EEG-based detection of the locus of auditory attention with convolutional neural networks
- Department of Neurosciences, Experimental Oto-rhino-laryngology, Belgium
- Department of Electrical Engineering (ESAT), Stadius Center for Dynamical Systems, Signal Processing and Data Analytics, Belgium
Figures
Figure 1
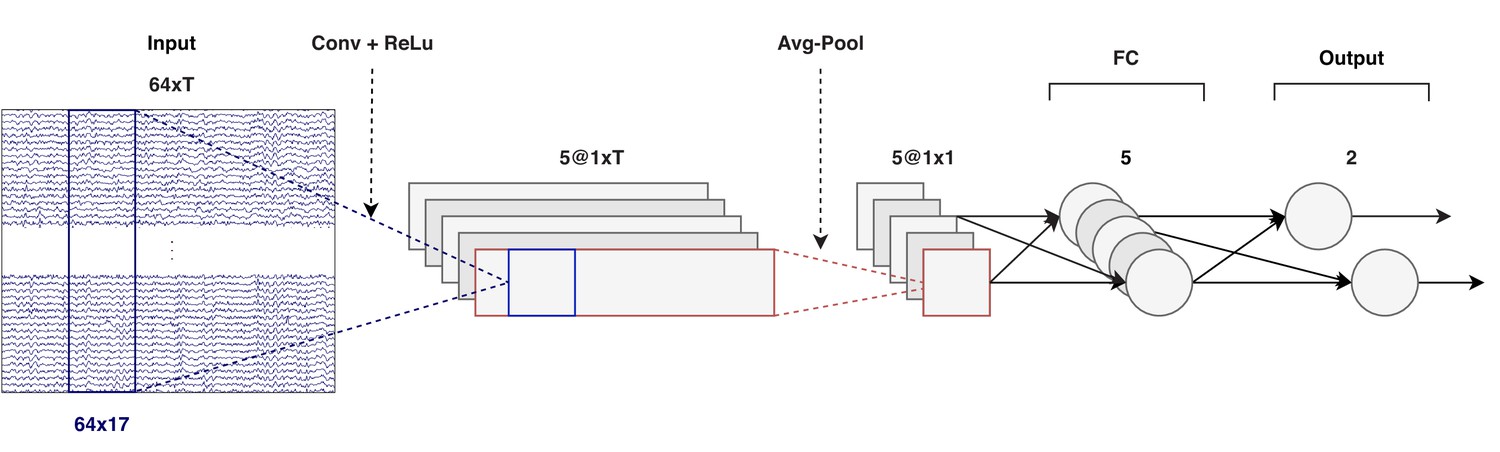
CNN architecture (windows of T samples).
Input: T time samples of a 64-channel EEG signal, at a sampling rate of 128 Hz. Output: two scalars that determine the attended direction (left/right). The convolution, shown in blue, considers 130 ms of data over all channels. EEG = electroencephalography, CNN = convolutional neural network, ReLu = rectifying linear unit, FC = fully connected.
Figure 2
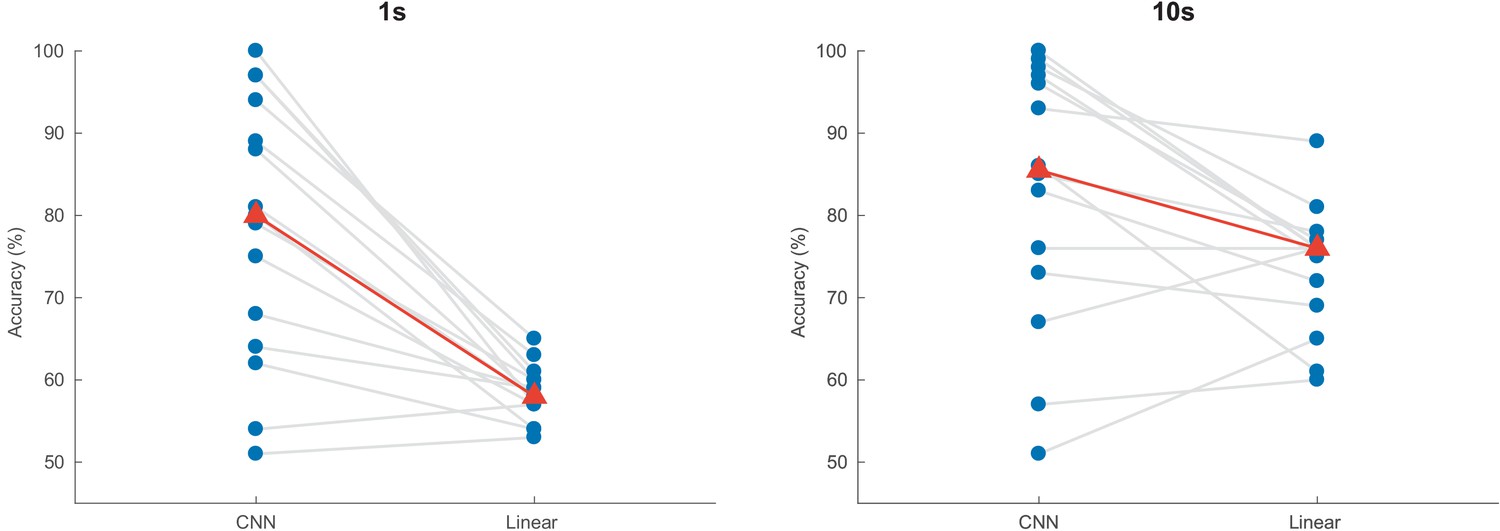
Auditory attention detection performance of the CNN for two different window lengths.
Linear decoding model shown as baseline. Blue dots: per-subject results, averaged over two test stories. Gray lines: same subjects. Red triangles: median accuracies. CNN = convolutional neural network.
Figure 3
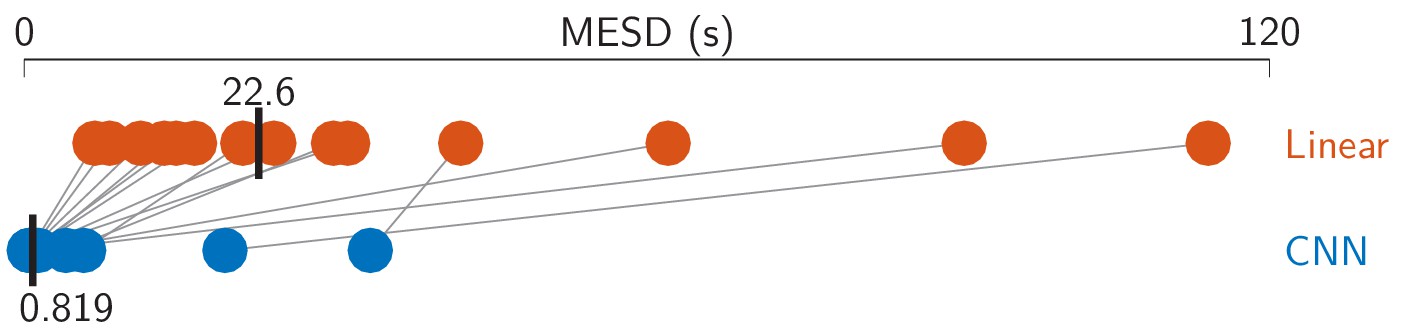
Minimal expected switch durations (MESDs) for the CNN and the linear baseline.
Dots: per-subject results, averaged over two test stories. Gray lines: same subjects. Vertical black bars: median MESD. As before, two poorly performing subjects were excluded from the analysis. CNN = convolutional neural network.
Figure 4
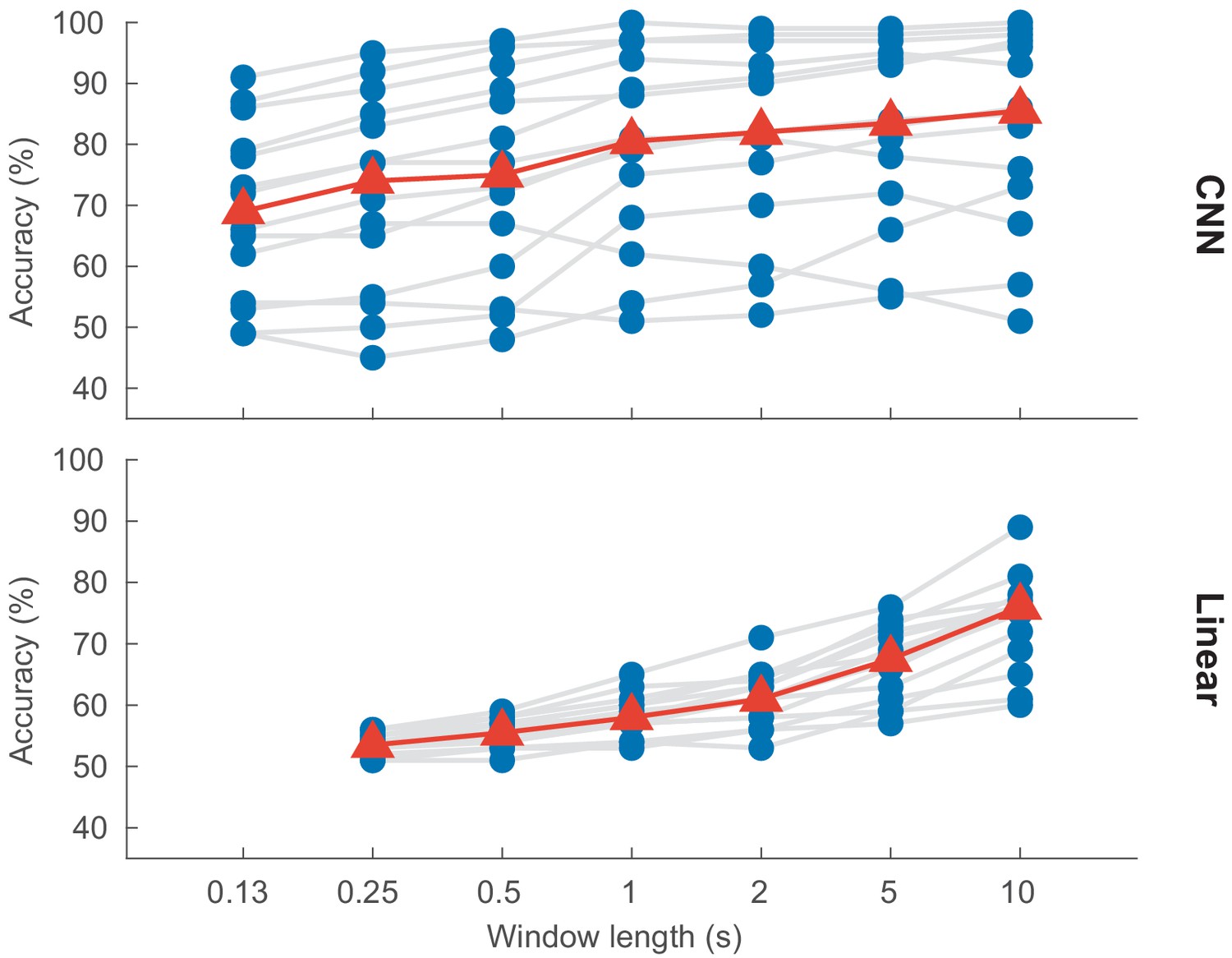
Auditory attention detection performance as a function of the decision window length.
Blue dots: per-subject results, averaged over two test stories. Gray lines: same subjects. Red triangles: median accuracies. CNN = convolutional neural network.
Figure 5
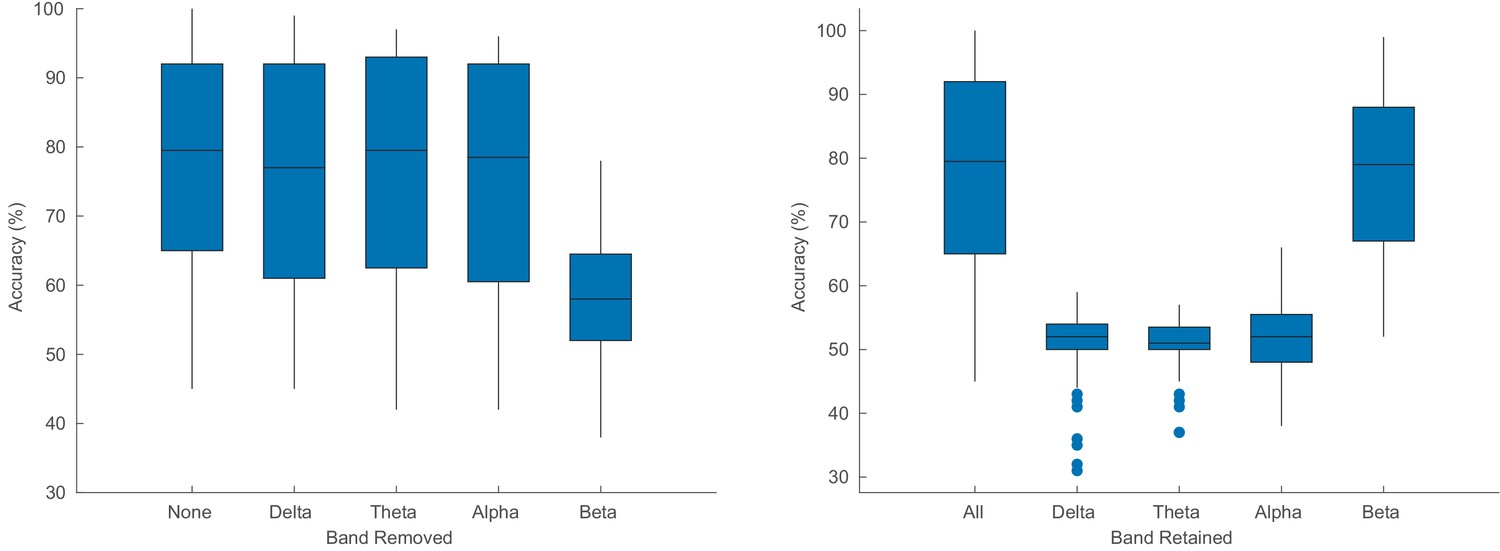
Auditory attention detection performance of the CNN when one particular frequency band is removed (left) and when only one band is used (right).
The original results are also shown for reference. Each box plot contains results for all window lengths and for the two test stories.
Figure 6
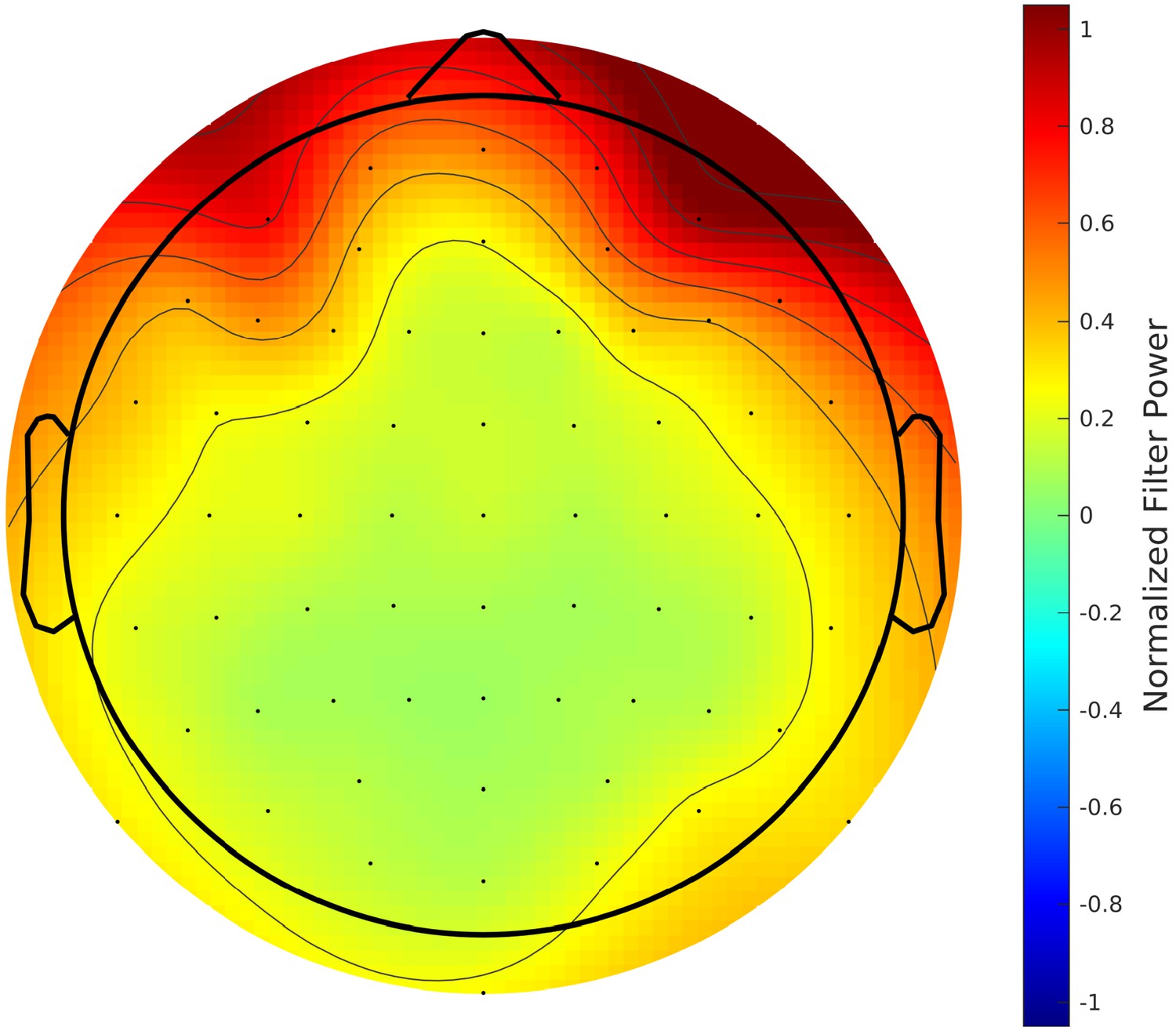
Grand-average topographic map of the normalized power of convolutional filters.
Figure 7
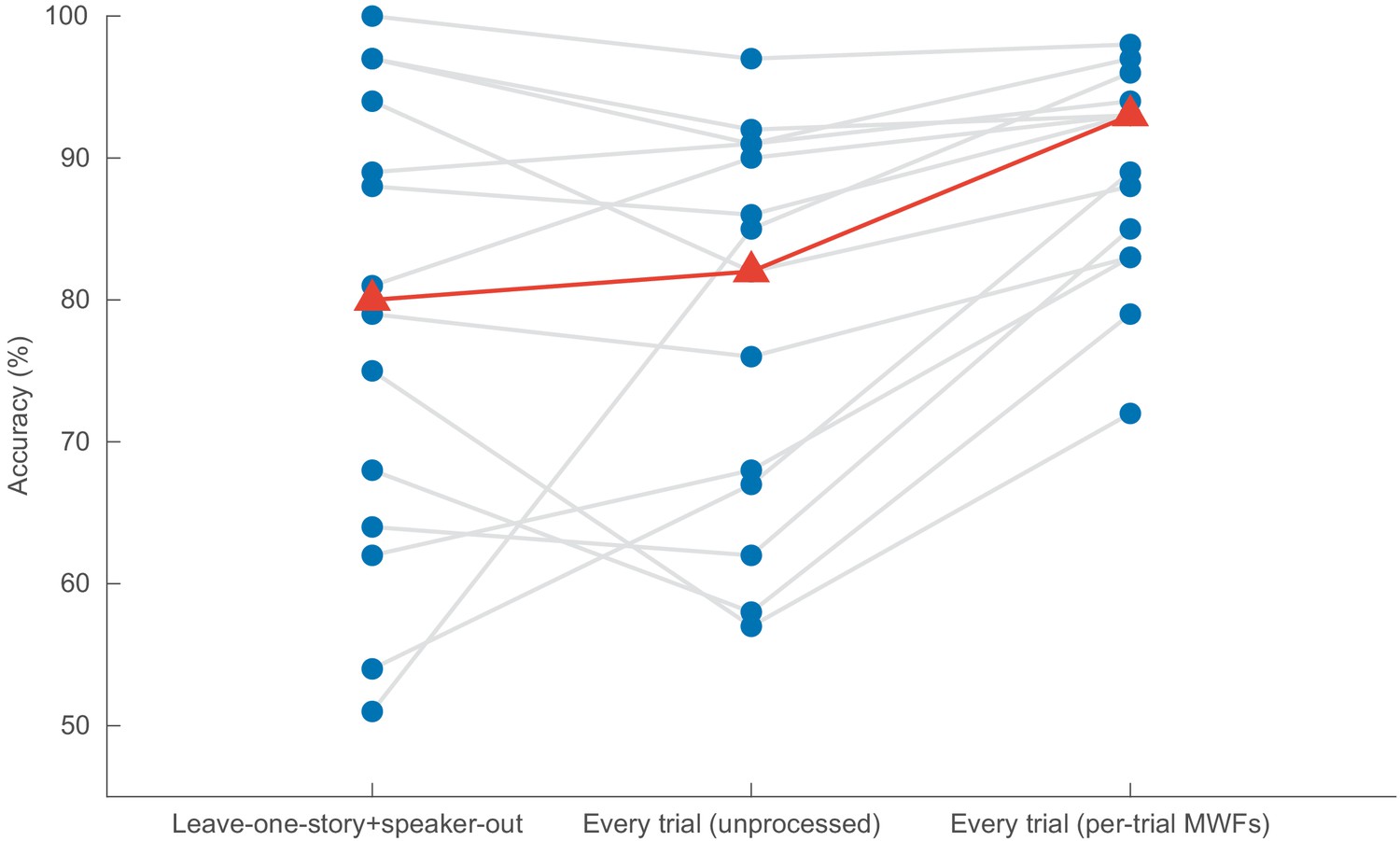
Impact of the model validation strategy on the performance of the CNN (decision windows of 1 s).
In Leave-one-story+speaker-out, the training set does not contain examples of the speakers or stories that appear in the test set. In Every trial (unprocessed), the training, validation, and test sets are extracted from every trial (although always disjoint), and no spatial filtering takes places. In Every trial (per-trial MWFs), data is again extracted from every trial, but this time per-trial MWF filters are applied. CNN = convolutional neural network.
Figure 8
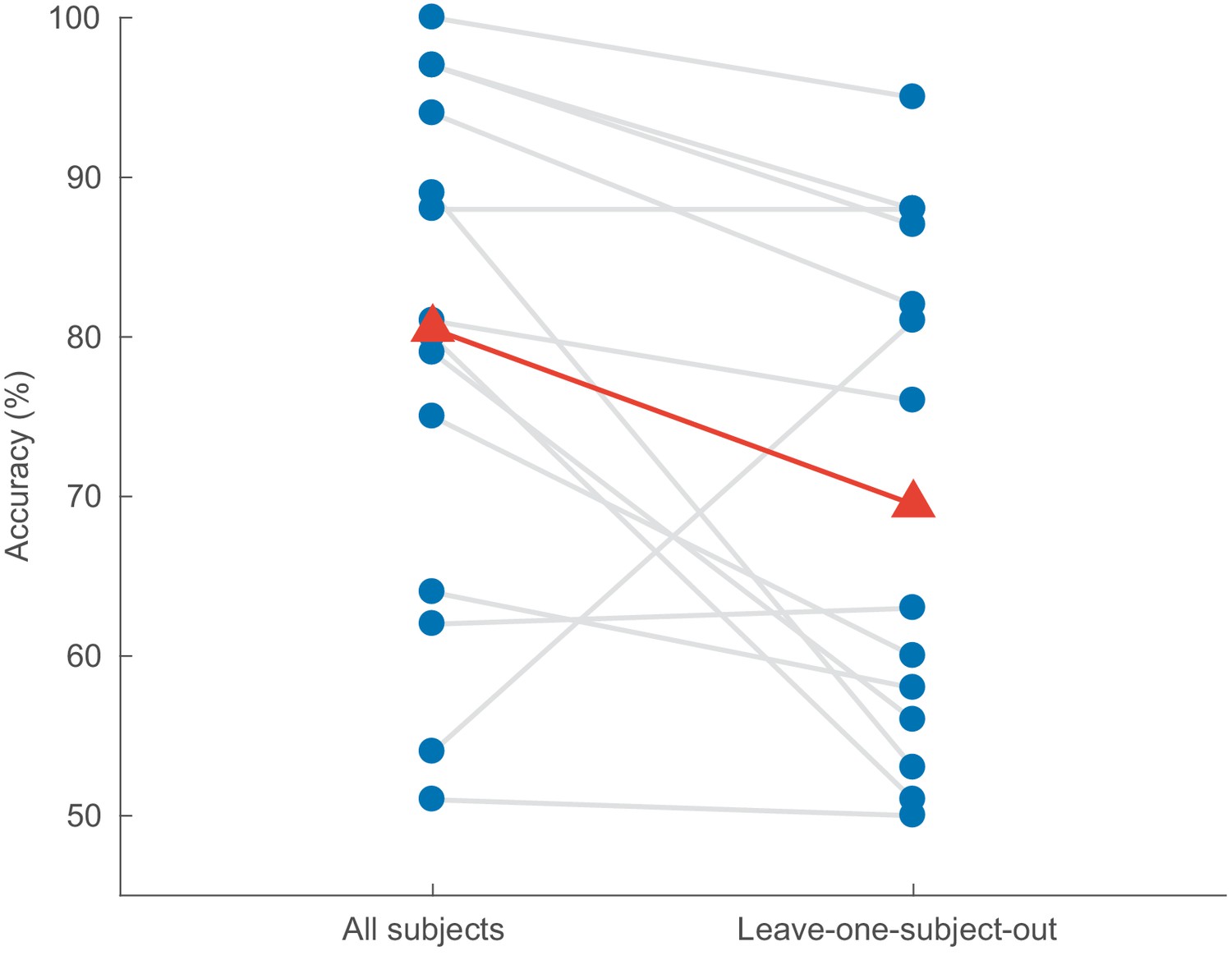
Impact of leaving out the test subject on the accuracy of the CNN model (decision windows of 1 s).
Blue dots: per-subject results, averaged over two test stories. Gray lines: same subjects. Red triangles: median accuracies. CNN = convolutional neural network.
Author response image 1
Grand-average temporal profile of the filters in the convolutional layer.
Tables
Table 1
First eight trials for a random subject.
Trials are numbered according to the order in which they were presented to the subject. Which ear was attended to first was determined randomly. After that, the attended ear was alternated. Presentation (dichotic/HRTF) was balanced over subjects with respect to the attended ear. Adapted from Das et al., 2016. HRTF = head-related transfer function.
| Trial | Left stimulus | Right stimulus | Attended ear | Presentation |
|---|---|---|---|---|
| 1 | Story1, part1 | Story2, part1 | Left | Dichotic |
| 2 | Story2, part2 | Story1, part2 | Right | HRTF |
| 3 | Story3, part1 | Story4, part1 | Left | Dichotic |
| 4 | Story4, part2 | Story3, part2 | Right | HRTF |
| 5 | Story2, part1 | Story1, part1 | Left | Dichotic |
| 6 | Story1, part2 | Story2, part2 | Right | HRTF |
| 7 | Story4, part1 | Story3, part1 | Left | Dichotic |
| 8 | Story3, part2 | Story4, part2 | Right | HRTF |
Table 2
Cross-validating over stories and speakers.
With the current dataset, there are only two folds that do not mix stories and speakers across training and test sets. Top: Story 1 as test data; story 2, 3, and 4 as training data and validation data (85/15% division, per story). Bottom: similarly, but now with a different story and speaker as test data. In both cases, the story and speaker are completely unseen by the model. The model is trained on the same training set for all subjects and tested on a unique, subject-specific, test set.
| Story | Speaker | Subject 1 | Subject 2 | … | Subject 16 |
|---|---|---|---|---|---|
| 1 | 1 | test | test | … | test |
| 2 | 2 | train/val | |||
| 3 | 3 | train/val | |||
| 4 | 3 | train/val | |||
| Story | Speaker | Subject 1 | Subject 2 | … | Subject 16 |
| 1 | 1 | train/val | |||
| 2 | 2 | test | test | … | test |
| 3 | 3 | train/val | |||
| 4 | 3 | train/val | |||
Author response table 1
Leave-one-story-out scheme.
Example of one out of four folds. In this particular fold, the test set consists of story 1, and the training and validation sets consist of stories 2, 3, and 4. Training and validation sets are completely separate from the test set. Per-subject accuracies are based on a subject-specific test set (noted by multiple mentions of "test" in Author response table 1). The model is trained on data of all subjects (noted by a single mention of "train/val").
| Story | Subject 1 | Subject 2 | …. | Subject 16 |
|---|---|---|---|---|
| 1 | test | test | test | test |
| 2 | train/val | |||
| 3 | train/val | |||
| 4 | train/val |
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
EEG-based detection of the locus of auditory attention with convolutional neural networks
eLife 10:e56481.
https://doi.org/10.7554/eLife.56481




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}