Building accurate sequence-to-affinity models from high-throughput in vitro protein-DNA binding data using FeatureREDUCE
- Columbia University, United States
- University of Massachusetts Boston, United States
Abstract
Transcription factors are crucial regulators of gene expression. Accurate quantitative definition of their intrinsic DNA binding preferences is critical to understanding their biological function. High-throughput in vitro technology has recently been used to deeply probe the DNA binding specificity of hundreds of eukaryotic transcription factors, yet algorithms for analyzing such data have not yet fully matured. Here, we present a general framework (FeatureREDUCE) for building sequence-to-affinity models based on a biophysically interpretable and extensible model of protein-DNA interaction that can account for dependencies between nucleotides within the binding interface or multiple modes of binding. When training on protein binding microarray (PBM) data, we use robust regression and modeling of technology-specific biases to infer specificity models of unprecedented accuracy and precision. We provide quantitative validation of our results by comparing to gold-standard data when available.
https://doi.org/10.7554/eLife.06397.001eLife digest
Transcription is the process by which the information contained within DNA is copied to a short-lived molecule called RNA so that it can be transported to other areas of the cell for various purposes. Transcription factors are key components in this process. These proteins recognise and gather at specific sequences of DNA near genes, and then assist the enzymes that copy the information in the gene into a molecule of RNA. This means that transcription factors essentially control which genes are expressed, and when and where these genes are expressed.
Recent technological advances have made it possible to identify where transcription factors can bind within DNA sequences. Yet, while a lot of data has been generated in this area, the computational tools needed to make sense of it have not kept pace.
Now, Riley et al. have developed software called FeatureREDUCE that will allow researchers to build computer predictions of how strongly a transcription factor will interact with specific short sections of DNA sequence. The software can be applied to experimental data collected in so-called ‘protein binding microarray’ experiments. FeatureREDUCE can also be used to investigate questions in the field of transcription factor research that had previously remained unanswered. First, to what level of detail can data obtained from recent technological advances be understood? Second, can transcription factors bind to DNA in more than one way, and can data from protein binding microarrays be used to uncover this?
Riley et al. show that FeatureREDUCE can produce accurate and interpretable clues about the biology behind how transcription factors recognize DNA sequences. This includes how mutations as small as a change to single DNA letter can affect recognition. The next step will be to use the software to make sense of the existing volume of experimental data regarding protein-DNA interactions and data that will be generated in future experiments.
https://doi.org/10.7554/eLife.06397.002Introduction
Transcription factors (TFs) play a central role in the regulation of gene expression. To be able to understand and predict the behavior of the gene regulatory circuitry in any given organism, we need to know the in vivo DNA binding preferences of the TFs that its genome encodes. In recent years, a number of high-throughput in vitro technologies have been introduced that can provide such information (Berger and Bulyk, 2009; Warren et al., 2006; Maerkl and Quake, 2007; Zhao et al., 2009; Slattery et al., 2011; Berger et al., 2006). However, while the volume of the data generated using these assays dwarfs that of more traditional measurements of protein-DNA interaction strength, the available computational methodology for analyzing them has not fully matured (Weirauch, 2013).
The number of base pairs that constitute the DNA 'footprint' within which base identity can influence binding affinity depends strongly on the three-dimensional structure of the DNA-binding domain (DBD) of the TF. In theory, as long as thermodynamic equilibrium can be assumed, sequence specificity is completely defined by a table containing the (relative) affinity with which the DBD binds to each possible oligonucleotide within the footprint. This tabular approach has been widely used to analyze Protein Binding Microarray (PBM) data (Berger and Bulyk, 2009). It comes with significant challenges, however. First, the size of the oligomer table grows exponentially with footprint size, which in practice limits it to eight base pairs, shorter than the footprint of most TFs. Even for octamer tables, the number of affinity parameters to be estimated is on the same order as the number of PBM data points. This limits precision and necessitates the use of non-parametric methods (as opposed to parameterized biophysical methods), resulting in an associated loss of quantitative information.
A long-standing alternative has been to assume that each nucleotide position within the footprint contributes independently to the overall binding affinity. The most commonly used representation of sequence specificity that makes this independence assumption is the position weight matrix (PWM) (Berg and von Hippel, 1987; Stormo and Fields, 1998; Stormo, 2000; Djordjevic et al., 2003), which defines position-specific base frequencies. Algorithms for inferring the PWM coefficients traditionally aim to maximize its information content relative to a random background model (Lawrence et al., 1993; Frech et al., 1997; Bailey, 1995; Roth et al., 1998). In an alternative approach, sequence specificity is represented in terms of the relative affinity (or, equivalently, the difference, △△G, in binding free energy) associated with each possible point mutation of the optimal sequence (Stormo and Yoshioka, 1991; Stormo et al., 1993), and summarized in the form of a position-specific affinity matrix (PSAM) (Foat et al., 2006; Bussemaker et al., 2007). The difference in philosophy between the PWM and PSAM representations also leads to a different approach to estimating their coefficients. It is no longer the information content (i.e. the height of the letters in the standard sequence logo) that is being optimized, but rather the ability of the PSAM to quantitatively explain the variation in a measurable quantity in terms of variation in the nucleotide sequence associated with each quantity (for instance, the expression level of a gene in terms of its upstream promoter sequence). In the case of PBM data, the PSAM parameters are inferred by performing a nonlinear fit of a sequence-based model that predicts the signal intensity for each probe. The first implementations of this idea were the MatrixREDUCE (Foat et al., 2006; Foat et al., 2005) and PREGO (Tanay, 2006) algorithms; a more recent extension is BEEML-PBM (Zhao and Stormo, 2011).
Whether dependencies between nucleotide positions can be accurately estimated from PBM data and used to refine models of binding specificity remains an open question (Weirauch, 2013; Zhao and Stormo, 2011; Benos et al., 2002). Furthermore, while the existence of alternative binding modes is now widely recognized, accurate quantification of their relative usage has not yet been attempted. To address these needs, we developed our FeatureREDUCE software. It provides a flexible framework for building sequence-to-affinity models from PBM data (Figure 1).
Figure 1
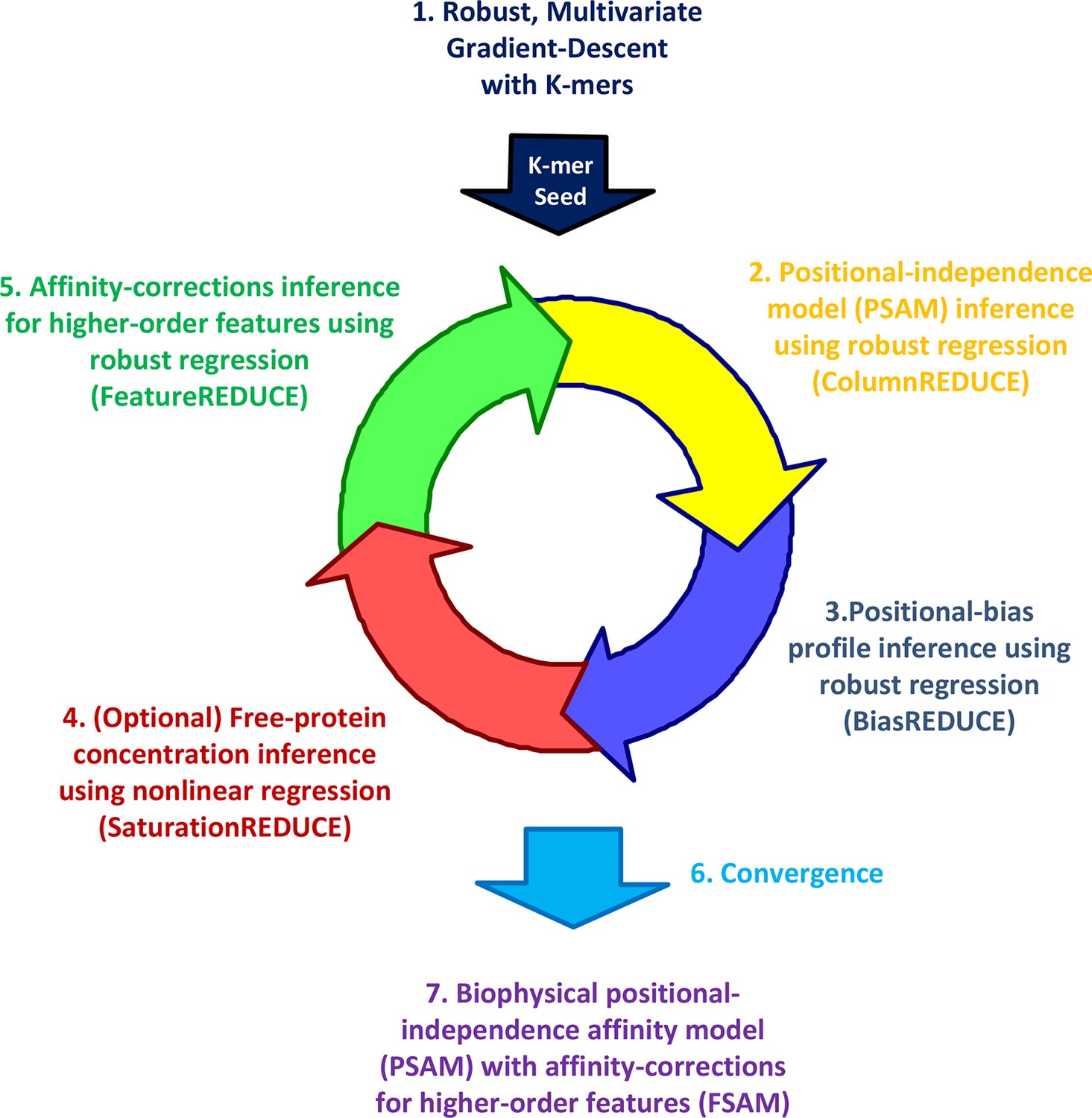
The FeatureREDUCE workflow for analyzing PBM intensities.
(1) A robust method is used to estimate relative affinities for each K-mer of a given length. The K-mer with the highest affinity is chosen as the seed. (2) Using the seed as a reference, robust linear regression is used to estimate the relative affinity parameters in each column of the position-specific affinity matrix (PSAM). (3) With the current affinity model, linear regression is used to estimate the positional bias profile across the probe. (4) An optional step uses nonlinear regression to solve for the free protein concentration. (5) Robust regression is used to estimate free energy contributions associated with higher-order sequence features such as dinucleotides. (6) Steps 2 through 5 are repeated until convergence. (7) The procedure results in a feature-specific affinity model (FSAM) that can be used to predict the relative affinity for any DNA sequence.
Results and discussion
FeatureREDUCE is based on an extensible biophysical model in which the binding free energy difference △△G(Sref→S) between an arbitrary nucleotide sequence S and a reference sequence Sref (usually taken as the highest-affinity sequence) is defined as a sum of parameters △△Gφ over all nucleotide sequence 'features' φ that distinguish S from Sref (see Materials and methods). The full set of possible features in which S and Sref differ includes all possible single-base substitutions by default, but can be supplemented with dinucleotides that model dependencies and/or insertions at specific positions within the binding site that model variation in binding mode. Such a feature-based approach has been used previously (Sharon et al., 2008; Gordân et al., 2013; Zhou et al., 2015), but, as we will argue below, our approach to estimating the coefficients of the model is different and optimal.
The contribution of a binding site to the PBM intensity depends on its position within the probe, as was previously demonstrated by planting the same motif at different offsets (Berger et al., 2006). This may preclude accurate model estimation unless it is dealt with explicitly. Moreover, whenever the TF binds near the free end of a probe, loss of contacts with the DNA backbone can reduce binding affinity. FeatureREDUCE captures such spatial bias by introducing an independent multiplicative correction factor for the ratio [TF]/Kd at each offset within the probe (Figure 2a). These coefficients are estimated from the PBM intensities in parallel with the △△G parameters (see Materials and methods). The positional bias profile inferred by FeatureREDUCE for the homo-dimer Cbf1p is shown in Figure 2b. It indicates that the magnitude of the contribution of an individual binding site to the PBM intensity can vary by an order of magnitude depending on its offset within the probe, and that there is preference for Cbf1p binding away from the substrate. For Pho4p, binding near the free end of the probe shows an opposite trend (Figure 2—figure supplement 1). The fraction of the variance (R2) in PBM intensity explained by a 10-bp independent-nucleotide model increases dramatically, from 48% to 71%, after accounting for the positional bias. FeatureREDUCE can also detect any preference for monomeric TFs to bind in one of the two possible orientations on the dsDNA probes. For example, Zif268 exhibits a strong bias for binding to the negative strand over the positive strand (Figure 2c). Indeed, it is known that Zif268 requires non-specific contacts with the DNA backbone on the 5'-end of the motif (Berger et al., 2006). BEEML-PBM (Zhao and Stormo, 2011) also models positional biases along the probes, but it does not account for orientation preference, or for overhang binding at the free end of the probe.
Figure 2 with 1 supplement see all
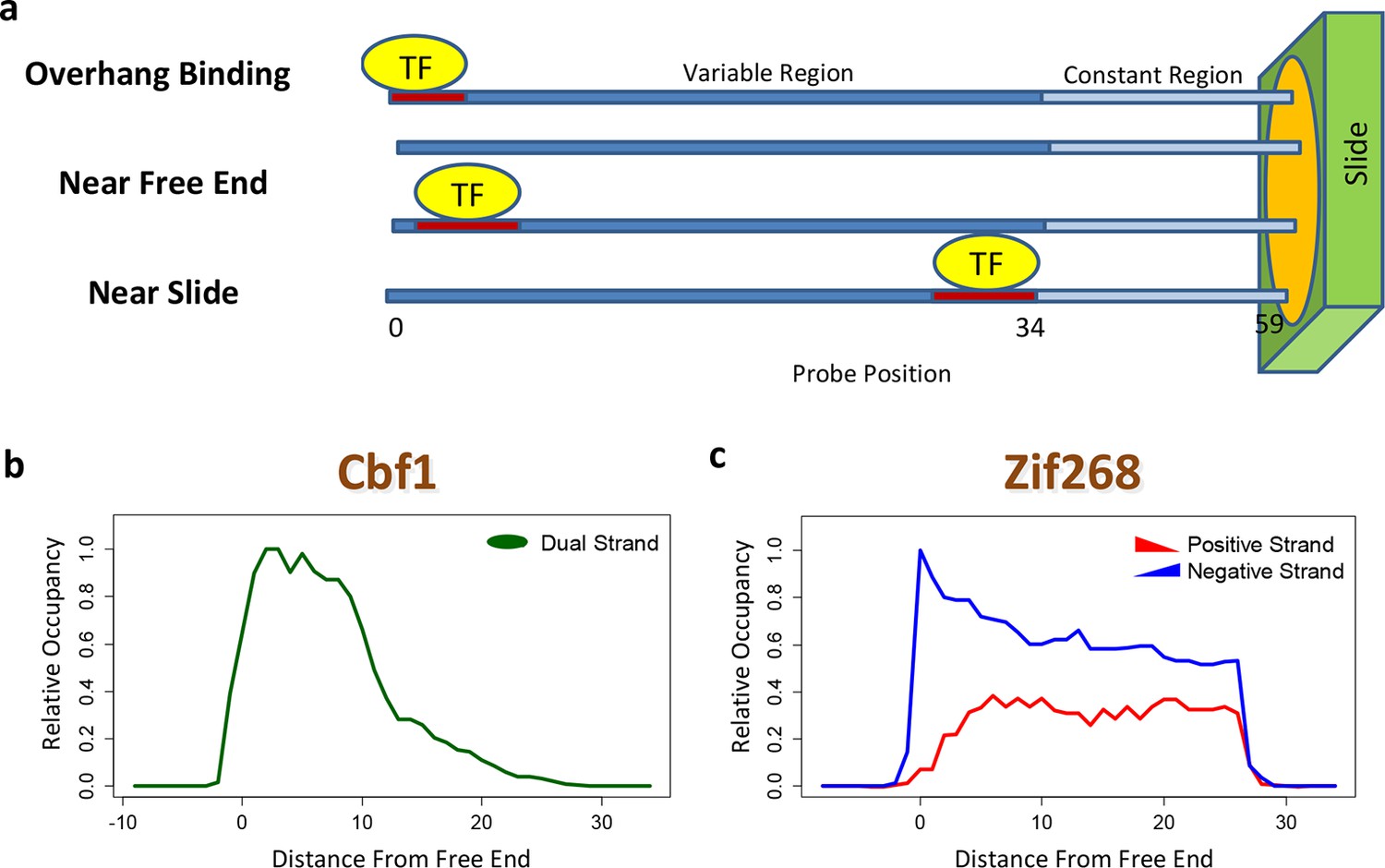
Quantifying PBM-specific positional and orientational bias.
(a) Accounting for biases related to the position of the binding site within the probe. The effective protein concentration is lower closer to the substrate, presumably due to steric hindrance. Furthermore, binding near the free end of probe is associated with loss of contacts with the DNA backbone. (b) Positional bias profile for the homo-dimeric bHLH transcription factor Cbf1p, as inferred by a model fit to the PBM intensities. (c) Idem, for the monomeric zinc finger transcription factor Zif268. Figure 2—figure supplement 1 shows how positional bias can be used as an indicator of data quality.
The readout of base identity at different nucleotide positions is only approximately independent. Indeed, various studies have analyzed whether representations of sequence specificity that account for nucleotide dependencies are more accurate than those that do not (Sharon et al., 2008; Agius et al., 2010; Lee et al., 2002; Stormo et al., 1986; Zhou and Liu, 2004). Controversy, however, remains about whether the additional parameters associated with such dependencies reflect structural mechanisms or technology-specific biases (Weirauch, 2013). In the biophysical model that underlies FeatureREDUCE, we model dependencies by simply including additional DNA sequence features φ that define base identity at two (or more) nucleotide positions, and estimating the corresponding free energy parameters △△Gφ along with those for single nucleotides (see Materials and methods). The nucleotide dependencies discovered by FeatureREDUCE for Cbf1p are shown in Figure 3a. As expected for a model with additional parameters, accounting for dependencies significantly increased the fraction of the variance that could be explained when training on PBM intensities (R2 improved from 71% to 96%). The real question, however, is how well the inferred model parameters perform on independent validation data.
Figure 3 with 2 supplements see all

Robust estimation of dependencies between nucleotide positions.
(a) Overview of the dependencies between pairs of neighboring nucleotides positions identified by FeatureREDUCE for homodimers of the basic helix-loop-helix (bHLH) factor Cbf1p. (b) Including dinucleotide dependencies in the sequence-to-affinity model, in combination with the use of robust regression, improves the ability to delineate Gene Ontology associations with Cbf1p targets predicted from the genome sequence. Figure 3—figure supplement 1 shows the crucial importance of using robust inference methods for estimating the binding free energy correction terms associated with dinucleotide features. Figure 3—figure supplement 2 shows the underlying cumulative distributions of yeast promoter affinities for 'sulfur compound metabolic process', the GO category with the most statistically significant association with Cbf1p.
A unique aspect of FeatureREDUCE is the use of robust inference techniques (Huber and Ronchetti, 2009), which, as it turns out, is crucial for obtaining accurate estimates of the various contributions to the binding free energy. To demonstrate this, we compared our results to measurements of binding affinity for Cbf1p obtained using the orginal version of the MITOMI technology (Maerkl and Quake, 2007), which are in excellent (R2 = 0.95) agreement with similar measurements obtained using surface plasmon resonance (Berger et al., 2006; Teh et al., 2007). We used these 'gold-standard' binding affinity measurements to assess the quality of the sequence-to-affinity models inferred from PBM data by FeatureREDUCE. When we fit a position-specific affinity matrix (PSAM) based model that ignores dependencies between nucleotides, the root-mean-square error (RMSE) between FeatureREDUCE model predictions and gold-standard MITOMI 1.0 measurements improved from 0.071 to 0.035 when standard least-squares fitting was replaced by robust iteratively re-weighted least-squares (Figure 3—figure supplement 1, left panels). When positional dependencies were added to the model (feature-specific affinity model; FSAM), it actually performed worse than the model assuming independence between nucleotides (position-specific affinity matrix; PSAM) when we used standard least-squares fitting, indicative of over-fitting to noise in the training data. When we used robust regression, however, the RMSE for the FSAM-based model was significantly better than for the PSAM-based model (Figure 3—figure supplement 1, right panels). These results indicate that dependencies within the binding interface indeed exist, and that they can be modeled incorrectly when non-robust regression techniques are used.
We also assessed the ability of our models to make predictions regarding in vivo TF function. First, we found that the inclusion of nucleotide dependencies when predicting aggregated yeast promoter affinities improves the ability to delineate Gene Ontology categories associated with regulation by Cbf1p (see Materials and methods), but again only when robust inference techniques are used (Figure 3B; see also Figure 3—figure supplement 2). Second, to assess the extent to which we can quantitatively predict in vivo binding, we considered the degree of occupancy by Cbf1p at 955 potential genomic binding sites of type NNCACGTGNN (E-box) in yeast cells growing in rich media as measured by ChIP-seq (Zhou and O'Shea, 2011). Using a simple thermodynamic equilibrium model with a single free protein concentration parameter to account for binding saturation in the ChIP-seq experiment, we found that by this in vivo measure, FeatureREDUCE performs well (RMSE = 0.075), and significantly better than BEEML-PBM (Zhao and Stormo, 2011) (RMSE = 0.156); full data are shown in Figure 4.
Figure 4
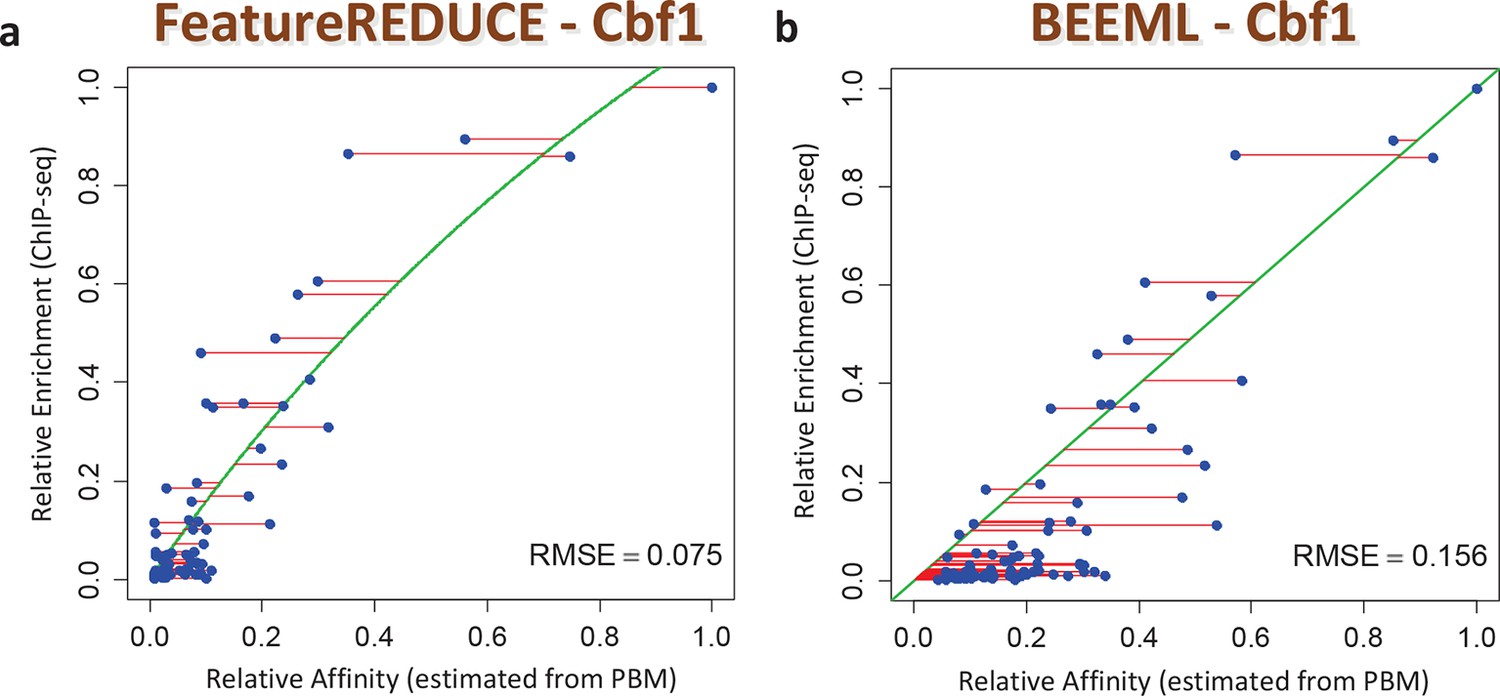
ChIP-seq based validation of position-specific affinity matrix (PSAM) inferred for Cbf1p.
(a) Direct comparison between relative affinities for 10-mers inferred from PBM intensities by FeatureREDUCE and relative in vivo occupancy at 955 genomic locations of type NNCACGTGNN (E-box with flanks) as measured by ChIP-seq (Zhou and O'Shea, 2011). Trimmed-mean (trim = 10%) ChIP-seq fold-enrichments were computed for all unique 10-mer sequences that occur at least three times in the genome. To account for saturation of higher-affinity binding sites, a basic equilibrium model (green curve) was fit with a single free-protein parameter. Red lines indicate the error between the observed and predicted relative ChIP enrichments. (b) The same plot for the BEEML-PBM algorithm (Zhao and Stormo, 2011). The same equilibrium model (green curve) was fit, but the optimal free protein concentration parameter was much lower than in (a), so the saturation is not apparent in this case.
The accuracy of FeatureREDUCE was demonstrated more broadly in a recent benchmark comparison between 26 different PBM data analysis algorithms (Weirauch, 2013). This study employed two distinct performance metrics. The in vitro metric quantified the accuracy with which probe intensities were predicted in a test PBM experiment using a model trained on independent training data from a PBM experiment for the same TF but with a different probe design; this was done for 66 different TFs from various structural families. The in vivo metric used a non-parametric score to quantify accuracy in ranking sequences in terms of their local ChIP-seq enrichment, for nine different TFs. FeatureREDUCE emerged as the top-performing algorithm according to both criteria.
Weirauch et al. (Weirauch, 2013) first assessed algorithm performance across a large dataset by using cross-validation between two different PBM designs. However, one of their surprising findings was that some algorithms generate models that perform well across different PBM designs but poorly when predicting in vivo binding, presumably due to over-fitting to PBM-specific biases. For example, the performance of one of the algorithms went from second-best in the PBM cross-validation test to worst in the ChIP-seq prediction test (Weirauch, 2013). Likewise, an extension of BEEML-PBM that adds dinucleotide parameters (Zhao et al., 2012) did not perform well on ChIP-seq data (Weirauch, 2013), presumably because it does not employ robust inference techniques. We conclude that FeatureREDUCE is currently the only algorithm that succeeds in parameterizing dependencies within the binding site.
Another current debate in the field is whether or not PBM data can provide evidence of alternative DNA binding modes employed by the same TF (Zhao and Stormo, 2011; Badis et al., 2009; Morris et al., 2011; Gordân et al., 2011). Oligomeric TF complexes can often bind DNA using different relative orientations of and/or spacing between their subunits (Gordân et al., 2011). The modeling framework employed by FeatureREDUCE provides a natural opportunity to perform forward selection of multiple binding modes, represented by distinct PSAMs, which can subsequently be combined into a single predictive model and refined in an iterative manner (see Materials and methods). We applied this procedure for the basic leucine zipper (bZIP) proteins Yap1p and Gcn4p. FeatureREDUCE accurately captures the known intrinsic differences in half-site preference of Yap1p (which prefers TTAC, typical for the C/EBP subfamily (Warren et al., 2012); Figure 5a) and Gcn4p (which prefers TGAC, typical for the CREB subfamily; Figure 5b). It is well known that each protein, when binding DNA as a homo-dimer, can do so with or without a 1-bp overlap between the half-sites. What is unique about our approach is that the multi-PSAM model captures fold-differences in thermodynamic stability between the binding modes by estimating an overall relative affinity coefficient for the secondary PSAM. For instance, the binding affinity of Gcn4p for TGACGTCA is predicted to be 24% of that of TGASTCA (cf. Figure 5b). This is in good agreement with recent high-throughput measurements of Gcn4 binding constants for all 12-mers using HiTS-FLIP (Nutiu et al., 2011), specifically, Kd = 65 nM and 15 nM for the respective sequences. In addition, while the accuracy of the dominant TGASTCA motif essentially does not change, the accuracy of the weaker TGACGTCA motif increases significantly when using our multi-PSAM model compared to the single-fit model (R2 improved from 69% to 80% for sites with relative affinity > 0.1). We note that the results of our analysis can be used in a straightforward manner to predict which binding mode is dominant for a particular DNA sequence.
Figure 5
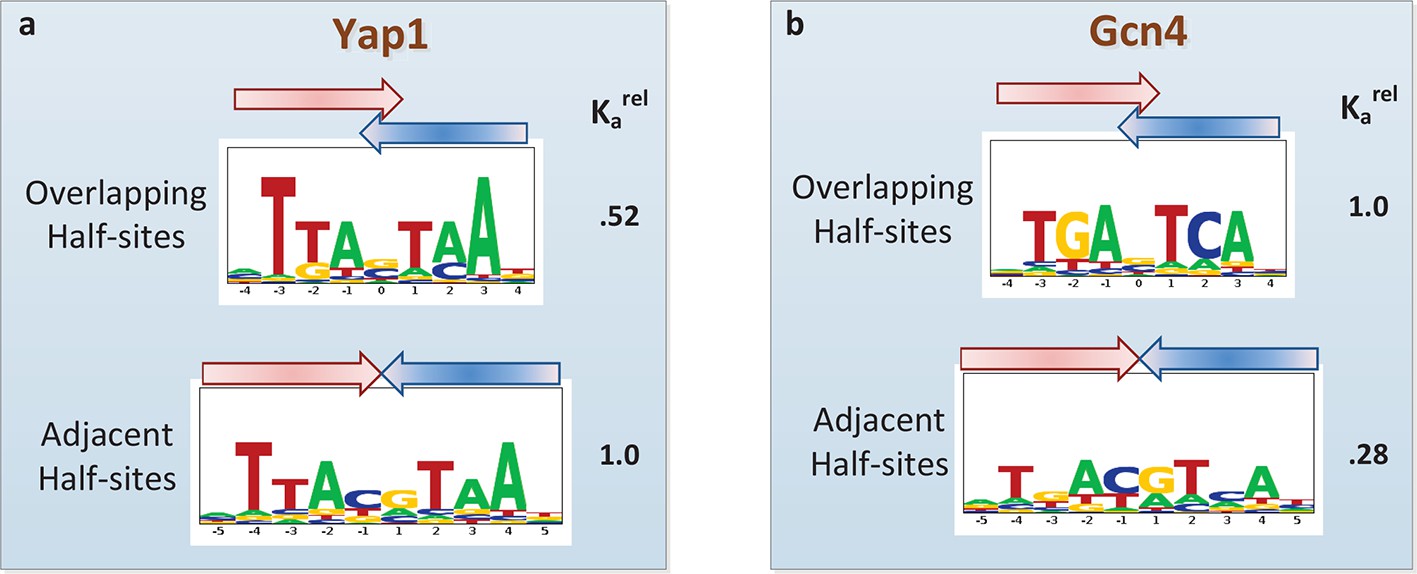
Quantifying the differential usage of alternative binding modes.
The transcription factors Yap1p (a) and Gcn4p (b) can each bind in two distinct modes, in which the two half-sites respectively do (top) and do not (bottom) overlap. Not only is the sequence of preferred half-site different between the two factors, the preferred binding mode is different too, as indicated by the relative association constant (Ka) inferred from the PBM data by FeatureREDUCE.
In conclusion, FeatureREDUCE analysis yields an accurate and interpretable biophysical affinity model that can provide detailed clues about the structural mechanisms that underlie protein-DNA recognition (Roider et al., 2007; Kinney et al., 2007), such as dependencies between nucleotide positions and the modulation of binding mode by variation in the underlying DNA sequence. Our algorithm allows one to make optimal use of the large volume of data that has been generated using microarray-based protein-nucleotide interaction profiling technology.
Materials and methods
Equilibrium model for TF-DNA interaction
Request a detailed protocolFeatureREDUCE builds upon the biophysical model for protein-DNA interaction on which Matrix-REDUCE (Foat et al., 2006) is based. A transcription factor P binds to DNA sequence S to form a TF-DNA complex PS, with forward and backward rate constants kon and koff, respectively:
(1)
The affinity of P for S can be expressed in terms of an equilibrium association constant Ka(S) or dissociation constant Kd(S):
(2)
The Gibbs free energy of binding per mole (relative to a 1M reference concentration) is given by ∆G = RT ln(Kd /1M) is, where R is the universal gas constant and T the absolute temperature. The fractional occupancy, N(S), defined as the probability that S is bound by P, can be expressed as:
(3)
If we assume a low-concentration regime where where no saturation occurs, the expression for the occupancy simplifies to:
(4)
Relative to a reference sequence Sref (typically chosen to be the highest-affinity sequence), there will be multiplicative change in the affinity Ka, or, equivalently, an additive change ∆∆G in the free energy of binding, for any other sequence S:
(5)
where
(6)
Feature-based model of sequence specificity
Request a detailed protocolFeatureREDUCE models the relative binding free energy for sequence S as a sum of parameters associated with the DNA sequence features that characterize S:
(7)
In this study, we considered both single-nucleotide features (e.g. φ = A1, denoting the presence of an A at position 1 within the binding site window) and adjacent-dinucleotide ones (e.g., φ = C3G4, denoting the presence of a CpG dinucleotide starting at position 3). At a given position, exactly one of a set of 4 single-nucleotide features (A, C, G, or T) will be present in any particular sequence. We refer to such a set of mutually exclusive and jointly exhaustive features as a 'block'. Each sequence has exactly one feature from each block. A binding window of length L contains L mononucleotide blocks. There is a one-to-one correspondence between the (exponentiated) ∆∆Gφ/RT values in a mononucleotide block and a column in a position-specific affinity matrix (PSAM). Together, the dinucleotide features constitute L − 1 dinucleotide blocks, each consisting of 16 features. Within each block, the 4 or 16 ∆∆Gφ values are only defined up to a common additive constant. The convention we use for mononucleotide blocks is that ∆∆Gφ = 0 for the feature that occurs in the reference sequence. For dinucleotide blocks, however, we use a different convention intended to minimize the number of ∆∆Gφ values that are significantly different from zero (see below for details).
Modeling PBM intensity
Request a detailed protocolThe model on which MatrixREDUCE (Foat et al., 2006) was based assumes that the measured fluorescence intensity y(S) for probe S is given by a sum over all possible ways in which the TF can bind to the probe (all possible offsets in either the forward or the reverse direction), which we will here refer to as partial 'views' Sv on the full probe sequence S:
(8)
In FeatureREDUCE, to account for positional and directional biases in the extent to which binding affinity in a particular view contributes to the probe intensity, we introduce coefficients γν that are shared across all probes:
(9)
We do not necessarily assume a low TF concentration (cf. Equation 4). Moreover, we include a term ∆∆Gns that accounts for non-specific binding, which helps capture the DNA binding characteristics of the protein succinctly and has a positive effect on numerical convergence when estimating the model parameters. Together, this leads to the following model:
(10)
Robust model parameter estimation
Request a detailed protocolFeatureREDUCE estimates the parameters in Equation 9 using iteratively reweighted least squares (IRLS). This procedure down-weights data points that have high residuals compared to the fitted model. However, the weights depend on the residuals and the residuals depend on the weights. This dependency is broken by first choosing uniform initial weights, then iteratively refitting the model and re-calculating new residuals and weights, until convergence. IRLS prevents over-fitting and thereby allows for improved parameter estimation. FeatureREDUCE uses the 'rlm' function in the MASS package for R to perform the robust regression. We set the trimmed probes hyperparameter to 20%, as we previously found this value to be optimal during cross-validation on the DREAM5 dataset (Weirauch, 2013). Repeated rounds of parameter re-estimation that cycle over feature 'blocks' are performed until convergence, first for mononucleotide blocks (resulting in a converged PSAM), and subsequently for dinucleotide blocks. Specifically, when estimating the free energy parameters for a given block B, the following model is fit:
(11)
Here Vφ(S) denotes the subset of views on S that contain feature φ. Note that only the βφ coefficients are treated as fit parameters here. The ∆∆Gφ values come from the previous iteration. However, they are re-estimated as:
(12)
Here βPSAM stands for the value of β1 in Equation 12 when only mononucleotide features are fit. With this normalization, ∆∆Gφ is no longer equal to zero for dinucleotide features occurring in the reference sequence. However, most of the ∆∆Gφ values for dinucleotide features now tend to be close to zero, which is desirable. In each round, the spatial bias parameters γν are also re-estimated using robust regression. After iteration and convergence over multiple such rounds, FeatureREDUCE fits the additional parameters in the non-linear model in Equation 10 using the Levenberg-Marquardt nonlinear least-squares algorithm.
Seed discovery
Request a detailed protocolFinding a good seed for the feature-based regression procedure is a crucial first step in our algorithm. To select the seed from the set of all oligomers of length K, we developed a dedicated robust iterative algorithm based on trimmed means designed to deal with the sparseness of the design matrix. We fit probe intensities as a weighted sum of the number of occurrences of each of the 4K oligomers:
(13)
Here Xm(S) denotes the number of occurrences of oligomer m in sequence S. Regression coefficients βm were initialized to a small value (10−4) representative of non-specific binding. Next, for each individual probe S, we determined the coefficient value β’m(S) that exactly predicts the intensity:
(14)
We then computed the trimmed mean (removing the top and bottom 15% values) of all β’m(S) values across all probes for which Xm > 0. Finally, we updated the coefficient according to:
(15)
using a step size α = 0.1. This was done for all oligomers in parallel. After iteration and convergence, the oligomer with the highest regression coefficient value was chosen as the seed.
Palindromic symmetry
Request a detailed protocolThis step in the algorithm starts by separately fitting and then comparing positive and negative strand PSAMs. If these are similar according to the L1-norm (within a small tolerance) then the motif is flagged as symmetric. The PSAM is then rebuilt using the highest-affinity symmetric seed. The symmetric version of the binding motif tends to be more accurate while using half the number of parameters.
Motif length
Request a detailed protocolWe determine the length of the binding site by adding columns to either side of the PSAM until the coefficient of determination (R2) decreases. An increase indicates that there are direct or indirect protein-DNA contacts being made at the additional positions, while a decrease indicates that we have increased the length of the motif past the effective range of specificity and inadvertently excluded valid binding sites at the end of the PBM probe.
Testing for gene ontology association
Request a detailed protocolFollowing (Ward and Bussemaker, 2008), we first predict the total affinity of each gene’s upstream region, as a sum over a sliding window of binding affinities computed using our model. Next, all genes were ranked by this total promoter affinity and the Wilcoxon-Mann-Whitney rank-sum test was used to score association with each Gene Ontology category (Gene Ontology and Consortium, 2015). P-values were corrected for multiple testing using a Bonferroni correction based on the total number of GO categories tested in parallel.
Alternative binding modes
Request a detailed protocolTo infer multiple-binding models for a single TF, the following procedure was used: (i) Fit a single-binding-model using the standard algorithm. (ii) Fit additional binding-mode model(s) to the residuals of the previous model. (iii) Iteratively update each binding mode as a weighted mean between a newly fit model and the model from the previous iteration, until convergence. (iv) Perform a final multiple regression to determine the relative preference for (and statistical significance of) each binding mode.
Motifs containing poly-G/C stretches
Request a detailed protocolStretches of four or more guanines affect the efficiency of PBM probe synthesis and were replaced by their reverse complement in some PBM designs (Berger et al., 2008). Therefore, if the highest-affinity motif contains four or more consecutive cytosines, FeatureREDUCE uses only the positive strand to generate the biophysical model; conversely, if the highest-affinity motif contains a poly-G stretch, only the negative strand is used.
Software availability
Request a detailed protocolData availability
-
Transcription factor Zif268Publicly available at the Uni Probe Database (Accession no: UP00400).
-
Integrated approaches reveal determinants of genome-wide binding and function of the transcription factor Pho4Publicly available at the Gene Expression Omnibus (Accession no: GSE29506).
-
Transcription factor Cbf1Publicly available at the Uni Probe Database (Accession no: UP00397).
-
Integrated approaches reveal determinants of genome-wide binding and function of the transcription factor Pho4Publicly available at the Gene Expression Omnibus (Accession no: GSE29506).
-
Pho2_ChIP_HighPiPublicly available at the Gene Expression Omnibus (Accession no: GSM730520).
-
Cbf1 MITOMI dataPublicly available at sciencemag.org.
-
Transcription factor Pho4Publicly available at the Uni Probe Database (Accession no: UP00332).
-
Transcription factor Yap1Publicly available at the Uni Probe Database (Accession no: UP00327).
-
Transcription factor Gcn4Publicly available at the Uni Probe Database (Accession no: UP00285).
References
-
Additivity in protein-DNA interactions: how good an approximation is it?Nucleic Acids Research 30:4442–4451.https://doi.org/10.1093/nar/gkf578
-
Predictive modeling of genome-wide mRNA expression: from modules to moleculesAnnual Review of Biophysics and Biomolecular Structure 36:329–347.https://doi.org/10.1146/annurev.biophys.36.040306.132725
-
A biophysical approach to transcription factor binding site discoveryGenome Research 13:2381–2390.https://doi.org/10.1101/gr.1271603
-
Profiling condition-specific, genome-wide regulation of mRNA stability in yeastProceedings of the National Academy of Sciences of the United States of America 102:17675–17680.https://doi.org/10.1073/pnas.0503803102
-
Gene ontology consortium: going forwardNucleic Acids Research 43:D1049–D1056.https://doi.org/10.1093/nar/gku1179
-
Wiley Series in Probability and Statistics354, Robust statistics. 2nd, Wiley Series in Probability and Statistics, Hoboken, NJ, Wiley. .
-
Precise physical models of protein-DNA interaction from high-throughput dataProceedings of the National Academy of Sciences of the United States of America 104:501–506.https://doi.org/10.1073/pnas.0609908104
-
A mathematical analysis of SELEXComputational Biology and Chemistry 31:11–35.https://doi.org/10.1016/j.compbiolchem.2006.10.002
-
Jury remains out on simple models of transcription factor specificityNature Biotechnology 29:483–484.https://doi.org/10.1038/nbt.1892
-
Direct measurement of DNA affinity landscapes on a high-throughput sequencing instrumentNature Biotechnology 29:659–664.https://doi.org/10.1038/nbt.1882
-
A feature-based approach to modeling protein–DNA interactionsPLoS Computational Biology 4:e1000154.https://doi.org/10.1371/journal.pcbi.1000154
-
Quantitative analysis of the relationship between nucleotide sequence and functional activityNucleic Acids Research 14:6661–6679.https://doi.org/10.1093/nar/14.16.6661
-
Specificity of the mnt protein determined by binding to randomized operatorsProceedings of the National Academy of Sciences of the United States of America 88:5699–5703.https://doi.org/10.1073/pnas.88.13.5699
-
Specificity of the mnt protein. independent effects of mutations at different positions in the operatorJournal of Molecular Biology 229:821–826.https://doi.org/10.1006/jmbi.1993.1088
-
Specificity, free energy and information content in protein–DNA interactionsTrends in Biochemical Sciences 23:109–113.https://doi.org/10.1016/S0968-0004(98)01187-6
-
DNA binding sites: representation and discoveryBioinformatics 16:16–23.https://doi.org/10.1093/bioinformatics/16.1.16
-
Extensive low-affinity transcriptional interactions in the yeast genomeGenome Research 16:962–972.https://doi.org/10.1101/gr.5113606
-
Defining the sequence-recognition profile of DNA-binding moleculesProceedings of the National Academy of Sciences of the United States of America 103:867–872.https://doi.org/10.1073/pnas.0509843102
-
Evaluation of methods for modeling transcription factor sequence specificityNature Biotechnology 31:126–134.https://doi.org/10.1038/nbt.2486
-
Inferring binding energies from selected binding sitesPLoS Computational Biology 5:e1000590.https://doi.org/10.1371/journal.pcbi.1000590
-
Quantitative modeling of transcription factor binding specificities using DNA shapeProceedings of the National Academy of Sciences of the United States of America 112:4654–4659.https://doi.org/10.1073/pnas.1422023112
Article and author information
Author details
Funding
National Human Genome Research Institute (R01HG003008)
- Harmen J Bussemaker
John Simon Guggenheim Memorial Foundation
- Harmen J Bussemaker
National Institute of General Medical Sciences (R01GM058575)
- Richard S Mann
National Cancer Institute (U54CA121852)
- Richard S Mann
- Harmen J Bussemaker
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank the members of the Bussemaker and Mann labs for comments and feedback during the course of these studies. This work was supported by National Institute of Health grants R01HG003008 to HJB, GM058575 to RSM, F32GM087047 to MS, and F32GM099160 to NA, a John Simon Guggenheim Foundation Fellowship (HJB), and pilot funding from Columbia University’s Research Initiatives in Science and Engineering (RISE) program to HJB and RSM.
Copyright
© 2015, Riley et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 0
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Building accurate sequence-to-affinity models from high-throughput in vitro protein-DNA binding data using FeatureREDUCE
eLife 4:e06397.
https://doi.org/10.7554/eLife.06397




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}