The intricate relationship of G-Quadruplexes and bacterial pathogenicity islands
- Division of Plant Science and Technology, University of Missouri, United States
eLife assessment
This fundamental study explores the relationship between guanine-quadruplex structures and pathogenicity islands in 89 bacterial strains representing a range of pathogens. Guanine-quadruplex structures were found to be non-randomly distributed within pathogenicity islands and conserved within the same strains. These compelling findings shed light on the molecular mechanisms of Guanine-quadruplex structure-pathogenicity island interactions and will be of interest to all microbiologists.
https://doi.org/10.7554/eLife.91985.3.sa0Significance of the findings:
Fundamental: Findings that substantially advance our understanding of major research questions
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Compelling: Evidence that features methods, data and analyses more rigorous than the current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
The dynamic interplay between guanine-quadruplex (G4) structures and pathogenicity islands (PAIs) represents a captivating area of research with implications for understanding the molecular mechanisms underlying pathogenicity. This study conducted a comprehensive analysis of a large-scale dataset from reported 89 pathogenic strains of bacteria to investigate the potential interactions between G4 structures and PAIs. G4 structures exhibited an uneven and non-random distribution within the PAIs and were consistently conserved within the same pathogenic strains. Additionally, this investigation identified positive correlations between the number and frequency of G4 structures and the GC content across different genomic features, including the genome, promoters, genes, tRNA, and rRNA regions, indicating a potential relationship between G4 structures and the GC-associated regions of the genome. The observed differences in GC content between PAIs and the core genome further highlight the unique nature of PAIs and underlying factors, such as DNA topology. High-confidence G4 structures within regulatory regions of Escherichia coli were identified, modulating the efficiency or specificity of DNA integration events within PAIs. Collectively, these findings pave the way for future research to unravel the intricate molecular mechanisms and functional implications of G4-PAI interactions, thereby advancing our understanding of bacterial pathogenicity and the role of G4 structures in pathogenic diseases.
Introduction
The discovery of the DNA double helix by Watson and Crick in 1953 revolutionized our understanding of genetics and laid the foundation for the modern field of molecular biology (Watson and Crick, 1953). Nonetheless, the intricate nature of DNA continues to surprise us even today. One such captivating feature is the DNA guanine (G)-quadruplex (G4) structure, a unique arrangement that defies the conventional double helix (Rhodes and Lipps, 2015; Spiegel et al., 2020). A G4 consists of four guanine bases and is stabilized by Hoogsteen hydrogen bonds. These stacked tetrads are interconnected by loop regions, which can vary in length and sequence, adding further complexity to the structure (Figure 1). It is important to consider the inherent directionality of nucleic acids, with all four strands having the possibility to run in the same 5' to 3' direction, referred to as ‘parallel,’ or alternatively, they can run in different directions, known as ‘antiparallel.’. G4 regions can be very stable in vitro, particularly in the presence of K+ (Stegle et al., 2009). G4 structures are often found in regions of the genome with crucial regulatory functions, such as telomeres, promoters, and enhancers (Rhodes and Lipps, 2015; Huppert, 2010). These structures play a role in various biological processes, including gene expression, DNA replication, and telomere maintenance (Rhodes and Lipps, 2015; Zybailov et al., 2013). Further research into G4 structures will undoubtedly uncover new insights into their functions and facilitate the development of innovative technologies.
Figure 1
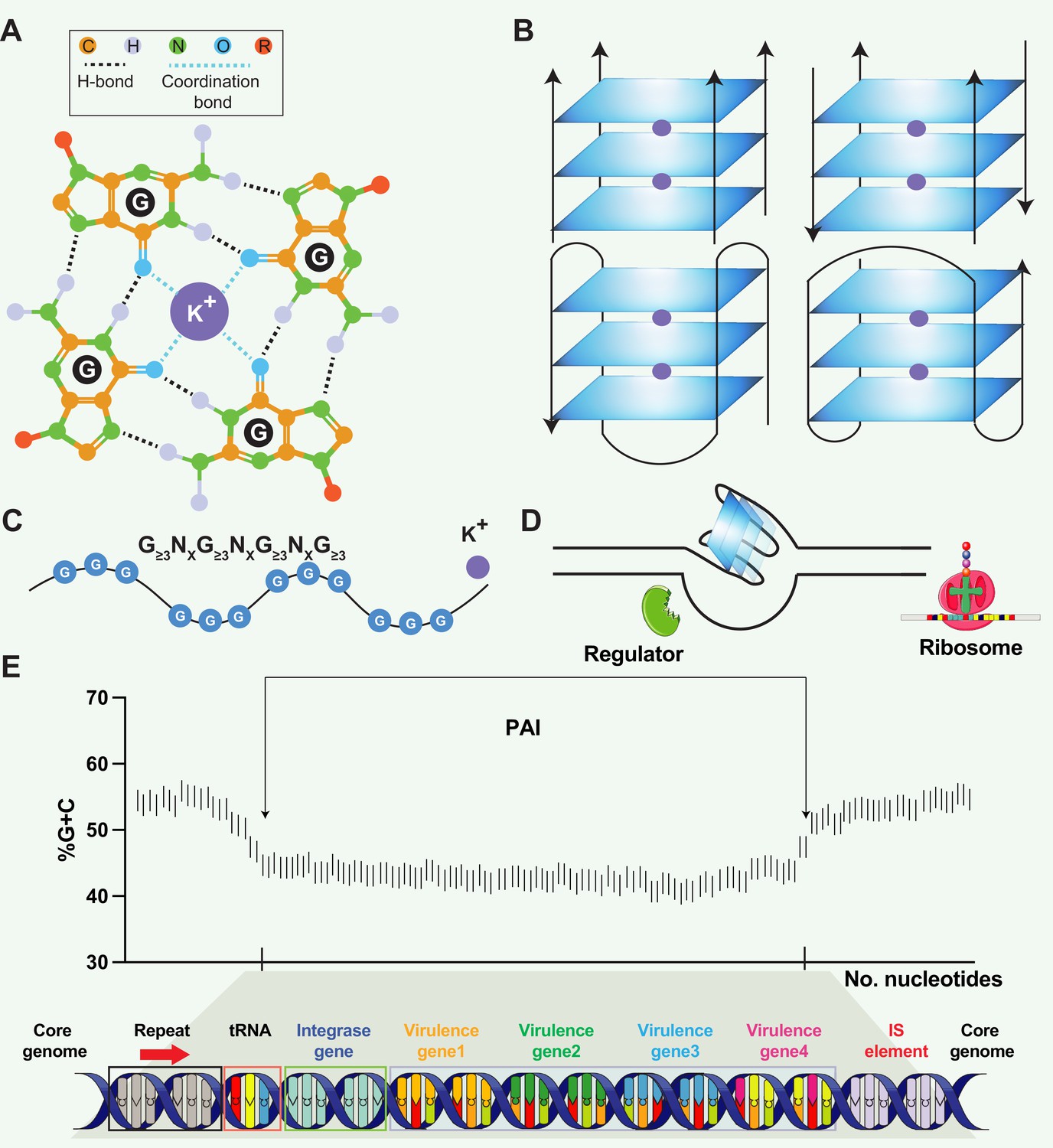
Structural and functional aspects of G-quadruplex (G4) structures and pathogenicity islands (PAIs).
(A) Schematic representation of a guanine tetrad stabilized by Hoogsten base pairing and a positively charged central ion, illustrating the key elements of G4 structures. (B) Structural heterogeneity of G4 structures. G4 structures exhibit polymorphism and can be categorized into different families, such as parallel or antiparallel, based on the orientation of the DNA strands. They can fold either intramolecularly or intermolecularly, leading to diverse structural configurations. (C) General sequence formula for G4, highlighting the repeated occurrence of guanine-rich sequences that form G4 structures. (D) Regulatory roles of G4 in transcription. G4 can regulate transcription by blocking RNA polymerase from binding to promoter sequences or aiding in single-stranded DNA (ssDNA) formation, thereby enhancing transcription. (E) General structure of pathogenicity islands (PAI). PAIs are characteristic regions of DNA found within the genomes of pathogenic bacteria, distinguishing them from nonpathogenic strains of the same or related species. Repeat sequences are DNA segments duplicated within the PAI and can serve as recognition sites for various enzymes involved in the integration and excision of the PAI from the bacterial chromosome. tRNA genes act as anchor points for the insertion of foreign DNA acquired through horizontal gene transfer. Virulence genes encode proteins or factors that play crucial roles in the virulence and pathogenicity of the bacterium, contributing to adhesion, invasion, immune evasion, toxin production, or other pathogenic mechanisms. Insertion elements include transposons, bacteriophages, or plasmids, enabling the PAI to be transferred between bacterial cells and potentially disseminated to different strains or species.
PAIs are genomic regions that contribute to the virulence and pathogenic potential of various microorganisms (Schmidt and Hensel, 2004; Groisman and Ochman, 1996). PAIs are distinct segments of the bacterial genome that exhibit unique characteristics compared to the rest of the DNA (Hacker and Kaper, 2000). They are often large in size, ranging from tens of kilobases to hundreds of kilobases, and can be integrated into the chromosome or exist as extra-chromosomal elements, such as plasmids. PAIs often exhibit close proximity to tRNA genes, suggesting a putative mechanism where tRNA genes act as anchor points for the integration of foreign DNA acquired through horizontal gene transfer (Figure 1E). One notable feature is their variable GC content, which tends to deviate from the average GC content of the genome in various organisms, such as Streptomyces (Kers et al., 2005), Salmonella (Kombade and Kaur, 2021), and Yersinia (Carniel, 1999). PAIs typically contain clusters of genes involved in pathogenesis, including those encoding secretion systems (e.g. LEE (locus of enterocyte effacement) in Escherichia coli), superantigen (e.g. SaPI1 and SaPI2 in Staphylococcus aureus), and enterotoxin (e.g. she PAI in Shigella flexneri). PAIs can be acquired through the transfer of mobile genetic elements, such as plasmids, phages, or integrative and conjugative elements (ICEs), facilitating the incorporation of pathogenicity-associated genes into the recipient genome (Schmidt and Hensel, 2004; Syvanen, 2012; Chen et al., 2015). One question raised in PAI is that PAIs often exhibit distinct base composition (G+C contents) compared to the core genome. The underlying reasons for this variation remain unknown, but the preservation of a genus- or species-specific base composition represents a noteworthy characteristic of bacteria (Schmidt and Hensel, 2004). Schmidt and Hensel proposed a hypothetical mechanism to explain the observed variation, suggesting that factors such as DNA topology and codon message in the virulence regions present could contribute to the preservation of the distinct base composition (Schmidt and Hensel, 2004). Hopefully, the availability of genome sequences from pathogenic bacteria and their non-pathogenic counterparts presents an exceptional opportunity to explore the intricate structure variance and underlying mechanisms within PAIs.
Growing evidence has shown that G4 structures exhibit a striking colocalization with functional regions of the genome, and their high conservation across different species suggests a selective pressure to maintain these sequences at specific genomic regions (e.g. genome islands, resistance islands, CpG islands, and PAIs) (Rhodes and Lipps, 2015; Frees et al., 2014; König et al., 2010). The possibility of interactions between G4 structures and pathogens has been suggested, although this field of study is still in its nascent phase. Some studies observed that bacterial genomes possess G4-forming sequences within their genome regions (Yadav et al., 2021; Harris and Merrick, 2015). G4 structures are formed by G-rich DNA sequences, and their stability is influenced by the G+C content and arrangement of G tetrads. Interestingly, PAIs often exhibit an altered GC content, putatively contributing to the propensity of G4 structure formation within these regions. The G4 structures in PAIs might modulate the accessibility of transcription factors, DNA-binding proteins, or RNA polymerase in pathogens, as documented in eukaryotes (Rhodes and Lipps, 2015; Varshney et al., 2020), thereby influencing the expression of virulence-associated genes (Cahoon and Seifert, 2009). The formation of G4 structures within PAIs may serve as an additional layer of regulation that fine-tunes the expression of genes critical for pathogenesis. Hence, the investigation of G4 structures within PAIs may open new avenues for the development of therapeutic strategies aimed at disrupting the regulatory mechanisms of pathogenicity-associated genes.
Results
Genomic information, PAI patterns, and the presence of G4 structures in 89 reported pathogenic strains
A dataset of PAIs was compiled from 89 reported pathogenic strains of bacteria, encompassing 222 distinct types of PAIs. Pathogens exhibiting similar PAIs displayed closely clustered patterns on phylogenetic branches, such as LEE in E. coli strains (Figure 2A). Additional information, including the genome length (bp), G+C content (%), rRNA density, tRNA density, and PAI length (bp), was present and showed conserved patterns in the same species (Figure 2A; Supplementary file 1a). PAIs commonly exhibit mosaic-like patterns, exemplified by the presence of distinct PAIs like FPI in Francisella tularensis, SaPIbov in Staphylococcus aureus, and Hrp PAI in Xanthomonas campestris (Figure 2B). Many PAIs were present associated with tRNAs, such as the insertions of tRNAThr, tRNAPhe, and tRNAGly in E. coli strains (Figure 2B; Supplementary file 1b). The presence of PAIs distributes in similar genomic regions across different pathogens or strains, showing non-random patterns and functionally clustered. Employing the G4Hunter search algorithm, the study identified a total of 225,376 putative G4 sequences in these 89 pathogenic genomes (Supplementary file 1a). The heatmap also showed that the number of G4 structures was diverse in the pathogen genomes (Figure 2C).
Figure 2 with 1 supplement see all
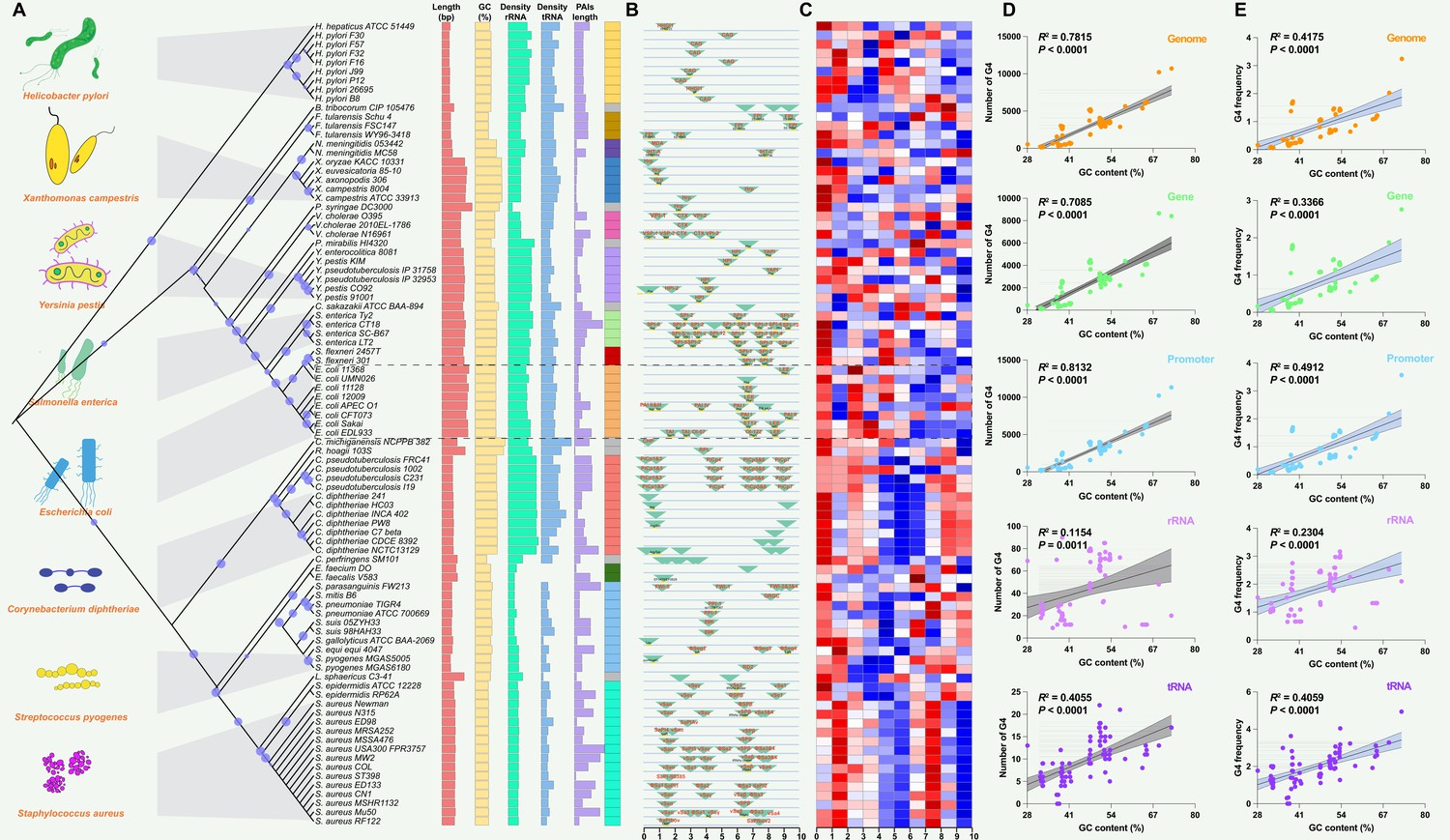
Analysis of pathogenicity islands (PAIs) and G-quadruplexes (G4) in pathogen genomes.
(A) Phylogenetic analysis of pathogen genomes based on 89 bacterial strains, showing the evolutionary relationships among species. Additional genomic information, including genome size, GC content, rRNA density, tRNA density, and PAI length, is provided. The same color indicates the same species. (B) Genomic location of specific PAIs in bacterial genomes, divided into ten regions. PAIs are represented by green triangles, and their names are indicated. The tRNA insertion sites are also marked. (C) Heatmap illustrating the relative abundance of G4 structures in bacterial genomes, divided into ten regions. Red indicates a higher relative abundance, while blue indicates a lower relative abundance. (D & E) Correlation analysis between the number of G4 structures, the frequency of G4 structures, and GC content in various genomic features, including the whole genome, genes, promoters, rRNA, and tRNA. R-squared and p-values were derived through linear regression analysis performed in GraphPad Prism.
Interaction between PAIs and G4 structures in different genomic features
The analysis of G4 structures across all pathogen species demonstrated a positive correlation between the number of G4 structures and the GC content in various genomic features, including the whole genome, gene, promoter, rRNA, and tRNA regions (Figure 2D). The frequency of G4 structures, measured as the frequency of predicted G4-forming sequences per 1000 base pairs (bp), also showed a positive correlation with the GC content across the analyzed genomic elements (Figure 2E). A G4 score of 1.4 and 1.6 consistently supported a positive correlation between the number and frequency of G4 structures and the GC content across diverse genomic features (Figure 2—figure supplement 1). Additionally, this study observed that the GC contents in the genome region were significantly higher compared to the corresponding PAIs region that was classified into five parts according to the genome datasets (Figure 3A–E). Nonetheless, this study noted a unique pattern in the frequency of G4 structures within diverse regions of the PAIs, particularly in regions with GC contents less than 30% and greater than 60%.
Figure 3
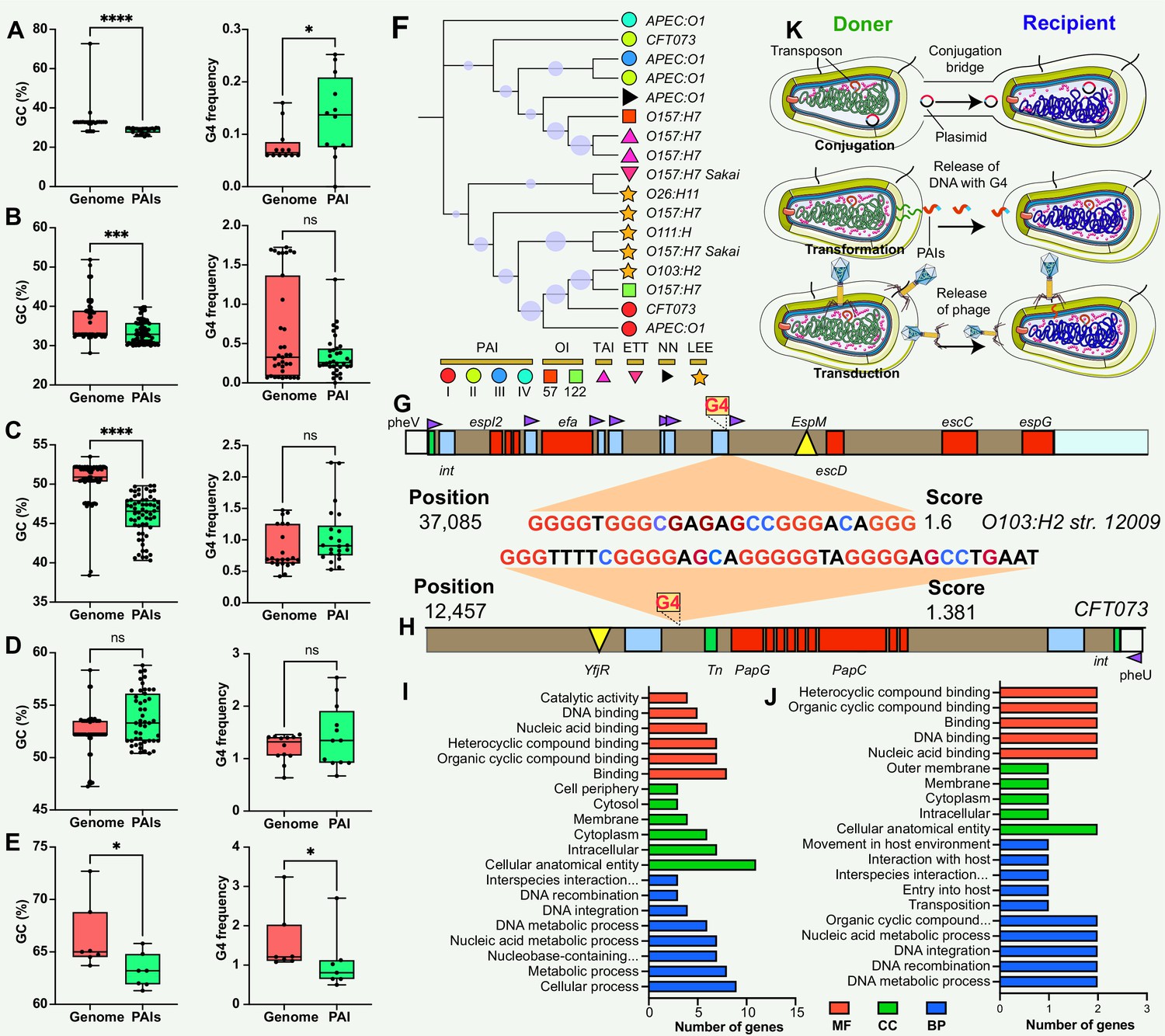
Comparison and functional annotation of G-quadruplexes (G4) within pathogenicity islands (PAIs).
(A–E) Comparison of GC content (left panel) and GC frequency (right panel) between the genome and PAIs, categorized into five regions (20–30%, 30–40%, 40–50%, 50–60%, and 60–70%). */**/***/**** indicates significant difference (p<0.05/0.01/0.001/0.0001). (F) Evolutionary relatedness of 10 types of PAIs (categorized into six main categories) in E. coli strains. (G & H) Examples of G4 structures within PAIs in E. coli strains. The gray bar represents the virulence region, the red box indicates a virulence gene, the blue box represents an insertion site region or repeat, the green box denotes an integrase, the purple triangle indicates a tRNA insertion site, and the yellow triangle indicates an effector. (I &J) Functional annotation analysis of G4-covered genes within PAIs in two E. coli strains, including biological process (BP), cellular component (CC), and molecular function (MF) categories. (K) Hypotheses on the origin of G4 structures within PAIs, involving gene horizontal transfer mechanisms (conjugation, transduction, and transformation).
Putative functions of G4 structures in PAIs
The study used E. coli as an example to investigate the potential regulatory role and function of genes covered by G4 structures in PAIs. E. coli contains at least ten types of PAIs in different strains, and one of the well-known PAIs is LEE (Figure 3F), harboring genes responsible for causing attaching and effacing lesions (Franzin and Sircili, 2015; Jores et al., 2004). One stable G4 structure with a G4Hunter score of 1.6 was identified at position 37,085 in the LEE PAI of E. coli str. O103:H2 12009 (Figure 3G), located between an IS element and a tRNA insertion site. The tRNA region generally contains a higher G4 frequency compared with transfer-messenger RNA (tmRNA) and rRNA regions in the bacterial genome (Bartas et al., 2019). Interestingly, this G4 structure was found in E. coli str. O103:H2 12009 was present in close proximity to a tRNA region, suggesting a potential regulatory role of G4 structures in the tRNA gene, or upstream- and downstream-genes that are responsible for LEE virulence. Additionally, another stable G4 sequence with a score of 1.381 was discovered at position 12,457 in the E. coli str. CFT073 PAI II to provide more evidence of G4 in PAI regions (Figure 3H). Functional enrichment analysis was conducted to explore the putative functions of G4-covered genes in the two E. coli strains (Supplementary file 1c and d). The results revealed that the genes covered by G4 structures were predominantly involved in genetic information processes, including DNA binding, DNA integration, and nucleic acid metabolism processes (Figure 3I & J).
Discussion
This study found that the non-random distribution of G4 structures within PAIs across different bacterial species, signifies a potential regulatory role in bacterial pathogenicity. The conservation of G4 structures within the same pathogenic strains suggests a crucial and possibly conserved function in regulating pathogenic traits. The findings are similar to previous reports that showed that the G4 structures display uneven distribution patterns in eukaryotic and prokaryotic genomes and are conserved evolutionary groups (Bartas et al., 2019; Du et al., 2009; Puig Lombardi et al., 2019). To understand the origin of G4 structures within PAIs, we hypothesized that these G4 sequences could be acquired through three types of horizontal gene transfer mechanisms: conjugation, transformation, and transduction (Figure 3K). These mechanisms serve as means for genetic material exchange between different organisms. Considering the presence of G4 sequences within the PAIs, it is plausible that these sequences are transferred along with the PAIs through these horizontal gene transfer mechanisms. Additionally, the presence of G4 structures within the promoter, rRNA, and tRNA regions may have functional implications for the regulation of DNA replication, ribosome biogenesis, protein synthesis, and other RNA-related processes (Zybailov et al., 2013; Ivanov et al., 2014; Mestre-Fos et al., 2019). Throughout evolution, there seems to be a greater frequency of G4 structures in regulatory genes, such as the tRNA region, compared to other genes, enabling intricate control of gene expression in signal transduction pathways (Wu et al., 2021).
The study found that the genomic regions surrounding the PAIs (i.e. core genome) tend to have a higher GC content than PAI regions, which was consistent with the fact that PAIs often exhibit distinct base compositions compared with the core genome (Schmidt and Hensel, 2004). The variation was explained by the presence of G4 sequences within the PAIs, whereas the results were surprising. This study observed a distinct pattern in the frequency of G4 structures within different regions of the PAIs. This differential distribution of G4 structures suggests that (i) specific genomic segments within the PAIs may be more prone to induce G4 formation discrepancy; (ii) the variation of base composition between core genome and PAIs is partially correlated with the presence of G4 structures; (iii) the frequency of G4 structures in PAIs present stable as the core genome in the most situation; (iv) an alternative hypothesis, other factors, such as i-motif (i.e. the anti-G4 structure) and CpG island, may work synergistically with G4 and potentially contribute the base composition variation (Deaton and Bird, 2011; Sushmita, 2020).
Enrichment analysis indicated a predominant involvement of these G4-covered genes in genetic information processes, encompassing DNA binding, DNA integration, and nucleic acid metabolism. This suggests that G4 structures may play a regulatory role in these essential cellular processes, especially gene expression and DNA-related functions. For instance, G4 structures in the promoter regions of certain transcription factors may influence their binding affinity to DNA and subsequently affect downstream gene expression patterns (Niu et al., 2018; Xiang et al., 2022). These elements frequently utilize DNA integration mechanisms mediated by integrases, recombinases, or transposases to transfer or incorporate genetic material into the bacterial genome (Arkhipova and Rice, 2016; Wozniak and Waldor, 2010). One compelling illustration is a study that identified a 16-base pair cis-acting G4 sequence near the pilin locus in Neisseria gonorrhoeae, demonstrating its pivotal role in antigenic variation and directing recombination to a specific chromosomal locus (Cahoon and Seifert, 2009; Cahoon and Seifert, 2013). Disruption of the G4 structure in this context impeded pilin antigenic variation and recombination, highlighting its significance in immune evasion mechanisms. Additionally, considering the distance between G4 structures and the beginning site of gene (e.g. transcription start site (TSS)) in the analysis of promoter regions is pivotal for a comprehensive understanding of their regulatory impact on gene expression (Huppert, 2010). The spatial proximity to the TSS influences interactions with regulatory elements, potentially modulating the binding of transcription factors and RNA polymerase. This spatial relationship affects accessibility, with G4 structures closer to the TSS potentially acting as direct impediments to transcription initiation. Acknowledging these spatial nuances would provide crucial insights into the functional implications of G4 structures in promoters.
Overall, the conserved evolutionary relatedness of PAIs, the detection of stable G4 structures in specific genomic positions, and the enrichment of G4-covered genes in genetic information processes collectively support the hypothesis that G4 structures may have regulatory functions in key biological processes in pathogens. However, it is important to acknowledge and address certain limitations that could potentially affect the interpretation of the results. One such limitation is the reliance on genome sequences obtained from external laboratories and datasets, which introduces a level of uncertainty regarding the accuracy and completeness. Furthermore, the dynamic nature of bacterial genomes, including genetic rearrangements and horizontal gene transfer events, can complicate the accurate assembly and annotation of genome sequences. Lastly, the stability of G4 structures seems to be important for their function according to recent evidence (Jara-Espejo and Line, 2020). Hence, exploring the relationship between G4 stability and function is a valuable and intriguing topic that could provide insights into the nuanced ways G4 structures contribute to cellular processes and potentially offer new avenues for therapeutic interventions or molecular engineering. To overcome these constraints, fostering collaboration among research teams and participating in data-sharing endeavors becomes imperative to guarantee access to high-quality genome data for exhaustive analyses. Moreover, it is crucial to interpret the results with caution and continue refining this understanding through validation experiments and collaborative efforts.
Methods
Selection and extraction of DNA sequences
A total of 89 genomes corresponding to the identified pathogens from the Pathogenicity Island Database (PAIDB) were included in the study. The complete bacterial genomic DNA sequences and their corresponding annotation files in.gff and.fna formats were obtained from the Genome database of the National Center for Biotechnology Information (NCBI, https://www.ncbi.nlm.nih.gov/genome). To ensure the reliability and completeness of the dataset, only completely assembled genomes were included in the analysis. To avoid redundancy and incomplete sequences, one representative genome was selected for each species or strain. The selection of representative genomes was based on a careful examination of the supplementary material (Supplementary file 1a) accompanying the study. TBtools II (Toolbox for Biologists, RRID:SCR_023018, v2.042) (https://cj-chen.github.io/tbtools), a versatile bioinformatics tool with extensive applications in both eukaryotes and prokaryotes (Chen et al., 2020; Chen et al., 2023), was employed for extracting genomic sequences. This tool facilitated the retrieval of gene regions, promoters (2 kb upstream of the genes), tRNA regions, and rRNA regions from the selected genomes. PAI regions were downloaded following previously documented information in PAIDB (Supplementary file 1a and b). Default thresholds and parameters were applied during extraction to maintain consistency across all genomes.
Data process and detection of G4 structures in genomic features
The G4Hunter algorithm, a widely used tool for G4 prediction, was employed for the identification of G4 motifs in the genomic sequences (Brázda et al., 2019). The G4Hunter parameters were set to a window size of ‘25’ and a G4 score threshold of 1.2, which ensured the identification of potential G4 sequences (Bartas et al., 2019; Brázda et al., 2020). The study additionally utilized G4 scores of 1.4 and 1.6 as a means of cross-verification for the results. The study quantified the predicted number of putative G4-forming sequences within different genomic features, including the whole genome, gene, promoter, tRNA, rRNA, and PAI regions. The density of G4 motifs was determined by dividing the number of G4 sequences by the total length of the genome, while the length ratio of G4 motifs was calculated by dividing the total length of the G4 sequences by the total length of the genome.
Relationship between G4 structures and PAIs
The heatmap was used to show the distribution of G4 motifs in the genome divided by ten parts as PAI regions using R package ‘pheatmap.’ The correlation between the number of G4 structures and the GC content was analyzed across various genomic elements, including the whole genome, gene, promoter, rRNA, and tRNA regions. The analysis utilized the R-squared value (R2) to determine the fit goodness of the correlation. The correlation’s significance was evaluated through p-values along with a 95% confidence interval. Subsequently, a ROC analysis, yielding an area greater than 0.90, was employed to quantify sensitivity and specificity. The GC content in the genome regions and corresponding PAI regions was compared and classified into different ranges to explore the variation in base composition. GraphPad Prism (V.5.02, GraphPad Software, Inc) was employed to conduct Normality and Lognormality Tests. The K-S test and F-test were used to assess normal distribution and variances, and the Student’s t-test was used to identify significant differences.
Phylogenetic tree construction
The exact Taxonomy ID (taxid) for each analyzed group was obtained from the NCBI Taxonomy Database using the Taxonomy Browser. The Neighbor-Joining (NJ) method was employed to construct the phylogenetic trees for the analyzed groups. The phylogenetic trees were generated using MEGA11 software (https://www.megasoftware.net/), which offers robust algorithms and comprehensive tools for phylogenetic analysis. To assess the reliability and statistical support of the phylogenetic tree branches, bootstrap analysis was performed. One thousand bootstrap replicates were used to estimate the confidence levels of the branching patterns in the phylogenetic trees. The phylogenetic trees, along with the bootstrap support values, were displayed and visualized using the Interactive Tree of Life (ITOL) platform (https://itol.embl.de/).
Gene functional annotation
The gene sequences covered by G4 structures within PAIs were subjected to gene ontology (GO) annotation (https://geneontology.org/). The gene sequences were translated into protein sequences using the Expasy online toolkit (https://web.expasy.org/translate/). This tool performs the translation based on the standard genetic code, converting the DNA nucleotide sequence into its corresponding amino acid sequence. The GO annotation database assigned GO terms to the protein sequences based on their predicted functions and known biological process (BP), molecular function (MF), and cellular component (CC). Fisher’s exact test was employed to determine the statistical significance of the enrichment results. The obtained p-values indicated the overrepresentation of specific GO terms, with lower p-values suggesting higher significance.
Statistics and reproducibility
All genomic data utilized in this study, including the species-specific datasets, were obtained from publicly available sources. Statistical analyses, such as the Student’s t-test, Wilcoxon test, correlation test, and linear regression analysis, were performed using GraphPad Prism software. The samples used in the statistical analyses corresponded to the genomic data, PAIs, or specific genes under investigation.
Data availability
The original reported PAIs datasets analyzed in this study are available from the publication Yoon et al., 2015. Additionally, Supplementary file 1 provides further PAIs data analyzed in the study.
-
NCBI BioProjectID PRJNA28109. Intracellular pathogen isolated from wild rats.
-
NCBI BioProjectID PRJNA19643. Phytopathogen that causes bacterial wilt and canker of tomato.
-
NCBI BioProjectID PRJNA707150. Clostridium perfringens isolates and their heat resistance.
-
NCBI BioProjectID PRJNA42407. Corynebacterium diphtheriae 241 genome sequencing.
-
NCBI BioProjectID PRJNA42401. Corynebacterium diphtheriae C7 (beta) genome sequencing.
-
NCBI BioProjectID PRJNA42405. Corynebacterium diphtheriae CDCE 8392 genome sequencing.
-
NCBI BioProjectID PRJNA42415. Corynebacterium diphtheriae HC03 genome sequencing.
-
NCBI BioProjectID PRJNA42419. Corynebacterium diphtheriae INCA 402 genome sequencing.
-
NCBI BioProjectID PRJNA87. Causative agent of diphtheria.
-
NCBI BioProjectID PRJNA42403. Corynebacterium diphtheriae PW8 genome sequencing.
-
NCBI BioProjectID PRJNA40687. Corynebacterium pseudotuberculosis 1002 genome sequencing.
-
NCBI BioProjectID PRJNA40875. Corynebacterium pseudotuberculosis strain C231, whole genome sequencing.
-
NCBI BioProjectID PRJNA48979. Corynebacterium pseudotuberculosis FRC41 genome sequencing project.
-
NCBI BioProjectID PRJNA52845. Corynebacterium pseudotuberculosis I19 genome sequencing.
-
NCBI BioProjectID PRJNA12720. Isolated from dried infant formula and causes infant septicemia.
-
NCBI BioProjectID PRJNA70. Opportunistic pathogen that transfers vancomycin resistance to other bacteria.
-
NCBI BioProjectID PRJNA30627. reference genome for the Human Microbiome Project.
-
NCBI BioProjectID PRJNA16718. Avian pathogenic strain.
-
NCBI BioProjectID PRJNA624646. Escherichia coli CFT073 isolate:199310 Genome sequencing.
-
NCBI BioProjectID PRJDA32509. Enterohemorrhagic strain.
-
NCBI BioProjectID PRJDA32511. This strain will be used for comparative genome analysis.
-
NCBI BioProjectID PRJDA32513. This strain will be used for comparative genome analysis.
-
NCBI BioProjectID PRJNA253471. Escherichia coli O157:H7 str. EDL933 Genome sequencing.
-
NCBI BioProjectID PRJNA226. Enterohemorrhagic Escherichia coli.
-
NCBI BioProjectID PRJNA33415. Urinary tract infection isolate.
-
NCBI BioProjectID PRJNA19571. Causative agent of tularemia.
-
NCBI BioProjectID PRJNA239340. Francisella tularensis tularensis Schu_S4 Genome sequencing.
-
NCBI BioProjectID PRJNA18459. Causative agent of tularemia.
-
NCBI BioProjectID PRJNA185. Causes hepatitis, typhlitis, hepatocellular tumors, and gastric bowel disease.
-
NCBI BioProjectID PRJNA175543. Helicobacter pylori 26695 Genome sequencing.
-
NCBI BioProjectID PRJEA41831. Helicobacter pylori B8 genome sequencing project.
-
NCBI BioProjectID PRJDA50589. Helicobacter pylori F16 genome sequencing project.
-
NCBI BioProjectID PRJDA50591. Helicobacter pylori F30 genome sequencing project.
-
NCBI BioProjectID PRJDA50593. Helicobacter pylori F32 genome sequencing project.
-
NCBI BioProjectID PRJDA50595. Helicobacter pylori F57 genome sequencing project.
-
NCBI BioProjectID PRJNA281410. Multi-strain, long-read bacterial genome sequencing.
-
NCBI BioProjectID PRJNA32291. Clinical isolate.
-
NCBI BioProjectID PRJNA19619. Mosquito larvae pathogen.
-
NCBI BioProjectID PRJNA251. Causes meningitis and septicemia.
-
NCBI BioProjectID PRJEA41335. Rhodococcus equi strain 103S whole genome sequencing project.
-
NCBI BioProjectID PRJNA12624. An opportunistic pathogen in normal gut flora.
-
NCBI BioProjectID PRJNA9618. Extremely invasive Salmonella that causes severe disease in pigs and humans.
-
NCBI BioProjectID PRJNA236. Human-specific Salmonella that causes Typhoid fever.
-
NCBI BioProjectID PRJNA371. Human-specific Salmonella that causes Typhoid fever.
-
NCBI BioProjectID PRJNA241. Major laboratory strain of Salmonella typhimurium.
-
NCBI BioProjectID PRJNA310. Human-specific pathogen that causes endemic dysentery.
-
NCBI BioProjectID PRJNA408. Human-specific pathogen that causes endemic dysentery.
-
NCBI BioProjectID PRJNA63. Associated with mastitis in cattle.
-
NCBI BioProjectID PRJNA162343. Staphylococcus aureus subsp. aureus CN1 Genome sequencing.
-
NCBI BioProjectID PRJNA238. Methicillin resistant strain.
-
NCBI BioProjectID PRJNA39547. Staphylococcus aureus ED98 genome sequencing.
-
NCBI BioProjectID PRJNA41277. Staphylococcus aureus subsp. aureus ED133 genome sequencing project.
-
NCBI BioProjectID PRJNA265. Methicillin resistant strain from the UK.
-
NCBI BioProjectID PRJNA266. Methicillin sensitive strain from the UK.
-
NCBI BioProjectID PRJNA263. Methicillin and vancomycin resistant strain.
-
NCBI BioProjectID PRJNA306. Methicillin resistant strain.
-
NCBI BioProjectID PRJNA264. Methicillin resistant strain.
-
NCBI BioProjectID PRJEA29427. Staphylococcus aureus subsp. aureus ST398.
-
NCBI BioProjectID PRJDA18801. An opportunistic pathogen in humans and animals.
-
NCBI BioProjectID PRJNA16313. A methicillin resistant strain of Staphylococcus aureus.
-
NCBI BioProjectID PRJNA279. Used for detection of residual antibiotics in food products.
-
NCBI BioProjectID PRJNA64. Pathogenic clinical isolate that causes toxic-shock syndrome and staphylococcal scarlet fever.
-
NCBI BioProjectID PRJEA30765. Causes strangles disease.
-
NCBI BioProjectID PRJEA63179. Streptococcus gallolyticus subsp. galloyticus ATCC BAA-2069 genome sequencing.
-
NCBI BioProjectID PRJNA16302. Clinical isolate.
-
NCBI BioProjectID PRJNA76769. Streptococcus parasanguinis FW213 Genome sequencing.
-
NCBI BioProjectID PRJEA31233. multidrug resistant strain.
-
NCBI BioProjectID PRJNA76613. Genome sequencing with short reads.
-
NCBI BioProjectID PRJNA13888. Causative agent of a wide range of human and animal infections.
-
NCBI BioProjectID PRJNA13887. Causative agent of a wide range of human and animal infections.
-
NCBI BioProjectID PRJNA17153. Causes disease in pigs and occasionally humans.
-
NCBI BioProjectID PRJNA17155. Causes disease in pigs and occasionally humans.
-
NCBI BioProjectID PRJEB22249. Updated VC N16961 reference genome.
-
NCBI BioProjectID PRJNA59943. Vibrio cholerae O1 str. 2010EL-1786 genome sequencing project.
-
NCBI BioProjectID PRJNA586749. Vibrio cholerae O395 isolate:TCP2 Genome sequencing.
-
NCBI BioProjectID PRJNA297. Plant-specific pathogen that causes citrus canker.
-
NCBI BioProjectID PRJNA15. Causes black rot and citrus canker.
-
NCBI BioProjectID PRJNA296. Plant-specific pathogen that causes black rot.
-
NCBI BioProjectID PRJNA298596. Xanthomonas campestris pv. vitistrifoliae strain:LMG940 Genome sequencing and assembly.
-
NCBI BioProjectID PRJNA12931. Causes rice bacterial blight disease.
-
NCBI BioProjectID PRJNA190. Food and waterborn pathogen that causes gastroenteritis.
-
NCBI BioProjectID PRJNA10638. Extremely virulent organism that causes plague.
-
NCBI BioProjectID PRJNA34. Extremely virulent organism that causes plague.
-
NCBI BioProjectID PRJNA41469. Yersinia pestis KIM D27 genome sequencing project.
-
NCBI BioProjectID PRJNA16070. Serotype 1b strain isolated from a patient in Russia.
-
NCBI BioProjectID PRJNA239344. Yersinia pseudotuberculosis IP 32953 Genome sequencing.
-
NCBI BioProjectID PRJEA62885. Staphylococcus aureus subsp. aureus MSHR1132 genome sequencing project.
References
-
Mobile genetic elements: in silico, in vitro, in vivoMolecular Ecology 25:1027–1031.https://doi.org/10.1111/mec.13543
-
CpG islands and the regulation of transcriptionGenes & Development 25:1010–1022.https://doi.org/10.1101/gad.2037511
-
Genome-wide colonization of gene regulatory elements by G4 DNA motifsNucleic Acids Research 37:6784–6798.https://doi.org/10.1093/nar/gkp710
-
Pathogenicity islands and the evolution of microbesAnnual Review of Microbiology 54:641–679.https://doi.org/10.1146/annurev.micro.54.1.641
-
Structure, location and interactions of G-quadruplexesThe FEBS Journal 277:3452–3458.https://doi.org/10.1111/j.1742-4658.2010.07758.x
-
Impact of the locus of enterocyte effacement pathogenicity island on the evolution of pathogenic Escherichia coliInternational Journal of Medical Microbiology 294:103–113.https://doi.org/10.1016/j.ijmm.2004.06.024
-
A large, mobile pathogenicity island confers plant pathogenicity on Streptomyces speciesMolecular Microbiology 55:1025–1033.https://doi.org/10.1111/j.1365-2958.2004.04461.x
-
Seven essential questions on G-quadruplexesBiomolecular Concepts 1:197–213.https://doi.org/10.1515/bmc.2010.011
-
G-Quadruplexes in human ribosomal RNAJournal of Molecular Biology 431:1940–1955.https://doi.org/10.1016/j.jmb.2019.03.010
-
BmILF and i-motif structure are involved in transcriptional regulation of BmPOUM2 in Bombyx moriNucleic Acids Research 46:1710–1723.https://doi.org/10.1093/nar/gkx1207
-
G-quadruplexes and their regulatory roles in biologyNucleic Acids Research 43:8627–8637.https://doi.org/10.1093/nar/gkv862
-
Pathogenicity islands in bacterial pathogenesisClinical Microbiology Reviews 17:14–56.https://doi.org/10.1128/CMR.17.1.14-56.2004
-
The structure and function of DNA G-QuadruplexesTrends in Chemistry 2:123–136.https://doi.org/10.1016/j.trechm.2019.07.002
-
Predicting and understanding the stability of G-quadruplexesBioinformatics 25:i374–i382.https://doi.org/10.1093/bioinformatics/btp210
-
I-motif DNA: significance and future prospectiveExploratory Animal and Medical Research 10:18–23.https://doi.org/10.1093/af/vfaa021
-
Evolutionary implications of horizontal gene transferAnnual Review of Genetics 46:341–358.https://doi.org/10.1146/annurev-genet-110711-155529
-
The regulation and functions of DNA and RNA G-quadruplexesNature Reviews. Molecular Cell Biology 21:459–474.https://doi.org/10.1038/s41580-020-0236-x
-
Integrative and conjugative elements: mosaic mobile genetic elements enabling dynamic lateral gene flowNature Reviews. Microbiology 8:552–563.https://doi.org/10.1038/nrmicro2382
-
G-Quadruplex structures in bacteria: biological relevance and potential as an antimicrobial targetJournal of Bacteriology 203:e0057720.https://doi.org/10.1128/JB.00577-20
-
PAIDB v2.0: exploration and analysis of pathogenicity and resistance islandsNucleic Acids Research 43:624–630.https://doi.org/10.1093/nar/gku985
-
G4-quadruplexes and genome instabilityMolecular Biology 47:197–204.https://doi.org/10.1134/S0026893313020180
Article and author information
Author details
Funding
No external funding was received for this work.
Acknowledgements
The sincere appreciation extends to Dr. Sung Ho Yoon and his colleagues for their dedicated efforts in identifying PAIs and establishing the Pathogenicity Island Database for public analysis. Their commitment to advancing the field of pathogen genomics has greatly facilitated this research. This study would like to thank Dr. Jingjing Li (Zhejiang University) and Dr. Mingyu Zhou (Sun Yat-Sen University) for their insightful suggestions and constructive comments regarding the exploration of G4 structures in genomes. Their expertise and guidance have significantly enriched the understanding of the potential roles and implications of G4 structures in the context of PAIs.
Version history
- Sent for peer review:
- Preprint posted:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.91985. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2023, Lyu and Song
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,728
- views
-
- 183
- downloads
-
- 9
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 7
- citations for umbrella DOI https://doi.org/10.7554/eLife.91985
-
- 2
- citations for Version of Record https://doi.org/10.7554/eLife.91985.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
The intricate relationship of G-Quadruplexes and bacterial pathogenicity islands
eLife 12:RP91985.
https://doi.org/10.7554/eLife.91985.3




{kind=link}
{kind=link}
{kind=link}