How microscopic epistasis and clonal interference shape the fitness trajectory in a spin glass model of microbial long-term evolution
- Courant Institute of Mathematical Sciences, New York University, United States
- Janelia Research Campus, United States
- Department of Mathematics, University of Wisconsin–Madison, United States
- Mathematics Group, Lawrence Berkeley National Laboratory, United States
- Weizmann Institute of Science, Israel
- John A. Paulson School of Engineering and Applied Sciences, Harvard University, United States
eLife assessment
This important study describes a high performance computational approach to interrogate how microscopic epistasis and clonal interference affect evolutionary dynamics in a spin glass model of microbial evolution. The study offers several insights that can aid in our understanding of the forces that operate in adaptive evolution. The evidence provided is compelling, with its rigorous use of models and analytical descriptions of how these forces manifest in evolution.
https://doi.org/10.7554/eLife.87895.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Compelling: Evidence that features methods, data and analyses more rigorous than the current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
The adaptive dynamics of evolving microbial populations takes place on a complex fitness landscape generated by epistatic interactions. The population generically consists of multiple competing strains, a phenomenon known as clonal interference. Microscopic epistasis and clonal interference are central aspects of evolution in microbes, but their combined effects on the functional form of the population’s mean fitness are poorly understood. Here, we develop a computational method that resolves the full microscopic complexity of a simulated evolving population subject to a standard serial dilution protocol. Through extensive numerical experimentation, we find that stronger microscopic epistasis gives rise to fitness trajectories with slower growth independent of the number of competing strains, which we quantify with power-law fits and understand mechanistically via a random walk model that neglects dynamical correlations between genes. We show that increasing the level of clonal interference leads to fitness trajectories with faster growth (in functional form) without microscopic epistasis, but leaves the rate of growth invariant when epistasis is sufficiently strong, indicating that the role of clonal interference depends intimately on the underlying fitness landscape. The simulation package for this work may be found at https://github.com/nmboffi/spin_glass_evodyn.
Introduction
Laboratory evolution experiments have demonstrated the widespread prevalence of microscopic epistasis, the tendency for the phenotype associated with a mutation to depend on the background genotype in which it emerged (Khan et al., 2011; Chou et al., 2011; Wang et al., 2013; Good and Desai, 2015; Bakerlee et al., 2022; Kryazhimskiy et al., 2014; DiazColunga et al., 2023). Basic evolutionary theory indicates that for moderate mutation rates the overall population will consist of many competing strains, because additional mutations can emerge before an existing mutation has time to fix in the culture (Gerrish and Lenski, 1998; Desai and Fisher, 2007; de Visser and Rozen, 2006; Park and Krug, 2007). This clonal interference is consistently observed in laboratory experiments such as Lenski’s long-term evolution experiment (LTEE; Fogle et al., 2008; Lenski et al., 1991; Lenski and Travisano, 1994; Lenski, 2017; Wiser et al., 2013). Yet, despite the agreed-upon ubiquity of both aspects of evolution, there are few quantitative predictions for how they affect some of the most common experimental outputs, such as the mean fitness of the population. The central difficulty arises from the need to treat both the population and the genome at the microscopic level, which requires sophisticated analytical tools or high-resolution experiments.
The traditional approach in evolutionary theory is to make use of assumptions and statistical model classes that sidestep these complexities. Most theoretical studies of long-term adaptation take place in the strong selection weak mutation (SSWM) limit (Gillespie, 1983; Gillespie, 1984; Gillespie, 1991; Orr, 2002; Good et al., 2012), where the time for a beneficial mutation event to occur is large in comparison to the time for a typical beneficial mutation to fix in the population. While convenient due to analytical simplifications, this limit neglects clonal interference by ensuring that the culture consists of a single dominant strain at almost all times, and is hence known to be invalid for populations under standard laboratory conditions (de Visser and Rozen, 2006). As an unfortunate by-product, even if the predictions of a model are found to match experimental data, it is not clear how the addition of clonal interference will change the results.
To avoid the analytical and computational challenges associated with modeling the genome at microscopic granularity, significant theoretical effort has been spent studying macroscopic “rugged” or uncorrelated models (Kauffman and Levin, 1987; Kauffman and Weinberger, 1989; Wilke, 2004; Macken and Perelson, 1989; Flyvbjerg and Lautrup, 1992; Kingman, 1978), which posit the fitness of a mutant to be drawn at random from a fixed distribution (Park and Krug, 2008). More recently, macroscopic “fitness-parameterized” models, which assume the distribution of fitness effects (DFE) depends only on the fitness of the parent, have garnered interest as a way to model correlations in the fitness landscape (Kryazhimskiy et al., 2009). Although macroscopic models have provided significant insight into evolutionary dynamics, both classes exhibit serious disadvantages. Rugged landscapes make predictions that are known to violate experimental measurements, such as the typical length of an adaptive walk (Orr, 2006). Fitness-parameterized models can help correct some of these issues, but to do so they require an assumption about how the DFE depends on fitness, which is typically unknown because of its experimental intractability.
One approach that corrects the deficiencies of macroscopic models is the use of microscopic models, which treat the genome as a sequence of loci each with a binary label indicating the presence or absence of a mutation. Perhaps the most well-studied microscopic model in evolutionary theory is Kauffmans NK model (Kauffman and Levin, 1987), but similar microscopic models can be obtained systematically via Fourier expansion (Neher and Shraiman, 2011). This approach leads to the class of spin glass models well-studied in statistical physics (Sherrington and Kirkpatrick, 1975; Sompolinsky and Zippelius, 1982; Arous et al., 2001), theoretical neuroscience (Amit et al., 1985a; Amit et al., 1985b; Hopfield, 1982), ecology (Roy et al., 2020), machine learning (Choromanska et al., 2015), and combinatorial optimization (Mézard and Montanari, 2009; Mezard et al., 1986). Recently, spin glass models have been used to study the role of epistasis in adaptive dynamics, leading to insight into the generation of slow, logarithmic fitness trajectories (Guo et al., 2019) and into how macroscopic epistasis emerges from widespread microscopic interactions (Reddy and Desai, 2021). But due to the computational expense of full-scale microscopic simulations, these prior works make the SSWM assumption, which greatly simplifies the resulting adaptive dynamics to a process that is analytically tractable.
In order to understand the role played by microscopic epistasis and clonal interference in real-world evolving populations, we present a systematic numerical study of the evolutionary dynamics of a microbial culture under serial dilution on a microscopic fitness landscape far from the SSWM regime. To do so, we consider a spin glass type model that enables us to independently tune the magnitude of epistasis and the level of clonal interference in the culture. The model contains both additive and epistatic terms. The relative magnitude of the two terms can be adjusted, and the epistatic interaction takes place pairwise between two loci on the genome.
To resolve the adaptive dynamics, we develop a high-performance, OpenMP-based multi-threaded implementation of the resulting stochastic process in C++ (https://github.com/nmboffi/spin_glass_evodyn copy archived at Boffi, 2023), which we use to study an adaptive walk to a fitness peak comprising a few hundred fixation events. The implementation leverages several algorithmic advances to capture the complete microscopic details of the process over long timescales: an efficient algorithm for computation of the fitness that leverages the structure of the epistatic interaction, a hashing-based method for storage of strains by genotype for fast splitting and joining, and an efficient approach for diluting the culture. These algorithmic advances render tractable the computation of the entire distribution of fitness effects, the complete sequence of fixed mutations along with their individual effects, and the number of remaining beneficial mutations for any strain at any time with realistic population sizes (one hundred million bacteria) over realistic timescales (tens of thousands of generations). In the strong clonal interference regime, tracking all microscopic details generates hundreds of gigabytes of data; the resulting datasets are processed by custom-built Python code that produces standard, experimentally-measurable observables.
Our framework brings insight into both real-world experimental systems and modern approaches in evolutionary theory. To this end, we show that hill-climbing dynamics on a random and sparse fitness landscape with two-point interactions cannot give rise to the slow, low-exponent power law trajectories observed in Lenskis LTEE even with clonal interference, suggesting that other factors such as structured interactions might be at play. Moreover, we show that any macroscopic fitness-parameterized model used to describe a microscopic process must depend intrinsically on the level of clonal interference in the population, implying that the DFE in a macroscopic model for an experimental system must be tuned to the mutation rate of the culture.
The paper is organized as follows. In 'Model details', we describe details of the fitness landscape and the simulation. In 'Landscape ruggedness slows the fitness trajectory', we show how microscopic epistasis slows the functional form of the fitness trajectory independent of the level of clonal interference. In 'A fitness-parameterized mapping' and 'A random walk model', we develop simplified macrosopic models to interpret and explain mechanistically the effect of microscopic epistasis. In 'The effect of clonal interference', we show how the effect of clonal interference depends on the strength of microscopic epistasis, and that an accurate fitness parameterized model must be tuned to the level of clonal interference in the population. We conclude with a discussion in 'Discussion and conclusions' Equation 1.
Model details
Definition
To study the effect of microscopic epistasis on the average fitness trajectory, it is useful to model the genome as a sequence of sites and to consider fitness landscapes that specify the fitness as a function of the state of the genome. We study a generic finite-sites microscopic model (Figure 1) inspired by the Sherrington Kirkpatrick spin glass in statistical physics (Sherrington and Kirkpatrick, 1975). In the next subsection, we elaborate on the generality of a model of this form.
Figure 1
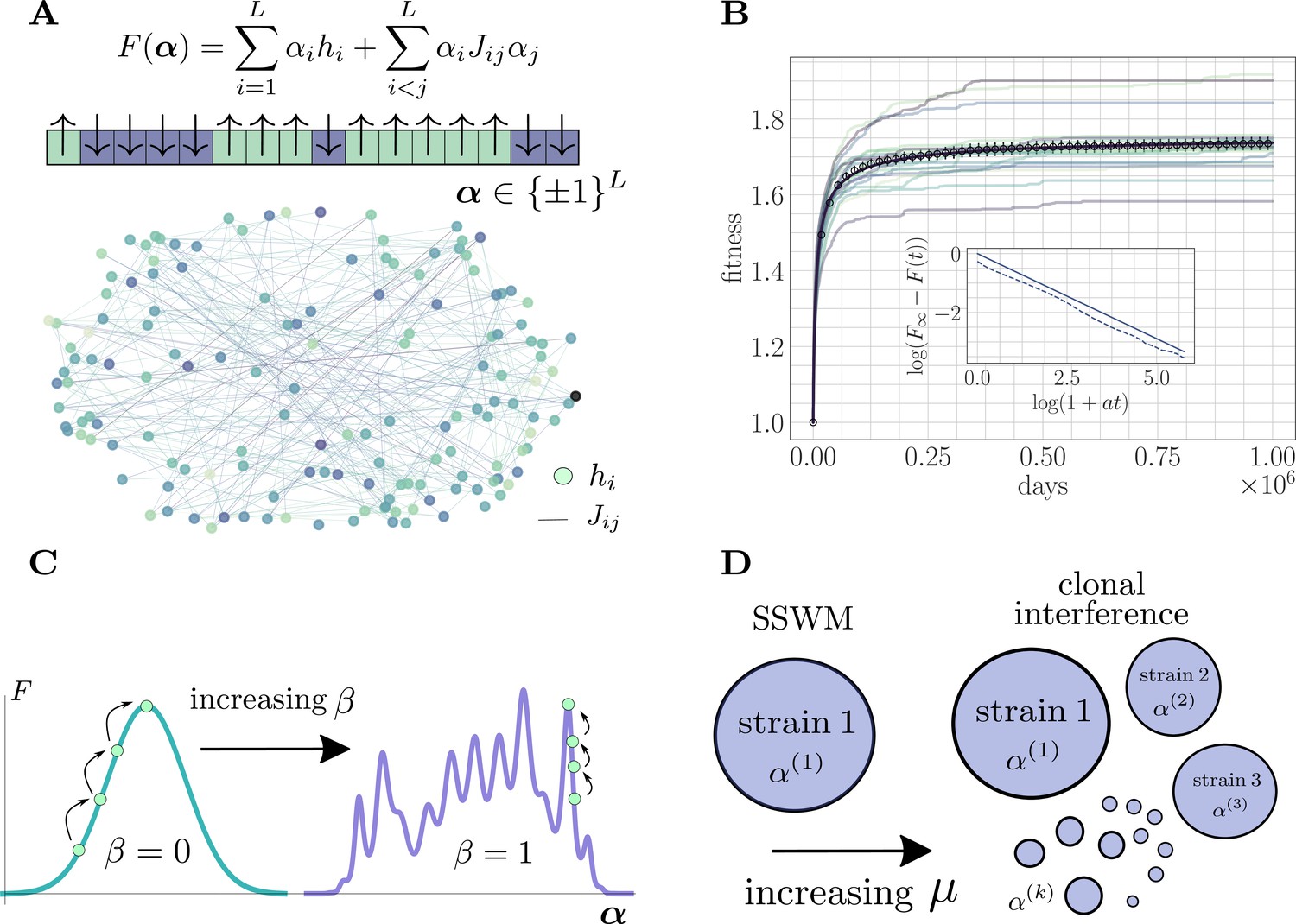
The microscopic epistasis model.
(A) The fitness of a given strain is defined by its genotype . Each gene contributes independent of the background genotype and an epistatic contribution due to its interaction with all other genes. The and values are drawn randomly, and the relative magnitudes of the two contributions can be tuned by adjusting a parameter . Each gene interacts, on average, with a fraction of other genes. The fitness landscape is thus described by a disordered network, here shown for and , with color indicating magnitude and connectivity demonstrating the sparsity pattern of the . (B) A typical hill-climbing trajectory with both clonal interference () and microscopic epistasis (). Replicate trajectories are displayed in low opacity, while the mean over all replicates is shown in open circles with error bars depicting the standard error of the mean. The mean fitness is consistent with a power-law relaxation with exponent (solid). The inset displays the trajectory (dashed) and the best-fit power law (solid, shifted for visual clarity) on a log-log scale. (C) As β is increased, the epistatic contribution becomes more significant, and the landscape smoothly becomes more rugged. (D) As the mutation rate increases, the magnitude of clonal interference can be smoothly tuned.
The fitness model
With denoting the length of the genome, the fitness of a strain with genotype is given by the expression
(1)
Here, is an arbitrary offset value that can be used to fix the initial fitness independent of the initial genotype. Inspired by experimental competition assays in typical laboratory microbial evolution settings, we compare the fitness of a given strain to the fitness of the ancestral strain. To do so, we choose so that the fitness of the ancestral strain is equal to one; this arbitrary shift has no effect on the dynamics or our conclusions.
In Equation 1, each represents the instantaneous contribution of a mutation at gene to the fitness of the strain in the absence of epistasis. Each describes the microscopic epistasis between mutations at genes and . Realistic biological fitness landscapes are thought to be rugged, containing many local extrema. By taking the values of and to be random, Equation 1 gives rise to such a complex fitness landscape.
Disorder statistics
Because biological networks are typically sparse (Tong et al., 2004; Costanzo et al., 2016), our model is such that each gene only interacts on average with a fraction of the other genes. is typically on the order of a few percent in realistic networks, and we set accordingly. These considerations lead to the choice of distributions
with for all . Above, denotes a normal distribution with mean and variance , and denotes a Bernoulli distribution with parameter . The variances are set to and where sets the magnitude of microscopic epistasis and sets the magnitude of generic fitness increments. This scaling with β ensures that the fitness increase at initialization is approximately independent of β. This choice provides a useful setting to qualitatively compare the speed of fitness trajectories in addition to quantitative measures such as fitting parametric functional forms (Guo and Amir, 2022). Typical fitness increments in laboratory experiments are on the order of a few percent of the fitness of the ancestral strain (Barrick et al., 2009), and we choose to match this observation. Our conclusions about the roles of epistasis and clonal interference (and their mechanisms) do not depend on the specific choice.
Fitness trajectories
The fitness landscape is defined by a sparse and random genetic interaction network (Figure 1A). Adaptation dynamics produce fitness trajectories (Figure 1B) qualitatively consistent with experimental observations of long-term evolution in microbial populations (Lenski, 2017), leading to power-law trajectories with exponents between and . For details on how these trajectories and exponents are produced, see 'Further simulation details'.
Landscape structure
The parameter can be used to continuously tune the ruggedness of the landscape (Figure 1C). For , there is no microscopic epistasis, and the evolutionary dynamics corresponds to a hill-climbing event towards the single fitness maximum with value . In the opposite extreme for , mutations do not have any effect independent of the genetic background, and the landscape is rife with local fitness maxima. In particular, for , the landscape exhibits widespread sign epistasis, which is known to be necessary to generate rugged features thought to be present in realistic experimental fitness landscapes (Weinreich et al., 2005). By systematically varying this parameter and observing its effect on the average fitness trajectory throughout the approach to a fitness maximum, we quantify the role of microscopic epistasis in slowing the functional form (i.e. reducing the power-law exponent) of the fitness trajectory both with and without clonal interference.
The structure of the landscape near the initialization can also be tuned by adjusting the number of available beneficial mutations, or the rank , of the ancestral strain. To remove this source of variability, we fix the rank of the ancestral strain to be identical across all experiments.
Dilution and selection
We study a batch culture subject to a standard serial dilution protocol (Lenski et al., 1991; Lin et al., 2020; Desai et al., 2007; Kryazhimskiy et al., 2012). The population is allowed to grow until the total number of bacteria in the simulation reaches where is the dilution factor. When the total population size reaches , we say that a day has been completed. At the end of each day, the population is diluted back to size by sampling from a multivariate hypergeometric distribution. Repeated sampling from this distribution is computationally intensive, and we developed an efficient approximate scheme to do so in the strong clonal interference regime (see 'Further simulation details').
Simulation parameters
Motivated by Lenski’s long-term evolution experiment (Lenski et al., 1991; Lenski and Travisano, 1994), we set , and in all simulations. We fix and , respectively motivated by sparsity of biological networks and the overall magnitude of typical fitness increments in laboratory experiments. We set , which corresponds to considering mutations at the level of each gene in E. coli. Because typically only a fraction of possible mutations are beneficial, we fix the initial rank to 100. The mutation rate µ and epistatic parameter β are varied and will be specified along with the results.
Choice of model
There are several compelling reasons to study the fitness model in Equation 1 that we now highlight.
Generality
Equation 1 represents the two lowest-order terms in a Fourier expansion of an arbitrary function defined on the Boolean hypercube (Neher and Shraiman, 2011). As such, our model represents a rigorously quantifiable approximation of any choice of fitness model defined on the hypercube.
Tunable epistasis
The presence of the continuous parameter allows us to systematically vary the relative contribution of the epistatic interaction, enabling a detailed study of the effect of microscopic epistasis on the dynamics of adaptation. The well-known NK model (Kauffman and Levin, 1987) similarly contains a parameter (, the number of genes in an epistatic interaction) that can be used to tune the ruggedness of the landscape. However, this parameter is discrete and changing it leads to a more drastic shift in the structure of the fitness landscape.
Tunable clonal interference
For low mutation rate, the population is in the SSWM regime and the evolutionary dynamics correspond to sequential sweeps of beneficial mutations throughout the population, which consists of a single dominant strain (Figure 1D). As the mutation rate increases, the adaptation dynamics become richer, enabling higher-order effects such as multiple mutations (Weissman et al., 2009), stochastic tunneling (Iwasa et al., 2004; Guo et al., 2019), and competing populations, all of which emerge naturally in our simulations.
Efficiency
Equation 1 has significant computational advantages–summarized by Lemma 1–that enable us to develop a large-scale simulation. Leveraging algebraic simplifications intrinsic to the model’s mathematical structure, the fitness of a given strain may be computed as a correction to the fitness of a reference strain that is updated adaptively to track the state of the population. The resulting adaptive fast fitness computation is several orders of magnitude faster than a naive calculation, and our ability to simulate to long times in the strong clonal interference regime hinges upon it.
Results
Landscape ruggedness slows the fitness trajectory
We first study the effect of microscopic epistasis on the functional form of the fitness trajectory in both the SSWM () and clonal interference () mutation regimes (Figure 2). Intuitively, by complicating the fitness landscape and increasing the difficulty of the corresponding optimization problem, we expect greater levels of microscopic epistasis to lead to a slower fitness trajectory. Empirically, we find that the value of the fitness peak increases slightly with increasing β. To eliminate this variability, each mean fitness trajectory is normalized to lie between the values 1 and 2 for visualization. The fitness trajectory takes more time to approach its asymptotic value as β increases, indicating a slower approach towards equilibrium (Figure 2A/B).
Figure 2
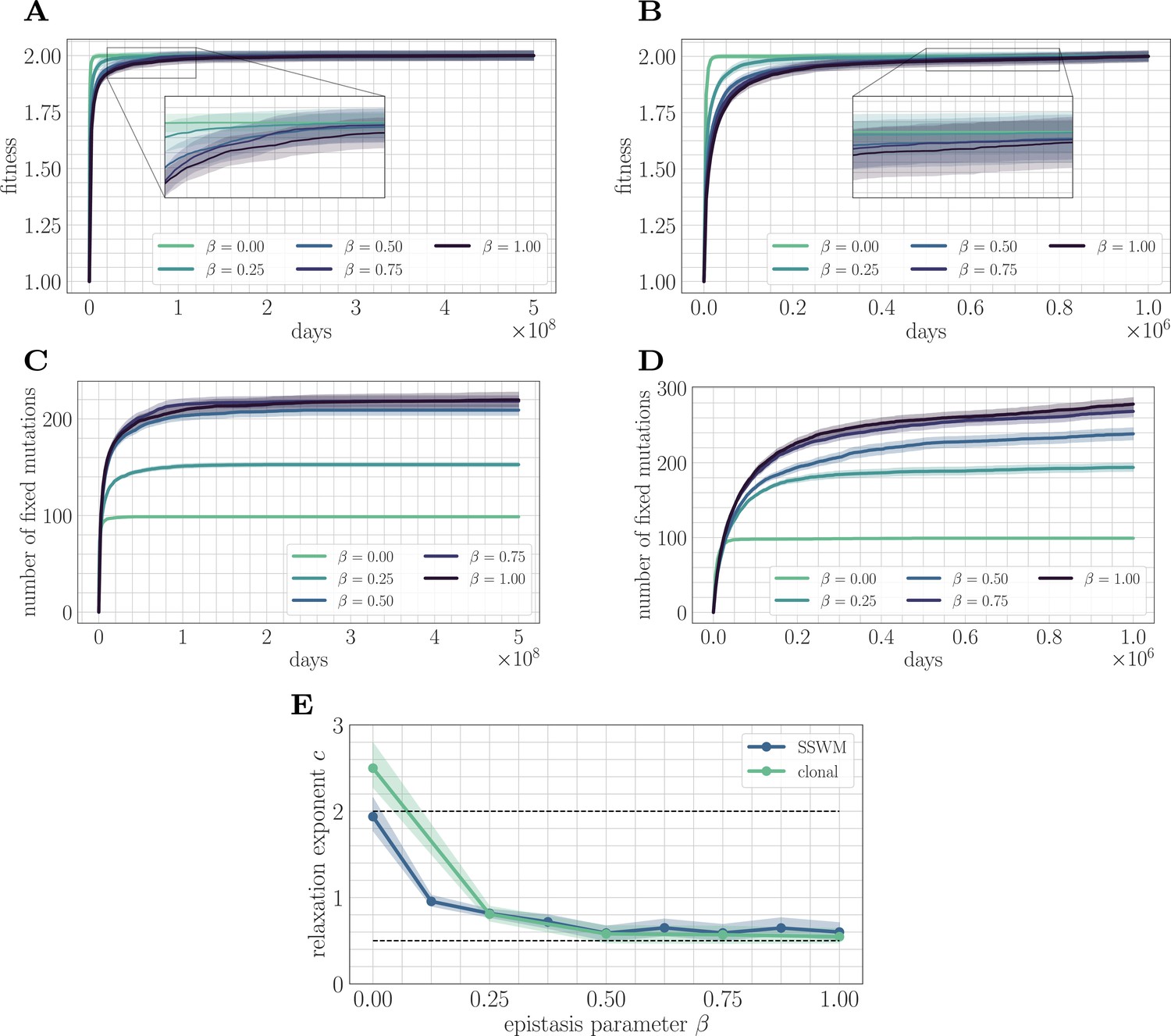
Increasing landscape ruggedness slows the fitness trajectory.
Left: SSWM. Right: Clonal interference. Error bars for the first four panes (shown as shaded regions, for this and other figures) indicate standard error of the mean over replicates. (A) Normalized fitness trajectories as a function of in the SSWM limit (). Higher values of β exhibit a slower approach towards the fitness peak. (B) Normalized fitness trajectories in the clonal interference regime (). (C) Substitution trajectories in the SSWM limit (). Higher values of β lead to a greater number of fixed mutations. (D) Substitution trajectories in the clonal interference regime (). (E) Fitness relaxation exponents as a function of in the SSWM limit and clonal interference regimes. As increases, the fitness relaxation slows. Dashed lines indicate analytically computable exponents for and for in the SSWM regime. Error bars indicate 95% quantiles computed from the bootstrap distribution (for details, see 'Further simulation details').
Insight into the mechanism by which epistasis slows the fitness trajectory can be obtained by visualizing the substitution trajectories (Figure 2C/D), which describe the number of mutations that have fixed in the population at time . The substitution trajectories demonstrate that increasing the amount of microscopic epistasis smoothly leads to an accumulation of more fixed mutations at each time. Because the initial rank (the number of available beneficial mutations) is identical for each value of β, the substitution trajectories suggest a simple picture: as β increases, a greater number of new available beneficial mutations are generated per each typical fixation event. Moreover, because more mutations are needed to cease adaptation, each typical fixation event must provide less progress towards the fitness peak. Mathematically, this corresponds to a greater prevalence of flat regions in the fitness landscape, which have been identified as a source of slow dynamics in previous studies of spin-glass physics (Kurchan and Laloux, 1996).
These observations highlight the role of microscopic epistasis in slowing down long-term evolutionary dynamics, but they do not make a quantitative claim about the functional form of the fitness trajectory. To make such a claim, we can fit the data to a predictive model and study how the model parameters depend on β. The functional form of the fitness trajectory can be computed analytically in the SSWM regime in a fitness-parameterized context approximately met by our fitness model with (Good and Desai, 2015); the resulting trajectory is given by the power-law relaxation
(2)
with , , and by our choice of . We find empirically that in both the SSWM and clonal interference regimes, the power-law in Equation 2 provides a good fit to the mean fitness trajectory for .
We fit Equation 2 to the mean fitness trajectory (see 'Further simulation details') over a range of values of β (Figure 2E). In both regimes, the relaxation exponent decreases monotonically with increasing β, indicating a quantitative slowdown of the fitness trajectory with increasing levels of microscopic epistasis. In the next section, we will show that we can estimate the exponent for in the SSWM regime.
A fitness-parameterized mapping
The mechanism suggested by the substitution trajectories can be confirmed by mapping the microscopic model to a fitness-parameterized landscape with two effective parameters: a single beneficial fitness increment given by the expected beneficial fitness increment , and a beneficial mutation rate set by the rank (Figure 3). The reduction to a few-parameter fitness-parameterized model has been justified both theoretically (Good et al., 2012) and experimentally (Hegreness et al., 2006) in the clonal interference regime, and we find that it similarly provides useful insight in the SSWM regime.
Figure 3
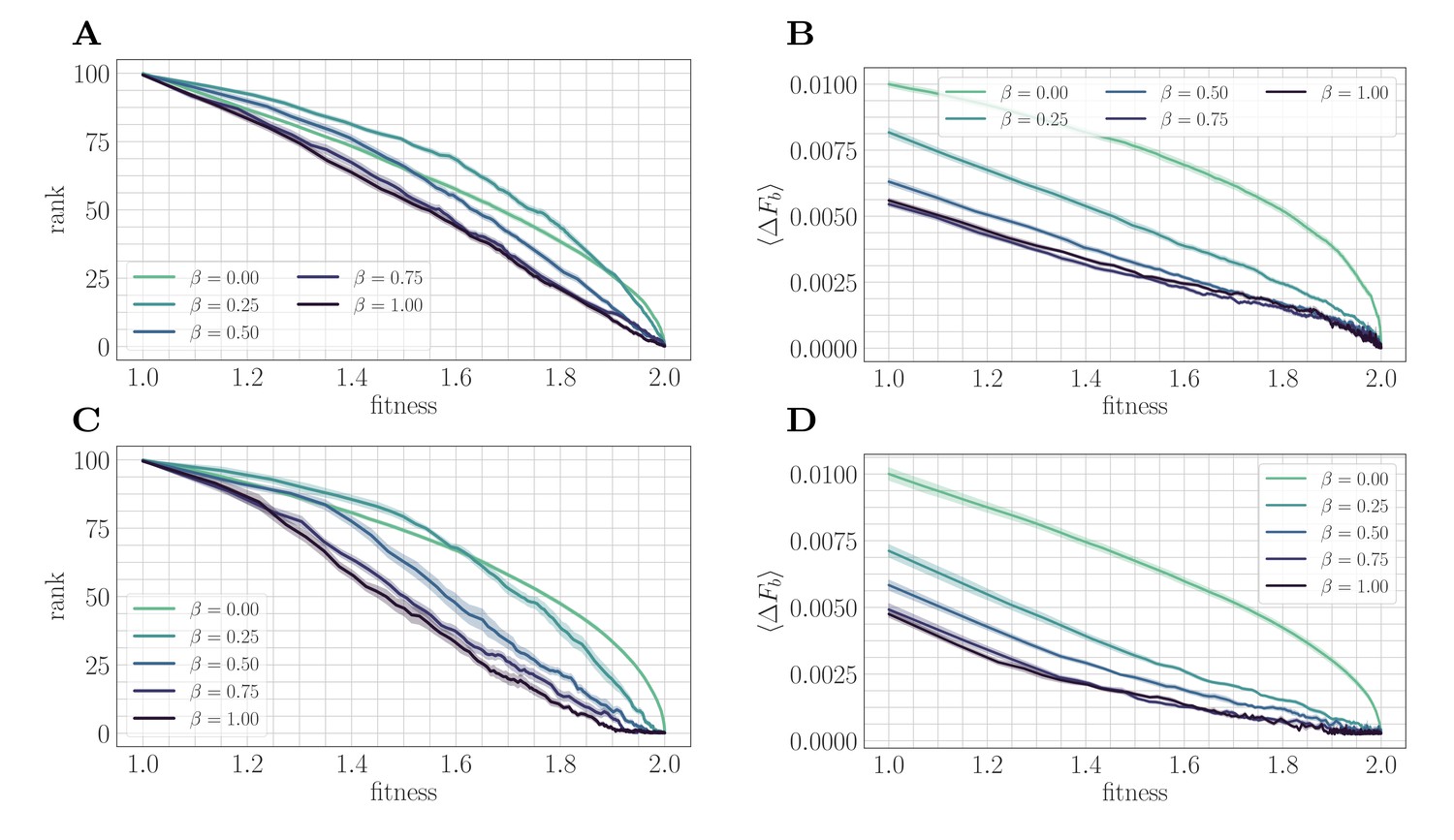
A mapping to a fitness-parameterized landscape as a function of .
Top: SSWM. Bottom: Clonal interference. Error bars in the first four panes indicate standard error of the mean over replicates. (A) Rank as a function of fitness in the SSWM regime. The functional form of changes significantly as β varies, progressing from a concave decreasing function for towards a linear form for . For all , the rank decreases monotonically with . (B) Expected normalized beneficial fitness increment as a function of normalized fitness in the SSWM regime. Global epistasis emerges naturally in our model, leading to a linear decrease in with for all nonzero values of β. For all values of β, the increment decreases monotonically with β. (C/D) Rank/expected increment as a function of fitness with clonal interference; similar observations hold as for SSWM.
In both mutation regimes, for all nonzero values of β, the expected beneficial increment behaves linearly as a function of fitness (Figure 3B/D). This phenomenon is known as macroscopic or global epistasis, and has been shown to be an emergent property of a class of finite-sites models similar to the one considered here (Reddy and Desai, 2021). Consistent with the observations of the previous section, the expected beneficial increment (scaled relative to the fitness peak) decreases with at fixed fitness, which highlights that microscopic epistasis tends to reduce the progress towards the peak provided by each typical fixation event.
Unlike the beneficial fitness increment, the rank exhibits more variation in functional form as β is varied, which progresses towards linearity as β tends to one (Figure 3A/C). Considering only , decreases with increasing β at each ; including , this is also true for sufficiently large . This indicates that at any fixed relative distance from the fitness peak, beneficial mutation events become more rare as increases.
Taken together, these observations demonstrate that microscopic epistasis leads to a slower fitness trajectory through two complementary effects. At each fixed value of fitness, beneficial mutations are less likely to be found by random mutation; moreover, more of them are required to reach the peak due to a lower typical (normalized) increment. These additional beneficial mutations are generated by the epistatic interaction as each fixation event occurs.
Quantitative model
These arguments can also be justified mathematically, leading to a quantitative prediction of for , consistent with the result in Figure 2E. In such a two-parameter macroscopic model, the fitness evolves according to the dynamics
(3)
where each quantity on the right-hand side is evaluated at . In the SSWM regime, according to Haldane’s formula (Haldane, 1927). The preceding paragraphs demonstrate that decreases as a function of β for each fixed , giving rise to a slower trajectory. From Figure 3A/B, both and are approximately linear and reach zero at . Hence for a fixed . Equation 3 then reads
which predicts that asymptotically
for a fixed . This prediction provides a complement to the analytical result of in the SSWM regime with .
A random walk model
The previous sections provided an explanation for the effect of microscopic epistasis on long-term adaptation dynamics: as the level of microscopic epistasis increases, the typical number of available beneficial mutations at a given fitness decreases while the number of fixed mutations required to reach the peak increases, leading to a slower trajectory. In this section, we formulate a mechanistic model that provides a qualitative explanation for why microscopic epistasis generates new beneficial mutations and slows the trajectory.
Distribution of increments
The previous sections highlighted that the mechanism is common to both the SSWM and clonal interference regimes, for which reason we restrict to the SSWM limit in the subsequent analysis. In the SSWM limit, a single empirical distribution of fitness effects is induced by the fitness landscape
(4)
where is the fitness effect of a mutation at gene at time . Because there is only a single strain, the dynamics of adaptation can be characterized entirely by the evolution of in time. When a mutation at site fixes (which can only occur if ), the corresponding increment is updated:
(5)
In the absence of microscopic epistasis, each such fixation event would decrease the rank by one until all available beneficial mutations have fixed. However, due to microscopic epistasis, the fixation of a mutation at gene causes a change in all other fitness increments:
(6)
The update to the fitness increment in Equation 6 is complex due to the presence of correlations between and induced by the coupling . Moreover, the distribution of must be conditioned on the event that . Previous studies in spin glass (Horner, 2007; Eastham et al., 2006) and electron glass (Mogilyanskii and Raikh, 1989; Amir et al., 2008) physics have obtained significant physical insight by neglecting these dynamical correlations, and here we take a similar approach.
Update statistics
The neglect of dynamical correlations implies that the effect of each fixation event is to add a random Gaussian noise term with probability (the network sparsity parameter) to all other increments,
(7)
Above, and are mean and variance parameters of the noise distribution; these can be estimated numerically from data to account for initialization from a state with and to condition on beneficial mutation events (see 'Further simulation details'). This process corresponds to a biased random walk (Equation 7) with nonlocal transport (Equation 5) on the fitness increments.
Coarse-grained simulation
To test this mechanistic model, we developed a coarse-grained simulation methodology based on Gillespie’s stochastic simulation algorithm (Gillespie, 1976) (see 'Further simulation details'). Fitting the power law in Equation 2 to the mean fitness trajectories shows that the random walk model predicts a monotonically decreasing exponent and a monotonically increasing number of fixed mutations as a function of β (Figure 4A). This is qualitatively consistent with the results of applying the same coarse-grained simulation approach in the SSWM approximation to the full fitness model (Figure 4B). Due to the neglect of correlations, the random walk model predicts a lower number of generated beneficial mutations and a correspondingly higher fitness exponent.
Figure 4
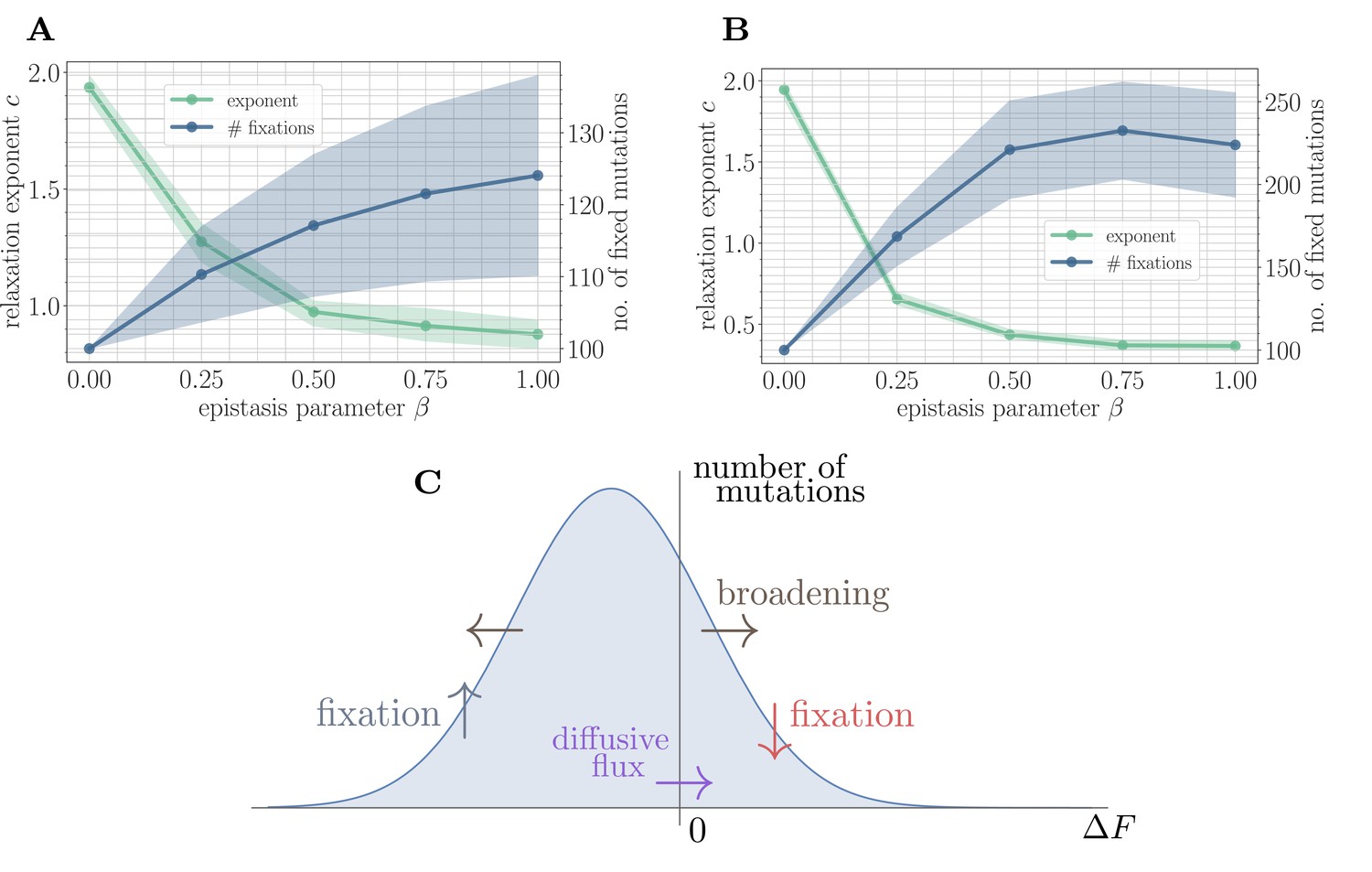
A simple random walk model captures the generation of beneficial mutations and a decreasing exponent with increasing microscopic epistasis.
(A) Fitness relaxation exponent and number of fixed mutations to reach a local fitness maximum (zero rank) as a function of β, computed within a random walk model (which neglects correlations). The model predicts a monotonically decreasing exponent and a monotonically increasing number of fixations as a function of β. Error bars around exponents indicate 95% quantiles from the bootstrap distribution (100 samples) while central line depicts the median. Error bars around the number of fixations indicate the standard deviation over 200 replicates and central line the mean. (B) Analogous figure to (A), but within the SSWM approximation using a coarse-grained Gillespie simulation framework (where correlations develop over time). The behavior is qualitatively similar to the random walk model, though the exponent decreases further and the number of fixation events is larger. (C) Illustration of the diffusive generation of mutations. As beneficial mutations fix, the beneficial half of the distribution of fitness increments is depleted and transported to the deleterious half. Each fixation event causes the distribution to broaden due to the epistatic interaction, which combines with a buildup of deleterious mutations to create a diffusive flux from the deleterious half to the beneficial half of the distribution.
Why are beneficial mutations generated?
Because only beneficial mutations can fix in the SSWM limit, the transport in Equation 5 is asymmetric, and beneficial mutations will be rapidly converted to deleterious mutations with equal magnitude but opposite sign. The noise in Equation 7 broadens the distribution of fitness increments, which converts deleterious mutations with small magnitude into beneficial mutations with small magnitude and vice-versa. The buildup of deleterious mutations results in a diffusive flux from the deleterious half to the beneficial half, providing a simple mechanism for the formation of new beneficial mutations (Figure 4C). Empirically, we find that increases with , driving the generation of a greater number of mutations with increasing and a correspondingly slower trajectory.
The effect of clonal interference
Clonal interference is known to reduce fixation probabilities (Gerrish and Lenski, 1998; Lin et al., 2020), and hence to slow down the rate of adaptation when compared to an SSWM model with the same parameters. Given its prevalence in realistic evolving laboratory populations, models incorporating both clonal interference and macroscopic epistasis have been developed to predict the slow power law fitness trajectory observed in Lenski’s long-term evolution experiment (Wiser et al., 2013). Despite this interest, the effect of clonal interference on the shape of the fitness trajectory is still poorly understood.
In fitness-parameterized models, for sufficiently weak clonal interference, the way clonal interference affects the shape of the fitness trajectory depends on how the beneficial mutation rate changes with fitness (Guo and Amir, 2022). In particular, for typical models where beneficial mutations become less prevalent as the population climbs up the hill, clonal interference accelerates the fitness trajectory. While this result provides insight into the role of clonal interference in laboratory populations, its not clear if it holds more generally in a microscopic framework, or when the magnitude of clonal interference becomes large. Here, we demonstrate that the effect of clonal interference on the fitness trajectory depends on the strength of microscopic epistasis. In its absence, clonal interference is seen to accelerate the trajectory, while for a sufficiently strong epistatic interaction, clonal interference does not quantitatively affect the speed of the trajectory.
In simulation, the magnitude of clonal interference is tuned by adjusting the mutation rate µ. Increasing the mutation rate increases clonal interference, but also accelerates adaptation by allowing for more mutations each day. This effect can be eliminated by normalizing time by the mutation rate, so as to isolate the role of clonal interference itself. Viewed in these units, clonal interference decelerates the fitness trajectory due to the suppression of fixation probabilities (Appendix 1—figure 1). However, when measuring the speed of a fitness trajectory, it is more rigorous to assign a quantitative measure by fitting a functional form such as the power law in Equation 2, which will directly estimate the timescale parameter independently for each µ. Fitting this power law reveals exponents that hover around in the epistatic setting (here, ), but increase from for to for in the non-epistatic setting (Figure 5). These results can also be visualized qualitatively by normalizing time in units such that the initial rate of fitness increase is constant for different values of µ, as was done for the results in Figure 2 via the definition of (Appendix 1—figure 2).
Figure 5
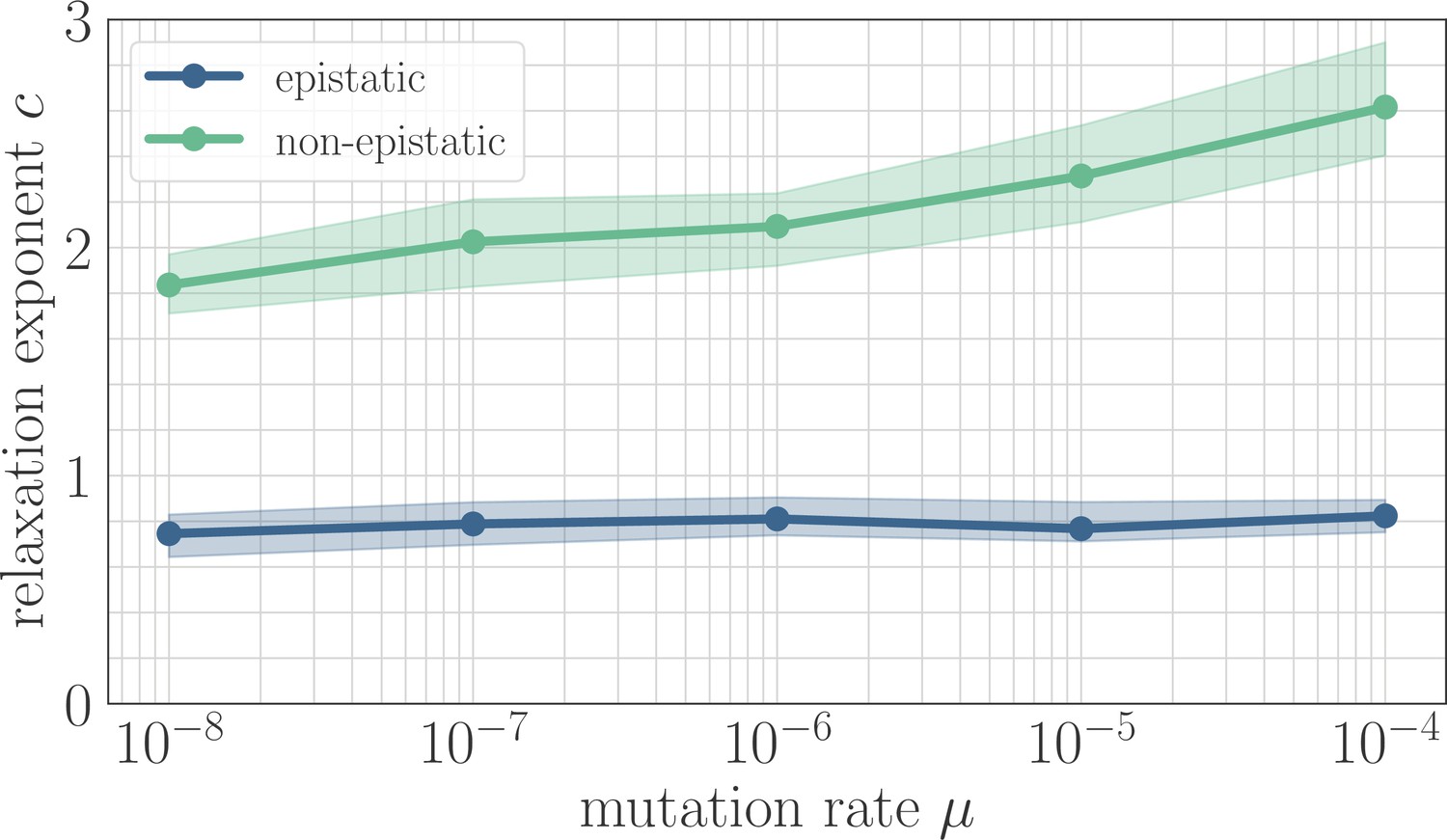
The effect of clonal interference on the fitness trajectory depends on the strength of microscopic epistasis.
Results of fitting the power law in Equation 2 as a function of µ. The relaxation exponent increases monotonically with µ for the non-epistatic model , while the exponent remains essentially constant in the epistatic model .
A change in the effective landscape
To understand this result and why it differs from the predictions of the fitness-parameterized setting, we can map the microscopic model to an effective fitness-parameterized landscape (Figure 6). This mapping reveals a striking observation: the effective macroscopic model depends on the mutation rate, which is typically treated as an independent parameter in the standard fitness-parameterized framework. Intuitively, there are many states in the landscape with the same value of but which differ in their conditional distribution of increments ; these states are dynamically selected in a way that depends on the level of clonal interference. In both the epistatic and non-epistatic landscapes, we find that the distribution becomes more sharply peaked for higher levels of clonal interference, while it has a heavier tail for lower levels (Figure 6A/B). This occurs because clonal interference suppresses the fixation of low-effect mutations. The result is that systems with high clonal interference typically reach a given through fewer, more valuable mutations, while systems with low clonal interference typically reach through the accumulation of more low-value mutations.
Figure 6
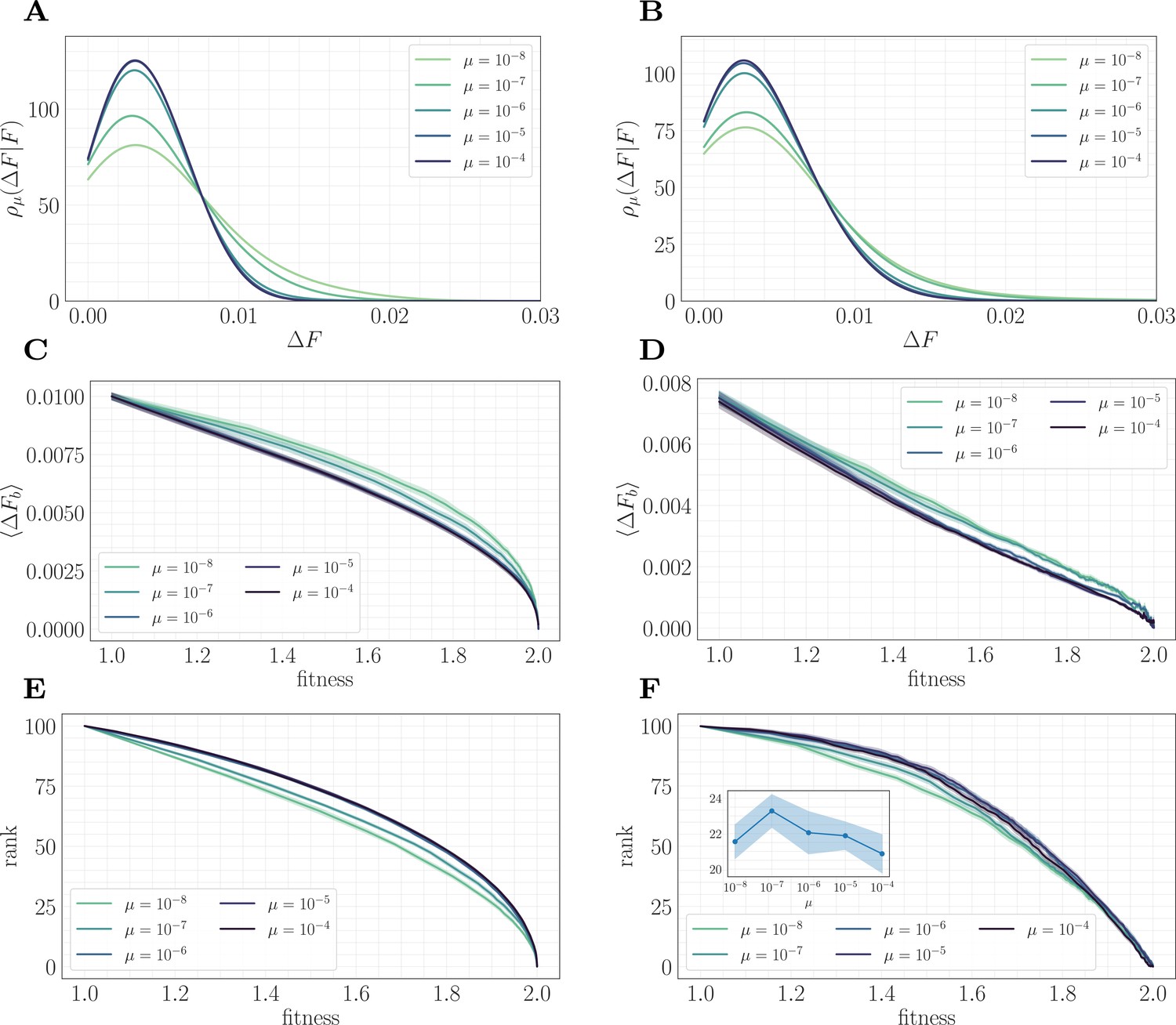
A mapping to a fitness-parameterized landscape as a function of µ.
Left: non-epistatic (). Right: epistatic (). (A/B) Unlike in classical fitness-parameterized models, the level of clonal interference cannot be tuned independently from the landscape. Because clonal interference modifies fixation probabilities, the conditional distribution of fitness effects depends on µ both with and without epistasis (epistatic: ; non-epistatic: . Distributions were approximated via kernel density estimation with a bandwidth parameter ). (C/D) Expected beneficial increment as a function of fitness. Both with and without epistasis, the expected increment tends to decrease with increasing µ at fixed fitness, capturing the fact that higher µ favors the fixation of mutations with higher effect. (E/F) Average rank as a function of fitness. Without epistasis, the rank increases with increasing µ at fixed fitness. With epistasis, the rank curves behave non-monotonically in µ at fixed fitness, and become comparable at high fitness. Inset in (F) shows rank as a function of µ for fixed , highlighting the non-monotonic behavior.
This effect can be visualized over the trajectory by making use of the summary statistics (expected increment) and (rank) viewed as a function of the fitness. In both landscapes, the expected increment decreases with increasing µ (Figure 6C/D). By contrast, the behavior of the rank depends on the strength of microscopic epistasis. Without epistasis, the rank increases with µ (Figure 6E), while with epistasis, the rank becomes non-monotonic in µ, and becomes comparable at high fitness (Figure 6F). This observation highlights the importance of the rank in setting the speed of the fitness trajectory, analogous to the results presented in 'A fitness-parameterized mapping'. Both with and without microscopic epistasis, the behavior of the rank with parallels that of the exponent .
Discussion and conclusions
In this paper, motivated by laboratory serial dilution experiments, we developed a high-performance simulation approach to study the dynamics of long-term adaptation. We focused on a generic microscopic model that considers the microbial genome as a collection of sites with a binary value indicating the presence of a mutation. Our model contains a non-dimensional parameter that enables us to smoothly tune the relative contribution of microscopic epistasis to the fitness effect of a mutation at gene . In addition, we can tune an overall mutation rate µ to adjust the magnitude of clonal interference in the culture. By independently varying the parameters β and µ, we mapped out a phase diagram that describes the effects of microscopic epistasis and clonal interference on the functional form of the mean fitness trajectory.
Our simulation approach gives us the ability to probe microscopic details that are challenging to obtain experimentally, such as statistics of the distribution of fitness effects and the rank over time. The approach also allows us to study regimes such as strong microscopic epistasis and strong clonal interference that have eluded previous theoretical study. In addition to its generality, our model has computational advantages that enable us to probe the long-time dynamics required to reach a local fitness maximum.
The role of microscopic epistasis
By mapping the model to a simplified fitness-parameterized landscape, we showed that as the strength of microscopic epistasis increases, more mutations are needed to reach a local fitness maximum. In addition, beneficial mutations become less likely; these two properties together lead to a slower trajectory. We isolated a mechanism for this phenomenon -- the generation of new, low-effect beneficial mutations mediated by the epistatic interaction when the culture is at high fitness -- and we showed through a random walk model that this generation is sufficient to slow the fitness trajectory.
A by-product of our analysis is an observation that, as microscopic epistasis increases in strength, the beneficial mutation rate becomes an increasingly linear function of fitness, similar to the phenomenon of global epistasis observed for the expected beneficial fitness increment (Reddy and Desai, 2021). This suggests that the strength of epistasis in realistic microbial populations could be inferred by measuring the beneficial mutation rate as a function of fitness experimentally.
The role of clonal interference
Through a similar analysis, we observed that in the microscopic context considered here, any equivalent fitness-parameterized model must depend on the mutation rate µ, a parameter that is typically tuned independently. In effect, the change in fixation probabilities induced by clonal interference filters the accessible genotypes with a given fitness , giving rise to a conditional distribution of fitness increments that depends on µ.
Based on this observation, we showed that the effect of clonal interference on the fitness trajectory differs from prior predictions made in the fitness-parameterized setting, and moreover that it depends on the strength of microscopic epistasis. In a non-epistatic model, increasing clonal interference accelerates the fitness trajectory. For sufficiently strong microscopic epistasis, clonal interference has no effect on the speed of the fitness trajectory. We leave the development of a mechanistic model capturing this phenomenon to future work.
The beneficial mutation rate
A surprising observation is that the trend of the rank with β in Figure 3A/B and with µ in Figure 6E/F is consistent with the behavior of the exponent with and . This is similar to predictions made within the fitness-parameterized framework, where it was found that the effect of clonal interference depends on how the beneficial mutation rate changes with fitness (Guo and Amir, 2022). Taken together, these results suggest that the behavior of the beneficial mutation rate as a function of fitness plays a central role in setting the speed of the fitness trajectory.
Connections to spin glass physics
In this work, we studied a model inspired by the Sherrington-Kirkpatrick spin glass using the techniques of microbial population genetics. Nevertheless, the fundamental questions we study here -- such as characterizing the speed and functional form of relaxation processes -- are also studied in the spin glass literature using seemingly different tools. In particular, the two- and four-point correlation functions
and
are often studied as a function of the waiting time and the lag time to characterize the decay of spin correlations and the importance of correlated spin flips, respectively (Castellani and Cavagna, 2005; Toninelli et al., 2005) (Here, angular brackets denote an average over independent trajectories).
It is a simple calculation to show that the two-point correlation function obeys the identity
(8)
where denotes the population mean substitution trajectory at time . For general , simply shifts the definition of the ancestral strain. This relation provides a novel link between standard techniques in spin glass physics and microscopic population genetics. Yet, the dynamics of fixation induce important differences: it is well-known that in the absence of epistasis the substitution trajectory follows a power law relaxation similar to Equation 2 with (Good and Desai, 2015). This stands in contrast to the standard setting in spin glasses, where the two-point correlation function often exhibits stretched exponential relaxations (Phillips, 1996).
We fit power law relaxations to the trajectories in the SSWM regime as a function of β and found a median exponent 1.03 for . For , we still found good agreement with a power law functional form and obtained a decaying exponent with increasing β (Appendix 1—figure 3). We also found that the average over sites in the definitions of and are roughly equivalent to the angular average over trajectories, so that (Appendix 1—figure 4). This demonstrates that it is sufficient to consider the two-point correlation function, or equivalently the substitution trajectory, and that no additional information is contained in the four-point correlator.
Future directions
Our model and simulation can be extended in many exciting directions. One possibility is to allow for horizontal gene transfer between bacterial strains. By allowing large jumps across the fitness landscape, horizontal gene transfer may have a similar effect to microscopic epistasis, and could slow the fitness trajectory by generating groups of new beneficial mutations (Slomka et al., 2020); on the other hand, it could also accelerate the fitness trajectory by allowing for larger steps towards a fitness maximum. Another possibility is to bias the model, so that the and have non-zero means, and to study the effect of these mean values on the long-term dynamics. A third possibility is to allow for further structure in the interaction matrix , rather than the i.i.d. random entries considered here. For example, by allowing for low-rank structure in , one could in principle quantify the role of connected modules of mutations on the functional form of the fitness trajectory (Parter et al., 2008; Landau et al., 2016; Landau and Sompolinsky, 2021). A final direction would be to form a mechanistic model for the effect of clonal interference both with and without epistasis, similar to the random walk model developed to understand the effect of microscopic epistasis.
Our work focuses primarily on clonal interference between potential mutations, which is the most well-studied form of clonal interference. However, recent work has shown that an alternative within-path clonal interference between a mutant and its ancestor has a significant effect on both the rate of adaptation and on the specific adaptive trajectories selected in evolving populations (Ogbunugafor and Eppstein, 2016); within-path clonal interference can be quantified along a given trajectory as the sum of the inverse fitness increments. In the clonal interference regime, Figure 3D shows that the expected fitness increment decreases at fixed fitness with increasing β. This implies that at a given fitness, the total level of within-path clonal interference increases with β on average. It would be interesting to study how much this contributes to the decrease in exponent with increasing β in the clonal interference regime. This could be quantified, for example, by computing the total within-path clonal interference along potential trajectories and identifying how well it correlates with the preferred trajectories as a function of β.
Figure 5 shows that for , clonal interference has no effect on the fitness trajectory. Moreover, Figure 2E highlights that this remains true for . It would be interesting to carefully probe the value of β for which the effect of clonal interference vanishes, and to determine if this occurs as a sharp phase transition or if there is a gradual decay of the effect of clonal interference with β. Understanding this behavior could lead to a way to measure the strength of epistasis in experimental systems, by studying how the fitness trajectory depends on the level of clonal interference.
In addition to the extensions considered above, our simulation environment forms a fertile testing ground for theoretical predictions. The relaxation exponents as a function of β considered in Figure 2E could in principle be predicted within the random walk approximation using the techniques developed by Horner, 2007, or within a dynamical mean-field theory that studies the evolution of the average value of the mutation variables over time (Ginzburg and Sompolinsky, 1994; Sompolinsky and Zippelius, 1981; Sommers, 1987). Solving such a model, in addition to analytically quantifying the slowing of the fitness trajectory with β, would provide a prediction for a functional form that could be tested against experimental fitness trajectories.
Appendix 1
Further simulation details
Here, we provide an overview of the simulation methodology, as well as values for the parameters used in our numerical experiments.
Strains
We begin with a population of size and with an initial ancestral genotype drawn randomly as i.i.d. random variables taking the values ±1 with equal probability. We define mutations with respect to this initial sequence and define a strain by the path taken on the hypercube from the initial genotype to its current genotype. Due to microscopic epistasis, the fitness effect of a mutation can only be defined in the context of its genetic background. Defining strains by their path ensures that mutations at the same site with different fitness effects are correctly tracked throughout the simulation.
Fitness and growth
We assume that each strain grows exponentially with rate given by its fitness. The primary quantity we study is the population mean fitness , which is defined as the average fitness over all cells in the population. To obtain , we average its value over replicate trajectories initialized from different ancestral genotypes within the same fitness landscape.
Recall that the fitness of a strain with genotype is given by
(9)
Because each strain grows with rate proportional to its fitness, we may write
(10)
In Equation 10, represents the size of strain at time , is the genotype for strain , and is a timestep (set to in all simulations). To avoid biasing the growth for strains with low bacteria count, we allow throughout the simulation.
Mutations
As the strains grow, mutants are generated with a fixed mutation rate , which describes the probability of a cell gaining a mutation when it divides. The genotype of a mutant is obtained from the genotype of the parent by flipping a site uniformly at random. A mutation is said to have fixed if it is present in all strains. For a mutant with genotype produced from a parent with genotype , the fitness increment is , while the selection coefficient is .
After a step of size , following Equation 10, the number of new bacteria produced by a given strain is equal to
To ensure that the number of mutants generated by strain does not exceed the number of bacteria generated by strain , we draw a Poisson random variable
and then set the number of mutants to be
As new strains are generated through mutation events, we must check if they already exist in the population. If the strain already exists, the mutant joins the existing strain rather than defining a new one. Checking for the existence of a newly generated strain in the overall population can be performed efficiently by hashing the list of integers defining the path through genome space. All current paths can be stored in a set defining the active strains: the time complexity of checking set membership scales as with the number of strains, which is a significant reduction compared to checking all new mutant strains against all existing strains.
Dilution protocol
The number of bacteria in each strain that make it through dilution to the following day follows a multivariate hypergeometric distribution. To efficiently sample from this distribution, we sequentially draw from the hypergeometric marginal distributions (Gentle, 1998). We first sort the population by number of bacteria in descending order. We then sample where is the size of the largest strain. We then recursively apply this procedure, choosing until we have drawn bacteria or we have gone through the entire population. For greater efficiency, each hypergeometric marginal distribution can be replaced with a draw from a binomial distribution. We verified that our results are independent to this approximation.
Replicates
Each simulation is performed with a number of replicate populations. Each replicate is instantiated with the same quenched disorder as specified by the and . The dynamics for each replicate differ through the random initialization of the ancestral genotype and through the sequence of random mutations. In the experiments studying the role of clonal interference, the same and are used as is varied.
Power-law fitting methodology
To obtain fitness exponents, the mean (computed over replicates) trajectory is fit via nonlinear least-squares using the scipy function curve_fit. The standard error of the mean is used to weight the residuals in the loss function. Error bars are computed via the bootstrap method, by randomly sampling subsets of trajectories and fitting models to the mean over each subset. The corresponding estimates define an empirical distribution over parameters, from which we compute quantiles and use the median as the estimate of the parameters.
Random walk statistics
We perform the following procedure to obtain an estimate of and . We average over initial landscapes and n_inits initializations with rank for each value of β. For each initialization, we select a single beneficial mutation at random and compute the changes to all other beneficial fitness increments. We compute the empirical mean and variance of these changes and average the resulting estimates over all landscapes and initializations. In the numerical experiments reported here, we set , , and , though we found that our results were insensitive to the choice of number of landscapes and initializations.
Coarse-grained simulation methodology
To simulate the discrete random walk model, we compute an initial empirical distribution of fitness increments according to Equation 9 and save the sparsity pattern defined by the randomly drawn . At each fixation event, we flip and adjust each for as discussed in the main text. If in the originally drawn genetic network, we set . For comparison, the full SSWM dynamics can be simulated using Equation 9 directly.
Fixation probabilities are determined by Haldane’s formula . To fit our discrete random walk model into the framework of Gillespie’s stochastic simulation algorithm, we define chemical reactions corresponding to each possible fixation event. The reaction propensity for a mutation at site is taken to be equal to . We choose a mutation site at random with probability proportional to its fixation probability. We randomly draw the time that occurred before the next fixation event according to an exponential distribution with mean (up to an overall mutation rate fixing the units of time).
Fast fitness computation
The following lemma gives a fast algorithm for computing the fitness of a given bacterial strain. The proof proceeds by noting that rather than computing Equation 1 directly, we can compute the fitness of a strain with respect to its parent strain . It concludes by observing that the fitness of can be related to the fitness of an arbitrary reference strain . This reference strain can be adjusted on-the-fly to track the state of the population.
Lemma 1. Let denote the genotype of a reference strain, denote the genotype of the parent strain, and denote the genotype of the child strain obtained from via a mutation at gene . Then,
(11)
where denotes the set of mutations of the parent with respect to the reference strain.
Equation 11 states that if we store the elements of the vector , we can compute the fitness of a child strain in terms of the fitness of the parent strain in time complexity . This is a massive improvement over the complexity corresponding to a naive calculation of the quadratic form, and a large improvement over the complexity corresponding to computing the fitness of the child with respect to the fitness of the parent, particularly if the reference strain is updated to keep small. We found empirically that setting the reference strain to be equal to the dominant strain every time the dominant strain accumulates 15 new fixed mutations was a good heuristic.
Proof. Observe that we may write
Now, write that with
(12)
Plugging this in completes the proof.
Additional figures
Appendix 1—figures 1 and 2 visualize the fitness trajectory as a function of normalized time, as referenced in the main text.
Appendix 1—figures 3 and 4 consider the correlation functions
and
from spin glass physics, as referenced in the main text.
Appendix 1—figure 1
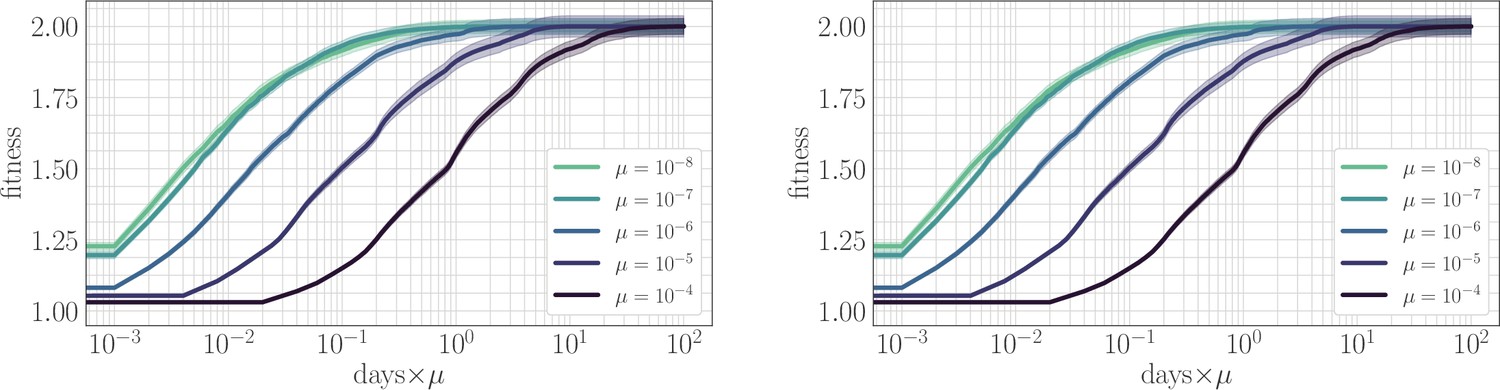
The effect of clonal interference on the fitness trajectory: re-scaling by µ.
Left: epistatic. Right: non-epistatic. When measuring time in units of the mutation rate, clonal interference slows the fitness trajectory due to a suppresion of fixation probabilities. All trajectories are initialized at one, consistent with previous result: logarithmic time axis hides the very early time dynamics.
Appendix 1—figure 2
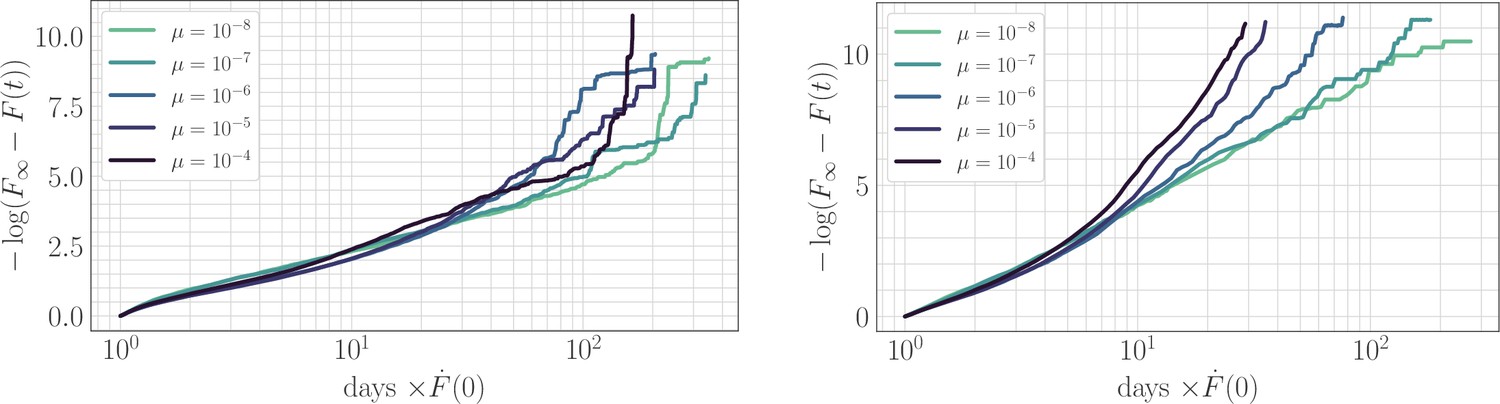
The effect of clonal interference on the fitness trajectory: rescaling by .
Left: epistatic. Right: non-epistatic. Geometrically, rescaling time by the initial rate of fitness increase ensures that slower trajectories reach the fitness peak at a later time, in qualitative agreement with the results of power-law fitting. Assuming a power law functional form as in the main text, at long times becomes linear with slope given by the exponent . The asymptotic slope increases with µ without microscopic epistasis (left, ), but does not clearly depend on the mutation rate with microscopic epistasis (right, ).
Appendix 1—figure 3
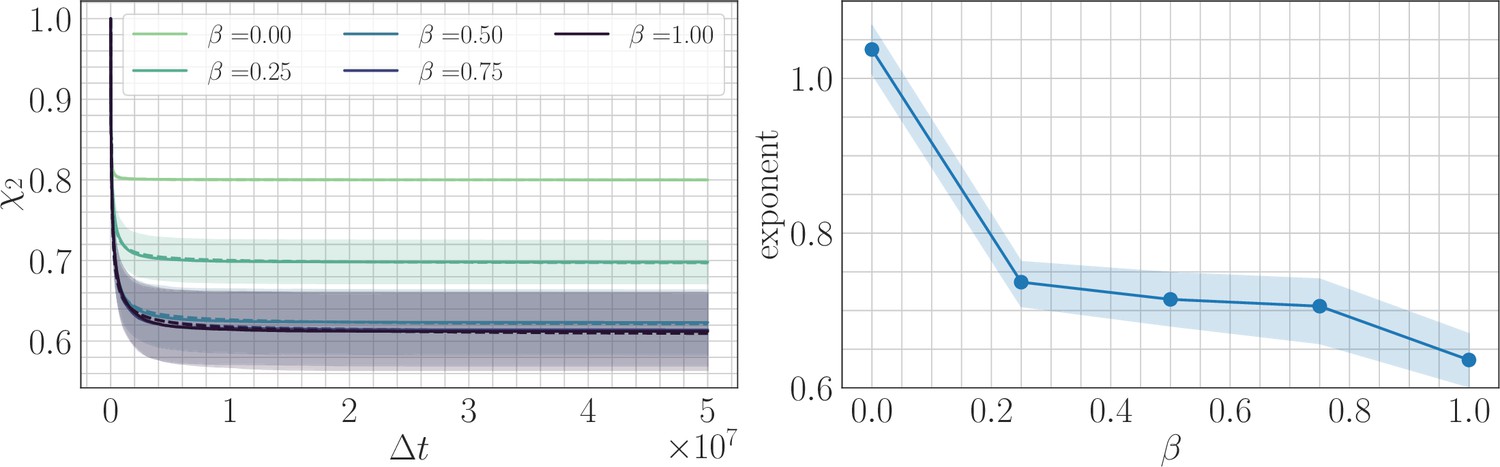
Two point correlation function.
(Left) trajectories as a function of β and the lag time in the SSWM limit. Solid lines show the mean over 200 independent trajectories and errorbars show ± one standard deviation. Dashed line shows best fit to the power law . (Right) Relaxation exponents for as a function of β. Similar to the fitness trajectory, the exponent decreases with increasing β. Solid point shows median of the bootstrap distribution computed over 250 estimates; errorbars show 95% confidence intervals.
Appendix 1—figure 4
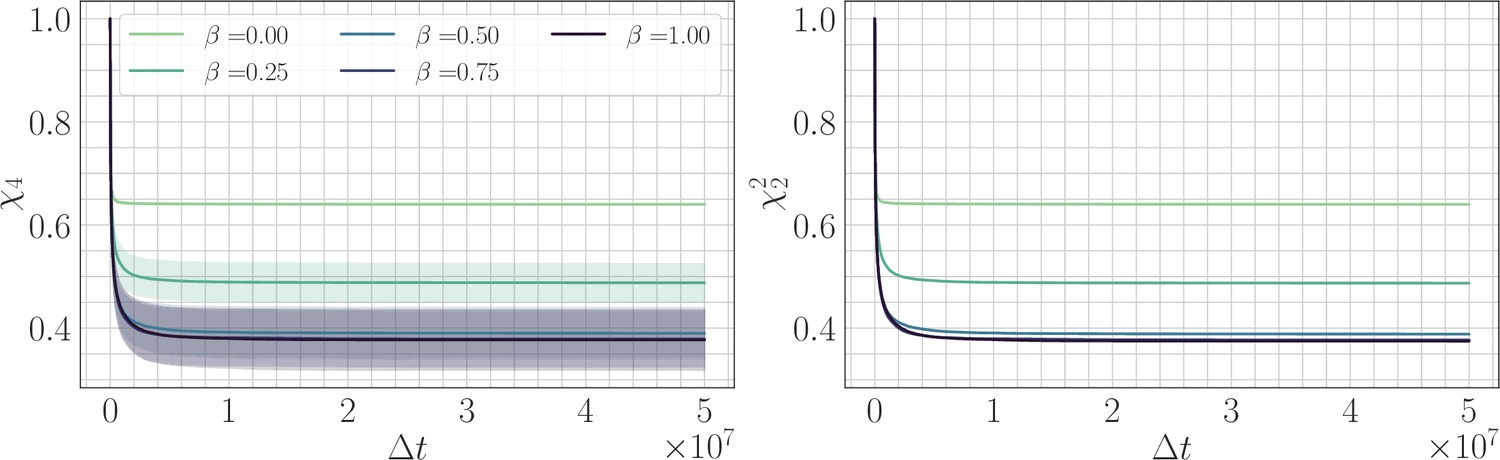
Four-point correlation function.
(Left) trajectories as a function of β and the lag time in the SSWM limit. Solid lines show the mean over 200 independent trajectories and errorbars show ± one standard deviation. (Right) trajectories as a function of β. Because the genomic average of is approximately equal to an average over trajectories, we find that . Visually, the mean trajectories are nearly indistinguishable.
Data availability
The current manuscript is a computational study, so no data have been generated for this manuscript. Modelling code is available at https://github.com/nmboffi/spin_glass_evodyn/tree/main (copy archived at Boffi, 2023).
References
-
Mean-field model for electron-glass dynamicsPhysical Review B 77:165207.https://doi.org/10.1103/PhysRevB.77.165207
-
Spin-glass models of neural networksPhysical Review. A, General Physics 32:1007–1018.https://doi.org/10.1103/physreva.32.1007
-
Storing infinite numbers of patterns in a spin-glass model of neural networksPhysical Review Letters 55:1530–1533.https://doi.org/10.1103/PhysRevLett.55.1530
-
Aging of spherical spin glassesProbability Theory and Related Fields 120:1–67.https://doi.org/10.1007/PL00008774
-
SoftwareSpin_Glass_Evodyn, version swh:1:rev:d0f957d2679f06b3927206e1a00e0094c5be7e96Software Heritage.
-
Spin-glass theory for pedestriansJournal of Statistical Mechanics 2005:05012.https://doi.org/10.1088/1742-5468/2005/05/P05012
-
ConferenceOpen Problem: The landscape of the loss surfaces of multilayer networksProceedings of The 28th Conference on Learning Theory.
-
Global epistasis on fitness landscapesPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 378:20220053.https://doi.org/10.1098/rstb.2022.0053
-
Evolution in a rugged fitness landscapePhysical Review A 46:6714–6723.https://doi.org/10.1103/PhysRevA.46.6714
-
A general method for numerically simulating the stochastic time evolution of coupled chemical reactionsJournal of Computational Physics 22:403–434.https://doi.org/10.1016/0021-9991(76)90041-3
-
A simple stochastic gene substitution modelTheoretical Population Biology 23:202–215.https://doi.org/10.1016/0040-5809(83)90014-X
-
Theory of correlations in stochastic neural networksPhysical Review E 50:3171–3191.https://doi.org/10.1103/PhysRevE.50.3171
-
A mathematical theory of natural and artificial selection, part v: selection and mutationMathematical Proceedings of the Cambridge Philosophical Society 23:838–844.https://doi.org/10.1017/S0305004100015644
-
Time dependent local field distribution and metastable states in the SK-spin-glassThe European Physical Journal B 60:413–422.https://doi.org/10.1140/epjb/e2008-00017-1
-
Stochastic tunnels in evolutionary dynamicsGenetics 166:1571–1579.https://doi.org/10.1534/genetics.166.3.1571
-
Towards a general theory of adaptive walks on rugged landscapesJournal of Theoretical Biology 128:11–45.https://doi.org/10.1016/S0022-5193(87)80029-2
-
The NK model of rugged fitness landscapes and its application to maturation of the immune responseJournal of Theoretical Biology 141:211–245.https://doi.org/10.1016/S0022-5193(89)80019-0
-
A simple model for the balance between selection and mutationJournal of Applied Probability 15:1–12.https://doi.org/10.2307/3213231
-
Population subdivision and adaptation in asexual populations of Saccharomyces cerevisiaeEvolution; International Journal of Organic Evolution 66:1931–1941.https://doi.org/10.1111/j.1558-5646.2011.01569.x
-
Phase space geometry and slow dynamicsJournal of Physics A 29:1929–1948.https://doi.org/10.1088/0305-4470/29/9/009
-
Long-term experimental evolution in Escherichia coli I adaptation and divergence during 2,000 generationsThe American Naturalist 138:1315–1341.https://doi.org/10.1086/285289
-
BookInformation, Physics, and ComputationOxford University Press, Inc.https://doi.org/10.1093/acprof:oso/9780198570837.001.0001
-
Self-consistent description of Coulomb gap at finite temperaturesSoviet Physics - JETP 68:1081–1086.
-
Statistical genetics and evolution of quantitative traitsReviews of Modern Physics 83:1283–1300.https://doi.org/10.1103/RevModPhys.83.1283
-
The population genetics of adaptation on correlated fitness landscapes: the block modelEvolution; International Journal of Organic Evolution 60:1113–1124.https://doi.org/10.1111/j.0014-3820.2006.tb01191.x
-
Clonal interference in large populationsPNAS 104:18135–18140.https://doi.org/10.1073/pnas.0705778104
-
Evolution in random fitness landscapes: the infinite sites modelJournal of Statistical Mechanics 2008:04014.https://doi.org/10.1088/1742-5468/2008/04/P04014
-
Facilitated variation: how evolution learns from past environments to generalize to new environmentsPLOS Computational Biology 4:e1000206.https://doi.org/10.1371/journal.pcbi.1000206
-
Stretched exponential relaxation in molecular and electronic glassesReports on Progress in Physics 59:1133–1207.https://doi.org/10.1088/0034-4885/59/9/003
-
Complex interactions can create persistent fluctuations in high-diversity ecosystemsPLOS Computational Biology 16:e1007827.https://doi.org/10.1371/journal.pcbi.1007827
-
Solvable model of a spin-glassPhysical Review Letters 35:1792–1796.https://doi.org/10.1103/PhysRevLett.35.1792
-
Path-integral approach to Ising spin-glass dynamicsPhysical Review Letters 58:1268–1271.https://doi.org/10.1103/PhysRevLett.58.1268
-
Dynamic theory of the spin-glass phasePhysical Review Letters 47:359–362.https://doi.org/10.1103/PhysRevLett.47.359
-
Dynamical susceptibility of glass formers: contrasting the predictions of theoretical scenariosPhysical Review. E, Statistical, Nonlinear, and Soft Matter Physics 71:041505.https://doi.org/10.1103/PhysRevE.71.041505
-
Perspective: Sign epistasis and genetic constraint on evolutionary trajectoriesEvolution; International Journal of Organic Evolution 59:1165–1174.
-
The rate at which asexual populations cross fitness valleysTheoretical Population Biology 75:286–300.https://doi.org/10.1016/j.tpb.2009.02.006
Article and author information
Author details
Funding
National Science Foundation (RTG/DMS - 1646339)
- Nicholas M Boffi
U.S. Department of Energy (DE-AC02-05CH11231)
- Chris H Rycroft
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Haim Sompolinsky, Guy Bunin, and Yoav Ram for many useful discussions, and we thank Jimmy Almgren-Bell for contributions to an initial version of the simulation software. M B was partially supported by the Research Training Group in Modeling and Simulation funded by the National Science Foundation via grant RTG/DMS 1646339. H R was partially supported by the Applied Mathematics Program of the U.S. DOE Office of Science Advanced Scientific Computing Research under Contract No. DE-AC02-05CH11231.
Version history
- Preprint posted:
- Sent for peer review:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.87895. This DOI represents all versions, and will always resolve to the latest one.
Copyright
This is an open-access article, free of all copyright, and may be freely reproduced, distributed, transmitted, modified, built upon, or otherwise used by anyone for any lawful purpose. The work is made available under the Creative Commons CC0 public domain dedication.
Metrics
-
- 1,555
- views
-
- 142
- downloads
-
- 8
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 2
- citations for umbrella DOI https://doi.org/10.7554/eLife.87895
-
- 3
- citations for Reviewed Preprint v2 https://doi.org/10.7554/eLife.87895.2
-
- 3
- citations for Version of Record https://doi.org/10.7554/eLife.87895.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
How microscopic epistasis and clonal interference shape the fitness trajectory in a spin glass model of microbial long-term evolution
eLife 12:RP87895.
https://doi.org/10.7554/eLife.87895.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}