By David Moulton, Senior Front-End Developer
I recently had the privilege of being involved in the ground-up rebuild of eLife. The whole stack was rebuilt from scratch using a microservices approach. The journal is building a reputation for innovation in science publishing, and it was a great opportunity to get involved in a green-field project to build best web practice into this arena. In this post I’ll be focusing on how we built the front end, covering our design strategy (Atomic Design using PatternLab) and principles as well as the nitty gritty of our front-end development process. A companion post is planned about how we integrated the pattern library into the site.
Note that the code examples throughout have been simplified for clarity.
Design systems and Atomic Design
During the design phase, I had many constructive conversations with our User Experience Designer, including prototyping some ideas to help decide on an overall approach to various things. He decided we needed a design system in order to retain both flexibility and design coherence not only for the initial build, but for what we might want to create in the future.
Building a design system requires a modular, hierarchical approach, and this approach is well supported by using a pattern library. Brad Frost’s Atomic Design principles are a natural fit with the designer’s concept for the design system, and so we chose Atomic Design as the mental model for our new site.
Atomic Design considers reusable, composable design patterns in a hierarchy described in terms of ‘atoms’, ‘molecules’ and ‘organisms’. An atom is the smallest unit of the design system, for example a button or a link. A more complex molecule pattern may be composed by assembling a collection of atom-level patterns, for example a teaser within a listing. An organism is more complex again and may comprise a number of included atoms and molecules.
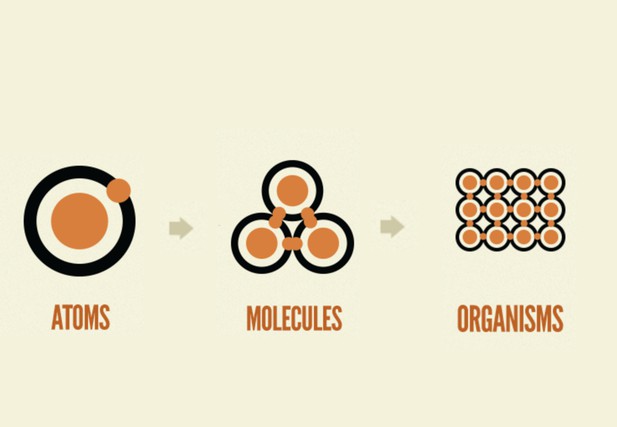
Modified from Brad Frost’s blog (CC-BY 4.0). This version of the image removes the mention of templates and pages.
We discovered that it’s not really worth trying to impose a strict hierarchy to distinguish molecules from organisms. Whilst trying generally to maintain the distinction that organisms are higher-order patterns than molecules, it’s okay for molecules to contain other molecules as well as atoms, and for organisms to contain organisms as well as lower-order patterns. With only three hierarchy levels to play with, we found we got most benefit from a pragmatic interpretation of the Atomic Design hierarchy.
PatternLab
Having decided on Atomic Design, we chose Brad Frost’s PatternLab as the natural tool to deliver it. PatternLab uses mustache templating and provides a web interface to display the patterns next to the markup that defines them, along with any optional annotations you may wish to supply.
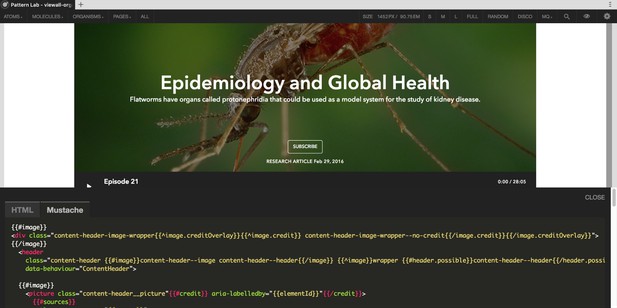
A variant of the content header pattern within PatternLab, showing the mustache code that generates it.
Since we started the project, other pattern library candidates have appeared that may have served just as well, for example Fractal, but they weren’t available then; PatternLab was the the best available tool at the time, and it has served us well.
Useful abilities of PatternLab include:
- You can view the template code and the compiled HTML next to its pattern.
- You can annotate a pattern with style-guide level information.
- You can search for patterns.
- It includes the option to view any PatternLab page without the PatternLab user interface in case it’s getting in the way.
- As well as dragging the viewport, you can set the effective viewport width in px or ems to see how patterns behave in that situation.
- It includes more general one-click buttons to set a general viewport width.
- DISCO MODE! This provides constant automatic changing of the viewport to random widths to see what breaks (music not included).
You can also break down Atomic Design levels to group patterns of a particular type within a level. This can make it easier to track down a pattern on the file system; for example, the molecule patterns might be grouped like this:
molecules
├── general
│ ├── ...
│ └── ...
├── navigation
│ ├── ...
│ └── ...
└── teasers
├── ...
└── ...PatternLab also has template and page-level composition. This enables you to build up sample pages, illustrating how the patterns might work together. From a technical perspective this is very useful for checking things, such as a baseline grid, that can’t be properly set on a pattern in isolation without observing it in a higher-level context. It’s also great for stakeholders’ engagement too! It can sometimes be difficult to communicate the value of a modular build approach to people who are used to thinking of the web in terms of pages, not patterns. Being able to mock up a page displaying real patterns can help communicate this.
Before starting work, we agreed a set of principles that would guide our approach to decision making along the way.
Principle: don’t lock out the readers
- Progressively enhance: a reader could be on any platform anywhere in the world. It’s vital that the content (mainly results of scientific research) and core functionality be available to everyone, regardless of platform, so we couldn’t mandate a high technological baseline in order to read the journal. For this reason, and to be a good web citizen generally, we would use a progressive enhancement approach to ensure that JavaScript is not required to use the site: you get an enhanced experience if it’s available, but content and core functionality does not require it.
- Make it responsive: it should be a given these days, but it’s worth mentioning anyway that the website should be responsive, so it will display appropriately, whatever the size of the users’ screens.
- Make it performant: no one likes waiting for a web page to load and, if it takes too long, users will bail. If a user is on a narrow bandwidth or a high-latency connection, then any performance problems are exacerbated. Data costs vary across the world, and we don’t want it to cost more in data charges than necessary to read our content. Performance was considered throughout the build, using ideas of a performance budget, techniques such as responsive images, allowing for the HTTP/2 serving of smaller resources, and not using a library unless we needed it.
- Make it accessible: it’s vital that our site content is accessible to all to read and use.
Principle: maintain the value of the pattern library
One of the aims of a pattern library is to be the canonical source of truth for the design and front-end implementation of the design patterns. This is the case at launch, but it’s common for the value of a pattern library to drop dramatically over time if it’s not easy to update, or it’s difficult to do so in a way that maintains the value of the underlying design system.
After launch, pattern libraries are often susceptible to ‘pattern rot’ when, for whatever reason, the patterns used on the live website are updated but the pattern library is not. This usually occurs when there is some kind of copy/paste step necessary in order to apply an update from a pattern library pattern to its version on the live site. This step needs to be short-circuited only once with an update being applied only to the live site, then the pattern library and the live site would diverge. Once this happens, the pattern library is no longer the canonical source of truth, so you can no longer have complete confidence that what you see in the pattern library is what you get on the site. Much of the work that went into building the pattern library becomes lost.
In summary, for a pattern library to retain its value, it must:
- Be built in such a way as to reflect the intent of the design system.
- Be easy to maintain.
- Be as easy as possible to integrate into the website it’s defining the patterns for (avoid ‘pattern rot’).
Integration is the hardest problem to solve and has been the holy grail for pattern libraries for years. We managed to crack this, but you’ll have to wait for the companion post to find out how!
Our aims for the front-end build
Before we started writing code, we documented our lower-level aims, based on the principles we’d already decided upon. Our priority of concerns, in decreasing order, were:
- Access.
- Maintainability.
- Performance (with the assumption that we would not let maintainability negatively affect it).
- Taking advantage of browser capabilities.
- Visual appeal.
We also documented some of the techniques we’d use:
- Progressive enhancement.
- min-width media queries.
- Small-screen-first responsive images.
- Only add libraries as needed.
Identifying and naming the patterns
Before we could build any patterns, we needed to identify what things we were building and decide how to talk about them: without a common vocabulary, things could fall apart very quickly. So, embarking on building a brand new look for an online-only journal, we took a large slice of irony pie and started by printing off wireframes of all the patterns.
Having cut out each pattern, we took up most of the floor of the room we were in, laying them out to take stock of what we had. We grouped similar patterns together, enabling us to distinguish those that were essentially duplicates from those we could treat as variants of the same underlying pattern, and to confirm which were actually distinct patterns.

Once distinct patterns were identified, we opened up the room to anyone who wanted to help us agree names for each pattern. Fresh minds at this point helped us get better names.
We thought the whole process would take a couple of hours, but it took most of a day to complete. The benefits were well worth the time: it was a great way to expose many hidden assumptions, identify gaps in thinking and discover inconsistencies that had crept in during the design process. If we hadn’t done the exercise, all those problems would still exist, but they’d have only manifested later when they’d be more expensive in time and effort to fix.
Process
With two front-end developers liaising closely with the Product team (the designer and the product owner), and facilitated by our tireless scrum master, we decided on two-week scrum sprints, managing the scrum board in Trello.
The fact that we were using progressive enhancement affected the tickets we created: each pattern had a first pass ticket for building its markup and CSS. We used a checklist to manage the work for each ticket:
- Semantic HTML is built.
- CSS is applied correctly.
- Core content and functionality is available without JavaScript or CSS.
- Accessibility testing performed.
- Browser testing performed.
If a pattern had some behaviour, then a second pass ticket was created for building its JavaScript. Each second pass ticket had the checklist:
- JavaScript tests written.
- JavaScript behaviour written.
- JavaScript tests pass.
Some patterns have variants (a variant is a different way the pattern could be displayed, depending on the context). For these, the one ticket described building all the variants. They would all have to be considered at the same time in order to build them in a way that works for all of the variants anyway, so it didn’t make sense to split them up.
Individual tickets had additional, pattern-specific checklist items as necessary.
The Trello board was initially created with the columns:
- Backlog (all tickets start here).
- Sprint items (committed to in the current sprint).
- In progress (in active development).
- In testing (in browser/accessibility testing).
- In review (being reviewed).
- Done (finished).
We created a feature branch in the Git repository for each ticket as we started work on it. Once a ticket’s code was approved, it was merged into the GitHub master branch from the feature branch via pull request.
We discovered in the first retrospective that the Product team was not feeling sufficiently involved in the review process for a pattern, resulting in patterns sometimes being classed as done when they weren’t. This was quickly addressed in two ways:
1. The addition of two more columns to separate out the product review from the technical review. The board columns were then:
- Backlog (to be done).
- Sprint items (committed to in the current sprint).
- In progress (in active development).
- For feedback (ready for product review).
- Feedback provided (reviewed by Product).
- In testing (in browser/accessibility testing).
- In review (in technical review).
- Done (finished).
2. The addition of an approval checklist, with each Product team member having a dedicated box to check to indicate sign off.
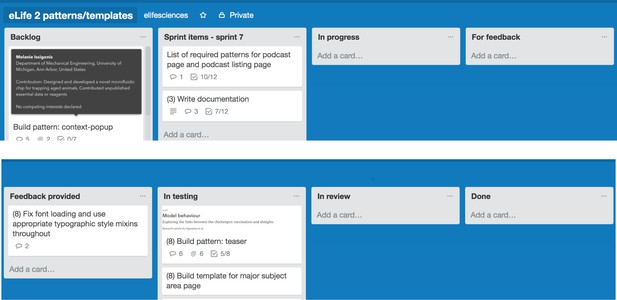
With the revised board, once the pattern was built and ready for product approval it was moved from ‘in progress’ to ‘for feedback’. The Product team members then specified any changes to be made or checked their name off the checklist if they were happy with the pattern as it was. They then moved the cards to ‘feedback provided’. Tickets were able to go around the ‘for feedback’ -> ‘feedback provided’ -> ‘for feedback’ loop a number of times until the pattern was right. Once a ticket arrived in ‘feedback provided’ with all Product team members’ approval boxes checked, the pattern was ready for testing.
Build scope
Currently, the pattern library defines just under 100 patterns. Each pattern comprises:
- Exactly one .scss file.
- Exactly one .mustache file.
- One or more .json files, one per pattern variant.
- Zero or one .js files, built in the second pass.
- Exactly one .yaml file to define the data structure. This is helpful when integrating the patterns into the site and will be expanded on in the forthcoming companion post.
Each pattern’s accessibility was tested using Khan Academy’s tota11y for accessibility testing in the browser. We used Browserstack for browser/device testing.
We started off with a minimal build pipeline, originally in Grunt (we switched to Gulp when we introduced JavaScript, see below), knowing that we could add to it when we needed to.
SCSS
Although PatternLab can compile SCSS, we elected not to do this as we wanted to control the SCSS compilation with the build pipeline. The first iteration was only for linting and compiling SCSS and moving asset files where they needed to be for the PatternLab server to display them correctly.
We agreed a few simple style rules with the aim of keeping the SCSS maintainable in the longer term:
- One SCSS file per pattern.
- Use Harry Robert’s flavour of BEM (Block, Element, Modifier) for CSS class naming. This works well with a pattern-based approach, as the root of each pattern can define a BEM block. Coupled with the decision to have one SCSS file per pattern, this namespacing kept the separation of the styles for individual patterns nice and clean.
- Keep selector specificity as low as possible, and with a maximum selector nesting of three (not including pseudo elements). As selectors need only to start from the root of a pattern (or deeper), this seemed a pragmatic maximum. We agreed that we’d increase it if we really, really needed to, but up to now we haven’t had to.
- Don’t use ‘&’ as partial completion for a class name, as it makes searching/refactoring across a code base more error-prone.
- Avoid @extends; use mixins instead for greater flexibility.
- Only mixins that are completely pattern-specific may live in a pattern’s SCSS file; other mixins must live in higher-level files (see Architecture).
- List property names alphabetically.
We implemented style linting with stylelint.
We settled on the following architectural approach to try to keep the design system reasonably easily maintainable:
- Meaningful values for the design system: colours, font sizes, quantities for spacing and element sizing, media query breakpoints, transition parameters and so on are defined in the variables partial.
- For a sensible reset starting point we included Nicholas Gallagher’s normalise CSS stylesheet as an SCSS partial.
- Our own base styles and any necessary overrides to normalise are defined in the normalise-overrides partial.
- The typography component of the design system is defined in the typographic-hierarchy partial: this contains numerous mixins responsible for enforcing a consistent typographic style across the site.
- The grid partial contains all SCSS and mixins required for both the horizontal and baseline grid systems.
- The mixins partial contains all other mixins.
These are imported along with the pattern-specific SCSS files to create the main build CSS file like this:
build.scss
├── base.scss
│ ├── _definitions
│ │ ├── _variables
│ │ ├── _mixins
│ │ └── _typographic-hierarchy
│ ├── reset
│ │ ├── _normalize
│ │ ├── _normalize-overrides
│ └── _grid
├── pattern-1.scss
├── pattern-2.scss
├── pattern-3.scss
├── ...
└── pattern-n.scssEach individual [pattern].scss file also imports the definitions partial so it has access to all the necessary shared knowledge of the design system as distilled into the variables and various mixins.
With an eye on delivery over HTTP/2, we ensured that we could produce individual pattern-level CSS files as well as one main stylesheet for traditional HTTP/1.1 delivery.
Organising the typography
The designer documented the typographical part of the design system as a hierarchy of definitions. The lowest level is used to set relevant variables in the variables partial, and set the base styles in normalise-overrides partial.
| Style name | Default narrow screen | Media query |
|---|---|---|
| Body | PT Serif 16px/1.5 space after 24px | None |
| H1 | Avenir Next Demi Bold 24px/1.3 | Font-size 36px |
| H2 | Avenir Next Demi Bold 21px/1.3 space after 5px | None |
| ... | ... | ... |
The media query column specifies what (if any) change occurs when the viewport is wider than the relevant site breakpoint. Note that the breakpoints themselves are not specified here, to keep things loosely coupled.
These base styles are then used as part of the specification for the next level up:
| Style name | Default narrow screen | Media query |
|---|---|---|
| Title-lg | PT Serif 16px/1.5 space after 24px | None |
| Title-md | h1 font-size 42px | Font-size 54px |
| Title-sm | h1 font-size 30px | Font-size 44px |
| Title-xs | h1 | Font-size 36px |
| ... | ... | ... |
These all specify different title sizes (which one gets applied depends on how long the title is).
Typographical styles are defined for all aspects of the design, like this tiny fraction of the set:
| Style name | Default narrow screen | Media query |
|---|---|---|
| CONTENT LABEL [grey] | Avenir Next Demi Bold, 11px/1 | None |
| SUBJECT LABEL [blue] | Avenir Next Demi Bold, 11px/1 | None |
| Article title (main list) | h2 | None |
| Article title (side list) | PT Serif Bold 16px | None |
| ... | ... | ... |
All these definitions are captured in mixins within typographical-hierarchy. For example, for the two labels, we abstract out the common aspects:
@mixin _label-typeg() {
font-family: $font-secondary;
font-weight: normal;
@include font-size-and-vertical-height(11);
letter-spacing: 0.5px;
text-transform: uppercase;
}and then create a mixin for each label type, based on it:
@mixin label-content-typeg() {
@include _label-typeg();
color: $color-text-secondary; // grey
}
@mixin label-subject-typeg() {
@include _label-typeg();
color: $color-primary; // blue
}Note that all typographical style mixin names include 'typeg' for clarity when viewed out of context.
In the design system specification, all the patterns have their typography defined in terms of these typographical style names. Often a particular style name is used for more than one pattern. With this approach, we can easily apply the correct typographical style to the pattern’s CSS via the mixins and, at the same time, keep the design system highly maintainable. If a particular named style is updated, then a simple update to one ‘typeg’ mixin will permeate to all parts of the system that use it.
Note: these examples are taken from an early draft of the spec and the final values used on the site may have changed – although the system defining them hasn’t, indicating that it’s working well!
Markup
Compilation of the mustache templates with their JSON data files is handled by PatternLab, producing a user-friendly and, to some extent, configurable web view of the patterns.
A basic pattern with no variants has exactly one mustache template and one corresponding JSON data file.
For a more complex pattern that has variants, an example of each variant can be produced by supplying a separate JSON file for each. For example, the teaser pattern has 13 variants (an extreme case; most variant patterns have fewer than a handful). It has only one mustache file, but 13 associated JSON files:
.
├── teaser.mustache
├── teaser~05-main.json
├── teaser~10-main-small-image.json
├── teaser~15-main-big-image.json
├── teaser~20-secondary.json
├── teaser~25-secondary-small-image.json
├── teaser~30-secondary-big-image.json
├── teaser~35-related-item.json
├── teaser~40-basic.json
├── teaser~45-main-event.json
├── teaser~50-secondary-event.json
├── teaser~55-grid-style--labs.json
├── teaser~60-grid-style--podcast.json
└── teaser~65-main--with-list.jsonPatternLab uses the ~ in a filename to identify a variant. The numerals in the filenames control the ordering of the presentation of the variants.
Sometimes, when coming to build a pattern with variants, we discovered that one or more variants required a significant change to the markup of the main pattern, which suggested a new pattern rather than just a variant. In these cases, we created the ticket(s) for it and put them into the backlog, moving the appropriate spec from the old to the new ticket.
Images
Scholarly content contains a lot of figures, mainly in the form of images. We use responsive images techniques (<picture>, srcset and sometimes sizes) to stop the browser downloading more image data than it needs. For example, the compiled HTML from the captioned-asset pattern’s mustache template looks like this:
<figure class="captioned-asset">
<picture class="captioned-asset__picture">
<source
srcset="
/path-to-1076-px-wide-image 1076w,
/path-to-538-px-wide-image 538w"
type="image/jpeg" />
<img
src="/path-to-538-px-wide-image"
alt=""
class="captioned-asset__image" />
</picture>
<figcaption class="captioned-asset__caption">
<h6 class="caption-text__heading">Title of the figure caption</h6>
<div class="caption-text__body">The figure caption</div>
<span class="doi doi--asset">The DOI link</span>
</figcaption>
</figure>Note the empty alt attribute: as the image is within a <figure>, the <figcaption> provides the description.
To handle the large amount of image variants that can be required when implementing responsive images, we used the International Image Interoperability Framework (IIIF) to serve most of our images.
Extended build pipeline
When we came to build the patterns’ behaviours, we needed to add JavaScript linting, transpiling and test running to the build pipeline. It quickly became apparent that Gulp was much more flexible than Grunt for this, so we switched from a wild boar to a huge caffeinated beverage (and the caffeine would come in handy).
We author in ES6, and transpire using Babel. Linting is performed with a mixture of jshint and jscs, although there is a pending upgrade to eslint.
Pattern behaviour with JavaScript
A pattern’s JavaScript behaviour is defined in a discrete component with the same name as the pattern. This JavaScript component is referenced from the root element of the pattern’s mustache template by the attribute:
data-behaviour="ComponentName".For example, the content-header pattern has its associated behaviour defined in the ContentHeader class, which is found in the ContentHeader.js file. The content-header.mustache template starts with:
<div... data-behaviour="ContentHeader">...which causes this HTML element to be passed as an argument to the class constructor in ContentHeader.js when the page’s JavaScript loads and runs:
// 1. Load the components
const Components = {};
Components.ContentHeader = require('./components/ContentHeader');
// ... load more components ...
// 4. This bit does the actual initialising
function initialiseComponent($component) {
const handler = $component.getAttribute('data-behaviour');
if (!!Components[handler] && typeof Components[handler] === 'function') {
new Components[handler]($component, window, window.document);
}
$component.dataset.behaviourInitialised = true;
}
// 2. Find all patterns in the document that have declared a js component
const components = document.querySelectorAll('[data-behaviour]');
// 3. Initialise each component with the HTMLElement that declared it
if (components) {
[].forEach.call(components, (el) => initialiseComponent(el));
}This applies the pattern’s JavaScript behaviour to each instance of the pattern on the page.
Notice we’re additionally passing in the window and document objects to the component’s constructor. This dependency injection enables us to mock these objects and subsequently write better tests.
JavaScript testing
We test in the browser using the tripod of the mocha test framework, the chai assertion library, and with sinon for providing spies, mocks and stubs. At the moment we’re using phantomjs as the test environment but, now this is not currently under active maintenance, we’re looking to switch to using puppeteer with headless Chrome.
For each pattern under test there are two files: the spec file and the fixture file. The spec file contains the tests. The fixture file contains the HTML of the pattern whose component is under test. This is obtained by finding the pattern’s compiled HTML generated by PatternLab and manually copying across the relevant code.
By way of example, these are the guts of the fixture file for the ToggleableCaption component:
<!-- Results of test run end up here -->
<div id="mocha"></div>
<!-- This is the test fixture -->
<div data-behaviour="ToggleableCaption" data-selector=".caption-text__body">
<div class="caption-text__body">
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. In interdum, metus quis sodales pharetra, odio justo
blandit mi, at porta augue felis sit amet metus. Aliquam porta, justo dapibus vulputate aliquet, arcu quam tempor
metus, et aliquam nisi nunc in est. Cras vitae leo pretium, tincidunt nisi ac, varius neque. Donec nec posuere
sem. Integer felis risus, sagittis et pulvinar pretium, rutrum sit amet odio. Proin erat purus, sodales a gravida
vitae, malesuada non sem. Integer semper enim ante. Donec odio ipsum, ultrices vel quam at, condimentum eleifend
augue. Pellentesque id ipsum nec dui dictum commodo. Donec quis sagittis ex, sit amet tempus nisi. Nulla eu tortor
vitae felis porta faucibus in eu leo. Donec ultrices vehicula enim, quis maximus nulla rhoncus sed. Vestibulum
elementum ligula quis mi aliquet, tincidunt finibus mi hendrerit.</p>
</div>
</div>
<!-- Load the test frameworks -->
<script src="../node_modules/mocha/mocha.js"></script>
<script src="../node_modules/chai/chai.js"></script>
<script src="../node_modules/sinon/pkg/sinon.js"></script>
<!-- Initialise the test suite -->
<script>mocha.setup('bdd')</script>
<!-- Load the spec file -->
<script src="build/toggleablecaption.spec.js"></script>
<!-- Run the tests -->
<script>
mocha.run();
</script>We’ve found that keeping the test fixtures up-to-date can be difficult, because it takes a developer to remember to re-copy and paste the HTML from the compiled mustache pattern template every time a pattern’s source or source-generating JavaScript is updated.
The tests are run under Gulp using gulp-mocha-phantomjs.
Where is it, tho’?
The website using the patterns is https://elifesciences.org/.
All the code for the pattern library is available on GitHub under the MIT license at https://github.com/elifesciences/pattern-library.
The PatternLab pattern library generated by this code is at https://ui-patterns.elifesciences.org/.
Lessons learned
- Take the time to agree your principles and build aims up front. Set the expectations that derive from these in the wider team, so no one’s surprised when you start challenging demands for moarLibrareez, etc.
- When following Atomic Design principles, don’t worry too much about strict molecule/organism hierarchy: get it as good as you can, but a slightly fuzzy but usable system is better than a system that’s strictly correct but horrible to use.
- Implementing a design system requires excellent communication between designers and front-end developers. A designer who understands front-end code, and developers with a design eye, both really help with this: the more shared context, the better the mutual understanding.
- Regularly review your process: if we hadn’t had the retrospective that uncovered the frustrations of the Product team over sign off, work quality could have been reduced and relationships strained.
- Don’t be afraid to iterate on the patterns and set the expectation early that this is a good thing. More complex patterns and/or patterns that have multiple variants may need a few shots at them to make them work. Remember that if you’re implementing a design system, the patterns don’t only have to work individually, but they have to be easily maintainable along with the design system. It’s worth spending more time to iterate to get it right at this stage, because fundamental changes later are bound to be more expensive in time, effort and complexity.
- Concentrating the design system typography in one place made thinking about it, talking about it and subsequently maintaining it a lot easier than it might otherwise have been.
- TDD FTW! The few times we didn’t use test-driven development for the JavaScript, it was always painful to fill in the gaps afterwards.
- Grunt is good to get up and running quickly for simple build pipelines, but if you’re trying to do more complicated things, it’s probably easier to use Gulp: Gulp build files are written in JavaScript, which is more versatile and less confusing than trying to wrangle a Grunt config JavaScript object for a complex build pipeline.
For the future, it’d be great to improve the JavaScript loader so that only the components on a particular page are loaded, and then initialisation can occur after these loads have completed.
Also, because we have a 1:1 relationship between JavaScript component and pattern, we should be able to support HTTP/2 delivery of individual JavaScript assets, only providing what is required to the client (once we’ve upgraded our CDN).
In conclusion
This is one of the most rewarding projects I’ve worked on: a truly honourable combination of open-source code enabling open-access science publishing. There’s loads more I could say, but this post is already long enough. Be sure to check back soon for the companion post about how we solved ‘pattern rot’ through enabling use of the patterns we built in PatternLab directly in the website.
If you have feedback or questions about our approach, please contact David by email via innovation [at] elifesciences [dot] org.
The original version of this article was published at http://decodeuri.net/2017/11/17/building-a-pattern-library-for-scholarly-publishing/. This post was updated with minor edits on January 5, 2018.
Would you like to get involved in developing for open research communication? Register your interest to participate in the eLife Innovation Sprint (May 2018) or send a short outline of your idea for a Labs blogpost to innovation [at] elifesciences [dot] org.
For the latest in innovation, eLife Labs and new open-source tools, sign up for our technology and innovation newsletter. You can also follow @eLifeInnovation on Twitter.



