Open-source tools for behavioral video analysis: Setup, methods, and best practices
- Cellular Neuroscience, Leibniz Institute for Neurobiology, Germany
- Department of Computing and Mathematical Sciences, California Institute of Technology, United States
- Rodent Behavioral Core, National Institute of Mental Health, National Institutes of Health, United States
- Department of Biochemistry and Cellular & Molecular Biology, University of Tennessee, United States
- Department of Biological Sciences, Carnegie Mellon University, United States
- Department of Neuroscience, University of Minnesota, United States
- The Salk Institute of Biological Studies, United States
- Department of Neuroscience, American University, United States
Figures
Figure 1
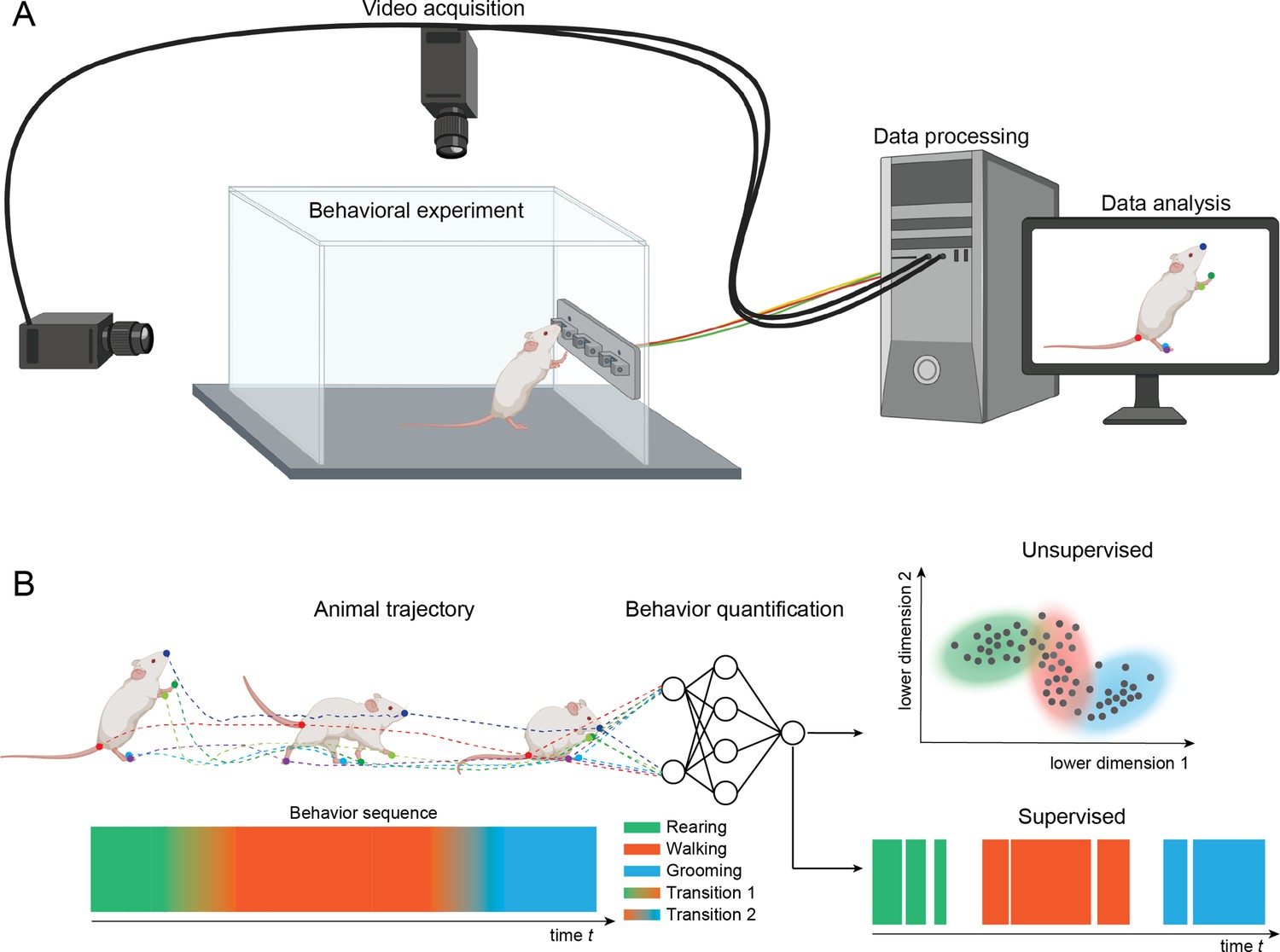
Setup for video recording.
(A) Cameras are mounted above and to the side of a behavioral arena. The cameras record sequences of images of an animal performing a behavioral task. The recordings are stored on a computer and analyzed with methods for pose estimation and behavior classification. (B) The animal’s pose trajectory captures the relevant kinematics of the animal’s behavior and is used as input to behavior quantification algorithms. Quantification can be done using either unsupervised (learning to recognize behavioral states) or supervised (learning to classify behaviors based on human annotated labels). In this example, transitions among three example behaviors (rearing, walking, and grooming) are depicted on the lower left and classification of video frames into the three main behaviors are depicted on the lower right.
Figure 2
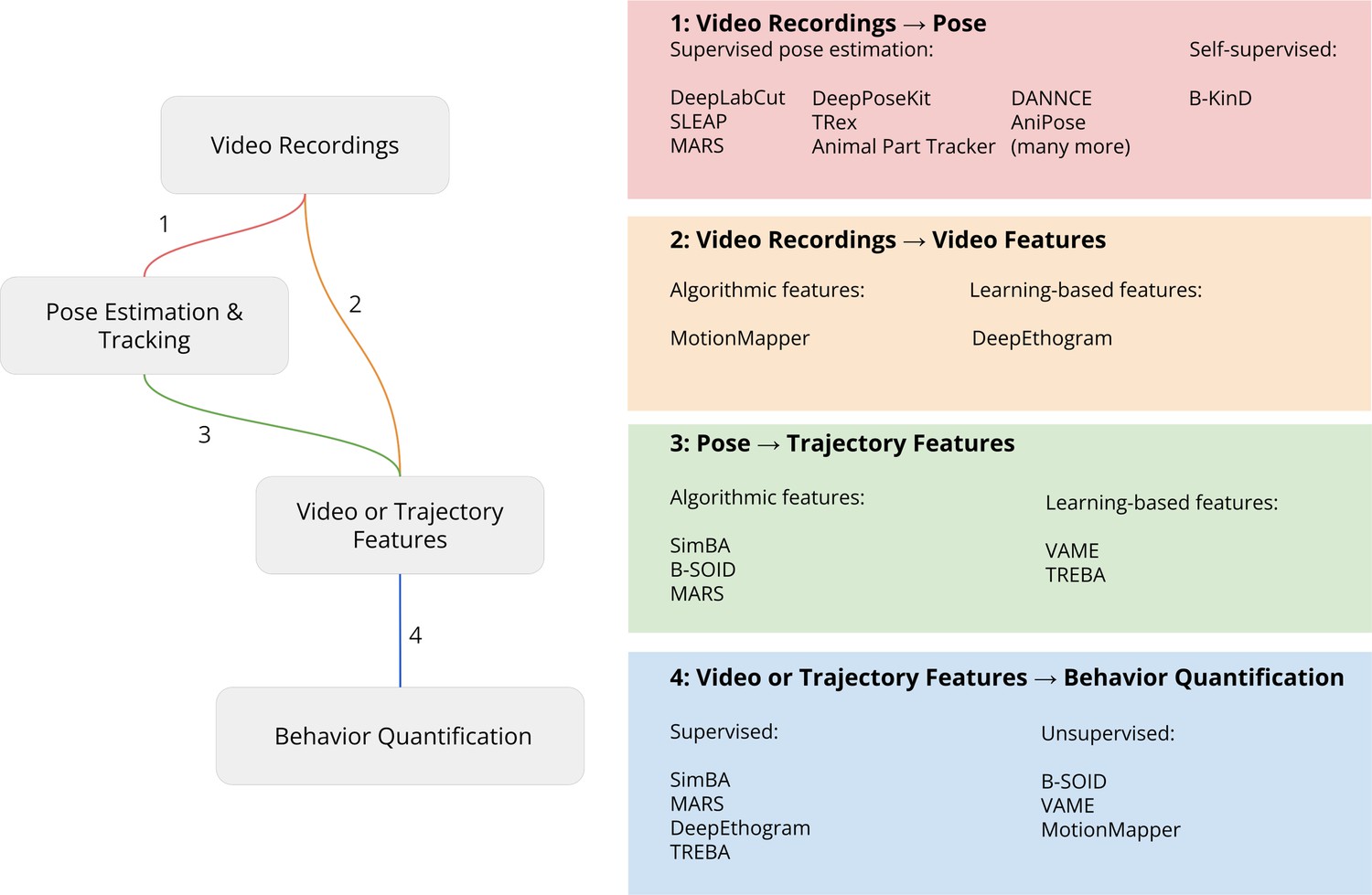
Pipeline for video analysis.
Video recordings are analyzed with either keypoints from 2D or 3D pose estimation or directly by computing video features. These videos or trajectory features are then used by downstream algorithms to relate the keypoints to behavioral constructs such as predicting human-defined behavior labels (supervised learning) or discovering behavior motifs (unsupervised learning). Each part of the analysis steps outlined in the figure is described in more detail below.
Tables
Table 1
Frequently used terms for video analysis.
| pose | The configuration (position and/or orientation) of an animal, object, or body parts in an image or video recording |
| keypoints/landmarks | Distinct identifiable morphological features (e.g., the tip of the snout or the base of the tail in a rodent) that can be localized in 2D or 3D from images, typically via pose estimation |
| part grouping | A process for assigning keypoints to individual animals |
| multi-object tracking | In multi-animal pose tracking, the task of determining which detected poses belong to which individual animal across time |
| re-identification | A process for identifying all images containing the same individual animal based primarily on their distinct appearance |
| kinematics | Information about the angles and velocities of a set of keypoints |
| supervised learning | Machine learning methods that use experimenter-provided labels (e.g., ground truth poses, or ‘running’ vs ‘grooming’) to train a predictive model |
| unsupervised learning | Machine learning methods that only use unlabeled data to find patterns based on its intrinsic structure (e.g., clustering behavioral motifs based on the statistics of their dynamics) |
| transfer learning | Machine learning methods that use models trained on one dataset to analyze other datasets (e.g., models of grooming in mice applied to rats) |
| self-supervised learning | Machine learning methods that use only unlabeled data for training by learning to solve artificially constructed tasks (e.g., comparing two variants of the same image with noise added against other images; predicting the future; or filling in blanks) |
| embedding | A representation of high-dimensional data into lower dimensional representation |
| lifting | A process through which 2D pose data are converted to 3D representations |
| behavioral segmentation | A process for detecting occurrences of behaviors (i.e., starting and ending frames) from video or pose sequences |
Table 2
Methods for 2D pose estimation.
| DeepLabCut | DeepLabCut (Mathis et al., 2018a; Mathis et al., 2018b) uses a popular architecture for deep learning (He et al., 2016), called ResNet. DeepLabCut models are pre-trained on a massive dataset for object recognition called ImageNet (Russakovsky et al., 2015). Through a process called transfer learning, the DeepLabCut model learns the position of keypoints using as few as 200 labeled frames. This makes the model very robust and flexible in terms of what body parts (or objects) users want to label as the model provides a strong backbone of image filters within their ResNet architecture. To detect the keypoint position, DeepLabCut replaces the classification layer of the ResNet with deconvolutional layers to produce spatial probability densities from which the model learns to assign high probabilities to regions with the user labeled keypoints. DeepLabCut can provide very accurate pose estimations but can require extensive time for training. |
| SLEAP | SLEAP (Pereira et al., 2022) is based on an earlier method called LEAP (Pereira et al., 2022), which performed pose estimation on single animals. SLEAP uses simpler CNN architectures with repeated convolutional and pooling layers. This makes the model more lightweight compared to DLC’s ResNet architecture and, hence, the model is faster to train with comparable accuracy. Similar to DeepLabCut, the model uses a stack of upsampling or deconvolutional layers to estimate confidence maps during training and inference. Unlike DLC, SLEAP does not solely rely on transfer learning from general-purpose network models (though this functionality is also provided for flexible experimentation). Instead, it uses customizable neural network architectures that can be tuned to the needs of the dataset. SLEAP can produce highly accurate pose estimates starting at about 100 labeled frames for training combined and is quick to train on a GPU (<1 hour). |
| DeepPoseKit | DeepPoseKit (Graving et al., 2019a; Graving et al., 2019b) uses a type of CNN architecture, called stacked DenseNet, an efficient variant of the stacked hourglass (Newell et al., 2016), and uses multiple down- and upsampling steps with densely connected hourglass networks to produce confidence maps on the input image. The model uses only about 5% of the amount of parameters used by DeepLabCut, providing speed improvements over DeepLabCut and LEAP. |
| B-KinD | B-KinD (Sun et al., 2021a; Sun et al., 2021b) discovers key points without human supervision. B-KinD has the potential to transform how pose estimation is done, as keypoint analysis is one of the most time-consuming aspects of doing pose estimation analysis. However, there are challenges for the approach when occlusions occur in the video recordings, e.g., recordings of animals tethered to brain recording systems. |
Table 3
Methods for behavioral segmentation using pose data.
| SimBA | SimBA (Nilsson et al., 2020a; Nilsson et al., 2020b) is a supervised learning pipeline for importing pose estimation data and a graphical interface for interacting with a popular machine learning algorithm called Random Forest (Breiman, 2001). SimBA was developed for studies in social behavior and aggression and has been shown to be able to discriminate between attack, pursuit, and threat behaviors in studies using rats and mice. |
| MARS | MARS (Segalin et al., 2021a; Segalin et al., 2021b) is another supervised learning pipeline developed for studies of social interaction behaviors in rodents, such as attacking, mounting, and sniffing, and uses the XGBoost gradient boosting classifier (Chen and Guestrin, 2016). |
| B-SOiD | B-SOiD (Hsu and Yttri, 2021a; Hsu and Yttri, 2021b) uses unsupervised methods to learn and discover the spatiotemporal features in pose data of ongoing behaviors, such as grooming and other naturalistic movements in rodents, flies, or humans. B-SOiD uses UMAP embedding (McInnes et al., 2020) to account for dynamic features within video frames that are grouped using an algorithm for cluster analysis, HDBSCAN (McInnes et al., 2017). Clustered spatiotemporal features are then used to train a classifier (Random Forest; Breiman, 2001) to detect behavioral classes in data sets that were not used to train the model and with millisecond precision. |
| VAME | VAME (Luxem et al., 2022a; Luxem et al., 2022b) uses self-supervised deep learning models to infer the full range of behavioral dynamics based on the animal movements from pose data. The variational autoencoder framework (Kingma and Welling, 2019) is used to learn a generative model. An encoder network learns a representation from the original data space into a latent space. A decoder network learns to decode samples from this space back into the original data space. The encoder and decoder are parameterized with recurrent neural networks. Once trained, the learned latent space is parameterized by a Hidden Markov Model to obtain behavioral motifs. |
| TREBA | TREBA (Sun et al., 2021c; Sun et al., 2021d) relates measures from pose estimation to other quantitative or qualitative data associated with each frame in a video recording. Similar to VAME, a neural network is trained to learn to predict movement trajectories in an unsupervised manner. TREBA can then incorporate behavioral attributes, such as movement speed, distance traveled, and heuristic labels for behavior (e.g., sniffing, mounting, attacking) into representations of the pose estimation data learned by its neural networks, thereby bringing aspects of supervised learning. This is achieved using a technique called task programming. |
Table 4
Datasets for model development.
| Dataset | Task | Setting | Organism |
|---|---|---|---|
| Human3.6M | 2D/3D Pose Estimation | Videos from 4 camera views with poses from motion capture | Human (single-agent) |
| MS COCO | 2D Pose Estimation | Images from uncontrolled settings with annotated poses | Human (multi-agent) |
| PoseTrack | 2D Pose Estimation & Tracking | Videos from crowded scenes with annotated poses | Human (multi-agent) |
| AP-10K | 2D Pose Estimation | Images of diverse animal species with annotated poses | Diverse species (single & multi-agent) |
| MARS | 2D Pose Estimation | Videos from 2 camera views with annotated poses | Mouse (multi-agent) |
| 3D-ZEF | 2D/3D Pose Estimation & Tracking | Videos from 2 camera views with annotated poses | Zebrafish (multi-agent) |
| OpenMonkeyStudio | 2D/3D Pose Estimation | Images with annotated poses from a 62 camera setup | Monkey (single-agent) |
| PAIR-R24M | 2D/3D Pose Estimation & Tracking | Videos from 12 camera views with poses from motion capture | Rat (multi-agent) |
| 3DPW | 2D/3D Pose Estimation & Tracking | Videos from moving phone camera in challenging outdoor settings | Human (multi-agent) |
| 3DHP | 2D/3D Pose Estimation | Videos from 14 camera views with poses from motion capture | Human (single-agent) |
| Rat 7M | 2D/3D Pose Estimation | Videos from 12 camera views with poses from motion capture | Rat (single-agent) |
| Kinetics | Video-level Action Classification | Videos from uncontrolled settings that cover 700 human actions | Human (single & agent, may interact with other organisms/objects) |
| NTU-RGBD | Video-level Action Classification (also has 3D poses) | Videos from 80 views and depth with 60 human actions | Human (single & multi-agent) |
| MultiTHUMOS | Frame-level Action Classification | Videos from uncontrolled settings with 65 action classes | Human (single & multi-agent) |
| CRIM13 | Frame-level Behavior Classification | Videos from 2 views, with 13 annotated social behaviors | Mouse (multi-agent) |
| Fly vs. Fly | Frame-level Behavior Classification (also has 2D poses) | Videos & trajectory, with 10 annotated social behaviors | Fly (multi-agent) |
| CalMS21 | Frame-level Behavior Classification (also has 2D poses) | Videos & trajectory, with 10 annotated social behaviors | Mouse (multi-agent) |
| MABe | Frame-level Behavior Classification (also has 2D poses) | Top-down views, 7 annotated keypoints, hundreds of videos | Mouse (multi-agent) |
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Open-source tools for behavioral video analysis: Setup, methods, and best practices
eLife 12:e79305.
https://doi.org/10.7554/eLife.79305




{kind=link}
{kind=link}