Predicting non-linear dynamics by stable local learning in a recurrent spiking neural network
- École Polytechnique Fédérale de Lausanne, Switzerland
Abstract
The brain needs to predict how the body reacts to motor commands, but how a network of spiking neurons can learn non-linear body dynamics using local, online and stable learning rules is unclear. Here, we present a supervised learning scheme for the feedforward and recurrent connections in a network of heterogeneous spiking neurons. The error in the output is fed back through fixed random connections with a negative gain, causing the network to follow the desired dynamics. The rule for Feedback-based Online Local Learning Of Weights (FOLLOW) is local in the sense that weight changes depend on the presynaptic activity and the error signal projected onto the postsynaptic neuron. We provide examples of learning linear, non-linear and chaotic dynamics, as well as the dynamics of a two-link arm. Under reasonable approximations, we show, using the Lyapunov method, that FOLLOW learning is uniformly stable, with the error going to zero asymptotically.
https://doi.org/10.7554/eLife.28295.001Introduction
Over the course of life, we learn many motor tasks such as holding a pen, chopping vegetables, riding a bike or playing tennis. To control and plan such movements, the brain must implicitly or explicitly learn forward models (Conant and Ross Ashby, 1970) that predict how our body responds to neural activity in brain areas known to be involved in motor control (Figure 1A). More precisely, the brain must acquire a representation of the dynamical system formed by our muscles, our body, and the outside world in a format that can be used to plan movements and initiate corrective actions if the desired motor output is not achieved (Pouget and Snyder, 2000; Wolpert and Ghahramani, 2000; Lalazar and Vaadia, 2008). Visual and/or proprioceptive feedback from spontaneous movements during pre-natal (Khazipov et al., 2004) and post-natal development (Petersson et al., 2003) or from voluntary movements during adulthood (Wong et al., 2012; Hilber and Caston, 2001) are important to learn how the body moves in response to neural motor commands (Lalazar and Vaadia, 2008; Wong et al., 2012; Sarlegna and Sainburg, 2009; Dadarlat et al., 2015), and how the world reacts to these movements (Davidson and Wolpert, 2005; Zago et al., 2005, 2009; Friston, 2008). We wondered whether a non-linear dynamical system, such as a forward predictive model of a simplified arm, can be learned and represented in a heterogeneous network of spiking neurons by adjusting the weights of recurrent connections.
Figure 1 with 1 supplement see all

Schematic for learning a forward model.
(A) During learning, random motor commands (motor babbling) cause movements of the arm, and are also sent to the forward predictive model, which must learn to predict the joint angles and velocities (state variables) of the arm. The deviation of the predicted state from the reference state, obtained by visual and proprioceptive feedback, is used to learn the forward predictive model with architecture shown in B. (B) Motor command is projected onto neurons with random weights . The spike trains of these command representation neurons are sent via plastic feedforward weights into the neurons of the recurrent network having plastic weights (plastic weights in red). Readout weights decode the filtered spiking activity of the recurrent network as the predicted state . The deviations of the predicted state from the reference state of the reference dynamical system in response to the motor command, is fed back into the recurrent network with error encoding weights . (C) A cartoon depiction of feedforward, recurrent and error currents entering a neuron in the recurrent network. (D) Spike trains of a few randomly selected neurons of the recurrent network from the non-linear oscillator example are plotted (alternate red and blue colours are for guidance of eye only). A component of the network output during a period of the oscillator is overlaid on the spike trains to indicate their relation to the output.
Supervised learning of recurrent weights to predict or generate non-linear dynamics, given command input, is known to be difficult in networks of rate units, and even more so in networks of spiking neurons (Abbott et al., 2016). Ideally, in order to be biologically plausible, a learning rule must be online that is constantly incorporating new data, as opposed to batch learning where weights are adjusted only after many examples have been seen; and local that is the quantities that modify the weight of a synapse must be available locally at the synapse as opposed to backpropagation through time (BPTT) (Rumelhart et al., 1986) or real-time recurrent learning (RTRL) (Williams and Zipser, 1989) which are non-local in time or in space, respectively (Pearlmutter, 1995; Jaeger, 2005). Even though Long-Short-Term-Memory (LSTM) units (Hochreiter and Schmidhuber, 1997) avoid the vanishing gradient problem (Bengio et al., 1994; Hochreiter et al., 2001) in recurrent networks, the corresponding learning rules are difficult to interpret biologically.
Our approach toward learning of recurrent spiking networks is situated at the crossroads of reservoir computing (Jaeger, 2001; Maass et al., 2002; Legenstein et al., 2003; Maass and Markram, 2004; Jaeger and Haas, 2004; Joshi and Maass, 2005; Legenstein and Maass, 2007), FORCE learning (Sussillo and Abbott, 2009, 2012; DePasquale et al., 2016; Thalmeier et al., 2016; Nicola and Clopath, 2016), function and dynamics approximation (Funahashi, 1989; Hornik et al., 1989; Girosi and Poggio, 1990; Sanner and Slotine, 1992; Funahashi and Nakamura, 1993; Pouget and Sejnowski, 1997; Chow and Xiao-Dong Li, 2000; Seung et al., 2000; Eliasmith and Anderson, 2004; Eliasmith, 2005) and adaptive control theory (Morse, 1980; Narendra et al., 1980; Slotine and Coetsee, 1986; Weiping Li et al., 1987; Narendra and Annaswamy, 1989; Sastry and Bodson, 1989; Ioannou and Sun, 2012). In contrast to the original reservoir scheme (Jaeger, 2001; Maass et al., 2002) where learning was restricted to the readout connections, we focus on a learning rule for the recurrent connections. Whereas neural network implementations of control theory (Sanner and Slotine, 1992; DeWolf et al., 2016) modified adaptive feedback weights without a synaptically local interpretation, we modify the recurrent weights in a synaptically local manner. Compared to FORCE learning where recurrent synaptic weights have to change rapidly during the initial phase of learning (Sussillo and Abbott, 2009, 2012), we aim for a learning rule that works in the biologically more plausible setting of slow synaptic changes. While previous work has shown that linear dynamical systems can be represented and learned with local online rules in recurrent spiking networks (MacNeil and Eliasmith, 2011; Bourdoukan and Denève, 2015), for non-linear dynamical systems the recurrent weights in spiking networks have typically been computed offline (Eliasmith, 2005).
Here, we propose a scheme for how a recurrently connected network of heterogeneous deterministic spiking neurons may learn to mimic a low-dimensional non-linear dynamical system, with a local and online learning rule. The proposed learning rule is supervised, and requires access to the error in observable outputs. The output errors are fed back with random, but fixed feedback weights. Given a set of fixed error-feedback weights, the learning rule is synaptically local and combines presynaptic activity with the local postsynaptic error variable.
Results
A forward predictive model (Figure 1A) takes, at each time step, a motor command as input and predicts the next observable state of the system. In the numerical implementation, we consider ms, but for the sake of notational simplicity we drop the in the following. The predicted system state (e.g., the vector of joint angles and velocities of the arm) is assumed to be low-dimensional with dimensionality (4-dimensional for a two-link arm). The motor command is used to generate target movements such as ‘lift your arm to a location’, with a dimensionality of the command typically smaller than the dimensionality of the system state.
The actual state of the reference system (e.g., actual joint angles and velocities of the arm) is described by a non-linear dynamical system, which receives the control input and evolves according to a set of coupled differential equations
(1)
where with components (where ) is the vector of observable state variables, and is a vector whose components are arbitrary non-linear functions . For example, the observable system state could be the joint angles and velocities of the arm deduced from visual and proprioceptive input (Figure 1A). We show that, with training, the forward predictive model learns to make the error
(2)
between the actual state and the predicted state negligible.
Network architecture for learning the forward predictive model
In our neural network model (Figure 1B), the motor command drives the spiking activity of a command representation layer of 3000 to 5000 leaky integrate-and-fire neurons via connections with fixed random weights. These neurons project, via plastic feedforward connections, to a recurrent network of also 3000 to 5000 integrate-and-fire neurons. We assume that the predicted state is linearly decoded from the activity of the recurrent network. Denoting the spike train of neuron by , the component of the predicted system state is
(3)
where are the readout weights. The integral represents a convolution with a low-pass filter
(4)
with a time constant ms, and is denoted by .
The current into a neuron with index (), in the command representation layer comprising neurons, is
(5)
Where are fixed random weights, while is a neuron-specific constant for bias (see Materials and methods) (Eliasmith and Anderson, 2004). We use Greek letters for the indices of low-dimensional variables (such as command) and Latin letters for neuronal indices, with summations going over the full range of the indices. The number of neurons in the command representation layer is much larger than the dimensionality of the input, that is .
The input current to a neuron with index () in the recurrent network is
(6)
where and are the feedforward and recurrent weights, respectively, which are both subject to our synaptic learning rule, whereas are fixed error feedback weights (see below). The spike trains travelling along the feedforward path and those within the recurrent network are both low-pass filtered (convolution denoted by ) at the synapses with the exponential filter defined above. The constant parameter is a neuron specific bias (see Materials and methods). The constant is the gain for feeding back the output error. The number of neurons in the recurrent network is much larger than the dimensionality of the represented variable , that is .
For all numerical simulations, we used deterministic leaky integrate and fire (LIF) neurons. The voltage of each LIF neuron indexed by , was a low-pass filter of its driving current :
(7)
with a membrane time constant, of ms. The neuron fired when the voltage crossed a threshold from below, after which the voltage was reset to zero for a refractory period of 2 ms. If the voltage went below zero, it was clipped to zero. Mathematically, the spike trains in the command representation layer and in the recurrent network, are a sequence of events, modelled as a sum of Dirac delta-functions.
Biases and input weights of the spiking neurons vary between one neuron and the next, both in the command representation layer and the recurrent network, yielding different frequency versus input curves for different neurons (Figure 1—figure supplement 1). Since arbitrary low-dimensional functions can be approximated by linear decoding from a basis of non-linear functions (Funahashi, 1989; Girosi and Poggio, 1990; Hornik et al., 1989), such as neuronal tuning curves (Sanner and Slotine, 1992; Seung et al., 2000; Eliasmith and Anderson, 2004), we may expect that suitable feedforward weights onto, and lateral weights within, the recurrent network can be found that approximate the role of the function in Equation (1). In the next subsection, we propose an error feedback architecture along with a local and online synaptic plasticity rule that can train these feedforward and recurrent weights to approximate this role, while the readout weights are kept fixed, so that the network output mimics the dynamics in Equation (1).
Negative error feedback via auto-encoder enables local learning
To enable weight tuning, we make four assumptions regarding the network architecture. The initial two assumptions are related to input and output. First, we assume that, during the learning phase, a random time-dependent motor command input is given to both the muscle-body reference system described by Equation (1) and to the spiking network. The random input generates irregular trajectories in the observable state variables, mimicking motor babbling (Meltzoff and Moore, 1997; Petersson et al., 2003). Second, we assume that each component of the output predicted by the spiking network is compared to the actual observable output produced by the reference system of Equation (1) and their difference (the output error ; Equation (2)) is calculated, similar to supervised learning schemes such as perceptron learning (Rosenblatt, 1961).
The final two assumptions are related to the error feedback. Our third assumption is that the readout weights have been pre-learned, possibly earlier in development, in the absence of feedforward and recurrent connections, so as to form an auto-encoder of gain with the fixed random feedback weights . Specifically, an arbitrary value sent via the error feedback weights to the recurrent network and read out, from its neurons, via the decoding weights gives back (approximately) . Thus, we set the decoding weights so as to minimize the squared error between the decoded output and required output for a set of randomly chosen vectors while setting feedforward and recurrent weights to zero (see Materials and methods). We used an algorithmic learning scheme here, but we expect that these decoding weights can also be pre-learned by biologically plausible learning schemes (D'Souza et al., 2010; Urbanczik and Senn, 2014; Burbank, 2015).
Fourth, we assumed that the error is projected back to neurons in the recurrent network through the above-mentioned fixed random feedback weights. From the third term in Equation (6) and Figure 1B–C, we define a total error input that neuron receives:
(8)
with feedback weights , where is fixed at a large constant positive value.
The combination of the auto-encoder and the error feedback implies that the output stays close to the reference, as explained now. In open loop that is without connecting the output and the reference to the error node, an input to the network generates an output due to the auto-encoder of gain . In closed loop, that is with the output and reference connected to the error node (Figure 1B), the error input is , and the network output settles to:
(9)
that is approximately the reference for large positive . The fed-back residual error drives the neural activities and thence the network output. Thus, feedback of the error causes the output to approximately follow , for each component , as long as the error feedback time scale is fast compared to the reference dynamical system time scale, analogous to negative error feedback in adaptive control (Narendra and Annaswamy, 1989; Ioannou and Sun, 2012).
While error feedback is on, the synaptic weights and on the feedforward and recurrent connections, respectively, are updated as:
(10)
where is the learning rate (which is either fixed or changes on the slow time scale of minutes), and is an exponentially decaying filter kernel with a time constant of 80 or 200 ms. For a postsynaptic neuron , the error term is the same for all its synapses, while the presynaptic contribution is synapse-specific.
We call the learning scheme ‘Feedback-based Online Local Learning Of Weights’ (FOLLOW), since the predicted state follows the true state from the start of learning. Under precise mathematical conditions, we show in Materials and methods that the FOLLOW scheme converges to a stable solution, while simultaneously deriving the learning rule (Materials and methods).
Because of the error feedback, with constant , the output is close to the reference from the start of learning. However, initially the error is not exactly zero, and this non-zero error drives the weight updates via Equation (10). After a sufficiently long learning time, a vanishing error ( for all components) indicates that the neuronal network now autonomously generates the desired output, so that feedback is no longer required. In the Methods section, we show that not just the low-dimensional output , but also the spike trains , for , are entrained by the error feedback to be close to the ideal ones required to generate .
During learning, the error feedback via the auto-encoder in a loop serves two roles: (i) to make the error current available in each neuron, projected correctly, for a local synaptic plasticity rule, and (ii) to drive the spike trains to the target ones for producing the reference output. In other learning schemes for recurrent neural networks, where neural activities are not constrained by error feedback, it is difficult to assign credit or blame for the momentarily observed error, because neural activities from the past affect the present output in a recurrent network. In the FOLLOW scheme, the spike trains are constrained to closely follow the ideal time course throughout learning, so that the present error can be attributed directly to the weights, enabling us to change the weights with a simple perceptron-like learning rule (Rosenblatt, 1961) as in Equation (10), bypassing the credit assignment problem. In the perceptron rule, the weight change is proportional to the presynaptic input and the error . In the FOLLOW learning rule of Equation (10), we can identify with and with . In Methods, we derive the learning rule of Equation (10) in a principled way from a stability criterion.
FORCE learning (Sussillo and Abbott, 2009, 2012; DePasquale et al., 2016; Thalmeier et al., 2016; Nicola and Clopath, 2016) also clamps the output and neural activities to be close to ideal during learning, by using weight changes that are faster than the time scale of the dynamics. In our FOLLOW scheme, clamping is achieved via negative error feedback using the auto-encoder, which allows weight changes to be slow and makes the error current available locally in the post-synaptic neuron. Other methods used feedback based on adaptive control for learning in recurrent networks of spiking neurons, but were limited to linear systems (MacNeil and Eliasmith, 2011; Bourdoukan and Denève, 2015), whereas the FOLLOW scheme was derived for non-linear systems (see Methods). Our learning rule of Equation (10) uses an error in the observable state, rather than an error involving the derivative in Equation (1), as in other schemes (see Appendix 1) (Eliasmith, 2005; MacNeil and Eliasmith, 2011). The reader is referred to Discussion for detailed further comparisons. The FOLLOW learning rule is local since all quantities needed on the right-hand-side of Equation (10) could be available at the location of the synapse in the postsynaptic neuron. For a potential implementation and prediction for error-based synaptic plasticity, and for a critical evaluation of the notion of ‘local rule’, we refer to the Discussion.
Spiking networks learn target dynamics via FOLLOW learning
In order to check whether the FOLLOW scheme would enable the network to learn various dynamical systems, we studied three systems describing a non-linear oscillator (Figure 2), low-dimensional chaos (Figure 3) and simulated arm movements (Figure 4) (additional examples in Figure 2—figure supplement 2, Figure 2—figure supplement 4 and Materials and methods). In all simulations, we started with vanishingly small feedforward and recurrent weights (tabula rasa), but assumed pre-learned readout weights matched to the error feedback weights. For each of the three dynamical systems, we had a learning phase and a testing phase. During each phase, we provided time-varying input to both the network (Figure 1B) and the reference system. During the learning phase, rapidly changing control signals mimicked spontaneous movements (motor babbling) while synaptic weights were updated according to the FOLLOW learning rule Equation (10).
Figure 2 with 5 supplements see all
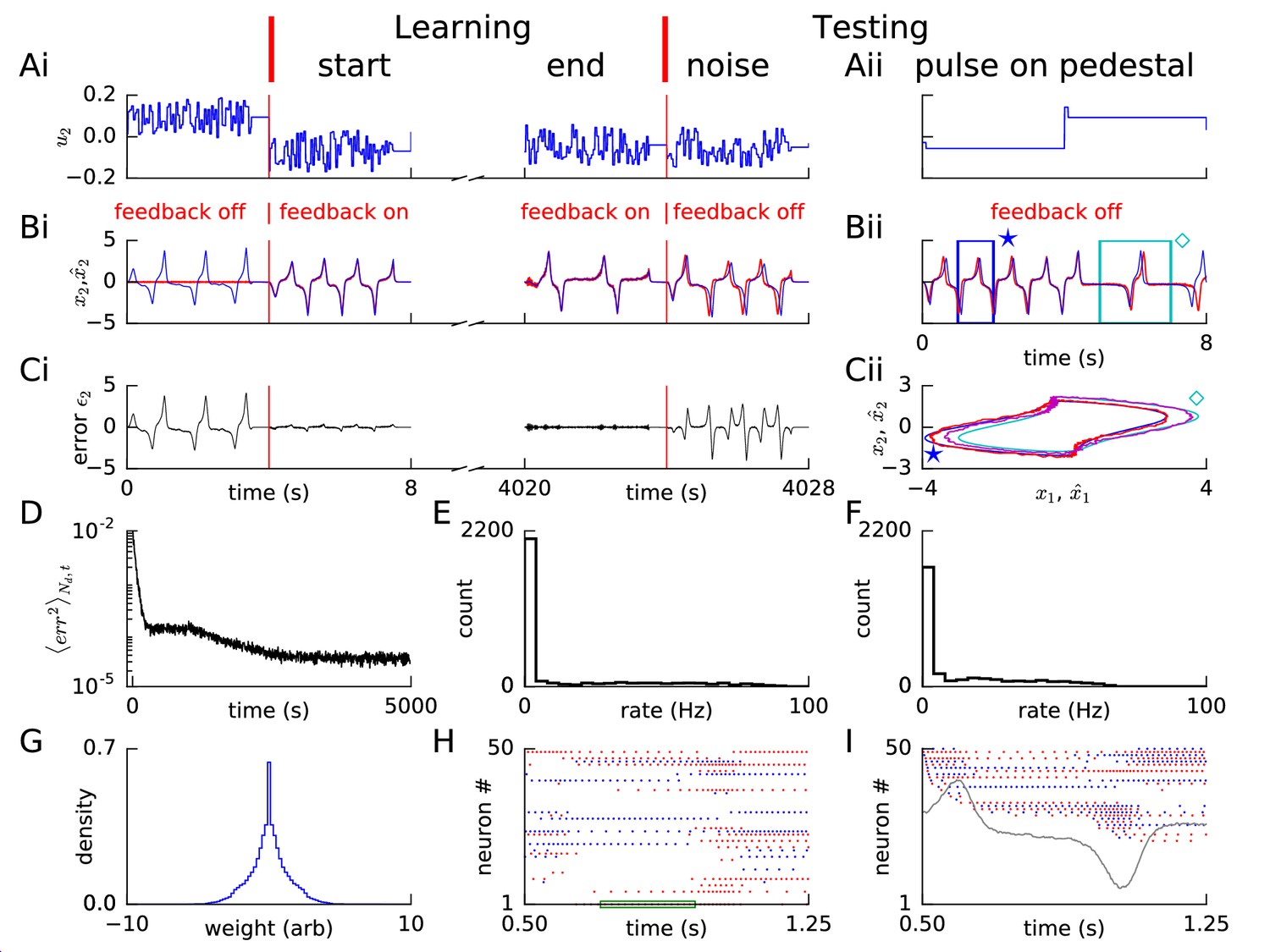
Learning non-linear dynamics via FOLLOW: the van der Pol oscillator.
(A-C) Control input, output, and error are plotted versus time, before the start of learning; in the first 4 s and last 4 s of learning; and during testing without error feedback (demarcated by the vertical red lines). Weight updating and error current feedback were both turned on after the vertical red line on the left at the start of learning, and turned off after the vertical red line in the middle at the end of learning. (A) Second component of the input . (B) Second component of the learned dynamical variable (red) decoded from the network, and the reference (blue). After the feedback was turned on, the output tracked the reference. The output continued to track the reference approximately, even after the end of the learning phase, when feedback and learning were turned off. The output tracked the reference approximately, even with a very different input (Bii). With higher firing rates, the tracking without feedback improved (Figure 2—figure supplement 1). (C) Second component of the error between the reference and the output. (Cii) Trajectory in the phase plane for reference (red,magenta) and prediction (blue,cyan) during two different intervals as indicated by and in Bii. (D) Mean squared error per dimension averaged over 4 s blocks, on a log scale, during learning with feedback on. Learning rate was increased by a factor of 20 after 1,000 s to speed up learning (as seen by the sharp drop in error at 1000 s). (E) Histogram of firing rates of neurons in the recurrent network averaged over 0.25 s (interval marked in green in H) when output was fairly constant (mean across neurons was 12.4 Hz). (F) As in E, but averaged over 16 s (mean across neurons was 12.9 Hz). (G) Histogram of weights after learning. A few strong weights are out of bounds and not shown here. (H) Spike trains of 50 randomly-chosen neurons in the recurrent network (alternating colors for guidance of eye only). (I) Spike trains of H, reverse-sorted by first spike time after 0.5 s, with output component overlaid for timing comparison.
Figure 3 with 1 supplement see all
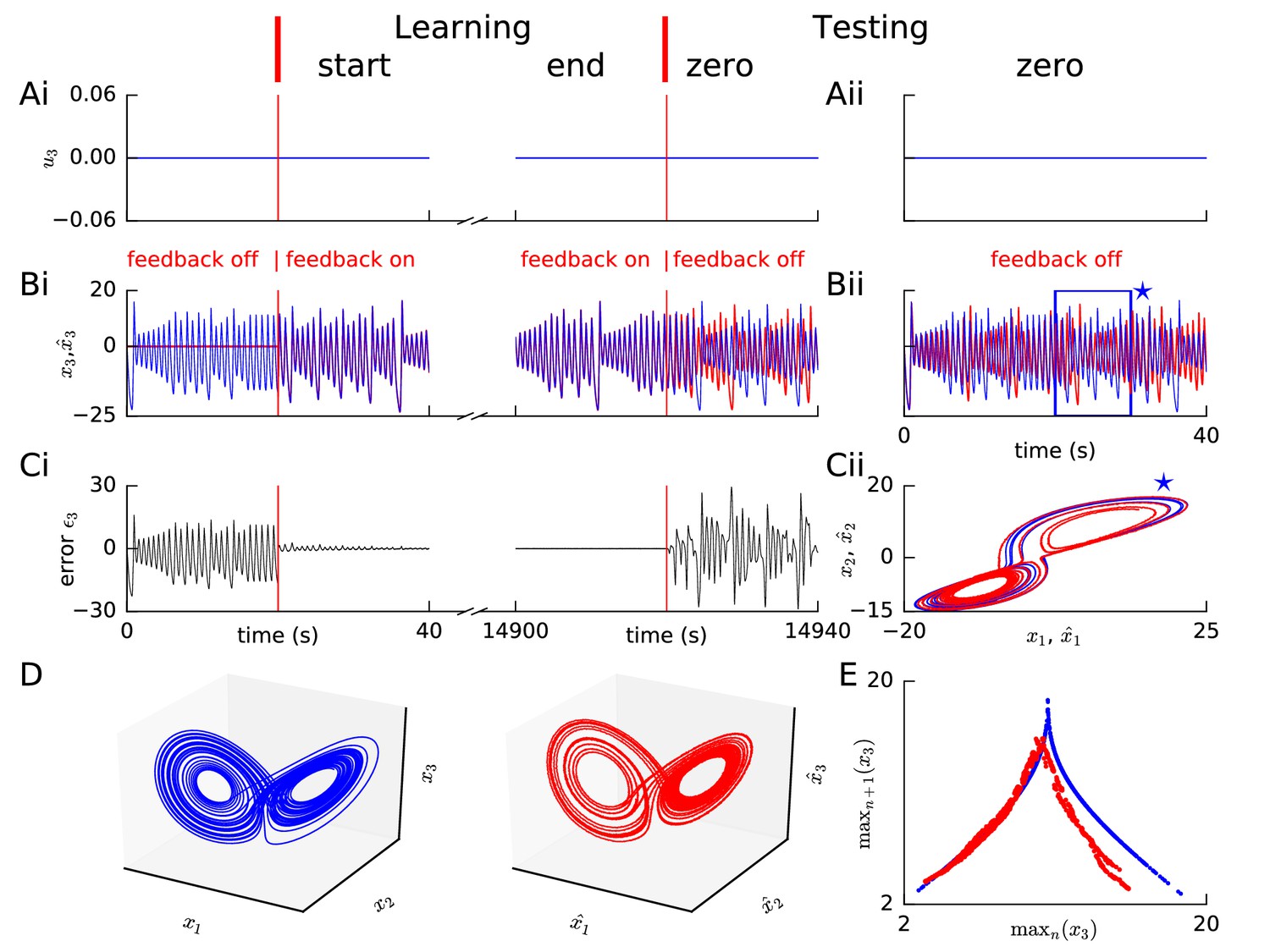
Learning chaotic dynamics via FOLLOW: the Lorenz system.
Layout and legend of panels (A-C) are analogous to Figure 2A–C. (D) The trajectories of the reference (left panel) and the learned network (right panel) are shown in state space for 40 s with zero input during the testing phase, forming the well-known Lorenz attractor. (E) Tent map, that is local maximum of the third component of the reference signal (blue)/network output (red) is plotted versus the previous local maximum, for 800 s of testing with zero input. The reference is plotted with filtering in panels (A-C), but unfiltered for the strange attractor (panel D left) and the tent map (panel E blue).
Figure 4

Learning arm dynamics via FOLLOW.
Layout and legend of panels A-C are analogous to Figure 2A–C except that: in panel (A), the control input (torque) on the elbow joint is plotted; in panel (B), reference and decoded angle (solid) and angular velocity (dotted) are plotted, for the elbow joint; in panel (C), the error in the elbow angle is plotted. (Aii-Cii) The control input was chosen to perform a swinging acrobot-like task by applying small torque only on the elbow joint. (Cii) The shoulder angle is plotted versus the elbow angle for the reference (blue) and the network (red) for the full duration in Aii-Bii. The green arrow shows the starting direction. (D) Reaching task. Snapshots of the configuration of the arm, reference in blue (top panels) and network in red (bottom panels) subject to torques in the directions shown by the circular arrows. After 0.6 s, the tip of the forearm reaches the cyan target. Gravity acts downwards in the direction of the arrow. (E) Acrobot-inspired swinging task (visualization of panels of Aii-Cii). Analogous to D, except that the torque is applied only at the elbow. To reach the target, the arm swings forward, back, and forward again.
During learning, the mean squared error, where the mean was taken over the number of dynamical dimensions and over a duration of a few seconds, decreased (Figure 2D). We stopped the learning phase that is weight updating, when the mean squared error approximately plateaued as a function of learning time (Figure 2D). At the end of the learning phase, we switched the error feedback off (‘open loop’) and provided different test inputs to both the reference system and the recurrent spiking network. A successful forward predictive model should be able to predict the state variables in the open-loop model over a finite time horizon (corresponding to the planning horizon of a short action sequence) and in the closed-loop mode (with error feedback) without time limit.
Non-linear oscillator
Our FOLLOW learning scheme enabled a network with 3000 neurons in the recurrent network and 3000 neurons in the motor command representation layer to approximate the non-linear 2-dimensional van der Pol oscillator (Figure 2). We used a superposition of random steps as input, with amplitudes drawn uniformly from an interval, changing on two time scales, 50 ms and 4 s (see Materials and methods).
During the four seconds before learning started, we blocked error feedback. Because of zero error feedback and our initialization with zero feedforward and recurrent weights, the output decoded from the network of spiking neurons remained constant at zero while the reference system performed the desired oscillations. Once the error feedback with large gain () was turned on, the feedback forced the network to roughly follow the reference. Thus, with feedback, the error dropped to a very low value, immediately after the start of learning (Figure 2B,C). During learning, the error dropped even further over time (Figure 2D). After having stopped learning at 5000 s (2 hr), we found the weight distribution to be uni-modal with a few very large weights (Figure 2G). In the open-loop testing phase without error feedback, a sharp square pulse as initial input on different 4 s long pedestal values caused the network to track the reference as shown in Figure 2Aii–Cii panels. For some values of the constant pedestal input, the phase of the output of the recurrent network differed from that of the reference (Figure 2Bii), but the shape of the non-linear oscillation was well predicted as indicated by the similarity of the trajectories in state space (Figure 2Cii).
The spiking pattern of neurons of the recurrent network changed as a function of time, with inter-spike intervals of individual neurons correlated with the output, and varying over time (Figure 2H,I). The distributions of firing rates averaged over a 0.25 s period with fairly constant output, and over a 16 s period with time-varying output, were long-tailed, with the mean across neurons maintained at approximately 12–13 Hz (Figure 2E,F). The distribution averaged over 16 s had a smaller number of neurons firing at very low and very high rates compared to the distribution over 0.25 s, consistent with the expectation that the identity of low-rate and high-rate neurons changed over time for time-varying output (Figure 2E,F). We repeated this example experiment (‘van der Pol oscillator’) with a network of equal size but with neurons that had higher firing rates, so that some neurons could reach a maximal rate of 400 Hz (Figure 1—figure supplement 1). The reference was approximated better and learning time was shorter with higher rates (Figure 2—figure supplement 1 – 10,000 s with constant learning rate) compared to the low rates here (Figure 2 – 5,000 s with 20 times the learning rate after 1,000 s). Hence, for all further simulations, we set neuronal parameters to enable peak firing rates up to 400 Hz (Figure 1—figure supplement 1B).
Figure 5
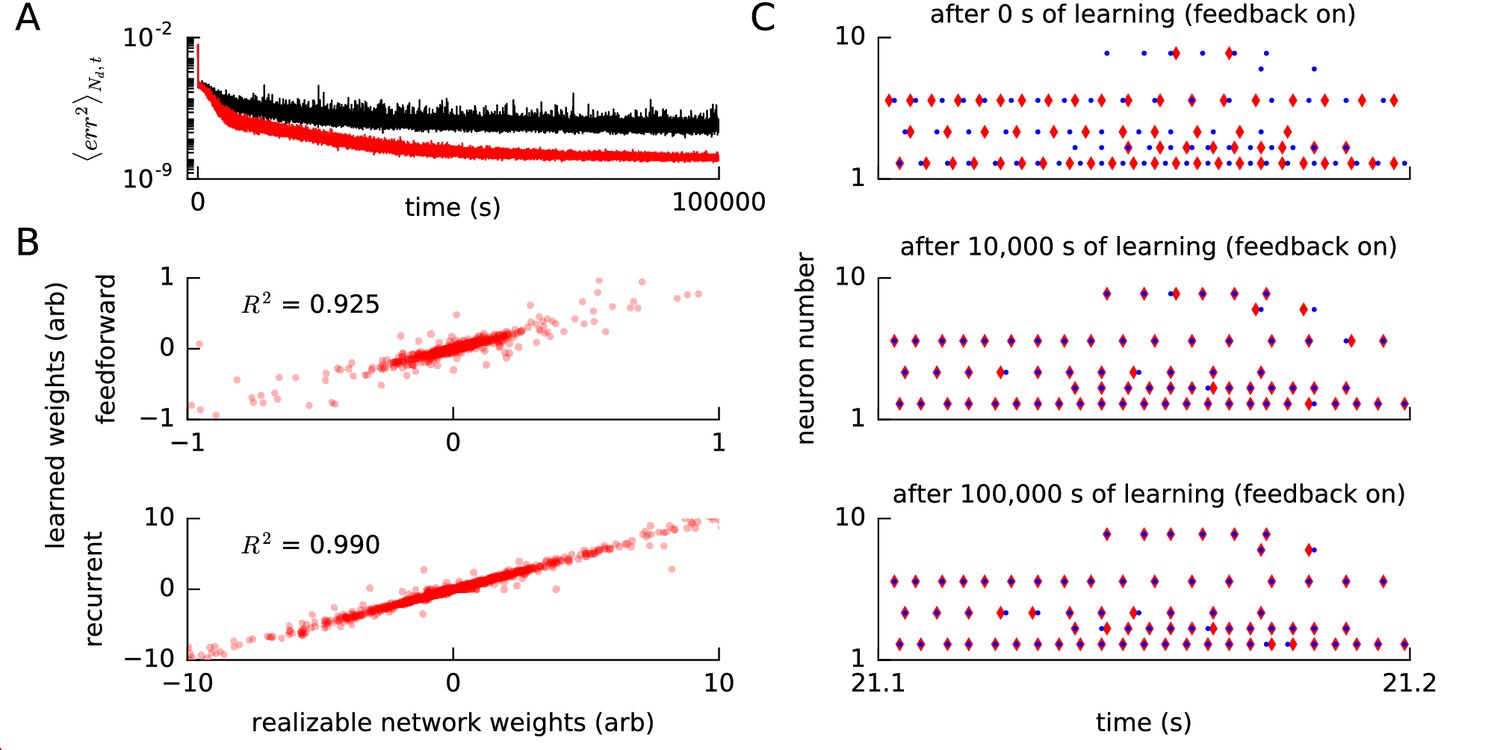
Convergence of error, weights and spike times for a realizable reference network.
(A) We ran our FOLLOW scheme on a network for learning one of two different implementations of the reference van der Pol oscillator: (1) differential equations, versus (2) a network realized using FOLLOW learning for 10,000 s (3 hr). We plot the evolution of the mean squared error, mean over number of dimensions and over 4 s time blocks, from the start to 100,000 s of learning, with the weights starting from zero. Mean squared error for the differential equations reference (1) is shown in black, while that for the realizable network reference (2) is in red. (B) The feedforward weights (top panel) and the recurrent weights (bottom panel) at the end of 100,000 s (28 hr) of learning, are plotted versus the corresponding weights of the realizable target network. The coefficient of determination i.e the value of the fit to the identity line () is also displayed for each panel. A value of denotes perfect equality of weights to those of the realizable network. Some weights fall outside the plot limits. (C) After 0 s, 10,000 s (3 hr), and 100,000 s (28 hr) of the learning protocol against the realizable network as reference, we show spike trains of a few neurons in the recurrent network (red) and the reference network (blue) in the top, middle and bottom panels respectively, from test simulations while providing the same control input and keeping error feedback on. With error feedback off, the low-dimensional output diverged slightly from the reference, hence the spike trains did too (not shown).
We also asked whether merely the distribution of the learned weights in the recurrent layer was sufficient to perform the task, or whether the specific learned weight matrix was required. This question was inspired from reservoir computing (Jaeger, 2001; Maass et al., 2002; Legenstein et al., 2003; Maass and Markram, 2004; Jaeger and Haas, 2004; Joshi and Maass, 2005; Legenstein and Maass, 2007), where the recurrent weights are random, and only the readout weights are learned. To answer this question, we implemented a perceptron learning rule on the readout weights initialized at zero, with the learned network’s output as the target, after setting the feedforward and/or recurrent weights to either the learned weights as is or after shuffling them. The readout weights could be approximately learned only for the network having the learned weights and not the shuffled ones (Figure 2—figure supplement 3), supporting the view that the network does not behave like a reservoir (Materials and methods).
Chaotic lorenz system
Our FOLLOW scheme also enabled a network with 5000 neurons each in the command representation layer and recurrent network, to learn the 3-dimensional non-linear chaotic Lorenz system (Figure 3). We considered a paradigm where the command input remained zero so that the network had to learn the autonomous dynamics characterized in chaos theory as a ’strange attractor’ (Lorenz, 1963). During the testing phase without error feedback minor differences led to different trajectories of the network and the reference which show up as large fluctuations of (Figure 3A–C). Such a behaviour is to be expected for a chaotic system where small changes in initial condition can lead to large changes in the trajectory. Importantly, however, the activity of the spiking network exhibits qualitatively the same underlying strange attractor dynamics, as seen from the butterfly shape (Lorenz, 1963) of the attractor in configuration space, and the tent map (Lorenz, 1963) of successive maxima versus the previous maxima (Figure 3D,E). The tent map generated from our network dynamics (Figure 3E) has lower values for the larger maxima compared to the reference tent map. However, very large outliers like those seen in a network trained by FORCE (Thalmeier et al., 2016) are absent. Since we expected that the observed differences are due to the filtering of the reference by an exponentially-decaying filter, we repeated learning without filtering the Lorenz reference signal (Figure 3—figure supplement 1), and found that the mismatch for large maxima reduced, but a doubling appeared in the tent map (Figure 3—figure supplement 1E) which had been almost imperceptible with filtering (cf. Figure 3E).
FOLLOW enables learning a two-link planar arm model under gravity
To turn to a task closer to real life, we next wondered if a spiking network can also learn the dynamics of a two-link arm via the FOLLOW scheme. We used a two-link arm model adapted from (Li, 2006) as our reference. The two links in the model correspond to the upper and fore arm, with the elbow joint in between and the shoulder joint at the top. The arm moved in the vertical plane under gravity, while torques were applied directly at the two joints, so as to coarsely mimic the action of muscles. To avoid full rotations, the two joints were constrained to vary in the range from to where the resting state is at (see Materials and methods).
The dynamical system representing the arm is four-dimensional with the state variables being the two joint angles and two angular velocities. The network must integrate the torques to obtain the angular velocities which in turn must be integrated for the angles. Learning these dynamics is difficult due to these sequential integrations involving non-linear functions of the state variables and the input. Still, our feedforward and recurrent network architecture (Figure 1B) with 5000 neurons in each layer was able to approximate these dynamics.
Similar to the previous examples, random input torque with amplitudes of short and long pulses changing each 50 ms and 1 s, respectively, was provided to each joint during the learning phase. The input was linearly interpolated between consecutive values drawn every 50 ms. In the closed loop scenario with error feedback, the trajectory converged rapidly to the target trajectory (Figure 4). We found that the FOLLOW scheme learned to reproduce the arm dynamics even without error feedback for a few seconds during the test phase (Figure 4 and Video 1 and Video 2), which corresponds to the time horizon needed for the planning of short arm movements.
Video 1
Reaching by the reference arm is predicted by the network.
After training the network as a forward model of the two-link arm under gravity as in Figure 4, we tested the network without feedback on a reaching task. Command input was provided to both joints of the two-link reference arm so that the tip reached the cyan square. The same command input was also provided to the network without error feedback. The state (blue, left) of the reference arm and the state predicted (red, right) by the learned network without error feedback are animated as a function of time. The directions of the circular arrows indicate the directions of the command torques at the joints. The animation is slowed compared to real life.
Video 2
Acrobot-like swinging by the reference arm is predicted by the network.
After training the network as a forward model of the two-link arm under gravity as in Figure 4, we tested the network without feedback on a swinging task analogous to an acrobot. Command input was provided to the elbow joint of the two-link reference arm so that the tip reached the cyan square by swinging. The same command input was also provided to the network without error feedback. The state (blue, left) of the reference arm and the state predicted (red, right) by the learned network without error feedback are animated as a function of time. The directions of the circular arrows indicate the directions of the command torques at the joints. The animation is slowed compared to real life.
To assess the generalization capacity of the network, we fixed the parameters post learning, and tested the network in the open-loop setting on a reaching task and an acrobot-inspired swinging task (Sutton, 1996). In the reaching task, torque was provided to both joints to enable the arm-tip to reach beyond a specific position from rest. The arm dynamics of the reference model and the network are illustrated in Figure 4D and animated in Video 1. We also tested the learned network model of the 2-link arm on an acrobot-like task that is a gymnast swinging on a high-bar (Sutton, 1996), with the shoulder joint analogous to the hands on the bar, and the elbow joint to the hips. The gymnast can only apply small torques at the hip and none at the hands, and must reach beyond a specified position by swinging. Thus, during the test, we provided input only at the elbow joint, with a time course that could make the reference reach beyond the target position from rest by swinging. The control input and the dynamics (Figure 4A–C right panels, Figure 4E and Video 2) show that the network can perform the task in open-loop condition suggesting that it has learned the inertial properties of the arm model, necessary for this simplified acrobot task.
Feedback in the FOLLOW scheme entrains spike timings
In Methods, we show that the FOLLOW learning scheme is Lyapunov stable and that the error tends to zero under certain reasonable assumptions and approximations. Two important assumptions of the proof are that the weights remain bounded and that the desired dynamics are realizable by the network architecture, that is there exist feedforward and recurrent weights that enable the network to mimic the reference dynamics perfectly. However, in practice the realizability is limited by at least two constraints. First, even in networks of rate neurons with non-linear tuning curves, the non-linear function of the reference system in Equation (1) can in general only be approximated with a finite error (Funahashi, 1989; Girosi and Poggio, 1990; Hornik et al., 1989; Sanner and Slotine, 1992; Eliasmith and Anderson, 2004) which can be interpreted as a form of frozen noise, i.e. even with the best possible setting of the weights, the network predicts, for most values of the state variables, a next state which is slightly different than the one generated by the reference differential equation. Second, since we work with spiking neurons, we expect on top of this frozen noise the effect of shot noise caused by pseudo-random spiking. Both noise sources may potentially cause drift of the weights (Narendra and Annaswamy, 1989; Ioannou and Sun, 2012) which in turn can make the weights grow beyond any reasonable bound. Ameliorative techniques from adaptive control are discussed in Appendix 1. In our simulations, we did not find any effect of drift of weights on the error during a learning time up to 100,000 s (Figure 5A), 10 times longer than that required for learning this example (Figure 2—figure supplement 1).
To highlight the difference between a realizable reference system and non-linear differential equations as a reference system, we used, in an additional simulation experiment, a spiking network with fixed weights as the reference. More precisely, instead of using directly the differential equations of the van der Pol oscillator as a reference, we now used as a reference a spiking approximation of the van der Pol oscillator, i.e. the spiking network that was the final result after 10,000 s (3 hr) of FOLLOW learning in Figure 2—figure supplement 1. For both the spiking reference network and the to-be-trained learning network we used the same architecture, the same number of neurons, and the same neuronal parameters as in Figure 2—figure supplement 1 for the learning of the van der Pol oscillator. The readout and feedback weights of the learning network also had the same parameters as those of the spiking reference network, but the feedforward and recurrent weights of the learning network were initialized to zero and updated, during the learning phase, with the FOLLOW rule. We ran FOLLOW learning against the reference network for 100,000 s (28 hr) (Figure 5). With the realizable network as reference, learning was more rapid than with the original van der Pol oscillator as reference (Figure 5A).
We emphasize that, analogous to the earlier simulations, the feedback error was low-dimensional and calculated from the decoded outputs. Nevertheless, the low-dimensional error feedback was able to entrain the network spike times to the reference spike times (Figure 5C). In particular, a few neurons learned to fire only two or three spikes at very precise moments in time. For example, after learning, the spikes of neuron in the learning network were tightly aligned with the spike times of the neuron with the same index in the spiking reference network. Similarly, neuron that was inactive at the beginning of learning was found to be active, and aligned with the spikes of the reference network, after 100,000 s (28 hr) of learning. The spike trains were entrained by the low-dimensional feedback. With the feedback off, even the low-dimensional output, and hence the spike trains, diverged from the reference. It will be interesting to explore if this entrainment by low-dimensional feedback via an auto-encoder loop can be useful in supervised spike train learning (Gütig and Sompolinsky, 2006; Pfister et al., 2006; Florian, 2012; Mohemmed et al., 2012; Gütig, 2014; Memmesheimer et al., 2014; Gardner and Grüning, 2016).
Our results with the spiking reference network suggest that the error is reduced to a value close to zero for a realizable or closely-approximated system (Figure 5A) as shown in Methods, analogous to proofs in adaptive control (Ioannou and Sun, 2012; Narendra and Annaswamy, 1989). Moreover, network weights became very similar, though not completely identical, to the weights of the realizable reference network (Figure 5B), which suggests that the theorem for convergence of parameters from adaptive control should carry over to our learning scheme.
Learning is robust to sparse connectivity, noisy error or reference, and noisy decoding weights, but not to delays
So far, our spiking networks had all-to-all connectivity. We next tested whether sparse connectivity (Markram et al., 2015; Brown and Hestrin, 2009) of the feedforward and recurrent connections was sufficient for learning low-dimensional dynamics. We ran the van der Pol oscillator learning protocol with the connectivity varying from 0.1 (10 percent connectivity) to 1 (full connectivity). Connections that were absent after the sparse initialization could not appear during learning, while the existing sparse connections were allowed to evolve according to FOLLOW learning. As shown in Figure 6A, we found that learning was slower with sparser connectivity; but with twice the learning time, a sparse network with about 25% connectivity reached similar performance as the fully connected network with standard learning time.
Figure 6

Robustness of FOLLOW learning.
We ran the van der Pol oscillator (A–D) or the linear decaying oscillator (F,H) learning protocol for 10,000 s for different parameter values and measured the mean squared error, over the last 400 s before the end of learning, mean over number of dimensions and time. (A) We evolved only a fraction of the feedforward and recurrent connections, randomly chosen as per a specific connectivity, according to FOLLOW learning, while keeping the rest zero. The round dots show the mean squared error for different connectivity after a 10,000 s learning protocol (default connectivity = 1 is starred); while the square dots show the same after a 20,000 s protocol. (B) Mean squared error after 10,000 s of learning versus the standard deviation of noise added to each component of the error, or equivalently to each component of the reference, is plotted. (C) We multiplied the original decoding weights (that form an auto-encoder with the error encoders) by a random factor (1 + uniform) drawn for each weight. The mean squared error at the end of a 10,000 s learning protocol for increasing values of is plotted (default is starred). (D) We multiplied the original decoding weights by a random factor (1 + uniform), fixing , drawn independently for each weight. The mean squared error at the end of a 10,000 s learning protocol, for a few values of on either side of zero, is plotted. (E,G) Architectures for learning the forward model when the reference is available after a sensory feedback delay for computing the error feedback. The forward model may be trained without a compensatory delay in the motor command path (E) or with it (G). (F,H) Mean squared error after 10,000 s of learning the linear decaying oscillator is plotted (default values are starred) versus the sensory feedback delay in the reference, for the architectures without and with compensatory delay, in F and H respectively.
We added Gaussian white noise to each component of the error, which is equivalent to adding it to each component of the reference, and ran the van der Pol oscillator learning protocol for 10,000 s for different standard deviations of the noise (Figure 6B). The learning was robust to noise with standard deviation up to around , which must be compared with the error amplitude of the order of at the start of learning, and orders of magnitude lower later.
The readout weights have been pre-learned until now, so that, in the absence of recurrent connections, error feedback weights and decoding weights formed an auto-encoder. We sought to relax this requirement. Simulations showed that with completely random readout weights, the system did not learn to reproduce the target dynamical system. However, if the readout weights had some overlap with the auto-encoder, learning was still possible (Figure 6C). If for a feedback error , the error encoding followed by output decoding yields , where is a vector of arbitrary functions not having linear terms and small in magnitude compared to the first term, and is sufficiently greater than so that the effective gain remains large enough, then the term that is linear in error can still drive the output close to the desired one (see Materials and methods).
To check this intuition in simulations, we incorporated multiplicative noise on the decoders by multiplying each decoding weight of the auto-encoder by one plus , where for each weight was drawn independently from a uniform distribution between and . We found that the system was still able to learn the van der Pol oscillator up to and , or and variable (Figure 6B,C). Negative values of result in a lower overlap with the auto-encoder leading to the asymmetry seen in Figure 6C. Thus, the FOLLOW learning scheme is robust to multiplicative noise on the decoding weights. Alternative approaches for other noise models are discussed in Appendix 1.
We also asked if the network could handle sensory feedback delays in the reference signal. Due to the strong limit cycle attractor of the van der Pol oscillator, the effect of delay is less transparent than for the linear decaying oscillator (Figure 2—figure supplement 2), so we decided to focus on the latter. For the linear decaying oscillator, we found that learning degraded rapidly with a few milliseconds of delay in the reference, that is if was provided as reference instead of (Figure 6E–F). We compensated for the sensory feedback delay by delaying the motor command input by identical (Figure 6G), which is equivalent to time-translating the complete learning protocol, to which the learning is invariant, and thus the network would learn for arbitrary delay (Figure 6H). In the Discussion, we suggest how a forward model learned with a compensatory delay (Figure 6G) could be used in control mode to compensate for sensory feedback delays.
Discussion
The FOLLOW learning scheme enables a spiking neural network to function as a forward predictive model that mimics a non-linear dynamical system activated by one or several time-varying inputs. The learning rule is supervised, local, and comes with a proof of stability.
It is supervised because the FOLLOW learning scheme uses error feedback where the error is defined as the difference between predicted output and the actual observed output. Error feedback forces the output of the system to mimic the reference, an effect that is widely used in adaptive control theory (Narendra and Annaswamy, 1989; Ioannou and Sun, 2012).
The learning rule is local in the sense that it combines information about presynaptic spike arrival with an abstract quantity that we imagine to be available in the postsynaptic neuron. In contrast to standard Hebbian learning, the variable representing this postsynaptic quantity is not the postsynaptic firing rate, spike time, or postsynaptic membrane potential, but the error current projected by feedback connections onto the postsynaptic neuron, similar in spirit to modern biological implementations of approximated backpropagation (Roelfsema and van Ooyen, 2005), (Lillicrap et al., 2016) or local versions of FORCE (Sussillo and Abbott, 2009) learning rules. We emphasize that the postsynaptic quantity is different from the postsynaptic membrane potential or the total postsynaptic current which would also include input from feedforward and recurrent connections.
A possible implementation in a spatially extended neuron would be to imagine that the postsynaptic error current arrives in the apical dendrite where it stimulates messenger molecules that quickly diffuse or are actively transported into the soma and basal dendrites where synapses from feedfoward and feedback input could be located, as depicted in Figure 7A. Consistent with the picture of a messenger molecule, we low-pass filtered the error current with an exponential filter of time constant 80 ms or 200 ms, much longer than the synaptic time constant of 20 ms of the filter . Simultaneously, filtered information about presynaptic spike arrival is available at each synapse, possibly in the form of glutamate bound to the postsynaptic receptor or by calcium triggered signalling chains localized in the postsynaptic spines. Thus the combination of effects caused by presynaptic spike arrival and error information available in the postsynaptic cell drives weight changes, in loose analogy to standard Hebbian learning.
Figure 7
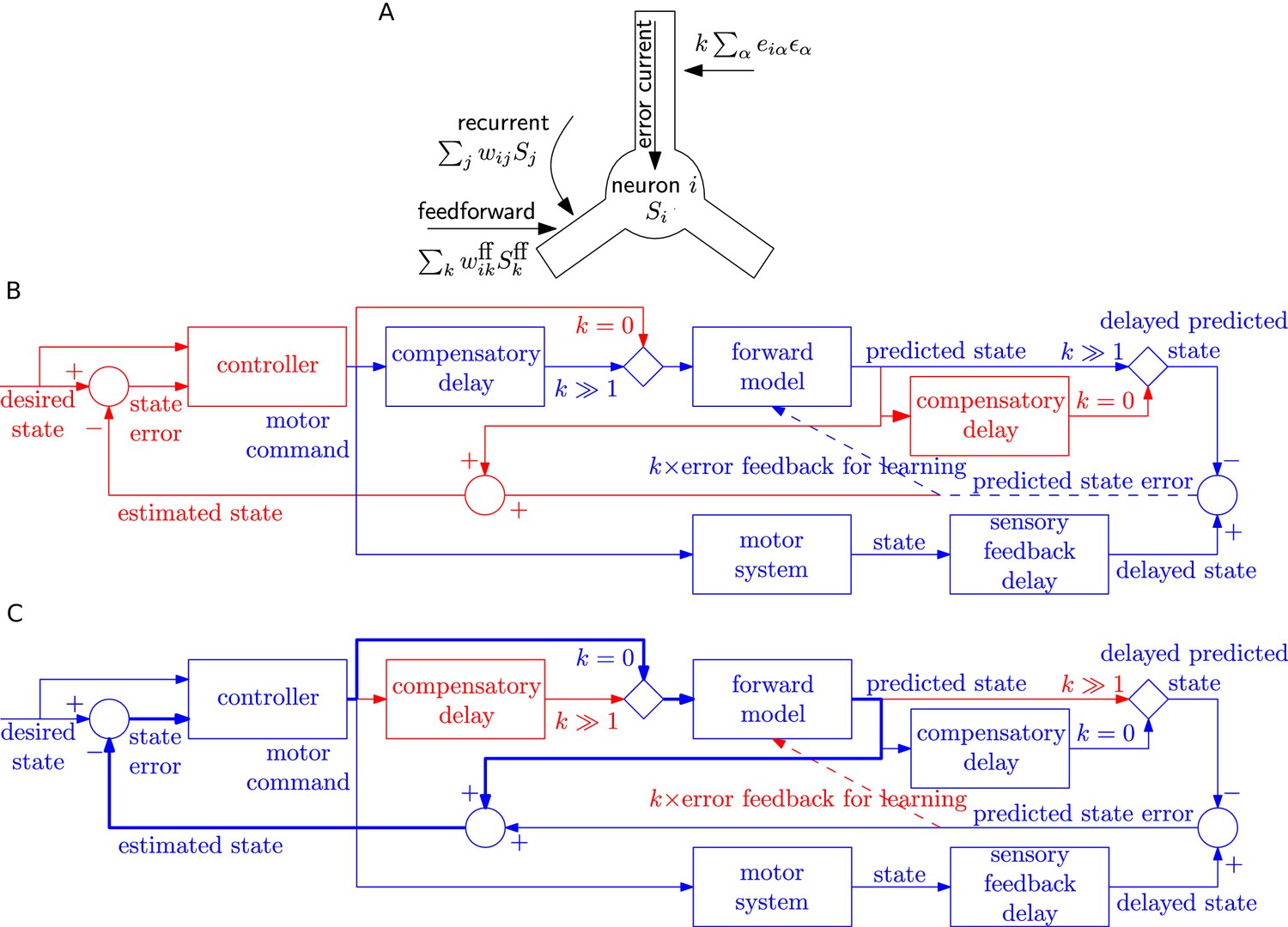
Possible implementation of learning rule, and delay compensation using forward model.
(A) A cartoon depiction of feedforward, recurrent and error currents entering a neuron in the recurrent network. The error current enters the apical dendrite and triggers an intra-cellular chemical cascade generating a signal that is available at the feedforward and recurrent synapses in the soma and basal dendrites, for weight updates. The error current must trigger a cascade isolated from the other currents, here achieved by spatial separation. (B-C) An architecture based on the Smith predictor, that can switch between learning the forward model (B), versus using the forward model for motor control (C, adapted from (Wolpert and Miall, 1996)), to compensate for the delay in sensory feedback. Active pathways are in blue and inactive ones are in red. (B) The learning architecture (blue) is identical to Figure 6G, but embedded within a larger control loop (red). During learning, when error feedback gain , the motor command is fed in with a compensatory delay identical to the sensory feedback delay. Thus motor command and reference state are equally delayed, hence temporally matched, and the forward model learns to produce the motor system output for given input. (C) Once the forward model is learned, the system switches to motor control mode (feedback gain ). In this mode, the forward model receives the present motor command and predicts the current state of the motor system, for rapid feedback to the controller (via loop indicated by thick lines), even before the delayed sensory feedback arrives. Of course the delayed sensory feedback can be further taken into account by the controller, by comparing it with the delayed output of the forward model, to better estimate the true state. Thus the forward model learned as in B provides a prediction of the state, even before feedback is received, acting to compensate for sensory feedback delays in motor control.
The separation of the error current from the currents at feedforward or recurrent synapses could be spatial (such as suggested in Figure 7A) or chemical if the error current projects onto synapses that trigger a signalling cascade that is different from that at other synapses. Importantly, whether it is a spatial or chemical separation, the signals triggered by the error currents need to be available throughout the postsynaptic neuron. This leads us to a prediction regarding synaptic plasticity that, say in cortical pyramidal neurons, the plasticity of synapses that are driven by pre-synaptic input in the basal dendrites, should be modulated by currents injected in the apical dendrite or on stimulation of feedback connections.
The learning scheme is provenly stable with errors converging asymptotically to zero under a few reasonable assumptions (Methods). The first assumption is that error encoding feedback weights and output decoding readout weights form an auto-encoder. This requirement can be met if, at an early developmental stage, either both sets of weights are learned using say mirrored STDP (Burbank, 2015), or the output readout weights are learned, starting with random encoding weights, via a biological perceptron-like learning rule (D'Souza et al., 2010; Urbanczik and Senn, 2014). A pre-learned auto-encoder in a high-gain negative feedback loop is in fact a specific prediction of our learning scheme, to be tested in systems-level experiments. The second assumption is that the reference dynamics is realizable. This requirement can be approximately met by having a recurrent network with a large number of neurons with different parameters (Eliasmith and Anderson, 2004). The third assumption is that the state variables are observable. While currently we calculate the feedback error directly from the state variables as a difference between reference and predicted state, we could soften this condition and calculate the difference in a higher-dimensional space with variables as long as is an invertible function of (Appendix 1). The fourth assumption is that the system dynamics be slower than synaptic dynamics. Indeed, typical reaching movements extend over hundreds of milliseconds or a few seconds whereas neuronal spike transmission delays and synaptic time constants can be as short as a few milliseconds. In our simulations, neuronal and synaptic time constants were set to 20 ms, yet the network dynamics evolved on the time scale of hundreds of milliseconds or a few seconds, even in the open-loop condition when error feedback was switched off (Figures 2 and 4). The fifth assumption is that weights stay bounded. Indeed, in biology, synaptic weights should not grow indefinitely. Algorithmically, a weight decay term in the learning rule can suppress the growth of large weights (see also Appendix 1), though we did not need to implement a weight decay term in our simulations.
One of the postulated uses of the forward predictive model is to compensate for delay in the sensory feedback during motor control (Wolpert and Miall, 1996; Wolpert et al., 1995) using the Smith predictor configuration (Smith, 1957). We speculate that the switch from the closed-loop learning of forward model with feedback gain to open-loop motor prediction could also be used to switch delay lines: the system can have either a delay before the forward model as required for learning (Figure 7B), or after the forward model as required for the Smith predictor (Figure 7C). We envisage that FOLLOW learning of the forward model occurs in closed loop mode () with a delay in the motor command path, as outlined earlier in Figure 6G and now embedded in the Smith predictor architecture in Figure 7B. After learning, the network is switched to motor control mode, with the forward predictive model in open loop (), implementing the Smith predictor (Figure 7C). In this motor control mode, the motor command is fed with zero delay to the forward model. This enables to rapidly feed the estimated state back to the motor controller so as to take corrective actions, even before sensory feedback arrives. In parallel, available sensory feedback is compared with a copy of the forward model that has passed through a compensatory delay after the forward model (Figure 7C).
Simulations with the FOLLOW learning scheme have demonstrated that strongly non-linear dynamics can be learned in a recurrent spiking neural network using a local online learning rule that does not require rapid weight changes. Previous work has mainly focused on a limited subset of these aspects. For example, Eliasmith and colleagues used a local learning rule derived from stochastic gradient descent, in a network structure comprising heterogeneous spiking neurons with error feedback (MacNeil and Eliasmith, 2011), but did not demonstrate learning non-linear dynamics (Appendix 1). Denève and colleagues used error feedback in a homogeneous spiking network with a rule similar to ours, for linear dynamics only (Bourdoukan and Denève, 2015), and while this article was in review, also for non-linear dynamics (Alemi et al., 2017), but their network requires instantaneous lateral interactions and in the latter case, also non-linear dendrites.
Reservoir computing models exploit recurrent networks of non-linear units in an activity regime close to chaos where temporal dynamics is rich (Jaeger, 2001; Maass et al., 2002; Legenstein et al., 2003; Maass and Markram, 2004; Jaeger and Haas, 2004; Joshi and Maass, 2005; Legenstein and Maass, 2007). While typical applications of reservoir computing are concerned with tasks involving a small set of desired output trajectories (such as switches or oscillators), our FOLLOW learning enables a recurrent network with a single set of parameters to mimic a dynamical system over a broad range of time-dependent inputs with a large family of different trajectories in the output.
Whereas initial versions of reservoir computing focused on learning the readout weights, applications of FORCE learning to recurrent networks of rate units made it possible to also learn the recurrent weights (Sussillo and Abbott, 2009, 2012). However, in the case of a multi-dimensional target, multi-dimensional errors were typically fed to distinct parts of the network, as opposed to the distributed encoding used in our network. Moreover, the time scale of synaptic plasticity in FORCE learning is faster than the time scale of the dynamical system which is unlikely to be consistent with biology. Modern applications of FORCE learning to spiking networks (DePasquale et al., 2016; Thalmeier et al., 2016; Nicola and Clopath, 2016) inherit these issues.
Adaptive control of non-linear systems using continuous rate neurons (Sanner and Slotine, 1992; Weiping Li et al., 1987; Slotine and Coetsee, 1986) or spiking neurons (DeWolf et al., 2016) has primarily focused on learning parameters in adaptive feedback paths, rather than learning weights in a recurrent network, using learning rules involving quantities that do not appear in the pre- or post-synaptic neurons, making them difficult to interpret as local to synapses. Recurrent networks of rate units have occasionally been used for control (Zerkaoui et al., 2009), but trained either via real-time recurrent learning or the extended Kalman filter which are non-local in space, or via backpropagation through time which is offline (Pearlmutter, 1995). Recent studies have used neural network techniques to train inverse models by motor babbling, to describe behavioral data in humans (Berniker and Kording, 2015) and song birds (Hanuschkin et al., 2013), albeit with abstract networks. Optimal control methods (Hennequin et al., 2014) or stochastic gradient descent (Song et al., 2016) have also been applied in recurrent networks of neurons, but with limited biological plausibility of the published learning rules. As an alternative to supervised schemes, biologically plausible forms of reward-modulated Hebbian rules on the output weights of a reservoir have been used to learn periodic pattern generation and abstract computations (Hoerzer et al., 2014; Legenstein et al., 2010), but how such modulated Hebbian rules could be used in predicting non-linear dynamics given time-dependent control input remains open.
Additional features of the FOLLOW learning scheme are that it does not require full connectivity but also works with biologically more plausible sparse connectivity; and it is robust to multiplicative noise in the output decoders, analogous to recent results on approximate error backpropagation in artificial neural networks (Lillicrap et al., 2016). Since the low-dimensional output and all neural currents are spatially averaged over a large number of synaptically-filtered spike trains, neurons in the FOLLOW network do not necessarily need to fire at rates higher than the inverse of the synaptic time scale. In conclusion, we used a network of heterogeneous neurons as in the Neural Engineering Framework (Eliasmith and Anderson, 2004), employed a pre-learned auto-encoder to enable negative feedback of error as in adaptive control theory (Morse, 1980; Narendra et al., 1980; Slotine and Coetsee, 1986; Weiping Li et al., 1987; Narendra and Annaswamy, 1989; Sastry and Bodson, 1989; Ioannou and Sun, 2012), and derived and demonstrated a local and online learning rule for recurrent connections that learn to reproduce non-linear dynamics.
Our present implementation of the FOLLOW learning scheme in spiking neurons violates Dale’s law because synapses originating from the same presynaptic neuron can have positive or negative weights, but in a different context extensions incorporating Dale’s law have been suggested (Parisien et al., 2008). Neurons in cortical networks are also seen to maintain a balance of excitatory and inhibitory incoming currents (Denève and Machens, 2016). It would be interesting to investigate a more biologically plausible extension of FOLLOW learning that maintains Dale’s law; works in the regime of excitatory-inhibitory balance, possibly using inhibitory plasticity (Vogels et al., 2011); pre-learns the auto-encoder, potentially via mirrored STDP (Burbank, 2015); and possibly implements spatial separation between different compartments (Urbanczik and Senn, 2014). It would also be interesting for future work to see whether our model of an arm trained on motor babbling with FOLLOW, can explain aspects of human behavior in reaching tasks involving force fields (Shadmehr and Mussa-Ivaldi, 1994), uncertainty (Körding and Wolpert, 2004; Wei and Körding, 2010) or noise (Burge et al., 2008). Further directions worth pursuing include learning multiple different dynamical transforms within one recurrent network, without interference; hierarchical learning with stacked recurrent layers; and learning the inverse model of motor control so as to generate the control input given a desired state trajectory.
Materials and methods
Simulation software
Request a detailed protocolAll simulation scripts were written in python (https://www.python.org/) for the Nengo simulator (Stewart et al., 2009) (http://www.nengo.ca/, version 2.4.0) with minor custom modifications to support sparse weights. We ran the model using the Nengo GPU back-end (https://github.com/nengo/nengo_ocl) for speed. The script for plotting the figures was written in python using the matplotlib module (http://matplotlib.org/). These simulation and plotting scripts are available online at https://github.com/adityagilra/FOLLOW.
Network parameters
Initialization of plastic weights
Request a detailed protocolThe feedforward weights from the command representation layer to the recurrent network and the recurrent weights inside the network were initialized to zero.
Update of plastic weights
Request a detailed protocolWith the error feedback loop closed, that is with reference output and predicted output connected to the error node, and feedback gain , the FOLLOW learning rule, Equation (10), was applied on the feedforward and recurrent weights, and . The error for our learning rule was the error in the observable output , not the error in the desired function (cf. [Eliasmith, 2005; MacNeil and Eliasmith, 2011], Appendix 1). The observable reference state was obtained by integrating the differential equations of the dynamical system. The synaptic time constant was 20 ms in all synapses, including those for calculating the error and for feeding the error back to the neurons (decaying exponential with time constant in Equation (6)). The error used for the weight update was filtered by a 200 ms decaying exponential ( in Equation (10)).
Random setting of neuronal parameters and encoding weights
Request a detailed protocolWe used leaky integrate-and-fire neurons with a threshold and time constant ms. After each spike, the voltage was reset to zero, and the neuron entered an absolute refractory period of ms. When driven by a constant input current , a leaky integrate-and-fire neuron with absolute refractoriness fires at a rate where is the gain function with value for and
(11)
Our network was inhomogeneous in the sense that different neurons had different parameters as described below. The basic idea is that the ensemble of neurons, with different parameters, forms a rich set of basis functions in the or dimensional space of inputs or outputs, respectively. This is similar to tiling the space with radial basis functions, except that here we replace the radial functions by the gain functions of the LIF neurons (Equation (11)) each having different parameters (Eliasmith and Anderson, 2004). These parameters were chosen randomly once at the beginning of a simulation and kept fixed during the simulation.
For the command representation layer, we write the current into neuron , in the case of a constant input , as
(12)
where and are neuron-specific gains and biases, and are ‘normalized’ encoding weights (cf. Equation (5)).
These random gains, biases and ‘normalized’ encoding weights must be chosen so that the command representation layer adequately represents the command input , whose norm is bounded in the interval (Table 1). First, we choose the ‘normalized’ encoding weight vectors on a hypersphere of radius , so that the scalar product between the command vector and the vector of ‘normalized’ encoding weights, , lies in the normalized range . Second, the distribution of the gains sets the distribution of the firing rates in a target range. Third, we see from Equation (11) that the neuron starts to fire at the rheobase threshold . The biases randomly shift this rheobase threshold over an interval (see Figure 1—figure supplement 1). For the distributions used to set the fixed random gains and biases, see Table 1.
Table 1
Network and simulation parameters for example systems.
* 4e-2 after 1,000 s for Figures 1 and 2. 1e-4 for readout weights in Figure 2—figure supplement 3.
Nengo v2.4.0 sets the gains and biases indirectly, by default. The projected input at which the neuron just starts firing (i.e. ) is chosen uniformly from , while the firing rate for is chosen uniformly between 200 and 400 Hz. From these, and are computed using Equations (11) and (13).
| Linear | Van der pol | Lorenz | Arm | Non-linear feedforward | |
|---|---|---|---|---|---|
| Number of neurons/layer | 2000 | 3000 | 5000 | 5000 | 2000 |
| (s) | 2 | 4 | 20 | 2 | 2 |
| Representation radius | 0.2 | 0.2 | 6 | 0.2 | 0.2 |
| Representation radius | 1 | 5 | 30 | 1 | 1 |
| Gains and biases for command representation and recurrent layers | Nengo v2.4.0 default | Figures 1 and 2: and chosen uniformly from . all other Figures: Nengo v2.4.0 default | Nengo v2.4.0 default | Nengo v2.4.0 default | Nengo v2.4.0 default |
| Learning pulse | |||||
| Learning pedestal | , | 0 | |||
| Learning rate | 2e-3 | 2e-3* | 2e-3 | 2e-3 | 2e-3 |
| Figures | Figure 2—figure supplement 2 | Figure 1, Figure 2, Figure 2—figure supplement 1, Figure 2—figure supplement 3, Figure 5, Figure 6, Figure 7 | Figure 3, Figure 3—figure supplement 1 | Figure 4 | Figure 2—figure supplement 4, Figure 2—figure supplement 5 |
Analogously, for the recurrent network, we write the current into neuron , for a constant ‘pseudo-input’ vector being represented in the network, as
(13)
where , are neuron-specific gains and biases, and are ‘normalized’ encoding weights. We call a ‘pseudo-input’ for two reasons. First, the error encoding weights are used to feed the error back to neuron in the network (cf. Equation (6)). However, , due to the feedback loop according to Equation (9). Thus, the ‘pseudo-input’ has a similar range as , whose norm lies in the interval (see Table 1). Second, the neuron also gets feedforward and recurrent input. However, the feedforward and recurrent inputs get automatically adjusted during learning (starting from zero), so their absolute values do not matter for the initialization of parameters that we discuss here. Thus, we choose the ‘normalized’ encoding weight vectors on a hypersphere of radius . For the distributions used to set the fixed random gains and biases, see Table 1.
Setting output decoding weights to form an auto-encoder with respect to error encoding weights
Request a detailed protocolThe linear readout weights from the recurrently connected network were pre-computed algorithmically so as to form an auto-encoder with the error encoding weights (for ), while setting the feedforward and recurrent weights to zero ( and ). To do this, we randomly selected error vectors , that we used as training samples for optimization, with sample index , and having vector components , . Since the observable system is -dimensional, we chose the training samples randomly from within an -dimensional hypersphere of radius . We applied each of the error vectors statically as input for the error feedback connections and calculated the activity
(14)
of neuron for error vector using the static rate Equation (11). The decoders acting on these activities should yield back the encoded points thus forming an auto-encoder. A squared-error loss function , with L2 regularization of the decoders,
(15)
setting with number of samples , was used for this linear regression (default in Nengo v2.4.0) (Eliasmith and Anderson, 2004; Stewart et al., 2009). Biologically plausible learning rules exist for auto-encoders, either by training both encoding and decoding weights (Burbank, 2015), or by training decoding weights given random encoding weights (D'Souza et al., 2010; Urbanczik and Senn, 2014), but we simply calculated and set the decoding weights as if they had already been learned.
Compressive and expansive auto-encoder
Request a detailed protocolClassical three-layer (input-hidden-output-layer) auto-encoders come in two different flavours, viz. compressive or expansive, which have the dimensionality of the hidden layer smaller or larger respectively, than that of the input and output layers. Instead of a three-layer feedfoward network, our auto-encoder forms a loop from the neurons in the recurrent network via readout weights to the output and from there via error-encoding weights to the input. Since the auto-encoder is in the loop, we expect that it works both as a compressive one (from neurons in the recurrent network over the low-dimensional output back to the neurons) and as an expansive one (from the output through the neurons in the recurrent network back to the output).
Rather than constraining, as in Equation (15), the low-dimensional input and round-trip output to be equal for each component (expansive auto-encoder), we can alternatively enforce the high dimensional input (projection into neuron of low-dimensional input ).
(16)
And round-trip output , where , to be equal for each neuron in the recurrent network (compressive auto-encoder) in order to optimize the decoding weights of the auto-encoder. Thus, the squared-error loss for this compressive auto-encoder becomes:
(17)
where in the approximation, we exploit that (i) the relative importance of the term involving tends to zero as , since and are independent random variables; and (ii) is independent of . Thus, the loss function of Equation (17) is approximately proportional to the squared-error loss function of Equation (15) (not considering the L2 regularization) used for the expansive auto-encoder, showing that for an auto-encoder embedded in a loop with fixed random encoding weights, the expansive and compressive descriptions are equivalent for those -dimensional inputs that lie in the -dimensional sub-space spanned by i.e. is of the form where lies in a finite domain (hypersphere). We employed a large number of random low--dimensional inputs when constraining the expansive auto-encoder.
Command input
Request a detailed protocolThe command input vector to the network was -dimensional ( for all systems except the arm) and time-varying. During the learning phase, input changed over two different time scales. The fast value of each command component was switched every 50 ms to a level chosen uniformly between and this number was added to a more slowly changing input variable (called ’pedestal’ in the main part of the paper) which changed with a period . Here is the component of a vector of length with a randomly chosen direction. The value of component of the command is then . Parameter values for the network and input for each dynamical system are provided in Table 1. Further details are noted in the next subsection.
During the testing phase without error feedback, the network reproduced the reference trajectory of the dynamical system for a few seconds, in response to the same kind of input as during learning. We also tested the network on a different input not used during learning as shown in Figures 2 and 4.
Equations and parameters for the example dynamical systems
The equations and input modifications for each dynamical system are detailed below. Time derivatives are in units of .
Linear system
Request a detailed protocolThe equations for a linear decaying oscillator system (Figure 2—figure supplement 2) are
For this linear dynamical system, we tested the learned network on a ramp of 2 s followed by a step to a constant non-zero value. A ramp can be viewed as a preparatory input before initiating an oscillatory movement, in a similar spirit to that observed in (pre-)motor cortex (Churchland et al., 2012). For such input too, the network tracked the reference for a few seconds (Figure 2—figure supplement 2A–C).
van der Pol oscillator
Request a detailed protocolThe equations for the van der Pol oscillator system are
Each component of the pedestal input was scaled differently for the van der Pol oscillator as reported in Table 1.
Lorenz system
Request a detailed protocolThe equations for the chaotic Lorenz system (Lorenz, 1963) are
In our equations above, of the original Lorenz equations (Lorenz, 1963) is represented by an output variable so as to have observable variables that vary around zero. This does not change the system dynamics, just its representation in the network. For the Lorenz system, only a pulse at the start for 250 ms, chosen from a random direction of norm , was provided to set off the system, after which the system followed autonomous dynamics.
Non-linearly transformed input to linear system
Request a detailed protocolFor the above dynamical systems, the input adds linearly on the right hand sides of the differential equations. Our FOLLOW scheme also learned non-linear feedforward inputs to a linear dynamical system, as demonstrated in Figure 2—figure supplement 4 and Figure 2—figure supplement 5. As the reference, we used the linear dynamical system above, but with its input transformed non-linearly by . Thus, the equations of the reference were:
The input to the network remained . Thus, effectively the feedforward weights had to learn the non-linear transform while the recurrent weights learned the linear system.
Arm dynamics
Request a detailed protocolIn the example of learning arm dynamics, we used a two-link model for an arm moving in the vertical plane with damping, under gravity (see for example http://www.gribblelab.org/compneuro/5_Computational_Motor_Control_Dynamics.html and https://github.com/studywolf/control/tree/master/studywolf_control/arms/two_link), with parameters from (Li, 2006). The differential equations for the four state variables, namely the shoulder and elbow angles and the angular velocities , given input torques are:
(18)
(19)
with
where is the mass, the length, the distance from the joint centre to the centre of the mass, and the moment of inertia, of link ; is the moment of inertia matrix; contains centripetal and Coriolis terms; is for joint damping; and contains the gravitational terms. Here, the state variable vector , but the effective torque is obtained from the input torque as follows.
To avoid any link from rotating full 360 degrees, we provide an effective torque to the arm, by subtracting a term proportional to the input torque , if the angle crosses 90 degrees and is in the same direction:
where increases linearly from 0 to 1 as goes from to :
The parameter values were taken from the human arm (Model 1) in section 3.1.1 of the PhD thesis of Li (Li, 2006) from the Todorov lab; namely , , , , , , , , and , . Acceleration due to gravity was set at . For the arm, we did not filter the reference variables for calculating the error.
The input torque for learning the two-link arm was generated, not by switching the pulse and pedestal values sharply, every 50 ms and as for the others, but by linearly interpolating in-between to avoid oscillations from sharp transitions.
The input torque and the variables , obtained on integrating the arm model above were scaled by , and respectively, and then used as the input and reference for the spiking network. Effectively, we scaled the input torques to cover one-fifth of the representation radius , the angular velocities one-half, and the angles full, as each successive variable was the integral of the previous one.
Learning readout weights with recurrent weights fixed
Request a detailed protocolFor learning the readout weights after setting either the true or shuffled set of learned recurrent weights (Figure 2—figure supplement 3), we used a perceptron learning rule.
(20)
with learning rate .
Derivation and proof of stability of the FOLLOW learning scheme
We derive the FOLLOW learning rule Equation (10), while simultaneously proving the stability of the scheme. We assume that: (1) the feedback and readout weights form an auto-encoder with gain ; (2) given the gains and biases of the spiking LIF neurons, there exist feedforward and recurrent weights that make the network follow the reference dynamics perfectly (in practice, the dynamics is only approximately realizable by our network, see Appendix 1 for a discussion); (3) the state of the dynamical system is observable; (4) the intrinsic time scales of the reference dynamics are much larger than the synaptic time scale and the time scale of the error feedback loop, and much smaller than the time scale of learning; (5) the feedforward and recurrent weights remain bounded; and (6) the input and reference output remain bounded.
The proof proceeds in three major steps: (1) using the auto-encoder assumption to write the evolution equation of the low-dimensional output state variable in terms of the recurrent and feedforward weights; (2) showing that output follows the reference due to the error feedback loop; and (3) obtaining the evolution equation for the error and using it in the time-derivative of a Lyapunov function , to show that for uniform stability, similar to proofs in adaptive control theory (Narendra and Annaswamy, 1989; Ioannou and Sun, 2012).
Role of network weights for low-dimensional output
Request a detailed protocolThe filtered low-dimensional output of the recurrent network is given by Equation (3) of Results and repeated here:
(21)
where are the readout weights. Since is an exponential filter with time constant , Equation (21) can also be written as
(22)
We convolve this equation with kernel , multiply by the error feedback weights, and sum over the output components
(23)
We would like to write Equation (23) in terms of the recurrent and feedforward weights in the network.
To do this, we exploit assumptions (1) and (4). Having shown the equivalence of the compressive and expansive descriptions of our auto-encoder in the error-feedback loop (Equation (15) and (Equation (17))), we formulate our non-linear auto-encoder as compressive: we start with a high-dimensional set of inputs (where is the current into neuron with bias , cf. Equations (5) and (6)); transform these inputs non-linearly into filtered spike trains ; decode these filtered spike trains into a low-dimensional representation with components ; and increase the dimensionality back to the original one, via weights , to get inputs:
(24)
Using assumption (1) we expect that the final inputs are approximately times the initial inputs :
(25)
This is valid only if the high--dimensional input lies in the low--dimensional subspace spanned by (Equation (17)). We show that this requirement is fulfilled in the next major step of the proof (see text accompanying Equations (31–35)).
Our assumption (4) says that the state variables of the reference dynamics change slowly compared to neuronal dynamics. Due to the spatial averaging (sum over in Equation (25)) over a large number of neurons, individual neurons do not necessarily have to fire at a rate higher than the inverse of the synaptic time scale, while we can still assume that the total round trip input on the left hand side of Equation (25) is varying only on the slow time scale. Therefore, we used firing rate equations to compute mean outputs given static input when pre-calculating the readout weights (earlier in Materials and methods).
Inserting the approximate Equation (25) into Equation (23) we find
(26)
We replace , using the current from Equation (6) for neuron of the recurrent network, to obtain
(27)
Thus, the change of the low-dimensional output depends on the network weights, which need to be learned. This finishes the first step of the proof.
Error-feedback loop ensures that output follows reference
Request a detailed protocolBecause of assumption (2), we may assume that there exists a recurrent network of spiking neurons that represents the desired dynamics of Equation (1) without any error feedback. This second network serves as a target during learning and has variables and parameters indicated with an asterisk. In particular, the second network has feedforward weights and recurrent weights . We write an equation similar to Equation (27) for the output of the target network:
(28)
where and are defined as the filtered spike trains of neurons in the realizable target network. We emphasize that this target network does not need error feedback because its output is, by definition, always correct. In fact, the readout from the spike trains gives the target output which we denote by . The weights of the target network are constant and their actual values are unimportant. They are mere mathematical devices to demonstrate stable learning of the first network which has adaptable weights. For the first network, we choose the same number of neurons and the same neuronal parameters as for the second network; moreover, the input encoding weights from the command input to the representation layer and the readout weights from the recurrent network to the output are identical for both networks. Thus, the only difference is that the feedforward and recurrent weights of the target network are realized, while for the first network they need to be learned.
In view of potential generalization, we note that any non-linear dynamical system is approximately realizable due to the expansion in a high-dimensional non-linear basis that is effectively performed by the recurrent network (see Appendix 1). Approximative weights (close to the ideal ones) could in principle also be calculated algorithmically (see Appendix 1). In the following we exploit assumption (2) and assume that the dynamics is actually (and not only approximately) realized by the target network.
Our assumption (3) states that the output is observable. Therefore the error component can be computed directly via a comparison of the true output of the reference with the output of the network: (In view of potential generalizations, we remark that the observable output need not be the state variables themselves, but could be a higher-dimensional non-linear function of the state variables, as shown for a general dynamical system in Appendix 1.)
As the second step of the proof, we now show that the error feedback loop enables the first network to follow the target network under assumptions (4 - 6). More precisely, we want to show that the readout and neural activities of the first network remain close to those of the target network at all times, that is for each component and for each neuron index . To do so, we use assumption (4) and exploit that (i) learning is slow compared to the network dynamics so the weights of the first network can be considered momentarily constant, and (ii) the reference dynamics is slower than the synaptic and feedback loop time scales, so the reference output can be assumed momentarily constant. Thus, we have a separation of time scales in Equation (27): for a given input (transmitted via the feedforward weights) and a given target value , the network dynamics settles on the fast time scale to a momentary fixed point which we find by setting the derivative on the left-hand side of Equation (27) to zero:
(29)
We rewrite this equation in the form
(30)
We choose the feedback gain for the error much larger than 1 (), such that . Using our assumption (5) that the feedforward and recurrent weights are bounded, and since the filtered spike trains remain bounded due to the refractory period, the term in parentheses multiplying remains bounded, by say . We further use assumption (6) that the target output is bounded by say . Choosing , the second term can be made negligible compared to the first. Thus, to obtain , we set and .
To show that the momentary fixed point is stable at the fast synaptic time scale, we calculate the Jacobian , for the dynamical system given by Equation (27). We introduce auxiliary variables to rewrite Equation (27) with the new variables in the form ; and then we take derivative of its right hand side to obtain the elements of the Jacobian matrix at the fixed point :
where is the Kronecker delta function. We note that is a spatially and temporally averaged measure of the population activity in the network with appropriate weighting factors . We assume that the population activity varies smoothly with input, which is equivalent to requiring that on the time scale , the network fires asynchronously, i.e. there are no precisely timed population spikes. Then we can take the second term to be bounded, in absolute value, by say . The Jacobian matrix is of the form , where is the identity matrix and is a matrix with each element bounded in absolute value by . If we set , then all eigenvalues of the Jacobian have negative real parts, applying the Gerschgorin circle theorem (the second term can perturb any eigenvalue from to within a circle of radius at most), rendering the momentary fixed point asymptotically stable.
Thus, we have shown that if the initial state of the first network is close to the initial state of the target network, e.g., both start from rest, then on the slow time scale of the system dynamics of the reference , the first network output follows the target network output at all times, .
We now show that neurons are primarily driven by inputs close to those in the target network due to error feedback, and that these lie in the low-dimensional manifold spanned by , as required for Equation (25). We compute the projected error using Equation (30):
(31)
and insert it into Equation (6) to obtain the current into a neuron in the recurrent network:
(32)
At the start of learning, if the feedforward and recurrent weights are small, then the neural input is dominated by the fed-back error input that is the first term, making close to the ideal current
(33)
Thus, the neural input at the start of learning is of the form which lies in the low-dimensional subspace spanned by as required for Equation (25). Furthermore, over time, the feedforward and recurrent weights get modified so that their contribution tends towards , such that the two terms of Equation (32) add to make even closer to the ideal current given by Equation (33). This is made clearer by considering the weight update rule Equation 10 as stochastic gradient descent on a loss function,
(34)
leading us to (for each recurrent weight , and similarly for ):
(35)
which is identical to the FOLLOW learning rule for in Equation (10) except for the time-scale of filtering of the error current (see Discussion), and a factor involving that can be absorbed into the learning rate . In the last step above, we used the projected error current from Equation (31) and the definition of in Equation (8). Thus, the feedforward and recurrent connections evolve to inject, after learning, the same ideal input within the low-dimensional manifold, as was provided by the error feedback during learning. Hence, the neural input remains in the low-dimensional manifold spanned by throughout learning, as required for Equation (25), making this major step and the previous one self-consistent.
Since the driving neural currents are close to ideal throughout learning, the filtered spike trains of the recurrent neurons in the first network will also be approximately the same as those of the target network, so that can be used instead of in (Equation (28)). Moreover, the filtered spike trains of the command representation layer in the first network are the same as those in the target network, since they are driven by the same command input and the command encoding weights are, by construction, the same for both networks. The similarity of the spike trains in the first and target networks will be used in the next major part of the proof.
Stability of learning via Lyapunov’s method
Request a detailed protocolWe now turn to the third step of the proof and consider the temporal evolution of the error . We exploit that the network dynamics is realized by the target network and insert Equations (27) and (28) so as to find
(36)
In the second line, we have replaced the reference output by the target network output; and in the third line we have used Equations (27) and (28), and replaced the filtered spike trains of the target network by those of the first network, exploiting the insights from the previous paragraph. In the last line, we have introduced abbreviations and .
In order to show that the absolute value of the error decreases over time with an appropriate learning rule, we consider the candidate Lyapunov function:
(37)
where and are positive constants. We use Lyapunov’s direct method to show the stability of learning. For this, we require the following properties for the Lyapunov function. (a) The Lyapunov function is positive semi-definite , with the equality to zero only at . (b) It has continuous first-order partial derivatives. Furthermore, is (c) radially unbounded since
and (d) decrescent since
where and take the minimum/maximum of their respective arguments.
Apart from the above conditions (a)-(d), we need to show the key property for uniform global stability (which implies that bounded orbits remain bounded, so the error remains bounded); or the stronger property for asymptotic global stability (see for example [Narendra and Annaswamy, 1989; Ioannou and Sun, 2012]). Taking the time derivative of , and replacing that is from (Equation (36)), we have:
(38)
If we enforce the first two terms above to be zero, we derive a learning rule
(39)
and then
requiring , which is subsumed under for the error feedback. The condition Equation 39 with and , and replaced by a longer filtering kernel , is the learning rule used in the main text, Equation (10).
Thus, in the -system given by Equations (36) and (39), we have proven the global uniform stability of the fixed point , which is effectively , choosing and , under assumptions (1 - 6), while simultaneously deriving the learning rule (Equation (39)).
This ends our proof. So far, we have shown that the system is Lyapunov stable, that is bounded orbits remain bounded, and not asymptotically stable. Indeed, with bounded firing rates and fixed readout weights, the output will remain bounded, as will the error (for a bounded reference). However, here, we also derived the FOLLOW learning rule, and armed with the inequality for the time derivative of the Lyapunov function in terms of the error, we further show in the following subsection that the error goes to zero asymptotically, so that after learning, even without error feedback, reproduces the dynamics of .
A major caveat of this proof is that under assumption (2) the dynamics be realizable by our network. In a real application this might not be the case. Approximation errors arising from a mismatch between the best possible network and the actual target dynamics are currently ignored. The adaptive control literature has shown that errors in approximating the reference dynamics appear as frozen noise and can cause runaway drift of the parameters (Narendra and Annaswamy, 1989; Ioannou and Sun, 2012). In our simulations with a large number of neurons, the approximations of a non-realizable reference dynamics (e.g., the Van der Pol oscillator) were sufficiently good, and thus the expected drift was possibly slow, and did not cause the error to rise during typical time-scales of learning. A second caveat is our assumption (5). While the input is under our control and can therefore be kept bounded, some additional bounding is needed to stop weights from drifting. Various techniques to address such model-approximation noise and bounding weights have been studied in the robust adaptive control literature (e.g., (Ioannou and Tsakalis, 1986; Slotine and Coetsee, 1986; Narendra and Annaswamy, 1989; Ioannou and Fidan, 2006; Ioannou and Sun, 2012)). We discuss this issue and briefly mention some of these ameliorative techniques in Appendix 1.
To summarize, the FOLLOW learning rule (Equation (39)) on the feedforward or recurrent weights has two terms: (i) a filtered presynaptic firing trace or that is available locally at each synapse; and (ii) a projected filtered error used for all synapses in neuron that is available as a current in the postsynaptic neuron due to error feedback, see Equation (6). Thus the learning rule can be classified as local. Moreover, it uses an error in the observable , not in its time-derivative. While we have focused on spiking networks, the learning scheme can be easily used for non-linear rate units by replacing the filtered spikes by the output of the rate units . Our proof is valid for arbitrary dynamical transforms as long as they are realizable in a network. The proof shows uniform global stability using Lyapunov’s method.
Proof of error tending to zero asymptotically
Request a detailed protocolIn the above subsection, we showed uniform global stability using , with and . This only means that bounded errors remain bounded. Here, we show more importantly that the error tends to zero asymptotically with time. We adapt the proof in section 4.2 of (Ioannou and Sun, 2012), to our spiking network.
Here, we want to invoke a special case of Barbălat’s lemma: if and for some , then as . Recall the definitions: function when exists (is finite); and similarly function when exists (is finite).
Since is positive semi-definite () and is a non-increasing function of time (), its exists and is finite. Using this, the following limit exists and is finite:
Since each term in the above sum is positive semi-definite, also exists and is finite , and thus .
To show that , consider Equation (36). We use assumption (6) that the input and the reference output are bounded. Since network output is also bounded due to saturation of firing rates (as are the filtered spike trains), the error (each component) is bounded i.e. . If we also bound the weights from diverging during learning (assumption (5)), then . With these reasonable assumptions, all terms on the right hand side of the Equation (36) for are bounded, hence .
Since and , invoking Barbălat’s lemma as above, we have as . We have shown that the error tends to zero asymptotically under assumptions (1 - 6). In practice, the error shows fluctuations on a short time scale while the mean error over a longer time scale reduces and then plateaus, possibly due to approximate realizability, imperfections in the error-feedback, and spiking shot noise (cf. Figure 5).
We do not further require the convergence of parameters to ideal ones for our purpose, since the error tending to zero, that is network output matching reference, is functionally sufficient for the forward predictive model. In the adaptive control literature (Ioannou and Sun, 2012; Narendra and Annaswamy, 1989), the parameters (weights) are shown to converge to ideal ones if input excitation is ‘persistent’, loosely that it excites all modes of the system. It should be possible to adapt the proof to our spiking network, as suggested by simulations (Figure 5), but is not pursued here.
Appendix 1
Decoding
Consider only the command representation layer without the subsequent recurrent network. Assume, following (Eliasmith and Anderson, 2004), we wish to decode an arbitrary output corresponding to the encoded in the command representation layer, from the spike trains of the neurons, by synaptically filtering and linearly weighting the trains with decoding weights :
(40)
where denotes convolution , and is a normalized filtering kernel.
We can obtain the decoders by minimizing the loss function
(41)
with respect to the decoders. The average over guarantees that the same constant decoders are used over the whole range of constant inputs . The time average denotes an analytic rate computed for each constant input for a LIF neuron. Linear regression with a finite set of constant inputs was used to obtain the decoders (see Materials and methods). With these decoders, if the input varies slowly compared to the synaptic time constant , we have .
Any function of the input can be approximated with appropriate linear decoding weights from the high-dimensional basis of non-linear tuning curves of heterogeneous neurons with different biases, encoding weights and gains, schematized in Figure 1—figure supplement 1. With a large enough number of such neurons, the function is expected to be approximated to arbitrary accuracy. While this has not been proven rigorously for spiking neurons, this has theoretical underpinnings from theorems on universal function approximation using non-linear basis functions (Funahashi, 1989; Hornik et al., 1989; Girosi and Poggio, 1990) successful usage in spiking neural network models by various groups (Seung et al., 2000; Eliasmith and Anderson, 2004; Eliasmith, 2005), and biological plausibility (Poggio, 1990; Burnod et al., 1992; Pouget and Sejnowski, 1997).
Here, the neurons that are active at any given time operate in the mean driven regime i.e. the instantaneous firing rate increases with the input current (Gerstner et al., 2014). The dynamics is dominated by synaptic filtering, and the membrane time constant does not play a significant role (Eliasmith and Anderson, 2004; Eliasmith, 2005; Seung et al., 2000; Abbott et al., 2016). Thus, the decoding weights derived from Equation (41) with stationary input are good approximations even in the time-dependent case, as long as the input varies on a time scale slower than the synaptic time constant.
Online learning based on a loss function and its shortcomings
Suppose that a dynamical system given by
(42)
is to be mimicked by our spiking network implementing a different dynamical system with an extra error feedback term as in Equation (27). This can be interpreted as:
(43)
Comparing with the reference Equation (42), after learning we want that should approximate . One way to achieve this (Eliasmith and Anderson, 2004) is to ensure that and approximate and respectively, as used in the loss functions below. In our simulations, we usually start with zero feedforward and recurrent weights, so that initially .
Assuming that the time scales of dynamics are slower than synaptic time scale , we can approximate the requisite feedforward and recurrent weights, by minimizing the following loss functions respectively, with respect to the weights (Eliasmith and Anderson, 2004):
(44)
(45)
Using these loss functions, we can pre-calculate the weights required for any dynamical system numerically, similarly to the calculation of decoders in the subsection above.
We now derive rules for learning the weights online based on stochastic gradient descent of these loss functions, similar to (MacNeil and Eliasmith, 2011), and point out some shortcomings.
The learning rule for the recurrent weights by gradient descent on the loss function given by Equation (45) is
(46)
In the second line, the effect of the weight change on the filtered spike trains is assumed small and neglected, using a small learning rate . With requisite dynamics slower than synaptic , and with large enough number of neurons, we have approximated . The third line defines an error in the projected , which is the supervisory signal.
If we assume that the learning rate is slow, and the input samples the range of uniformly, then we can remove the averaging over , similar to stochastic gradient descent.
(47)
where . This learning rule is the product of a multi-dimensional error and the filtered presynaptic spike train . However, this error in the unobservable is not available to the postsynaptic neuron, making the learning rule non-local. A similar issue arises in the feedforward case.
In mimicking a dynamical system, we want only the observable output of the dynamical system i.e. to be used in a supervisory signal, not a term involving the unknown that appears in the derivative . Even if this derivative is computed from the observable , it will be noisy. Furthermore, this derivative cannot be obtained by differentiating the observable versus time, if the observable is not directly the state variable, but an unknown non-linear function of it, which however our FOLLOW learning can handle (see next subsection). Thus, this online rule, if using just the observable error, can learn only an integrator for which (MacNeil and Eliasmith, 2011).
Indeed, learning both the feedforward and recurrent weights simultaneously using gradient descent on these loss functions, requires two different and unavailable error currents to be projected into the postsynaptic neuron to make the rule local.
General dynamical system and transformed observable
General dynamical systems of the form
can be learned with the same network configuration (Figure 1B) used for systems of the form Equation 1. Here, the state variable is , but the observable which serves as the reference to the network is . The transformation equation of the observable (second equation) can be absorbed into the first equation as below.
Consider the transformation equation for the observable. The dimensionality of the relevant variables: (1) the state variables (say joint angles and velocities) ; (2) the observables represented in the brain (say sensory representations of the joint angles and velocities) ; and (3) the control input (motor command) , can be different from each other, but must be small compared to the number of neurons. Furthermore, we require the observable to not lose information compared to , that is must be invertible, so will have at least the same dimension as .
The time evolution of the observable is
The last step follows since function is invertible, so that . So we essentially need to learn .
Having solved the observable transformation issue, we use now for our observable, consistent with the main text. The dynamical system to be learned is now . Since our learning network effectively evolves as Equation (43), it can approximate . Thus our network can learn general dynamical systems with observable transformations.
Approximation error causes drift in weights
A frozen noise term due to the approximate decoding from non-linear tuning curves of neurons, by the feedforward weights, recurrent weights and output decoders, will appear additionally in Equation (36). If this frozen noise has a non-zero mean over time as varies, leading to a non-zero mean error, then it causes a drift in the weights due to the error-based learning rules in Equations (10), and possibly a consequent increase in error. Note that the stability and error tending to zero proofs assume that this frozen noise is negligible.
Multiple strategies with contrasting pros and cons have been proposed to counteract this parameter drift in the robust adaptive control literature (Ioannou and Sun, 2012; Narendra and Annaswamy, 1989; Ioannou and Fidan, 2006). These include a weight leakage/regularizer term switched slowly on, when a weight crosses a threshold (Ioannou and Tsakalis, 1986; Narendra and Annaswamy, 1989), or a dead zone strategy with no updating of weights once the error is lower than a set value (Slotine and Coetsee, 1986; Ioannou and Sun, 2012). In our simulations, the error continued to drop even over longer than typical learning time scales (Figure 5), and so, we did not implement these strategies.
In practice, the learning can be stopped once error is low enough, while the error feedback can be continued, so that the learned system does not deviate too much from the observed one.
References
-
Building functional networks of spiking model neuronsNature Neuroscience 19:350–355.https://doi.org/10.1038/nn.4241
-
Learning long-term dependencies with gradient descent is difficultIEEE Transactions on Neural Networks 5:157–166.https://doi.org/10.1109/72.279181
-
Deep networks for motor control functionsFrontiers in Computational Neuroscience 9:32.https://doi.org/10.3389/fncom.2015.00032
-
BookEnforcing balance allows local supervised learning in spiking recurrent networksIn: Cortes C, Lawrence N. D, Lee D. D, Sugiyama M, Garnett R, Garnett R, editors. Advances in Neural Information Processing Systems, 28. Curran Associates, Inc. pp. 982–990.
-
Mirrored STDP implements autoencoder learning in a network of spiking neuronsPLoS Computational Biology 11:e1004566.https://doi.org/10.1371/journal.pcbi.1004566
-
Visuomotor transformations underlying arm movements toward visual targets: a neural network model of cerebral cortical operationsJournal of Neuroscience 12:1435–1453.
-
Modeling of continuous time dynamical systems with input by recurrent neural networksIEEE Transactions on Circuits and Systems I: Fundamental Theory and Applications 47:575–578.https://doi.org/10.1109/81.841860
-
Every good regulator of a system must be a model of that system †International Journal of Systems Science 1:89–97.https://doi.org/10.1080/00207727008920220
-
A learning-based approach to artificial sensory feedback leads to optimal integrationNature Neuroscience 18:138–144.https://doi.org/10.1038/nn.3883
-
Widespread access to predictive models in the motor system: a short reviewJournal of Neural Engineering 2:S313–S319.https://doi.org/10.1088/1741-2560/2/3/S11
-
Efficient codes and balanced networksNature Neuroscience 19:375–382.https://doi.org/10.1038/nn.4243
-
A spiking neural model of adaptive arm controlProceedings of the Royal Society B: Biological Sciences 283:20162134.https://doi.org/10.1098/rspb.2016.2134
-
BookNeural Engineering: Computation, Representation, and Dynamics in Neurobiological SystemsMIT Press.
-
A unified approach to building and controlling spiking attractor networksNeural Computation 17:1276–1314.https://doi.org/10.1162/0899766053630332
-
Hierarchical models in the brainPLoS Computational Biology 4:e1000211.https://doi.org/10.1371/journal.pcbi.1000211
-
BookNeuronal Dynamics: From Single Neurons to Networks and Models of Cognition (1st edition)Cambridge, United Kingdom: Cambridge University Press.https://doi.org/10.1017/CBO9781107447615
-
Networks and the best approximation propertyBiological Cybernetics 63:169–176.https://doi.org/10.1007/BF00195855
-
The tempotron: a neuron that learns spike timing-based decisionsNature Neuroscience 9:420–428.https://doi.org/10.1038/nn1643
-
To spike, or when to spike?Current Opinion in Neurobiology 25:134–139.https://doi.org/10.1016/j.conb.2014.01.004
-
Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term DependenciesGradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies.
-
BookAdaptive Control TutorialPhiladelphia, PA: SIAM, Society for Industrial and Applied Mathematics.https://doi.org/10.1137/1.9780898718652
-
A robust direct adaptive controllerIEEE Transactions on Automatic Control 31:1033–1043.https://doi.org/10.1109/TAC.1986.1104168
-
ReportThe ”Echo State” Approach to Analysing and Training Recurrent Neural NetworksTechnical report.
-
A Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the "Echo StateNetwork" ApproachA Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the "Echo StateNetwork" Approach.
-
Movement generation with circuits of spiking neuronsNeural Computation 17:1715–1738.https://doi.org/10.1162/0899766054026684
-
Neural basis of sensorimotor learning: modifying internal modelsCurrent Opinion in Neurobiology 18:573–581.https://doi.org/10.1016/j.conb.2008.11.003
-
Input prediction and autonomous movement analysis in recurrent circuits of spiking neuronsReviews in the Neurosciences 14:5–19.https://doi.org/10.1515/REVNEURO.2003.14.1-2.5
-
On the adaptive control of robot manipulatorsThe International Journal of Robotics Research 6:49–59.https://doi.org/10.1177/027836498700600303
-
BookOptimal Control for Biological Movement SystemsSan Diego: University of California.
-
Random synaptic feedback weights support error backpropagation for deep learningNature Communications 7:13276.https://doi.org/10.1038/ncomms13276
-
Deterministic nonperiodic flowJournal of the Atmospheric Sciences 20:130–141.https://doi.org/10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2
-
On the computational power of circuits of spiking neuronsJournal of Computer and System Sciences 69:593–616.https://doi.org/10.1016/j.jcss.2004.04.001
-
Explaining facial imitation: a theoretical modelEarly Development and Parenting 6:179–192.https://doi.org/10.1002/(SICI)1099-0917(199709/12)6:3/4<179::AID-EDP157>3.0.CO;2-R
-
Span: spike pattern association neuron for learning spatio-temporal spike patternsInternational Journal of Neural Systems 22:1250012.https://doi.org/10.1142/S0129065712500128
-
Global stability of parameter-adaptive control systemsIEEE Transactions on Automatic Control 25:433–439.https://doi.org/10.1109/TAC.1980.1102364
-
Stable adaptive controller design, part II: Proof of stabilityIEEE Transactions on Automatic Control 25:440–448.https://doi.org/10.1109/TAC.1980.1102362
-
Solving the problem of negative synaptic weights in cortical modelsNeural Computation 20:1473–1494.https://doi.org/10.1162/neco.2008.07-06-295
-
Gradient calculations for dynamic recurrent neural networks: a surveyIEEE Transactions on Neural Networks 6:1212–1228.https://doi.org/10.1109/72.410363
-
A theory of how the brain might workCold Spring Harbor Symposia on Quantitative Biology 55:899–910.https://doi.org/10.1101/SQB.1990.055.01.084
-
Spatial transformations in the parietal cortex using basis functionsJournal of Cognitive Neuroscience 9:222–237.https://doi.org/10.1162/jocn.1997.9.2.222
-
Computational approaches to sensorimotor transformationsNature Neuroscience 3:1192–1198.https://doi.org/10.1038/81469
-
Principles of neurodynamics. perceptrons and the theory of brain mechanismsTechnical report.
-
Parallel Distributed Processing: Explorations in the Microstructure of CognitionLearning Internal Representations by Error Propagation, Parallel Distributed Processing: Explorations in the Microstructure of Cognition, 1, Cambridge, MA, USA, MIT Press.
-
Gaussian networks for direct adaptive controlIEEE Transactions on Neural Networks 3:837–863.https://doi.org/10.1109/72.165588
-
The roles of vision and proprioception in the planning of reaching movementsAdvances in Experimental Medicine and Biology 629:317–335.https://doi.org/10.1007/978-0-387-77064-2_16
-
BookAdaptive Control: Stability, Convergence, and RobustnessUpper Saddle River, NJ, USA: Prentice-Hall, Inc.
-
Adaptive representation of dynamics during learning of a motor taskJournal of Neuroscience 14:3208–3224.
-
Adaptive sliding controller synthesis for non-linear systemsInternational Journal of Control 43:1631–1651.https://doi.org/10.1080/00207178608933564
-
Python scripting in the Nengo simulatorFrontiers in Neuroinformatics 3:.https://doi.org/10.3389/neuro.11.007.2009
-
Generalization in reinforcement learning: Successful examples using sparse coarse codingAdvances in Neural Information Processing Systems 8:138–1044.
-
Learning universal computations with spikesPLoS Computational Biology 12:e1004895.https://doi.org/10.1371/journal.pcbi.1004895
-
Uncertainty of feedback and state estimation determines the speed of motor adaptationFrontiers in Computational Neuroscience 4:11.https://doi.org/10.3389/fncom.2010.00011
-
Computational principles of movement neuroscienceNature Neuroscience 3:1212–1217.https://doi.org/10.1038/81497
-
Forward models for physiological motor controlNeural Networks 9:1265–1279.https://doi.org/10.1016/S0893-6080(96)00035-4
-
Can proprioceptive training improve motor learning?Journal of Neurophysiology 108:3313–3321.https://doi.org/10.1152/jn.00122.2012
-
Fast adaptation of the internal model of gravity for manual interceptions: evidence for event-dependent learningJournal of Neurophysiology 93:1055–1068.https://doi.org/10.1152/jn.00833.2004
-
Visuo-motor coordination and internal models for object interceptionExperimental Brain Research 192:571–604.https://doi.org/10.1007/s00221-008-1691-3
-
Stable adaptive control with recurrent neural networks for square MIMO non-linear systemsEngineering Applications of Artificial Intelligence 22:702–717.https://doi.org/10.1016/j.engappai.2008.12.005
Article and author information
Author details
Funding
European Research Council (Multirules 268 689)
- Aditya Gilra
- Wulfram Gerstner
Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung (CRSII2_147636)
- Aditya Gilra
- Wulfram Gerstner
Horizon 2020 Framework Programme (Human Brain Project 720270)
- Wulfram Gerstner
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Johanni Brea, Samuel Muscinelli and Laureline Logiaco for helpful discussions, and Samuel Muscinelli, Laureline Logiaco, Chris Stock, Tilo Schwalger, Olivia Gozel, Dane Corneil and Vasiliki Liakoni for comments on the manuscript. Financial support was provided by the European Research Council (Multirules, grant agreement no. 268689), the Swiss National Science Foundation (Sinergia, grant agreement no. CRSII2_147636), and the European Commission Horizon 2020 Framework Program (H2020) (Human Brain Project, grant agreement no. 720270).
Copyright
© 2017, Gilra et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 5,264
- views
-
- 979
- downloads
-
- 82
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 82
- citations for umbrella DOI https://doi.org/10.7554/eLife.28295
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Predicting non-linear dynamics by stable local learning in a recurrent spiking neural network
eLife 6:e28295.
https://doi.org/10.7554/eLife.28295




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}