Reverse engineering of metacognition
- Health and Medical University, Institute for Mind, Brain and Behavior, Germany
- Charité – Universitätsmedizin Berlin, Department of Psychiatry and Neurosciences, corporate member of Freie Universität Berlin and Humboldt-Universität zu Berlin, Germany
Figures
Figure 1
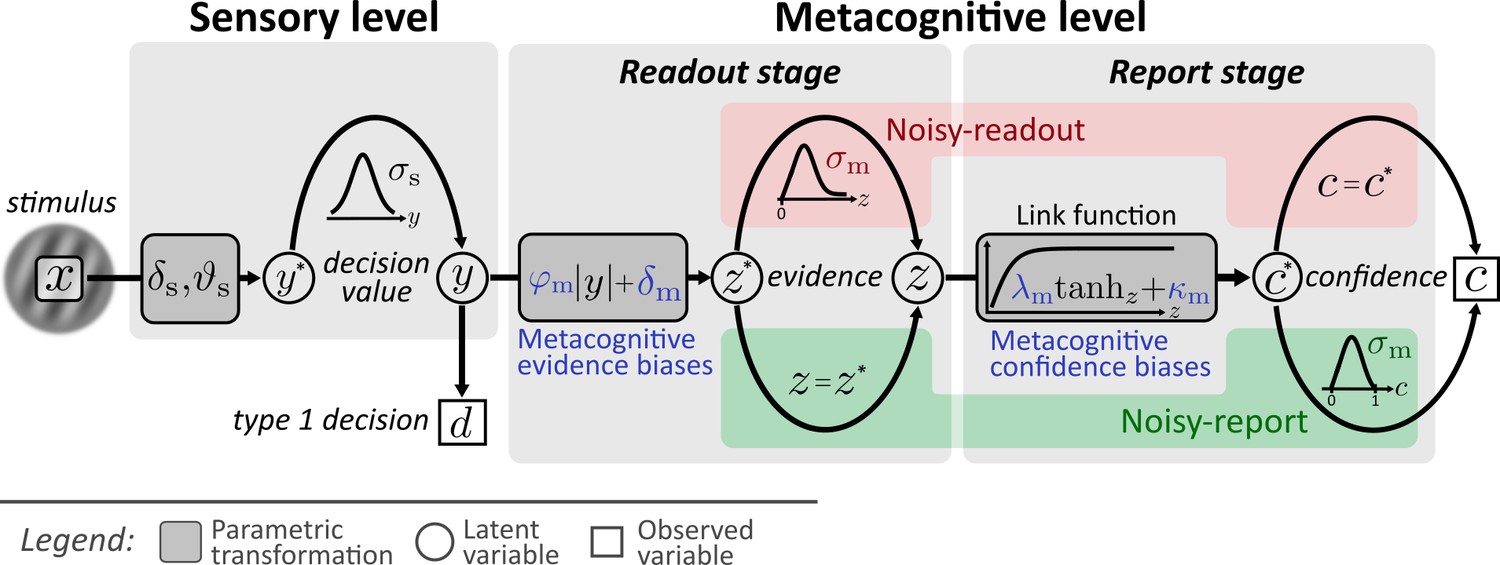
Computational model.
Input to the model is the stimulus variable x, which codes the stimulus category (sign) and the intensity (absolute value). Type 1 decision-making is controlled by the sensory level. The processing of stimuli x at the sensory level is described by means of sensory noise (σs), bias (δs) and threshold (ϑs) parameters. The output of the sensory level is the decision value y, which determines type 1 decisions d and provides the input to the metacognitive level. At the metacognitive level it is assumed that the dominant source of metacognitive noise is either noise at the readout of decision values (noisy-readout model) or at the reporting stage (noisy-report model). In both cases, metacognitive judgements are based on the absolute decision value |y| (referred to as sensory evidence), leading to a representation of metacognitive evidence at the metacognitive level. While the “readout” of this decision value is considered precise for the noisy-report model (z = ), it is subject to metacognitive readout noise z ∼ fm(z; z*,σm) in the noisy-readout model, described by a metacognitive noise parameter σm. A link function transforms metacognitive evidence to internal confidence . In the case of a noisy-report model, the dominant metacognitive noise source is during the report of confidence, that is confidence reports c are noisy expressions of the internal confidence representation: c ∼ fm(c; c*,σm). Metacognitive biases operate at the level of sensory evidence (multiplicative evidence bias φm, additive evidence bias δm) or at the level of the confidence link function (multiplicative confidence bias λm, additive confidence bias κm).
Figure 2 with 1 supplement
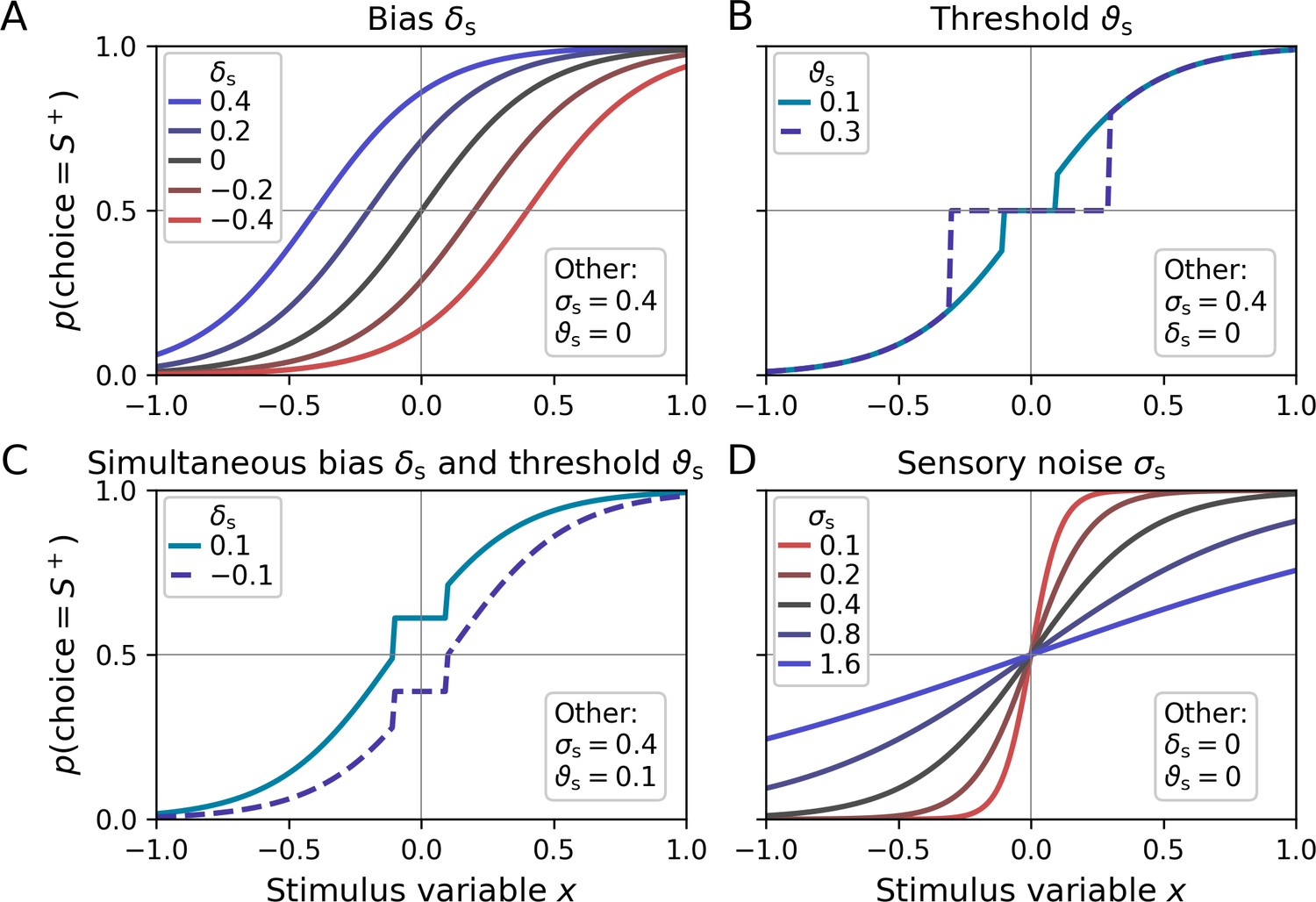
Psychometric functions for different settings of sensory model parameters.
Top left legends indicate the values of varied parameters, bottom right legends settings of the respective other parameters. (A) The sensory bias parameter δs horizontally shifts the psychometric function, leading to a propensity to choose stimulus category S− (δs < 0) or stimulus category S+ (δs > 0). (B) Stimulus intensities below the threshold parameter ϑs lead to chance-level performance. (C) Example for simultaneous non-zero values of the bias and threshold parameter. (D) The sensory noise parameter σs changes the slope of the psychometric function.
Figure 2—figure supplement 1
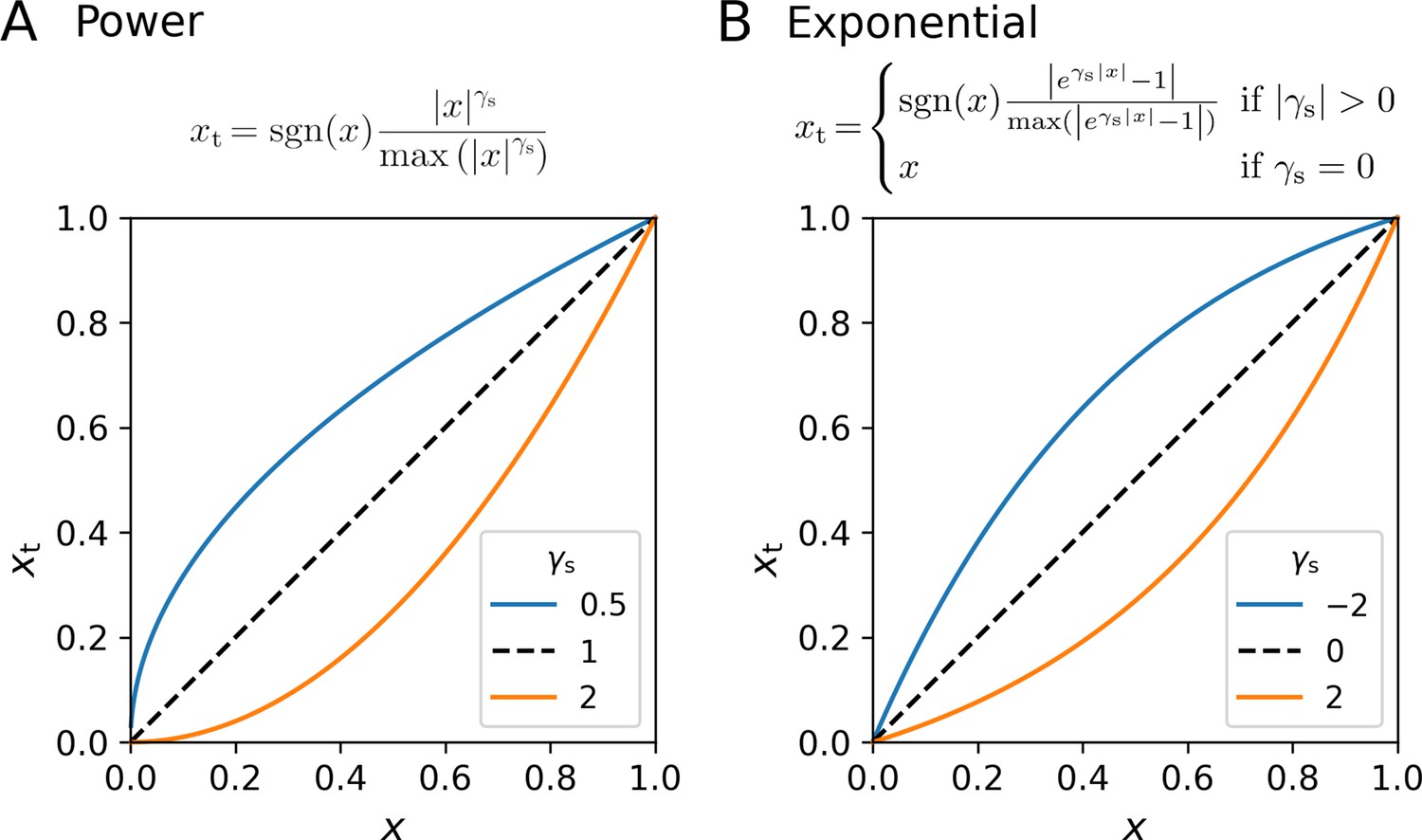
Nonlinear transformation of the stimulus variable.
Early visual processing likely involves nonlinear transformations of stimulus signals, including processes such as contrast gain control nonlinearities or nonlinear transduction. In the toolbox, either a power transformation or an exponential transformation is considered. In both cases, the transformation includes a renormalization to 1, such that any difference in linear stimulus intensity scaling between participants is captured by the decision noise parameter σs. (A) Power transformation. (B) Exponential transformation.
Figure 3 with 1 supplement
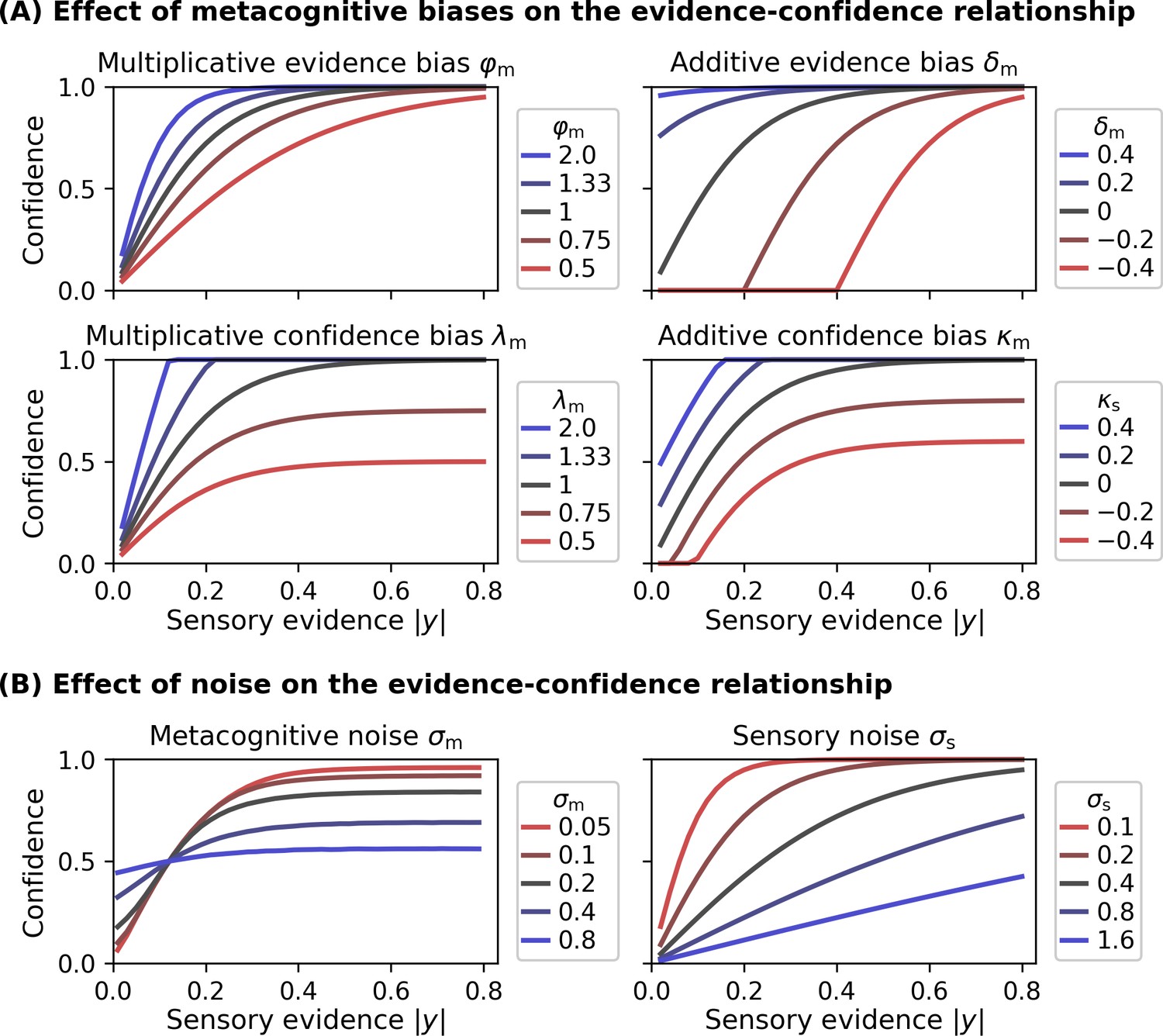
Effect of model parameters on the evidence-confidence relationship.
All metacognitive bias parameters and noise parameters affect the relationship between the sensory evidence |y| and confidence, assuming the link function provided in Equation 5. (A) Effect of metacognitive bias parameters on the evidence-confidence relationship. Metacognitive noise was set to zero for simplicity. (B) Effect of metacognitive noise σm and sensory noise σs on the evidence-confidence relationship. Metacognitive noise renders confidence ratings more indifferent with respect to the level of sensory evidence. Note that, due to the absence of an analytic expression, the illustration for the effect of metacognitive noise is based on simulation. Increasing sensory noise affects the slope of the confidence-evidence relationship, reflecting changes to be expected from an ideal metacognitive observer.
Figure 3—figure supplement 1
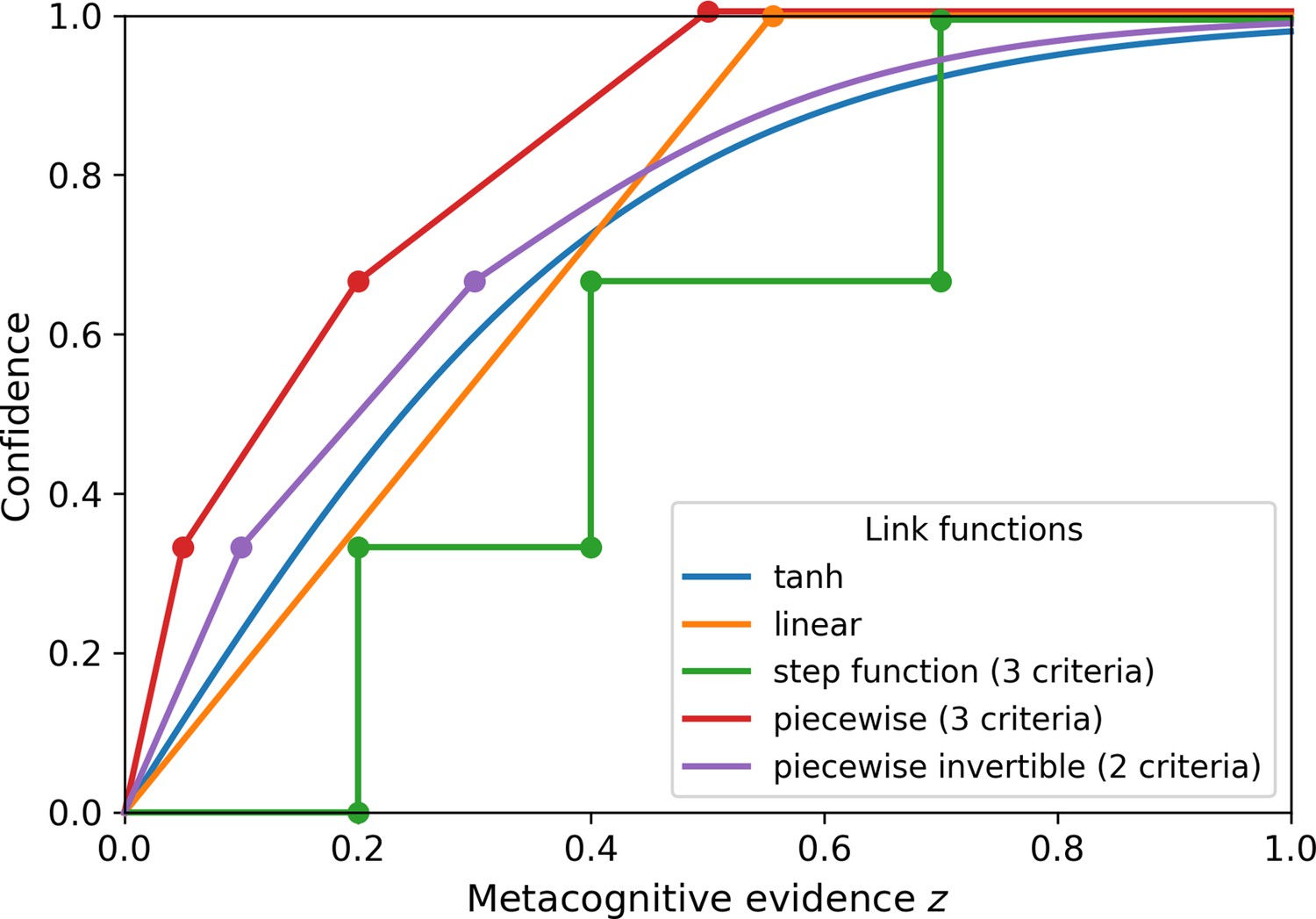
Confidence link functions.
Alternative choices for link functions provided by the ReMeta toolbox describing the relationship between metacognitive evidence and confidence. Note that these link functions do not compute the subjective probability of being correct. Link functions: tanh (simple tangens hyperbolicus), linear (linear slope, no intercept), step function (criterion-based link function with three criteria placed at evidence levels 0.2, 0.4, and 0.7), piecewise (piecewise linear function with three criteria placed at evidence levels of 0.05, 0.2, and 0.5), piecewise invertible (piecewise linear function with two criteria placed at evidence levels of 0.1 and 0.3; to attain invertibility, the last piece is described by a tangens hyperbolicus with an additional parameter).
Figure 4
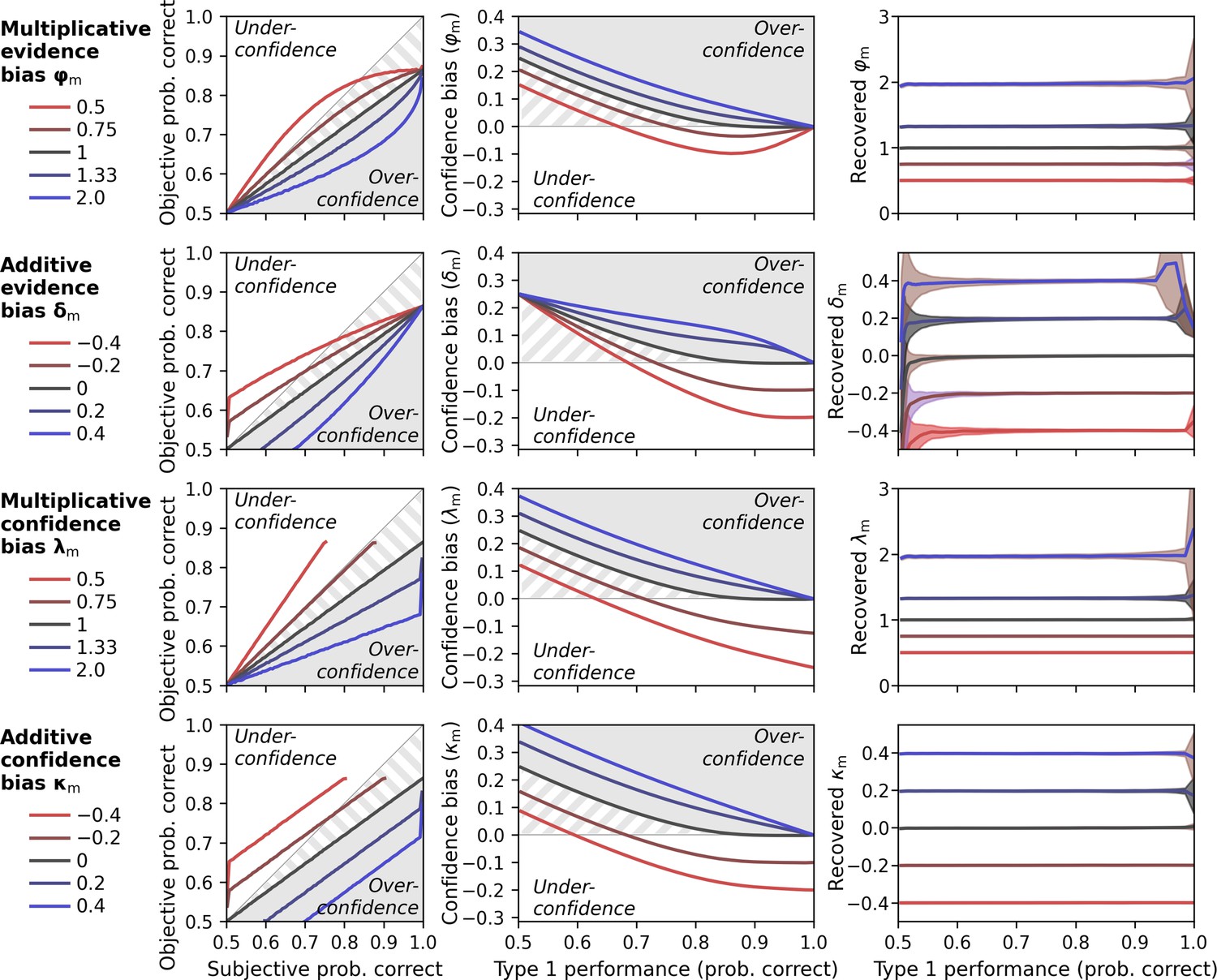
Metacognitive bias parameters (φm, δm, λm, κm).
Gray shades indicate areas of true overconfidence according to the generative model. Gray stripes areas indicate additional areas that would be classified as overconfidence in conventional analyses of confidence data, i.e. when simply comparing objective und subjective probability correct. Simulations are based on a noisy-report model with a truncated normal metacognitive noise distribution. Metacognitive noise was set close to zero for simplicity. (Left panels) Calibration curves. Calibration curves compute the proportion of correct responses (objective probability correct) for each interval of subjective confidence reports. Calibration curves above and below the diagonal indicate under- and overconfident observers, respectively. For this analysis, confidence was transformed from rating space [0; 1] to probability space [0.5; 1] and divided in 100 intervals with bin size 0.01. Average type 1 performance for this simulation was around 70%. (Middle panels) Confidence bias in dependence of type 1 performance. Different levels of type 1 performance were simulated by sweeping the sensory noise parameter between 0.01 and 50. Confidence bias was computed as the difference between subjective probability correct and objective proportion correct. (Right panels) Recovery of metacognitive bias parameters in dependence of performance. Shades indicate standard deviations.
Figure 5
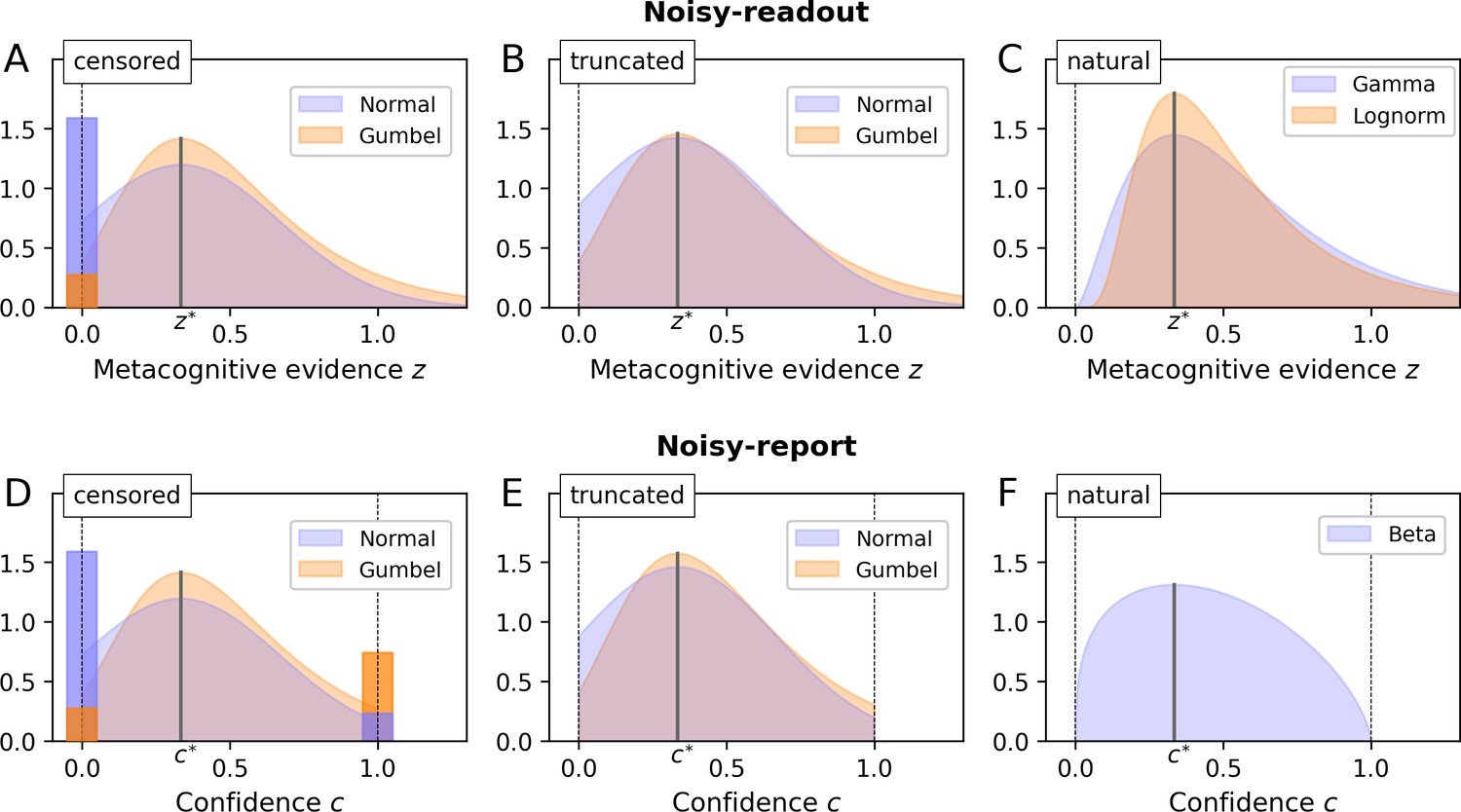
Metacognitive noise.
Considered noise distributions are either censored, truncated or naturally bounded. In case of censoring, protruding probability mass accumulates at the bounds (depicted as bars with a darker shade; the width of these bars was chosen such that the area corresponds to the probability mass). The parameter σm and the distributional mode was set to ⅓ in all cases (arbitrary value). (A - C) Noisy-readout models. Metacognitive noise is considered at the level of readout, affecting metacognitive evidence z. Only a lower bound at z = 0 applies. (D - F) Noisy-report models. Metacognitive noise is considered at the level of the confidence report, affecting internal confidence representations c. Confidence reports are bounded between 0 and 1.
Figure 6 with 2 supplements

Comparison of Mratio and metacognitive noise σm.
Different performance levels were induced by varying the sensory noise of the forward model. Five different levels of metacognitive noise were simulated for a truncated normal noise distribution, covering the range between low and high metacognitive noise. While Mratio showed a nonlinear dependency with varying type 1 performance levels both for (A) noisy-report models and (B) noisy-readout models, the recovered metacognitive noise parameter σm was largely independent of type 1 performance. Shaded areas indicate standard deviations across 100 simulated subjects. Right panels: Relationship between metacognitive noise and Mratio. Simulated data were generated with a range of varying metacognitive noise parameters σm and constant sensory noise (σs = 0.5; proportion correct responses: 0.82). Computed Mratio values show a clear negative correspondence with σm, reflecting the fact that metacognitive performance decreases with higher metacognitive noise.
Figure 6—figure supplement 1
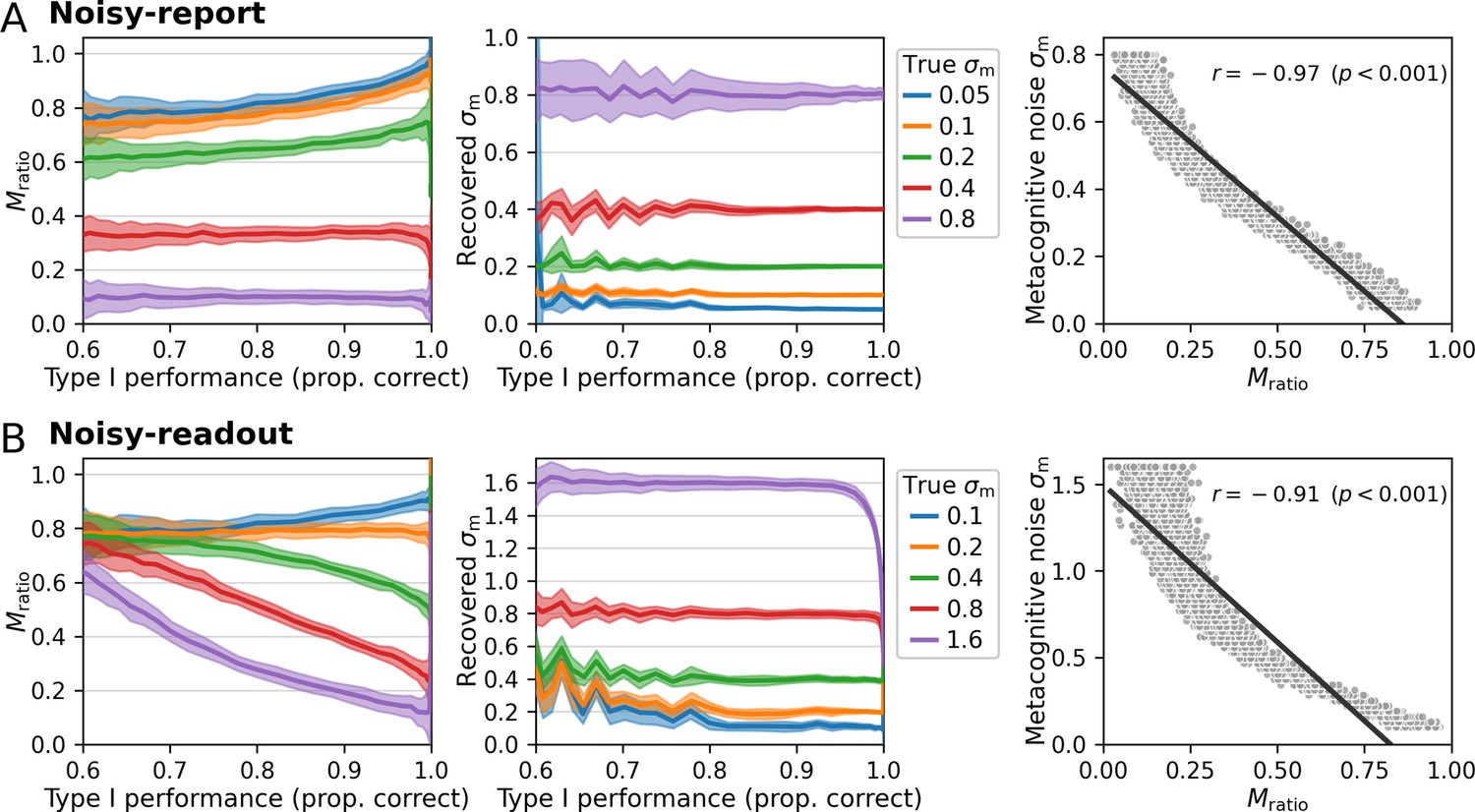
Comparison of Mratio and metacognitive noise σm for constant stimuli.
This simulation mirrors the simulations in Figure 6 but is based on only a single stimulus intensity level for both stimulus categories. While parameter recovery improves for the noisy-readout model under the extreme regime of low sensory and high metacognitive noise relative to a scenario with varying stimulus levels (Figure 6), parameter recovery becomes somewhat more unstable at low type 1 performance levels / high sensory noise.
Figure 6—figure supplement 2
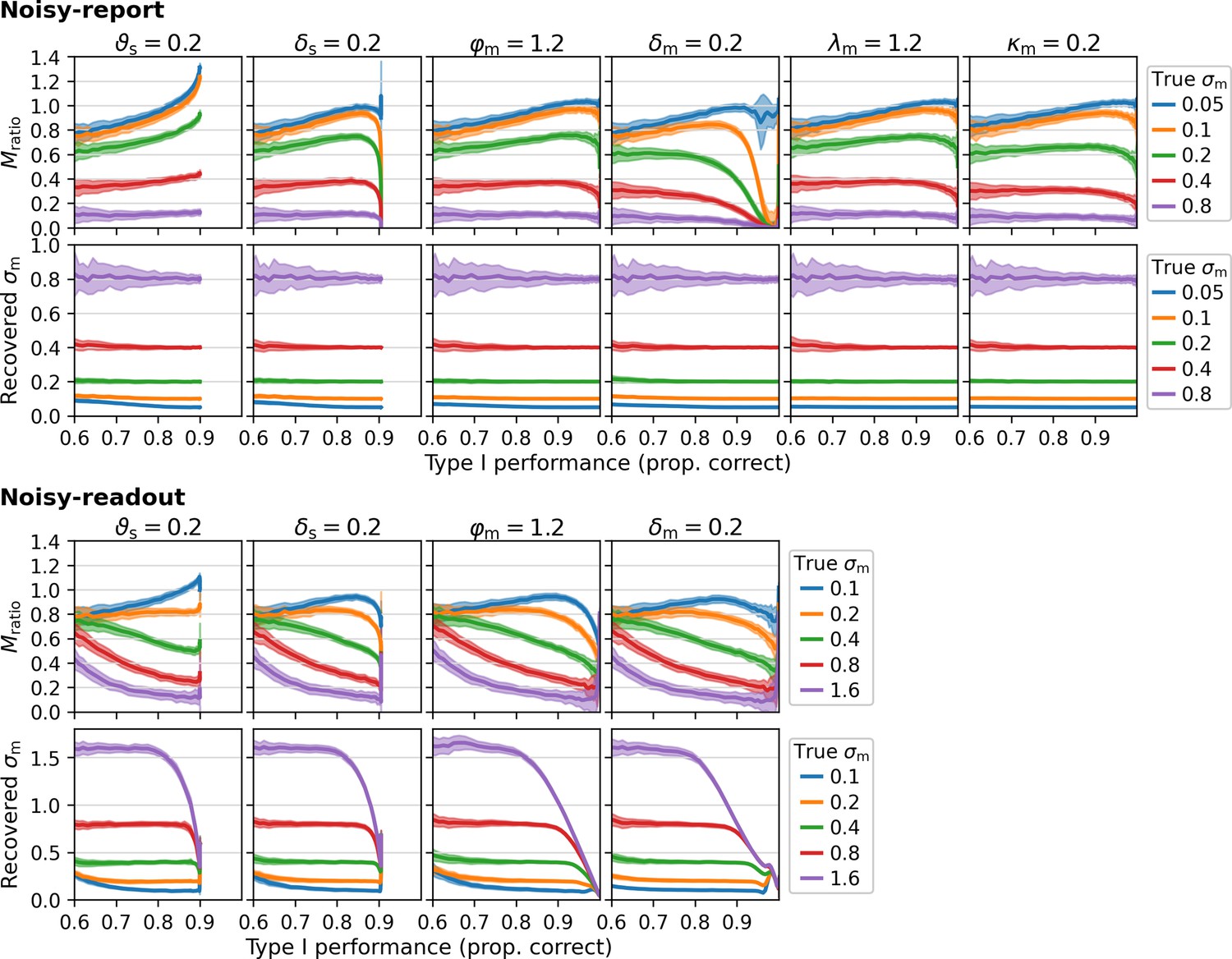
Type 1 dependency of Mratio and metacognitive noise σm for various settings of other parameters.
This simulation mirrors the simulations in Figure 6, while varying settings for other parameters (as indicated in the title for each column). Changed parameters: sensory threshold ϑs, sensory bias δs, multiplicative evidence bias φm, additive evidence bias δm, multiplicative confidence bias λm, additive confidence bias κm. Note that metacognitive confidence biases are incompatible with a noisy-readout model and hence this combination was omitted.
Figure 7 with 6 supplements
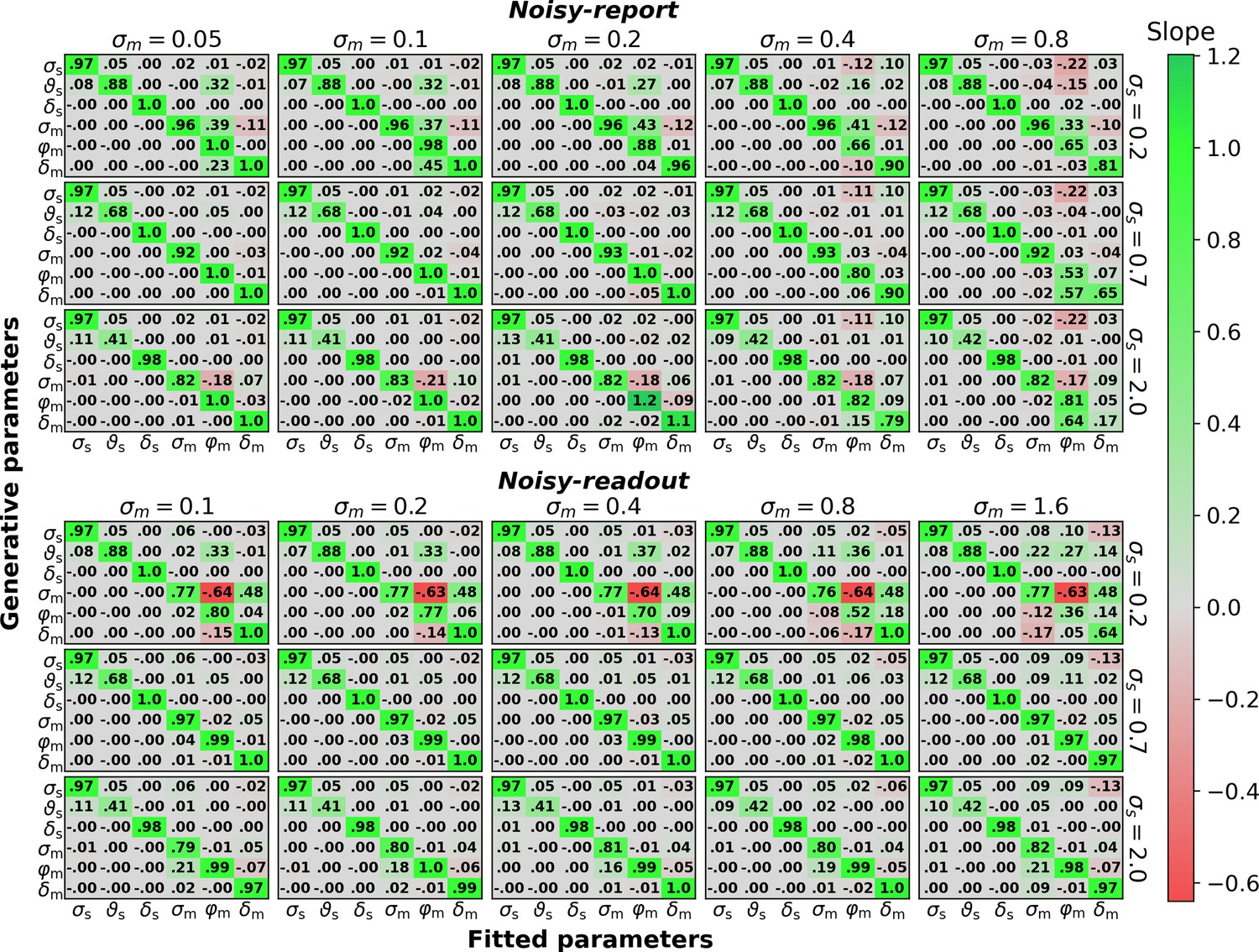
Parameter recovery (500 trials per observer).
Linear dependency between generative parameters and fitted parameters for the six parameters of the noisy-report and noisy-readout model (σs, , δs, σm, φm, δm). Linear dependency between generative and fitted parameters was assessed through robust linear slopes. The optimal value for diagonal elements is 1 while off-diagonal elements should be close to zero. Multiple slope matrices were computed for each node of a coarse parameter grid (see text). The figure thus shows average slope matrices, expanded along the coarse parameter grid axes for sensory noise σs and metacognitive noise σm. The row-wise values for σs and the column-wise values for σm indicate the parameter values used for data generation, except when σs or σm where themselves varied.
Figure 7—figure supplement 1
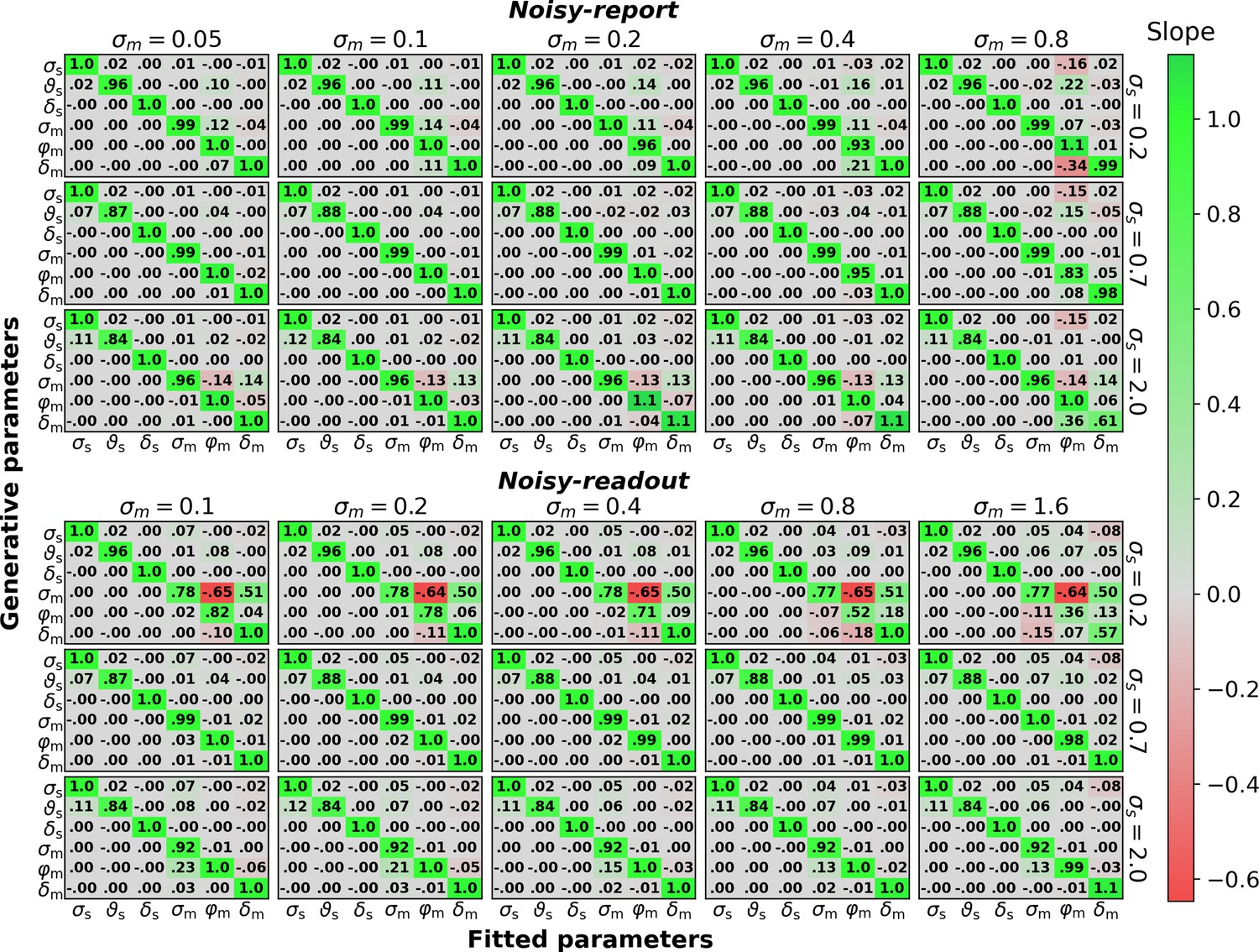
The figure mirrors the parameter recovery analysis in Figure 7 with 10,000 instead of 500 trials.
Sensory parameters: sensory noise σs, sensory threshold ϑs, sensory bias δs. Metacognitive parameters: metacognitive noise σm, multiplicative evidence bias φm, additive evidence bias δm.
Figure 7—figure supplement 2
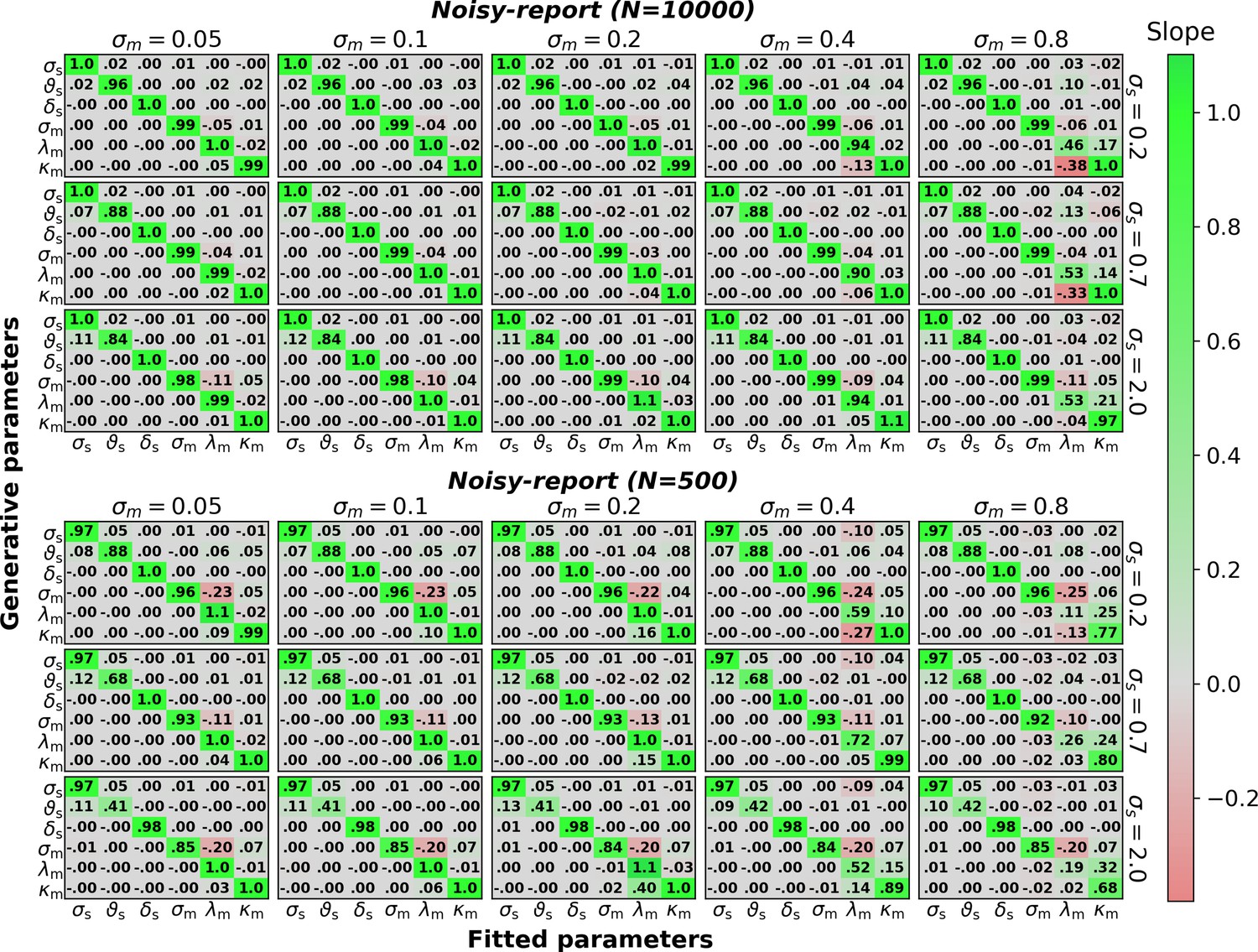
The figure mirrors the parameter recovery analysis in Figure 7 for a model with metacognitive confidence biases (λm, κm) instead of metacognitive evidence biases and for either 500 or 10,000 trials.
Note that metacognitive confidence biases are incompatible with a noisy-readout model and hence this combination was omitted. Sensory parameters: sensory noise σs, sensory threshold ϑs, sensory bias δs. Metacognitive parameters: metacognitive noise σm, multiplicative confidence bias λm, additive confidence bias κm.
Figure 7—figure supplement 3
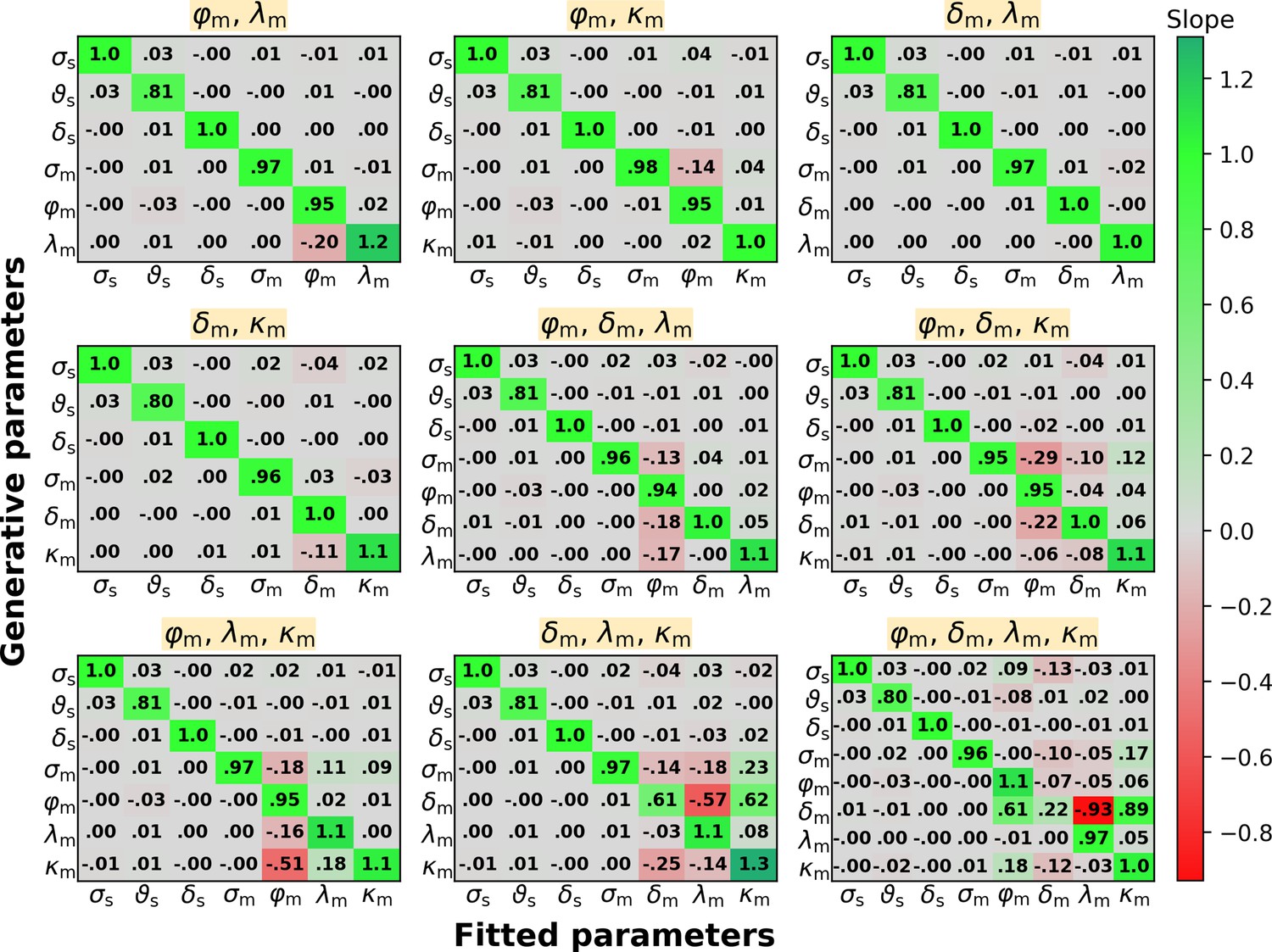
Parameter recovery for a mix of evidence-related and confidence-related metacognitive bias parameters.
For simplicity and clarity, this figure shows only slope matrices for intermediate levels of sensory (σs = 0.7) and metacognitive (σm = 0.2) noise, and for 10,000 trials. Sensory parameters: sensory noise σs, sensory threshold ϑs, sensory bias δs. Metacognitive parameters: metacognitive noise σm, multiplicative evidence bias φm, additive evidence bias δm, multiplicative confidence bias λm, additive confidence bias κm. The title displayed over each slope matrix indicates the metacognitive bias parameters that were included in the model.
Figure 7—figure supplement 4
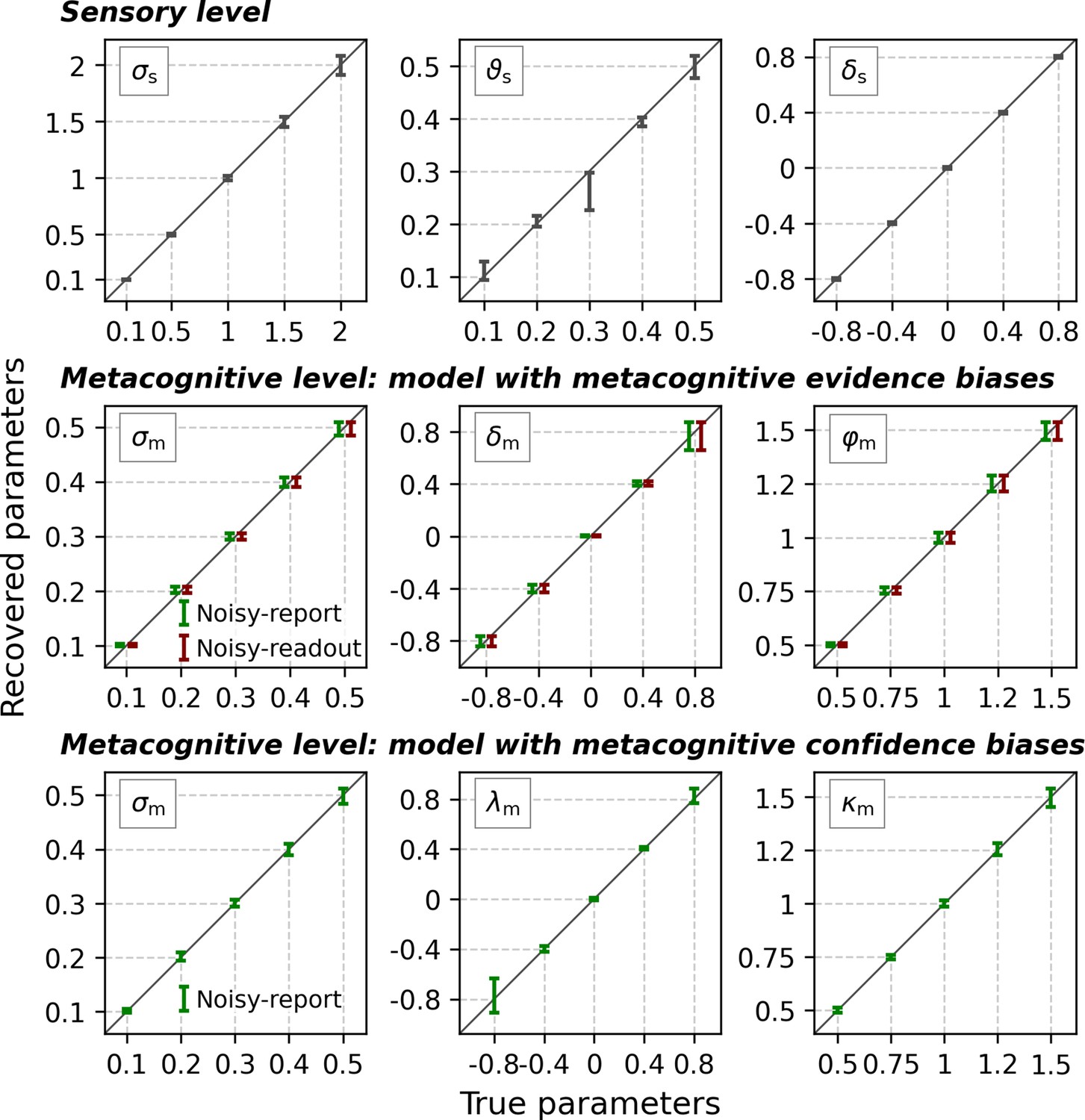
No indication of biases in parameter recovery.
For these analyses, the sample size was fixed to 10,000 trials. Sensory parameters: sensory noise σs, sensory threshold ϑs, sensory bias δs. At the metacognitive level the model was specified either with evidence-related (middle row) or confidence-related (bottom row) metacognitive bias parameters. Metacognitive parameters: metacognitive noise σm, multiplicative evidence bias φm, additive evidence bias δm, multiplicative confidence bias λm, additive confidence bias κm. Note that confidence-based metacognitive bias parameters are incompatible with a noisy-readout model and hence this combination was omitted. Error bars represent mean ± standard deviation. Dashed lines indicate the true values of the parameters. The error bars for the model with metacognitive evidence biases were displaced horizontally by −3% (noisy-report) and +3% (noisy-readout) of the full x-range to avoid mutual occlusion.
Figure 7—figure supplement 5
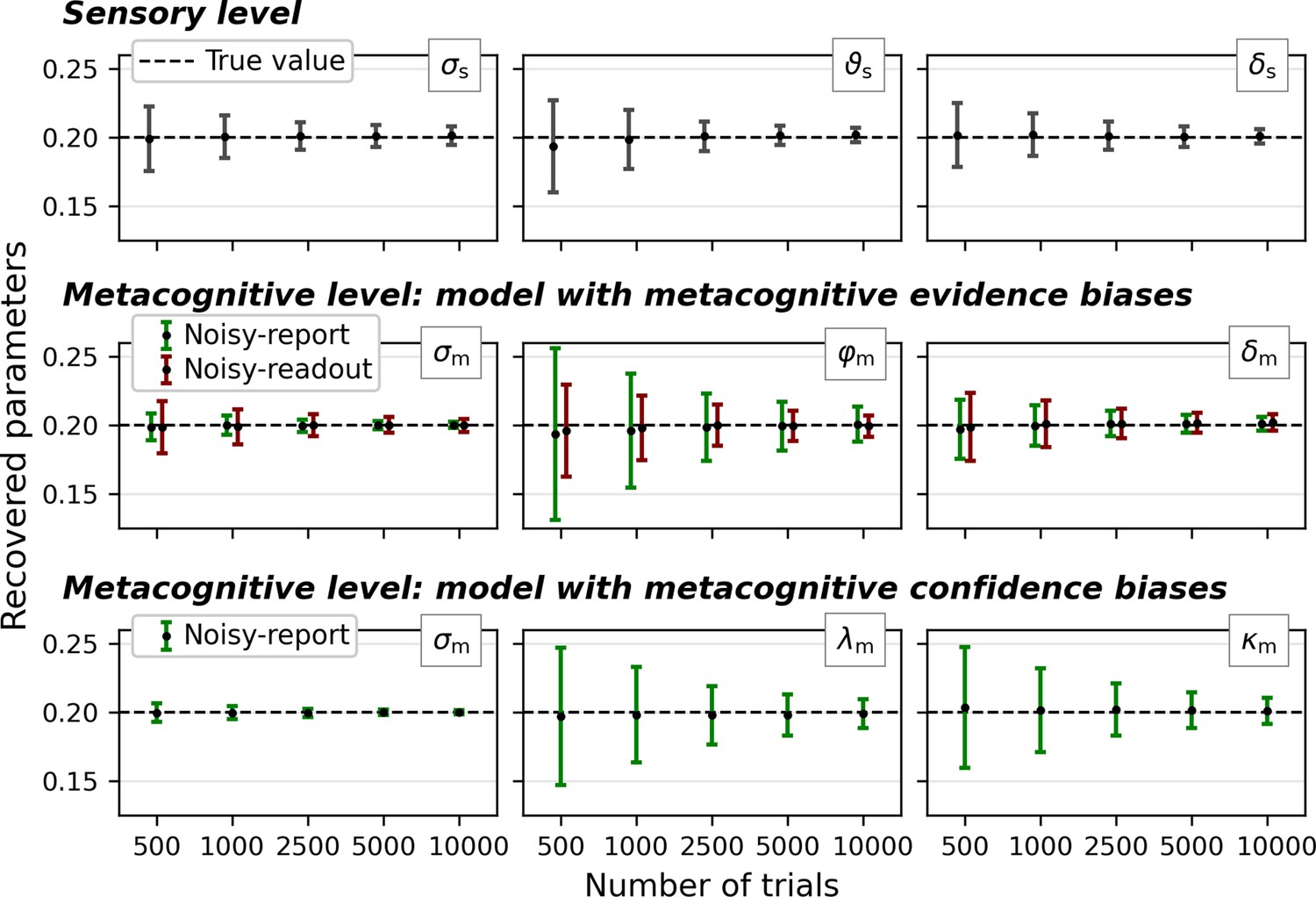
Parameter recovery across a range of trial numbers (500 to 10,000).
Sensory parameters: sensory noise σs, sensory threshold ϑs, sensory bias δs. At the metacognitive level the model was specified either with evidence-related (middle row) or confidence-related (bottom row) metacognitive bias parameters. Metacognitive parameters: metacognitive noise σm, multiplicative evidence bias φm, additive evidence bias δm, multiplicative confidence bias λm, additive confidence bias κm. Note that confidence-based metacognitive bias parameters are incompatible with a noisy-readout model and hence this combination was omitted. For simplicity, all parameters of the generative models were set to 0.2. Error bars represent mean ± standard deviation, dashed lines the true parameter value.
Figure 7—figure supplement 6
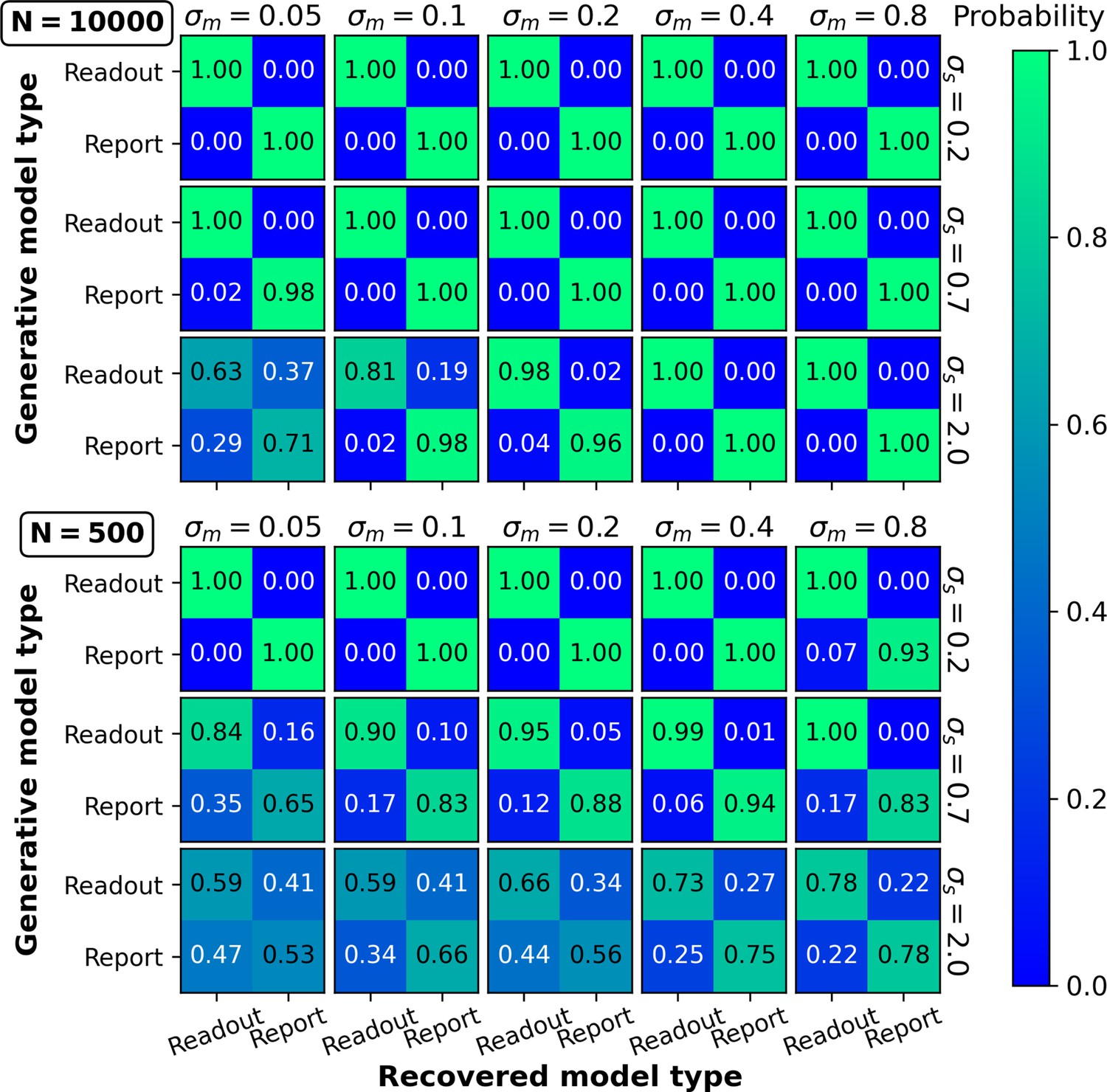
Model recovery.
Data were generated for noisy-readout and noisy-report models with different settings for sensory noise (σs) and metacognitive noise (σm). Model recovery was quantified by the frequency/probability with which the data of a particular generative model were best fitted by the noisy-readout and the noisy-report model. Top panel: 10,000 trials per observer. Bottom panel: 500 trials per observer.
Figure 8 with 1 supplement
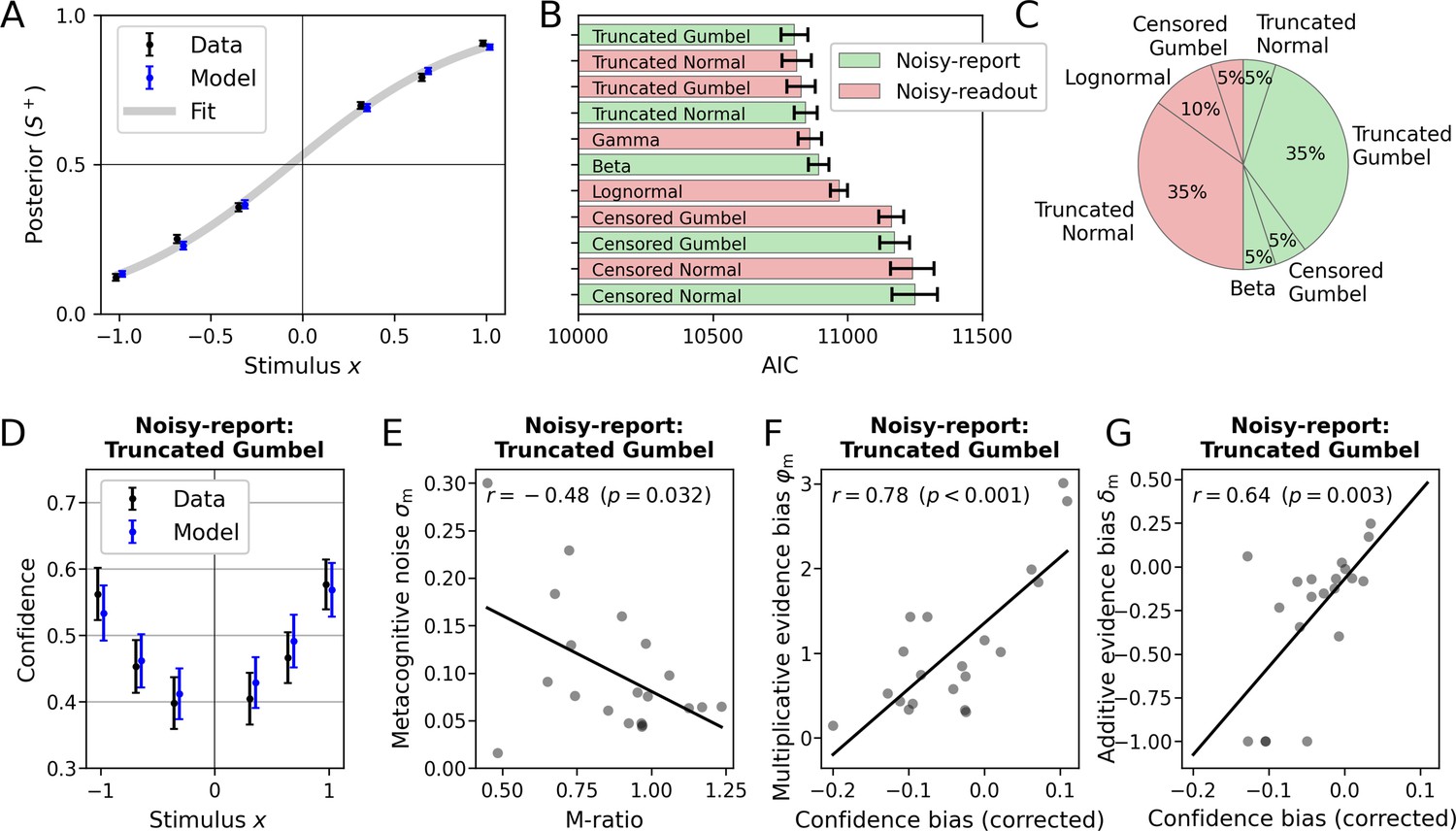
Application of the model to empirical data from Shekhar and Rahnev, 2021 (N=20).
(A) Posterior probability (choice probability for S+) as a function of normalized signed stimulus intensity. Model-based predictions closely follow the empirical data. Means and standard errors across subjects were computed for the three difficulty levels of each stimulus category. The fit is based on a logistic function with a sensory bias parameter δs. (B) Comparison of noisy-readout and noisy-report models featuring different metacognitive noise distributions. Model comparison was based on the Akaike information criterion (AIC) which quantified model evidence at the metacognitive level (the sensory level is identical between models). Error bars indicate standard errors of the mean (SEM). (C) Breakdown of best-fitting models across participants. (D–G) Inspection of the metacognitive level for the winning model of the type noisy-report with a truncated Gumbel noise distribution. (D) Empirical confidence is well-fitted by model-based predictions of confidence which are based on an average of 1000 runs of the generative model. Error bars represent SEM. (E) Relationship of empirical Mratio and model-based metacognitive noise σm. (F) Partial correlation of the empirical confidence bias the and model-based multiplicative evidence bias φm. The additive evidence bias was partialed out from the confidence bias. (G) Partial correlation of the empirical confidence bias and the model-based additive evidence bias δm. The multiplicative evidence bias was partialed out from the confidence bias.
Figure 8—figure supplement 1

Empirical confidence distributions and generative models of all 20 subjects in Shekhar and Rahnev, 2021.
Empirical confidence distributions are depicted as gray histograms. Distributions of generative models are depicted as orange line plots for the winning model at the group level (noisy-report+truncated Gumbel) and as green line plots for the winning model at the single-subject level.
Figure 9
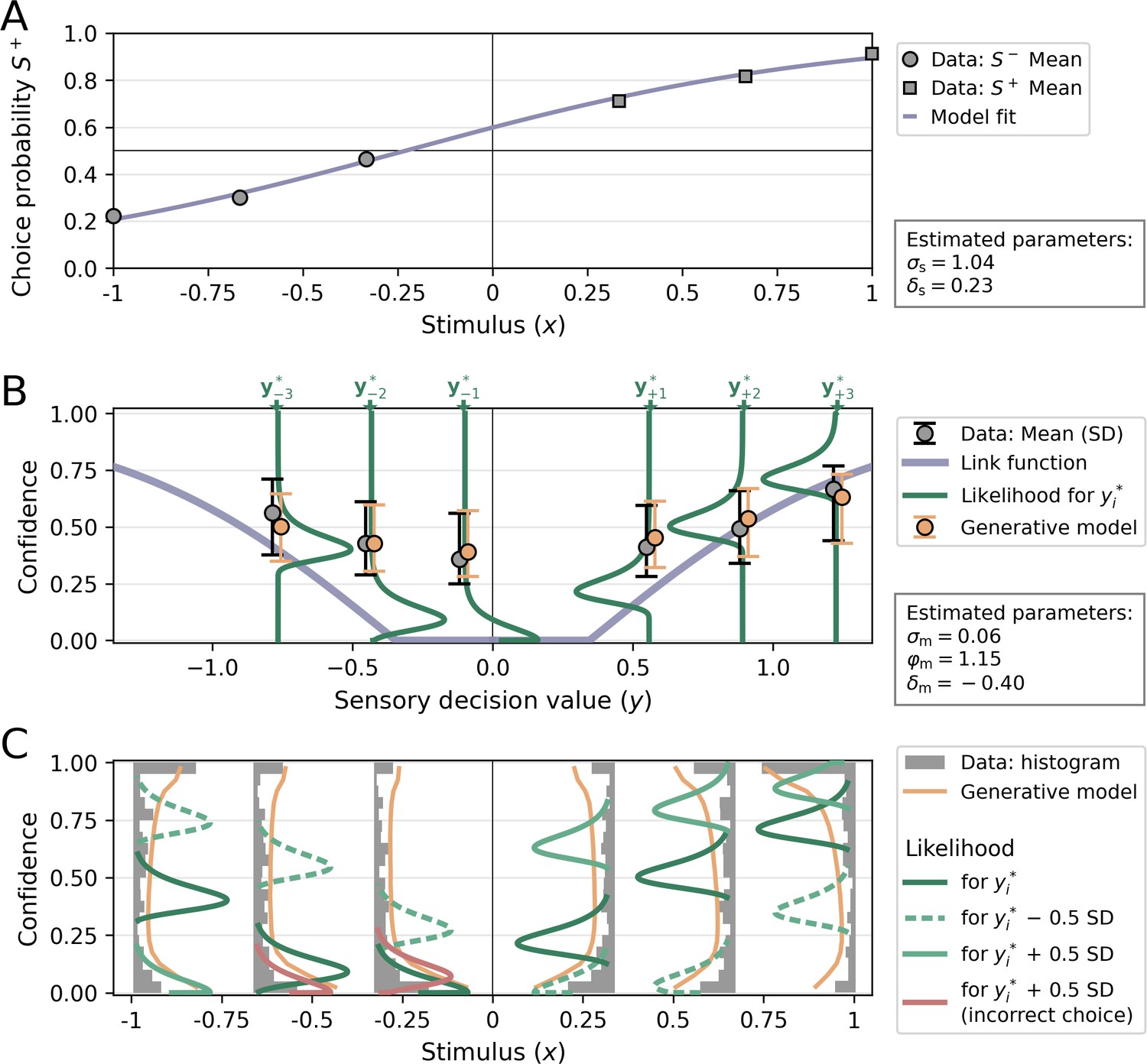
Visualization of a model fit for a single participant from Shekhar and Rahnev, 2021.
The applied model was a noisy-report model with a metacognitive noise distribution of the type truncated Gumbel and metacognitive evidence biases Each stimulus category in Shekhar and Rahnev, 2021 was presented with three intensity levels, corresponding to values of ±1/3, ±2/3, and ±1 in normalized stimulus space (variable x). (A) Choice probability for S+ as a function of stimulus intensity. The positive sensory bias δs shifts the logistic function toward the left, thereby increasing the choice probability for S+. (B) Link function, average confidence ratings and likelihood. The link function was transformed into decision value space y, for illustratory purposes. The flat range of the link function is caused by a relatively large additive evidence bias δm. Confidence ratings from empirical data (gray) and from the generative model (orange) for each stimulus levels i are indicated by their mean and standard deviation. Note that these confidence averages derive from the whole range of possible decision values and they are anchored at the most likely decision values of each stimulus level i only for illustratory purposes. The likelihood for confidence ratings is shown only for the most likely decision values of each stimulus level i. (C) Confidence distributions and likelihood. Empirical confidence ratings are shown as a histograms and confidence ratings obtained from the generative model as line plots. To visualize the effect of sensory uncertainty on the metacognitive level, likelihood distributions are plotted not only for the most likely values of the decision value distributions, but also half a standard deviation below (dashed and lighter color) and above (solid and lighter color). The width of likelihood distributions is controlled by the metacognitive noise parameter σm. Distributions colored in red indicate that a sign flip of decision values has occurred, i.e. responses based on these decision values would be incorrect.
Tables
Appendix 2—table 1
Metacognitive noise distributions.
All distributions are parameterized such that is the mode and σm is the standard deviation of the distribution (the only exception is the Beta distribution, for which σm is a spread parameter that cannot be identified with a statistical quantity). For the Gumbel distribution the auxiliary parameter ηm was defined as ηm = π/(σm√6), such that σm corresponds to the standard deviation of the distribution.
| Noisy-readout | Noisy-report | |
|---|---|---|
| Censored Normal | ||
| Censored Gumbel | ||
| Truncated Normal | ||
| Truncated Gumbel | ||
| Gamma/ Beta | Parameterization: | Parameterization: |
| Lognormal | Note: and represent an analytic parameterization such that the lognormal distribution has mode z* and standard deviation σm. See the published code for details. |
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Reverse engineering of metacognition
eLife 11:e75420.
https://doi.org/10.7554/eLife.75420




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}