Efficient sampling and noisy decisions
- Department of Health Sciences and Technology, Federal Institute of Technology (ETH), Switzerland
- Department of Economics, Columbia University, United States
Abstract
Human decisions are based on finite information, which makes them inherently imprecise. But what determines the degree of such imprecision? Here, we develop an efficient coding framework for higher-level cognitive processes in which information is represented by a finite number of discrete samples. We characterize the sampling process that maximizes perceptual accuracy or fitness under the often-adopted assumption that full adaptation to an environmental distribution is possible, and show how the optimal process differs when detailed information about the current contextual distribution is costly. We tested this theory on a numerosity discrimination task, and found that humans efficiently adapt to contextual distributions, but in the way predicted by the model in which people must economize on environmental information. Thus, understanding decision behavior requires that we account for biological restrictions on information coding, challenging the often-adopted assumption of precise prior knowledge in higher-level decision systems.
Main text
'We rarely know the statistics of the messages completely, and our knowledge may change … what is redundant today was not necessarily redundant yesterday.’ Barlow, 2001.
Introduction
It has been suggested that the rules guiding behavior are not arbitrary, but follow fundamental principles of acquiring information from environmental regularities in order to make the best decisions. Moreover, these principles should incorporate strategies of information coding in ways that minimize the costs of inaccurate decisions given biological constraints on information acquisition, an idea known as efficient coding (Attneave, 1954; Barlow, 1961; Niven and Laughlin, 2008; Sharpee et al., 2014). While early applications of efficient coding theory have primarily been to early stages of sensory processing (Laughlin, 1981; Ganguli and Simoncelli, 2014; Wei and Stocker, 2015), it is worth considering whether similar principles may also shape the structure of internal representations of higher-level concepts, such as the perceptions of value that underlie economic decision making (Louie and Glimcher, 2012; Polanía et al., 2019; Rustichini et al., 2017). In this work, we contribute to the efficient coding framework applied to cognition and behavior in several respects.
A first aspect concerns the range of possible internal representation schemes that should be considered feasible, which determines the way in which greater precision of discrimination in one part of the stimulus space requires less precision of discrimination elsewhere. Implementational architectures proposed in previous work assume a population coding scheme in which different neurons have distinct 'preferred' stimuli (Ganguli and Simoncelli, 2014; Wei and Stocker, 2015). While this is clearly relevant for some kinds of low-level sensory features such as orientation, it is not obvious that this kind of internal representation is used in representing higher-level concepts such as economic values. We instead develop an efficient coding theory for a case in which an extensive magnitude (something that can be described by a larger or smaller number) is represented by a set of processing units that 'vote' in favor of the magnitude being larger rather than small. The internal representation therefore necessarily consists of a finite collection of binary signals.
Our restriction to representations made up of binary signals is in conformity with the observation that neural systems at many levels appear to transmit information via discrete stochastic events (Schreiber et al., 2002; Sharpee, 2017). Moreover, cognitive models with this general structure have been argued to be relevant for higher-order decision problems such as value-based choice. For example, it has been suggested that the perceived values of choice options are constructed by acquiring samples of evidence from memory regarding the emotions evoked by the presented items (Shadlen and Shohamy, 2016). Related accounts suggest that when a choice must be made between alternative options, information is acquired via discrete samples of information that can be represented as binary responses (e.g., 'yes/no' responses to queries) (Norman, 1968; Weber and Johnson, 2009). The seminal decision by sampling (DbS) theory (Stewart et al., 2006) similarly posits an internal representation of magnitudes relevant to a decision problem by tallies of the outcomes of a set of binary comparisons between the current magnitude and alternative values sampled from memory. The architecture that we assume for imprecise internal representations has the general structure of proposals of these kinds; but we go beyond the above-mentioned investigations, in analyzing what an efficient coding scheme consistent with our general architecture would be like.
A second aspect concerns the objective for which the encoding system is assumed to be optimized. Information maximization theories (Laughlin, 1981; Ganguli and Simoncelli, 2014; Wei and Stocker, 2015) assume that the objective should be maximal mutual information between the true stimulus magnitude and the internal representation. While this may be a reasonable assumption in the case of early sensory processing, it is less obvious in the case of circuits involved more directly in decision making, and in the latter case an obvious alternative is to ask what kind of encoding scheme will best serve to allow accurate decisions to be made. In the theory that we develop here, our primary concern is with encoding schemes that maximize a subject's probability of giving a correct response to a binary decision. However, we compare the coding rule that would be optimal from this standpoint to one that would maximize mutual information, or to one that would maximize the expected value of the chosen item.
Third, we extend our theory of efficient coding to consider not merely the nature of an efficient coding system for a single environmental frequency distribution assumed to be permanently relevant — so that there has been ample time for the encoding rule to be optimally adapted to that distribution of stimulus magnitudes — but also an efficient approach to adjusting the encoding as the environmental frequency distribution changes. Prior discussions of efficient coding have often considered the optimal choice of an encoding rule for a single environmental frequency distribution that is assumed to represent a permanent feature of the natural environment (Laughlin, 1981; Ganguli and Simoncelli, 2014). Such an approach may make sense for a theory of neural coding in cortical regions involved in early-stage processing of sensory stimuli, but is less obviously appropriate for a theory of the processing of higher-level concepts such as economic value, where the idea that there is a single permanently relevant frequency distribution of magnitudes that may be encountered is doubtful.
A key goal of our work is to test the relevance of these different possible models of efficient coding in the case of numerosity discrimination. Judgments of the comparative numerosity of two visual displays provide a test case of particular interest given our objectives. On the one hand, a long literature has argued that imprecision in numerosity judgments has a similar structure to psychophysical phenomena in many low-level sensory domains (Nieder and Dehaene, 2009; Nieder and Miller, 2003). This makes it reasonable to ask whether efficient coding principles may also be relevant in this domain. At the same time, numerosity is plainly a more abstract feature of visual arrays than low-level properties such as local luminosity, contrast, or orientation, and therefore can be computed only at a later stage of processing. Moreover, processing of numerical magnitudes is a crucial element of many higher-level cognitive processes, such as economic decision making; and it is arguable that many rapid or intuitive judgments about numerical quantities, even when numbers are presented symbolically, are based on an 'approximate number system' of the same kind as is used in judgments of the numerosity of visual displays (Piazza et al., 2007; Nieder and Dehaene, 2009). It has further been argued that imprecision in the internal representation of numerical magnitudes may underly imprecision and biases in economic decisions (Khaw et al., 2020; Woodford, 2020).
It is well-known that the precision of discrimination between nearby numbers of items decreases in the case of larger numerosities, in approximately the way predicted by Weber's Law, and this is often argued to support a model of imprecise coding based on a logarithmic transformation of the true number (Nieder and Dehaene, 2009; Nieder and Miller, 2003). However, while the precision of internal representations of numerical magnitudes is arguably of great evolutionary relevance (Butterworth et al., 2018; Nieder, 2020), it is unclear why a specifically logarithmic transformation of number information should be of adaptive value, and also whether the same transformation is used independent of context (Pardo-Vazquez et al., 2019; Brus et al., 2019). Here, we report new experimental data on numerosity discrimination by human participants, where we find that our data are most consistent with an efficient coding theory for which the performance measure is the frequency of correct comparative judgments, and where people economize on the costs associated to learn about the statistics of the environment.
Results
A general efficient sampling framework
We consider a situation in which the objective magnitude of a stimulus with respect to some feature can be represented by a quantity . When the stimulus is presented to an observer, it gives rise to an imprecise representation in the nervous system, on the basis of which the observer produces any required response. The internal representation can be stochastic, with given values being produced with conditional probabilities that depend on the true magnitude. Here, we are more specifically concerned with discrimination experiments, in which two stimulus magnitudes and are presented, and the subject must choose which of the two is greater. We suppose that each magnitude has an internal representation , drawn independently from a distribution that depends only on the true magnitude of that individual stimulus. The observer’s choice must be based on a comparison of with .
One way in which the cognitive resources recruited to make accurate discriminations may be limited is in the variety of distinct internal representations that are possible. When the complexity of feasible internal representations is limited, there will necessarily be errors in the identification of the greater stimulus magnitude in some cases, even assuming an optimal decoding rule for choosing the larger stimulus on the basis of and . One can then consider alternative encoding rules for mapping objective stimulus magnitudes to feasible internal representations. The answer to this efficient coding problem generally depends on the prior distribution from which the different stimulus magnitudes are drawn. The resources required for more precise internal representations of individual stimuli may be economized with respect to either or both of two distinct cognitive costs. The first goal of this work is to distinguish between these two types of efficiency concerns.
One question that we can ask is wheter the observed behavioral responses are consistent with the hypothesis that the conditional probabilities are well-adapted to the particular frequency distribution of stimuli used in the experiment, suggesting an efficient allocation of the limited encoding neural resources. The assumption of full adaptation is typically adopted in efficient coding formulations of early sensory systems (Laughlin, 1981; Wei and Stocker, 2017), and also more recently in applications of efficient coding theories in value-based decisions (Louie and Glimcher, 2012; Polanía et al., 2019; Rustichini et al., 2017).
There is also a second cost in which it may be important to economize on cognitive resources. An efficient coding scheme in the sense described above economizes on the resources used to represent each individual new stimulus that is encountered; however, the encoding and decoding rules are assumed to be precisely optimized for the specific distribution of stimuli that characterizes the experimental situation. In practice, it will be necessary for a decision maker to learn about this distribution in order to encode and decode individual stimuli in an efficient way, on the basis of experience with a given context. In this case, the relevant design problem should not be conceived as choosing conditional probabilities once and for all, with knowledge of the prior distribution from which will be drawn. Instead, it should be to choose a rule that specifies how the probabilities should adapt to the distribution of stimuli that have been encountered in a given context. It then becomes possible to consider how well a given learning rule economizes on the degree of information about the distribution of magnitudes associated with one’s current context that is required for a given level of average performance across contexts. This issue is important not only to reduce the cognitive resources required to implement the rule in a given context (by not having to store or access so detailed a description of the prior distribution), but in order to allow faster adaptation to a new context when the statistics of the environment can change unpredictably (Młynarski and Hermundstad, 2019).
Coding architecture
We now make the contrast between these two types of efficiency more concrete by considering a specific architecture for internal representations of sensory magnitudes. We suppose that the representation of a given stimulus will consist of the output of a finite collection of processing units, each of which has only two possible output states ('high' or 'low' readings), as in the case of a simple perceptron. The probability that each of the units will be in one output state or the other can depend on the stimulus that is presented. We further restrict the complexity of feasible encoding rules by supposing that the probability of a given unit being in the 'high’ state must be given by some function that is the same for each of the individual units, rather than allowing the different units to coordinate in jointly representing the situation in some more complex way. We argue that the existence of multiple units operating in parallel effectively allows multiple repetitions of the same 'experiment’, but does not increase the complexity of the kind of test that can be performed. Note that we do not assume any unavoidable degree of stochasticity in the functioning of the individual units; it turns out that in our theory, it will be efficient for the units to be stochastic, but we do not assume that precise, deterministic functioning would be infeasible. Our resource limits are instead on the number of available units, the degree of differentiation of their output states, and the degree to which it is possible to differentiate the roles of distinct units.
Given such a mechanism, the internal representation of the magnitude of an individual stimulus will be given by the collection of output states of the processing units. A specification of the function then implies conditional probabilities for each of the possible representations. Given our assumption of a symmetrical and parallel process, the number of units in the 'high' state will be a sufficient statistic, containing all of the information about the true magnitude that can be extracted from the internal representation. An optimal decoding rule will therefore be a function only of , and we can equivalently treat (an integer between 0 and ) as the internal representation of the quantity . The conditional probabilities of different internal representations are then
(1)
The efficient coding problem for a given environment, specified by a particular prior distribution will be to choose the encoding rule so as to allow an overall distribution of responses across trials that will be as accurate as possible (according to criteria that we will elaborate further below). We can further suppose that each of the individual processing units is a threshold unit, that produces a 'high’ reading if and only if the value exceeds some threshold where is a random term drawn independently on each trial from some distribution (Figure 1). The encoding function can then be implemented by choosing an appropriate distribution . This implementation requires that be a non-decreasing function, as we shall assume.
Figure 1
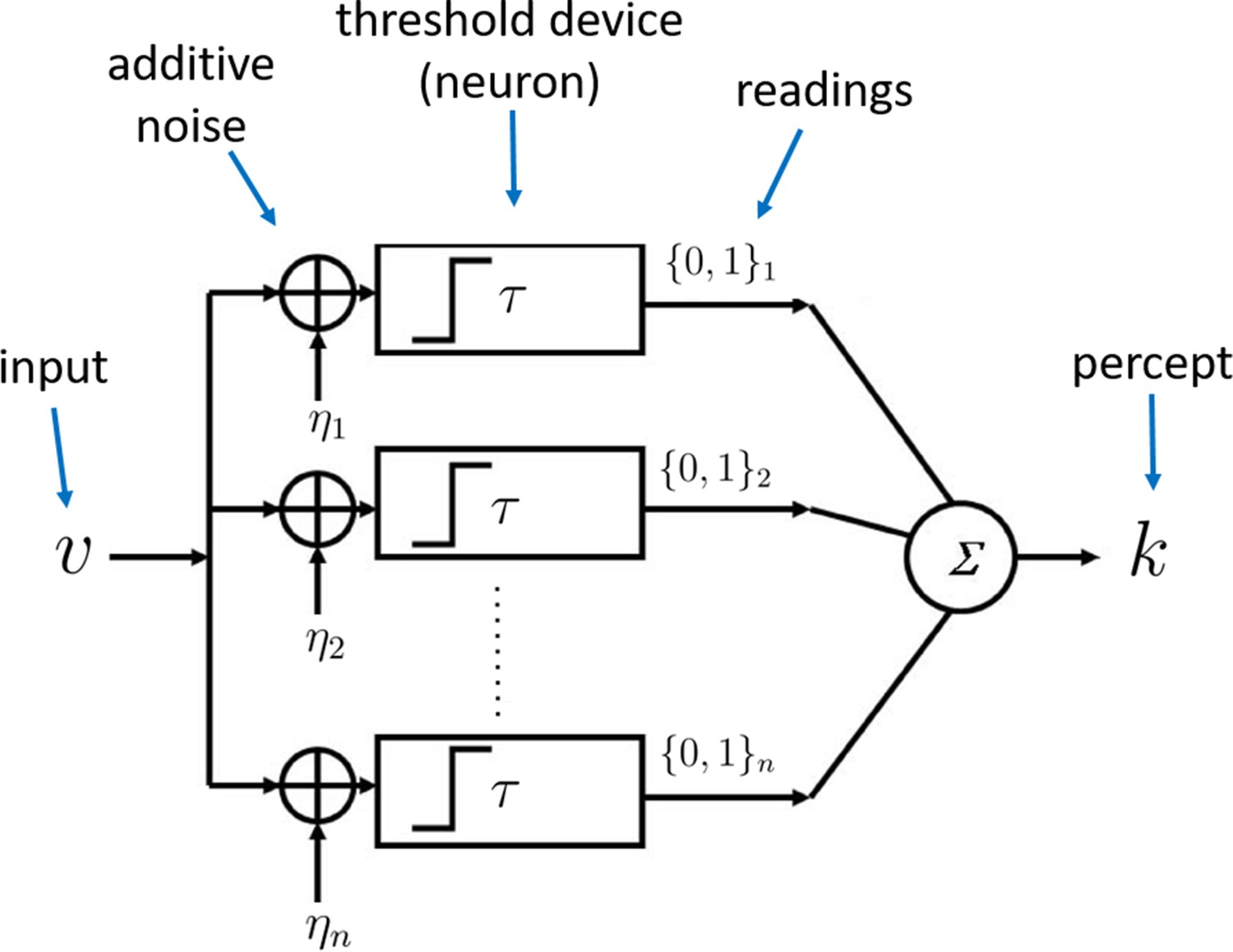
Architecture of the sampling mechanism.
Each processing unit receives noisy versions of the input , where the noisy signals are i.i.d. additive random signals independent of . The output of the neuron for each sample is 'high' (one) reading if and zero otherwise. The noisy percept of the input is simply the sum of the outputs of each sample given by .
Limited cognitive resources
One measure of the cognitive resources required by such a system is the number of processing units that must produce an output each time an individual stimulus is evaluated. We can consider the optimal choice of in order to maximize, for instance, average accuracy of responses in a given environment , in the case of any bound on the number of units that can be used to represent each stimulus. But we can also consider the amount of information about the distribution that must be used in order to decide how to encode a given stimulus . If the system is to be able to adapt to changing environments, it must determine the value of (the probability of a 'high' reading) as a function of both the current and information about the distribution , in a way that must now be understood to apply across different potential contexts. This raises the issue of how precisely the distribution associated with the current context is represented for purposes of such a calculation. A more precise representation of the prior (allowing greater sensitivity to fine differences in priors) will presumably entail a greater resource cost or very long adaptation periods.
We can quantify the precision with which the prior is represented by supposing that it is represented by a finite sample of independent draws from the prior (or more precisely, from the set of previously experienced values, an empirical distribution that should after sufficient experience provide a good approximation to the true distribution). We further assume that an independent sample of previously experienced values is used by each of the processing units (Figure 1). Each of the individual processing units is then in the 'high' state with probability . The complete internal representation of the stimulus is then the collection of independent realizations of this binary-valued random variable. We may suppose that the resource cost of an internal representation of this kind is an increasing function of both and .
This allows us to consider an efficient coding meta-problem in which for any given values the function is chosen so as to maximize some measure of average perceptual accuracy, where the average is now taken not only over the entire distribution of possible occurring under a given prior but over some range of different possible priors for which the adaptive coding scheme is to be optimized. We wish to consider how each of the two types of resource constraint (a finite bound on as opposed to a finite bound on ) affects the nature of the predicted imprecision in internal representations, under the assumption of a coding scheme that is efficient in this generalized sense, and then ask whether we can tell in practice how tight each of the resource constraints appears to be.
Efficient sampling for a known prior distribution
We first consider efficient coding in the case that there is no relevant constraint on the size of , while instead is bounded. In this case, we can assume that each time an individual stimulus must be encoded, a large enough sample of prior values is used to allow accurate recognition of the distribution and the problem reduces to a choice of a function that is optimal for each possible prior
Maximizing mutual information
The nature of the resource-constrained problem to be optimized depends on the performance measure that we use to determine the usefulness of a given encoding scheme. A common assumption in the literature on efficient coding has been that the encoding scheme maximizes the mutual information between the true stimulus magnitude and its internal representation (Ganguli and Simoncelli, 2014; Polanía et al., 2019; Wei and Stocker, 2015). We start by characterizing the optimal for a given prior distribution , according to this criterion. It can be shown that for large , the mutual information between and (hence the mutual information between and ) is maximized if the prior distribution over is Jeffreys’ prior (Clarke and Barron, 1994)
(2)
also known as the arcsine distribution. Hence, the mapping induces a prior distribution over θ given by the arcsine distribution (Figure 2a, right panel). Based on this result, it can be shown that the optimal encoding rule that guarantees maximization of mutual information between the random variable and the noisy encoded percept is given by (see Appendix 1)
(3)
where is the CDF of the prior distribution .
Figure 2
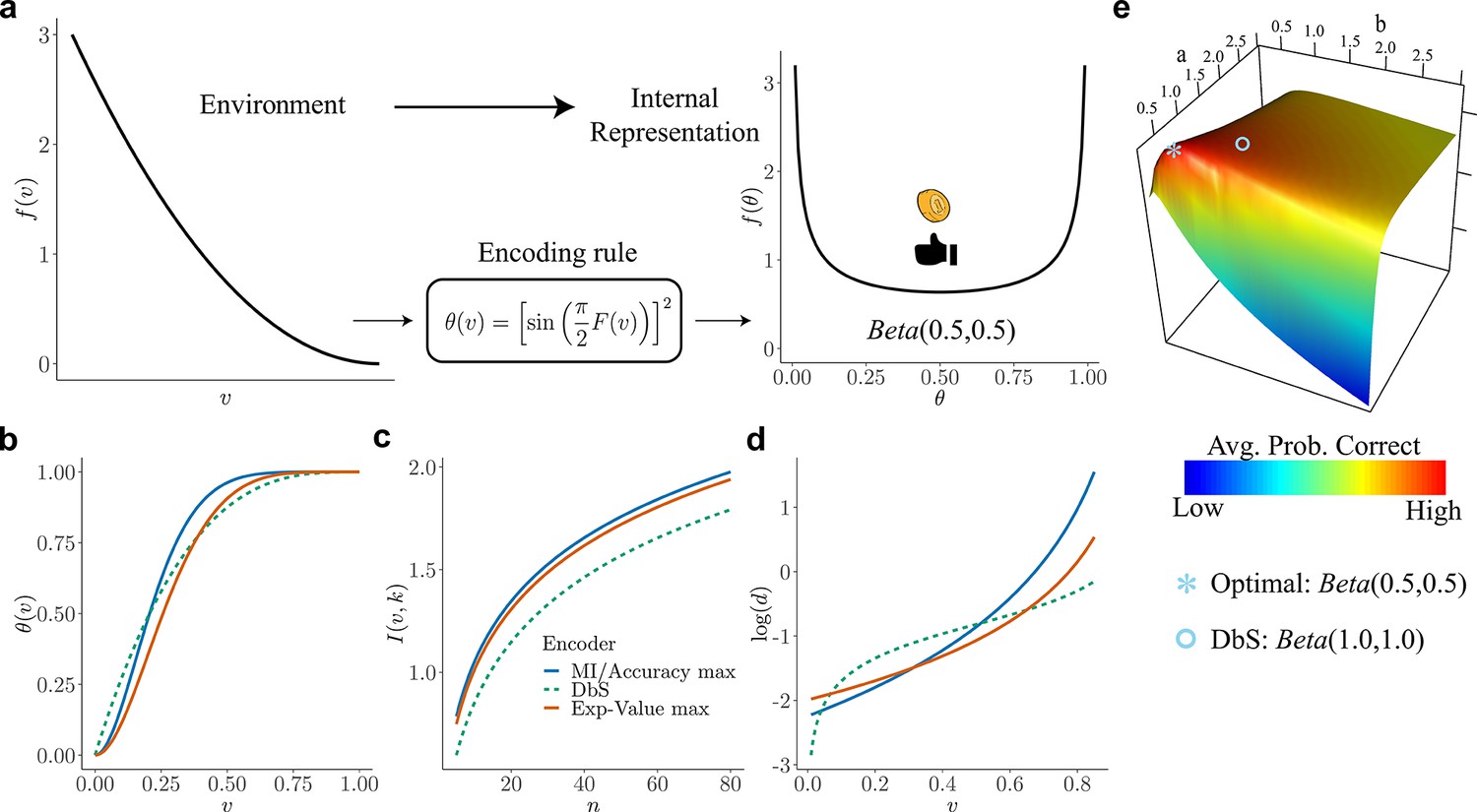
Overview of our theory and differences in encoding rules.
(a) Schematic representation of our theory. Left: example prior distribution of values encountered in the environment. Right: Prior distribution in the encoder space (Equation 2) due to optimal encoding (Equation 3). This optimal mapping determines the probability of generating a 'high' or 'low' reading. The ex-ante distribution over that guarantees maximization of mutual information is given by the arcsine distribution (Equation 2). (b) Encoding rules for different decision strategies under binary sampling coding: accuracy maximization (blue), reward maximization (red), DbS (green dashed). (c) Mutual information for the different encoding rules as a function of the number of samples . As expected increases with , however the rule that results in the highest loss of information is DbS. (d) Discriminability thresholds (log-scaled for better visualization) for the different encoding rules as a function of the input values for the prior given in panel a. (e) Graphical representation of the perceptual accuracy optimization landscape. We plot the average probability of correct responses for the large- limit using as benchmark a Beta distribution with parameters and . The blue star shows the average error probability assuming that is the arcsine distribution (Equation 2), which is the optimal solution when the prior distribution in known. The blue open circle shows the average error probability based on the encoding rule assumed in DbS, which is located near the optimal solution. Please note that when formally solving this optimization problem, we did not assume a priori that the solution is related to the beta distribution. We use the beta distribution in this figure just as a benchmark for visualization. Detailed comparison of performance for finite samples is presented in Appendix 7.
Accuracy maximization for a known prior distribution
So far, we have derived the optimal encoding rule to maximize mutual information. However, one may ask what the implications are of such a theory for discrimination performance. This is important to investigate given that achieving channel capacity does not necessarily imply that the goals of the organism are also optimized (Park and Pillow, 2017). Independent of information maximization assumptions, here, we start from scratch and investigate what are the necessary conditions for minimizing discrimination errors given the resource-constrained problem considered here. We solve this problem for the case of two alternative forced choice tasks, where the average probability of error is given by (see Appendix 2)
(4)
where represents the probability of erroneously choosing the alternative with the lowest value given a noisy percept (assuming that the goal of the organism in any given trial is to choose the alternative with the highest value). Here, we want to find the density function that guarantees the smallest average error (Equation 4). The solution to this problem is (Appendix 2)
(5)
which is exactly the same prior density function over that maximizes mutual information (Equation 2). Crucially, please note that we have obtained this expression based on minimizing the frequency of erroneous choices and not the maximization of mutual information as a goal in itself. This provides a further (and normative) justification for why maximizing mutual information under this coding scheme is beneficial when the goal of the agent is to minimize discrimination errors (i.e., maximize accuracy).
Optimal noise for a known prior distribution
Based on the coding architecture presented in Figure 1, the optimal encoding function can then be implemented by choice of an appropriate distribution . It can be shown that discrimination performance can be optimized by finding the optimal noise distribution (Appendix 3) (McDonnell et al., 2007)
(6)
Remarkably, this result is independent of the number of samples available to encode the input variable, and generalizes to any prior distribution (recall that is defined as its cumulative density function).
This result reveals three important aspects of neural function and decision behavior: First, it makes explicit why a system that evolved to code information using a coding scheme of the kind assumed in our framework must be necessarily noisy. That is, we do not attribute the randomness of peoples’ responses to a particular set of stimuli or decision problem to unavoidable randomness of the hardware used to process the information. Instead, the relevant constraints are assumed to be the limited set of output states for each neuron, the limited number of neurons, and the requirement that the neurons operate in parallel (so that each one’s output state must be statistically independent of the others, conditional on the input stimulus). Given these constraints, we show that it is efficient for the operation of the neurons to be random. Second, it shows how the nervous system may take advantage of these noisy properties by reshaping its noise structure to optimize decision behavior. Third, it shows that the noise structure can remain unchanged irrespective of the amount of resources available to guide behavior (i.e., the noise distribution does not depend on , Equation 6). Please note however, that this minimalistic implementation does not directly imply that the samples in our algorithmic formulation are necessarily drawn in this way. We believe that this implementation provides a simple demonstration of the consequences of limited resources in systems that encode information based on discrete stochastic events (Sharpee, 2017). Interestingly, it has been shown that this minimalistic formulation can be extended to more realistic population coding specifications (Nikitin et al., 2009).
Efficient coding and the relation between environmental priors and discrimination
The results presented above imply that this encoding framework imposes limitations on the ability of capacity-limited systems to discriminate between different values of the encoded variables. Moreover, we have shown that error minimization in discrimination tasks implies a particular shape of the prior distribution of the encoder (Equation 5) that is exactly the prior density that maximizes mutual information between the input and the encoded noisy readings (Equation 2, Figure 2a right panel). Does this imply a relation between prior and discriminability over the space of the encoded variable? Intuitively, following the efficient coding hypothesis, the relation should be that lower discrimination thresholds should occur for ranges of stimuli that occur more frequently in the environment or context.
Recently, it was shown that using an efficiency principle for encoding sensory variables (e.g., with a heterogeneous population of noisy neurons [Ganguli and Simoncelli, 2016]) it is possible to obtain an explicit relationship between the statistical properties of the environment and perceptual discriminability (Ganguli and Simoncelli, 2016). The theoretical relation states that discriminability thresholds should be inversely proportional to the density of the prior distribution . Here, we investigated whether this particular relation also emerges in the efficient coding scheme that we propose in this study.
Remarkably, we obtain the following relation between discriminability thresholds, prior distribution of input variables, and the number of limited samples (Appendix 4):
(7)
Interestingly, this relationship between prior distribution and discriminability thresholds holds empirically across several sensory modalities (Appendix 4), thus once again demonstrating that the efficient coding framework that we propose here seems to incorporate the right kind of constraints to explain observed perceptual phenomena as consequences of optimal allocation of finite capacity for internal representations.
Maximizing the expected size of the selected option (fitness maximization)
Until now, we have studied the case when the goal of the organism is to minimize the number of mistakes in discrimination tasks. However, it is important to consider the case when the goal of the organism is to maximize fitness or expected reward (Pirrone et al., 2014). For example, when spending the day foraging fruit, one must make successive decisions about which tree has more fruits. Fitness depends on the number of fruit collected which is not a linear function of the number of accurate decisions, as each choice yields a different amount of fruit.
Therefore, in the case of reward maximization, we are interested in minimizing reward loss which is given by the following expression
(8)
where is the probability of choosing option when the input values are and . Thus, the goal is to find the encoding rule which guarantees that the amount of reward loss is as small as possible given our proposed coding framework.
Here we show that the optimal encoding rule that guarantees maximization of expected value is given by
(9)
where is a normalizing constant which guarantees that the expression within the integral is a probability density function (Appendix 5). The first observation based on this result is that the encoding rule for maximizing fitness is different from the encoding rule that maximizes accuracy (compare Equations 3 and 9), which leads to a slight loss of information transmission (Figure 2c). Additionally, one can also obtain discriminability threshold predictions for this new encoding rule. Assuming a right-skewed prior distribution, which is often the case for various natural priors in the environment (e.g., like the one shown in Figure 2a), we find that discriminability for small input values is lower for reward maximization compared to perceptual maximization, however this pattern inverts for higher values (Figure 2d). In other words, when we intend to maximize reward (given the shape of our assumed prior, Figure 2a), the agent should allocate more resources to higher values (compared to the perceptual case), however without completely giving up sensitivity for lower values, as these values are still encountered more often.
Efficient sampling with costs on acquiring prior knowledge
In the previous section, we obtained analytical solutions that approximately characterize the optimal in the limit as is made sufficiently large. Note however that we are always assuming that is finite, and that this constrains the accuracy of the decision maker’s judgments, while is instead unbounded and hence no constraint.
The nature of the optimal function is different, however, when is small. We argue that this scenario is particularly relevant when full knowledge of the prior is not warranted given the costs vs benefits of learning, for instance, when the system expects contextual changes to occur often. In this case, as we will formally elaborate below, it ceases to be efficient for θ to vary only gradually as a function of , rather than moving abruptly from values near zero to values near one (Appendix 6). In the large- limiting case, the distributions of sample values used by the different processing units will be nearly the same for each unit (approximating the current true distribution ). Then if were to take only the values zero and one for different values of its arguments, the units would simply produce copies of the same output (either zero or one) for any given stimulus and distribution . Hence only a very coarse degree of differentiation among different stimulus magnitudes would be possible. Having vary more gradually over the range of values of in the support of instead makes the representation more informative. But when is small (e.g., because of costs vs benefits of accurately representing the prior ), this kind of arbitrary randomization in the output of individual processing units is no longer essential. There will already be considerable variation in the outputs of the different units, even when the output of each unit is a deterministic function of , owing to the variability in the sample of prior observations that is used to assess the nature of the current environment. As we will show below, this variability will already serve to allow the collective output of the several units to differentiate between many gradations in the magnitude of , rather than only being able to classify it as 'small' or 'large' (because either all units are in the 'low’ or 'high’ states).
Robust optimality of decision by sampling
Because of the way in which sampling variability in the values used to adapt each unit’s encoding rule to the current context can substitute for the arbitrary randomization represented by the noise term (see Figure 1), a sharp reduction in the value of need not involve a great loss in performance relative to what would be possible (for the same limit on ) if were allowed to be unboundedly large (Appendix 7). As an example, consider the case in which , so that each unit ’s output state must depend only on the value of the current stimulus and one randomly selected draw from the prior distribution . A possible decision rule that is radically economical in this way is one that specifies that the unit will be in the 'high' state if and only if In this case, the internal representation of a stimulus will be given by the number out of independent draws from the contextual distribution with the property that the contextual draw is smaller than , as in the model of decision by sampling (DbS) (Stewart et al., 2006). However, it remains to be determined to what degree it might be beneficial for a system to adopt such coding strategy.
In any given environment (characterized by a particular contextual distribution ), DbS will be equivalent to an encoding process with an architecture of the kind shown in Figure 1, but in which the distribution (compare to the optimal noise distribution for the full prior adaptation case in Equation 6). This makes vary endogenously depending on the contextual distribution . And indeed, the way that varies with the contextual distribution under DbS is fairly similar to the way in which it would be optimal for it to vary in the absence of any cost of precisely learning and representing the contextual distribution. This result implies that will be a monotonic transformation of a function that increases more steeply over those regions of the stimulus space where is higher, regardless of the nature of the contextual distribution. We consider its performance in a given environment, from the standpoint of each of the possible performance criteria considered for the case of full prior adaptation (i.e., maximize accuracy or fitness), and show that it differs from the optimal encoding rules under any of those criteria (Figure 2b–d). In particular, here, we show that using the encoding rule employed in DbS results in considerable loss of information compared to the full-prior adaptation solutions (Figure 2c). An additional interesting observation is that for the strategy employed in DbS, the agent appears to be more sensitive for extreme input values, at least for a wide set of skewed distributions (e.g., for the prior distribution in Figure 2a, the discriminability thresholds are lower at the extremes of the support of ). In other words, agents appear to be more sensitive to salience in the DbS rule. Despite these differences, here it is important to emphasize that in general for all optimization objectives, the encoding rules will be steeper for regions of the prior with higher density. However, mild changes in the steepness of the curves will be represented in significant discriminability differences between the different encoding rules across the support of the prior distribution (Figure 2d).
While the predictions of DbS are not exactly the same as those of efficient coding in the case of unbounded , under any of the different objectives that we consider, our numerical results show that it can achieve performance nearly as high as that of the theoretically optimal encoding rule; hence radically reducing the value of does not have a large cost in terms of the accuracy of the decisions that can be made using such an internal representation (Appendix 7 and Figure 2e). Under the assumption that reducing either or would serve to economize on scarce cognitive resources, we formally prove that it might well be most efficient to use an algorithm with a very low value of (even as assumed by DbS), while allowing to be much larger (Appendix 6, Appendix 7).
Crucially, here, it is essential to emphasize that the above-mentioned results are derived for the case of a particular finite number of processing units (and a corresponding finite total number of samples from the contextual distribution used to encode a given stimulus), and do not require that must be large (Appendix 6, Appendix 7).
Testing theories of numerosity discrimination
Our goal now is to compare back-to-back the resource-limited coding frameworks elaborated above in a fundamental cognitive function for human behavior: numerosity perception. We designed a set of experiments that allowed us to test whether human participants would adapt their numerosity encoding system to maximize fitness or accuracy rates via full prior adaptation as usually assumed in optimal models, or whether humans employ a 'less optimal' but more efficient strategy such as DbS, or the more established logarithmic encoding model.
In Experiment 1, healthy volunteers (n = 7) took part in a two-alternative forced choice numerosity task in which each participant completed ∼2400 trials across four consecutive days (Materials and methods). On each trial, they were simultaneously presented with two clouds of dots and asked which one contained more dots, and were given feedback on their reward and opportunity losses on each trial (Figure 3a). Participants were either rewarded for their accuracy (perceptual condition, where maximizing the amount of correct responses is the optimal strategy) or the number of dots they selected (value condition, where maximizing reward is the optimal strategy). Each condition was tested for two consecutive days with the starting condition randomized across participants. Crucially, we imposed a prior distribution with a right-skewed quadratic shape (Figure 3b), whose parametrization allowed tractable analytical solutions of the encoding rules , and , that correspond to the encoding rules for Accuracy maximization, Reward maximization, and DbS, respectively (Figure 3e and Materials and methods). Qualitative predictions of behavioral performance indicate that the accuracy-maximization model is the most accurate for trials with lower numerosities (the most frequent ones), whereas the reward-maximization model outperforms the others for trials with larger numerosities (trials where the difference in the number of dots in the clouds, and thus the potential reward, is the largest, Figure 2d and Figure 3f). In contrast, the DbS strategy presents markedly different performance predictions, in line with the discriminability predictions of our formal analyses (Figure 2c,d).
Figure 3 with 3 supplements see all
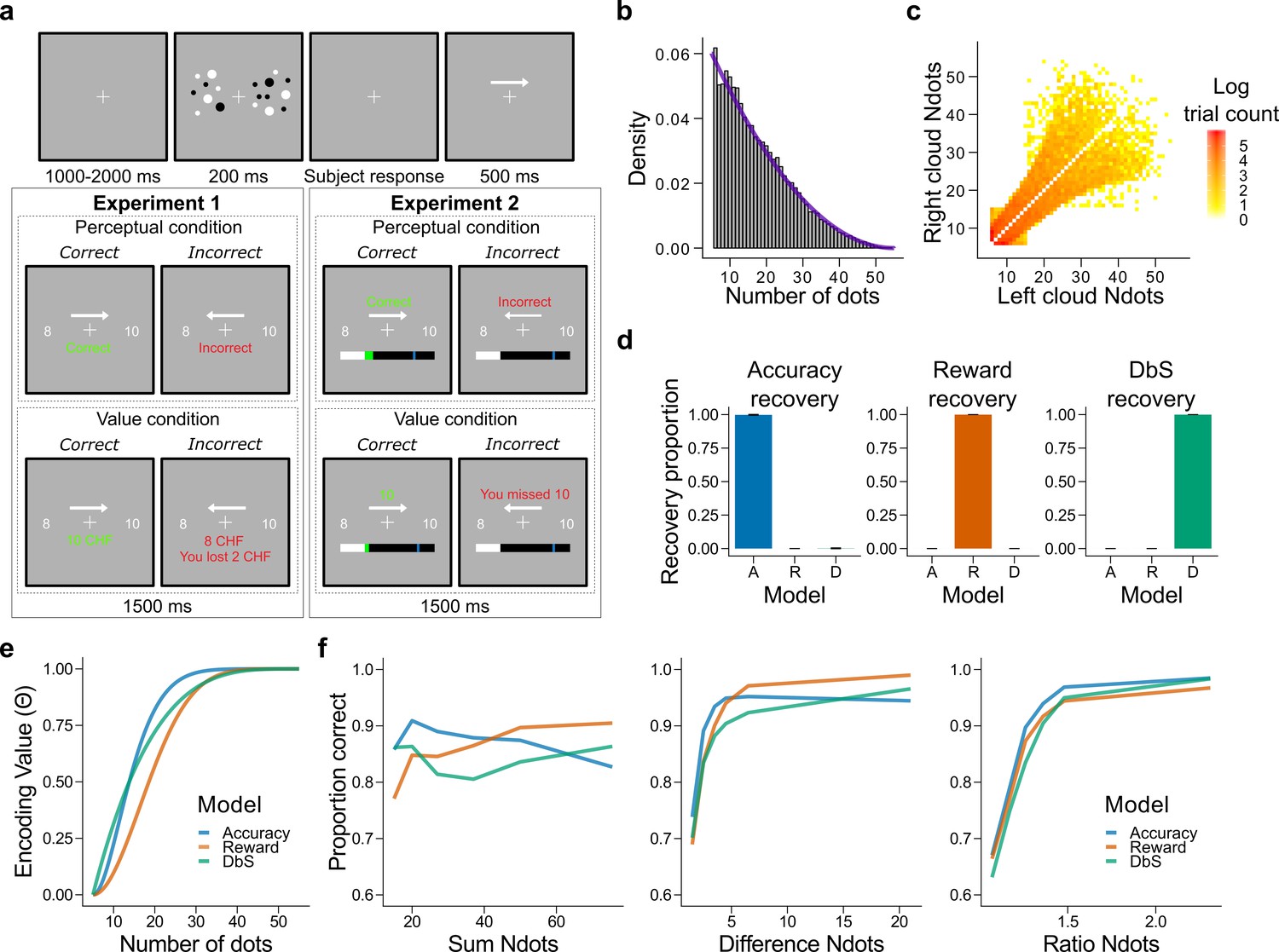
Experimental design, model simulations and recovery.
(a) Schematic task design of Experiments 1 and 2. After a fixation period (1–2 s) participants were presented two clouds of dots (200 ms) and had to indicate which cloud contained the most dots. Participants were rewarded for being accurate (perceptual condition) or for the number of dots they selected (value condition) and were given feedback. In Experiment 2 participants collected on correctly answered trials a number of points equal to a fixed amount (perceptual condition) or a number equal to the dots in the cloud they selected (value condition) and had to reach a threshold of points on each run. (b) Empirical (grey bars) and theoretical (purple line) distribution of the number of dots in the clouds of dots presented across Experiments 1 and 2. (c) Distribution of the numerosity pairs selected per trial. (d) Synthetic data preserving the trial set statistics and number of trials per participant used in Experiment 1 was generated for each encoding rule (Accuracy (left), Reward (middle), and DbS (right)) and then the latent-mixture model was fitted to each generated dataset. The figures show that it is theoretically possible to recover each generated encoding rule. (e) Encoding function for the different sampling strategies as a function of the input values (i.e., the number of dots). (f) Qualitative predictions of the three models (blue: Accuracy, red: Reward, green: Decision by Sampling) on trials from Experiment 1 with . Performance of each model as a function of the sum of the number of dots in both clouds (left), the absolute difference between the number of dots in both clouds (middle) and the ratio of the number of dots in the most numerous cloud over the less numerous cloud (right).
In our modelling specification, the choice structure is identical for the three different sampling models, differing only in the encoding rule (Materials and methods). Therefore, answering the question of which encoding rule is the most favored for each participant can be parsimoniously addressed using a latent-mixture model, where each participant uses , or to guide their decisions (Materials and methods). Before fitting this model to the empirical data, we confirmed the validity of our model selection approach through a validation procedure using synthetic choice data (Figure 3d, Figure 3—figure supplement 1, and Materials and methods).
After we confirmed that we can reliably differentiate between our competing encoding rules, the latent-mixture model was initially fitted to each condition (perceptual or value) using a hierarchical Bayesian approach (Materials and methods). Surprisingly, we found that participants did not follow the accuracy or reward optimization strategy in the respective experimental condition, but favored the DbS strategy (proportion that DbS was deemed best in the perceptual and value conditions, Figure 4). Importantly, this population-level result also holds at the individual level: DbS was strongly favored in 6 out of 7 participants in the perceptual condition, and seven out of seven in the value condition (Figure 4—figure supplement 1). These results are not likely to be affected by changes in performance over time, as performance was stable across the four consecutive days (Figure 4—figure supplement 2). Additionally, we investigated whether biases induced by choice history effects may have influenced our results (Abrahamyan et al., 2016; Keung et al., 2019; Talluri et al., 2018). Therefore, we incorporated both choice- and correctness-dependence history biases in our models and fitted the models once again (Materials and methods). We found similar results to the history-free models ( in perceptual and in value conditions, Figure 4c). At the individual level, DbS was again strongly favored in 6 out of 7 participants in the perceptual condition, and 7 out of 7 in the value condition (Figure 4—figure supplement 1).
Figure 4 with 8 supplements see all
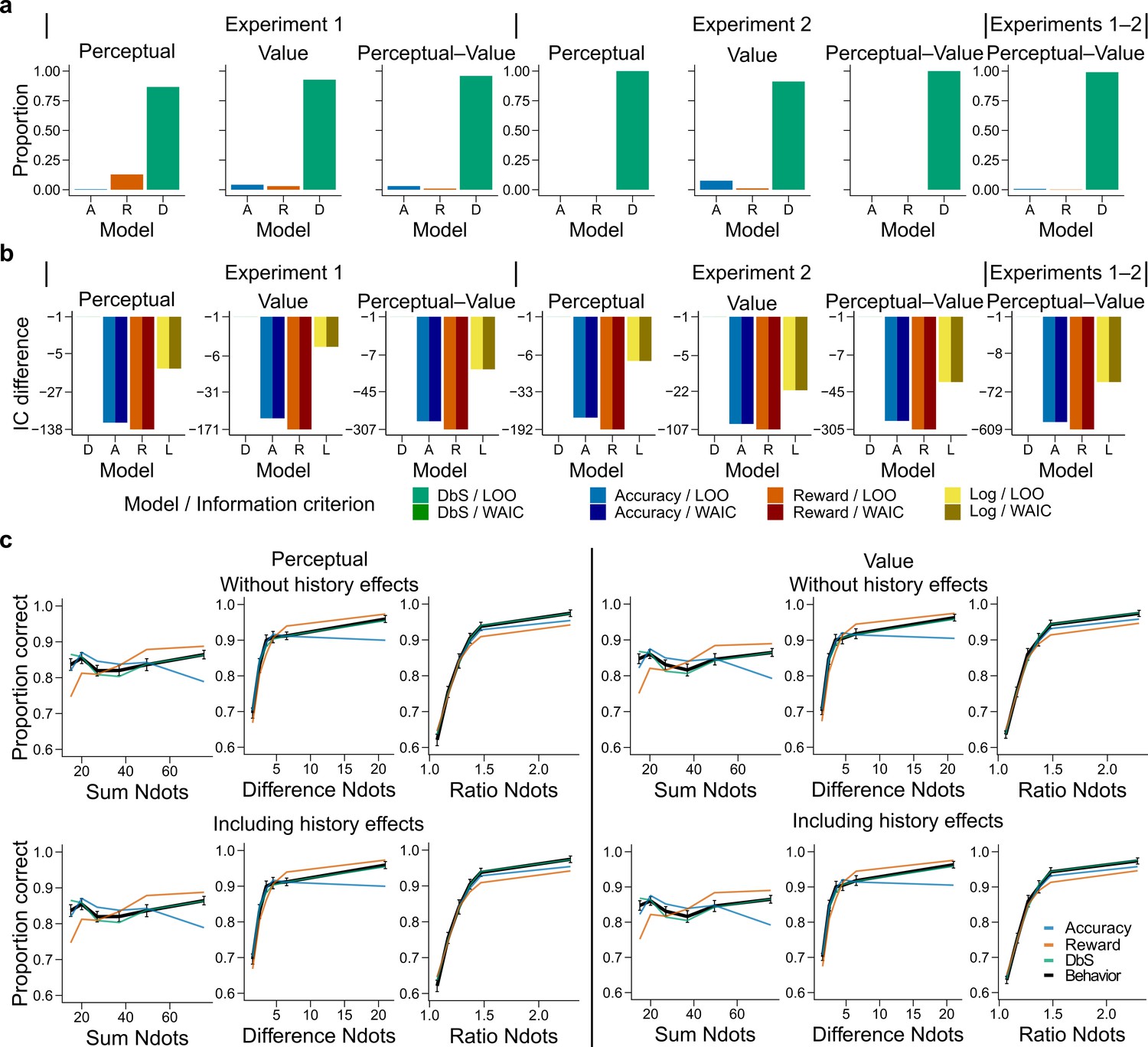
Behavioral results.
(a) Bars represent proportion of times an encoding rule (Accuracy [A, blue], Reward [R, red], DbS [D, green]) was selected by the Bayesian latent-mixture model based on the posterior estimates across participants. Each panel shows the data grouped for each and across experiments and experimental conditions (see titles on top of each panel). The results show that DbS was clearly the favored encoding rule. The latent vector posterior estimates are presented in Figure 4—figure supplement 4. (b) Difference in LOO and WAIC between the best model (DbS (D) in all cases) and the competing models: Accuracy (A), Reward (R) and Logarithmic (L) models. Each panel shows the data grouped for each and across experimental conditions and experiments (see titles on top of each panel). (c) Behavioral data (black, error bars represent SEM across participants) and model predictions based on fits to the empirical data. Data and model predictions are presented for both the perceptual (left panels) or value (right panels) conditions, and excluding (top panels) or including (bottom panels) choice history effects. Performance of data model predictions is presented as function of the sum of the number of dots in both clouds (left), the absolute difference between the number of dots in both clouds (middle) and the ratio of the number of dots in the most numerous cloud over the less numerous cloud (right). Results reveal a remarkable overlap of the behavioral data and predictions by DbS, thus confirming the quantitative results presented in panels a and b.
In order to investigate further the robustness of this effect, we introduced a slight variation in the behavioral paradigm. In this new experiment (Experiment 2), participants were given points on each trial and had to reach a certain threshold in each run for it to be eligible for reward (Figure 3a and Materials and methods). This class of behavioral task is thought to be in some cases more ecologically valid than trial-independent choice paradigms (Kolling et al., 2014). In this new experiment, either a fixed amount of points for a correct trial was given (perceptual condition) or an amount equal to the number of dots in the chosen cloud if the response was correct (value condition). We recruited a new set of participants (n = 6), who were tested on these two conditions, each for two consecutive days with the starting condition randomized across participants (each participant completed trials). The quantitative results revealed once again that participants did not change their encoding strategy depending on the goals of the task, with DbS being strongly favored for both perceptual and value conditions ( and , respectively; Figure 4a), and these results were confirmed at the individual level where DbS was strongly favored in 6 out of 6 participants in both the perceptual and value conditions (Figure 4—figure supplement 1). Once again, we found that inclusion of choice history biases in this experiment did not significantly affect our results both at the population and individual levels. Population probability that DbS was deemed best in the perceptual () and value () conditions (Figure 4—figure supplement 1), and at the individual level DbS was strongly favored in 6 out of 6 participants in the perceptual condition and 5 of 6 in the value condition (Figure 4—figure supplement 1). Thus, Experiments 1 and 2 strongly suggest that our results are not driven by specific instructions or characteristics of the behavioral task.
As a further robustness check, for each participant we grouped the data in different ways across experiments (Experiments 1 and 2) and experimental conditions (perceptual or value) and investigated which sampling model was favored. We found that irrespective of how the data was grouped, DbS was the model that was clearly deemed best at the population (Figure 4) and individual level (Figure 4—figure supplement 3). Additionally, we investigated whether these quantitative results specifically depended on our choice of using a latent-mixture model. Therefore, we also fitted each model independently and compared the quality of the model fits based on out-of-sample cross-validation metrics (Materials and methods). Once again, we found that the DbS model was favored independently of experiment and conditions (Figure 4).
One possible reason why the two experimental conditions did not lead to differences could be that, after doing one condition for two days, the participants did not adapt as easily to the new incentive rule. However, note that as the participants did not know of the second condition before carrying it out, they could not adopt a compromise between the two behavioral objectives. Nevertheless, we fitted the latent-mixture model only to the first condition that was carried out by each participant. We found once again that DbS was the best model explaining the data, irrespective of condition and experimental paradigm (Figure 4—figure supplement 7). Therefore, the fact that DbS is favored in the results is not an artifact of carrying out two different conditions in the same participants.
We also investigated whether the DbS model makes more accurate predictions than the widely used logarithmic model of numerosity discrimination tasks (Dehaene, 2003). We found that DbS still made better out-of-sample predictions than the log-model (Figure 4b, Figure 5f,g). Moreover, these results continued to hold after taking into account possible choice history biases (Figure 4—figure supplement 4). In addition to these quantitative results, qualitatively we also found that behavior closely matched the predictions of the DbS model remarkably well (Figure 4c), based on virtually only one free parameter, namely, the number of samples (resources) . Together, these results provide compelling evidence that DbS is the most likely resource-constrained sampling strategy used by participants in numerosity discrimination tasks.
Figure 5 with 3 supplements see all
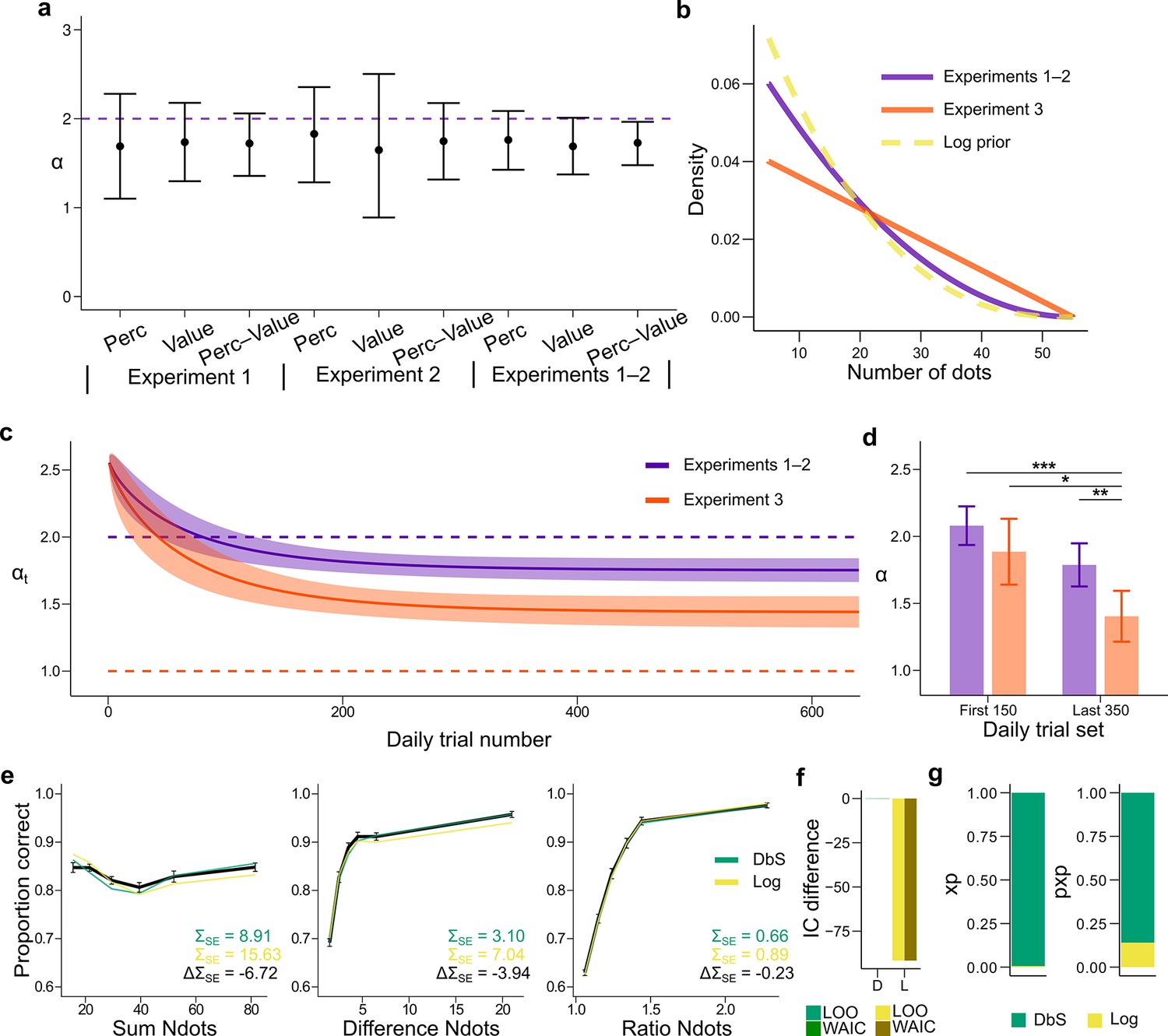
Prior adaptation analyses.
(a) Estimation of the shape parameter for the DbS model by grouping the data for each and across experimental conditions and experiments. Error bars represent the 95% highest density interval of the posterior estimate of at the population level. The dashed line shows the theoretical value of . (b) Theoretical prior distribution in Experiments 1 and 2 (, purple) and 3 (, orange). The dashed line represents the value of of our prior parametrization that approximates the DbS and log discriminability models. (c) Posterior estimation of (Equation 18) as a function of the number of trials in each daily session for Experiments 1 and 2 (purple) and Experiment 3 (orange). The results reveal that, as expected, reaches a lower asymptotic value . Error bars represent ± SD of 3000 simulated values drawn from the posterior estimates of the HBM (see Materials and methods). (d) Model fit to the first 150 and last 350 trials of each daily session. The parameter was allowed to vary between the first and last sets of daily trials and between Experiments 1–2 and Experiment 3. In Experiment 3, is lower in the last set of trials compared to the first set of trials (). In addition, for the last trials is lower for Experiment 3 than for Experiments 1–2 (). This confirms that the results presented in panel c are not artifacts of the adaptation parametrization assumed for . Error bars represent ± SD of the posterior chains of the corresponding parameter. (*P<0.05, **P<0.01, and ***P<0.001). (e) Behavioral data (black) and model fit predictions of the DbS (green) and Log (yellow) models. Performance of each model as a function of the sum of the number of dots in both clouds (left), the absolute difference between the number of dots in both clouds (middle) and the ratio of the number of dots in the most numerous cloud over the less numerous cloud (right). Error bars represent SEM (f) Difference in LOO and WAIC between the best fitting DbS (D) and logarithmic encoding (Log) model. (g) Population exceedance probabilities (xp, left) and protected exceedance probabilities (pxp, right) for DbS (green) vs Log (yellow) of a Bayesian model selection analysis (Stephan et al., 2009): , . These results provide a clear indication that the adaptive DbS explains the data better than the Log model.
Recent studies have also investigated behavior in tasks where perceptual and preferential decisions have been investigated in paradigms with identical visual stimuli (Dutilh and Rieskamp, 2016; Polanía et al., 2014; Grueschow et al., 2015). In these tasks, investigators have reported differences in behavior, in particular in the reaction times of the responses, possibly reflecting differences in behavioral strategies between perceptual and value-based decisions. Therefore, we investigated whether this was the case also in our data. We found that reaction times did not differ between experimental conditions for any of the different performance assessments considered here (Figure 4—figure supplement 5). This further supports the idea that participants were in fact using the same sampling mechanism irrespective of behavioral goals.
Here it is important to emphasize that all sampling models and the logarithmic model of numerosity have the same degrees of freedom (performance is determined by in the sampling models and Weber’s fraction in the log model, Materials and methods). Therefore, qualitative and quantitative differences favoring the DbS model cannot be explained by differences in model complexity. It could also be argued that normal approximation of the binomial distributions in the sampling decision models only holds for large enough . However, we find evidence that the large- optimal solutions are also nearly optimal for low values (Appendix 7). Estimates of in our data are in general (Table 1) and we find that the large- rule is nearly optimal already for (Appendix 7). Therefore the asymptotic approximations should not greatly affect the conclusions of our work.
Table 1
Resource parameter fits.
Fits of the resource parameter for the Accuracy, Reward and Decision by Sampling (DbS) models including data across experiments and conditions (perceptual (P) or value (V)) either including or ignoring choice history effects. The values represent the mean ± SD of the posterior distributions at the population level for parameter . Note that Reward and in particular the DbS encoding models require a higher number of resources than the Accuracy model, which is coherent with the fact that the Accuracy model allocates its resources to maximize efficiency, therefore reducing the number of resources needed to reach a given accuracy. DbS has the highest values of because it is the most inefficient model.
| Model | |||||
|---|---|---|---|---|---|
| Experiment | Condition | History effects | nAccuracy | nReward | nDbS |
| 1 | V | not included | 15.24 ± 3.09 | 17.54 ± 3.98 | 24.40 ± 5.16 |
| 2 | V | not included | 22.48 ± 2.43 | 27.58 ± 3.81 | 35.40 ± 3.44 |
| 1 | P | not included | 15.19 ± 3.99 | 17.84 ± 4.85 | 24.64 ± 6.59 |
| 2 | P | not included | 20.99 ± 1.59 | 24.22 ± 1.93 | 33.54 ± 2.45 |
| 1 | P/V | not included | 15.33 ± 3.41 | 17.25 ± 4.45 | 24.15 ± 5.75 |
| 2 | P/V | not included | 21.30 ± 0.96 | 25.27 ± 1.99 | 33.90 ± 1.51 |
| 1/2 | V | not included | 18.56 ± 2.04 | 22.05 ± 2.73 | 29.52 ± 3.25 |
| 1/2 | P | not included | 17.91 ± 2.09 | 20.66 ± 2.59 | 28.62 ± 3.51 |
| 1/2 | P/V | not included | 17.93 ± 1.87 | 21.03 ± 2.46 | 28.58 ± 3.04 |
| 1 | V | included | 15.50 ± 3.13 | 17.50 ± 3.91 | 24.68 ± 5.08 |
| 2 | V | included | 22.92 ± 2.37 | 28.07 ± 3.73 | 36.18 ± 2.91 |
| 1 | P | included | 15.41 ± 3.81 | 17.96 ± 4.88 | 24.70 ± 6.62 |
| 2 | P | included | 21.57 ± 1.71 | 24.88 ± 2.17 | 34.37 ± 2.93 |
| 1 | P/V | included | 15.16 ± 3.55 | 17.43 ± 4.39 | 24.30 ± 5.94 |
| 2 | P/V | included | 21.80 ± 0.92 | 25.81 ± 1.86 | 34.60 ± 1.40 |
| 1/2 | V | included | 18.86 ± 2.07 | 22.48 ± 2.75 | 29.85 ± 3.17 |
| 1/2 | P | included | 18.15 ± 2.17 | 21.11 ± 2.72 | 29.01 ± 3.47 |
| 1/2 | P/V | included | 18.22 ± 1.93 | 21.34 ± 2.50 | 29.12 ± 3.12 |
Dynamics of adaptation
Up to now, fits and comparison across models have been done under the assumption that the participants learned the prior distribution imposed in our task. If participants are employing DbS, it is important to understand the dynamical nature of adaptation in our task. Note that the shape of the prior distribution is determined by the parameter (Figure 5b, Equation 10 in Materials and methods). First, we made sure based on model recovery analyses that the DbS model could jointly and accurately recover both the shape parameter and the resource parameter based on synthetic data (Figure 3—figure supplement 2). Then we fitted this model to the empirical data and found that the recovered value of the shape parameter closely followed the value of the empirical prior with a slight underestimation (Figure 5a). Next, we investigated the dynamics of prior adaptation. To this end, we ran a new experiment (Experiment 3, n = 7 new participants) in which we set the shape parameter of the prior to a lower value compared to Experiments 1–2 (Figure 5b, Materials and methods). We investigated the change of over time by allowing this parameter to change with trial experience (Equation 18, Materials and methods) and compared the evolution of for Experiments 1 and 2 (empirical ) with Experiment 3 (empirical , Figure 5b). If participants show prior adaptation in our numerosity discrimination task, we hypothesized that the asymptotic value of should be higher for Experiments 1–2 than for Experiment 3. First, we found that for Experiments 1–2, the value of quickly reached an asymptotic value close to the target value (Figure 5c). On the other hand, for Experiment 3 the value of continued to decrease during the experimental session, but slowly approaching its target value. This seemingly slower adaptation to the shape of the prior in Experiment 3 might be explained by the following observation. The prior parametrized with in Experiment 3 is further away from an agent hypothesized to have a natural numerosity discrimination based on a log scale (, Materials and methods), which is closer in value to the shape of the prior in Experiments 1 and 2 (). Irrespective of these considerations, the key result to confirm our adaptation hypothesis is that the asymptotic value of is lower for Experiment 3 compared to Experiments 1 and 2 ().
In order to make sure that this result was not an artifact of the parametric form of adaptation assumed here (Equation 18, Materials and methods), we fitted the DbS model to trials at the beginning and end of each experimental session allowing to be a free but fixed parameter in each set of trials. The results of these new analyses are virtually identical to the results obtained with the parametric form, in which is smaller at the end of Experiment 3 sessions relative to beginning of Experiments 1 and 2 (), beginning of Experiments 3 () and end of Experiments 1 and 2 (, Figure 5d). In this model, we did not allow to freely change for each condition, and therefore a concern might be that the results might be an artifact of changes in , which could for example change with the engagement of the participants across the session. Given that we already demonstrated that both parameters and are identifiable, we fitted the same model as in Figure 5d, however this time we allowed to be free parameter alongside . We found that the results obtained in Figure 5d remained virtually unchanged (Figure 5—figure supplement 3), in addition to the result that the resource parameter remained virtually identical across the session (Figure 5—figure supplement 3).
We further investigated evidence for adaptation using an alternative quantitative approach. First, we performed out-of-sample model comparisons based on the following models: (i) the adaptive- model, (ii) free- model with free but non-adapting over time, and (iii) fixed- model with . The results of the out-of-sample predictions revealed that the best model was the free- model, followed closely by the adaptive- model () and then by fixed- model (). However, we did not interpret the apparent small difference between the adaptive- and the free- models as evidence for lack of adaptation, given that the more complex adaptive- model will be strongly penalized after adaptation is stable. That is, if adaptation is occurring, then the adaptive- only provides a better fit for the trials corresponding to the adaptation period. After adaptation, the adaptive- should provide a similar fit than the free- model, however with a larger complexity that will be penalized by model comparison metrics. Therefore, to investigate the presence of adaptation, we took a closer quantitative look at the evolution of the fits across trial experience. We computed the average trial-wise predicted Log-Likelihood (by sampling from the hierarchical Bayesian model) and compared the differences of this metric between the competing models and the adaptive model. We hypothesized that if adaptation is taking place, the adaptive- model would have an advantage relative to the free- model at the beginning of the session, with these differences vanishing toward the end. On the other hand, the fixed- should roughly match the adaptive- model at the beginning and then become worse over time, but these differences should stabilize after the end of the adaptation period. The results of these analyses support our hypotheses (Figure 5—figure supplement 2), thus providing further evidence of adaptation, highlighting the fact that the DbS model can parsimoniously capture adaptation to contextual changes in a continuous and dynamical manner. Furthermore, we found that the DbS model again provides more accurate qualitative and quantitative out-of-sample predictions than the log model (Figure 5e,f).
Discussion
The brain is a metabolically expensive inference machine (Hawkes et al., 1998; Navarrete et al., 2011; Stone, 2018). Therefore, it has been suggested that evolutionary pressure has driven it to make productive use of its limited resources by exploiting statistical regularities (Attneave, 1954; Barlow, 1961; Laughlin, 1981). Here, we incorporate this important — often ignored — aspect in models of behavior by introducing a general framework of decision-making under the constraints that the system: (i) encodes information based on binary codes, (ii) has limited number of samples available to encode information, and (iii) considers the costs of contextual adaptation.
Under the assumption that the organism has fully adapted to the statistics in a given context, we show that the encoding rule that maximizes mutual information is the same rule that maximizes decision accuracy in two-alternative decision tasks. However, note that there is nothing privileged about maximizing mutual information, as it does not mean that the goals of the organism are necessarily achieved (Park and Pillow, 2017; Salinas, 2006). In fact, we show that if the goal of the organism is instead to maximize the expected value of the chosen options, the system should not rely on maximizing information transmission and must give up a small fraction of precision in information coding. Here, we derived analytical solution for each of these optimization objective criteria, emphasizing that these analytical solutions were derived for the large- limiting case. However, we have provided evidence that these solutions continue to be more efficient relative to DbS for small values of , and more importantly, they remain nearly optimal even at relatively low values of , in the range of values that might be relevant to explain human experimental data (Appendix 7).
Another key implication of our results is that we provide an alternative explanation to the usual conception of noise as the main cause of behavioral performance degradation, where noise is usually artificially added to models of decision behavior to generate the desired variability (Ratcliff and Rouder, 1998; Wang, 2002). On the contrary, our work makes it formally explicit why a system that evolved to encode information based on binary codes must be necessarily noisy, also revealing how the system could take advantage of its unavoidable noisy properties (Faisal et al., 2008) to optimize decision behavior (Tsetsos et al., 2016). Here, it is important to highlight that this conclusion is drawn from a purely homogeneous neural circuit, in other words, a circuit in which all neurons have the same properties (in our case, the same activation thresholds). This is not what is typically observed, as neural circuits are typically very heterogeneous. However, in the neural circuit that we consider here, it could mean that the firing thresholds can vary across neurons (Orbán et al., 2016), which could be used by the system to optimize the required variability of binary neural codes. Interestingly, it has been shown in recent work that stochastic discrete events also serve to optimize information transmission in neural population coding (Ashida and Kubo, 2010; Nikitin et al., 2009; Schmerl and McDonnell, 2013). Crucially, in our work we provide a direct link of the necessity of noise for systems that aim at optimizing decision behavior under our encoding and limited-capacity assumptions, which can be seen as algorithmic specifications of the more realistic population coding specifications mentioned above (Nikitin et al., 2009). We argue that our results may provide a formal intuition for the apparent necessity of noise for improving training and learning performance in artificial neural networks (Dapello et al., 2020; Findling and Wyart, 2020), and we speculate that an implementation of 'the right' noise distribution for a given environmental statistic could be seen as a potential mechanism to improve performance in capacity-limited agents generally speaking (Garrett et al., 2011). We acknowledge that based on the results of our work, we cannot confirm whether this is the case for higher order neural circuits, however, we leave it as an interesting theoretical formulation, which could be addressed in future work.
Interestingly, our results could provide an alternative explanation of the recent controversial finding that dynamics of a large proportion of LIP neurons likely reflect binary (discrete) coding states to guide decision behavior (Latimer et al., 2015; Zoltowski et al., 2019). Based on this potential link between their work and ours, our theoretical framework generates testable predictions that could be investigated in future neurophysiological work. For instance, noise distribution in neural circuits should dynamically adapt according to the prior distribution of inputs and goals of the organism. Consequently, the rate of 'step-like' coding in single neurons should also be dynamically adjusted (perhaps optimally) to statistical regularities and behavioral goals.
Our results are closely related to Decision by Sampling (DbS), which is an influential account of decision behavior derived from principles of retrieval and memory comparison by taking into account the regularities of the environment, and also encodes information based on binary codes (Stewart et al., 2006). We show that DbS represents a special case of our more general efficient sampling framework, that uses a rule that is similar to (though not exactly like) the optimal encoding rule that assumes full (or costless) adaptation to the prior statistics of the environment. In particular, we show that DbS might well be the most efficient sampling algorithm, given that a reduction in the full representation of the prior distribution might not come at a great loss in performance. Interestingly, our experimental results (discussed in more detail below) also provide support for the hypothesis that numerosity perception is efficient in this particular way. Crucially, DbS automatically adjusts the encoding in response to changes in the frequency distribution from which exemplars are drawn in approximately the right way, while providing a simple answer to the question of how such adaptation of the encoding rule to a changing frequency distribution occurs, at a relatively low cost.
On a related line of work, Bhui and Gershman, 2018 develop a similar, but different specification of DbS, in which they also consider only a finite number of samples that can be drawn from the prior distribution to generate a percept, and ask what kind of algorithm would be required to improve coding efficiency. However, their implementation differs from ours in various important ways (see Appendix 8 for a detailed discussion). One of the main distinctions is that they consider the case in which only a finite number of samples can be drawn from the prior and show that a variant of DbS with kernel-smoothing is superior to its standard version. However, a key difference to our implementation is that they allow the kernel-smoothed quantity (computed by comparing the input with a sample from the prior distribution) to vary continuously between 0 and 1, rather than having to be either 0 or 1 as in our implementation (Figure 1). Thus, they show that coding efficiency can be improved by allowing a more flexible implementation of the coding scheme for the case when the agent is allowed to draw few samples from the prior distribution (Appendix 8). On the other hand, we restrict our framework to a coding scheme that is only allowed to encode information based on zeros or ones, where we show that coding efficiency can be improved relative to DbS only under a more complete knowledge of the prior distribution, where the optimal solutions can be formally derived in the large- limit. Nevertheless, we have shown that even under the operation of few sampling units, the optimal rules will be still superior to the standard DbS (if the agent has fully adapted to the statistics of the environment in a given context), even when a few number of processing units are available to generate decision relevant percepts.
We tested these resource-limited coding frameworks in non-symbolic numerosity discrimination, a fundamental cognitive function for behavior in humans and other animals, which may have emerged during evolution to support fitness maximization (Nieder, 2020). Here, we find that the way in which the precision of numerosity discrimination varies with the size of the numbers being compared is consistent with the hypothesis that the internal representations on the basis of which comparisons are made are sample-based. In particular, we find that the encoding rule varies depending on the frequency distribution of values encountered in a given environment, and that this adaptation occurs fairly quickly once the frequency distribution changes.
This adaptive character of the encoding rule differs, for example, from the common hypothesis of a logarithmic encoding rule (independent of context), which we show fits our data less well. Nonetheless, we can reject the hypothesis of full optimality of the encoding rule for each distribution of values used in our experiments, even after participants have had extensive experience with a given distribution. Thus, a possible explanation of why DbS is the favored model in our numerosity task is that accuracy and reward maximization requires optimal adaptation of the noise distribution based on our imposed prior, requiring complex neuroplastic changes to be implemented, which are in turn metabolically costly (Buchanan et al., 2013). Relying on samples from memory might be less metabolically costly as these systems are plastic in short time scales, and therefore a relatively simpler heuristic to implement allowing more efficient adaptation. Here, it is important to emphasize, as it has been discussed in the past (Tajima et al., 2016; Polanía et al., 2015), that for decision-making systems beyond the perceptual domain, the identity of the samples is unclear. We hypothesize, that information samples derive from the interaction of memory on current sensory evidence depending on the retrieval of relevant samples to make predictions about the outcome of each option for a given behavioral goal (therefore also depending on the encoding rule that optimizes a given behavioral goal).
Interestingly, it was recently shown that in a reward learning task, a model that estimates values based on memory samples from recent past experiences can explain the data better than canonical incremental learning models (Bornstein et al., 2017). Based on their and our findings, we conclude that sampling from memory is an efficient mechanism for guiding choice behavior, as it allows quick learning and generalization of environmental contexts based on recent experience without significantly sacrificing behavioral performance. However, it should be noted that relying on such mechanisms alone might be suboptimal from a performance- and goal-based point of view, where neural calibration of optimal strategies may require extensive experience, possibly via direct interactions between sensory, memory and reward systems (Gluth et al., 2015; Saleem et al., 2018).
Taken together, our findings emphasize the need of studying optimal models, which serve as anchors to understand the brain's computational goals without ignoring the fact that biological systems are limited in their capacity to process information. We addressed this by proposing a computational problem, elaborating an algorithmic solution, and proposing a minimalistic implementational architecture that solves the resource-constrained problem. This is essential, as it helps to establish frameworks that allow comparing behavior not only across different tasks and goals, but also across different levels of description, for instance, from single cell operation to observed behavior (Marr, 1982). We argue that this approach is fundamental to provide benchmarks for human performance that can lead to the discovery of alternative heuristics (Qamar et al., 2013; Gardner, 2019) that could appear to be in principle suboptimal, but that might be in turn the optimal strategy to implement if one considers cognitive limitations and costs of optimal adaptation. We conclude that the understanding of brain function and behavior under a principled research agenda, which takes into account decision mechanisms that are biologically feasible, will be essential to accelerate the elucidation of the mechanisms underlying human cognition.
Materials and methods
Participants
The study tested young healthy volunteers with normal or corrected-to-normal vision (total n = 20, age 19–36 years, nine females: n = 7 in Experiment 1, two females; n = 6 new participants in Experiment 2, three females; n = 7 new participants in Experiment 3, four females). Participants were randomly assigned to each experiment and no participant was excluded from the analyses. Participants were instructed about all aspects of the experiment and gave written informed consent. None of the participants suffered from any neurological or psychological disorder or took medication that interfered with participation in our study. Participants received monetary compensation for their participation in the experiment partially related to behavioral performance (see below). The experiments conformed to the Declaration of Helsinki and the experimental protocol was approved by the Ethics Committee of the Canton of Zurich (BASEC: 2018–00659).
Experiment 1
Request a detailed protocolParticipants (n = 7) carried out a numerosity discrimination task for four consecutive days for approximately one hour per day. Each daily session consisted of a training run followed by 8 runs of 75 trials each. Thus, each participant completed ∼2400 trials across the four days of experiment.
After a fixation period (1–1.5 s jittered), two clouds of dots (left and right) were presented on the screen for 200 ms. Participants were asked to indicate the side of the screen where they perceived more dots. Their response was kept on the screen for 1 s followed by feedback consisting of the symbolic number of dots in each cloud as well as the monetary gains and opportunity losses of the trial depending on the experimental condition. In the value condition, participants were explicitly informed that each dot in a cloud of dots corresponded to 1 Swiss Franc (CHF). Participants were informed that they would receive the amount in CHF corresponding to the total number of dots on the chosen side. At the end of the experiment a random trial was selected and they received the corresponding amount. In the accuracy condition, participants were explicitly informed that they could receive a fixed reward (15 Swiss Francs (CHF)) for each correct trial. This fixed amount was selected such that it approximately matched the expected reward received in the value condition (as tested in pilot experiments). At the end of the experiment, a random trial was selected and they would receive this fixed amount if they chose the cloud with more dots (i.e., the correct side). Each condition lasted for two consecutive days with the starting condition randomized across participants. Only after completing all four experiment days, participants were compensated for their time with 20 CHF per hour, in addition to the money obtained based on their decisions on each experimental day.
Experiment 2
Request a detailed protocolParticipants (n = 6) carried out a numerosity discrimination task in which each of four daily sessions consisted of 16 runs of 40 trials each, thus each participant completed ∼2560 trials. A key difference with respect to Experiment 1 is that participants had to accumulate points based on their decisions and had to reach a predetermined threshold on each run. The rules of point accumulation depended on the experimental condition. In the perceptual condition, a fixed amount of points was awarded if the participants chose the cloud with more dots. In this condition, participants were instructed to accumulate a number of points and reach a threshold given a limited number of trials. Based on the results obtained in Experiment 1, the threshold corresponded to 85% of correct trials in a given run, however the participants were unaware of this. If the participants reached this threshold, they were eligible for a fixed reward (20 CHF) as described in Experiment 1. In the value condition, the number of points received was equal to the number of dots in the cloud, however, contrary to Experiment 1, points were only awarded if the participant chose the cloud with the most dots. Participants had to reach a threshold that was matched in the expected collection of points of the perceptual condition. As in Experiment 1, each condition lasted for two consecutive days with the starting condition randomized across participants. Only after completing all the four days of the experiment, participants were compensated for their time with 20 CHF per hour, in addition to the money obtained based on their decisions on each experimental day.
Experiment 3
Request a detailed protocolThe design of Experiment 3 was similar to the value condition of Experiment 2 (n = 7 participants) and was carried out over three consecutive days. The key difference between Experiment 3 and Experiments 1–2 was the shape of the prior distribution that was used to draw the number of dots for each cloud in each trial (see below).
Stimuli statistics and trial selection
Request a detailed protocolFor all experiments, we used the following parametric form of the prior distribution
(10)
initially defined in the interval [0,1] for mathematical tractability in the analytical solution of the encoding rules (see below), with determining the shape of the distribution, and is a normalizing constant. For Experiments 1 and 2 the shape parameter was set to , and for Experiment 3 was set to . i.i.d. samples drawn from this distribution were then multiplied by 50, added an offset of 5, and finally were rounded to the closest integer (i.e., the numerosity values in our experiment ranged from to ). The pairs of dots on each trial were determined by sampling from a uniform density window in the CDF space (Equation 10 is its corresponding PDF). The pairs of dots in each trial were selected with the conditions that, first, their distance in the CDF space was less than a constant (0.25, 0.28 and 0.23 for Experiments 1, 2 and 3 respectively), and second, the number of dots in both clouds was different. Figure 3c illustrates the probability that a pair of choice alternatives was selected for a given trial in Experiments 1 and 2.
Power analyses and model recovery
Request a detailed protocolGiven that adaptation dynamics in sensory systems often require long-term experience with novel prior distributions, we opted for maximizing the number of trials for a relatively small number of participants per experiment, as it is commonly done for this type of psychophysical experiments (Brunton et al., 2013; Stocker and Simoncelli, 2006; Zylberberg et al., 2018). Note that based on the power analyses described below, we collected in total ∼45,000 trials across the three Experiments, which is above the average number of trials typically collected in human studies.
In order to maximize statistical power in the differentiation of the competing encoding rules, we generated 10,000 sets of experimental trials for each encoding rule and selected the sets of trials with the highest discrimination power (i.e., largest differences in Log-Likelihood) between the encoding models. In these power analyses, we also investigated what was the minimum number of trials that would allow accurate generative model selection at the individual level. We found that ∼1000 trials per participant in each experimental condition would be sufficient to predict accurately (P>0.95) the true generative model. Based on these analyses, we decided to collect at least 1200 trials per participant and condition (perceptual and value) in each of the three experiments. Model recovery analyses presented in Figure 3d illustrate the result of our power analyses (see also Figure 3—figure supplement 1).
Apparatus
Eyetracking (EyeLink 1000 Plus) was used to check the participants' fixation during stimulus presentation. When participants blinked or moved their gaze (more than 2° of visual angle) away from the fixation cross during the stimulus presentation, the trial was canceled (only 212 out of 45,600 trials were canceled, that is, <0.5% of the trials). Participants were informed when a trial was canceled and were encouraged not to do so as they would not receive any reward for this trial. A chinrest was used to keep the distance between the participants and the screen constant (55 cm). The task was run using Psychtoolbox Version 3.0.14 on Matlab 2018a. The diameter of the dots varied between 0.42° and 1.45° of visual angle. The center of each cloud was positioned 12.6° of visual angle horizontally from the fixation cross and had a maximum diameter of 19.6° of visual angle. Following previous numerosity experiments (van den Berg et al., 2017; Izard and Dehaene, 2008), either the average dot size or the total area covered by the dots was maintained constant in both clouds for each trial. The color of each dot (white or black) was randomly selected for each dot. Stimuli sets were different for each participant but identical between the two conditions.
Encoding rules and model fits
Request a detailed protocolThe parametrization of the prior (Equation 10) allows tractable analytical solutions of the encoding rules , and , that correspond to Accuracy maximization, Reward maximization, and DbS, respectively:
(11)
(12)
(13)
Graphical representation of the respective encoding rules is shown in Figure 3e for Experiments 1 and 2. Given an encoding rule , we now define the decision rule. The goal of the decision maker in our task is always to decide which of two input values and is larger. Therefore, the agent choses if and only if the internal readings . Following the definitions of expected value and variance of binomial variables, and approximating for large (see Appendix 2), the probability of choosing is given by
(14)
where is the standard CDF, and and are the encoding rules for the input values and , respectively. Thus, the choice structure is the same for all models, only differing in their encoding rule. The three models generate different qualitative performance predictions for a given number of samples (Figure 3f).
Crucially, this probability decision rule (Equation 14) can be parsimoniously extended to include potential side biases independent of the encoding process as follows
(15)
where is the bias term. This is the base model used in our work. We were also interested in studying whether choice history effects (Abrahamyan et al., 2016; Talluri et al., 2018) may have influence in our task, thus possibly affecting the conclusions that can be drawn from the base model. Therefore, we extended this model to incorporate the effect of decision learning and choices from the previous trial
(16)
where is the choice made on the previous trial (+1 for left choice and −1 for right choice) and is the 'outcome learning' on the previous trial (+1 for correct choice and −1 for incorrect choice). and capture the effect of decision learning and choice in the previous trial, respectively.
Given that the choice structure is the same for all three sampling models considered here, we can naturally address the question of what decision rule the participants favor via a latent-mixture model. We implemented this model based on a hierarchical Bayesian modelling (HBM) approach. The base-rate probabilities for the three different encoding rules at the population level are represented by the vector , so that is the probability of selecting encoding rule model . We initialize the model with an uninformative prior given by
This base-rate is updated based on the empirical data, where we allow each participant to draw from each model categorically based on the updated base-rate
where the encoding rule for model is given by
The selected rule was then fed into Equations 15 and 16 to determine the probability of selecting a cloud of dots. The number of samples was also estimated within the same HBM with population mean and standard deviation initialized based on uninformative priors with plausible ranges
allowing each participant to draw from this population prior assuming that is normally distributed at the population level
Similarly, the latent variables in equations Equations 15 and 16 were estimated by setting population mean and standard deviation initialized based on uninformative priors
allowing each participant to draw from this population prior assuming that is normally distributed at the population level
In all the results reported in Figure 3 and Figure 4, the value of the shape parameter of the prior was set to its true value . The estimation of in Figure 5a was investigated with a similar hierarchical approach, allowing each participant to sample from the normal population distribution with uninformative priors over the population mean and standard deviation
The choice rule of the standard logarithmic model of numerosity discrimination is given by
(17)
where is the internal noise in the logarithmic space. This model was extended to incorporate bias and choice history effects in the same way as implemented in the sampling models. Here, we emphasize that all sampling and log models have the same degrees of freedom, where performance is mainly determined by in the sampling models and Weber’s fraction in the log model, and biases are determined by parameters . For all above-mentioned models, the trial-by-trial likelihood of the observed choice (i.e., the data) given probability of a decision was based on a Bernoulli process
where is the decision of each participant in each trial . In order to allow for prior adaptation, the model fits presented in Figure 3 and Figure 4 were fit starting after a fourth of the daily trials (corresponding to 150 trials for Experiment 1 and 160 trials for Experiment 2) to allow for prior adaptation and fixing the shape parameter to its true generative value .
The dynamics of adaptation (Figure 5) were studied by allowing the shape parameter α to evolve through trial experience using all trials collected on each experiment day. This was studied using the following function
(18)
where represents a possible target adaptation value of , is the trial number, and , determine the shape of the adaptation. Therefore, the encoding rule of the DbS model also changed trial-to-trial
(19)
Adaptation was tested based on the hypothesis that participants initially use a logarithmic discrimination rule (Equation 17) (this strategy also allowed improving identification of the adaptation dynamics). Therefore, Equation 18 was parametrized such that the initial value of the shape parameter () guaranteed that discriminability between the DbS and the logarithmic rule was as close as possible. This was achieved by finding the value of α in the DbS encoding rule () that minimizes the following expression
(20)
where and are the numerosity inputs for each trial . This expression was minimized based on all trials generated in Experiments 1–3 (note that minimizing this expression does not require knowledge of the sensitivity levels and for the log and DbS models, respectively). We found that the shape parameter value that minimizes Equation 20 is . Based on our prior parametrization (Equation 10), this suggests that the initial prior is more skewed than the priors used in Experiments 1–3 (Figure 5b). This is an expected result given that log-normal priors, typically assumed in numerosity tasks, are also highly skewed. We fitted the parameter independently for Experiments 1–2 and Experiment 3 but kept the parameter shared across all experiments. If adaptation is taking place, we hypothesized that the asymptotic value of the shape parameter should be larger for Experiments 1–2 compared to Experiment 3.
Posterior inference of the parameters in all the hierarchical models described above was performed via the Gibbs sampler using the Markov Chain Monte Carlo (MCMC) technique implemented in JAGS. For each model, a total of 50,000 samples were drawn from an initial burn-in step and subsequently a total of new 50,000 samples were drawn for each of three chains (samples for each chain were generated based on a different random number generator engine, and each with a different seed). We applied a thinning of 50 to this final sample, thus resulting in a final set of 1000 samples for each chain (for a total of 3000 pooling all three chains). We conducted Gelman–Rubin tests for each parameter to confirm convergence of the chains. All latent variables in our Bayesian models had , which suggests that all three chains converged to a target posterior distribution. We checked via visual inspection that the posterior population level distributions of the final MCMC chains converged to our assumed parametrizations. When evaluating different models, we are interested in the model's predictive accuracy for unobserved data, thus it is important to choose a metric for model comparison that considers this predictive aspect. Therefore, in order to perform model comparison, we used a method for approximating leave-one-out cross-validation (LOO) that uses samples from the full posterior (Vehtari et al., 2017). These analyses were repeated using an alternative Bayesian metric: the WAIC (Vehtari et al., 2017).
Appendix 1
Infomax coding rule
We assume that the subjective perception of an environmental variable with value is determined by independent samples of a binary random variable, that is, outcomes are either 'high’ (ones) or 'low’ (zeros) readings. Here, the probability of a 'high' reading is the same on each draw, but can depend on the input stimulus value, via the function . Additionally, we assume that the input value on a given trial is an independent draw from some prior distribution in a given environment or context (with being the corresponding cumulative distribution function). As we mentioned before, the choice of (i.e., encoding of the input value) depends on . Now suppose that the mapping (the encoding rule) is chosen so as to maximize the mutual information between the random variable and the subjective value representation . The mutual information is computed under the assumption that is drawn from a particular prior distribution , and is assumed to be optimized for this prior. The mutual information between and is defined as
(21)
where the marginal entropy quantifies the uncertainty of the marginal response distribution , and is the average conditional entropy of given . The output distribution is given by
(22)
where is defined as the input density function. For the encoding framework that we consider here, which is given by the binomial channel, the conditional probability mass function of the output given the input is
(23)
Thus, we have all the ingredients to write the expression of the mutual information
(24)
We then seek to determine the encoding rule that solves the optimization problem
(25)
It can be shown that for large , the mutual information between and (hence the mutual information between and ) is maximized if the prior distribution over is the Jeffreys prior (Clarke and Barron, 1994)
(26)
also known as the arcsine distribution. Hence, the mapping induces a prior distribution over given by the arcsine distribution. This means that for each , the encoding function must be such that
(27)
Solving for we finally obtain the optimal encoding rule
(28)
Appendix 2
Accuracy maximization for a known prior distribution
Here we derive the optimal encoding rule when the criterion to be maximized is the probability of a correct response in a binary comparison task, rather than mutual information as in Appendix 1. As in Appendix 1, we assume that the prior distribution from which stimuli are drawn is known, and that the encoding rule is optimized for this particular distribution. (The case in which we wish the encoding rule to be robust to variations in the distribution from which stimuli are drawn is instead considered in Appendix 6.) Note that the objective assumed here corresponds to maximization of expected reward in the case of a perceptual experiment in which a subject must indicate which of two presented magnitudes is greater, and is rewarded for the number of correct responses. (In Appendix 5, we instead consider the encoding rule that would maximize expected reward if the subject’s reward is proportional to the magnitude selected by their response).
As above, we assume encoding by a binomial channel. The encoded value (number of ‘high’ readings) is given by , which is consequently an integer between 0 and . This is a random variable with a binomial distribution with expected value and variance given by
(29)
Suppose that the task of the decision maker is to decide which of two input values and is larger. Assuming that and are encoded independently, then the decision maker choses if and only if the internal readings (here we may suppose that the probability of choosing stimulus 1 is 0.5 in the event that ). Thus, the probability of choosing stimulus 1 is:
(30)
In the case of large , we can use a normal approximation to the binomial distribution to obtain
(31)
and hence the probability of choosing is given by
(32)
where is the standard CDF. Thus the probability of an incorrect choice (i.e., choosing the item with the lower value) is approximately
(33)
Now, suppose that the encoding rule, together with the prior distribution for (the same for both inputs that are independent draws from the prior distribution) results in an ex-ante distribution for θ (same for both goods) with density function . Then the probability of error is given by
(34)
Our goal is to evaluate Equation 34 for any choice of the density . First, we fix the value of and integrate over :
(35)
with , the expression above then becomes
(36)
Then we can integrate over to obtain:
(37)
This problem can be solved using the method of Lagrange multipliers:
(38)
We now calculate the gradient
(39)
and then find the optimum for by setting
(40)
then solving for to obtain
(41)
Taken into consideration our optimization constraint, it can be shown that
and therefore this implies:
thus requiring:
Replacing in Equation 41 we finally obtain
Thus the optimal encoding rule is the same (at least in the large- limit) in this case as when we assume an objective of maximum mutual information (the case considered in Appendix 1), though here we assume that the objective is accurate performance of a specific discrimination task.
Appendix 3
Optimal noise for a known prior distribution
Interestingly, we found that the fundamental principles of the theory independently developed in our work are directly linked to the concept of suprathreshold stochastic resonance (SSR) discovered about two decades ago. Briefly, SSR occurs in an array of identical threshold non-linearities, each of which is subject to independently sampled random additive noise (Figure 1 in main text). SSR should not be confused with the standard stochastic resonance (SR) phenomenon. In SR, the amplitude of the input signal is restricted to values smaller than the threshold for SR to occur. On the other hand, in SSR, random draws from the distribution of input values can exist above threshold levels. Using the simplified implementational scheme proposed in our work, it can be shown that mutual information can be also optimized by finding the optimal noise distribution. This is important as it provides a normative justification as for why sampling must be noisy in capacity-limited systems. Actually, SSR was initially motivated as a model of neural arrays such as those synapsing with hair cells in the inner ear, with the direct application of establishing the mechanisms by which information transmission can be optimized in the design of cochlear implants (Stocks et al., 2002). Our goal in this subsection is to make evident the link between the novel theoretical implications of our work and the SSR phenomenon developed in previous work (Stocks et al., 2002; McDonnell et al., 2007), which should further justify our argument of efficient noisy sampling as a general framework for decision behavior, crucially, with a parsimonious implementational nature.
Following our notation, each threshold device (we will call it from now on a neuron) can be seen as the number of resources available to encode an input stimulus . Here, we assume that each neuron produces a 'high’ reading if and only if , where η is i.i.d. random additive noise (independent of ) following a distribution function , and is the minimum threshold required to produce a 'high' reading. If we define the noise CDF as , then the probability of the neuron giving a 'high' reading in response to the input signal is given by
(42)
It can be shown that the mutual information between the input and the number of 'high’ readings for large is given by McDonnell et al., 2007,
(43)
where is the Jeffreys prior (Equation 26). Therefore, Jeffreys’ prior can also be derived making it a function of the noise distribution
(44)
Given that the first term in Equation 43 is always non-negative, a sufficient condition for achieving channel capacity is given by
(45)
Typically, the nervous system of any organism has little influence on the distribution of physical signals in the environment. However, it has the ability to shape its internal signals to optimize information transfer. Therefore, a parsimonious solution that the nervous system may adopt to adapt to statistical regularities of environmental signals in a given context is to find the optimal noise distribution to achieve channel capacity. Note that this is different from classical problems in communication theory where the goal is usually to find the signal distribution that maximizes mutual information for a channel. Solving Equation 44 to find one can find such optimal noise distribution
(46)
A further interesting consequence of this set of results is that the ratio between the signal PDF and the noise PDF is
(47)
Using the definition given in Equation 42 to make this expression a function of , one finds the optimal PDF of the encoder
(48)
which is once again the arcsine distribution (See Equations 2 and 5 in main text).
Appendix 4
Efficient coding and the relation between environmental priors and discrimination
Appendix 4—figure 1
Recently, it was shown that using an efficiency principle for encoding sensory variables, based on population of noisy neurons, it was possible to obtain an explicit relationship between the statistical properties of the environment (the prior) and perceptual discriminability (Ganguli and Simoncelli, 2016).
The theoretical relation states that discriminability should be inversely proportional to the density of the prior distribution. Interestingly, this relationship holds across several sensory modalities such as (a) acoustic frequency, (b) local orientation, (c) speed (figure adapted with permission from the authors Ganguli and Simoncelli, 2016). Here, we investigate whether this particular relation also emerges in our efficient sampling framework.
We first show that we obtain a prediction of exactly the same kind from our model of encoding using a binary channel, in the case that (i) we assume that the encoding rule is optimized for a single environmental distribution, as in the theory of Ganguli and Simoncelli, 2014; Ganguli and Simoncelli, 2016, and (ii) the objective that is maximized is either mutual information (as in the theory of Ganguli and Simoncelli) or the probability of an accurate binary comparison (as considered in Appendix 2).
Note that the expected value and variance of a binomial random variable are given by
(49)
where we let here . In Appendix 2, we show that if the objective is accuracy maximization, an efficient binomial channel requires that
Thus, replacing in Equation 49 implies the following relations
(50)
where we let here . Discrimination thresholds in sensory perception are defined as the ratio between the precision of the representation and the rate of change in the perceived stimulus
(51)
Substituting the expressions for expected value and variance in Equation 50 results in
(52)
Thus under our theory, this implies
(53)
This is exactly the relationship derived and tested by Ganguli and Simoncelli, 2016.
Our model instead predicts a somewhat different relationship if the encoding rule is required to be robust to alternative possible environmental frequency distributions (the case further discussed in Appendix 6). In this case, the robustly optimal encoding rule is DbS, which corresponds to rather than the relation (53). Substituting this into Equations 49 and 51 yields the prediction
(54)
instead of Equation 52.
One interpretation of the experimental support for relation (53) reviewed by Ganguli and Simoncelli, 2016 could be that in the case of early sensory processing of the kind with which they are concerned, perceptual processing is optimized for a particular environmental frequency distribution (representing the long-run experience of an organism or even of the species), so that the assumptions used in Appendix 2 are the empirically relevant ones. Even so, it is arguable that robustness to changing contextual frequency distributions should be important in the case of higher forms of cognition, so that one might expect prediction of Equation 54 to be more relevant for these cases; and indeed, our experimental results for the case of numerosity discrimination are more consistent with Equation 54 than with Equation 52.
One should also note that even in a case where Equation 54 holds, if one measures discrimination thresholds over a subset of the stimulus space, over which there is non-trivial variation in but does not change very much (because the prior distribution for which the encoding rule is optimized assigns a great deal of probability to magnitudes both higher and lower than those in the experimental data set), then relation (54) restricted to this subset of the possible values for will imply that relation (53) should approximately hold. This provides another possible interpretation of the fact that the relation (53) holds fairly well in the data considered by Ganguli and Simoncelli, 2016.
Appendix 5
Maximizing expected size of the selected item (fitness maximization)
We now consider the optimal encoding rule under a different assumed objective, namely, maximizing the expected magnitude of the item selected by the subject’s response (that is, the stimulus judged to be larger by the subject), rather than maximizing the probability of a correct response as in Appendix 2. While in many perceptual experiments, maximizing the probability of a correct response would correspond to maximization of the subject’s expected reward (or at least maximization of a psychological reward to the subject, who is given feedback about the correctness of responses but not about true magnitudes), in many of the ecologically relevant cases in which accurate discrimination of numerosity is useful to an organism (Butterworth et al., 2018; Nieder, 2020), the decision maker’s reward depends on how much larger one number is than another, and not simply their ordinal ranking. This would also be true of typical cases in which internal representations of numerical magnitudes must be used in economic decision making: the reward from choosing an investment with a larger monetary payoff is proportional to the size of the payoff afforded by the option that is chosen. Hence it is of interest to consider the optimal encoding rule if we suppose that encoding is optimized to maximize performance in a decision task with this kind of reward structure.
As in Appendix 1 and Appendix 2, we again consider the problem of optimizing the encoding rule for a specific prior distribution for the magnitudes that may be encountered, and we assume that it is only possible to encode information via ‘high’ or ‘low’ readings. The optimization problem that we need to solve is to find the optimal encoding function that guarantees a maximal expected value of the chosen outcome, for any given prior distribution . Thus the quantity that we seek to maximize is given by
(55)
where is the probability of choosing option when the encoded values of the two options are and respectively.
We begin by noting that for any pair of input values the integrand in Equation 55 can be written as
(56)
where is the indicator function (taking the value 1 if statement A is true, and the value 0 otherwise), and is the probability of choosing the lower-valued of the two options.
Substituting this last expression for the integrand in Equation 55, we see that we can equivalently write
(57)
where
(58)
is a quantity which is independent of the encoding function Hence choosing to maximize Equation 55 is equivalent to choosing it to minimize
(59)
As previously specified, the probability of error given two internal noisy readings and is given by
where in this case we assume that is the lower-valued option and is the higher-valued option on any given trial. This implies that is very close to zero, except when . In this case we have
(62)
As in the case of accuracy maximization, here we assume that are independent draws from the same distribution of possible values . Thus . Then fixing and integrating over all possible values of in Equation 59, the expected loss is approximately
where in Equation 66 we have applied the change of variable
(69)
and in the integral of Equation 67 we have used
where is the standard normal PDF. Then integrating over , we have:
(73)
Thus we want to find the encoding rule to minimize this integral given the prior . We now apply the change of variable , where is an increasing function with a range for all . Then we have
and therefore we have
(76)
This allows us to rewrite Equation 73 as follows
(77)
Now the problem is to choose the function to minimize subject to . Equivalently, we can choose the function to minimize subject to . Defining , the optimization problem to solve is to choose the function to
(78)
Due to FOC, it can be shown that
(79)
Note also that the constraint must hold with equality, thus arriving at
(80)
Therefore, we finally obtain the efficient encoding rule that maximizes the expected magnitude of the selected item
(81)
Appendix 6
Robust optimality of DbS among encoding rules with
Here we consider the nature of the optimal encoding function when the cost of increasing the size of the sample of values from prior experience that are used to adjust the encoding rule to the contextual distribution of stimulus values is great enough to make it optimal to base the encoding of a new stimulus magnitude on a single sampled value from the contextual distribution. (The conditions required for this to be the case are discussed further in Appendix 7).
We assume that for each of the independent processing units, the probability of a 'high' reading is given by , where is the draw from the contextual distribution by processor , and is the same function for each of the processing units. The for are independent draws from the contextual distribution We further assume that the function satisfies certain regularity conditions. First, we assume that is a piecewise continuous function. That is, we assume that the plane can be divided into a countable number of connected regions, with the boundaries between regions defined by continuous curves; and that the function is continuous in the interior of any of these regions, though it may be discontinuous at the boundaries between regions. And second, we assume that is necessarily weakly increasing in and weakly decreasing in The function is otherwise unrestricted.
For any prior distribution and any encoding function we can compute the probability of an erroneous comparison when two stimulus magnitudes are independently drawn from the distribution , and each of these stimuli is encoded using additional independent draws from the same distribution. Let this error probability be denoted We wish to find an encoding rule (for given ) that will make this error probability as small as possible; however, the answer to this question will depend on the prior distribution Hence we wish to find an encoding rule that is robustly optimal, in the sense that it achieves the minimum possible value for the upper bound
for the probability of an erroneous comparison. Here, the class of possible priors to consider is the set of all possible probability distributions (over values of ) that can be characterized by an integrable probability density function . (We exclude from consideration priors in which there is an atom of probability mass at some single magnitude , since in that case there would be a positive probability of a situation in which it is not clear which response should be considered ‘correct’, so that is not well-defined.) Note that the criterion for ranking encoding rules is not without content, since there exist encoding rules (including DbS) for which the upper bound is less than 1/2 (the error probability in the case of a completely uninformative internal representation).
Let us consider first the case in which there is some part of the diagonal line along which which is not a boundary at which the function is discontinuous. Then we can choose an open interval such that all values with the property that both and lie within the interval are part of a single region on which is a continuous function. Then let be the greatest lower bound with the property that for all lying within the specified interval, and similarly let be the lowest upper bound such that for all values within the specified interval. Because of the continuity of on this region, as the values are chosen to be close enough to each other, the bounds can be made arbitrarily close to one another.
Now for any probabilities let be the quantity defined in Equation 30, when and that is, for any that are not equal to one another, is the probability of an erroneous comparison if the units representing the smaller magnitude each give a 'high' reading with probability and those representing the larger magnitude each give a 'high' reading with probability Then the probability of erroneous choice when is a distribution with support entirely within the interval is necessarily greater than or equal to the lower bound . The reason is that for any in the support of the probabilities
will necessarily lie within the bounds for both Given these bounds, the most favorable case for accurate discrimination between the two magnitudes will be to assign the largest possible probability to units being on in the representation of the larger magnitude, and the smallest possible probability to units being on in the representation of the smaller magnitude. Since the lower bound applies in the case of any individual values drawn from the support of , this same quantity is also a lower bound for the average error rate integrating over the prior distributions for and .
One can also show that as the two bounds approach one another, the lower bound approaches 1/2, regardless of the common value that and both approach. Hence it is possible to make arbitrarily close to 1/2, by choosing values for that are close enough to one another. It follows that for any bound less than 1/2 (including values arbitrarily close to 1/2), we can choose a prior distribution for which is necessarily equal to or larger. It follows that in the case of a function of this kind, the upper bound is equal to 1/2.
In order to achieve an upper bound lower than 1/2, then, we must choose a function that is discontinuous along the entire line . For any such function, let us consider a value with the property that all points near with belong to one region on which is continuous, and all points near with belong to another region. Then under the assumption of piecewise continuity, must approach some value as the values converge to from within the region where and similarly must approach some value as the values converge to from within the region where
It must also be possible to choose values such that all points with are points on the boundary between the two regions on which is continuous. Given such values, we can then define bounds and such that
for all and
for all . Moreover, piecewise continuity of the function implies that by choosing both and close enough to we can make the bounds arbitrarily close to and make the bounds arbitrarily close to
Next, for any set of four probabilities and let us define
(82)
where
(83)
and are two independent random variables, each distributed uniformly on [0, 1]. Then if lies between the lower bound and upper bound whenever , and between the lower bound and upper bound whenever , then the probability of a processing unit representing the magnitude giving a 'high' reading will lie between the bounds where is the quantile of within the prior distribution. It follows that in the case of any two magnitudes with the probability of an erroneous comparison will be bounded below by where for since the probability of a correct discrimination will be maximized by making the units representing give as few high readings as possible and the units representing give as many high readings as possible. Integrating over all possible draws of , one finds that the quantity defined in Equation 82 is a lower bound for the overall probability of an erroneous comparison, given that regardless of the prior the quantiles will be two independent draws from the uniform distribution on
Now consider again an encoding function of the kind discussed two paragraphs above, and an interval of stimulus values of the kind discussed there. For any prior distribution with support entirely contained within the interval , the probability of an erroneous comparison is bounded below by
where the function is defined in Equation 82. Moreover, by choosing the values close enough to , we can make this lower bound arbitrarily close to where for any probabilities we define
(84)
Hence in the case of the encoding function considered, the upper bound must be at least as large as We further observe that the quantity defined in Equation 84 is just the probability of an erroneous comparison in the case of an encoding rule according to which
Note that in the case of such an encoding rule, the probability of an erroneous comparison is the same for all prior distributions, since under this rule all that matters is the distribution of the quantile ranks of and . It is moreover clear that is an increasing function of and a decreasing function of It thus achieves its minimum possible value if and only if and , in which case it takes the value the probability of erroneous comparison in the case of decision by sampling (again, independent of the prior distribution).
Thus in the case that there exists any magnitude for which or both, there exist priors for which must exceed Hence in order to minimize the upper bound it must be the case that and for all . But then our assumption that the encoding rule is at least weakly increasing in and at least weakly decreasing in requires that
Thus the encoding rule must be the DbS rule, the unique rule for which is no greater than
Appendix 7
Sufficient conditions for the optimality of DbS
Here we consider the general problem of choosing a value of (the number of samples from the contextual distribution to use in encoding any individual stimulus) and an encoding rule to be used by each of the processing units that encode the magnitude of that single stimulus, so as to minimize the compound objective
where is the upper bound on the probability of an erroneous comparison under the encoding rule θ, and is the cost of using a sample of size when encoding each stimulus magnitude. The value of is taken as fixed at some finite value. (This too can be optimized subject to some cost of additional processing units, but we omit formal analysis of this problem.) We assume that is an increasing function of , and can without loss of generality assume the normalization In this optimization problem, we assume that the only encoding functions to be considered are ones that are piecewise continuous, at least weakly increasing in , and weakly decreasing in each of the .
For any value of , let be the minimum achievable value for (Appendix 6 illustrates how this kind of problem can be solved, for the case .) Then the optimal value of will be the one that minimizes
We can establish a lower bound for that holds for any :
(85)
In the second line, we allow the function to be chosen after a particular prior has already been selected, which cannot increase the worst-case error probability. In the third line, we note that the only thing that matters about the encoding function chosen in the second line is the mean value of for each possible magnitude , integrating over the possible samples of size that may be drawn from the specified prior; hence we can more simply write the problem on the second line as one involving a direct choice of a function which may be different depending on the prior that has been chosen. The problem on the third line defines a bound that does not depend on .
A set of sufficient conditions for to be optimal is then given by the assumptions that
, and
.
Condition (a) implies that will be inferior to : the cost of a single sample is not so large as to outweigh the reduction in that can be achieved using even one sample. Condition (b) implies that will be superior to any The lower bound (Equation 85), together with our monotonicity assumption regarding , implies that for any ,
and hence that
While condition (b) is stronger than is needed for this conclusion, the sufficient conditions stated in the previous paragraph have the advantage that we need only consider optimal encoding rules for the cases and , and the efficient coding problem stated in definition (Equation 85), in order to verify that the conditions are both satisfied. The efficient coding problem for the case is treated in Appendix 6, where we show that Using the calculations explained in Appendix 2, we can provide an analytical approximation to this quantity in the limiting case of large .
Equation 37 states that for any encoding rule and any prior distribution , the value of for any large enough value of will approximately equal
where is the probability density function of the distribution of values for implied by the function and the distribution of values for . In the case of DbS, the probability distribution over alternative internal representations (and hence the probability of error) is the same as in the case of an encoding rule so that Equation 37 can be applied. Furthermore, for any prior distribution the probability distribution of values for the quantile will be a uniform distribution over the interval , so that for all θ. It follows that
(86)
In the case that instead, the same function must be used regardless of the contextual distribution Under the assumption that is piecewise continuous, there must exist a magnitude such that is continuous over some interval containing in its interior. Let be the greatest lower bound and least upper bound respectively, such that
for all The continuity of on this interval means that by choosing both and close enough to we can make both and arbitrarily close to
By the same argument as in Appendix 6, for any prior distribution with support entirely contained in the interval , the pair of stimulus magnitudes will have to imply with probability 1, and as a consequence the error probability will necessarily be greater than or equal to the lower bound By choosing both and close enough to we can make this lower bound arbitrarily close to Hence for any encoding rule with the upper bound cannot be lower than 1/2. It follows that
Given this, condition (a) can alternatively be expressed as
Note that if remains less than 1/2 no matter how large is, this condition will necessarily be satisfied for all large enough values of , since Equation 86 implies that eventually becomes arbitrarily small, in the case of large enough . (On the other hand, the condition can easily be satisfied for some range of smaller values of , even if once becomes very large.)
In order to consider the conditions under which condition (b) will also be satisfied, it is necessary to further analyze the efficient coding problem stated in Equation 85. We first observe that for any prior and encoding rule the encoding rule can always be expressed in the form where is a piecewise-continuous, weakly increasing function giving the probability of a 'high' reading as a function of the quantile of the stimulus magnitude in the prior distribution. We then note that when this representation is used for the encoding function in Equation 85, the error probability depends only on the function in a way that is independent of the prior Hence the inner minimization problem in Equation 85 can equivalently be written as
(87)
This problem has a solution for the optimal for any number of processing units , and an associated value that is independent of the prior Hence we can write the bound defined in Equation 85 more simply as
(88)
Condition (b) will be satisfied as long as the bound defined in Equation 88 is not too much lower than In fact, this bound can be a relatively large fraction of We consider the problem of the optimal choice of an encoding function for a known prior in Appendix 2. In the limiting case of a sufficiently large , substitution of Equation 2 into 37 yields the approximate solution
(89)
Thus as n is made large, the ratio converges to the value
(90)
This means that increases in the sample size above one cannot reduce by even 20 percent relative to , no matter how large the sample may be, whereas may be only a small fraction of (as is necessarily the case when is large). This makes it quite possible for to be larger than while at the same time is larger than . In this case, the optimal sample size will be and the optimal encoding rule will be DbS.
While these analytical results for the asymptotic (large-) case are useful, we can also numerically estimate the size of the terms and in the case of any finite value for . We have derived an exact analytical value for above. The quantity can be computed through Monte Carlo simulation for any value of . (Note that this calculation depends only on , and is independent of the contextual distribution ; we need only to calculate for the function .) The calculation of for a given finite value of is instead more complex, since it requires us to optimize over the entire class of possible functions
Our approach is to estimate the minimum achievable value of by finding the minimum achievable value over a flexible parametric family of possible functions We specify the function in terms of the implied the CDF for values of . We let be implicitly defined by
(91)
where is a function of with the properties that as required for to be the CDF of a probability distribution. More specifically, we assume that is a finite-order polynomial function consistent with these properties, which require that it can be written in the form
(92)
where are a set of parameters over which we optimize. Note that for a large enough value of , any smooth function can be well approximated by a member of this family. At the same time, our choice of a parametric family of functions has the virtue that the CDF that corresponds to the optimal coding rule in the large- limit belongs to this family (regardless of the value of ), since this coding rule (Equation 3) corresponds to the case of Equation 92.
We computed via numerical simulations the best encoder function assuming to be of order 5 (Equation 92) for various finite values of , and we define the expected error of this optimal encoder for a given to be (i.e., a lower bound for within the family of functions defined by ). Our goal is to compare this quantity to the asymptotic approximation , in order to evaluate how accurate the asymptotic approximation is.
Additionally, we also compute the value for each finite value of through Monte Carlo simulation (please note that is different from the quantity defined in Equation 86, that is only an asymptotic approximation for large ). Then, we can compare to the value predicted by the asymptotic approximations and .
Another quantity that is important to compute, in order to determine whether DbS can be optimal when is not too large, is the size of relative to the quantities computed above. Since does not shrink as increases, it is obvious that is much larger than the other quantities in the large- limit. But how much bigger is it when is small? To investigate this, we compute the value of the ratio when is small. This quantity is given by
(93)
In Appendix 7—figure 1, all error quantities discussed above are normalized relative to . The black dashed lines in both panels represent . The ratio of the asymptotic approximation for relative to is plotted with the red dashed lines, where . Note that the sufficient conditions for DbS to be optimal can be stated as
, and
.
Therefore, Appendix 7—figure 1 shows the numerical magnitudes of the expressions on the right-hand side of both inequalities (normalized by the value of ). The most important result from the analyses presented in this figure is that even for small values of , the right-hand side of the first inequality (see right panel) will be a much larger quantity than the right-hand side of the second inequality (see left panel). Thus it can easily be the case that and are such that both inequalities are satisfied: it is worth increasing from 0 to 1, but not worth increasing to any value higher than 1. In this case, the optimal sample size will be and the optimal encoding rule will be DbS.
Appendix 7—figure 1
Performance of efficient coding rules.
Additionally, we found that the computations of for each finite value of are slightly higher than even for small values (blue line in the left panel), but quickly reach the asymptotic value as increases. Thus, even for small values of , the asymptotic approximation of optimal performance for the case of complete prior knowledge is superior than DbS. We also found that the computations of for each finite value of cannot reduce by even five percent for small values (orange line in the left panel). Moreover, quickly reached the asymptotic value , thus suggesting that the asymptotic solution is virtually indistinguishable from the optimal solution (at least based on the flexible family of functions) also for finite values of , which crucially are in the range of the values found to explain the data in the numerosity discrimination experiment of our study. Thus, these results confirm that the asymptotic approximations used in our study are not likely to influence the conclusions of the experimental data in our work.
Appendix 8
Relation to Bhui and Gershman, 2018
Bhui and Gershman, 2018 also argue that an efficient coding scheme can be implemented by a version of DbS. However, both the efficient coding problem that they consider, and the version of DbS that they consider, are different than in our analysis, so that our results are not implied by theirs.
Like us, Bhui and Gershman consider encoding schemes in which the internal representation must take one of a finite number of values. However, their efficient coding problem considers the class of all encoding rules that assign one or another of possible values of to a given stimulus . In their discussion of the ideal efficient coding benchmark, they do not require to be the ensemble of output states of a set of neurons, each of which must use the same rule as the other units, and therefore consider a more flexible family of possible encoding rules, as we explain in more detail below.
The encoding rule that solves our efficient coding problem is stochastic; even under the assumption that the prior is known with perfect precision (the case of unbounded in the more general specification of our framework, so that sampling error in estimation of this distribution from prior experience is not an issue), we show that it is optimal for the probabilities not to all equal either zero or one. The optimal rule within the more flexible class considered by Bhui and Gershman is instead deterministic: each stimulus magnitude is assigned to exactly one category with certainty. The boundaries between the set of categories furthermore correspond to the quantiles of the prior distribution, so that each category is used with equal frequency. Thus the optimal encoding rule is given by a deterministic function a non-decreasing step function that takes discrete values.
Bhui and Gershman show that when there is no bound on , the number of samples from prior experience that can be used to estimate the contextual distribution — their optimal encoding rule for a given number of categories — can be implemented by a form of DbS. However, the DbS algorithm that they describe is different than in our discussion. Bhui and Gershman propose to implement the deterministic classification by computing the fraction of the sampled values that are less than . In the limiting case of an infinite sample from the prior distribution, this fraction is equal to with probability one, and is then determined by which of the intervals the quantile falls within. Thus whereas in our discussion, DbS is an algorithm that allows each of our units to compute its state using only a single sampled value the DbS algorithm proposed by Bhui and Gershman to implement efficient coding is one in which a large number of sampled values are used to jointly compute the output states of all of the units in a coordinated way.
Bhui and Gershman also consider the case in which only a finite number of samples can be used to compute the representation of a given stimulus magnitude , and ask what kind of rule is efficient in that case. They show that in this case a variant of DbS with kernel-smoothing is superior to the version based on the empirical quantile of (which now involves sampling error). In this more general case, the variant DbS algorithms considered by Bhui and Gershman make the representation of a given stimulus probabilistic; but the class of probabilistic algorithms that they consider remains different from the one that we discuss. In particular, they continue to consider algorithms in which the category can be an arbitrary function of and a single set of sampled values that is used to compute the complete representation; they do not impose the restriction that be the number of units giving a 'high' reading when the output state of each of individual processing units is computed independently using the same rule (but an independent sample of values from prior experience in the case of each unit).
The kernel-smoothing algorithms that they consider are based on a finite set of pairwise comparisons between the stimulus magnitude and particular sampled values , the outcomes of which are then aggregated to obtain the internal representation . However, they allow the quantity computed by comparing to an individual sampled value to vary continuously between 0 and 1, rather than having to equal either 0 or 1, as in our case (where the state of an individual unit must be either 'high' or 'low'). The quantities are able to be summed with perfect precision, before the resulting sum is then discretized to produce a final representation that takes one of only possible values. Thus an assumption that only finite-precision calculations are possible is made only at the stage where the final output of the joint computation of the processors must be ‘read out’; the results of the individual binary comparisons are assumed to be integrated with infinite precision. In this respect, the algorithms considered by Bhui and Gershman are not required to economize on processing resources in the same sense as the class that we consider; the efficient coding problem for which they present results is correspondingly different from the problem that we discuss for the case in which is finite.
Data availability
Data and essential code that support the findings of this study have been made available at the Open Science Framework (https://osf.io/xgfu9/).
References
-
Suprathreshold stochastic resonance induced by ion channel fluctuationPhysica D: Nonlinear Phenomena 239:327–334.https://doi.org/10.1016/j.physd.2009.12.002
-
Some informational aspects of visual perceptionPsychological Review 61:183–193.https://doi.org/10.1037/h0054663
-
Possible principles underlying the transformations of sensory messagesSensory Communication 1:217–234.https://doi.org/10.7551/mitpress/9780262518420.003.0013
-
Redundancy reduction revisitedNetwork: Computation in Neural Systems 12:241–253.https://doi.org/10.1080/net.12.3.241.253
-
Decision by sampling implements efficient coding of psychoeconomic functionsPsychological Review 125:985–1001.https://doi.org/10.1037/rev0000123
-
Reminders of past choices bias decisions for reward in humansNature Communications 8:15958.https://doi.org/10.1038/ncomms15958
-
Weber's Law: A mechanistic foundation after two centuriesTrends in Cognitive Sciences 23:906–908.https://doi.org/10.1016/j.tics.2019.09.001
-
Condition dependence, developmental plasticity, and cognition: implications for ecology and evolutionTrends in Ecology & Evolution 28:290–296.https://doi.org/10.1016/j.tree.2013.02.004
-
Introduction: the origins of numerical abilitiesPhilosophical Transactions of the Royal Society B: Biological Sciences 373:20160507.https://doi.org/10.1098/rstb.2016.0507
-
Jeffreys' prior is asymptotically least favorable under entropy riskJournal of Statistical Planning and Inference 41:37–60.https://doi.org/10.1016/0378-3758(94)90153-8
-
The neural basis of the Weber-Fechner law: a logarithmic mental number lineTrends in Cognitive Sciences 7:145–147.https://doi.org/10.1016/S1364-6613(03)00055-X
-
Comparing perceptual and preferential decision makingPsychonomic Bulletin & Review 23:723–737.https://doi.org/10.3758/s13423-015-0941-1
-
Efficient sensory encoding and bayesian inference with heterogeneous neural populationsNeural Computation 26:2103–2134.https://doi.org/10.1162/NECO_a_00638
-
Optimality and heuristics in perceptual neuroscienceNature Neuroscience 22:514–523.https://doi.org/10.1038/s41593-019-0340-4
-
The importance of being variableJournal of Neuroscience 31:4496–4503.https://doi.org/10.1523/JNEUROSCI.5641-10.2011
-
Calibrating the mental number lineCognition 106:1221–1247.https://doi.org/10.1016/j.cognition.2007.06.004
-
Regulation of evidence accumulation by pupil-linked arousal processesNature Human Behaviour 3:636–645.https://doi.org/10.1038/s41562-019-0551-4
-
Cognitive imprecision and Small-Stakes risk aversionThe Review of Economic Studies rdaa044.https://doi.org/10.1093/restud/rdaa044
-
A simple coding procedure enhances a neuron's Information CapacityZeitschrift Für Naturforschung C 36:910–912.https://doi.org/10.1515/znc-1981-9-1040
-
Efficient coding and the neural representation of valueAnnals of the New York Academy of Sciences 1251:13–32.https://doi.org/10.1111/j.1749-6632.2012.06496.x
-
BookVision: A Computational Investigation Into the Human Representation and Processing of Visual InformationWH Freeman and Company.
-
The adaptive value of numerical competenceTrends in Ecology & Evolution 35:605–617.https://doi.org/10.1016/j.tree.2020.02.009
-
Representation of number in the brainAnnual Review of Neuroscience 32:185–208.https://doi.org/10.1146/annurev.neuro.051508.135550
-
Neural population coding is optimized by discrete tuning curvesPhysical Review Letters 103:138101.https://doi.org/10.1103/PhysRevLett.103.138101
-
Energy limitation as a selective pressure on the evolution of sensory systemsJournal of Experimental Biology 211:1792–1804.https://doi.org/10.1242/jeb.017574
-
Toward a theory of memory and attentionPsychological Review 75:522–536.https://doi.org/10.1037/h0026699
-
The mechanistic foundation of Weber's lawNature Neuroscience 22:1–10.https://doi.org/10.1038/s41593-019-0439-7
-
When natural selection should optimize speed-accuracy trade-offsFrontiers in Neuroscience 8:73.https://doi.org/10.3389/fnins.2014.00073
-
Efficient coding of subjective valueNature Neuroscience 22:134–142.https://doi.org/10.1038/s41593-018-0292-0
-
Modeling response times for Two-Choice decisionsPsychological Science 9:347–356.https://doi.org/10.1111/1467-9280.00067
-
Optimal coding and neuronal adaptation in economic decisionsNature Communications 8:1208.https://doi.org/10.1038/s41467-017-01373-y
-
Energy-efficient coding with discrete stochastic eventsNeural Computation 14:1323–1346.https://doi.org/10.1162/089976602753712963
-
Information theory of adaptation in neurons, behavior, and moodCurrent Opinion in Neurobiology 25:47–53.https://doi.org/10.1016/j.conb.2013.11.007
-
Bayesian model selection for group studiesNeuroImage 46:1004–1017.https://doi.org/10.1016/j.neuroimage.2009.03.025
-
Noise characteristics and prior expectations in human visual speed perceptionNature Neuroscience 9:578–585.https://doi.org/10.1038/nn1669
-
The application of suprathreshold stochastic resonance to cochlear implant codingFluctuation and Noise Letters 02:L169–L181.https://doi.org/10.1142/S0219477502000774
-
BookPrinciples of Neural Information Theory: Computational Neuroscience and Metabolic EfficiencySebtel Press.
-
Optimal policy for value-based decision-makingNature Communications 7:12400.https://doi.org/10.1038/ncomms12400
-
Recent is more: a negative time-order effect in nonsymbolic numerical judgmentJournal of Experimental Psychology: Human Perception and Performance 43:1084–1097.https://doi.org/10.1037/xhp0000387
-
Practical bayesian model evaluation using leave-one-out cross-validation and WAICStatistics and Computing 27:1413–1432.https://doi.org/10.1007/s11222-016-9696-4
-
Mindful judgment and decision makingAnnual Review of Psychology 60:53–85.https://doi.org/10.1146/annurev.psych.60.110707.163633
-
A bayesian observer model constrained by efficient coding can explain 'anti-Bayesian' perceptsNature Neuroscience 18:1509–1517.https://doi.org/10.1038/nn.4105
-
Modeling imprecision in perception, valuation, and choiceAnnual Review of Economics 12:579–601.https://doi.org/10.1146/annurev-economics-102819-040518
Article and author information
Author details
Funding
European Commission (grant agreement No. 758604)
- Rafael Polania
ERC (ENTRAINER)
- Rafael Polania
National Science Foundation
- Michael Woddford
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was supported by an ERC starting grant (ENTRAINER) to RP and by a grant of the U.S. National Science Foundation to M.W. This project has received funding from the European Research Council (ERC) under the European Union's Horizon 2020 research and innovation programme (grant agreement No. 758604).
Ethics
Human subjects: Informed consent, and consent to publish, was obtained. The experiments conformed to the Declaration of Helsinki and the experimental protocol was approved by the Ethics Committee of the Canton of Zurich (BASEC: 2018-00659).
Copyright
© 2020, Heng et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,003
- views
-
- 445
- downloads
-
- 57
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 57
- citations for umbrella DOI https://doi.org/10.7554/eLife.54962
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Efficient sampling and noisy decisions
eLife 9:e54962.
https://doi.org/10.7554/eLife.54962




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}