Amyloid-beta Peptides: How γ-secretase hits a moving target
- Vanderbilt Univeristy, United States
γ-Secretase is a protease enzyme that can cleave a wide range of different transmembrane proteins. One of these is a protein called C99 that is involved in the production of the Aβ polypeptides that are thought to lead to Alzheimer’s disease (Selkoe and Hardy, 2016). C99 contains 99 amino acid residues in three domains: the amyloid intracellular domain extends into the cytosol; the transmembrane domain, which has a helical structure, is embedded in the membrane that surrounds the cell or one of the many subcellular compartments within it; and the N-terminal domain extends outside the cell or into a subcellular compartment (Figure 1).
Figure 1
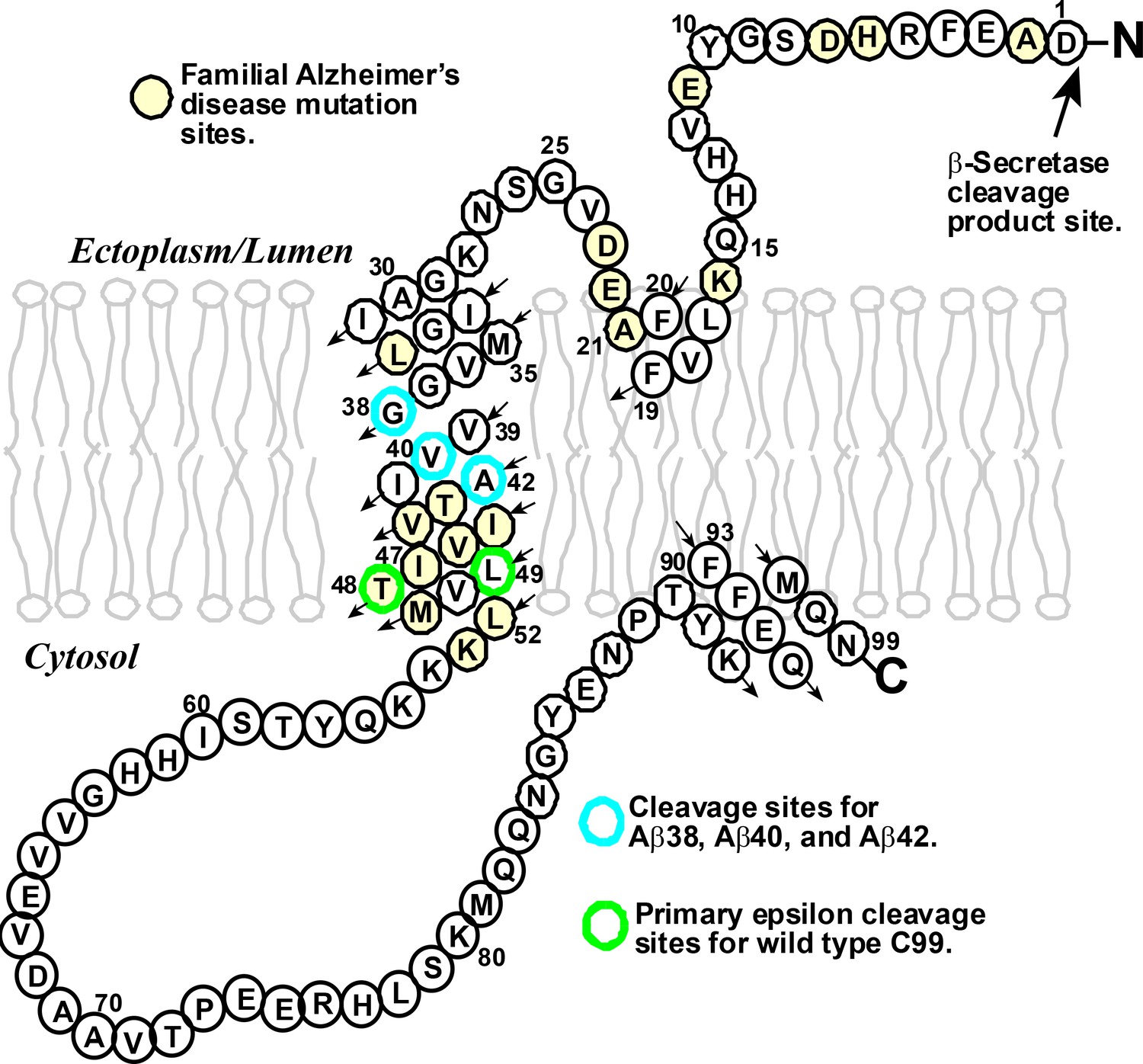
The structure of the human amyloid precursor protein C99.
C99 is a transmembrane protein that contains 99 amino acids derived from β-secretase cleavage of the amyloid precursor protein. Mutations at certain amino acid sites (highlighted in yellow) can lead to the inherited form of Alzheimer’s disease. Wild-type C99 is normally first cleaved by the γ-secretase enzyme after site 48 or 49 (green), followed by additional "processive cleavage" events that shorten the polypeptide (which is still bound to the membrane) . The polypeptide is released from the membrane by a final cleavage event after one of the sites highlighted in blue. The small arrows indicate the direction of the amino acid chain in an N- to C-terminal manner.
Years of patient toil by a number of labs have revealed that the γ-secretase enzyme acts by first cleaving C99 near the cytosolic end of its transmembrane domain (Langosch et al., 2015; Morishima-Kawashima, 2014). This “epsilon cleavage” reaction releases the amyloid intracellular domain into the cytosol, leaving behind a amyloid-beta (Aβ) polypeptide that is still bound to the membrane. The γ-secretase enzyme then starts to shorten this Aβ polypeptide – which usually contains either 48 or 49 residues – by "clipping off" short peptides (typically containing just three residues) in a process known as "processive cleavage". Once the length of the Aβ polypeptide has been shortened to between 38 and 43 residues, it is released from the membrane.
Understanding the actions of the γ-secretase enzyme is extremely important because small differences in the lengths of the Aβ polypeptides are thought to have crucial roles in several forms of Alzheimer’s disease. In general, an Aβ polypeptide that starts with 49 residues is shortened by the γ-secretase enzyme to one with 40 (which is called Aβ40), and a polypeptide that starts with 48 residues is shortened to one with 42 (Aβ42). The production of too much Aβ42, relative to Aβ40, is associated with the rare inherited forms of Alzheimer’s disease; high levels of Aβ42 have also been linked to the more common sporadic form of the disease (Gregory and Halliday, 2005). There is, accordingly, a clear need for drugs that can reduce the production of Aβ polypeptides overall, and also for drugs that can modulate the cleavage of C99 to reduce the production of Aβ42 relative to Aβ40 (Figure 1). The Aβ42 polypeptides cause Alzheimer’s disease by forming highly toxic oligomers that go on to form immunogenic amyloid deposits.
Now, in eLife, Dennis Selkoe, Michael Wolfe and co-workers – including David Bolduc as first author, Daniel Montagna and Matthew Seghers – report results that improve our understanding of the competing reaction pathways that lead to the production of Aβ polypeptides of different length (Bolduc et al., 2016). A central result is that the various cleavage reactions of C99 by the γ-secretase enzyme depend on the properties of the three residues after the cleavage site (which are called the S1', S2' and S3' sites). In particular, the γ-secretase enzyme cannot cleave C99 after a given site if the amino acid at its S2' site is aromatic. Since wild-type C99 does not have any aromatic amino acids in its transmembrane domain, there are no absolute sequence restrictions on where a cleavage event can take place. However, if genetic techniques are used to replace the amino acid at, say, site 50, with an aromatic amino acid, then the γ-secretase enzyme cannot cleave C99 after site 48. Bolduc et al. – who are based at Brigham and Women's Hospital and Harvard Medical School – took advantage of this to make a number of other important observations.
To begin, for wild-type C99 under both purified and cellular conditions, it was confirmed that epsilon cleavage after residue 49 results in the production of Aβ40, and that epsilon cleavage after residue 48 results in the production of Aβ42. It was also shown that introducing aromatic mutations in residues before the normal cleavage sites at residues 48 and 49 can have two effects. First, these mutations can change the relative probability that C99 will be cleaved after site 48 or site 49. (This ratio is normally sensitive to the exact experimental conditions: however, introducing aromatic mutations before these two sites can change this ratio for a given set of experimental conditions). Second, these mutations can also disrupt the normal Aβ48–> Aβ45–>Aβ42 and Aβ49–>Aβ46–>Aβ43–>Aβ40 reaction pathways (thus “uncoupling” the connection between the initial epsilon cleavage event and the subsequent processive cleavage events). This is an important observation that provides insight into how certain mutations in C99 that cause the inherited form of Alzheimer’s disease can increase the Aβ42-to-Aβ40 ratio.
Bolduc et al. also showed that replacing the amino acids at sites 50 and 51 (which are the S2’ positions for the two normal epsilon cleavage sites) with phenylalanine (which is aromatic) blocked the normal epsilon cleavage reactions and, surprisingly, activated epsilon-like cleavage after site 47 instead. The resulting Aβ47 was then shortened by γ-secretase to produce Aβ40, confirming that processive cleavage sometimes involves the "clipping off" of short peptides that contain four rather than three residues (Takami et al., 2009).
Moreover, Bolduc et al. found that replacing entire tracts of residues in the lower transmembrane domain of C99 with aromatic amino acids resulted in cleavage after site 38, which is near the middle of the domain – a shift of some 10–11 residues from the normal epsilon cleavage sites! This provides significant insight because site 37 and site 38 both contain the amino acid glycine (Gly), and it is known that this double-glycine motif destabilizes the helix in the transmembrane domain (Figure 1; Barrett et al., 2012). This suggests that the initial epsilon cleavage site must be part of a destabilized helix. For wild-type C99 the proximity of the lower end of the transmembrane domain to both the cytosol and to a stop motif formed by three lysine amino acids at sites 53–55 almost certainly leads to a transient fraying of the helix there. If the two normal epsilon cleavage sites (48 and 49) are blocked by an aromatic residue at the S2' position, there is still enough fraying for site 47 to be a viable alternative site. And if the whole lower transmembrane domain is blocked, C99 can still form a complex with γ-secretase, and this allows the enzyme to recognize the destabilization of the helix caused by the double glycine motif, which leads to cleavage after site 38.
For many enzymes, the initial binding event leads directly to the substrate occupying the catalytic site of the enzyme, poised for the chemical reaction. Bolduc et al. found that the γ-secretase enzyme was different: a second step is needed. This result is supported by previous studies of γ-secretase with active site-directed inhibitors (see, for example, Li et al., 2014). Indeed, the γ-secretase enzyme is similar in many ways to another protease enzyme, rhomboid (Cho et al., 2016), even though there appears to be no evolutionary relationship between the two. It seems as if Nature has converged on mechanistic traits that are shared by otherwise unrelated intramembrane proteases. These traits appear to include the following: control of water access to active sites that are buried inside membrane; different mechanisms for initial substrate binding and formation of the catalytic complex; and the ability to scan bound transmembrane segments for suitable cleavage sites (Baker and Urban, 2012; Cho et al., 2016; Dickey et al., 2013; Langosch et al., 2015).
The work of Bolduc et al. represents a major advance in our understanding of catalysis by the γ-secretase enzyme. And while many questions remain unanswered, the availability of near-atomic resolution structures for both C99 (Barrett et al., 2012) and γ-secretase (Bai et al., 2015a; Bai et al., 2015b; Lu et al., 2014) means that further advances are likely to follow as researchers combine biochemical results with structural data and insights.
References
-
Architectural and thermodynamic principles underlying intramembrane protease functionNature Chemical Biology 8:759–768.https://doi.org/10.1038/nchembio.1021
-
What is the dominant Aβ species in human brain tissue? A reviewNeurotoxicity Research 7:29–41.https://doi.org/10.1007/BF03033774
-
Understanding intramembrane proteolysis: from protein dynamics to reaction kineticsTrends in Biochemical Sciences 40:318–327.https://doi.org/10.1016/j.tibs.2015.04.001
-
The amyloid hypothesis of Alzheimer's disease at 25 yearsEMBO Molecular Medicine 8:595–608.https://doi.org/10.15252/emmm.201606210
Article and author information
Author details
Publication history
Copyright
© 2016, Sanders
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,097
- views
-
- 349
- downloads
-
- 11
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 11
- citations for umbrella DOI https://doi.org/10.7554/eLife.20043
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Amyloid-beta Peptides: How γ-secretase hits a moving target
eLife 5:e20043.
https://doi.org/10.7554/eLife.20043




{kind=link}