Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorSrdjan OstojicÉcole Normale Supérieure - PSL, Paris, France
- Senior EditorMichael FrankBrown University, Providence, United States of America
Reviewer #1 (Public review):
In this study the authors aim to understand why decision formation during behavioural tasks is distributed across multiple brain areas. They hypothesize that multiple areas are used in order to implement an information bottleneck (IB). Using neural activity recorded from monkey DLPFC and PMd performing a 2-AFC task, they show that DLPFC represents various task variables (decision, color, target configuration), while downstream PMd primarily represents decision information. Since decision information is the only information needed to make a decision, the authors suggest that PMd has a minimal sufficient representation (as expected from an IB). They then train 3-area RNNs on the same task, and show that activity in the first and third areas resemble the neural representations of DLPFC and PMd, respectively. In order to propose a mechanism, they analyse the RNN and find that area 3 ends up with primarily decision information because feedforward connections between areas primarily propagate decision information.
Overall, the paper reads well and the data analysis and RNN modeling are well done and mostly correct. I agree with the authors that PMd has less information than DLPFC, meaning that some of the target and color information is attenuated. I also agree that this also happens in their multi-area RNN.
However, I find the use of the IB principle here muddles the water rather than clarifying anything. The key problem is that the authors evoke the information bottleneck in a mostly intuitive sense, but they do not actually use it (say, in their modelling). Rather, the IB is simply used to motivate why information will be or should be lost. Since the IB is a generic compressor, however, it does not make any statements about how a particular compression should be distributed or computed across brain areas.
If I ignore the reference to the information bottleneck, I still see a more mechanistic study that proposes a neural mechanism of how decisions are formed, in the tradition of RNN-modelling of neural activity as in Mante et al 2013. Seen through this more limited sense, the present study succeeds at pointing out a good model-data match.
Major points
(1) The IB is a formal, information-theoretic method to identify relevant information. However, in the paper, reference to the information bottleneck method (IB) is only used to motivate why (task-irrelevant) information should be lost in higher areas. The IB principle itself is actually never used. The RNNs are fitted using standard techniques, without reference to the IB. Without a formal link, I think the authors should describe their findings using words (e.g., task-irrelevant information is lost), rather than stating this as evidence for an information-theoretic principle.
(2) The advantage of employing a formal theory is that all assumptions have to be clarified. Since the authors only evoke the IB, but never employ it, they refrain from clarifying some of their assumptions. That is what creates unnecessary confusion.
For instance, the authors cite the following predictions of the IB principle: "(1) There exists a downstream area of cortex that has a minimal and sufficient representation to perform a task ... (2) there exists an upstream area of cortex that has more task information than the minimal sufficient area" - However, since the information bottleneck method is a generic compressor, it does not make any predictions about areas (or neurons). For a given sensory input p(x), a given task output p(y|x), and a given information loss, the IB generates exactly one optimal representation. In other words, the predictions made by the authors relie on other assumptions (e.g. feedforward processing, hierarchy, etc.) and these are not clearly stated.
(3) A corrollary to this problem is that the authors do not formally define task-irrelevant information. It seems the authors simply use the choice or decision as the thing that needs to be computed, and identify all other information as task-irrelevant. That's at least what I glean from the RNN model. However, I find that highly confusing because it suggests the conclusion that color information or target information are task-irrelevant. Surely, that cannot be true, since the decision is based on these quantities!
(4) If we define the output as the only task-relevant information, then any representation that is a pure motor representation would qualify as a minimal sufficient representation to carry out the correct actions. However, it is well-known that sensory information is lost in motor areas. It is not clear to me what exactly we gain by calling motor representations "minimal sufficient representations."
In summary, I think the authors should refrain from evoking the IB - which is a formal, mathematical principle - unless they actually use it formally as well.
Reviewer #2 (Public review):
This study advances our understanding of information encoding in the DLPFC and PMD brain regions. The conclusions are supported with convincing and robust analyses conducted on monkey datasets and trained RNN models. However, there are some concerns regarding the interpretation of findings related to the information bottleneck theory and the mapping of brain areas in the RNN simulations.
The authors' justification regarding mapping between model areas and anatomical areas remains insufficient, in my opinion. However, I recognize that my initial critique may not have been fully clear. The issue I see is this: whichever area is mapped to the first RNN module will trivially exhibit stimulus information, and downstream regions will naturally show a gradual loss of that information if one simply reads out their responses.
Thus, the observed stimulus loss in later modules could be an inevitable consequence of the model's structure, rather than a meaningful analog to the PFC-PMd transition. This point requires more careful justification or a reevaluation of the proposed mapping.
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public Review):
In this study, the authors aim to understand why decision formation during behavioural tasks is distributed across multiple brain areas. They hypothesize that multiple areas are used in order to implement an information bottleneck (IB). Using neural activity recorded from monkey DLPFC and PMd performing a 2-AFC task, they show that DLPFC represents various task variables (decision, color, target configuration), while downstream PMd primarily represents decision information. Since decision information is the only information needed to make a decision, the authors point out that PMd has a minimal sufficient representation (as expected from an IB). They then train 3-area RNNs on the same task and show that activity in the first and third areas resemble the neural representations of DLPFC and PMd, respectively. In order to propose a mechanism, they analyse the RNN and find that area 3 ends up with primarily decision information because feedforward connections between areas primarily propagate decision information.
The paper addresses a deep, normative question, namely why task information is distributed across several areas.
Overall, it reads well and the analysis is well done and mostly correct (see below for some comments). My major problem with the paper is that I do not see that it actually provides an answer to the question posed (why is information distributed across areas?). I find that the core problem is that the information bottleneck method, which is evoked throughout the paper, is simply a generic compression method.
Being a generic compressor, the IB does not make any statements about how a particular compression should be distributed across brain areas - see major points (1) and (2).
If I ignore the reference to the information bottleneck and the question of why pieces of information are distributed, I still see a more mechanistic study that proposes a neural mechanism of how decisions are formed, in the tradition of RNN-modelling of neural activity as in Mante et al 2013. Seen through this more limited sense, the present study succeeds at pointing out a good model-data match, and I could support a publication along those lines. I point out some suggestions for improvement below.
We thank the reviewer for their comments, feedback and suggestions. We are glad to hear you support the good model-data match for this manuscript. With your helpful comments, we have clarified the connections to the information bottleneck principle and also contrasted it against the information maximization principle (the InfoMax principle), an alternative hypothesis. We elaborate on these issues in response to your points below, particularly major points (1) and (2). We also address all your other comments below.
Major points
(1) It seems to me that the author's use of the IB is based on the reasoning that deep neural networks form decisions by passing task information through a series of transformations/layers/areas and that these deep nets have been shown to implement an IB. Furthermore, these transformations are also loosely motivated by the data processing inequality.
On Major Point 1 and these following subpoints, we first want to make a high-level statement before delving into a detailed response to your points as it relates to the information bottleneck (IB). We hope this high-level statement will provide helpful context for the rest of our point-by-point responses.
We want to be clear that we draw on the information bottleneck (IB) principle as a general principle to explain why cortical representations differ by brain area. The IB principle, as applied to cortex, is only stating that a minimal sufficient representation to perform the task is formed in cortex, not how it is formed. The alternative hypothesis to the IB is that brain areas do not form minimal sufficient representations. For example, the InfoMax principle states that each brain area stores information about all inputs (even if they’re not necessary to perform the task). InfoMax isn’t unreasonable: it’s possible that storing as much information about the inputs, even in downstream areas, can support flexible computation and InfoMax also supports redundancy in cortical areas. Indeed, many studies claim that action choice related signals are in many cortical areas, which may reflect evidence of an InfoMax principle in action for areas upstream of PMd.
While we observe an IB in deep neural networks and cortex in our perceptual decision-making task, we stress that its emergence across multiple areas is an empirical result. At the same time, multiple areas producing an IB makes intuitive sense: due to the data processing inequality, successive transformations typically decrease the information in a representation (especially when, e.g., in neural networks, every activation passes through the Relu function, which is not bijective). Multiple areas are therefore a sufficient and even ‘natural’ way to implement an IB, but multiple areas are not necessary for an IB. That we observe an IB in deep neural networks and cortex emerge through multi-area computation is empirical, and, contrasting InfoMax, we believe it is an important result of this paper.
Nevertheless, your incisive comments have helped us to update the manuscript that when we talk about the IB, we should be clear that the alternative hypothesis is non-minimal representations, a prominent example of which is the InfoMax principle. We have now significantly revised our introduction to avoid this confusion. We hope this provides helpful context for our point-by-point replies, below.
However, assuming as a given that deep neural networks implement an IB does not mean that an IB can only be implemented through a deep neural network. In fact, IBs could be performed with a single transformation just as well. More formally, a task associates stimuli (X) with required responses (Y), and the IB principle states that X should be mapped to a representation Z, such that I(X;Z) is minimal and I(Y,Z) is maximal. Importantly, the form of the map Z=f(X) is not constrained by the IB. In other words, the IB does not impose that there needs to be a series of transformations. I therefore do not see how the IB by itself makes any statement about the distribution of information across various brain areas.
We agree with you that an IB can be implemented in a single transformation. We wish to be clear that we do not intend to argue necessity: that multiple areas are the only way to form minimal sufficient representations. Rather, multiple areas are sufficient to induce minimal sufficient representations, and moreover, they are a natural and reasonably simple way to do so. By ‘natural,’ we mean that minimal sufficient representations empirically arise in systems with multiple areas (more than 2), including deep neural networks and the cortex at least for our task and simulations. For example, we did not see minimal sufficient representations in 1- or 2-area RNNs, but we did see them emerge in RNNs with 3 areas or more. One potential reason for this result is that sequential transformations through multiple areas can never increase information about the input; it can only maintain or reduce information due to the data processing inequality.
Our finding that multiple areas facilitate IBs in the brain is therefore an empirical result: like in deep neural networks, we observe the brain has minimal sufficient representations that emerge in output areas (PMd), even as an area upstream (DLPFC) is not minimal. While the IB makes a statement that this minimal sufficient representation emerges, to your point, the fact that it emerges over multiple areas is not a part of the IB – as you have pointed out, the IB doesn’t state where or how the information is discarded, only that it is discarded. Our RNN modeling later proposes one potential mechanism for how it is discarded. We updated the manuscript introduction to make these points:
“An empirical observation from Machine Learning is that deep neural networks tend to form minimal sufficient representations in the last layers. Although multi-layer computation is not necessary for an IB, they provide a sufficient and even “natural” way to form an IB. A representation z = f(x) cannot contain more information than the input x itself due to the data processing inequality[19]. Thus, adding additional layers typically results in representations that contain less information about the input.”
And later in the introduction:
“Consistent with these predictions of the IB principle, we found that DLPFC has information about the color, target configuration, and direction. In contrast, PMd had a minimal sufficient representation of the direction choice. Our recordings therefore identified a cortical IB. However, we emphasize the IB does not tell us where or how the minimal sufficient representation is formed. Instead, only our empirical results implicate DLPFC-PMd in an IB computation. Further, to propose a mechanism for how this IB is formed, we trained a multi-area RNN to perform this task. We found that the RNN faithfully reproduced DLPFC and PMd activity, enabling us to propose a mechanism for how cortex uses multiple areas to compute a minimal sufficient representation.”
In the context of our work, we want to be clear the IB makes these predictions:
Prediction 1: There exists a downstream area of cortex that has a minimal and sufficient representation to perform a task (i.e.,. I(X;Z) is minimal while preserving task information so that I(Z;Y) is approximately equal to I(X;Y)). We identify PMd as an area with a minimal sufficient representation in our perceptual-decision-making task.
Prediction 2 (corollary if Prediction 1 is true): There exists an upstream brain area that contains more input information than the minimal sufficient area. We identify DLPFC as an upstream area relative to PMd, which indeed has more input information than downstream PMd in our perceptual decision-making task.
Note: as you raise in other points, it could have been possible that the IB is implemented early on, e.g., in either the parietal cortex (dorsal stream) or inferotemporal cortex (ventral stream), so that DLPFC and PMd both contained minimal sufficient representations. The fact that it doesn’t is entirely an empirical result from our data. If DLPFC had minimal sufficient representations for the perceptual decision making task, we would have needed to record in other regions to identify brain areas that are consistent with Prediction 2. But, empirically, we found that DLPFC has more input information relative to PMd, and therefore the DLPFC-PMd connection is implicated in the IB process.
What is the alternative hypothesis to the IB? We want to emphasize: it isn’t single-area computation. It’s that the cortex does not form minimal sufficient representations. For example, an alternative hypothesis (“InfoMax”) would be for all engaged brain areas to form representations that retain all input information. One reason this could be beneficial is because each brain area could support a variety of downstream tasks. In this scenario, PMd would not be minimal, invalidating Prediction 1. However, this is not supported by our empirical observations of the representations in PMd, which has a minimal sufficient representation of the task. We updated our introduction to make this clear:
“But cortex may not necessarily implement an IB. The alternative hypothesis to IB is that the cortex does not form minimal sufficient representations. One manifestation of this alternative hypothesis is the “InfoMax” principle, where downstream representations are not minimal but rather contain maximal input information22. This means information about task inputs not required to perform the task are present in downstream output areas. Two potential benefits of an InfoMax principle are (1) to increase redundancy in cortical areas and thereby provide fault tolerance, and (2) for each area to support a wide variety of tasks and thereby improve the ability of brain areas to guide many different behaviors. In contrast to InfoMax, the IB principle makes two testable predictions about cortical representations. Prediction 1: there exists a downstream area of cortex that has a minimal and sufficient representation to perform a task (i.e., I(X; Z) is minimal while preserving task information so that I(Z; Y) ≈ I(X; Y)). Prediction 2 (corollary if Prediction 1 is true): there exists an upstream area of cortex that has more task information than the minimal sufficient area.”
Your review helped us realize we should have been clearer in explaining that these are the key predictions of the IB principle tested in our paper. We also realized we should be much clearer that these predictions aren’t trivial or expected, and there is an alternative hypothesis. We have re-written the introduction of our paper to highlight that the key prediction of the IB is minimal sufficient representations for the task, in contrast to the alternative hypothesis of InfoMax.
A related problem is that the authors really only evoke the IB to explain the representation in PMd: Fig 2 shows that PMd is almost only showing decision information, and thus one can call this a minimal sufficient representation of the decision (although ignoring substantial condition independent activity).
However, there is no IB prediction about what the representation of DLPFC should look like.
Consequently, there is no IB prediction about how information should be distributed across DLPFC and PMd.
We agree: the IB doesn’t tell us how information is distributed, only that there is a transformation that eventually makes PMd minimal. The fact that we find input information in DLPFC reflects that this computation occurs across areas, and is an empirical characterization of this IB in that DLPFC has direction, color and context information while PMd has primarily direction information. To be clear: only our empirical recordings verified that the DLPFC-PMd circuit is involved in the IB. As described above, if not, we would have recorded even further upstream to identify an inter-areal connection implicated in the IB.
We updated the text to clearly state that the IB predicts that an upstream area’s activity should contain more information about the task inputs. We now explicitly describe this in the introduction, copy and pasted again here for convenience.
“In contrast to InfoMax, the IB principle makes two testable predictions about cortical representations. Prediction 1: there exists a downstream area of cortex that has a minimal and sufficient representation to perform a task (i.e., I(X; Z) is minimal while preserving task information so that I(Z; Y) ≈ I(X; Y)). Prediction 2 (corollary if Prediction 1 is true): there exists an upstream area of cortex that has more task information than the minimal sufficient area.
Consistent with the predictions of the IB principle, we found that DLPFC has information about the color, target configuration, and direction. In contrast, PMd had a minimal sufficient representation of the direction choice. Our recordings therefore identified a cortical IB. However, we emphasize the IB does not tell us where or how the minimal sufficient representation is formed. Instead, only our empirical results implicate DLPFC-PMd in an IB computation Further, to propose a mechanism for how this IB is formed, we trained a multi-area RNN to perform this task.”
The only way we knew DLPFC was not minimal was through our experiments. Please also note that the IB principle does not describe how information could be lost between areas or layers, whereas our RNN simulations show that this may occur through preferential propagation of task-relevant information with respect to the inter-area connections.
(2) Now the authors could change their argument and state that what is really needed is an IB with the additional assumption that transformations go through a feedforward network. However, even in this case, I am not sure I understand the need for distributing information in this task. In fact, in both the data and the network model, there is a nice linear readout of the decision information in dPFC (data) or area 1 (network model). Accordingly, the decision readout could occur at this stage already, and there is absolutely no need to tag on another area (PMd, area 2+3).
Similarly, I noticed that the authors consider 2,3, and 4-area models, but they do not consider a 1-area model. It is not clear why the 1-area model is not considered. Given that e.g. Mante et al, 2013, manage to fit a 1-area model to a task of similar complexity, I would a priori assume that a 1-area RNN would do just as well in solving this task.
While decision information could indeed be read out in Area 1 in our multi-area model, we were interested in understanding how the network converged to a PMd-like representation (minimal sufficient) for solving this task. Empirically, we only observed a match between our model representations and animal cortical representations during this task when considering multiple areas. Given that we empirically observed that our downstream area had a minimal sufficient representation, our multi-area model allowed how this minimal sufficient representation emerged (through preferential propagation of task-relevant information).
We also analyzed single-area networks in our initial manuscript, though we could have highlighted these analyses more clearly to be sure they were not overlooked. We are clearer in this revision that we did consider a 1-area network (results in our Fig 5). While a single-area RNN can indeed solve this task, the single area model had all task information present in the representation, and did not match the representations in DLPFC or PMd. It would therefore not allow us to understand how the network converged to a PMd-like representation (minimal sufficient) for solving this task. We updated the schematic in Fig 5 to add in the single-area network (which may have caused the confusion).
We have added an additional paragraph commenting on this in the discussion. We also added an additional supplementary figure with the PCs of the single area RNN (Fig S15). We highlight that single area RNNs do not resemble PMd activity because they contain strong color and context information.
In the discussion:
“We also found it was possible to solve this task with single area RNNs, although they did not resemble PMd (Figure S15) since it did not form a minimal sufficient representation. Rather, for our RNN simulations, we found that the following components were sufficient to induce minimal sufficient representations: (1) RNNs with at least 3 areas, following Dale’s law (independent of the ratio of feedforward to feedback connections).”
I think there are two more general problems with the author's approach. First, transformations or hierarchical representations are usually evoked to get information into the right format in a pure feedforward network. An RNN can be seen as an infinitely deep feedforward network, so even a single RNN has, at least in theory, and in contrast to feedforward layers, the power to do arbitrarily complex transformations. Second, the information coming into the network here (color + target) is a classical xor-task. While this task cannot be solved by a perceptron (=single neuron), it also is not that complex either, at least compared to, e.g., the task of distinguishing cats from dogs based on an incoming image in pixel format.
An RNN can be viewed as an infinitely deep feedforward network in time. However, we wish to clarify two things. First, our task runs for a fixed amount of time, and therefore this RNN in practice is not infinitely deep in time. Second, if it were to perform an IB operation in time, we would expect to see color discriminability decrease as a function of time. Indeed, we considered this as a mechanism (recurrent attenuation, Figure 4a), but as we show in Supplementary Figure S9, we do not observe it to be the case that discriminability decreases through time. This is equivalent to a dynamical mechanism that removes color through successive transformations in time, which our analyses reject (Fig 4). We therefore rule out that an IB is implemented through time via an RNN’s recurrent computation (viewed as feedforward in time). Rather, as we show, the IB comes primarily through inter-areal connections between RNN areas. We clarified that our dynamical hypothesis is equivalent to rejecting the feedforward-in-time filtering hypothesis in the Results:
“We first tested the hypothesis that the RNN IB is implemented primarily by recurrent dynamics (left side of Fig. 4a). These recurrent dynamics can be equivalently interpreted as the RNN implementing a feedforward neural network in time.”
The reviewer is correct that the task is a classical XOR task and not as complex as e.g., computer vision classification. That said, our related work has looked at IBs for computer vision tasks and found them in deep feedforward networks (Kleinman et al., ICLR 2021). Even though the task is relatively straightforward, we believe it is appropriate for our conclusions because it does not have a trivial minimal sufficient representation: a minimal sufficient representation for XOR must contain only target, but not color or target configuration information. This can only be solved via a nonlinear computation. In this manner, we favor this task because it is relatively simple, and the minimal sufficient representations are interpretable, while at the same time not being so trivially simple (the minimal sufficient representations require nonlinearity to compute).
Finally, we want to note that this decision-making task is a logical and straightforward way to add complexity to classical animal decision-making tasks, where stimulus evidence and the behavioral report are frequently correlated. In tasks such as these, it may be challenging to untangle stimulus and behavioral variables, making it impossible to determine if an area like premotor cortex represents only behavior rather than stimulus. However, our task decorrelates both the stimulus and the behaviors.
(3) I am convinced of the author's argument that the RNN reproduces key features of the neural data. However, there are some points where the analysis should be improved.
(a) It seems that dPCA was applied without regularization. Since dPCA can overfit the data, proper regularization is important, so that one can judge, e.g., whether the components of Fig.2g,h are significant, or whether the differences between DLPFC and PMd are significant.
We note that the dPCA codebase optimizes the regularization hyperparameter through cross-validation and requires single-trial firing rates for all neurons, i.e., data matrices of the form (n_Neurons x Color x Choice x Time x n_Trials), which are unavailable for our data. We recognized that you are fundamentally asking whether differences are significant or not. We therefore believe it is possible to address this through a statistical test, described further below.
In order to test whether the differences of variance explained by task variables between DLPFC and PMd are significant, we performed a shuffle test. For this test, we randomly sampled 500 units from the DLPFC dataset and 500 units from the PMd dataset. We then used dPCA to measure the variance explained by target configuration, color choice, and reach direction (e.g., VarTrueDLPFC,Color, VarTruePMd,Color).
To test if this variance was significant, we performed the following shuffle test. We combined the PMd and DLPFC dataset into a pool of 1000 units and then randomly selected 500 units from this pool to create a surrogate PMd dataset and used the remaining 500 units as a surrogate DLPFC dataset. We then again performed dPCA on these surrogate datasets and estimated the variance for the various task variables (e.g., VarShuffledDLPFC,Color ,VarShuffledPMd,Color).
We repeated this process for 100 times and estimated a sampling distribution for the true difference in variance between DLPFC and PMd for various task variables (e.g., VarTrueDLPFC,Color - VarTruePMd,Color). At the same time, we estimated the distribution of the variance difference between surrogate PMd and DLPFC dataset for various task variables (e.g., VarShuffleDLPFC,Color - VarShufflePMd,Color).
We defined a p-value as the number of shuffles in which the difference in variance was higher than the median of the true difference and divided it by 100. Note, for resampling and shuffle tests with n shuffles/bootstraps, the lowest theoretical p-value is given as 2/n, even in the case that no shuffle was higher than the median of the true distribution. Thus, the differences were statistically significant (p < 0.02) for color and target configuration but not for direction (p=0.72). These results are reported in Figure S6 and show both the true sampling distribution and the shuffled sampling distributions.
(b) I would have assumed that the analyses performed on the neural data were identical to the ones performed on the RNN data. However, it looked to me like that was not the case. For instance, dPCA of the neural data is done by restretching randomly timed trials to a median trial. It seemed that this restretching was not performed on the RNN. Maybe that is just an oversight, but it should be clarified. Moreover, the decoding analyses used SVC for the neural data, but a neural-net-based approach for the RNN data. Why the differences?
Thanks for bringing up these points. We want to clarify that we did include SVM decoding for the multi-area network in the appendix (Fig. S4), and the conclusions are the same. Moreover, in previous work, we also found that training with a linear decoder led to analogous conclusions (Fig. 11 of Kleinman et al, NeurIPS 2021). As we had a larger amount of trials for the RNN than the monkey, we wanted to allow a more expressive decoder for the RNN, though this choice does not affect our conclusions. We clarified the text to reflect that we did use an SVM decoder.
“We also found analogous conclusions when using an SVM decoder (Fig. S4).”
dPCA analysis requires trials of equal length. For the RNN, this is straightforward to generate because we can set the delay lengths to be equal during inference (although the RNN was trained on various length trials and can perform various length trials). Animals must have varying delay periods, or else they will learn the timing of the task and anticipate epoch changes. Because animal trial lengths were therefore different, their trials had to be restretched. We clarified this in the Methods.
“For analyses of the RNN, we fixed the timing of trials, obviating the need to to restretch trial lengths. Note that while at inference, we generated RNN trials with equal length, the RNN was trained with varying delay periods.”
(4) The RNN seems to fit the data quite nicely, so that is interesting. At the same time, the fit seems somewhat serendipitous, or at least, I did not get a good sense of what was needed to make the RNN fit the data. The authors did go to great lengths to fit various network models and turn several knobs on the fit. However, at least to me, there are a few (obvious) knobs that were not tested.
First, as already mentioned above, why not try to fit a single-area model? I would expect that a single area model could also learn the task - after all, that is what Mante et al did in their 2013 paper and the author's task does not seem any more complex than the task by Mante and colleagues.
Thank you for bringing up this point. As mentioned in response to your prior point, we did analyze a single-area RNN (Fig. 5d). We updated the schematic to clarify that we analyzed a single area network. Moreover, we also added a supplementary figure to qualitatively visualize the PCs of the single area network (Fig. S15). While a single area network can solve the task, it does not allow us to study how representations change across areas, nor did it empirically resemble our neural recordings. Single-area networks contain significant color, context, and direction information. They therefore do not form minimal representations and do not resemble PMd activity.
Second, I noticed that the networks fitted are always feedforward-dominated. What happens when feedforward and feedback connections are on an equal footing? Do we still find that only the decision information propagates to the next area? Quite generally, when it comes to attenuating information that is fed into the network (e.g. color), then that is much easier done through feedforward connections (where it can be done in a single pass, through proper alignment or misalignment of the feedforward synapses) than through recurrent connections (where you need to actively cancel the incoming information). So it seems to me that the reason the attenuation occurs in the inter-area connections could simply be because the odds are a priori stacked against recurrent connections. In the real brain, of course, there is no clear evidence that feedforward connections dominate over feedback connections anatomically.
We want to clarify that we did pick feedforward and feedback connections based on the following macaque atlas, reference 27 in our manuscript:
Markov, N. T., Ercsey-Ravasz, M. M., Ribeiro Gomes, A. R., Lamy, C., Magrou, L., Vezoli, J., Misery, P., Falchier, A., Quilodran, R., Gariel, M. A., Sallet, J., Gamanut, R., Huissoud, C., Clavagnier, S., Giroud, P., Sappey-Marinier, D., Barone, P., Dehay, C., Toroczkai, Z., … Kennedy, H. (2014). A weighted and directed interareal connectivity matrix for macaque cerebral cortex. Cerebral Cortex , 24(1), 17–36.
We therefore believe there is evidence for more feedforward than feedback connections. Nevertheless, as stated in response to your next point below, we ran a simulation where feedback and feedforward connectivity were matched.
More generally, it would be useful to clarify what exactly is sufficient:
(a) the information distribution occurs in any RNN, i.e., also in one-area RNNs
(b) the information distribution occurs when there are several, sparsely connected areas
(c) the information distribution occurs when there are feedforward-dominated connections between areas
We better clarify what exactly is sufficient.
- We trained single-area RNNs and found that these RNNs contained color information; additionally two area RNNs also contained color information in the last area (Fig 5d).
- We indeed found that the minimal sufficient representations emerged when we had several areas, with Dale’s law constraint on the connectivity. When we had even sparser connections, without Dale’s law, there was significantly more color information, even at 1% feedforward connections; Fig 5a.
- When we matched the percentage of feedforward and feedback connections with Dale’s law constraint on the connectivity (10% feedforward and 10% feedback), we also observed minimal sufficient representations (Fig S9).
Together, we found that minimal sufficient representations emerged when we had several areas (3 or greater), with Dale’s law constraint on the connectivity, independent of the ratio of feedforward/feedback connections. We thank the reviewer for raising this point about the space of constraints leading to minimal sufficient representations in the late area. We clarified this in the Discussion.
“We also found it was possible to solve this task with single area RNNs, although they did not resemble PMd (Figure S15) since it did not form a minimal sufficient representation. Rather, for our RNN simulations, we found that the following components were sufficient to induce minimal sufficient representations: RNNs with at least 3 areas, following Dale’s law (independent of the ratio of feedforward to feedback connections).”
Thank you for your helpful and constructive comments!
Reviewer #2 (Public Review):
Kleinman and colleagues conducted an analysis of two datasets, one recorded from DLPFC in one monkey and the other from PMD in two monkeys. They also performed similar analyses on trained RNNs with various architectures.
The study revealed four main findings. (1) All task variables (color coherence, target configuration, and choice direction) were found to be encoded in DLPFC. (2) PMD, an area downstream of PFC, only encoded choice direction. (3) These empirical findings align with the celebrated 'information bottleneck principle,' which suggests that FF networks progressively filter out task-irrelevant information. (4) Moreover, similar results were observed in RNNs with three modules.
We thank the reviewer for their comments, feedback and suggestions, which we address below.
While the analyses supporting results 1 and 2 were convincing and robust, I have some concerns and recommendations regarding findings 3 and 4, which I will elaborate on below. It is important to note that findings 2 and 4 had already been reported in a previous publication by the same authors (ref. 43).
Note the NeurIPS paper only had PMd data and did not contain any DLPFC data. That manuscript made predictions about representations and dynamics upstream of PMd, and subsequent experiments reported in this manuscript validated these predictions. Importantly, this manuscript observes an information bottleneck between DLPFC and PMd.
Major recommendation/comments:
The interpretation of the empirical findings regarding the communication subspace in relation to the information bottleneck theory is very interesting and novel. However, it may be a stretch to apply this interpretation directly to PFC-PMd, as was done with early vs. late areas of a FF neural network.
In the RNN simulations, the main finding indicates that a network with three or more modules lacks information about the stimulus in the third or subsequent modules. The authors draw a direct analogy between monkey PFC and PMd and Modules 1 and 3 of the RNNs, respectively. However, considering the model's architecture, it seems more appropriate to map Area 1 to regions upstream of PFC, such as the visual cortex, since Area 1 receives visual stimuli. Moreover, both PFC and PMd are deep within the brain hierarchy, suggesting a more natural mapping to later areas. This contradicts the CCA analysis in Figure 3e. It is recommended to either remap the areas or provide further support for the current mapping choice.
We updated the Introduction to better clarify the predictions of the information bottleneck (IB) principle. In particular, the IB principle predicts that later areas should have minimal sufficient representations of task information, whereas upstream areas should have more information. In PMd, we observed a minimal sufficient representation of task information during the decision-making task. In DLPFC, we observed more task information, particularly more information about the target colors and the target configuration.
In terms of the exact map between areas, we do not believe or intend to claim the DLPFC is the first area implicated in the sensorimotor transformation during our perceptual decision-making task. Rather, DLPFC best matches Area 1 of our model. It is important to note that we abstracted our task so that the first area of our model received checkerboard coherence and target configuration as input (and hence did not need to transform task visual inputs). Indeed, in Figure 1d we hypothesize that the early visual areas should contain additional information, which we do not model directly in this work. Future work could model RNNs to take in an image or video input of the task stimulus. In this case, it would be interesting to assess if earlier areas resemble visual cortical areas. We updated the results, where we first present the RNN, to state the inputs explicitly and be clear the inputs are not images or videos of the checkerboard task.
“The RNN input was 4D representing the target configuration and checkerboard signed coherence, while the RNN output was 2D, representing decision variables for a left and right reach (see Methods).”
Another reason that we mapped Area 1 to DLPFC is because anatomical, physiological and lesion studies suggest that DLPFC receives inputs from both the dorsal and ventral stream (Romanski, et, al, 2007; Hoshi, et al, 2006; Wilson, at al, 1993). The dorsal stream originates from the occipital lobe, passes through the posterior parietal cortex, to DLPFC, which carries visuospatial information of the object. The ventral stream originates from the occipital lobe, passes through the inferior temporal cortex, ventrolateral prefrontal cortex to DLPFC, which encodes the identity of the object, including color and texture. In our RNN simulation, Area 1 receives processed inputs of the task: target configuration and the evidence for each color in the checkerboard. Target configuration contains information of the spatial location of the targets, which represents the inputs from the dorsal stream, while evidence for each color by analogy is the input from the ventral stream. Purely visual areas would not fit this dual input from both the dorsal and ventral stream. A potential alternative candidate would be the parietal cortex which is largely part of the dorsal stream and is thought to have modest color inputs (although there is some shape and color selectivity in areas such as LIP, e.g., work from Sereno et al.). On balance given the strong inputs from both the dorsal and ventral stream, we believe Area 1 maps better on to DLPFC than earlier visual areas.
Recommendations for the authors:
Reviewer #1 (Recommendations For The Authors):
(1) Line 35/36: Please specify the type of nuisance that the representation is robust to. I guess this refers to small changes in the inputs, not to changes in the representation itself.
Indeed it refers to input variability unrelated to the task. We clarified the text.
(2) For reference, it would be nice to have a tick for the event "Targets on" in Fig.2c.
In this plot, the PSTHs are aligned to the checkerboard onset. Because there is a variable time between target and checkerboard onset, there is a trial-by-trial difference of when the target was turned on, so there is no single place on the x-axis where we could place a “Targets on” tick. In response to this point, we generated a plot with both targets on and check on alignment, with a break in the middle, shown in Supplementary Figure S5.
(3) It would strengthen the comparison between neural data and RNN if the DPCA components of the RNN areas were shown, as they are shown in Fig.2g,h for the neural data.
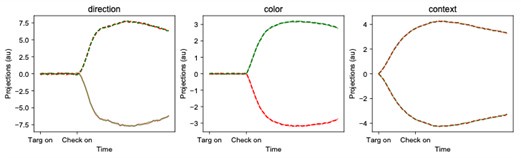
We include the PSTHs plotted onto the dPCA components here for Area 1 of the exemplar network. Dashed lines indicate a left reach, while solid lines indicate a right reach, and the color corresponds to the color of the selected target. As expected, we find that the dPCA components capture the separation between components. We emphasize that the trajectory paths along the decoder axes are not particularly meaningful to interpret, except to demonstrate whether variables can be decoded or not (as in Fig 2g,h, comparing DLPFC and PMd). The decoder axes of dPCA are not constrained in any way, in contrast to the readout (encoder) axis (see Methods). This is why our manuscript focuses on analyzing the readout axes. However, if the reviewer strongly prefers these plots to be put in the manuscript, we will add them.
Author response image 1.
(4) The session-by-session decode analysis presented in Fig.2i suggests that DLPFC has mostly direction information while in Area 1 target information is on top, as suggested by Fig.3g. An additional decoding analysis on trial averaged neural data, i.e. a figure for neural data analogous to Fig.3g,h, would allow for a more straightforward and direct comparison between RNN and neural data.
We first clarify that we did not decode trial-averaged neural data for either recorded neural data or RNNs. In Fig 3g, h (for the RNN) all decoding was performed on single trial data and then averaged. We have revised the main manuscript to make this clear. Because of this, the mean accuracies we reported for DLPFC and PMd in the text are therefore computed in the same way as the mean accuracies presented in Fig 3g, h. We believe this likely addresses your concern: i.e., the mean decode accuracies presented for both neural data and the RNN were computed the same way.
If the above paragraph did not address your concern, we also wish to be clear that we presented the neural data as histograms, rather than a mean with standard error, because we found that accuracies were highly variable depending on electrode insertion location. For example, some insertions in DLPFC achieved chance-levels of decoding performance for color and target configuration. For this reason, we prefer to keep the histogram as it shows more information than reporting the mean, which we report in the main text. However, if the reviewer strongly prefers us to make a bar plot of these means, we will add them.
(5) Line 129 mentions an analysis of single trials. But in Fig.2i,j sessions are analyzed. Please clarify.
For each session, we decode from single trials and then average these decoding accuracies, leading to a per-session average decoding accuracy. Note that for each session, we record from different neurons. In the text, we also report the average over the sessions. We clarified this in the text and Methods.
(6) Fig.4c,f show how color and direction axes align with the potent subspaces. We assume that the target axis was omitted here because it highly aligns with the color axis, yet we note that this was not pointed out explicitly.
You are correct, and we revised the text to point this out explicitly.
“We quantified how the color and direction axis were aligned with these potent and null spaces of the intra-areal recurrent dynamics matrix of Area 1 ($\W^1_{rec}$). We did not include the target configuration axis for simplicity, since it highly aligns with the color axis for this network.”
(7) The caption of Fig.4c reads: "Projections onto the potent space of the intra-areal dynamics for each area." Yet, they only show area 1 in Fig.4c, and the rest in a supplement figure. Please refer properly.
Thank you for pointing this out. We updated the text to reference the supplementary figure.
(8) Line 300: "We found the direction axis was more aligned with the potent space and the color axis was more aligned with the null space." They rather show that the color axis is as aligned to the potent space as a random vector, but nothing about the alignments with the null space. Contrarily, on line 379 they write "...with the important difference that color information isn't preferentially projected to a nullspace...". Please clarify.
Thank you for pointing this out. We clarified the text to read: “We found the direction axis was more aligned with the potent space”. The text then describes that the color axis is aligned like a random vector: “In contrast, the color axis was aligned to a random vector.”
(9) Line 313: 'unconstrained' networks are mentioned. What constraints are implied there, Dale's law? Please define and clarify.
Indeed, the constraint refers to Dale’s law constraints. We clarified the text: “Further, we found that W21 in unconstrained 3 area networks (i.e., without Dale's law constraints) had significantly reduced…”
(10) Line 355 mentions a 'feedforward bottleneck'. What does this exactly mean? No E-I feedforward connections, or...? Please define and clarify.
This refers to sparser connections between areas than within an area, as well as a smaller fraction of E-I connections. We clarified the text to read:
“Together, these results suggest that a connection bottleneck in the form of neurophysiological architecture constraints (i.e., sparser connections between areas than within an area, as well as a smaller fraction of E-I connections) was the key design choice leading to RNNs with minimal color representations and consistent with the information bottleneck principle.”
(11) Fig.5c is supposedly without feedforward connections, but it looks like the plot depicts these connections (i.e. identical to Fig.5b).
In Figure 5, we are varying the E to I connectivity in panel B, and the E-E connectivity in panel C. We vary the feedback connections in Supp Fig. S12. We updated the caption accordingly.
(12) For reference, it would be nice to have the parameters of the exemplar network indicated in the panels of Fig.5.
We updated the caption to reference the parameter configuration in Table 1 of the Appendix.
(13) Line 659: incomplete sentence
Thank you for pointing this out. We removed this incomplete sentence.
(14) In the methods section "Decoding and Mutual information for RNNs" a linear neural net decoder as well as a nonlinear neural net decoder are described, yet it was unclear which one was used in the end.
We used the nonlinear network, and clarified the text accordingly. We obtained consistent conclusions using a linear network, but did not include these results in the text. (These are reported in Fig. 11 of Kleinman et al, 2021). Moreover, we also obtain consistent results by using an SVM decoder in Fig. S4 for our exemplar parameter configuration.
(15) In the discussion, the paragraph starting from line 410 introduces a new set of results along with the benefits of minimal representations. This should go to the results section.
We prefer to leave this as a discussion, since the task was potentially too simplistic to generate a clear conclusion on this matter. We believe this remains a discussion point for further investigation.
(16) Fig S5: hard to parse. Show some arrows for trajectories (a) (d) is pretty mysterious: where do I see the slow dynamics?
Slow points are denoted by crosses, which forms an approximate line attractor. We clarified this in the caption.
Reviewer #2 (Recommendations For The Authors):
Minor recommendations (not ordered by importance)
(1) Be more explicit that the recordings come from different monkeys and are not simultaneously recorded. For instance, say 'recordings from PFC or PMD'. Say early on that PMD recordings come from two monkeys and that PFC recordings come from 1 of those monkeys. Furthermore, I would highlight which datasets are novel and which are not. For instance, I believe the PFC dataset is a previously unpublished dataset and should be highlighted as such.
We added: “The PMd data was previously described in a study by Chandrasekaran and colleagues” to the main text which clarifies that the PMd data was previously recorded and has been analyzed in other studies.
(2) I personally feel that talking about 'optimal', as is done in the abstract, is a bit of a stretch for this simple task.
In using the terminology “optimal,” we are following the convention of IB literature that optimal representations are sufficient and minimal. The term “optimal” therefore is task-specific; every task will have its own optimal representation. We clarify in the text that this definition comes from Machine Learning and Information Theory, stating:
“The IB principle defines an optimal representation as a representation that is minimal and sufficient for a task or set of tasks.”
In this way, we take an information-theoretic view for describing multi-area representations. This view was satisfactory for explaining and reconciling the multi-area recordings and simulations for this task, and we think it is helpful to provide a normative perspective for explaining the differences in cortical representations by brain area. Even though the task is simple, it still allows us to study how sensory/perceptual information is represented, and well as how choice-related information is being represented.
(3) It is mentioned (and even highlighted) in the abstract that we don't know why the brain distributes computations. I agree with that statement, but I don't think this manuscript answers that question. Relatedly, the introduction mentions robustness as one reason why the brain would distribute computations, but then raises the question of whether there is 'also a computational benefit for distributing computations across multiple areas'. Isn't the latter (robustness) a clear 'computational benefit'?
We decided to keep the word “why” in the abstract, because this is a generally true statement (it is unclear why the brain distributes computation) that we wish to convey succinctly, pointing to the importance of studying this relatively grand question (which could only be fully answered by many studies over decades). We consider this the setting of our work. However, to avoid confusion that we are trying to give a full answer to this question, we are now more precise in the first paragraph of our introduction as to the particular questions we ask that will take a step towards this question. In particular, the first paragraph now asks these questions, which we answer in our study.
“For example, is all stimuli and decision-related information present in all brain areas, or do the cortical representations differ depending on their processing stage? If the representations differ, are there general principles that can explain why the cortical representations differ by brain area?”
We also removed the language on robustness, as we agree it was confusing. Thank you for these suggestions.
(4) Figure 2e and Fig. 3d, left, do not look very similar. I suggest zooming in or rotating Figure 2 to highlight the similarities. Consider generating a baseline CCA correlation using some sort of data shuffle to highlight the differences.
The main point of the trajectories is to demonstrate that both Area 1 and DLPFC represent both color and direction. We now clarify this in the manuscript. However, we do not intend for these two plots to be a rigorous comparison of similarity. Rather, we quantify similarity using CCA and our decoding analysis. We also better emphasize the relative values of the CCA, rather than the absolute values.
(5) Line 152: 'For this analysis, we restricted it to sessions with significant decode accuracy with a session considered to have a significant decodability for a variable if the true accuracy was above the 99th percentile of the shuffled accuracy for a session.' Why? Sounds fishy, especially if one is building a case on 'non-decodability'. I would either not do it or better justify it.
The reason to choose only sessions with significant decoding accuracy is that we consider those sessions to be the sessions containing information of task variables. In response to this comment, we also now generate a plot with all recording sessions in Supplementary Figure S7. We modified the manuscript accordingly.
“For this analysis, we restricted it to sessions with significant decode accuracy with a session considered to have a significant decodability for a variable if the true accuracy was above the 99th percentile of the shuffled accuracy for a session. This is because these sessions contain information about task variables. However, we also present the same analyses using all sessions in Fig. S7.”
(6) Line 232: 'The RNN therefore models many aspects of our physiological data and is therefore'. Many seems a stretch?
We changed “many” to “key.”
(7) The illustration in Fig. 4B is very hard to understand, I recommend removing it.
We are unsure what this refers to, as Figure 4B represents data of axis overlaps and is not an illustration.
(8) At some point the authors use IB instead of information bottleneck (eg line 288), I would not do it.
We now clearly write that IB is an abbreviation of Information Bottleneck the first time it is introduced.
(9) Fig. 5 caption is insufficient to understand it. Text in the main document does not help. I would move most part of this figure, or at least F, to supplementary. Instead, I would move the results in S11 and S10 to the main document.
We clarified the caption to summarize the key points. It now reads:
“Overall, neurophysiological architecture constraints in the form of multiple areas, sparser connections between areas than within an area, as well as a smaller fraction of E-I connections lead to a minimal color representation in the last area.”
(10) Line 355: 'Together, these results suggest that a connection bottleneck in the form of neurophysiological architecture constraints was the key design choice leading to RNNs with minimal color representations and consistent with the information bottleneck principle.' The authors show convincingly that increased sparsity leads to the removal of irrelevant information. There is an alternative model of the communication subspace hypothesis that uses low-rank matrices, instead of sparse, to implement said bottlenecks (https://www.biorxiv.org/content/10.1101/2022.07.21.500962v2)
We thank the reviewer for pointing us to this very nice paper. Indeed, a low-rank connectivity matrix is another mechanism to limit the amount of information that is passed to subsequent areas. In fact, the low-rank matrix forms a hard-version of our observations as we found that task-relevant information was preferentially propagated along the top singular mode of the inter-areal connectivity matrix. In our paper we observed this tendency naturally emerges through training with neurophysiological architecture constraints. In the paper, for the multi-area RNN, they hand-engineered the multi-area network, whereas our network is trained. We added this reference to our discussion.
Thank you for your helpful and constructive comments.



