Functional characteristics and computational model of abundant hyperactive loci in the human genome
- National Institute for Biotechnology and Information, National Library of Medicine, National Institutes of Health, United States
Figures
Figure 1 with 6 supplements
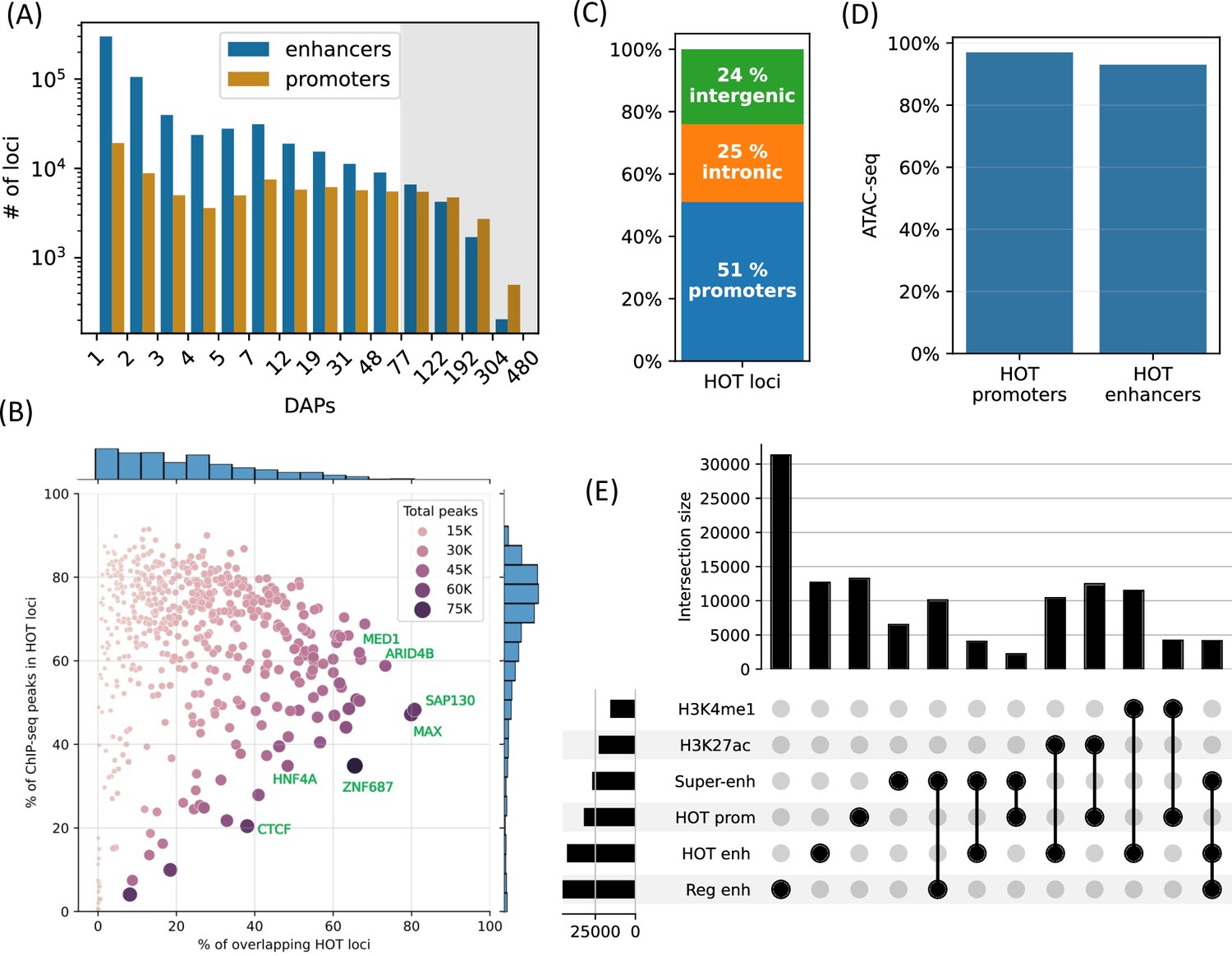
High-occupancy target (HOT) loci are prevalent in the genome.
(A) Distribution of the number of loci by the number of overlapping peaks 400 bp loci. Loci are binned on a logarithmic scale (Table 1, Methods). The shaded region represents the HOT loci. (B) Prevalence of DNA-associated proteins (DAPs) in HOT loci. Each dot represents a DAP. X-axis: percentage of HOT loci in which DAP is present (e.g. MAX is present in 80% of HOT loci). Y-axis: percentage of total peaks of DAPs that are located in HOT loci (e.g. 45% of all the ChIP-seq peaks of MAX is located in the HOT loci). Dot color and size are proportional to the total number of ChIP-seq peaks of DAP. (C) Breakdown of HepG2 HOT loci to the promoter, intronic, and intergenic regions. (D) Fractions of HOT enhancer and promoter loci located in ATAC-seq. (E) Overlaps between the HOT enhancer, HOT promoter, super-enhancer, regular enhancer, H3K27ac, and H4K4me1 regions. Horizontal bars on bottom left represent the total number of loci of the corresponding class of loci. All of the visualized data is generated from the HepG2 cell line.
Figure 1—figure supplement 1
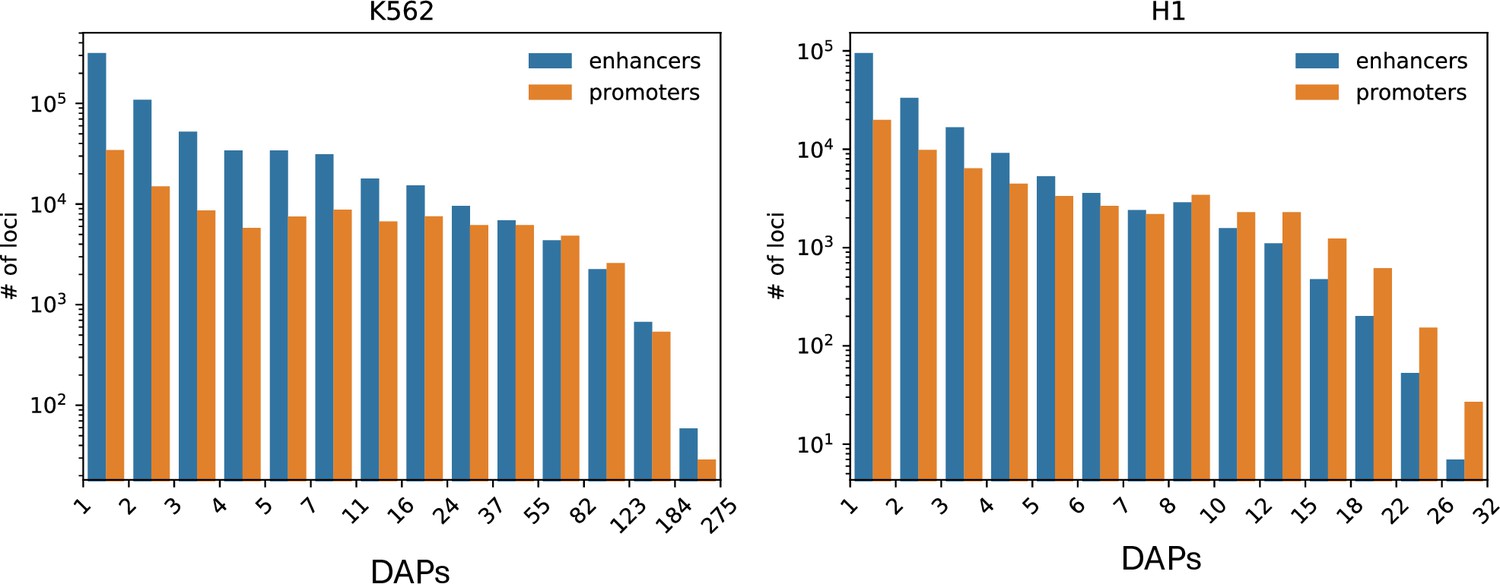
Distribution of the number of loci by the number of overlapping peaks 400 bp loci in K562 and H1.
Loci are binned on a logarithmic scale (Table 1, see Methods).
Figure 1—figure supplement 2
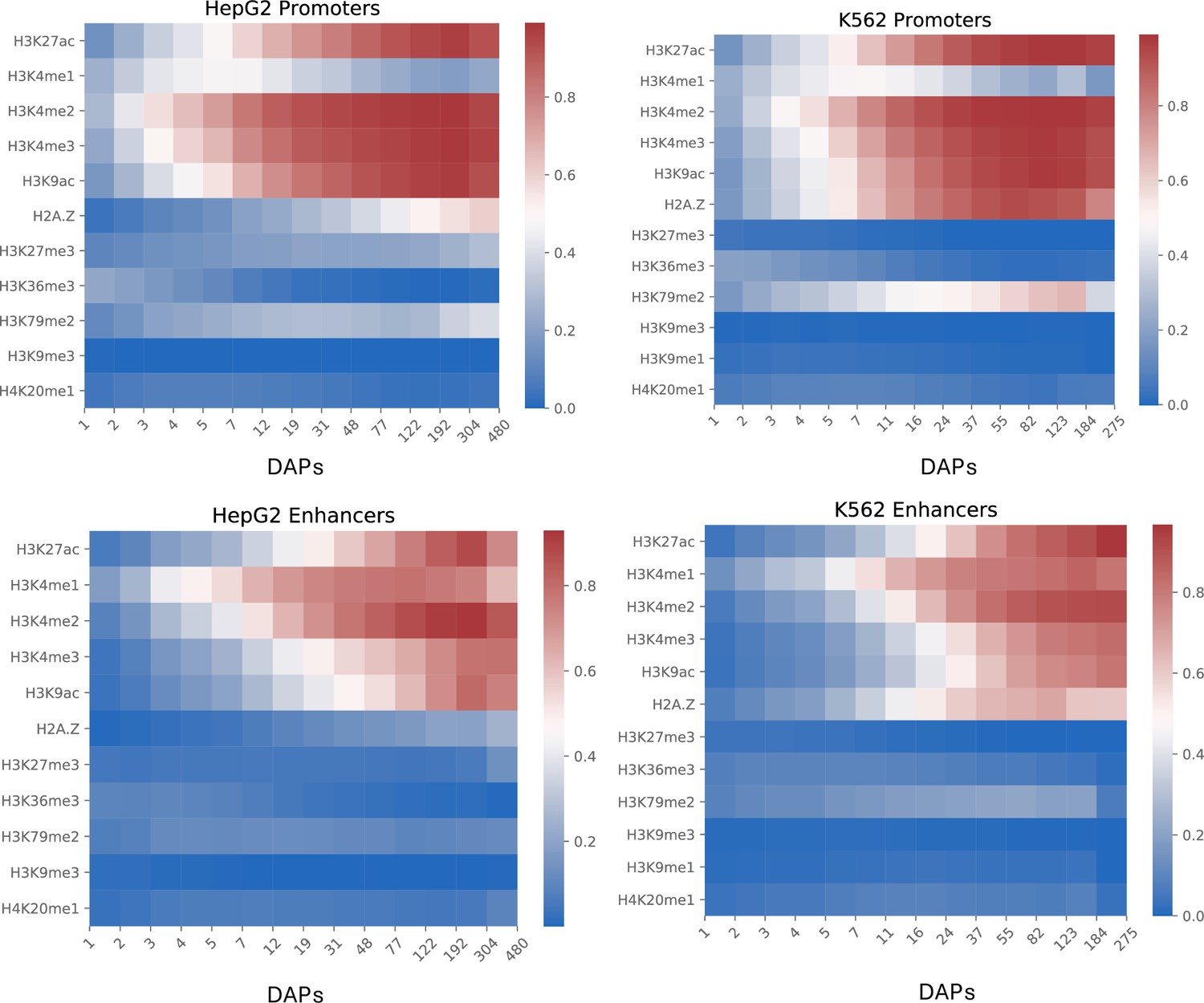
Percentages of overlapping promoter (top row) and enhancer (bottom row) loci binned by bound DNA-associated proteins (DAPs) with histone modification regions in HepG2 (left column) and K562 (right column).
Figure 1—figure supplement 3
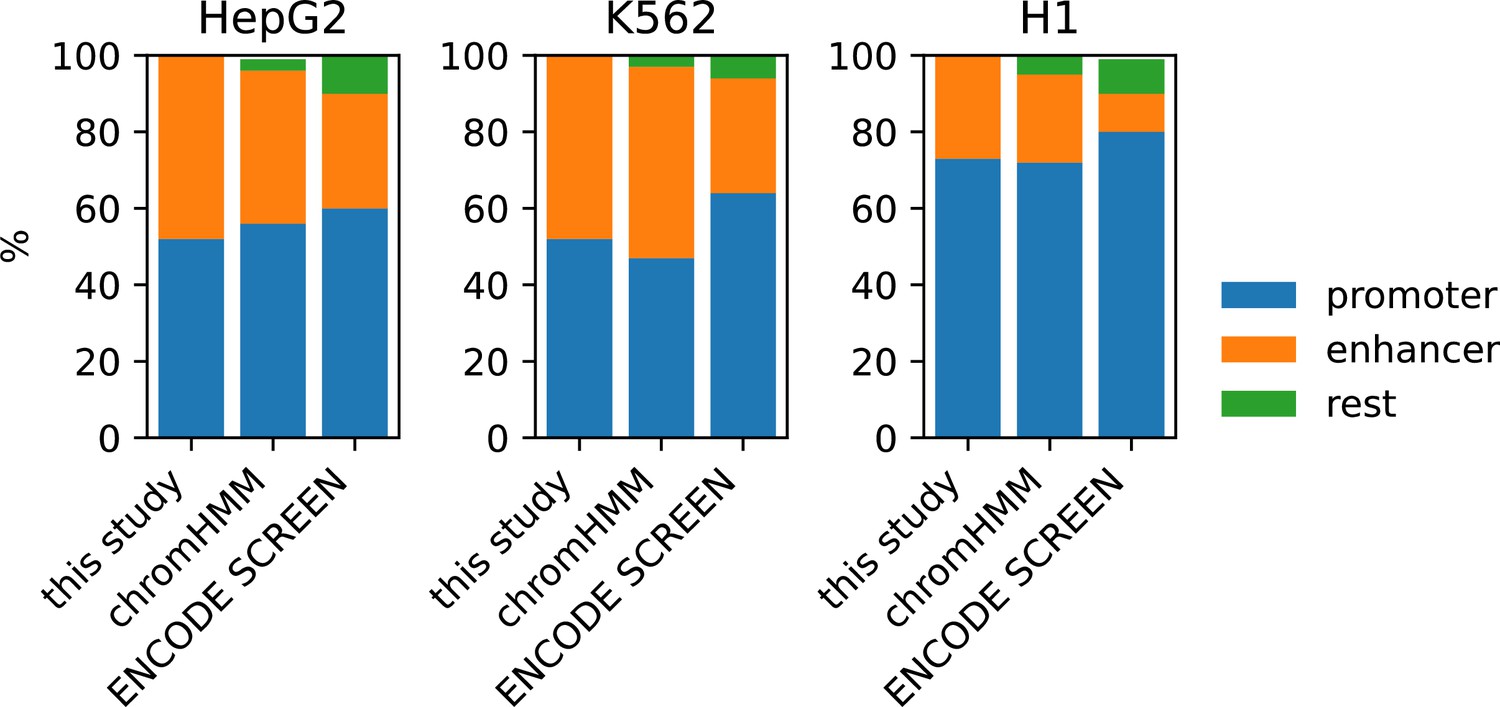
Composition of the high-occupancy target (HOT) loci to promoter and enhancer regions based on the definitions used in this study, chromHMM states and ENCODE SCREEN annotations.
Figure 1—figure supplement 4
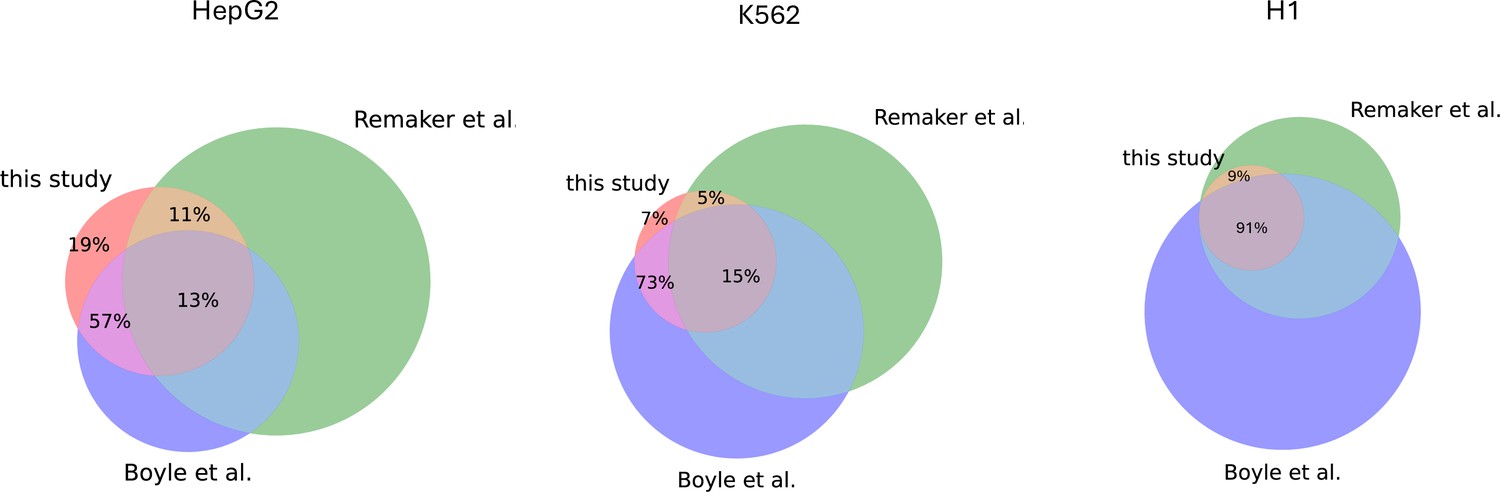
Overlaps between the high-occupancy target (HOT) loci as reported in this study (Ramaker et al., 2020 and Boyle et al., 2014).
Overlaps are calculated in terms of fractions of overlapping bps.
Figure 1—figure supplement 5
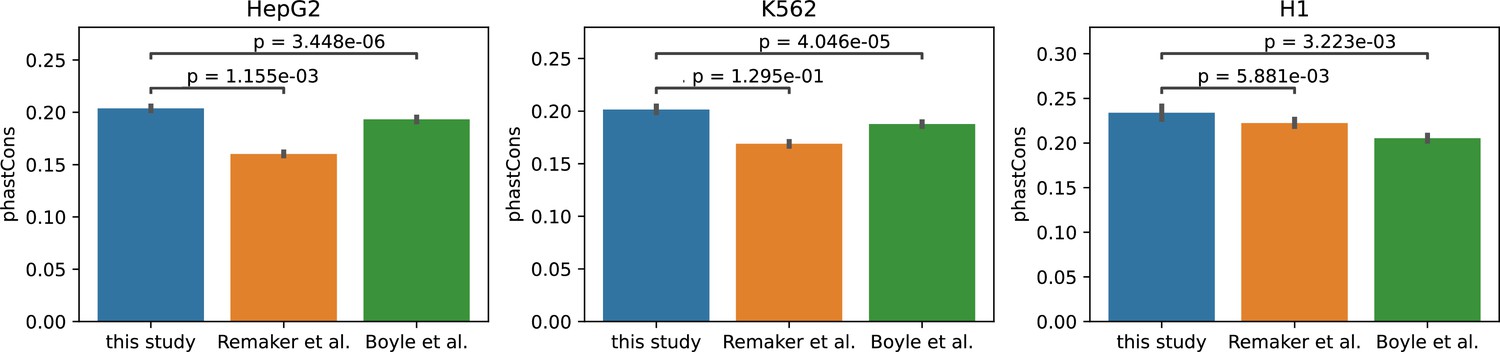
phastCons conservation scores of high-occupancy target (HOT) loci defined by this study (Ramaker et al., 2020 and Boyle et al., 2014).
Bar plots depict median values, error bars are 95% confidence intervals. p-Values are Mann-Whitney U test results.
Figure 1—figure supplement 6
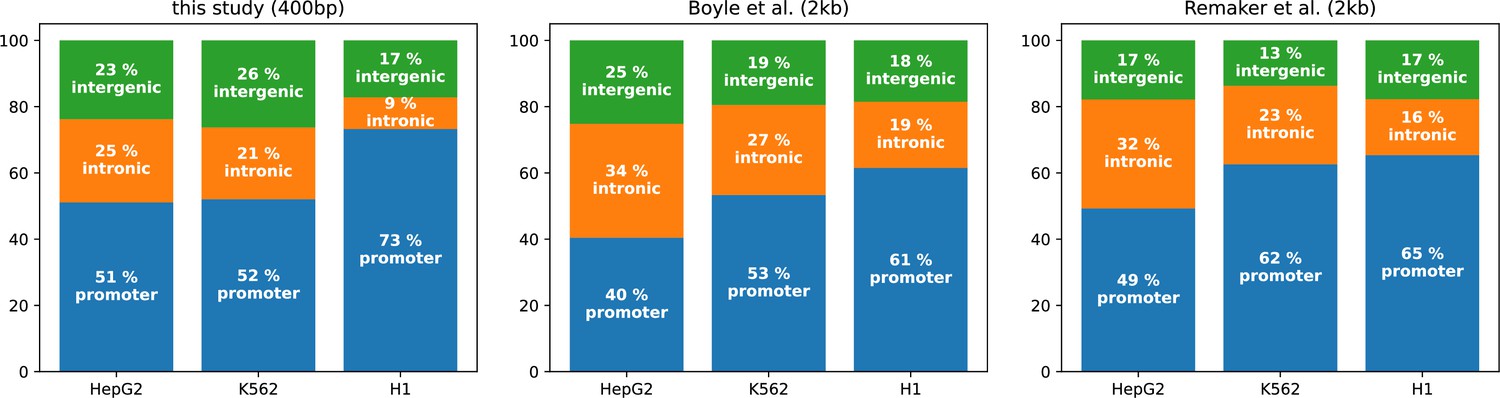
Compositions of high-occupancy target (HOT) loci as reported in this study (Ramaker et al., 2020 and Boyle et al., 2014) in terms of promoter, intronic, and intergenic regions.
Figure 2 with 4 supplements
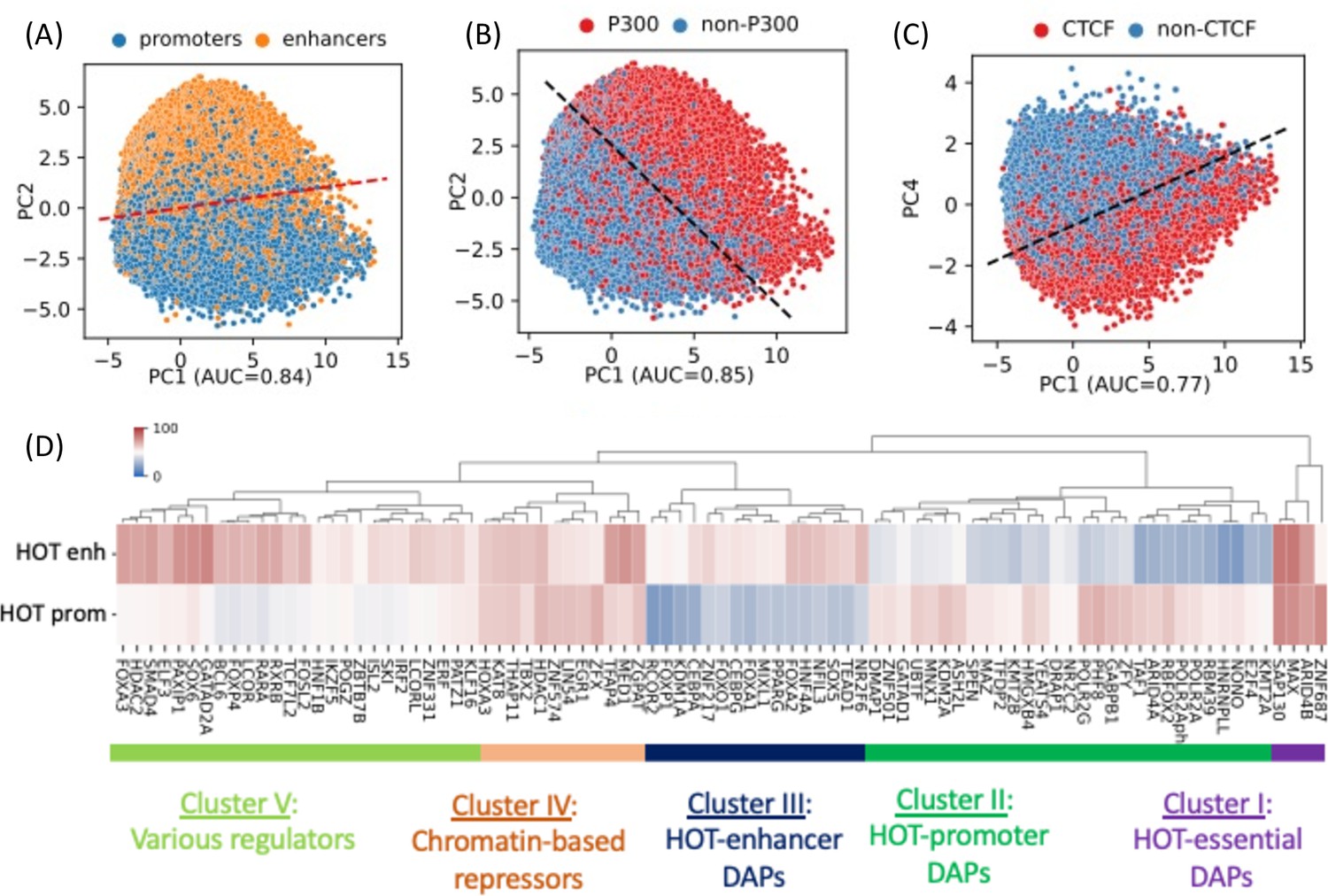
PCA plots of high-occupancy target (HOT) loci based on the DNA-associated protein (DAP) presence vectors.
Each dot represents a HOT locus: (A) PC1 and PC2, marked promoters and enhancers. (B) PC1 and PC2, marked p300-bound HOT loci. (C) PC1 and PC4, marked CTCF-bound HOT loci. The dashed lines in A, B, C are logistic regression lines. auROC values are results of logistic regression. (D) DAPs hierarchically clustered by their involvement in HOT promoters and HOT enhancers. Heatmap colors indicate the % of HOT enhancers or promoters that a given DAP overlaps with. All of the visualized data is generated from the HepG2 cell line.
Figure 2—figure supplement 1
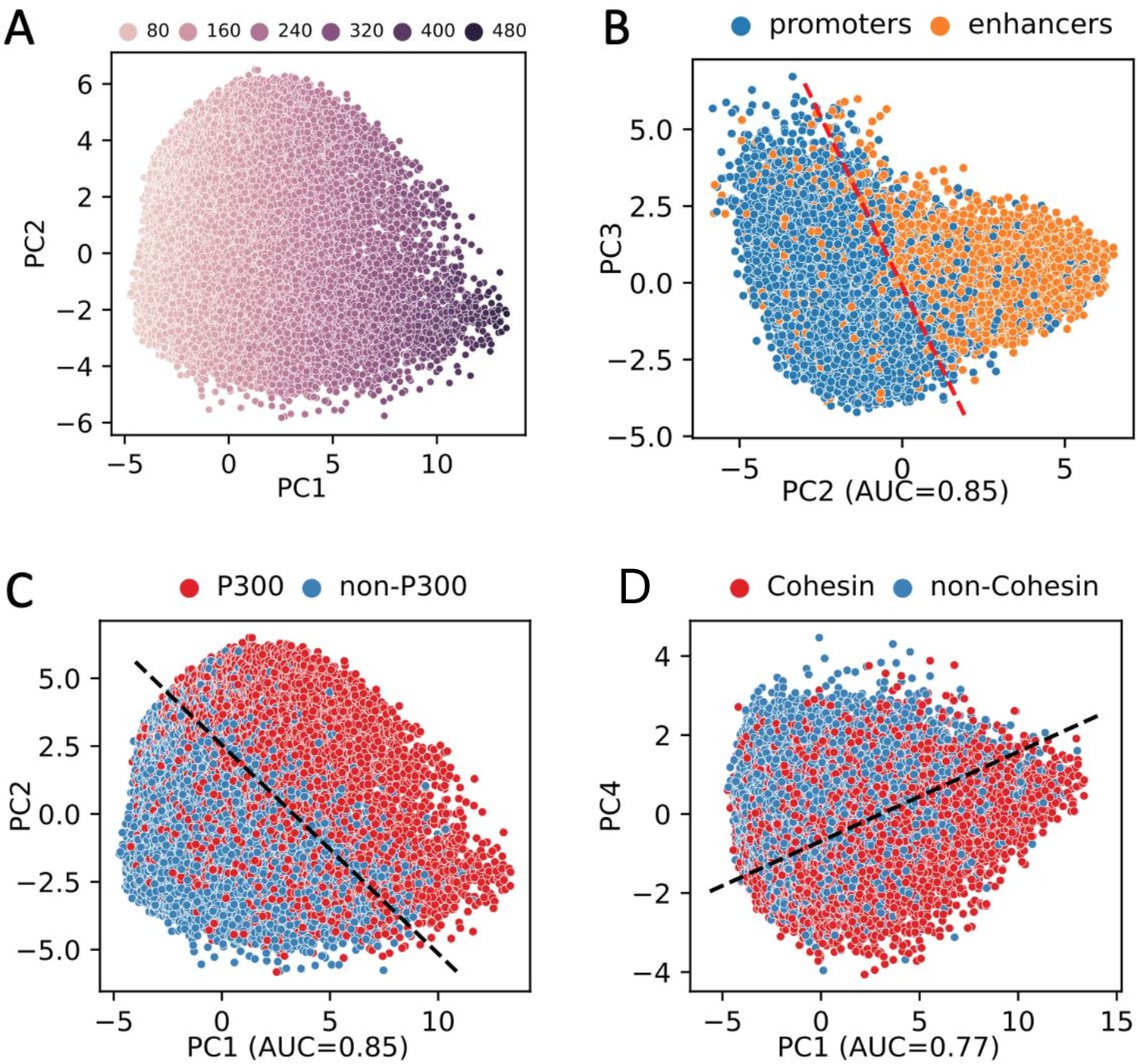
PCA plots of high-occupancy target (HOT) loci in HepG2 based on the DNA-associated protein (DAP) presence vectors.
Each dot represents a HOT locus: (A) PC1 and PC2 correlated with the number of overlapping DAPs. (B) PC2 and PC3, with promoter and enhancer marked. (C) PC1 and PC2, marked p300-bound HOT loci. (D) PC1 and PC4, marked Cohesin-bound HOT loci.
Figure 2—figure supplement 2
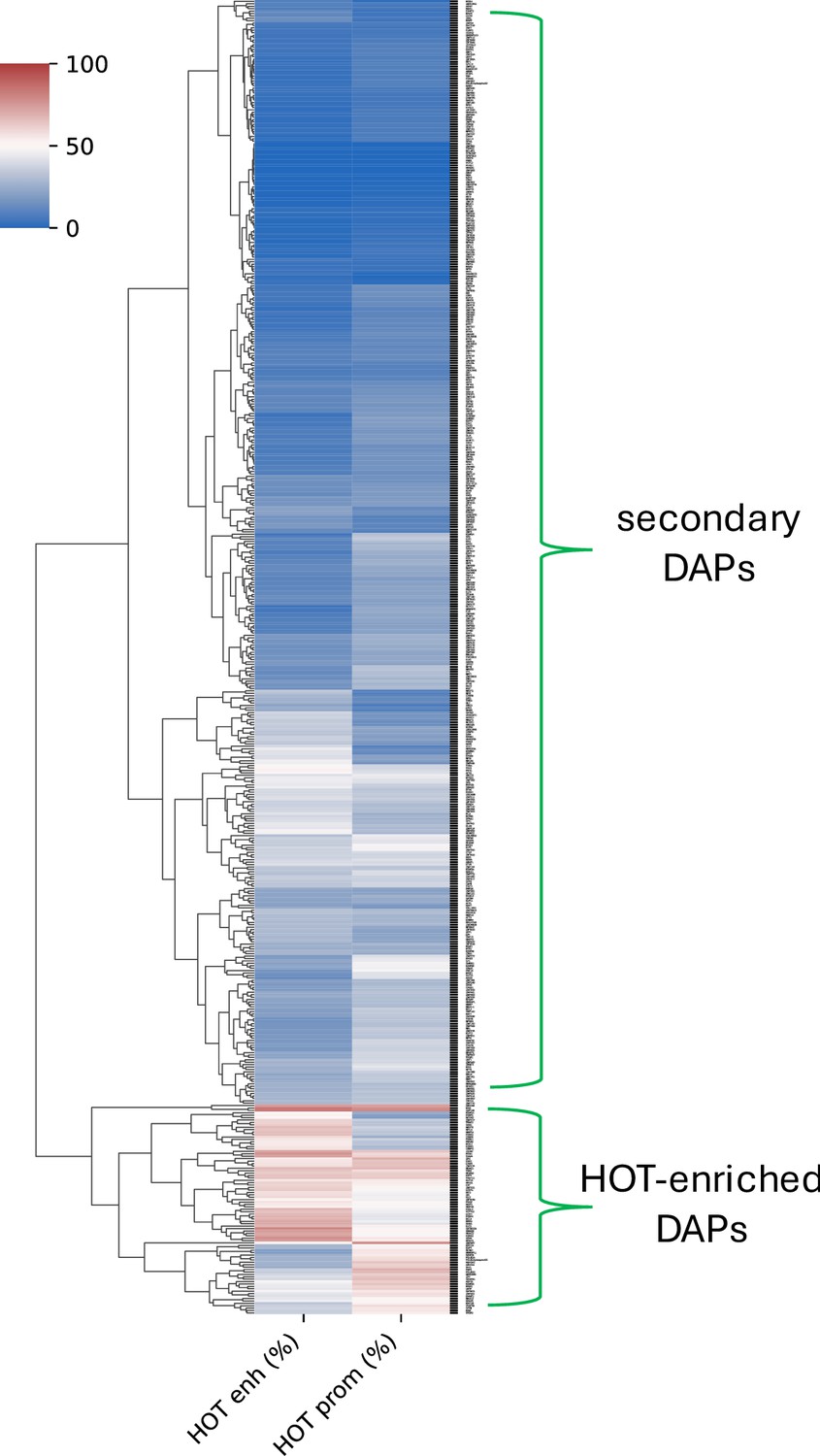
DNA-associated proteins (DAPs) clustered by percentage of high-occupancy target (HOT) promoters and HOT enhancers that the ChIP-seq peaks overlap.
The top cluster comprises the DAPs which on average overlap with 13% of HOT loci. The DAPs which form the bottom cluster are present in 53% of HOT loci.
Figure 2—figure supplement 3
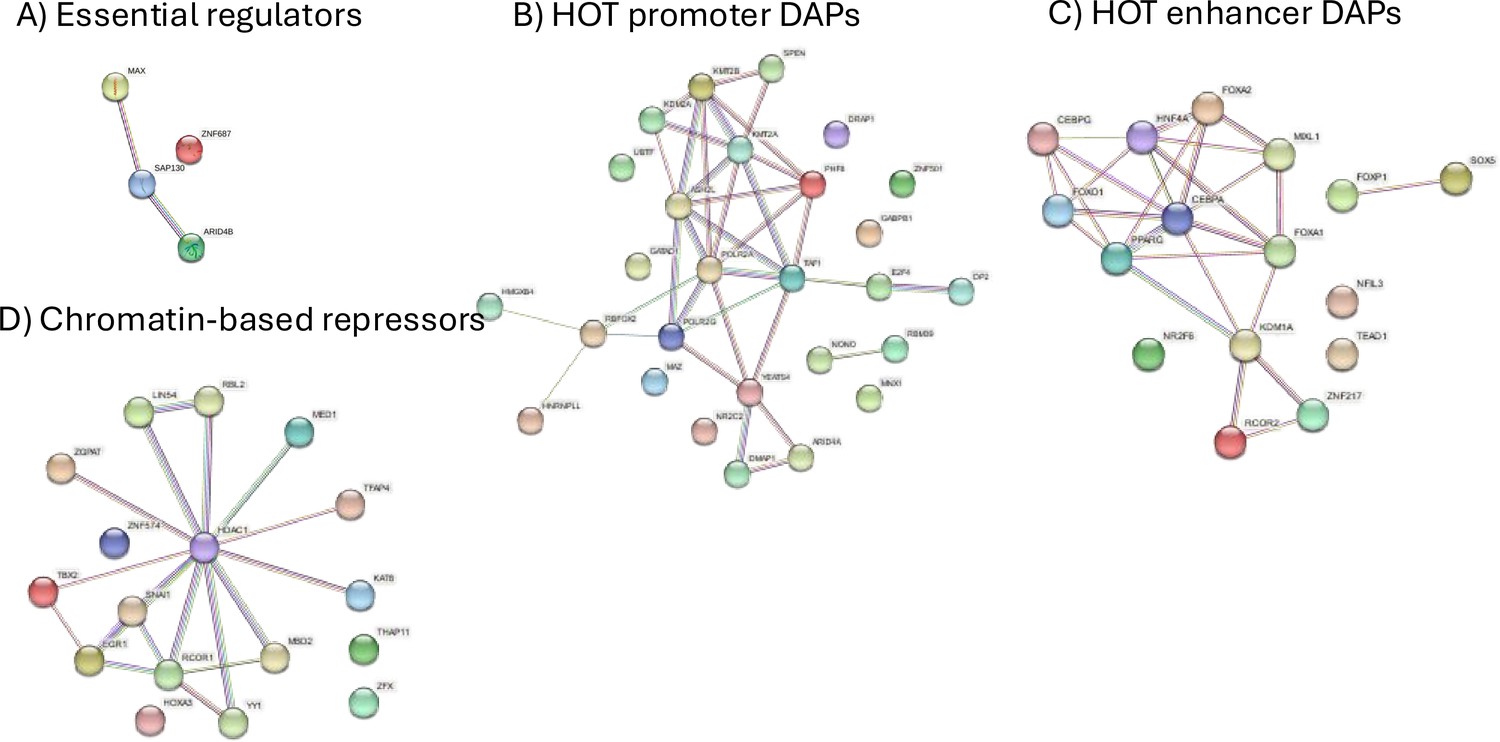
PPI networks of four clusters.
Names of the clusters are indicated as titles. Refer to the text for interpretations.
Figure 2—figure supplement 4

CTCF and Cohesin in high-occupancy target (HOT) loci.
(A) Distances to the nearest TSSs in HOT loci bound by CTCF and Cohesin. (B) Numbers of total DNA-associated proteins (DAPs) in HOT loci bound by CTCF and Cohesin.
Figure 3
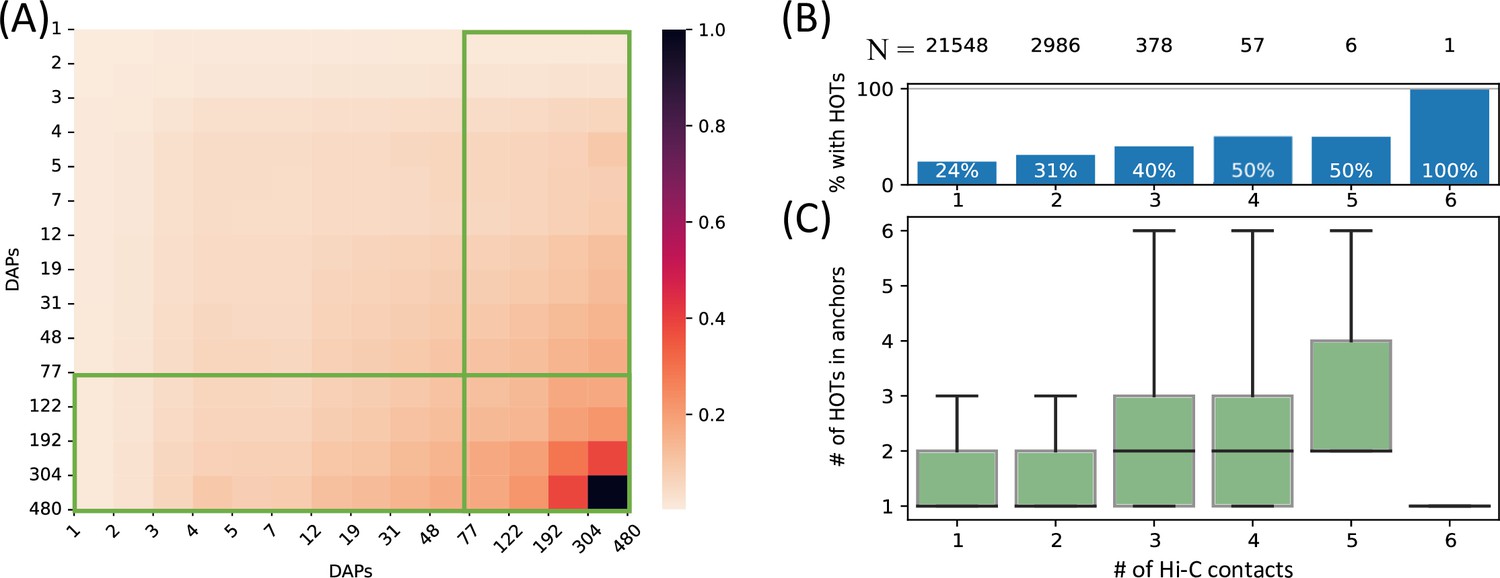
High-occupancy target (HOT) loci in high-frequency 3D chromatin interaction regions.
(A) Densities of long-range Hi-C chromatin contacts between the DNA-associated protein (DAP)-bound loci. Each horizontal and vertical bin represents the loci with the number of bound DAPs between the edge values. The density values of each cell are normalized by the maximum value across all pairwise bins. Green boxes represent HOT loci. (B) Distribution of HOT loci in Hi-C contact regions. X-axis is the number of Hi-C contacts. Numbers in the top row indicate the total number of genomic loci engaging in the given number of Hi-C contacts. Bars indicate the % of Hi-C loci that contain at least one HOT locus. (C) Distribution of the number of HOT loci in regions with a given number of Hi-C contacts. X-axis is the same as B. All of the visualized data is generated from the HepG2 cell line.
Figure 4 with 2 supplements
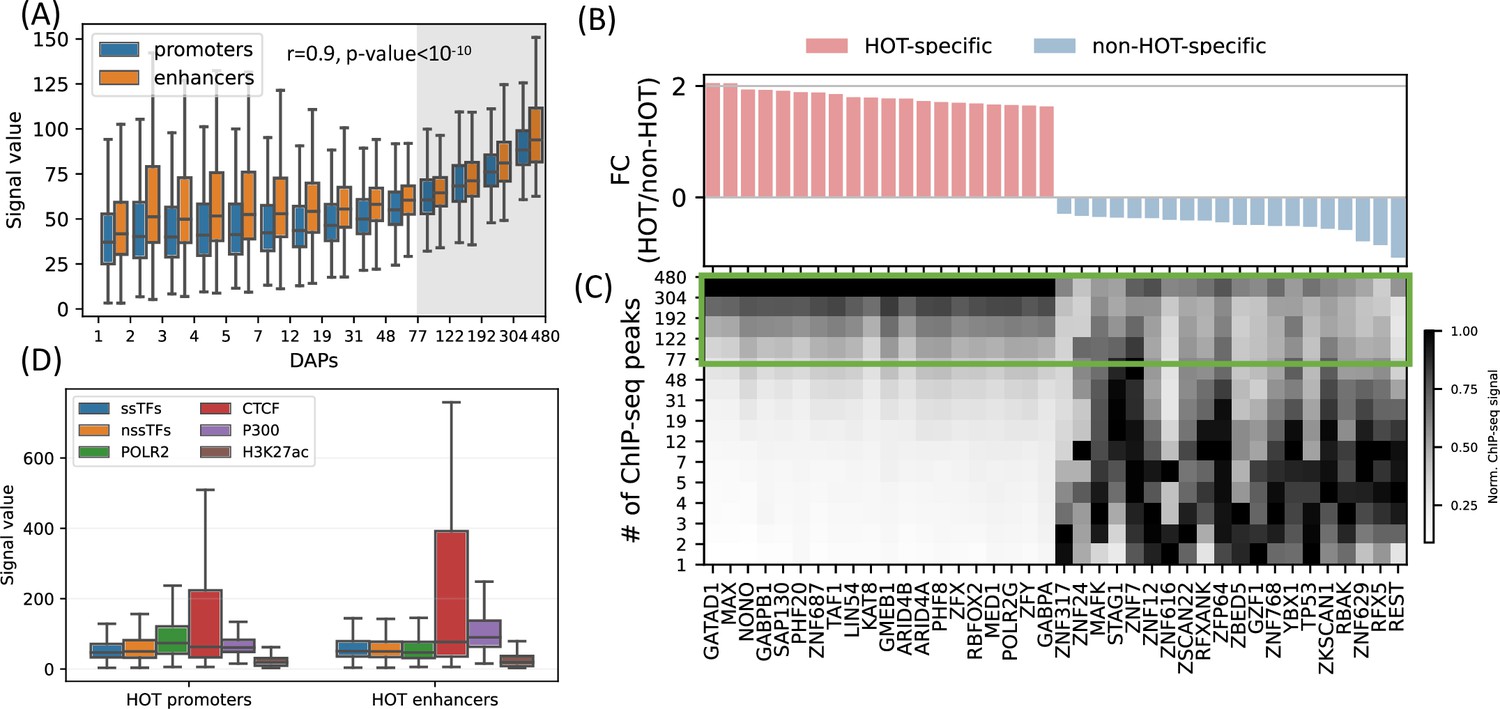
High-occupancy target (HOT) regions induce strong ChIP-seq signals.
(A) Distribution of the signal values of the ChIP-seq peaks by the number of bound DNA-associated proteins (DAPs). The shaded region represents the HOT loci. (B, C) DAPs sorted by the ratio of ChIP-seq signal strength of the peaks located in HOT loci and non-HOT loci. 20 most HOT-specific (red bars) and 20 most non-HOT-specific (blue bars) DAPs are depicted. (B) Fold-change (log2) of the HOT and non-HOT loci ChIP-seq signals. (C) Distribution of the average ChIP-seq signal in the loci binned by the number of bound DAPs. Rows represent the loci with the bound DAPs indicated by the values of the edges (y-axis). Green box regions demarcate the HOT regions. (D) Signal values of sequence-specific DAPs (ssDAPs), non-sequence-specific DAPs (nssDAPs) (see the text for description), H3K27ac, CTCF, P300 peaks in HOT promoters and enhancers. All of the visualized data is generated from the HepG2 cell line.
Figure 4—figure supplement 1
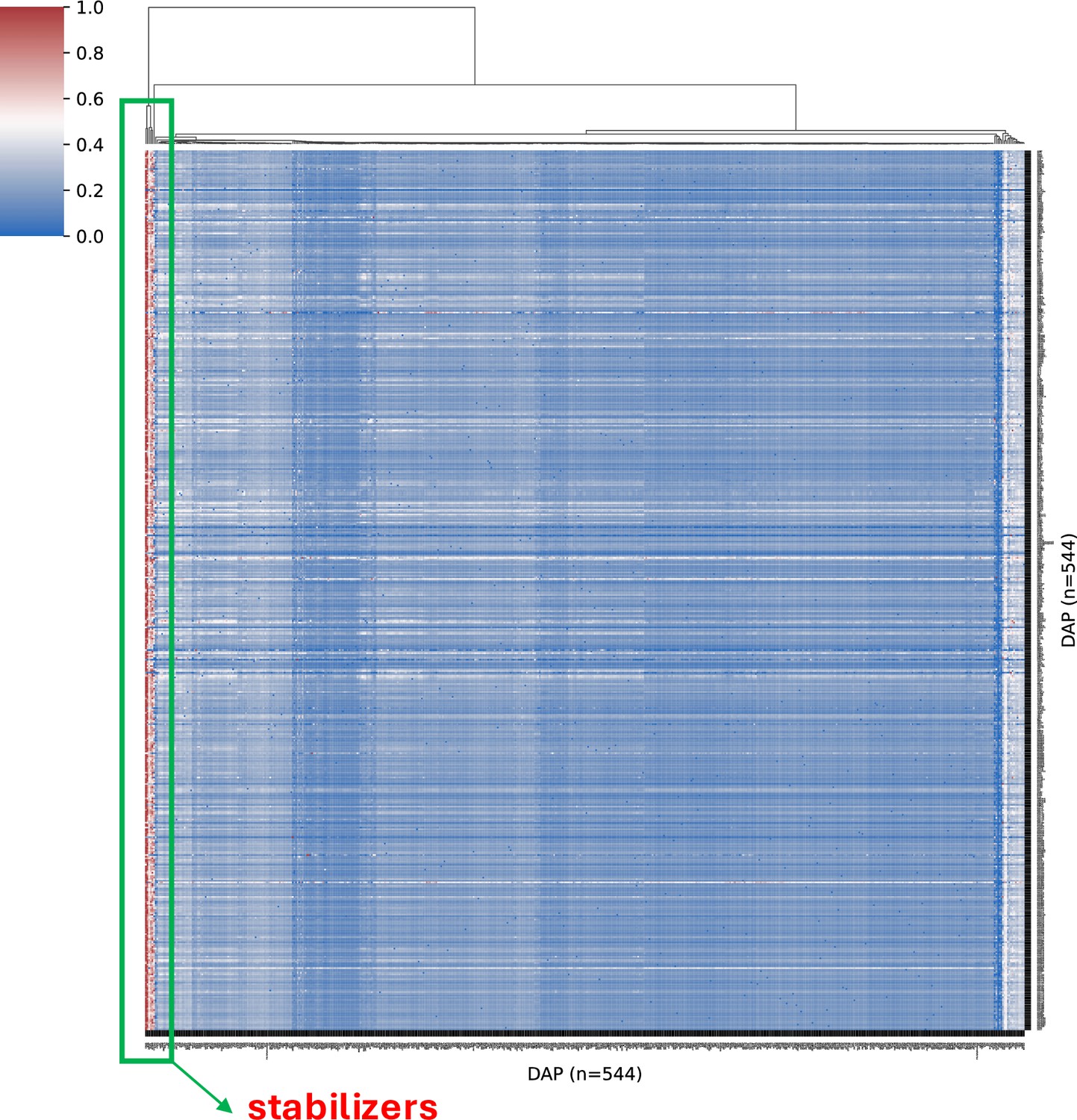
Normalized ChIP-seq signal values of DNA-associated proteins (DAPs) in high-occupancy target (HOT) loci (rows) in the presence of other DAPs (columns).
The hierarchical clustering is done using the columns. That is, the leftmost outer group (in the green box) contains the DAPs in the presence of which most of the other DAPs yield highest ChIP-seq signal values.
Figure 4—figure supplement 2
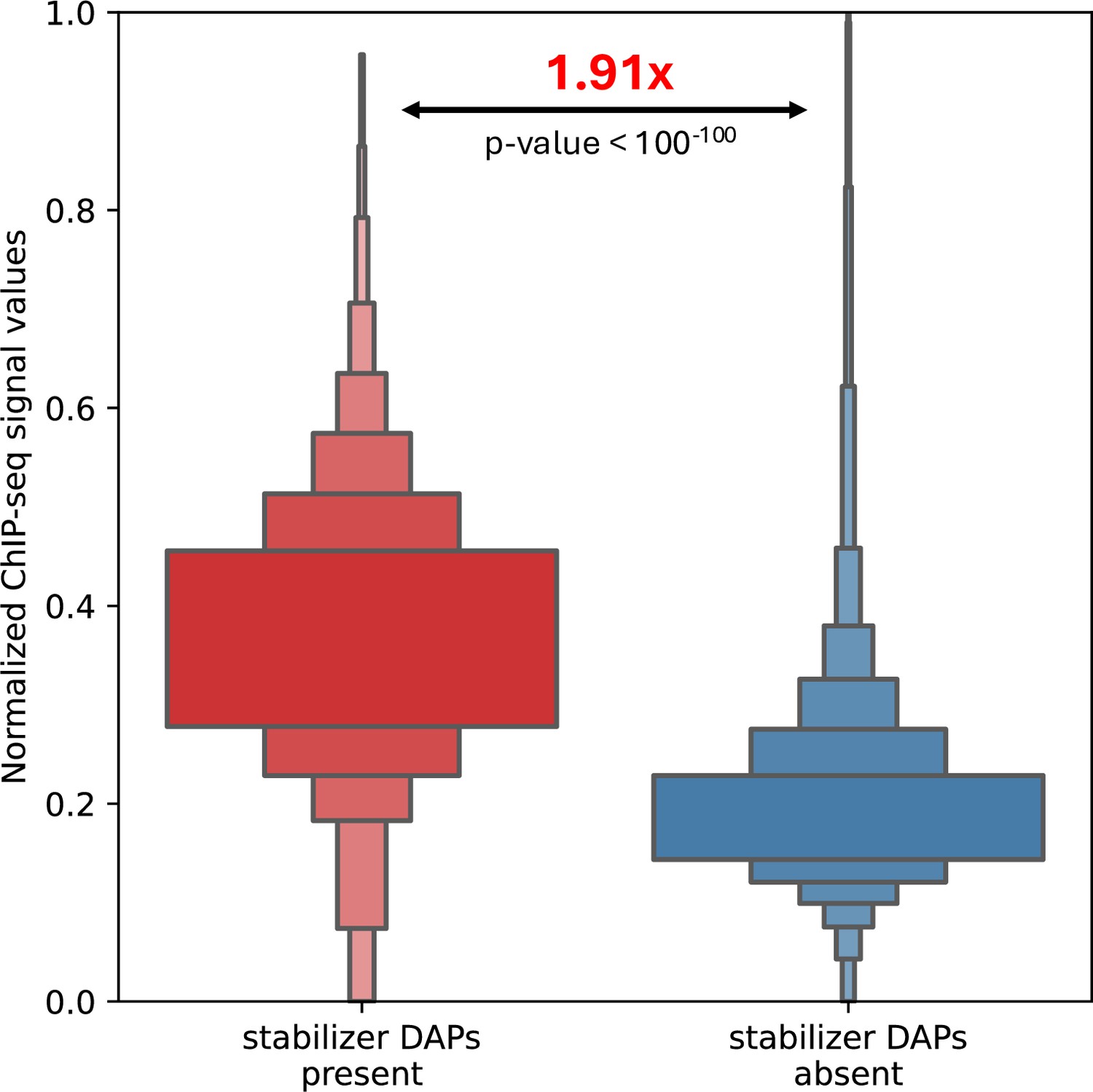
Distribution of the ChIP-seq signal values of DNA-associated proteins (DAPs) when the stabilizing DAPs (Figure 4—figure supplement 1) are present vs. absent.
Figure 5 with 4 supplements
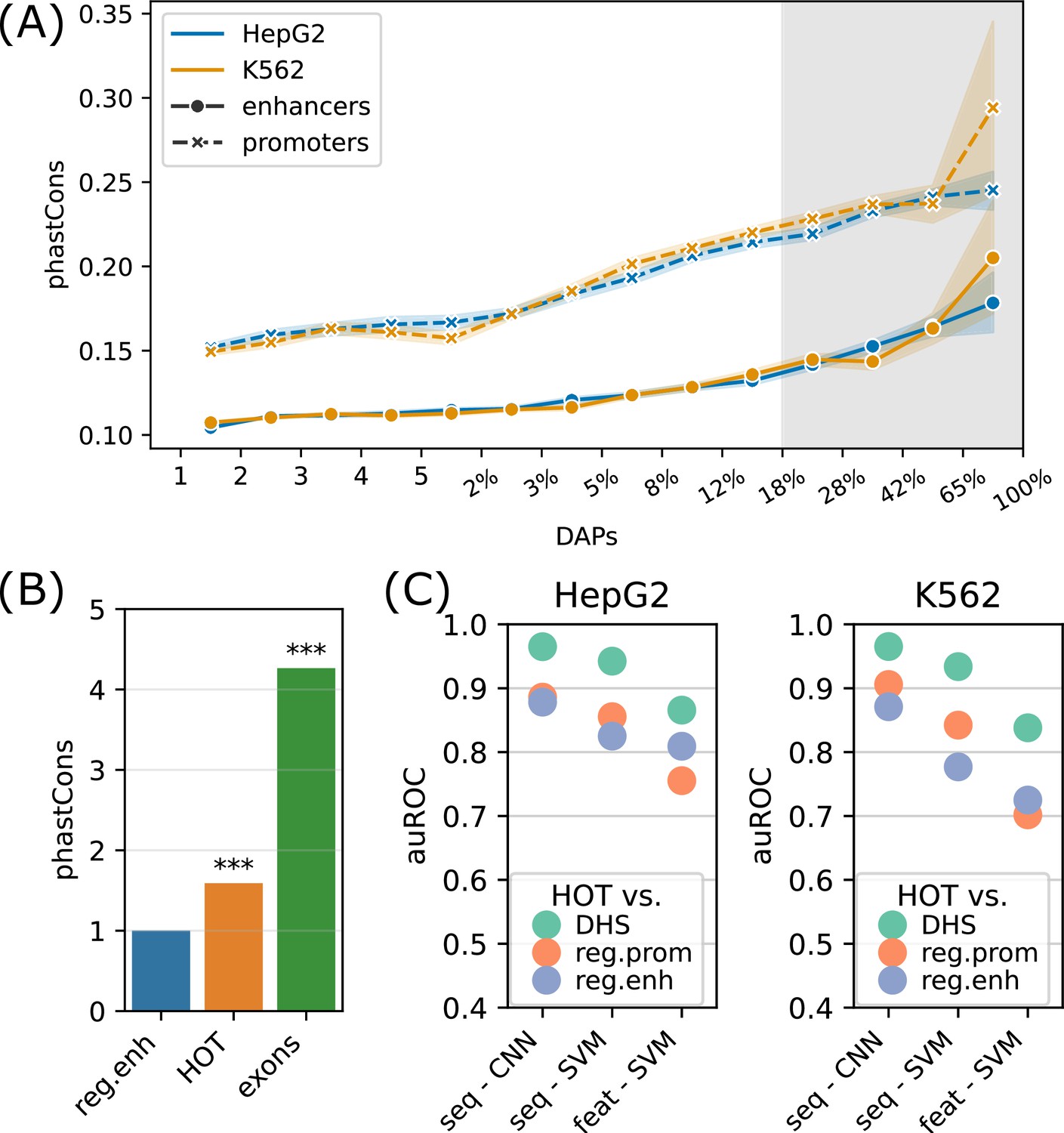
Sequence features of high-occupancy target (HOT) loci.
(A) Distribution of conservation score in loci bound by DNA-associated proteins (DAPs) in HepG2 and K562. The logarithmic part of the bins is expressed in terms of the percentages of loci that each bin covers, averaged over two cell lines. The shaded region represents HOT loci. (B) phastCons conservation scores of regular enhancer, HOT loci, and exon regions. The values are normalized by the average scores of regular enhancers. (C) Classification performances (auROC) of HOT loci against the backgrounds of DNase-I hypersensitivity sites (DHS), promoter, and regular enhancer regions. The x-axis values are the methods used for classifications. Methods starting with ‘seq -’ are based on sequences (convolutional neural networks [CNNs] and gkmSVM). Starting with ‘feat -’ are methods where all sequence features are used (GC, CpG, GpC, CpG island).
Figure 5—figure supplement 1
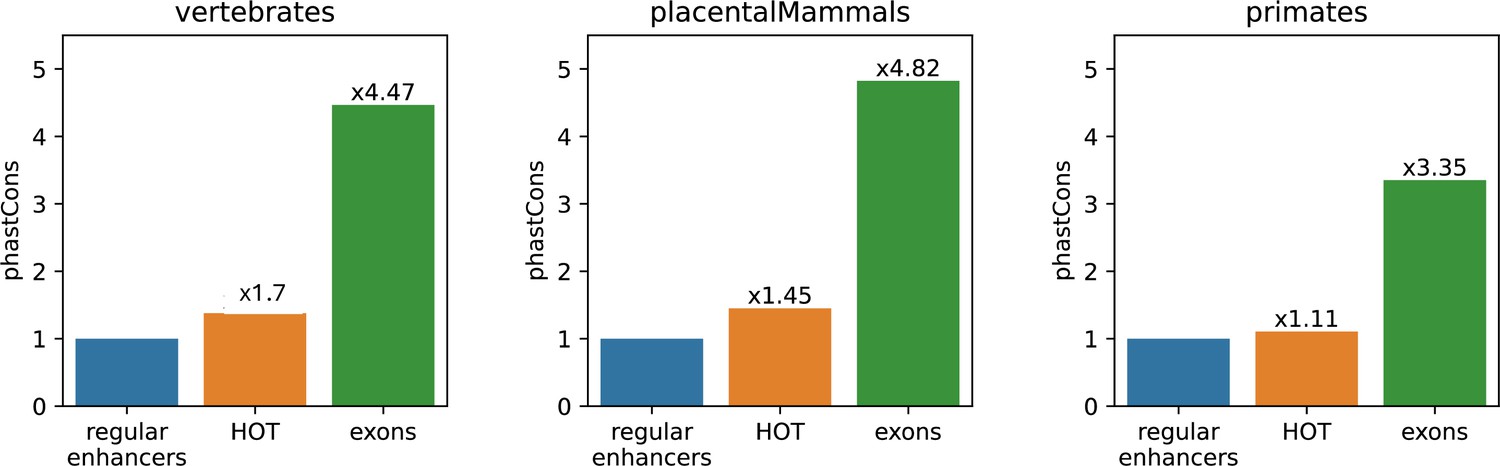
Comparison of phastCons conservation scores of regular enhancers, high-occupancy target (HOT) loci, and exons using the score extracted from vertebrates, placental mammals, and primates.
Figure 5—figure supplement 2
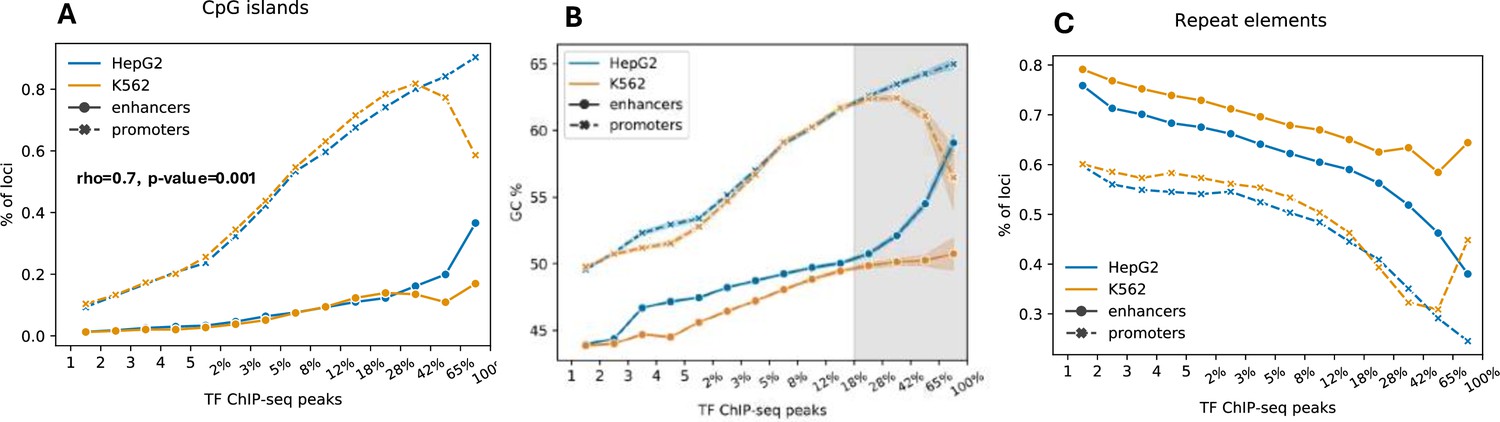
Sequence features of high-occupancy target (HOT) loci.
(A) Fractions of DNA-associated protein (DAP)-bound loci overlapping CpG islands. X-axis is bins of number of bound DAPs. The logarithmic bins are represented in terms of percent of total number of DAPs in given cell line. (B) GC contents of DAP-bound loci. X-axis is the same as in A. (C) Fractions of loci DAP-bound overlapping repeat elements. X-axis is the same as in A.
Figure 5—figure supplement 3
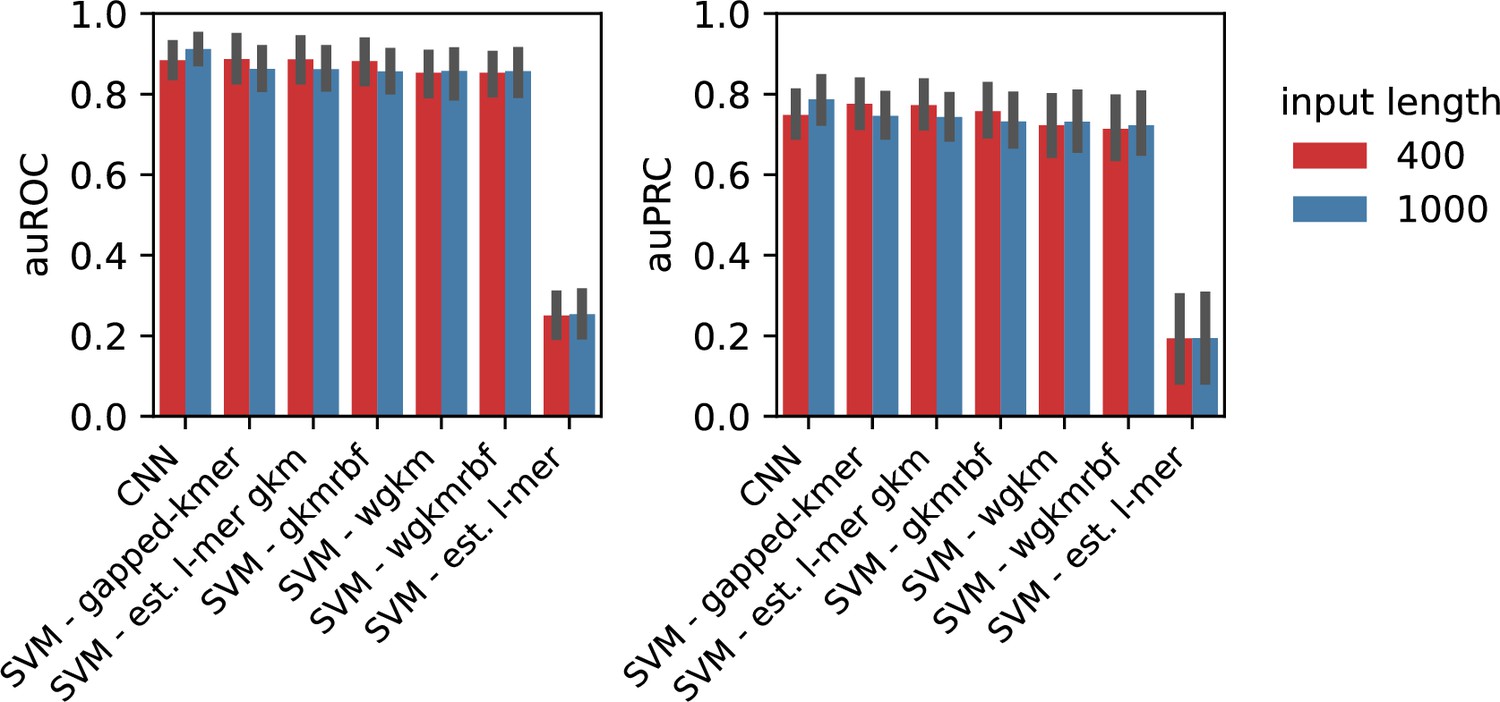
Comparison of classification performances for sequences in different lengths.
Figure 5—figure supplement 4
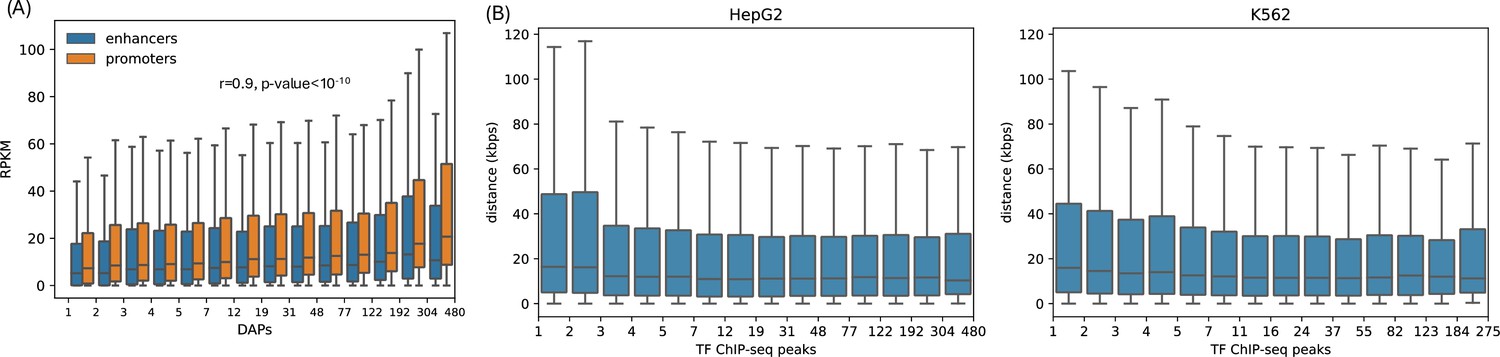
Distances and expressions of flanking genes of DNA-associated protein (DAP)-bound loci.
(A) Expression levels of target genes of DAP-bound loci in HepG2. (B) Distance to the nearest TSS from the DAP-bound non-promoter loci in HepG2 and K562.
Figure 6
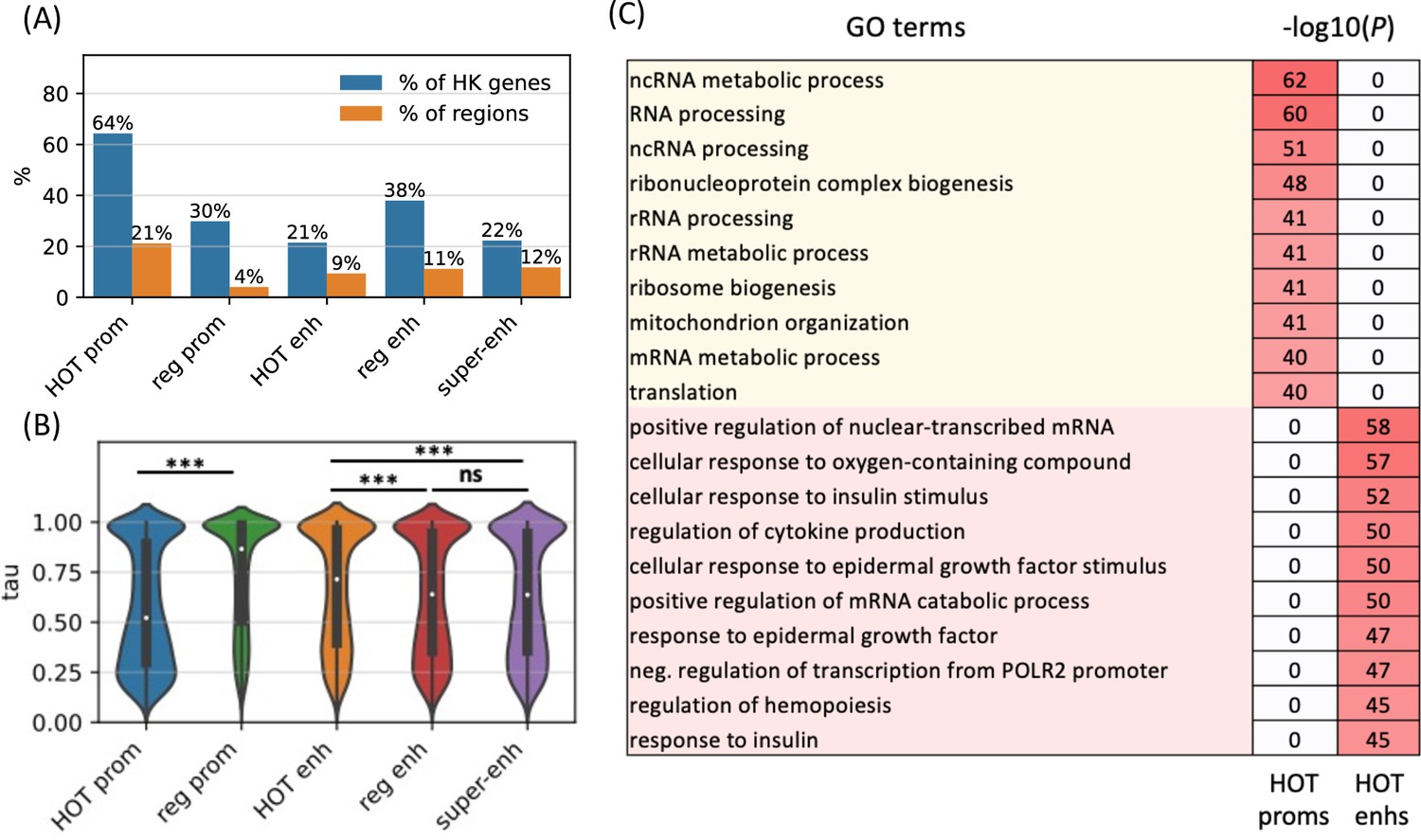
High-occupancy target (HOT) promoters are ubiquitous and HOT enhancers are tissue-specific.
(A) Fractions of housekeeping genes regulated by the given category of loci (blue). Fractions of the loci which regulate the housekeeping genes (orange). (B) Tissue specificity (tau) scores of the target genes of different types of regulatory regions. (C) GO enriched terms of HOT promoters and enhancers of HepG2. 0 values in the p-values columns indicate that the GO term was not present in the top 50 enriched terms as reported by the GREAT tool. All of the visualized data is generated from the HepG2 cell line.
Figure 7 with 1 supplement
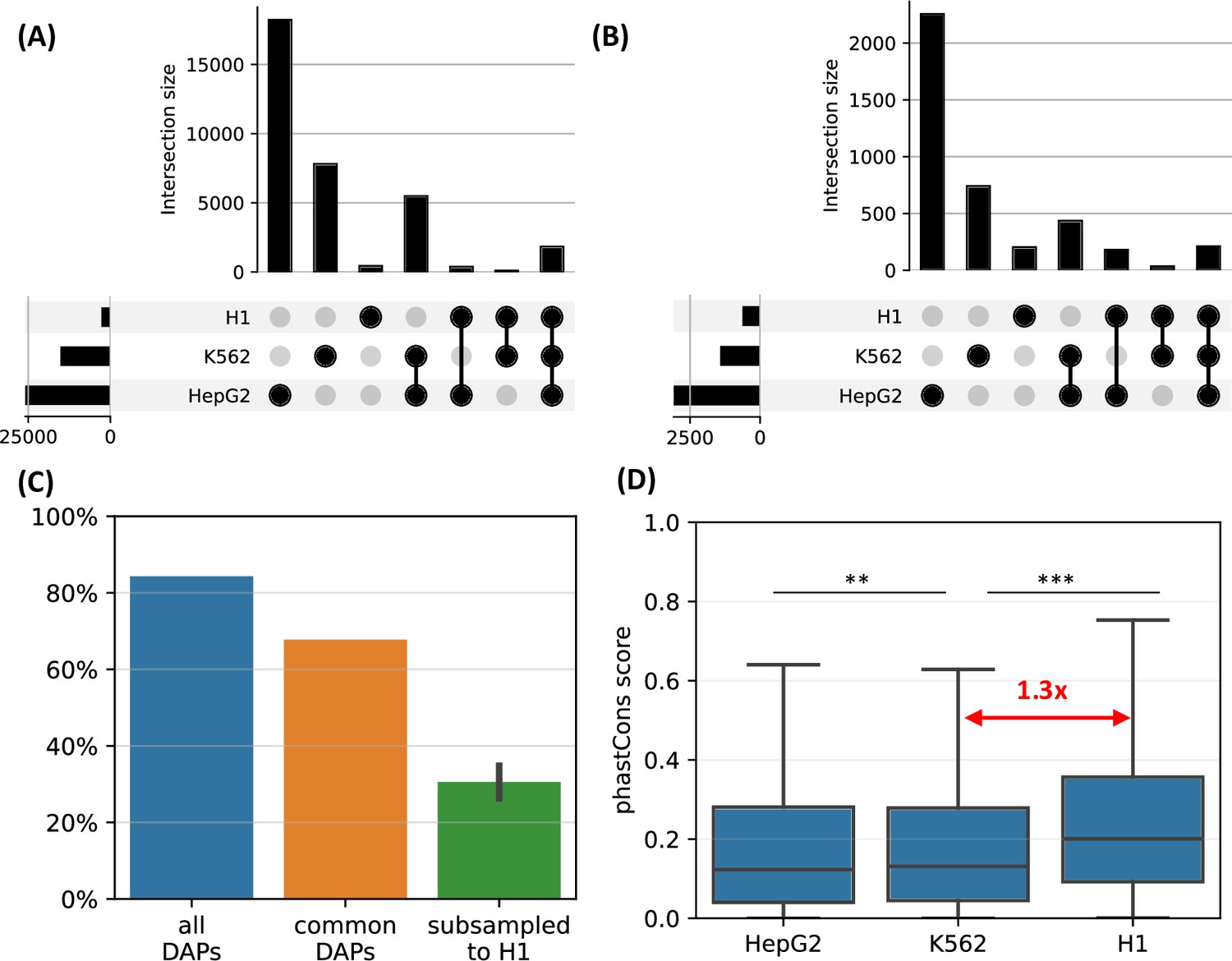
H1-hESC high-occupancy target (HOT) loci.
(A) Overlaps between the HOT loci of three cell lines. (B) Overlaps between the HOT loci of cell lines defined using the set of DNA-associated proteins (DAPs) available in all three cell lines. (C) Fractions of H1 HOT loci overlapping with that of the HepG2 and K562 using the complete set of DAPs, common DAPs, and DAPs randomly subsampled in HepG2/K562 to match the size of H1 DAPs set. (D) phastCons scores of HOT loci in HepG2, K562, and H1.
Figure 7—figure supplement 1
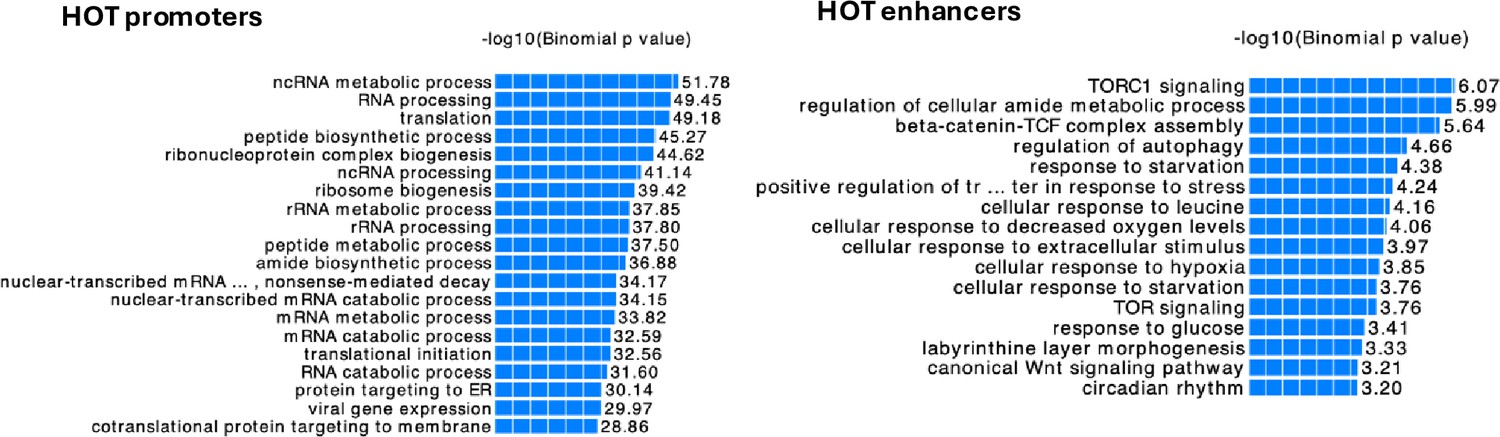
GO terms associated with the high-occupancy target (HOT) enhancers and promoters in H1-hESC.
Figure 8 with 1 supplement
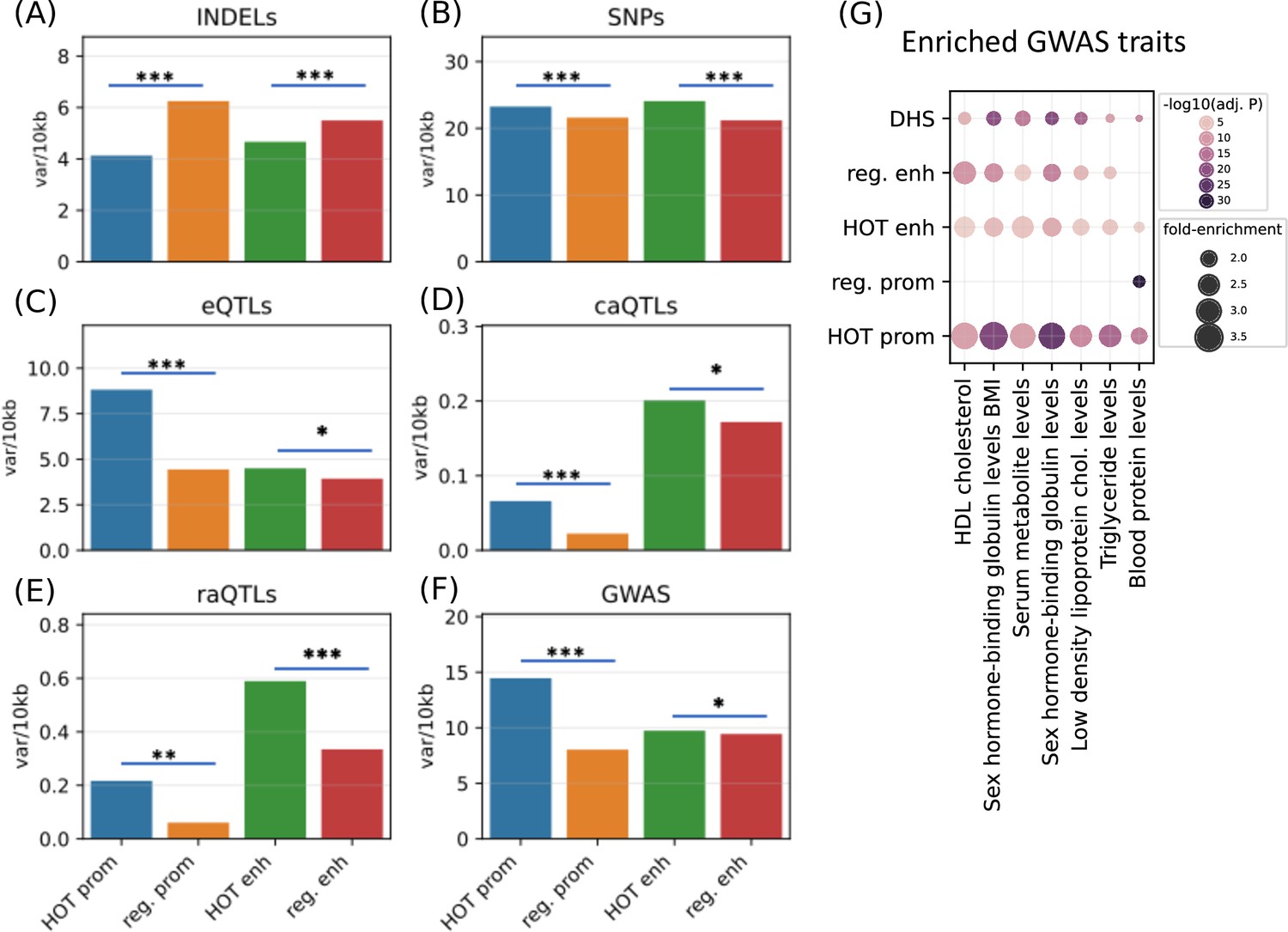
Densities of variants.
(A) Common INDELs (MAF>5%), (B) common SNPs (MAF >5%), (C) eQTLs, (D) chromatin accessibility QTLs (caQTLs), (E) reporter array QTLs (raQTLs), and (F) GWAS and LD (r2>0.8) variants in high-occupancy target (HOT) loci and regular promoters and enhancers. (G) Enriched GWAS traits in HOT enhancers and promoters. All of the visualized data is generated from the HepG2 cell line.
Figure 8—figure supplement 1
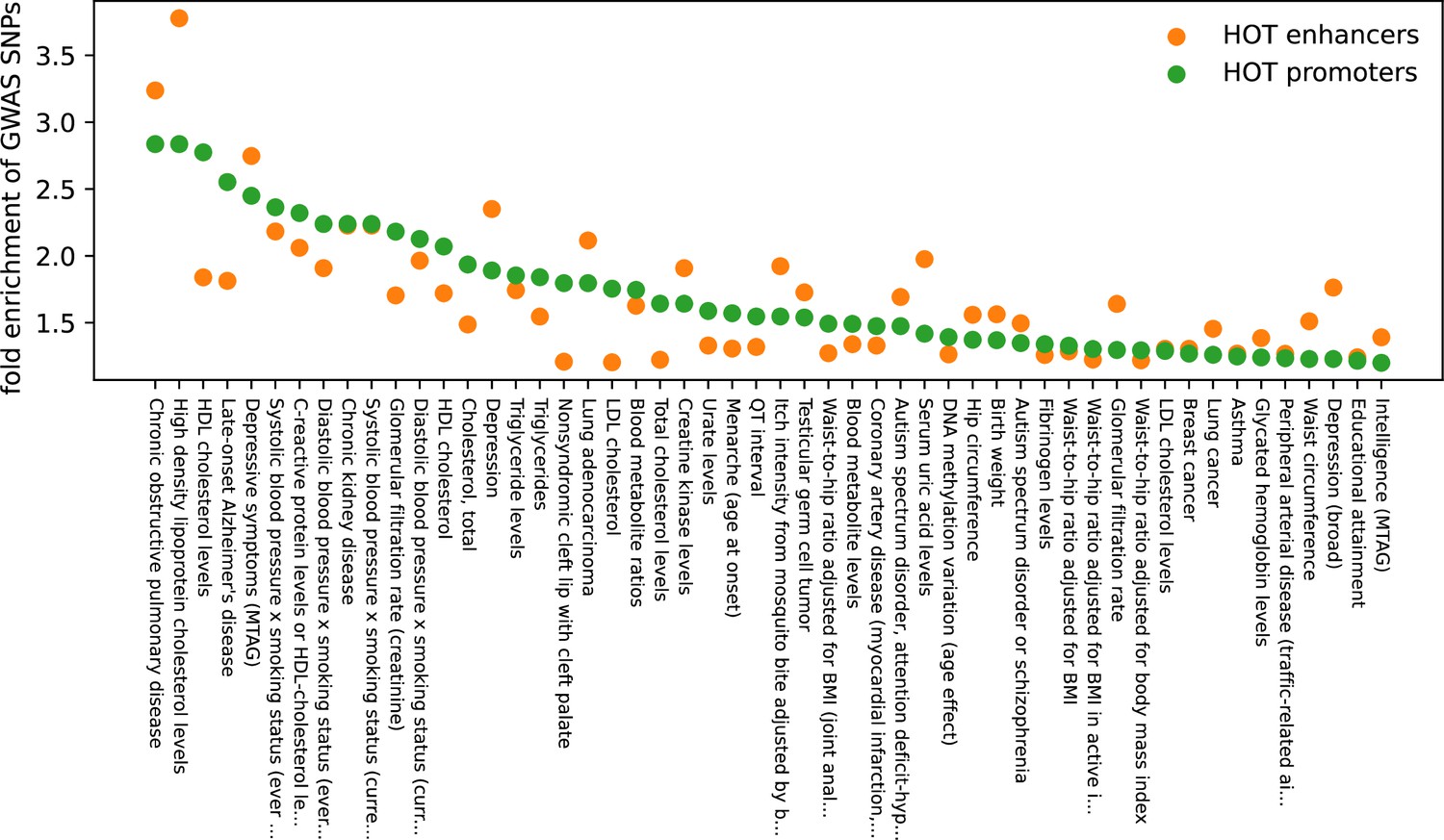
GWAS traits enrichment analysis filtered by unadjusted p-values (p-value<0.001).
Figure 9
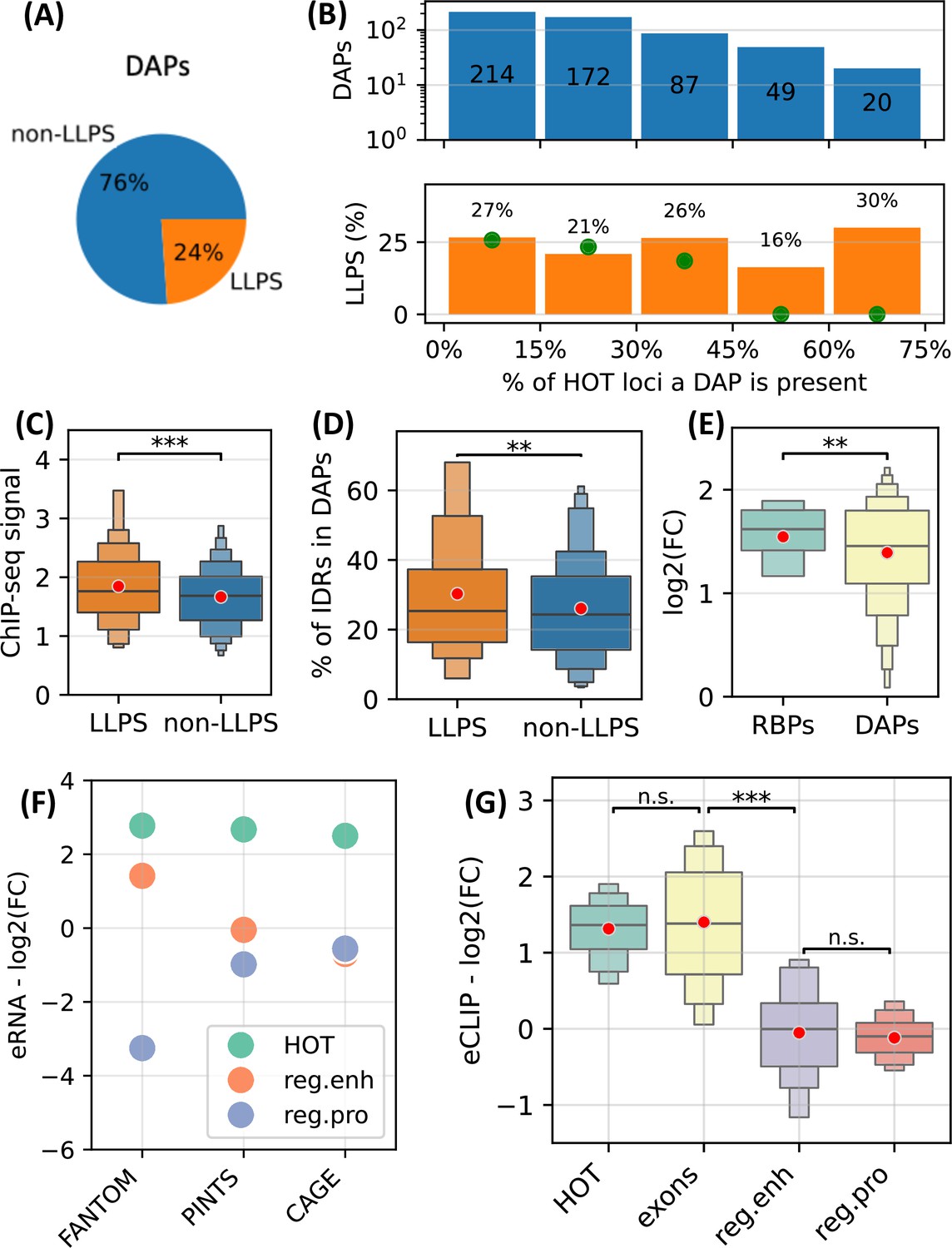
High-occupancy target (HOT) loci as transcriptional condensates.
(A) Fraction of DNA-associated proteins (DAPs) annotated as liquid-to-liquid phase separation (LLPS) proteins in CD-CODE database. (B) (Upper) Distribution of DAPs in HOT loci binned by the % of HOT loci they overlap with. (Lower) % of DAPs in the bins annotated as LLPS. Green points are the expected percentage values obtained by randomly shuffling the peaks in HOT loci 10 times. (C) Z-scores of ChIP-seq signal values of LLPS proteins and the rest of the DAPs in HOT loci. (D) % of the protein lengths predicted as IDRs (MobiDB) in LLPS proteins and the rest of the DAPs. (E) Enrichment of ChIP-seq peaks of RNA-binding proteins (RBP) and the rest of the DAPs. (F) Enrichment of FANTOM, PINTS, and CAGE regions in HOT, regular enhancers, and regular promoters. (G) Enrichment of eCLIP RBP-RNA interactions in HOT, exons, regular enhancers, and regular promoters. (E–G) Enrichment values are quantified as log2(fold-change) with ATAC-seq regions as a background. (C–E, G) Red dots represent the mean values of the boxplots.
Appendix 1—figure 1
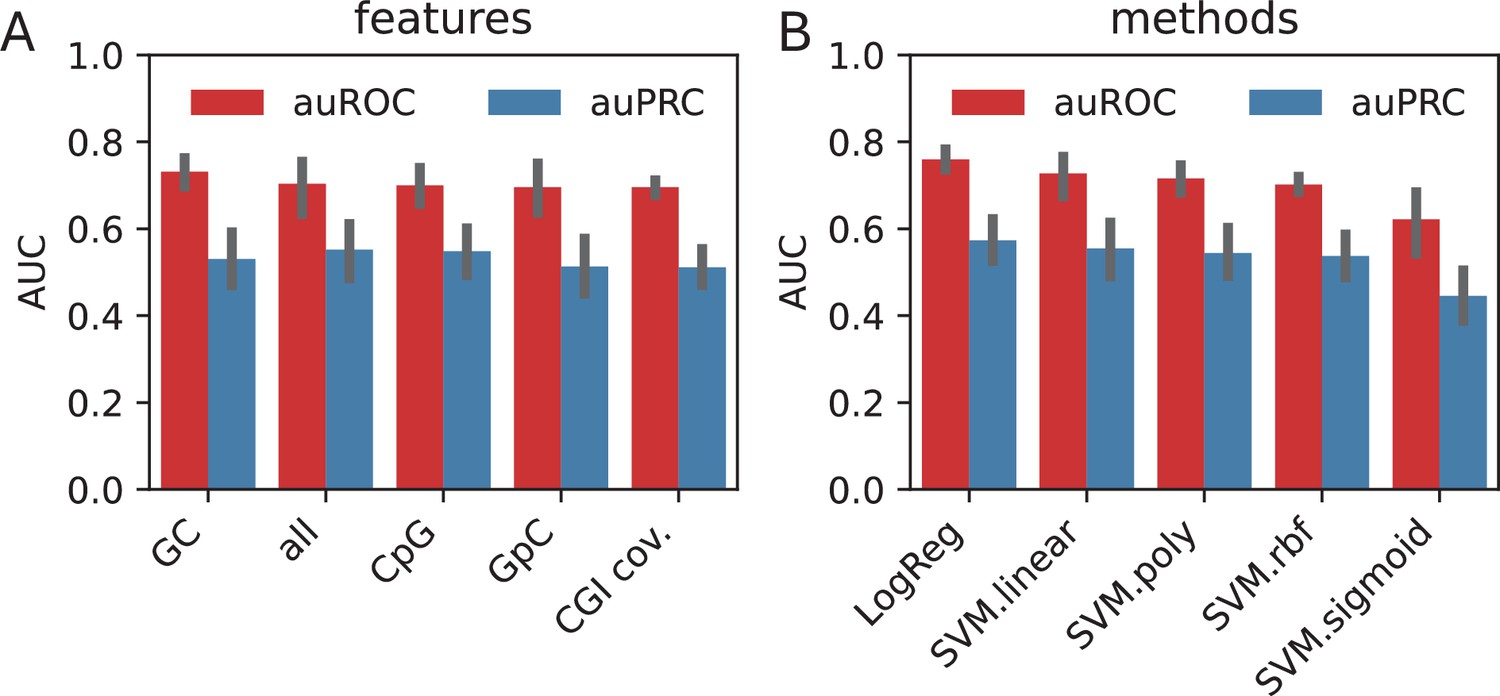
Classification of high-occupancy target (HOT) loci using the sequence features.
(A) Classification performances when each sequence feature (GC, GpC, CpG, CGI) is used separately and all of them simultaneously (all). Error bar variations across cell lines, classification methods, and control sets. (B) Classification performances of different methods. Error bar variations across cell lines, sequence features, and control sets.
Appendix 1—figure 2
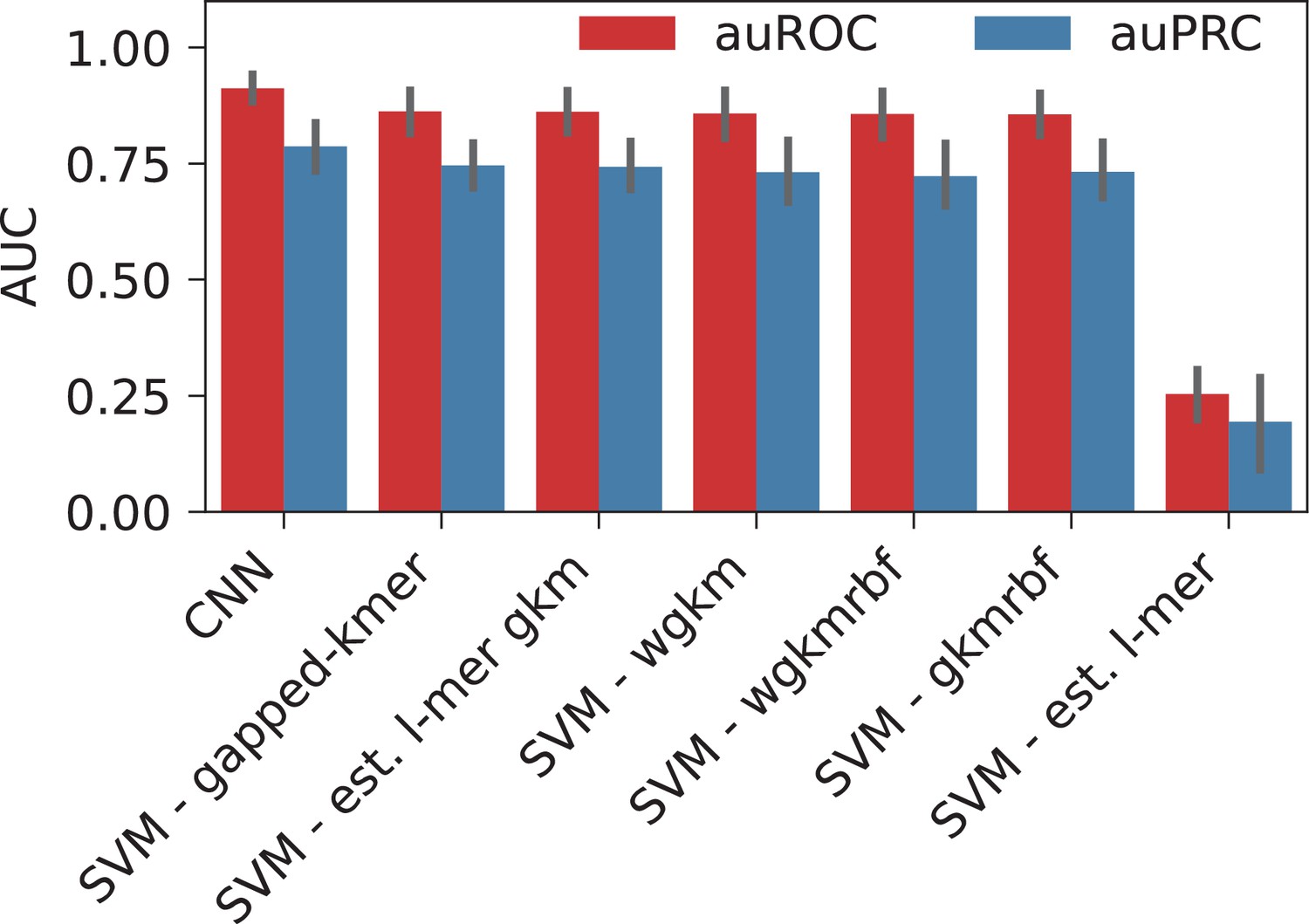
Classification of high-occupancy target (HOT) loci using the sequences directly.
Error bar variations across cell lines and control sets. See Appendix 1 – Sequence-based classification for details of methods used.
Author response image 1
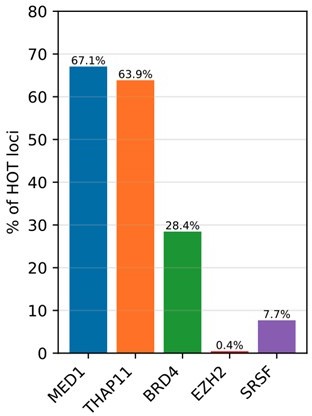
Author response image 2
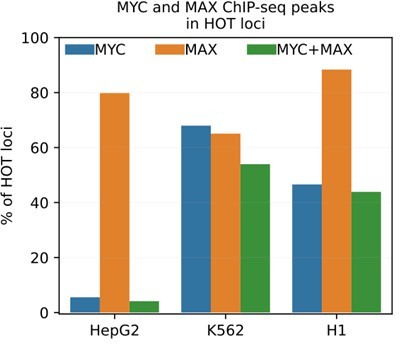
Author response image 3
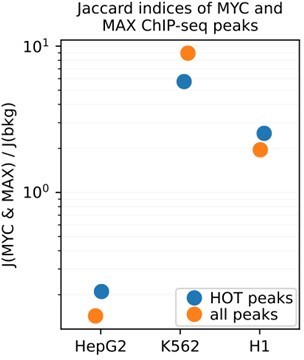
Author response image 4
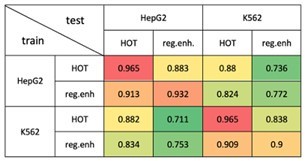
Tables
Table 1
Schema of classifying loci according to the number of bound DNA-associated proteins (DAPs).
The initial 4 bins are loci bound by DAPs increasing linearly from 1 to 5 (gray fields). The remaining 10 bins are defined by edge values increasing on a logarithmic scale from 5 to the maximum number of available DAPs in each cell line (orange and red fields) using the Numpy formula np.logspace(np.log10(5), np.log10(max_tfs), 11, dtype = int). HOT loci correspond to the last 5 bin edges (red fields).
| Bin edges (n=15) | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HepG2 | 1 | 2 | 3 | 4 | 5 | 7 | 12 | 19 | 31 | 48 | 77 | 122 | 192 | 304 | 480 |
| K562 | 1 | 2 | 3 | 4 | 5 | 7 | 11 | 16 | 24 | 37 | 55 | 82 | 123 | 184 | 275 |
| H1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 10 | 12 | 15 | 18 | 22 | 26 | 32 |
| Linear growth (n=4) | Logarithmic growth (n=10) | ||||||||||||||
Additional files
-
MDAR checklist
- https://cdn.elifesciences.org/articles/95170/elife-95170-mdarchecklist1-v1.docx
-
Supplementary file 1
Supplementary tables.
Columns are explained in each sheet. S1: List of ENCODE ChIP-seq datasets used in the study. S2: Coordinates of high-occupancy target (HOT) loci defined in three cell lines. S3: List of DNA-associated proteins (DAPs) clustered into four groups and their PPI enrichment summary statistics. S4: List of ultraconserved regions overlapping with HOT loci. S5: Comparison of HOT loci defined using ENCODE vs. Roadmap Epigenome Project datasets. S6: List of ChIP-seq datasets of RNA-binding protein used in the study. S7: List of eCLIP datasets of RNA-binding proteins used in the study.
- https://cdn.elifesciences.org/articles/95170/elife-95170-supp1-v1.xlsx
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Functional characteristics and computational model of abundant hyperactive loci in the human genome
eLife 13:RP95170.
https://doi.org/10.7554/eLife.95170.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}