Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorPaschalis KratsiosUniversity of Chicago, Chicago, United States of America
- Senior EditorPiali SenguptaBrandeis University, Waltham, United States of America
Reviewer #1 (Public Review):
In this paper, the authors developed an image analysis pipeline to automatically identify individual neurons within a population of fluorescently tagged neurons. This application is optimized to deal with multi-cell analysis and builds on a previous software version, developed by the same team, to resolve individual neurons from whole-brain imaging stacks. Using advanced statistical approaches and several heuristics tailored for C. elegans anatomy, the method successfully identifies individual neurons with a fairly high accuracy. Thus, while specific to C. elegans, this method can become instrumental for a variety of research directions such as in-vivo single-cell gene expression analysis and calcium-based neural activity studies.
Reviewer #2 (Public Review):
The authors succeed in generalizing the pre-alignment procedure for their cell identification method to allow it to work effectively on data with only small subsets of cells labeled. They convincingly show that their extension accurately identifies head angle, based on finding auto florescent tissue and looking for a symmetric l/r axis. They demonstrate method works to allow the identification of a particular subset of neurons. Their approach should be a useful one for researchers wishing to identify subsets of head neurons in C. elegans, and the ideas might be useful elsewhere.
The authors also assess the relative usefulness of several atlases for making identity predictions. They attempt to give some additional general insights on what makes a good atlas, but here insights seem less clear as available data does not allow for experiments that cleanly decouple: 1. the number of examples in the atlas 2. the completeness of the atlas. and 3. the match in strain and imaging modality discussed. In the presented experiments the custom atlas, besides the strain and imaging modality mismatches discussed is also the only complete atlas with more than one example. The neuroPAL atlas, is an imperfect stand in, since a significant fraction of cells could not be identified in these data sets, making it a 60/40 mix of Openworm and a hypothetical perfect neuroPAL comparison. This waters down general insights since it is unclear if the performance is driven by strain/imaging modality or these difficulties creating a complete neuroPal atlas. The experiments do usefully explore the volume of data needed. Though generalization remains to be shown the insight is useful for future atlas building that for the specific (small) set of cells labeled in the experiments 5-10 examples is sufficient to build a accurate atlas.
Author Response
The following is the authors’ response to the original reviews.
eLife assessment
This research advance arctile describes a valuable image analysis method to identify individual cells (neurons) within a population of fluorescently labeled cells in the nematode C. elegans. The findings are solid and the method succeeds to identify cells with high precision. The method will be valuable to the C. elegans research community.
Public Reviews:
Reviewer #1 (Public Review):
In this paper, the authors developed an image analysis pipeline to automatically identify individual neurons within a population of fluorescently tagged neurons. This application is optimized to deal with multi-cell analysis and builds on a previous software version, developed by the same team, to resolve individual neurons from whole-brain imaging stacks. Using advanced statistical approaches and several heuristics tailored for C. elegans anatomy, the method successfully identifies individual neurons with a fairly high accuracy. Thus, while specific to C. elegans, this method can become instrumental for a variety of research directions such as in-vivo single-cell gene expression analysis and calcium-based neural activity studies.
The analysis procedure depends on the availability of an accurate atlas that serves as a reference map for neural positions. Thus, when imaging a new reporter line without fair prior knowledge of the tagged cells, such an atlas may be very difficult to construct. Moreover, usage of available reference atlases, constructed based on other databases, is not very helpful (as shown by the authors in Fig 3), so for each new reporter line a de-novo atlas needs to be constructed.
We thank the reviewer for pointing out a place where we can use some clarification. While in principle that every new reporter line would need fair prior knowledge, atlases are either already available or not difficult to construct. If one can make the assumption that the anatomy of a particular line is similar to existing atlases (Yemini 2021,Nejatbakhsh 2023,Toyoshima 2020), the cell ID can be immediately performed. Even in the case that one suspects the anatomy may have changes from existing atlases (e.g. in the case of examining mutants), existing atlases can serve as a starting point to provide a draft ID, which facilitates manual annotation. Once manual annotations on ~5 animals are available as we have shown in this work (which is a manageable number in practice), this new dataset can be used to build an updated atlas that can be used for future inferences. We have added this discussion in the manuscript: “If one determines that the anatomy of a particular animal strain is substantially different from existing atlases, new atlases can be easily constructed using existing atlases as starting points.” (page 18).
I have a few comments that may help to better understand the potential of the tool to become handy.
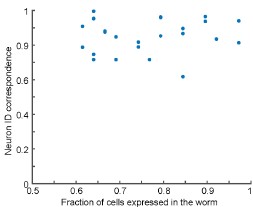
- I wonder the degree by which strain mosaicism affects the analysis (Figs 1-4) as it was performed on a non-integrated reporter strain. As stated, for constructing the reference atlas, the authors used worms in which they could identify the complete set of tagged neurons. But how senstiive is the analysis when assaying worms with different levels of mosaicism? Are the results shown in the paper stem from animals with a full neural set expression? Could the authors add results for which the assayed worms show partial expression where only 80%, 70%, 50% of the cells population are observed, and how this will affect idenfication accuracy? This may be important as many non-integrated reporter lines show high mosaic patterns and may therefore not be suitable for using this analytic method. In that sense, could the authors describe the mosaic degree of their line used for validating the method.
We appreciate the reviewer for this comment. We want to clarify that most of the worms used in the construction of the atlas are indeed affected by mosaicism and thus do not express the full set of candidate neurons. We have added such a plot as requested (Figure 3 – figure supplement 2, copied below). Our data show that there is no correlation between the fraction of cells expressed in a worm and neuron ID correspondence. We agree with the reviewer this additional insight may be helpful; we have modified the text to include this discussion: “Note that we observed no correlation between the degree of mosaicism and neuron ID correspondence (Figure 3- figure supplement 2).” (page 10).
Author response image 1.
No correlation between the degree of mosaicism (fraction of cells expressed in the worm) and neuron ID correspondence.
- For the gene expression analysis (Fig 5), where was the intensity of the GFP extracted from? As it has no nuclear tag, the protein should be cytoplasmic (as seen in Fig 5a), but in Fig 5c it is shown as if the region of interest to extract fluorescence was nuclear. If fluorescence was indeed extracted from the cytoplasm, then it will be helpful to include in the software and in the results description how this was done, as a huge hurdle in dissecting such multi-cell images is avoiding crossreads between adjacent/intersecting neurons.
For this work, we used nuclear-localized RFP co-expressed in the animal, and the GFP intensities were extracted from the same region RFP intensities were extracted. If cytosolic reporters are used, one would imagine a membrane label would be necessary to discern the border of the cells. We clarified our reagents and approach in the text: “The segmentation was done on the nuclear-localized mCherry signals, and GFP intensities were extracted from the same region.” (page21).
- In the same mater: In the methods, it is specified that the strain expressing GCAMP was also used in the gene expression analysis shown in Figure 5. But the calcium indicator may show transient intensities depending on spontaneous neural activity during the imaging. This will introduce a significant variability that may affect the expression correlation analysis as depicted in Figure 5.
We apologize for the error in text. The strain used in the gene expression analysis did not express GCaMP. We did not analyze GCaMP expression in figure 5. We have corrected the error in the methods.
Reviewer #2 (Public Review):
The authors succeed in generalizing the pre-alignment procedure for their cell idenfication method to allow it to work effectively on data with only small subsets of cells labeled. They convincingly show that their extension accurately identifies head angle, based on finding auto fluorescent tissue and looking for a symmetric l/r axis. They demonstrate that the method works to identify known subsets of neurons with varying accuracy depending on the nature of underlying atlas data. Their approach should be a useful one for researchers wishing to identify subsets of head neurons in C. elegans, for example in whole brain recording, and the ideas might be useful elsewhere.
The authors also strive to give some general insights on what makes a good atlas. It is interesting and valuable to see (at least for this specific set of neurons) that 5-10 ideal examples are sufficient. However, some critical details would help in understanding how far their insights generalize. I believe the set of neurons in each atlas version are matched to the known set of cells in the sparse neuronal marker, however this critical detail isn't explicitly stated anywhere I can see.
This is an important point. We have made text modifications to make it clear to the readers that for all atlases, the number of entities (candidate list) was kept consistent as listed in the methods. In the results section under “CRF_ID 2.0 for automatic cell annotation in multi-cell images,” we added the following sentence: “Note that a truncated candidate list can be used for subse-tspecific cell ID if the neuronal expression is known” (page 3). In the methods section, we added the following sentence: “For multi-cell neuron predictions on the glr-1 strain, a truncated atlas containing only the above 37 neurons was used to exclude neuron candidates that are irrelevant for prediction” (Page 20).
In addition, it is stated that some neuron positions are missing in the neuropal data and replaced with the (single) position available from the open worm atlas. It should be stated how many neurons are missing and replaced in this way (providing weaker information).
We modified the text in the result section as follows: “Eight out of 37 candidate neurons are missing in the neuroPAL atlas, which means 40% of the pairwise relationships of neurons expressing the glr-1p::NLS-mcherry transgene were not augmented with the NeuroPAL data but were assigned the default values from the OpenWorm atlas” (page 10).
It also is not explicitly stated that the putative identities for the uncertain cells (designated with Greek letters) are used to sample the neuropal data. Large numbers of openworm single positions or if uncertain cells are misidentified forcing alignment against the positions of nearby but different cells would both handicap the neuropal atlas relative to the matched florescence atlas. This is an important question since sufficient performance from an ideal neuropal atlas (subsampled) would avoid the need for building custom atlases per strain.
The putative identities are not used to sample the NeuroPAL data. They were used in the glr-1 multi-cell case to indicate low confidence in manual identification/annotation. For all steps of manual annotation and CRF_ID predictions, we used real neuron labels, and the Greek labels were used for reporting purposes only. It is true that the OpenWorm values (40% of the atlas) would be a handicap for the neuroPAL atlas. This is mainly due to the difficulty of obtaining NeuroPAL data as it requires 3-color fluorescence microscopy and significant time and labor to annotate the large set of neurons. This is one reason to take a complementary approach as we do in this paper.
Reviewer #1 (Recommendations For The Authors):
- Figure 3, there is a confusion in the legend relating to panels c-e (e.g. panel c is neuron ID accuracy but it is described per panel e in the legend.
We made the necessary changes.
- Figure 3, were statistical tests performed for panels d-e? if so, and the outcome was not significant, then it might be good to indicate this in the legend.
We have added results of statistical tests in the legend as the following sentence: “All distributions in panel d and e had a p-value of less than 0.0001 for one sample t-test against zero.” One sample t-tests were performed because what is plotted already represents each atlas’ differences to the glr-1 25 dataset atlas, we didn’t think the statistical analyses between the other atlases would add significant value.
- Figure 4, no asterisks are shown in the figure so it is possible to remove the sentence in the legend describing what the asterisk stands for.
Thank you. We made the necessary changes.
Reviewer #2 (Recommendations For The Authors):
Comparison with deep learning approaches could be more nuanced and structured, the authors (prior) approach extended here combines a specific set of comparative relationship measurements with a general optimization approach for matching based on comparative expectations. Other measurements could be used whether explicit (like neighbor expectations) or learned differences in embeddings. These alternate measurements would both need to be extensively re-calibrated for different sets of cells but might provide significant performance gains. In addition deep learning approaches don't solve the optimization part of the matching problem, so the authors approach seems to bring something strong to the table even if one is committed to learned methods (necessary I suspect for human level performance in denser cell sets than the relatively small number here). A more complete discussion of these themes might better frame the impact of the work and help readers think about the advantages and disadvantages or different methods for their own data.
We thank the reviewer for bringing up this point. We apologize perhaps not making the point clearer in the original submission. This extension of the original work (Chaudhary et al) is not changing the CRF-based framework, but only augmenting the approach with a better defined set of axes (solely because in multicell and not whole-brain datasets, the sparsity of neurons degrades the axis definition and consequently the neuron ID predictions). We are not fundamentally changing the framework, and therefore all the advantages (over registration-based approaches for example) also apply here. The other purpose of this paper is to demonstrate a couple of use-cases for gene expression analysis, which is common in studies in C. elegans (and other organisms). We hope that by showing a use-case others can see how this approach is useful for their own applications.
We have clarified these points in the paper (page 18). “The fundamental framework has not been changed from CRF_ID 1.0, and therefore the advantages of CRF_ID outlined in the original work apply for CRF_ID 2.0 as well.”
The atribution of anatomical differences to strain is interesting, but seems purely speculative, and somewhat unlikely. I would suspect the fundamentally more difficult nature of aligning N items to M>>N items in an atlas accounts for the differences in using the neuroPAL vs custom atlas here. If this is what is meant, it could be stated more clearly.
It is important to note that the same neuron candidate list (listed in methods) was used for all atlases, so there is no difference among the atlases in terms of the number of cells in the query vs. candidate list. In other words, the same values for M and for N are used regardless of the reference atlas used.
We have preliminary data indicating differences between the NeuroPAL and custom atlas. For instance, the NeuroPAL atlas scales smaller than the custom glr-1 atlas. Since direct comparisons of the different atlases are beyond the scope of this paper, we will leave the exact comparisons for future work. We suspect that the differences are from a combination of differences in anatomy and imaging conditions. While NeuroPAL atlas may not be exactly fitting for the custom dataset, it can serve as a good starting point for guesses when no custom atlases are available, as we have discussed earlier (response to Public Comments from Reviewer 1 Point 1). As explained earlier, we have added these discussions in the paper (see page 18).
I was also left wondering if the random removal of landmarks had to be adjusted in this work given it is (potentially) helping cope with not just occasional weak cells but the systematic loss of most of the cells in the atlas. If the parameters of this part of the algorithm don't influence the success for N to M>>N alignment (here when the neuroPAL or OpenWorm atlas is used) this seems interesting in itself and worth discussing. Conversely, if these parameters were opitmized for the matched atlas and used for the others, this would seem to bias performance results.
We may have failed to make this clear in the main text. As we have stated in our responses in the public review section, we do systematically limit the neuron labels in the candidate list to neurons that are known to be expressed by the promotor. The candidate list, which is kept consistent for all atlases, has more neurons than cells in the query, so it is always an N-to-M matching where M>N. We did not use landmarks, but such usage is possible and will only improve the matching.
We have attempted to clarify these points in the manuscript. In the results section under “CRF_ID 2.0 for automatic cell annotation in multi-cell images,” we added the following sentence: “Note that a truncated candidate list can be used for subset-specific cell ID if the neuronal expression is known” (page 3). In the methods section, we added the following sentence: “For multi-cell neuron predictions on the glr-1 strain, a truncated atlas containing only the above 37 neurons was used to exclude neuron candidates that are irrelevant for prediction” (Page 20).



