Peer review process
Not revised: This Reviewed Preprint includes the authors’ original preprint (without revision), an eLife assessment, public reviews, and a provisional response from the authors.
Read more about eLife’s peer review process.Editors
- Reviewing EditorIgnacio SanchezCONICET / Universidad de Buenos Aires, Buenos Aires, Argentina
- Senior EditorDominique Soldati-FavreUniversity of Geneva, Geneva, Switzerland
Reviewer #1 (Public Review):
Summary
This work contains 3 sections. The first section describes how protein domains with SQ motifs can increase the abundance of a lacZ reporter in yeast. The authors call this phenomenon autonomous protein expression-enhancing activity, and this finding is well supported. The authors show evidence that this increase in protein abundance and enzymatic activity is not due to changes in plasmid copy number or mRNA abundance, and that this phenomenon is not affected by mutants in translational quality control. It was not completely clear whether the increased protein abundance is due to increased translation or to increased protein stability.
In section 2, the authors performed mutagenesis of three N-terminal domains to study how protein sequence changes protein stability and enzymatic activity of the fusions. These data are very interesting, but this section needs more interpretation. It is not clear if the effect is due to the number of S/T/Q/N amino acids or due to the number of phosphorylation sites.
In section 3, the authors undertake an extensive computational analysis of amino acid runs in 27 species. Many aspects of this section are fascinating to an expert reader. They identify regions with poly-X tracks. These data were not normalized correctly: I think that a null expectation for how often poly-X track occur should be built for each species based on the underlying prevalence of amino acids in that species. As a result, I believe that the claim is not well supported by the data.
Strengths
This work is about an interesting topic and contains stimulating bioinformatics analysis. The first two sections, where the authors investigate how S/T/Q/N abundance modulates protein expression level, is well supported by the data. The bioinformatics analysis of Q abundance in ciliate proteomes is fascinating. There are some ciliates that have repurposed stop codons to code for Q. The authors find that in these proteomes, Q-runs are greatly expanded. They offer interesting speculations on how this expansion might impact protein function.
Weakness
At this time, the manuscript is disorganized and difficult to read. An expert in the field, who will not be distracted by the disorganization, will find some very interesting results included. In particular, the order of the introduction does not match the rest of the paper.
In the first and second sections, where the authors investigate how S/T/Q/N abundance modulates protein expression levels, it is unclear if the effect is due to the number of phosphorylation sites or the number of S/T/Q/N residues. The authors also do not discuss if the N-end rule for protein stability applies to the lacZ reporter or the fusion proteins.
The most interesting part of the paper is an exploration of S/T/Q/N-rich regions and other repetitive AA runs in 27 proteomes, particularly ciliates. However, this analysis is missing a critical control that makes it nearly impossible to evaluate the importance of the findings. The authors find the abundance of different amino acid runs in various proteomes. They also report the background abundance of each amino acid. They do not use this background abundance to normalize the runs of amino acids to create a null expectation from each proteome. For example, it has been clear for some time (Ruff, 2017; Ruff et al., 2016) that Drosophila contains a very high background of Q's in the proteome and it is necessary to control for this background abundance when finding runs of Q's. The authors could easily address this problem with the data and analysis they have already collected. However, at this time, without this normalization, I am hesitant to trust the lists of proteins with long runs of amino acid and the ensuing GO enrichment analysis.
Ruff KM. 2017. Washington University in St.
Ruff KM, Holehouse AS, Richardson MGO, Pappu RV. 2016. Proteomic and Biophysical Analysis of Polar Tracts. Biophys J 110:556a.
Reviewer #2 (Public Review):
Summary:
This study seeks to understand the connection between protein sequence and function in disordered regions enriched in polar amino acids (specifically Q, N, S and T). While the authors suggest that specific motifs facilitate protein-enhancing activities, their findings are correlative, and the evidence is incomplete. Similarly, the authors propose that the re-assignment of stop codons to glutamine-encoding codons underlies the greater user of glutamine in a subset of ciliates, but again, the conclusions here are, at best, correlative. The authors perform extensive bioinformatic analysis, with detailed (albeit somewhat ad hoc) discussion on a number of proteins. Overall, the results presented here are interesting, but are unable to exclude competing hypotheses.
Strengths:
Following up on previous work, the authors wish to uncover a mechanism associated with poly-Q and SCD motifs explaining proposed protein expression-enhancing activities. They note that these motifs often occur IDRs and hypothesize that structural plasticity could be capitalized upon as a mechanism of diversification in evolution. To investigate this further, they employ bioinformatics to investigate the sequence features of proteomes of 27 eukaryotes. They deepen their sequence space exploration uncovering sub-phylum-specific features associated with species in which a stop-codon substitution has occurred. The authors propose this stop-codon substitution underlies an expansion of ploy-Q repeats and increased glutamine distribution.
Weaknesses:
The preprint provides extensive, detailed, and entirely unnecessary background information throughout, hampering reading and making it difficult to understand the ideas being proposed.
The introduction provides a large amount of detailed background that appears entirely irrelevant for the paper. Many places detailed discussions on specific proteins that are likely of interest to the authors occur, yet without context, this does not enhance the paper for the reader.
The paper uses many unnecessary, new, or redefined acronyms which makes reading difficult. As examples: (1) Prion forming domains (PFDs). Do the authors mean prion-like domains (PLDs), an established term with an empirical definition from the PLAAC algorithm? If yes, they should say this. If not, they must define what a prion-forming domain is formally. (2) SCD is already an acronym in the IDP field (meaning sequence charge decoration) - the authors should avoid this as their chosen acronym for Serine(S) / threonine (T)-glutamine (Q) cluster domains. Moreover, do we really need another acronym here (we do not). (3) Protein expression-enhancing (PEE) - just say expression-enhancing, there is no need for an acronym here.
The results suggest autonomous protein expression-enhancing activities of regions of multiple proteins containing Q-rich and SCD motifs. Their definition of expression-enhancing activities is vague and the evidence they provide to support the claim is weak. While their previous work may support their claim with more evidence, it should be explained in more detail. The assay they choose is a fusion reporter measuring beta-galactosidase activity and tracking expression levels. Given the presented data they have shown that they can drive the expression of their reporters and that beta gal remains active, in addition to the increase in expression of fusion reporter during the stress response. They have not detailed what their control and mock treatment is, which makes complete understanding of their experimental approach difficult. Furthermore, their nuclear localization signal on the tag could be influencing the degradation kinetics or sequestering the reporter, leading to its accumulation and the appearance of enhanced expression. Their evidence refuting ubiquitin-mediated degradation does not have a convincing control.
Based on the experimental results, the authors then go on to perform bioinformatic analysis of SCD proteins and polyX proteins. Unfortunately, there is no clear hypothesis for what is being tested; there is a vague sense of investigating polyX/SCD regions, but I did not find the connection between the first and section compelling (especially given polar-rich regions have been shown to engage in many different functions). As such, this bioinformatic analysis largely presents as many lists of percentages without any meaningful interpretation. The bioinformatics analysis lacks any kind of rigorous statistical tests, making it difficult to evaluate the conclusions drawn.
The methods section is severely lacking. Specifically, many of the methods require the reader to read many other papers. While referencing prior work is of course, important, the authors should ensure the methods in this paper provide the details needed to allow a reader to evaluate the work being presented. As it stands, this is not the case.
Overall, my major concern with this work is that the authors make two central claims in this paper (as per the Discussion).
The authors claim that Q-rich motifs enhance protein expression. The implication here is that Q-rich motif IDRs are special, but this is not tested. As such, they cannot exclude the competing hypothesis ("N-terminal disordered regions enhance expression"). The authors also do not explore the possibility that this effect is in part/entirely driven by mRNA-level effects (see Verma Na Comms 2019). As such, while these observations are interesting, they feel preliminary and, in my opinion, cannot be used to draw hard conclusions on how N-terminal IDR sequence features influence protein expression. This does not mean the authors are necessarily wrong, but from the data presented here, I do not believe strong conclusions can be drawn.
That re-assignment of stop codons to Q increases proteome-wide Q usage. I was unable to understand what result led the authors to this conclusion. My reading of the results is that a subset of ciliates has re-assigned UAA and UAG from the stop codon to Q. Those ciliates have more polyQ-containing proteins. However, they also have more polyN-containing proteins and proteins enriched in S/T-Q clusters. Surely if this were a stop-codon-dependent effect, we'd ONLY see an enhancement in Q-richness, not a corresponding enhancement in all polar-rich IDR frequencies? It seems the better working hypothesis is that free-floating climate proteomes are enriched in polar amino acids compared to sessile ciliates. Regardless, the absence of any kind of statistical analysis makes it hard to draw strong conclusions here.
Author Response
eLife assessment
This study presents potentially valuable results on glutamine-rich motifs in relation to protein expression and alternative genetic codes. The author's interpretation of the results is so far only supported by incomplete evidence, due to a lack of acknowledgment of alternative explanations, missing controls and statistical analysis and writing unclear to non experts in the field. These shortcomings could be at least partially overcome by additional experiments, thorough rewriting, or both.
We thank both the Reviewing Editor and Senior Editor for handling this manuscript and will submit our revised manuscript after the reviewed preprint is published by eLife.
Reviewer #1 (Public Review):
Summary
This work contains 3 sections. The first section describes how protein domains with SQ motifs can increase the abundance of a lacZ reporter in yeast. The authors call this phenomenon autonomous protein expression-enhancing activity, and this finding is well supported. The authors show evidence that this increase in protein abundance and enzymatic activity is not due to changes in plasmid copy number or mRNA abundance, and that this phenomenon is not affected by mutants in translational quality control. It was not completely clear whether the increased protein abundance is due to increased translation or to increased protein stability.
In section 2, the authors performed mutagenesis of three N-terminal domains to study how protein sequence changes protein stability and enzymatic activity of the fusions. These data are very interesting, but this section needs more interpretation. It is not clear if the effect is due to the number of S/T/Q/N amino acids or due to the number of phosphorylation sites.
In section 3, the authors undertake an extensive computational analysis of amino acid runs in 27 species. Many aspects of this section are fascinating to an expert reader. They identify regions with poly-X tracks. These data were not normalized correctly: I think that a null expectation for how often poly-X track occur should be built for each species based on the underlying prevalence of amino acids in that species. As a result, I believe that the claim is not well supported by the data.
Strengths
This work is about an interesting topic and contains stimulating bioinformatics analysis. The first two sections, where the authors investigate how S/T/Q/N abundance modulates protein expression level, is well supported by the data. The bioinformatics analysis of Q abundance in ciliate proteomes is fascinating. There are some ciliates that have repurposed stop codons to code for Q. The authors find that in these proteomes, Q-runs are greatly expanded. They offer interesting speculations on how this expansion might impact protein function.
Weakness
At this time, the manuscript is disorganized and difficult to read. An expert in the field, who will not be distracted by the disorganization, will find some very interesting results included. In particular, the order of the introduction does not match the rest of the paper.
In the first and second sections, where the authors investigate how S/T/Q/N abundance modulates protein expression levels, it is unclear if the effect is due to the number of phosphorylation sites or the number of S/T/Q/N residues.
There are three reasons why the number of phosphorylation sites in the Q-rich motifs is not relevant to their autonomous protein expression-enhancing (PEE) activities:
First, we have reported previously that phosphorylation-defective Rad51-NTD (Rad51-3SA) and wild-type Rad51-NTD exhibit similar autonomous PEE activity. Mec1/Tel1-dependent phosphorylation of Rad51-NTD antagonizes the proteasomal degradation pathway, increasing the half-life of Rad51 from ∼30 min to ≥180 min (Ref 27; Woo, T. T. et al. 2020).
- T. T. Woo, C. N. Chuang, M. Higashide, A. Shinohara, T. F. Wang, Dual roles of yeast Rad51 N-terminal domain in repairing DNA double-strand breaks. Nucleic Acids Res 48, 8474-8489 (2020).
Second, in our preprint manuscript, we have also shown that phosphorylation-defective Rad53-SCD1 (Rad51-SCD1-5STA) also exhibits autonomous PEE activity similar to that of wild-type Rad53-SCD (Figure 2D, Figure 4A and Figure 4C).
Third, as revealed by the results of our preprint manuscript (Figure 4), it is the percentages, and not the numbers, of S/T/Q/N residues that are correlated with the PEE activities of Q-rich motifs.
The authors also do not discuss if the N-end rule for protein stability applies to the lacZ reporter or the fusion proteins.
The autonomous PEE function of S/T/Q-rich NTDs is unlikely to be relevant to the N-end rule. The N-end rule links the in vivo half-life of a protein to the identity of its N-terminal residues. In S. cerevisiae, the N-end rule operates as part of the ubiquitin system and comprises two pathways. First, the Arg/N-end rule pathway, involving a single N-terminal amidohydrolase Nta1, mediates deamidation of N-terminal asparagine (N) and glutamine (Q) into aspartate (D) and glutamate (E), which in turn are arginylated by a single Ate1 R-transferase, generating the Arg/N degron. N-terminal R and other primary degrons are recognized by a single N-recognin Ubr1 in concert with ubiquitin-conjugating Ubc2/Rad6. Ubr1 can also recognize several other N-terminal residues, including lysine (K), histidine (H), phenylalanine (F), tryptophan (W), leucine (L) and isoleucine (I) (Bachmair, A. et al. 1986; Tasaki, T. et al. 2012; Varshavshy, A. et al. 2019). Second, the Ac/N-end rule pathway targets proteins containing N-terminally acetylated (Ac) residues. Prior to acetylation, the first amino acid methionine (M) is catalytically removed by Met-aminopeptides, unless a residue at position 2 is non-permissive (too large) for MetAPs. If a retained N-terminal M or otherwise a valine (V), cysteine (C), alanine (A), serine (S) or threonine (T) residue is followed by residues that allow N-terminal acetylation, the proteins containing these AcN degrons are targeted for ubiquitylation and proteasome-mediated degradation by the Doa10 E3 ligase (Hwang, C. S., 2019).
A. Bachmair, D. Finley, A. Varshavsky, In vivo half-life of a protein is a function of its amino-terminal residue. Science 234, 179-186 (1986).
T. Tasaki, S. M. Sriram, K. S. Park, Y. T. Kwon, The N-end rule pathway. Annu Rev Biochem 81, 261-289 (2012).
A. Varshavsky, N-degron and C-degron pathways of protein degradation. Proc Natl Acad Sci 116, 358-366 (2019).
C. S. Hwang, A. Shemorry, D. Auerbach, A. Varshavsky, The N-end rule pathway is mediated by a complex of the RING-type Ubr1 and HECT-type Ufd4 ubiquitin ligases. Nat Cell Biol 12, 1177-1185 (2010).
The PEE activities of these S/T/Q-rich domains are unlikely to arise from counteracting the N-end rule for two reasons. First, the first two amino acid residues of Rad51-NTD, Hop1-SCD, Rad53-SCD1, Sup35-PND, Rad51-ΔN, and LacZ-NVH are MS, ME, ME, MS, ME, and MI, respectively, where M is methionine, S is serine, E is glutamic acid and I is isoleucine. Second, Sml1-NTD behaves similarly to these N-terminal fusion tags, despite its methionine and glutamine (MQ) amino acid signature at the N-terminus.
The most interesting part of the paper is an exploration of S/T/Q/N-rich regions and other repetitive AA runs in 27 proteomes, particularly ciliates. However, this analysis is missing a critical control that makes it nearly impossible to evaluate the importance of the findings. The authors find the abundance of different amino acid runs in various proteomes. They also report the background abundance of each amino acid. They do not use this background abundance to normalize the runs of amino acids to create a null expectation from each proteome. For example, it has been clear for some time (Ruff, 2017; Ruff et al., 2016) that Drosophila contains a very high background of Q's in the proteome and it is necessary to control for this background abundance when finding runs of Q's.
We apologize for not explaining sufficiently well the topic eliciting this reviewer’s concern in our preprint manuscript. In the second paragraph of page 14, we cite six references to highlight that SCDs are overrepresented in yeast and human proteins involved in several biological processes (32, 74), and that polyX prevalence differs among species (43, 75-77).
-
Cheung HC, San Lucas FA, Hicks S, Chang K, Bertuch AA, Ribes-Zamora A. An S/T-Q cluster domain census unveils new putative targets under Tel1/Mec1 control. BMC Genomics. 2012;13:664.
-
Mier P, Elena-Real C, Urbanek A, Bernado P, Andrade-Navarro MA. The importance of definitions in the study of polyQ regions: A tale of thresholds, impurities and sequence context. Comput Struct Biotechnol J. 2020;18:306-13.
-
Cara L, Baitemirova M, Follis J, Larios-Sanz M, Ribes-Zamora A. The ATM- and ATR-related SCD domain is over-represented in proteins involved in nervous system development. Sci Rep. 2016;6:19050.
-
Kuspa A, Loomis WF. The genome of Dictyostelium discoideum. Methods Mol Biol. 2006;346:15-30.
-
Davies HM, Nofal SD, McLaughlin EJ, Osborne AR. Repetitive sequences in malaria parasite proteins. FEMS Microbiol Rev. 2017;41(6):923-40.
-
Mier P, Alanis-Lobato G, Andrade-Navarro MA. Context characterization of amino acid homorepeats using evolution, position, and order. Proteins. 2017;85(4):709-19.
We will cite the two references by Kiersten M. Ruff in our revised manuscript.
K. M. Ruff and R. V. Pappu, (2015) Multiscale simulation provides mechanistic insights into the effects of sequence contexts of early-stage polyglutamine-mediated aggregation. Biophysical Journal 108, 495a.
K. M. Ruff, J. B. Warner, A. Posey and P. S. Tan (2017) Polyglutamine length dependent structural properties and phase behavior of huntingtin exon1. Biophysical Journal 112, 511a.
The authors could easily address this problem with the data and analysis they have already collected. However, at this time, without this normalization, I am hesitant to trust the lists of proteins with long runs of amino acid and the ensuing GO enrichment analysis.
Ruff KM. 2017. Washington University in St.
Ruff KM, Holehouse AS, Richardson MGO, Pappu RV. 2016. Proteomic and Biophysical Analysis of Polar Tracts. Biophys J 110:556a.
We thank Reviewer #1 for this helpful suggestion and now address this issue by means of a different approach described below.
Based on a previous study (43; Palo Mier et al. 2020), we applied seven different thresholds to seek both short and long, as well as pure and impure, polyX strings in 20 different representative near-complete proteomes, including 4X (4/4), 5X (4/5-5/5), 6X (4/6-6/6), 7X (4/7-7/7), 8-10X (≥50%X), 11-10X (≥50%X) and ≥21X (≥50%X).
To normalize the runs of amino acids and create a null expectation from each proteome, we determined the ratios of the overall number of X residues for each of the seven polyX motifs relative to those in the entire proteome of each species, respectively. The results of four different polyX motifs are shown below, i.e., polyQ (Author response image 1), polyN (Author response image 2), polyS (Author response image 3) and polyT (Author response image 4).
Author response image 1.
Q contents in 7 different types of polyQ motifs in 20 near-complete proteomes. The five ciliates with reassigned stops codon (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.
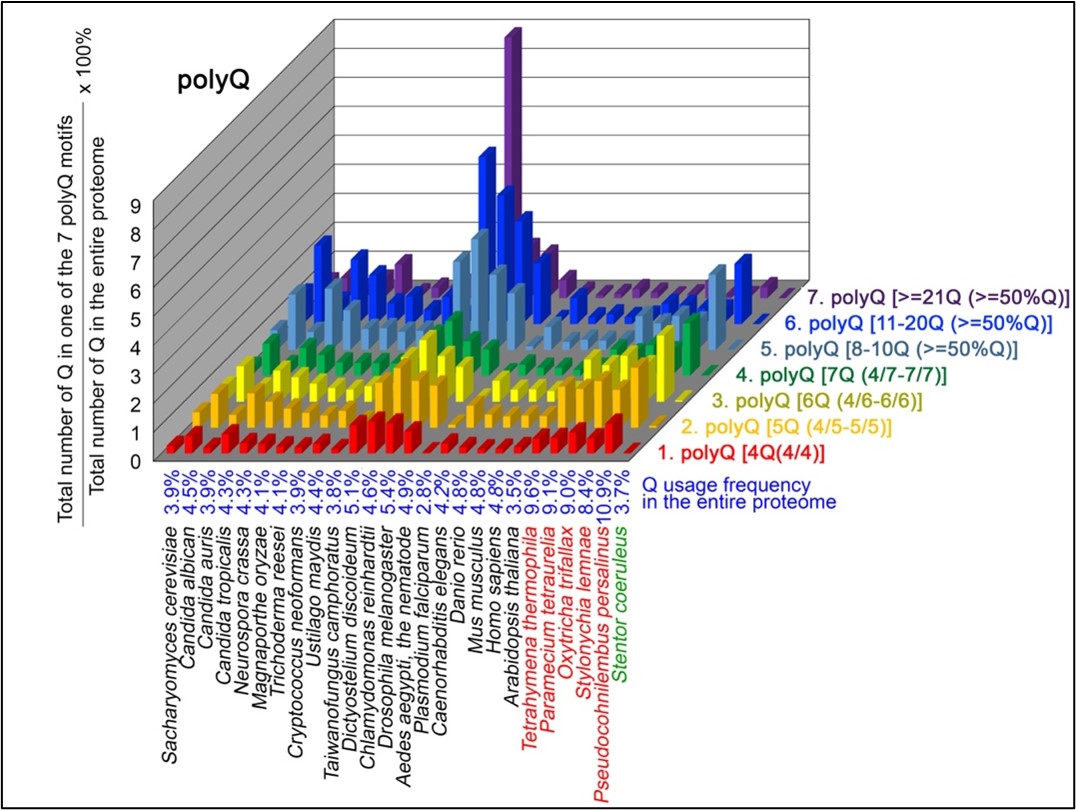
Author response image 2.
N contents in 7 different types of polyN motifs in 20 near-complete proteomes. The five ciliates with reassigned stops codon (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.
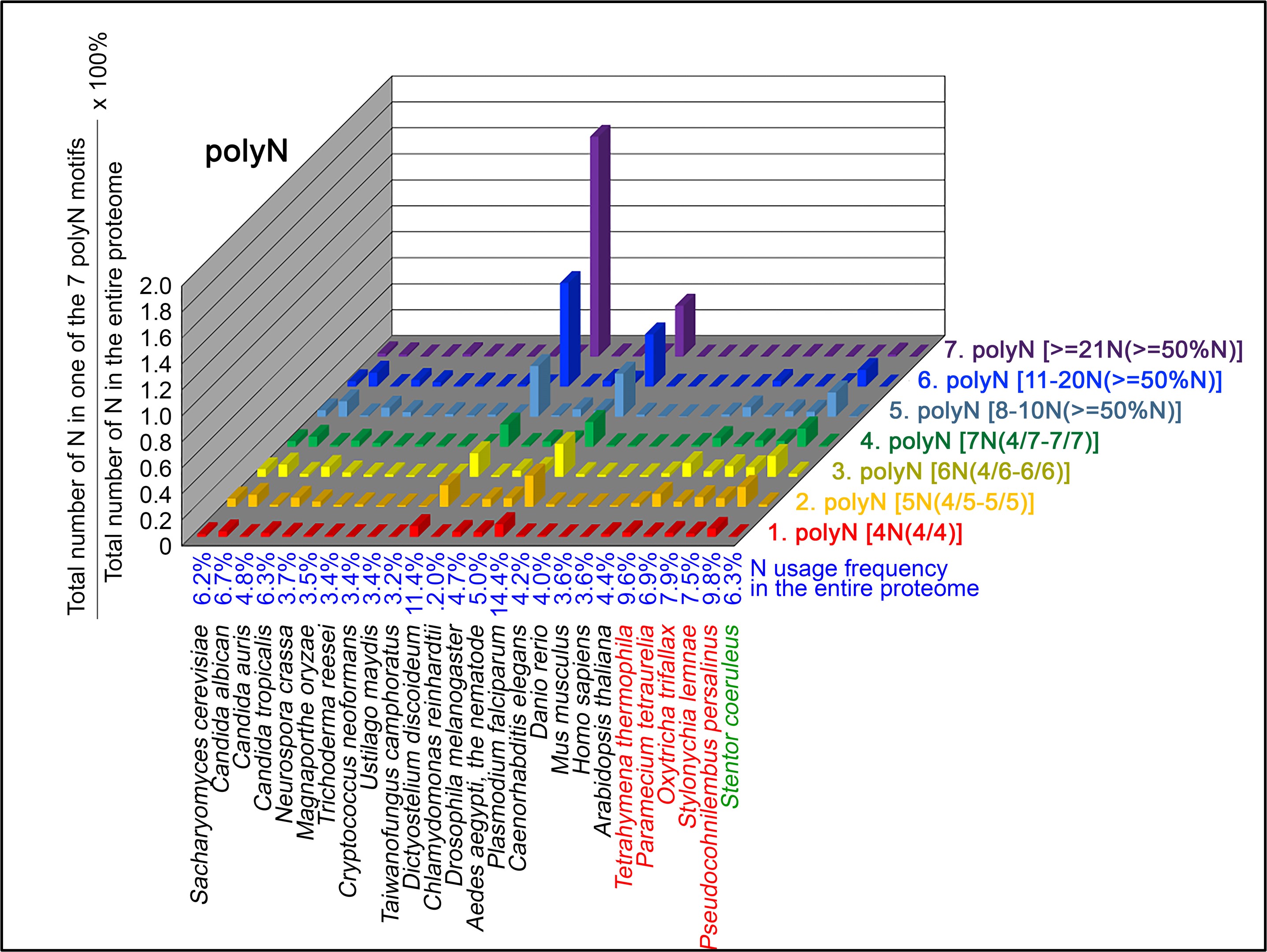
Author response image 3.
S contents in 7 different types of polyS motifs in 20 near-complete proteomes. The five ciliates with reassigned stops codon (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.
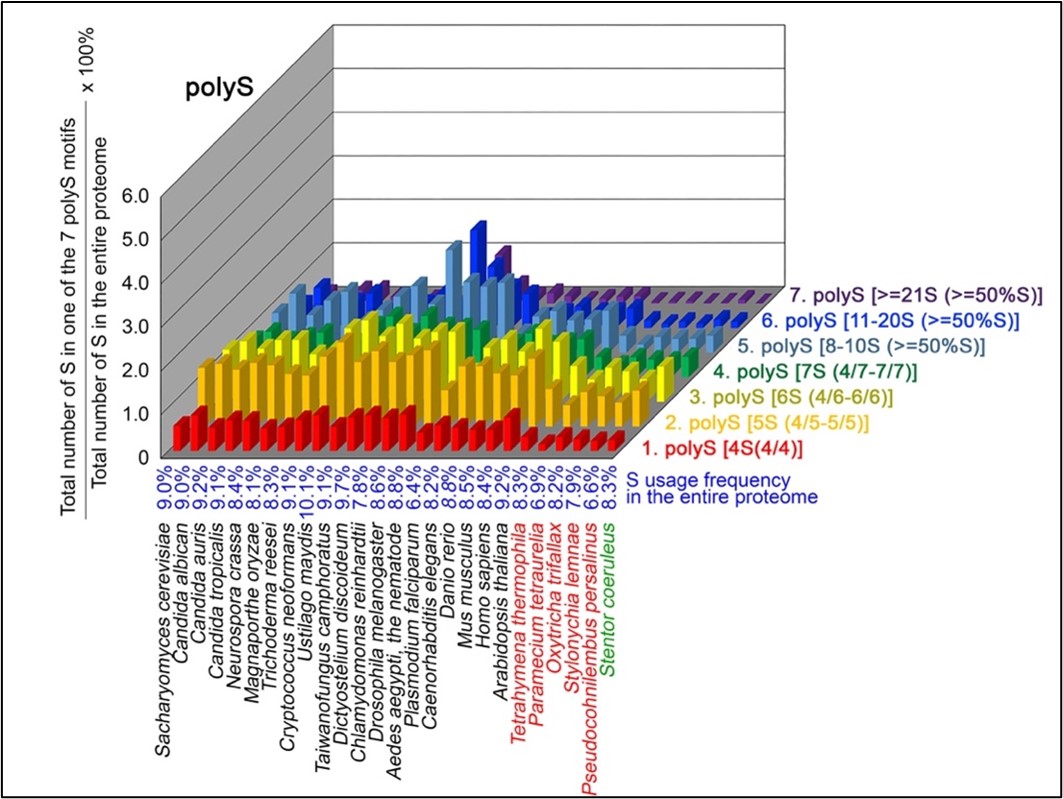
Author response image 4.
T contents in 7 different types of polyT motifs in 20 near-complete proteomes. The five ciliates with reassigned stops codon (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.
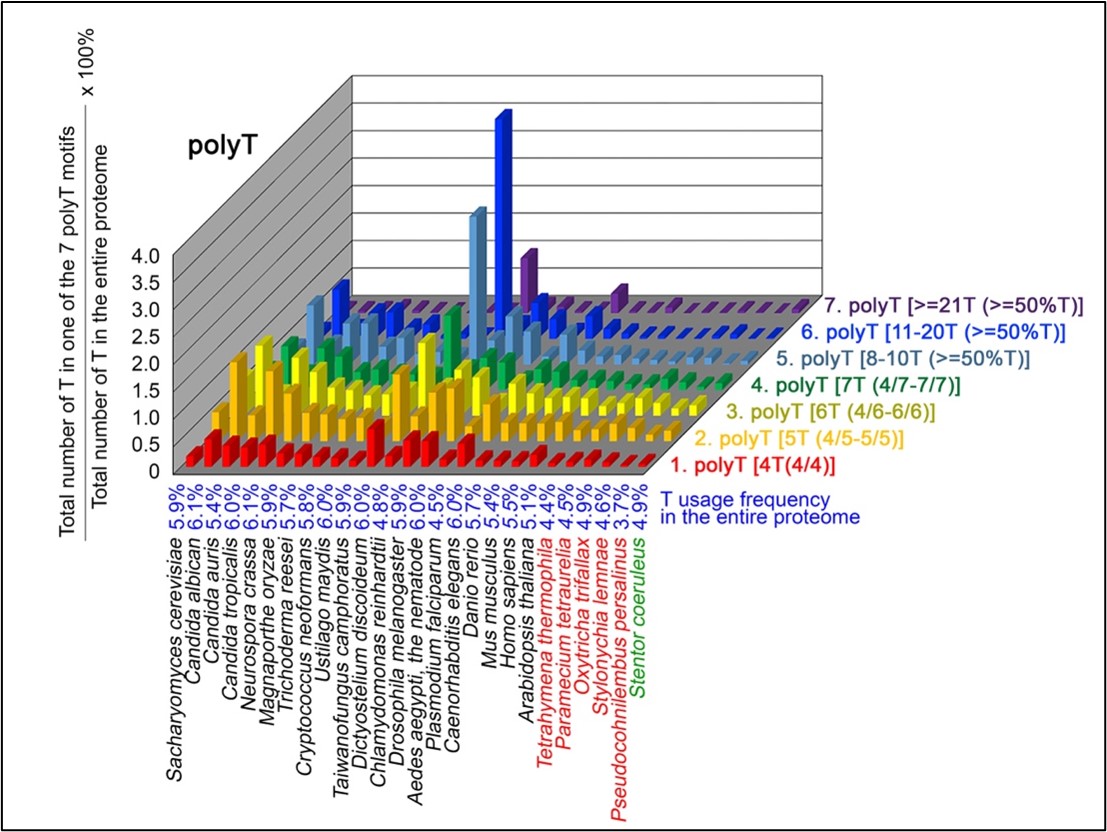
The results summarized in these four new figures support that polyX prevalence differs among species and that the overall X contents of polyX motifs often but not always correlate with the X usage frequency in entire proteomes (43; Palo Mier et al. 2020).
Most importantly, our results reveal that, compared to Stentor coeruleus or several non-ciliate eukaryotic organisms (e.g., Plasmodium falciparum, Caenorhabditis elegans, Danio rerio, Mus musculus and Homo sapiens), the five ciliates with reassigned TAAQ and TAGQ codons not only have higher Q usage frequencies, but also more polyQ motifs in their proteomes (Figure 1). In contrast, polyQ motifs prevail in Candida albicans, Candida tropicalis, Dictyostelium discoideum, Chlamydomonas reinhardtii, Drosophila melanogaster and Aedes aegypti, though the Q usage frequencies in their entire proteomes are not significantly higher than those of other eukaryotes (Figure 1). Due to their higher N usage frequencies, Dictyostelium discoideum, Plasmodium falciparum and Pseudocohnilembus persalinus have more polyN motifs than the other 23 eukaryotes we examined here (Figure 2). Generally speaking, all 26 eukaryotes we assessed have similar S usage frequencies and percentages of S contents in polyS motifs (Figure 3). Among these 26 eukaryotes, Dictyostelium discoideum possesses many more polyT motifs, though its T usage frequency is similar to that of the other 25 eukaryotes (Figure 4).
In conclusion, these new normalized results confirm that the reassignment of stop codons to Q indeed results in both higher Q usage frequencies and more polyQ motifs in ciliates.
Reviewer #2 (Public Review):
Summary:
This study seeks to understand the connection between protein sequence and function in disordered regions enriched in polar amino acids (specifically Q, N, S and T). While the authors suggest that specific motifs facilitate protein-enhancing activities, their findings are correlative, and the evidence is incomplete. Similarly, the authors propose that the re-assignment of stop codons to glutamine-encoding codons underlies the greater user of glutamine in a subset of ciliates, but again, the conclusions here are, at best, correlative. The authors perform extensive bioinformatic analysis, with detailed (albeit somewhat ad hoc) discussion on a number of proteins. Overall, the results presented here are interesting, but are unable to exclude competing hypotheses.
Strengths:
Following up on previous work, the authors wish to uncover a mechanism associated with poly-Q and SCD motifs explaining proposed protein expression-enhancing activities. They note that these motifs often occur IDRs and hypothesize that structural plasticity could be capitalized upon as a mechanism of diversification in evolution. To investigate this further, they employ bioinformatics to investigate the sequence features of proteomes of 27 eukaryotes. They deepen their sequence space exploration uncovering sub-phylum-specific features associated with species in which a stop-codon substitution has occurred. The authors propose this stop-codon substitution underlies an expansion of ploy-Q repeats and increased glutamine distribution.
Weaknesses:
The preprint provides extensive, detailed, and entirely unnecessary background information throughout, hampering reading and making it difficult to understand the ideas being proposed. The introduction provides a large amount of detailed background that appears entirely irrelevant for the paper. Many places detailed discussions on specific proteins that are likely of interest to the authors occur, yet without context, this does not enhance the paper for the reader.
The paper uses many unnecessary, new, or redefined acronyms which makes reading difficult. As examples:
(1) Prion forming domains (PFDs). Do the authors mean prion-like domains (PLDs), an established term with an empirical definition from the PLAAC algorithm? If yes, they should say this. If not, they must define what a prion-forming domain is formally.
The N-terminal domain (1-123 amino acids) of S. cerevisiae Sup35 was already referred to as a “prion forming domain (PFD)” in 2006 (Tuite, M. F. 2006). Since then, PFD has also been employed as an acronym in other yeast prion papers (Cox, B.S. et al. 2007; Toombs, T. et al. 2011).
M. F., Tuite, Yeast prions and their prion forming domain. Cell 27, 397-407 (2005).
B. S. Cox, L. Byrne, M. F., Tuite, Protein Stability. Prion 1, 170-178 (2007).
J. A. Toombs, N. M. Liss, K. R. Cobble, Z. Ben-Musa, E. D. Ross, [PSI+] maintenance is dependent on the composition, not primary sequence, of the oligopeptide repeat domain. PLoS One 6, e21953 (2011).
(2) SCD is already an acronym in the IDP field (meaning sequence charge decoration) - the authors should avoid this as their chosen acronym for Serine(S) / threonine (T)-glutamine (Q) cluster domains. Moreover, do we really need another acronym here (we do not).
SCD was first used in 2005 as an acronym for the Serine (S)/threonine (T)-glutamine (Q) cluster domain in the DNA damage checkpoint field (Traven, A. and Heierhorst, J. 2005). Almost a decade later, SCD became an acronym for “sequence charge decoration” (Sawle, L. et al. 2015; Firman, T. et al. 2018).
A. Traven and J, Heierhorst, SQ/TQ cluster domains: concentrated ATM/ATR kinase phosphorylation site regions in DNA-damage-response proteins. Bioessays. 27, 397-407 (2005).
L. Sawle and K, Ghosh, A theoretical method to compute sequence dependent configurational properties in charged polymers and proteins. J. Chem Phys. 143, 085101(2015).
T. Firman and Ghosh, K. Sequence charge decoration dictates coil-globule transition in intrinsically disordered proteins. J. Chem Phys. 148, 123305 (2018).
(3) Protein expression-enhancing (PEE) - just say expression-enhancing, there is no need for an acronym here.
Thank you. Since we have shown that addition of Q-rich motifs to LacZ affects protein expression rather than transcription, we think it is better to use the “PEE” acronym.
The results suggest autonomous protein expression-enhancing activities of regions of multiple proteins containing Q-rich and SCD motifs. Their definition of expression-enhancing activities is vague and the evidence they provide to support the claim is weak. While their previous work may support their claim with more evidence, it should be explained in more detail. The assay they choose is a fusion reporter measuring beta-galactosidase activity and tracking expression levels. Given the presented data they have shown that they can drive the expression of their reporters and that beta gal remains active, in addition to the increase in expression of fusion reporter during the stress response. They have not detailed what their control and mock treatment is, which makes complete understanding of their experimental approach difficult. Furthermore, their nuclear localization signal on the tag could be influencing the degradation kinetics or sequestering the reporter, leading to its accumulation and the appearance of enhanced expression. Their evidence refuting ubiquitin-mediated degradation does not have a convincing control.
Based on the experimental results, the authors then go on to perform bioinformatic analysis of SCD proteins and polyX proteins. Unfortunately, there is no clear hypothesis for what is being tested; there is a vague sense of investigating polyX/SCD regions, but I did not find the connection between the first and section compelling (especially given polar-rich regions have been shown to engage in many different functions). As such, this bioinformatic analysis largely presents as many lists of percentages without any meaningful interpretation. The bioinformatics analysis lacks any kind of rigorous statistical tests, making it difficult to evaluate the conclusions drawn. The methods section is severely lacking. Specifically, many of the methods require the reader to read many other papers. While referencing prior work is of course, important, the authors should ensure the methods in this paper provide the details needed to allow a reader to evaluate the work being presented. As it stands, this is not the case.
Thank you. As described in detail below, we have now performed rigorous statistical testing using the GofuncR package.
Overall, my major concern with this work is that the authors make two central claims in this paper (as per the Discussion). The authors claim that Q-rich motifs enhance protein expression. The implication here is that Q-rich motif IDRs are special, but this is not tested. As such, they cannot exclude the competing hypothesis ("N-terminal disordered regions enhance expression").
In fact, “N-terminal disordered regions enhance expression” exactly summarizes our hypothesis.
On pages 12-13 and Figure 4 of our preprint manuscript, we explained our hypothesis in the paragraph entitled “The relationship between PEE function, amino acid contents, and structural flexibility”.
The authors also do not explore the possibility that this effect is in part/entirely driven by mRNA-level effects (see Verma Na Comms 2019).
As pointed out by the first reviewer, we show evidence that the increase in protein abundance and enzymatic activity is not due to changes in plasmid copy number or mRNA abundance (Figure 2), and that this phenomenon is not affected by translational quality control mutants (Figure 3).
As such, while these observations are interesting, they feel preliminary and, in my opinion, cannot be used to draw hard conclusions on how N-terminal IDR sequence features influence protein expression. This does not mean the authors are necessarily wrong, but from the data presented here, I do not believe strong conclusions can be drawn. That re-assignment of stop codons to Q increases proteome-wide Q usage. I was unable to understand what result led the authors to this conclusion.
My reading of the results is that a subset of ciliates has re-assigned UAA and UAG from the stop codon to Q. Those ciliates have more polyQ-containing proteins. However, they also have more polyN-containing proteins and proteins enriched in S/T-Q clusters. Surely if this were a stop-codon-dependent effect, we'd ONLY see an enhancement in Q-richness, not a corresponding enhancement in all polar-rich IDR frequencies? It seems the better working hypothesis is that free-floating climate proteomes are enriched in polar amino acids compared to sessile ciliates.
Thank you. These comments are not supported by the results in Figure 1.
Regardless, the absence of any kind of statistical analysis makes it hard to draw strong conclusions here.
We apologize for not explaining more clearly the results of Tables 5-7 in our preprint manuscript.
To address the concerns about our GO enrichment analysis by both reviewers, we have now performed rigorous statistical testing for SCD and polyQ protein overrepresentation using the GOfuncR package (https://bioconductor.org/packages/release/bioc/html/GOfuncR.html). GOfuncR is an R package program that conducts standard candidate vs. background enrichment analysis by means of the hypergeometric test. We then adjusted the raw p-values according to the Family-wise error rate (FWER). The same method had been applied to GO enrichment analysis of human genomes (Huttenhower, C., et al. 2009).
Curtis Huttenhower, C., Haley, E. M., Hibbs, M., A., Dumeaux, V., Barrett, D. R., Hilary A. Coller, H. A., and Olga G. Troyanskaya, O., G. Exploring the human genome with functional maps, Genome Research 19, 1093-1106 (2009).
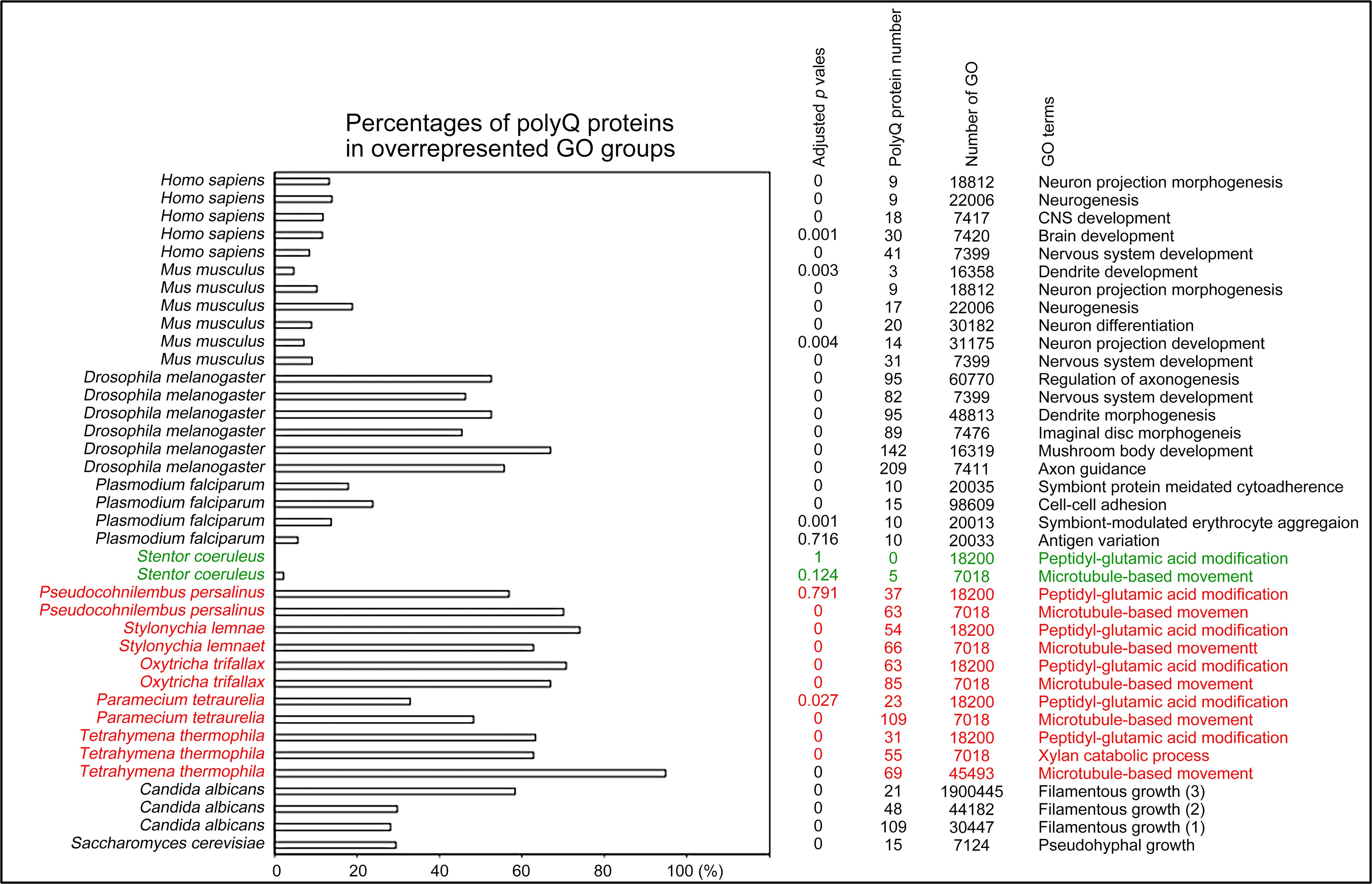
The results presented in Author response image 5 and Author response image 6 support our hypothesis that Q-rich motifs prevail in proteins involved in specialized biological processes, including Saccharomyces cerevisiae RNA-mediated transposition, Candida albicans filamentous growth, peptidyl-glutamic acid modification in ciliates with reassigned stop codons (TAAQ and TAGQ), Tetrahymena thermophila xylan catabolism, Dictyostelium discoideum sexual reproduction, Plasmodium falciparum infection, as well as the nervous systems of Drosophila melanogaster, Mus musculus, and Homo sapiens (74). In contrast, peptidyl-glutamic acid modification and microtubule-based movement are not overrepresented with Q-rich proteins in Stentor coeruleus, a ciliate with standard stop codons.
- Cara L, Baitemirova M, Follis J, Larios-Sanz M, Ribes-Zamora A. The ATM- and ATR-related SCD domain is over-represented in proteins involved in nervous system development. Sci Rep. 2016;6:19050.
Author response image 5.
Selection of biological processes with overrepresented SCD-containing proteins in different eukaryotes. The percentages and number of SCD-containing proteins in our search that belong to each indicated Gene Ontology (GO) group are shown. GOfuncR (Huttenhower, C., et al. 2009) was applied for GO enrichment and statistical analysis. The p values adjusted according to the Family-wise error rate (FWER) are shown. The five ciliates with reassigned stop codons (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.
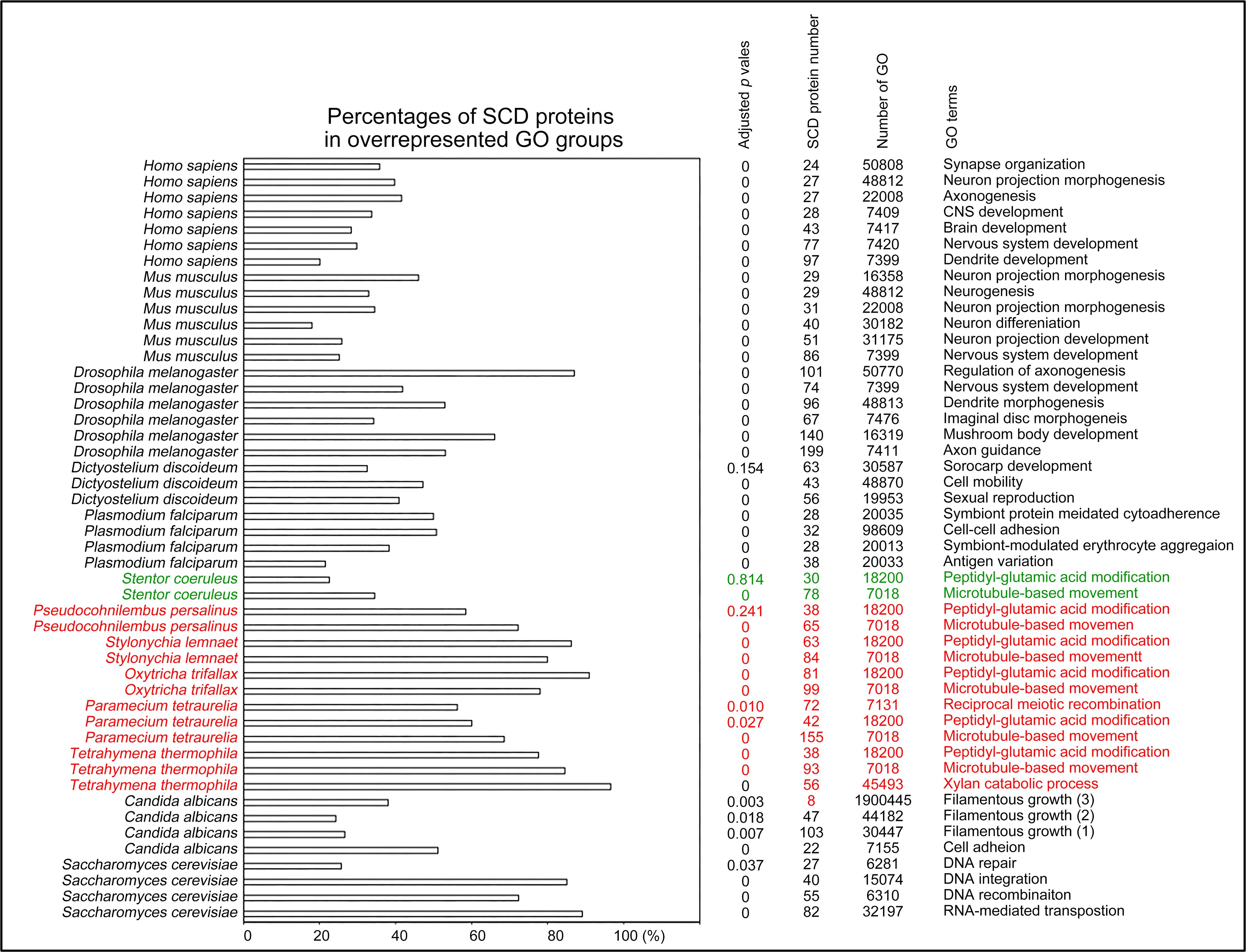
Author response image 6.
Selection of biological processes with overrepresented polyQ-containing proteins in different eukaryotes. The percentages and numbers of polyQ-containing proteins in our search that belong to each indicated Gene Ontology (GO) group are shown. GOfuncR (Huttenhower, C., et al. 2009) was applied for GO enrichment and statistical analysis. The p values adjusted according to the Family-wise error rate (FWER) are shown. The five ciliates with reassigned stops codons (TAAQ and TAGQ) are indicated in red. Stentor coeruleus, a ciliate with standard stop codons, is indicated in green.