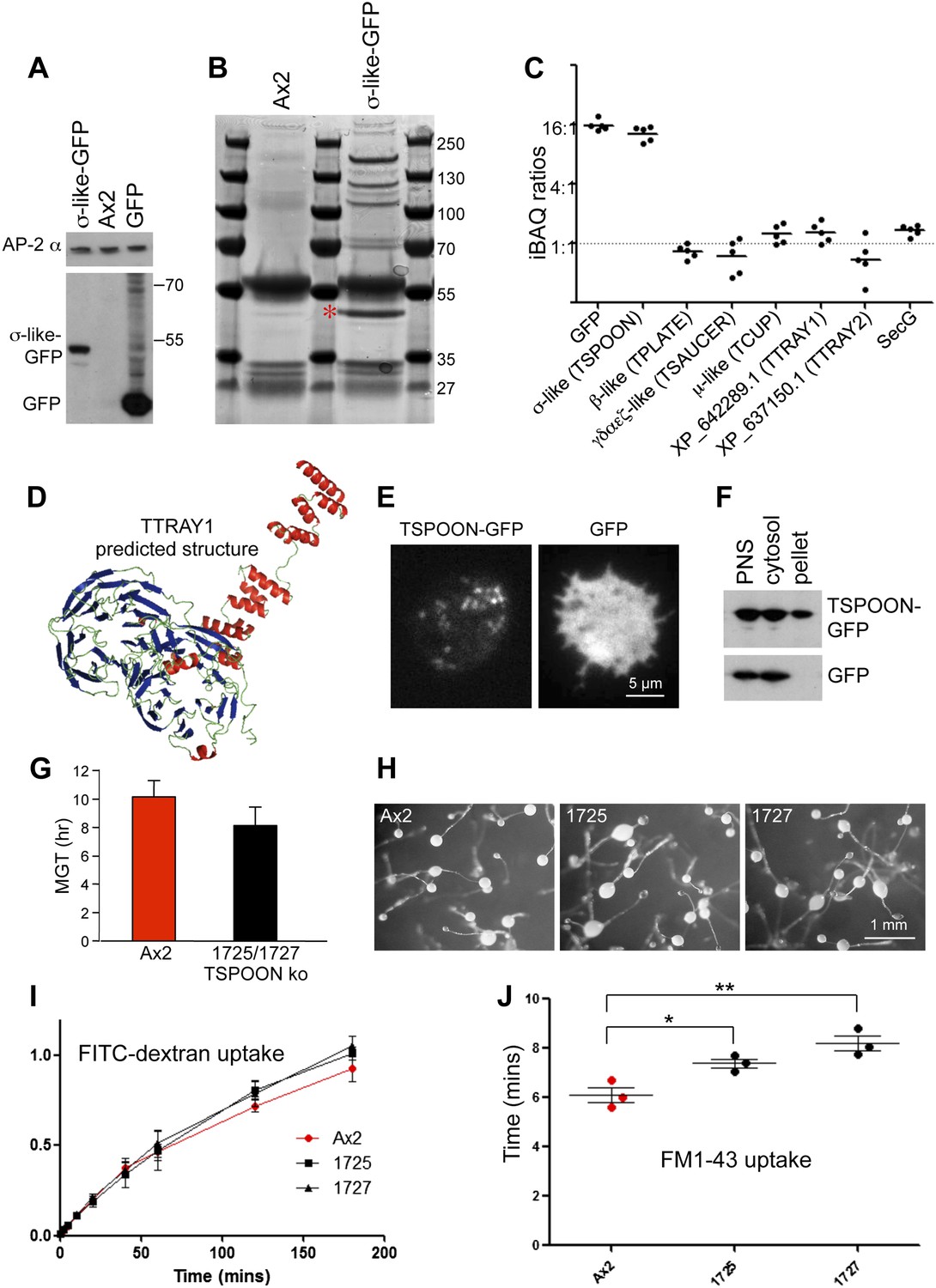
Characterisation of the TSET complex in Dictyostelium.
(A) Western blots of axenic D. discoideum expressing either GFP-tagged small subunit (σ-like) or free GFP, under the control of the Actin15 promoter, labelled with anti-GFP. The Ax2 parental cell strain was included as a control, and an antibody against the AP-2α subunit was used to demonstrate that equivalent amounts of protein were loaded. (B) Coomassie blue-stained gel of GFP-tagged small subunit and associated proteins immunoprecipitated with anti-GFP. The GFP-tagged protein is indicated with a red asterix. (C) iBAQ ratios (an estimate of molar ratios) for the proteins that consistently coprecipitated with the GFP-tagged small subunit. All appear to be equimolar with each other, and the higher ratios for the small (σ-like/TSPOON) subunit and GFP are likely to be a consequence of their overexpression, which we also saw in a repeat experiment in which we used the small subunit's own promoter (Figure 2—figure supplement 1). (D) Predicted structure of the N-terminal portion of D. discoideum TTRAY1, shown as a ribbon diagram. (E) Stills from live cell imaging of cells expressing either TSPOON-GFP or free GFP, using TIRF microscopy. The punctate labelling in the TSPOON-GFP-expressing cells indicates that some of the construct is associated with the plasma membrane. See Videos 1 and 2. (F) Western blots of extracts from cells expressing either TSPOON-GFP or free GFP. The post-nuclear supernatants (PNS) were centrifuged at high speed to generate supernatant (cytosol) and pellet fractions. Equal protein loadings were probed with anti-GFP. Whereas the GFP was exclusively cytosolic, a substantial proportion of TSPOON-GFP fractionated into the membrane-containing pellet. (G) Mean generation time (MGT) for control (Ax2) and TSPOON knockout cells. The knockout cells grew slightly faster than the control. (H) Differentiation of the Ax2 control strain and two TSPOON knockout strains (1725 and 1727). All three strains produced fruiting bodies upon starvation. (I) Assay for fluid phase endocytosis. The control and knockout strains took up FITC-dextran at similar rates. (J) Assay for endocytosis of membrane, labelled with FM1-43, showing the time taken to internalise the entire surface area. The knockout strains took significantly longer than the control (*p<0.05; **p<0.01). See also Figure 2—figure supplements 1 and 2, Figure 2; Videos 1 and 2.
Figure 2—figure supplement 1
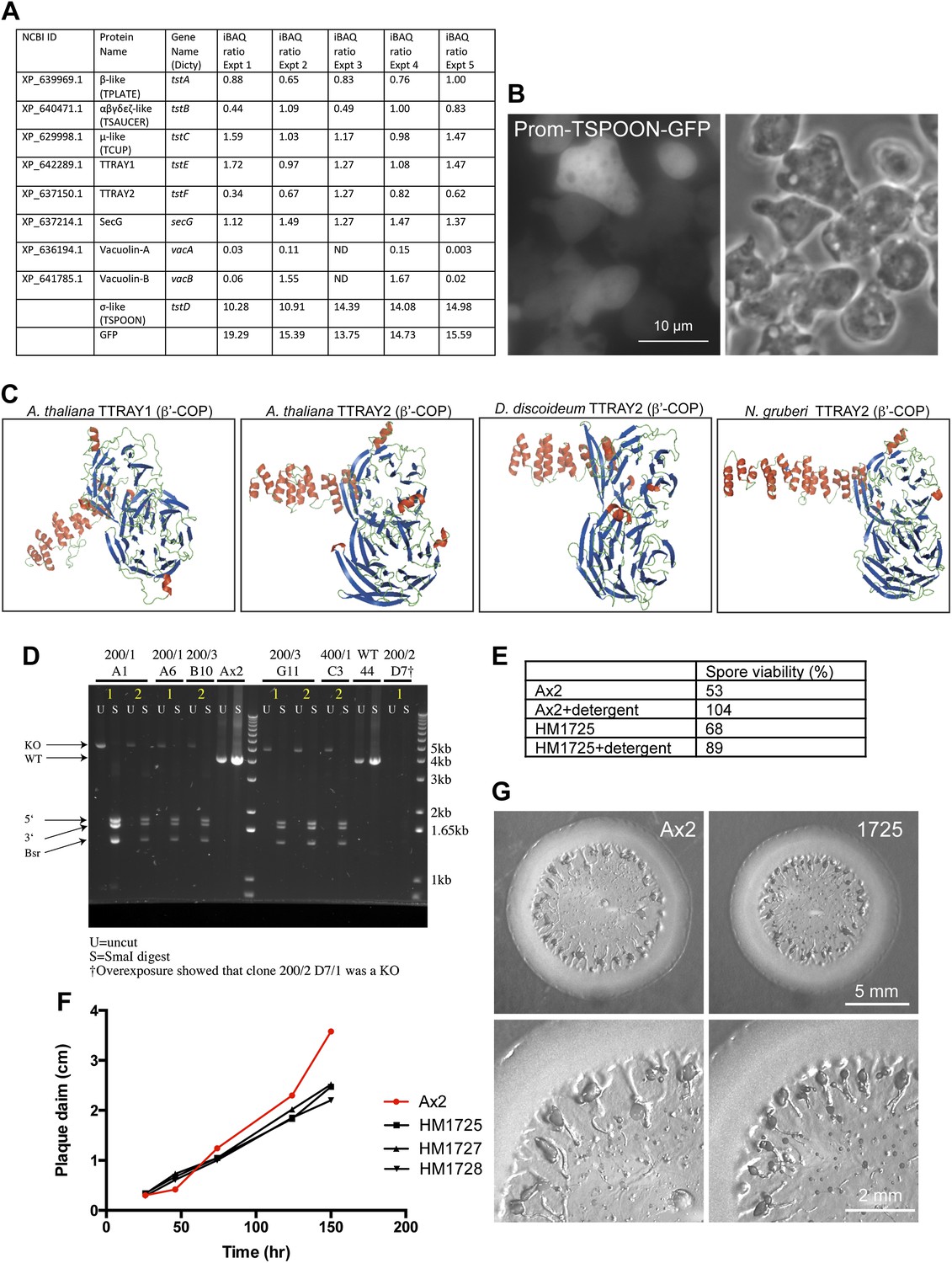
Further characterisation of Dictyostelium TSET.
(A) iBAQ ratios for the proteins that coprecipitated with TSPOON-GFP, normalized to the median abundance of all proteins across five experiments. ND = not detected. (B) Fluorescence and phase contrast micrographs of cells expressing GFP-tagged TSPOON under the control of its own promoter (Prom-TSPOON-GFP). The construct appears mainly cytosolic. (C) Homology modeling of TTRAYs from A. thaliana, D. discoideum, and N. gruberi, revealing two β-propeller domains followed by an α-solenoid. (D) Disruption of the TSPOON gene. PCR was used to amplify either the wild-type TSPOON gene (in Ax2) or the disrupted TSPOON gene. The resulting products were either left uncut (U) or digested with SmaI (S), which should not cut the wild-type gene, but should cleave the disrupted gene into three bands. Several clones are shown, including HM1725 (200/1 A1). (E) Spore viability after detergent treatment was used to test for integrity of the cellulosic spore and the ability to hatch in a timely manner. The control (Ax2) strain and the knockout (HM1725) strain both showed good viability. (F) Expansion rate of plaques on bacterial lawns. The rates for control (Ax2) and knockout (HM1725, 1727, and 1728) strains were similar initially, but by 2 days the control plaques were larger. (G) Micrographs of plaques from control and knockout strains.
Figure 2—figure supplement 2
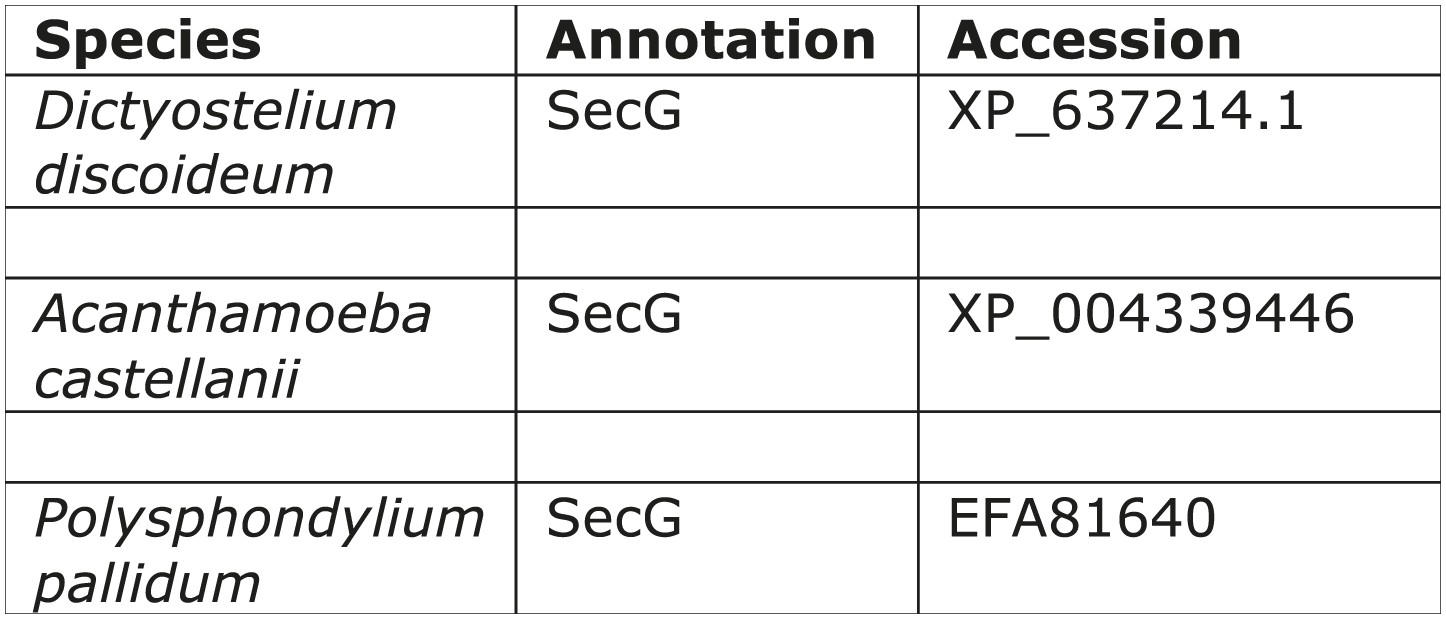
Distribution of secG.
https://doi.org/10.7554/eLife.02866.013
Figure 2—figure supplement 3
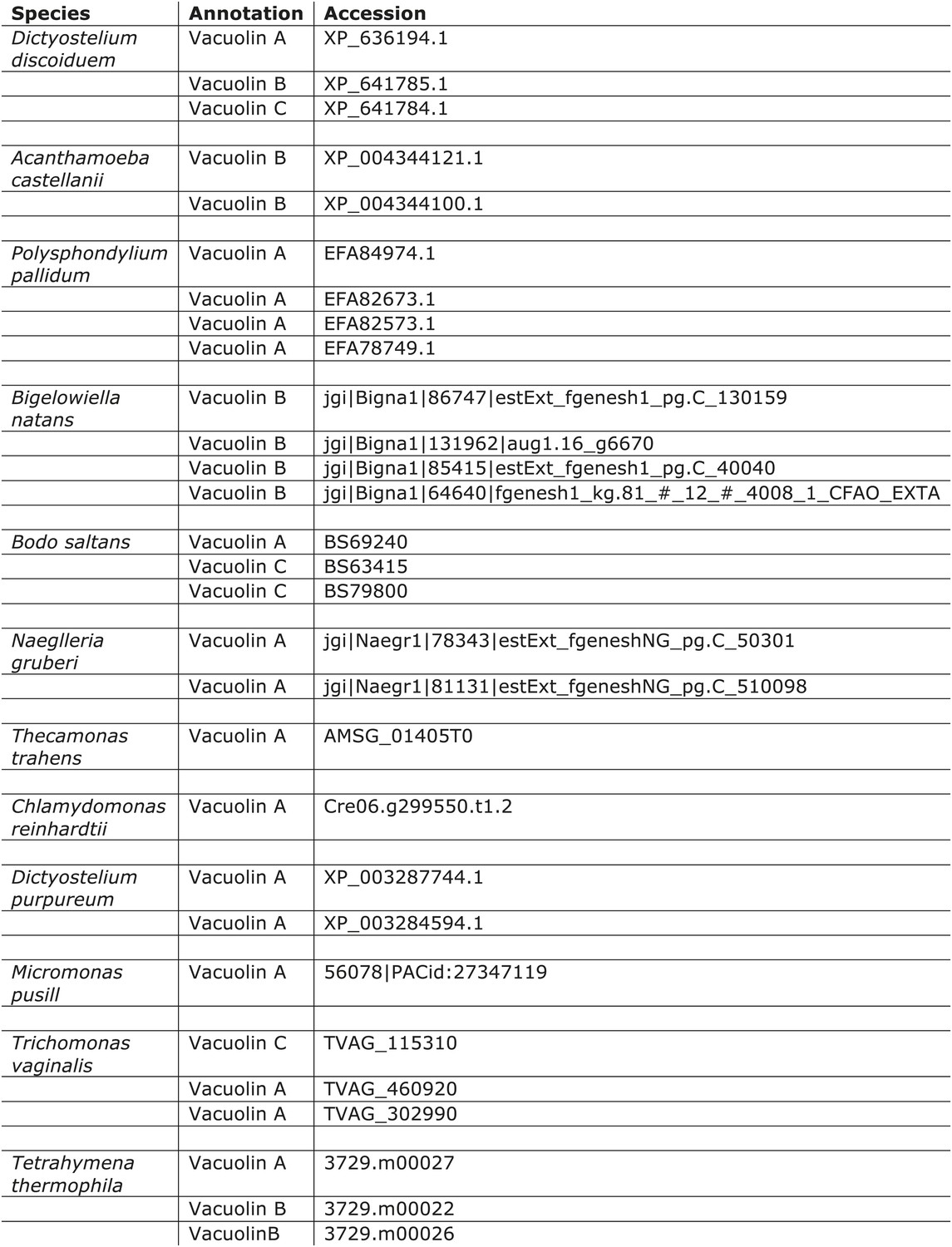
Distribution of vacuolins.
https://doi.org/10.7554/eLife.02866.014
Figure 3 with 1 supplement
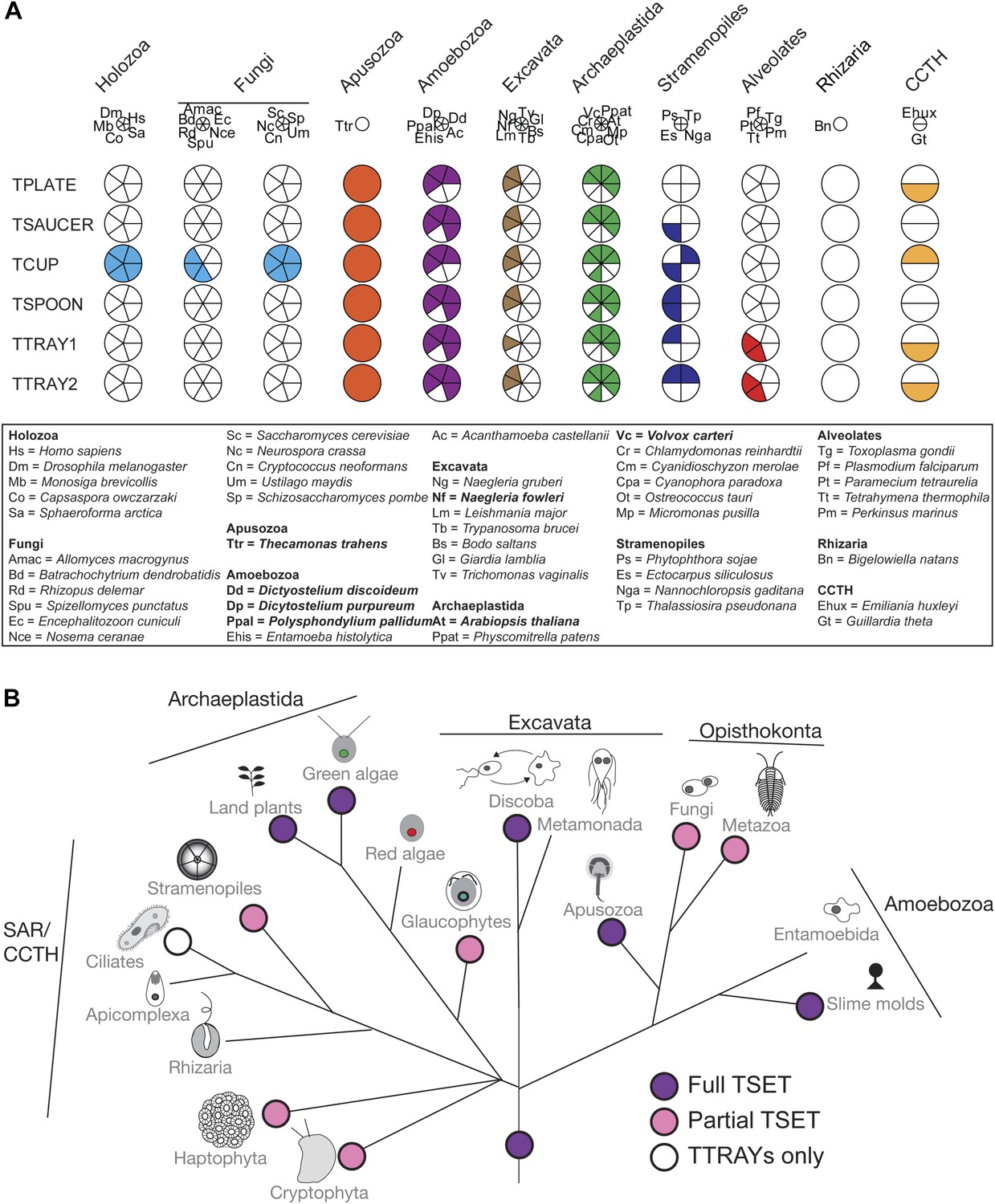
Distribution of TSET subunits.
(A) Coulson plot showing the distribution of TSET in a diverse set of representative eukaryotes. Presence of the entire complex in at least four supergroups suggests its presence in the last eukaryotic common ancestor (LECA) with frequent secondary loss. Solid sectors indicate sequences identified and classified using BLAST and HMMer. Empty sectors indicate taxa in which no significant orthologues were identified. Filled sectors in the Holozoa and Fungi represent F-BAR domain-containing FCHo and Syp1, respectively. Taxon name abbreviations are inset. Names in bold indicate taxa with all six components. (B) Deduced evolutionary history of TSET as present in the LECA but independently lost multiple times, either partially or completely. See also Figure 3—source data 1, Figure 3—figure supplement 1.
-
Figure 3—source data 1
Sequences used for phylogenetic analyses.
- https://doi.org/10.7554/eLife.02866.018
Figure 3—figure supplement 1
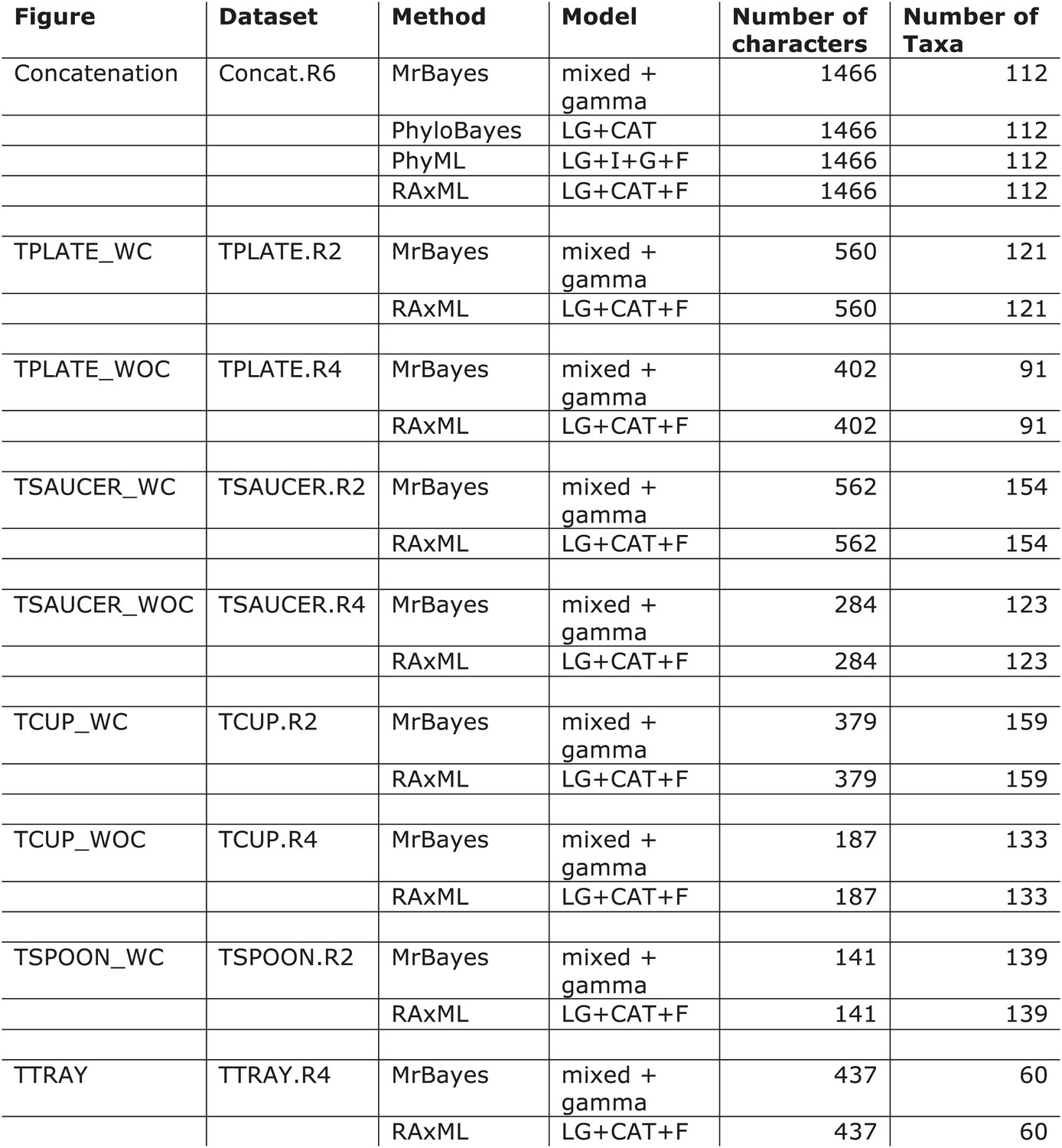
Models used for phylogenetic analyses.
WC = with COPI; WOC = without COPI.
Figure 4 with 10 supplements

Evolution of TSET.
(A) Simplified diagram of the concatenated tree for TSET, APs, and COPI, based on Figure 4—figure supplement 8. Numbers indicate posterior probabilities for MrBayes and PhyloBayes and maxium-likelihood bootstrap values for PhyML and RAxML, in that order. (B) Schematic diagram of TSET. (C) Possible evolution of the three families of heterotetramers: TSET, APs, and COPI. We propose that the earliest ancestral complex was a likely a heterotrimer or a heterohexamer formed from two identical heterotrimers, containing large (red), small (yellow), and scaffolding (blue) subunits. All three of these proteins were composed of known ancient building blocks of the membrane-trafficking system (Vedovato et al., 2009): α-solenoid domains in both the large and scaffolding subunits; two β-propellers in the scaffolding subunit; and a longin domain forming the small subunit. The gene encoding the large subunit then duplicated and mutated to generate the two distinct types of large subunits (red and magenta), and the gene encoding the small subunit also duplicated and mutated (yellow and orange), with one of the two proteins (orange) acquiring a μ homology domain (MHD) to form the ancestral heterotetramer, as proposed by Boehm and Bonifacino (12). However, the scaffolding subunit remained a homodimer. Upon diversification into three separate families, the scaffolding subunit duplicated independently in TSET and COPI, giving rise to TTRAY1 and TTRAY2 in TSET, and to α- and β′-COP in COPI. COPI also acquired a new subunit, ε-COP (purple). The scaffolding subunit may have been lost in the ancestral AP complex, as indicated in the diagram; however, AP-5 is tightly associated with two other proteins, SPG11 and SPG15, and the relationship of SPG11 and SPG15 to TTRAY/B-COPI remains unresolved, so it is possible that SPG11 and SPG15 are highly divergent descendants of the original scaffolding subunits. The other AP complexes are free heterotetramers when in the cytosol, but membrane-associated AP-1 and AP-2 interact with another scaffold, clathrin; and AP-3 has also been proposed to interact transiently with a protein with similar architecture, Vps41 (Rehling et al., 1999; Cabrera et al., 2010; Asensio et al., 2013). So far no scaffold has been proposed for AP-4. Although the order of emergence of TSET and COP relative to adaptins is unresolved, our most recent analyses indicate that, contrary to previous reports (Hirst et al., 2011), AP-5 diverged basally within the adaptin clade, followed by AP-3, AP-4, and APs 1 and 2, all prior to the LECA. This still suggests a primordial bridging of the secretory and phagocytic systems prior to emergence of a trans-Golgi network. The muniscins arose much later, in ancestral opisthokonts, from a translocation of the TSET MHD-encoding sequence to a position immediately downstream from an F-BAR domain-encoding sequence. Another translocation occurred in plants, where an SH3 domain-coding sequence was inserted at the 3′ end of the TSAUCER-coding sequence. See also Figure 4—figure supplements 1–10.
Figure 4—figure supplement 1
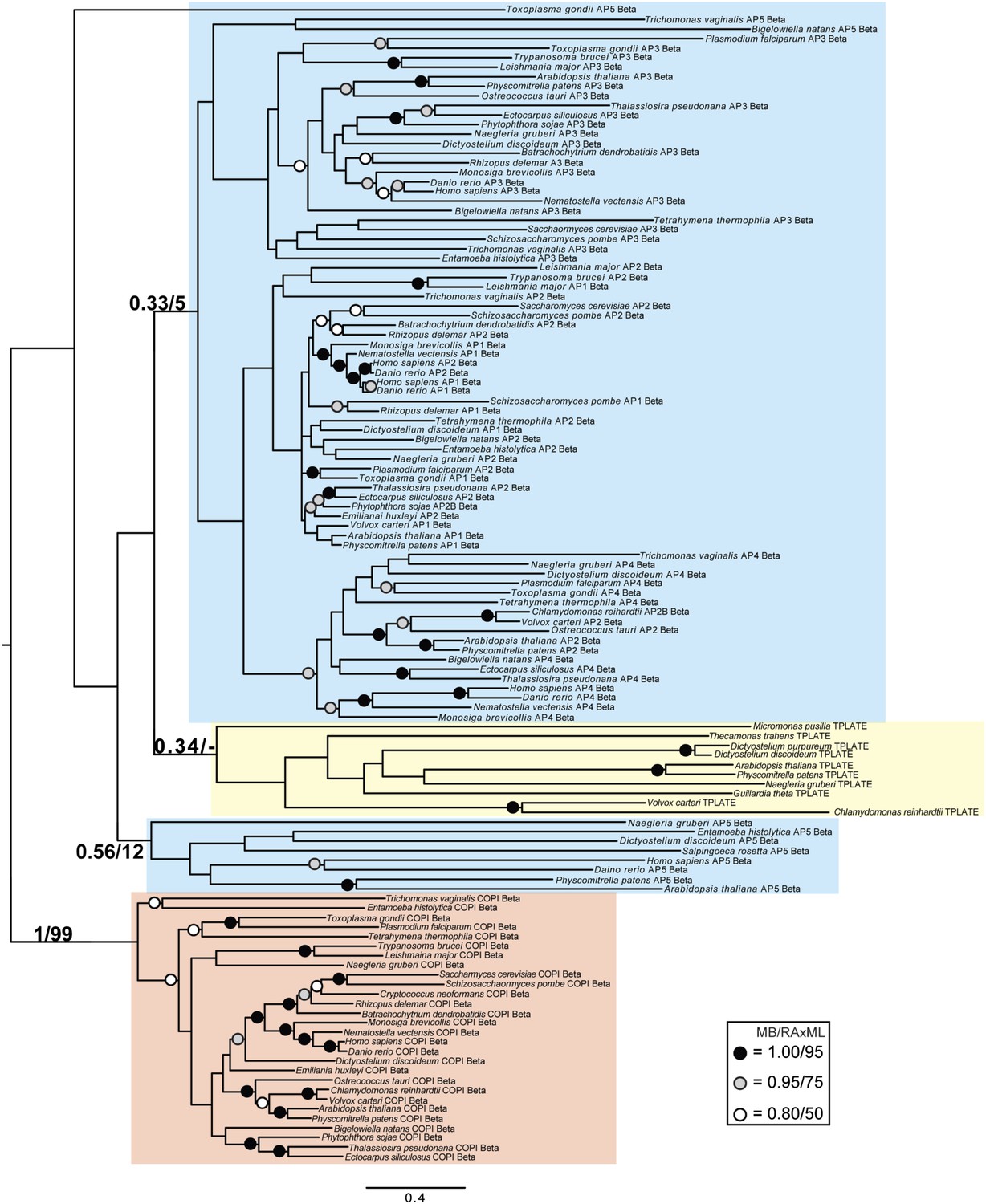
Phylogenetic analysis of TPLATE, β-COP, and β-adaptin, with TPLATE robustly excluded from the β-COP clade.
In this and all other figure supplements to Figure 4, AP subunits are boxed in blue, F-COPI subunits are boxed in red, and subunits of TSET are boxed in yellow. Node support for critical nodes is shown. Numbers indicate Bayesian posterior probabilities (MrBayes) and bootstrap support from Maximum-likelihood analysis (RAxML). Support values for other nodes are denoted by symbols (see inset).
Figure 4—figure supplement 2
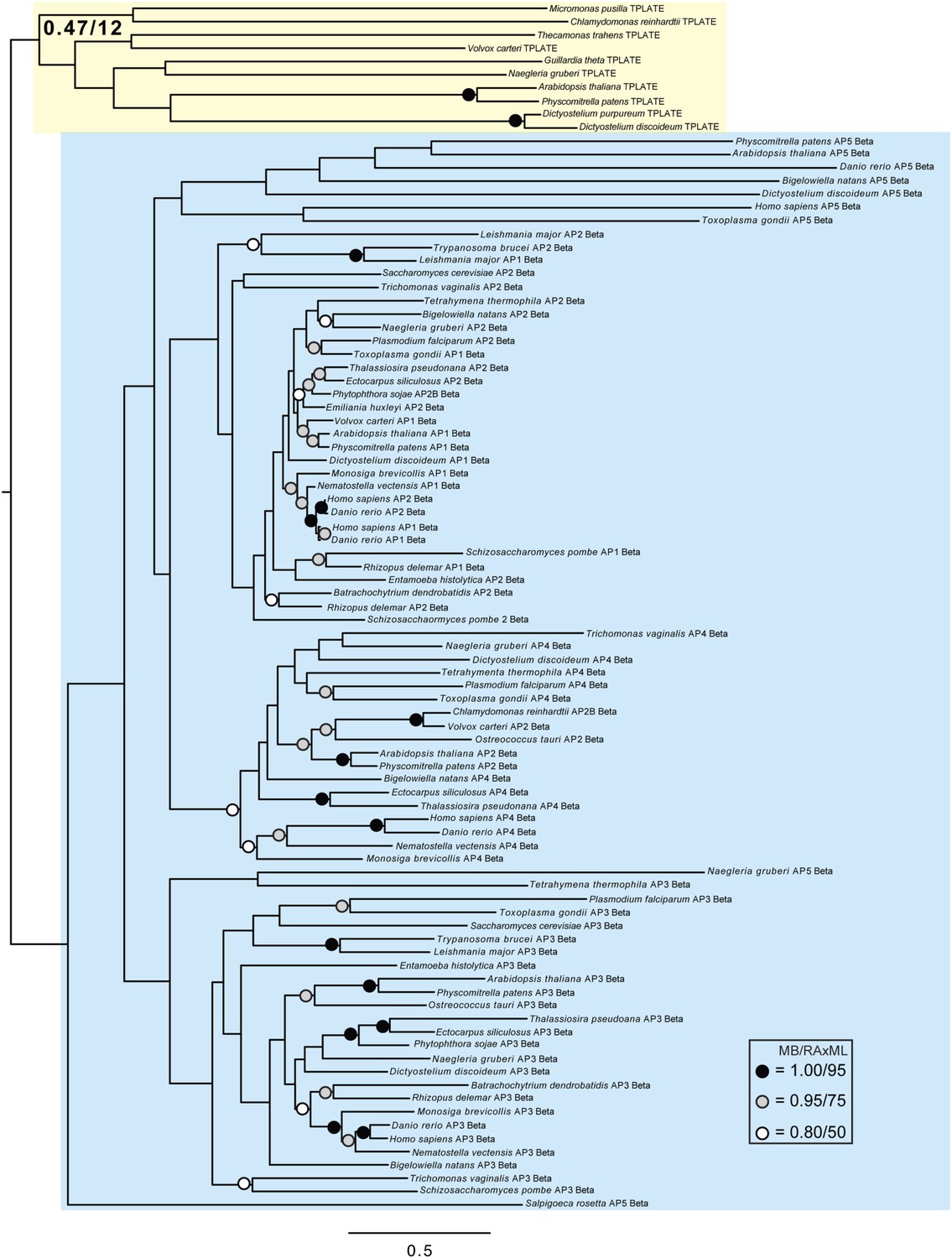
Phylogenetic analysis of TPLATE and β-adaptin subunits (β-COP removed) showing, with weak support, that TPLATE is excluded from the adaptin clade.
https://doi.org/10.7554/eLife.02866.022
Figure 4—figure supplement 3
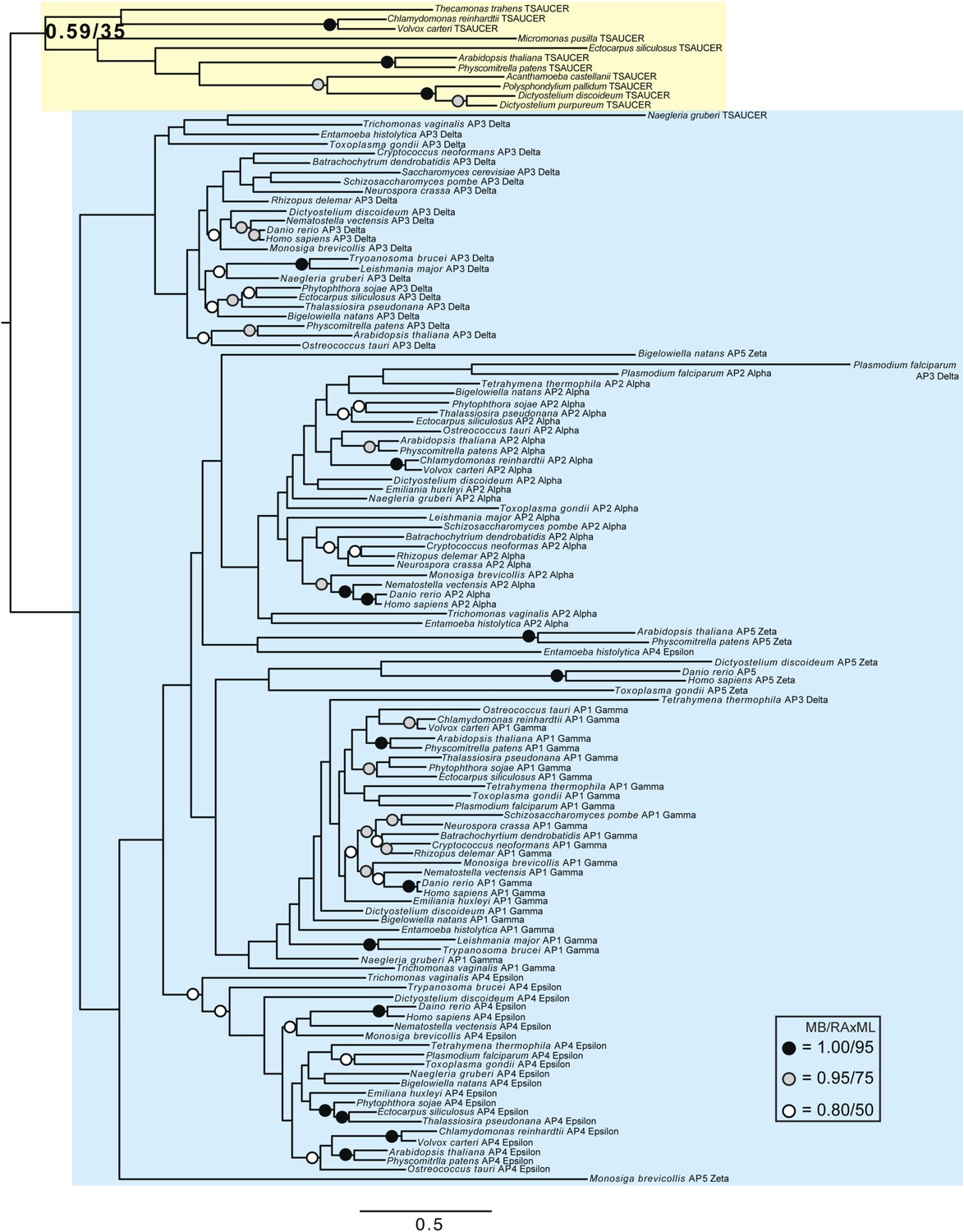
Phylogenetic analysis of TSAUCER, γ-COP, and γαδεζ-adaptin subunits, with TCUP robustly excluded from the γ-COP clade, and weakly excluded from the adaptin clade.
https://doi.org/10.7554/eLife.02866.023
Figure 4—figure supplement 4
Phylogenetic analysis of TSAUCER and γαδεζ-adaptin subunits (γ-COP removed), showing weak support for the exclusion of TSAUCER from the adaptin clade.
https://doi.org/10.7554/eLife.02866.024
Figure 4—figure supplement 5
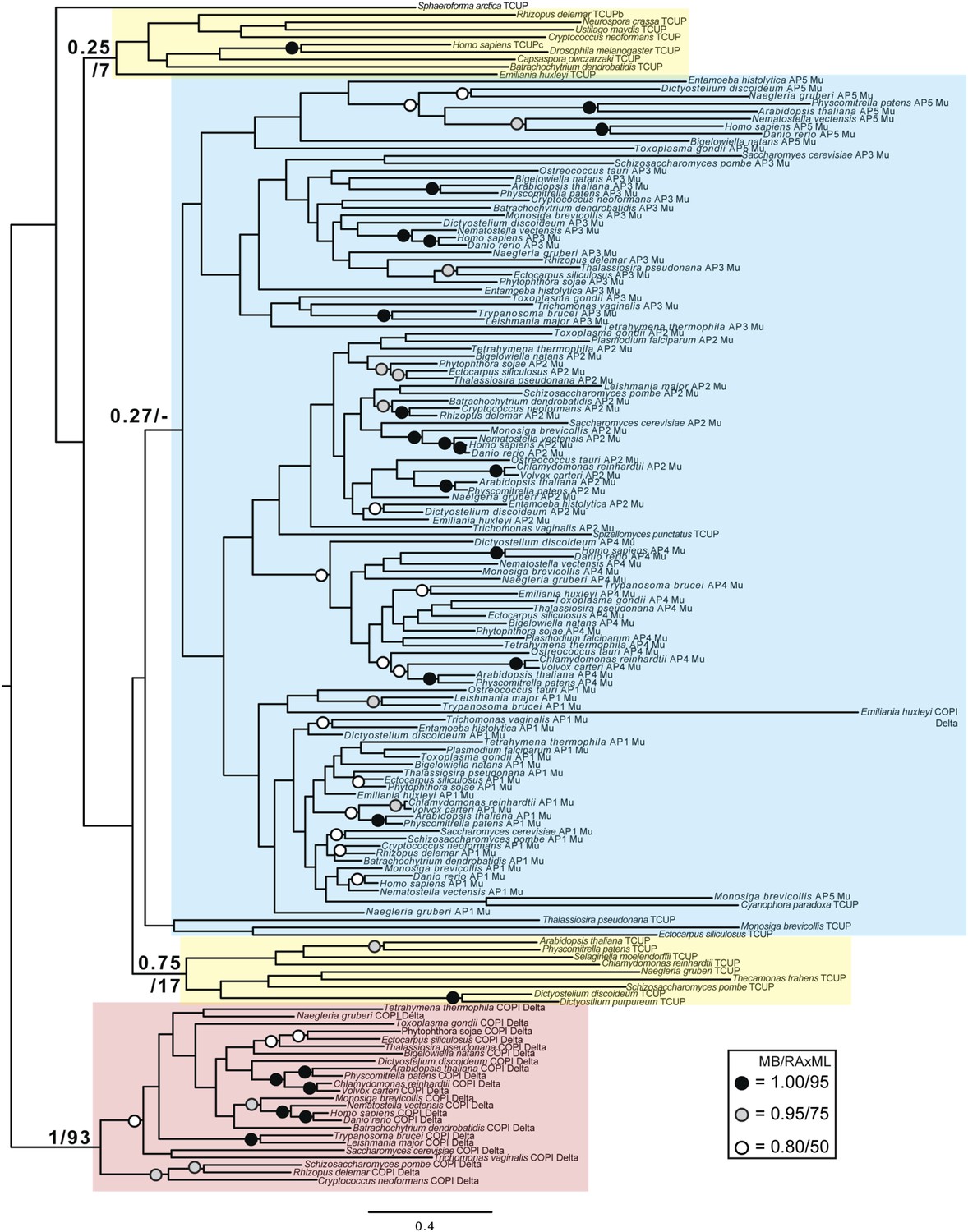
Phylogenetic analysis of TCUP, δ-COP, and μ-adaptin subunits, with TSAUCER robustly excluded from the δ-COP clade and weakly excluded from the adaptin clade.
https://doi.org/10.7554/eLife.02866.025
Figure 4—figure supplement 6
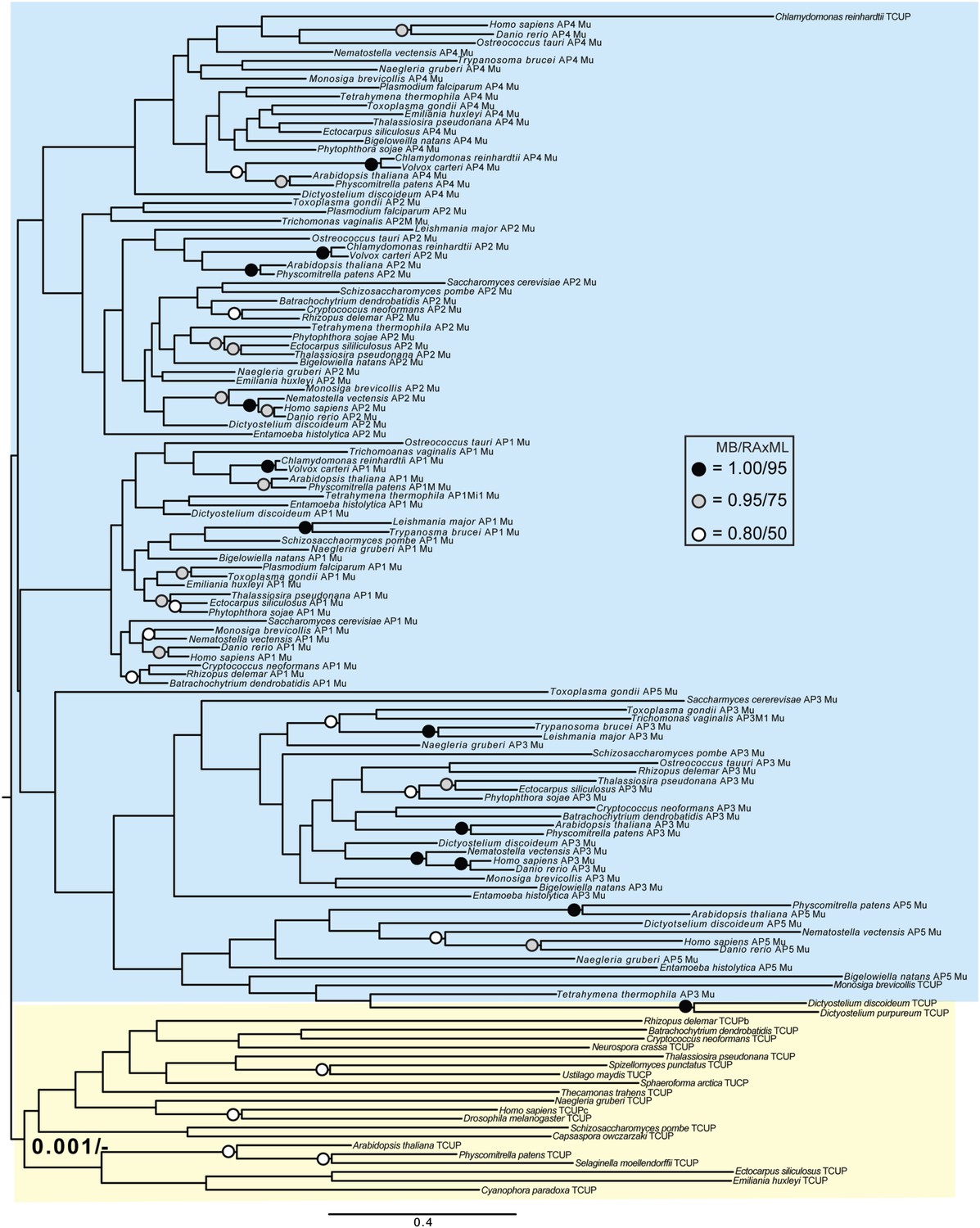
Phylogenetic analysis of TCUP and μ-adaptin subunits (δ-COP removed), showing weak support for the exclusion of TCUP from the adaptin clade.
https://doi.org/10.7554/eLife.02866.026
Figure 4—figure supplement 7
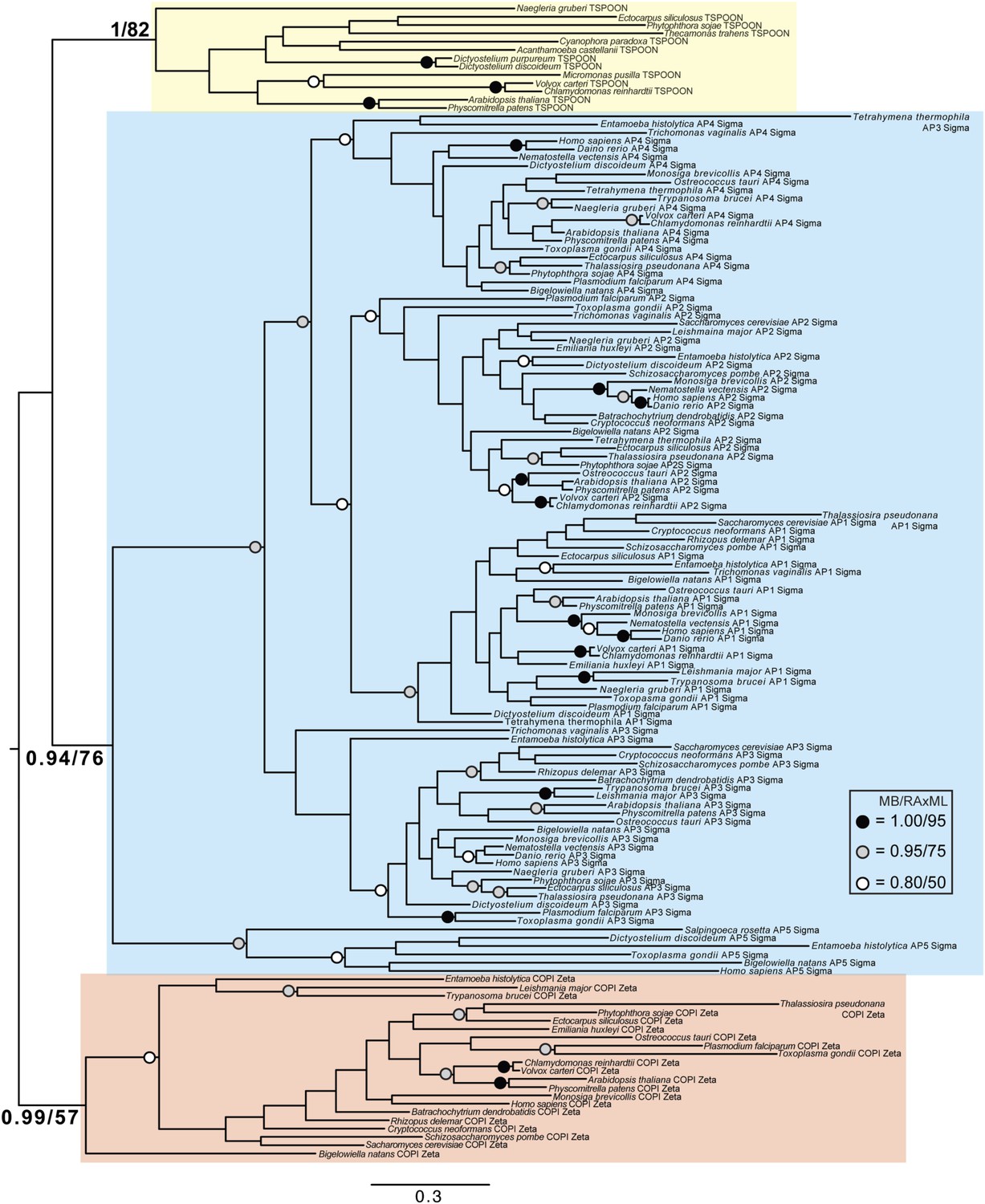
Phylogenetic analysis of TSPOON with ζ-COP and σ–adaptin subunits with moderate support for the exclusion of TSPOON from both the COPI and adaptin clades, in addition to moderate support for the monophyly of the TSPOON clade.
https://doi.org/10.7554/eLife.02866.027
Figure 4—figure supplement 8
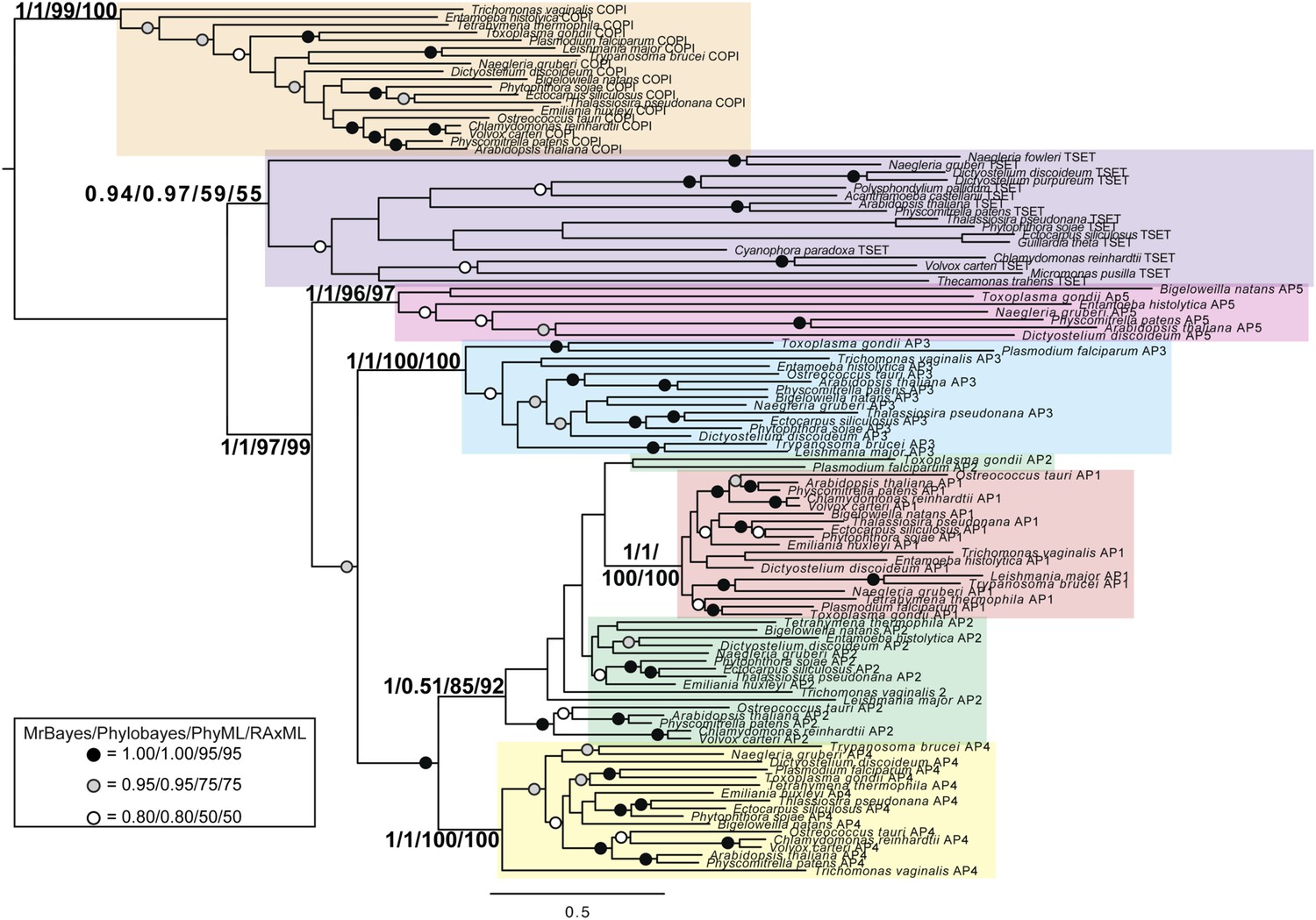
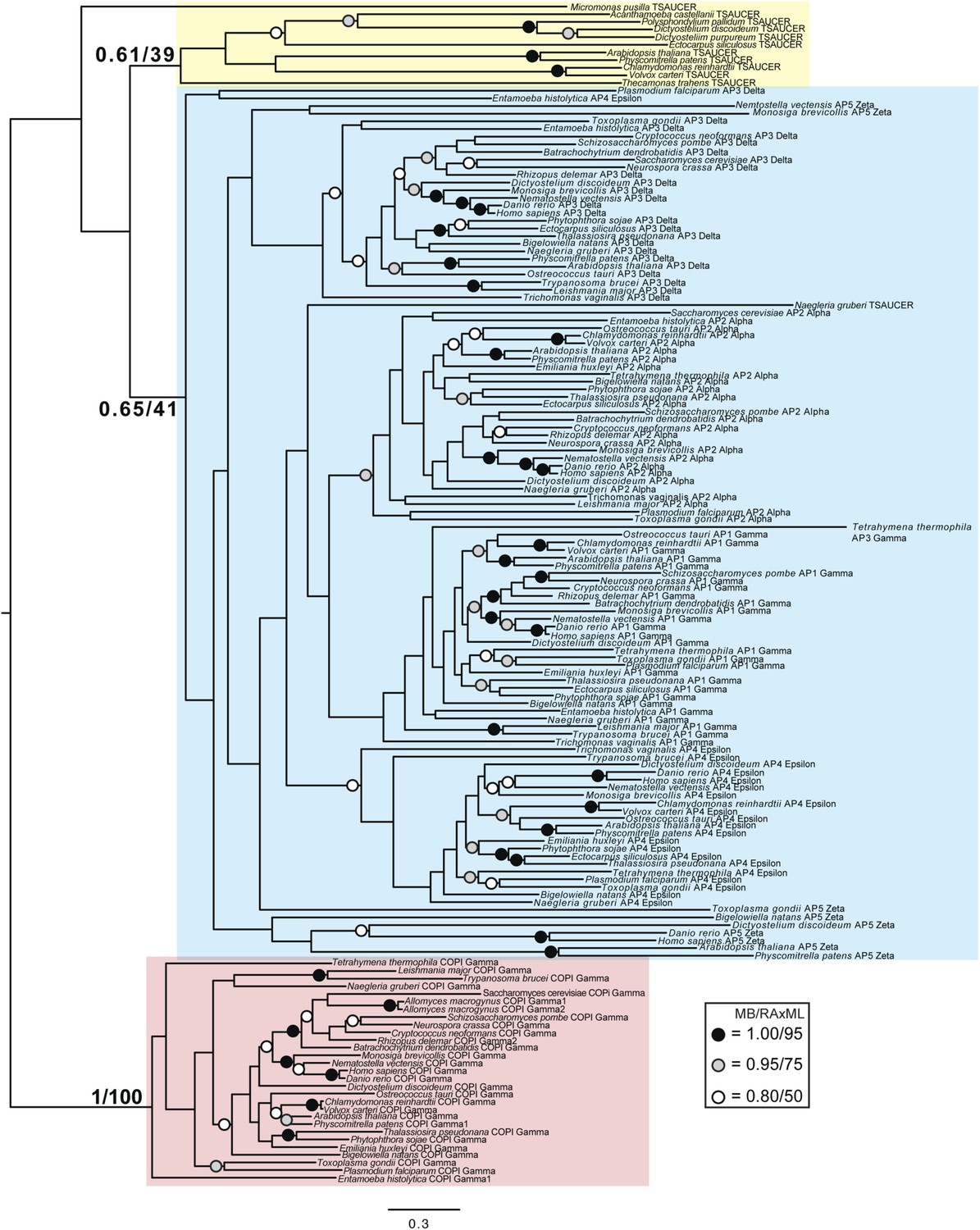
TSET is a phylogenetically distinct lineage from F-COPI and the AP complexes.
Phylogenetic analysis of the heterotetrameric complexes: F-COPI (orange), TSET (purple), and AP (magenta, blue, red, green, and yellow for 5, 3, 1, 2, and 4, respectively), shows strong, weak, and moderate support for clades of each complex, respectively. Node support for critical nodes is shown. Numbers indicate Bayesian posterior probabilities (MrBayes and PhyloBayes) and bootstrap support from Maximum-likelihood analysis (PhyML and RAXML). Support values for other nodes are denoted by symbols (see inset).
Figure 4—figure supplement 9
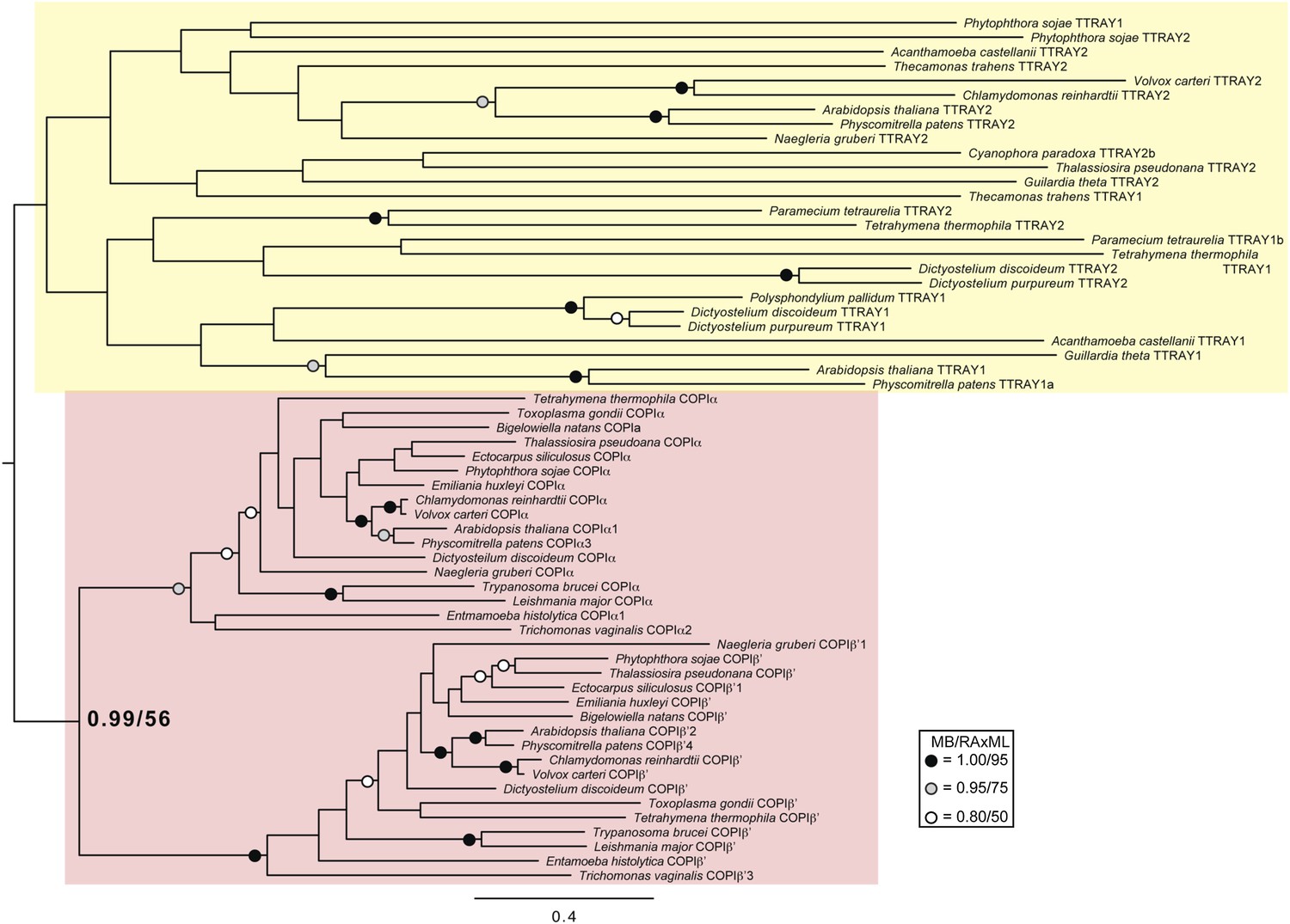
Phylogenetic analysis of TTRAY1, TTRAY2, α-COP, and β′-COP.
TTRAYs 1 and 2, and COPI α and β′, arose from separate gene duplications, indicating that the ancestral complex had only one such protein, although possibly present as two identical copies. Phylogenetic analysis of α- and β′-COPI (red), and TTRAYs 1 and 2 (yellow), shows a well supported COPI clade excluding all of the TTRAY1 and 2 sequences, suggesting that the duplications giving rise to these proteins occurred independently, and the utilization of two different outer coat members occurred through convergent evolution. Node support for critical nodes is shown. Numbers indicate Bayesian posterior probabilities (MrBayes) and bootstrap support from Maximum-likelihood analysis (RAxML). Support values for other nodes are denoted by symbols (see inset).
Figure 4—figure supplement 10
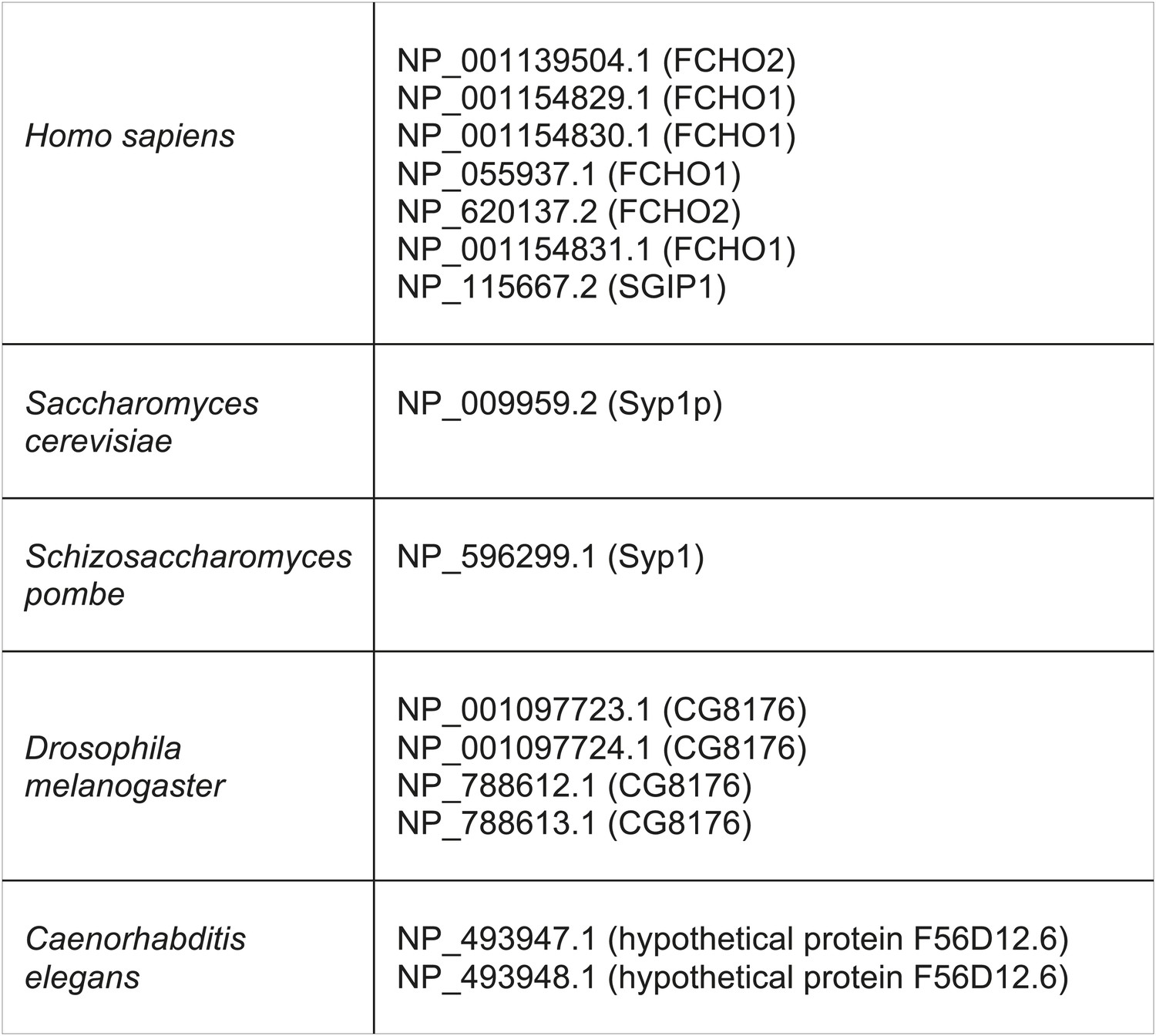
Muniscin family members identified by reverse HHpred, using the following PDB structures.
2V0O_A (Chain A, Fcho2 F-Bar Domain); 3 G9H_A (Chain A, Crystal Structure Of The C-Terminal Mu Homology Domain Of Syp1); 3G9G_A (Chain A, Crystal Structure Of The N-Terminal EfcF-Bar Domain Of Syp1).
Videos
Video 1
Related to Figure 2.
TIRF microscopy of D. discoideum expressing TSPOON-GFP, expressed off its own promoter in TSPOON knockout cells. One frame was collected every second. Dynamic puncta can be seen, indicating that the construct forms patches at the plasma membrane.
Video 2
Related to Figure 2.
TIRF microscopy of D. discoideum expressing free GFP, driven by the Actin15 promoter in TSPOON knockout cells. One frame was collected every second. The signal is diffuse and cytosolic.
Additional files
-
Supplementary file 1
Untrimmed, masked alignments used in phylogenetic analysis (Figure 4A, and Supplemental Figures. Masks indicated regions of sequences retained for phylogenetic analysis. Text files containing aligned sequences are in FASTA format. Alignment for the concatenated tree is composed of the trimmed TPLATE.R2, TSAUCER.R2, TCUP.R2, and TSPOON.R2 alignments.
- https://doi.org/10.7554/eLife.02866.031
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Characterization of TSET, an ancient and widespread membrane trafficking complex
eLife 3:e02866.
https://doi.org/10.7554/eLife.02866




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}