Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorThorsten KahntNational Institute on Drug Abuse Intramural Research Program, Baltimore, United States of America
- Senior EditorMichael FrankBrown University, Providence, United States of America
Reviewer #1 (Public Review):
Summary:
Willems and colleagues test whether unexpected shock omissions are associated with reward-related prediction errors by using an axiomatic approach to investigate brain activation in response to unexpected shock omission. Using an elegant design that parametrically varies shock expectancy through verbal instructions, they see a variety of responses in reward-related networks, only some of which adhere to the axioms necessary for prediction error. In addition, there were associations between omission-related responses and subjective relief. They also use machine learning to predict relief-related pleasantness, and find that none of the a priori "reward" regions were predictive of relief, which is an interesting finding that can be validated and pursued in future work.
Strengths:
The authors pre-registered their approach and the analyses are sound. In particular, the axiomatic approach tests whether a given region can truly be called a reward prediction error. Although several a priori regions of interest satisfied a subset of axioms, no ROI satisfied all three axioms, and the authors were candid about this. A second strength was their use of machine learning to identify a relief-related classifier. Interestingly, none of the ROIs that have been traditionally implicated in reward prediction error reliably predicted relief, which opens important questions for future research.
Weaknesses:
To ensure that the number of omissions is similar across conditions, the task employs inaccurate verbal instructions; i.e. 25% of shocks are omitted, regardless of whether subjects are told that the probability is 100%, 75%, 50%, 25%, or 0%. Given previous findings on interactions between verbal instruction and experiential learning (Doll et al., 2009; Li et al., 2011; Atlas et al., 2016), it seems problematic a) to treat the instructions as veridical and b) average responses over time. Based on these prior work, it seems reasonable to assume that participants would learn to downweight the instructions over time through learning (particularly in the 100% and 0% cases); this would be the purpose of prediction errors as a teaching signal. The authors do recognize this and perform a subset analysis in the 21 participants who showed parametric increases in anticipatory SCR as a function of instructed shock probability, which strengthened findings in the VTA/SN; however given that one third of participants (n=10) did not show parametric SCR in response to instructions, it seems like some learning did occur. As prediction error is so important to such learning, a weakness of the paper is that conclusions about prediction error might differ if dynamic learning were taken into account.
Reviewer #2 (Public Review):
The question of whether the neural mechanisms for reward and punishment learning are similar has been a constant debate over the last two decades. Numerous studies have shown that the midbrain dopamine neurons respond to both negative and salient stimuli, some of which can't be well accounted for by the classic RL theory (Delgado et al., 2007). Other research even proposed that aversive learning can be viewed as reward learning, by treating the omission of aversive stimuli as a negative PE (Seymour et al., 2004).
Although the current study took an axiomatic approach to search for the PE encoding brain regions, which I like, I have major concerns regarding their experimental design and hence the results they obtained. My biggest concern comes from the false description of their task to the participants. To increase the number of "valid" trials for data analysis, the instructed and actual probabilities were different. Under such a circumstance, testing axiom 2 seems completely artificial. How does the experimenter know that the participants truly believe that the 75% is more probable than, say, the 25% stimulation? The potential confusion of the subjects may explain why the SCR and relief report were rather flat across the instructed probability range, and some of the canonical PE encoding regions showed a rather mixed activity pattern across different probabilities. Also for the post-hoc selection criteria, why pick the larger SCR in the 75% compared to the 25% instructions? How would the results change if other criteria were used?
To test axiom 3, which was to compare the 100% stimulation to the 0% stimulation conditions, how did the actual shock delivery affect the fMRI contrast result? It would be more reasonable if this analysis could control for the shock delivery, which itself could contaminate the fMRI signal, with extra confound that subjects may engage certain behavioral strategies to "prepare for" the aversive outcome in the 100% stimulation condition. Therefore, I agree with the authors that this contrast may not be a good way to test axiom 3, not only because of the arguments made in the discussion but also the technical complexities involved in the contrast.
Comments on revised version:
I want to thank the authors for their thorough and comprehensive work in revising this manuscript. I agree with the authors that learning paradigms might not be a necessity when it comes to study the PE signals, but I don't particularly agree with some of the responses in the rebuttal letter ("Furthermore, conditioning paradigms generally only include one level of aversive outcome: the electrical stimulation is either delivered or omitted."). This is of course correct description for the conditioning paradigm, but the same can be said for an instructed design: the aversive outcome was either delivered or not. That being said, adopting the instructed design itself is legitimate in my opinion.
My main concern, which the authors spent quite some length in the rebuttal letter to address, still remains about the validity for different instructed probabilities. Although subjects were told that the trials were independent, the big difference between 75% and 25% would more than likely confuse the subjects, especially given that most of us would fall prey to the Gambler's fallacy (or the law of small numbers) to some degree. When the instruction and subjective experience collides, some form of inference or learning must have occurred, making the otherwise straightforward analysis more complex. Therefore, I believe that a more rigorous/quantitative learning modeling work can dramatically improve the validity of the results. Of course, I also realize how much extra work is needed to append the computational part but without it there is always a theoretical loophole in the current experimental design.
As the authors mentioned in the rebuttal letter, "selecting participants only if their anticipatory SCR monotonically increased with each increase in instructed probability 0% < 25% < 50% < 75% < 100%, N = 11 participants", only ~1/3 of the subjects actually showed strong evidence for the validity of the instructions. This further raises the question of whether the instructed design, due to the interference of false instruction and the dynamic learning among trials, is solid enough to test the hypothesis.
Reviewer #3 (Public Review):
Summary:
The authors conducted a human fMRI study investigating the omission of expected electrical shocks with varying probabilities. Participants were informed of the probability of shock and shock intensity trial-by-trial. The time point corresponding to the absence of the expected shock (with varying probability) was framed as a prediction error producing the cognitive state of relief/pleasure for the participant. fMRI activity in the VTA/SN and ventral putamen corresponded to the surprising omission of a high probability shock. Participants' subjective relief at having not been shocked correlated with activity in brain regions typically associated with reward-prediction errors. The overall conclusion of the manuscript was that the absence of an expected aversive outcome in human fMRI looks like a reward-prediction error seen in other studies that use positive outcomes.
Strengths:
Overall, I found this to be a well-written human neuroimaging study investigating an often overlooked question on the role of aversive prediction errors, and how they may differ from reward-related prediction errors. The paper is well-written and the fMRI methods seem mostly rigorous and solid.
Comments on revised version:
The authors were extremely responsive to the comments and provided a comprehensive rebuttal letter with a lot of detail to address the comments. The authors clarified their methodology, and rationale for their task design, which required some more explanation (at least for me) to understand. Some of the design elements were not clear to me in the original paper.
The initial framing for their study is still in the domain of learning. The paper starts off with a description of extinction as the prime example of when threat is omitted. This could lead a reader to think the paper would speak to the role of prediction errors in extinction learning processes. But this is not their goal, as they emphasize repeatedly in their rebuttal letter. The revision also now details how using a conditioning/extinction framework doesn't suit their experimental needs.
It is reasonable to develop a new task to answer their experimental questions. By no means is there a requirement to use a conditioning/extinction paradigm to address their questions. As they say, "it is not necessary to adopt a learning paradigm to study omission responses", which I agree with.
But the authors seem to want to have it both ways: they frame their paper around how important prediction errors are to extinction processes, but then go out of their way to say how they can't test their hypotheses with a learning paradigm.
Part of their argument that they needed to develop their own task "outside of a learning context" goes as follows:
(1) "...conditioning paradigms generally only include one level of aversive outcome: the electrical stimulation is either delivered or omitted. As a result, the magnitude-related axiom cannot be tested."
(2) "....in conditioning tasks people generally learn fast, rendering relatively few trials on which the prediction is violated. As a result, there is generally little intra-individual variability in the PE responses"
(3) "...because of the relatively low signal to noise ratio in fMRI measures, fear extinction studies often pool across trials to compare omission-related activity between early and late extinction, which further reduces the necessary variability to properly evaluate the probability axiom"
These points seem to hinge on how tasks are "generally" constructed. However, there are many adaptations to learning tasks:
(1) There is no rule that conditioning can't include different levels of aversive outcomes following different cues. In fact, their own design uses multiple cues that signal different intensities and probabilities. Saying that conditioning "generally only include one level of aversive outcome" is not an explanation for why "these paradigms are not tailored" for their research purposes. There are also several conditioning studies that have used different cues to signal different outcome probabilities. This is not uncommon, and in fact is what they use in their study, only with an instruction rather than through learning through experience, per se.
(2) Conditioning/extinction doesn't have to occur fast. Just because people "generally learn fast" doesn't mean this has to be the case. Experiments can be designed to make learning more challenging or take longer (e.g., partial reinforcement). And there can be intra-individual differences in conditioning and extinction, especially if some cues have a lower probability of predicting the US than others. Again, because most conditioning tasks are usually constructed in a fairly simplistic manner doesn't negate the utility of learning paradigms to address PE-axioms.
(3) Many studies have tracked trial-by-trial BOLD signal in learning studies (e.g., using parametric modulation). Again, just because other studies "often pool across trials" is not an explanation for these paradigms being ill-suited to study prediction errors. Indeed, most computational models used in fMRI are predicated on analyzing data at the trial level.
Again, the authors are free to develop their own task design that they think is best suited to address their experimental questions. For instance, if they truly believe that omission-related responses should be studied independent of updating. The question I'm still left puzzling is why the paper is so strongly framed around extinction (the word appears several times in the main body of the paper), which is a learning process, and yet the authors go out of their way to say that they can only test their hypotheses outside of a learning paradigm.
The authors did address other areas of concern, to varying extents. Some of these issues were somewhat glossed over in the rebuttal letter by noting them as limitations. For example, the issue with comparing 100% stimulation to 0% stimulation, when the shock contaminates the fMRI signal. This was noted as a limitation that should be addressed in future studies, bypassing the critical point.
Author response:
The following is the authors’ response to the original reviews.
As you will see, the main changes in the revised manuscript pertain to the structure and content of the introduction. Specifically, we have tried to more clearly introduce our paradigm, the rationale behind the paradigm, why it is different from learning paradigms, and why we study “relief”.
In this rebuttal letter, we will go over the reviewers’ comments one-by-one and highlight how we have adapted our manuscript accordingly. However, because one concern was raised by all reviewers, we will start with an in-depth discussion of this concern.
The shared concern pertained to the validity of the EVA task as a model to study threat omission responses. Specifically, all reviewers questioned the effectivity of our so-called “inaccurate”, “false” or “ruse” instructions in triggering an equivalent level of shock expectancy, and relatedly, how this effectivity was affected by dynamic learning over the course of the task.
We want to thank the reviewers for raising this important issue. Indeed, it is a vital part of our design and it therefore deserves considerable attention. It is now clear to us that in the previous version of the manuscript we may have focused too little on why we moved away from a learning paradigm, and how we made sure that the instructions were successful at raising the necessary expectations; and how the instructions were affected by learning. We believe this has resulted in some misunderstandings, which consequently may have cast doubts on our results. In the following sections, we will go into these issues.
The rationale behind our instructed design
The main aim of our study was to investigate brain responses to unexpected omissions of threat in greater detail by examining their similarity to the reward prediction error axioms (Caplin & Dean, 2008), and exploring the link with subjective relief. Specifically, we hypothesized that omission-related responses should be dependent on the probability and the intensity of the expected-but-omitted aversive event (i.e., electrical stimulation), meaning that the response should be larger when the expected stimulation was stronger and more expected, and that fully predicted outcomes should not trigger a difference in responding.
To this end, we required that participants had varying levels of threat probability and intensity predictions, and that these predictions would most of the time be violated. Although we fully agree with the reviewers that fear conditioning and extinction paradigms can provide an excellent way to track the teaching properties of prediction error responses (i.e., how they are used to update expectancies on future trials), we argued that they are less suited to create the varying probability and intensity-related conditions we required (see Willems & Vervliet, 2021). Specifically, in a standard conditioning task participants generally learn fast, rendering relatively few trials on which the prediction is violated. As a result, there is generally little intraindividual variability in the prediction error responses. This precludes an in-depth analysis of the probability-related effects. Furthermore, conditioning paradigms generally only include one level of aversive outcome: the electrical stimulation is either delivered or omitted. As a result, intensity-related effects cannot be tested. Finally, because CS-US contingencies change over the course of a fear conditioning and extinction study (e.g. from acquisition to extinction), there is never complete certainty about when the US will (not) follow. This precludes a direct comparison of fully predicted outcomes.
Another added value of studying responses to the prediction error at threat omission outside a learning context is that it can offer a way to disentangle responses to the violation of threat expectancy, with those of subsequent expectancy updating.
Also note that Rutledge and colleagues (2010), who were the first to show that human fMRI responses in the Nucleus Accumbens comply to the reward prediction error axioms also did not use learning experiences to induce expectancy. In that sense, we argued it was not necessary to adopt a learning paradigm to study threat omission responses.
Adaptations in the revised manuscript: We included two new paragraphs in the introduction of the revised manuscript to elaborate on why we opted not to use a learning paradigm in the present study (lines 90-112).
“However, is a correlation with the theoretical PE over time sufficient for neural activations/relief to be classified as a PE-signal? In the context of reward, Caplin and colleagues proposed three necessary and sufficient criteria all PE-signals should comply to, independent of the exact operationalizations of expectancy and reward (the socalled axiomatic approach24,25; which has also been applied to aversive PE26–28). Specifically, the magnitude of a PE signal should: (1) be positively related to the magnitude of the reward (larger rewards trigger larger PEs); (2) be negatively related to likelihood of the reward (more probable rewards trigger smaller PEs); and (3) not differentiate between fully predicted outcomes of different magnitudes (if there is no error in prediction, there should be no difference in the PE signal).”
“It is evident that fear conditioning and extinction paradigms have been invaluable for studying the role of the threat omission PE within a learning context. However, these paradigms are not tailored to create the varying intensity and probability-related conditions that are required to evaluate the threat omission PE in the light of the PE axioms. First, conditioning paradigms generally only include one level of aversive outcome: the electrical stimulation is either delivered or omitted. As a result, the magnitude-related axiom cannot be tested. Second, in conditioning tasks people generally learn fast, rendering relatively few trials on which the prediction is violated. As a result, there is generally little intra-individual variability in the PE responses. Moreover, because of the relatively low signal to noise ratio in fMRI measures, fear extinction studies often pool across trials to compare omission-related activity between early and late extinction16, which further reduces the necessary variability to properly evaluate the probability axiom. Third, because CS-US contingencies change over the course of the task (e.g. from acquisition to extinction), there is never complete certainty about whether the US will (not) follow. This precludes a direct comparison of fully predicted outcomes. Finally, within a learning context, it remains unclear whether PErelated responses are in fact responses to the violation of expectancy itself, or whether they are the result of subsequent expectancy updating.”
Can verbal instructions be used to raise the expectancy of shock?
The most straightforward way to obtain sufficient variability in both probability and intensityrelated predictions is by directly providing participants with instructions on the probability and intensity of the electrical stimulation. In a previous behavioral study, we have shown that omission responses (self-reported relief and omission SCR) indeed varied with these instructions (Willems & Vervliet, 2021). In addition, the manipulation checks that are reported in the supplemental material provided further support that the verbal instructions were effective at raising the associated expectancy of stimulation. Specifically, participants recollected having received more stimulations after higher probability instructions (see Supplemental Figure 2). Furthermore, we found that anticipatory SCR, which we used as a proxy of fearful expectation, increased with increasing probability and intensity (see Supplemental Figure 3). This suggests that it is not necessary to have expectation based on previous experience if we want to evaluate threat omission responses in the light of the prediction error axioms.
Adaptations in the revised manuscript: We more clearly referred to the manipulation checks that are presented in the supplementary material in the results section of the main paper (lines 135-141).
“The verbal instructions were effective at raising the expectation of receiving the electrical stimulation in line with the provided probability and intensity levels. Anticipatory SCR, which we used as a proxy of fearful expectation, increased as a function of the probability and intensity instructions (see Supplementary Figure 3). Accordingly, post-experimental questions revealed that by the end of the experiment participants recollected having received more stimulations after higher probability instructions, and were willing to exert more effort to prevent stronger hypothetical stimulations (see Supplementary Figure 2).”
How did the inconsistency between the instructed and experienced probability impact our results?
All reviewers questioned how the inconsistency between the instructed and experienced probability might have impacted the probability-related results. However, judging from the way the comments were framed, it seems that part of the concern was based on a misunderstanding of the design we employed. Specifically, reviewer 1 mentions that “To ensure that the number of omissions is similar across conditions, the task employs inaccurate verbal instructions; I.e., 25% of shocks are omitted regardless of whether subjects are told that the probability is 100%, 75%, 50%, 25%, 0%.”, and reviewer 3 states that “... the fact remains that they do not get shocks outside of the 100% probability shock. So learning is occurring, at least for subjects who realize the probability cue is actually a ruse.” We want to emphasize that this was not what we did, and if it were true, we fully agree with the reviewers that it would have caused serious trust- and learning related issues, given that it would be immediately evident to participants that probability instructions were false. It is clear that under such circumstances, dynamic learning would be a big issue.
However, in our task 0% and 100% instructions were always accurate. This means that participants never received a stimulus following 0% instructions and always received the stimulation of the given intensity on the 100% instructions (see Supplemental Figure 1 for an overview of the trial types). Only for the 25%, 50% and 75% trials an equal reinforcement rate (25%) was maintained, meaning that the stimulation followed in 25% of the trials, irrespective of whether a 25%, 50% or 75% instruction was given. The reason for this was that we wanted to maximize and balance the number of omission trials across the different probability levels, while also keeping the total number of presentations per probability instruction constant. We reasoned that equating the reinforcement rate across the 25%, 50% and 75% instructions should not be detrimental, because (1) in these trials there was always the possibility that a stimulation would follow; and (2) we instructed the participants that each trial is independent of the previous ones, which should have discouraged them to actively count the number of shocks in order to predict future shocks.
Adaptations in the revised manuscript: We have tried to further clarify the design in several sections of the manuscript, including the introduction (lines 121-125), results (line 220) and methods (lines 478-484) sections:
Adaptation in the Introduction section: “Specifically, participants received trial-by-trial instructions about the probability (0%, 25%, 50%, 75% and 100%) and intensity (weak, moderate, strong) of a potentially painful upcoming electrical stimulation, time-locked by a countdown clock (see Fig.1A). While stimulations were always delivered on 100% trials and never on 0% trials, most of the other trials (25%-75%) did not contain the expected stimulation and hence provoked an omission PE.”
Adaptation in the Results section: “Indeed, the provided instructions did not map exactly onto the actually experienced probabilities, but were all followed by stimulation in 25% on the trials (except for the 0% trials and the 100% trials).”
Adaptation in the Methods section: “Since we were mainly interested in how omissions of threat are processed, we wanted to maximize and balance the number of omission trials across the different probability and intensity levels, while also keeping the total number of presentations per probability and intensity instruction constant. Therefore, we crossed all non-0% probability levels (25, 50, 75, 100) with all intensity levels (weak, moderate, strong) (12 trials). The three 100% trials were always followed by the stimulation of the instructed intensity, while stimulations were omitted in the remaining nine trials. Six additional trials were intermixed in each run: Three 0% omission trials with the information that no electrical stimulation would follow (akin to 0% Probability information, but without any Intensity information as it does not apply); and three trials from the Probability x Intensity matrix that were followed by electrical stimulation (across the four runs, each Probability x Intensity combination was paired at least once, and at most twice with the electrical stimulation).”
Could the incongruence between the instructed and experienced reinforcement rate have detrimental effects on the probability effect? We agree with reviewer 2 that it is possible that the inconsistency between instructed and experienced reinforcement rates could have rendered the exact probability information less informative to participants, which might have resulted in them paying less attention to the probability information whenever the probability was not 0% or 100%. This might to some extent explain the relatively larger difference in responding between 0% and 25% to 75% trials, but the relatively smaller differences between the 25% to 75% trials.
However, there are good reasons to believe that the relatively smaller difference between 25% to 75% trials was not caused by the “inaccurate” nature of our instructions, but is inherent to “uncertain” probabilities.
We added a description of these reasons to the supplementary materials in a supplementary note (supplementary note 4; lines 97-129 in supplementary materials), and added a reference to this note in the methods section (lines 488-490).
“Supplementary Note 4: “Accurate” probability instructions do not alter the Probability-effect
A question that was raised by the reviewers was whether the inconsistency between the probability instruction and the experienced reinforcement rate could have detrimental effects on the Probability-related results; especially because the effect of Probability was smaller when only including non-0% trials.
However, there are good reasons to believe that the relatively smaller difference between 25% to 75% trials was not caused by the “inaccurate” nature of our instructions, but that they are inherent to “uncertain” probabilities.
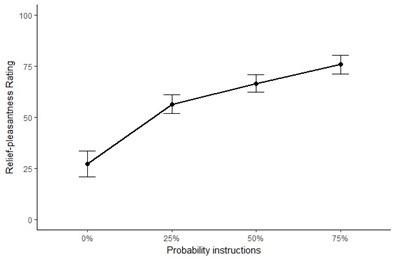
First, in a previously unpublished pilot study, we provided participants with “accurate” probability instructions, meaning that the instruction corresponded to the actual reinforcement rate (e.g., 75% instructions were followed by a stimulation in 75% of the trials etc.). In line with the present results and our previous behavioral study (Willems & Vervliet, 2021), the results of this pilot (N = 20) showed that the difference in the reported relief between the different probability levels was largest when comparing 0% and the rest (25%, 50% and 75%). Furthermore the overall effect size of Probability (excluding 0%) matched the one of our previous behavioral study (Willems & Vervliet, 2021): ηp2 = +/- 0.50.”
Author response image 1.
Main effect of Probability including 0% : F(1.74,31.23) = 53.94, p < .001, ηp2 = 0.75. Main effect of Probability excluding 0%: F(1.50, 28.43) = 21.03, p < .001, ηp2 = 0.53.
Second, also in other published studies that used CSs with varying reinforcement rates (which either included explicit written instructions of the reinforcement rates or not) showed that the difference in expectations, anticipatory SCR or omission SCR was largest when comparing the CS0% to the other CSs of varying reinforcement rates (Grings & Sukoneck, 1971; Öhman et al., 1973; Ojala et al., 2022).
Together, this suggests that when there is a possibility of stimulation, any additional difference in probability will have a smaller effect on the omission responses, irrespective of whether the underlying reinforcement rate is accurate or not.
Adaptation to methods section: “Note that, based on previous research, we did not expect the inconsistency between the instructed and perceived reinforcement rate to have a negative effect on the Probability manipulation (see Supplementary Note 4).”
Did dynamic learning impact the believability of the instructions?
Although we tried to minimize learning in our paradigm by providing instructions that trials are independent from one another, we agree with the reviewers that this cannot preclude all learning. Any remaining learning effects should present themselves by downweighing the effect of the probability instructions over time. We controlled for this time-effect by including a “run” regressor in our analyses. Results of the Run regressor for subjective relief and omission-related SCR are presented in Supplemental Figure 5. These figures show that although there was a general drop in reported relief pleasantness and omission SCR over time, the effects of probability and intensity remained present until the last run. This indicates that even though some learning might have taken place, the main manipulations of probability and intensity were still present until the end of the task.
Adaptations in the revised manuscript: We more clearly referred to the results of the Blockregressor which were presented in the supplementary material in the results section of the main paper (lines 159-162).
Note that while there was a general drop in reported relief pleasantness and omission SCR over time, the effects of Probability and Intensity remained present until the last run (see Supplementary Figure 5). This further confirms that probability and intensity manipulations were effective until the end of the task.
In the following sections of the rebuttal letter, we will go over the rest of the comments and our responses one by one.
Reviewer #1 (Public Review):
Summary:
Willems and colleagues test whether unexpected shock omissions are associated with reward-related prediction errors by using an axiomatic approach to investigate brain activation in response to unexpected shock omission. Using an elegant design that parametrically varies shock expectancy through verbal instructions, they see a variety of responses in reward-related networks, only some of which adhere to the axioms necessary for prediction error. In addition, there were associations between omission-related responses and subjective relief. They also use machine learning to predict relief-related pleasantness, and find that none of the a priori "reward" regions were predictive of relief, which is an interesting finding that can be validated and pursued in future work.
Strengths:
The authors pre-registered their approach and the analyses are sound. In particular, the axiomatic approach tests whether a given region can truly be called a reward prediction error. Although several a priori regions of interest satisfied a subset of axioms, no ROI satisfied all three axioms, and the authors were candid about this. A second strength was their use of machine learning to identify a relief-related classifier. Interestingly, none of the ROIs that have been traditionally implicated in reward prediction error reliably predicted relief, which opens important questions for future research.
Weaknesses:
To ensure that the number of omissions is similar across conditions, the task employs inaccurate verbal instructions; i.e. 25% of shocks are omitted, regardless of whether subjects are told that the probability is 100%, 75%, 50%, 25%, or 0%. Given previous findings on interactions between verbal instruction and experiential learning (Doll et al., 2009; Li et al., 2011; Atlas et al., 2016), it seems problematic a) to treat the instructions as veridical and b) average responses over time. Based on this prior work, it seems reasonable to assume that participants would learn to downweight the instructions over time through learning (particularly in the 100% and 0% cases); this would be the purpose of prediction errors as a teaching signal. The authors do recognize this and perform a subset analysis in the 21 participants who showed parametric increases in anticipatory SCR as a function of instructed shock probability, which strengthened findings in the VTA/SN; however given that one-third of participants (n=10) did not show parametric SCR in response to instructions, it seems like some learning did occur. As prediction error is so important to such learning, a weakness of the paper is that conclusions about prediction error might differ if dynamic learning were taken into account.
We thank the reviewer for raising this important concern. We believe we replied to all the issues raised in the general reply above.
Lastly, I think that findings in threat-sensitive regions such as the anterior insula and amygdala may not be adequately captured in the title or abstract which strictly refers to the "human reward system"; more nuance would also be warranted.
We fully agree with this comment and have changed the title and abstract accordingly.
Adaptations in the revised manuscript: We adapted the title of the manuscript.
“Omissions of Threat Trigger Subjective Relief and Prediction Error-Like Signaling in the Human Reward and Salience Systems”
Adaptations in the revised manuscript: We adapted the abstract (lines 27-29).
“In line with recent animal data, we showed that the unexpected omission of (painful) electrical stimulation triggers activations within key regions of the reward and salience pathways and that these activations correlate with the pleasantness of the reported relief.”
Reviewer #2 (Public Review):
The question of whether the neural mechanisms for reward and punishment learning are similar has been a constant debate over the last two decades. Numerous studies have shown that the midbrain dopamine neurons respond to both negative and salient stimuli, some of which can't be well accounted for by the classic RL theory (Delgado et al., 2007). Other research even proposed that aversive learning can be viewed as reward learning, by treating the omission of aversive stimuli as a negative PE (Seymour et al., 2004).
Although the current study took an axiomatic approach to search for the PE encoding brain regions, which I like, I have major concerns regarding their experimental design and hence the results they obtained. My biggest concern comes from the false description of their task to the participants. To increase the number of "valid" trials for data analysis, the instructed and actual probabilities were different. Under such a circumstance, testing axiom 2 seems completely artificial. How does the experimenter know that the participants truly believe that the 75% is more probable than, say, the 25% stimulation? The potential confusion of the subjects may explain why the SCR and relief report were rather flat across the instructed probability range, and some of the canonical PE encoding regions showed a rather mixed activity pattern across different probabilities. Also for the post-hoc selection criteria, why pick the larger SCR in the 75% compared to the 25% instructions? How would the results change if other criteria were used?
We thank the reviewer for raising this important concern. We believe the general reply above covers most of the issues raised in this comment. Concerning the post-hoc selection criteria, we took 25% < 75% as criterium because this was a quite “lenient” criterium in the sense that it looked only at the effects of interest (i.e., did anticipatory SCR increase with increasing instructed probability?). However, also when the criterium was more strict (e.g., selecting participants only if their anticipatory SCR monotonically increased with each increase in instructed probability 0% < 25% < 50% < 75% < 100%, N = 11 participants), the probability effect (ωp2 = 0.08), but not the intensity effect, for the VTA/SN remained.
To test axiom 3, which was to compare the 100% stimulation to the 0% stimulation conditions, how did the actual shock delivery affect the fMRI contrast result? It would be more reasonable if this analysis could control for the shock delivery, which itself could contaminate the fMRI signal, with extra confound that subjects may engage certain behavioral strategies to "prepare for" the aversive outcome in the 100% stimulation condition. Therefore, I agree with the authors that this contrast may not be a good way to test axiom 3, not only because of the arguments made in the discussion but also the technical complexities involved in the contrast.
We thank the reviewer for addressing this additional confound. It was indeed impossible to control for the delivery of shock since the delivery of the shock was always present on the 100% trials (and thus completely overlapped with the contrast of interest). We added this limitation to our discussion in the manuscript. In addition, we have also added a suggestion for a contrast that can test the “no surprise equivalence” criterium.
Adaptations in the revised manuscript: We adapted lines 358-364.
“Thus, given that we could not control for the delivery of the stimulation in the 100% > 0% contrast (the delivery of the stimulation completely overlapped with the contrast of interest), it is impossible to disentangle responses to the salience of the stimulation from those to the predictability of the outcome. A fairer evaluation of the third axiom would require outcomes that are roughly similar in terms of salience. When evaluating threat omission PE, this implies comparing fully expected threat omissions following 0% instructions to fully expected absence of stimulation at another point in the task (e.g. during a safe intertrial interval).”
Reviewer #3 (Public Review):
We thank the reviewer for their comments. Overall, based on the reviewer’s comments, we noticed that there was an imbalance between a focus on “relief” in the introduction and the rest of the manuscript and preregistration. We believe this focus raised the expectation that all outcome measures were interpreted in terms of the relief emotion. However, this was not what we did nor what we preregistered. We therefore restructured the introduction to reduce the focus on relief.
Adaptations in the revised manuscript: We restructured the introduction of the manuscript. Specifically, after our opening sentence: “We experience a pleasurable relief when an expected threat stays away1” we only introduce the role of relief for our research in lines 79-89.
“Interestingly, unexpected omissions of threat not only trigger neural activations that resemble a reward PE, they are also accompanied by a pleasurable emotional experience: relief. Because these feelings of relief coincide with the PE at threat omission, relief has been proposed to be an emotional correlate of the threat omission PE. Indeed, emerging evidence has shown that subjective experiences of relief follow the same time-course as theoretical PE during fear extinction. Participants in fear extinction experiments report high levels of relief pleasantness during early US omissions (when the omission was unexpected and the theoretical PE was high) and decreasing relief pleasantness over later omissions (when the omission was expected and the theoretical PE was low)22,23. Accordingly, preliminary fMRI evidence has shown that the pleasantness of this relief is correlated to activations in the NAC at the time of threat omission. In that sense, studying relief may offer important insights in the mechanism driving safety learning.”
Summary:
The authors conducted a human fMRI study investigating the omission of expected electrical shocks with varying probabilities. Participants were informed of the probability of shock and shock intensity trial-by-trial. The time point corresponding to the absence of the expected shock (with varying probability) was framed as a prediction error producing the cognitive state of relief/pleasure for the participant. fMRI activity in the VTA/SN and ventral putamen corresponded to the surprising omission of a high probability shock. Participants' subjective relief at having not been shocked correlated with activity in brain regions typically associated with reward-prediction errors. The overall conclusion of the manuscript was that the absence of an expected aversive outcome in human fMRI looks like a reward-prediction error seen in other studies that use positive outcomes.
Strengths:
Overall, I found this to be a well-written human neuroimaging study investigating an often overlooked question on the role of aversive prediction errors, and how they may differ from reward-related prediction errors. The paper is well-written and the fMRI methods seem mostly rigorous and solid.
Weaknesses:
I did have some confusion over the use of the term "prediction-error" however as it is being used in this task. There is certainly an expectancy violation when participants are told there is a high probability of shock, and it doesn't occur. Yet, there is no relevant learning or updating, and participants are explicitly told that each trial is independent and the outcome (or lack thereof) does not affect the chances of getting the shock on another trial with the same instructed outcome probability. Prediction errors are primarily used in the context of a learning model (reinforcement learning, etc.), but without a need to learn, the utility of that signal is unclear.
We operationalized “prediction error” as the response to the error in prediction or the violation of expectancy at the time of threat omission. In that sense, prediction error and expectancy violation (which is more commonly used in clinical research and psychotherapy; Craske et al., 2014) are synonymous. While prediction errors (or expectancy violations) are predominantly studied in learning situations, the definition in itself does not specify how the “expectancy” or “prediction” arises: whether it was through learning based on previous experience or through mere instruction. The rationale why we moved away from a conditioning study in the present manuscript is discussed in our general reply above.
We agree with the reviewer that studying prediction errors outside a learning context limits the ecological validity of the task. However, we do believe there is also a strength to this approach. Specifically, the omission-related responses we measure are less confounded by subsequent learning (or updating of the wrongful expectation). Any difference between our results and prediction error responses in learning situation can therefore point to this exact difference in paradigm, and can thus identify responses that are specific to learning situations.
An overarching question posed by the researchers is whether relief from not receiving a shock is a reward. They take as neural evidence activity in regions usually associated with reward prediction errors, like the VTA/SN . This seems to be a strong case of reverse inference. The evidence may have been stronger had the authors compared activity to a reward prediction error, for example using a similar task but with reward outcomes. As it stands, the neural evidence that the absence of shock is actually "pleasurable" is limited-albeit there is a subjective report asking subjects if they felt relief.
We thank the reviewer for cautioning us and letting us critically reflect on our interpretation. We agree that it is important not to be overly enthusiastic when interpreting fMRI results and to attribute carelessly psychological functions to mere activations. Therefore, we will elaborate on the precautions we took not to minimize detrimental reverse inference.
First, prior to analyzing our results, we preregistered clear hypotheses that were based on previous research, in addition to clear predictions, regions of interest and a testing approach on OSF. With our study, we wanted to investigate whether unexpected omissions of threat: (1) triggered activations in the VTA/SN, putamen, NAc and vmPFC (as has previously been shown in animal and human studies); (2) represent PE signals; and (3) were related to self-reported relief, which has also been shown to follow a PE time-curve in fear extinction (Vervliet et al., 2017). Based on previous research, we selected three criteria all PE signals should comply to. This means that if omission-related activations were to represent true PE signals, they should comply to these criteria. However, we agree that it would go too far to conclude based on our research that relief is a reward, or even that the omission-related activations represent only PE signals. While we found support for most of our hypotheses, this does not preclude alternative explanations. In fact, in the discussion, we acknowledge this and also discuss alternative explanations, such as responding to the salience (lines 395-397; “One potential explanation is therefore that the deactivation resulted from a switch from default mode to salience network, triggered by the salience of the unexpected threat omission or by the salience of the experienced stimulation.”), or anticipation (line 425-426; “... we cannot conclusively dismiss the alternative interpretation that we assessed (part of) expectancy instead”).
Second, we have deliberately opted to only use descriptive labels such as omission-related activations when we are discussing fMRI results. Only when we are talking about how the activations were related to self-reported relief, we talk about relief-related activations.
I have some other comments, and I elaborate on those above comments, below:
(1) A major assumption in the paper is that the unexpected absence of danger constitutes a pleasurable event, as stated in the opening sentence of the abstract. This may sometimes be the case, but it is not universal across contexts or people. For instance, for pathological fears, any relief derived from exposure may be short-lived (the dog didn't bite me this time, but that doesn't mean it won't next time or that all dogs are safe). And even if the subjective feeling one gets is temporary relief at that moment when the expected aversive event is not delivered, I believe there is an overall conflation between the concepts of relief and pleasure throughout the manuscript. Overall, the manuscript seems to be framed on the assumption that "aversive expectations can transform neutral outcomes into pleasurable events," but this is situationally dependent and is not a common psychological construct as far as I am aware.
We thank the reviewer for their comment. We have restructured the introduction because we agree with the reviewer that the introduction might have set false expectations concerning our interpretation of the results. The statements related to relief have been toned down in the revised manuscript.
Still, we want to note that the initial opening statement “unexpected absence of danger constitutes the pleasurable emotion relief” was based on a commonly used definition of relief that states that relief refers to “the emotion that is triggered by the absence of expected or previously experienced negative stimulation ” (Deutsch, 2015). Both aspects that it is elicited by the absence of an otherwise expected aversive event and that it is pleasurable in nature has received considerable empirical support in emotion and fear conditioning research (Deutsch et al., 2015; Leknes et al., 2011; Papalini et al., 2021; Vervliet et al., 2017; Willems & Vervliet, 2021).
That said, the notion that the feeling of relief is linked to the (reward) prediction error underlying the learning of safety is included in several theoretical papers in order to explain the commonly observed dopaminergic response at the time of threat omission (both in animals and humans; Bouton et al., 2020; Kalisch et al., 2019; Pittig et al., 2020).
Together, these studies indicate that the definition of relief, and its potential role in threat omission-driven learning is – at least in our research field – established. Still, we felt that more direct research linking feelings of relief to omission-related brain responses was warranted.
One of the main reasons why we specifically focus on the “pleasantness” of the relief is to assess the hedonic impact of the threat omission, as has been done in previous studies by our lab and others (Leknes et al., 2011; Leng et al., 2022; Papalini et al., 2021; Vervliet et al., 2017; Willems & Vervliet, 2021). Nevertheless, we agree with the reviewer that the relief we measure is a short-lived emotional state that is subjected to individual differences (as are all emotions).
(2) The authors allude to this limitation, but I think it is critical. Specifically, the study takes a rather simplistic approach to prediction errors. It treats the instructed probability as the subjects' expectancy level and treats the prediction error as omission related activity to this instructed probability. There is no modeling, and any dynamic parameters affected by learning are unaccounted for in this design . That is subjects are informed that each trial is independently determined and so there is no learning "the presence/absence of stimulations on previous trials could not predict the presence/absence of stimulation on future trials." Prediction errors are central to learning. It is unclear if the "relief" subjects feel on not getting a shock on a high-probability trial is in any way analogous to a prediction error, because there is no reason to update your representation on future trials if they are all truly independent. The construct validity of the design is in question.
(3) Related to the above point, even if subjects veered away from learning by the instruction that each trial is independent, the fact remains that they do not get shocks outside of the 100% probability shock. So learning is occurring, at least for subjects who realize the probability cue is actually a ruse.
We thank the reviewer for raising these concerns. We believe that the general reply above covers the issues raised in points 2 and 3.
(4) Bouton has described very well how the absence of expected threat during extinction can create a feeling of ambiguity and uncertainty regarding the signal value of the CS. This in large part explains the contextual dependence of extinction and the "return of fear" that is so prominent even in psychologically healthy participants. The relief people feel when not receiving an expected shock would seem to have little bearing on changing the long-term value of the CS. In any event, the authors do talk about conditioning (CS-US) in the paper, but this is not a typical conditioning study, as there is no learning.
We fully agree with the reviewer that our study is no typical conditioning study. Nevertheless, because our research mostly builds on recent advances in the fear extinction domain, we felt it was necessary to introduce the fear extinction procedure and related findings. In the context of fear extinction learning, we have previously shown that relief is an emotional correlate of the prediction error driving acquisition of the novel safety memory (CSnoUS; Papalini et al., 2021; Vervliet et al., 2017). The ambiguity Bouton describes is the result of extinguished CS holding multiple meanings once the safety memory is acquired. Does it signal danger or safety? We agree with Bouton that the meaning of the CS for any new encounter will depend on the context, and the passage of time, but also on the initial strength of the safety acquisition (which is dependent on the size of the prediction error, and hence the amount of relief; Craske et al., 2014). However, it was not our objective to directly study the relation of relief to subsequent CS value, and our design is not tailored to do so post hoc.
(5) In Figure 2 A-D, the omission responses are plotted on trials with varying levels of probability. However, it seems to be missing omission responses in 0% trials in these brain regions. As depicted, it is an incomplete view of activity across the different trial types of increasing threat probability.
We thank the reviewer for pointing out this unclarity. The betas that are presented in the figures represent the ROI averages from each non-0% vs 0% contrasts (i.e., 25%>0%; 50%>0%; and 75%>0% for the weak, moderate and strong intensity levels). Any positive beta therefore indicates a stronger activation in the given region compared to a fully predicted omission. Any negative beta indicates a weaker activation.
Adaptations in the revised manuscript: We have adapted the figure captions of figures 2 and 3.
“The extracted beta-estimates in figures A-D represent the ROI averages from each non0% > 0% contrast (i.e., 25%>0%; 50%>0%; and 75%>0% for the weak, moderate and strong intensity levels). Any positive beta therefore indicates a stronger activation in the given region compared to a fully predicted omission. Any negative beta indicates a weaker activation.”
(6) If I understand Figure 2 panels E-H, these are plotting responses to the shock versus no-shock (when no-shock was expected). It is unclear why this would be especially informative, as it would just be showing activity associated with shocks versus no-shocks. If the goal was to use this as a way to compare positive and negative prediction errors, the shock would induce widespread activity that is not necessarily reflective of a prediction error. It is simply a response to a shock. Comparing activity to shocks delivered after varying levels of probability (e.g., a shock delivered at 25% expectancy, versus 75%, versus 100%) would seem to be a much better test of a prediction error signal than shock versus no-shock.
We thank the reviewer for this comment. The purpose of this preregistered contrast was to test whether fully predicted outcomes elicited equivalent activations in our ROIs (corresponding to the third prediction error axiom). Specifically, if a region represents a pure prediction error signal, the 100% (fully predicted shocks) > 0% (fully predicted shock omissions) contrast should be nonsignificant, and follow-up Bayes Factors would further provide evidence in favor of this null-hypothesis.
We agree with the reviewer that the delivery of the stimulation triggers widespread activations in our regions of interest that confounded this contrast. However, given that it was a preregistered test for the prediction error axioms, we cannot remove it from the manuscript. Instead, we have argued in the discussion that future studies who want to take an axiomatic stance should consider alternative tests to examine this axiom.
Adaptations in the revised manuscript: We adapted lines 358-364.
“Thus, given that we could not control for the delivery of the stimulation in the 100% > 0% contrast (the delivery of the stimulation completely overlapped with the contrast of interest), it is impossible to disentangle responses to the salience of the stimulation from those to the predictability of the outcome. A fairer evaluation of the third axiom would require outcomes that are roughly similar in terms of salience. When evaluating threat omission PE, this implies comparing fully expected threat omissions following 0% instructions to fully expected absence of stimulation at another point in the task (e.g. during a safe intertrial interval).”
Also note that our task did not lend itself for an in-depth analysis of aversive (worse-thanexpected) prediction error signals, given that there was only one stimulation trial for each probability x intensity level (see Supplemental Figure 1). The most informative contrast that can inform us about aversive prediction error signals contrasts all non-100% stimulation trials with all 100% stimulation trials. The results of this contrast are presented in Supplemental Figure 16 and Supplemental Table 11 for completeness.
(7) I was unclear what the results in Figure 3 E-H were showing that was unique from panels A-D, or where it was described. The images looked redundant from the images in A-D. I see that they come from different contrasts (non0% > 0%; 100% > 0%), but I was unclear why that was included.
We thank the reviewer for this comment. Our answer is related to that of the previous comment. Figure 3 presents the results of the axiomatic tests within the secondary ROIs we extracted from a wider secondary mask based on the non0%>0% contrast.
(8) As mentioned earlier, there is a tendency to imply that subjects felt relief because there was activity in "the reward pathway ."
We thank the reviewer for their comment, but we respectfully disagree. Subjective relief was explicitly probed when the instructed stimulations stayed away. In the manuscript we only talk about “relief” when discussing these subjective reports. We found that participants reported higher levels of relief-pleasantness following omissions of stronger and more probable threat. This was an observation that matches our predictions and replicates our previous behavioral study (Willems & Vervliet, 2021).
The fMRI evidence is treated separately from the “pleasantness” of the relief. Specifically, we refrain from calling the threat omission-related neural responses “relief-activity” as this would indeed imply that the activation would only be attributed to this psychological function. Instead, we talked about omission-related activity, and we assessed whether it complied to the prediction error criteria as specified by the axiomatic approach.
Only afterwards, because we hypothesized that omission-related fMRI activation and selfreported relief-pleasantness were related, and because we found a similar response pattern for both measures, we examined how relief and omission-related fMRI activations within our ROIs were related on a trial-by-trial basis. To this end, we entered relief-pleasantness ratings as a parametric modulator to the omission regressor.
By no means do we want to reduce an emotional experience (relief) to fMRI activations in isolated regions in the brain. We agree with the reviewer that this would be far too reductionist. We therefore also ran a pre-registered LASSO-PCR analysis in order to identify whether a whole-brain pattern of activations can predict subjective relief (independent from the exact instructions we gave, and independent of our a priori ROIs). This analysis used trialby-trial patterns of activation across all voxels in the brain as the predictor and self-reported relief as the outcome variable. It is therefore completely data-driven and can be seen as a preregistered exploratory analysis that is intended to inform future studies.
(9) From the methods, it wasn't entirely clear where there is jitter in the course of a trial. This centers on the question of possible collinearity in the task design between the cue and the outcome. The authors note there is "no multicollinearity between anticipation and omission regressors in the firstlevel GLMs," but how was this quantified? b The issue is of course that the activity coded as omission may be from the anticipation of the expected outcome.
We thank the reviewer for pointing out this unclarity. Jitter was introduced in all parts of the trial: i.e., the duration of the inter-trial interval (4-7s), countdown clock (3-7s), and omission window (4-8s) were all jittered (see fig. 1A and methods section, lines 499-507). We added an additional line to the method section.
Adaptations in the revised manuscript: We added an additional line of to the methods section to further clarify the jittering (lines 498-500).
“The scale remained on the screen for 8 seconds or until the participant responded, followed by an intertrial interval between 4 and 7 seconds during which only a fixation cross was shown. Note that all phases in the trial were jittered (i.e., duration countdown clock, duration outcome window, duration intertrial interval).”
Multicollinearity between the omission and anticipation regressors was assessed by calculating the variance inflation factor (VIF) of omission and anticipation regressors in the first level GLM models that were used for the parametric modulation analyses.
Adaptations in the revised manuscript: We replaced the VIF abbreviation with “variance inflation factor” (line 423-424).
“Nevertheless, there was no multicollinearity between anticipation and omission regressors in the first-level GLMs (VIFs Variance Inflation Factor, VIF < 4), making it unlikely that the omission responses purely represented anticipation.”
(10) I did not fully understand what the LASSO-PCR model using relief ratings added. This result was not discussed in much depth, and seems to show a host of clusters throughout the brain contributing positively or negatively to the model. Altogether, I would recommend highlighting what this analysis is uniquely contributing to the interpretation of the findings.
The main added value of this analyses is that it uses a different approach altogether. Where the (mass univariate) parametric modulation analysis estimated in each voxel (and each ROI) whether the activity in this voxel/ROI covaried with the reported relief, a significant activation only indicated that this voxel was related to relief. However, given that each voxel/ROI is treated independently in this analysis, it remains unclear how the activations were embedded in a wider network across the brain, and which regions contributed most to the prediction of relief. The multivariate LASSO-PCR analysis approach we took attempts to overcome this limitation by examining if a more whole-brain pattern can predict relief. Because we use the whole-brain pattern (and not only our a priori ROIs), this analysis is completely data-driven and is intended to inform future studies. In addition, the LASSO-PCR model was cross-validated using five-fold cross-validation, which is also a difference (and a strength) compared to the mass univariate GLM approach.
One interesting finding that only became evident when we combined univariate and multivariate approaches is that despite that the parametric modulation analysis showed that omission-related fMRI responses in the ROIs were modulated by the reported relief, none of these ROIs contributed significantly to the prediction of relief based on the identified signature. Instead, some of the contributing clusters fell within other valuation and errorprocessing regions (e.g. lateral OFC, mid cingulate, caudate nucleus). This suggests that other regions than our a priori ROIs may have been especially important for the subjective experience of relief, at least in this task. However, all these clusters were small and require further validation in out of sample participants. More research is necessary to test the generalizability and validity of the relief signature to new individuals and tasks, and to compare the signature with other existing signature models (e.g., signature of pain, fear, reward, pleasure). However, this was beyond the scope of the present study.
Adaptations in the revised manuscript: We altered the explanation of the LASSO-PCR approach in the results section (lines 286-295) and the discussion (lines 399-402)
Adaptations in the Results section: “The (mass univariate) parametric modulation analysis showed that omission-related fMRI activity in our primary and secondary ROIs correlated with the pleasantness of the relief. However, given that each voxel/ROI is treated independently in this analysis, it remains unclear how the activations were embedded in a wider network of activation across the brain, and which regions contributed most to the prediction of relief. To overcome these limitations, we trained a (multivariate) LASSO-PCR model (Least Absolute Shrinkage and Selection Operator-Regularized Principle Component Regression) in order to identify whether a spatially distributed pattern of brain responses can predict the perceived pleasantness of the relief (or “neural signature” of relief)31. Because we used the whole-brain pattern (and not only our a priori ROIs), this analysis is completely data driven and can thus identify which clusters contribute most to the relief prediction.”
Adaptations in the Discussion section: “In addition to examining the PE-properties of neural omission responses in our a priori ROIs, we trained a LASSO-PCR model to establish a signature pattern of relief. One interesting finding that only became evident when we compared the univariate and multivariate approach was that none of our a priori ROIs appeared to be an important contributor to the multivariate neural signature, even though all of them (except NAc) were significantly modulated by relief in the univariate analysis.”
In addition to the public peer review, the reviewers provided some recommendation on how to further improve our manuscript. We will reply to the recommendations below.
Reviewer #1 (Recommendations For The Authors):
Given that you do have trial-level estimates from the classifier analysis, it would be very informative to use learning models and examine responses trial-by-trial to test whether there are prediction errors that vary over time as a function of learning.
We thank the reviewer for the suggestion. However, based on the results of the run-regressor, we do not anticipate large learning effects in our paradigm. As we mentioned in our responses above, we controlled for time-related drops in omission-responding by including a “run” regressor in our analyses. Results of this regressor for subjective relief and omission-related SCR showed that although there was a general drop in reported relief pleasantness and omission SCR over time, the effects of probability and intensity remained present until the last run. This suggests that even though some learning might have taken place, its effect was likely small and did not abolish our manipulations of probability and intensity. In any case, we cannot use the LASSO-PCR signature model to investigate learning, as this model uses the trial-level brain pattern at the time of US omission to estimate the associated level of relief. These estimates can therefore not be used to examine learning effects.
Reviewer #2 (Recommendations For The Authors):
The LASSO-PCR model feels rather disconnected from the rest of the paper and does not add much to the main theme. I would suggest to remove this part from the paper.
We thank the reviewer for this suggestion. However, the LASSO-PCR analysis was a preregistered. We therefore cannot remove it from the manuscript. We hope to have clarified its added value in the revised version of the manuscript.



