Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorXue-Xin WeiThe University of Texas at Austin, Austin, United States of America
- Senior EditorJoshua GoldUniversity of Pennsylvania, Philadelphia, United States of America
Reviewer #1 (Public Review):
Summary:
Working memory is imperfect - memories accrue error over time and are biased towards certain identities. For example, previous work has shown memory for orientation is more accurate near the cardinal directions (i.e., variance in responses is smaller for horizontal and vertical stimuli) while being biased towards diagonal orientations (i.e., there is a repulsive bias away from horizontal and vertical stimuli). The magnitude of errors and biases increase the longer an item is held in working memory and when more items are held in working memory (i.e., working memory load is higher). Previous work has argued that biases and errors could be explained by increased perceptual acuity at cardinal directions. However, these models are constrained to sensory perception and do not explain how biases and errors increase over time in memory. The current manuscript builds on this work to show how a two-layer neural network could integrate errors and biases over a memory delay. In brief, the model includes a 'sensory' layer with heterogenous connections that lead to the repulsive bias and decreased error at the cardinal directions. This layer is then reciprocally connected with a classic ring attractor layer. Through their reciprocal interactions, the biases in the sensory layer are constantly integrated into the representation in memory. In this way, the model captures the distribution of biases and errors for different orientations that has been seen in behavior and their increasing magnitude with time. The authors compare the two-layer network to a simpler one-network model, showing that the one model network is harder to tune and shows an attractive bias for memories that have lower error (which is incompatible with empirical results).
Strengths:
The manuscript provides a nice review of the dynamics of items in working memory, showing how errors and biases differ across stimulus space. The two-layer neural network model is able to capture the behavioral effects as well as relate to neurophysiological observations that memory representations are distributed across sensory cortex and prefrontal cortex.
The authors use multiple approaches to understand how the network produces the observed results. For example, analyzing the dynamics of memories in the low-dimensional representational space of the networks provides the reader with an intuition for the observed effects.
As a point of comparison with the two-layer network, the authors construct a heterogenous one-layer network (analogous to a single memory network with embedded biases). They argue that such a network is incapable of capturing the observed behavioral effects but could potentially explain biases and noise levels in other sensory domains where attractive biases have lower errors (e.g., color).
The authors show how changes in the strength of Hebbian learning of excitatory and inhibitory synapses can change network behavior. This argues for relatively stronger learning in inhibitory synapses, an interesting prediction.
The manuscript is well-written. In particular, the figures are well done and nicely schematize the model and the results.
Weaknesses:
Despite its strengths, the manuscript does have some weaknesses. These weaknesses are adequately discussed in the manuscript and motivate future research.
One weakness is that the model is not directly fit to behavioral data, but rather compared to a schematic of behavioral data. As noted above, the model provides insight into the general phenomenon of biases in working memory. However, because the models are not fit directly to data, they may miss some aspects of the data.
In addition, directly fitting the models to behavioral data could allow for a broader exploration of parameter space for both the one-layer and two-layer models (and their alternatives). Such an approach would provide stronger support for the papers claims (such as "....these evolving errors...require network interaction between two distinct modules."). That being said, the manuscript does explore several alternative models and also acknowledges the limitation of not directly fitting behavior, due to difficulties in fitting complex neural network models to data.
One important behavioral observation is that both diffusive noise and biases increase with the number of items in working memory. The current model does not capture these effects and it isn't clear how the model architecture could be extended to capture these effects. That being said, the authors note this limitation in the Discussion and present it as a future direction.
Overall:
Overall, the manuscript was successful in building a model that captured the biases and noise observed in working memory. This work complements previous studies that have viewed these effects through the lens of optimal coding, extending these models to explain the effects of time in memory. In addition, the two-layer network architecture extends previous work with similar architectures, adding further support to the distributed nature of working memory representations.
Reviewer #2 (Public Review):
In this manuscript, Yang et al. present a modeling framework to understand the pattern of response biases and variance observed in delayed-response orientation estimation tasks. They combine a series of modeling approaches to show that coupled sensory-memory networks are in a better position than single-area models to support experimentally observed delay-dependent response bias and variance in cardinal compared to oblique orientations. These errors can emerge from a population-code approach that implements efficient coding and Bayesian inference principles and is coupled to a memory module that introduces random maintenance errors. A biological implementation of such operation is found when coupling two neural network modules, a sensory module with connectivity inhomogeneities that reflect environment priors, and a memory module with strong homogeneous connectivity that sustains continuous ring attractor function. Comparison with single-network solutions that combine both connectivity inhomogeneities and memory attractors shows that two-area models can more easily reproduce the patterns of errors observed experimentally.
Strengths:
The model provides an integration of two modeling approaches to the computational bases of behavioral biases: one based on Bayesian and efficient coding principles, and one based on attractor dynamics. These two perspectives are not usually integrated consistently in existing studies, which this manuscript beautifully achieves. This is a conceptual advancement, especially because it brings together the perceptual and memory components of common laboratory tasks.
The proposed two-area model provides a biologically plausible implementation of efficient coding and Bayesian inference principles, which interact seamlessly with a memory buffer to produce a complex pattern of delay-dependent response errors. No previous model had achieved this.
Weaknesses:
The correspondence between the various computational models is not clearly shown. It is not easy to see clearly this correspondence because network function is illustrated with different representations for different models. In particular, the Bayesian model of Figure 2 is illustrated with population responses for different stimuli and delays, while the attractor models of Figure 3 and 4 are illustrated with neuronal tuning curves but not population activity.
The proposed model has stronger feedback than feedforward connections between the sensory and memory modules (J_f = 0.1 and J_b = 0.25). This is not the common assumption when thinking about hierarchical processing in the brain. The manuscript argues that error patterns remain similar as long as the product of J_f and J_b is constant, so it is unclear why the authors preferred this network example as opposed to one with J_b = 0.1 and J_f = 0.25.
Reviewer #3 (Public Review):
Summary:
The present study proposes a neural circuit model consisting of coupled sensory and memory networks to explain the circuit mechanism of the cardinal effect in orientation perception which is characterized by the bias towards the oblique orientation and the largest variance at the oblique orientation.
Strengths:
The authors have done numerical simulations and preliminary analysis of the neural circuit model to show the model successfully reproduces the cardinal effect. And the paper is well-written overall. As far as I know, most of the studies on the cardinal effect are at the level of statistical models, and the current study provides one possibility of how neural circuit models reproduce such an effect.
Weaknesses:
There are no major weaknesses and flaws in the present study, although I suggest the author conduct further analysis to deepen our understanding of the circuit mechanism of the cardinal effects. Please find my recommendations for concrete comments.
Author response:
The following is the authors’ response to the original reviews.
In this important paper, the authors propose a computational model for understanding how the dynamics of neural representations may lead to specific patterns of errors as observed in working memory tasks. The paper provides solid evidence showing how a two-area model of sensory-memory interactions can account for the error patterns reported in orientation estimation tasks with delays. By integrating ideas from efficient coding and attractor networks, the resulting theoretical framework is appealing, and nicely captures some basic patterns of behavior data and the distributed nature of memory representation as reported in prior neurophysiological studies. The paper can be strengthened if (i) further analyses are conducted to deepen our understanding of the circuit mechanisms underlying the behavior effects; (ii) the necessity of the two-area network model is better justified; (iii) the nuanced aspects of the behavior that are not captured by the current model are discussed in more detail.
We thank the Editors and Reviewers for their constructive comments. In response to the suggestions provided, we have implemented the following revisions:
- Clarified the origin of the specific pattern of diffusion: We showed that variance patterns remain consistent across different noise types or levels in new Figure 5 – Figure supplement 2 and Figure 9 – Figure supplement 1 (uniform Gaussian noise with varying strengths). This is connected to the representation geometry induced by heterogeneous connections (Eq. 21).
- Provided an intuitive explanation of the two-module network’s advantages: Additional simulations demonstrated that heterogeneity degree of sensory connections and intermodal connection strengths affect drift and diffusion terms differently (new Figure 6). This endows an extra degree of freedom in controlling heterogeneity in drift and diffusion terms in the two-module network (new Figure 9).
- Addressed a limitation and future directions in the Discussion: Our study is limited to the dynamic evolution of memory representation for a single orientation stimulus and its associated error patterns. We acknowledge the need for further investigation to capture nuanced error patterns in broader experimental settings, such as changes in error patterns for varying stimulus presentation durations in perception tasks. We have discussed potential extensions, such as incorporating more biologically plausible baseline activities, external noise, or variations of loss functions.
Additionally, we showed consistent error patterns when decoded from activities of the sensory module (Figure 4 – Figure supplement 1), and incorrect error patterns with autapses in the sensory module (Figure 7 – Figure supplement 2). Below, we have reorganized each Reviewer’s comments and separately addressed them. All changes were shown in red in the manuscript submitted as Related Manuscript File.
Reviewer #1:
Summary:
Working memory is imperfect - memories accrue errors over time and are biased towards certain identities. For example, previous work has shown memory for orientation is more accurate near the cardinal directions (i.e., variance in responses is smaller for horizontal and vertical stimuli) while being biased towards diagonal orientations (i.e., there is a repulsive bias away from horizontal and vertical stimuli). The magnitude of errors and biases increase the longer an item is held in working memory and when more items are held in working memory (i.e., working memory load is higher). Previous work has argued that biases and errors could be explained by increased perceptual acuity at cardinal directions. However, these models are constrained to sensory perception and do not explain how biases and errors increase over time in memory. The current manuscript builds on this work to show how a two-layer neural network could integrate errors and biases over a memory delay. In brief, the model includes a 'sensory' layer with heterogenous connections that lead to the repulsive bias and decreased error in the cardinal directions. This layer is then reciprocally connected with a classic ring attractor layer. Through their reciprocal interactions, the biases in the sensory layer are constantly integrated into the representation in memory. In this way, the model captures the distribution of biases and errors for different orientations that have been seen in behavior and their increasing magnitude with time. The authors compare the two-layer network to a simpler one-network model, showing that the one-model network is harder to tune and shows an attractive bias for memories that have lower error (which is incompatible with empirical results).
Strengths:
The manuscript provides a nice review of the dynamics of items in working memory, showing how errors and biases differ across stimulus space. The two-layer neural network model is able to capture the behavioral effects as well as relate to neurophysiological observations that memory representations are distributed across the sensory cortex and prefrontal cortex.
The authors use multiple approaches to understand how the network produces the observed results. For example, analyzing the dynamics of memories in the low-dimensional representational space of the networks provides the reader with an intuition for the observed effects.
As a point of comparison with the two-layer network, the authors construct a heterogenous one-layer network (analogous to a single memory network with embedded biases). They argue that such a network is incapable of capturing the observed behavioral effects but could potentially explain biases and noise levels in other sensory domains where attractive biases have lower errors (e.g., color).
The authors show how changes in the strength of Hebbian learning of excitatory and inhibitory synapses can change network behavior. This argues for relatively stronger learning in inhibitory synapses, an interesting prediction.
The manuscript is well-written. In particular, the figures are well done and nicely schematize the model and the results.
Overall:
Overall, the manuscript was successful in building a model that captured the biases and noise observed in working memory. This work complements previous studies that have viewed these effects through the lens of optimal coding, extending these models to explain the effects of time in memory. In addition, the two-layer network architecture extends previous work with similar architectures, adding further support to the distributed nature of working memory representations.
We appreciate the reviewer’s comments that the work successfully explains error patterns of working memory, extends previous models of optimal coding to include temporal effects, and supports the distributed nature of working memory representations. Below, we address the specific concerns of the reviewer.
Weaknesses:
Despite its strengths, the manuscript does have some weaknesses.
Major Point 1: First, as far as we can tell, behavioral data is only presented in schematic form. This means some of the nuances of the effects are lost. It also means that the model is not directly capturing behavioral effects. Therefore, while providing insight into the general phenomenon, the current manuscript may be missing some important aspects of the data.
Relatedly, the models are not directly fit to behavioral data. This makes it hard for the authors to exclude the possibility that there is a single network model that could capture the behavioral effects. In other words, it is hard to support the authors' conclusion that "....these evolving errors...require network interaction between two distinct modules." (from the abstract, but similar comments are made throughout the manuscript). Such a strong claim needs stronger evidence than what is presented. Fitting to behavioral data could allow the authors to explore the full parameter space for both the one-layer and two-layer network architectures.
In addition, directly comparing the ability of different model architectures to fit behavioral data would allow for quantitative comparison between models. Such quantitative comparisons are currently missing from the manuscript.
We agree with the reviewer that incorporating quantitative comparisons to the data will strengthen our results. However, we note the limitations in fitting network models to behavior data. Previous studies employed drift-diffusion models to fit error patterns observed in visual working memory tasks (Panichello, DePasquale et al. 2019, Gu, Lee et al. 2023). In contrast to these phenomenological models, network models have more parameters that can cause overfitting. Consequently, we focused on comparing the qualitative differences between onemodule and two-module networks, examining whether each network can generate the correct shape of bias and variance patterns. In response to the reviewers’ suggestions, we have revised the manuscript to reinforce our claim by providing an intuitive explanation of the qualitative differences between these two models (see response to your Major Point 3) and conducting additional simulations to support our claim that error patterns are consistent under different noise types or levels (see responses to Major Points 2 of Reviewer 2, and Minor point 1 of Reviewer 3).
Major Point 2: To help broaden the impact of the paper, it would be helpful if the authors provided insight into how the observed behavioral biases and/or network structures influence cognition. For example, previous work has argued that biases may counteract noise, leading to decreased variance at certain locations. Is there a similar normative explanation for why the brain would have repulsive biases away from commonly occurring stimuli? Are they simply a consequence of improved memory accuracy? Why isn't this seen for all stimulus domains?
Previous work has found both diffusive noise and biases increase with the number of items in working memory. It isn't clear how the current model would capture these effects. The authors do note this limitation in the Discussion, but it remains unclear how the current model can be generalized to a multi-item case.
As pointed by the reviewer, attractors counteract noise and lead to reduced variance around the attracting locations. However, most attractor models reporting such effects did not consider the interaction of attractor dynamics with the sensory network. For the repulsive biases considered here, previous studies on the sensory stage have theoretically demonstrated that they could lower the discrimination threshold around cardinal orientations (e.g., see Wei and Stocker, 2017). In Wei and Stocker (2017), the authors showed that this relationship between bias and discrimination threshold was observed across many stimulus modalities. In the present study, we demonstrated that the bias and variability patterns naturally emerged from the underlying neural dynamics. Nonetheless, we also noted that color working memory shows attractive biases, which necessitates further study of the underlying neural mechanisms of color perception. A plausible explanation is that the categorical effect dominates color perception and memory processes, as suggested by existing modelling work (Tajima et al., 2016).
However, we do note the limitation of our current work that does not capture nuanced error patterns in broader experimental settings, such as variation of perception tasks or memory of multiple items. For instance, while shorter stimulus presentations with no explicit delay lead to larger biases experimentally, our current model, which starts activities from a flat baseline, shows an increase in bias throughout the stimulus presentation. Additionally, the error variance during stimulus presentation is almost negligible compared to that during the delay period, as the external input overwhelms the internal noise. These mismatches during stimulus presentation have minimal impact on activities during the delay period when the internal dynamics dominate. Nonetheless, the model needs further refinement to accurately reproduce activities during stimulus presentation, possibly by incorporating more biologically plausible baseline activities. Also, a recent Bayesian perception model suggested different types of noise like external noise or variations in loss functions that adjust tolerance to small errors may help explain various error patterns observed across different modalities (Hahn and Wei, 2024). Even for memories involving multiple items, noise can be critical in determining error patterns, as encoding more items might be equivalent to higher noise for each individual item (Chunharas, Rademaker et al. 2022).
To make this limitation clear, we included the above response in a new paragraph on limitations and future directions in the Discussion (2nd paragraph in p. 11). Also, we modified the text that previously described that our model can “explain error patterns in both perception and working memory tasks” in p. 3 and p. 5 as
“explain error patterns in working memory tasks that are similar to those observed in perception tasks.”
And we added the bias and variance pattern right after the stimulus offset in Figure 4C,D with the following note in p. 6:
“Note that the variance of errors is nearly zero during stimulus presentation because the external input overwhelms internal noise, which does not fully account for the variability observed during perception tasks (see Discussion).”
Major Point 3: The role of the ring attractor memory network isn't completely clear. There is noise added in this stage, but how is this different from the noise added at the sensory stage? Shouldn't these be additive? Is the noise necessary?
Similarly, it isn't clear whether the memory network is necessary - can it be replaced by autapses (self-connections) in the sensory network to stabilize its representation? In short, it would be helpful for the authors to provide an intuition for why the addition of the memory network facilitates the repulsive bias.
Internal noise in the circuits is necessary to replicate the variability of the readout in estimating the stimulus because our model did not incorporate external noise (i.e., noise associated with the stimulus). We note the distinct noise implementation in both extension of the previous Bayesian model (Fig. 2) and the network models (Fig. 3 and beyond). In Fig. 2, we followed previous studies by employing static tuning curves for the sensory module and Poisson noise to account for variability in the perception stage. In the memory stage, sensory output undergoes the addition of constant Gaussian noise, replicating the diffusion process along the memory manifolds as shown in traditional memory network models. In the network models, we do consider the same noise in both sensory and memory modules, subjecting all units to Poisson noise to simulate neuronal spiking variability. In the network models, the two modules dynamically interact, which warp the energy landscape and generate uneven noise coefficients along the memory manifold, reminiscent of the conditions shown in Fig. 1.
From the bias and variance patterns, we can infer two requirements the network to fulfill – one is efficient coding suggested by sensory perception stage and the other is memory maintenance. The former is achieved by realizing the previous Bayesian models in the sensory networks with specific heterogeneous connections. In our work, the latter is achieved by strong recurrent connections to sustain persistent activity during the delay period. On the other hand, as the reviewer noted, memory can be maintained through autapses in the sensory network, which is equivalent to elongating intrinsic time constants of individual units (Seung, Lee et al. 2000). We simulated such sensory network and showed the results in Figure 7 – Figure Supplement 2. As shown in the figure, a larger time constant also slows down the increase in bias significantly, which can be deduced from Eq. 20.
When memory is maintained through strong recurrent connections, there are two possible scenarios, one-module network combining both efficient coding and memory maintenance (Fig. 8), or two-module network satisfying each condition in different modules (Fig. 7). In both networks, heterogeneous connections achieving efficient coding shape drift and diffusion dynamics similarly as illustrated in Figure 9 (previous Figure 7 – Supplement 1). Discrete attractors are formed near oblique orientations, inducing an increase of repulsive bias during the delay period. Also, noise coefficient is lowest at cardinal orientations. However, there is a difference in the asymmetry degrees of the drift and diffusion at cardinal and oblique orientations the one-module network shows larger asymmetry in potential energy, while the two-module network shows larger asymmetry in the noise coefficient. These varying degrees of heterogeneity in drift and diffusion lead to qualitative differences in bias and variance patterns in estimation. Shallower potential differences with more asymmetrical noise coefficients result in correct bias and variance patterns in the two-module network, while the opposite leads to flipped variance patterns in the one-module network.
An intuitive explanation of how connectivity heterogeneity differentially affects the asymmetry degrees of drift and diffusion in one-module and two-module networks is detailed in our response to Major Point 3 of Reviewer 2. In summary, separating the memory module from the sensory module imposes an additional degree of freedom, allowing for more flexible control over drift and diffusion, thereby bias and variance patterns. To clarify this, we have added simulations in Figure 6 and Figure 9 and provided an intuitive explanation in the accompanying texts in pp. 6-7 and p. 9.
Minor Point 1: The code is stated to be available on GitHub, but I could not access it.
Thank you for pointing it out. The repository is now publicly available.
Minor Point 2: The legend for late/mid/early is in an odd place in Figure 1, as it is in panel E where you can't see the difference between the lines. We would suggest moving this to another panel where the different time points are clear. In general, we would suggest adding more text (legends and titles) to the figure to help the reader understand the figures without having to refer to the details in the text and/or figure legends.
We have now moved the legend to panel B where late/mid/early is first introduced. Also, we added more text to the figure legend (Figure 3,4,5,8).
Minor Point 3: The last line of the first paragraph of the Introduction ends awkwardly. I assume it's referring to indirect evidence for dynamics in memory?
Thank you. We have modified the sentence as follows:
“For instance, biases of errors, the systematic deviation from the original stimuli, observed in estimation tasks have been used as indirect evidence to infer changes in internal representations of stimuli.”
Minor Point 4: Similarly, the first line of the second paragraph of the Introduction was also awkward. Specifically, the clause "..., such as nonuniform stimulus distribution in nature." Seems to be missing a 'the' before 'nonuniform'.
We have modified the sentence as follows:
“One important source of biases is adaptation to environmental statistics, such as the nonuniform stimulus distribution found in nature or the limited range in specific settings.”
Reviewer #2:
In this manuscript, Yang et al. present a modeling framework to understand the pattern of response biases and variance observed in delayed-response orientation estimation tasks. They combine a series of modeling approaches to show that coupled sensory-memory networks are in a better position than single-area models to support experimentally observed delay-dependent response bias and variance in cardinal compared to oblique orientations. These errors can emerge from a population-code approach that implements efficient coding and Bayesian inference principles and is coupled to a memory module that introduces random maintenance errors. A biological implementation of such operation is found when coupling two neural network modules, a sensory module with connectivity inhomogeneities that reflect environment priors, and a memory module with strong homogeneous connectivity that sustains continuous ring attractor function. Comparison with single-network solutions that combine both connectivity inhomogeneities and memory attractors shows that two-area models can more easily reproduce the patterns of errors observed experimentally. This, the authors take as evidence that a sensory-memory network is necessary, but I am not convinced about the evidence in support of this "necessity" condition. A more in-depth understanding of the mechanisms operating in these models would be necessary to make this point clear.
Strengths:
The model provides an integration of two modeling approaches to the computational bases of behavioral biases: one based on Bayesian and efficient coding principles, and one based on attractor dynamics. These two perspectives are not usually integrated consistently in existing studies, which this manuscript beautifully achieves. This is a conceptual advancement, especially because it brings together the perceptual and memory components of common laboratory tasks.
The proposed two-area model provides a biologically plausible implementation of efficient coding and Bayesian inference principles, which interact seamlessly with a memory buffer to produce a complex pattern of delay-dependent response errors. No previous model had achieved this.
We appreciate the reviewer’s comments that the work is a conceptual advancement, combining Bayesian perception models and attractor memory models, and produces error patterns which wasn’t achieved by previous models. Below, we address the specific concerns of the reviewer.
Major Point 1: The correspondence between the various computational models is not fully disclosed. It is not easy to see this correspondence because the network function is illustrated with different representations for different models and the correspondence between components of the various models is not specified. For instance, Figure 1 shows that a specific pattern of noise is required in the low-dimensional attractor model, but in the next model in Figure 2, the memory noise is uniform for all stimuli. How do these two models integrate? What element in the population-code model of Figure 2 plays the role of the inhomogeneous noise of Figure 1? Also, the Bayesian model of Figure 2 is illustrated with population responses for different stimuli and delays, while the attractor models of Figures 3 and 4 are illustrated with neuronal tuning curves but not population activity. In addition, error variance in the Bayesian model appears to be already higher for oblique orientations in the first iteration whereas it is only first shown one second into the delay for the attractor model in Figure 4. It is thus unclear whether variance inhomogeneities appear already at the perceptual stage in the attractor model, as it does in the population-code model. Of course, correspondences do not need to be perfect, but the reader does not know right now how far the correspondence between these models goes.
Thank you for pointing out the lack of clarity in the correspondence between different models. We note the distinct noise implementation in extension of the previous Bayesian model (Fig. 2) and the network models (Fig. 3 and beyond). In Fig. 2, we followed previous studies by employing static tuning curves for the sensory module and Poisson noise to account for variability in the perception stage. In the memory stage, sensory output undergoes the addition of constant Gaussian noise, replicating the diffusion process along the memory manifolds as shown in traditional memory network models. In the network models in Fig. 3 and beyond, we do consider the same noise in both sensory and memory modules, subjecting all units to Poisson noise to simulate neuronal spiking variability. In the network models, the two modules dynamically interact, which warp the energy landscape and generate uneven noise coefficients along the memory manifold, reminiscent of the conditions shown in Fig. 1.
However, we do note the limitation of the current study which cannot fully replicate behavior patterns observed in variation of perception tasks. For instance, while shorter stimulus presentations with no explicit delay lead to larger biases experimentally, our current model, which starts activities from a flat baseline, shows an increase in bias throughout the stimulus presentation. Additionally, the error variance during stimulus presentation is almost negligible compared to that during the delay period, as the external input overwhelms the internal noise. These mismatches during stimulus presentation have minimal impact on activities during the delay period when the internal dynamics dominate. Nonetheless, the model needs further refinement to accurately reproduce activities during stimulus presentation, possibly by incorporating more biologically plausible baseline activities. To make this limitation clear, we included the above response in a new paragraph on limitations and future directions in the Discussion (2nd paragraph in p. 11). Also, we modified the text that previously described that our model can “explain error patterns in both perception and working memory tasks” in p. 3 and p. 5 as “explain error patterns in working memory tasks that are similar to those observed in perception tasks.”
And we added the bias and variance pattern right after the stimulus offset in Figure 4C,D with the following note in p. 6:
“Note that the variance of errors is nearly zero during stimulus presentation because the external input overwhelms internal noise, which does not fully account for the variability observed during perception tasks (see Discussion).”
Major Point 2: The manuscript does not identify the mechanistic origin in the model of Figure 4 of the specific noise pattern that is required for appropriate network function (with higher noise variance at oblique orientations). This mechanism appears critical, so it would be important to know what it is and how it can be regulated. In particular, it would be interesting to know if the specific choice of Poisson noise in Equation (3) is important. Tuning curves in Figure 4 indicate that population activity for oblique stimuli will have higher rates than for cardinal stimuli and thus induce a larger variance of injected noise in oblique orientations, based on this Poissonnoise assumption. If this explanation holds, one wonders if network inhomogeneities could be included (for instance in neural excitability) to induce higher firing rates in the cardinal/oblique orientations so as to change noise inhomogeneities independently of the bias and thus control more closely the specific pattern of errors observed, possibly within a single memory network.
The specific pattern of noise coefficient, lower variability at cardinal orientations in the network models, inherited that of the previous Bayesian perception models (Wei and Stocker, 2017). Either in one-module or two-module networks, the specific pattern of heterogeneous connections induces more neurons tuned to cardinal orientations with narrower tuning widths. Such sparser representation near cardinal stimuli generates lower noise variability even with constant Gaussian noise. This is verified in Eq. 21 in Methods, showing the derivation of noise coefficients – with constant Gaussian noise, Eq. 21 is modified as
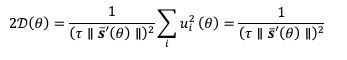
because 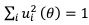 . Thus, 𝒟(𝜃) is inversely proportional to
. Thus, 𝒟(𝜃) is inversely proportional to 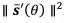 , which reflects the length travelled on the stable trajectory 𝒔𝒔‾(𝜃𝜃) when θ increases by one unit. For sparser representation, becomes larger and 𝒟(𝜃) is reduced. Intuitively, with more neurons tuned to cardinal stimuli, noise is averaged and reduced. In sum, the heterogeneous connection induces the specific noise coefficient, and the choice of Poisson-like noise is not essential, although it facilitates the correct variance pattern. To clarify this point, we have added the results of using uniform Gaussian noise in new Figure 5 – Figure Supplement 2 and Figure 9 – Figure Supplement 1.
, which reflects the length travelled on the stable trajectory 𝒔𝒔‾(𝜃𝜃) when θ increases by one unit. For sparser representation, becomes larger and 𝒟(𝜃) is reduced. Intuitively, with more neurons tuned to cardinal stimuli, noise is averaged and reduced. In sum, the heterogeneous connection induces the specific noise coefficient, and the choice of Poisson-like noise is not essential, although it facilitates the correct variance pattern. To clarify this point, we have added the results of using uniform Gaussian noise in new Figure 5 – Figure Supplement 2 and Figure 9 – Figure Supplement 1.
Major point 3: The main conclusion of the manuscript, that the observed patterns of errors "require network interaction between two distinct modules" is not convincingly shown. The analyses show that there is a quantitative but not a qualitative difference between the dynamics of the single memory area compared to the sensory-memory two-area network, for specific implementations of these models (Figure 7 - Figure Supplement 1). There is no principled reasoning that demonstrates that the required patterns of response errors cannot be obtained from a different memory model on its own. Also, since the necessity of the two-area configuration is highlighted as the main conclusion of the manuscript, it is inconvenient that the figure that carefully compares these conditions is in the Supplementary Material.
Following the suggestion by the reviewer, we moved Figure 7 – Figure supplement 1 as new Figure 9. As noted by the reviewer, drift dynamics and diffusion projected onto the lowdimensional memory manifold have similar shapes in both one-module and two-module networks, with the lowest potential and highest noise coefficient observed at the oblique orientations. However, there is a difference in the asymmetry degrees of the drift and diffusion at cardinal and oblique orientations: the one-module network shows larger asymmetry in potential energy, while the two-module network shows larger asymmetry in the noise coefficient. These varying degrees of heterogeneity in drift and diffusion lead to qualitative differences in bias and variance patterns in estimation. Shallower potential differences with more asymmetrical noise coefficients result in correct bias and variance patterns in the two-module network, while the opposite leads to flipped variance patterns in the one-module network.
To intuitively understand how connectivity heterogeneity differentially affects the asymmetry degrees of drift and diffusion in one-module and two-module networks, consider a simple case where only the excitatory connection is heterogeneous, denoted as α. The asymmetry of diffusion reflects the degree of heterogeneity in either the sensory or memory modules. The noise coefficient derived from the low-dimensional projection is mainly determined by the heterogeneity of . While the one-module network, with a much lower α, shows almost flat , the two-module network shows more prominent asymmetry in with a larger α in the sensory module.
On the other hand, the asymmetry in the potential energy is influenced differently by the connectivity heterogeneity of the sensory module and that of the memory module. For memory maintenance, overall recurrent connections need to be strong enough to overcome intrinsic decay, simplifying to w = 1. In the one-module network, α in the memory module creates potential differences at cardinal and oblique orientations as 1± α. On the other hand, in the two-module network, with w = 1 fulfilled by the memory module, α in the sensory module acts as a perturbation. The effect of α is modulated by the connectivity strengths between sensory and memory module, denoted by γ. Potential differences at cardinal and oblique orientations can be represented as 1± γα. While both α and γ determine the energy level, the noise coefficient less depends on γ (see response to your Major Point 4). Thus, even for relatively larger α in the sensory module leading to more asymmetrical noise coefficients, the potential difference could be shallower in the two-module network with small γ<1.
In sum, in the two-module network, there is an additional degree of freedom, connectivity strengths between sensory and memory modules, which provides the flexibility to control drift and diffusion separately, unlike in the one-module network. To clarify this, we have added simulations in Figure 6 and Figure 9 and provided an intuitive explanation in the accompanying texts in pp. 6-7 and p. 9.
Major Point 4: The proposed model has stronger feedback than feedforward connections between the sensory and memory modules. This is not a common assumption when thinking about hierarchical processing in the brain, and it is not discussed in the manuscript.
As noted in the previous response, the connectivity strengths between the sensory and memory modules, denoted as γ, are important parameters determining the qualitative features of bias and variance patterns. γ corresponds to the product of Jf and Jb, feedforward and feedback strengths, and our additional simulation shows that the bias and variance patterns remain similar for a fixed γ. Note that further simulation revealed that the heterogeneity degree, α, and the intermodal connectivity strengths, γ, influence the drift and diffusion terms differently. As this result highlights the advantage of the two-module network, we moved the dependence of error patterns on intermodal connectivity strengths to the main figure (previous Figure 5 – Figure supplement 2), which now includes more simulations showing bias and variance patterns for different Jf and Jb and for different α and Jb (new Figure 6).
Minor Point 1: page 11: "circular standard deviation of sigma_theta = 1.3º at cardinal orientations" but in Figure 2 we see sigma_theta = 2º at cardinal orientations.
The circular standard deviation of 𝜎𝜎𝜃𝜃 = 1.3º refers to the standard deviation of the sensory module output in iteration 1, that is, before feeding into the memory module to complete this iteration. In figure 2, the standard deviation plotted is that of the output of the memory module, which has a Gaussian memory noise with standard deviation 1.3º added on top of the sensory output. Hence we see a standard deviation of √(1.32 + 1.32) = 1.84º which seems close to 2º in the figure. We added a sentence in this paragraph of Methods (p. 13) to avoid confusion.
Minor Point 2: equation (19): What does the prime of ||s'(theta)|| mean?
The prime represents taking the derivative with respect to θ:
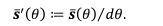
reflects the length travelled on the stable trajectory 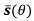 when θ increases by one unit. As we plotted in Figure 9 and Figure 5 – Figure supplement 2, we clarified it in the legend.
when θ increases by one unit. As we plotted in Figure 9 and Figure 5 – Figure supplement 2, we clarified it in the legend.
Minor Point 3: page 15: "The Fisher information (F) is estimated by assuming that the likelihood function p(r|theta) is Gaussian", but the whole point of Wei and Stocker (2015) and your Figure 2 is that likelihoods are skewed in these networks. This could be clarified.
Thank you for pointing out the lack of clarity. In Wei and Stocker (2015) and our Figure 2, the likelihood is skewed with respect to 𝜃 (note the horizontal axes). However, in the Methods section, we assumed the distribution function 𝑝(𝑟|𝜃) is Gaussian with respect to 𝑟𝑟 when 𝜃 is considered fixed:
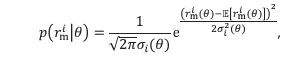
where 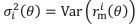 . The distribution function is skewed with respect to 𝜃 because the tuning curves
. The distribution function is skewed with respect to 𝜃 because the tuning curves 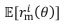 are skewed with respect to 𝜃 (see Figure 4B). We have clarified our assumption in p. 16 to avoid confusion.
are skewed with respect to 𝜃 (see Figure 4B). We have clarified our assumption in p. 16 to avoid confusion.
Reviewer #3:
Summary:
The present study proposes a neural circuit model consisting of coupled sensory and memory networks to explain the circuit mechanism of the cardinal effect in orientation perception which is characterized by the bias towards the oblique orientation and the largest variance at the oblique orientation.
Strengths:
The authors have done numerical simulations and preliminary analysis of the neural circuit model to show the model successfully reproduces the cardinal effect. And the paper is wellwritten overall. As far as I know, most of the studies on the cardinal effect are at the level of statistical models, and the current study provides one possibility of how neural circuit models reproduce such an effect.
We appreciate the reviewer’s comments that the work successfully reproduces error patterns through circuit models, advancing beyond previous statistical models. Below, we address the specific concerns of the reviewer.
Weaknesses:
There are no major weaknesses and flaws in the present study, although I suggest the author conduct further analysis to deepen our understanding of the circuit mechanism of the cardinal effects. Please find my recommendations for concrete comments.
Minor Point 1: Likely, the interplay of the potential function (Figure 5D) and the noise amplitude (Figure 5C) in the memory network is the key to reproducing the cardinal effect. For me, it is obvious to understand the spatial profile of the potential function as what it currently looks like (Figure 5D), while I haven't had an intuitive understanding of how the spatial profile of noise structure emerges from the circuit model. Therefore I suggest the authors provide a more comprehensive analysis, including theory and simulation, to demonstrate how the noise structure depends on the network parameters. I am concerned about whether the memory network can still reproduce the minimal variance at the cardinal orientation if we reduce the Fano factor of single neuron variabilities. In this case, the shape of the potential function will be dominant in determining the variance over orientation (Figure 5F) and the result might be reverted.
Thank you for the suggestion. Either in one-module or two-module networks, the specific pattern of heterogeneous connections induces more neurons tuned to cardinal orientations with narrower tuning widths. Such sparser representation near cardinal stimuli generates lower noise variability even with constant Gaussian noise, which is now added in Figure 5 – Figure Supplement 2. We also showed that the distinctive error patterns in one-module and two-module networks are maintained under Gaussian noise with varying amplitude in Figure 9 – Figure supplement 1.
Minor Point 2: In addition, it is interesting to show how the representation of the sensory module looks like, e.g., plotting the figures similar to Figures B-F but from the sensory module. I feel the sensory module doesn't have a result similar to Figure 5F. Is it?
Yes, decoded error patterns obtained from the sensory module are similar to the results obtained from the memory module. We have added Figure 4 – Figure supplement 1 to show that our conclusions remain valid when decoding from the sensory module.
Minor point 3: Last but not least, I have a conceptual question about the presentation mechanism in the proposed circuit model. The present study refers to Wei, et al., 2015 and 2017 about the statistical model mechanism of the cardinal effect. If I remember correctly, Wei's papers considered joint encoding and decoding processes to render the cardinal effect. Can the authors regard the processes in the proposed circuit model with the stages in the statistical model? Or at least the authors should discuss this link in the Discussions.
We now included a mention of using a population vector decoder that mimics Bayesian optimal readout in the Result section (p. 6), in addition to the Discussion and Methods. However, we acknowledge that this decoder is only optimal under a specific loss function. A recent Bayesian perception model suggested different types of noise like external noise or variations in loss functions that adjust tolerance to small errors may help explain various error patterns observed across different modalities (Hahn and Wei, 2024). We have now added this limitation in the Discussion, along with the inconsistency of the current model with experimental observations during perception tasks and future directions (p. 11).



