Emergence and propagation of epistasis in metabolic networks
- Division of Biological Sciences, University of California, San Diego, United States
Abstract
Epistasis is often used to probe functional relationships between genes, and it plays an important role in evolution. However, we lack theory to understand how functional relationships at the molecular level translate into epistasis at the level of whole-organism phenotypes, such as fitness. Here, I derive two rules for how epistasis between mutations with small effects propagates from lower- to higher-level phenotypes in a hierarchical metabolic network with first-order kinetics and how such epistasis depends on topology. Most importantly, weak epistasis at a lower level may be distorted as it propagates to higher levels. Computational analyses show that epistasis in more realistic models likely follows similar, albeit more complex, patterns. These results suggest that pairwise inter-gene epistasis should be common, and it should generically depend on the genetic background and environment. Furthermore, the epistasis coefficients measured for high-level phenotypes may not be sufficient to fully infer the underlying functional relationships.
Introduction
Life emerges from an orchestrated performance of complex regulatory and metabolic networks within cells. The blueprint for these networks is encoded in the genome. Mutations alter the genome. Some of them, once decoded by the cell, perturb cellular networks and thereby change the phenotypes important for life. Understanding how mutations affect the function of cellular networks is key to solving many practical and fundamental problems, such as finding mechanistic causes of genetic disorders (Hu et al., 2011; Fang et al., 2019), deciphering the architecture of complex traits (Zuk et al., 2012; Mackay, 2014; Wei et al., 2014), building artificial cells (Hutchison et al., 2016), explaining past, and predicting future evolution (Blount et al., 2008; Wiser et al., 2013; de Visser and Krug, 2014; Harms and Thornton, 2014; Kryazhimskiy et al., 2014; Sailer and Harms, 2017a; Sohail et al., 2017). Conversely, mutations can help us learn how cellular networks are organized (Phillips, 2008; van Opijnen and Camilli, 2013).
To infer the wiring diagram of a cellular network that produces a certain phenotype, one approach in genetics is to measure the pairwise and higher-order genetic interactions (or ‘epistasis’) between mutations that perturb it (Phillips, 2008). Much effort has been devoted in the past 20 years to a systematic collection of such genetic interaction data for several model organisms and cell lines (Kelley and Ideker, 2005; Lehner et al., 2006; Jasnos and Korona, 2007; Collins et al., 2007; St Onge et al., 2007; Typas et al., 2008; Roguev et al., 2008; Costanzo et al., 2010; Szappanos et al., 2011; Huang et al., 2012; Roguev et al., 2013; Bassik et al., 2013; Babu et al., 2014; Costanzo et al., 2016; van Leeuwen et al., 2016; Skwark et al., 2017; Du et al., 2017; Heigwer et al., 2018; Horlbeck et al., 2018; Norman et al., 2019; Liu et al., 2019; Kuzmin et al., 2018; New and Lehner, 2019; Celaj et al., 2020). This approach is particulary powerful when the phenotypic effect of one mutation changes qualitatively depending on the presence or absence of a second mutation in another gene, for example when a mutation has no effect on the phenotype in the wildtype background, but abolishes the phenotype when introduced together with another mutation, such as synthetic lethality (Tong et al., 2001). Such qualitative genetic interactions can often be directly interpreted in terms of a functional relationship between gene products (Tong et al., 2001; Davierwala et al., 2005; Phillips, 2008).
Most pairs of mutations do not exhibit qualitative genetic interactions. Instead, the phenotypic effect of a mutation may change measurably but not qualitatively depending on the presence or absence of other mutations in the genome (Babu et al., 2014; Costanzo et al., 2016). The genetic interactions can in this case be quantified with one of several metrics that are termed ‘epistasis coefficients’ (Wagner et al., 1998; Hansen and Wagner, 2001; Mani et al., 2008; Wagner, 2015; Poelwijk et al., 2016). Although some rules have been proposed for interpreting epistasis coefficients, in particular, their sign (Dixon et al., 2009; Lehner, 2011; Baryshnikova et al., 2013), the validity, and robustness of these rules are unknown because there is no theory for how functional relationships translate into measurable epistasis coefficients in any system (Lehner, 2011; Domingo et al., 2019). To avoid this major difficulty, most large-scale empirical studies focus on correlations between epistasis coefficients rather than on their actual values (but see Velenich and Gore, 2013, for a notable exception). Genes with highly correlated epistasis profiles are then interpreted as being functionally related (Segrè et al., 2005; Bellay et al., 2011; Babu et al., 2014; Costanzo et al., 2016; Horlbeck et al., 2018). Although this approach successfully groups genes into protein complexes and larger functional modules (Michaut et al., 2011; Bellay et al., 2011), it does not reveal the functional relationships themselves. As a result, many if not most, genetic interactions between genes and modules still await their biological interpretation (Costanzo et al., 2016; Fang et al., 2019).
While geneticists measure epistasis to learn the architecture of biological networks, evolutionary biologists face the reverse problem: they need to know how the genetic architecture constrains epistasis at the level of fitness. Epistasis determines the structure of fitness landscapes on which populations evolve (Fragata et al., 2019). Understanding it would bear on many important evolutionary questions, such as why so many organisms reproduce sexually (Kondrashov, 2018), how novel phenotypes evolve (Blount et al., 2008; Bridgham et al., 2009; Natarajan et al., 2013; Harms and Thornton, 2014), how predictable evolution is (Weinreich et al., 2006; Tenaillon et al., 2012; Wiser et al., 2013; Kryazhimskiy et al., 2014), etc. So far, evolutionary biologists have relied primarily on abstract models of fitness landscapes (see Orr, 2005, for a review), rather than those firmly grounded in organismal biochemistry and physiology (e.g. Dykhuizen et al., 1987; Das et al., 2020). For example, Fisher’s geometric model—one of the most widely used fitness landscape models—is explicitly devoid of the physiological and biochemical details (Fisher, 1930; Tenaillon, 2014; Martin, 2014).
A theory of epistasis must address two challenges. First, it must specify how the architecture of a biological network constrains epistasis. Such knowledge is important not only for evolutionary questions, but also for the inference problem in genetics. Consider a biological network module that produces a phenotype of interest but whose internal structure is unknown. By genetically perturbing all genes within the module and measuring the phenotype in all single, double and possibly some higher-order mutants, we can obtain the matrix of epistasis coefficients. In principle, we can then fit a network topology and parameters to these data. However, without knowing what information about the network is contained in the matrix in the first place, we cannot be sure whether the inferred topology and parameters are close to their true values or represent one of many possible solutions consistent with the data.
The second challenge is that epistasis may arise at a different level of biological organization than where it is measured by the experimentalist or by natural selection. For example, geneticists are often interested in understanding the structures of specific regulatory or metabolic network modules (Collins et al., 2007; Costanzo et al., 2010). However, measuring the peformance of a module directly is often experimentally difficult or impossible. Then epistasis is measured for an experimentally accessible ‘high-level’ phenotype, such as fitness, which depends on the performance of the focal ‘lower-level’ module, but also on other unrelated modules. However, if we do not know how epistasis that originally emerged in one module maps onto epistasis that is measured, it is unclear what we can infer about module’s internal structure.
Evolutionary biologists encounter a related problem when they wish to learn the evolutionary history of a protein or a larger cellular module. To do so, they would in principle need to know how different mutations in this module affected fitness of the whole organism in its past environment. But such information is rarely available. Instead, it is sometimes possible to reconstruct past mutations and measure their biochemical effects in the lab (Lunzer et al., 2005; Bridgham et al., 2009; Natarajan et al., 2013; Sarkisyan et al., 2016). When interesting patterns of epistasis are identified at the biochemical level, it is usually assumed that the same patterns manifested themselved at the level of fitness and drove module’s evolution. However, this is not obvious. If interactions with other modules distort epistasis as it propagates from the biochemical level to the level of fitness (Snitkin and Segrè, 2011), our ability to infer past evolutionary history from in vitro biochemical measurements could be diminished. Therefore, the second challenge that a theory of epistasis must address is how epistasis propagates from lower-level phenotypes to higher-level phenotypes.
There is a large body of theoretical and computational literature on epistasis. As early as 1934, Sewall Wright realized that epistasis naturally emerges in molecular networks (Wright, 1934). This was later explicitly demonstrated in many mathematical and computational models (e.g. Kacser and Burns, 1981; Keightley, 1989; Szathmáry, 1993; Gibson, 1996; Keightley, 1996; Wagner et al., 1998; Omholt et al., 2000; Peccoud et al., 2004; Gjuvsland et al., 2007; Gertz et al., 2010; Fiévet et al., 2010; Pumir and Shraiman, 2011). Metabolic control analysis became one of the most successful and general frameworks for understanding epistasis between metabolic genes (Kacser and Burns, 1973). Dean et al., 1986, Dykhuizen et al., 1987, Dean, 1989, Lunzer et al., 2005, MacLean, 2010 used it to interpret the empirically measured fitness effects of mutations and their interactions in terms of the metabolic relationships between the products of mutated genes. Kacser and Burns, 1981, Hartl et al., 1985, Keightley, 1989, Clark, 1991, Keightley, 1996, Bagheri-Chaichian et al., 2003, Bagheri and Wagner, 2004, Fiévet et al., 2010 explored the implications of epistasis in metabolism for genetic variation in populations, their response to selection, long-term evolutionary dynamics and outcomes, such as the evolution of dominance. However, most studies analyzed only the linear metabolic pathway (but see Keightley, 1989) and assumed that fitness equals flux through the pathway (but see Szathmáry, 1993), thereby bypassing the problem of epistasis propagation.
There have been few attempts to theoretically relate the molecular architecture of an organism to the types of epistasis that would arise for its high-level phenotypes, such as fitness. Segrè et al., 2005 and He et al., 2010 used flux balance analysis (FBA, Orth et al., 2010) to compute genome-wide distributions of epistasis coefficients in metabolic models of Escherichia coli and Saccharomyces cerevisiae and arrived at starkly discordant conclusions. Recently, Alzoubi et al., 2019 showed that FBA is generally poor in predicting experimentally measured genetic interactions, suggesting that it might be difficult to understand the emergence and propagation of epistasis by relying exclusively on genome-scale computational models. Sanjuán and Nebot, 2008 and Macía et al., 2012 modeled various abstract metabolic and regulatory networks and found a possible link between epistasis and network complexity. The work by Chiu et al., 2012 is a more systematic attempt to develop a general theory of epistasis. They established a fundamental connection between epistasis and the curvature of the function that maps lower-level phenotypes onto a higher-level phenotype. However, further progress has been so far hindered by uncertainty in what types of functions map phenotypes onto one another in real biological systems. Previous studies made various idiosyncratic choices with respect to this mapping, leaving us without a clear guidance as to the conditions or systems where they are expected to hold.
To overcome this problem, here I consider a whole class of hierarchical metabolic networks and obtain the family of all functions that determine how the effective activity of a larger metabolic module can depend on the activities of smaller constituent modules. There are several advantages to this approach. First, it leads to an intuitive understanding of how the structure of the network influences epistasis emergence and propagation. Second, my approach is based on basic biochemical principles, so it should be relevant for many phenotypes. For example, epistasis is often measured at the level of growth rate (Jasnos and Korona, 2007; St Onge et al., 2007; Babu et al., 2014; Costanzo et al., 2016), and metabolism fuels growth. Moreover, metabolic genes occupy a large fraction of most genomes (Orth et al., 2011) and the general organization of metabolism is conserved throughout life (Csete and Doyle, 2004). Thus, by understanding genetic interactions between metabolic genes, we will gain an understanding of a large fraction of all genetic interactions.
In my model, I consider a hierarchical network with first-order kinetics but arbitrary topology, and ask two questions related to the two challenges mentioned above. (1) How does an epistasis coefficient that arose at some level of the metabolic hierarchy propagate to higher levels of the hierarchy? (2) How does the network topology constrain the value of an epistasis coefficient between two mutations that affect different enzymes in this network? I obtain answers to these questions analytically in the limiting case when the effects of mutations are vanishingly small. I then computationally probe the validity of the conclusions outside of the domain where they are expected to hold.
My model is not intended to generate predictions of epistasis for any specific organism. Instead, its main purpose is to provide a baseline expectation for how epistasis that emerges at lower-level phenotypes manifests itself at higher-level whole-organism phenotypes, such as fitness, and what kind of information may be gained from measurements of such higher-level epistasis. One possible outcome of this analysis is that there may be fundamental limitations to what an epistasis measurement at one level of biological organization can tell us about epistasis at another level. On the other hand, if it turns out that there is a general correspondence between epistasis coefficients at different levels in this simple model, then it may be worth developing more sophisticated and general models on which inference from data can be based.
Model
Hierarchical metabolic network
Consider a set of metabolites with concentrations which can be interconverted by reversible first-order biochemical reactions. The rate of the reaction converting metabolite into metabolite is where is the equilibrium constant. The rate constants , which satisfy the Haldane relationships (Cornish-Bowden, 2013), form the matrix . The metabolite set and the rate matrix define a biochemical network .
The first-order kinetics assumption makes the model analytically tractable, as discussed below; biologically, it is equivalent to assuming that all enzymes are far from saturation. The rate constants depend on the concentrations and the specific activities of enzymes and therefore can be altered by mutations. characterize the fundamental chemical nature of metabolites and and cannot be altered by mutations (Savageau, 1976).
The whole-cell metabolic network is large, and it is often useful to divide it into subnetworks that carry out certain functions important for the cell. I define subnetworks mathematically as follows. I say that two metabolites and are adjacent (in the graph-theoretic sense) if there exists an enzyme that catalyzes a biochemical reaction between them, that is, if . Now consider a subset of metabolites . For this subset, let be the set of all metabolites that do not belong to but are adjacent to at least one metabolite from . Let be the submatrix of which corresponds to all reactions where both the product and the substrate belong to either or . The metabolite subset and the rate matrix form a subnetwork of network . I refer to and as the sets of internal and ‘input/output’ (‘I/O’ for short) metabolites for subnetwork μ, respectively. Thus, all internal metabolites and all reactions that involve only internal and I/O metabolites are part of the subnetwork. Note that the I/O metabolites do not themselves belong to the subnetwork, but reactions between them, if they exist, are part of the subnetwork. Metabolites that are neither internal nor I/O for μ are referred to as external to subnetwork μ. These definitions are illustrated in Figure 1A.
Figure 1
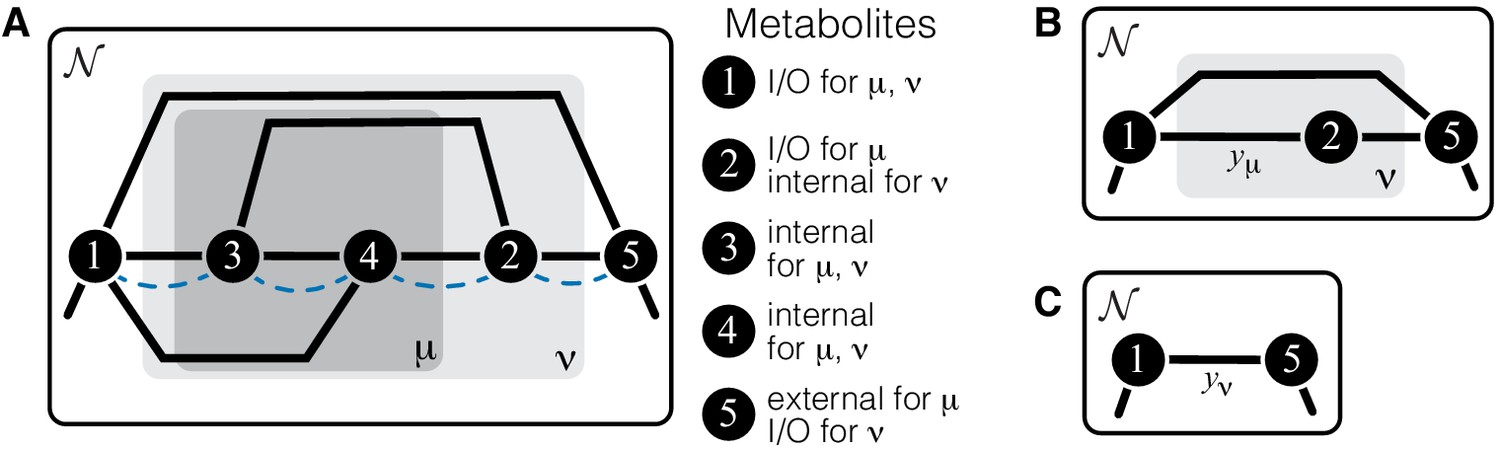
Illustration of a hierarchical metabolic network and its coarse-graining.
(A) White rectangle represents the whole metabolic network . Example subnetworks μ and ν are represented by the dark and light gray rectangles. Only metabolites and reactions that belong to these subnetworks are shown; other metabolites and reactions in are not shown. Metabolites 1 and 5 may be adjacent to other metabolites in ; this fact is represented by short black lines that do not terminate in metabolites. Subnetworks μ and ν are both modules because there exists a simple path connecting their I/O metabolites that lies within μ and ν and contains all their internal metabolites (dashed blue line). (B) Network can be coarse-grained by replacing module μ at steady state with an effective reaction between its I/O metabolites 1 and 2, with the rate constant is . (C) Network can be coarse-grained by replacing module ν at steady state with an effective reaction between its I/O metabolites 1 and 5, with the rate constant is .
The main objects in this work are biochemical modules, which are a special type of subnetworks. To define modules, I introduce some auxiliary concepts. I say that two metabolites and are connected if there exists a series of enzymes that interconvert and , possibly through a series of intermediates. Mathematically, and are connected if there exists a simple (i.e. non-self-intersecting) path between them. If all metabolites in this path are internal to the subnetwork μ (possibly excluding the terminal metabolites and themselves) then and are connected within the subnetwork μ, and such path is said to lie within μ. By this definition, metabolites and can be connected within μ only if they are either internal or I/O metabolites for μ.
Definition 1
A subnetwork μ is called a module if (a) it has two I/O metabolites, and (b) for every internal metabolite , there exists a simple path between the I/O metabolites that lies within μ and contains .
This definition is illustrated in Figure 1A. The assumption that modules only have two I/O metabolites is not essential. However, mathematical calculations become unwieldy when the number of I/O metabolites increases. Moreover, modules with just two I/O metabolites already capture two most salient features of metabolism: its directionality, and its complex branched topology (Csete and Doyle, 2004). Such modules are a natural generalization of the linear metabolic pathway which has been extensively studied in the previous literature (Kacser and Burns, 1973; Szathmáry, 1993; Bagheri-Chaichian et al., 2003; MacLean, 2010).
Modules have two important properties. First, for any given concentrations of the two I/O metabolites, all internal metabolites in the module can achieve a unique steady state which depends only on concentrations of these I/O metabolites but not on the concentrations of any other metabolites in the network (see Proposition 1 in Materials and methods). Now consider a module μ whose I/O metabolites are (without loss of generality) labeled 1 and 2 (Figure 1A). The second property is that, at steady state, the flux through this module is , where
(1)
is the effective reaction rate constant of module μ (Figure 1B). Importantly, depends only on the rate matrix , but not on any other rate constants (see Corollary 2 in Materials and methods), and it can be recursively computed for any module, as described in Materials and methods. In other words, metabolic network can be coarse-grained by replacing module μ at steady state with a single first-order biochemical reaction with rate . Importantly, such coarse-graining does not alter the dynamics of any metabolites outside of module μ (see Proposition 1 in Materials and methods). This statement is the biochemical analog of the star-mesh transformation (and its generalization, Kron reduction, Rao et al., 2014) well known in the theory of electric circuits (Versfeld, 1970). The biological interpretation of these properties is that a module is somewhat isolated from the rest of the metabolic network. And vice versa, the larger network (i.e. the cell) ‘cares’ only about the total rate at which the I/O metabolites are interconverted by the module but ‘does not care’ about the details of how this conversion is enzymatically implemented. In this sense, the effective rate quantifies the function of module μ (a macroscopic parameter) while the rates describe the specific biochemical implementation of the module (microscopic parameters).
The effective rate constant of module μ depends on the entire rate matrix . In general, a single mutation may perturb several rate constants within a module, so that the entire shape of the function may be important. Here, I focus on a special case when each mutation perturbs one reaction (real or effective) within a module, while all others remain constant. To examine epistasis between mutations, I will also consider two different mutations that perturb two separate reactions within a module. In these special cases, we do not need to know the entire function . We only need to know how module’s effective rate constant depends on the one or two rate constants of the perturbed reactions. When is considered as a function of the rate constant ξ of one reaction, I write
(2)
and when is considered as a function of the rate constants ξ and η of two reactions, I write
(3)
The rate constants of all other reactions within module μ play a role of parameters in functions and .
Consider now a network that has a hierarchical structure, such that there is a series of nested modules , in the sense that (Figure 1A). Since any module at steady state can be replaced with an effective first-order biochemical reaction, there exists a hierarchy of quantitative metabolic phenotypes (Figure 1B,C). These phenotypes are of course functionally related to each other. Specifically, because ν is a ‘higher-level’ module (in the sense that it contains a ‘lower-level’ module μ), the matrix can be decomposed into two submatrices and where the latter is the matrix of rate constants of reactions that belong to module ν but not to module μ. Since replacing the lower-level module μ with an effective reaction with rate constant does not alter the dynamics of metabolites outside of μ, must depend on all elements of only through , that is,
(4)
where rates act as parameters of function . Thus, in the hierarchy of metabolic phenotypes , a phenotype at each subsequent level depends on the phenotype at the preceding level according to Equation 4, and the lowest level phenotype depends on the actual rate constants accroding to Equation 1. This hierarchy of functionally nested phenotypes is conceptually similar to the hierarchical ‘ontotype’ representation of genomic data proposed recently by Yu et al., 2016.
Quantification of epistasis
Consider a mutation A that perturbs only one rate constant , such that the wildtype value changes to . This mutation can be quantified at the microscopic level by its relative effect . If the reaction between metabolites and belongs to nested modules , then mutation A may impact the functions of these modules, which can be quantified by the relative effects , , etc. at each level of the hierarchy.
Consider now another mutation B that only perturbs the rate constant of another reaction. Since mutations A and B perturb distinct enzymes, they by definition do not genetically interact at the microscopic level. However, if both perturbed reactions belong to the metabolic module μ (and, as a consequence, to all higher-level modules which contain μ), they may interact at the level of the function of this module, in the sense that the effect of mutation B on the effective rate may depend on whether mutation A is present or not. Such epistasis between mutations A and B can be quantified at the level μ of the metabolic hierarchy by a number of various epistasis coefficients (Wagner et al., 1998; Hansen and Wagner, 2001; Mani et al., 2008). I will quantify it with the epistasis coefficient
(5)
where denotes the effect of the combination of mutations A and B on phenotype relative to the wildtype. Since I only consider two mutations A and B, I will write instead of to simplify notations. Note that other epistasis coefficients can always be computed from , and , if necessary. Expressions for epistasis coefficients at other levels of the metabolic hierarchy are analogous.
Results
The central goal of this paper is to understand the patterns of epistasis between mutations that affect reaction rates in the hieararchical metabolic network described above. Specifically, I am interested in two questions. (1) Given that two mutations A and B have an epistasis coefficient at a lower level μ of the metabolic hierarchy, what can we say about their epistasis coefficient at a higher level ν of the hierarchy? In other words, how does epistasis propagate through the metabolic hierarchy? (2) If mutation A only perturbs the activity of one enzyme and mutation B only perturbs the activity of another enzyme that belongs to the same module μ, then what values of can we expect to observe based on the topological relationship between the two perturbed reactions within module μ? In other words, what kinds of epistasis emerge in a metabolic network?
Propagation of epistasis through the hierarchy of metabolic phenotypes
Assuming that the effects of both individual mutations and their combined effect at the lower-level μ are small, it follows from Equation 4 and Equation 5 that
(6)
where and are the first- and second-order control coefficients of the lower-level module μ with respect to the flux through the higher-level module ν and denotes all terms that vanish as the effects of mutations tend to zero (see Materials and methods for details). Note that Equation 6 is a special case of a more general Equation 49 which describes the case when mutations affect multiple enzymes. Equation 6 defines a linear map with slope and a fixed point , which both depend on the topology of the higher-level module ν and the rate constants .
To gain some intuition for how the map governs the propagation of epistasis from a lower level μ to a higher level ν, suppose that module ν is a linear metabolic pathway. In this case, it is intuitively clear that function is monotonically increasing (i.e. the higher , the more flux can pass through the linear pathway ν) and concave (i.e. as grows, other reactions in ν become increasingly more limiting, such that further gains in yield smaller gains in ). Indeed, it is easy to show that and , where α is a positive constant that depends on other reactions in the pathway (see Materials and methods for details). It then immediately follows that any zero or negative epistasis that already arose at the lower level would propagate to negative epistasis at the level of the linear pathway ν. Moreover, since , the fixed point of the map in Equation 6 is unstable. Therefore, if epistasis was already sufficiently large at the lower level, it would induce even larger positive epistasis at the level of the linear pathway ν. In fact, when module ν is a linear pathway, , so that whenever .
The first result of this paper is the following theorem, which shows that the same rules of propagation of epistasis hold not only for a linear pathway but for any module (Figure 2).
Figure 2
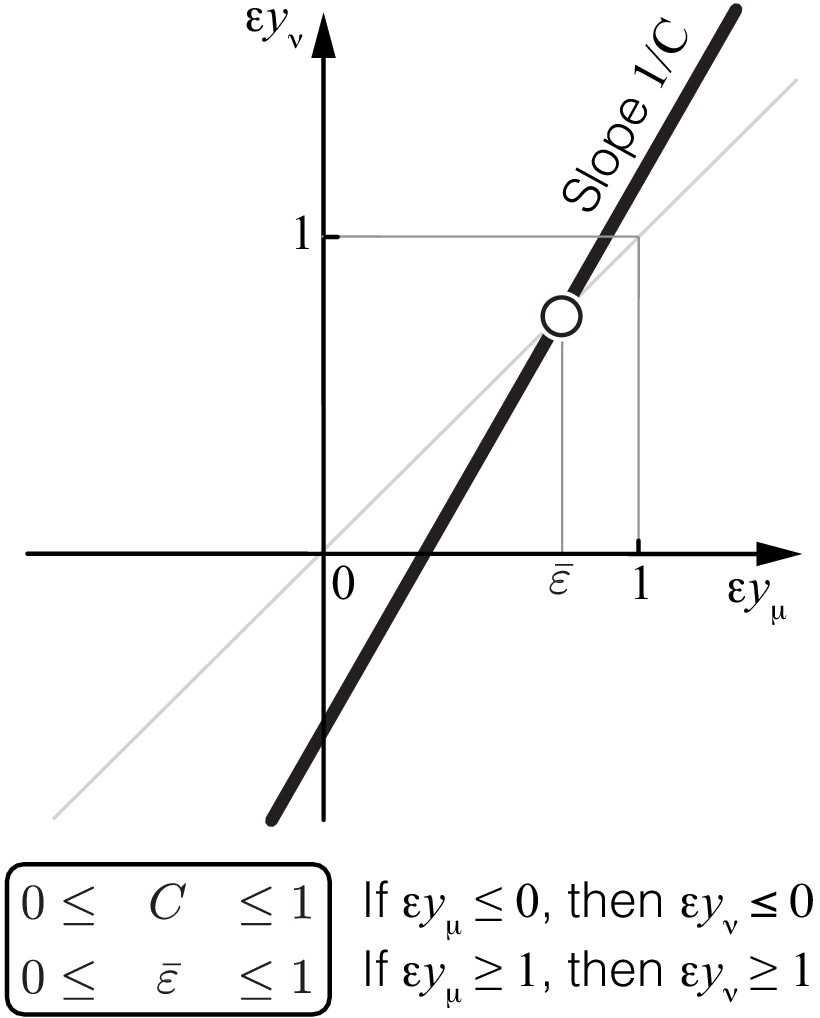
Propagation of epistasis.
Properties of Equation 6 that maps lower-level epistasis onto higher-level epistasis . Slope and fixed point depend on the topology and the rate constants of the higher-level module ν, but they are bounded, as shown. Thus, the fixed point of this map lies between 0 and 1 and is always unstable (open circle).
Theorem 1
For any module ν,
(7)
and
(8)
The proof of Theorem 1 is given in Materials and methods. Its main idea is the following. The functional form of in Equation 4 depends on the topology of module ν. Since the number of topologies of ν is infinite, we might a priori expect that there is also an infinite number of functional forms of . However, this is not the case. In fact, all higher-level modules that contain a lower-level module fall into three topological classes defined by the location of the lower-level module with respect to the I/O metabolites of the higher-level module (see Proposition 2 and Figure 7 in Materials and methods). To each topological class corresponds a parametric family of the function , so that there are only three such families. For each family, the values of and can be explicitly calculated, yielding the bounds in Equation 7 and Equation 8.
Equation 6 together with Equation 7 and Equation 8 show that the linear map from epistasis at a lower-level to epistasis at the higher-level has an unstable fixed point between 0 and 1 (Figure 2). This implies that negative epistasis at a lower level of the metabolic hierarchy necessarily induces negative epistasis of larger magnitude at the next level of the hierarchy, that is, . Therefore, once negative epistasis emerges somewhere along the hierarchy, it will induce negative epistasis at all higher levels of the hierarchy, irrespectively of the topology or the kinetic parameters of the network.
Similarly, if epistasis at the lower level of the metabolic hierarchy is positive and strong, , it will induce even stronger positive epistasis at the next level of the hierarchy, that is, . Therefore, once strong positive epistasis emerges somewhere in the metabolic hierarchy, it will induce strong positive epistasis of larger magnitude at all higher levels of the hierarchy, irrespectively of the topology or the kinetic parameters of the network. If positive epistasis at a lower level of the hierarchy is weak, , it could induce either negative, weak positive or strong positive epistasis at the higher level of the hierarchy, depending on the precise value of , the topology of the higher-level module ν and the microscopic rate constants .
In summary, there are three regimes of how epistasis propagates through a hierarchical metabolic network. Negative and strong positive epistasis propagate robustly irrespectively of the topology and kinetic parameters of the metabolic network, whereas the propagation of weakly positive epistasis depends on these details. The strongest qualitative prediction that follows from Theorem 1 is that negative epistasis for a lower-level phenotype cannot turn into positive epistasis for a higher-level phenotype, but the converse is possible.
Emergence of epistasis between mutations affecting different enzymes
Which of the three regimes described above can emerge in metabolic networks and under what circumstances? In other words, if two mutations affect the same module, are there any constraints on epistasis that might arise at the level of the effective rate constant of this module? To address this question, I consider two mutations A and B that affect the rate constants of different single reactions within a given module.
Consider a relatively simple module ν shown in Figure 1A and two mutations A and B that affect the reactions, as shown in Figure 3A. I will now show that the epistasis coefficient can take values in all three domains described above, depending on the biochemical details of this module. Using the recursive procedure for evaluating described in Materials and methods, it is straightforward to obtain an analytical expression for as a function of the rate matrix , from which can also be obtained (see Materials and methods for details). To demonstrate that can take values below 0, between 0 and 1, and above 1, it is convenient to keep all of the rate constants fixed except for the rate constant of a reaction that is not affected by mutations A or B, as shown in Figure 3A. Figure 3B then shows how the epistasis coefficient varies as a function of for one particular choice of all other rate constants. When is small, . As increases, it becomes weakly positive () and eventually strongly positive (). Thus, in my model, there are no fundamental constraints on the types of epistasis that can emerge between mutations.
Figure 3
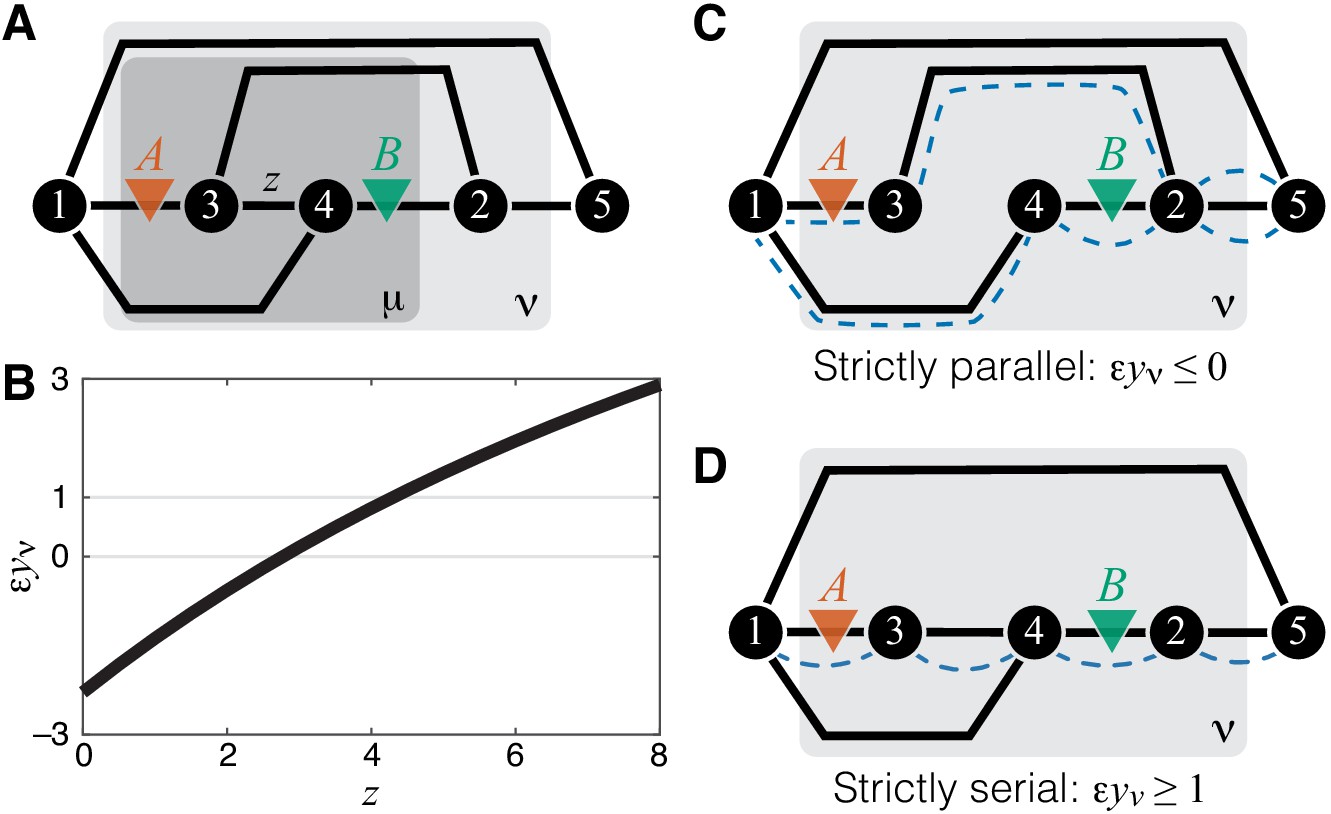
Emergence of epistasis and its dependence on the topological relationship between the reactions affected by mutations.
(A) An example of a simple module ν (same as in Figure 1A) where negative, weak positive and strong positive epistasis can emerge between two mutations A and B. (B) Epistasis between mutations A and B at the level of module ν depicted in (A) as a function of the rate constant of a third reaction. The values of other parameters of the network are given in Materials and Methods. (C) An example of a simple module where reactions affected by mutations are strictly parallel. In such cases, epistasis for the effective rate constant is non-positive. Dashed blue lines highlight paths that connect the I/O metabolites and each contain only one of the affected reactions. (D) An example of a simple module where reactions affected by mutations are strictly serial. In such cases, epistasis for the effective rate constant is equal to or greater than 1 (i.e. strongly positive). Dashed blue line highlights a path that connects the I/O metabolites and contains both affected reactions.
This simple example also reveals that not only the value but also the sign of epistasis generically depend on the rates of other reactions in the network, such that other mutations or physiological changes in enzyme expression levels can modulate epistasis sign and strength. In other words, ‘higher-order’ and ‘environmental’ epistasis are generic features of metabolic networks.
Upon closer examination, the toy example in Figure 3 also suggests that the sign of may depend predictably on the topological relationship between the affected reactions. When , the two reactions affected by mutations are parallel, and epistasis is negative. When is very large, most of the flux between the I/O metabolites passes through such that the two reactions affected by mutations become effectively serial, and epistasis is strongly positive. Other toy models show consistent results: epistasis between mutations affecting different reactions in a linear pathway is always positive and epistasis between mutations affecting parallel reactions is negative (see Materials and methods for details). These observation suggest an interesting conjecture. Do mutations affecting parallel reactions always exhibit negative epistasis and do mutations affecting serial reactions always exhibit positive epistasis? In fact, such relationship between sign of epistasis and topology has been previously suggested in the literature (e.g. Dixon et al., 2009; Lehner, 2011).
To formalize and mathematically prove this hypothesis, I first define two reactions as parallel within a given module if there exist at least two distinct simple (i.e. non-self-intersecting) paths that connect the I/O metabolites, such that each path lies within the module and contains only one of the two focal reactions. Analogously, two reactions are serial within a given module if there exists at least one simple path that connects the I/O metabolites, lies within the module and contains both focal reactions.
According to these definitions, two reactions can be simultaneously parallel and serial, as, for example, the reactions affected by mutations A and B in Figure 3A. I call such reaction pairs serial-parallel. I define two reactions to be strictly parallel if they are parallel but not serial (Figure 3C) and I define two reactions to be strictly serial if they are serial but not parallel (Figure 3D). Thus, each pair of reactions within a module can be classified as either strictly parallel, strictly serial or serial-parallel.
The second result of this paper is the following theorem.
Theorem 2
Let ξ and η be the rate constants of two different reactions in module μ. Suppose that mutation A perturbs only one of these reactions by and mutation B perturbs only the other reaction by . In the limit and , the following statements are true. If the affected reactions are strictly parallel then . If the affected reactions are strictly serial, then .
The detailed proof of this theorem is given in Materials and methods. Its key ideas and the logic are the following. It follows from Equation 3 and Equation 5 that
(9)
where , , are the first- and second-order control coefficients of the affected reactions with respect to the flux through module μ and denotes terms that vanish when and approach zero (see Materials and methods for details). Note that Equation 9 was previously derived by Chiu et al., 2012.
To compute the epistasis coefficient for an arbitrary module μ, we need to know the first and second derivatives of function . Analogous to function , there is a finite number of parametric families to which can belong. Specifically, all modules fall into nine topological classes with respect to the locations of the affected reactions within the module (see Figure 8), and each of these topologies defines a parametric family of function (see Proposition 3 and its Corollary 3 in Materials and methods). Most of these topological classes are broad and contain modules where the affected reactions are strictly parallel, those where they are strictly serial as well as those where they are serial-parallel. And it is easy to show that not all members of each topological class have the same sign of . However, modules from the same topological class where the affected reactions are strictly parallel or strictly serial fall into a finite number of topological sub-classes (see Figure 10 through Figure 14, Table 2 and Table 3). Overall, there are only 17 distinct topologies where the affected reactions are strictly parallel (Table 2), which define 17 parametric sub-families of function . For all members of these sub-families, Equation 9 yields (see Proposition 7 in Materials and methods). Similarly, there are only 11 distinct topologies where the affected reactions are strictly serial (Table 3), which define 11 parametric sub-families of function . For all members of these sub-families, Equation 9 yields (see Proposition 8 in Materials and methods).
The results of Theorem 1 and Theorem 2 together imply that the topological relationship at the microscopic level between two reactions affected by mutations constrains the values of their epistasis coefficient at all higher phenotypic levels. Specifically, if negative epistasis is detected at any phenotypic level, the affected reactions cannot be strictly serial. And conversely, if strong positive epistasis is detected at any phenotypic level, the affected reactions cannot be strictly parallel. In this model, weak positive epistasis in the absence of any additional information does not imply any specific topological relationship between the affected reactions.
Sensitivity of results with respect to the magnitude of mutational effects
Both Theorem 1 and Theorem 2 strictly hold only when the effects of both mutations are infinitesimal. Next, I investigate how these results might change when the mutational effects are finite.
Propagation of epistasis between mutations with finite effect sizes
As mentioned above and discussed in detail in Materials and methods, all higher-level modules that contain a lower-level module fall into three topological classes, which I label , and , depending on the location of the lower-level module within the higher- level module (see Figure 7). The topological class specifies the parametric family of the function which maps the effective rate constant onto the effective rate constant (see Equation 4). For all modules from the topological class , function is linear (see Equation 29), which implies that the results of Theorem 1 hold exactly even when the effects of mutations are finite. For modules from the topological classes and , function is hyperbolic (see Equation 30 and Equation 31), so that the results of Theorem 1 may not hold when the effects of mutations are finite. To test the validity of Theorem 1 in these cases, I calculated the non-linear function that maps the epistasis coefficient onto the epistasis coefficient for 1000 randomly generated modules from each of the two topological classes and for mutations that increase or decrease the effective rate constant of the lower-level module by up to 50% (see Materials and methods for details).
The validity of Theorem 1 depended on the sign of mutational effects. When at least one of the two mutations had a negative effect on , map had the same properties as described in Theorem 1, even for mutations with large effect, that is, it had a fixed point in the interval and this fixed point was unstable. When the effects of both mutations on were positive and small, these results also held in about 82% of sampled modules (see Figure 4A, Figure 4—figure supplement 1, Figure 4—figure supplement 2). In the remaining ∼18% of sampled modules, the fixed point shifted slightly above 1. As the magnitude of mutational effects increased, the fraction of sampled modules with grew, reaching 42% when both mutations increased by 50%. In most of these cases, remained below 2, and I found only one module with (Figure 4A, Figure 4—figure supplement 1, Figure 4—figure supplement 2). Whenever the fixed point existed, it was unstable, with the exception of 12 modules for which was very close to the identity map. For 289 modules (14.5%), the fixed point disappeared when both mutations increased by 50%. In all these cases, , indicating that even large positive epistasis may decline as it propagates through the metabolic hierarchy when the effects of mutations are finite.
Figure 4 with 3 supplements see all
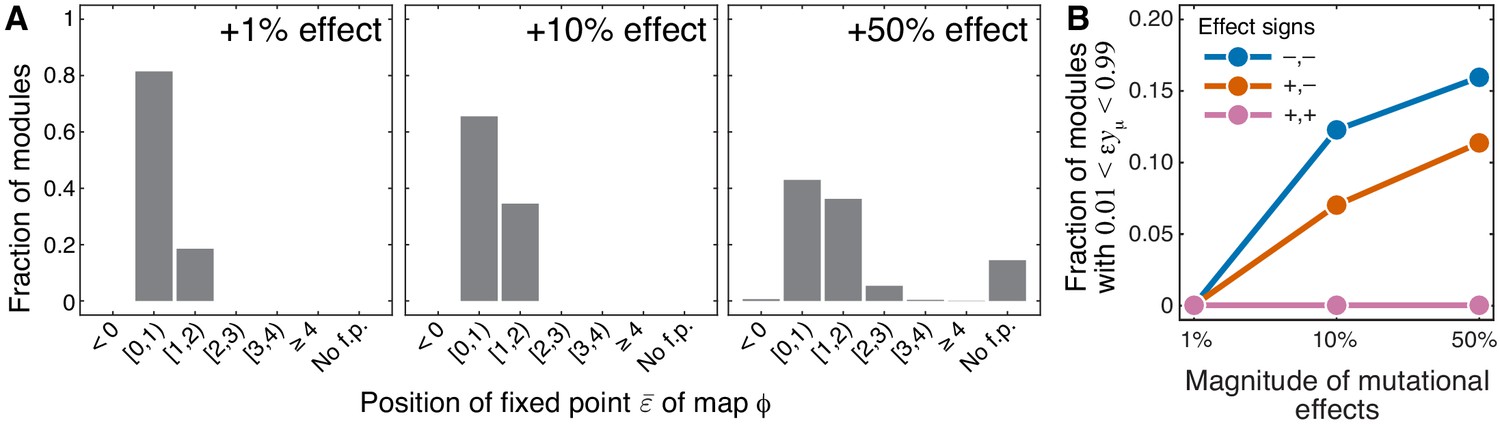
Sensitivity of results of Theorem 1 and Theorem 2 with respect to the magnitude of mutational effects.
(A) Distribution of the position of the fixed point of the function that maps lower-level epistasis onto higher-level epistasis in modules with random parameters and for mutations with positive effects on (see text and Materials and methods for details). All cases are shown in Figure 4—figure supplement 1 and Figure 4—figure supplement 2. The effect size of both mutations is indicated on each panel. ‘No f.p'. indicates that no fixed point exists. (B) Fraction of sampled modules (averaged across generating topologies) where mutations affect strictly serial reactions but the epistasis coefficient is less than 1, contrary to the statement of Theorem 2 (see text and Materials and methods for details). All cases stratified by generating topology are shown in Figure 4—figure supplement 3.
Emergence of epistasis between mutations with finite effect sizes
As mentioned above and discussed in detail in Materials and methods, modules where the reactions affected by mutations are strictly parallel fall into 17 topological classes (see Table 2) and modules where the reactions affected by mutations are strictly serial fall into 11 topological classes (see Table 3). The topological class specifies the parametric family of the function which maps the rate constants ξ and η of the affected reactions onto the effective rate constant . To test how well Theorem 2 holds when the effects of mutations are finite, I calculated for randomly generated modules from these topological classes and for mutations increasing or decreasing ξ and η by up to 50% (see Materials and methods for details).
The validity of Theorem 2 depended most strongly on the topological relationship between the reaction affected by mutations. Whenever the affected reactions were strictly parallel, the epistasis coefficient at the level of module μ was always less than or equal to zero, even when mutations perturbed the rate constants by as much as 50%, consistent with Theorem 2. This was also true for strictly serial reactions, as long as both mutations had positive effects. When the affected reaction were strictly serial and at least one of the mutations had a negative effect, the epistasis coefficient was always positive, but in some cases it was less than 1 (see Figure 4B, Figure 4—figure supplement 3), in disagreement with Theorem 2. This indicates that when the effects of mutations are not infinitesimal, even mutations that affect strictly serial reactions can potentially produce negative epistasis for higher-level phenotypes.
Taken together, these results suggest that both Theorem 1 and Theorem 2 extend reasonably well, but not perfectly, to mutations with finite effect sizes. The domains of validity of both theorems appear to depend on the sign of mutational effects. The way in which the theorems break down as their assumptions are violated appears to be stereotypical: when the mutational effects increase, more types of mutations produce weak epistasis, and the bias toward negative epistasis increases during propagation from lower to higher levels of the metabolic hierarchy.
Beyond first-order kinetics: epistasis in a kinetic model of glycolysis
The results of previous sections revealed a relationship between network topology and the ensuing epistasis coefficients in an analytically tractable model. However, the assumptions of this model are most certainly violated in many realistic situations. It is therefore important to know whether the same or similar rules of epistasis emergence and propagation hold beyond the scope of this model. I address this question here by analyzing a computational kinetic model of glycolysis developed by Chassagnole et al., 2002. This model keeps track of the concentrations of 17 metabolites, reactions between which are catalyzed by 18 enzymes (Figure 5A and Figure 5—figure supplement 1; see Materials and methods for details). This model falls far outside of the analytical framework introduced in this paper: some reactions are second-order, reaction kinetics are non-linear, and in several cases the reaction rates are modulated by other metabolites (Chassagnole et al., 2002).
Figure 5 with 3 supplements see all
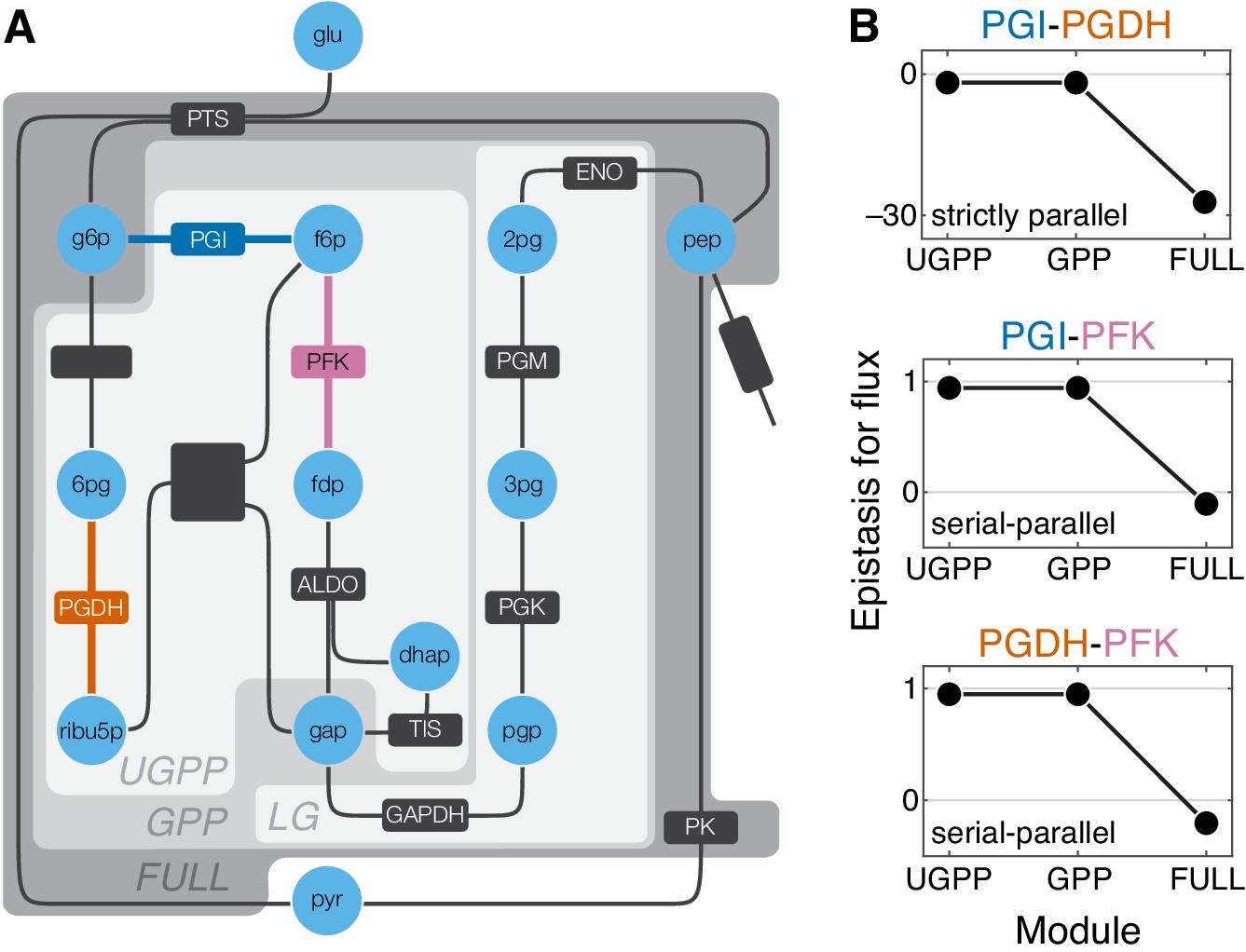
Epistasis in a kinetic model of Escherichia coli glycolysis.
(A) Simplified schematic of the model (see Figure 5—figure supplement 1 for details). Different shades of gray in the background highlight four modules as indicated (see text). Light blue circles represent metabolites. Reactions are shown as lines with dark gray boxes. The enzymes catalyzing reactions whose control coefficients with respect to the flux through the module are positive are named; other enzyme names are ommitted for clarity (see Table 5 and Table 6 for abbreviations). Three reactions, catalyzed by PGI, PFK, PGDH, for which the epistasis coefficients are shown in panel B are highlighted in dark blue, red, and orange, respectively. (B) Epistasis coefficients for flux through each module between mutations perturbing the respective reactions, computed at steady state (see text and Materials and methods for details). Reactions catalyzed by PGI and PGDH are strictly parallel (path g6p-f6p-fdp-gap contains only PGI, path g6p-6pg-ribu5p-gap contains only PGDH and there is no simple path in UGPP between g6p and gap that contains both PGI and PGDH). Reactions catalyzed by PGI and PFK are serial-parallel (path g6p-f6p-fdp-gap contains both reactions, path g6p-f6p-gap contains only PGI, path g6p-6pg-ribu5p-f6p-fdp-gap contains only PFK). Reactions catalyzed by PFK and PGDH are also serial-parallel (path g6p-6pg-ribu5p-f6p-fdp-gap contains both reactions, path g6p-f6p-fdp-gap contains only PFK, path g6p-6pg-ribu5p-gap contains only PGDH).
Testing the predictions of the analytical theory in this computational model faces two complications. First, in a non-linear model, modules are no longer fully characterized by their effective rate constants, even at steady state. Instead, each module is described by the flux between its I/O metabolites which non-linearly depends on the concentrations of these metabolites. Consequently, the effects of mutations and epistasis coefficients also become functions of the I/O metabolite concentrations. An epistasis coefficient at the level of module ν can still be evaluated according to Equation 5, with now representing the flux through module ν evaluated at a particular concentration of the I/O metabolites. For simplicity, I computationally find the steady state of the full glycolysis network and evaluate the epistasis coefficients only at this steady state, that is, for each module, I keep the concentrations of the I/O metabolites fixed at their steady-state values for the full network (see Materials and methods for details).
The second complication is that some control coefficients are so small that they fall below the threshold of numerical precision. Perturbing such reactions has no detectable effect on flux (Figure 5—figure supplement 2). In the analysis that follows, I ignore such reactions because the epistasis coefficient defined by Equation 5 can only be computed for mutations with non-zero effects on flux. In addition, the control coefficients of some reactions are negative, which implies that an increase in the rate of such reaction decreases the flux through the module (Figure 5—figure supplement 2). I also ignore such reactions because there is no analog for them in the analytical theory presented above. After excluding seven reactions for these reasons, I examine epistasis in 55 pairs of mutations that affect the remaining 11 reactions.
The glycolysis network shown in Figure 5A (see also Figure 5—figure supplement 1) can be naturally partitioned into four modules which I name ‘LG’ (lower glycolysis), ‘UGPP’ (upper glycolysis and pentose phosphate), ‘GPP’ (glycolysis and pentose phosophate), and ‘FULL’. Modules LG and UGPP are non-overlappng and both of them are nested in module GPP which in turn is nested in the FULL module. Thus, at least for some reaction pairs it is possible to calculate epistasis coefficients at three levels of metabolic hierarchy. There are three such pairs, and the results for them are shown in Figure 5B. Epistasis for the remaining pairs of reactions can be evaluated only at one or two levels of the hierarchy because these reactions belong to different modules at the lowest levels or because their individual effects are too small. The results for all reaction pairs are shown in Figure 5—figure supplement 3.
The strongest qualitative prediction of the analytical theory described above is that negative epistasis for a lower-level phenotype cannot turn into positive epistasis for a higher-level phenotype, while the converse is possible. Figure 5B and Figure 5—figure supplement 3 show that the data are consistent with this prediction. Another prediction is that epistasis between strictly parallel reactions should be negative. There is only one pair of reactions that are strictly parallel, those catalyzed by glucose-6-phosphate isomerase (PGI) and 6-phosphogluconate dehydrogenase (PGDH), and indeed the epistasis coefficients between mutations affecting these reactions are negative at all levels of the hierarchy (Figure 5B). Finally, the analytical theory predicts that mutations affecting strictly serial reactions should exhibit strong positive epistasis. There are 36 reaction pairs that are strictly serial. Epistasis is positive between mutations in 33 of them, and it is strongly positive in 17 of them (Figure 5—figure supplement 3). Three pairs of strictly serial reactions (those where one reaction is catalyzed by PK and the other is catalyzed by PGI, PGDH, or PFK) exhibit negative epistasis (Figure 5—figure supplement 3). These results suggest that, although one may not be able to naively extrapolate the rules of emergence and propagation of epistasis derived in the simple analytical model to more complex networks, some generalized versions of these rules may nevertheless hold more broadly.
Discussion
Genetic interactions are a powerful tool in genetics, and they play an important role in evolution. Yet, how epistasis emerges from the molecular architecture of the cell and how it propagates to higher-level phenotypes, such as fitness, remains largely unknown. Several recent studies made a statistical argument that the structure of the fitness landscape (and, as a consequence, the epistatic interactions between mutations at the level of fitness) may be largely independent of the underlying molecular architecture of the organism (Martin, 2014; Lyons et al., 2020; Reddy and Desai, 2020). If mutations are typically highly pleiotropic (i.e. affect many independent phenotypes relevant for fitness) or are engaged in a large number of idiosyncratic epistatic interactions with other mutations in the genome, the resulting fitness landscapes converge to certain limiting shapes, such as the Fisher’s geometric model (Martin, 2014; Tenaillon, 2014). To what extent these arguments indeed apply in practice is unclear. But if they do, most genetic interactions detected at the fitness level may be uninformative about the architecture of the underlying biological networks.
In this paper, I took a ‘mechanistic’ approach, which is in a sense orthogonal to the statistical one. In my model of a hierarchical metabolic network, mutations are highly pleiotropic (a mutation in any enzyme affects all the fluxes in the module) and highly epistatic (a mutation in any enzyme interacts with mutations in any other enzyme). Yet, these pleiotropic and epistatic effects appear to be sufficiently structured that some information about the topology of the network is preserved through all levels of the hierarchy. Indeed, the emergence and propagation of epistasis follow two simple rules in my model. First, once epistasis emerges at some level of the hierarchy, its propagation through the higher levels of the hierarchy depends weakly on the details of the network. Specifically, negative epistasis at a lower level induces negative epistasis at all higher levels and strong positive epistasis induces strong positive epistasis at all higher levels, irrespectively of the topology or the kinetic parameters of the network. Second, what type of epistasis emerges in the first place depends on the topological relationship between the reactions affected by mutations. In particular, negative epistasis emerges between mutations that affect strictly parallel reactions and positive epistasis emerges between mutations that affect strictly serial reactions. Insofar as my model is relevant to nature, the key conclusion from it is that epistasis at high-level phenotypes carries some, albeit incomplete, information about the underlying topological relationship between the affected reactions.
These results have implications for the interpretation of empirically measured epistasis coefficients. It is often assumed that a positive epistasis coefficient between mutations that affect distinct genes signals that their gene products act in some sense serially, whereas a negative epistasis coefficient is a signal of genetic redundency, that is, a parallel relationship between gene products (Dixon et al., 2009). My results suggest that this reasoning is generally correct, but that the relationship between epistasis and topology is more nuanced. In particular, the sign of the epistasis coefficient in my model constrains but does not uniquely specify the topological relationship, such that a negative epistasis coefficient implies that the affected reactions are not strictly serial (but may or may not be strictly parallel) and an epistasis coefficient exceeding unity excludes a strictly parallel relationship (but does not necessarily imply a strictly serial relationship). My model suggests that one should also be careful with inferences going in the other direction, that is, extrapolating the patterns of epistasis measured at the biochemical level to those at the level of fitness. For example, if one wishes to infer the past evolutionary trajectory of an enzyme and finds two amino acid changes that exhibit a positive interaction at the level of enzymatic activity, it does not automatically imply that these mutations will exhibit a positive interaction at the level of fitness.
The strongest results presented here rely on several assumptions. I proved Theorem 1 and Theorem 2 in the limit of vanishingly small mutational effects. Some results of the metabolic control analysis, notably the summation theorem, are sensitive to this assumption (Bagheri-Chaichian et al., 2003; Bagheri and Wagner, 2004). To test the sensitivity of my analytical results with respect to this assumption, I used numerical simulations of networks with randomly sampled kinetic parameters and found that the results hold reasonably well when the effects of mutations are not infinitesimal.
The most restrictive assumption in the present work is that of first-order kinetics. Networks with only first-order kinetics clearly fail to capture some biologically important phenomena, such as sign epistasis (Weinreich et al., 2005; Chou et al., 2014; Ewald et al., 2017; Kemble et al., 2020). I discuss possible ways to relax this assumption below. But at present, a major question remains whether the rules of epistasis and propagation described here hold for realistic biological networks and whether they can be directly used to interpret empirical epistasis coefficients. My analysis of a fairly realistic computational model of glycolysis cautions against overinterpreting empirical epistasis coefficients using the rules derived here. But it also suggests that more general rules of propagation and emergence of epistasis may be found for more realistic networks. Thus, the simple rules derived here should probably be thought of as null expectations.
Relaxing the first-order kinetics assumption is analytically challenging because it is critical for replacing a module with a single effective reaction without altering the dynamics of the rest of the network. Although such lossless replacement is almost certainly not possible in networks with more complex kinetics, advanced network coarse-graining techniques may offer a promising way forward (Rao et al., 2014). Flux balance analysis (FBA) is an alternative approach (Orth et al., 2010). FBA is appealing because it entirely removes the dependence of the model on reaction kinetics. However, this comes at a substantial cost. In FBA models, fitness and other high-level phenotypes become independent of the internal kinetic parameters, which is clearly unrealistic. Nevertheless, FBA is often very good at capturing the effects of mutations that change the topology of metabolic networks, such as reaction additions and deletions (reviewed in Gu et al., 2019). At the same time, there is no natural way within FBA to model mutations that perturb reaction kinetics (He et al., 2010; Alzoubi et al., 2019). In short, FBA and my approach are complementary (see Appendix 5 for a more detailed discussion).
Generic properties of epistasis in biological systems
Simple models help us identify generic phenomena—those that are shared by a large class of systems—which should inform our ‘null’ expectations in empirical studies. Deviations from such null in a given system under examination inform us about potentially interesting peculiarities of this system. The model presented here suggests several generic features of epistasis between genome-wide mutations.
Epistasis has two contributions
My analysis shows that the value of an epistasis coefficient measured for a higher level phenotype is a result of two contributions (Domingo et al., 2019), propagation and emergence, which correspond to two terms in Equation 6 (or the more general Equation 49). The first term, propagation, shows that if two mutations exhibit epistasis for a lower-level phenotype they also generally exhibit epistasis for a higher-level phenotype. The second contribution comes from the fact that lower-level phenotypes map onto higher-level phenotypes via non-linear functions. This is true even in a simple model with linear kinetics considered here. As a result, even if two mutations exhibit no epistasis at the lower-level phenotype, epistasis must emerge for the higher-level phenotype, as previously pointed out by multiple authors (e.g. Kacser and Burns, 1981; DePristo et al., 2005; Martin et al., 2007; Chiu et al., 2012; Otwinowski et al., 2018; Domingo et al., 2019; Husain and Murugan, 2020).
Epistasis depends on the genetic background and environment
My analysis shows that the value of an epistasis coefficient for a particular pair of mutations is in large part determined by the topological relationship between reactions affected by them. Since the topology of the metabolic network itself depends on the genotype (which genes are present in the genome) and on the environment (which enzymes are active or not), the topological relationship between two specific reactions might change if, for example, a third mutation knocks out another enzyme or if an enzyme is up- or down-regulated due to an environmental change (see Figure 3). Thus, we should generically expect epistasis between mutations to depend on the environment and on the presence or absence of other mutations in the genome. In other words, interactions (higher-oder epistasis) and interactions (environmental epistasis) should be common (Snitkin and Segrè, 2011; Flynn et al., 2013; Lindsey et al., 2013; Taylor and Ehrenreich, 2015; Sailer and Harms, 2017a). This fact complicates the interpretation of inter-gene epistasis since mutations in the same pair of genes can exhibit qualitatively different genetic interactions in different strains, organisms and environments, as has been observed (St Onge et al., 2007; Musso et al., 2008; Tischler et al., 2008; Dowell et al., 2010; Heigwer et al., 2018; Li et al., 2019). However, the situation may not be hopeless because the topological relationship between two reactions cannot change arbitrarily after addition or removal of a single reaction. For example, if two reactions are strictly parallel, removing a third reaction does not alter their relationship (see Proposition 5). Thus, comparing matrices of epistasis coefficients measured in different environments or genetic backgrounds could inform us about how the organism rewires its metabolic network in response to these perturbations (St Onge et al., 2007; Musso et al., 2008; Heigwer et al., 2018; Li et al., 2019).
Skew in the distribution of epistasis coefficients
Studies that measure epistasis for fitness-related phenotypes among genome-wide mutations usually find both positive and negative epistases, but the preponderance of positive and negative epistasis varies. Some authors reported a skew toward positive interactions among deleterious mutations (Jasnos and Korona, 2007; He et al., 2010; Johnson et al., 2019), whereas others reported a skew toward negative interactions (Szappanos et al., 2011; Costanzo et al., 2016). Beneficial mutations appear to predominantly exhibit negative epistasis, also known as ‘diminishing returns’ epistasis (e.g. Martin et al., 2007; Khan et al., 2011; Chou et al., 2011; Kryazhimskiy et al., 2014; Schoustra et al., 2016). The reasons for these patterns are currently unclear. Several recent theoretical papers offer possible statistical explanations for them (Martin, 2014; Lyons et al., 2020; Reddy and Desai, 2020). On the other hand, mechanistic predictions for the distribution of epistasis coefficients are not yet available (but see Sanjuán and Nebot, 2008; Macía et al., 2012; Chiu et al., 2012). The present work does not directly address this problem either, but it provides some additional clues.
First, my model shows that the sign of epistasis at least to some extent reflects the topology of the network. Thus, the distribution of epistasis coefficients at high-level phenotypes in real organisms should ultimately depend on the preponderance of different topological relationships between the edges in biological networks. It then seems a priori unlikely that positive and negative interactions would be exactly balanced. Thus, we should expect the distribution of epistasis coefficients to be skewed in one or another direction.
The second observation is that in the metabolic model considered here a positive epistasis coefficient at one level of the hierarchy can turn into a negative one at a higher level, but the reverse is not possible. This bias toward negative epistasis at higher-level phenotypes appears to be even stronger in networks with saturating kinetics (Figure 5 and Figure 5—figure supplement 3).
The third observation is that epistasis among beneficial and deleterious mutations affecting metabolic genes should be identical at the level where they arise, provided that beneficial and deleterious mutations are identically distributed among metabolic reactions. Thus, a stronger skew toward negative epistasis among beneficial mutations at the level of fitness could arise in my model for two mutually non-exclusive reasons. One possibility is that beneficial mutations tend to affect certain special subsets of genes, those that predominantly give rise to negative epistasis. For example, beneficial mutations may for some reason predominantly arise in enzymes that catalyze strictly parallel reactions. Another possibility is that when epistasis between beneficial mutations propagates through the metabolic hierarchy it tends to exhibit a stronger negative bias compared to epistasis between deleterious mutations. Indeed, this phenomenon arises in my model among mutations with large effect (see Figure 4A, Figure 4—figure supplement 1 and Figure 4—figure supplement 2).
Epistasis is generic
Perhaps the most important—and also the most intuitive—conclusion of this work is that we should expect epistasis for high-level phenotypes, such as fitness, to be extremely common. Consider first a unicellular organism growing exponentially. Its fitness is fully determined by its growth rate, which can be thought of as the rate constant of an effective biochemical reaction that converts external nutrients into cells (see Appendix 6 for a simple mathematical model of this statement). In other words, growth rate is the most coarse-grained description of a metabolic network and, as such, it depends on the rate constants of all underlying biochemical reactions. Many previous studies have shown that within-protein epistasis is extremely common (e.g. Lunzer et al., 2005; DePristo et al., 2005; Sailer and Harms, 2017b; Husain and Murugan, 2020). Present work shows that, once epistasis arises at the level of protein activity, it will propagate all the way up the metabolic hierarchy and will manifest itself as epistasis for growth rate. It also suggests that growth rate is a generically non-linear function of the rate constants of the underlying biochemical reactions, such that all mutations that affect growth rate individually would also exhibit pairwise epistasis for growth rate with each other (Kacser and Burns, 1981; DePristo et al., 2005; Martin et al., 2007; Chiu et al., 2012; Otwinowski et al., 2018; Husain and Murugan, 2020).
In more complex organisms and/or in certain variable environments, it may be possible to decompose fitness into multiplicative or additive components, for example, plant’s fitness may be equal to the product of the number of seeds it produces and their germination probability, as pointed out by Chou et al., 2011. Then, mutations that affect different components of fitness would exhibit no epistasis. However, such situations should be considered exceptional, as they require fitness to be decomposable and mutations to be non-pleiotropic.
If epistasis is in fact generic for high-level phenotypes, why do we not observe it more frequently? For example, a recent study that tested almost all pairs of gene knock-out mutations in yeast found genetic interactions for fitness for only about 4% of them (Costanzo et al., 2016). One possibility is that many pairs of mutations exhibit epistasis that is simply too small to detect with current methods. As the precision of fitness measurements improves, we would then expect the fraction of interacting gene pairs to grow. Another possibility is that systematic shifts in the distribution of estimated epistasis coefficients away from zero are taken by researchers as systematic errors rather than real phenomena, and are normalized out. Thus, some epistasis that would otherwise be detectable may be lost during data processing.
If epistasis is indeed as ubiquituous as the present analysis suggests, it would call into question how observations of inter-gene epistasis are interpreted. In particular, contrary to a common belief, a non-zero epistasis coefficient does not necessarily imply any specific functional relationship between the components affected by mutations beyond the fact that both components somehow contribute to the measured phenotype (Boyle et al., 2017). The focus of future research should then be not merely on documenting epistasis but on developing theory and methods for a robust inference of biological relationships from measured epistasis coefficients.
Materials and methods
Key ideas and logic of proofs of Theorems 1 and 2
Request a detailed protocolBefore proceeding to the detailed proofs of Theorem 1 and Theorem 2, I informally outline some key ideas and the basic logic.
The central object of the theory is a metabolic module. Modules have two key properties. First, a module is somewhat isolated from the rest of the metabolic network, in the sense that all metabolites inside it interact with only two metabolites outside, the I/O metabolites. The second property is that the metabolites within the module are sufficiently connected that each of them individually as well as any subset of them collectively can achieve a quasi-steady state (QSS), given the concentrations of the remaining metabolites. This property is proven in Proposition 1.
When some metabolites are at QSS, they can be effectively removed from the network and replaced with effective reactions among the remaining metabolites. In other words, one can ‘coarse-grain’ the network by removing metabolites. This approach is a standard biochemical-network reduction technique (Segel, 1988); for example, the Briggs-Haldane derivation of the Michaelis-Menten formula is based on this idea. In general, the resulting effective reactions have more complex (non-linear) kinetics than the original reactions. However, when the original reactions are first-order, the effective reactions are also first-order, that is, there is no increase in complexity. In Network coarse graining and an algorithm for evaluating the effective rate constant for an arbitrary module, I formally define the coarse-graining procedure (CGP) that eliminates one or multiple metabolites and replaces them with effective reactions.
CGP is an essential concept in my theory. I use it to compute the QSS concentrations for internal metabolites within a module (Corollary 1) and thereby prove Proposition 1, mentioned above. Since any module μ can achieve a QSS at any concentrations of its I/O metabolites and since any module has only two I/O metabolites, it can be replaced with a single effective reaction (Corollary 2). CGP provides a way to calculate the rate constant of this reaction. In other words, the CGP is an algorithm for evaluating function in Equation 1 for any module μ.
CGP has an important property: its result does not depend on the order in which metabolites are eliminated. Therefore, in computing the effective rate constant of a module, we can choose any convinient way to eliminate its metabolites. Suppose that one module μ is nested within another module ν as in Figure 1A. A convenient way to compute the effective rate of the larger module is to first coarse-grain the smaller module μ, replacing it with an effective rate , and then eliminate all the remaining metabolites in ν. Since effective rates after coarse-graining do not depend on the order of metabolite elimination, must depend on the rate constants only indirectly, through . In other words, all the information about the smaller module μ that is relevant for the performance of the larger module ν is contained in . Therefore, if a mutation or mutations perturb only reactions inside of the smaller module μ, we only need to know their effects on the effective rate constant to completely understand how they will perturb the performance of the larger module ν. Specifically, if we have two such mutations A and B, all the information about them is contained in three numbers, , and . Theorem 1 then describes how epistasis at the level of module μ propagates to epistasis at the level of module ν.
The proof of Theorem 1 proceeds as follows. Let be the effective reaction with rate constant that represents module μ within the larger module ν, and consider as a function of , as in Equation 4. To obtain , it is convenient to first eliminate all metabolites that do not participate in reaction . No matter what the initial structure of module ν is, such coarse-graining will produce only one of three topologically distinct ‘minimal’ modules, which differ by the location of reaction with respect to the I/O metabolites of module ν (Figure 7). This implies that the function can belong to three parameteric families, where the parameters are the effective rate constants of reactions other than in each of the minimal modules. This is the essence of Proposition 2. Then Theorem 1 can be easily proven by explicitly evaluating the first- and second-order control coefficients for each of the three functions and showing that the statements of the theorem hold for all of them, irrespectively of the function’s parameters.
Now consider two reactions and with rate constants ξ and η, and imagine the two mutations A and B that affect these reactions. To understand what value of will occur, we need to obtain as a function of ξ and η (Equation 3). To do so, it is convenient to first eliminate all metabolites that do not participate in reactions or . No matter what the initial structure of module μ is, such coarse-graining will produce only one of nine topologically distinct minimal modules, which differ by the location of reactions and with respect to the I/O metabolites of module μ and each other (Figure 8). This implies that the function can belong to nine parameteric families. This is the essence of Proposition 3 and Corollary 3.
How does the topological relationship between reactions and translate into epistasis? First, there are only three types of relationships between any pair of reactions in a module: strictly serial, strictly parallel, or serial-parallel (see Figure 3). Second, Proposition 4 and Corollary 4 show that coarse-graining does not alter the strict relationships, that is, if reactions and are strictly serial or strictly parallel before coarse-graining they will remain so after coarse-graining. This is important because it implies that to prove Theorem 2 we do not need to consider an infinitely large space of all modules but only a much smaller space of all minimal modules, that is, those that have only those metabolites that participate in the affected reactions and . Although the space of all minimal modules is still infinite, the space of their topologies is finite (see Figure 8). For some minimal topologies, the connection between the strictly serial or strictly parallel relationship and epistasis can be established very easily. For example, if reaction and reaction both share an I/O metabolite as a substrate (see topological class in Figure 8), then they are always strictly parallel, no matter what the rest of the module looks like. Evaluating the first- and second-order control coefficients for the function that corresponds to this topological class reveals that for any parameter values of .
Unfortunately, most topological classes are too broad and include modules where reactions and are strictly serial as well as modules where they are strictly parallel or serial-parallel (e.g., class ). Consequently, the sign of for such modules can change depending on the values of the rate constants. However, since the number of distinct minimal topologies is finite, it is possible to identify all minimal topologies where the reactions and are strictly serial or strictly parallel. These topological sub-classes define parametric sub-families of function , and we can explicitly calculate for all such functions. However, such brute-force approach is extremely cumbersome because the number of distinct minimal topologies is very large.
Fortunately, the following simple and intuitive fact greatly simplifies this problem. If two reactions are strictly serial or strictly parallel, this relationship does not change if a third reaction is removed from the module. This statement is the essence of Proposition 5. However, if the two reactions are serial-parallel, removal of a third reaction can change the relationship to a strictly serial or a strictly parallel one. As a consequence, there exist certain most connected ‘generating’ topologies where the relationship between the focal reactions is strictly parallel or strictly serial, and any other strictly serial minimal topology can be produced from at least one of the generating topologies by removal of reactions. This is the essence of Proposition 6. All generating topologies can be discovered by a simple algorithm provided in Appendix 3. They are listed in Table 2 and Table 3 and shown in Figure 10 through Figure 14. Each generating topology defines a parametric sub-family of function , and I explicitly evaluate the first- and second-order control coefficients for all these sub-families (see Proposition 7 and Proposition 8) which essentially completes the proof of Theorem 2.
Network coarse-graining
Notations and definitions
Request a detailed protocolHere, I give a more precise definition of the model and introduce additional notations and definitions. As mentioned above, all reactions are first order and reversible. Thus, each reaction has one substrate and one product , and it is fully described by its rate constant . By definition, . I denote the set of all reactions by . The dynamics of metabolite concentrations in the network are governed by equations
(10)
where
(11)
In what follows, it will be important to distinguish three types of reactions within a module, based on their topological relationship to the I/O metabolites of that module. The topology of the module μ is determined by its set of reactions . I call all reactions where both the substrate and the product are internal to module μ as reactions internal to μ, and I denote the set of all such reactions by . For example, module μ in Figure 1A has one internal reaction . I call all reactions where one of the metabolites is internal to μ and the other is an I/O metabolite as the i/o reactions for μ, and I denote the set of all such reactions by . (I reserve upper-case ‘I/O’ for metabolites and use lower-case ‘i/o’ for reactions.) For example, module μ in Figure 1A has three i/o reactions , and . Finally, I refer to reactions between any two I/O metabolites for module μ as bypass reactions for module μ, and I denote the set of all such reactions by . For example, module μ in Figure 1A has no bypass reactions but reaction is a bypass reaction for module ν. By definition, all these three sets of reactions , and are non-overlapping, and .
Another important concept are the simple paths that lie within a module. For any two metabolites , I denote a simple path between them that lies within μ as or, equivalently as (where all ). I say that each of the metabolites belongs to (or is contained in) path (denoted by ). Similarly, I say that each of the reactions belong to (or are contained in) path (denoted by ). I will drop superindex μ from if it is clear what module is being referred to.
Network coarse graining and an algorithm for evaluating the effective rate constant for an arbitrary module
Request a detailed protocolIn this section, I formally introduce and characterize the coarse-graining procedure (CGP). First, I introduce the main idea, which is to eliminate a metabolite that is at QSS and to replace it with a set of new reactions between metabolites adjacent to the eliminated one. This is exactly analogous to the star-mesh transformation in the theory of electric circuits (Versfeld, 1970). The resulting network is a coarse-grained version of the original network in the sense that it has one less metabolite. Next, I define the CGP, which is simply multiple metabolite eliminations applied successively. I prove Proposition 1, which justifies applying the CGP to a whole module and replacing it with a single effective reaction (Corollary 2). Finally, I show how to apply the CGP in practice to compute function from Equation 1 for modules with some simple topologies.
Elimination of a single metabolite
Request a detailed protocolI begin by outlining the main idea behind the CGP, which is to replace one metabolite internal to a module with a series of effective reactions between metabolites adjacent to it. If the effective rate constants are defined appropriately, the dynamics of all metabolites in the resulting coarse-grained network are the same as in the original network, provided that the eliminated metabolite is at QSS in the original network.
To formalize this idea, suppose that module contains internal metabolites. Let be the internal metabolites that will be eliminated. Let be the reduced metabolite set and let be the reduced matrix of rate constants defined by
(12)
(13)
where is given by Equation 11.
Such metabolite elimination has three properties that follow immediately from Equation 12 and Equation 13. First, the rate constants of reactions do not change as long as the eliminated metabolite does not participate in them. Mathematically, for all metabolites and that are not adjacent to the eliminated metabolite . In particular, this is true for all metabolites external to module μ. Second, because equilibrium constants have the property for any metabolites , the rate constants obey Haldane’s relationships. Therefore, the reduced metabolite set and the reduced rate matrix define a new ‘coarse-grained’ metabolic network . It is easy to show that subnetwork μ after the elimination of metabolite is still a module. Third, the reaction set of module μ (i.e., its topology) in the coarse-grained network depends only on the reaction set of this module in the original network , but not on the particular values in the rate matrix .
Next, I will show that the dynamics of metabolites in the coarse-grained network are identical to the dynamics of metabolites in the original network where metabolite is at QSS. Note that if metabolite is at QSS in the network , its concentration is given by
(14)
which follows from Equation 10. Now, the dynamics of metabolites in the network are governed by equations
(15)
where . As mentioned above, for all pairs of metabolites where at least one metabolite is external to module μ. Therefore, Equation 15 for the external metabolites are identical to Equation 10 that govern the dynamics of these metabolites in the original network . Next, consider the dynamics of the I/O and internal metabolites for module μ in the coarse-grained network , that is, those in the set . For any such metabolite , the sum in the righthand side of Equation 15 can be re-written as
(16)
According to Equation 14, the second term in Equation 16 equals , so that Equation 16 becomes
(17)
For any metabolite , the second term in the righthand side of Equation 15 can be re-written as
(18)
Substituting Equation 17 and Equation 18 into Equation 15, we see that Equation 15 is in fact equivalent to Equation 10 for all with given by Equation 14.
The coarse-graining procedure (CGP)
Here, I define the CGP for an arbitrary set of internal metabolites by applying metabolite elimination recursively.
Let be an arbitrary subset of metabolites internal to module μ in the metabolic network and let be the number of elements in . Let be the reduced metabolite set after the metabolites have been eliminated. I define the reduced matrix of rate constants as follows. If , the matrix is defined by Equation 12 and Equation 13. If , then I define it recursively. Suppose that all metabolites in other than some metabolite have been previously eliminated, such that the coarse-grained network is defined, with the set of eliminated metabolites , , and the known matrix . Then, I define the matrix through the elimination of metabolite from , that is,
(19)
(20)
with
(21)
I define the the coarse-graining procedure that eliminates the metabolite set E as a map
As with the elimination of a single metabolite, it is straightforward to show that the rate constants obey Haldane’s relationships, so that is indeed a metabolic network. maps module μ within the metabolic network onto a subnetwork within the metabolic network . It is straightforward to show that is a module. Whenever there is no ambiguity, I will label both the original and the coarse-grained versions of the module by μ. To simplify notations, if the CGP eliminates the entire module μ (i.e., if ), I label it . I label the coarse-grained network that restults from the application of by and I label the effective rate of the reaction substituting module μ in network as .
Intuitively, the result of coarse-graining should not depend on the order in which the metabolites are eliminated. To see this, let us obtain explicit (i.e. not recursive) expressions for . First, by applying the recursion Equation 19, it is easy to show that elimination of two metabolites yields effective rate constants
As expected, Equation 22 and Equation 23 are symmetric with respect to the eliminated metabolites k and . Extrapolating from Equation 23, it is possible to show that for an arbitrary metabolite subset that contains metabolites,
(24)
Here, the second sum is taken over all ordered lists of metabolites from . Each list can be thought of as a simple path within that connects metabolites and . The proof of Equation 24 can be found in Appendix 1. As expected, Equation 24 shows that the effective reation rate does not depend on the order in which metabolites are eliminated. This and other properties of the CGP are listed in Box 1.
Box 1.
Properties of the coarse-graining procedure.
The coarse-graining procedure eliminating metabolites in set has the following useful properties which follow from Equation 24.
The effective rate constants do not depend on the order in which metabolites are eliminated. Therefore, the composition of coarse-graining procedures is commutative, that is, if , where and are two non-overlapping subsets of , then
If at least one of the metabolites or is not adjacent to any of the eliminated metabolites, then . In particular, if either and/or are external to μ.
The topology of module μ after the application of depends only on its original topology but not on the values of its rate constants .
If both metabolites and are adjacent to at least one eliminated metabolite, then where depends only on the rate constants of reactions that involve at least one eliminated metabolite. In particular, if both and are from , then is independent of .
If , then the effective rate constant of module μ depends on the rate matrix but does not depend on any other reaction rates, that is, Equation 1 holds. Furthermore, the functional form of depends only on the topology of module μ, that is, all modules with the same topology are mapped onto by the same function .
Suppose that module μ is nested in a larger module (see Figure 1A). It follows from Property #1 that , that is, can be obtained by carrying out the CGP in two stages, by first eliminating module μ and replacing it with the effective reaction with the rate constant and then eliminating the remaining metabolites in . In the network after the first stage of coarse-graining, all rate constants are identical to those in the original network, that is, they are independent of , by virtue of Property #2. Therefore depends on the rate constants of reactions within module μ only through the effective rate constant of module μ. In other words, Equation 4 holds.
If, in the original network , metabolites and are adjacent or connected by a simple path that contains only the eliminated metabolites, then metabolites and are adjacent in the coarse-grained network .
If, in the metabolic network , metabolites and are not adjacent (i.e. ) and no simple path exists within the set (i.e. such that all non-terminal metabolites in this path are from ) that connects metabolites and , then metabolites and are also not adjacent in the coarse-grained network (i.e., ).
It follows from properties #7 and #8 that for a simple path to exist in module μ after the application of , it is neccessary and sufficient that for each , either and are adjacent in the original module μ or there exists a simple path within the original module μ all of whose non-terminal metabolites are from E.
One of key building blocks of the proofs of Theorem 1 and Theorem 2 is the fact that modules can be classified into a finite number of topological classes (see below). To arrive at this classification, it will be convenient to define a composition of coarse-graining procedures, as follows. Suppose that and are two coarse-graining procedures of network for two subsets of metabolites and . If the sets and are non-overlapping, is also defined for the coarse-grained network which is the result of applying to the original network . The result of applying to the is called the composition of coarse-graining procedures and of the original network and is denoted as .
As defined above, coarse-graining is a formal procedure, and there is no a priori guarantee that (a) it can in fact be carried out for every set of metabolites and (for example, because a metabolite set does not have a steady-state solution); and (b) it will not distort the dynamics in the rest of the network. The following proposition alleviates both of these concerns and thereby justifies the use of the CGP for any subset of internal metabolites within a module (including the entire module μ). It is straightforward to prove it by induction, using the same logic as in the elimination of a single metabolite.
Proposition 1
Request a detailed protocolLet be any subset of metabolites internal to module μ. Then,
There exists a joint QSS solution for all metabolites , given the concentrations of the remaining internal and I/O metabolites for module μ.
The dynamics of all remaining metabolites in in the coarse-grained metabolic network are the same as in where all metabolites in are at QSS.
Corollary 1
Request a detailed protocolWithout loss of generality, suppose that the I/O metabolites for module μ are labeled 1 and 2 and its internal metabolites are labeled . There exists a unique QSS for all . The QSS concentrations can be obtained by recursively applying equation.
(25)
for .
Equation 25 follows from Equation 10 for the coarse-grained network obtained by eliminating metabolites .
Corollary 2
Request a detailed protocolWithout loss of generality, suppose that the I/O metabolites for module μ are labeled 1 and 2. Module μ can be replaced with a single effective reaction between its I/O metabolites, whose rate constant can be calculated using Equation 19 and Equation 20 or Equation 24. The dynamics of all metabolites in the resulting coarse-grained metabolic network are identical to their dynamics in the original network where all metabolites internal to module μ are at the QSS determined by Equation 25.
Computation of effective rate constants for simple modules
Request a detailed protocolCorollary 2 provides a method for replacing any module μ at QSS with an effective rate , which can be calculated using Equation 19 and Equation 20 or Equation 24. Here, I show how to implement this calculation for three simple metabolic modules.
Linear pathway
Request a detailed protocolConsider a linear pathway with I/O metabolites 1 and and internal metabolites (Figure 6A). This labeling of metabolites is more convenient for the linear pathway. To calculate , I will apply recursion Equation 19 and Equation 20. I start by eliminating metabolite 2. After this initial coarse-graining step, the resulting module is still a linear pathway, where two reactions were replaced with a single reaction with the effective rate constant.
Figure 6
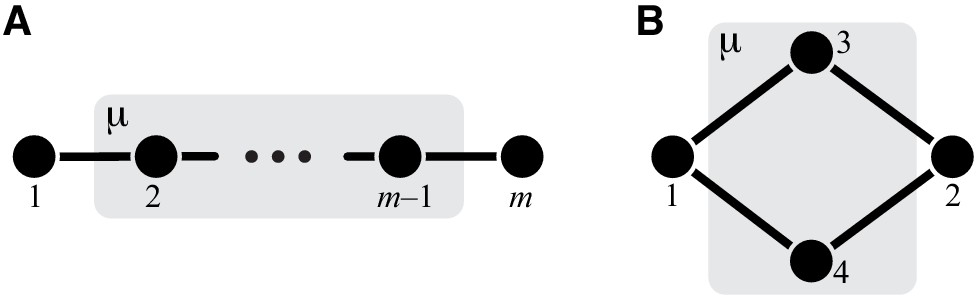
Simple modules.
(A) Linear pathway. (B) Two parallel pathways.
All other rate constants remain unchanged. Next, I eliminate metabolite 3. The resulting module is still a linear pathway, where now three reactions were replaced with a single reaction with the effective rate constant
All other rate constants remain unchanged. Continuing this process until all internal metabolites are eliminated, I obtain
(26)
which is identical to the expression originally obtained by Kacser and Burns, 1973.
Two parallel pathways
Request a detailed protocolConsider two parallel pathways with I/O metabolites 1 and 2 and internal metabolites 3 and 4 (Figure 6B). I obtain the effective rate constant using Equation 22 with , , , . Since , Equation 22 simplifies to
(27)
Thus, the contributions of parallel pathways are simply added.
Module μ in Figure 1
Request a detailed protocolTo obtain the effective rate constant for module μ shown in Figure 1, I again use Equation 22 with , , , .
(28)
with and .
Classification of modules with respect to ‘marked’ reactions, and the parametric families of functions f1 and f2
The CGP described above allows us to calculate the function that maps the rate matrix for an arbitrary module μ onto the module’s effective rate constant . is a multivariate function of the entire matrix . However, in many applications, only one or two reactions are varied at a time while all others remain constant, and we want to know how module’s effective parameter depends on these one or two perturbed reactions. I refer to such singled-out reactions as ‘marked’. When is considered as a function of the rate constant ξ of one marked reaction, I write , as in Equation 2. When is considered as a function of the rate constants ξ and η of two marked reactions, I write as in Equation 3.
The functional form of and, as a consequence, the functional forms of and depend only on the topology of module μ (see Property #5 of the CGP in Box 1). In other words, modules with identical topologies have the same functional forms of and , such that each topology of module μ defines a parametric family of functions and , where all rate constants within module μ other than ξ, or ξ and η, play a role of parameters.
Since the number of possible topologies is infinite, there is an infinite number of functional forms of . However, the number of parameteric families of functions and is finite, and it turns out to be small. To see this, notice that for any module with a single marked reaction, the CGP can be carried out in two stages. In the first stage, we can eliminate all metabolites that do not participate in the marked reaction. The resulting coarse-grained module is minimal in the sense that it can have at most two internal metabolites. Such minimal modules (and, as a consequence, all modules with one marked reaction) fall into three distinct topological classes, which are specified by the location of the marked reaction with respect to the I/O metabolites, as shown in Figure 7. This implies that there are only three parameteric families of the function . The topologies of the three minimal modules are sufficiently simple that the three corresponding parametric functional forms of can be easily computed by applying the coarse-graining Equation 19 or Equation 22. This result is formulated in Proposition 2.
Figure 7
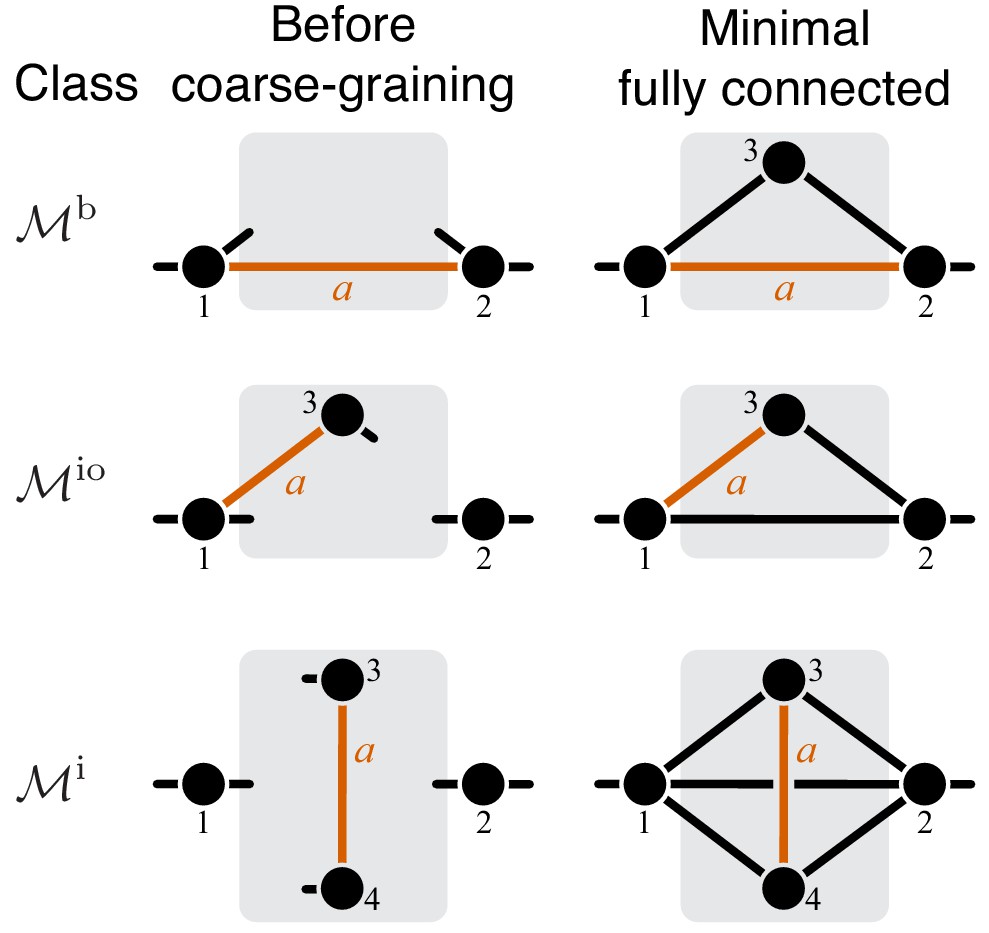
Classification of single-marked modules.
Left column shows a general module from each topological class. The right column shows a minimal fully connected module in each topological class (see text for details). Circles represent metabolites and lines represent reactions. Only the I/O metabolites and the metabolites that participate in the marked reaction are shown, all other metabolites are suppressed. Short lines that have only one terminal metabolite represent all remaining reactions in which this metabolite participates, reactions between all other metabolites are suppressed. Metabolites are labeled according to the conventions listed in the text. The marked reaction is colored orange and labeled . The module is represented by a gray rectangle, and the rest of the network is not shown.
The same logic applies to modules with two marked reactions. CGP that eliminates all metabolites that do not participate in the marked reactions maps all such modules onto respective minimal modules, which can have at most four internal metabolites (see Figure 8). This result is formulated in Proposition 3. Minimal modules (and, as a consequence, all modules with two marked reactions) fall into nine distinct topological classes, which are specified by the locations of the marked reactions. All modules from the same topological class are described by functions from the same parametric family. These families are characterized in Corollary 3.
Figure 8
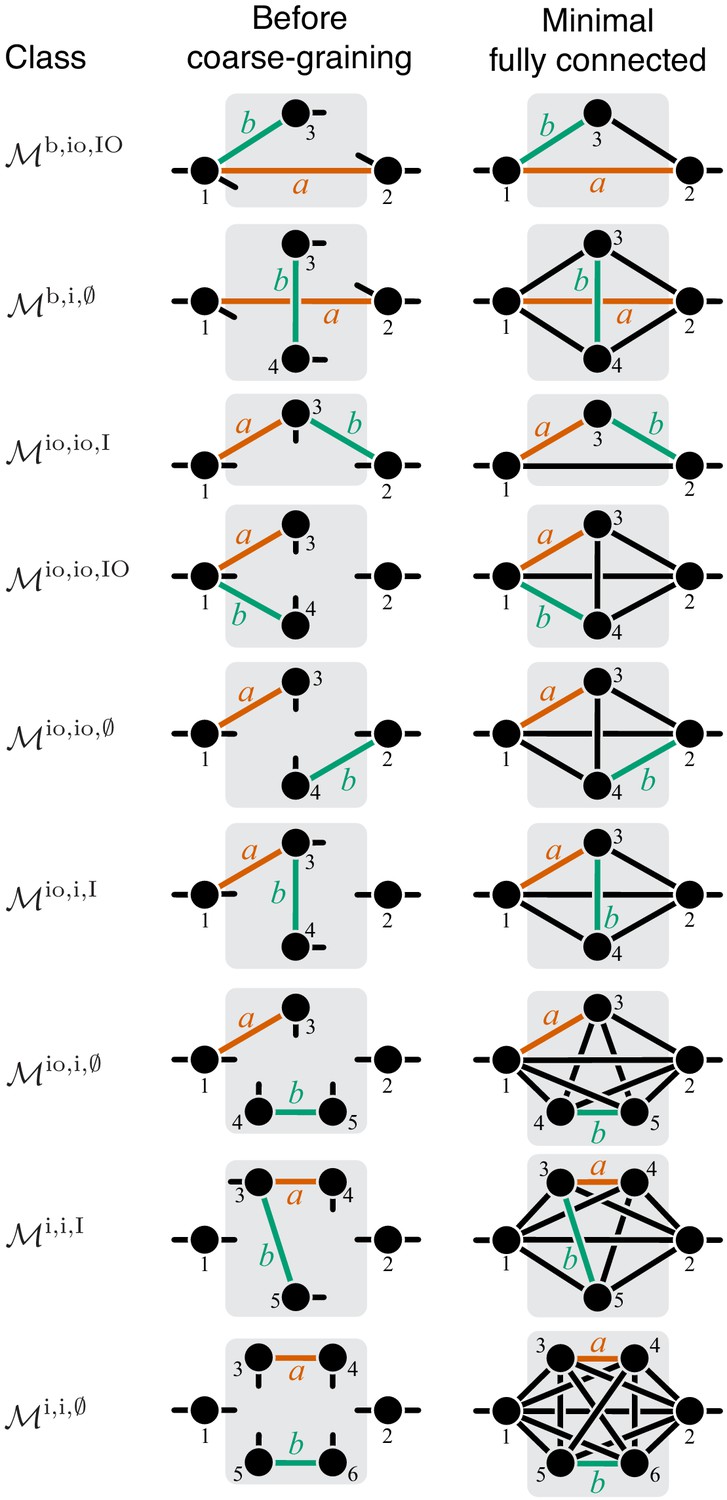
Classification of double-marked modules.
Notations as in Figure 7.
These topological classifications are extremely useful for the following reason. If we can show that all functions from the same parameteric family (corresponding to a given topological class) have some common property irrespectively of the values of the parameters, it would imply that this property holds for all modules from the corresponding topological class. This logic is a key part of the proofs of both Theorem 1 and Theorem 2.
To formalize this reasoning, consider module and let and be two reactions from its set of reactions . I call a pair a single-marked module and I call a triplet a double-marked module, and I refer to reactions and as marked within module μ. The topology of a single-marked module is determined not only by the reaction matrix , but also by the position of the marked reaction, so I refer to the pair as the topology of the single-marked module . Similarly, I refer to the triplet as the topology of the double-marked module . I denote by the matrix of rate constants of all reactions in module μ other than reaction and I denote by the matrix of all rate constants in module μ other than reactions and . I denote the sets of all single- and double-marked modules by and , respectively. To avoid metabolite labeling ambiguities, I adopt the following conventions:
The I/O metabolites are labeled 1 and 2 and the internal metabolites are labeled ;
; ;
, , , .
It is easy to see that the set of all single-marked modules can be partitioned into three non-overlapping topological classes depending on the type of the marked reaction . I denote the classes of all single-marked modules where the marked reaction is bypass, i/o or internal (see Notations and definitions) by , and , respectively (Figure 7). Similarly, the set can be partitioned into nine non-overlapping topological classes according to the types of marked reactions and the type of metabolite that is shared by both of these reactions (I/O, internal, or none). These classes are listed in Table 1 and illustrated in Figure 8.
Table 1
Classification of double-marked modules.
Metabolites are labeled according to conventions described in the text. is the minimum number of internal metabolites in a module from class . is the set of internal and I/O metabolites in all minimal modules in class .
| Class | Shared metab. | Verbal description | Equation for f2 | ||||
|---|---|---|---|---|---|---|---|
| 1 | Bypass and i/o reactions, shared I/O metabolite | 2 | Equation (34) | ||||
| – | Bypass and internal reactions, no shared metabolies | 2 | Equation (35) | ||||
| 3 | i/o reactions, shared internal metabolite | 1 | Equation (36) | ||||
| 1 | i/o reactions, shared I/O metabolite | 2 | Equation (37) | ||||
| – | i/o reactions, no shared metabolites | 2 | Equation (38) | ||||
| 3 | i/o and internal reactions, shared internal metabolite | 2 | Equation (39) | ||||
| – | i/o and internal reactions, no shared metabolites | 3 | Equation (40) | ||||
| 3 | Internal reactions, shared internal metabolite | 3 | Equation (41) | ||||
| – | Internal reactions, no shared metabolites | 4 | Equation (42) |
Each topological class contains infinitely many modules, with various numbers of metabolites and various topologies. However, for each topological class , there is a minimum number of internal metabolites , such that all modules within must have at least internal metabolites. I denote the set of metabolites minimal in the topological class by . It is clear that for the single-marked module classes and for , and , and for , and (see second column in Figure 7). For the double-marked modules, and are given in Table 1 and illustrated in Figure 8.
If a single-marked module from the topological class has the minimum number of metabolites in that class, I call such module and its topology minimal in . There may be several minimal topologies in a topological class, but there is only one minimal topology that is fully connected. A topology is called fully connected if the reaction set is complete in the sense that it contains reactions between all pairs of metabolites in the minimal metabolite set . I denote such complete reaction set for the class by , and I denote the respective fully connected topology by . I employ the same terminology and analogous notations for double-marked modules. The minimal fully connected topologies are shown in the second column in Figure 7 and Figure 8.
Next, I prove Proposition 2, which is the key step toward the proof of Theorem 1. This proposition states that there are only three functional forms for the function and characterizes them. The idea of the proof is the following. According to Property 5 (Box 1), all single-marked modules that are mapped by the CGP onto a minimal module with the same topology have the same functional form of . In other words, each minimal topology specifies a parameteric family of the function . Since the number of possible minimal topologies is finite, the claim of Theorem 1 can be tested for each corresponding functional form of . However, the number of minimal topologies is rather large. Fortunately, another simplification is possible. Since the reaction set of any minimal single-marked module is a subset of the complete reaction set , the fully connected topology specifies the largest parametric family of the function for the class , such that all other families can be obtained from it by setting some parameters to zero, which is equivalent to removing reactions from the fully connected topology. In other words, all single-marked modules that belong to the topological class are described by functions that belong to one parameteric family corresponding to the fully connected topology minimal in . The three parameteric families of are characterized by Proposition 2.
One important consequence of Proposition 2 is that it is not necessary to test the claim of Theorem 1 for each family of that corresponds to each minimal topology. Instead, it is sufficient to test it for the three families that correspond to the fully connected minimal topologies in each class.
Proposition 2
Request a detailed protocolLet be a single-marked module, and let ξ be the rate constant of reaction . Then , where for some , and the function is given by one of the following expressions.
(29)
(30)
(31)
Here , , and all are independent of ξ.
Proof
Request a detailed protocolSince any single-marked module belongs to exactly one of three classes , and , I consider these three cases one by one.
Case . According to the labeling conventions outlined above, (see Figure 7). Equation 29 follows directly from Property #4 of the CGP (Box 1).
Case . According to the labeling conventions, (see Figure 7). According to Property #1 of the CGP, module μ can be coarse-grained in two stages, by first applying which eliminates metabolites (those that do not participate in the marked reaction) and then applying which eliminates the remaining metabolite 3. Mathematically, . After applying , the resulting coarse-grained module has a single internal metabolite 3 and at most three effective reactions , and (Figure 7), that is, it is minimal in . By virtue of Properties #2 and #4 of the CGP, the effective rate constants , are independent of ξ and . Note that may equal zero, but because is a module. Regardless, the reaction set of module is always a subset of the complete reaction set . Thus, to obtain the effective rate constant , I consider the most general case when is fully connected and eliminate the remaining internal metabolite 3, which leads to Equation 30.
Case . According to the labeling conventions, (see Figure 7). Otherwise, the logic of the proof is exactly the same as for the case .
Next I prove Proposition 3 which states that, for any double-marked module that belongs to a given topological class, there exists a double-marked module that is minimal in the same class, such that both modules have the same function . The corresponding minimal module is obtained from the original module by applying the CGP. This proposition is important because it implies that all functions can be completely characterized by only examing minimal modules. Then, analogously to single-marked modules, Corollary 3 states that function can belong to one of nine parameteric families which are defined by the fully connected minimal topologies in each topological class.
Proposition 3
Request a detailed protocolLet be a double-marked module that belongs to the topological class , and let ξ and η be the rate constants of reactions and , respectively. Then there exist non-negative constants α and β and a double-marked module minimal in such that , where
(32)
(33)
are the rate constants of the marked reactions and in , respectively, and all other rate constants in are independent of ξ or η. Module is obtained from μ by the coarse-graining procedure that eliminates all metabolites internal to module μ that do not participate in reactions or .
Proof
Request a detailed protocolTo prove this proposition, I will construct the double-marked module minimal in by applying . Let be the mimimal number of internal metabolites in class (see Table 1). According to the metabolite labeling conventions, metabolites are neither I/O nor do they participate in the marked reactions. eliminates all these metabolites and maps module μ onto module , all of whose internal metabolites participate in reactions and/or . Therefore, is minimal in class (Figure 8). According to Properties #2 and #4 of the CGP (Box 1), the effective rate constants and of reactions and in module are given by linear relationships in Equation 32 and Equation 33, and the remaining effective rate constants are independent of ξ and η. The fact that follows from Property #1 of the CGP, .
Corollary 3
Request a detailed protocolLet be a double-marked module, and let ξ and η be the rate constants of reactions and , respectively. The function that maps ξ and η onto module’s effective rate constant belongs to one of nine parametric families. If , then
(34)
If , then
(35)
If , then
(36)
If , then
(37)
If , then
(38)
If , then
(39)
If , then
(40)
If , then
(41)
If , then
In Equation 34 through Equation 35, and are given by Equation 32 and Equation 33. All effective activities are constants (other than cases where they stand for or ) that depend on the topology of module μ and on the parameters but do not depend on ξ and η.
Proof
Request a detailed protocolThis statement and Equation 34 through Equation 35 follow directly from Proposition 3 and the fact that the reaction set of any double-marked module in any given topological class is a subset of the complete reaction set in that topological class.
Derivation of Equation 6 and Equation 9
Request a detailed protocolConsider a higher-level phenotype , such as the effective activity of a module, which is function of a multivariate lower-level phenotype , such as the rates of individual reactions within the module, . Denote the wildtype values of the phenotypes as and . Consider a mutation that perturbes these values, so that the mutant has lower-level phenotypic values . The relative effect of the mutation on phenotype xi is . If all where denotes the length of vector , then the value of the higher-level phenotype in the mutant is given by
(44)
where
(45)
(46)
which I refer to as first- and second-order control coefficients of the lower-level phenotypes and with respect to the higher-level phenotype .
Now consider two single mutants, A and B, and the double-mutant AB. Each mutation A and B and their combination may perturb all phenotypes such that , , and
Assuming that , and , using the approximation in Equation 44 and the definition of (analogous to Equation 5), I obtain
(47)
(48)
(49)
where refers to terms that are vanishingly small as , , .
I examine two special cases of Equation 49. The first special case is when both mutations affect a single phenotype , that is, when all and all except for . Then Equation 47, Equation 48, Equation 49 simplify to
(50)
(51)
(52)
Equation 52 is equivalent to Equation 6.
The second special case is when mutation A affects a single phenotypes and mutation B affects a single phenotype (), i.e., all except for , all except for , and all . Then Equation 47, Equation 48, Equation 49 simplify to
(53)
(54)
(55)
Equation 55 is equivalent to Equation 9.
Calculation of epistasis in simple modules
Request a detailed protocolEquation 52 and Equation 55 allow me to compute how epistasis propagates and emerges in arbitrary metabolic networks. In this section, I show how to implement these calculations for three simple metabolic modules considered above and in module ν shown in Figure 3.
Linear pathway
Request a detailed protocolFirst, consider how epistasis propagates through a linear pathway (Figure 6A). For simplicity, assume that both mutations A and B affect the same reaction . It follows from Equation 26 that
where α is a positive constant. Therefore, the first- and second-order control coefficients of reaction with respect to the flux through the linear pathway μ are given by
Substituting these expressions into the expression for the fixed point , I find that , irrespectively of the rates of other reactions in the linear pathway. This implies that epistasis at the level of reaction would induce a lower value of epistasis at the level of the entire linear pathway, any value would induce a higher value of epistasis , and would induce .
Now consider emergence of epistasis in a linear pathway. Suppose that mutation A affects reaction and mutation B affects reaction . Denote the rate constant of reactions and by and , respectively. It follows from Equation 26 that
where β is a positive constant. Therefore,
which, after substituting into Equation 9, yield . Together with the fact that (see above), this result implies that epistasis coefficient between any two mutations that affect different reactions in a linear pathway equals 1.
Two parallel pathways
Request a detailed protocolSuppose that mutation A affects reaction and mutation B affects reaction in the linear metabolic pathway shown in Figure 6B. Denote the rate constants of reaction and by and . It follows from Equation 27 that
where and . Thus, we have , and there is no epistasis between such mutations.
Module ν in Figure 3A
Request a detailed protocolI denote the rate of the reactions affected by mutations A and B by and , and I also denote . I will calculate the epistasis coefficient in two stages, by first calculating the epistasis coefficient and then propagating it to using Equation 6. Here I am specifically interested in how depends on the rate constant .
To compute epistasis between mutations A and B at the level of module μ, I rewrite Equation 28 as
where , , , , , , , . I obtain the following expressions for the first- and second-order control coefficients.
(56)
(57)
(58)
where , , , , . Substituting Equation 56 through Equation 58 into Equation 53 through Equation 55, I obtain
(59)
(60)
(61)
where and .
To obtain the expression for , I coarse-grain module ν by eliminating the only remaining internal metabolite 2 and obtain
I then apply equation Equation 6 with
(62)
(63)
Figure 3B illustrates how changes as a function of . It was generated using the following matrix of rate constants:
The Matlab code is available at https://github.com/skryazhi/epistasis_theory.
Next, I consider thress special cases of the toy network depicted in Figure 3A that relate this network to those in Figure 3C and D.
. According to Equation 61, and hence , with and given by Equation 62 and Equation 63. It is easy to see that in this case the reactions and that are affected by mutations are strictly parallel because there is a simple path that contains only reaction and there is a simple path that contains only reaction (Figure 3C).
. In this case, module ν is a linear pathway. Therefore, independently of , as shown above. This fact can also be obtained directly from Equation 61, Equation 62, Equation 63 and Equation 6.
. In this case, module μ becomes an effectively linear pathway because most of the metabolic flux between the I/O metabolites 1 and 2 passes through reaction . Thus, it follows from Equation 61 that , as expected. Then, according to Theorem 1, .
Proof of Theorem 1
As discussed above, the key step toward the proof is Proposition 2, which states that the function belongs to one of three parameteric families, given by Equation 29, Equation 30, Equation 31. To complete the proof, I now explicitly evalute the control coefficient and the in Equation 6 for each of these functions and show that the inequalities in Equation 7 and Equation 8 hold for all parameter values.
Proof of Theorem 1
Request a detailed protocolLet be the effective reaction within higher-level module ν that represents the lower-level module μ. To simplify notations, I denote . According to Proposition 2, the functional from of depends only on the topological class of the single-marked module . So, I consider the three classes one by one.
Case . From Equation 29, and . Therefore, inequalities in Equation 7 and Equation 8 hold.
Case . From Equation 30,
(64)
(65)
where . From Equation 64, it is clear that . Re-writing Equation 64 as
it is also clear that since both ratios in this expression do not exceed 1. From Equation 65 and the fact that , it follows that . To show that , note that
Therefore,
Therefore, inequalities in Equation 7 and Equation 8 hold.
Case . I re-write Equation 31 as
with , , , , , , which yields
(66)
(67)
Next, it is straightforward to show that , which implies that . To show that , I expand the denominator in Equation 66 and obtain
Therefore, numerator in Equation 66 cannot exceed the denominator. The fact that follows directly from Equation 67 together with . To show that , first note that
Therefore,
Hence,
Therefore, inequalities in Equation 7 and Equation 8 hold in this case as well, which completes the proof.
Proof of Theorem 2
Proving Theorem 2 involves several auxiliary steps. First, I note that any two reactions and within any module μ can be either strictly serial, strictly parallel or serial-parallel. Then, Proposition 4 and its Corollary 4 establish that strictly parallel (serial) reactions in are also strictly parallel (serial) in a minimal module , which is obtained from μ by eliminating all metabolites that do not participate in the marked reactions. Next, recall that in both modules and the same function maps the rate constants of two marked reactions onto module’s effective rate constant (Proposition 3). Since the epistasis coefficient depends only on the shape of this function, we only need to consider all minimal modules in order to understand what kinds of epistasis may arise between mutations affecting strictly serial and strictly parallel reactions in any module. This is a big simplification because the number of different minimal topologies is finite and the parameteric families of function are known for all of them (see Corollary 3). As a consequence, to prove Theorem 2, we could in principle list all of the minimal topologies, identify those where the marked reactions are strictly serial or strictly parallel and evalulate the epistasis coefficient using Equation 9 for every respective function .
Unfortunately, the number of minimal topologies is very large, so that such brute-force approach would be quite cumbersome. I take a less cumbersome approach which is based on the realization that a strictly serial or strictly parallel relationship between two reactions cannot be altered by removing a third reaction from the module (Proposition 5). This implies that every minimal topology where the two reactions are strictly serial can be produced from another, more connected, ‘generating’ topology by removing some reactions; and similarly for minimal modules where the reactions are strictly parallel (Proposition 6). All generating topologies can be identified by a simple algorithm given in Appendix 3.
Finally, I prove Theorem 2 in three steps. First, Proposition 7 shows that for any minimal module μ with any strictly parallel generating topology. Second, Proposition 8 shows that that for any minimal module μ with any strictly serial generating topology. Third, the proof of Theorem 2 formally extends this argument to all modules with strictly serial and strictly parallel reactions.
Topological relationships between reactions within a module
Request a detailed protocolConsider module μ with the I/O metabolites 1 and 2. As described above, a simple path connecting two metabolites and within module μ is denoted by . If such path contains reactions and does not contain reactions , I denote it as . I denote the set of all paths by .
According to Lemma 1 proven in Appendix 2, any reaction in the module belongs to at least one simple path within module μ that connects the I/O metabolites. Mathematically, for any reaction . Thus, we can define different topological relationships between any two reactions within a module based on the existence of various paths that do or do not contain them. Consequently, we can classify any double-marked module based on the toplogocial relationship between its marked reactions. This classification is orthogonal to that given in Table 1.
Two reactions and are called parallel within module μ if there exists a simple path and a simple path . Two reactions and are called serial within module μ if there exist at least one simple path . Two reactions are called strictly parallel within module μ if they are parallel but not serial, they are called strictly serial within module μ if they are serial but not parallel, and they are called serial-parallel within module μ if they are both serial and parallel. It is straightforward to show that there are no other logical possibilities for any two reactions to be anything other than strictly serial, strictly parallel or serial-parallel. This implies that two reactions are strictly parallel if they are not serial, and they are strictly serial if they are not parallel. If reactions and are serial, parallel, strictly serial, strictly parallel or serial-parallel within module μ, I also refer to the double-marked module as serial, parallel, etc. Since the relationship between reactions depends only on the topology of the module, but not on its rate constants, I also refer to the topology as serial, parallel, etc.
Recall that coarse-graining procedure eliminates all metabolites internal to module μ other than those participating in reactions and . If the double-marked module belongs to the topological class , then, according to Proposition 3, maps onto a minimal double-marked module from the same class . The following proposition, which is easy to prove using Property #9 of the CGP (see Box 1), establishes how this procedure alters the topological relationship between reactions and .
Proposition 4
Request a detailed protocolLet be a double-marked module from the topological class (Table 1) and let be the minimal double-marked module in onto which is mapped by .
Reactions and are serial in if and only if they are serial in .
If reactions and are parallel in , then they are also parallel in .
Note that the converse of the second claim in Proposition 4 is not true. In other words, if two reactions and are parallel in , they may not be parallel in . Figure 9 shows a counter-example illustrating this.
Figure 9

A counter example illustrating that the converse to claim 2 in Proposition 4 may not be true.
Reactions and are parallel in . CGP maps the double-marked module onto the minimal double-marked module where reactions and are not parallel.
Corollary 4
Request a detailed protocolIf reactions and are strictly serial in , they are also strictly serial in .
If reactions and are strictly parallel in , they are also strictly parallel in .
If reactions and are serial-parallel in , they are either strictly serial or serial-parallel in .
Corollary 4 is an important step toward proving Theorem 2. According to Proposition 3, the function that maps the rate constants ξ and η of the reactions and in module μ onto the effective rate constant is the same function that maps the rate constants and of these reactions in the minimal module onto the effective rate constant . It then immediately follows from Equation 9 that the epistasis coefficient between mutations affecting reactions and in the original module μ is the same as the epistasis coefficient in the minimal module . Now, if the reactions and are strictly parallel in , then, according to Corollary 4, these reactions are also strictly parallel in . Hence, to demonstrate that for any such double-marked module , it is sufficient to show that for all double-marked modules that are minimal in and where the reactions and are strictly parallel. And similarly for the strictly serial reactions.
According to this logic, Theorem 2 can be proven by identifying all double-marked modules that are minimal in each of the topological classes listed in Table 1 and where the marked reactions are strictly parallel, evaluating epistasis for all of them, and showing that it is non-positive, irrespectively of the rate constants of any reactions, and similarly for the strictly serial reactions.
Generating topologies
Request a detailed protocolSince the number of topologically distinct minimal double-marked modules is finite, the approach outlined above is in principle feasible. Unfortunately, the number of topologies to be considered is very large, so in practice it is very cumbersome. To avoid this complication, I take an alternative approach that is based on the same key idea as the proof of Theorem 1. Rather than considering one by one, each minimal topology where the marked reactions are strictly serial or strictly parallel (and the corresponding parametric families of ), the idea is to identify the most connected minimal topologies (and the corresponding largest parametric families of ) such that all the other minimal topologies with the strictly serial or strictly parallel reactions (and the corresponding parametric families) can be obtained from them by removing reactions (i.e. setting some parameters to zero).
This idea can be implemented using the following observations. If the two marked reactions are strictly parallel or strictly serial in a minimal module, then removing a third reaction from it does not change this relationship. This statement is proven in Proposition 5. As a consequence, all minimal modules in the topological classes , and must be strictly parallel because the fully connected minimal topologies are strictly parallel (Figure 8). Similarly, all minimal modules in the topological class must be strictly serial because the fully connected minimal topology is strictly serial (Figure 8). The fully connected minimal topologies in all other topological classes are serial-parallel. If the two reactions are serial-parallel, removing a third reaction can change their relationship into a strictly serial or strictly parallel one, depending on which reaction is removed, as shown for example in Figure 3A,C and D. In fact, by removing reactions from the fully connected minimal modules shown in Figure 8, it is easy to show that the topological classes , , , , contain both strictly serial and strictly parallel modules.
These observations suggests that adding reactions to a minimal module where the marked reactions are strictly serial or strictly parallel will either change their relationship into serial-parallel or will preserve their relationship until the minimal module is fully connected. Therefore, among all minimal modules in a topological class, there must exist the most connected modules where the marked reactions are strictly parallel or strictly serial, such that all other less connected strictly serial or strictly parallel modules can be produced from the most connected ones by removal of reactions. This statement is proven in Proposition 6. Such most connected strictly parallel and strictly serial minimal topologies, which I refer to as ‘generating’, are listed in Table 2 and Table 3. They define the largest parameteric familes of functions which I then examine for the value of .
Table 2
Proposition 5
Request a detailed protocolLet and be two minimal double-marked modules from the same topological class whose sets of reactions are and , respectively, and where .
If reactions and are strictly parallel in , they are also strictly parallel in .
If reactions and are strictly serial in , they are also strictly serial in .
Proof
Request a detailed protocolDenote the I/O metabolites in both modules μ and by 1 and 2. Since and μ are topologically identical except for lacking one reaction , it must be true that for any reactions , from . In other words, there could only be fewer paths connecting the I/O metabolites within module compared to module μ. The rest of the proof follows immediately from this fact and the definitions of strictly serial and strictly parallel relatioships.
Next, I define a minimal topology as generating either if it is a fully connected topology (as in topological classes , and , ) or if adding any reaction to it would make the marked reactions serial-parallel.
Denote the sets of all double-marked topologies minimal in class where the marked reactions are strictly serial, strictly parallel and serial-parallel by by , and , respectively.
Definition 2
Request a detailed protocolTopology minimal in is called a strictly serial generating topology in if it is strictly serial (i.e. ) and either it is fully connected (i.e. ) or for any reaction .
Definition 3
Request a detailed protocolTopology minimal in is called a strictly parallel generating topology in if it is strictly parallel (i.e. ) and either it is fully connected (i.e. ) or for any reaction .
Clearly, a topological class may have multiple generating topologies, and it is easy to show that every topological class has at least one generating topology. I denote the set of all strictly serial generating topologies for the class by and I denote the set of all strictly parallel generating topologies for class by . The following proposition justifies the name ‘generating topology’. It states that any strictly serial minimal topology can be produced from some strictly serial generating topology by removing one or multiple reactions, and similarly for any strictly parallel minimal topology.
Proposition 6
Request a detailed protocolIf is a strictly parallel topology minimal in the topological class , then there exists a strictly parallel generating topology in , such that . If is a strictly serial topology minimal in the topological class , then there exists a strictly serial generating topology in , such that .
Proof
Request a detailed protocolSuppose that is one of the topological classes , , or . Since the fully connected minimal topology is strictly parallel, it is a generating topology in . Then, according to Proposition 5, any topology minimal in is strictly parallel, and Proposition 6 holds. By the same logic, Proposition 6 holds for the topological class .
Suppose that is one of the remaining topological classes , , , or . Then the fully connected minimal topology is serial-parallel. Suppose that is strictly parallel. Then must be a strict subset of , so that the set is not empty. Then, either or . If , the Proposition 6 holds. Suppose that . This implies that there exists a reaction , such that and ( cannot be in due to Proposition 5). There are three possibilities.
.
and .
and .
Option (a) is not possible since while . Option (b) implies that the Proposition 6 holds. Option (c) implies that there exists a reaction , such that and , and we have the same three possibilities for as above. Thus, by induction, Proposition 6 must hold. The proof is analogous if is strictly serial.
Discovering all strictly serial and strictly parallel generating topologies in any given topological class is straightforward because all minimal topologies within can be produced by removing reactions from the unique fully connected topology minimal in shown in Figure 8. In Appendix 3, I provide an algorithm that discovers all strictly serial and strictly parallel generating topologies by sequentially removing reactions from the fully connected minimal topology in each topological class. The code implementing this algorithm in Matlab is available at https://github.com/skryazhi/epistasis_theory. All strictly parallel generating topologies are listed in Table 2 and all strictly serial generating topologies are listed in Table 3. They are also illustrated in Figure 8 and Figure 10 through Figure 14. I label each generating topology by a four-letter combination (see column 4 in Table 2 and Table 3): the first three letters denote the topological class and the last letter (F, P, or S) denotes the specific generating topology within that class. Letter ‘F’ (stands for ‘full’) denotes the fact that the reaction set in the generating topology is complete. Letters ‘P’ (for ‘parallel’) and ‘S’ (stands for ‘serial’) denote strictly parallel and strictly serial generating topologies, respectively; if there are a multiple generating topologies within the same class, they are distinguished by subindices, for example, ; , etc.
Figure 10
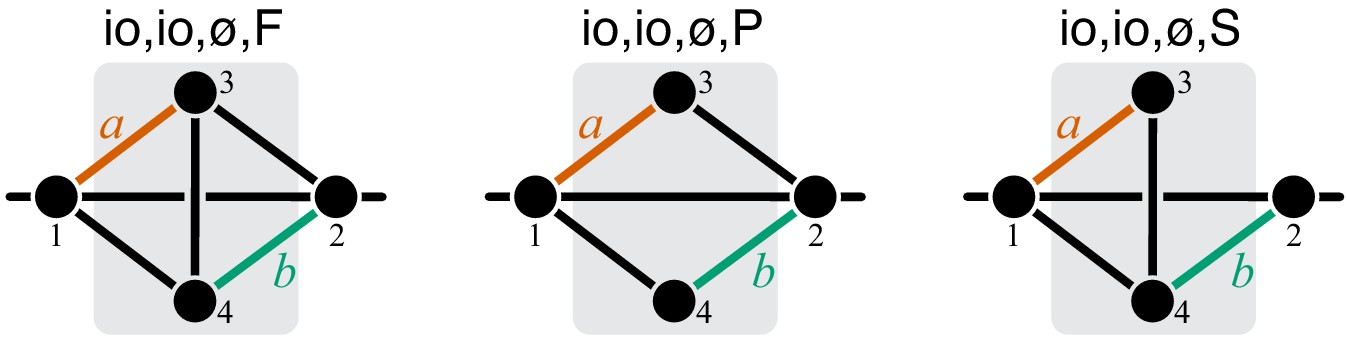
Graphical representation of strictly serial and strictly parallel generating topologies in the class .
Fully connected topology is shown for reference (same as in Figure 8).
Topological relationship between reactions and epistasis
Request a detailed protocolEach strictly serial and strictly parallel generating topology in a given class (listed in Table 2 and Table 3) is produced by removing reactions from the fully connected topology minimal in (shown in Figure 8). This implies that the parametric family of function that corresponds to any generating topology is obtained from Equation 34 through Equation 35 by setting some parameters to zero. In other words, these parametric families are known. Next, I prove Proposition 7 that shows that for every member of every parameteric family of that corresponds to a strictly parallel generating topology and the analogous Proposition 8 for strictly serial topologies.
Now, any minimal strictly parallel topology can in turn be produced by removing reactions from some strictly parallel generating topology, and any minimal strictly serial topology can be produced by removing reactions from some strictly serial generating topology. This implies that any function that corresponds to any strictly parallel minimal topology belongs to the parametric family that corresponds to some strictly parallel generating topology; and any function that corresponds to any strictly serial minimal topology belongs to the parametric family that corresponds to some strictly serial generating topology. Therefore, Propositions 7 and 8 imply that for any minimal strictly parallel topology and that for any minimal strictly serial topology. The proof of Theorem 2 is then concluded by recalling that every strictly parallel module is mapped onto its effective rate constant via function that corresponds to some minimal strictly parallel module, and similarly for strictly serial modules.
Proposition 7
Request a detailed protocolLet be a minimal double-marked module in the topological class , with and being the rates of reactions and , respectively, and let be the effective rate constant of this module. Suppose that mutation A perturbs only reaction by , and mutation B perturbs only reaction by , such that , . If reactions and are strictly parallel in , then .
Proof
Request a detailed protocolAccording to Proposition 6, the topology of module can be produced by removing reactions from some strictly parallel generating topology . Therefore, the function that maps and in this module onto its effective rate constant belongs to the parametric family that corresponds to . According to Equation 55,
(68)
where
(69)
(70)
(71)
According to Theorem 1, and . And since all , , , to prove Proposition 7, it is sufficient to show that for any member of any parametric family that corresponds to generating topologies listed in Table 2.
Generating topologies and (Figure 8). According to Equation 34 and Equation 35, , which implies that .
Generating topology (Figure 8). According to Equation 37,
where , , , , , . Therefore,
Generating topology (Figure 10). According to Equation 38, , which implies .
Generating topology (Figure 11). Notice that metabolite 4 together with reactions , and form a double-marked module whose I/O metabolites are 1 and 3 and which is minimal in the topological calss . Denote the effective reaction rate of module by . Therefore, , as shown above. Since module is contained in μ, by Theorem 1, .
Figure 11

Graphical representation of strictly serial and strictly parallel generating topologies in class .
Fully connected topology is shown for reference (same as in Figure 8).
Generating topology (Figure 12). According to Property 1 of the CGP (Box 1), module μ can be coarse-grained by first eliminating metabolite 3. In the resulting module , mutation A perturbs only the rate constant of the effective reaction (by Properties 2 and 4 of the CGP). Then, according to Equation 50 and Theorem 1, . The double-marked module is minimal in the topological class which implies that , as shown above.
Figure 12
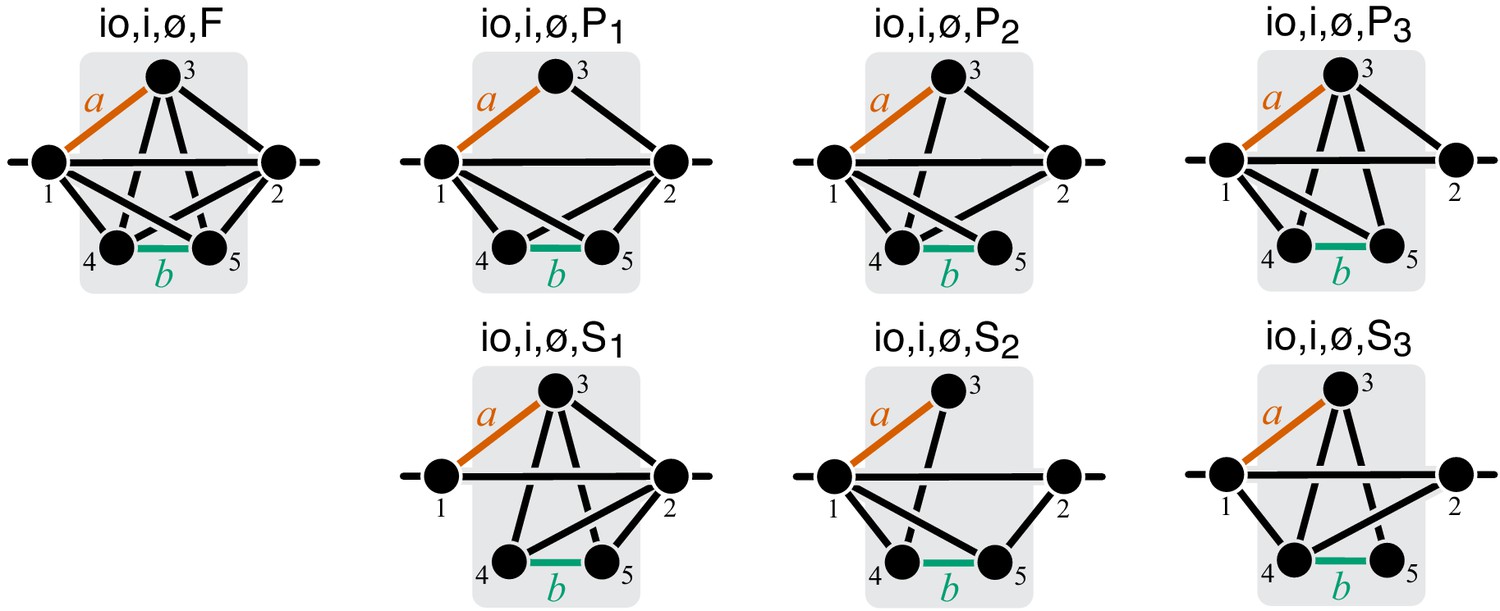
Graphical representation of strictly serial and strictly parallel generating topologies in class .
Fully connected topology is shown for reference (same as in Figure 8).
Generating topology (Figure 12). Module μ can be coarse-grained by first eliminating metabolite 5, which will result in a double-marked module that is minimal in the topological class . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 12). Notice that metabolites 4 and 5 together with reactions , , , , and form a double-marked module whose I/O metabolites are 1 and 3 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 13). Notice that metabolites 4 and 5 together with reactions , , , , and form a double-marked module whose I/O metabolites are 1 and 3 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Figure 13

Graphical representation of strictly serial and strictly parallel generating topologies in class .
Fully connected topology is shown for reference (same as in Figure 8).
Generating topology (Figure 13). Notice that metabolite 5 together with reactions , , and form a double-marked module whose I/O metabolites are 3 and 4 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). According to Equation 35, , which implies .
Figure 14
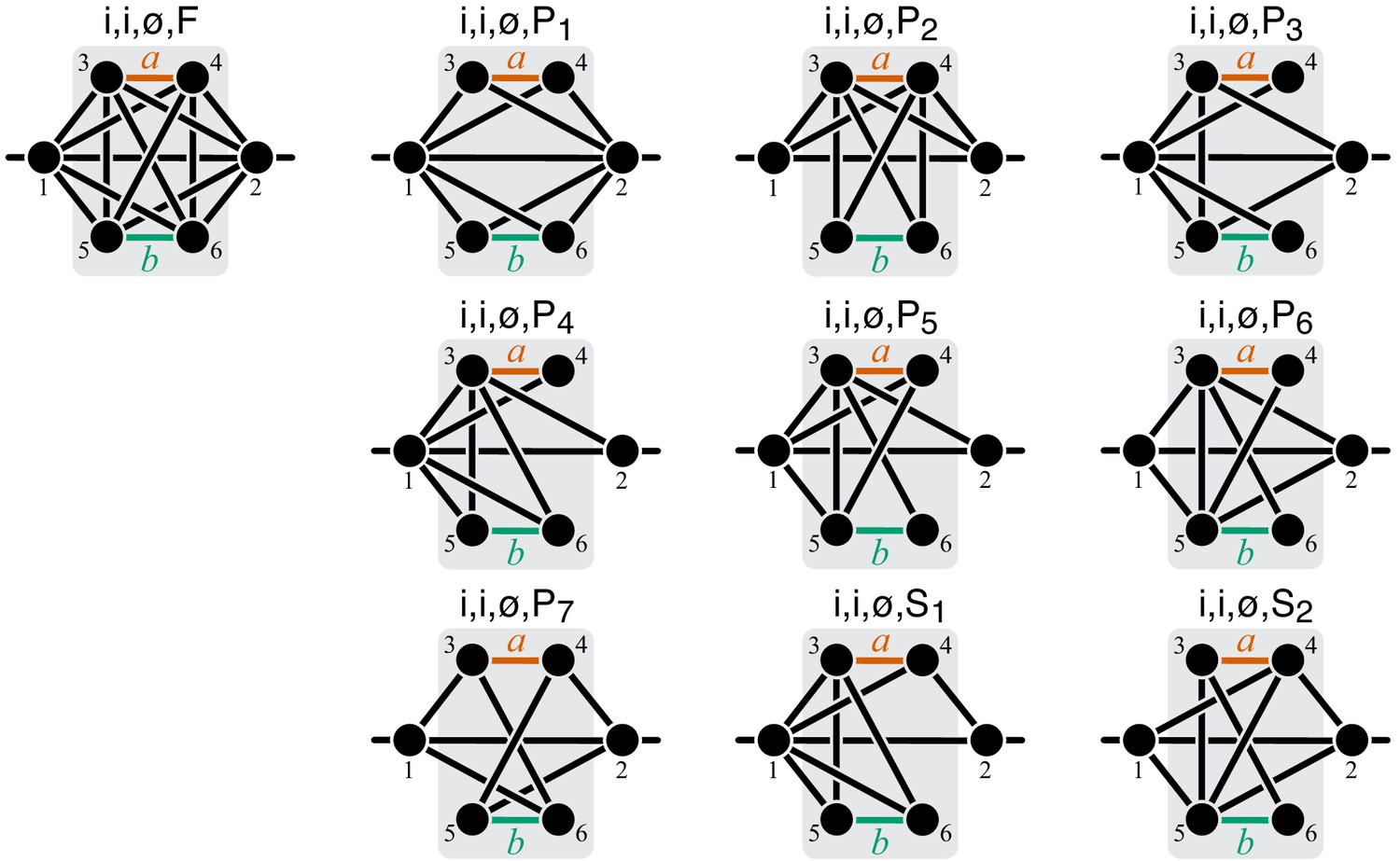
Graphical representation of strictly serial and strictly parallel generating topologies in class .
Fully connected topology is shown for reference (same as in Figure 8).
Generating topology (Figure 14). Notice that metabolites 5 and 6 together with reactions , , , , and form a double-marked module whose I/O metabolites are 3 and 4 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Module μ can be coarse-grained by first eliminating metabolites 4 and 6, which will result in a double-marked module that is minimal in the topological class . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Module μ can be coarse-grained by first eliminating metabolite 4, which will result in a double-marked module that is minimal in the topological class with a strictly parallel generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Module μ can be coarse-grained by first eliminating metabolite 6, which will result in a double-marked module that is minimal in the topological class with a strictly parallel generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Notice that metabolites 4 and 6 together with reactions , , , , form a double-marked module whose I/O metabolites are 3 and 5 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Using Equation 42, I show in Appendix 4 that
(72)
where , , , are all non-negative constants and .
Proposition 8
Request a detailed protocolLet be a minimal double-marked module in the topological class , with and being the rates of reactions and , respectively, and let be the effective rate constant of this module. Suppose that mutation A perturbs only reaction by , and mutation B perturbs only reaction by , such that , . If reactions and are strictly serial in , then .
Proof
Request a detailed protocolThe logic of the proof is the same as for Proposition 7, that is, it is sufficient to show that for any double-marked module with any strictly serial generating topology listed in Table 3.
Generating topology (Figure 8). According to Equation 36,
(73)
where . Therefore,
Substituting these expressions into Equation 68, I obtain
because according to Equation 73.
Generating topology (Figure 10). According to Property 1 of the CGP (Box 1), module μ can be coarse-grained by first eliminating metabolite 3. In the resulting module , mutation A perturbs only the rate constant of the effective reaction (by Properties 2 and 4 of the CGP). Then, according to Equation 50 and Theorem 1, . The double-marked module is minimal in the topological class which implies that , as shown above.
Generating topology (Figure 11). Notice that metabolite 3 together with reactions , , and form a double-marked module whose I/O metabolites are 1 and 4 and which is minimal in the topological calss . Therefore, if the effective reaction rate of module is , , as shown above. According to Equation 50, Equation 51 and Theorem 1, , . Since module is contained in μ, by Theorem 1, .
Generating topology (Figure 11). Module μ can be coarse-grained by first eliminating metabolite 4, which results in a double-marked module that is minimal in the topological class . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 12). Module μ can be coarse-grained by first eliminating metabolites 4 and 5, which results in a double-marked module that is minimal in the topological class . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 12). Notice that metabolites 3 and 4 together with reactions , , , and form a double-marked module whose I/O metabolites are 1 and 5 and which is minimal in the topological calss with the strictly serial generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 12). Notice that metabolites 3 and 5 together with reactions , , , , and form a double-marked module whose I/O metabolites are 1 and 4 and which is minimal in the topological calss with the strictly serial generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 13). Notice that metabolite 3 together with reactions , , and form a double-marked module whose I/O metabolites are 4 and 5 and which is minimal in the topological calss . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 13). Notice that metabolites 3 and 5 together with reactions , , , , and form a double-marked module whose I/O metabolites are 1 and 4 and which is minimal in the topological calss with the strictly serial generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Module μ can be coarse-grained by first eliminating metabolites 5 and 6, which results in a double-marked module that is minimal in the topological class with the strictly serial generating topology . The rest of the proof for this topology is analogous to that for the topology .
Generating topology (Figure 14). Module μ can be coarse-grained by first eliminating metabolite 6, which results in a double-marked module that is minimal in the topological class with the strictly serial generating topology . The rest of the proof for this topology is analogous to that for the topology .
Proof of Theorem 2
Request a detailed protocolAccording to Proposition 3, the coarse-graining procedure maps the double-marked module onto a double-marked module that is minimal in the same topological class as , and the rates , of reactions , in are given by linear relations in Equation 32 and Equation 33. Clearly, and . Furthermore, none of the other reaction rates in depend on ξ or η, so that and for all other than and , and for all including and . It then follows from Proposition 3 that .
Now, according to Corollary 4, if reactions and are strictly parallel in , they are also strictly parallel in . Therefore, by Proposition 7, . Analogously, if reactions and are strictly serial in , they are also strictly serial in . Therefore, by Proposition 8, .
Sensitivity of Theorem 1 and Theorem 2 with respect to the magnitude of mutational effects
Request a detailed protocolAccording to Proposition 2, function for any module belongs to one of three parametric families, which correspond to the three minimal fully connected modules shown in Figure 7. As mentioned in the Results, for modules in the class , function f1 is linear, so that the claims of Theorem 1 continue to hold for mutations with finite effects. To evaluate the sensitivity of Theorem 1 with respect to the effect sizes of mutations for the topological classes and , I generated 1000 minimal single-marked modules ν from each of these topological classes with random parameters. Evaluating only minimal modules is sufficient because for any module from a given topological class there exists a minimal module from the same class, such that both of them map the lower level phenotype onto the higher-level phenotype via the same function f1 (see Proposition 2).
To this end, I drew each () from a mixture of a point measure at 0 (with weight 0.25) and an exponential distribution with mean 1 (with weight 0.75). The point measure at 0 ensures that minimal modules that are not fully connected are represented in the sample. I drew each () as a ratio of two random numbers from an exponential distribution with mean 1. As a result, the distribution of non-zero values had the interdecile range of with median 0.65.
I denote the effective rate constant of the reaction that represents the lower-level module μ by . In modules from the topological class , it is reaction and in modules from the topological class , it is the reaction . I perturbed ξ by two mutations A and B with relative effects and and epistasis . I chose nine different pairs of mutational effects , , , , , , , , , and 16 different values of ranging from −1 to 2 with an increment of 0.2. Since the rate constant of the double mutant cannot be negative, I skipped those combinations of perturbations and epistasis values for which . I then computed the resulting values , and at the level of the effective rate constant of the higher-level module ν.
Using these data, I inferred the function that maps lower-level epistasis onto higher-level epistasis , as follows. For any minimal single-marked module from the topological classes or , the effective rate constant can be written as
where and , , , for modules from the topological class (see Equation 30), and , , , for modules from the topological class (see Equation 31). Therefore, for any perturbation , we have
Since is a linear function of , is a hyperbolic function of . Therefore, is also a hyperbolic function of ,
(74)
where constants , and depend on the parameters of module ν and on the mutational effect sizes and . I numerically calculated these parameters for each sampled module and each pair of mutational effects.
The main results of Theorem 1 are that, when the effects of mutations are infinitesimal, the map has a fixed point , this fixed point is located between 0 and 1, and it is unstable. I use equation Equation 74 to test whether these statements also hold when the effects of mutations are finite. Specifically, it is easy to see that the map has a fixed point if the discriminant is positive. In this case, I designate as the one of two roots that is closer to zero. I then check whether this fixed point is located between 0 and 1. I check whether it is unstable by comparing the derivative of at with 1.
According to Proposition 6, function for any module where the reactions affected by mutations are strictly parallel belongs to one of 17 parameteric families, which correspond to the strictly parallel generating topologies listed in Table 2. And similarly, function for any module where the reactions affected by mutations are strictly serial belongs to one of 11 parameteric families, which correspond to the strictly serial generating topologies listed in Table 3. Therefore, to evaluate the sensitivity of Theorem 2 with respect to the effect sizes of mutations I generated 104 double-marked modules with each of the strictly serial and strictly parallel topologies with random parameters. I drew and as described above. I chose the same nine pairs of mutational effects as above, where ξ and η are the rate constants of reactions affected by mutations A and B: , , , , , , , , .
I found that, for some modules, individual mutational perturbations and/or at the level of the whole module were too small, which resulted in numerical instabilities. To avoid them, I calculated epistasis only for cases where the effects of both mutations and exceeded the precision threshold of . As a result, I evaluated epistasis in less than 104 modules per generating topology and pair of mutational effects, but this number never fell below 1000. When comparing the values of epistasis with 0 and 1, I used the same precision threshold of to avoid numerical problems. In addition, I found that for mutations affecting strictly serial reactions there is a substantial fraction of modules where falls between 0.99 and 1 (see Figure 4—figure supplement 3). This is not a numerical artifact, but probably reflects real clustering of epistasis coefficients around 1, which is expected for the linear pathway irrespective of its parameters (see above).
The Matlab code for this analysis is available at https://github.com/skryazhi/epistasis_theory.
Kinetic model of glycolysis
I downloaded the kinetic metabolic model of E. coli glycolysis by Chassagnole et al., 2002 from the BioModels database (Malik-Sheriff et al., 2019) on September 15, 2015 (model ID BIOMD0000000051). I used the Matlab SimBiology toolbox to interpret the model. To validate the model, I simulated it for 40 s and reproduced Figures 4 and 5 from Chassagnole et al., 2002. The Matlab code is available at https://github.com/skryazhi/epistasis_theory.
Modifications to the original model
Request a detailed protocolI simplified and modified the model by (a) fixing the concentrations of ATP, ADP, AMP, NADPH, NADP, NADH, NAD at their steady-state values given in Table V of Chassagnole et al., 2002 and (b) removing dilution by growth. I then created four models of sub-modules of glycolysis by retaining the subsets of metabolites and enzymes shown in Figure 5—figure supplement 1 and Table 4 and removing other metabolites and enzymes. Each sub-module has one input and one output metabolite. Note that, since some reactions are irreversible, it is important to distinguish the input metabolite from the output metabolite. The concentrations of the input and the output metabolites in each model are held constant at their steady-state values given in Table 4. I defined the flux through the sub-module as the flux toward the output metabolite contributed by the sub-module (Table 4). This flux is the equivalent of the quantitative phenotype of a module in the analytical model. In addition, I made the following modifications specific to individual sub-modules.
Table 4
Definition of modules in the glycolysis network shown in Figure 5—figure supplement 1.
| Model | Internal metabolites | Concentrations of I/O metabolites | Reactions | Output flux |
|---|---|---|---|---|
| UGPP | 6 pg, dhap, e4p, f6p, fdp, rib5p, ribu5p, sed7p, xyl5p | [g6p]=3.82 mM, [gap]=0.44 mM | ALDO, G6PDH, PFK, PGDH, PGI, Ru5P, R5PI, TA, TIS, TKa, TKb | |
| LG | 2 pg, 3 pg, pgp | [gap]=0.44 mM, [pep]=0.08 mM | ENO, GAPDH, PGK, PGM | |
| GPP | all in UGPP and in LG, gap | [g6p]=3.82 mM, [pep]=0.08 mM | all in UGPP and in LG | |
| FULL | all in GPP, g6p, pep | [Ext glu]=2 µM, [pyr]=10 µM | all in GPP, PTS, PK, PEPCxyl |
Table 5
Names of metabolites used in the kinetic model of glycolysis.
| 2 pg | 2-Phosphoglycerate |
|---|---|
| 3 pg | 3-Phosphoglycerate |
| 6 pg | 6-Phosphogluconate |
| dhap | Dihydroxyacetonephosphate |
| e4p | Erythrose-4-phosphate |
| f6p | Fructose-6-phosphate |
| fdp | Fructose-1,6-bisphosphate |
| g6p | Glucose-6-phosphate |
| gap | Glyceraldehyde-3-phosphate |
| glu | Glucose |
| pep | Phosphoenolpyruvate |
| pgp | 1,3-Diphosphoglycerate |
| pyr | Pyruvate |
| rib5p | Ribose-5-phosphate |
| ribu5p | Ribulose-5-phosphate |
| sed7p | Sedoheptulose-7-phosphate |
| xyl5p | Xylulose-5-phosphate |
Table 6
Names of enzymes used in the kinetic model of glycolysis.
| ALDO | Aldolase |
|---|---|
| ENO | Enolase |
| G6PDH | Glucose-6-phosphate dehydrogenase |
| GAPDH | Glyceraldehyde-3-phosphate dehydrogenase |
| PFK | Phosphofructokinase |
| PGDH | 6-Phosphogluconate dehydrogenase |
| PGI | Glucose-6-phosphateisomerase |
| PGK | Phosphoglycerate kinase |
| PGM | Phosphoglycerate mutase |
| PEPCxyl | PEP carboxylase |
| PK | Pyruvate kinase |
| PTS | Phosphotransferase system |
| R5PI | Ribose-phosphateisomerase |
| Ru5P | Ribulose-phosphate epimerase |
| TA | Transaldolase |
| TIS | Triosephosphate isomerase |
| TKa | Transketolase, reaction a |
| TKb | Transketolase, reaction b |
In the FULL model, the stoichiometry of the PTS reaction was changed to
and the value of the constant was set to 0.02 mM, based on the values found in the literature (Stock et al., 1982; Natarajan and Srienc, 1999).
In all models other than FULL, the extracellular compartment was deleted.
In all models, the concentrations of the I/O metabolites were set to values shown in Table 4, which are the steady-state concentrations achieved in the FULL model with the concentration of extracellular glucose being 2 µM and pyruvate concentration being 10 µM.
Calculation of flux control coefficients and epistasis coefficients
Request a detailed protocolI calculate the first- and second-order flux control coefficients (FCC) and for flux with respect to reactions and as follows (see Equation 45 and Equation 46). I perturb the of reaction by factor between 0.75 and 1.25 (10 values in a uniformly-spaced grid), such that . Then, I obtain the steady-state flux in each perturbed model and calculate the flux perturbations , where is the corresponding flux in the unperturbed model. Then, to obtain and , I fit the linear model
by least squares. If the estimated value of was below for a given sub-module, I set to zero and exclude this reaction from further consideration in that sub-module because it does not affect flux to the degree that is accurately measurable. If the estimated value of is below , I set to zero.
To calculate the non-diagonal second-order control coefficients , I create a grid of perturbations of and and calculate the resulting flux perturbations (16 perturbations total). Since , , and are known, I obtain , by regressing
against
If the estimated value of is below , I set to zero. I estimate the epistasis coefficient between mutations affecting reactions and as
Establishing the topological relationships between pairs of reactions
Request a detailed protocolTo establish the topological relationship (strictly serial, strictly parallel, or serial-parallel) between two reactions, I consider the smallest module (LG, UGPP, GPPP, or FULL) which contains both reactions. I then manually identify whether there exists a simple path connecting the input metabolite with the output metabolite for that module that passes through both reactions. (Note that, since some reactions are irreversible in this model, it is important to distinguish the input metabolite from the output metabolite). If such path does not exist, I classify the topological relationship between the two reactions as strictly parallel. If such path exists, I check if there are two paths connecting the input to the output metabolites such that each path contains only one of the two focal reactions. If such paths do not exist, I classify the topological relationship between the two reactions as strictly serial. Otherwise, I classify it as serial-parallel.
Appendix 1
Proof of Equation 24
First, the terms in Equation 24 can be re-arranged as follows
(75)
Next, I will demonstrate the validity of Equation 75 by induction. It is clear that for , Equation 24 reduces to Equation 12. Now suppose that and that there exists a metabolite , such that Equation 75 holds for the subset , that is,
(76)
I will now show that then Equation 75 also holds for . To do so, I use the definition of (Equation 19) and apply Equation 76 to expand terms and as follows.
(77)
Recalling that , I re-write Equation 75 as
(78)
Since the first and third terms of Equation 77 and Equation 78 are identical, to complete the proof, it is sufficient to show that for any ,
(79)
To show that Equation 79 holds, I first use Equation 19 and Equation 21 to express and in terms of effective reaction rates after the elimination of the metabolite set ,
(80)
which imply that
Finally, it follows from Equation 80 that which completes the proof of Equation 79. Thus, Equation 75 and equivalently Equation 24 hold for any metabolite subset .
Appendix 2
Existence of a simple path that contains a given reaction
Lemma 1
Let μ be a module with the reaction set . Then, for any reaction , there exists a simple path within μ that connects the I/O metabolites and contains reaction , that is, .
Proof
Reaction is either a bypass, i/o, or internal reaction for module μ. If is a bypass reaction, then the statement is trivially true. If is an i/o reaction, then, without loss of generality, let . Since μ is a module, there exists a simple path that connects the internal metabolite j to the I/O metabolite 2. Therefore, the path connects the I/O metabolites and contains reaction .
Suppose that is an internal reaction. To prove the statement, it is sufficient to show that there exists a pair of non-intersecting paths and , such that one of them contains and the other does not. Since μ is a module, there exists a pair of non-intersecting paths and and a pair of non-intersecting paths and within module μ (I omitted super-index μ to simplify notations). There are two mutually exclusive possibilities. (i) Metabolite is contained in either of the paths or and/or metabolite is contained in either of the paths or . (ii) Metabolite is not contained in either of the paths or and metabolite is not contained in either of the paths or , that is, and , . It is trivial to construct the neccessary paths and in case (i).
Appendix 2—figure 1
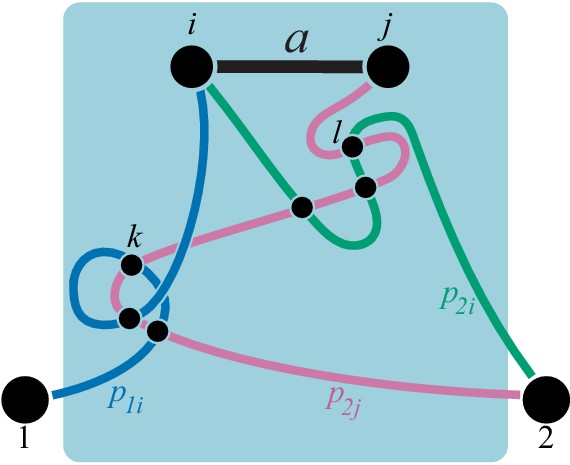
Illustration for the proof of Lemma 1.
Consider case (ii). If paths and do not intersect, then let and
and the statement is true. Suppose paths and intersect. Then, among all metabolites that belong to both and , let metabolite be the one closest to along the path (see Figure). Then the segment of path and the path do not intersect. Let
If and do not intersect, then the lemma is true. If and do intersect, this intersetion can only occur within the segment of path , excluding metabolites and (see Figure). This is because the remaining segment of path is also a segment of , which, by assumption, does not intersect . Suppose that among all metabolites that belong to both the segment of path and the path metabolite is the one closest to along the path . Then let
The path does not intersect the path because its first segment belongs to path and its second segment belongs to the segment of path (and, as mentioned above, segment does not intersect ). Thus, the statement holds for case (ii) as well.
Appendix 3
An algorithm for discovering all strictly serial and strictly parallel generating topologies
Suppose that , that is, is a strictly serial generating topology in the topological class . Since where is the complete reaction set for class , R can be discovered by sequentially removing reactions from . The same logic holds for strictly parallel generating topologies. The following algorithm implements this idea.
Define function generate_topology_list. This function takes a topology as input and returns a new list of topologies as output, which is produced as follows. Initialize . For every reaction , construct the reaction subset and use Definition 1 to test whether corresponds to a valid module. If corresponds to a module, add to list ; otherwiese, discard. It can be proven that, as long as , there exists at least one , such that corresponds to a module, that is, . Return list .
Initialization.
Pick a topological class .
Test whether . If so, and . Return , .
Test whether . If so, and . Return , .
Set , . Use function generate_topology_list with as input and obtain the list of reaction sets . Proceed to Step 3 with list .
Take list as input. Set . Proceed to Step a with .
Test whether belongs to , or . Choose one of the alternatives b, c, or d.
. If is not in the set and if for all , then add to . Proceed to Step e.
. If is not in the set and if for all , then add to . Proceed to Step e.
. Use function generate_topology_list with as input and obtain the list of reaction sets . Replace with . Proceed to Step e.
If , proceed to Step f. Otherwise, proceed to Step a with .
If , then proceed to Step 3 with as input. Otherwise, return , .
Appendix 4
Derivation of Equation 72
In this case, Equation (42) simplify to
where
Notice that the only effective rate constant that depends on is , and . Thus, it is easy to differentiate , given by Equation 35, with respect to , if we isolate the term in both the numerator and the denomintor,
(81)
where
It is also useful to obtain another expression for , which is easier to differentiate with respect to . To do that, we can first eliminate metabolites 3 and 4 to obtain effective reaction rates
where
The only effective activity that depends on is , and . Thus, isolating the term (and recalling that ), we obtain the following expression for , which is easy to differentiate with respect to .
(82)
where
Using symbolic computation it is possible to show that (see Mathematica notebook [Supplementary file 1] and Mathematica notebook pdf [Supplementary file 2], p. 2)
(83)
Also notice that, any module with the reaction set is symmetric with respect to swapping metabolite labels 1 with 2, 3 with 5, and 4 with 6. It is easy to check that Equations (81), (82) respect this symmetry.
Differentiating Equation 81 with respect to , after some algebra I obtain
(84)
Analogously, differentiating Equation 82 with respect to , I obtain
(85)
Notice that Equation 85 can also be obtained from Equation 84 by symmetry with respect to the aforementioned metabolite relabeling.
Next, using symbolic computation (see Mathematica notebook (Supplementary file 1) and Mathematica notebook pdf (Supplementary file 2), p. 3), it is possible to show that
(86)
where all coefficients
and
are independent of and and are non-negative. Similarly (see Mathematica notebook (Supplementary file 1) and Mathematica notebook pdf (Supplementary file 2), p. 4),
(87)
where
We can now obtain the second derivative , taking into account Equation 86. Alternatively, we can obtain by differentiating with respect to , taking into account Equation 87. The denominators in both expressions would be identical due to Equation 83. Therefore the expression for the second derivative must have the form given by Equation 72, that is,
where β is independent of and . Thus, according to Equation 84, Equation 86,
which is verified in Mathematica notebook (Supplementary file 1) and Mathematica notebook pdf (Supplementary file 2), p. 4. Similarly, according to Equation 85, Equation 87,
which is verified in Mathematica notebook (Supplementary file 1) and Mathematica notebook pdf (Supplementary file 2), p. 5.
Appendix 5
Relationship to the flux balance analysis
Here, I discuss the relationship of the model presented in this paper to the flux balance analysis (FBA), a widely used approach to modeling whole-cell metabolism (Orth et al., 2010). FBA and my model are designed to address different questions. My model was designed to explore how the flux depends on the kinetic parameters of a module. FBA was designed to avoid this dependence. Nevertheless, the two models are conceptually and mathematically related and in fact are in some sense equivalent, as discussed below. The most important similarity is that both models rely on flux balance—the assumption that internal metabolites are at steady state—as a key simplification.
The major difference is that my model assumes that all reaction kinetics are first order, which allows for analytical tractability, while FBA is agnostic with respect to reaction kinetics and takes into account only their stoichiometries and possibly some additional ‘capacity’ constraints on the reaction rates (Orth et al., 2010). This difference deserves some additional discussion. In real cells, the concentrations of internal metabolites and the resulting fluxes (which are functions of these concentrations) are determined by the stoichiometries of reactions, the activities of enzymes and the concentrations of external nutrients. A general approach to modeling such systems, adopted by the metabolic control analysis and related theories, is to explicitly specify the dynamic equations for the metabolites, such as Equation 10, and solve them to find steady-state concentrations of internal metabolites (see e.g. Savageau, 1976). The steady-state fluxes are then determined automatically. In my model, the internal steady state exists and is unique for any module (see Corollary 1). In contrast, there are no dynamic equations within FBA. Instead, the steady-state fluxes are subject only to the mass-balance equations and the capacity conditions, which typically form a severely underdetermined system. Therefore, arriving at a unique flux distribution in FBA requires additional assumptions. The typical approach is to first fix at least some nutrient uptake rates and then maximize an objective function, such as the growth rate or biomass yield (Feist and Palsson, 2010). In other words, FBA trades-off the ability to handle reactions with arbitrary kinetics and unknown kinetic parameters against the necessity to impose auxiliary conditions to find the right solution among many plausible ones.
As a consequence of these model design choices, mutations that add or remove reactions can be naturally studied within the FBA framework, but there is no natural way to incorporate mutations that perturb the kinetic parameters of reactions (He et al., 2010; Alzoubi et al., 2019). In contrast, mutations of small or large effect, including reaction additions and deletions, can be in principle naturally studied within my model.
Due to differences in the assumptions, my model and FBA describe different sets of biological systems. However, there are special cases which can be described by both FBA and my model, and in these special cases the two models are mathematically equivalent.
From the perspective of FBA, modules with two I/O metabolites and first-order kinetics described by my model are a special case. So, let us apply FBA to a metabolic module with two I/O metabolites 1 and 2. For the purposes of FBA, let the I/O metabolite 1 be the ‘external nutrient’ and let the I/O metabolite 2 be the ‘biomass’. Suppose that metabolites in the set are adjacent to the external nutrient and metabolites in the set are adjacent to the biomass. Then reactions for , that is, those that convert the nutrient into intermediate metabolites, are the ‘uptake reactions’. And the reactions for , that is, those that convert intermediate metabolites into biomass, are the ‘biomass reactions’. Denote the rate of reaction consuming metabolite and producing metabolite by and let and be the input and output fluxes, respectively. To study epistasis within the FBA framework, we would need to obtain .
The assumption of my model that all reaction kinetics are first-order translates into the FBA formalism as the fact that the elements of the stoichiometry matrix take values −1, +1 or 0 and there are no capacity constraints on the rates of reactions. Then, the mass-balance equation leads to the equality , so that the flux through the module does not depend on module’s internal structure. Instead, it must be given as an auxiliary condition.
In my model, the steady-state flux through the module depends in general on the internal structure of the module (through the effective rate constant ) and is given by for any concentrations and of the external nutrient and the biomass. However, in the degenerate case where all uptake reactions are irreversible (i.e., for all ), , such that it is independent of the internal structure of the module. In this sense, this special case of my model is equivalent to FBA. However, my model and FBA are not equivalent in terms of the distribution of internal fluxes. My model still produces a unique steady sate and the corresponding flux distribution, whereas FBA does not specify a unique flux distribution in this case without additional auxiliary conditions.
Appendix 6
Connection between metabolism and growth
Here I describe a simple ‘bioreactor’ model for connecting a hierarchical metabolic network described in this paper with cellular growth. Suppose that module μ with I/O metabolites 1 and is at the top level of the metabolic hierarchy and describes the whole cell. The I/O metabolite 1 can be thought of as nutrients, and the I/O metabolite can be thought of as proteins, so that cellular metabolism converts nutrients into biomass. Denote the concentrations of metabolites and proteins within cells by and . Suppose that cells have a fixed volume and the number of cells is . Then, the absolute abundance of proteins and metabolites across all cells is and , .
The proteins produced by the cell are the enzymes that catalyze all the reactions inside module μ. Let the relative expression level of the enzyme catalyzing reaction , be (with ), so that its concentration inside cells is . If the specific forward and reverse activities of this enzyme are and (so that obey the Haldane equalities and ), then the total forward and reverse activities are and .
Finally, I assume that all reactions converting internal metabolites into biomass are irreversible, and I assume that the cell density in the bioreactor is small enough that the nutrient concentration stays constant. In other words, I model early exponential growth. Then the dynamics of metabolite and protein abundances are governed by equations
(88)
(89)
where .
I assume that all cells are identical and at steady state, such that protein and metabolite concetrations inside cells are constants and the production of proteins and metabolites manifests itself in the multiplication of cells. Then Equation 88 and Equation 89 become
(90)
(91)
where is the steady-state flux into biomass which defines the exponential growth rate of the system.
Finally, assuming that the rates of consumption and production of all metabolites are much greater than their dilution by growth, I set . Then Equation 90 defines the same steady state for module μ as described in the section Network coarse-graining. Therefore, module μ can be replaced with the effective activity between nutrients and biomass, yielding .
Data availability
All data generated or analyzed during this study are included in the manuscript and supporting files. Code is available on GitHub.
References
-
Evolution of dominance in metabolic pathwaysGenetics 168:1713–1735.https://doi.org/10.1534/genetics.104.028696
-
Effects of epistasis on phenotypic robustness in metabolic pathwaysMathematical Biosciences 184:27–51.https://doi.org/10.1016/S0025-5564(03)00057-9
-
Genetic interaction networks: toward an understanding of heritabilityAnnual Review of Genomics and Human Genetics 14:111–133.https://doi.org/10.1146/annurev-genom-082509-141730
-
Dynamic modeling of the central carbon metabolism of Escherichia coliBiotechnology and Bioengineering 79:53–73.https://doi.org/10.1002/bit.10288
-
Epistasis from functional dependence of fitness on underlying traitsProceedings of the Royal Society B: Biological Sciences 279:4156–4164.https://doi.org/10.1098/rspb.2012.1449
-
Bow ties, metabolism and diseaseTrends in Biotechnology 22:446–450.https://doi.org/10.1016/j.tibtech.2004.07.007
-
The synthetic genetic interaction spectrum of essential genesNature Genetics 37:1147–1152.https://doi.org/10.1038/ng1640
-
Empirical fitness landscapes and the predictability of evolutionNature Reviews Genetics 15:480–490.https://doi.org/10.1038/nrg3744
-
Missense meanderings in sequence space: a biophysical view of protein evolutionNature Reviews Genetics 6:678–687.https://doi.org/10.1038/nrg1672
-
Systematic mapping of genetic interaction networksAnnual Review of Genetics 43:601–625.https://doi.org/10.1146/annurev.genet.39.073003.114751
-
The causes and consequences of genetic interactions (epistasis)Annual Review of Genomics and Human Genetics 20:433–460.https://doi.org/10.1146/annurev-genom-083118-014857
-
The biomass objective functionCurrent Opinion in Microbiology 13:344–349.https://doi.org/10.1016/j.mib.2010.03.003
-
Systemic properties of metabolic networks lead to an epistasis-based model for heterosisTheoretical and Applied Genetics 120:463–473.https://doi.org/10.1007/s00122-009-1203-2
-
Evolution in the light of fitness landscape theoryTrends in Ecology & Evolution 34:69–82.https://doi.org/10.1016/j.tree.2018.10.009
-
Epistasis in a quantitative trait captured by a molecular model of transcription factor interactionsTheoretical Population Biology 77:1–5.https://doi.org/10.1016/j.tpb.2009.10.002
-
Epistasis and pleiotropy as natural properties of transcriptional regulationTheoretical Population Biology 49:58–89.https://doi.org/10.1006/tpbi.1996.0003
-
Modeling genetic architecture: a multilinear theory of gene interactionTheoretical Population Biology 59:61–86.https://doi.org/10.1006/tpbi.2000.1508
-
Physical constraints on epistasisMolecular Biology and Evolution 37:2865–2874.https://doi.org/10.1093/molbev/msaa124
-
Epistatic buffering of fitness loss in yeast double deletion strainsNature Genetics 39:550–554.https://doi.org/10.1038/ng1986
-
Models of quantitative variation of flux in metabolic pathwaysGenetics 121:869–876.
-
Metabolic models of selection responseJournal of Theoretical Biology 182:311–316.https://doi.org/10.1006/jtbi.1996.0169
-
Systematic interpretation of genetic interactions using protein networksNature Biotechnology 23:561–566.https://doi.org/10.1038/nbt1096
-
Through sex, nature is telling us something importantTrends in Genetics 34:352–361.https://doi.org/10.1016/j.tig.2018.01.003
-
Molecular mechanisms of epistasis within and between genesTrends in Genetics 27:323–331.https://doi.org/10.1016/j.tig.2011.05.007
-
Changes in gene expression predictably shift and switch genetic interactionsNature Communications 10:1–15.https://doi.org/10.1038/s41467-019-11735-3
-
Idiosyncratic epistasis creates universals in mutational effects and evolutionary trajectoriesNature Ecology & Evolution 4:1685–1693.https://doi.org/10.1038/s41559-020-01286-y
-
Epistasis and quantitative traits: using model organisms to study gene-gene interactionsNature Reviews Genetics 15:22–33.https://doi.org/10.1038/nrg3627
-
Predicting epistasis: an experimental test of metabolic control theory with bacterial transcription and translationJournal of Evolutionary Biology 23:488–493.https://doi.org/10.1111/j.1420-9101.2009.01888.x
-
BioModels—15 years of sharing computational models in life scienceNucleic Acids Research 48:D407–D415.https://doi.org/10.1093/nar/gkz1055
-
Protein complexes are central in the yeast genetic landscapePLOS Computational Biology 7:e1001092.https://doi.org/10.1371/journal.pcbi.1001092
-
Dynamics of glucose uptake by single Escherichia coli cellsMetabolic Engineering 1:320–333.https://doi.org/10.1006/mben.1999.0125
-
Gene regulatory networks generating the phenomena of additivity, dominance and epistasisGenetics 155:969–980.
-
The genetic theory of adaptation: a brief historyNature Reviews Genetics 6:119–127.https://doi.org/10.1038/nrg1523
-
A comprehensive genome-scale reconstruction of Escherichia coli metabolism--2011Molecular Systems Biology 7:535.https://doi.org/10.1038/msb.2011.65
-
Inferring the shape of global epistasisPNAS 115:E7550–E7558.https://doi.org/10.1073/pnas.1804015115
-
Epistasis — the essential role of gene interactions in the structure and evolution of genetic systemsNature Reviews Genetics 9:855–867.https://doi.org/10.1038/nrg2452
-
The context-dependence of mutations: a linkage of formalismsPLOS Computational Biology 12:e1004771.https://doi.org/10.1371/journal.pcbi.1004771
-
Epistasis in a model of molecular signal transductionPLOS Computational Biology 7:e1001134.https://doi.org/10.1371/journal.pcbi.1001134
-
A model reduction method for biochemical reaction networksBMC Systems Biology 8:52.https://doi.org/10.1186/1752-0509-8-52
-
Quantitative genetic-interaction mapping in mammalian cellsNature Methods 10:432–437.https://doi.org/10.1038/nmeth.2398
-
High-order epistasis shapes evolutionary trajectoriesPLOS Computational Biology 13:e1005541.https://doi.org/10.1371/journal.pcbi.1005541
-
BookBiochemical Systems Analysis. a Study of Function and Design in Molecular BiologyReading, MA: Addison-Wesley Publishing Company, Inc.
-
Diminishing-returns epistasis among random beneficial mutations in a multicellular fungusProceedings of the Royal Society B: Biological Sciences 283:20161376.https://doi.org/10.1098/rspb.2016.1376
-
On the validity of the steady state assumption of enzyme kineticsBulletin of Mathematical Biology 50:579–593.https://doi.org/10.1016/S0092-8240(88)80057-0
-
Sugar transport by the bacterial phosphotransferase system. the glucose receptors of the Salmonella typhimurium phosphotransferase systemJournal of Biological Chemistry 257:14543–14552.https://doi.org/10.1016/S0021-9258(19)45412-4
-
The utility of Fisher's geometric model in evolutionary geneticsAnnual Review of Ecology, Evolution, and Systematics 45:179–201.https://doi.org/10.1146/annurev-ecolsys-120213-091846
-
Evolutionary plasticity of genetic interaction networksNature Genetics 40:390–391.https://doi.org/10.1038/ng.114
-
Transposon insertion sequencing: a new tool for systems-level analysis of microorganismsNature Reviews Microbiology 11:435–442.https://doi.org/10.1038/nrmicro3033
-
Remarks on star-mesh transformation of electrical networksElectronics Letters 6:597–599.https://doi.org/10.1049/el:19700417
-
Genetic measurement of theory of epistatic effectsGenetica 102-103:569–580.https://doi.org/10.1023/A:1017088321094
-
BookTwo rules for the detection and quantification of epistasis and other interaction effectsIn: Moore J, Williams S, editors. Epistasis. Humana Press. pp. 145–157.https://doi.org/10.1007/978-1-4939-2155-3_8
-
Detecting epistasis in human complex traitsNature Reviews Genetics 15:722–733.https://doi.org/10.1038/nrg3747
-
Physiological and evolutionary theories of dominanceThe American Naturalist 68:24–53.https://doi.org/10.1086/280521
Article and author information
Author details
Sergey Kryazhimskiy

Funding
Burroughs Wellcome Fund (Career Award at Scientific Interface (1010719.01))
- Sergey Kryazhimskiy
Alfred P. Sloan Foundation (FG-2017-9227)
- Sergey Kryazhimskiy
Hellman Foundation (Hellman Fellowship)
- Sergey Kryazhimskiy
National Institutes of Health (1R01GM137112)
- Sergey Kryazhimskiy
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
I thank Chris Marx for discussions that stimulated this work, David McCandlish for making me aware of the Kron reduction, Daniel P Rice, the Kryazhimskiy lab, and the reviewers for feedback on the manuscript. This work was supported by the BWF Career Award at Scientific Interface (Grant 1010719.01), the Alfred P Sloan Foundation (Grant FG-2017–9227), the Hellman Foundation and NIH (Grant 1R01GM137112).
Copyright
© 2021, Kryazhimskiy
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,396
- views
-
- 533
- downloads
-
- 37
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 37
- citations for umbrella DOI https://doi.org/10.7554/eLife.60200
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Emergence and propagation of epistasis in metabolic networks
eLife 10:e60200.
https://doi.org/10.7554/eLife.60200




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}