Endotaxis: A neuromorphic algorithm for mapping, goal-learning, navigation, and patrolling
- Division of Biology and Biological Engineering, California Institute of Technology, United States
- Center for the Physics of Biological Function, Princeton University, United States
- Division of Engineering and Applied Science, California Institute of Technology, United States
Figures
Figure 1
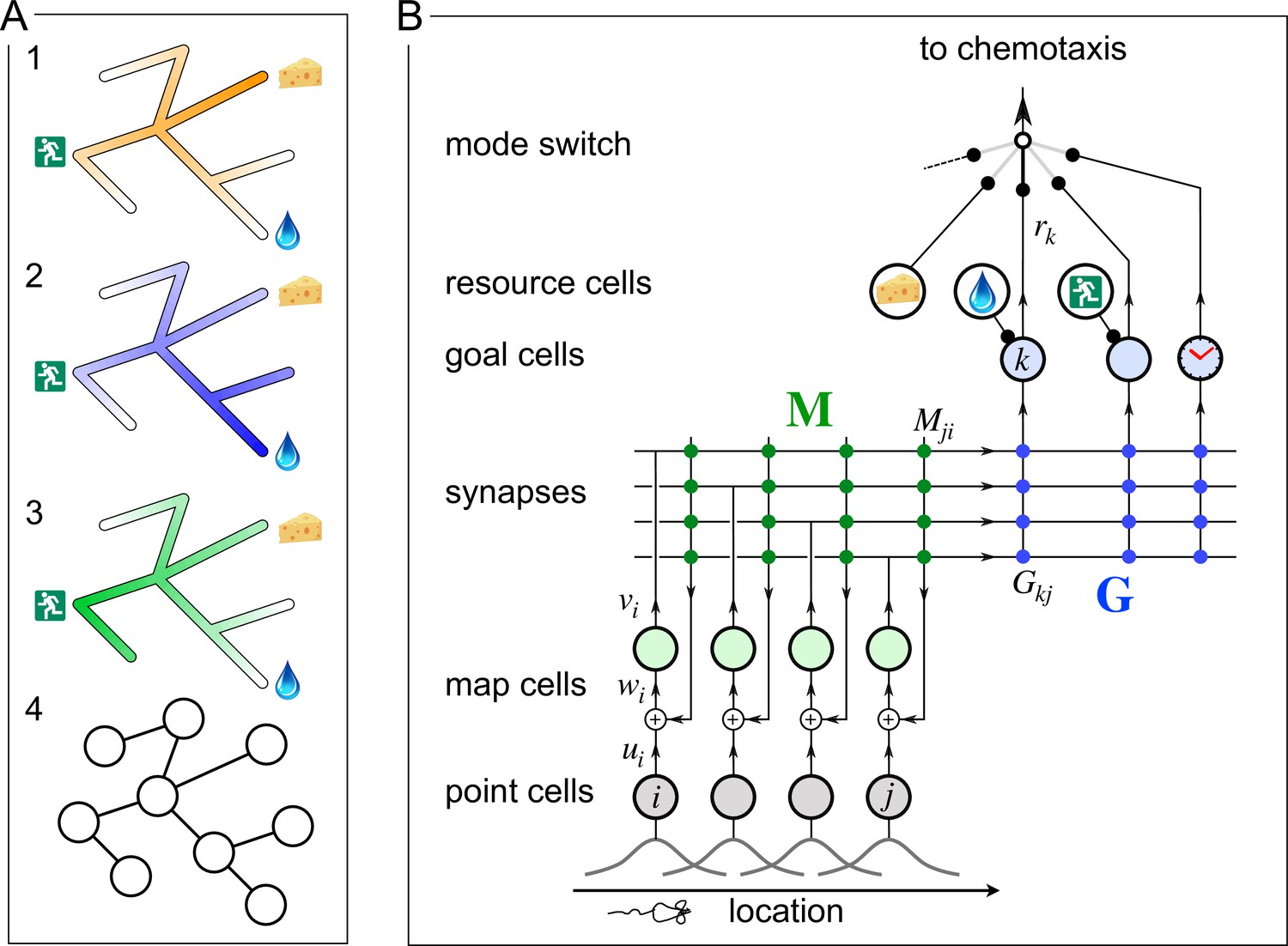
A mechanism for endotaxis.
(A) A constrained environment of tunnels linked by intersections, with special locations offering food, water, and the exit. (1) A real odor emitted by the food source decreases with distance (shading). (2) A virtual odor tagged to the water source. (3) A virtual odor tagged to the exit. (4) Abstract representation of this environment by a graph of nodes (intersections) and edges (tunnels). (B) A neural circuit to implement endotaxis. Open circles: four populations of neurons that represent ‘resource,’ ‘point,’ ‘map,’ and ‘goal.’ Arrows: signal flow. Solid circles: synapses. Point cells have small receptive fields localized in the environment and excite map cells. Map cells excite each other (green synapses) and also excite goal cells (blue synapses). Resource cells signal the presence of a resource, for example, cheese, water, or the exit. Map synapses and goal synapses are modified by activity-dependent plasticity. A ‘mode’ switch selects among various goal signals depending on the animal’s need. They may be virtual odors (water, exit) or real odors (cheese). Another goal cell (clock) may report how recently the agent has visited a location. The output of the mode switch gets fed to the chemotaxis module for gradient ascent. Mathematical symbols used in the text: is the output of a point cell at location , is the input to the corresponding map cell, is the output of that map cell, is the matrix of synaptic weights among map cells, are the synaptic weights from the map cells onto goal cells, and is the output of goal cell .
Figure 2
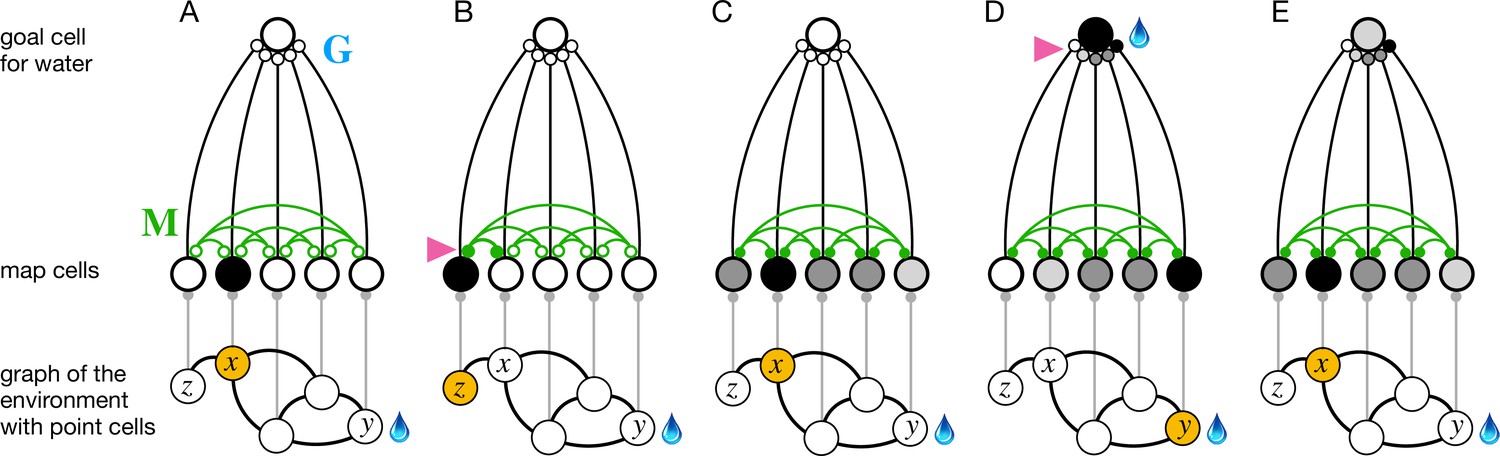
The phases of endotaxis during exploration, goal-tagging, and navigation.
A portion of the circuit in Figure 1 is shown, including a single goal cell that responds to the water resource. Bottom shows a graph of the environment, with nodes linked by edges, and the agent’s current location shaded in orange. Each node has a point cell that reports the presence of the agent to a corresponding map cell. Map cells are recurrently connected (green) and feed convergent signals onto the goal cell. (A) Initially the recurrent synapses are weak (empty circles). (B) During exploration, the agent moves between two adjacent nodes on the graph, and that strengthens (arrowhead) the connection between their corresponding map cells (filled circles). (C) After exploration, the map synapses reflect the connectivity of the graph. Now the map cells have an extended profile of activity (darker = more active), centered on the agent’s current location and decreasing from there with distance on the graph. (D) When the agent reaches the water source , the goal cell gets activated by the sensation of water, and this triggers plasticity (arrowhead) at its input synapses. Thus, the state of the map at the water location gets stored in the goal synapses. This event represents tagging of the water location. (E) During navigation, as the agent visits different nodes, the map state gets filtered through the goal synapses to excite the goal cell. This produces a signal in the goal cell that declines with the agent’s distance from the water location.
Figure 3
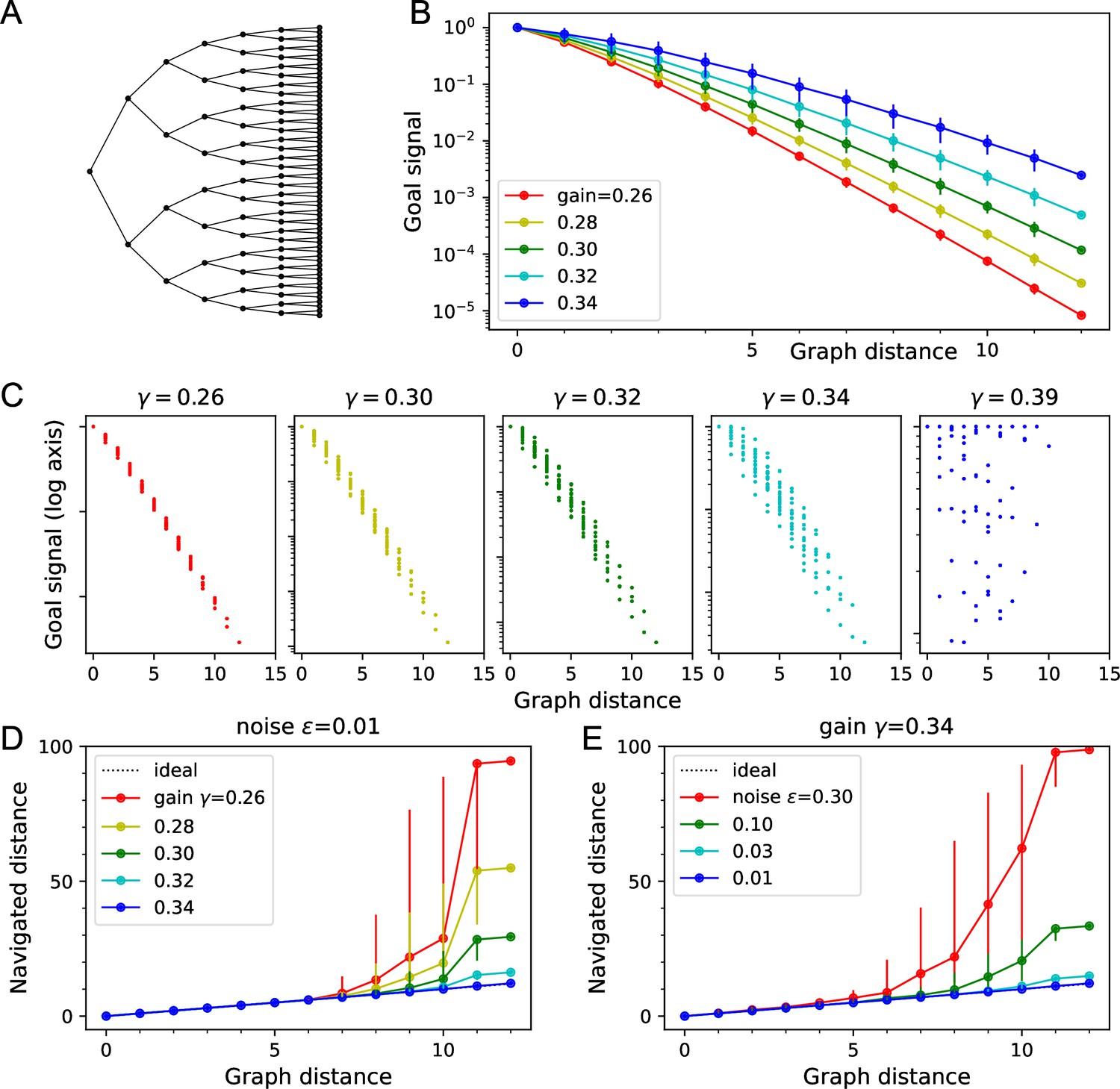
Theory of the goal signal.
Dependence of the goal signal on graph distance, and the consequences for endotaxis navigation. (A) The graph representing a binary tree labyrinth (Rosenberg et al., 2021) serves for illustration. Suppose the endotaxis model has acquired the adjacency matrix perfectly: . We compute the goal signal between any two nodes on the graph and compare the results at different values of the map gain . (B) Dependence of the goal signal on the graph distance between the two nodes. Mean ± SD, error bars often smaller than markers. The maximal distance on this graph is 12. Note logarithmic vertical axis. The signal decays exponentially over many log units. At high , the decay distance is greater. (C) A detailed look at the goal signal, each point is for a pair of nodes . For low , the decay with distance is strictly monotonic. At high , there is overlap between the values at different distances. As exceeds the critical value , the distance dependence breaks down. (D) Using the goal signal for navigation. For every pair of start and end nodes, we navigate the route by following the goal signal and compare the distance traveled to the shortest graph distance. For all routes with the same graph distance, we plot the median navigated distance with 10 and 90% quantiles. Variable gain at a constant noise value of . (E) As in panel (D) but varying the noise at a constant gain of .
Figure 4
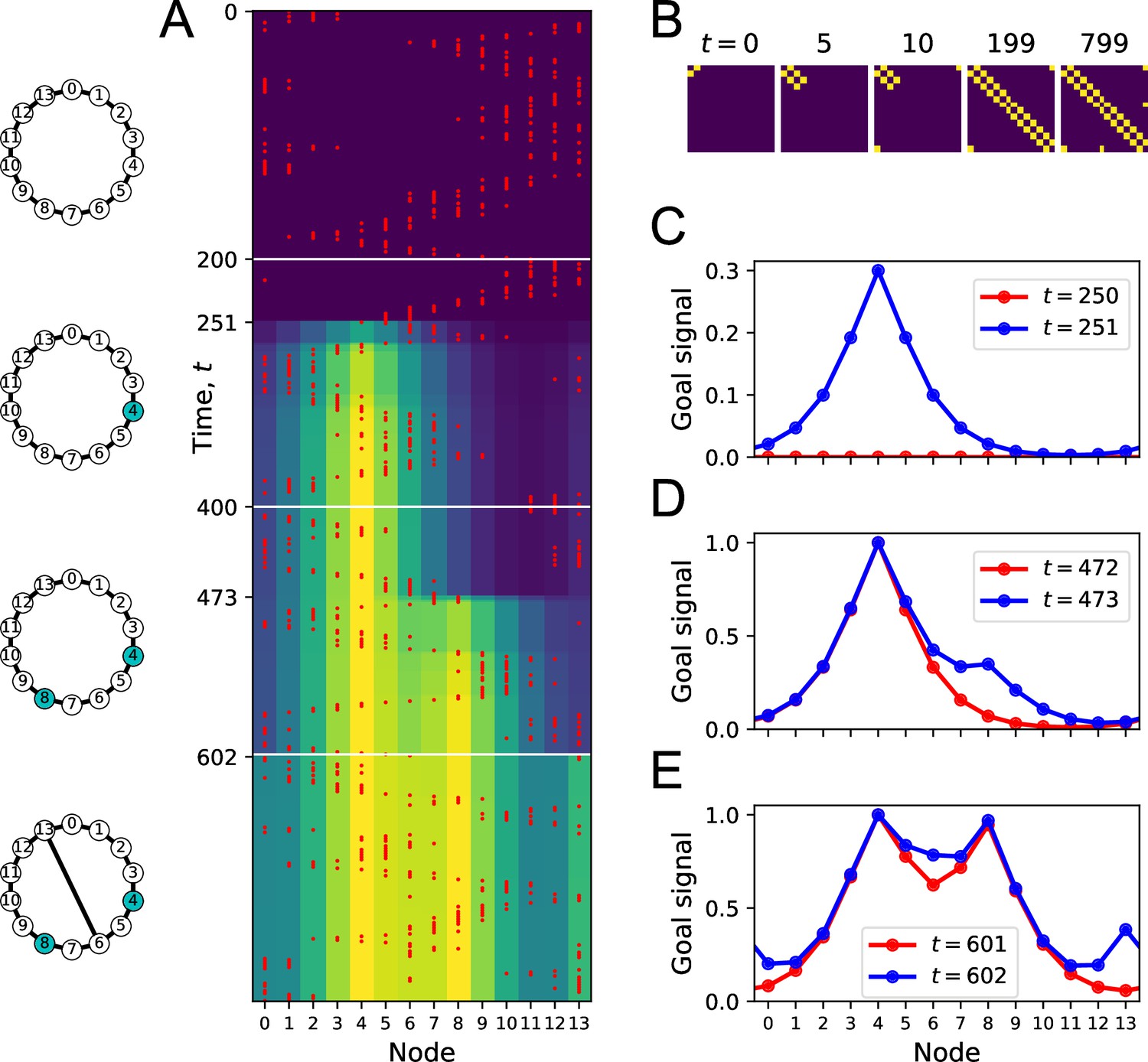
Learning the map and the targets during exploration.
(A) Simulation of a random walk on a ring with 14 nodes. Left: layout of the ring, with resource locations marked in blue. The walk progresses in 800 time steps (top to bottom); with the agent’s position marked in red (nodes 0–13, horizontal axis). At each time, the color map shows the goal signal that would be produced if the agent were at position ‘Node.’ White horizontal lines mark the appearance of a target at , a second target with the same resource at , and a new link across the ring at step . (B) The matrix of map synapses at various times. The pixel in row and column represents the matrix element . Color purple =0. Note the first few steps (number above graph) each add a new synapse. Eventually, reflects the adjacency matrix of nodes on the graph. (C) Goal signals just before and just after the agent encounters the first target. (D) Goal signals just before and just after the agent encounters the second target. (E) Goal signals just before and just after the agent travels the new link for the first time. Parameters: .
Figure 5
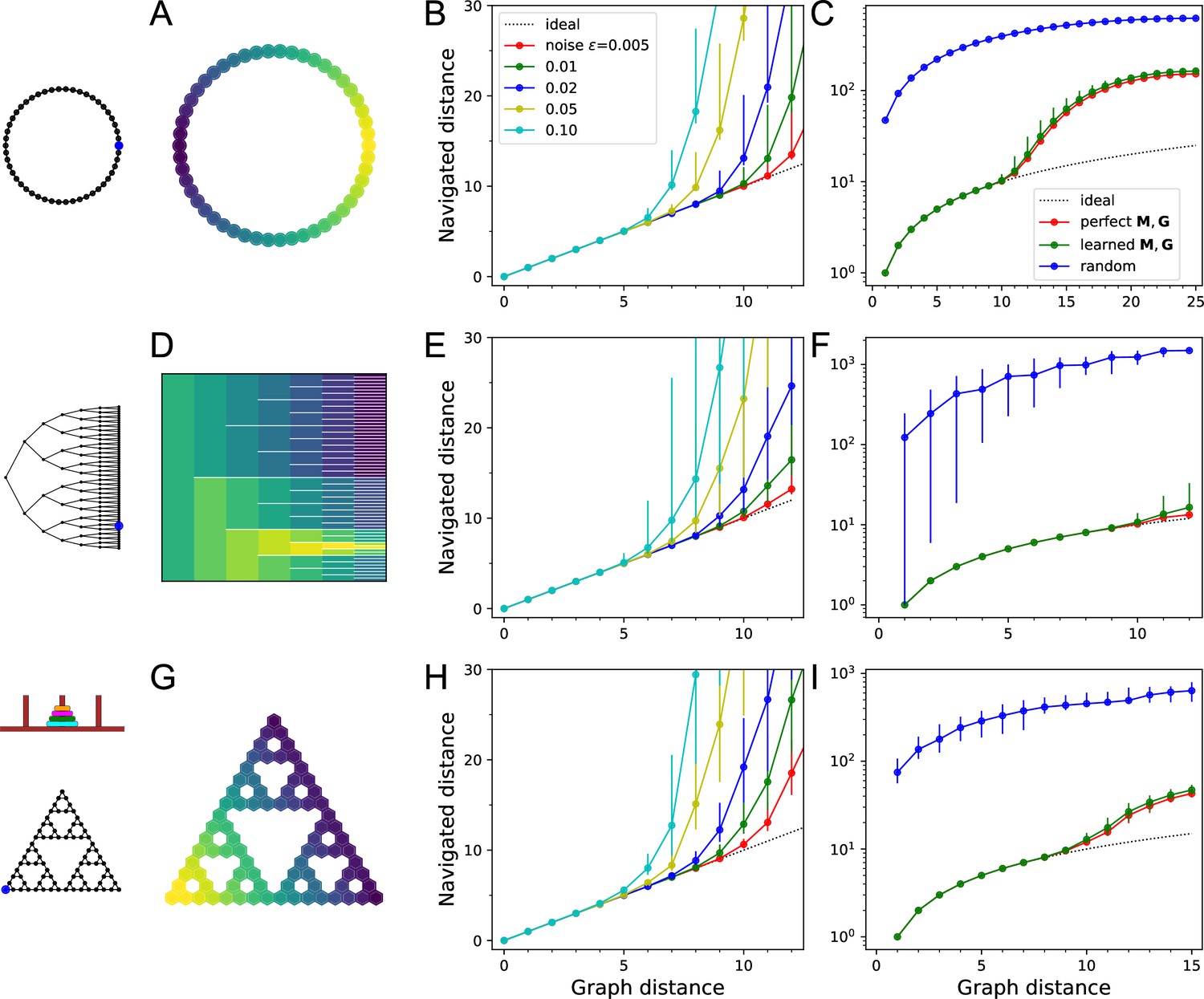
Navigation using the learned map and targets.
(A–C) Ring with 50 nodes. (A) Goal signal for a single target location (blue dot on left icon) after learning during random exploration with 10,000 steps. Color scale is logarithmic, yellow = high. Note the monotonic decay of the goal signal with graph distance from the target. (B) Results of all-to-all navigation where every node is a separate goal. For all pairs of nodes, this shows the navigated distance vs the graph distance. Median ±10/90 percentiles for all routes with the same graph distance. ‘Ideal’ navigation would follow the identity. The actual navigation is ideal over short distances, then begins to deviate from ideal at a critical distance that depends on the noise level . (C) As in (B) over a wider range, note logarithmic axis. Noise . Includes comparison to navigation by a random walk; and navigation using the optimal goal signal based on knowledge of the graph structure and target location. . (D–F) As in (A–C) for a binary tree graph with 127 nodes. (D) Goal signal to the node marked on the left icon. This was the reward port in the labyrinth experiments of Rosenberg et al., 2021. White lines separate the branches of the tree. . (G–I) As in (A–C) for a ‘Tower of Hanoi’ graph with 81 nodes. .
Figure 6
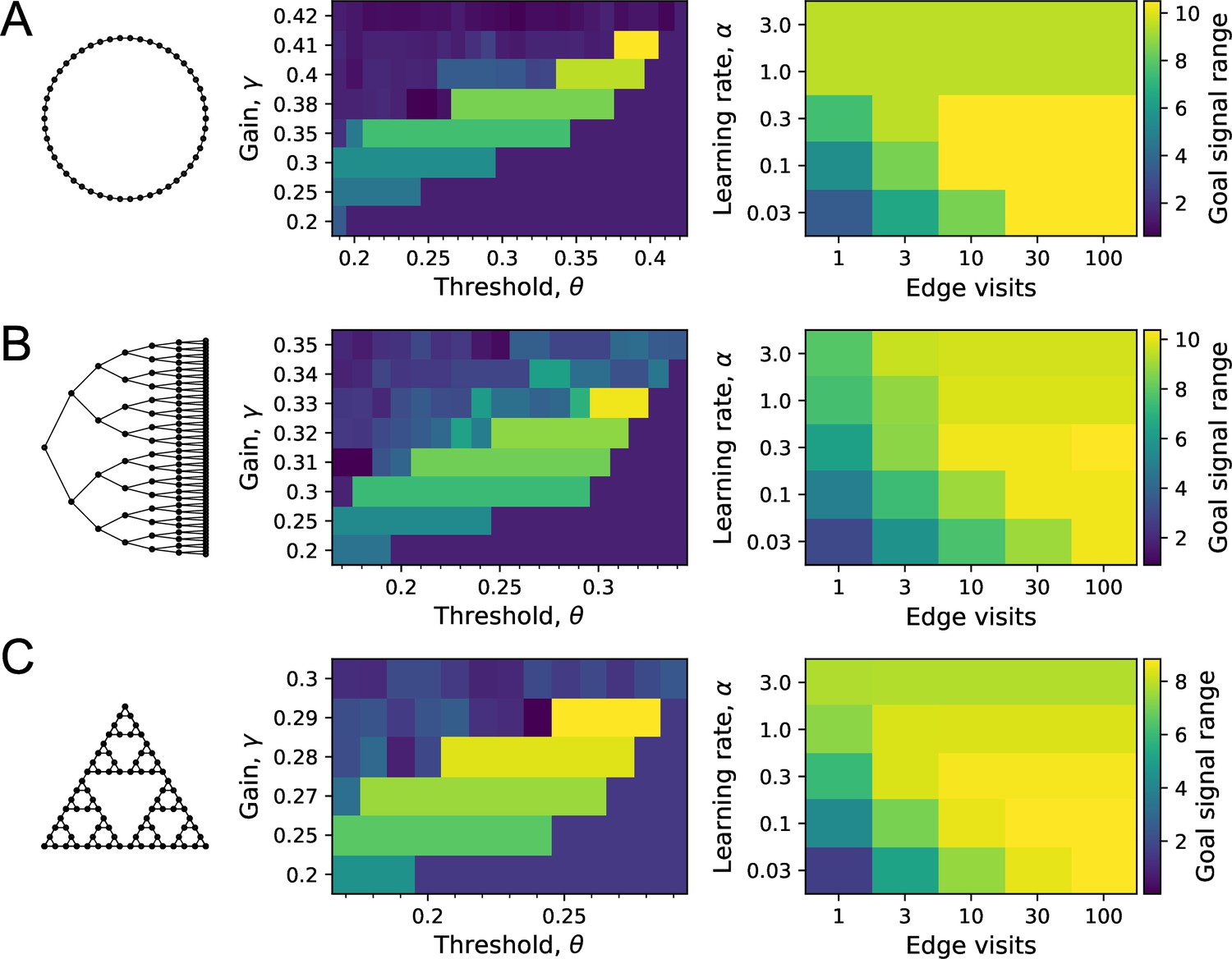
Sensitivity of performance to the model parameters.
On each of the three graphs, we simulated endotaxis for all-to-all navigation, where each node serves as a start and a goal node. The performance measure was the range of the goal signal, defined as the graph distance over which at least half the navigated routes follow the shortest path. The exploration path for synaptic learning was of medium length, visiting each edge on the graph approximately 10 times. The noise was set to . (A) Ring graph with 50 nodes. Left: dependence of the goal signal range on the gain and the threshold for learning map synapses. Performance increases with higher gain until it collapses beyond the critical value. For each gain, there is a sharply defined range of useful thresholds, with lower values at lower gain. Right: dependence of the goal signal range on the learning rate at goal synapses, and the length of the exploratory walk, measured in visits per edge of the graph. For a short walk (one edge visit), a high learning rate is best. For a long walk (100 edge visits), a lower learning rate wins out. (B) As in (A) for the Binary tree maze with 127 nodes. (C) As in (A) for the Tower of Hanoi graph with 81 nodes.
Figure 7
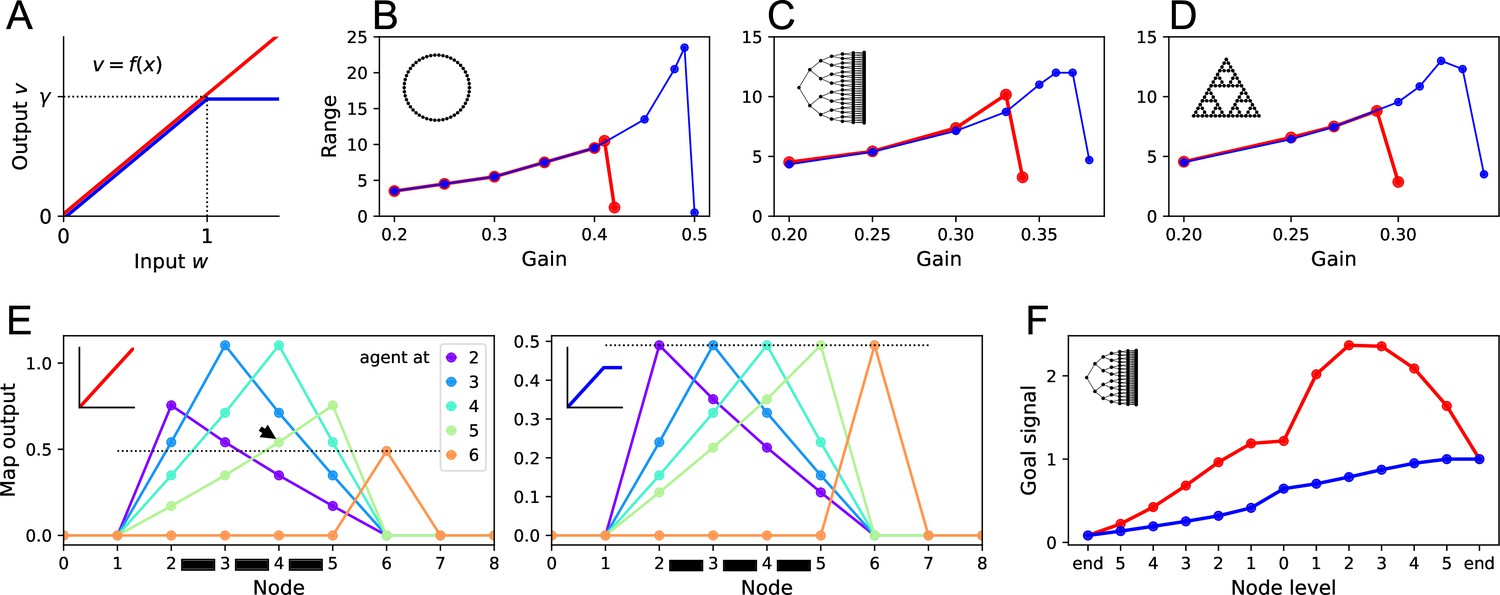
Benefits of a nonlinear activation function.
(A) The activation function relating a map neuron’s output to its total input . Red: linear function with gain . Blue: nonlinear function with saturation at . (B–D) Range of the goal signal, as defined in Figure 6, as a function of the gain (noise ). Range increases with gain up to a maximal value. The maximal range achieved is higher with nonlinear activation (blue) than linear activation (red). Results for the ring graph (B), binary tree maze (C), and Tower of Hanoi graph (D). (E) Output of map cells during early exploration of the ring graph (gain ). Suppose the agent has walked back and forth between nodes 2 and 5, so all their corresponding map synapses are established (black bars). Then the agent steps to node 6 for the first time (orange). Lines plot the output of the map cells with the agent at locations 2, 3, 4, 5, or 6. Dotted line indicates the maximal possible setting of the threshold in the learning rule. With linear activation (left), a map cell receiving purely recurrent input (4) may produce a signal larger than threshold (arrowhead above the dotted line). Thus, cells 4 and 6 would form an erroneous synapse. With a saturating activation function (right), the map amplitude stays constant throughout learning, and this confound does not happen. (F) The goal signal from an end node of the binary maze, plotted along the path from another end node. Map and goal synapses set to their optimal values assuming full knowledge of the graph and the target (gain ). With linear activation (red), the goal signal has a local maximum, so navigation to the target fails. With a saturating activation function (blue), the goal signal is monotonic and leads the agent to the target.
Figure 8
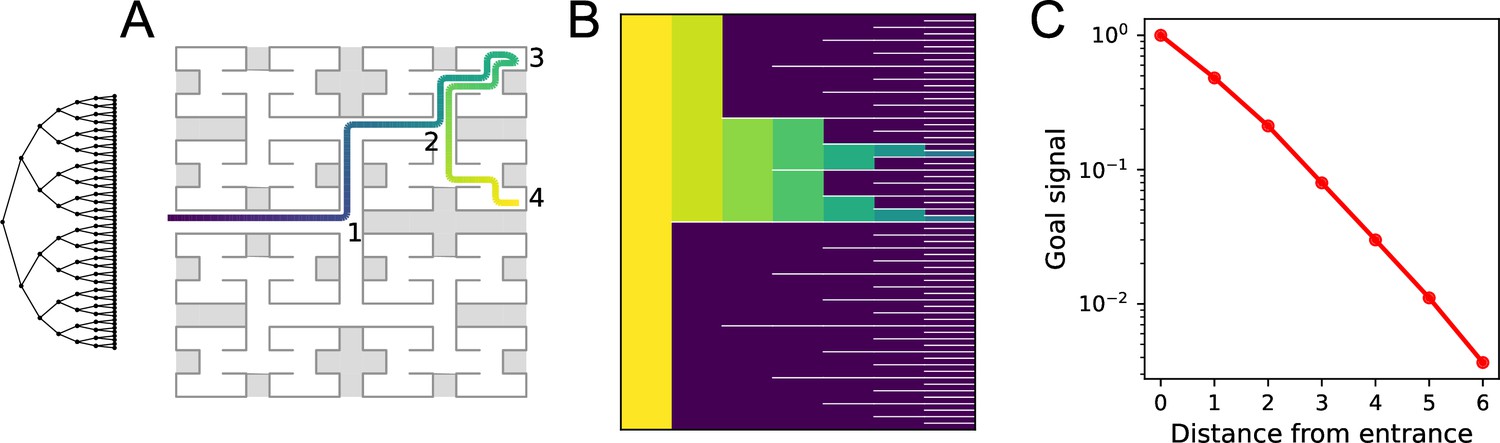
Homing by endotaxis.
(A) A binary tree maze as used in Rosenberg et al., 2021. A simulated mouse begins to explore the labyrinth (colored trajectory, purple = early, yellow = late), traveling from the entrance (1) to one of the end nodes (3), then to another end node (4). Can it return to the entrance from there using endotaxis? (B) Goal signal learned by the end of the walk in (A), displayed as in Figure 5D, purple = 0. Note the goal signal is nonzero only at the nodes that have been encountered so far. From all those nodes, it increases monotonically toward the entrance. (C) Detailed plot of the goal signal along the shortest route for homing. Parameters .
Figure 9
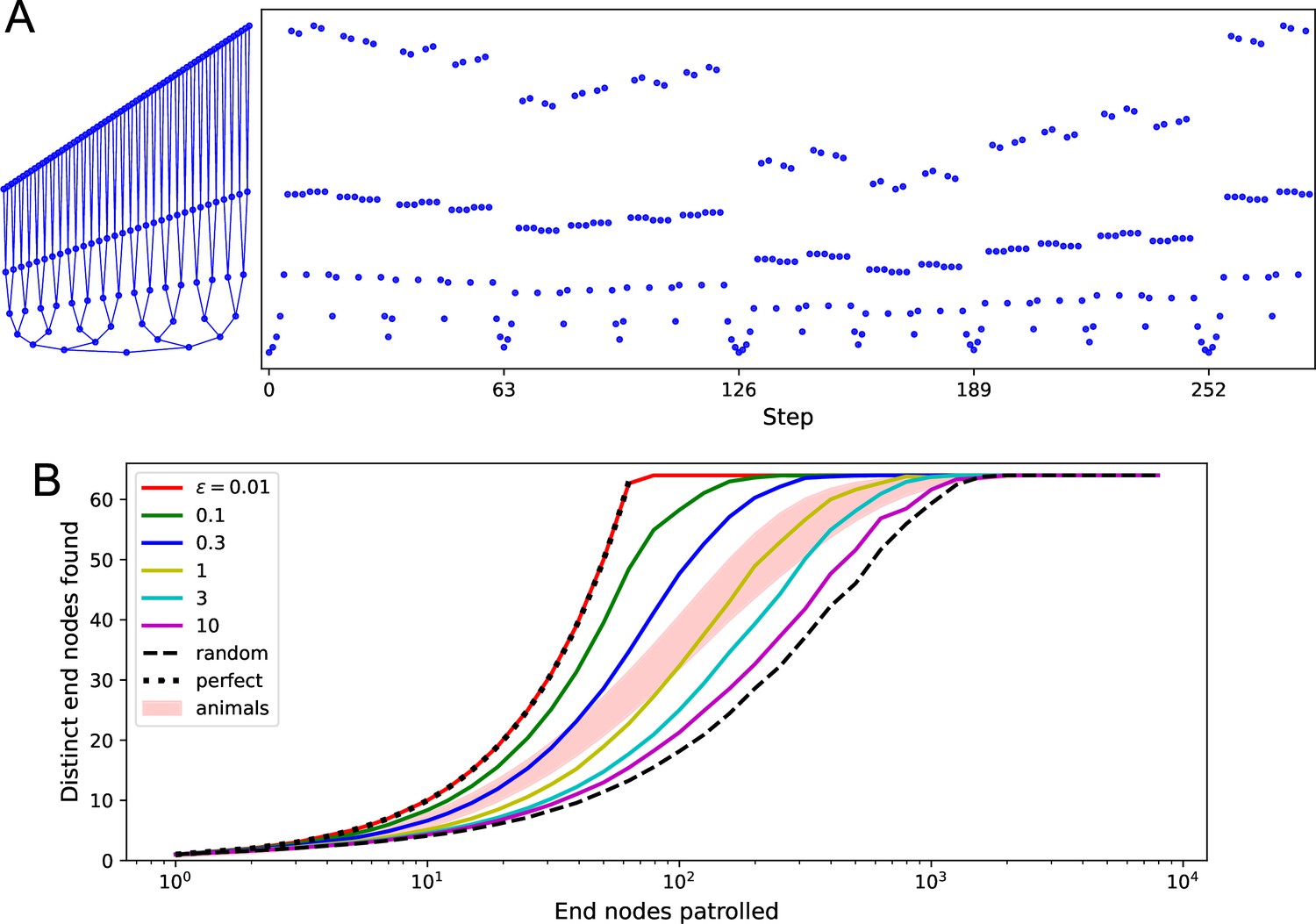
Patrolling by endotaxis.
(A) Left: a binary tree maze as used in Rosenberg et al., 2021, plotted here so every node has a different vertical offset. Right: a perfect patrol path through this environment. It visits every node in 252 steps, then starts over. (B) Patrolling efficiency of different agents on the binary tree maze. The focus here is on the 64 end nodes of the labyrinth. We ask how many distinct end nodes are found (vertical axis) as a function of the number of end nodes visited (horizontal axis). For the perfect patrolling path, that relationship is the identity (‘perfect’). For a random walk, the curve is shifted far to the right (‘random’, note log axis). Ten mice in Rosenberg et al., 2021 showed patrolling behavior within the shaded range. Solid lines are the endotaxis agent, operating at different noise levels . Note produces perfect patrolling; in fact, panel (A) is a path produced by this agent. Higher noise levels lead to lower efficiency. The behavior of mice corresponds to . Gain , habituation , with recovery time steps.
Figure 10
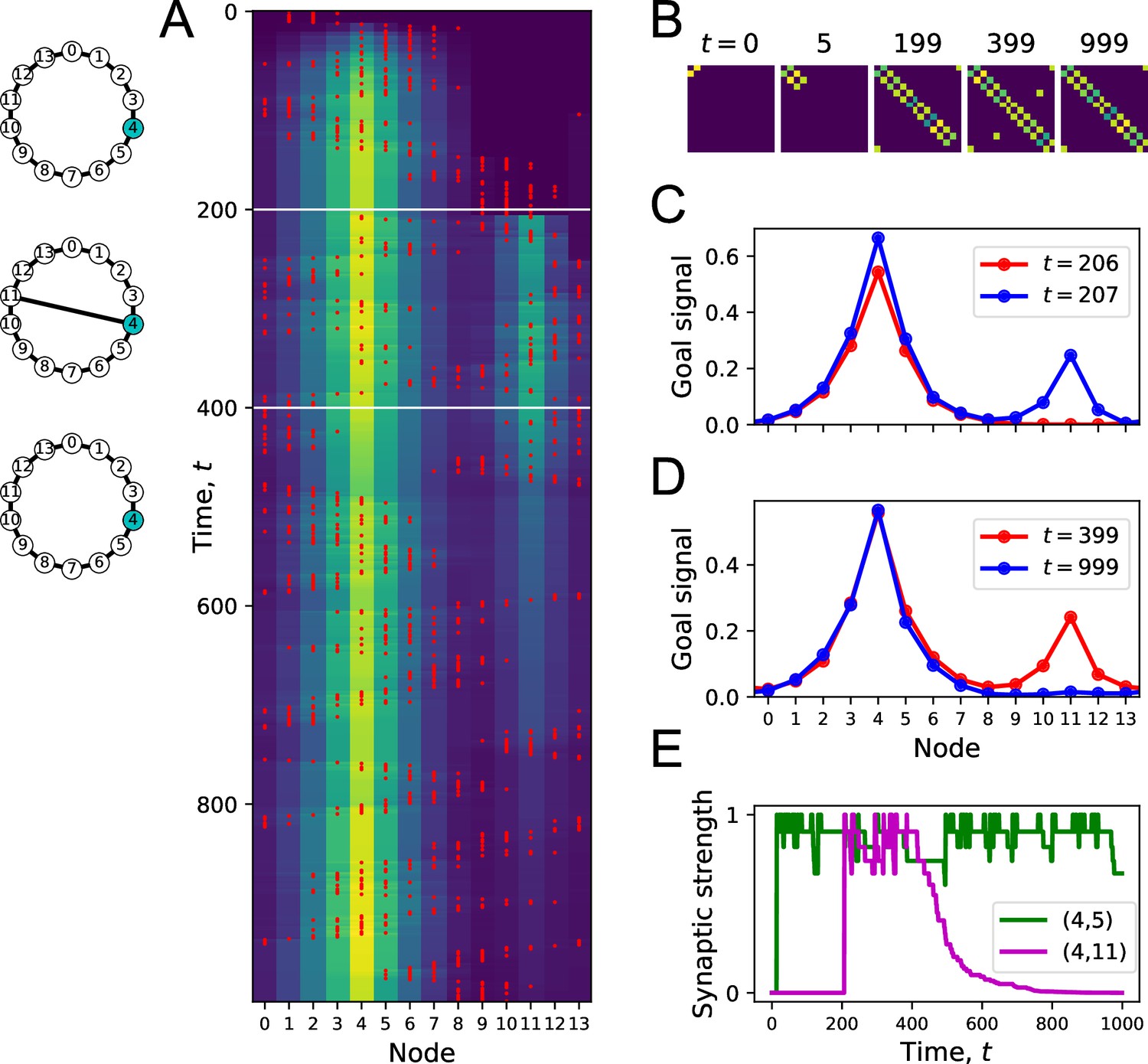
Forgetting a link during exploration.
(A) Simulation of a random walk on a ring with 14 nodes as in Figure 4. Left: layout of the ring, with resource locations marked in blue. The walk progresses in 1000 time steps (top to bottom); with the agent’s position marked in red (nodes 0–13, horizontal axis). At each time, the color map shows the goal signal that would be produced if the agent were at position ‘Node.’ White horizontal lines mark the appearance of a new link between nodes 4 and 11 at , and disappearance of that link at . (B) The matrix of map synapses at various times. The pixel in row and column represents the matrix element . Color purple = 0. Note the first few steps (number above graph) each add a new synapse. Eventually, reflects the adjacency matrix of nodes on the graph, and changes as a link is added and removed. (C) Goal signals just before and just after the agent travels the new link. (D) Goal signals just before the link disappears and at the end of the walk. (E) Strength of two synapses in the map, and , plotted against time during the random walk. Model parameters: .
Figure 11
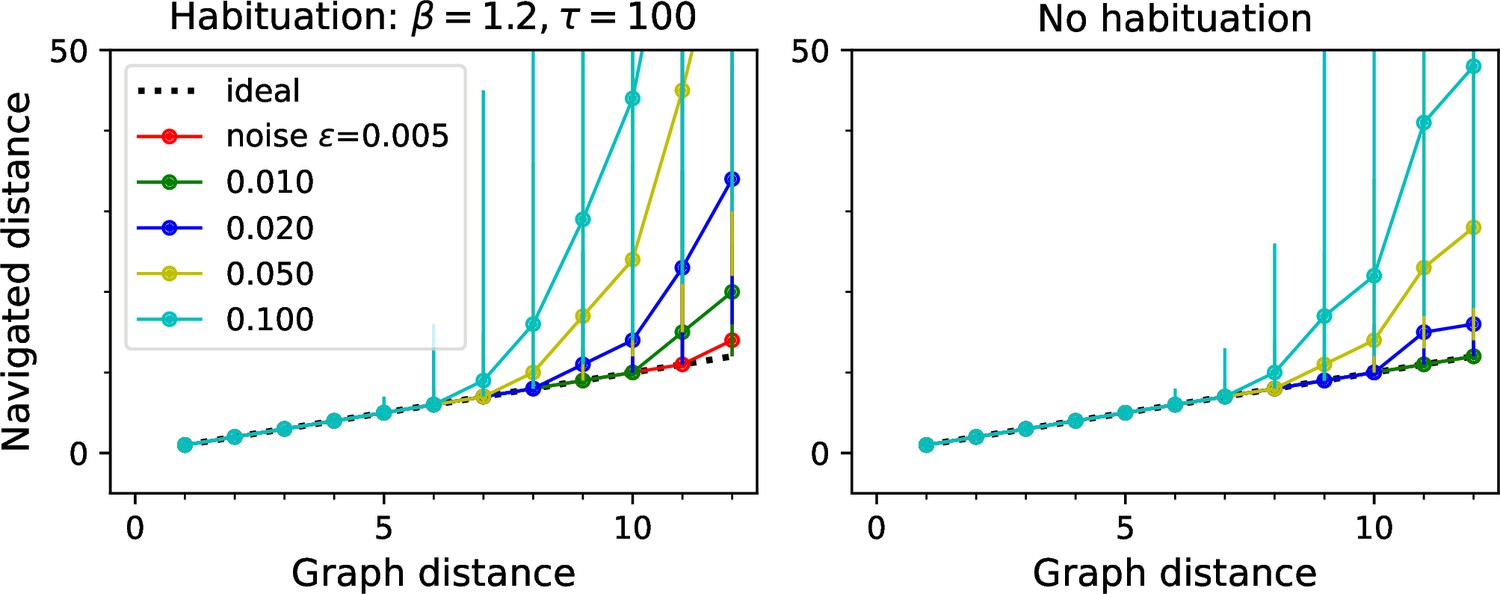
Navigation performance with and without habituation.
Navigated distance on the binary tree maze, displayed as in Figure 5E. Left: an agent with strong habituation: . Right: no habituation: . The agent learned the map and the goal signals for every node during a random walk with 30,000 steps. Then the agent navigated between all pairs of points on the maze. Graphs show the median ± 10/90 percentile of the navigated distance for all routes with the same graph distance. Other model parameters: as listed.
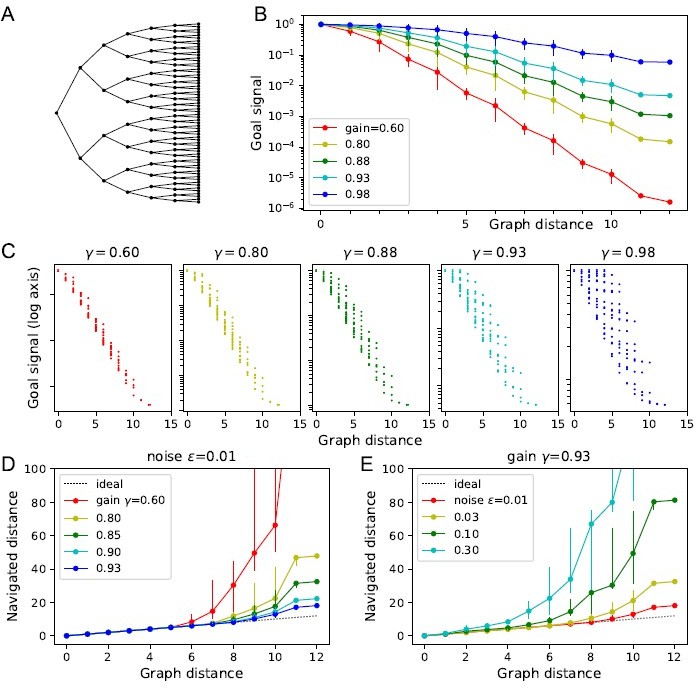
Author response image 1
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Endotaxis: A neuromorphic algorithm for mapping, goal-learning, navigation, and patrolling
eLife 12:RP84141.
https://doi.org/10.7554/eLife.84141.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}