Cerebellar learning using perturbations
- École normale supérieure, CNRS, INSERM, PSL University, France
- University of Chicago, United States
- Imperial College London, United Kingdom
- École normale supérieure, CNRS, PSL University, Sorbonne Université, France
- EHESS, CNRS, PSL University, France
Abstract
The cerebellum aids the learning of fast, coordinated movements. According to current consensus, erroneously active parallel fibre synapses are depressed by complex spikes signalling movement errors. However, this theory cannot solve the credit assignment problem of processing a global movement evaluation into multiple cell-specific error signals. We identify a possible implementation of an algorithm solving this problem, whereby spontaneous complex spikes perturb ongoing movements, create eligibility traces and signal error changes guiding plasticity. Error changes are extracted by adaptively cancelling the average error. This framework, stochastic gradient descent with estimated global errors (SGDEGE), predicts synaptic plasticity rules that apparently contradict the current consensus but were supported by plasticity experiments in slices from mice under conditions designed to be physiological, highlighting the sensitivity of plasticity studies to experimental conditions. We analyse the algorithm’s convergence and capacity. Finally, we suggest SGDEGE may also operate in the basal ganglia.
https://doi.org/10.7554/eLife.31599.001Introduction
A central contribution of the cerebellum to motor control is thought to be the learning and automatic execution of fast, coordinated movements. Anatomically, the cerebellum consists of a convoluted, lobular cortex surrounding the cerebellar nuclei (Figure 1A, Eccles et al., 1967; Ito, 1984). The main input to the cerebellum is the heterogeneous mossy fibres, which convey multiple modalities of sensory, contextual and motor information. They excite both the cerebellar nuclei and the cerebellar cortex; in the cortex they synapse with the very abundant granule cells, whose axons, the parallel fibres, excite Purkinje cells. Purkinje cells constitute the sole output of the cerebellar cortex and project an inhibitory connection to the nuclei, which therefore combine a direct and a transformed mossy fibre input with opposite signs. The largest cell type in the nuclei, the projection neurone, sends excitatory axons to several motor effector systems, notably the motor cortex via the thalamus. Another nuclear cell type, the nucleo-olivary neurone, inhibits the inferior olive. The cerebellum receives a second external input: climbing fibres from the inferior olive, which form an extensive, ramified connection with the proximal dendrites of the Purkinje cell. Each Purkinje cell receives a single climbing fibre. A more modular diagram of the olivo-cerebellar connectivity relevant to this paper is shown in Figure 1B; numerous cell types and connections have been omitted for simplicity.
Figure 1

The cerebellar circuitry and properties of Purkinje cells.
(A) Simplified circuit diagram. MF, mossy fibres; CN, (deep) cerebellar nuclei; GC, granule cells; Cb Ctx, cerebellar cortex; PF, parallel fibres; PC, Purkinje cells; PN, projection neurones; NO, nucleo-olivary neurones; IO, inferior olive; CF, Climbing fibres. (B) Modular diagram. The signs next to the synapses indicate whether they are excitatory or inhibitory. The granule cell and indirect inhibitory inputs they recruit have been subsumed into a bidirectional mossy fibre–Purkinje cell input, M. Potentially plastic inputs of interest here are denoted with an asterisk. , input; , output; , error (which is a function of the output). (C) Typical Purkinje cell electrical activity from an intracellular patch-clamp recording. Purkinje cells fire two types of action potential: simple spikes and, in response to climbing fibre input, complex spikes. (D) According to the consensus plasticity rule, a complex spike will depress parallel fibre synapses active about 100 ms earlier. The diagram depicts idealised excitatory postsynaptic currents (EPSCs) before and after typical induction protocols inducing long-term potentiation (LTP) or depression (LTD). Grey, control EPSC; blue, green, post-induction EPSCs.
Purkinje cells discharge two distinct types of action potential (Figure 1C). They nearly continuously emit simple spikes—standard, if brief, action potentials—at frequencies that average 50 Hz. This frequency is modulated both positively and negatively by the intensity of inputs from the mossy fibre–granule cell pathway (which can also recruit interneurons that inhibit Purkinje cells; Eccles et al., 1967). Such modulations of Purkinje cell firing are thought to underlie their contributions to motor control. In addition, when the climbing fibre is active, an event that occurs continuously but in a somewhat irregular pattern with a mean frequency of around 1 Hz, the Purkinje cell emits a completely characteristic complex spike under the influence of the intense excitation from the climbing fibre (Figure 1C).
The history of research into cerebellar learning is dominated by the theory due to Marr (1969) and Albus (1971). They suggested that the climbing fibre acts as a ‘teacher’ to guide plasticity of parallel fibre–Purkinje cell synapses. It was several years, however, before experimental support for this hypothesis was obtained (Ito et al., 1982; Ito and Kano, 1982), by which time the notion that the climbing fibre signalled errors had emerged (Ito, 1972; Ito, 1984). Error modalities thought to be represented by climbing fibres include: pain, unexpected touch, imbalance, and retinal slip. According to the modern understanding of this theory, by signalling such movement errors, climbing fibres induce long-term depression (LTD) of parallel fibre synapses that were active at the same time (Ito et al., 1982; Ito and Kano, 1982; Sakurai, 1987; Crepel and Jaillard, 1991) or, more precisely, shortly before (Wang et al., 2000; Sarkisov and Wang, 2008; Safo and Regehr, 2008). A compensating long-term potentiation (LTP) is necessary to prevent synaptic saturation (Lev-Ram et al., 2002; Lev-Ram et al., 2003; Coesmans et al., 2004) and its induction is reported to follow high-frequency parallel fibre activity in the absence of complex spikes (Jörntell and Ekerot, 2002; Bouvier et al., 2016). Plasticity of parallel fibre synaptic currents according to these plasticity rules is diagrammed in Figure 1D.
Cerebellar learning with the Marr-Albus-Ito theory has mostly been considered, both experimentally and theoretically, at the level of single cells or of uniformly responding groups of cells learning a single stereotyped adjustment. Such predictable and constrained movements, exemplified by eye movements and simple reflexes, provide some of the best studied models of cerebellar learning: the vestibulo-ocular reflex (Robinson, 1976; Ito et al., 1974; Blazquez et al., 2004), nictitating membrane response/eye blink conditioning (McCormick et al., 1982; Yeo et al., 1984; Yeo and Hesslow, 1998), saccade adaptation (Optican and Robinson, 1980; Dash and Thier, 2014; Soetedjo et al., 2008) and regulation of limb movements by withdrawal reflexes (Ekerot et al., 1995; Garwicz et al., 2002). All of these motor behaviours have in common that there could conceivably be a fixed mapping between an error and a suitable corrective action. Thus, adaptations necessary to ensure gaze fixation are exactly determined by the retinal slip. Such fixed error-correction relations may have been exploited during evolution to create optimised correction circuitry.
The problems arise with the Marr-Albus-Ito theory if one tries to extend it to more complex situations, where neurones must respond heterogeneously (not uniformly) and/or where the flexibility to learn arbitrary responses is required. Many motor control tasks, for instance coordinated movements involving the hands, can be expected to fall into this class. To learn such complex/arbitrary movements with the Marr-Albus-Ito theory requires error signals that are specific for each cell, each movement and each time within each movement. The theory is thus incomplete, because it does not describe how a global evaluation of movement error can be processed to provide such detailed instructions for plasticity to large numbers of cells, a general difficulty which the brain has to face that was termed the credit assignment problem by Minsky (1961).
A suitable algorithm for solving the general cerebellar learning problem would be stochastic gradient descent, a classical optimisation method that Minsky (1961) suggested might operate in the brain. We shall speak of ‘descent’ when minimising an error and ‘ascent’ when maximising a reward, but the processes are mathematically equivalent. In stochastic gradient descent, the objective function is explored by random variations in the network that alter behaviour, with plasticity then retaining those variations that improve the behaviour, as signalled by a decreased error or increased reward. Several possible mechanisms of varying biological plausibility have been proposed. In particular, perturbations caused by synaptic release (Minsky, 1954; Seung, 2003) or external inputs (Doya and Sejnowski, 1988) have been suggested, while various (abstract) mechanisms have been proposed for extraction of changes in the objective function (Williams, 1992). To avoid confusion, note that these forms of stochastic gradient descent differ from those conforming to the more restrictive definition used in the machine learning community, in which the stochastic element is the random sampling of examples from the training set (Robbins and Monro, 1951; Shalev-Shwartz and Ben-David, 2014). This latter form has achieved broad popularity in online learning from large data sets and in deep learning. Although the theoretical framework for (perturbative) stochastic gradient descent is well established, the goal of identifying in the brain a network and cellular implementation of such an algorithm has proved elusive.
The learning behaviour with the best established resemblance to stochastic gradient ascent is the acquisition of song in male songbirds. The juvenile song is refined by a trial and error process to approach a template memorised from a tutor during a critical period (Konishi, 1965; Mooney, 2009). The analogy with stochastic gradient ascent was made by Doya and Sejnowski (1988) and was then further developed experimentally (Olveczky et al., 2005) and theoretically (Fiete et al., 2007). However, despite these very suggestive behavioural correlates, relatively little progress has been made in verifying model predictions for plasticity or identifying the structures responsible for storing the template and evaluating its match with the song.
A gradient descent mechanism for the cerebellum has been proposed by the group of Dean et al. (2002), who term their algorithm decorrelation. Simply stated (Dean and Porrill, 2014), if both parallel fibre and climbing fibre inputs to a Purkinje cell are assumed to vary about their respective mean values, their correlation or anticorrelation indicates the local gradient of the error function and thus the sign of the required plasticity. At the optimum, which is a minimum of the error function, there should be no correlation between variations of the climbing fibre rate and those of the parallel fibre input. Hence the name: the algorithm aims to decorrelate parallel and climbing fibre variations. An appropriate plasticity rule for implementing decorrelation is a modified covariance rule (Sejnowski, 1977; who moreover suggested in abridged form a similar application to cerebellar learning). Although decorrelation provides a suitable framework, its proponents are still in the process of developing a cellular implementation (Menzies et al., 2010). Moreover, we believe that the detailed implementation suggested by Menzies et al., 2010 is unable to solve a temporal credit assignment problem (that we identify below) arising in movements that can only be evaluated upon completion.
Below, we analyse in more detail how the Marr-Albus-Ito theory fails to solve the credit assignment problem and suggest how the cerebellum might implement stochastic gradient descent. We shall provide support for unexpected predictions the proposed implementation makes regarding cerebellar synaptic plasticity, which are different from those suggested for decorrelation. Finally, we shall perform a theoretical analysis demonstrating that learning with the algorithm converges and that it is able to attain maximal storage capacity.
Results
Requirements for cerebellar learning
We begin by examining the current consensus (Marr-Albus-Ito) theory of cerebellar learning and illustrating some of its limitations when extended to the optimisation of complex, arbitrary movements. The learning framework we consider is the following. The cerebellar circuitry must produce at its output trains of action potentials of varying frequencies at given times (Thach, 1968). We consider only firing rates , which are a function of time in the movement (Figure 2A). The cerebellar output influences the movement and the resulting movement error, which can be sensed and fed back to the Purkinje cells in the form of climbing fibre activity.
Figure 2
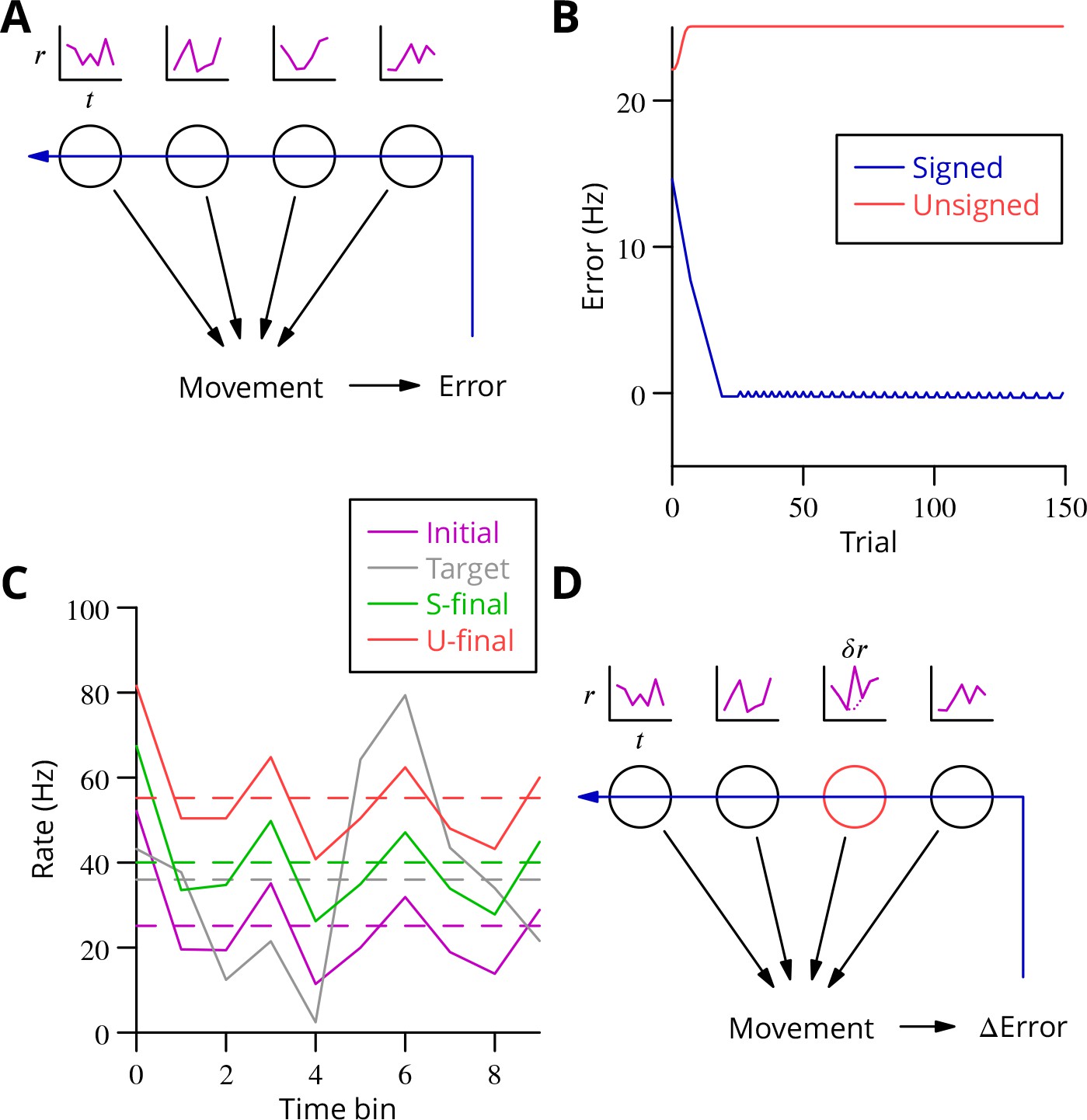
Analysis of cerebellar learning.
(A) The model of cerebellar learning we address is to adjust the temporal firing profiles (miniature graphs of rate as a function of time, , magenta) of multiple cerebellar output neurones (nuclear projection neurones) (black circles) to optimise a movement, exploiting the evaluated movement error, which is fed back to the cerebellar circuit (Purkinje cells) (blue arrow). (B) The Marr-Albus-Ito theory was simulated in a network simulation embodying different error definitions (Results, Materials and methods). The Marr-Albus-Ito algorithm is able to minimise the average signed error (blue, Signed) of a group of projection neurones, but not the unsigned error (red, Unsigned). (C) However, as expected, optimising the signed error does not optimise individual cell firing profiles: comparison of the underlying firing profiles (initial, magenta; final, green) with their target (grey) for a specimen projection neurone illustrates that neither the temporal profile nor even the mean single-cell firing rate is optimised. If the unsigned error is used, there is no convergence and the firing rates simply saturate (red) and the error increases. (D) A different learning algorithm will be explored below: stochastic gradient descent, according to which temporally and spatially localised firing perturbations (, red, of a Purkinje cell) are consolidated if the movement improves; this requires extraction of the change of error ( Error).
We constructed a simple network simulation to embody this framework (see Materials and methods). In it, mossy fibre drive to the cerebellum was considered to be movement- and time-dependent but not to vary during learning. Granule cells and molecular layer interneurons were collapsed into the mossy fibre inputs, which acted on Purkinje cells through unconstrained synapses (negative weights could arise through plasticity of interneuron synapses; Jörntell and Ekerot, 2002; Jörntell and Ekerot, 2003; Mittmann and Häusser, 2007) that were modified to optimise the firing profiles of the projection neurones of the deep cerebellar nuclei. We implemented the Marr-Albus-Ito algorithm via a plasticity rule in which synaptic weights were updated by the product of presynaptic activity and the presence of the error signal. Thus, active mossy fibre (pathway) inputs would undergo LTP (increasing Purkinje cell firing; Lev-Ram et al., 2003) after each movement unless the climbing fibre was active, in which case they would undergo LTD (decreasing activity). The model represented a microzone whose climbing fibres were activated uniformly by a global movement error.
The behaviour of the Marr-Albus-Ito algorithm in this network depends critically on how the definition of the error is extended from the error for an individual cell. The most natural definition for minimising all errors would be to sum the absolute differences between the actual firing profile of each cerebellar nuclear projection neurone and its target, see Equation 7. However, this error definition is incompatible with the Marr-Albus-Ito algorithm (Unsigned in Figure 2B). Examination in Figure 2C of the firing profile of one of the projection neurones shows that their rate simply saturates. The algorithm is able to minimise the average signed error defined in Equation 14 (Signed in Figure 2B). However, inspection of a specimen final firing profile illustrates the obvious limitation that neither the detail of the temporal profile nor even the mean firing rate for individual cells is optimised when using this error (see Figure 2C).
This limitation illustrates the credit assignment problem. How to work back from a single evaluation after the movement to optimise the firing rate of multiple cells at different time points, with all of those firing profiles also differing between multiple movements which must all be learnt in parallel? A model problem that the Marr-Albus-Ito algorithm cannot solve would be two neurones receiving the same inputs and error signal but needing to undergo opposite plasticity. In the general case of learning complex, arbitrary movements, this requires impractical foreknowledge to be embodied by the climbing fibre system, to know exactly which cell must be depressed to optimise each movement, and this still would not solve the problem of inducing plasticity differentially at different time points during a firing profile, given that often only a single, post-movement evaluation will be available. An example would be a saccade, where the proximity to the target can only be assessed once the movement of the eye has ceased.
The complex spike as trial and error
The apparent difficulty of solving the credit assignment problem within the Marr-Albus-Ito algorithm led us to consider whether the cerebellum might implement a form of stochastic gradient descent. By combining a known perturbation of one or a small group of neurones with information about the change of the global error (Figure 2D), it becomes possible to consolidate, specifically in perturbed neurones, those motor command modifications that reduce the error, thus leading to a progressive optimisation. We set out to identify a biologically plausible implementation in the cerebellum. In particular, that implementation should be able to optimise multiple movements in parallel, employing only feasible cellular computations—excitation, inhibition and thresholding.
A cerebellar implementation of stochastic gradient descent must include a source of perturbations of the Purkinje cell firing rate . The fact that Purkinje cells can contribute to different movements with arbitrary and unknown sequencing imposes an implementation constraint preventing simple-minded approaches like comparing movements performed twice in succession. We recall that we assume that no explicit information categorising or identifying movements is available to the Purkinje cell. It is therefore necessary that knowledge of both the presence and sign of be available within the context of a single movement execution.
In practice, a number of different perturbation mechanisms can still satisfy these requirements. For instance, any binary signal would be suitable, since the sign of the perturbation with respect to its mean would be determined by the simple presence or absence of the signal. Several plausible mechanisms along these lines have been proposed, including external modulatory inputs (Doya and Sejnowski, 1988; Fiete et al., 2007), failures and successes of synaptic transmission (Seung, 2003) or the absence and presence of action potentials (Xie and Seung, 2004). However, none of these mechanisms has yet attracted experimental support at the cellular level.
In the cerebellar context, parallel fibre synaptic inputs are so numerous that the correlation between individual input variations and motor errors is likely to be extremely weak, whereas we seek a perturbation that is sufficiently salient to influence ongoing movement. Purkinje cell action potentials are also a poor candidate, because they are not back-propagated to parallel fibre synapses (Stuart and Häusser, 1994) and therefore probably cannot guide their plasticity, but the ability to establish a synaptic eligibility trace is required. Bistable firing behaviour of Purkinje cells (Loewenstein et al., 2005; Yartsev et al., 2009), with the down-state (or long pauses) representing a clear perturbation towards lower (zero) firing rates, is a perturbation candidate. However, exploratory plasticity experiments did not support this hypothesis and the existence of bistability in vivo is disputed (Schonewille et al., 2006a).
We thus propose, in accordance with a suggestion due to Harris (1998), another possible perturbation of Purkinje cell firing: the complex spike triggered by the climbing fibre. We note that there are probably two types of inferior olivary activity. Olivary neurones mediate classical error signalling triggered by external synaptic input, but they also exhibit continuous and irregular spontaneous activity in the absence of overt errors. We suggest the spontaneous climbing fibre activations cause synchronised perturbation complex spikes (pCSs) in small groups of Purkinje cells via the 1:10 inferior olivary–Purkinje cell divergence (Schild, 1970; Mlonyeni, 1973; Caddy and Biscoe, 1976), dynamic synchronisation of olivary neurones through electrical coupling (Llinás and Yarom, 1986; Bazzigaluppi et al., 2012a) and common synaptic drive. The excitatory perturbation—a brief increase of firing rate (Ito and Simpson, 1971; Campbell and Hesslow, 1986; Khaliq and Raman, 2005; Monsivais et al., 2005)—feeds through the cerebellar nuclei (changing sign; Bengtsson et al., 2011) to the ongoing motor command and causes a perturbation of the movement, which in turn may modify the error of the movement.
The perturbations are proposed to guide learning in the following manner. If a perturbation complex spike results in an increase of the error, the raised activity of the perturbed Purkinje cells was a mistake and reduced activity would be preferable; parallel fibre synapses active at the time of the perturbing complex spikes should therefore be depressed. Conversely, if the perturbation leads to a reduction of error (or does not increase it), the increased firing rate should be consolidated by potentiation of the simultaneously active parallel fibres.
How could an increase of the error following a perturbation be signalled to the Purkinje cell? We suggest that the climbing fibre also performs this function. Specifically, if the perturbation complex spike increases the movement error, a secondary error complex spike (eCS) is emitted shortly afterwards, on a time scale of the order of 100 ms (50–300 ms). This time scale is assumed because it corresponds to the classical error signalling function of the climbing fibre, because it allows sufficient time for feedback via the error modalities known to elicit complex spikes (touch, pain, balance, vision) and because such intervals are known to be effective in plasticity protocols (Wang et al., 2000; Sarkisov and Wang, 2008; Safo and Regehr, 2008). The interval could also be influenced by the oscillatory properties of olivary neurones (Llinás and Yarom, 1986; Bazzigaluppi et al., 2012b).
The predicted plasticity rule is therefore as diagrammed in Figure 3. Only granule cell synapses active simultaneously with the perturbation complex spike undergo plasticity, with the sign of the plasticity being determined by the presence or absence of a subsequent error complex spike. Granule cell synapses active in the absence of a synchronous perturbation complex spike should not undergo plasticity, even if succeeded by an error complex spike. We refer to these different protocols with the abbreviations (and give our predicted outcome in parenthesis): G_ _ (no change), GP_ (LTP), G_E (no change), GPE (LTD), where G indicates granule cell activity, P the presence of a perturbation complex spike and E the presence of an error complex spike. Note that both granule cells and climbing fibres are likely to be active in high-frequency bursts rather than the single activations idealised in Figure 3.
Figure 3
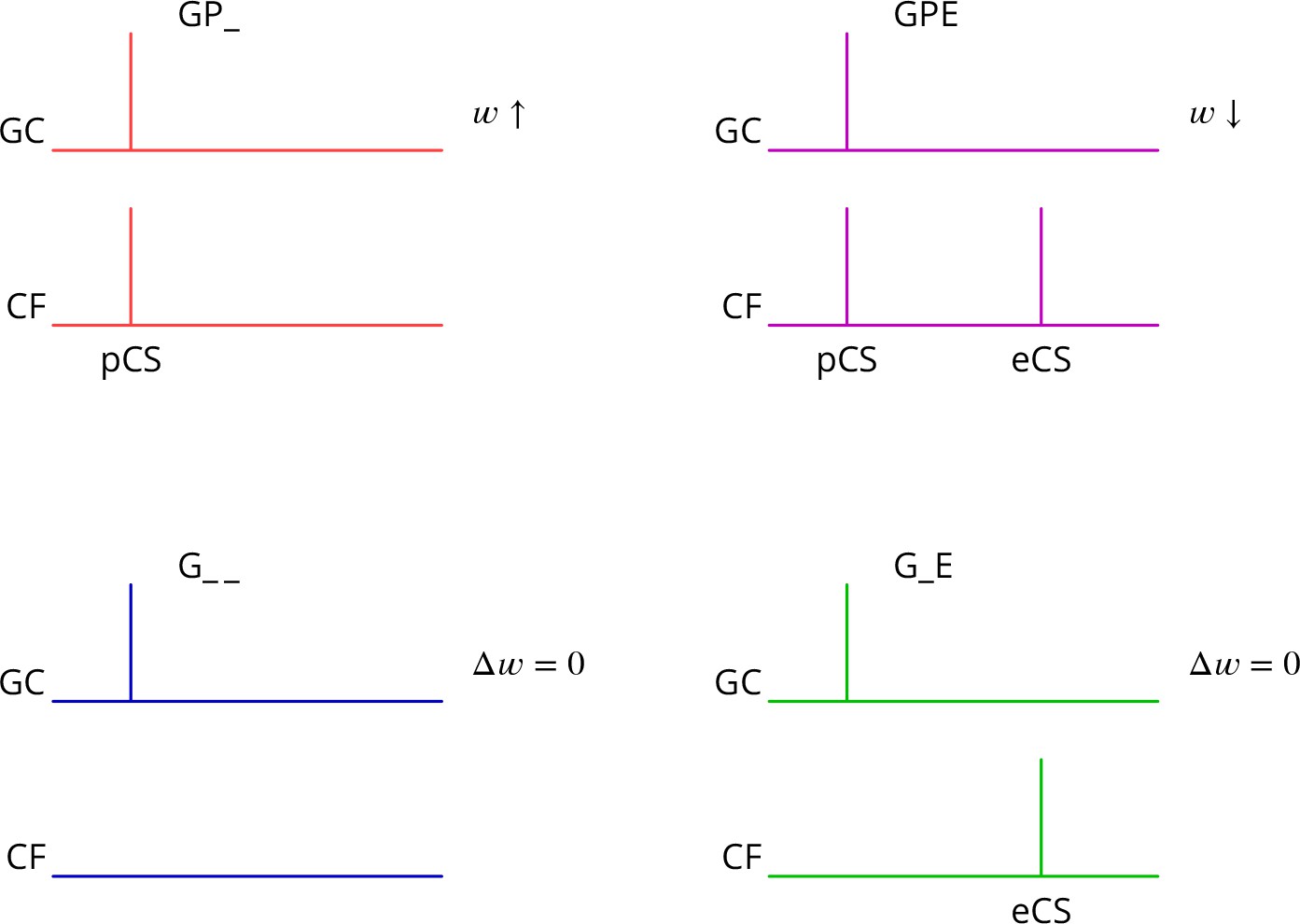
Predicted plasticity rules.
Synchronous activation of granule cell synapses and a perturbation complex spike (pCS) leads to LTP (GP_, increased synaptic weight ; top left, red), while the addition of a succeeding error complex spike (eCS) leads to LTD (GPE, top right, magenta). The bottom row illustrates the corresponding ‘control’ cases from which the perturbation complex spike is absent; no plasticity should result (G_ _ blue and G_E green).
Several of the predictions of this rule appear to be incompatible with the current consensus. Thus, parallel fibre synapses whose activity is simultaneous with (GP_) or followed by a complex spike (G_E) have been reported to be depressed (Sakurai, 1987; Crepel and Jaillard, 1991; Lev-Ram et al., 1995; Coesmans et al., 2004; Safo and Regehr, 2008; Gutierrez-Castellanos et al., 2017), while we predict potentiation and no change, respectively. Furthermore, parallel fibre activity alone (G_ _) leads to potentiation (Lev-Ram et al., 2002; Jörntell and Ekerot, 2002; Lev-Ram et al., 2003; Coesmans et al., 2004; Gutierrez-Castellanos et al., 2017), while we predict no change.
Synaptic plasticity under physiological conditions
As described above, the plasticity rules we predict for parallel fibre–Purkinje cell synapses are, superficially at least, close to the opposite of the consensus in the literature. Current understanding of the conditions for inducing plasticity gives a key role to the intracellular calcium concentration (combined with nitric oxide signalling; Coesmans et al., 2004; Bouvier et al., 2016), whereby high intracellular calcium concentrations are required for LTD and moderate concentrations lead to LTP. Standard experimental conditions for studying plasticity in vitro, notably the extracellular concentration of calcium, are likely to result in more elevated intracellular calcium concentrations during induction than pertain physiologically. Recognising that this could alter plasticity outcomes, we set out to test whether our predicted plasticity rules might be verified under more physiological conditions.
We made several changes to standard protocols (see Materials and methods); one was cerebellum-specific, but the others also apply to in vitro plasticity studies in other brain regions. We did not block GABAergic inhibition. We lowered the extracellular calcium concentration from the standard 2 mM (or higher) used in slice work to 1.5 mM (Pugh and Raman, 2008), which is near the maximum values measured in vivo in rodents (Nicholson et al., 1978; Jones and Keep, 1988; Silver and Erecińska, 1990). To avoid the compact bundles of active parallel fibres produced by the usual stimulation in the molecular layer, we instead used weak granule cell layer stimuli, which results in sparse and spatially dispersed parallel fibre activity. Interestingly, it has been reported that standard protocols using granule cell stimulation are unable to induce LTD (Marcaggi and Attwell, 2007). We used a pipette solution designed to prolong energy supply in extended cells like the Purkinje cell (see Materials and methods). Experiments were carried out in adult mouse sagittal cerebellar slices using otherwise standard patch-clamp techniques.
Pairs of granule cell test stimuli with an interval of 50 ms were applied at 0.1 Hz before and after induction; EPSCs were recorded in voltage clamp at 70 mV. Pairs of climbing fibre stimuli with a 2.5 ms interval were applied at 0.5 Hz throughout the test periods, mimicking tonic climbing fibre activity, albeit at a slightly lower rate. The interleaved test granule cell stimulations were sequenced 0.5 s before the climbing fibre stimulations. The analysis inclusion criteria and amplitude measurement for the EPSCs are detailed in the Materials and methods. The average amplitude of the granule cell EPSCs retained for analysis was 62 46 pA (mean s.d., = 58). The rise and decay time constants (of the global averages) were 0.74 0.36 ms and 7.2 2.7 ms (mean sd), respectively.
During induction, performed in current clamp without any injected current, the granule cell input consisted of a burst of five stimuli at 200 Hz, reproducing the propensity of granule cells to burst at high frequencies (Chadderton et al., 2004; Jörntell and Ekerot, 2006). The climbing fibre input reflected the fact that these can occur in very high-frequency bursts (Eccles et al., 1966; Maruta et al., 2007). We used two stimuli at 400 Hz to represent the perturbation complex spike and four for the subsequent error complex spike if it was included in the protocol. Depending on the protocol, the climbing fibre stimuli had different timings relative to the granule cell stimuli: a pair of climbing fibre stimuli at 400 Hz, 11–15 ms or 500 ms after the start of the granule cell burst and/or four climbing fibre stimuli at 400 Hz, 100–115 ms after the beginning of the granule cell burst (timing diagrams will be shown in the Results). In a fraction of cells, the climbing fibre stimuli after the first were not reliable; our grounds for including these cells are detailed in the Materials and methods. The interval between the two bursts of climbing fibre stimuli when the error complex spike was present was about 100 ms. We increased the interval between induction episodes from the standard one second to two, to reduce any accumulating signal during induction. 300 such induction sequences were applied (Lev-Ram et al., 2002).
We first show the protocols relating to LTP (Figure 4). A granule cell burst was followed by a distant perturbation climbing fibre stimulus or the two inputs were activated simultaneously. In the examples shown, the protocol with simultaneous activation (GP_, Figure 4C,D) caused a potentiation of about 40%, while the temporally separate inputs caused a smaller change of 15% in the opposite direction (G_ _, Figure 4A,B). We note that individual outcomes were quite variable; group data and statistics will be shown below. The mean paired-pulse ratio in our recordings was A2/A1 = 1.75 0.32 (mean sd, = 58). As here, no significant differences of paired-pulse ratio were observed with any of the plasticity protocols: plasticity baseline difference for GP_, mean 0.08, 95% confidence interval (0.34, 0.20), = 15; GPE, mean 0.12, 95 % c.i. (0.07, 0.33), = 10; G_ _, mean 0.01, 95 % c.i. (0.24, 0.24), = 18; G_E, mean 0.09, 95 % c.i. (0.23, 0.29), = 15.
Figure 4
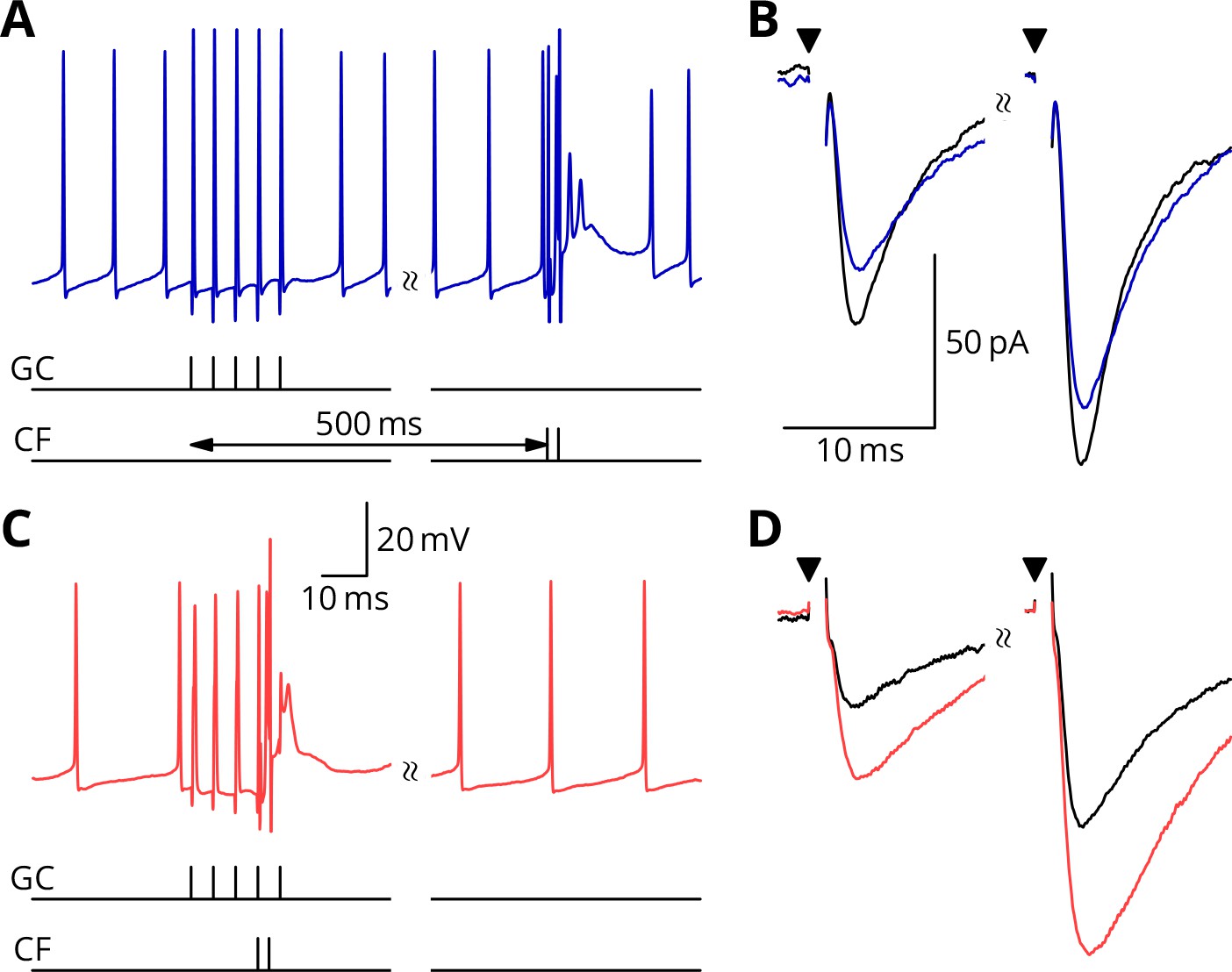
Simultaneous granule cell and climbing fibre activity induces LTP.
(A) Membrane potential (blue) of a Purkinje cell during an induction protocol (G_ _) where a burst of 5 granule cell stimuli at 200 Hz was followed after 0.5 s by a pair of climbing fibre stimuli at 400 Hz. (B) Average EPSCs recorded up to 10 min before (black) and 20–30 min after the end of the protocol of A (blue). Paired test stimuli (triangles) were separated by 50 ms and revealed the facilitation typical of the granule cell input to Purkinje cells. In this case, the induction protocol resulted in a small reduction (blue vs. black) of the amplitude of responses to both pulses. (C) Purkinje cell membrane potential (red) during a protocol (GP_) where the granule cells and climbing fibres were activated simultaneously, with timing otherwise identical to A. (D) EPSCs recorded before (black) and after (red) the protocol in C. A clear potentiation was observed in both of the paired-pulse responses.
Figure 5 illustrates tests of our predictions regarding the induction of LTD. As before, a granule cell burst was paired with the perturbation climbing fibre, but now a longer burst of climbing fibre stimuli was appended 100 ms later, representing an error complex spike (GPE, Figure 5C,D). A clear LTD of about 40% developed following the induction. In contrast, if the perturbation complex spike was omitted, leaving the error complex spike (G_E, Figure 5A,B), no clear change of synaptic weight occurred (an increase of about 10%). During induction, cells would generally begin in a tonic firing mode, but nearly all ceased firing by the end of the protocol. The specimen sweeps in Figure 5 are taken towards the end of the induction period and illustrate the Purkinje cell responses when spiking had ceased.
Figure 5
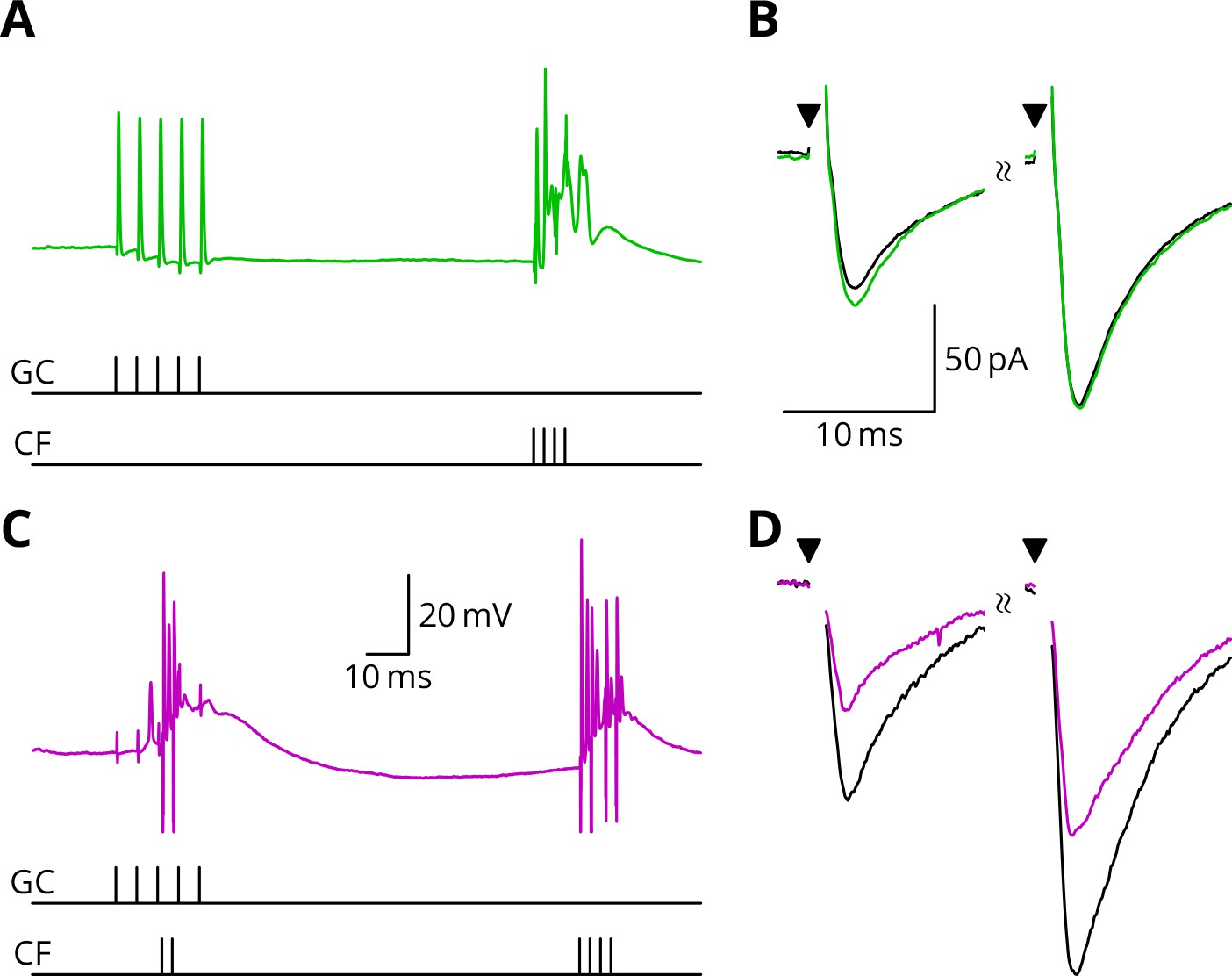
LTD requires simultaneous granule cell and climbing fibre activity closely followed by an additional complex spike.
(A) Membrane potential of a Purkinje cell (green) during a protocol where a burst of five granule cell stimuli at 200 Hz was followed after 100 ms by four climbing fibre stimuli at 400 Hz (G_E). (B) Average EPSCs recorded up to 10 min before (black) and 20–30 min after the end of the protocol of A (green). The interval between the paired test stimuli (triangles) was 50 ms. The induction protocol resulted in little change (green vs. black) of the amplitude of either pulse. (C) Purkinje cell membrane potential (magenta) during the same protocol as in A with the addition of a pair of climbing fibre stimuli simultaneous with the granule cell stimuli (GPE). (D) EPSCs recorded before (black) and after (magenta) the protocol in C. A clear depression was observed.
The time courses of the changes of EPSC amplitude are shown in normalised form in Figure 6 (see Materials and methods). The individual data points of the relative EPSC amplitudes for the different protocols are also shown. A numerical summary of the group data and statistical comparisons is given in Table 1.
Figure 6 with 1 supplement see all
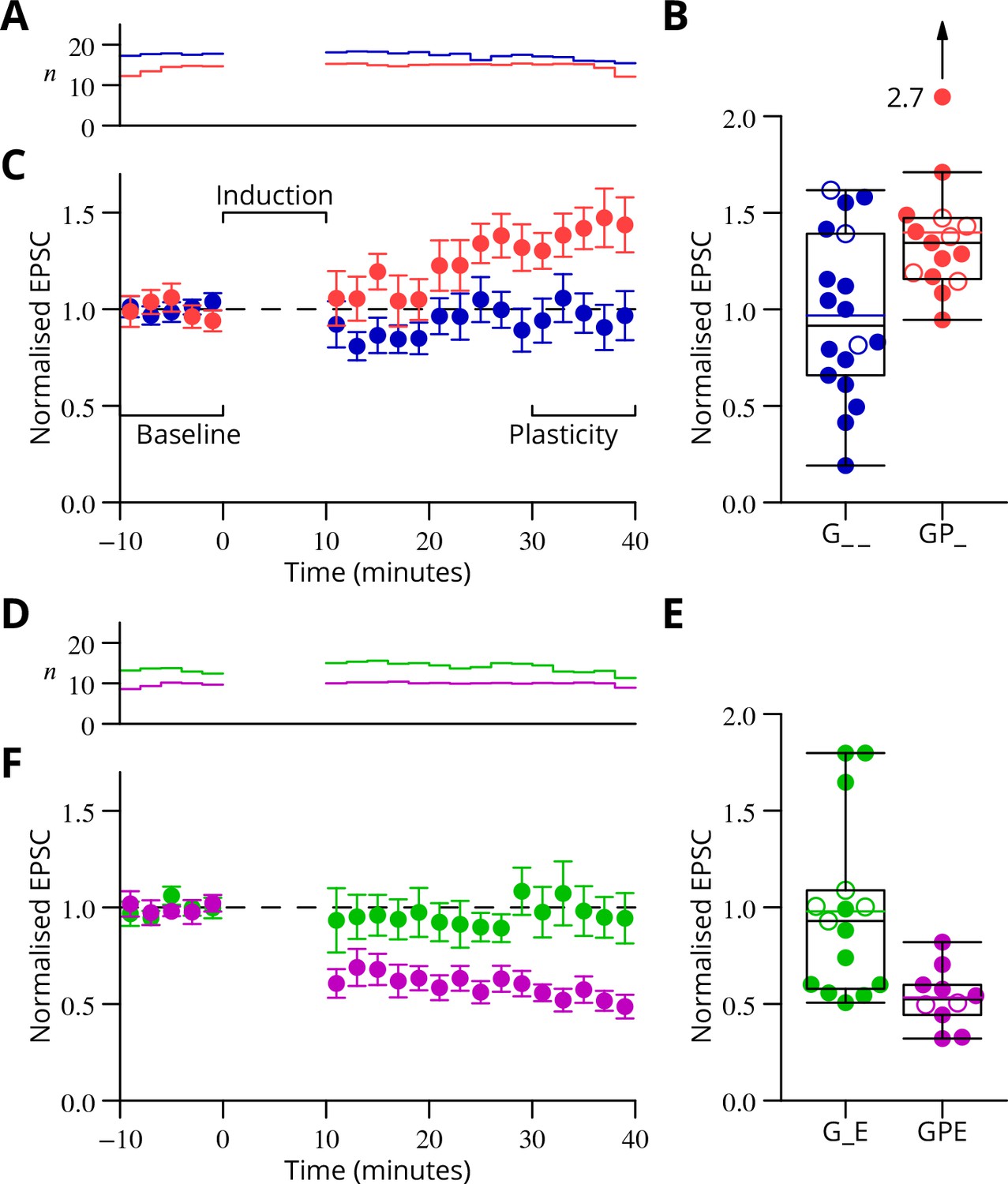
Time course and amplitude of plasticity.
(A) number, (B) box-and-whisker plots of individual plasticity ratios (coloured lines represent the means, open symbols represent cells with failures of climbing fibre stimulation; see Materials and methods) and (C) time course of the mean EPSC amplitude for GP_ (red) and G_ _ (blue) protocols of Figure 4, normalised to the pre-induction amplitude. Averages every 2 min, mean sem. Non-integer arise because the numbers of responses averaged were normalised by those expected in two minutes, but some responses were excluded (see Materials and methods) and some recordings did not extend to the extremities of the bins. Induction lasted for 10 min starting at time 0. (D, E) and (F) similar plots for the GPE (magenta) and G_E (green) protocols of Figure 5.
Table 1
Group data and statistical tests for plasticity outcomes.
In the upper half of the table, the ratios of EPSC amplitudes after/before induction are described and compared with a null hypothesis of no change (ratio = 1). The GP_ and GPE protocols both induced changes, while the control protocols (G_ _, G_E) did not. The bottom half of the table analyses differences of those ratios between protocols. The 95% confidence intervals (c.i.) were calculated using bootstrap methods, while the -values were calculated using a two-tailed Wilcoxon rank sum test. The p-values marked with an asterisk have been corrected for a two-stage analysis by a factor of 2 (Materials and methods).
| Comparison | Mean | 95 % c.i. | |||
|---|---|---|---|---|---|
GP_ | 1.40 | 1.26, | 1.72 | 0.0001 | 15 |
| GPE | 0.53 | 0.45, | 0.63 | 0.002 | 10 |
G_ _ | 0.97 | 0.78, | 1.16 | 0.77 | 18 |
| G_E | 0.98 | 0.79, | 1.24 | 0.60 | 15 |
| GP_ vs G_ _ | 0.43 | 0.19, | 0.74 | 0.021* | |
| GPE vs G_E | −0.44 | −0.72, | −0.24 | 0.0018* | |
| GP_ vs G_E | 0.42 | 0.14, | 0.73 | 0.01* | |
| GPE vs G_ _ | −0.43 | −0.65, | −0.22 | 0.008* | |
| G_ _ vs G_E | 0.01 | −0.26, | 0.32 | 0.93 | |
In a complementary series of experiments, we explored the plasticity outcome when six climbing fibre stimuli were grouped in a burst and applied simultaneously with the granule cell burst. This allowed comparison with the GPE protocol, which also contained 4 + 2 = 6 climbing fibre stimuli. The results in Figure 6—figure supplement 1 shows that a modest LTP was observed on average: after/before ratio 1.12 0.12 (mean SEM); 95% c.i. 0.89–1.35. This result is clearly different from the LTD observed under GPE (=0.0034; two-tailed Wilcoxon rank sum test, after Bonferroni correction for four possible comparisons).
These results therefore provide experimental support for all four plasticity rules predicted by our proposed mechanism of stochastic gradient descent. We argue in the Discussion that the apparent contradiction of these results with the literature is not unexpected if the likely effects of our altered conditions are considered in the light of known mechanisms of potentiation and depression.
Extraction of the change of error
Above we have provided experimental evidence in support of the counterintuitive synaptic plasticity rules predicted by our proposed learning mechanism. In that mechanism, following a perturbation complex spike, the sign of plasticity is determined by the absence or presence of a follow-up error complex spike that signals whether the movement error increased (spike present) or decreased (spike absent). We now return to the outstanding problem of finding a mechanism able to extract this change of error, .
Several roughly equivalent schemes have been proposed (Williams, 1992), including subtraction of the average error (Barto et al., 1983) and decorrelation (Dean and Porrill, 2014), a specialisation of the covariance rule (Sejnowski, 1977). However, in general, these suggestions have not extended to detailed cellular implementations. In order to restrict our implementation to biologically plausible mechanisms we selected a method that involves subtracting the average error from the trial-to-trial error (Barto et al., 1983; Doya and Sejnowski, 1988). The residual of the subtraction is then simply the variation of the error as desired.
As mechanism for this subtraction, we propose that the excitatory synaptic drive to the inferior olive is on average balanced by input from the GABAergic nucleo-olivary neurones. A diagram is shown in Figure 7 to illustrate how this might work in the context of repetitions of a single movement (we extend the mechanism to multiple interleaved movements below). Briefly, a feedback plasticity reinforces the inhibition whenever it is too weak to prevent an error complex spike from being emitted. When the inhibition is strong enough to prevent an error complex spike, the inhibition is weakened. If the variations of the strength of the inhibition are sufficiently small and the error does not change rapidly, the level of inhibition will attain a good approximation of the average error. Indeed, this mechanism can be viewed as maintaining an estimate of the movement error. However, the error still varies about its mean on a trial-to-trial basis because of the random perturbations that influence the movement and therefore the error. In consequence, error complex spikes are emitted when the error exceeds the (estimated) average; this occurs when the perturbation increases the error. This mechanism enables extraction of the sign of in the context of a single movement realisation. In support of such a mechanism, there is evidence that inhibition in the olive builds up during learning and reduces the probability of complex spikes (Kim et al., 1998).
Figure 7
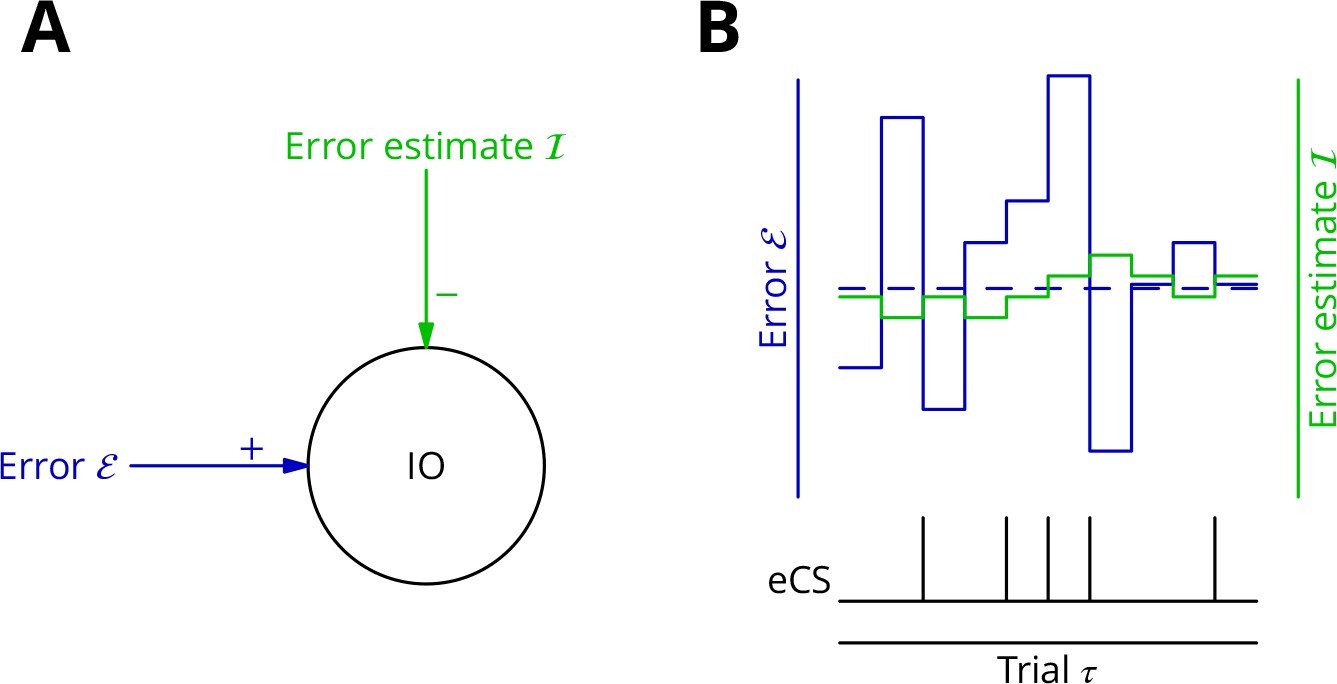
Adaptive tracking to cancel the mean error input to the inferior olive.
(A) The olive is assumed to receive an excitatory signal representing movement error and an inhibitory input from the nucleo-olivary neurones of the cerebellar nuclei. (B) The inputs to the inferior olive are represented in discrete time ()—each bar can be taken to represent a discrete movement realisation. The error (blue) varies about its average (dashed blue line) because perturbation complex spikes influence the movement and associated error randomly. The strength of the inhibition is shown by the green trace. When the excitatory error input exceeds the inhibition, an error complex spike is emitted (bottom black trace) and the inhibition is strengthened by plasticity, either directly or indirectly. In the converse situation and in the consequent absence of an error complex spike, the inhibition is weakened. In this way, the inhibition tracks the average error and the emission of an error complex spike signals an error exceeding the estimated average. Note that spontaneous perturbation complex spikes are omitted from this diagram.
More than one plasticity mechanism could produce the desired cancellation of excitatory drive to the inferior olive. We outline two possibilities here, but it will be necessary in the implementation below to make a concrete if somewhat arbitrary choice; we shall make it on the basis of the available, circumstantial evidence.
The first possible mechanism would involve plasticity of the inhibitory synapses made by nucleo-olivary neurones in the inferior olive (Figure 1A,B). Perturbation and error complex spikes would be distinguished in an appropriate plasticity rule by the presence of excitatory synaptic input to the olive. This would offer a simple implementation, since plastic and cancelled inputs would be at neighbouring synapses (De Zeeuw et al., 1998); information about olivary spikes would also be directly available. However, the lack of published evidence and our own unsuccessful exploratory experiments led us to consider an alternative plasticity locus.
A second possible implementation for cancelling the average error signal would make the mossy fibre to nucleo-olivary neurone synapses plastic. The presence of an error complex spike would need to potentiate these inputs, thereby increasing inhibitory drive to the olive and tending to reduce the likelihood of future error complex spikes being emitted. Inversely, the absence of the error complex spike should depress the same synapses. Movement specificity could be conferred by applying the plasticity only to active mossy fibres, the patterns of which would differ between movements. This would enable movement-specific cancellation as long as the overlap between mossy fibre patterns was not too great.
How would information about the presence or absence of the error complex spike be supplied to the nucleo-olivary neurones? A direct connection between climbing fibre collaterals and nucleo-olivary neurones exists (De Zeeuw et al., 1997), but recordings of cerebellar neurones following stimulation of the olive suggest that this input is not strong, probably eliciting no more than a single spike per activation (Bengtsson et al., 2011). The function of this apparently weak input is unknown.
An alternative route to the cerebellar nuclear neurones for information about the error complex spike is via the Purkinje cells. Climbing fibres excite Purkinje cells which in turn inhibit cerebellar nuclear neurones, in which a strong inhibition can cause a distinctive rebound of firing (Llinás and Mühlethaler, 1988). It has been reported that peripheral stimulation of the climbing fibre receptive field, which might be expected to trigger the emission of error complex spikes, causes large IPSPs and an excitatory rebound in cerebellar nuclear neurones (Bengtsson et al., 2011). These synaptically induced climbing fibre–related inputs were stronger than spontaneously occurring IPSPs. In our conceptual framework, this could be interpreted as indicating that error complex spikes are stronger and/or arise in a greater number of olivary neurones than perturbation complex spikes. The two types of complex spike would therefore be distinguishable, at least in the cerebellar nuclei.
Plasticity of active mossy fibre inputs to cerebellar nuclear neurones has been reported which follows a rule similar to that our implementation requires. Thus, mossy fibres that burst before a hyperpolarisation (possibly the result of an error complex spike) that triggers a rebound have their inputs potentiated (Pugh and Raman, 2008), while mossy fibres that burst without a succeeding hyperpolarisation and rebound are depressed (Zhang and Linden, 2006). It should be noted, however, that this plasticity was studied at the input to projection neurones and not at that to the nucleo-olivary neurones. Nevertheless, the existence of highly suitable plasticity rules in a cell type closely related to the nucleo-olivary neurones encouraged us to choose the cerebellar nuclei as the site of the plasticity that leads to cancellation of the excitatory input to the olive.
We now consider how synaptic integration in the olive leads to emission or not of error complex spikes. The nucleo-olivary synapses (in most olivary nuclei) display a remarkable degree of delayed and long-lasting release (Best and Regehr, 2009), suggesting that inhibition would build up during a command and thus be able to oppose the excitatory inputs signalling movement errors that appear some time after the command is transmitted. The error complex spike would therefore be produced (or not) after the command. On this basis, we shall make the simplifying assumption that the cerebellum generates a relatively brief motor control output or ‘command’, of the order of 100 ms or less and a single error calculation is performed after the end of that command. As for the saccade example previously mentioned, many movements can only be evaluated after completion. In effect, this corresponds to an offline learning rule.
Simulations
Above we outlined a mechanism for extracting the error change ; it is based on adapting the inhibitory input to the inferior olive to cancel the average excitatory error input in a movement-specific manner. To verify that this mechanism could operate successfully in conjunction with the scheme for cortical plasticity already described, we turned to simulation.
A reduced model of a cerebellar microzone was developed and is described in detail in the Materials and methods. In overview, mossy fibre input patterns drove Purkinje and cerebellar nuclear neurones during commands composed of 10 discrete time bins. Purkinje cell activity was perturbed by randomly occurring complex spikes, which each increased the firing in a single time bin. The learning task was to adjust the output patterns of the nuclear projection neurones to randomly chosen targets. Cancellation of the average error was implemented by plasticity at the mossy fibre to nucleo-olivary neurone synapse while modifications of the mossy fibre pathway input to Purkinje cells reflected the rules for stochastic gradient descent described earlier. Synaptic weights were updated offline after each command. The global error was the sum of absolute differences between the projection neurone outputs and their target values. Error complex spikes were broadcast to all Purkinje cells when the error exceeded the integral of inhibitory input to the olive during the movement. There were thus 400 (40 projection neurones 10 time bins) variables to optimise using a single error value.
The progress of the simulation is illustrated in Figure 8, in which two different movements were successfully optimised in parallel; only one is shown. The error can be seen to decrease throughout the simulation, indicating the progressive improvement of the learnt command. The effect of learning on the difference between the output and the target values can be seen in Figure 8C and D. The initial match is very poor because of random initial weight assignments, but it has become almost exact by the end of the simulation.
Figure 8
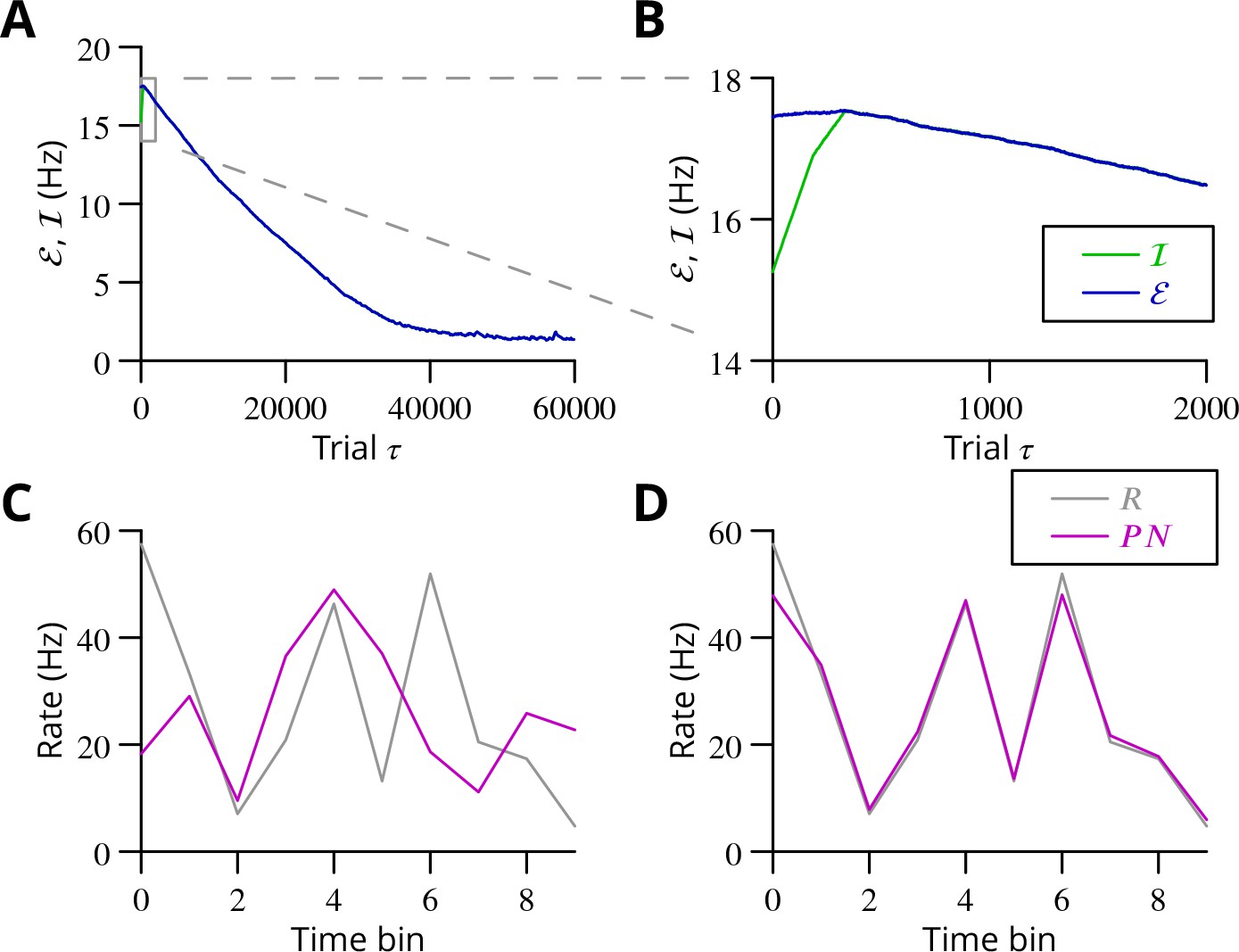
Simulated cerebellar learning by stochastic gradient descent with estimated global errors.
The total error (, blue) at the cerebellar nuclear output and the cancelling inhibition (, green) reaching the inferior olive are plotted as a function of trial number () in (A and B) for one of two interleaved patterns learnt in parallel. An approximately 10-fold reduction of error was obtained. It can be seen in A that the cancelling inhibition follows the error very closely over most of the learning time course. However, the zoom in B shows that there is no systematic reduction in error until the inhibition accurately cancels the mean error. (C) Initial firing profile of a typical cerebellar nuclear projection neurone (, magenta); the simulation represented 10 time bins with initially random frequency values per neurone, with a mean of 30 Hz. The target firing profile for the same neurone (, grey) is also plotted. (D) At the end of the simulation, the firing profile closely matched the target.
The optimisation only proceeds once the inhibitory input to the olive has accurately subtracted the average error. Thus, in Figure 8B it can be seen that the initial values of the inhibitory and excitatory (error) inputs to the olive differed. The inhibition tends towards the error. Until the two match, the overall error shows no systematic improvement. This confirms the need for accurate subtraction of the mean error to enable extraction of the error changes necessary to descend the error gradient. This simulation supports the feasibility of our proposed cerebellar implementation of stochastic gradient descent.
Algorithm convergence and capacity
The simulations above provide a proof of concept for the proposed mechanism of cerebellar learning. Nonetheless, even for the relatively simple network model in the simulations, it is by no means obvious to determine the regions of parameter space in which the model converges to the desired outputs. It is also difficult to analyse the algorithm’s performance compared to other more classical ones. To address these issues, we abstract the core mechanism of stochastic gradient descent with estimated global errors in order to understand better the algorithm dynamics and to highlight the role of four key parameters. Analysis of this mechanism shows that this algorithm, even in this very reduced form, exhibits a variety of dynamical regimes, which we characterise. We then show how the key parameters and the different dynamical learning regimes directly appear in an analog perceptron description of the type considered in the previous section. We find that the algorithm’s storage capacity is similar to the optimal capacity of an analog perceptron.
Reduced model
In order to explore more exhaustively the convergence of the learning algorithm, we considered a reduced version with a single principal cell that nevertheless captures its essence (Figure 9A). A detailed analysis of this circuit is presented in the Appendix 1, which we summarise and illustrate here.
Figure 9
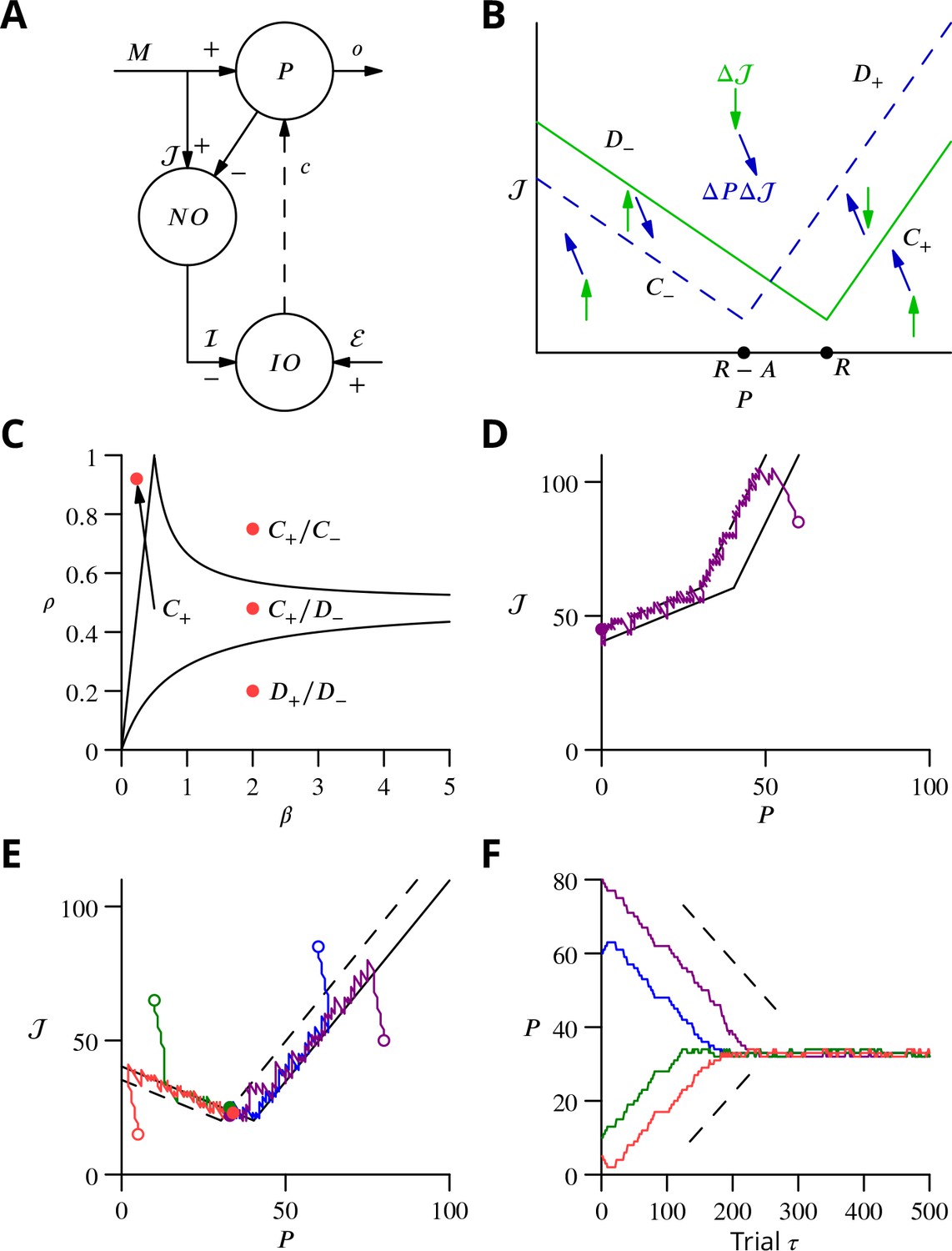
Single-cell convergence dynamics in a reduced version of the algorithm.
(A) Simplified circuitry implementing stochastic gradient descent with estimated global errors. Combined Purkinje cells/projection neurones (P) provide the output . These cells receive an excitatory plastic input from mossy fibres (). Mossy fibres also convey a plastic excitatory input to the nucleo-olivary neurones (NO), which receive inhibitory inputs from the Purkinje cells and supply the inhibitory input to the inferior olive (IO). The inferior olive receives an excitatory error input . The olivary neurones emit spikes that are transmitted to the P-cells via the climbing fibre . (B) Effects of plasticity on the simplified system in the plane defined by the P-cell rate (with optimum , perturbation ) and excitatory drive to the nucleo-olivary neurones . Plastic updates of type (blue arrows) and (green arrows) are shown. The updates change sign on the line C (dashed blue) and D (solid green), respectively. Lines and delimit the ‘convergence corridors’. The diagram is drawn for the case , in which , the perturbation of is larger than the perturbation of . (C) Parameters and determine along which lines the system converges to . The red dot in the region shows the parameter values used in panels E and F and also corresponds to the effective parameters of the perceptron simulation of Figure 10. The other red dots show the parameters used in the learning examples displayed in Appendix 1—figure 1. (D) When , and do not cross and learning does not converge to the desired rate. After going down the corridor, the point continues along the corridor without stopping close to the desired target rate . Open circle, start point; filled circle, end point. (E) Dynamics in the plane for and (). Trajectories (coloured lines) start from different initial conditions (open circles). Open circles, start points; filled circles, end points. (F) Time courses of as a function of trial for the trajectories in C (same colours). Dashed lines: predicted rate of convergence (Appendix 1). All trajectories end up fluctuating around , which is with the chosen parameters. Open circles, start points; filled circles, end points.
Figure 10

Convergence and capacity for an analog perceptron.
(A) Convergence for a single learned pattern for stochastic gradient descent with estimated global errors (SGDEGE). Different lines (thin grey lines) correspond to distinct simulations. The linear decrease of the error () predicted from the simplified model without zero-weight synapses is also shown (dashed lines). When learning increases the rate towards its target, the predicted convergence agrees well with the simulation. When learning decreases the rate towards its target, the predicted convergence is larger than observed because a fraction of synapses have zero weight. (B) Mean error vs. number of trials (always per pattern) for different numbers of patterns for SGDEGE with . Colours from black to red: 50, 100, 200, 300, 350, 380, 385, 390, 395, 400, 410, 420, 450. (C) Mean error vs. number of trials when learning using the delta rule. The final error is zero when the number of patterns is below capacity (predicted to be 391 for these parameters), up to finite size effects. Colours from black to blue: same numbers of patterns as listed for B. (D) Mean error after trials for the delta rule (blue) and for the SGDEGE with (cyan), 0.25 (green), 0.5 (red), 0.75 (magenta), as a function of the number of patterns . The mean error diverges from its minimal value close to the theoretical capacity (dashed line) for both learning algorithms. (E) Dynamics of pattern learning in the or more precisely plane below maximal capacity (). The error () corresponding to each pattern (grey) is reduced as it moves down its convergence corridor. The trajectory for a single specimen pattern is highlighted in red, while the endpoints of all trajectories are indicated by salmon filled circles but are all obscured at (0,0) by the red filled circle of the specimen trajectory. (F) Same as in E for a number of patterns above maximal capacity (). After learning several patterns, rates remain far from their targets (salmon filled circles). The SGDEGE algorithm parameters used to generate this figure are . The parameter except in panel D where it is explicitly varied. The analog perceptron parameters are and the threshold with ).
We focus on the rate of a single P-cell (principal cell, in essence a combination of a Purkinje cell and a nuclear projection neurone), without considering how the firing is driven by synaptic inputs. The other variable of the model is the strength of the plastic excitatory input from mossy fibres to nucleo-olivary neurones Figure 9. The learning task is to bring the firing rate of the P-cell to a desired target rate , guided by an estimation of the current error relying on , which is refined concurrently with from trial to trial.
The error is determined by the difference between and ; we choose the absolute difference . In the presence of a perturbation , occurring with probability , the rate becomes and so . The current estimate of the error is measured by the strength of the inhibition on the olivary neurone associated with the P-cell. It assumes the value (the brackets denoting the rectified value of X, if and otherwise); represents the strength of P-cell (in reality Purkinje cell) synapses on nucleo-olivary neurones. The inhibition of the inferior olive (IO) arises from the discharge of the nucleo-olivary neurones (NO) induced by the mossy fibre inputs, the component of . The NOs are themselves inhibited by the P-cell which is accounted for by the component of (Figure 9A). Note that in the presence of a perturbation of the P-cell, the estimate of the error is itself modified to to account for the decrease (for ) of the NO discharge arising from the P-cell firing rate increase.
The system learning dynamics can be analysed in the - plane (Figure 9B). After each ‘movement’ realisation, the two system variables, and are displaced within the - plane by plasticity according to the algorithm. In the presence of a perturbation, is decreased (a leftwards displacement) if and otherwise increased. However, remains unchanged if there is no perturbation. Conversely, is always updated irrespective of the presence or absence of a perturbation. If in the presence of a perturbation or in its absence, is increased (upwards displacement) and it is decreased otherwise.
Updates can therefore be described as or . The resultant directions vary between the different regions of the -plane (Figure 9B) delimited by the two borders and , defined as and , respectively. The two half-lines bordering each sector are denoted by a plus or minus index according to their slopes.
Stochastic gradient descent is conveniently analysed with a phase-plane description, by following the values from one update to the next. The dynamics randomly alternate between updates of type and which leads to follow a biased random walk in the plane. Mathematical analysis (see Appendix 1) shows that the dynamics proceed in three successive phases, as observed in the simulations of Figure 8. First, the pair of values drifts from the initial condition towards one of the two ‘corridors’ between the lines and or between and (see Figure 9B). This first phase leads the estimated error to approximate closely the error , as seen in the full network simulation (Figure 8).
When a corridor is reached, in a second phase, follows a stochastic walk in the corridor with, under suitable conditions, a mean linear decrease of the error in time with bounded fluctuations. The precise line followed and the mean rate of error decrease depends on the initial conditions and two parameters: the probability of a perturbation occurring and , as indicated in Figure 9C. Typical trajectories and time courses for specific values of and and different initial conditions are shown in Figure 9D,E,F as well as in Appendix 1—figure 1.
Error decrease in this second phase requires certain restrictions upon the four key parameters—, , , . These restrictions are that , which ensures that updates are not restricted to a line, and as well as , which are sufficient to ensure that a trajectory will eventually enter a convergence corridor (large updates might always jump over the corridor).
In a final phase, fluctuates around the intersection of and , when it exists.
and do not cross for , when the perturbation of the estimated error is larger than the perturbation of the P-cell discharge. In this case, does not stop close to its target value, as illustrated in Figure 9D. For , and intersect at . The final error in the discharge rate fluctuates around . Namely, the mean final error grows from when (vanishing inhibition of the nucleo-olivary discharge by the P-cell) to when (maximal admissible inhibition of the nucleo-olivary discharge by the P-cell). The failed convergence for could be expected, since in this scenario the perturbation corrupts the error estimate more than it influences the global error due to the perturbed P-cell firing rate.
Analog perceptron
In order to extend the above analysis to include multiple synaptic inputs and to explore the algorithm’s capacity to learn multiple movements, we considered an analog perceptron using the algorithm of stochastic gradient descent with estimated global errors. This allowed us to investigate the storage capacity attainable with the algorithm and to compare it to the theoretical maximal capacity for an analog perceptron (Clopath and Brunel, 2013).
The architecture was again that of Figure 9A; the details of the methods can be found in Appendix 1 and we summarise the conclusions here, with reference to Figure 10. The simulation included 1000 inputs (mossy fibres) to a P-cell; note that much larger numbers of inputs pertain in vivo (Napper and Harvey, 1988).
As found in the reduced model above, convergence of the algorithm requires the perturbation of the error estimate to be smaller than the effect of the P-cell perturbation on the true error, namely . When this condition holds, the rate of learning a single pattern and the final error can be related to that predicted from the simplified analysis above (Figure 10A and in Appendix 1).
Learning using perturbations is slower than when using the full error information (i.e., the ‘delta rule’ (Dayan and Abbott, 2001); compare Figure 10B and C), for all numbers of patterns. The difference can be attributed to the different knowledge requirement of the two algorithms. When the error magnitude is known, which requires knowledge of the desired endpoint, large updates can be made for large errors, as done in the delta rule. In contrast, the proposed SGDEGE algorithm does not require knowledge of the error absolute magnitude or sign and thus proceeds with constant updating steps. Extensions of the SGDEGE algorithm that incorporate adaptive weight updates and could accelerate learning are mentioned in the Discussion.
The precision of learning is limited by the on-going perturbations to (e.g. for or, for as used in Figure 10B), but the final average error increases beyond this floor only very close to the theoretical capacity computed for the input-output association statistics (Figure 10D). The contribution of interfering patterns to the slowed learning is similar for the two algorithms. The behaviour of individual learning trajectories below maximal capacity is shown in Figure 10E and F.
These analyses establish the convergence mechanisms of stochastic gradient descent with estimated global errors and show that it can attain the maximum theoretical storage capacity up to a non-zero final error resulting from the perturbation. Learning is slower than when the full error information is used in the delta rule, but we argue that the availability of that information would not be biologically plausible for most complex movements.
Discussion
A cellular implementation of stochastic gradient descent
Analysis of the requirements and constraints for a general cerebellar learning algorithm highlighted the fact that the current consensus Marr-Albus-Ito model is only capable of learning simple reflex movements. Optimisation of complex, arbitrary movements, of which organisms are certainly capable and to which the cerebellum is widely believed to contribute, would require a different algorithm. We therefore sought to identify within the cerebellar system an implementation of stochastic gradient descent. This should comprise several elements: a source of perturbations, a mechanism for extracting the change of error, and a plasticity rule incorporating this information. We identified a strong constraint on any implementation, requiring each calculation to be made in the context of a single movement realisation. This arises from the potentially arbitrary sequencing of movements with different optima. We also sought a mechanism that only makes use of plausible cellular calculations: summation of excitation and inhibition in the presence of a threshold.
We suggest that the perturbation is provided by the complex spike, which has suitable properties: spontaneous irregular activity, an unambiguous sign during the action potential burst, salience at a cellular and network level, and the ability to influence synaptic plasticity. This choice of perturbation largely determines the predicted cerebellar cortical plasticity rules: only granule cell inputs active at the same time as a perturbation complex spike undergo plasticity, whose sign is determined by the absence (LTP) or presence (LTD) of a succeeding error complex spike. We have provided evidence that the synaptic plasticity rules do operate as predicted, in vitro under conditions designed to be more physiological than is customary.
An additional plasticity mechanism seems to be required to read off the change of error. The general mechanism we propose involves subtraction of the average error to expose the random variations caused by the perturbations of the movement. The subtraction results from adaptive tracking of the excitatory input to the olivary neurones by the inhibitory input from the nucleo-olivary neurones of the cerebellar nuclei. We chose to place the plasticity at the mossy fibre–nucleo-olivary neurone synapse, mostly because of the existence of suitable plasticity rules at the mossy fibre synapse onto the neighbouring projection neurones. However, plasticity in the olive at the nucleo-olivary input would probably be functionally equivalent and we do not intend to rule out this or alternative sites of the error-cancelling plasticity.
By simulating a simplified cerebellar network implementing this mechanism, we established the ability of our proposed mechanism to learn multiple arbitrary outputs, optimising 400 variables per movement with a single error value. More formal analysis of a simplified version of stochastic gradient descent with estimated global errors established convergence of the algorithm and allowed us to estimate its storage capacity.
Implications for studies of synaptic plasticity
The plasticity rules for parallel fibre–Purkinje cell synapses predicted by our algorithm appeared to be incompatible with the well-established consensus. However, we show that under different, arguably more physiological, conditions, we were able to provide support for the four predicted outcomes.
We made several changes to the experimental conditions, only one of which is specific to the cerebellum. Thus, keeping synaptic inhibition intact has long been recognised as being of potential importance, with debates regarding its role in hippocampal LTP dating back decades (Wigström and Gustafsson, 1983a; Wigström and Gustafsson, 1983b; Arima-Yoshida et al., 2011). Very recent work also highlights the importance of inhibition in the induction of cerebellar plasticity (Rowan et al., 2018; Suvrathan and Raymond, 2018).
We also made use of a lower extracellular calcium concentration than those almost universally employed in studies of plasticity in vitro. In vivo measurements of the extracellular calcium concentration suggest that it does not exceed 1.5 mM in rodents, yet most studies use at least 2 mM. A 25% alteration of calcium concentration could plausibly change plasticity outcomes, given the numerous nonlinear calcium-dependent processes involved in synaptic transmission and plasticity (Nevian and Sakmann, 2006; Graupner and Brunel, 2007).
A major change of conditions we effected was cerebellum-specific. Nearly all studies of granule cell–Purkinje cell plasticity have employed stimulation of parallel fibres in the molecular layer. Such concentrated, synchronised input activity is unlikely to arise physiologically. Instead of this, we stimulated in the granule cell layer, a procedure expected to generate a more spatially dispersed input on the Purkinje cell, presumably leading to minimised dendritic depolarisations. Changing the stimulation method has been reported to prevent induction of LTD using standard protocols (Marcaggi and Attwell, 2007).
Although we cannot predict in detail the mechanistic alterations resulting from these changes of conditions, it is nevertheless likely that intracellular calcium concentrations during induction will be reduced, and most of the changes we observed can be interpreted in this light. It has long been suggested that high calcium concentrations during induction lead to LTD, while lower calcium concentrations generate LTP (Coesmans et al., 2004); we have recently modelled the induction of this plasticity, incorporating both calcium and nitric oxide signalling (Bouvier et al., 2016). Consistently with this viewpoint, a protocol that under standard conditions produce LTD—simultaneous activation of granule cells and climbing fibres—could plausibly produce LTP in the present conditions as a result of reduced intracellular calcium. Analogously, granule cell stimulation that alone produces LTP under standard conditions might elicit no change if calcium signalling were attenuated under our conditions.
Interestingly, LTP resulting from conjunctive granule cell and climbing fibre stimulation has been previously reported, in vitro (Mathy et al., 2009; Suvrathan et al., 2016) and in vivo (Wetmore et al., 2014). In contrast, our results do not fit well with several other studies of plasticity in vivo (Ito et al., 1982; Jörntell and Ekerot, 2002; Jörntell and Ekerot, 2003; Jörntell and Ekerot, 2011). However, in these studies quite intense stimulation of parallel and/or climbing fibre inputs was used, which may result in greater depolarisations and calcium entry than usually encountered. This difference could therefore account for the apparent discrepancy with the results we predict and have found in vitro.
It is unlikely that the interval between perturbation and error complex spikes would be fixed from trial to trial and it is certainly expected to vary with sensory modality (vision being slow). Our theoretical framework would therefore predict that a relatively wide range of intervals should be effective in inducing LTD through the GPE protocol. However, this prediction is untested and it remains possible that different intervals (potentially in different cerebellar regions) may lead to different plasticity outcomes, as suggested by the recent work of Suvrathan et al. (2016); this might also contribute to some of the variability of individual plasticity outcomes we observe.
Another open question is whether different relative timings of parallel and climbing fibre activity would result in different plasticity outcomes. In particular, one might hypothesise that parallel fibres active during a pause following a perturbation complex spike might display plasticity of the opposite sign to that reported here for synchrony with the complex spike itself.
In summary, while in vitro studies of plasticity are likely to reveal molecular mechanisms leading to potentiation and depression, the outcomes from given stimulation protocols may be very sensitive to the precise conditions, making it difficult to extrapolate to the in vivo setting, as we have shown here for the cerebellum. Similar arguments could apply to in vitro plasticity studies in other brain regions.
Current evidence regarding stochastic gradient descent
As mentioned in the introductory sections, the general cerebellar learning algorithm we propose here is not necessarily required in situations where movements are simple or constrained, admitting a fixed mapping between errors and corrective action. Furthermore, such movements constitute the near totality of well-studied models of cerebellar learning. Thus, the vestibulo-ocular reflex and saccade adaptation involve eye movements, which are naturally constrained, while the eyeblink is a stereotyped protective reflex. There is therefore a possibility that our mechanism does not operate in the cerebellar regions involved in oculomotor behaviour, even if it does operate elsewhere.
In addition, these ocular behaviours apparently display error functions that are incompatible with our assumptions. In particular, disturbance of a well optimised movement would be expected to increase error. However, it has been reported multiple times that climbing fibre activity can provide directional error information, including reductions of climbing fibre activity below baseline (e.g. Soetedjo et al., 2008). This argument is not totally conclusive, however. Firstly, we recall that the error is represented by the input to the inferior olive, not its output. It is thus possible that inputs from the nucleo-olivary neurones (or external inhibitory inputs) to the olive also have their activity modified by the disturbance of the movement, causing the reduction of climbing fibre activity. Secondly, what matters for our algorithm is the temporal sequence of perturbation and error complex spikes, but investigation of these second-order statistics of complex spike activity in relation to plasticity has, to our knowledge, not been reported. Similarly, it has been reported that learning and plasticity (LTD) occur in the absence of modulation of climbing fibre activity (Ke et al., 2009). Although this is difficult to reconcile with either the standard theory or our algorithm, it does not entirely rule out the existence of perturbation-error complex spike pairs that we predict lead to LTD.
Trial-to-trial plasticity correlated with the recent history of complex spikes has been demonstrated in oculomotor adaptation (Medina and Lisberger, 2008; Yang and Lisberger, 2014). This suggests that one way of testing whether our algorithm operates would be to examine whether the history of complex spike activity can predict future changes in the simple spike firing rate, according to the plasticity rules described above. For instance, two complex spikes occurring at a short interval should cause at the time of the first an increase of simple spike firing in subsequent trials. However, the most complete datasets reported to date involve oculomotor control (Yang and Lisberger, 2014; Catz et al., 2005; Soetedjo et al., 2008; Ke et al., 2009), where, as mentioned above, our algorithm may not be necessary.
Beyond the predictions for the plasticity rules at parallel fibre–Purkinje cell synapses tested above, there are a number of aspects of our theory that do fit well with existing observations. The simple existence of spontaneous climbing fibre activity is one. Additional suggestive features concern the evolution of climbing fibre activity during eyeblink conditioning (Ohmae and Medina, 2015). Once conditioning has commenced, the probability of complex spikes in response to the unconditioned stimulus decreases, which would be consistent with the build-up of the inhibition cancelling the average error signal in the olive. Furthermore, omission of the unconditioned stimulus then causes a reduction in the probability of complex spikes below the baseline rate, strongly suggesting a specifically timed inhibitory signal has indeed developed at the time of the unconditioned stimulus (Kim et al., 1998).
We suggest that the cancellation of average error involves plasticity at mossy fibre–nucleo-olivary neurone synapses. To date no study has reported such plasticity, but the nucleo-olivary neurones have only rarely been studied. Plasticity at the mossy fibre synapses on projection neurones has been studied both in vitro (Pugh and Raman, 2006; Pugh and Raman, 2008; Zhang and Linden, 2006) and in vivo (Ohyama et al., 2006), but is not used in our proposed algorithm. Axonal remodelling and synaptogenesis of mossy fibres in the cerebellar nuclei may underlie this plasticity (Kleim et al., 2002; Boele et al., 2013; Lee et al., 2015) and could also contribute to the putative plasticity at mossy fibre synapses on nucleo-olivary neurones.
Finally, our theory of course predicts that perturbation complex spikes perturb ongoing movements. It is well established that climbing fibre activation can elicit movements (Barmack and Hess, 1980; Kimpo et al., 2014; Zucca et al., 2016), but it remains to be determined whether the movements triggered by spontaneous climbing fibre activity are perceptible. Stone and Lisberger (1986) reported the absence of complex-spike-triggered eye movements in the context of the vestibulo-ocular reflex. However, it is known that the visual system is very sensitive to retinal slip (Murakami, 2004), so it may be necessary to carry out high-resolution measurements and careful averaging to confirm or exclude the existence of perceptible movement perturbations.
Climbing fibre receptive fields and the bicycle problem
If the cerebellum is to contribute to the optimisation of complex movements, its output controlling any given muscle must be adjustable by learning involving multiple error signals. Thus, it may be useful to adjust an arm movement using vestibular error information as part of a balancing movement, but using touch information in catching a ball. However, it is currently unclear to what extent individual Purkinje cells can access different error signals.
There is an extensive literature characterising the modalities and receptive fields of climbing fibres. The great majority of reports are consistent with climbing fibres having fixed, specific modalities or very restricted receptive fields, with neighbouring fibres having similar properties (Garwicz et al., 1998; Jörntell et al., 1996). Examples would be a climbing fibre driven by retinal slip in a specific direction (Graf et al., 1988) or responding only to a small patch of skin (Garwicz et al., 2002). These receptive fields are quite stereotyped and have proven to be reliable landmarks in the functional regionalisation of the cerebellum; they are moreover tightly associated with the genetically specified zebrin patterning of the cerebellum (Schonewille et al., 2006b; Mostofi et al., 2010; Apps and Hawkes, 2009).
The apparently extreme specialisation of climbing fibres would limit the ability of the cerebellar circuitry to optimise complex movements. We can illustrate this with a human behaviour: riding a bicycle, which is often taken as an example of a typical cerebellar behaviour. This is an acquired skill for which there is little evolutionary precedent. It is likely to involve learning somewhat arbitrary arm movements in response to vestibular input (it is possible to ride a bike with one’s eyes closed). The error signals guiding learning could be vestibular, visual or possibly cutaneous/nociceptive (as a result of a fall), but not necessarily those related to the arm whose movement is learnt. How can such disparate or uncommon but sometimes essential error signals contribute to cerebellar control of the arm? We call this the ‘bicycle problem’.
At least two, non-exclusive solutions to this problem can be envisaged (see Figure 11). The first we term ‘output convergence’; it involves the convergence of multiple cerebellar regions receiving climbing fibres of different modalities onto each specific motor element (for instance a muscle) being controlled. Striking, if partial, evidence for this is found in a study by (Ruigrok et al., 2008), who injected the retrograde, trans-synaptic tracer rabies virus into individual muscles. Multiple cerebellar zones were labelled, showing that they all contribute to the control of those muscles, as posited. What is currently less clear is whether such separate zones receive climbing fibre inputs with different modalities. We note that the output convergence solution to the bicycle problem implies that the synaptic changes in those regions receiving the appropriate error information must outweigh any drift in synaptic weights from those regions deprived of meaningful error information. Adaptation of the learning rate, an algorithmic extension we suggest below, could contribute to ensuring that useful synaptic changes dominate.
Figure 11
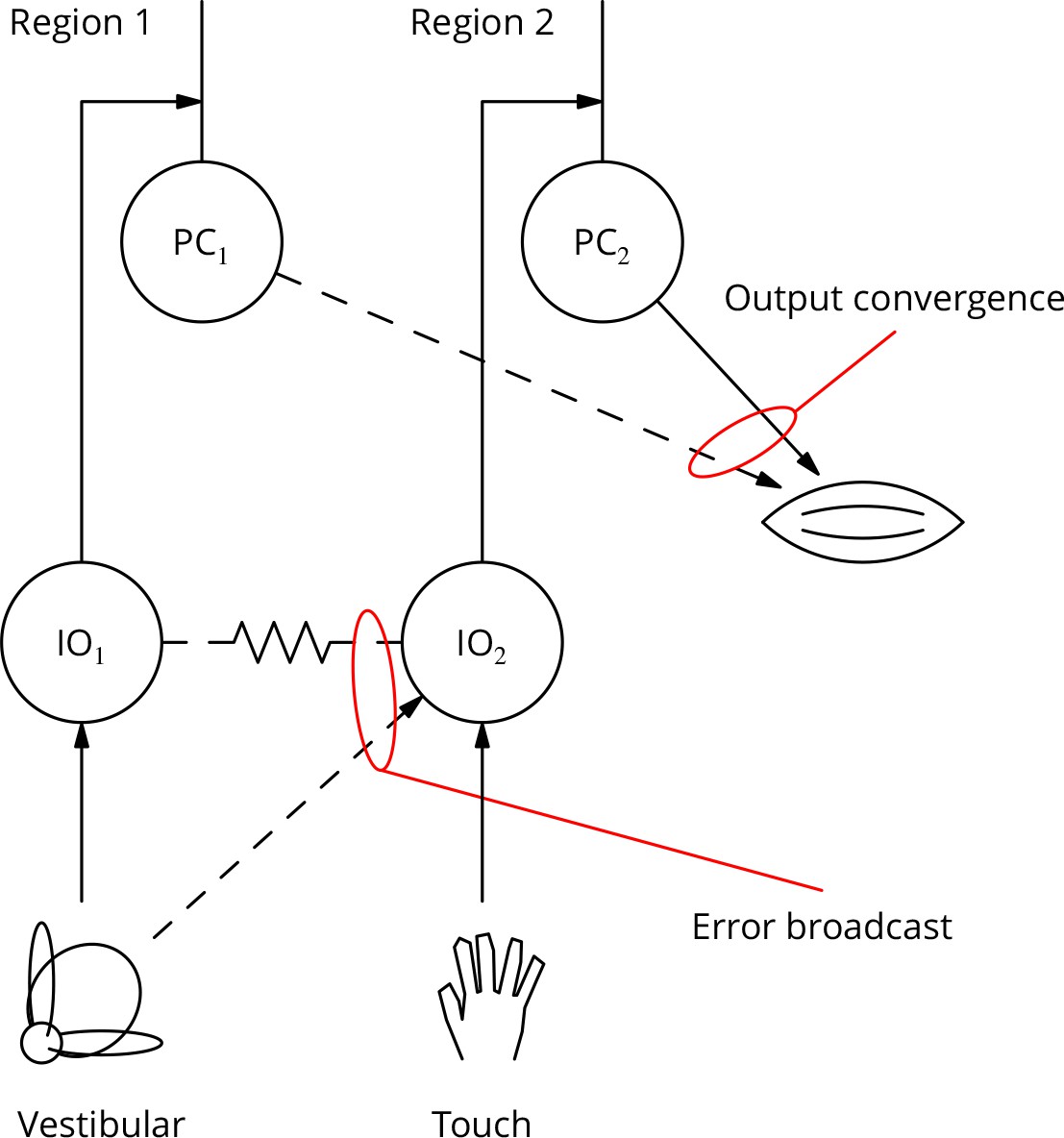
Diagram illustrating two possible solutions to the ‘bicycle problem’: how to use vestibular error information to guide learning of arm movements to ride a bicycle.
In the ‘output convergence’ solution, the outputs from cerebellar regions receiving different climbing fibre modalities converge onto a motor unit (represented by a muscle in the diagram). In the ‘error broadcast’ solution, error complex spikes are transmitted beyond their traditional receptive fields, either by divergent synaptic inputs and/or via the strong electrical coupling between inferior olivary neurones.
We term the second solution to the bicycle problem the ‘error broadcast’ solution. According to this, error inputs to the olive are broadcast to olivary neurones (and Purkinje cells) outside the traditional receptive field. Although the weight of literature appears to be against this, there are both possible mechanisms and a small amount of supporting data for this suggestion. In terms of mechanism, the well-known electrical coupling of olivary neurones (Devor and Yarom, 2002) could recruit cells that do not directly receive suprathreshold synaptic input. This may occur much more frequently in vivo than in the quiescent/anesthetised conditions employed for most studies of climbing fibre receptive fields. Evidence for ‘broadcast’ of what we would term error complex spikes in vivo has been reported for visual and auditory stimuli (Mortimer, 1975; Ozden et al., 2012); these stimuli may be correlated with startle responses. Eye blink conditioning using a visual unconditioned stimulus has also been reported (Rogers et al., 1999).
The existence of broadcast error complex spikes would provide a mechanism explaining the giant IPSPs in the cerebellar nuclei elicited by peripheral stimulation (Bengtsson et al., 2011) and could also account for the correlation between visual smooth pursuit behaviour and the nature of individual complex spikes (Yang and Lisberger, 2014): behaviour could only correlate with a single cell if others were receiving the same input.
Possible extensions to the algorithm
Our implementation of cerebellar stochastic gradient descent and its simulation were purposefully kept as simple as possible, to provide a proof-of-concept with a minimum of assumptions and to simplify parallel analyses. It is likely that parts of the implementation will need to be altered and/or extended as further information becomes available.
Probably the most uncertain element of the implementation is the adaptive site in the cancellation of the average error. We chose to make the mossy fibre–nucleo-olivary neurone synapse plastic, but the plasticity could certainly operate in the olive instead of or in addition to the cerebellar nuclear site. Further studies of synaptic transmission and plasticity in both structures are clearly warranted in this context.
A simplification in our implementation is that it represents brief, discrete commands in what amounts to an offline learning rule. Error complex spikes are only emitted after the command and indeed were not simulated explicitly. This has the great advantage of avoiding the question of whether Purkinje cells that have not received a perturbation complex spike would interpret a broadcast error complex spike as a perturbation. A first remark is to stress the fact that the movement evaluation will often only occur after the movement is complete. Even if an eCS caused a small movement or some additional plasticity, that might be less of an issue outside of a movement context. Additionally, it is possible that cellular mechanisms could exist that would enable the Purkinje cell to distinguish the two types of input and therefore avoid spurious plasticity. The most obvious mechanism would be that, as already hinted at in the literature, error complex spikes are likely to be stronger. An extended synaptic plasticity rule could therefore include a case in which an error complex spike received in the absence of a recent perturbation spike has a neutral plasticity effect. There is currently little data on which to base a detailed implementation, although we note that in our experiments, bursts of 6 climbing fibre stimuli—a strong complex spike—resulted in only a modest LTP compared to the GP_ protocol.
A potentially unsatisfactory aspect of our simulations was the time taken to learn. Of the order of 50,000 iterations were required to optimise the 400 independent variables of the cerebellar output. Stochastic gradient descent is inherently slow, since just one or a few of those variables can be perturbed in one movement realisation, and the weight changes are furthermore individually small. Before considering possible acceleration methods, we note that some motor behaviours are repeated huge numbers of times. An obvious example is locomotion. Thus, public health campaigns in vogue in the USA at the time of writing aim for people to take 10,000 steps per day. So, clearly, a target of a few hundred thousand steps could be achieved in a matter of days or weeks.
Part of the slowness of learning results from the conflicting pressures on the plastic weight changes. Large changes allow rapid learning, but could prevent accurate optimisation. An obvious extension of our implementation that would resolve this conflict would be to allow large plastic changes far from the optimum but to reduce them as the optimum is approached. The information required to do this is available as the net drive (error excitation cancellation inhibition) to the olivary neurones at the time of emission of an error complex spike. If the drive is strong, one can imagine a long burst of action potentials being emitted. There is in vitro (Mathy et al., 2009) and in vivo (Yang and Lisberger, 2014; Rasmussen et al., 2013) evidence that climbing fibre burst length can influence plasticity in Purkinje cells. It seems possible that the same could be true in the cerebellar nuclei (or alternative plastic site in the subtraction of the average error). However, the above mechanism for adapting learning rates would only work directly in the LTD direction, since olivary cells cannot signal the strength of a net inhibition when no error complex spike is emitted.
A mechanism that could regulate the speed of learning in both LTP and LTD directions would be to target perturbations to the time points where they would be most useful—those with the greatest errors. This might be achieved by increasing the probability (and possibly the strength) of the perturbation complex spikes shortly before strongly unbalanced (excitatory or inhibitory) inputs to the olive. This process offers a possible interpretation for various observations of complex spikes occurring before error evaluation: related to movements (Bauswein et al., 1983; Kitazawa et al., 1998) or triggered by conditioned stimuli (Rasmussen et al., 2014; Ohmae and Medina, 2015).
Movement-specific adaptations of the learning rates could provide an explanation for the phenomenon of ‘savings’, according to which relearning a task after extinction occurs at a faster rate than the initial learning. The adaptations could plausibly be maintained during extinction and therefore persist until the relearning phase. These adaptations could appear to represent memories of previous errors (Herzfeld et al., 2014).
Finally, the output convergence solution we proposed above for the bicycle problem could also reflect a parallelisation strategy enabling the computations involved in stochastic gradient descent to be scaled from the small circuit we have simulated to the whole cerebellum. As mentioned above, this might involve one of the above schemes for adjusting learning rates in a way that would help plasticity in regions with ‘useful’ error information to dominate changes in those without.
Insight into learning in other brain regions
We believe that our proposed implementation of stochastic gradient descent offers possible insight into learning processes in other brain regions.
To date, the most compelling evidence for a stochastic gradient descent mechanism has been provided in the context of the acquisition of birdsong. A specific nucleus, the ‘LMAN’ has been shown to be responsible for song variability during learning and also to be required for learning (Doya and Sejnowski, 1988; Olveczky et al., 2005). Its established role is therefore analogous to our perturbation complex spike. Our suggestion that the same input signals both perturbation and error change may also apply in the birdsong context, where it would imply that LMAN also assumes the role of determining the sign of plasticity at the connections it perturbed. However, such an idea has for now not been examined and there is as yet a poor understanding of how the trial song is evaluated and of the mechanism for transmitting that information to the adaptive site; indeed the adaptive site itself has not been identified unequivocally.
We see a stronger potential analogy with our mechanism of stochastic gradient descent in the learning of reward-maximising action sequences by the basal ganglia. Under the stimulus of cortical inputs, ensembles of striatal medial spiny neurones become active, with the resulting activity partition determining the actions selected by disinhibition of central pattern generators through inhibition of the globus pallidus (Grillner et al., 2005). It is thought that the system learns to favour the actions that maximise the (discounted) reward, which is signalled by activity bursts in dopaminergic midbrain neurones and phasic release of dopamine, notably in the striatum itself (Schultz, 1986). This has been argued (Schultz et al., 1997) to reflect reinforcement learning or more specifically temporal difference learning (Sutton and Barto, 1998).
We note that temporal difference learning can be decomposed into two problems: linking actions to potential future rewards and a gradient ascent to maximise reward. In respect of the gradient ascent, we note that dopamine has a second, very well-known action in the striatum: it is necessary for the initiation of voluntary movements, since reduction of dopaminergic input to the striatum is the cause of Parkinson’s disease, in which volitional movement is severely impaired. The key point is to combine the two roles of the dopaminergic system in the initiation of movement and in signalling reward. The initiation of movement by dopamine, which could contribute to probabilistic action selection, would be considered analogous to our perturbation complex spike and could create an eligibility trace. A subsequent reward signal would result in plasticity of eligible synapses reinforcing the selection of that action, with possible sites of plasticity including the cortico-striatal synapses that were successful in exciting an ensemble of striatal neurones (Rui Costa made a similar suggestion at the 5th Colloquium of the Institut du Fer à Moulin, Paris, 2014). This would constitute a mechanism of gradient ascent analogous to that we have proposed for gradient descent in the cerebellar system.
Of particular interest is whether correct optimisation also involves a mechanism for subtracting the average error in order to extract gradient information. Such subtraction would be entirely consistent with the reports of midbrain dopaminergic neurones responding more weakly to expected rewards and responding with sub-baseline firing to omission of a predicted reward. These phenomena moreover appear to involve an adaptive inhibitory mechanism (Eshel et al., 2015). These observations could be interpreted as a subtraction of the average reward by a process analogous to that we propose for the extraction of the change of error .
Conclusion
We have proposed a complete and plausible mechanism of stochastic gradient descent in the cerebellar system, in which the climbing fibre perturbs movements, creates an eligibility trace, signals error changes and guides plasticity at the sites of perturbation. We verify predicted plasticity rules that contradict the current consensus and highlight the importance of studying plasticity under physiological conditions. The gradient descent requires extraction of the change of error and we propose an adaptive inhibitory mechanism for doing this via cancellation of the average error. Our implementation of stochastic gradient descent suggests the operation of an analogous mechanism (of gradient ascent) in the basal ganglia initiated and rewarded by dopaminergic signalling.
Materials and methods
Electrophysiology
Request a detailed protocolAnimal experimentation methods were authorised by the ‘Charles Darwin N°5’ ethics committee (authorisation no. 4445). Adult female C57Bl/6 mice (2–5 months old) were anesthetised with isoflurane (Nicholas Piramal Ltd, India) and killed by decapitation. The cerebellum was rapidly dissected into cold solution containing (in mM): 230 sucrose, 26 NaHCO3, 3 KCl, 0.8 CaCl2, 8 MgCl2, 1.25 NaH2PO4, 25 d-glucose supplemented with 50 d-APV to protect the tissue during slicing. 300m sagittal slices were cut in this solution using a Campden Instruments 7000 smz and stored at 32 in a standard extracellular saline solution containing (in mM): 125 NaCl, 2.5 KCl, 1.5 CaCl2, 1.8 MgCl2, 1.25 NaH2PO4, 26 NaHCO3 and 25 d-glucose, bubbled with 95 % O2 and 5 % CO2 (pH 7.4). Slices were visualised using an upright microscope with a 40 X, 0.8 NA water-immersion objective and infrared optics (illumination filter 750 50 nm). The recording chamber was continuously perfused at a rate of 4–6 ml min with a solution containing (mM): 125 NaCl, 2.5 KCl, 1.5 CaCl2, 1.8 MgCl2, 1.25 NaH2PO4, 26 NaHCO3, 25 d-glucose and 10 tricine, a Zn buffer (Paoletti et al., 1997), bubbled with 95 % O2 and 5 % CO2 (pH 7.4). Patch pipettes had resistances in the range 2–4 M with the internal solutions given below. Unless otherwise stated, cells were voltage clamped at −70 mV in the whole-cell configuration. Voltages are reported without correction for the junction potential, which was about 10 mV (so true membrane potentials were more negative than we report). Series resistances were 4–10 M and compensated with settings of ~90 % in a Multiclamp 700B amplifier (Molecular Devices). Whole-cell recordings were filtered at 2 kHz and digitised at 10 kHz. Experiments were performed at 32–34°C. The internal solution contained (in mM): 128 K-gluconate, 10 HEPES, 4 KCl, 2.5 K2HPO4, 3.5 Mg-ATP, 0.4 Na2-GTP, 0.5 l-(–)-malic acid, 0.008 oxaloacetic acid, 0.18 -ketoglutaric acid, 0.2 pyridoxal 5’-phosphate, 5 l-alanine, 0.15 pyruvic acid, 15 l-glutamine, 4 l-asparagine, 1 reduced l-glutathione, 0.5 NAD+, 5 phosphocreatine, 1.9 CaCl2, 1.5 MgCl2, 0.1 K3.8EGTA. Free [Ca2+] was calculated with Maxchelator (C. Patton, Stanford) to be 120 nM. Chemicals were purchased from Sigma-Aldrich, D-APV from Tocris.
Recordings were made in the vermis of lobules three to eight of the cerebellar cortex. Granule cell EPSCs were elicited with stimulation in the granule cell layer with a glass pipette of tip diameter 8–12 μm filled with HEPES-buffered saline. Climbing fibre electrodes had m diameter and were also positioned in the granule cell layer. Images were taken every 5 min; experiments showing significant slice movement (20 m) were discarded. Stimulation intensity was fixed at the beginning of the experiment (1–15 V; 50–200 μs) and maintained unchanged during the experiment.
Analysis
No formal power calculation to determine the sample sizes was performed for the plasticity experiments. Recordings were analysed from 75 cells in 55 animals. Slices were systematically changed after each recording. Animals supplied 1–3 cells to the analysis, usually with rotating induction protocols, but there was no formal randomisation or blocking and there was no blinding. An initial analysis focusing on between-protocol comparisons was performed when cells were retained for analysis (criteria detailed below). Because the p-value for the GPE vs. G_E difference was close to a threshold (Colquhoun, 2014) and the confidence interval for the GPE plasticity ratio was narrower than for the others, acquisition for that protocol was reduced and additional experiments prioritised the G_ _, GP_ and G_E protocols. Experiments were ultimately halted for external reasons, when cells were retained. The two-stage analysis is a form of multiple comparison; in consequence, the output of the statistical test on the final data has been corrected by doubling the indicated p-values in Table 1.
Inspection of acquired climbing fibre responses revealed some failures of stimuli after the first in a fraction of cells, presumably because the second and subsequent stimuli at short intervals fell within the relative refractory period. As a complex spike was always produced these cells have been included in our analysis, but where individual data are displayed, we identify those cells in which failures of secondary climbing fibre stimuli were observed before the end of the induction period.
Analysis made use of a modular Python framework developed in house. Analysis of EPSC amplitudes for each cell began by averaging all of the EPSCs acquired to give a smooth time course. The time of the peak of this ‘global’ average response was determined. Subsequent measurement of amplitudes of other averages or of individual responses was performed by averaging the current over 0.5 ms centred on the time of the peak of the global average. The baseline calculated over 5 ms shortly before the stimulus artefact was subtracted to obtain the EPSC amplitude. Similar analyses were performed for both EPSCs of the paired-pulse stimulation.
Individual EPSCs were excluded from further analysis if the baseline current in the sweep exceeded 1 nA at 70 mV. Similarly, the analysis automatically excluded EPSCs in sweeps in which the granule cell stimuli elicited an action potential in the Purkinje cell (possibly through antidromic stimulation of its axon or through capacitive coupling to the electrode). However, during induction, in current clamp, such spikes were accepted. For displaying time series, granule cell responses were averaged in bins of 2 min.
The effects of series resistance changes in the Purkinje cell were estimated by monitoring the transient current flowing in response to a voltage step. The amplitude of the current 2 ms after the beginning of the capacity transient was measured. We shall call this the ‘dendritic access’. Modelling of voltage-clamp EPSC recordings in a two-compartment model of a Purkinje cell (Llano et al., 1991) suggests that this measure is approximately proportional to EPSC amplitude as the series resistance changes over a reasonable range (not shown). It therefore offers a better estimate of the effect on the EPSC amplitude of series resistance changes than would the value of the series resistance (or conductance), which is far from proportional to EPSC amplitude. Intuitively, this can be seen to arise because the EPSC is filtered by the dendritic compartment and the measure relates to the dendritic component of the capacitive transient, whereas the series resistance relates to the somatic compartment. We therefore calculated , the ratio of the dendritic access after induction (when plasticity was assessed) to the value before induction, in order to predict the changes the EPSC amplitude arising from changes of series resistance.
Because we elicited EPSCs using constant-voltage stimulation, variations of the resistance of the tip of the stimulating electrode (for instance if cells are drawn into it) could alter the stimulating current flow in the tissue. We monitored this by measuring the amplitude of the stimulus artefact. Specifically, we calculated , the after/before ratio of the stimulation artefact amplitude.
We then used a robust linear model to examine the extent to which changes of series resistance or apparent stimulation strength could confound our measurements of plasticity, which we represented as the after/before ratio of EPSC amplitudes ; the model (in R syntax) was:
This showed that series resistance changes, represented by , had a significant influence (-value 2.30, 69 degrees of freedom) with a slope close to the predicted unity (1.14). In contrast, changes of the stimulus artefact had no predictive value (slope −0.003, -value −0.01).
Extending our modelling using a mixed-effect model (call 'lmer' in the lme4 R package) to include animals as a random effect did not indicate that it was necessary to take into account any between-animal variance, as this was reported to be zero. On this basis, we consider each cell recorded to be the biological replicate.
We did not wish to rely on the parametric significance tests of the linear model for comparing the plasticity protocols (although all of comparisons we report below as significant were also significant in the model). Instead, we equalised the dendritic filtering and stimulation changes between groups by eliminating those cells in which or differed by more than 20% from the mean values for all cells (0.94 0.10 and 1.01 0.19, respectively; mean sd, 75). After this operation, which eliminated 17 cells out of 75 leaving 58 (from 47 animals), the mean ratios varied by only a few percent between groups (ranges 5 % and 2 % for and , respectively) and would be expected to have only a minimal residual influence. Normalising the s of the trimmed groups by did not alter the conclusions presented below. Note that after this trimming, the remaining changes of imply that all EPSC amplitudes after induction were underestimated by about 6 % relative to those at the beginning of the recording. The differences of between induction protocols were evaluated statistically using two-tailed nonparametric tests implemented by the 'wilcox.test' command in R (R Core Team, 2013).
95 % confidence limits were calculated using R bootstrap functions (‘BCa’ method). For confidence limits of differences between means, stratified resampling was used.
A small additional series of experiments of 16 cells from 16 animals of which 12 were retained by similar criteria to those explained above (except that series resistance changes had to be evaluated using the current amplitude 1 ms into the response to the voltage step) were analysed separately and underlie the plasticity data in Figure 6—figure supplement 1.
Simulation methods
Request a detailed protocolNetwork simulations were designed as follows (see also diagram in Figure 12). A total of Purkinje cells were placed on a rectangular grid of extent in the sagittal plane and width in the lateral direction. The activity of each Purkinje cell during a ‘movement’ was characterised by its firing rate in time bins .
(1)
Purkinje cells contacted projection neurones () and nucleo-olivary neurones () in the cerebellar nuclei that contained cells of each type. The activities of both types of nuclear cell were also characterised by their firing rates in the different time bins, and . Mossy fibres, granule cells (parallel fibres) and molecular layer interneurons were subsumed into a single cell type (for mossy fibre) with cells restricted to each row of Purkinje cells, with a total of mossy fibres. Mossy fibre activity was represented in a binary manner, or , with and .
Figure 12

Diagram of the simulated network model.
The details are explained in the text.
The connectivity was chosen such that all Purkinje cells in the sagittal ‘column’ projected to the -th nuclear projection neurone with identical inhibitory (negative) weights, as well as to the -th nucleo-olivary neurone with potentially different, but also identical inhibitory weights. Mossy fibres were chosen to project to Purkinje cells with groups of fibres at a given sagittal position , contacting cells on the row of Purkinje cells at the sagittal position with probability 1/2. The activity of Purkinje and cerebellar nuclear cells in the absence of climbing fibre activity was thus
(2)
(3)
(4)
where enforces the 1/2 probability of connection between a Purkinje cell and a parallel fibre that traverses its dendritic tree: is equal to or with probability 1/2, independently drawn for each triple . The f-I curve was taken to be a saturating threshold linear function, for for and for . The weights were non-plastic and chosen such that a given mossy fibre contacted a single projection neurone and a single nucleo-olivary neurone among the possible ones of each type. In other words, for each mossy fibre index , a number was chosen at random with uniform probability among the numbers and the weights were determined as
(5)
where was a constant. The weights and were plastic and followed the learning dynamics described below (see Equations 11 and 13).
The learning task itself consisted of producing, in response to spatiotemporal patterns of mossy fibre inputs , the corresponding output target rates of the projection neurones . For each pattern , the inputs were obtained by choosing at random with uniform probability active fibres. For each active fibre , a time bin was chosen at random with uniform probability and the activity of the fibre was set to one in this time bin, . The activity was set to zero in all time bins for the inactive fibres. The target rates where independently chosen with uniform probability between 0 and for each projection neurone in each pattern , where is the desired average firing rate for both projection and nucleo-olivary neurones in the cerebellar nuclei.
The olivary neurones were not explicitly represented. It was assumed that the Purkinje cells were contacted by climbing fibres with one climbing fibre contacting the Purkinje cells at a given lateral position.
The learning algorithm then proceeded as follows. Patterns were presented sequentially. After pattern was chosen, perturbations of Purkinje cell firing by complex spikes were generated as follows. The probability that each climbing fibre emitted a perturbation complex spike was taken to be per pattern presentation; when a climbing fibre was active, it was considered to perturb the firing of its Purkinje cells in a single time bin chosen at random. Denoting by that climbing fibre had emitted a spike in time bin (and when there was no spike), the firing rates of the Purkinje cell at position (see Equation 3) were taken to be
(6)
where defines the amplitude of the complex-spike perturbation of Purkinje cell firing.
Given the pattern and the firing of Purkinje cells (Equation 6), the activities of cerebellar nuclear neurones were given by Equations 3 and 4. The current ‘error’ for pattern/movement was quantified by the average distance of the projection neurones’ activity from their target rates
(7)
The learning step after the presentation of pattern was determined by the comparison (not explicitly implemented) in the olivary neurones between the excitation and the inhibition coming from the discharges ofnucleo-olivary neurones with
(8)
An error complex spike was propagated to all Purkinje cells after a ‘movement’ when the olivary activity was positive. Accordingly, modifications of the weights of mossy fibre synapses on perturbed Purkinje cells () and on nucleo-olivary neurones () were determined after presentation of pattern by the sign of , , as,
(9)
(10)
where the brackets served to enforce a positivity constraint on the weights ( and ).
In the reported simulations, the non-plastic weights in Equations 3–5 were identical and constant for all synapses of a given type:
(11)
(12)
(13)
where describes the strength of the connection relative to the connection. The initial weights of the plastic synapses were drawn from uniform distributions such that initial firing rates were on average given by and 15 Hz for Purkinje cells and nucleo-olivary neurones, respectively. The latter value was chosen such that the expected initial mismatch between inhibition and excitation for random pairings of initial firing rates and target rates was of the order of 1 Hz. Consequently, for synapses was drawn from and for synapses, weights were drawn from . These weights furthermore ensured initial average firing rates close to in the nuclear projection neurones. Target rates are uniformly distributed between 0 Hz and .
The parameters used in the reported simulation (full and simplified) are provided in Table 2.
Table 2
Parameters used in the simulation shown in Figure 12.
https://doi.org/10.7554/eLife.31599.016| Parameter | Symbol | Value |
|---|---|---|
| Sagittal extent | 10 | |
| Lateral extent | 40 | |
| Time bins per movement | 10 | |
| Mossy fibres per sagittal position | 2000 | |
| Maximum firing rate (all neurones) | 300 Hz | |
| pCS probability per cell per movement | 0.03 | |
| Amplitude of Purkinje cell firing perturbation | 2 Hz | |
| Learning rate of synapses | 0.02 | |
| Learning rate of synapses | 0.0002 | |
| Mean Purkinje cell firing rate | 50 Hz | |
| Mean firing rate for nuclear neurones | 30 Hz | |
| synaptic weight | 2.4 | |
| synaptic weight | 0.06 | |
| relative synaptic weight | 0.5 | |
| Weight increment of drift (simple model) | 0.002 |
In the following we describe the simplified version of the model without perturbations used to highlight shortcomings of the current Marr-Albus-Ito theory. , , and cell types are defined as above with identical synaptic connections and identical initial weights. The learning rules are different as no comparison between an estimated error (inhibition) and the global error (excitation) is made. We therefore do not consider the population of cells in this version. Two methods of calculating the error were tested. In the first, the error conveyed by the climbing fibres contains information about the sign of the movement error and is given by
(14)
In the second, the absolute values according to Equation 7 were used.
The synaptic weight changes are as follows. Whenever the error is positive, the synaptic weights of active connections are decreased by an amount , while otherwise there is a slow positive drift of synaptic weights with increments :
(15)
In order to show relaxation of the average of firing rates to the average of the target rates , we chose different initial distributions of uniformly distributed target rates with averages between 10 Hz and 50 Hz.
We show in the main text that the four key parameters governing convergence of our learning algorithm are the learning rates of mossy fibre–Purkinje cell synapses and mossy fibre–nucleo-olivary neurone synapses , as well as the probability of a perturbation complex spike occurring in a given movement in a given cell and the resulting amplitude of the perturbation of Purkinje cell firing . Varying each of these 10 % individually altered the final error (1.4 Hz, averaged over trials 55,000–60,000) by at most 7%, indicating that this final output was not ill-conditioned or finely tuned with respect to these parameters.
The simulation was coded in Python.
Appendix 1
Mathematical appendix
Reduced model
The model focuses on the rate of one P-cell. Learning a pattern (movement) requires adjustment of the rate to the target value . The movement error is defined as
(16)
Note that here represents trial/learning step number rather than temporal variations within a single movement realisation. In this simplified model, the P-cell activity during a movement is characterised by a single value rather than a sequence of values in time.
The other variable of the model besides is . It is used to quantify the strength
(17)
of the inhibitory input which provides the current value of the estimated global error. The two terms in the expression of the current are meant to represent the excitatory action of the MF inputs on the discharge of the and the inhibitory effects of the Purkinje cell discharge (). Learning steps consist of updates of the values and . They are of two kinds depending on whether the P-cell rate is perturbed or not.
Updates of type proceed as follows. The firing rate of the P-cell is increased by and becomes . The value of the global error corresponding to this perturbed firing rate is thus
(18)
and are updated depending on whether is smaller or greater than the current value of the estimated global error . The parameter quantifies how much the output is affected by the P-cell discharge, with the brackets indicating rectification (which imposes the constraint that the output remains non-negative).
If the perturbation is judged to have increased the error and therefore to have the wrong sign: the perturbed firing rate needs to be decreased. Concurrently, needs to be increased since is judged too low compared to the real value of the error. Thus and are changed to
(19)(20)
As above the brackets indicate rectification, which imposes the constraint that firing rates are non-negative.
If , the converse reasoning leads to changes of and in the opposite directions
(21)(22)
Updates of type are performed as described above but without any perturbation () and without any update of (only the estimated error is updated in updates of type ). Namely,
If the estimated error is judged too low compared to the real value of the error and needs to be increased. Thus is kept unchanged and is modified
(23)(24)
If , the converse reasoning leads to changes in the opposite directions
(25)(26)
The proposed core operation of the algorithm for one movement can thus be described as follows. At each time step, a perturbation occurs with probability . The occurrence of a perturbation gives rise to an update of type , performed as described by Equations 19-22. For the complementary fraction of time steps, no perturbation occurs and updates of type are performed, as described by Equations 23-26.
This abstract model depends on five parameters: , the amplitude of the rate perturbation, and , the update amplitudes of the rate and error estimate, respectively, the strength of inhibition of the NO by the P-cell, and , which describes the probability of an update of type (and the complementary probability of updates). The ratio of the update amplitudes play an important role and is denoted by , . The target firing rates are chosen in the range , which simply fixes the firing rate scale. We would like to determine the conditions on the five parameters and for the algorithm to ‘converge’. For simplicity, we here consider only constant perturbation and learning steps. Therefore, at best the rate and the error fluctuates around the target rates and zero error, in a bounded domain of size determined by the magnitude of the constant perturbation and learning steps. We say that the algorithm converges when this situation is reached. We would also like to understand how they determine the rate of convergence and the residual error.
Convergence in the one-cell case
Stochastic gradient descent is conveniently analysed with a phase-plane description, by following the values from one update to the next in the plane. The dynamics randomly alternate between updates of type and , depending on whether the P-cell rate is perturbed by the CF or not. We consider these two types of update in turn.
For updates of type , the update depends on whether the perturbed error is larger or smaller than the estimated error . Namely, it depends on the location of the current with respect to the two lines in the - plane, , , of slopes (see Figure 9B). The dynamics of Equations 19-22 are such that each update moves the point by adding to it the vectorial increment with the sign holding in the quadrant above the lines and the minus sign elsewhere. These updates move the point towards the lines . In the triangular domain below the line , the update does not directly move the trajectory towards the line, when and the update has an angle greater than the inclination of the . However, it reduces . When below , the updates are strictly upward and towards .
Updates of type depend on the location of the point with respect to the lines , , since the cell firing rate is not perturbed in these updates. In the quadrant above the lines , an update moves the point downwards by , in other words, adds the vectorial increment . In the complementary domain of the plane, an update moves the point upwards by , in other words, adds the opposite vectorial increment . Both updates move towards the lines .
Learning proceeds by performing updates of type and with respective probabilities and . Starting from an initial coordinate , three phases can be distinguished as described in the main text.
Above the lines and , the mixed updates lead the point to perform a random walk with a systematic mean rightward-downward drift per update equal to
(27)
for above and . Below the lines and , the updates are opposite and the mean drift per update is leftward-upward, equal to
(28)
for below and . Depending on its initial condition and the exact set of updates drawn, this leads to reach either one of the two ‘convergence corridors’, between the lines and , or between the lines and (see Figure 9B). In the triangular domain below the line , the mean leftward-upward drift has an angle greater than the inclination of the line for (i.e. ). In this case, the mean drift does not ensure that the trajectory crosses the line. However, if becomes zero before crossing , the positivity constraint on the rate, imposes that subsequent updates are strictly upward, until reaches . Examples of such trajectories can be seen in Appendix 1—figure 1C and D (red lines).
Appendix 1—figure 1

Reduced model: different cases of stochastic gradient learning are illustrated, for the parameters marked by solid red circles in Figure 9C, except for the case already shown in Figure 9E and F.
(A) Dynamics in the plane for and (). Trajectories (solid lines) from different initial conditions (open circles) are represented in the plane. The trajectories converge by oscillating around in the ‘corridor’ and around in the ‘corridor’. Trajectory endings are marked by filled circles. (B) Time courses of with corresponding colours. The slope of convergence (dotted lines) predicted by Equation 32 and 33 agrees well with the observed convergence rate for while it is less accurate for when the assumption that the ‘corridor’ width is much greater than and does not hold. (C, D) Same graphs for . The trajectories converge by oscillating around in the and around in the ‘corridor’. (E, F) Same graphs for and (i.e. ). The trajectories converge by oscillating around , which is the only attractive line.
When a corridor is reached, in a second phase, follows a stochastic walk in the corridor.
A sufficient condition for convergence is that a single update cannot cross the two boundary lines of a corridor at once. For the corridor, the crossing by a single update provides the most stringent requirement,.
(29)
The crossing of the corridor by a single provides the other requirement
(30)
When these conditions are met, alternation between the two types of updates produces a mean downward drift of the error. This downward drift controls the convergence rate and depends on the relative size of the perturbation and the discrete and modifications (in other words, the number of modifications that are needed to cross the convergence corridor). For simplicity, we consider the case where the perturbation is large compared to and , so that oscillations basically take place around one line of the corridor, as illustrated in Figure 9E and Appendix 1—figure 1. This amounts to being able to neglect the probability of crossing the other line of the corridor. The convergence rate then depends on the corridor line around which it takes place and can be obtained by noting that around a given corridor line, one of the two types of updates always has the same sign.
In the corridor, performing type updates for fraction of the steps and type updates for the complementary fraction leads to the average displacement per step,
(31)
Thus, as summarised in Figure 9C
For the average displacement leads to (Figure 9E). The average downward drift in the corridor can be obtained by noting that for a large , the trajectory has a negligibly small probability of crossing the line. Therefore, all the type updates are of the same sign, of the form , and chosen with probability . Since updates of type do not change the value of , approaches its target rate with a mean speed per step ,
(32)
A comparison between this computed drift and simulated trajectories is shown in Figure 9F.
For , the average displacement leads to (Appendix 1—figure 1A,C,E). In this case, all type updates are of the same sign, of the form . In contrast, a fraction of type updates are of the form , while a fraction is of the opposite form with to be determined. The average drift is thus . Requiring that this drift has slope , like , gives and (which indeed obeys in the parameter domain considered). Thus, approaches its target rate with a mean speed per step ,
(33)
A comparison between this computed drift and simulated trajectories is shown in Appendix 1—figure 1B,D,F.
In the corridor, the average drift per step is opposite to the drift in the corridor (Equation 31). Thus,
For and the average displacement leads to (Appendix 1—figure 1A). Updates of type are always of the form , while a fraction of type updates are of the form and a fraction are of the opposite form . Again, since the average drift is along of slope , one obtains or (which obeys in the parameter domain considered). The convergence speed is thus,
(34)
A comparison between this computed drift and simulated trajectories is shown in Appendix 1—figure 1B.
For , or , the complementary parameter domain, the drift in the corridor leads to (Appendix 1—figure 1A,C). The domain can be excluded, since when the point crosses , the drift in the upper quadrant (Equation 27) tends to bring it to the other corridor (Appendix 1—figure 1E). Near the line , type updates are always of the form . The convergence speed is thus
(35)
A comparison between this computed drift and simulated trajectories is shown in Figure 9F and Appendix 1—figure 1B.
Perceptron model and simulations
The architecture of the perceptron model is again the simplified circuit of Figure 9A, with mossy fibres projecting onto a single P-cell, with weights , (which are all positive or zero). patterns are generated randomly. Activities of mossy fibres in different patterns are i.i.d. binary random variables with coding level (i.e. with probability and with probability ; in the present simulations ). The P-cell desired rates for the patterns are i.i.d. uniform variables from 0 to (=100 Hz).
In the case of the stochastic gradient descent with estimated global errors algorithm, at each trial a pattern is randomly drawn without replacement among the total and there is a probability of a perturbation of amplitude . The output of the P-cell is
(36)
where with probability and otherwise, which thus introduces a random perturbation of amplitude into the P-cell firing. The error is defined as . Comparison with previously obtained results for the capacity of this analog perceptron (Clopath and Brunel, 2013) motivates our choice of weights normalisation and the parameterisation of the threshold as , where is a composite parameter reflecting the statistics of input and output firing, but here is equal to one.
An inferior olivary neurone receives the excitatory error signal but it also receives inhibitory inputs from the nucleo-olivary neurones driven by the mossy fibre inputs (which we have denoted above), with weights . These are also plastic and sign-constrained. They represent the current estimated error. The net drive of the inferior olivary neurone is
(37)
Here, the term represents the specific inhibition of nucleo-olivary neurones by Purkinje cells and the term proportional to represents non-specific inhibition. In other words, corresponds to in Equation 17. For simplicity we assume the non-specific inhibition to be constant and the value of equal to that used in Equation 36.
The climbing fibre signal controlling plasticity is
Weights are changed according to the following rule. Weights of synapses active simultaneously with a perturbation are increased if is negative and decreased if it is positive. Weights of synapses are increased if is positive and decreased if not. Thus
(38)
(39)
with the brackets indicating rectification (to impose the excitatory constraint).
The parameters of the simplified model of the previous subsection can be written as a function of those controlling the learning process in the present analog perceptron. The probability of the two types of updates (with and without perturbation) and the amplitude of perturbation are clearly identical in both models. In order to relate the previous and to the present amplitude change of the weights at mossy fibre–P-cell inputs and for the indirect drive to the inferior olive from mossy fibres, we neglect the rectification constraints in Equations 38 and 39 which is valid as long as synaptic weights are not very small (i.e. comparable to or ; see below for further discussion). Therefore, the weight modifications result in the changes , of the perceptron firing rate, and , of the inhibitory input to the olive,
(40)
(41)
The convergence rate estimates of the previous section are compared with direct stochastic gradient descent learning simulations of the analog perceptrons in Figure 10. As shown in Figure 10A, for many single patterns, the convergence rate agrees well with the estimate Equation 33. However, for a fraction of the trajectories, the rate of convergence is about half of the prediction. This arises because these simulations constrained synaptic weights to be non-negative, which creates a significant fraction of synapses with negligible weights (Brunel et al., 2004) and produces a smaller effective step than estimated without taking this positivity constraint into account. For a larger number of patterns below the maximal learning capacity, the convergence rate per pattern is slower by a factor of for between (Figure 10B).
The SGDEGE algorithm is compared to the usual delta rule in Figure 10. For the delta rule, the patterns are presented sequentially. When the pattern is presented, the weights are changed according to the signed error as,
(42)
The error is defined by the distance (positive or negative) of the P-cell firing rate to the target rate, , and is given as before by Equation 36 (with ).
The convergence of the SGDEGE algorithm is considerably slower than that obtained for the delta rule (Figure 10C), while the relative slowing due to interference of multiple patterns is comparable for the delta rule and the proposed algorithm (compare panels B,C in Figure 10). The slower convergence rate of the SGDEGE algorithm arises from the use of update steps of fixed amplitude while the update is proportional to the error magnitude for the delta rule. A modified delta rule with constant amplitude updates would give a convergence rate comparable to the SGDEGE one.
Data availability
Source data, analysis/simulation scripts and software libraries have been depositied at the Zenodo repository.
-
ZenodoCerebellar learning using perturbations: data, analysis/simulation scripts.https://doi.org/10.5281/zenodo.1481929
-
ZenodoCerebellar learning using perturbations: software libraries.https://doi.org/10.5281/zenodo.1481925
References
-
A theory of cerebellar functionMathematical Biosciences 10:25–61.https://doi.org/10.1016/0025-5564(71)90051-4
-
Cerebellar cortical organization: a one-map hypothesisNature Reviews Neuroscience 10:670–681.https://doi.org/10.1038/nrn2698
-
The mechanisms of the strong inhibitory modulation of long-term potentiation in the rat dentate gyrusEuropean Journal of Neuroscience 33:1637–1646.https://doi.org/10.1111/j.1460-9568.2011.07657.x
-
Eye movements evoked by microstimulation of dorsal cap of inferior olive in the rabbitJournal of Neurophysiology 43:165–181.https://doi.org/10.1152/jn.1980.43.1.165
-
ConferenceNeuronlike adaptive elements that can solve difficult learning control problemsIEEE Transactions on Systems, Man, and Cybernetics . pp. 834–846.https://doi.org/10.1109/TSMC.1983.6313077
-
Olivary subthreshold oscillations and burst activity revisitedFrontiers in Neural Circuits 6:91.https://doi.org/10.3389/fncir.2012.00091
-
Axonal sprouting and formation of terminals in the adult cerebellum during associative motor learningJournal of Neuroscience 33:17897–17907.https://doi.org/10.1523/JNEUROSCI.0511-13.2013
-
The secondary spikes of climbing fibre responses recorded from purkinje cell axons in cat cerebellumThe Journal of Physiology 377:225–235.https://doi.org/10.1113/jphysiol.1986.sp016183
-
Optimal properties of analog perceptrons with excitatory weightsPLOS Computational Biology 9:e1002919.https://doi.org/10.1371/journal.pcbi.1002919
-
An investigation of the false discovery rate and the misinterpretation of p-valuesRoyal Society Open Science 1:140216.https://doi.org/10.1098/rsos.140216
-
Cerebellum-dependent motor learning: lessons from adaptation of eye movements in primatesProgress in Brain Research 210:121–155.https://doi.org/10.1016/B978-0-444-63356-9.00006-6
-
Climbing fibre collaterals contact neurons in the cerebellar nuclei that provide a GABAergic feedback to the inferior oliveNeuroscience 80:981–986.
-
Microcircuitry and function of the inferior oliveTrends in Neurosciences 21:391–400.https://doi.org/10.1016/S0166-2236(98)01310-1
-
Decorrelation control by the cerebellum achieves oculomotor plant compensation in simulated vestibulo-ocular reflexProceedings of the Royal Society B: Biological Sciences 269:1895–1904.https://doi.org/10.1098/rspb.2002.2103
-
Decorrelation learning in the cerebellum: computational analysis and experimental questionsProgress in Brain Research 210:157–192.https://doi.org/10.1016/B978-0-444-63356-9.00007-8
-
Electrotonic coupling in the inferior olivary nucleus revealed by simultaneous double patch recordingsJournal of Neurophysiology 87:3048–3058.https://doi.org/10.1152/jn.2002.87.6.3048
-
BookA computational model of birdsong learning by auditory experience and auditory feedbackIn: Brugge J, Poon P, editors. Central Auditory Processing and Neural Modeling. New York: Plenum Press. pp. 77–88.
-
The excitatory synaptic action of climbing fibres on the purkinje cells of the cerebellumThe Journal of Physiology 182:268–296.https://doi.org/10.1113/jphysiol.1966.sp007824
-
Model of birdsong learning based on gradient estimation by dynamic perturbation of neural conductancesJournal of Neurophysiology 98:2038–2057.https://doi.org/10.1152/jn.01311.2006
-
Common principles of sensory encoding in spinal reflex modules and cerebellar climbing fibresThe Journal of Physiology 540:1061–1069.https://doi.org/10.1113/jphysiol.2001.013507
-
STDP in a bistable synapse model based on CaMKII and associated signaling pathwaysPLOS Computational Biology 3:e221.https://doi.org/10.1371/journal.pcbi.0030221
-
Mechanisms for selection of basic motor programs--roles for the striatum and pallidumTrends in Neurosciences 28:364–370.https://doi.org/10.1016/j.tins.2005.05.004
-
On the optimal control of behaviour: a stochastic perspectiveJournal of Neuroscience Methods 83:73–88.https://doi.org/10.1016/S0165-0270(98)00063-6
-
A memory of errors in sensorimotor learningScience 345:1349–1353.https://doi.org/10.1126/science.1253138
-
Brain fluid calcium concentration and response to acute hypercalcaemia during development in the ratThe Journal of Physiology 402:579–593.https://doi.org/10.1113/jphysiol.1988.sp017223
-
Properties of somatosensory synaptic integration in cerebellar granule cells in vivoJournal of Neuroscience 26:11786–11797.https://doi.org/10.1523/JNEUROSCI.2939-06.2006
-
Receptive field remodeling induced by skin stimulation in cerebellar neurons in vivoFrontiers in Neural Circuits 5:3.https://doi.org/10.3389/fncir.2011.00003
-
Elimination of climbing fiber instructive signals during motor learningNature Neuroscience 12:1171–1179.https://doi.org/10.1038/nn.2366
-
Axonal propagation of simple and complex spikes in cerebellar purkinje neuronsJournal of Neuroscience 25:454–463.https://doi.org/10.1523/JNEUROSCI.3045-04.2005
-
The role of auditory feedback in the control of vocalization in the white-crowned sparrowZeitschrift Für Tierpsychologie 22:770–783.
-
Reversing cerebellar long-term depressionPNAS 100:15989–15993.https://doi.org/10.1073/pnas.2636935100
-
Synaptic- and agonist-induced excitatory currents of purkinje cells in rat cerebellar slicesThe Journal of Physiology 434:183–213.https://doi.org/10.1113/jphysiol.1991.sp018465
-
Bistability of cerebellar purkinje cells modulated by sensory stimulationNature Neuroscience 8:202–211.https://doi.org/10.1038/nn1393
-
A theory of cerebellar cortexThe Journal of Physiology 202:437–470.https://doi.org/10.1113/jphysiol.1969.sp008820
-
Intraburst and interburst signaling by climbing fibersJournal of Neuroscience 27:11263–11270.https://doi.org/10.1523/JNEUROSCI.2559-07.2007
-
ThesisTheory of neural-analog reinforcement systems and its application to the brain-model problemPrinceton.
-
Steps toward artificial intelligenceProceedings of the IRE 49:8–30.https://doi.org/10.1109/JRPROC.1961.287775
-
The number of purkinje cells and inferior olivary neurones in the catThe Journal of Comparative Neurology 147:1–9.https://doi.org/10.1002/cne.901470102
-
Determinants of action potential propagation in cerebellar purkinje cell axonsJournal of Neuroscience 25:464–472.https://doi.org/10.1523/JNEUROSCI.3871-04.2005
-
Neurobiology of song learningCurrent Opinion in Neurobiology 19:654–660.https://doi.org/10.1016/j.conb.2009.10.004
-
Electrophysiological localization of eyeblink-related microzones in rabbit cerebellar cortexJournal of Neuroscience 30:8920–8934.https://doi.org/10.1523/JNEUROSCI.6117-09.2010
-
Number of parallel fiber synapses on an individual purkinje cell in the cerebellum of the ratThe Journal of Comparative Neurology 274:168–177.https://doi.org/10.1002/cne.902740204
-
Spine Ca2+ signaling in spike-timing-dependent plasticityJournal of Neuroscience 26:11001–11013.https://doi.org/10.1523/JNEUROSCI.1749-06.2006
-
Calcium and potassium changes in extracellular microenvironment of cat cerebellar cortexJournal of Neurophysiology 41:1026–1039.https://doi.org/10.1152/jn.1978.41.4.1026
-
Climbing fibers encode a temporal-difference prediction error during cerebellar learning in miceNature Neuroscience 18:1798–1803.https://doi.org/10.1038/nn.4167
-
Learning-induced plasticity in deep cerebellar nucleusJournal of Neuroscience 26:12656–12663.https://doi.org/10.1523/JNEUROSCI.4023-06.2006
-
Cerebellar-dependent adaptive control of primate saccadic systemJournal of Neurophysiology 44:1058–1076.https://doi.org/10.1152/jn.1980.44.6.1058
-
High-affinity zinc inhibition of NMDA NR1-NR2A receptorsThe Journal of Neuroscience 17:5711–5725.https://doi.org/10.1523/JNEUROSCI.17-15-05711.1997
-
SoftwareR: A Language and Environment for Statistical ComputingR Foundation for Statistical Computing, Vienna, Austria.
-
Number of spikes in climbing fibers determines the direction of cerebellar learningJournal of Neuroscience 33:13436–13440.https://doi.org/10.1523/JNEUROSCI.1527-13.2013
-
Changes in complex spike activity during classical conditioningFrontiers in Neural Circuits 8:90.https://doi.org/10.3389/fncir.2014.00090
-
A stochastic approximation methodThe Annals of Mathematical Statistics 22:400–407.https://doi.org/10.1214/aoms/1177729586
-
Adaptive gain control of vestibuloocular reflex by the cerebellumJournal of Neurophysiology 39:954–969.https://doi.org/10.1152/jn.1976.39.5.954
-
Timing dependence of the induction of cerebellar LTDNeuropharmacology 54:213–218.https://doi.org/10.1016/j.neuropharm.2007.05.029
-
On the inferior olive of the albino ratThe Journal of Comparative Neurology 140:255–259.https://doi.org/10.1002/cne.901400302
-
Purkinje cells in awake behaving animals operate at the upstate membrane potentialNature Neuroscience 9:459–461.https://doi.org/10.1038/nn0406-459
-
Zonal organization of the mouse flocculus: physiology, input, and outputThe Journal of Comparative Neurology 497:670–682.https://doi.org/10.1002/cne.21036
-
Responses of midbrain dopamine neurons to behavioral trigger stimuli in the monkeyJournal of Neurophysiology 56:1439–1461.https://doi.org/10.1152/jn.1986.56.5.1439
-
Storing covariance with nonlinearly interacting neuronsJournal of Mathematical Biology 4:303–321.https://doi.org/10.1007/BF00275079
-
BookUnderstanding Machine Learning: From Theory to AlgorithmsCambridge University Press.https://doi.org/10.1017/CBO9781107298019
-
Intracellular and extracellular changes of [Ca2+] in hypoxia and ischemia in rat brain in vivoThe Journal of General Physiology 95:837–866.https://doi.org/10.1085/jgp.95.5.837
-
Complex spike activity signals the direction and size of dysmetric saccade errorsProgress in brain research 171:153–159.https://doi.org/10.1016/S0079-6123(08)00620-1
-
Discharge of Purkinje and cerebellar nuclear neurons during rapidly alternating arm movements in the monkeyJournal of Neurophysiology 31:785–797.https://doi.org/10.1152/jn.1968.31.5.785
-
Coincidence detection in single dendritic spines mediated by calcium releaseNature Neuroscience 3:1266–1273.https://doi.org/10.1038/81792
-
Bidirectional plasticity of Purkinje cells matches temporal features of learningJournal of Neuroscience 34:1731–1737.https://doi.org/10.1523/JNEUROSCI.2883-13.2014
-
Learning in neural networks by reinforcement of irregular spikingPhysical Review E 69:041909.https://doi.org/10.1103/PhysRevE.69.041909
-
Pausing purkinje cells in the cerebellum of the awake catFrontiers in Systems Neuroscience 3:2.https://doi.org/10.3389/neuro.06.002.2009
-
Cerebellum and conditioned reflexesTrends in Cognitive Sciences 2:322–330.https://doi.org/10.1016/S1364-6613(98)01219-4
-
Long-term depression at the mossy fiber-deep cerebellar nucleus synapseJournal of Neuroscience 26:6935–6944.https://doi.org/10.1523/JNEUROSCI.0784-06.2006
Article and author information
Author details
Funding
Agence Nationale de la Recherche (ANR-08-SYSC-005)
- Boris Barbour
National Science Foundation (IIS-1430296)
- Johnatan Aljadeff
- Nicolas Brunel
Fondation pour la Recherche Médicale (DEQ20160334927)
- Boris Barbour
Fondation pour la Recherche Médicale
- Guy Bouvier
Région Ile-de-France
- Guy Bouvier
Labex (ANR-10-LABX-54 MEMOLIFE)
- Guy Bouvier
- Boris Barbour
Deutsche Forschungsgemeinschaft (RA-2571/1-1)
- Jonas Ranft
Idex PSL* Research University (ANR-11-IDEX-0001-02)
- Vincent Hakim
- Boris Barbour
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We are grateful to the following for discussion and/or comments on this manuscript: David Attwell, Mariano Casado, Paul Dean, Anne Feltz, Richard Hawkes, Clément Léna, Steven Lisberger, Tom Ruigrok, John Simpson, Brandon Stell, Stéphane Supplisson and German Szapiro. We thank Gary Bhumbra for sharing a native-python library for reading Clampex files. A preprint describing this work was posted on the bioRxiv repository on 2016-05-16.
Ethics
Animal experimentation: Animal experimentation methods were performed according to authorisation 04445.02 granted by the 'Charles Darwin N°5' ethics committee.
Copyright
© 2018, Bouvier et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 5,914
- views
-
- 743
- downloads
-
- 55
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 55
- citations for umbrella DOI https://doi.org/10.7554/eLife.31599
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Cerebellar learning using perturbations
eLife 7:e31599.
https://doi.org/10.7554/eLife.31599




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}