Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorRoshan CoolsDonders Institute for Brain, Cognition and Behaviour, Radboud University Nijmegen, Nijmegen, Netherlands
- Senior EditorMichael FrankBrown University, Providence, United States of America
Reviewer #1 (Public review):
Summary:
The authors use a sophisticated task design and Bayesian computational modeling to test their hypothesis that information generalization (operationalized as a combination of self-insertion and social contagion) in social situations is disrupted in Borderline Personality Disorder. Their main finding relates to the observation that two different models best fit the two tested groups: While the model assuming both self-insertion and social contagion to be present when estimating others' social value preferences fit the control group best, a model assuming neither of these processes provided the best fit to BPD participants.
Strengths:
The revisions have substantially strengthened the paper and the manuscript is much clearer and easier to follow now. The strengths of the presented work lie in the sophisticated task design and the thorough investigation of their theory by use of mechanistic computational models to elucidate social decision-making and learning processes in BPD.
Weaknesses:
Some critical concerns remain after the first revision, particularly regarding the use of causal language and the clarity of the hypotheses and results, specified in the points below.
(1) The authors frequently refer to their predictions and theory as being causal, both in the manuscript and in their response to reviewers. However, causal inference requires careful experimental design, not just statistical prediction. For example, the claim that "algorithmic differences between those with BPD and matched healthy controls" are "causal" in my opinion is not warranted by the data, as the study does not employ experimental manipulations or interventions which might predictably affect parameter values. Even if model parameters can be seen as valid proxies to latent mechanisms, this does not automatically mean that such mechanisms cause the clinical distinction between BPD and CON, they could plausibly also refer to the effects of therapy or medication. I recommend that such causal language, also implicit to expressions like "parameter influences on explicit intentional attributions", is toned down throughout the manuscript.
(2) Although the authors have now much clearer outlined the stuy's aims, there still is a lack of clarity with respect to the authors' specific hypotheses. I understand that their primary predictions about disruptions to self-other generalisation processes underlying BPD are embedded in the four main models that are tested, but it is still unclear what specific hypotheses the authors had about group differences with respect to the tested models. I recommend the authors specify this in the introduction rather than refering to prior work where the same hypotheses may have been mentioned.
(3) Caveats should also be added about the exploratory nature of the many parameter group comparisons. If there are any predictions about group differences that can be made based on prior literature, the authors should make such links clear.
(4) I'm not sure I understand why the authors, after adding multiple comparison correction, now list two kinds of p-values. To me, this is misleading and precludes the point of multiple comparison corrections, I therefore recommend they report the FDR-adjusted p-values only. Likewise, if a corrected p-value is greater than 0.05 this should not be interpreted as a result.
(5) Can the authors please elaborate why the algorithm proposed to be employed by BPD is more 'entropic', especially given both their self-priors and posteriors about partners' preferences tended to be more precise than the ones used by CON? As far as I understand, there's nothing in the data to suggest BPD predictions should be more uncertain. In fact, this leads me to wonder, similarly to what another reviewer has already suggested, whether BPD participants generate self-referential priors over others in the same way CON participants do, they are just less favourable (i.e., in relation to oneself, but always less prosocial) - I think there is currently no model that would incorporate this possibility? It should at least be possible to explore this by checking if there is any statistical relationship between the estimated θ_ppt^m and 〖p(θ〗_par |D^0).
"To note, social contagion under M3 was highly correlated with contagion under M1 (see Fig S11). This provides some preliminary evidence that trauma impacts beliefs about individualism directly, whereas trauma and persecutory beliefs impact beliefs about prosociality through impaired trait mentalising" - I don't understand what the authors mean by this, can they please elaborate and add some explanation to the main text?
Reviewer #2 (Public review):
Summary:
The paper investigates social-decision making, and how this changes after observing the behaviour of other people, in borderline personality disorder. The paper employs a task including three phases, the first where participants make decision on how to allocate rewards to oneself and to a virtual partner, the second where they observe the same task performed by someone else, and a third phase equivalent to phase one, but with a new partner. Using sophisticated computational modelling to analyse choice data, the study reports that borderline participants (versus controls) are more certain about their preferences in phase one, used more neutral priors and are less flexible during phase two, and are less influenced by partners in phase three.
Strengths:
The topic is interesting and important, and the findings are potentially intriguing. The computational methods employed is clever and sophisticated, at the cutting edge of research in the field.
Weaknesses:
The paper is not based on specific empirical hypotheses formulated at the outset, but, rather, it uses an exploratory approach. Indeed, the task is not chosen in order to tackle specific empirical hypotheses. This, in my view, is a limitation since the introduction reads a bit vague and it is not always clear which gaps in the literature the paper aims to fill. As a further consequence, it is not always clear how the findings speak to previous theories on the topic.
Reviewer #3 (Public review):
In this paper, the authors use a three-phase economic game to examine the tendency to engage in prosocial versus competitive exchanges with three anonymous partners. In particular, they consider individual differences in the tendency to infer about others' tendencies based on one's preferences and to update one's preferences based on observations of others' behavior. The study includes a sample of individuals diagnosed with borderline personality disorder and a matched sample of psychiatrically healthy control participants.
On the whole, the experimental design is well-suited to the questions and the computational model analyses are thorough, including modern model-fitting procedures. I particularly appreciated the clear exposition regarding model parameterization and the descriptive Table 2 for qualitative model comparison. In the revised manuscript, the authors now provide a more thorough treatment of examining group differences in computational parameters given that the best-fitting model differed by group. They also examine the connection of their task and findings to related research focusing on self-other representation and mentalization (e.g., Story et al., 2024).
The authors note that the task does not encourage competition and instead captures individual differences in the motivation to allocate rewards to oneself and others in an interdependent setting. The paper could have been strengthened by clarifying how the Social Value Orientation framework can be used to interpret the motivations and behavior of BPD versus CON participants on the task. Although the authors note that their approach makes "clear and transparent a priori predictions," the paper could be improved by providing a clear and consolidated statement of these predictions so that the results could be interpreted vis-a-vis any a priori hypotheses.
Finally, the authors have amended their individual difference analyses to examine psychometric measures such as the CTQ alongside computational model parameter estimate differences. I appreciate that these analyses are described as exploratory. The approach of using a partial correlation network with bootstrapping (and permutation) was interesting, but the logic of the analysis was not clearly stated. In particular, there are large group (Table 1: CON vs. BPD) differences in the measures introduced into this network. As a result, it is hard to understand whether any partial correlations are driven primarily by mean differences in severity (correlations tend to be inflated in extreme groups designs due to the absence of observation in middle of scales forming each bivariate distribution). I would have found these exploratory analyses more revealing if group membership was controlled for.
Author response:
The following is the authors’ response to the original reviews
Response to the Editors’ Comments
Thankyou for this summary of the reviews and recommendations for corrections. We respond to each in turn, and have documented each correction with specific examples contained within our response to reviewers below.
‘They all recommend to clarify the link between hypotheses and analyses, ground them more clearly in, and conduct critical comparisons with existing literature, and address a potential multiple comparison problem.’
We have restructured our introduction to include the relevant literature outlined by the reviewers, and to be more clearly ground the goals of our model and broader analysis. We have additionally corrected for multiple comparisons within our exploratory associative analyses. We have additionaly sign posted exploratory tests more clearly.
‘Furthermore, R1 also recommends to include a formal external validation of how the model parameters relate to participant behaviour, to correct an unjustified claim of causality between childhood adversity and separation of self, and to clarify role of therapy received by patients.’
We have now tempered our language in the abstract which unintentionally implied causality in the associative analysis between childhood trauma and other-to-self generalisation. To note, in the sense that our models provide causal explanations for behaviour across all three phases of the task, we argue that our model comparison provides some causal evidence for algorithmic biases within the BPD phenotype. We have included further details of the exclusion and inclusion criteria of the BPD participants within the methods.
R2 specifically recommends to clarify, in the introduction, the specific aim of the paper, what is known already, and the approach to addressing it.’
We have more thoroughly outlined the current state of the art concerning behavioural and computational approaches to self insertion and social contagion, in health and within BPD. We have linked these more clearly to the aims of the work.
‘R2 also makes various additional recommendations regarding clarification of missing information about model comparison, fit statistics and group comparison of parameters from different models.’
Our model comparison approach and algorithm are outlined within the original paper for Hierarchical Bayesian Model comparison (Piray et al., 2019). We have outlined the concepts of this approach in the methods. We have now additionally improved clarity by placing descriptions of this approach more obviously in the results, and added points of greater detail in the methods, such as which statistics for comparison we extracted on the group and individual level.
In addition, in response to the need for greater comparison of parameters from different models, we have also hierarchically force-fitted the full suite of models (M1-M4) to all participants. We report all group differences from each model individually – assuming their explanation of the data - in Table S2. We have also demonstrated strong associations between parameters of equivalent meaning from different models to support our claims in Fig S11. Finally, we show minimal distortion to parameter estimates in between-group analysis when models are either fitted hierarchically to the entire population, or group wise (Figure S10).
‘R3 additionally recommends to clarify the clinical and cognitive process relevance of the experiment, and to consider the importance of the Phase 2 findings.’
We have now included greater reference to the assumptions in the social value orientation paradigm we use in the introduction. We have also responded to the specific point about the shift in central tendencies in phase 2 from the BPD group, noting that, while BPD participants do indeed get more relatively competitive vs. CON participants, they remain strikingly neutral with respect to the overall statespace. Importantly, model M4 does not preclude more competitive distributions existing.
‘Critically, they also share a concern about analyzing parameter estimates fit separately to two groups, when the best-fitting model is not shared. They propose to resolve this by considering a model that can encompass the full dynamics of the entire sample.’
We have hierarchically force-fitted the full suite of models (M1-M4) to all participants to allow for comparison between parameters within each model assumption. We report all group differences from each model individually – assuming their explanation of the data - in Table S2 and Table S3. We have also demonstrated strong associations between parameters of equivalent meaning from different models to support our claims in Fig S11. We also show minimal distortion to parameter estimates in between-group analysis when models are either fitted hierarchically to the entire population, or group wise (Figure S10).
Within model M1 and M2, the 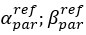 parameters quantify the degree to which participants believe their partner to be different from themselves. Under M1 and M2 model assumptions, BPD participants have meaningfully larger
parameters quantify the degree to which participants believe their partner to be different from themselves. Under M1 and M2 model assumptions, BPD participants have meaningfully larger 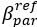 versus CON (Fig S10), which supports the notion that a new central tendency may be more parsimonious in phase 2 (as in the case of the optimal model for BPD, M4). We also show strong correlations across models between under M1 and M2, and the shift in central tendenices of beliefs between phase 1 and 2 under M3 and M4. This supports our primary comparison, and shows that even under non-dominant model assumptions, parameters demonstrate that BPD participants expect their partner’s relative reward preferences to be vastly different from themselves versus CON.
versus CON (Fig S10), which supports the notion that a new central tendency may be more parsimonious in phase 2 (as in the case of the optimal model for BPD, M4). We also show strong correlations across models between under M1 and M2, and the shift in central tendenices of beliefs between phase 1 and 2 under M3 and M4. This supports our primary comparison, and shows that even under non-dominant model assumptions, parameters demonstrate that BPD participants expect their partner’s relative reward preferences to be vastly different from themselves versus CON.
‘A final important point concerns the psychometric individual difference analyses which seem to be conducted on the full sample without considering the group structure.’
We have now more clearly focused our psychometric analysis. We control for multiple comparisons, and compare parameters across the same model (M3) when assessing the relationship between paranoia, trauma, trait mentalising, and social contagion. We have relegated all other exploratory analyses to the supplementary material and noted where p values survive correction using False Discovery Rate.
Reviewer 1:
‘The manuscript's primary weakness relates to the number of comparisons conducted and a lack of clarity in how those comparisons relate to the authors' hypotheses. The authors specify a primary prediction about disruption to information generalization in social decision making & learning processes, and it is clear from the text how their 4 main models are supposed to test this hypothesis. With regards to any further analyses however (such as the correlations between multiple clinical scales and eight different model parameters, but also individual parameter comparisons between groups), this is less clear. I recommend the authors clearly link each test to a hypothesis by specifying, for each analysis, what their specific expectations for conducted comparisons are, so a reader can assess whether the results are/aren't in line with predictions. The number of conducted tests relating to a specific hypothesis also determines whether multiple comparison corrections are warranted or not. If comparisons are exploratory in nature, this should be explicitly stated.’
We have now corrected for multiple comparisons when examining the relationship between psychometric findings and parameters, using partial correlations and bootstrapping for robustness. These latter analyses were indeed not preregistered, and so we have more clearly signposted that these tests were exploratory. We chose to focus on the influence of psychometrics of interest on social contagion under model M3 given that this model explained a reasonable minority of behaviour in each group. We have now fully edited this section in the main text in response, and relegated all other correlations to the supplementary materials.
‘Furthermore, the authors present some measures for external validation of the models, including comparison between reaction times and belief shifts, and correlations between model predicted accuracy and behavioural accuracy/total scores. However it would be great to see some more formal external validation of how the model parameters relate to participant behaviour, e.g., the correlation between the number of pro-social choices and ß-values, or the correlation between the change in absolute number of pro-social choices and the change in ß. From comparing the behavioural and computational results it looks like they would correlate highly, but it would be nice to see this formally confirmed.’
We have included this further examination within the Generative Accuracy and Recovery section:
‘We also assessed the relationship (Pearson rs) between modelled participant preference parameters in phase 1 and actual choice behaviour: 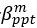 was negatively correlated with prosocial versus competitive choices (r=-0.77, p<0.001) and individualistic versus competitive choices (r=-0.59, p<0.001);
was negatively correlated with prosocial versus competitive choices (r=-0.77, p<0.001) and individualistic versus competitive choices (r=-0.59, p<0.001); 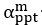 was positively correlated with individualistic versus competitive choices (r=0.53, p<0.001) and negatively correlated with prosocial versus individualistic choices (r=-0.69, p<0.001).’
was positively correlated with individualistic versus competitive choices (r=0.53, p<0.001) and negatively correlated with prosocial versus individualistic choices (r=-0.69, p<0.001).’
‘The statement in the abstract that 'Overall, the findings provide a clear explanation of how self-other generalisation constrains and assists learning, how childhood adversity disrupts this through separation of internalised beliefs' makes an unjustified claim of causality between childhood adversity and separation of self - and other beliefs, although the authors only present correlations. I recommend this should be rephrased to reflect the correlational nature of the results.’
Sorry – this was unfortunate wording: we did not intend to imply causation with our second clause in the sentence mentioned. We have amended the language to make it clear this relationship is associative:
‘Overall, the findings provide a clear explanation of how self-other generalisation constrains and assists learning, how childhood adversity is associated with separation of internalised beliefs, and makes clear causal predictions about the mechanisms of social information generalisation under uncertainty.’
‘Currently, from the discussion the findings seem relevant in explaining certain aberrant social learning and -decision making processes in BPD. However, I would like to see a more thorough discussion about the practical relevance of their findings in light of their observation of comparable prediction accuracy between the two groups.’
We have included a new paragraph in the discussion to address this:
‘Notably, despite differing strategies, those with BPD achieved similar accuracy to CON participants in predicting their partners. All participants were more concerned with relative versus absolute reward; only those with BPD changed their strategy based on this focus. Practically this difference in BPD is captured either through disintegrated priors with a new median (M4) or very noisy, but integrated priors over partners (M1) if we assume M1 can account for the full population. In either case, the algorithm underlying the computational goal for BPD participants is far higher in entropy and emphasises a less stable or reliable process of inference. In future work, it would be important to assess this mechanism alongside momentary assessments of mood to understand whether more entropic learning processes contribute to distressing mood fluctuation.’
‘Relatedly, the authors mention that a primary focus of mentalization based therapy for BPD is 'restoring a stable sense of self' and 'differentiating the self from the other'. These goals are very reminiscent of the findings of the current study that individuals with BPD show lower uncertainty over their own and relative reward preferences, and that they are less susceptible to social contagion. Could the observed group differences therefore be a result of therapy rather than adverse early life experiences?’
This is something that we wish to explore in further work. While verbal and model descriptions appear parsimonious, this is not straight forward. As we see, clinical observation and phenomenological dynamics may not necessarily match in an intuitive way to parameters of interest. It may be that compartmentalisation of self and other – as we see in BPD participants within our data – may counter-intuitively express as a less stable self. The evolutionary mechanisms that make social insertion and contagion enduring may also be the same that foster trust and learning.
‘Regarding partner similarity: It was unclear to me why the authors chose partners that were 50% similar when it would be at least equally interesting to investigate self-insertion and social contagion with those that are more than 50% different to ourselves? Do the authors have any assumptions or even data that shows the results still hold for situations with lower than 50% similarity?’
While our task algorithm had a high probability to match individuals who were approximately 50% different with respect to their observed behaviour, there was variation either side of this value. The value of 50% median difference was chosen for two reasons: 1. We wanted to ensure participants had to learn about their partner to some degree relative to their own preferences and 2. we did not want to induce extreme over or under familiarity given the (now replicated) relationship between participant-partner similarity and intentional attributions (see below). Nevertheless, we did have some variation around the 50% median. Figure 3A in the top left panel demonstrates this fluctuation in participant-partner similarity and the figure legend further described this distribution (mean = 49%, sd = 12%). In future work we want to more closely manipulate the median similarity between participants and partners to understand how this facilitates or inhibits learning and generalisation.
There is some analysis of the relationship between degrees of similiarity and behaviour. In the third paragraph of page 15 we report the influence of participant-partner similarity on reaction times. In prior work (Barnby et al., 2022; Cognition) we had shown that similarity was associated with reduced attributions of harm about a partner, irrespective of their true parameters (e.g. whether they were prosocial/competitive). We replicate this previous finding with a double dissociation illustrated in Figure 4, showing that greater discrepancies in participant-partner prosociality increases explicit harmful intent attributions (but not self-interest), and discrepancies in participant-partner individualism reduces explicit self-interest attributions (but not harmful intent). We have made these clearer in our results structure, and included FDR correction values for multiple comparisons.
The methods section is rather dense and at least I found it difficult to keep track of the many different findings. I recommend the authors reduce the density by moving some of the secondary analyses in the supplementary materials, or alternatively, to provide an overall summary of all presented findings at the end of the Results section.
We have now moved several of our exploratory findings into the supplementary materials, noteably the analysis of participant-partner similarity on reaction times (Fig S9), as well as the uncorrected correlation between parameters (Fig S7).
Fig 2C) and Discussion p. 21: What do the authors mean by 'more sensitive updates'? more sensitive to what?
We have now edited the wording to specify ‘more belief updating’ rather than ‘sensitive’ to be clearer in our language.
P14 bottom: please specify what is meant by axial differences.
We have changed this to ‘preference type’ rather than using the term ‘axial’.
It may be helpful to have Supplementary Figure 1 in the main text.
Thank you for this suggestion. Given the volume of information in the main text we hope that it is acceptable for Figure S1 to remain in the supplementary materials.
Figure 3D bottom panel: what is the difference between left and right plots? Should one of them be alpha not beta?
The left and right plots are of the change in standard deviation (left) and central tendency (right) of participant preference change between phase 1 and 3. This is currently noted in the figure legend, but we had added some text to be clearer that this is over prosocial-competitive beliefs specifically. We chose to use this belief as an example given the centrality of prosocial-comeptitive beliefs in the learning process in Figure 2. We also noticed a small labelling error in the bottom panels of 3D which should have noted that each plot was either with respect to the precision or mean-shift in beliefs during phase 3.
‘The relationship between uncertainty over the self and uncertainty over the other with respect to the change in the precision (left) and median-shift (right) in phase 3 prosocial-competitive beliefs 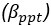 .’
.’
Supplementary Figure 4: The prior presented does not look neutral to me, but rather right-leaning, so competitive, and therefore does indeed look like it was influenced by the self-model? If I am mistaken please could the authors explain why.
This example distribution is taken from a single BPD participant. In this case, indeed, the prior is somewhat right-shifted. However, on a group level, priors over the partner were closely centred around 0 (see reported statistics in paragraph 2 under the heading ‘Phase 2 – BPD Participants Use Disintegrated and Neutral Priors). However, we understand how this may come across as misleading. For clarity we have expanded upon Figure S4 to include the phase 1 and prior phase 2 distributions for the entire BPD population for both prosocial and individualistic beliefs. This further demonstrates that those with BPD held surprisingly neutral beliefs over the expectations about their partners’ prosociality, but had minor shifts between their own individualistic preferences and the expected individualistic preferences of their partners. This is also visible in Figure S2.
Reviewer 2:
‘There are two major weaknesses. First, the paper lacks focus and clarity. The introduction is rather vague and, after reading it, I remained confused about the paper's aims. Rather than relying on specific predictions, the analysis is exploratory. This implies that it is hard to keep track, and to understand the significance, of the many findings that are reported.’
Thank you for this opportunity to be clearer in our framing of the paper. While the model makes specific causal predictions with respect to behavioural dynamics conditional on algorithmic differences, our other analyses were indeed exploratory. We did not preregister this work but now given the intriguing findings we intent to preregister our future analyses.
We have made our introduction clearer with respect to the aims of the paper:
‘Our present work sought to achieve two primary goals: 1. Extend prior causal computational theories to formalise the interrelation between self-insertion and social contagion within an economic paradigm, the Intentions Game and 2., Test how a diagnosis of BPD may relate to deficits in these forms of generalisation. We propose a computational theory with testable predictions to begin addressing this question. To foreshadow our results, we found that healthy participants employ a mixed process of self-insertion and contagion to predict and align with the beliefs of their partners. In contrast, individuals with BPD exhibit distinct, disintegrated representations of self and other, despite showing similar average accuracy in their learning about partners. Our model and data suggest that the previously observed computational characteristics in BPD, such as reduced self-anchoring during ambiguous learning and a relative impermeability of the self, arise from the failure of information about others to transfer to and inform the self. By integrating separate computational findings, we provide a foundational model and a concise, dynamic paradigm to investigate uncertainty, generalization, and regulation in social interactions.’
‘Second, although the computational approach employed is clever and sophisticated, there is important information missing about model comparison which ultimately makes some of the results hard to assess from the perspective of the reader.’
Our model comparison employed what is state of the art random-effects Bayesian model comparison (Piray et al., 2019; PLOS Comp. Biol.). It initially fits each individual to each model using Laplace approximation, and subsequently ‘races’ each model against each other on the group level and individual level through hierarchical constraints and random-effect considerations. We included this in the methods but have now expanded on the descrpition we used to compare models:
In the results -
‘All computational models were fitted using a Hierarchical Bayesian Inference (HBI) algorithm which allows hierarchical parameter estimation while assuming random effects for group and individual model responsibility (Piray et al., 2019; see Methods for more information). We report individual and group-level model responsibility, in addition to protected exceedance probabilities between-groups to assess model dominance.’
We added to our existing description in the methods –
‘All computational models were fitted using a Hierarchical Bayesian Inference (HBI) algorithm which allows hierarchical parameter estimation while assuming random effects for group and individual model responsibility (Piray et al., 2019). During fitting we added a small noise floor to distributions (2.22e-16) before normalisation for numerical stability. Parameters were estimated using the HBI in untransformed space drawing from broad priors (μM\=0, σ2M = 6.5; where M\={M1, M2, M3, M4}). This process was run independently for each group. Parameters were transformed into model-relevant space for analysis. All models and hierarchical fitting was implemented in Matlab (Version R2022B). All other analyses were conducted in R (version 4.3.3; arm64 build) running on Mac OS (Ventura 13.0). We extracted individual and group level responsibilities, as well as the protected exceedance probability to assess model dominance per group.’
(1) P3, third paragraph: please define self-insertion
We have now more clearly defined this in the prior paragraph when introducing concepts.
‘To reduce uncertainty about others, theories of the relational self (Anderson & Chen, 2002) suggest that people have availble to them an extensive and well-grounded representation of themselves, leading to a readily accessible initial belief (Allport, 1924; Kreuger & Clement, 1994) that can be projected or integrated when learning about others (self-insertion).’
(2) Introduction: the specific aim of the paper should be clarified - at the moment, it is rather vague. The authors write: "However, critical questions remain: How do humans adjudicate between self-insertion and contagion during interaction to manage interpersonal generalization? Does the uncertainty in self-other beliefs affect their generalizability? How can disruptions in interpersonal exchange during sensitive developmental periods (e.g., childhood maltreatment) inform models of psychiatric disorders?". Which of these questions is the focus of the paper? And how does the paper aim at addressing it?
(3) Relatedly, from the introduction it is not clear whether the goal is to develop a theory of self-insertion and social contagion and test it empirically, or whether it is to study these processes in BPD, or both (or something else). Clarifying which specific question(s) is addressed is important (also clarifying what we already know about that specific question, and how the paper aims at elucidating that specific question).
We have now included our specific aims of the paper. We note this in the above response to the reviwers general comments.
(4) "Computational models have probed social processes in BPD, linking the BPD phenotype to a potential over-reliance on social versus internal cues (Henco et al., 2020), 'splitting' of social latent states that encode beliefs about others (Story et al., 2023), negative appraisal of interpersonal experiences with heightened self-blame (Mancinelli et al., 2024), inaccurate inferences about others' irritability (Hula et al., 2018), and reduced belief adaptation in social learning contexts (Siegel et al., 2020). Previous studies have typically overlooked how self and other are represented in tandem, prompting further investigation into why any of these BPD phenotypes manifest." Not clear what the link between the first and second sentence is. Does it mean that previous computational models have focused exclusively on how other people are represented in BPD, and not on how the self is represented? Please spell this out.
Thank you for the opportunity to be clearer in our language. We have now spelled out our point more precisely, and included some extra relevant literature helpfully pointed out by another reviewer.
‘Computational models have probed social processes in BPD, although almost exclusively during observational learning. The BPD phenotype has been associated with a potential over-reliance on social versus internal cues (Henco et al., 2020), ‘splitting’ of social latent states that encode beliefs about others (Story et al., 2023), negative appraisal of interpersonal experiences with heightened self-blame (Mancinelli et al., 2024), inaccurate inferences about others’ irritability (Hula et al., 2018), and reduced belief adaptation in social learning contexts (Siegel et al., 2020). Associative models have also been adapted to characterize ‘leaky’ self-other reinforcement learning (Ereira et al., 2018), finding that those with BPD overgeneralize (leak updates) about themselves to others (Story et al., 2024). Altogether, there is currently a gap in the direct causal link between insertion, contagion, and learning (in)stability.’
(5) P5, first paragraph. The description of the task used in phase 1 should be more detailed. The essential information for understanding the task is missing.
We have updated this section to point toward Figure 1 and the Methods where the details of the task are more clearly outlined. We hope that it is acceptable not to explain the full task at this point for brevity and to not interrupt the flow of the results.
“Detailed descriptions of the task can be found in the methods section and Figure 1.’
(6) P5, second paragraph: briefly state how the Psychometric data were acquired (e.g., self-report).
We have now clarified this in the text.
‘All participants also self-reported their trait paranoia, childhood trauma, trust beliefs, and trait mentalizing (see methods).’
(7) "For example, a participant could make prosocial (self=5; other=5) versus individualistic (self=10; other=5) choices, or prosocial (self=10; other=10) versus competitive (self=10; other=5) choices". Not sure what criteria are used for distinguishing between individualistic and competitive - they look the same?
Sorry. This paragraph was not clear that the issue is that the interpretation of the choice depends on both members of the pair of options. Here, in one pair {(self=5,other=5) vs (self=10,other=5)}, it is highly pro-social for the self to choose (5,5), sacrificing 5 points for the sake of equality. In the second pair {(self=10,other=10) vs (self=10,other=5)}, it is highly competitive to choose (10,5), denying the other 5 points at no benefit to the self. We have clarified this:
‘We analyzed the ‘types’ of choices participants made in each phase (Supplementary Table 1). The interpretation of a participant’s choice depends on both values in a choice. For example, a participant could make prosocial (self=5; other=5) versus individualistic (self=10; other=5) choices, or prosocial (self=10; other=10) versus competitive (self=10; other=5) choices. There were 12 of each pair in phases 1 and 3 (individualistic vs. prosocial; prosocial vs. competitive; individualistic vs. competitive).’
(8) "In phase 1, both CON and BPD participants made prosocial choices over competitive choices with similar frequency (CON=9.67[3.62]; BPD=9.60[3.57])" please report t-test - the same applies also various times below.
We have now included the t test statistics with each instance.
‘In phase 3, both CON and BPD participants continued to make equally frequent prosocial versus competitive choices (CON=9.15[3.91]; BPD=9.38[3.31]; t=-0.54, p=0.59); CON participants continued to make significantly less prosocial versus individualistic choices (CON=2.03[3.45]; BPD=3.78 [4.16]; t=2.31, p=0.02). Both groups chose equally frequent individualistic versus competitive choices (CON=10.91[2.40]; BPD=10.18[2.72]; t=-0.49, p=0.62).’
(9) P 9: "Models M2 and M3 allow for either self-insertion or social contagion to occur independently" what's the difference between M2 and M3?
Model M2 hypothesises that participants use their own self representation as priors when learning about the other in phase 2, but are not influenced by their partner. M3 hypothesises that participants form an uncoupled prior (no self-insertion) about their partner in phase 2, and their choices in phase 3 are influenced by observing their partner in phase 2 (social contagion). In Figure 1 we illustrate the difference between M2 and M3. In Table 1 we specifically report the parameterisation differences between M2 and M3. We have also now included a correlational analysis of parameters between models to demonstrate the relationship between model parameters of equivalent value between models (Fig S11). We have also force fitted all models (M1-M4) to the data independently and reported group differences within each (see Table S2 and Table S3).
(10) P 9, last paragraph: I did not understand the description of the Beta model.
The beta model is outlined in detail in Table 1. We have also clarified the description of the beta model on page 9:
‘The ‘Beta model’ is equivalent to M1 in its causal architecture (both self-insertion and social contagion are hypothesized to occur) but differs in richness: it accommodates the possibility that participants might only consider a single dimension of relative reward allocation, which is typically emphasized in previous studies (e.g., Hula et al., 2018).’
(11) P 9: I wonder whether one could think about more intuitive labels for the models, rather than M1, M2 etc.. This is just a suggestion, as I am not sure a short label would be feasible here.
Thank you for this suggestion. We apologise that it is not very intitutive. The problem is that given the various terms we use to explain the different processes of generalisation that might occur between self and other, and given that each model is a different combination of each, we felt that numbering them was a lesser evil. We hope that the reader will be able to reference both Figure 1 and Table 1 to get a good feel for how the models and their causal implications differ.
(12) Model comparison: the information about what was done for model comparison is scant, and little about fit statistics is reported. At the moment, it is hard for a reader to assess the results of the model comparison analysis.
Model comparison and fitting was conducted using simultaneous hierarchical fitting and random-effects comparison. This is employed through the HBI package (Piray et al., 2019) where the assumptions and fitting proceedures are outlined in great detail. In short, our comparison allows for individual and group-level hierarchical fitting and comparison. This overcomes the issue of interdependence between and within model fitting within a population, which is often estimated separately.
We have outlined this in the methods, although appreciate we do not touch upon it until the reader reaches that point. We have added a clarification statement on page 9 to rectify this:
‘All computational models were fitted using a Hierarchical Bayesian Inference (HBI) algorithm which allows hierarchical parameter estimation while assuming random effects for group and individual model responsibility (Piray et al., 2019; see Methods for more information). We report individual and group-level model responsibility, in addition to protected exceedance probabilities between-groups to assess model dominance.’
(13) P 14, first paragraph: "BPD participants were also more certain about both types of preference" what are the two types of preferences?
The two types of preferences are relative (prosocial-competitive) and absolute (individualistic) reward utility. These are expressed as b and a respectively. We have expanded the sentence in question to make this clearer:
‘BPD participants were also more certain about both self-preferences for absolute and relative reward (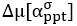 = -0.89, 95%HDI: -1.01, -0.75;
= -0.89, 95%HDI: -1.01, -0.75; 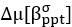 = -0.32, 95%HDI: -0.60, -0.04) versus CON participants (Figure 2B).’
= -0.32, 95%HDI: -0.60, -0.04) versus CON participants (Figure 2B).’
(14) "Parameter Associations with Reported Trauma, Paranoia, and Attributed Intent" the results reported here are intriguing, but not fully convincing as there is the problem of multiple comparisons. The combinations between parameters and scales are rather numerous. I suggest to correct for multiple comparisons and to flag only the findings that survive correction.
We have now corrected this and controlled for multiple comparisons through partial correlation analysis, bootstrapping assessment for robustness, permutation testing, and False Detection Rate correction. We only report those that survive bootstrapping and permutation testing, reporting both corrected (p[fdr]) and uncorrected (p) significance.
(15) Results page 14 and page 15. The authors compare the various parameters between groups. I would assume that these parameters come from M1 for controls and from M4 for BDP? Please clarify if this is indeed the case. If it is the case, I am not sure this is appropriate. To my knowledge, it is appropriate to compare parameters between groups only if the same model is fit to both groups. If two different models are fit to each group, then the parameters are not comparable, as the parameter have, so to speak, different "meaning" in two models. Now, I want to stress that my knowledge on this matter may be limited, and that the authors' approach may be sound. However, to be reassured that the approach is indeed sound, I would appreciate a clarification on this point and a reference to relevant sources about this approach.
This is an important point. First, we confirmed all our main conclusions about parameter differences using the maximal model M1 to fit all the participants. We added Supplementary Table 2 to report the outcome of this analysis. Second, we did the same for parameters across all models M1-M4, fitting each to participants without comparison. This is particularly relevant for M3, since at least a minority of participants of both groups were best explained by this model. We report these analyses in Fig S11:
Since the M4 is nested within M1, we argue that this comparison is still meaningful, and note explanations in the text for why the effects noted between groups may occur given the differences in their causal meaning, for example in the results under phase 2 analyses:
‘Belief updating in phase 2 was less flexible in BPD participants. Median change in beliefs (from priors to posteriors) about a partner’s preferences was lower versus. CON ( = -5.53, 95%HDI: -7.20, -4.00; = -10.02, 95%HDI: -12.81, -7.30). Posterior beliefs about partner were more precise in BPD versus CON ( = -0.94, 95%HDI: -1.50, -0.45; = -0.70, 95%HDI: -1.20, -0.25). This is unsurprising given the disintegrated priors of the BPD group in M4, meaning they need to ‘travel less’ in state space. Nevertheless, even under assumptions of M1 and M2 for both groups, BPD showed smaller posteriors median changes versus CON in phase 2 (see Table T2). These results converge to suggest those with BPD form rigid posterior beliefs.’
(16) "We built and tested a theory of interpersonal generalization in a population of matched participants" this sentence seems to be unwarranted, as there is no theory in the paper (actually, as it is now, the paper looks rather exploratory)
We thank the reviewer for their perspective. Formal models can be used as a theoretical statement on the casual algorithmic process underlying decision making and choice behaviour; the development of formal models are an essential theoretical tool for precision and falsification (Haslbeck et al., 2022). In this sense, we have built several competing formal theories that test, using casual architectures, whether the latent distribution(s) that generate one’s choices generalise into one’s predictions about another person, and simultaneously whether one’s latent distribution(s) that represent beliefs about another person are used to inform future choices.
Reviewer 3:
‘My broad question about the experiment (in terms of its clinical and cognitive process relevance): Does the task encourage competition or give participants a reason to take advantage of others? I don't think it does, so it would be useful to clarify the normative account for prosociality in the introduction (e.g., some of Robin Dunbar's work).’
We agree that our paradigm does not encourage competition. We use a reward structure that makes it contingent on participants to overcome a particular threshold before earning rewards, but there is no competitive element to this, in that points earned or not earned by partners have no bearing on the outcomes for the participant. This is important given the consideration of recursive properties that arise through mixed-motive games; we wanted to focus purely on observational learning in phase 2, and repercussion-free choices made by participants in phase 1 and 3, meaning the choices participants, and decisions of a partner, are theoretically in line with self-preferences irrespective of the judgement of others. We have included a clearer statement of the structure of this type of task, and more clearly cited the origin for its structure (Murphy & Ackerman, 2011):
‘Our present work sought to achieve two primary goals. 1. Extend prior causal computational theories to formalise and test the interrelation between self-insertion and social contagion on learning and behaviour to better probe interpersonal generalisation in health, and 2., Test whether previous computational findings of social learning changes in BPD can be explained by infractions to self-other generalisation. We accomplish these goals by using a dynamic, sequential social value economic paradigm, the Intentions Game, building upon a Social Value Orientation Framework (Murphy & Ackerman, 2011) that assumes motivational variation in joint reward allocation.’
Given the introductions structure as it stands, we felt providing another paragraph on the normative assumptions of such a game was outside the scope of this article.
‘The finding that individuals with BPD do not engage in self-other generalization on this task of social intentions is novel and potentially clinically relevant. The authors find that BPD participants' tendency to be prosocial when splitting points with a partner does not transfer into their expectations of how a partner will treat them in a task where they are the passive recipient of points chosen by the partner. In the discussion, the authors reasonably focus on model differences between groups (Bayesian model comparison), yet I thought this finding -- BPD participants not assuming prosocial tendencies in phase 2 while CON participant did -- merited greater attention. Although the BPD group was close to 0 on the \beta prior in Phase 2, their difference from CON is still in the direction of being more mistrustful (or at least not assuming prosociality). This may line up with broader clinical literature on mistrustfulness and attributions of malevolence in the BPD literature (e.g., a 1992 paper by Nigg et al. in Journal of Abnormal Psychology). My broad point is to consider further the Phase 2 findings in terms of the clinical interpretation of the shift in \beta relative to controls.’
This is an important point, that we contextualize within the parameterisation of our utility model. While the shift toward 0 in the BPD participants is indeed more competitive, as the reviewer notes, it is surprisingly centred closely around 0, with only a slight bias to be prosocial (mean = -0.47; = -6.10, 95%HDI: -7.60, -4.60). Charitably we might argue that BPD participants are expecting more competitive preferences from their partner. However even so, given their variance around their priors in phase 2, they are uncertain or unconfident about this. We take a more conservative approach in the paper and say that given the tight proximity to 0 and the variance of their group priors, they are likely to be ‘hedging their bets’ on whether their partner is going to be prosocial or competitive. While the movement from phase 1 to 2 is indeed in the competitive direction it still lands in neutral territory. Model M4 does not preclude central tendancies at the start of Phase 2 being more in the competitive direction.
‘First, the authors note that they have "proposed a theory with testable predictions" (p. 4 but also elsewhere) but they do not state any clear predictions in the introduction, nor do they consider what sort of patterns will be observed in the BPD group in view of extant clinical and computational literature. Rather, the paper seems to be somewhat exploratory, largely looking at group differences (BPD vs. CON) on all of the shared computational parameters and additional indices such as belief updating and reaction times. Given this, I would suggest that the authors make stronger connections between extant research on intention representation in BPD and their framework (model and paradigm). In particular, the authors do not address related findings from Ereira (2020) and Story (2024) finding that in a false belief task that BPD participants *overgeneralize* from self to other. A critical comparison of this work to the present study, including an examination of the two tasks differ in the processes they measure, is important.’
Thank you for this opportunity to include more of the important work that has preceded the present manuscript. Prior work has tended to focus on either descriptive explanations of self-other generalisation (e.g. through the use of RW type models) or has focused on observational learning instability in absence of a causal model from where initial self-other beliefs may arise. While the prior work cited by the reviewer [Ereira (2020; Nat. Comms.) and Story (2024; Trans. Psych.)] does examine the inter-trial updating between self-other, it does not integrate a self model into a self’s belief about an other prior to observation. Rather, it focuses almost exclusively on prediction error ‘leakage’ generated during learning about individual reward (i.e. one sided reward). These findings are important, but lie in a slightly different domain. They also do not cut against ours, and in fact, we argue in the discussion that the sort of learning instability described above and splitting (as we cite from Story ea. 2024; Psych. Rev.) may result from a lack of self anchoring typical of CON participants. Nevertheless we agree these works provide an important premise to contrast and set the groundwork for our present analysis and have included them in the framing of our introduction, as well as contrasting them to our data in the discussion.
In the introduction:
‘The BPD phenotype has been associated with a potential over-reliance on social versus internal cues (Henco et al., 2020), ‘splitting’ of social latent states that encode beliefs about others (Story et al., 2023), negative appraisal of interpersonal experiences with heightened self-blame (Mancinelli et al., 2024), inaccurate inferences about others’ irritability (Hula et al., 2018), and reduced belief adaptation in social learning contexts (Siegel et al., 2020). Associative models have also been adapted to characterize ‘leaky’ self-other reinforcement learning (Ereira et al., 2018), finding that those with BPD overgeneralize (leak updates) about themselves to others (Story et al., 2024). Altogether, there is currently a gap in the direct causal link between insertion, contagion, and learning (in)stability.’
In the discussion:
‘Disruptions in self-to-other generalization provide an explanation for previous computational findings related to task-based mentalizing in BPD. Studies tracking observational mentalizing reveal that individuals with BPD, compared to those without, place greater emphasis on social over internal reward cues when learning (Henco et al., 2020; Fineberg et al., 2018). Those with BPD have been shown to exhibit reduced belief adaptation (Siegel et al., 2020) along with ‘splitting’ of latent social representations (Story et al., 2024a). BPD is also shown to be associated with overgeneralisation in self-to-other belief updates about individual outcomes when using a one-sided reward structure (where participant responses had no bearing on outcomes for the partner; Story et al., 2024b). Our analyses show that those with BPD are equal to controls in their generalisation of absolute reward (outcomes that only affect one player) but disintegrate beliefs about relative reward (outcomes that affect both players) through adoption of a new, neutral belief. We interpret this together in two ways: 1. There is a strong concern about social relativity when those with BPD form beliefs about others, 2. The absence of constrained self-insertion about relative outcomes may predispose to brittle or ‘split’ beliefs. In other words, those with BPD assume ambiguity about the social relativity preferences of another (i.e. how prosocial or punitive) and are quicker to settle on an explanation to resolve this. Although self-insertion may be counter-intuitive to rational belief formation, it has important implications for sustaining adaptive, trusting social bonds via information moderation.’
In addition, perhaps it is fairer to note more explicitly the exploratory nature of this work. Although the analyses are thorough, many of them are not argued for a priori (e.g., rate of belief updating in Figure 2C) and the reader amasses many individual findings that need to by synthesized.’
We have now noted the primary goals of our work in the introduction, and have included caveats about the exploratory nature of our analyses. We would note that our model is in effect a causal combination of prior work cited within the introduction (Barnby et al., 2022; Moutoussis et al., 2016). This renders our computational models in effect a causal theory to test, although we agree that our dissection of the results are exploratory. We have more clearly signposted this:
‘Our present work sought to achieve two primary goals. 1. Extend prior causal computational theories to formalise and test the interrelation between self-insertion and social contagion on learning and behaviour to better probe interpersonal generalisation in health, and 2., Test whether previous computational findings of social learning changes in BPD can be explained by infractions to self-other generalisation. We accomplish these goals by using a dynamic, sequential economic paradigm, the Intentions Game, building upon a Social Value Orientation Framework (Murphy & Ackerman, 2011) that assumes innate motivational variation in joint reward allocation.‘
‘Second, in the discussion, the authors are too quick to generalize to broad clinical phenomena in BPD that are not directly connected to the task at hand. For example, on p. 22: "Those with a diagnosis of BPD also show reduced permeability in generalising from other to self. While prior research has predominantly focused on how those with BPD use information to form impressions, it has not typically examined whether these impressions affect the self." Here, it's not self-representation per se (typically, identity or one's view of oneself), but instead cooperation and prosocial tendencies in an economic context. It is important to clarify what clinical phenomena may be closely related to the task and which are more distal and perhaps should not be approached here.’
Thank you for this important point. We agree that social value orientation, and particularly in this economically-assessed form, is but one aspect of the self, and we did not test any others. A version of the social contagion phenomena is also present in other aspects of the self in intertemporal (Moutoussis et al., 2016), economic (Suzuki et al., 2016) and moral preferences (Yu et al., 2021). It would be most interesting to attempt to correlate the degrees of insertion and contagion across the different tasks.
We take seriously the wider concern that behaviour in our tasks based on economic preferences may not have clinical validity. This issue is central in the whole field of computational psychiatry, much of which is based on generalizing from tasks like ours, and discussing correlations with psychometric measures. We hope that it is acceptable to leave such discussions to the many reviews on computational psychiatry (Montague et al., 2012; Hitchcock et al., 2022; Huys et al., 2016). Here, we have just put a caveat in the dicussion:
‘Finally, a limitation may be that behaviour in tasks based on economic preferences may not have clinical validity. This issue is central to the field of computational psychiatry, much of which is based on generalising from tasks like that within this paper and discussing correlations with psychometric measures. Extrapolating economic tasks into the real world has been the topic of discussion for the many reviews on computational psychiatry (e.g. Montague et al., 2012; Hitchcock et al., 2022; Huys et al., 2016). We note a strength of this work is the use of model comparison to understand causal algorithmic differences between those with BPD and matched healthy controls. Nevertheless, we wish to further pursue how latent characteristics captured in our models may directly relate to real-world affective change.’
‘On a more technical level, I had two primary concerns. First, although the authors consider alternative models within a hierarchical Bayesian framework, some challenges arise when one analyzes parameter estimates fit separately to two groups, particularly when the best-fitting model is not shared. In particular, although the authors conduct a model confusion analysis, they do not as far I could tell (and apologies if I missed it) demonstrate that the dynamics of one model are nested within the other. Given that M4 has free parameters governing the expectations on the absolute and relative reward preferences in Phase 2, is it necessarily the case that the shared parameters between M1 and M4 can be interpreted on the same scale? Relatedly, group-specific model fitting has virtues when believes there to be two distinct populations, but there is also a risk of overfitting potentially irrelevant sample characteristics when parameters are fit group by group.
To resolve these issues, I saw one straightforward solution (though in modeling, my experience is that what seems straightforward on first glance may not be so upon further investigation). M1 assumes that participants' own preferences (posterior central tendency) in Phase 1 directly transfer to priors in Phase 2, but presumably the degree of transfer could vary somewhat without meriting an entirely new model (i.e., the authors currently place this question in terms of model selection, not within-model parameter variation). I would suggest that the authors consider a model parameterization fit to the full dataset (both groups) that contains free parameters capturing the *deviations* in the priors relative to the preceding phase's posterior. That is, the free parameters $\bar{\alpha}_{par}^m$ and $\bar{\beta}_{par}^m$ govern the central tendency of the Phase 2 prior parameter distributions directly, but could be reparametrized as deviations from Phase 1 $\theta^m_{ppt}$ parameters in an additive form. This allows for a single model to be fit all participants that encompasses the dynamics of interest such that between-group parameter comparisons are not biased by the strong assumptions imposed by M1 (that phase 1 preferences and phase 2 observations directly transfer to priors). In the case of controls, we would expect these deviation parameters to be centred on 0 insofar as the current M1 fit them best, whereas for BPD participants should have significant deviations from earlier-phase posteriors (e.g., the shift in \beta toward prior neutrality in phase 2 compared to one's own prosociality in phase 1). I think it's still valid for the authors to argue for stronger model constraints for Bayesian model comparison, as they do now, but inferences regarding parameter estimates should ideally be based on a model that can encompass the full dynamics of the entire sample, with simpler dynamics (like posterior -> prior transfer) being captured by near-zero parameter estimates.’
Thank you for the chance to be clearer in our modelling. In particular, the suggestion to include a model that can be fit to all participants with the equivalent of the likes of partial social insertion, to check if the results stand, can actually be accomplished through our existing models. That is, the 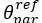 parameter that governs the flexibility over beliefs in phase 2 under models M1 (dominant for CON participant) and M2 parameterises the degree to which participants think their partner may be different from themselves. Thus, forcibly fitting M1 and M2 hierarchically to all participants, and then separately to BPD and CON participants, can quantify the issue raised: if BPD participants indeed distinguish partners as vastly different from themselves enough to warent a new central tendency, should be quantitively higher in BPD vs CON participants under M1 and M2.
parameter that governs the flexibility over beliefs in phase 2 under models M1 (dominant for CON participant) and M2 parameterises the degree to which participants think their partner may be different from themselves. Thus, forcibly fitting M1 and M2 hierarchically to all participants, and then separately to BPD and CON participants, can quantify the issue raised: if BPD participants indeed distinguish partners as vastly different from themselves enough to warent a new central tendency, should be quantitively higher in BPD vs CON participants under M1 and M2.
We therefore tested this, reporting the distributional differences between for BPD and CON participants under M1, both when fitted together as a population and as separate groups. As is higher for BPD participants under both conditions for M1 and M2 it supports our claim and will add more context for the comparison - may be large enough in BPD that a new central tendency to anchor beliefs is a more parsimonious explanation.
We cross checked this result by assessing the discrepancy between the participant’s and assumed partner’s central tendencies for both prosocial and individualistic preferences via best-fitting model M4 for the BPD group. We thereby examined whether belief disintegration is uniform across preferences (relative vs abolsute reward) or whether one tendency was shifted dramatically more than another. We found that beliefs over prosocial-competitive preferences were dramatically shifted, whereas those over individualistic preferences were not.
We have added the following to the main text results to explain this:
Model Comparison:
‘We found that CON participants were best fit at the group level by M1 (Frequency = 0.59, Protected Exceedance Probability = 0.98), whereas BPD participants were best fit by M4 (Frequency = 0.54, Protected Exceedance Probability = 0.86; Figure 2A). We first analyse the results of these separate fits. Later, in order to assuage concerns about drawing inferences from different models, we examined the relationships between the relevant parameters when we forced all participants to be fit to each of the models (in a hierarchical manner, separated by group). In sum, our model comparison is supported by convergence in parameter values when comparisons are meaningful. We refer to both types of analysis below.’
Phase 1:
‘These differences were replicated when considering parameters between groups when we fit all participants to the same models (M1-M4; see Table S2).’
Phase 2:
‘To check that these conclusions about self-insertion did not depend on the different models, we found that only under M1 and M2 were consistently larger in BPD versus CON. This supports the notion that new central tendencies for BPD participants in phase 2 were required, driven by expectations about a partner’s relative reward. (see Fig S10 & Table S2). 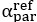 and parameters under assumptions of M1 and M2 were strongly correlated with median change in belief between phase 1 and 2 under M3 and M4, suggesting convergence in outcome (Fig S11).’
and parameters under assumptions of M1 and M2 were strongly correlated with median change in belief between phase 1 and 2 under M3 and M4, suggesting convergence in outcome (Fig S11).’
‘Furthermore, even under assumptions of M1-M4 for both groups, BPD showed smaller posterior median changes versus CON in phase 2 (see Table T2). These results converge to suggest those with BPD form rigid posterior beliefs.’
‘Assessing this same relationship under M1- and M2-only assumptions reveals a replication of this group effect for absolute reward, but the effect is reversed for relative reward (see Table S3). This accords with the context of each model, where under M1 and M2, BPD participants had larger phase 2 prior flexibility over relative reward (leading to larger initial surprise), which was better accounted for by a new central tendency under M4 during model comparison. When comparing both groups under M1-M4 informational surprise over absolute reward was consistently restricted in BPD (Table S3), suggesting a diminished weight of this preference when forming beliefs about an other.’
Phase 3
‘In the dominant model for the BPD group—M4—participants are not influenced in their phase 3 choices following exposure to their partner in phase 2. To further confirm this we also analysed absolute change in median participant beliefs between phase 1 and 3 under the assumption that M1 and M3 was the dominant model for both groups (that allow for contagion to occur). This analysis aligns with our primary model comparison using M1 for CON and M4 for BPD (Figure 2C). CON participants altered their median beliefs between phase 1 and 3 more than BPD participants (M1: linear estimate = 0.67, 95%CI: 0.16, 1.19; t = 2.57, p = 0.011; M3: linear estimate = 1.75, 95%CI: 0.73, 2.79; t = 3.36, p < 0.001). Relative reward was overall more susceptible to contagion versus absolute reward (M1: linear estimate = 1.40, 95%CI: 0.88, 1.92; t = 5.34, p<0.001; M3: linear estimate = 2.60, 95%CI: 1.57, 3.63; t = 4.98, p < 0.001). There was an interaction between group and belief type under M3 but not M1 (M3: linear estimate = 2.13, 95%CI: 0.09, 4.18, t = 2.06, p=0.041). There was only a main effect of belief type on precision under M3 (linear estimate = 0.47, 95%CI: 0.07, 0.87, t = 2.34, p = 0.02); relative reward preferences became more precise across the board. Derived model estimates of preference change between phase 1 and 3 strongly correlated between M1 and M3 along both belief types (see Table S2 and Fig S11).’
‘My second concern pertains to the psychometric individual difference analyses. These were not clearly justified in the introduction, though I agree that they could offer potentially meaningful insight into which scales may be most related to model parameters of interest. So, perhaps these should be earmarked as exploratory and/or more clearly argued for. Crucially, however, these analyses appear to have been conducted on the full sample without considering the group structure. Indeed, many of the scales on which there are sizable group differences are also those that show correlations with psychometric scales. So, in essence, it is unclear whether most of these analyses are simply recapitulating the between-group tests reported earlier in the paper or offer additional insights. I think it's hard to have one's cake and eat it, too, in this regard and would suggest the authors review Preacher et al. 2005, Psychological Methods for additional detail. One solution might be to always include group as a binary covariate in the symptom dimension-parameter analyses, essentially partialing the correlations for group status. I remain skeptical regarding whether there is additional signal in these analyses, but such controls could convince the reader. Nevertheless, without such adjustments, I would caution against any transdiagnostic interpretations such as this one in the Highlights: "Higher reported childhood trauma, paranoia, and poorer trait mentalizing all diminish other-to-self information transfer irrespective of diagnosis." Since many of these analyses relate to scales on which the groups differ, the transdiagnostic relevance remains to be demonstrated.’
We have restructured the psychometric section to ensure transparency and clarity in our analysis. Namely, in response to these comments and those of the other reviewers, we have opted to remove the parameter analyses that aimed to cross-correlate psychometric scores with latent parameters from different models: as the reviewer points out, we do not have parity between dominant models for each group to warrant this, and fitting the same model to both groups artificially makes the parameters qualitatively different. Instead we have opted to focus on social contagion, or rather restrictions on 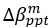 ,
, 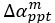 between phases 1 and 3 explained by M3. This provides us with an opportunity to examine social contagion on the whole population level isolated from self-insertion biases. We performed bootstrapping (1000 reps) and permutation testing (1000 reps) to assess the stability and significance of each edge in the partial correlation network, and then applied FDR correction (p[fdr]), thus controlling for multiple comparisons. We note that while we focused on M3 to isolate the effect across the population, social contagion across both relative and absolute reward under M3 strongly correlated with social contagion under M1 (see Fig S11).
between phases 1 and 3 explained by M3. This provides us with an opportunity to examine social contagion on the whole population level isolated from self-insertion biases. We performed bootstrapping (1000 reps) and permutation testing (1000 reps) to assess the stability and significance of each edge in the partial correlation network, and then applied FDR correction (p[fdr]), thus controlling for multiple comparisons. We note that while we focused on M3 to isolate the effect across the population, social contagion across both relative and absolute reward under M3 strongly correlated with social contagion under M1 (see Fig S11).
‘We explored whether social contagion may be restricted as a result of trauma, paranoia, and less effective trait mentalizing under the assumption of M3 for all participants (where everyone is able to be influenced by their partner). To note, social contagion under M3 was highly correlated with contagion under M1 (see Fig S11). We conducted partial correlation analysis to estimate relationships conditional on all other associations and retained all that survived bootstrapping (1000 reps), permutation testing (1000 reps), and subsequent FDR correction. Persecution and CTQ scores were both moderately associated with MZQ scores (RGPTSB r = 0.41, 95%CI: 0.23, 0.60, p = 0.004, p[fdr]=0.043; CTQ r = 0.354 95%CI: 0.13, 0.56, p=0.019, p[fdr]=0.02). MZQ scores were in turn moderately and negatively associated with shifts in prosocial-competitive preferences () between phase 1 and 3 (r = -0.26, 95%CI: -0.46, -0.06, p=0.026, p[fdr]=0.043). CTQ scores were also directly and negatively associated with shifts in individualistic preferences (; r = -0.24, 95%CI: -0.44, -0.13, p=0.052, p[fdr]=0.065). This provides some preliminary evidence that trauma impacts beliefs about individualism directly, whereas trauma and persecutory beliefs impact beliefs about prosociality through impaired mentalising (Figure 4A).’
(1) As far as I could tell, the authors didn't provide an explanation of this finding on page 5: "However, CON participants made significantly fewer prosocial choices when individualistic choices were available" While one shouldn't be forced to interpret every finding, the paper is already in that direction and I found this finding to be potentially relevant to the BPD-control comparison.
Thank you for this observation. This sentance reports the fact that CON participants were effectively more selfish than BPD participants. This is captured by the lower value of reported in Figure 2, and suggests that CON participants were more focused on absolute value – acting in a more ‘economically rational’ manner – versus BPD participants. This fits in with our fourth paragraph of the discussion where we discuss prior work that demonstrates a heightened social focus in those with BPD. Indeed, the finding the reviewer highlights further emphasises the point that those with BPD are much more sensitive, and motived to choose, options concerning relative reward than are CON participants. The text in the discussion reads:
‘We also observe this in self-generated participant choice behaviour, where CON participants were more concerned over absolute reward versus their BPD counterparts, suggesting a heighted focus on relative vs. absolute reward in those with BPD.’
(2) The adaptive algorithm for adjusting partner behavior in Phase 2 was clever and effective. Did the authors conduct a manipulation check to demonstrate that the matching resulted in approximately 50% difference between one's behavior in Phase 1 and the partner in Phase 2? Perhaps Supplementary Figure suffices, but I wondered about a simpler metric.
Thanks for this point. We highlight this in Figure 3B and within the same figure legend although appreciate the panel is quite small and may be missed. We have now highlighted this manipulation check more clearly in behavioural analysis section of the main text:
‘Server matching between participant and partner in phase 2 was successful, with participants being approximately 50% different to their partners with respect to the choices each would have made on each trial in phase 2 (mean similarity=0.49, SD=0.12).’
(3) The resolution of point-range plots in Figure 4 was grainy. Perhaps it's not so in the separate figure file, but I'd suggest checking.
Apologies. We have now updated and reorganised the figure to improve clarity.
(4) p. 21: Suggest changing to "different" as opposed to "opposite" since the strategies are not truly opposing: "but employed opposite strategies."
We have amended this.
(5) p. 21: I found this sentence unclear, particularly the idea of "similar updating regime." I'd suggest clarifying: "In phase 2, CON participants exhibited greater belief sensitivity to new information during observational learning, eventually adopting a similar updating regime to those with BPD."
We have clarified this statement:
‘In observational learning in phase 2, CON participants initially updated their beliefs in response to new information more quickly than those with BPD, but eventually converged to a similar rate of updating.’
(6) p. 23: The content regarding psychosis seemed out of place, particularly as the concluding remark. I'd suggest keeping the focus on the clinical population under investigation. If you'd like to mention the paradigm's relevance to psychosis (which I think could be omitted), perhaps include this as a future direction when describing the paradigm's strengths above.
We agree the paragraph is somewhat speculative. We have omitted it in aid of keeping the messaging succinct and to the point.
(7) p. 24: Was BPD diagnosis assess using unstructured clinical interview? Although psychosis was exclusionary, what about recent manic or hypomanic episodes or Bipolar diagnosis? A bit more detail about BPD sample ascertainment would be useful, including any instruments used to make a diagnosis and information about whether you measured inter-rater agreement.
Participants diagnosed with BPD were recruited from specialist personality disorder services across various London NHS mental health trusts. The diagnosis of BPD was established by trained assessors at the clinical services and confirmed using the Structured Clinical Interview for DSM-IV (SCID-II) (First et al., 1997). Individuals with a history of psychotic episodes, severe learning disability or neurological illness/trauma were excluded. We have now included this extra detail within our methods in the paper:
‘The majority of BPD participants were recruited through referrals by psychiatrists, psychotherapists, and trainee clinical psychologists within personality disorder services across 9 NHS Foundation Trusts in the London, and 3 NHS Foundation Trusts across England (Devon, Merseyside, Cambridgeshire). Four BPD participants were also recruited by self-referral through the UCLH website, where the study was advertised. To be included in the study, all participants needed to have, or meet criteria for, a primary diagnosis of BPD (or emotionally-unstable personality disorder or complex emotional needs) based on a professional clinical assessment conducted by the referring NHS trust (for self-referrals, the presence of a recent diagnosis was ascertained through thorough discussion with the participant, whereby two of the four also provided clinical notes). The patient participants also had to be under the care of the referring trust or have a general practitioner whose details they were willing to provide. Individuals with psychotic or mood disorders, recent acute psychotic episodes, severe learning disability, or current or past neurological disorders were not eligible for participation and were therefore not referred by the clinical trusts.‘



