Meta-Research: Releasing a preprint is associated with more attention and citations for the peer-reviewed article
- Vanderbilt University Medical Center, United States
Abstract
Preprints in biology are becoming more popular, but only a small fraction of the articles published in peer-reviewed journals have previously been released as preprints. To examine whether releasing a preprint on bioRxiv was associated with the attention and citations received by the corresponding peer-reviewed article, we assembled a dataset of 74,239 articles, 5,405 of which had a preprint, published in 39 journals. Using log-linear regression and random-effects meta-analysis, we found that articles with a preprint had, on average, a 49% higher Altmetric Attention Score and 36% more citations than articles without a preprint. These associations were independent of several other article- and author-level variables (such as scientific subfield and number of authors), and were unrelated to journal-level variables such as access model and Impact Factor. This observational study can help researchers and publishers make informed decisions about how to incorporate preprints into their work.
Introduction
Preprints offer a way to freely disseminate research findings while a manuscript undergoes peer review (Berg et al., 2016). Releasing a preprint is standard practice in several disciplines, such as physics and computer science (Ginsparg, 2011), and a number of organizations – including ASAPbio and bioRxiv.org (Sever et al., 2019) – are encouraging the adoption of preprints in biology and the life sciences. However, some researchers in these fields remain reluctant to release their work as preprints, partly for fear of being scooped as preprints are not universally considered a marker of priority (Bourne et al., 2017), and partly because some journals explicitly or implicitly refuse to accept manuscripts released as preprints (Reichmann et al., 2019). Whatever the reason, the number of preprints released each month in the life sciences is only a fraction of the number of peer-reviewed articles published (Penfold and Polka, 2019).
Although the advantages of preprints have been well articulated (Bourne et al., 2017; Sarabipour et al., 2019), quantitative evidence for these advantages remains relatively sparse. In particular, how does releasing a preprint relate to the outcomes – in so far as they can be measured – of the peer-reviewed article? Previous work found that papers posted on arXiv before acceptance at a computer science conference received more citations in the following year than papers posted after acceptance (Feldman et al., 2018). Another study found that articles with preprints on bioRxiv had higher Altmetric Attention Scores and more citations than those without, but the study was based on only 776 peer-reviewed articles with preprints (commensurate with the size of bioRxiv at the time) and did not examine differences between journals (Serghiou and Ioannidis, 2018). We sought to build on these efforts by leveraging the rapid growth of bioRxiv, which is now the largest repository of biology preprints. Independently from our work, a comprehensive recent study has replicated and extended the findings of Serghiou and Ioannidis, although it did not quantify journal-specific effects or account for differences between scientific fields (Fraser et al., 2019).
Results
We first assembled a dataset of peer-reviewed articles indexed in PubMed, including each article's Altmetric Attention Score and number of citations and whether it had a preprint on bioRxiv. (See Methods for full details. The code and data to reproduce this study are available on Figshare; see data availability statement below.) Because we sought to perform an analysis stratified by journal, we only included articles from journals that had published at least 50 articles with a preprint on bioRxiv. Overall, our dataset included 74,239 articles, 5,405 of which had a preprint, published in 39 journals between January 1, 2015 and December 31, 2018 (Supplementary file 1). Release of the preprint preceded publication of the peer-reviewed article by a median of 174 days (Figure 1—figure supplement 2).
Across journals and often within a journal, Attention Score and citations varied by orders of magnitude between articles (Figure 1—figure supplements 3 and 4). Older articles within a given journal tended to have more citations, whereas older and newer articles tended to have similar distributions of Attention Score. In addition, Attention Score and citations within a given journal were weakly correlated with each other (median Spearman correlation 0.18, Figure 1—figure supplement 5, and Supplementary file 2). These findings suggest that the two metrics capture different aspects of an article’s impact.
We next used regression modeling to quantify the associations of an article’s Attention Score and citations with whether the article had a preprint. To reduce the possibility of confounding (Falagas et al., 2013; Fox et al., 2016), each regression model included terms for an article’s preprint status, publication date, number of authors, number of references, whether any author had an affiliation in the United States (by far the most common country of affiliation in our dataset, Supplementary file 13), whether any author had an affiliation at an institution in the 2019 Nature Index for Life Sciences (a proxy for institutions that publish a large amount of high quality research), the last author publication age, and the article’s approximate scientific subfield within the journal (Supplementary file 4). We inferred each last author’s publication age (which is a proxy for the number of years the last author has been a principal investigator) using names and affiliations in PubMed (see Methods for details). We approximated scientific subfield as the top 15 principal components (PCs) of Medical Subject Heading (MeSH) term assignments calculated on a journal-wise basis (Figure 1—figure supplements 6 and 7 and Supplementary file 5), analogously to how genome-wide association studies use PCs to adjust for population stratification (Price et al., 2006).
For each journal and each of the two metrics, we fit multiple regression models. For Attention Scores, which are real numbers, we fit log-linear and Gamma models. For citations, which are integers, we fit log-linear, Gamma, and negative binomial models. Log-linear regression consistently gave the lowest mean absolute error and mean absolute percentage error (Figure 1—figure supplement 8 and Supplementary file 6), so we used only log-linear regression for all subsequent analyses (Supplementary file 7).
We used the regression fits to calculate predicted Attention Scores and citations for hypothetical articles with and without a preprint in each journal, holding all other variables fixed (Figure 1). We also examined the exponentiated model coefficients for having a preprint (equivalent to fold-changes), which allowed comparison of relative effect sizes between journals (Figure 2). Both approaches indicated higher Attention Scores and more citations for articles with preprints, although as expected Attention Score and citations showed large article-to-article variation (Figure 1—figure supplement 9). Similar to Attention Scores and citations themselves, fold-changes of the two metrics were weakly correlated with each other (Spearman correlation 0.19).
Figure 1 with 9 supplements see all
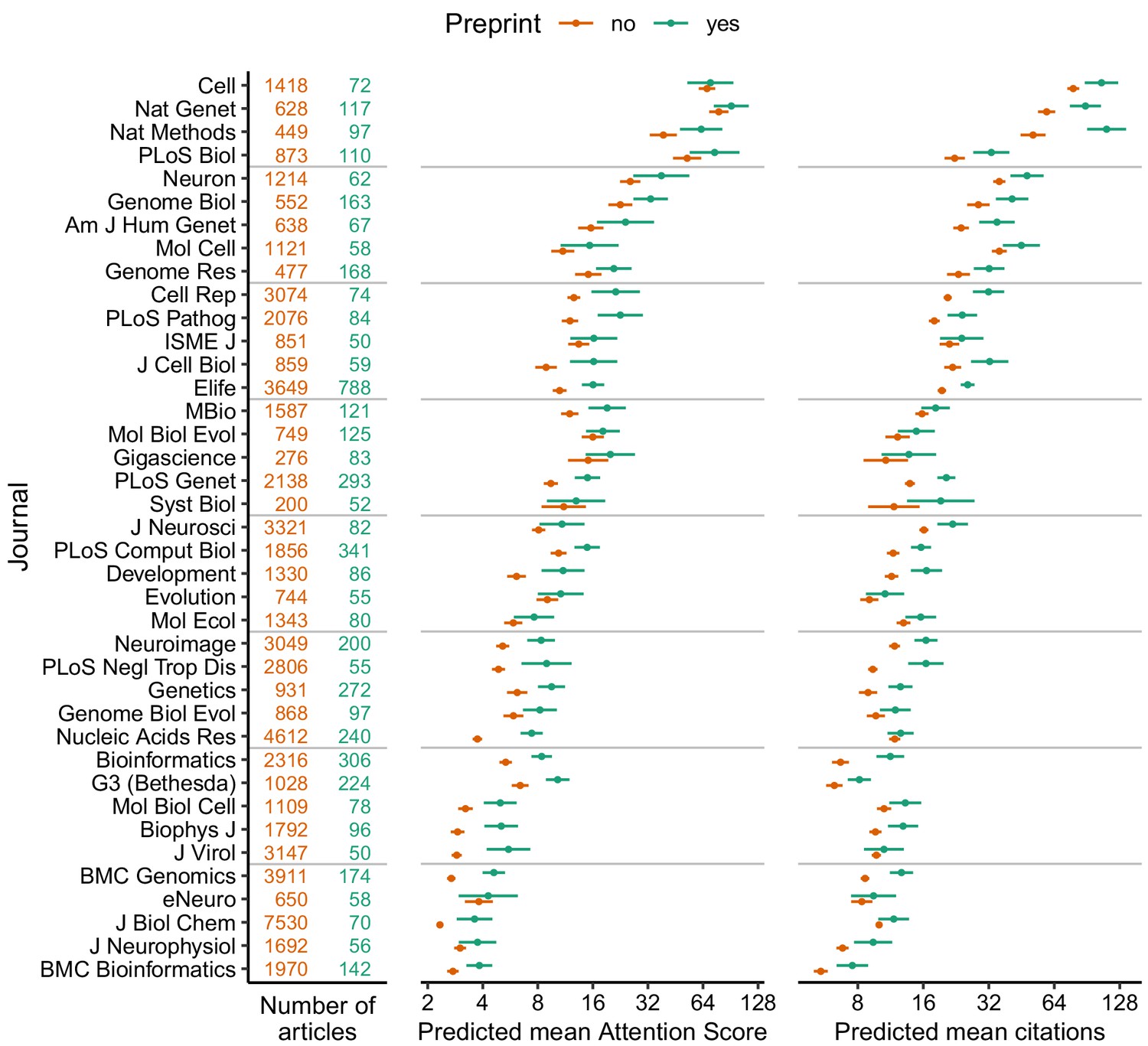
Absolute effect size of having a preprint, by metric (Attention Score and number of citations) and journal.
Each point indicates the predicted mean of the Attention Score (middle column) and number of citations (right column) for a hypothetical article with (green) or without (orange) a preprint, assuming the hypothetical article was published three years ago and had the mean value (i.e., zero) of each of the top 15 MeSH term PCs and the median value (for articles in that journal) of number of authors, number of references, U.S. affiliation status, Nature Index affiliation status, and last author publication age. Error bars indicate 95% confidence intervals. Journal names correspond to PubMed abbreviations: number of articles with (green) and without (orange) a preprint are shown in the left column. Journals are ordered by the mean of predicted mean Attention Score and predicted mean number of citations.
-
Figure 1—source data 1
Absolute effect size of having a preprint, by metric and journal.
- https://cdn.elifesciences.org/articles/52646/elife-52646-fig1-data1-v2.csv
Figure 2 with 2 supplements see all
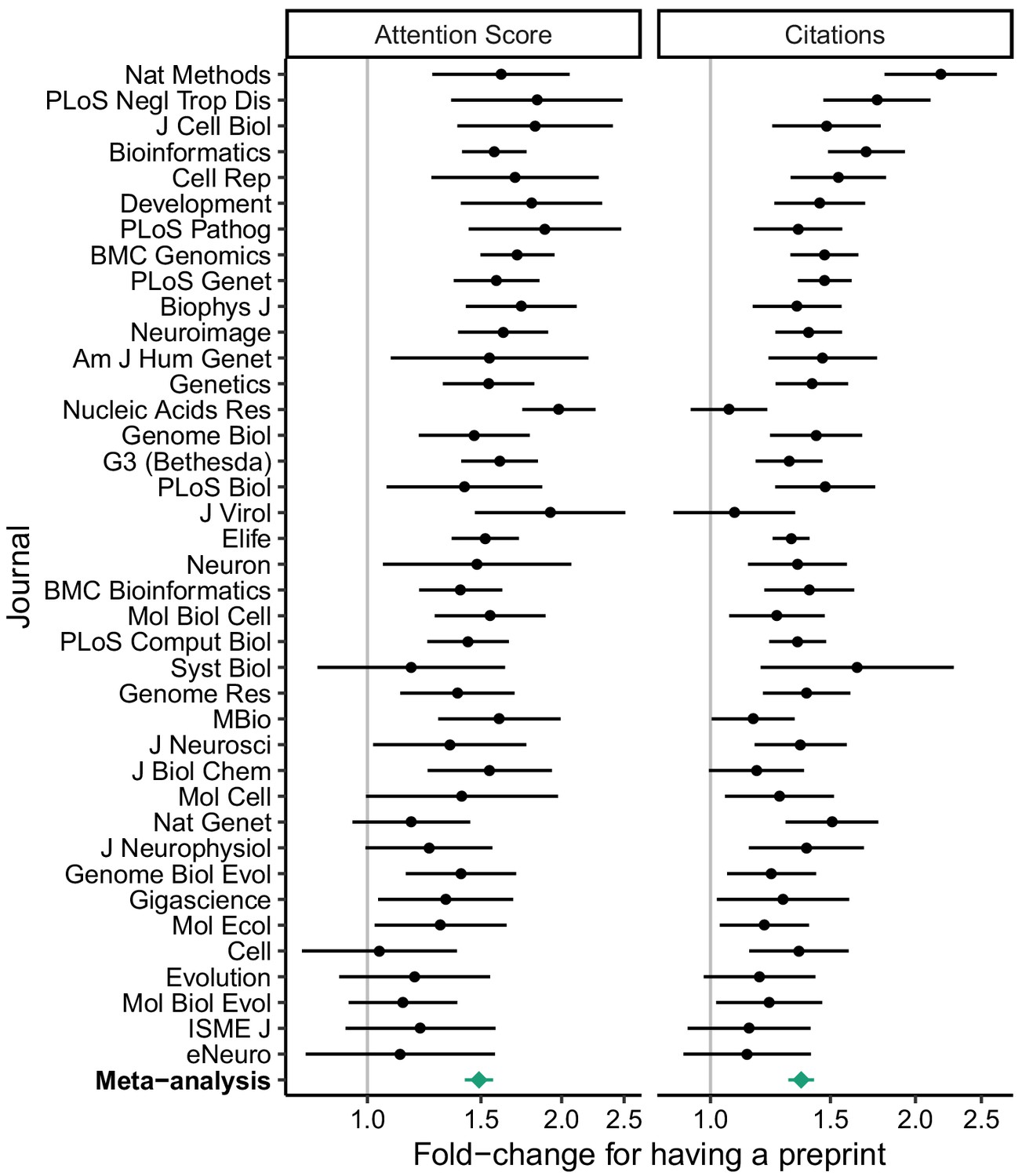
Relative effect size of having a preprint, by metric (Attention Score and number of citations) and journal.
Fold-change corresponds to the exponentiated coefficient from log-linear regression, where fold-change >1 indicates higher Attention Score or number of citations for articles that had a preprint. A fold-change of 1 corresponds to no association. Error bars indicate 95% confidence intervals. Journals are ordered by mean log fold-change. Bottom row shows estimates from random-effects meta-analysis (also shown in Table 1). The source data for this figure is in Supplementary file 7.
To quantify the overall evidence for each variable’s association with Attention Score and citations, we performed a random-effects meta-analysis of the respective model coefficients (Table 1 and Supplementary file 8). Based on the meta-analysis, an article’s Attention Score and citations were positively associated with its preprint status, number of authors, number of references, U.S. affiliation status, and Nature Index affiliation status, and slightly negatively associated with its last author publication age.
Table 1
Random-effects meta-analysis across journals of model coefficients from log-linear regression.
A positive coefficient (column 3) means that Attention Score or number of citations increases as that variable increases (or if the article had a preprint or had an author with a U.S. affiliation or a Nature Index affiliation). However, coefficients for some variables have different units and are not directly comparable. P-values were adjusted using the Bonferroni-Holm procedure, based on having fit two models for each journal. Effectively, for each variable, the procedure multiplied the lesser p-value by two and left the other unchanged. Meta-analysis statistics for the intercept and publication date are shown in Supplementary file 8.
| Metric | Article-level variable | Coef. | Std. error | 95% CI (lower) | 95% CI (upper) | p-value | Adj. p-value |
|---|---|---|---|---|---|---|---|
| Attention Score | Had a preprint | 0.575 | 0.036 | 0.502 | 0.647 | 1.91e-18 | 3.82e-18 |
| log2(number of authors) | 0.129 | 0.015 | 0.099 | 0.158 | 1.04e-10 | 1.04e-10 | |
| log2(number of references + 1) | 0.070 | 0.021 | 0.027 | 0.113 | 2.10e-03 | 2.10e-03 | |
| Had an author with U.S. affiliation | 0.143 | 0.021 | 0.100 | 0.187 | 6.08e-08 | 6.08e-08 | |
| Had an author with Nature Index affiliation | 0.147 | 0.020 | 0.106 | 0.188 | 1.20e-08 | 2.41e-08 | |
| Last author publication age (yrs) | −0.009 | 0.001 | −0.011 | −0.007 | 5.86e-10 | 1.17e-09 | |
| Citations | Had a preprint | 0.442 | 0.031 | 0.380 | 0.505 | 7.38e-17 | 7.38e-17 |
| log2(number of authors) | 0.181 | 0.009 | 0.163 | 0.200 | 9.76e-22 | 1.95e-21 | |
| log2(number of references + 1) | 0.217 | 0.020 | 0.176 | 0.258 | 4.87e-13 | 9.73e-13 | |
| Had an author with U.S. affiliation | 0.079 | 0.011 | 0.057 | 0.102 | 1.49e-08 | 2.98e-08 | |
| Had an author with Nature Index affiliation | 0.100 | 0.015 | 0.071 | 0.130 | 3.46e-08 | 3.46e-08 | |
| Last author publication age (yrs) | −0.003 | 0.001 | −0.004 | −0.001 | 8.61e-05 | 8.61e-05 |
In particular, having a preprint was associated with a 1.49 times higher Attention Score (95% CI 1.42 to 1.57) and 1.36 times more citations (95% CI 1.30 to 1.42) of the peer-reviewed article. These effect sizes were ~4 times larger than those for having an author with an affiliation in the U.S. or at a Nature Index institution. In a separate meta-analysis, the amount of time between release of the preprint and publication of the article was positively associated with the article’s Attention Score, but not its citations (Supplementary files 9 and 10). Taken together, these results indicate that having a preprint is associated with a higher Attention Score and more citations independently of other article-level variables.
Because we calculated the MeSH term PCs separately for each journal, we did not perform a random-effects meta-analysis of the corresponding coefficients. However, within each journal, typically several PCs had p-value≤0.05 for association with Attention Score or citations (Figure 2—figure supplement 1). In addition, if we excluded the MeSH term PCs from the regression, the fold-changes for having a preprint increased modestly (Figure 2—figure supplement 2 and Supplementary file 11). These results suggest that the MeSH term PCs capture meaningful variation in scientific subfield between articles in a given journal.
Finally, using meta-regression, we found that the log fold-changes of the two metrics were not associated with the journal’s access model, Impact Factor, or percentage of articles with preprints (Table 2 and Supplementary file 12). Thus, these journal-level characteristics do not explain journal-to-journal variation in the differences in Attention Score and citations between articles with and without a preprint.
Table 2
Meta-regression across journals of log fold-changes for having a preprint.
A positive coefficient means the log fold-change for having a preprint increases as that variable increases (or if articles in that journal are immediately open access). However, coefficients for different variables have different units and are not directly comparable. P-values were adjusted using the Bonferroni-Holm procedure, based on having fit two models. Depending on the two p-values for a given variable, the procedure may have left one p-value unchanged. Regression statistics for the intercept are shown in Supplementary file 12.
| Metric | Journal-level variable | Coef. | Std. error | 95% CI (lower) | 95% CI (upper) | t-statistic | p-value | Adj. p-value |
|---|---|---|---|---|---|---|---|---|
| Attention Score | Immediately open access | 0.118 | 0.076 | −0.037 | 0.273 | 1.551 | 0.130 | 0.260 |
| log2(Impact Factor) | −0.025 | 0.040 | −0.107 | 0.057 | −0.616 | 0.542 | 0.542 | |
| log2(% of articles with preprints) | −0.064 | 0.032 | −0.129 | 0.001 | −1.991 | 0.054 | 0.109 | |
| Citations | Immediately open access | −0.013 | 0.069 | −0.152 | 0.126 | −0.187 | 0.853 | 0.853 |
| log2(Impact Factor) | 0.044 | 0.036 | −0.030 | 0.117 | 1.211 | 0.234 | 0.468 | |
| log2(% of articles with preprints) | 0.037 | 0.029 | −0.022 | 0.095 | 1.283 | 0.208 | 0.208 |
Discussion
The decision of when and where to disclose the products of one’s research is influenced by multiple factors. Here we find that having a preprint on bioRxiv is associated with a higher Altmetric Attention Score and more citations of the peer-reviewed article. The associations appear independent of several other article- and author-level variables and unrelated to journal-level variables such as access model and Impact Factor.
The advantage of stratifying by journal as we did here is that it accounts for the journal-specific factors – both known and unknown – that affect an article’s Attention Score and citations. The disadvantage is that our results only apply to journals that have published at least 50 articles that have a preprint on bioRxiv (with multidisciplinary journals excluded). In fact, our preprint counts may be an underestimate, since some preprints on bioRxiv have been published as peer-reviewed articles, but not yet detected as such by bioRxiv's internal system (Abdill and Blekhman, 2019). Furthermore, the associations we observe may not apply to preprints on other repositories such as arXiv Quantitative Biology and PeerJ Preprints.
We used the Altmetric Attention Score and number of citations on CrossRef because, unlike other article-level metrics such as number of views, both are publicly and programmatically available for any article with a DOI. However, both metrics are only crude proxies for an article’s true scientific impact, which is difficult to quantify and can take years or decades to assess.
For multiple reasons, our analysis does not indicate whether the associations between preprints, Attention Scores, and citations have changed over time. First, historical citation counts are not currently available from CrossRef, so our data included each article’s citations at only one moment in time. Second, most journals had a relatively small number of articles with preprints and most preprints were relatively recent, so we did not model a statistical interaction between publication date and preprint status. We also largely ignored characteristics of the preprints themselves. In any case, the associations we observe may change as the culture of preprints in the life sciences evolves.
Grouping scientific articles by their research areas is an ongoing challenge (Piwowar et al., 2018; Waltman and van Eck, 2012). Although the principal components of MeSH term assignments are only a simple approximation, they do explain some variation in Attention Score and citations between articles in a given journal. Thus, our approach to estimating scientific subfield may be useful in other analyses of the biomedical literature.
Our heuristic approach to infer authors’ publication histories from their names and free-text affiliations in PubMed was accurate, but not perfect. The heuristic was necessary because unique author identifiers such as ORCID iDs currently have sparse coverage of the published literature. This may change with a recent requirement from multiple U.S. funding agencies (NIH, 2019), which would enhance future analyses of scientific publishing.
Because our data are observational, we cannot conclude that releasing a preprint is causal for a higher Attention Score and more citations of the peer-reviewed article. Even accounting for all the other factors we modeled, having a preprint on bioRxiv could be merely a marker for research likely to receive more attention and citations anyway. For example, perhaps authors who release their work as preprints are more active on social media, which could partly explain the association with Attention Score, although given the weak correlation between Attention Score and citations, it would likely not explain the association with citations. If there is a causal role for preprints, it may be related to increased visibility that leads to “preferential attachment” (Wang et al., 2013) while the manuscript is in peer review. These scenarios need not be mutually exclusive, and without a randomized trial they are extremely difficult to distinguish.
Altogether, our findings contribute to the growing observational evidence of the effects of preprints in biology (Fraser et al., 2019), and have implications for preprints in chemistry and medicine (Kiessling et al., 2016; Rawlinson and Bloom, 2019). Consequently, our study may help researchers and publishers make informed decisions about how to incorporate preprints into their work.
Methods
Collecting the data
Data came from four primary sources: PubMed, Altmetric, CrossRef, and Rxivist. We obtained data for peer-reviewed articles from PubMed using NCBI's E-utilities API via the rentrez R package (Winter, 2017). We obtained Altmetric Attention Scores using the Altmetric Details Page API via the rAltmetric R package. The Altmetric Attention Score is an aggregate measure of mentions from various sources, including social media, mainstream media, and policy documents (https://www.altmetric.com/about-our-data/our-sources/). We obtained numbers of citations using the CrossRef API (specifically, we used “is-referenced-by-count”). We obtained links between bioRxiv preprints and peer-reviewed articles using the CrossRef API via the rcrossref R package. We verified and supplemented the links from CrossRef using Rxivist (Abdill and Blekhman, 2019) via the Postgres database in the public Docker image (https://hub.docker.com/r/blekhmanlab/rxivist_data). We merged data from the various sources using the Digital Object Identifier (DOI) and PubMed ID of the peer-reviewed article.
We obtained Journal Impact Factors from the 2018 Journal Citation Reports published by Clarivate Analytics. We obtained journal access models from the journals' websites. As in previous work (Abdill and Blekhman, 2019), we classified access models as “immediately open” (in which all articles receive an open access license immediately upon publication) or “closed or hybrid” (anything else).
Starting with all publications indexed in PubMed, we applied the following inclusion criteria:
Published between January 1, 2015 and December 31, 2018 (inclusive). Since bioRxiv began accepting preprints on November 7, 2013, our start date ensured sufficient time for the earliest preprints to be published.
Had a DOI. This was required for obtaining Attention Score and number of citations, and excluded many commentaries and news articles.
Had a publication type in PubMed of Journal Article and not Review, Published, Erratum, Comment, Lecture, Personal Narrative, Retracted Publication, Retraction of Publication, Biography, Portrait, Autobiography, Expression of Concern, Address, or Introductory Journal Article. This filtered for original research articles.
Had at least one author. A number of editorials met all of the above criteria, but lacked any authors.
Had an abstract of sufficient length. A number of commentaries and news articles met all of the above criteria, but either lacked an abstract or had an anomalously short one. We manually inspected articles with short abstracts to determine a cutoff for each journal (Supplementary file 3).
Had at least one Medical Subject Headings (MeSH) term. Although not all articles from all journals had MeSH terms (which are added by PubMed curators), this requirement allowed us to adjust for scientific subfield within a journal using principal components of MeSH terms.
Inclusion criteria for bioRxiv preprints:
Indexed in CrossRef or Rxivist as linked to a peer-reviewed article in our dataset.
Released prior to publication of the corresponding peer-reviewed article.
Inclusion criteria for journals:
Had at least 50 peer-reviewed articles in our dataset previously released as preprints. Since we stratified our analysis by journal, this requirement ensured a sufficient number of peer-reviewed articles to reliably estimate each journal’s model coefficients and confidence intervals (Austin and Steyerberg, 2015).
We excluded the multidisciplinary journals Nature, Nature Communications, PLoS One, PNAS, Royal Society Open Science, Science, Science Advances, and Scientific Reports, since some articles published by these journals would likely not be released on bioRxiv, which could have confounded the analysis.
We obtained all data on September 28, 2019, thus all predictions of Attention Score and citations are for this date. Preprints and peer-reviewed articles have distinct DOIs, and accumulate Attention Scores and citations independently of each other. We manually inspected 100 randomly selected articles from the final set, and found that all 100 were original research articles. For those 100 articles, the Spearman correlation between number of citations from CrossRef and number of citations from Web of Science Core Collection was 0.98, with a mean difference of 2.5 (CrossRef typically being higher), which indicates that the citation data from CrossRef are reliable and different sources would likely not produce different results.
Inferring author-level variables
Institutional affiliation in PubMed is a free-text field, but is typically a series of comma-separated values with the country near the end. To identify the corresponding country of each affiliation, we used a series of heuristic regular expressions (Supplementary file 13 shows the number of affiliations for each identified country). Each author of a given article can have zero or more affiliations. For many articles, especially less recent ones, only the first author has any affiliations listed in PubMed, even though those affiliations actually apply to all the article’s authors (as verified by the version on the journal’s website). Therefore, the regression modeling used a binary variable for each article corresponding to whether any author had any affiliation in the United States.
To approximate institutions that may be associated with higher citation rates, we used the 2019 Nature Index for Life Sciences (Nature Index, 2019), which lists the 100 institutions with the highest fractional count of articles in Nature Index journals in the Life Sciences between January 1, 2018 and December 31, 2018. The fractional count accounts for the fraction of authors from that institution and the number of affiliated institutions per article. Nature Index journals are selected by panels of active scientists and are supposed to represent the “upper echelon” (Nature Index, 2014). They are not limited to journals of Nature Publishing Group. We used regular expressions to identify which affiliations corresponded to which Nature Index institutions. The regression modeling then used a binary variable for each article corresponding to whether any author had an affiliation at any of the Nature Index institutions.
For each article in our dataset, we sought to identify the last author’s *first* last-author publication, i.e., the earliest publication in which that person is the last author, in order to estimate how long a person has been a principal investigator. Author disambiguation is challenging, and unique identifiers are currently sparse in PubMed and bioRxiv. We developed an approach to infer an author’s previous publications in PubMed based only on that person’s name and affiliations.
The primary components of an author’s name in PubMed are last name, fore name (which often includes middle initials), and initials (which do not include last name). Fore names are present in PubMed mostly from 2002 onward. For each article in our dataset (each target publication), our approach went as follows:
Get the last author’s affiliations for the target publication. If the last author had no direct affiliations, get the affiliations of the first author. These are the target affiliations.
Find all publications between January 1, 2002 and December 31, 2018 in which the last author had a matching last name and fore name. We limited the search to last-author publications to approximate publications as principal investigator and to limit computation time. These are the query publications.
For each query publication, get that author’s affiliations. If the author had no direct affiliations, get the affiliations of the first author. These are the query affiliations.
Clean the raw text of all target and query affiliations (make all characters lowercase and remove non-alphanumeric characters, among other things).
Calculate the similarity between each target-affiliation-query-affiliation pair. Similarity was a weighted sum of the shared terms between the two affiliations. Term weights were calculated using the quanteda R package (Benoit et al., 2018) and based on inverse document frequency, i.e., log10(1/frequency), from all affiliations from all target publications in our dataset. Highly common (frequency >0.05), highly rare (frequency <10−4), and single-character terms were given no weight.
Find the earliest query publication for which the similarity between a target affiliation and a query affiliation is at least 4. This cutoff was manually tuned.
If the earliest query publication is within two years of when PubMed started including fore names, repeat the procedure using last name and initials instead of last name and fore name.
For a randomly selected subset of 50 articles (none of which had been used to manually tune the similarity cutoff), we searched PubMed and authors’ websites to manually identify each last author’s first last-author publication. The Spearman correlation between manually identified and automatically identified dates was 0.88, the mean error was 1.74 years (meaning our automated approach sometimes missed the earliest publication), and the mean absolute error was 1.81 years (Figure 1—figure supplement 1). The most common reason for error was that the author had changed institutions (Supplementary file 14).
Calculating principal components of MeSH term assignments
Medical Subject Headings (MeSH) are a controlled vocabulary used to index PubMed and other biomedical databases. For each journal, we generated a binary matrix of MeSH term assignments for the peer-reviewed articles (1 if a given term was assigned to a given article, and 0 otherwise). We only included MeSH terms assigned to at least 5% of articles in a given journal, and excluded the terms "Female" and "Male" (which referred to the biological sex of the study animals and were not related to the article's field of research). We calculated the principal components (PCs) using the prcomp function in the stats R package and scaling the assignments for each term to have unit variance. We calculated the percentage of variance in MeSH term assignment explained by each PC as that PC's eigenvalue divided by the sum of all eigenvalues. By calculating the PCs separately for each journal, we sought to capture the finer variation between articles in a given journal rather than the higher-level variation between articles in different journals.
Quantifying the associations
Attention Scores are real numbers ≥ 0, whereas citations are integers ≥ 0. Therefore, for each journal, we fit two types of regression models for Attention Score and three for citations:
Log-linear regression, in which the dependent variable was log2(Attention Score + 1) or log2(citations + 1).
Gamma regression with a log link, in which the dependent variable was “Attention Score + 1” or “citations + 1”. The response variable for Gamma regression must be >0.
Negative binomial regression, in which the dependent variable was citations. The response variable for negative binomial regression must be integers ≥ 0.
Each model had the following independent variables for each peer-reviewed article:
Preprint status, encoded as 1 for articles preceded by a preprint and 0 otherwise.
Publication date (equivalent to time since publication), encoded using a natural cubic spline with three degrees of freedom. The spline provides flexibility to fit the non-linear relationship between citations (or Attention Score) and publication date. In contrast to a single linear term, the spline does not assume, for example, that the average difference in the dependent variable between a 0-year-old article and a 1-year-old article is the same as between a 4-year-old article and a 5-year-old article. Source: PubMed.
Number of authors, log-transformed because it was strongly right-skewed. Source: PubMed.
Number of references, log-transformed because it was strongly right-skewed. Sources: PubMed and CrossRef. For some articles, either PubMed or CrossRef lacked complete information on the number of references. For each article, we used the maximum between the two.
U.S. affiliation status, encoded as 1 for articles for which any author had a U.S. affiliation and 0 otherwise. Source: inferred from PubMed as described above.
Nature Index affiliation status, encoded as 1 for articles for which any author had an affiliation at an institution in the 2019 Nature Index for Life Sciences and 0 otherwise. Source: inferred from PubMed and the Nature Index data as described above.
Last author publication age, encoded as the amount of time in years by which publication of the peer-reviewed article was preceded by publication of the last author’s *first* last-author publication. Source: inferred from PubMed as described above.
Top 15 PCs of MeSH term assignments (or all PCs, if there were fewer than 15). Source: calculated from PubMed as described above. Calculating the MeSH term PCs and fitting the regression models on a journal-wise basis means, for example, that the effect on Attention Score and citations of publishing a paper about Saccharomyces cerevisiae or about diffusion magnetic resonance imaging depends on whether the paper is in Molecular Cell or in Neuroimage.
We evaluated goodness-of-fit of each regression model using mean absolute error and mean absolute percentage error. To fairly compare the different model types, we converted each prediction to the original scale of the respective metric prior to calculating the error.
As a secondary analysis, we added to the log-linear regression model a variable corresponding to the amount of time in years by which release of the preprint preceded publication of the peer-reviewed article (using 0 for articles without a preprint). We calculated this variable based on preprint release dates from CrossRef and Rxivist and publication dates from PubMed.
We extracted coefficients and their 95% confidence intervals from each log-linear regression model. Because preprint status is binary, its model coefficient corresponded to a log2 fold-change. We used each regression model to calculate predicted Attention Score and number of citations, along with corresponding 95% confidence intervals and 95% prediction intervals, given certain values of the variables in the model. For simplicity in the rest of the manuscript, we refer to exponentiated model coefficients as fold-changes of Attention Score and citations, even though they are actually fold-changes of “Attention Score + 1” and “citations + 1”.
We performed each random-effects meta-analysis based on the Hartung-Knapp-Sidik-Jonkman method (IntHout et al., 2014) using the metagen function of the meta R package (Schwarzer et al., 2015). We performed meta-regression by fitting a linear regression model in which the dependent variable was the journal’s coefficient for preprint status (from either Attention Score or citations) and the independent variables were the journal’s access model (encoded as 0 for “closed or hybrid” and 1 for “immediately open”), log2(Impact Factor), and log2(percentage of articles released as preprints). We adjusted p-values for multiple testing using the Bonferroni-Holm procedure, which is uniformly more powerful than the standard Bonferroni procedure (Holm, 1979).
Data availability
Code and data to reproduce this study are available on Figshare (https://doi.org/10.6084/m9.figshare.8855795).
Data availability
Code and data to reproduce this study are available on Figshare (https://doi.org/10.6084/m9.figshare.8855795). In accordance with Altmetric's data use agreement, the Figshare repository does not include each article's Altmetric data, which are available from Altmetric after obtaining an API key.
-
figshareReproducible results for: Releasing a preprint is associated with more attention and citations for the peer-reviewed article.https://doi.org/10.6084/m9.figshare.8855795
References
-
The number of subjects per variable required in linear regression analysesJournal of Clinical Epidemiology 68:627–636.https://doi.org/10.1016/j.jclinepi.2014.12.014
-
Quanteda: an R package for the quantitative analysis of textual dataJournal of Open Source Software 3:774.https://doi.org/10.21105/joss.00774
-
Ten simple rules to consider regarding preprint submissionPLOS Computational Biology 13:e1005473.https://doi.org/10.1371/journal.pcbi.1005473
-
Citations increase with manuscript length, author number, and references cited in ecology journalsEcology and Evolution 6:7717–7726.https://doi.org/10.1002/ece3.2505
-
A simple sequentially rejective multiple test procedureScandinavian Journal of Statistics, Theory and Applications 6:65–70.
-
ChemRXiv: a chemistry preprint serverACS Nano 10:9053–9054.https://doi.org/10.1021/acsnano.6b07008
-
A new methodology for constructing a publication-level classification system of scienceJournal of the American Society for Information Science and Technology 63:2378–2392.https://doi.org/10.1002/asi.22748
-
Quantifying long-term scientific impactScience 342:127–132.https://doi.org/10.1126/science.1237825
-
PreprintRentrez: an R package for the NCBI eUtils APIPeerJ Preprints.https://doi.org/10.7287/peerj.preprints.3179v2
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
-
Olavo AmaralReviewer; Universidade Federal do Rio de Janeiro, Brazil
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
[Editors’ note: the original version of this study was declined after peer review. The authors submitted a revised version, which was reviewed, revised again, and accepted. The decision letter sent after the first round of peer review is immediately below, followed by the decision letter sent after the second round of peer review.]
Thank you for submitting your manuscript "Releasing a preprint is associated with more attention and citations" to eLife for consideration as a Feature Article. Your article has been reviewed by three peer reviewers, and the evaluation has been overseen by the eLife Features Editor.
Our decision has been reached after consultation between the reviewers. Based on these discussions and the individual reviews below, we regret to inform you that your work will not be considered further for publication in eLife.
Reviewer #1:
The submitted manuscript, "Releasing a preprint is associated with more attention and citations," examines more than 45,000 publications from 26 biology journals and compares the citation counts and Altmetric Attention Scores of publications that were or were not previously released as a preprint. After controlling for journal, publication date and a cleverly constructed "scientific subfield," the authors find articles that had been pre-printed are associated with higher citation counts and Attention Scores, and that these effects are diminished in journals with higher Journal Impact Factors. The code availability is exemplary, the results are conveyed clearly, and it's laudable that the Discussion section is so frank regarding the limitations of the study. However, I am unsure whether those limitations are acceptable – if they are, there are several issues that should be addressed before publication.
My primary concern is the large number of confounders that are unaccounted for in the study. Though the authors make a convincing case that the publications with preprints do have an advantage in citations and attention score, there is little attention given in the analysis to the numerous factors that have already been linked to increased attention or citations, factors that may be the actual driver of this effect, rendering preprint status irrelevant. For example, perhaps (published) preprints are longer than articles without preprints [1,2] or have more authors [2]. The results could be affected if senior authors with other highly cited papers are more likely to post a preprint [3,4], or if bioRxiv has an overrepresentation of researchers from "elite" institutions [5] or large research groups [6]. Or maybe authors enthusiastic about preprints also just happen to be more active on Twitter.
In short, I am unsure of the utility of measuring complex dynamics like citation count and attention score without incorporating any data about authors. Most importantly, I do not believe this work provides adequate support for the statement in its Abstract that "this observational study can help researchers and publishers make informed decisions about how to incorporate preprints into their work." This assertion is directly contradicted by the Discussion section, which accurately assesses the shortcomings of the study. I sympathize with the difficulties in obtaining data on authors, and I do not believe those shortcomings could be remediated in the two-month revision timeline given in the review instructions. I leave it to the discretion of the editors whether this represents an incremental improvement significant enough for publication.
Additional comments:
Results, first paragraph: I believe there are several ways for this finding to be strengthened, some of which pose significant problems as presented currently:
- Most straightforwardly, I don't believe the statement accurately reflects what is actually being measured: "Across journals, each article's Attention Score and citations were weakly correlated" does not convey that the metrics within each journal, and then again within individual years, are, on average, weakly correlated. Clarification would be helpful.
- This result would also benefit from elaboration, here or in the Materials and methods section, regarding why the data were segmented this way to begin with. While other results indicate that journal and year both influence the difference between preprinted and non-preprinted publications, is there any evidence that journal and/or year influence the relationship between citations and attention score overall? Comparing all articles together, it appears citations and attention score are correlated with Spearman's rho=0.32. Is there any benefit to instead separating the articles into "journal-years," calculating separate rho values, and finding the median is instead 0.29? If it is to measure the consistency of the relationship across years and journals, this should be stated more explicitly.
- The reported median Spearman correlation and the contents of Figure S2 exclude any consideration of the significance of the correlations, which, while it may not substantially affect the median, does obscure how frequently a journal-year does not have a significant correlation between citations and attention score. A quick estimation using the p-values from the "cor.test" function, corrected for performing 103 correlation tests, suggests there are 16 journal-years that have no significant correlation-changing those rho values to 0 makes Figure S2 look very different, and the largest bin becomes the one indicating no correlation at all. That said, I don't have the knowledge to say if the assumptions used to generate p-values in that package are appropriate here, since the end result is a median of correlations. At the least, if the authors keep the median Spearman correlation, this finding would benefit from performing a permutation test to help us understand whether this median is any better than would be expected at random: Scrambling the citation numbers (possibly within each journal?) and calculating a new median, say, 1,000 times, may help reveal how unexpected a median rho of 0.29 actually is.
Results, second paragraph: I'm curious about the reasoning given for using a log transformation here: "since both metrics were greater than or equal to zero and spanned orders of magnitude." While those are reasonable tests to see whether it's possible to log-transform the data, it seems like the actual reason was because it enables using the regression to discuss log-fold change rather than differences in absolute measurements. This statement would benefit from clarification, or a citation supporting why the stated criteria is appropriate.
Table 2: The authors state that they present uncorrected p-values here because "for each metric, the three variables were tested in one model." This is true, and a nice benefit of meta-regression. However, the paper describes the results of two different meta-regression models, which test two different hypotheses (one regarding attention score, and another regarding citations). Though a p-value threshold is not specified for these tests (Results, final paragraph, states only "significantly associated"), convention would suggest the cutoff was 0.05. A Bonferroni correction (for two tests) would push all p values in Table 2 above this threshold-the authors should correct these measurements and update the findings described in the final paragraph of the Results accordingly. Alternatively, it would be acceptable to leave these values as-is and provide further support for not correcting the p-values generated by multiple meta-regression analyses.
References:
(Not intended as a request for the authors to include citations to these papers, just offered here to support my feedback above.)
1) Falagas et al. 2013. The Impact of Article Length on the Number of Future Citations: A Bibliometric Analysis of General Medicine Journals. PLOS ONE. doi: 10.1371/journal.pone.0049476.
2) Fox et al. 2016. Citations increase with manuscript length, author number, and references cited in ecology journals. Ecology and Evolution. doi: 10.1002/ece3.2505.
3) Fu and Aliferis. 2008. Models for Predicting and Explaining Citation Count of Biomedical Articles. AMIA Annual Symposium Proceedings. PMID: 8999029.
4) Perc. 2014. The Matthew effect in empirical data. Journal of the Royal Society Interface. doi: 10.1098/rsif.2014.0378.
5) Medoff. 2007. Evidence of a Harvard and Chicago Matthew Effect. Journal of Economic Methodology. doi: 10.1080/13501780601049079.
6) van Raan. 2006. Performance‐related differences of bibliometric statistical properties of research groups: Cumulative advantages and hierarchically layered networks. Journal of the American Society for Information Science and Technology. doi: 10.1002/asi.20389.
Reviewer #2:
The article investigates the relationship between preprint posting and subsequent citations and Altmetric scores of published articles. The topic is interesting and worthy of attention and, although it has been approached previously in the literature with similar conclusions (Serghiou and Ioannidis, 2018), the authors perform a much more detailed analysis of the subject. Data and code for the performed analyses are available in figshare.
My major concerns and suggestions are the following:
1) Although the statistics used, based on multivariate linear regression, are generally solid, the visualization of results is frequently less intuitive than it could be, and seems to be aimed at the data scientist more than at the average reader. In summary:
- In Figure 1A, although the forest plot is a great way to show how results vary by journal, it does not allow the reader to appreciate the range of variability of citations among articles with and without preprints (as the confidence intervals shown depend both on variability and on sample size). As the article is ultimately the unit of analysis here, I miss a standard scatter plot showing unit-level citations for articles with and without preprints – either for the whole set of articles or divided by journal (although this might be too large and better left to a supplementary figure).
- Again in terms of visualizing variability, are the authors sure about using log scales in the figures? Although logarithmic transformation is useful for statistics, it is once again not the most intuitive way for the reader to get a sense of the full range of variability.
- Some of the supplementary figures (particularly Figures S3 and S5) are quite hard to read and understand due to the sheer volume of data presented and might not be very useful to the reader.
2) Did the author evaluate the interaction between preprints and publication year in the model? This seems like an important question to better assess the likelihood of causality between preprint availability and citations – for more recent articles, I would expect the preprint-related advantage to be greater, as the preprint-only period will account for a larger part of the paper's lifetime. Over time, this advantage is likely to taper off. On the other hand, if an interaction between publication year and preprint availability is not observed, this might suggest that the citation advantage is not necessarily due to the preprint's visibility, but rather to other features or confounders (e.g. articles with preprints being of higher interest, or stemming from groups with more visibility).
3) Similarly, it would be interesting to investigate whether metrics of the preprint such as altmetric scores, number of downloads, or even citations – all of which are available in bioRxiv or CrossRef) are related to the citation advantage for their published versions. Although showing that the advantage is larger for preprints with more visibility does not prove that posting a preprint leads to more citations, finding that the advantage does not correlate with attention received to the preprint would argue against it. All of these could be performed as secondary analyses similar to the one performed for the number of days the preprint preceded the peer-reviewed article.
4) The criteria for journal selection should be explained more clearly for the reader to assess the sample’s representativeness. Moreover, the principal components used in subfield analysis could be better described (explicitly showing the terms with high loading in each of them) for one to get a sense of how meaningful they are to define subfields. Both of these themes are expanded in the minor comments.
Reviewer #3:
This article first identified 26 journals in the life sciences that have published at least 50 articles with a preprint on bioRxiv. For each article published in these journals between 2015-2018 it then extracted citation count from CrossRef, attention score from Altmetric and presence of a preprint from CrossRef and Rxivist. It then used log-transformed linear regression to quantify the association of having a preprint to citation count and attention score, adjusting for time since publication using a spline and scientific field using principal components analysis (PCA) of MeSH terms. It finally used meta-regression to conclude that across journals, overall, having a preprint was associated with 1.53 higher attention score and 1.31 higher citation count.
The authors should be commended for attempting to study and promote the advantages of preprints, validate and extend previous work, for openly providing their data and code and for including a good limitations section. However, the chosen method of data collection is highly prone to selection bias, many of the descriptive and analytic choices are poorly justified and the magnitude of association, wherever presented, is quantified in relative rather than absolute terms, which in the setting of highly skewed data is very misleading.
As such, in view of significant limitations, I am afraid I cannot recommend publication at this time. In addition, there is a preprint on bioRxiv with seemingly more thorough and compelling analyses than the current manuscript (Fraser et al., 2019: https://www.biorxiv.org/content/10.1101/673665v1).
Major concerns:
1) The data collection process introduced serious selection bias. First, the manuscript uses a non-standard approach to recognizing research articles on PubMed, instead of using the "publication type" field. By using the "date received" and "date published" fields, this procedure immediately excludes dozens of journals that do not publish those dates, such as PNAS, which also happens to rank 6th in terms of total number of preprints published. Second, it is unclear why the manuscript only considers journals that have published at least 50 preprints. This decision introduces selection bias because journals publishing more articles will proportionally have more preprints and journals in certain fields publish more articles/preprints than others. Indeed, a quick look through Table 1 confirms that this analysis only includes articles from very large journals (e.g. PLoS journals) or from fields in which preprints are very popular (e.g. neuroscience and genetics). Third, it is unclear what the manuscript considers 'life sciences', what journals were initially eligible and what journals were excluded because of this definition – for example, what percentage of the articles published by a journal have to be "non-life-science" for it to be excluded?
2) Multiple problems with descriptive and regression analyses. First, it is impossible to appreciate and interpret the findings of the regression analyses without descriptive statistics. The manuscript has to provide a table with descriptive statistics about all covariates included in each regression (in terms of median and interquartile range) as well as a univariable test for each (e.g. p-values from a non-parametric test). Second, such count data are notoriously skewed. As such, even though the log-transformation attempts to capture this skewness, the confidence intervals and p-values may still be wrong. I recommend that the authors instead use bootstrapped confidence intervals and p-values, which can be calculated using the confint(model, method = "boot", boot.type = "basic", nsim = 2000) function of the lme4 package. I also recommend that the manuscript (a) uses a Negative Binomial regression instead of the log-transformation of the response and (b) reports on the diagnostic procedures used to confirm appropriate fit (e.g. by investigating Pearson residuals). The manuscript did well in presenting Figure S8 to illustrate effects without adjusting for the principal components (PCs), the number of which in relation to the number of preprints was quite large (the 1 covariate per 10 outcomes rule of thumb was violated in about ~ 70% of the journals (18/26)), to confirm the apparent absence of overfitting.
3) Interpretation of effect size is in relative rather than absolute terms. When presented, the size of association is interpreted in relative terms (e.g. 1.53 times), instead of absolute terms (e.g. a difference of 2 in median attention score, from 20 to 22). Relative terms are less meaningful and tend to unduly exaggerate the effects estimated. I recommend (a) that the authors present all measures of association (unlike Table 2, which only presents t-statistics) and (b) that all relative terms are either replaced or accompanied by absolute terms; here is an excellent guide on how to do this: https://www.healthnewsreview.org/toolkit/tips-for-understanding-studies/absolute-vs-relative-risk/. I also recommend that any talk of "statistically significant" or "not significant" is replaced by the magnitude of association, as this is what truly matters, and statistical significance language is often confusing and misleading to readers.
4) Inadequate adjustment for scientific field. Even though the authors correctly identify that adjusting for scientific field is hard, the PCA does not convincingly address this concern. First, the approach of using a fixed number of PCs for each journal, rather than a fixed percent of variance explained, means that in half of the journals (13/26) the PCs only explain 50% of the variance due to scientific field or less. Second, the approach of refitting the PCA within each journal, means that even though there was an attempt to account for within-journal variability in scientific field, the between-journal variability is not being accounted for. Third, because of these points, the meta-regression results in a messy estimate of effect from the combination of heterogeneous values (as seen in Figure 1) emanating from regressions adjusting for different study fields to different extends (this heterogeneity was never quantified). The manuscript could address these issues by (a) using a sensitivity analysis to explore the impact of adjusting for different numbers of PCs, (b) using previously published methods to account for scientific field (e.g. Piwowar et al., 2018) or (c) matching articles for subject field using a chosen measure of distance (e.g. Mahalanobis distance) and only using pairs within a pre-specified maximum distance from each other.
5) Lacking in principles of good scientific practice. Even though the authors should be commended for making their data and code available in a neatly-put ZIP file on figshare as well as making their article available as a preprint on bioRxiv, the manuscript would significantly benefit from the following additional practices: (a) make the protocol of this study openly available on either figshare or OSF Registries (https://osf.io/registries), (b) abide by and cite the STROBE guidelines for reporting observational studies (http://www.equator-network.org/reporting-guidelines/strobe/) and (c) include at least a statement on their sources of funding.
6) Poor reporting. This manuscript could derive significant benefit from (a) further and more comprehensive explanation of its methods (e.g. why the choice of 50 or 200, why use regressions followed by meta-regression instead of a random effects model to start with, why use log-transformation instead of Negative Binomial, why use the quoted type of meta-regression, why use the current covariates and not more/less, etc.), (b) avoiding language that may not be familiar to many readers (e.g. fold-change, population stratification, citations + 1, etc.) and (c) adding explanations to figures in the supplement (e.g. what do Figure 1—figure supplement 6 and Figure 1—figure supplement 7 tell us about the PCs, etc.). I actually had to read the Results in combination with the Materials and methods a couple of times to understand that a different regression was fitted for each journal.
[Editors' note: below is the decision letter sent after the second round of peer review.]
Thank you for submitting the revised version of "Releasing a preprint is associated with more attention and citations for the peer-reviewed article" to eLife. The revised version has been reviewed by two of the three reviewers who reviewed the previous version. The following individuals involved in review of your submission have agreed to reveal their identity: Olavo Amaral (Reviewer #1).
The reviewers have discussed the reviews with one another and myself, and we would like you to submit a revised version that addresses the points raised by the reviewers (see below). In particular, it is important that the datasets are better described so that other researchers can use them (see points 1 and 3 from Reviewer #1). Reviewer #1 also asks for some further analyses: these are optional – please see below for more details.
Reviewer #1:
The manuscript has been extensively revised and some of my main issues with it have been solved. In particular, methodology (especially article inclusion criteria) is much better described, and data visualization has been improved in many of the figures.
1) However, I still have some issues with data presentation, in particular concerning the supplementary files in which much of the data requested by reviewers has been included. These tables are essentially datasets in. csv format with no legend or clear annotation for the meaning of each column, which is not always obvious from the variable name. Although inclusion of this material is laudable in the sense of data sharing, if the authors mean to use them as a meaningful way to present the results cited in the text, I feel that it is unfair to leave the burden of understanding and analyzing the data on the reader. If they are meant as tables in a scientific paper, it is the author's job to synthesize the data and make them clear to the reader through formatting and annotation, including making variable names self-explanatory and providing legends.
Other general concerns involving analysis are described below:
2) Why is "affiliation in the US" the only geographical factor analyzed? This is rather US-centric, and does not really capture the vast differences between countries in the "non-US" category. Can't the authors make a more meaningful division – for example, based on region/continent, or of economical/scientific development of the country of affiliation?
Note from editor: Please either perform this extra analysis or explain why "affiliation in the US" is the only geographical factor analyzed.
3) I still can get no intuitive meaning of what each of the principal components stand for, and cannot evaluate whether they indeed capture what they mean to (e.g. scientific subfield). The authors do provide a supplementary file with the PC loading, but as the other supplementary files, it is pretty much the raw data, and don't think it's fair for the reader to have to mine it on its own to look for meaning. Can't the authors provide a list of the top MeSH terms loading onto each principal component (as a word cloud, for example), so as to make the meaning of each of them somewhat intuitive?
4) Moreover, if I understood correctly, the principal components are calculated separately for each journal – thus, their meaning varies from one journal to the next. Although that might increase their capability of capturing subfield-specific distinctions, this probably increases the potential that they capture noise rather than signal, due both to sample size decrease and to a decrease in meaningful variability within individual journals. Wouldn't it be more interesting to define subfields based on principal components for the whole sample? Note that this would have the added bonus of allowing inclusion of subfield in the metaregression analysis, and would probably facilitate visualization of the main factors loading onto each component, which would no longer be journal-dependent.
Note from editor: Please either perform this extra analysis or address the comments above about the consequences of the principal components being journal-specific.
5) I very much miss a table of descriptives and individual univariate associations for each variable included in the model before the data on multivariate regression are presented (as mentioned by reviewer #3 in their comments on the first version). Once again, I don't think that throwing in the raw data as a supplementary file substitutes for that.
6) If the authors used time since publication as one of the variables in the model, why didn't they directly test the interaction between this and having a preprint to see whether the relationship changes over time, rather than not doing it and discussing it in the limitations? I understand that there might be confounders, as the authors appropriately discuss in the response to reviewers. However, I feel that discussing the results for the interaction, taking into account the possible confounders and limitations, is still likely to be more interesting than discussing the limitations without a result.
Note from editor: Performing this extra analysis is optional.
Reviewer #2:
The revised manuscript includes a thorough response to the initial comments from reviewers. I believe the analysis has been much improved, and the manuscript now more clearly addresses the concerns that could not be practically addressed. There are only have a few points that could benefit from elaboration within the text.
Introduction, first paragraph: A concern in the previous review was that the statement regarding the proportion of papers that were preprinted was not supported by the provided citation. Though the authors state they have clarified the statement regarding "the number of preprints released [...] is only a fraction of the number of peer reviewed articles published," it remains true that the cited paper says nothing about the overall number of published papers. If the authors want to include a statement about the proportion of published papers, I would point them toward a dataset such as this one, which may provide an acceptable estimate: Penfold NC, Polka J. (2019). Preprints in biology as a fraction of the biomedical literature (Version 1.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3256298
Materials and methods, subsection “Quantifying the associations”: It's still not clear why a spline was used to find the publication date instead of, say, the number of days since 1 Jan 2015. I'm not disputing that it's an appropriate way to encode the dates, but elaboration, as mentioned by a previous reviewer, would be helpful for people like me who have not explicitly encountered this technique before.
Discussion: A previous review comment was that authors with large social media followings may be confounding the analysis by giving themselves a publicity advantage that wasn't included in the analysis. The authors state in their response, "given the weak correlation between Attention Score and citations, it seems unlikely this could explain the effect of preprint status on citations." This is a key point and an interesting rebuttal to the initial suggestion, but I don't believe it's made clear in the paper itself, which says only that online popularity "would likely not explain the association with citations." The manuscript would benefit from clarification here to point out that there is only a loose connection between Attention Score and citations.
Table 1 and Table 2: I believe the advice for multiple-test correction in my earlier review was misguided, I apologize. Though Table 1 now includes adjusted p-values, I'm confused by the approach taken. For 5 of the given p-values, the adjusted value is 2p, while the other 5 have identical adjusted values. Can the authors please check if these values are typos: if they are not, I would suggest they consult a statistician about this analysis, and also about the analysis in Table 2.
https://doi.org/10.7554/eLife.52646.sa1Author response
[Editors’ note: this is the author response to the decision letter sent after the first round of peer review.]
Reviewer #1:
[…]
My primary concern is the large number of confounders that are unaccounted for in the study. Though the authors make a convincing case that the publications with preprints do have an advantage in citations and attention score, there is little attention given in the analysis to the numerous factors that have already been linked to increased attention or citations, factors that may be the actual driver of this effect, rendering preprint status irrelevant.
For example, perhaps (published) preprints are longer than articles without preprints [1,2] or have more authors [2]. The results could be affected if senior authors with other highly cited papers are more likely to post a preprint [3,4], or if bioRxiv has an overrepresentation of researchers from "elite" institutions [5] or large research groups [6]. Or maybe authors enthusiastic about preprints also just happen to be more active on Twitter.
In short, I am unsure of the utility of measuring complex dynamics like citation count and attention score without incorporating any data about authors.
Most importantly, I do not believe this work provides adequate support for the statement in its abstract that "this observational study can help researchers and publishers make informed decisions about how to incorporate preprints into their work." This assertion is directly contradicted by the Discussion section, which accurately assesses the shortcomings of the study. I sympathize with the difficulties in obtaining data on authors, and I do not believe those shortcomings could be remediated in the two-month revision timeline given in the review instructions. I leave it to the discretion of the editors whether this represents an incremental improvement significant enough for publication.
Thank you for the constructive feedback. We have now added several variables to the model to reduce the possibility of confounding. Thus, for each peer-reviewed article, we also include:
- number of authors;
- number of references;
- whether any author had an affiliation in the U.S.;
- amount of time since the last author’s first last-author publication.
All these variables are positively associated with Attention Score and citations, except surprisingly, the last one. Importantly, even after adding these variables to the model, the effect size of releasing a preprint is just as strong. We believe this revision addresses the primary shortcoming in our original submission and improves the credibility of our results. We have revised the manuscript accordingly, including adding the appropriate references to prior work.
It could certainly be true that authors enthusiastic about preprints also just happen to be more active on Twitter, which could partly explain the effect of preprint status on Attention Score. However, given the weak correlation between Attention Score and citations, it seems unlikely this could explain the effect of preprint status on citations. We have added this point to the Discussion.
Additional commetns:
Results, first paragraph: I believe there are several ways for this finding to be strengthened, some of which pose significant problems as presented currently:
- Most straightforwardly, I don't believe the statement accurately reflects what is actually being measured: "Across journals, each article's Attention Score and citations were weakly correlated" does not convey that the metrics within each journal, and then again within individual years, are, on average, weakly correlated. Clarification would be helpful.
We have simplified and clarified this calculation to be the Spearman correlation between Attention Score and citations within each journal, ignoring time as a variable. The two metrics are still only weakly correlated, and we do not believe a p-value is necessary to make this point. We were originally trying to deal with the fact that both metrics could vary over time, but this turned out to be an unnecessary complication.
- This result would also benefit from elaboration, here or in the Materials and methods section, regarding why the data were segmented this way to begin with. While other results indicate that journal and year both influence the difference between preprinted and non-preprinted publications, is there any evidence that journal and/or year influence the relationship between citations and attention score overall? Comparing all articles together, it appears citations and attention score are correlated with Spearman's rho=0.32. Is there any benefit to instead separating the articles into "journal-years," calculating separate rho values, and finding the median is instead 0.29? If it is to measure the consistency of the relationship across years and journals, this should be stated more explicitly.
See response above.
- The reported median Spearman correlation and the contents of Figure S2 exclude any consideration of the significance of the correlations, which, while it may not substantially affect the median, does obscure how frequently a journal-year does not have a significant correlation between citations and attention score. A quick estimation using the p-values from the "cor.test" function, corrected for performing 103 correlation tests, suggests there are 16 journal-years that have no significant correlation-changing those rho values to 0 makes Figure S2 look very different, and the largest bin becomes the one indicating no correlation at all. That said, I don't have the knowledge to say if the assumptions used to generate p-values in that package are appropriate here, since the end result is a median of correlations. At the least, if the authors keep the median Spearman correlation, this finding would benefit from performing a permutation test to help us understand whether this median is any better than would be expected at random: Scrambling the citation numbers (possibly within each journal?) and calculating a new median, say, 1,000 times, may help reveal how unexpected a median rho of 0.29 actually is.
See response above.
Results, second paragraph: I'm curious about the reasoning given for using a log transformation here: "since both metrics were greater than or equal to zero and spanned orders of magnitude." While those are reasonable tests to see whether it's possible to log-transform the data, it seems like the actual reason was because it enables using the regression to discuss log-fold change rather than differences in absolute measurements. This statement would benefit from clarification, or a citation supporting why the stated criteria is appropriate.
We have expanded and clarified our reasoning for the regression modeling. Indeed, one reason we used log-linear regression is that it allowed us to compare the journal-wise log fold-changes, which are on a relative scale.
More importantly, log-linear regression gave the best fit to the data. We have now included direct comparisons of log-linear regression, Gamma regression with a log link, and negative binomial regression (the last one only for citations, since Attention Scores are not necessarily integers). For both metrics and for all journals, and comparing all models on the original scale of the respective metric, log-linear regression had the smallest mean absolute error and mean absolute percentage error.
Table 2: The authors state that they present uncorrected p-values here because "for each metric, the three variables were tested in one model." This is true, and a nice benefit of meta-regression. However, the paper describes the results of two different meta-regression models, which test two different hypotheses (one regarding attention score, and another regarding citations). Though a p-value threshold is not specified for these tests (Results, final paragraph, states only "significantly associated"), convention would suggest the cutoff was 0.05. A Bonferroni correction (for two tests) would push all p values in Table 2 above this threshold-the authors should correct these measurements and update the findings described in the final paragraph of the Results accordingly. Alternatively, it would be acceptable to leave these values as-is and provide further support for not correcting the p-values generated by multiple meta-regression analyses.
Point taken. We have purged the manuscript of all language related to statistical significance, and added Bonferroni-Holm correction where necessary.
References:
(Not intended as a request for the authors to include citations to these papers, just offered here to support my feedback above.)
1) Falagas et al. 2013. The Impact of Article Length on the Number of Future Citations: A Bibliometric Analysis of General Medicine Journals. PLOS ONE. doi: 10.1371/journal.pone.0049476.
2) Fox et al. 2016. Citations increase with manuscript length, author number, and references cited in ecology journals. Ecology and Evolution. doi: 10.1002/ece3.2505.
3) Fu and Aliferis. 2008. Models for Predicting and Explaining Citation Count of Biomedical Articles. AMIA Annual Symposium Proceedings. PMID: 8999029.
4) Perc. 2014. The Matthew effect in empirical data. Journal of the Royal Society Interface. doi: 10.1098/rsif.2014.0378.
5) Medoff. 2007. Evidence of a Harvard and Chicago Matthew Effect. Journal of Economic Methodology. doi: 10.1080/13501780601049079.
6) van Raan. 2006. Performance‐related differences of bibliometric statistical properties of research groups: Cumulative advantages and hierarchically layered networks. Journal of the American Society for Information Science and Technology. doi: 10.1002/asi.20389.
Reviewer #2:
[…] My major concerns and suggestions are the following:
1) Although the statistics used, based on multivariate linear regression, are generally solid, the visualization of results is frequently less intuitive than it could be, and seems to be aimed at the data scientist more than at the average reader. In summary:
- In Figure 1A, although the forest plot is a great way to show how results vary by journal, it does not allow the reader to appreciate the range of variability of citations among articles with and without preprints (as the confidence intervals shown depend both on variability and on sample size). As the article is ultimately the unit of analysis here, I miss a standard scatter plot showing unit-level citations for articles with and without preprints – either for the whole set of articles or divided by journal (although this might be too large and better left to a supplementary figure).
Thank you for the feedback. We have revised the figures for clarity. Among other changes, we have added a plot of expected Attention Score and citations for articles with and without a preprint in each journal. In the main text we show this plot with confidence intervals, which do get smaller as sample size increases. In the supplement we show the same plot with prediction intervals, which account for article-to-article variability and do not get smaller as sample size increases. Confidence intervals correspond to the estimate of a population mean, whereas prediction intervals correspond to the estimate of an individual observation.
We have explored various versions of a scatterplot, but the large number of articles, even within one journal, make it uninterpretable. The other advantage of the prediction interval is that it accounts for the other variables that we have now incorporated into the model, which a scatterplot would not.
- Again in terms of visualizing variability, are the authors sure about using log scales in the figures? Although logarithmic transformation is useful for statistics, it is once again not the most intuitive way for the reader to get a sense of the full range of variability.
We believe the revised figures have largely addressed this issue. Because the Attention Scores and citations span orders of magnitude across journals, using a linear scale would highly compress the data points for all but a few journals. The log scale makes it possible to visualize the results for each journal relatively fairly.
- Some of the supplementary figures (particularly Figures S3 and S5) are quite hard to read and understand due to the sheer volume of data presented and might not be very useful to the reader.
We have revised the supplementary figures. In some cases, we have moved the information to supplementary files.
2) Did the author evaluate the interaction between preprints and publication year in the model? This seems like an important question to better assess the likelihood of causality between preprint availability and citations – for more recent articles, I would expect the preprint-related advantage to be greater, as the preprint-only period will account for a larger part of the paper's lifetime. Over time, this advantage is likely to taper off. On the other hand, if an interaction between publication year and preprint availability is not observed, this might suggest that the citation advantage is not necessarily due to the preprint's visibility, but rather to other features or confounders (e.g. articles with preprints being of higher interest, or stemming from groups with more visibility).
Although we agree this is a fascinating suggestion, we are reluctant to perform such an analysis for a couple reasons. First, our data have a relatively small number of preprints and statistical interactions can be difficult to estimate reliably, especially because the rapid growth of preprints in the life sciences means that the majority of preprints in our dataset are linked to newer rather than older peer-reviewed articles. Also, because we encode publication date as a spline with three degrees of freedom, we would be adding three terms to the model, not just one.
Second, we believe the result would be difficult to interpret, because there are multiple factors that are difficult to disentangle. As you suggest, it’s possible that the advantage could taper off on a longer time scale (although the precise time scale is unclear). However, we also know that the advantage at the time of publication is zero (since all articles start at 0 Attention Score and citations). A single linear interaction would not capture non-monotonicity. Another issue is that because we only have Attention Score and citations at one moment in time (the time at which we queried the APIs), the oldest peer-reviewed articles with preprints in our dataset are also the ones published when preprints in the life sciences were just starting to take off, and thus may systematically differ from those with preprints published more recently.
The CrossRef API does not yet provide historical trends of number of citations, and the Altmetric API does not provide sufficient temporal resolution for historical Attention Score.
3) Similarly, it would be interesting to investigate whether metrics of the preprint such as altmetric scores, number of downloads, or even citations – all of which are available in bioRxiv or CrossRef) are related to the citation advantage for their published versions. Although showing that the advantage is larger for preprints with more visibility does not prove that posting a preprint leads to more citations, finding that the advantage does not correlate with attention received to the preprint would argue against it. All of these could be performed as secondary analyses similar to the one performed for the number of days the preprint preceded the peer-reviewed article.
Here we encounter a similar difficulty. To do such an analysis fairly and avoid analyzing positive feedback loops (e.g., in which the preprint gets attention and citations due to the peer-reviewed article), we would want Attention Scores and number of citations prior to publication of the peer-reviewed article. Because we lack sufficient historical data, we have left this analysis for future work.
4) The criteria for journal selection should be explained more clearly for the reader to assess the sample's representativeness. Moreover, the principal components used in subfield analysis could be better described (explicitly showing the terms with high loading in each of them) for one to get a sense of how meaningful they are to define subfields. Both of these themes are expanded in the minor comments.
We have revised and clarified the inclusion criteria for peer-reviewed articles and journals. We have also moved the PC loadings to a supplementary file, where they are easier to read.
Reviewer #3:
[…]
The authors should be commended for attempting to study and promote the advantages of preprints, validate and extend previous work, for openly providing their data and code and for including a good limitations section. However, the chosen method of data collection is highly prone to selection bias, many of the descriptive and analytic choices are poorly justified and the magnitude of association, wherever presented, is quantified in relative rather than absolute terms, which in the setting of highly skewed data is very misleading.
As such, in view of significant limitations, I am afraid I cannot recommend publication at this time. In addition, there is a preprint on bioRxiv with seemingly more thorough and compelling analyses than the current manuscript (Fraser et al., 2019: https://www.biorxiv.org/content/10.1101/673665v1).
Thank you for your feedback. We have thoroughly revised the analysis and manuscript in response to your concerns. We appreciate the study by Fraser et al. We believe our work has several strengths, and that the two studies complement each other well.
Major concerns:
1) The data collection process introduced serious selection bias. First, the manuscript uses a non-standard approach to recognizing research articles on PubMed, instead of using the "publication type" field. By using the "date received" and "date published" fields, this procedure immediately excludes dozens of journals that do not publish those dates, such as PNAS, which also happens to rank 6th in terms of total number of preprints published. Second, it is unclear why the manuscript only considers journals that have published at least 50 preprints. This decision introduces selection bias because journals publishing more articles will proportionally have more preprints and journals in certain fields publish more articles/preprints than others. Indeed, a quick look through Table 1 confirms that this analysis only includes articles from very large journals (e.g. PLoS journals) or from fields in which preprints are very popular (e.g. neuroscience and genetics). Third, it is unclear what the manuscript considers 'life sciences', what journals were initially eligible and what journals were excluded because of this definition – for example, what percentage of the articles published by a journal have to be "non-life-science" for it to be excluded?
Thank you for this suggestion. We were using the “publication type” field before, but are now using it more extensively. We have revised our inclusion criteria for articles and journals, and clearly described them in the Materials and methods. Revising the inclusion criteria increased the size of our dataset to ~74,000 peer-reviewed articles.
We selected the cutoff for number of articles released as preprints based on the number of variables in the regression models (Austin and Steyerberg, 2015). Because our analysis is stratified on journal, this ensures stable estimates of the model coefficients. We acknowledge that our results only apply to journals that have published a minimum number of articles previously released as preprints.
We excluded multidisciplinary journals because many articles published in these journals are unlikely to be released on bioRxiv, which could confound the analysis. We originally identified these journals manually, but we have now verified them using the categories in the Journal Citation Reports published by Clarivate Analytics.
2) Multiple problems with descriptive and regression analyses. First, it is impossible to appreciate and interpret the findings of the regression analyses without descriptive statistics. The manuscript has to provide a table with descriptive statistics about all covariates included in each regression (in terms of median and interquartile range) as well as a univariable test for each (e.g. p-values from a non-parametric test). Second, such count data are notoriously skewed. As such, even though the log-transformation attempts to capture this skewness, the confidence intervals and p-values may still be wrong. I recommend that the authors instead use bootstrapped confidence intervals and p-values, which can be calculated using the confint(model, method = "boot", boot.type = "basic", nsim = 2000) function of the lme4 package. I also recommend that the manuscript (a) uses a Negative Binomial regression instead of the log-transformation of the response and (b) reports on the diagnostic procedures used to confirm appropriate fit (e.g. by investigating Pearson residuals). The manuscript did well in presenting Figure S8 to illustrate effects without adjusting for the principal components (PCs), the number of which in relation to the number of preprints was quite large (the 1 covariate per 10 outcomes rule of thumb was violated in about ~ 70% of the journals (18/26)), to confirm the apparent absence of overfitting.
We have added a supplementary file of descriptive statistics for each variable in the model. Because each variable was associated with either Attention Score or citations at a nominal level by random-effects meta-analysis, we have not included the results of univariate tests.
For both metrics and for all journals, we have run log-linear regression and Gamma regression (latter with a log link). For citations, we have also run negative binomial regression. Attention Scores are not limited to integer values, and so are not appropriate for negative binomial regression. Comparing the fits from log-linear, Gamma, and negative binomial regression on the original scale of the respective metric, log-linear regression had the smallest mean absolute error and mean absolute percentage error for each metric and each journal. We also used the function glm.diag.plots to examine the distributions of residuals from each method. We believe these results establish the validity of our regression approach. We have revised the manuscript accordingly.
We initially considered fitting a mixed-effects model based on all the data, but decided to instead stratify our analysis by journal. Our primary concern is that a mixed-effects model would make unreasonably strong assumptions about the distribution of effects for a given variable (e.g., publication date or a MeSH term PC). Since we have not fit a mixed-effects model, we have not used lme4::confint.merMod.
3) Interpretation of effect size is in relative rather than absolute terms. When presented, the size of association is interpreted in relative terms (e.g. 1.53 times), instead of absolute terms (e.g. a difference of 2 in median attention score, from 20 to 22). Relative terms are less meaningful and tend to unduly exaggerate the effects estimated. I recommend (a) that the authors present all measures of association (unlike Table 2, which only presents t-statistics) and (b) that all relative terms are either replaced or accompanied by absolute terms; here is an excellent guide on how to do this: https://www.healthnewsreview.org/toolkit/tips-for-understanding-studies/absolute-vs-relative-risk/. I also recommend that any talk of "statistically significant" or "not significant" is replaced by the magnitude of association, as this is what truly matters, and statistical significance language is often confusing and misleading to readers.
We have purged the manuscript of all mention of statistical significance. We have revised the figures to show absolute effects along with relative effects for each journal. We believe the relative effects are useful for comparing across journals, and they are the natural output of log-linear regression, which gave the best fit to the data. We have included all measures of association in the revised tables.
4) Inadequate adjustment for scientific field. Even though the authors correctly identify that adjusting for scientific field is hard, the PCA does not convincingly address this concern. First, the approach of using a fixed number of PCs for each journal, rather than a fixed percent of variance explained, means that in half of the journals (13/26) the PCs only explain 50% of the variance due to scientific field or less. Second, the approach of refitting the PCA within each journal, means that even though there was an attempt to account for within-journal variability in scientific field, the between-journal variability is not being accounted for. Third, because of these points, the meta-regression results in a messy estimate of effect from the combination of heterogeneous values (as seen in Figure 1) emanating from regressions adjusting for different study fields to different extends (this heterogeneity was never quantified). The manuscript could address these issues by (a) using a sensitivity analysis to explore the impact of adjusting for different numbers of PCs, (b) using previously published methods to account for scientific field (e.g. Piwowar et al., 2018) or (c) matching articles for subject field using a chosen measure of distance (e.g. Mahalanobis distance) and only using pairs within a pre-specified maximum distance from each other.
We have tried to balance the number of PCs against the number of preprints per journal. For linear regression, previous work suggests that having as few as two observations per independent variable is sufficient to reliably estimate the coefficients (Austin and Steyerberg, 2015). This differs from the rule of thumb for logistic regression, which is ~10 observations per independent variable.
We have increased the number of MeSH PCs from 10 to 15 and obtained similar results. We have also included tables of all regression statistics for all variables. For a given journal, typically only a couple PCs are associated with either Attention Score or citations.
We intentionally calculated the PCs separately for each journal, because the MeSH terms associated with more citations in one journal could be irrelevant or associated with fewer citations in another journal. This is one reason we chose not to fit one mixed-effects model from all the data, as it would make strong assumptions about the distribution of effect sizes for a given PC. We believe this is a worthwhile tradeoff for performing meta-regression on the coefficients for preprint status.
Piwowar et al. only applied their article-by-article classification approach to articles published in multidisciplinary journals, which we have specifically excluded. In addition, their approach requires detailed information on the references for a given article, which does not exist for every article in our dataset. Matching would require another arbitrary parameter (e.g., maximum distance), would be complicated to incorporate alongside the other variables we have added to the model, and would likely also reduce our sample size, even if we attempted to match multiple articles without a preprint to one article with a preprint.
5) Lacking in principles of good scientific practice. Even though the authors should be commended for making their data and code available in a neatly-put ZIP file on figshare as well as making their article available as a preprint on bioRxiv, the manuscript would significantly benefit from the following additional practices: (a) make the protocol of this study openly available on either figshare or OSF Registries (https://osf.io/registries), (b) abide by and cite the STROBE guidelines for reporting observational studies (http://www.equator-network.org/reporting-guidelines/strobe/) and (c) include at least a statement on their sources of funding.
We have thoroughly revised our descriptions of the selection criteria for articles and journals and the source of each variable in the model. We have also added a funding statement, which we had mistakenly omitted. As far as we understand them, the STROBE guidelines are meant for studies on humans.
6) Poor reporting. This manuscript could derive significant benefit from (a) further and more comprehensive explanation of its methods (e.g. why the choice of 50 or 200, why use regressions followed by meta-regression instead of a random effects model to start with, why use log-transformation instead of Negative Binomial, why use the quoted type of meta-regression, why use the current covariates and not more/less, etc.), (b) avoiding language that may not be familiar to many readers (e.g. fold-change, population stratification, citations + 1, etc.) and (c) adding explanations to figures in the supplement (e.g. what do Figure 1—figure supplement 6 and Figure 1—figure supplement 7 tell us about the PCs, etc.). I actually had to read the results in combination with the methods a couple of times to understand that a different regression was fitted for each journal.
We have heavily revised the text to more clearly explain various aspects of the analysis. Please see our responses above for specific justifications.
[Editors' note: this is the author response to the decision letter sent after the second round of peer review.]
Reviewer #1:
The manuscript has been extensively reviewed and some of my main issues with it have been solved. In particular, methodology (especially article inclusion criteria) is much better described, and data visualization has been improved in many of the figures.
1) However, I still have some issues with data presentation, in particular concerning the supplementary files in which much of the data requested by reviewers has been included. These tables are essentially datasets in. csv with no legend or clear annotation for the meaning of each column, which is not always obvious from the variable name. Although inclusion of this material is laudable in the sense of data sharing, if the authors mean to use them as a meaningful way to present the results cited in the text, I feel that it is unfair to leave the burden of understanding and analyzing the data on the reader. If they are meant as tables in a scientific paper, it is the author's job to synthesize the data and make them clear to the reader through formatting and annotation, including making variable names self-explanatory and providing legends.
Thank you for the suggestion. We had originally included the supplementary files exactly as generated by the analysis code. We have now renamed the columns to be more interpretable, and added a description of each table in the manuscript file. We much prefer to keep them in plain text format (csv instead of xlsx) to prevent Excel from re-formatting the dates and numbers.
Other general concerns involving analysis are described below:
2) Why is "affiliation in the US" the only geographical factor analyzed? This is rather US-centric, and does not really capture the vast differences between countries in the "non-US" category. Can't the authors make a more meaningful division – for example, based on region/continent, or of economical/scientific development of the country of affiliation?
Note from editor: Please either perform this extra analysis or explain why "affiliation in the US" is the only geographical factor analyzed.
Although the binary variable of having a U.S. affiliation is admittedly crude, the U.S. was by far the most common country of affiliation in our dataset. In addition, according to Adbill and Blekhman 2019, “the majority of the top 100 universities (by author count) [of preprints on bioRxiv] are based in the United States”. We were also trying to avoid adding too many variables to the model.
We have now added a binary variable of having an affiliation at an institution in the Nature Index for Life Sciences. These 100 institutions have the highest number of articles published in the “upper echelon” of life science journals, and thus are a proxy for the world’s “elite” institutions (see revised Materials and methods section for details). Although affiliation at a Nature Index institution is associated with higher Attention Score and more citations, adding that variable to the model did not markedly change the coefficients for having a preprint. We have revised the manuscript accordingly.
3) I still can get no intuitive meaning of what each of the principal components stand for, and cannot evaluate whether they indeed capture what they mean to (e.g. scientific subfield). The authors do provide a supplementary file with the PC loading, but as the other supplementary files, it is pretty much the raw data, and don't think it's fair for the reader to have to mine it on its own to look for meaning. Can't the authors provide a list of the top MeSH terms loading onto each principal component (as a word cloud, for example), so as to make the meaning of each of them somewhat intuitive?
We have replaced the previous supplementary file of PC loadings with a file of the MeSH terms with the largest positive and negative loadings for each PC (Supplementary File 7). Since we have 39 journals and 15 PCs, we believe this is more practical than a word cloud.
4) Moreover, if I understood correctly, the principal components are calculated separately for each journal – thus, their meaning varies from one journal to the next. Although that might increase their capability of capturing subfield-specific distinctions, this probably increases the potential that they capture noise rather than signal, due both to sample size decrease and to a decrease in meaningful variability within individual journals. Wouldn't it be more interesting to define subfields based on principal components for the whole sample? Note that this would have the added bonus of allowing inclusion of subfield in the metaregression analysis, and would probably facilitate visualization of the main factors loading onto each component, which would no longer be journal-dependent.
Note from editor: Please either perform this extra analysis or address the comments above about the consequences of the principal components being journal-specific
You understood correctly, we calculate the PCs separately for each journal. We explained some of our reasoning previously to reviewer #3. We do not believe it would be more interesting to define subfields for the entire dataset. Because the journals cover disparate research areas, MeSH terms common in articles for one journal can be non-existent in articles for another. Our approach allows us to calculate PCs that are specifically tuned to the variation in MeSH term assignment between articles in a given journal, rather than having the majority of PCs describe irrelevant, higher-level variation between journals (which would add noise to each regression). Given the large number of articles from each journal (minimum 304 articles, and 25 of 39 journals have ≥ 1000 articles), we do not expect noise in the PCs to be an issue. This is supported by the fact that several PCs for each journal are associated with Attention Score and citations at p ≤ 0.05.
We think it would be statistically ill-advised to incorporate the PCs into both the regression and meta-regression, and we would much rather have them in the regressions. In any case, we do not believe incorporating subfield into the meta-regression would be advantageous, because it would assume, for example, that the effect on Attention Score and citations of publishing a paper about Saccharomyces cerevisiae is the same whether one publishes the paper in Molecular Cell or in Neuroimage. Such an assumption does not make sense to us. We have elaborated on our reasoning in the manuscript.
5) I very much miss a table of descriptives and individual univariate associations for each variable included in the model before the data on multivariate regression are presented (as mentioned by reviewer #3 in his comments on the first version). Once again, I don't think that throwing in the raw data as a supplementary file substitutes for that.
We had included a table of descriptive statistics, which we have annotated more thoroughly along with the other supplementary files. We do not believe a supplementary file of the univariate associations of each variable with each metric in each journal would be useful. Our results already show that each variable has a non-zero coefficient in the multivariate models for Attention Score and citations, so the results of univariate testing would not change the subsequent analysis (e.g., we’re not going to remove a variable that we added in response to reviewer comments).
6) If the authors used time since publication as one of the variables in the model, why didn't they directly test the interaction between this and having a preprint to see whether the relationship changes over time, rather than not doing it and discussing it in the limitations? I understand that there might be confounders, as the authors appropriately discuss in the response to reviewers. However, I feel that discussing the results for the interaction, taking into account the possible confounders and limitations, is still likely to be more interesting than discussing the limitations without a result.
Note from editor: Performing this extra analysis is optional.
We respectfully disagree. We believe the reasons to not test for an interaction greatly outweigh the reasons to test for one. Given the limitations, we do not want to put ourselves in the position of having to interpret complicated, questionable results that do not alter our study’s conclusions.
Reviewer #2:
The revised manuscript includes a thorough response to the initial comments from reviewers. I believe the analysis has been much improved, and the manuscript now more clearly addresses the concerns that could not be practically addressed. There are only have a few points that could benefit from elaboration within the text.
Introduction, first paragraph: A concern in the previous review was that the statement regarding the proportion of papers that were preprinted was not supported by the provided citation. Though the authors state they have clarified the statement regarding "the number of preprints released [...] is only a fraction of the number of peer reviewed articles published," it remains true that the cited paper says nothing about the overall number of published papers. If the authors want to include a statement about the proportion of published papers, I would point them toward a dataset such as this one, which may provide an acceptable estimate: Penfold NC, Polka J. (2019). Preprints in biology as a fraction of the biomedical literature (Version 1.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3256298
Thank you for the reference, we have now cited the dataset of Penfold and Polka.
Materials and methods, subsection “Quantifying the associations”: It's still not clear why a spline was used to find the publication date instead of, say, the number of days since 1 Jan 2015. I'm not disputing that it's an appropriate way to encode the dates, but elaboration, as mentioned by a previous reviewer, would be helpful for people like me who have not explicitly encountered this technique before.
We have elaborated on the reason for the spline. Unlike a single linear term such as “number of days since publication”, the spline does not assume, for example, that the average difference in the dependent variable (e.g., log citations) between a 0-year-old article and a 1-year-old article is the same as between a 4-year-old article and a 5-year-old article.
Discussion: A previous review comment was that authors with large social media followings may be confounding the analysis by giving themselves a publicity advantage that wasn't included in the analysis. The authors state in their response, "given the weak correlation between Attention Score and citations, it seems unlikely this could explain the effect of preprint status on citations." This is a key point and an interesting rebuttal to the initial suggestion, but I don't believe it's made clear in the paper itself, which says only that online popularity "would likely not explain the association with citations." The manuscript would benefit from clarification here to point out that there is only a loose connection between Attention Score and citations.
We have clarified that sentence in the Discussion.
Table 1 and Table 2: I believe the advice for multiple-test correction in my earlier review was misguided, I apologize. Though Table 1 now includes adjusted p-values, I'm confused by the approach taken: For 5 of the given p-values, the adjusted value is 2p, while the other 5 have identical adjusted values. Can the authors please check if these values are typos: if they are not, I would suggest they consult a statistician about this analysis, and also about the analysis in Yable 2.
They are not typos, that’s just how the Bonferroni-Holm correction works. One can verify this in R, e.g., “p.adjust(c(1e-3, 1e-4), method = 'holm')”. Bonferroni-Holm is uniformly more powerful than standard Bonferroni (https://en.wikipedia.org/wiki/Holm%E2%80%93Bonferroni_method). We have clarified this in the Materials and methods and the figure legends.
https://doi.org/10.7554/eLife.52646.sa2Article and author information
Author details
Funding
National Institute of General Medical Sciences (R35GM124685)
- Jacob J Hughey
U.S. National Library of Medicine (T15LM007450)
- Darwin Y Fu
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Altmetric for providing their data free of charge for research purposes. We thank Tony Capra and Doug Ruderfer for helpful comments on the manuscript.
Publication history
- Received:
- Accepted:
- Accepted Manuscript published:
- Version of Record published:
Copyright
© 2019, Fu and Hughey
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 14,250
- views
-
- 789
- downloads
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Meta-Research: Releasing a preprint is associated with more attention and citations for the peer-reviewed article
eLife 8:e52646.
https://doi.org/10.7554/eLife.52646




{kind=link}
{kind=link}