Neural assemblies uncovered by generative modeling explain whole-brain activity statistics and reflect structural connectivity
- Computational Neuroscience Lab, Department of Neurophysiology, Donders Center for Neuroscience, Radboud University, Netherlands
- Sorbonne Université, CNRS, Institut de Biologie Paris-Seine (IBPS), Laboratoire Jean Perrin (LJP), France
- Department of Physiology, Anatomy and Genetics, University of Oxford, United Kingdom
- Blavatnik School of Computer Science, Tel Aviv University, Israel
- Department Genes – Circuits – Behavior, Max Planck Institute for Biological Intelligence, Germany
- Allen Institute for Brain Science, United States
Figures
Figure 1
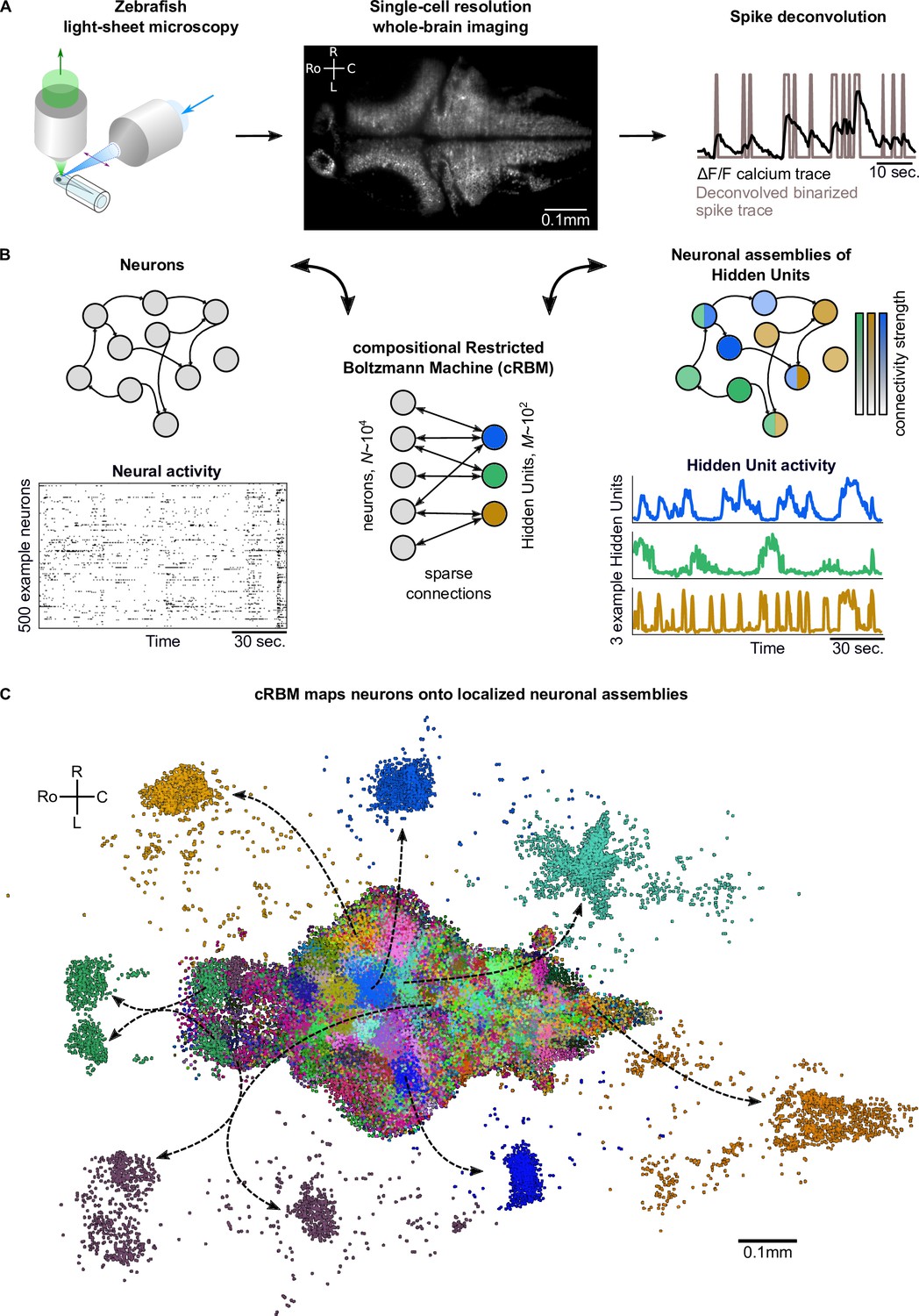
cRBMs construct Hidden Units by grouping neurons into assemblies.
(A) The neural activity of zebrafish larvae was imaged using light-sheet microscopy (left), which resulted in brain-scale, single-cell resolution data sets (middle, microscopy image of a single plane shown for fish #1). Calcium activity was deconvolved to binarized spike traces for each segmented cell (right, example neuron). (B) cRBM sparsely connects neurons (left) to Hidden Units (HUs, right). The neurons that connect to a given HU (and thus belong to the associated assembly), are depicted by the corresponding color labeling (right panel). Data sets typically consist of neurons and HUs. The activity of 500 randomly chosen example neurons (raster plot, left) and HUs 99, 26, 115 (activity traces, right) of the same time excerpt is shown. HU activity is continuous and is determined by transforming the neural activity of its assembly. (C) The neural assemblies of an example data set (fish #3) are shown by coloring each neuron according to its strongest-connecting HU. 7 assemblies are highlighted (starting rostrally at the green forebrain assembly, going clockwise: HU 177, 187, 7, 156, 124, 64, 178), by showing their neurons with a connection . See Figure 3 for more anatomical details of assemblies. R: Right, L: Left, Ro: Rostral, C: Caudal.
Figure 2 with 7 supplements
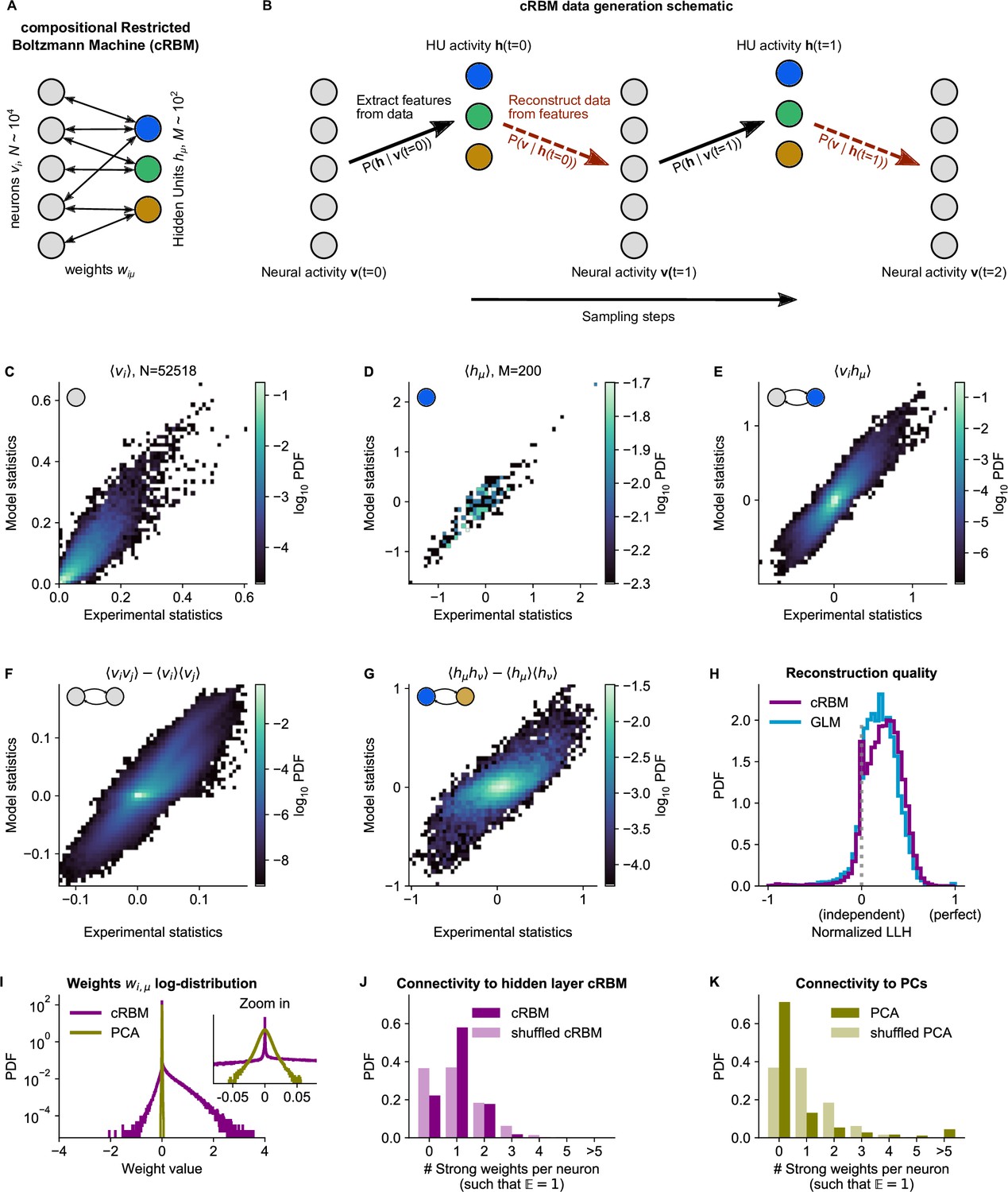
cRBM is optimized to accurately replicate data statistics.
(A) Schematic of the cRBM architecture, with neurons on the left, HUs on the right, connected by weights . (B) Schematic depicting how cRBMs generate new data. The HU activity is sampled from the visible unit (i.e. neuron) configuration , after which the new visible unit configuration is sampled and so forth. (C) cRBM-predicted and experimental mean neural activity were highly correlated (Pearson correlation , ) and had low error (, normalized Root Mean Square Error, see Materials and methods - ‘Calculating the normalized Root Mean Square Error’ ). Data displayed as 2D probability density function (PDF), scaled logarithmically (base 10). (D) cRBM-predicted and experimental mean Hidden Unit (HU) activity also correlated very strongly (, ) and had low (other details as in C) (E) cRBM-predicted and experimental average pairwise neuron-HU interactions correlated strongly (, ) and had a low error (). (F) cRBM-predicted and experimental average pairwise neuron-neuron interactions correlated well (, ) and had a low error (, where the negative nRMSE value means that cRBM-predictions match the test data slightly better than the train data). Pairwise interactions were corrected for naive correlations due to their mean activity by subtracting . (G) cRBM-predicted and experimental average pairwise HU-HU interactions correlated strongly (, ) and had a low error (). (H) The low-dimensional cRBM bottleneck reconstructs most neurons above chance level (purple), quantified by the normalized log-likelihood (nLLH) between neural test data vi and the reconstruction after being transformed to HU activity (see Materials and methods - ‘Reconstruction quality’). Median normalized = 0.24. Reconstruction quality was also determined for a fully connected Generalized Linear Model (GLM) that attempted to reconstruct the activity of a neuron vi using all other neurons (see Materials and methods - ‘Generalized Linear Model’). The distribution of 5000 randomly chosen neurons is shown (blue), with median . The cRBM distribution is stochastically greater than the GLM distribution (one-sided Mann Whitney U test, ). (I) cRBM (purple) had a sparse weight distribution, but exhibited a greater proportion of large weights than PCA (yellow), both for positive and negative weights, displayed in log-probability. (J) Distribution of above-threshold absolute weights per neuron vi (dark purple), indicating that more neurons strongly connect to the cRBM hidden layer than expected by shuffling the weight matrix of the same cRBM (light purple). The threshold was set such that the expected number of above-threshold weights per neuron . (K) Corresponding distribution as in (J) for PCA (dark yellow) and its shuffled weight matrix (light yellow), indicating a predominance of small weights in PCA for most neurons vi. All panels of this figure show the data statistics of the cRBM with parameters and (best choice after cross-validation, see Figure 2—figure supplement 1) of example fish #3, comparing the experimental test data test and model-generated data after cRBM training converged.
Figure 2—figure supplement 1
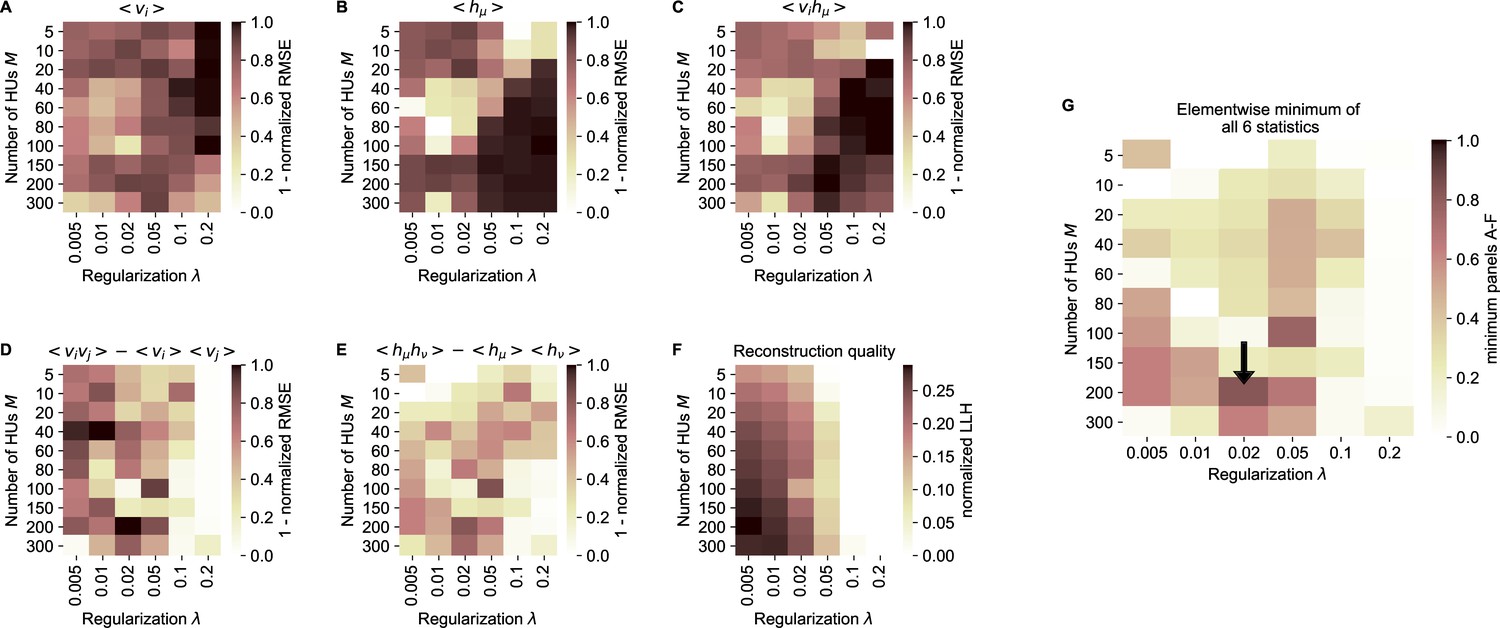
cRBM free parameter optimization by cross-validation.
(A) Model performance, as quantified by the normalized RMSE (nRMSE, see Materials and methods - ‘Calculating the normalized root mean square error’) of the mean neural activity , as a function of the sparsity regularization parameter (x-axis) and the number of HUs (y-axis). cRBM models were evaluated after training converged on withheld testing data. values are shown to enable optimization by maximization in panel G. Values below 0 were set to 0 for panels A-F. (B) Equivalent figure for the mean HU activity . (C) Equivalent figure for average pairwise neuron-HU interactions . (D) Equivalent figure for average pairwise neuron-neuron interactions . (E) Equivalent figure for average pairwise HU-HU interactions . (F) Equivalent figure for the reconstruction quality of the low-dimensional cRBM bottleneck, quantified by the median normalized LLH. (G) The cRBM free parameters were optimized by maximizing the element-wise minimum of panels A-F. Using the element-wise minimum to compare the six statistics ensures that the model performs performs well on all aspects. First, in order to compare panels A-E with panel F, the values of panel F were scaled to 1 by dividing all elements of panel F by its maximum value (=0.29). Next, for each combination the minimum value was determined from all 6 evaluation criteria. These are shown in this panel, with the black arrow indicating the resulting maximum of 0.83 at .
Figure 2—figure supplement 2
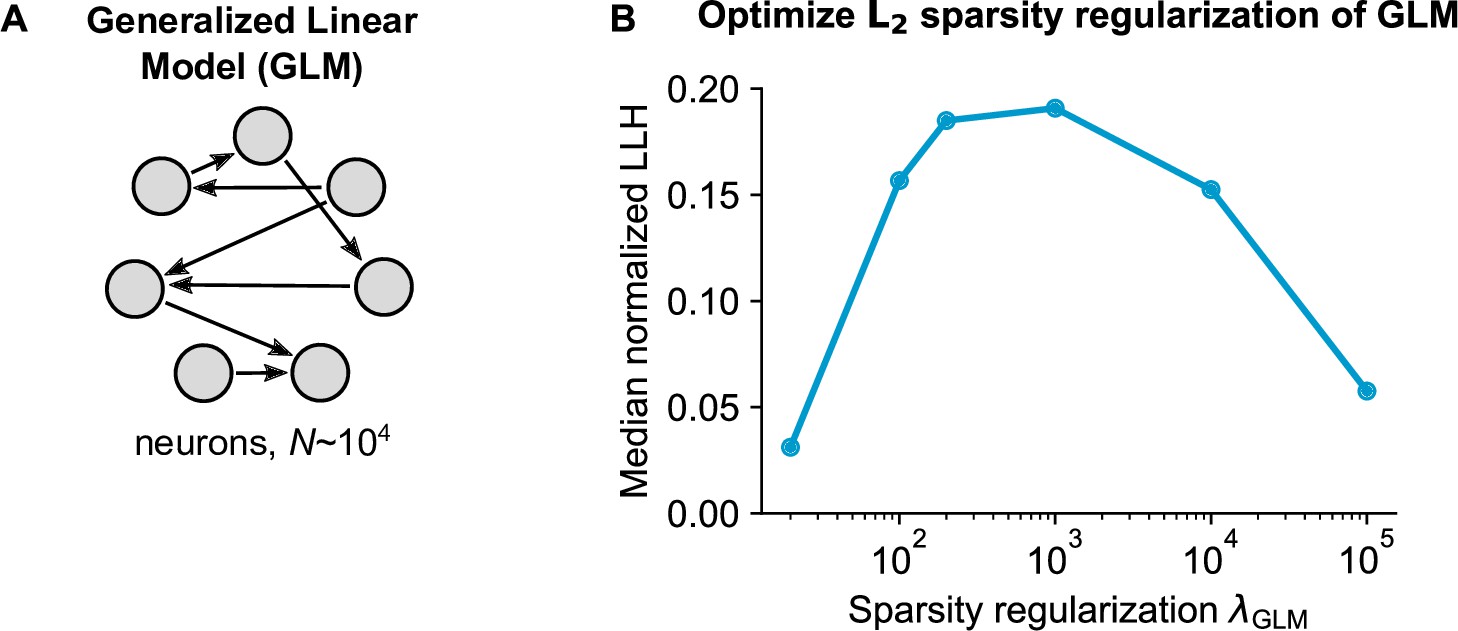
Generalized Linear Model (GLM) parameter optimization.
(A) Schematic of the pairwise GLM model. Connections were estimated with logistic regression and L2 sparsity regularization. (B) The sparsity regularization parameter was optimized using cross-validation of 6 parameter configurations, using 1000 randomly sampled neurons.
Figure 2—figure supplement 3
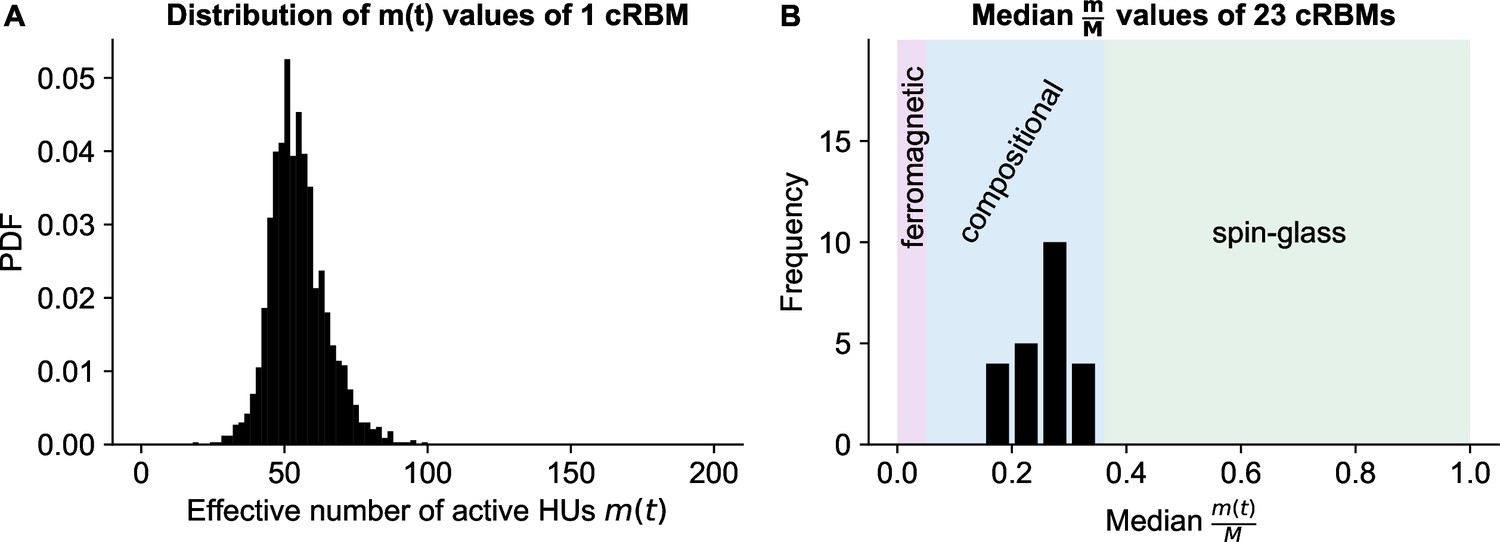
cRBMs are in the compositional phase after convergence.
(A) Distribution of , the number of effective active HUs per time point , calculated on the test data of example fish #3. is defined as , where PR is the Participation Ratio (Equation 19). Median . (B) The distribution of median values of the entire recordings of all cRBMs used for the connectivity analyses. The average across all cRBMs is 0.26. The compositional phase is characterized by which occurs for all cRBMs. The three phases are indicated. Here, the ferromagnetic phase upper bound was manually set at 5%, and the spin-glass phase lower bound was determined by computing the PR of normally distributed activity (with mean and standard deviation of the test data of example fish #3 of panel A).
Figure 2—figure supplement 4
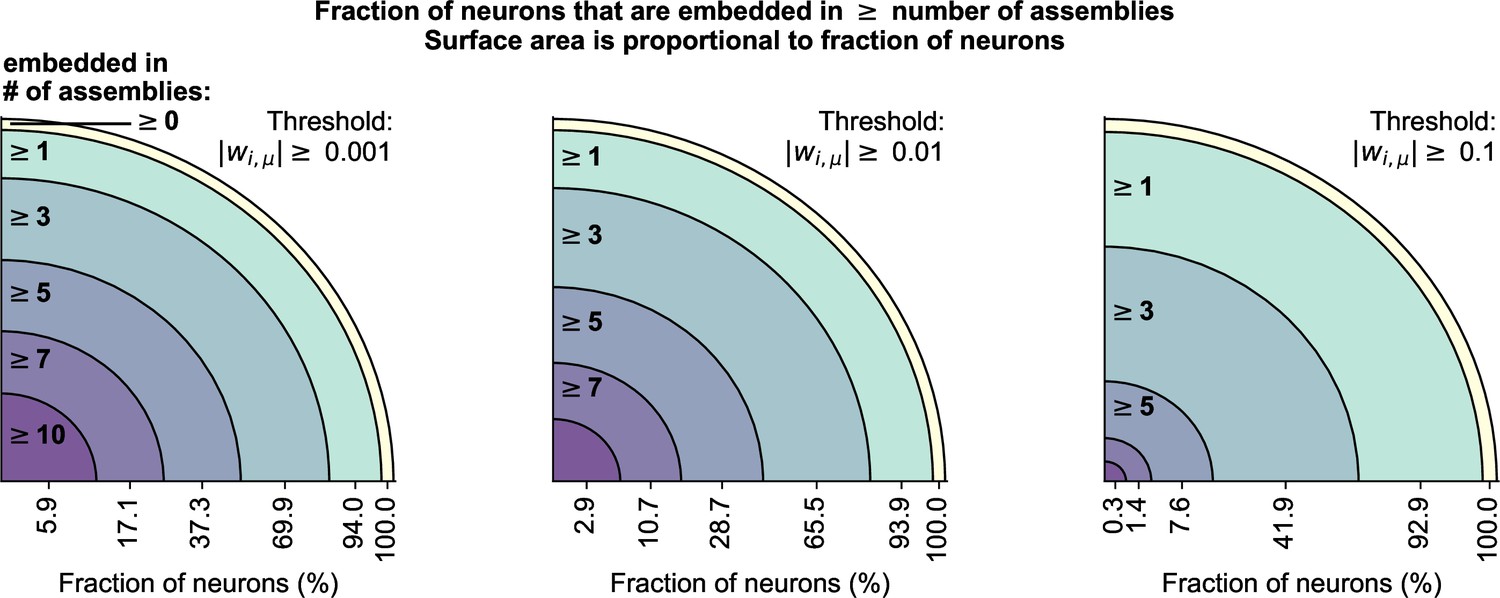
Neurons can be embedded in multiple assemblies.
cRBM allow neurons to be embedded in multiple assemblies, which we quantified by measuring the number of above-threshold weights per neuron.Threshold values of 0.001 (left), 0.01 (middle), and 0.1 (right) were used. For each threshold value, we counted the fraction of neurons that had at least 0, 1, 3, 5, 7, or 10 above-threshold weights (i.e. were embedded in at least that many assemblies), as denoted on the x-axis of each panel. Changing the threshold from 0.001 to 0.01 did not cause a large shift in the distribution of embedded assemblies (left vs middle), indicating that there were few connections in the range . Increasing the threshold to 0.1 strongly decreased the number of neurons with many (gt3) assembly embeddings, but not the number of neurons with at least 1 assembly embedding, indicating that most neurons have at least 1 strong assembly connection (in accordance with Figure 2J).
Figure 2—figure supplement 5
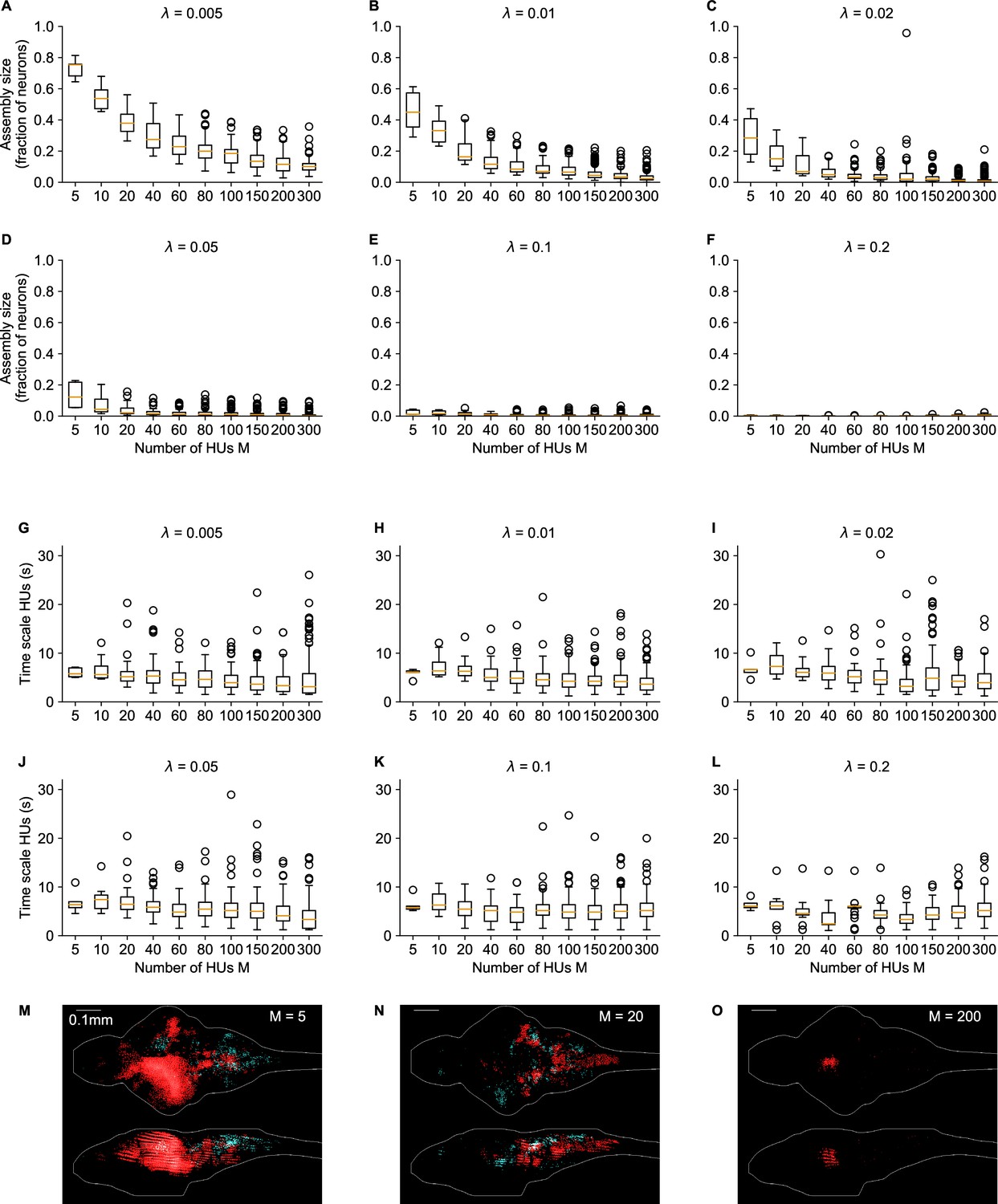
Influence of number of HUs and sparsity regularization on cRBM properties.
(A–F) The distribution of assembly sizes is shown as a function of number of HUs (x-axis) and sparsity regularization parameter (panels). Assembly size was determined by computing for each HU μ. Two-way ANOVA determined that both () and (), as well as their interaction () significantly explained the mean assembly size. (G–L) The distribution of HU dynamics time scales is shown as a function of (x-axis) and (panels). Time scales were calculated as in Figure 2F. There are 2 extra out-of-panel outliers for at 70 s and at 36 s. Two-way ANOVA determined that only () strongly significantly explained the mean time scale, while () did not and their interaction () only weakly. M-O Three example assemblies are shown, corresponding to the mean assembly size of (panel M), (N) and (O) cRBM models (all with ). Assembly sizes are 0.27 (M), 0.07 (N), 0.01 (O), respectively.
Figure 2—figure supplement 6
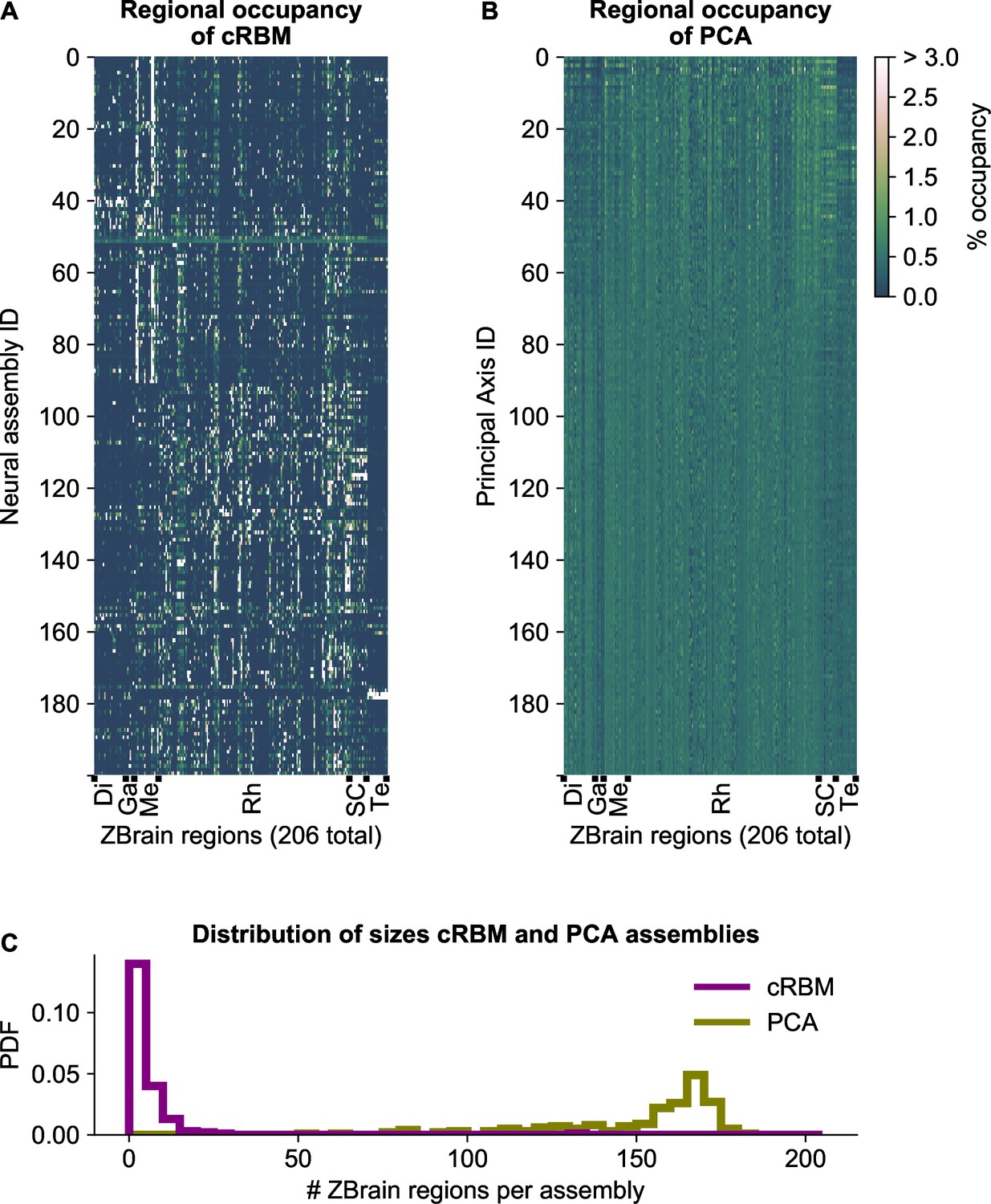
cRBM assemblies are sparse and spatially localized.
(A) For each neural assembly (y-axis), the occupancy of ZBrain Atlas (Randlett et al., 2015) brain regions (x-axis, sorted alphabetically) was determined, by quantifying the number of anatomical regions that each HU connects to (i.e. the overlap between cRBM assemblies and anatomical regions, see Materials and methods - ‘Regional occupancy’). ZBrain atlas regions that were not imaged were excluded, yielding regions in total. Occupancy was defined as the dot product between the binary ZBrain-label matrix (size , where 1 indicates that a neuron is embedded in an anatomical region, and 0 vice versa) and the cRBM weight matrix (size ), and was normalized to 100% for each assembly to account for different assembly sizes. Assemblies were sorted by their dynamics (Figure 2B, Materials and methods). ZBrain Atlas regions are abbreviated by: Diencephalon (Di), Ganglia (Ga), Mesencephalon (Me), Rhombencephalon (Rh), Spinal Cord (SC) and Telencephalon (Te). (B) Equivalent figure for Principal Axes of PCA (i.e. the PCA Eigenvectors). Principal Axes were sorted by Eigenvalue. Panels A and B share the same color scale (right). (C) Distributions of the effective number of ZBrain Atlas regions per assembly (Principal Axis) of the occupancy metric of panel A (B) for cRBM (PCA), respectively. The effective number of regions was determined by calculating the Participation Ratio per assembly (Principal Axis), multiplied with the total number of regions (see Materials and methods - ‘Regional occupancy’). cRBM assemblies occupy a median of 3 regions (interquartile range: 2–6 regions), while PCA assemblies occupy a median of 160 regions (interquartile range: 140–168 regions).
Figure 2—figure supplement 7
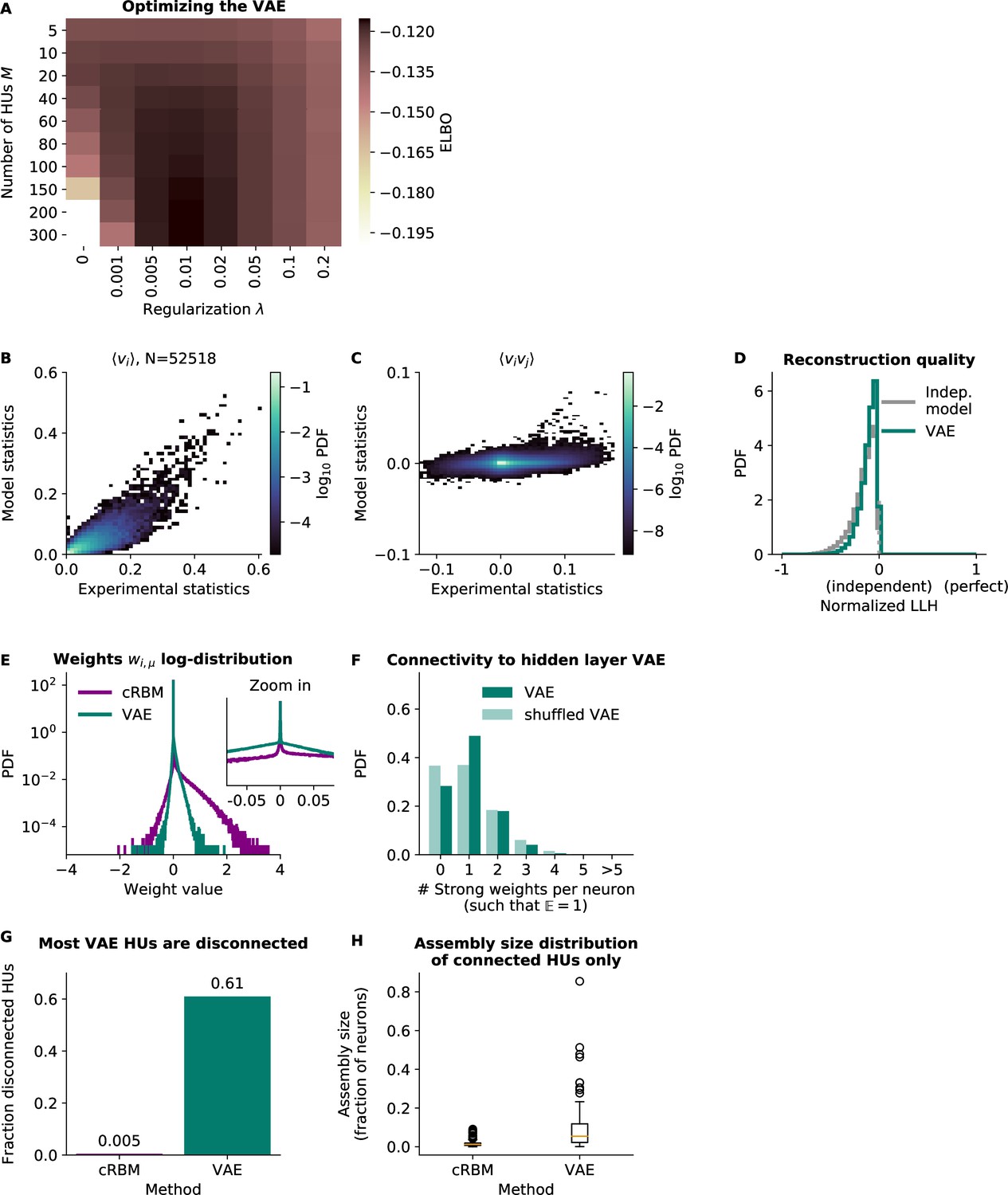
Variational Autoencoder (VAE) models do not fit the second-order statistics of the neural data.
(A) VAE model performance, quantified by its ELBO objective on withheld test data. The optimal VAE was found with parameters , and this optimum was very close to the performance of (the cRBM optimal parameters, see Figure 2—figure supplement 1). For ease of comparison, in the other panels we consider the latter VAE model, but also quantify the performance of the first in panels B and C. (B) VAE-predicted and experimental mean neural activity were strongly correlated Pearson correlation (, ) but still had fairly high error (), presumably because the model appeared to underestimate the activity of most neurons (linear regression determined the optimal slope to be 0.52). The (optimal) VAE model had a similar . (C) VAE-predicted and experimental average pairwise neuron-neuron interactions had a very high error of , demonstrating that the VAE did not capture the second-order statistics of the data at all. The (optimal) VAE model had a similar . (D) Reconstruction quality of VAE was also very low, performing almost equal to an independent model. (E) VAE weights were similarly sparsely distributed to cRBM weights. (VAE weights were also sign-swapped for consistency with cRBM, see Materials and methods - ‘Choice of HU potential’) (F) The distribution of above-threshold absolute weights was also similar to cRBM (Figure 2J). (G) Fraction of disconnected HUs of cRBM and VAE (defined for each HU μ by . (H) Distribution of assembly sizes (determined by ), excluding all disconnected HUs (1/200 for cRBM, 122/200 for VAE).
Figure 3
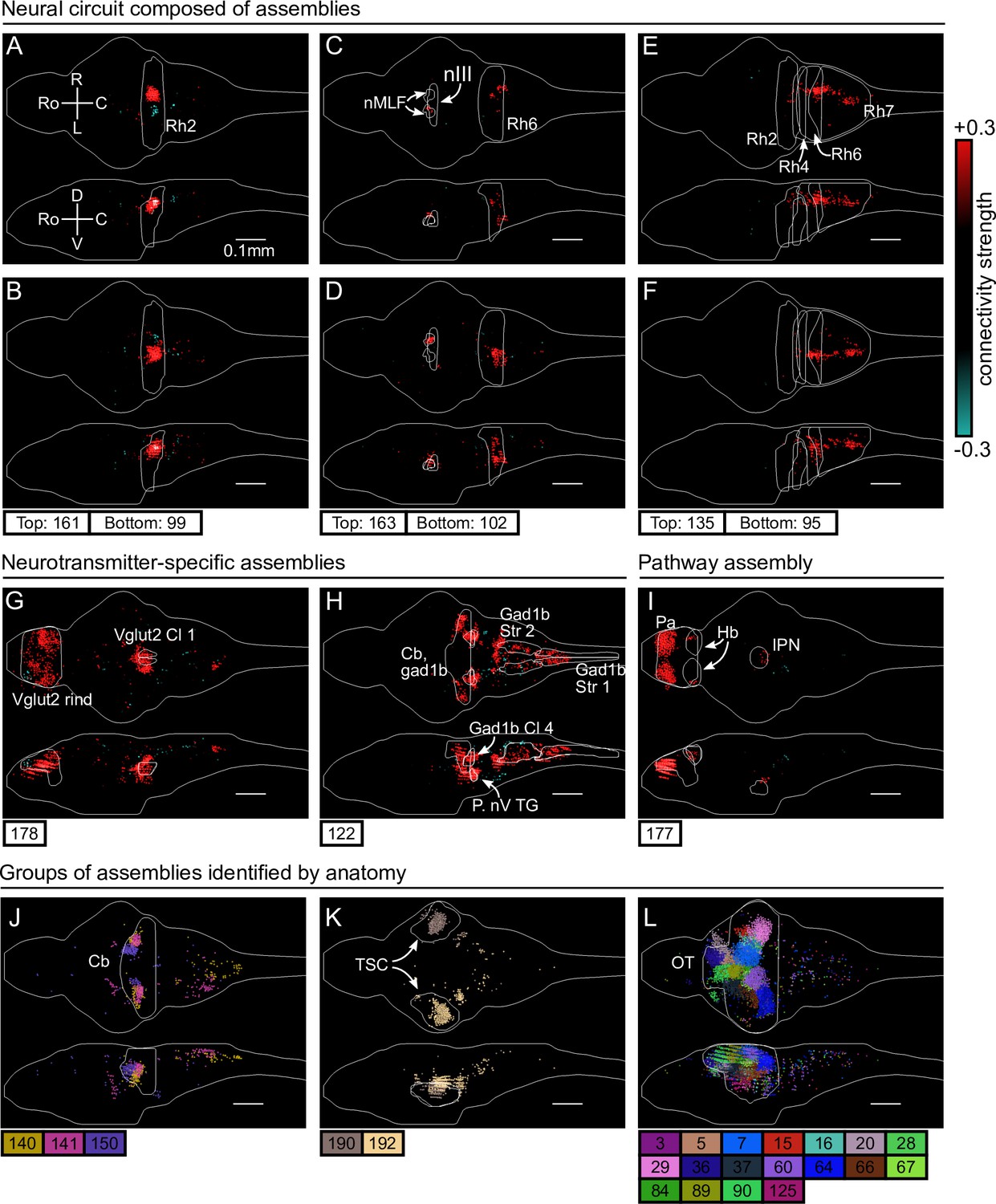
cRBM assemblies compose functional circuits and anatomical structures.
(A–I) Individual example assemblies μ are shown by coloring each neuron with its connectivity weight value (see color bar at the right hand side). The assembly index μ is stated at the bottom of each panel. The orientation and scale are given in panel A (Ro: rostral, C: caudal, R: right, L: left, D: dorsal, V: ventral). Anatomical regions of interest, defined by the ZBrain Atlas (Randlett et al., 2015), are shown in each panel (Rh: rhombomere, nMLF: nucleus of the medial longitudinal fascicle; nIII: oculomotor nucleus nIII, Cl: cluster; Str: stripe, P. nV TG: Posterior cluster of nV trigeminal motorneurons; Pa: pallium; Hb: habenula; IPN: interpeduncular nucleus). (J–L) Groups of example assemblies that lie in the same anatomical region are shown for cerebellum (Cb), torus semicircularis (TSC), and optic tectum (OT). Neurons i were defined to be in an assembly μ when , and colored accordingly. If neurons were in multiple assemblies shown, they were colored according to their strongest-connecting assembly.
Figure 4
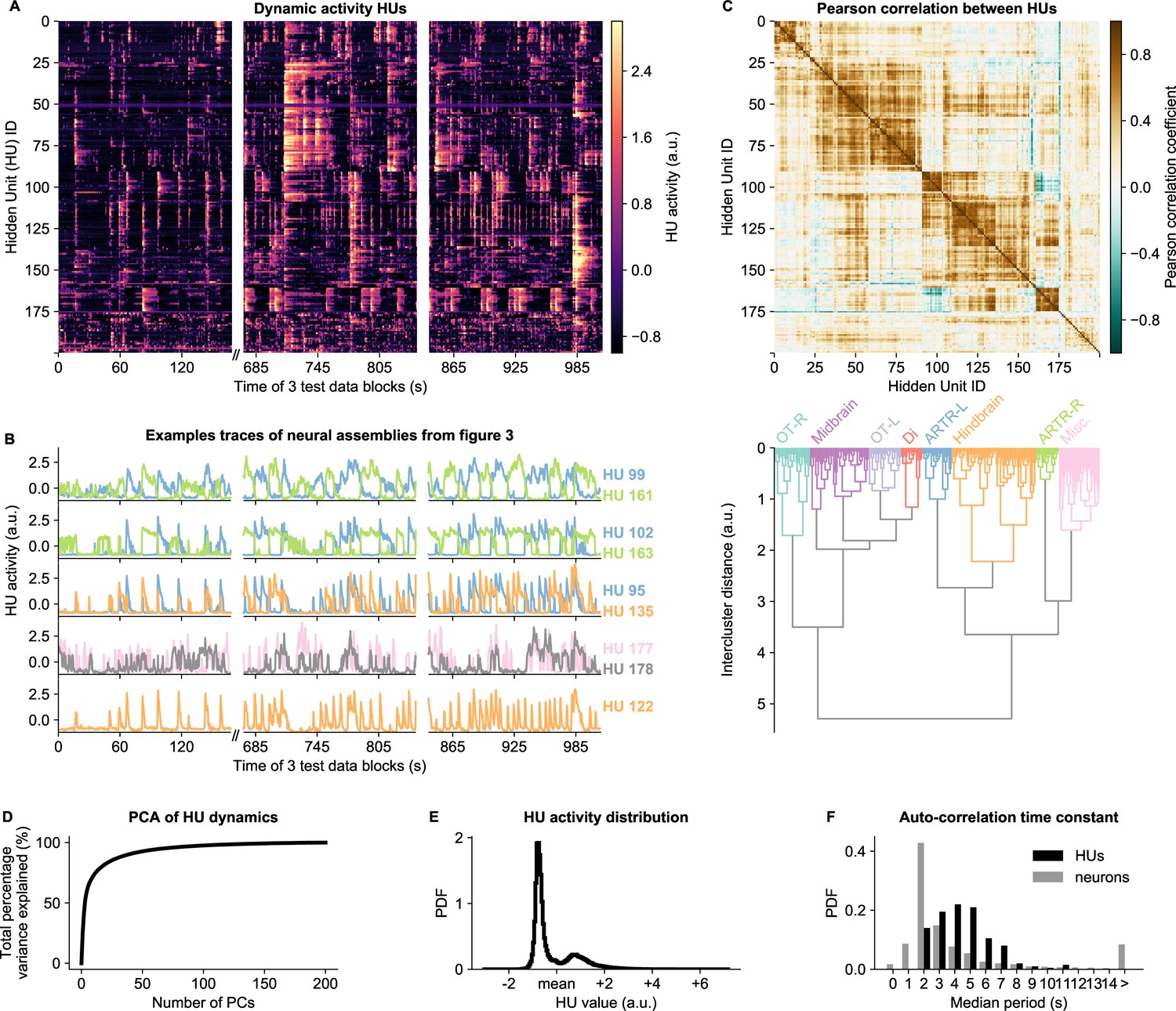
HU dynamics are bimodal and activate slower than neurons.
(A) HU dynamics are diverse and are partially shared across HUs. The bimodality transition point of each HU was determined and subtracted individually, such that positive values correspond to HU activation (see Materials and methods - ‘Time constant calculation’6.12). The test data consisted of three blocks, with a discontinuity in time between the first and second block (Materials and methods). (B) Highlighted example traces from panel A. HU indices are denoted on the right of each trace, colored according to their cluster from panel D. The corresponding cellular assemblies of these HU are shown in Figure 3A-I. (C) Top: Pearson correlation matrix of the dynamic activity of panel A. Bottom: Hierarchical clustering of the Pearson correlation matrix. Clusters (as defined by the colors) were annotated manually. This sorting of HUs is maintained throughout the manuscript. OT: Optic Tectum, Di: Diencephalon, ARTR: ARTR-related, Misc.: Miscellaneous, L: Left, R: Right. (D) A Principal Component Analysis (PCA) of the HU dynamics of panel A shows that much of the HU dynamics variance can be captured with a few PCs. The first 3 PCs captured 52%, the first 10 PCs captured 73% and the first 25 PCs captured 85% of the explained variance. (E) The distribution of all HU activity values of panel A shows that HU activity is bimodal and sparsely activated (because the positive peak is smaller than the negative peak). PDF: Probability Density Function. (F) Distribution of the time constants of HUs (black) and neurons (grey). Time constants are defined as the median oscillation period, for both HUs and neurons. An HU oscillation is defined as a consecutive negative and positive activity interval. A neuron oscillation is defined as a consecutive interspike-interval and spike-interval (which can last for multiple time steps, for example see Figure 1A). The time constant distribution of HUs is greater than the neuron distribution (Mann Whitney U test, ).
Figure 5 with 1 supplement
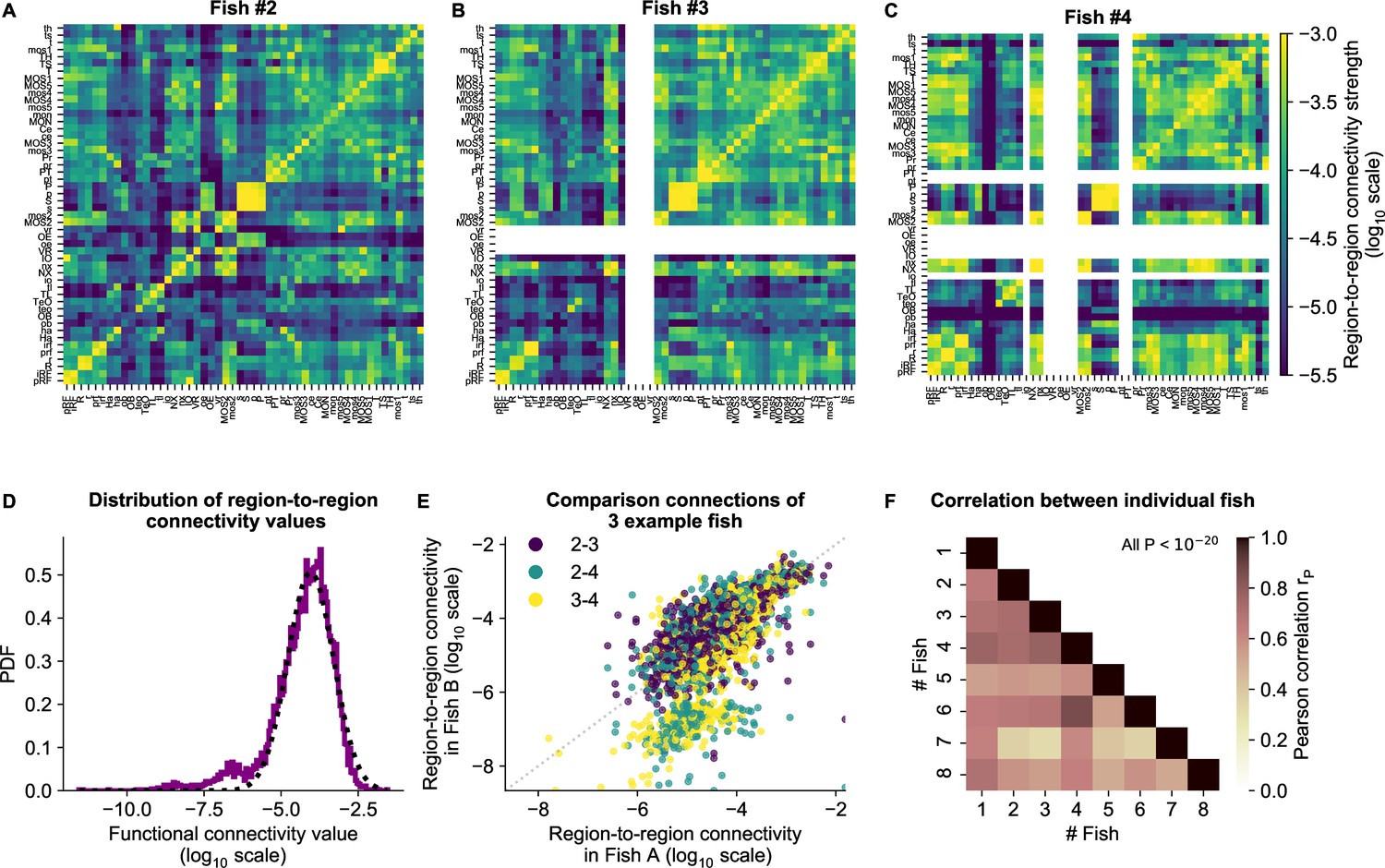
cRBM gives rise to functional connectivity that is strongly correlated across individuals.
(A) The functional connectivity matrix between anatomical regions of the mapzebrain atlas (Kunst et al., 2019) of example fish #2 is shown. Functional connections between two anatomical regions were determined by the similarity of the HUs to which neurons from both regions connect to (Materials and methods). Mapzebrain atlas regions with less than five imaged neurons were excluded, yielding regions in total. See Supplementary file 1 for region name abbreviations. The matrix is shown in log10 scale, because functional connections are distributed approximately log-normal (see panel D). (B) Equivalent figure for example fish #3 (example fish of prior figures). (C) Equivalent figure for example fish #4. Panels A-C share the same log10 color scale (right). (D) Functional connections are distributed approximately log-normal. (Mutual information with a log-normal fit (black dashed line) is 3.83, while the mutual information with a normal fit is 0.13). All connections of all eight fish are shown, in log10 scale (purple). (E) Functional connections of different fish correlate well, exemplified by the three example fish of panels A-C. All non-zero functional connections (x-axis and y-axis) are shown, in log10 scale. Pearson correlation between pairs: , , . All correlation p values (two-sided t-test). (F) Pearson correlations of region-to-region functional connections between all pairs of 8 fish. For each pair, regions with less than five neurons in either fish were excluded. All p values (two-sided t-test), and average correlation value is 0.69.
Figure 5—figure supplement 1

Functional connectivity matrices of all fish.
8 panels. (A–H) showing the individual cRBM functional connectivity matrices of all zebrafish recordings. Panels B, C, and D correspond to Figure 3A–C. All matrices share the same log10 color scale (bottom right). Regions that contained less than five neurons were left blank, for each fish individually.
Figure 6 with 1 supplement

cRBM-inferred functional connectivity reflects structural connectivity.
(A) Structural connectivity matrix is shown in log10 scale, updated from Figure 8C of Kunst et al., 2019. Regions that were not imaged in our experiments were excluded (such that out of 72 regions remain). Regions (x-axis and y-axis) were sorted according to Kunst et al., 2019. Compared to Figure 8C of Kunst et al., 2019 additional structural data was added and the normalization procedure was updated to include within-region connectivity (see Materials and methods - ‘Extensions of the structural connectivity matrix’). See Supplementary file 1 for region name abbreviations. (B) Average functional connectivity matrix is shown in log10 scale, as determined by averaging the cRBM functional connectivity matrices of all 8 fish (see Materials and methods - ‘Specimen averaging of connectivity matrices’). The same regions (x-axis and y-axis) are shown as in panel A. (C) The average functional and structural connectivity of panels A and B correlate well, with Spearman correlation (, two-sided t-test). Each data point corresponds to one region-to-region pair. Data points for which the structural connection was exactly 0 were excluded (see panel D for their analysis). (D) The distribution of average functional connections of region pairs with non-zero structural connections is greater than functional connections corresponding to region pairs without structural connections (, two-sided Kolmogorov-Smirnov test). The bottom panel shows the evidence for inferring either non-zero or zero structural connections, defined as the fraction between the PDFs of the top panel (fitted Gaussian distributions were used for denoising).
Figure 6—figure supplement 1
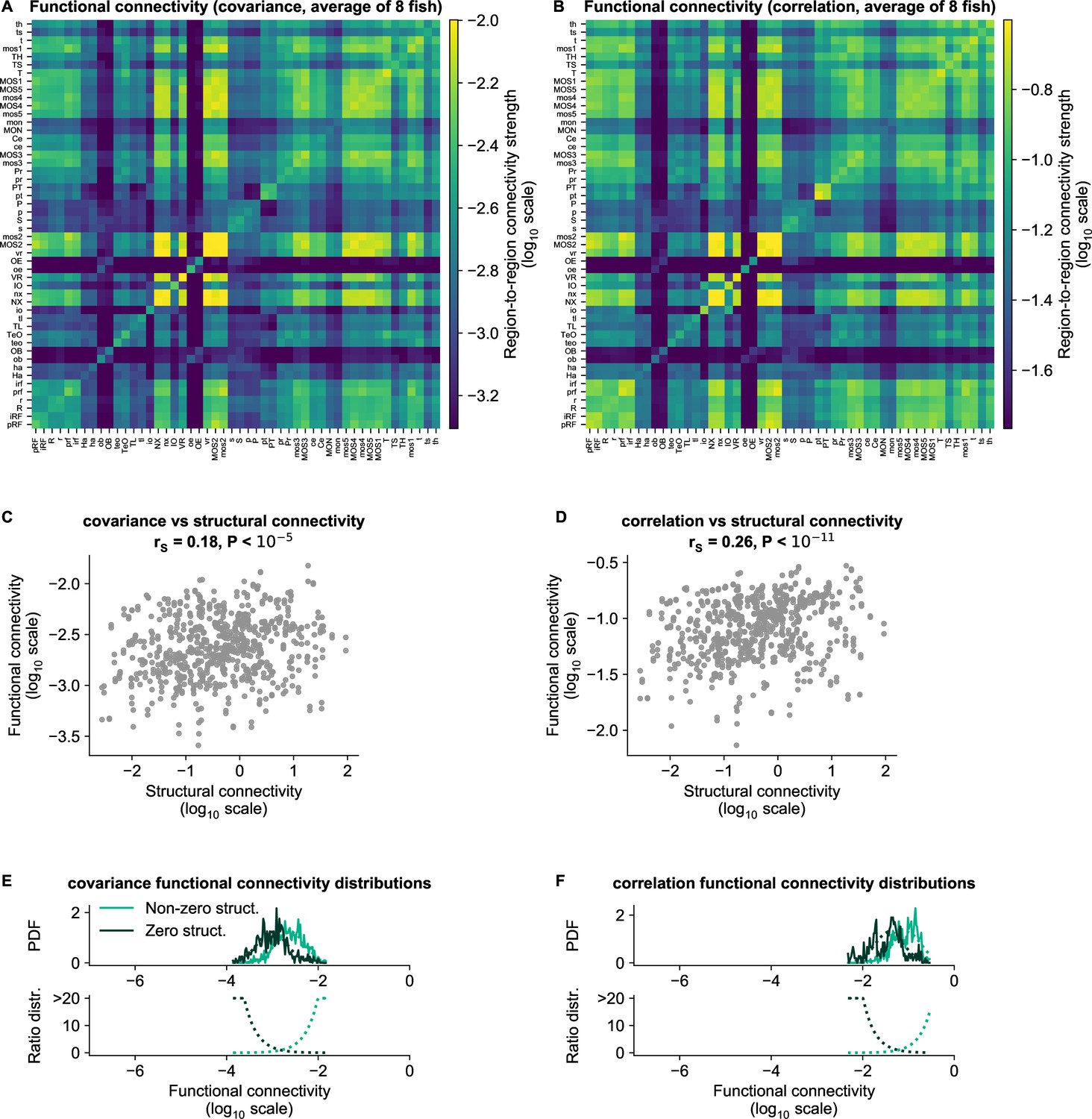
cRBM functional connectivity compared to baseline methods.
(A) Average functional connectivity matrix of the covariance baseline method (see Materials and methods - ‘Connectivity inference baselines’) in log10 scale. (B) Average functional connectivity matrix of the Pearson correlations baseline method (see Materials and methods - ‘Connectivity inference baselines’) in log10 scale. (C, D) Equivalent figure to Figure 4C for functional connections as determined by the covariance (C) and correlations (D) between neurons (see Materials and methods - ‘Correlation analysis of connectivity matrices’). The Spearman correlation coefficient between functional and structural connections for covariance is and for correlation . (E–F) Equivalent figure to Figure 4D for functional connections as determined by the covariance (E) and correlations (F) between neurons. Non-zero and zero distributions are significantly different (all p values , two-sided Kolmogorov-Smirnov tests).
Videos
Video 1
All neural assemblies of one example fish All 200 inferred assemblies of the example fish #2 of Figure 3 are shown in sequence.
Top: neural assembly. Bottom: HU activity of test data.
Tables
Key resources table
| Reagent type (species) or resource | Designation | Source or reference | Identifiers | Additional information |
|---|---|---|---|---|
| Software, algorithm | cRBM algorithm | This paper and Tubiana and Monasson, 2017 | github.com/jertubiana/PGM | Materials and methods - ‘Restricted Boltzmann Machines’ , ‘Compositional Restricted Boltzmann Machine’ and Algorithmic Implementation |
| Software, algorithm | Fishualizer | Migault et al., 2018 | bitbucket.org/benglitz/fishualizer_public | |
| Software, algorithm | Blind Sparse Deconvolution | Tubiana et al., 2020 | github.com/jertubiana/BSD | |
| Software, algorithm | ZBrain Atlas | Randlett et al., 2015 | engertlab.fas.harvard.edu/Z-Brain | |
| Software, algorithm | mapzebrain atlas | Kunst et al., 2019 | fishatlas.neuro.mpg.de | |
| Software, algorithm | MATLAB (data preprocessing) | MathWorks | mathworks.com/products/matlab.html | |
| Software, algorithm | Computational Morphometry Toolkit (CMTK) | NITRC | nitrc.org/projects/cmtk | |
| Software, algorithm | Python | Python Software Foundation | python.org | |
| Strain, strain background (Danio rerio, nacre mutant) | Tg(elavl3:H2B-GCaMP6f) | Quirin et al., 2016 | ||
| Strain, strain background (Danio rerio, nacre mutant) | Tg(elavl3:H2B-GCaMP6s) | Vladimirov et al., 2014 |
Additional files
-
Supplementary file 1
Table of abbreviations of mapzebrain atlas region names (used for interregional connectivity analyses).
- https://cdn.elifesciences.org/articles/83139/elife-83139-supp1-v2.pdf
-
Supplementary file 2
Properties (relevant to this study) of common-used methods for analysing neural recordings.
Abbreviations and example studies: Principal Component Analysis (PCA, Ahrens et al., 2012; Lopes-dos-Santos et al., 2013; Marques et al., 2020), Independent Component Analysis (ICA, Lopes-dos-Santos et al., 2013), k-means based algorithms (k-means, Panier et al., 2013; Chen et al., 2018; Stringer et al., 2019; Bartoszek et al., 2021), Non-Negative Matrix Factorization (NNMF, Mu et al., 2019), Variational Auto-Encoder (VAE, Tubiana et al., 2019b), Generalized Linear Model (GLM, Bishop, 2006), Boltzmann Machine (BM, Schneidman et al., 2006; Meshulam et al., 2017), compositional Restricted Boltzmann Machine (cRBM, this study). Question marks denote tasks that are in principle feasible but computationally expensive and/or not demonstrated.
- https://cdn.elifesciences.org/articles/83139/elife-83139-supp2-v2.pdf
-
MDAR checklist
- https://cdn.elifesciences.org/articles/83139/elife-83139-mdarchecklist1-v2.pdf
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Neural assemblies uncovered by generative modeling explain whole-brain activity statistics and reflect structural connectivity
eLife 12:e83139.
https://doi.org/10.7554/eLife.83139




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}