Local online learning in recurrent networks with random feedback
- Columbia University, United States
Figures
Figure 1
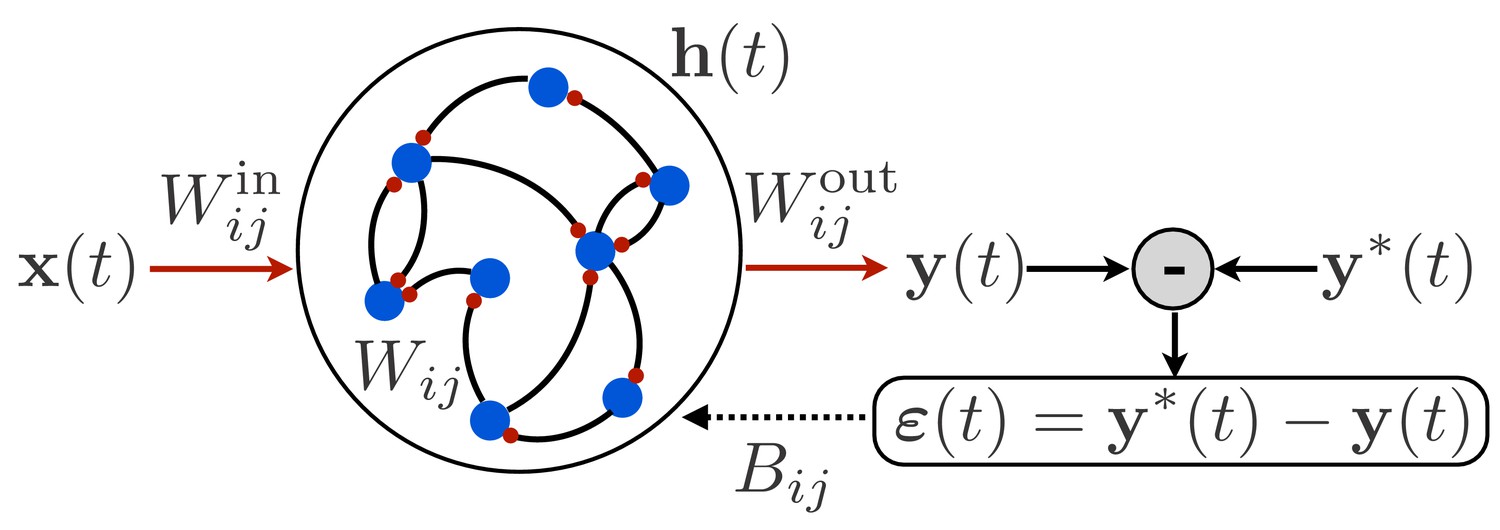
Schematic illustration of a recurrent neural network.
The network receives time-dependent input , and its synaptic weights are trained so that the output matches a target function . The projection of the error with feedback weights is used for learning the input weights and recurrent weights.
Figure 2 with 3 supplements
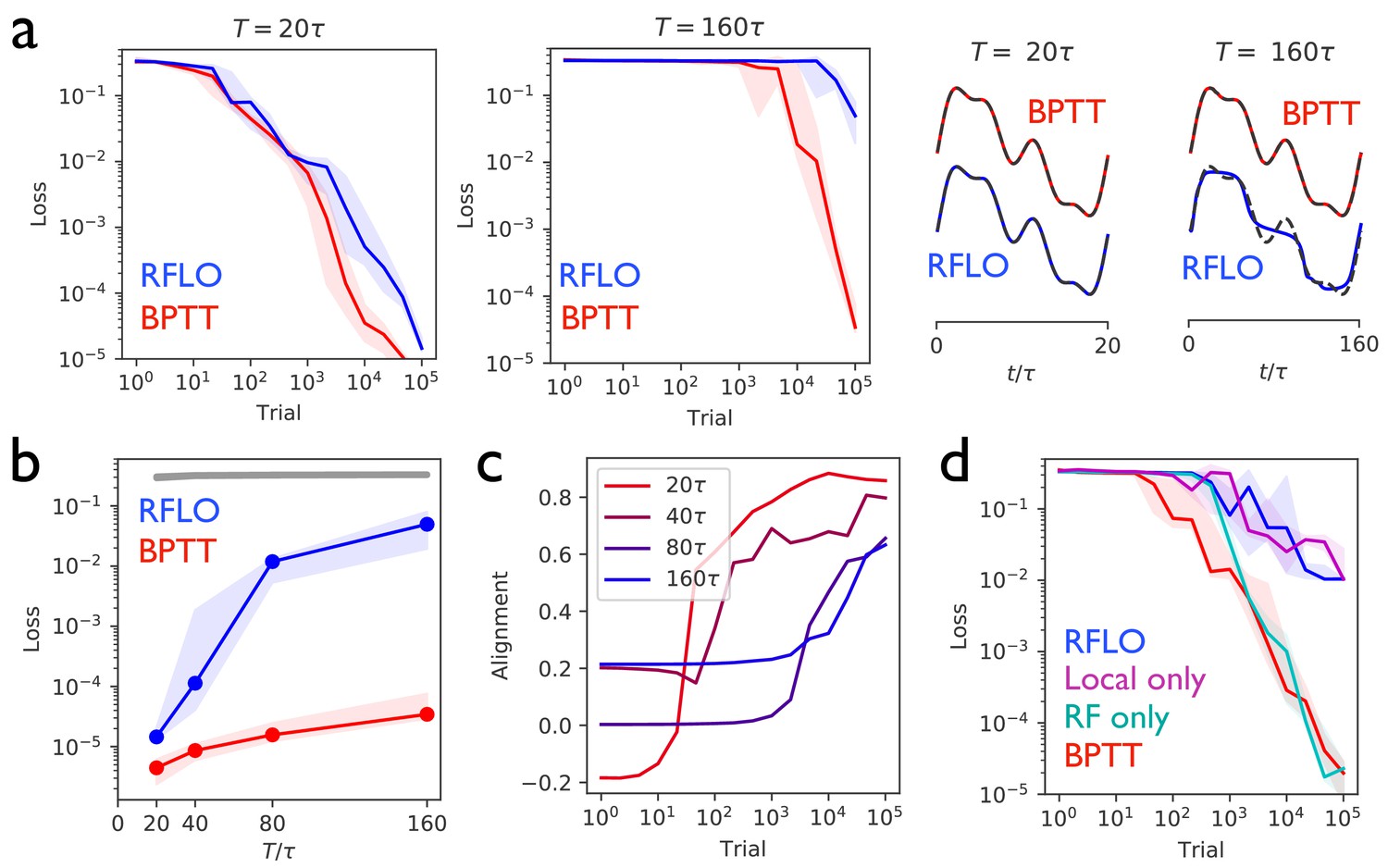
Periodic output task.
(a) Left panels: The mean squared output error during training for an RNN with recurrent units and no external input, trained to produce a one-dimensional periodic output with period of duration (left) or (right), where is the RNN time constant. The learning rules used for training were backpropagation through time (BPTT) and random feedback local online (RFLO) learning. Solid line is median loss over nine realizations, and shaded regions show 25/75 percentiles. Right panels: The RNN output at the end of training for each type of learning (dashed lines are target outputs, offset for clarity). (b) The loss function at the end of training for target outputs having different periods. The colored lines correspond to the two learning rules from (a), while the gray line is the loss computed for an untrained RNN. (c) The normalized alignment between the vector of readout weights and the vector of feedback weights during training with RFLO learning. (d) The loss function during training with for BPTT and RFLO, as well as versions of RFLO in which locality is enforced without random feedback (magenta) or random feedback is used without enforcing locality (cyan).
Figure 2—figure supplement 1
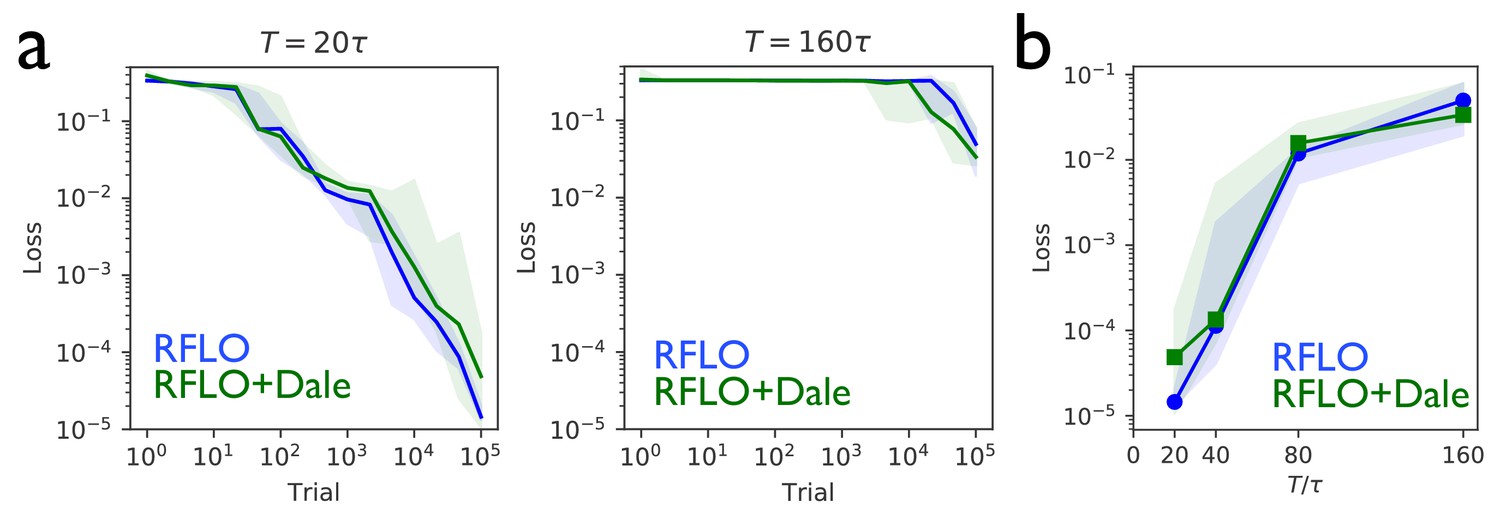
An RNN with sign-constrained synapses comporting with Dale’s law attains performance similar to an unconstrained RNN.
(a) In the periodic output task from Figure 2, the loss function during training with RFLO learning shows similar rate of decrease in an RNN with sign-constrained synapses (RFLO + Dale) compared with an RNN trained without sign constraint (RFLO), both for short-duration (left) and long-duration (right) outputs. (b) The final loss function value after training is similar for RNNs with and without sign-constrained synapses for outputs of various durations.
Figure 2—figure supplement 2
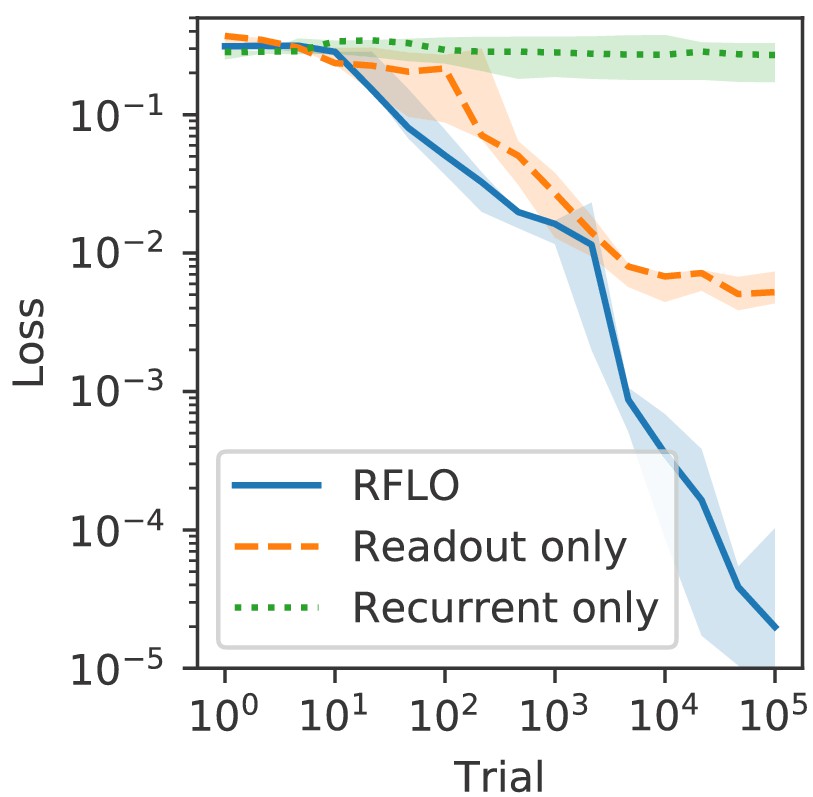
An RNN trained to perform the task from Figure 2 with RFLO learning on recurrent and readout weights outperforms an RNN in which only readout weights or only recurrent weights are trained.
https://doi.org/10.7554/eLife.43299.005
Figure 2—figure supplement 3

The performance of an RNN trained to perform the task from Figure 2 with RFLO learning improves with larger network sizes and larger initial recurrent weights.
(a) The loss after 104 trials in RNNs versus the number of recurrent units. (b) The loss after 104 trials in RNNs versus the standard deviation of the initial weights. In these RNNs, the recurrent weights were initialized as , and the readout weights were initialized as , where is the uniform distribution over (−1,1).
Figure 3
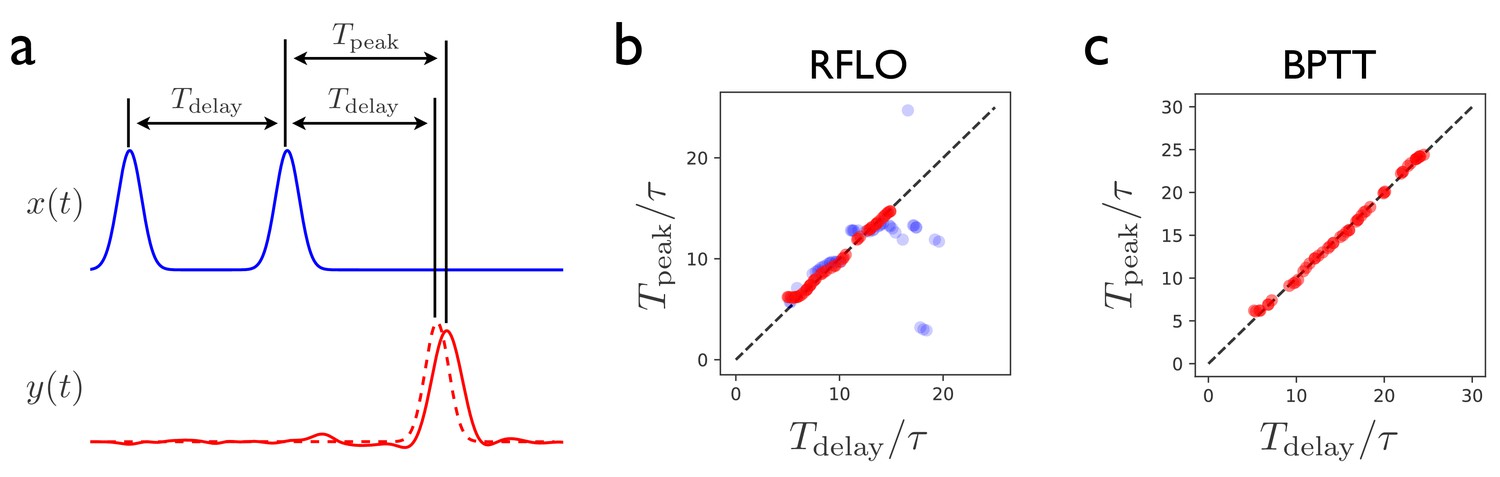
Interval-matching task.
(a) In the task, the RNN input consists of two input pulses, with a random delay between pulses in each trial. The target output (dashed line) is a pulse trailing the second input pulse by . (b) The time of the peak in the RNN output is observed after training with RFLO learning and testing in trials with various interpulse delays in the input. Red (blue) shows the case in which the RNN is trained with interpulse delays satisfying (). (c) Same as (b), but with the RNN trained using BPTT using interpulse delays for training and testing.
Figure 4
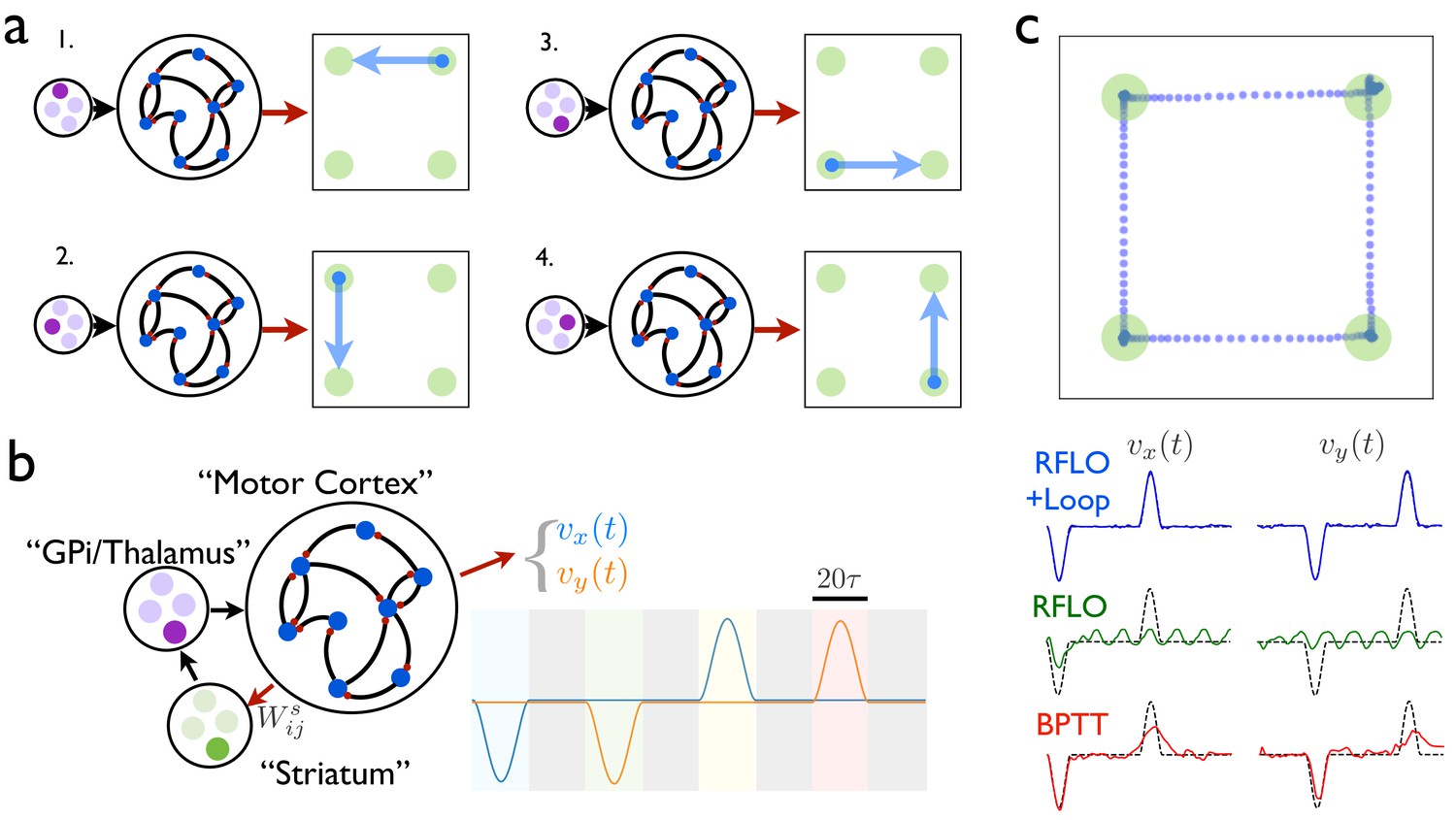
An RNN with multiple inputs controlled by an auxiliary loop learns to produce sequences.
(a) An RNN with a two-dimensional readout controlling the velocity of a cursor is trained to move the cursor in a different direction for each of the four possible inputs. (b) The RNN is augmented with a loop structure, which allows a readout from the RNN via learned weights to change the state of the input to the RNN, enabling the RNN state at the end of each cursor movement to trigger the beginning of the next movement. (c) The trajectory of a cursor performing four movements and four holds, where RFLO learning was used to train the individual movements as in (a), and learning of the weights was used to join these movements into a sequence, as illustrated in (b). Lower traces show comparison of this trajectory with those obtained by using either RFLO or BPTT to train an RNN to perform the entire sequence without the auxiliary loop.
Additional files
-
Source code 1
Example code implementing RFLO learning and BPTT.
- https://doi.org/10.7554/eLife.43299.009
-
Transparent reporting form
- https://doi.org/10.7554/eLife.43299.010
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Local online learning in recurrent networks with random feedback
eLife 8:e43299.
https://doi.org/10.7554/eLife.43299




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}