Visuomotor learning from postdictive motor error
- Institute for Psychology and Otto Creutzfeldt Center for Cognitive and Behavioral Neuroscience, University of Muenster, Germany
Figures
Figure 1
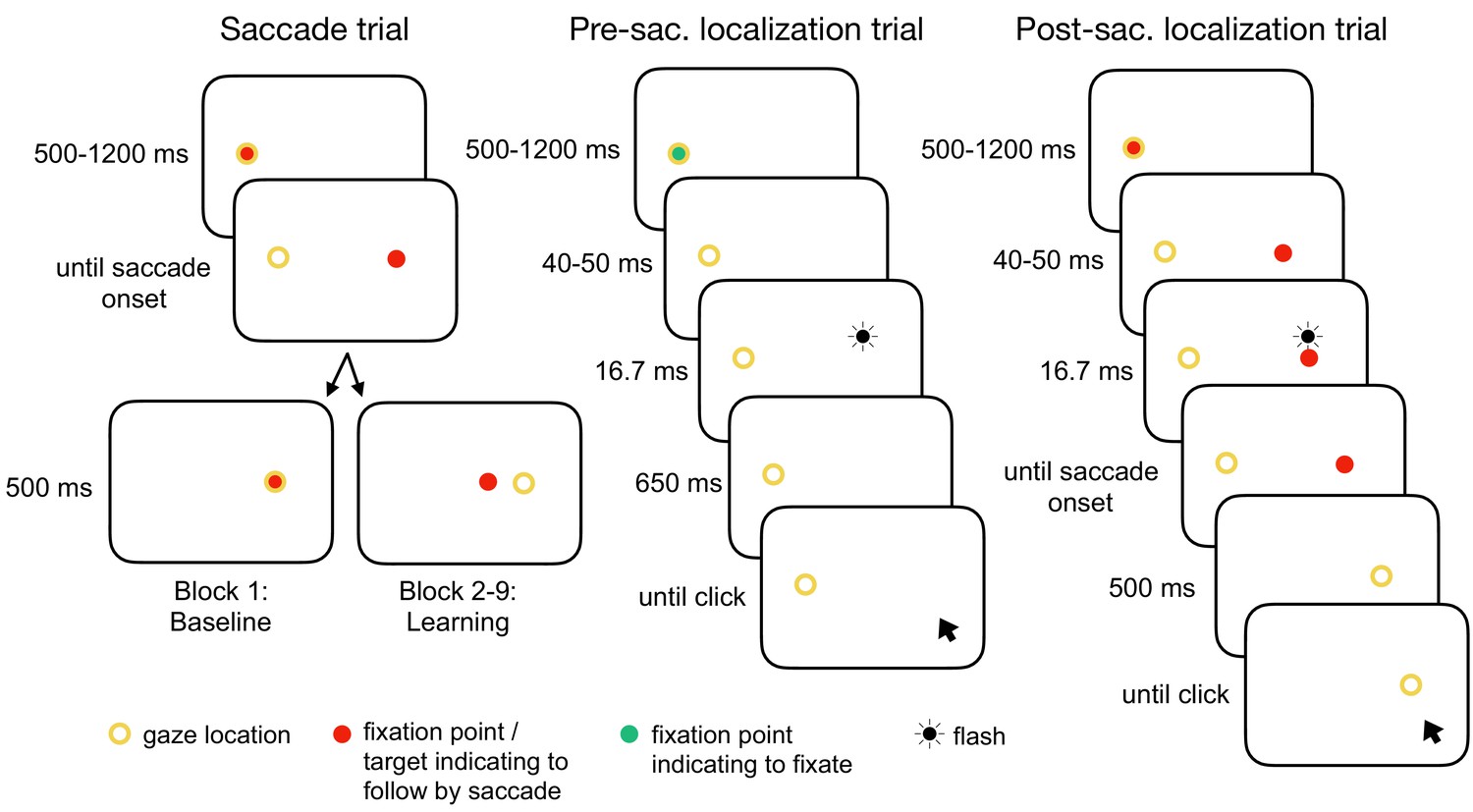
Experimental tasks.
In the saccade trials, subjects performed a reactive saccade to a 13° rightward target. During saccade execution from block 2 onwards, the target was shifted to a new location depending on the learning condition, e.g. 3° inward as shown here (CTSin). In the pre-saccadic localization trials, subjects hold their gaze at the fixation point while localizing a white 16.7 ms flash with a gray dot cursor. In the post-saccadic localization trials, subjects performed a saccade as in the saccade trials but hold their gaze after saccade landing and report the location of the pre-saccadic flash that had appeared 40–50 ms after target onset. The yellow circle illustrates gaze location but was not present at the stimulus monitor.
Figure 2
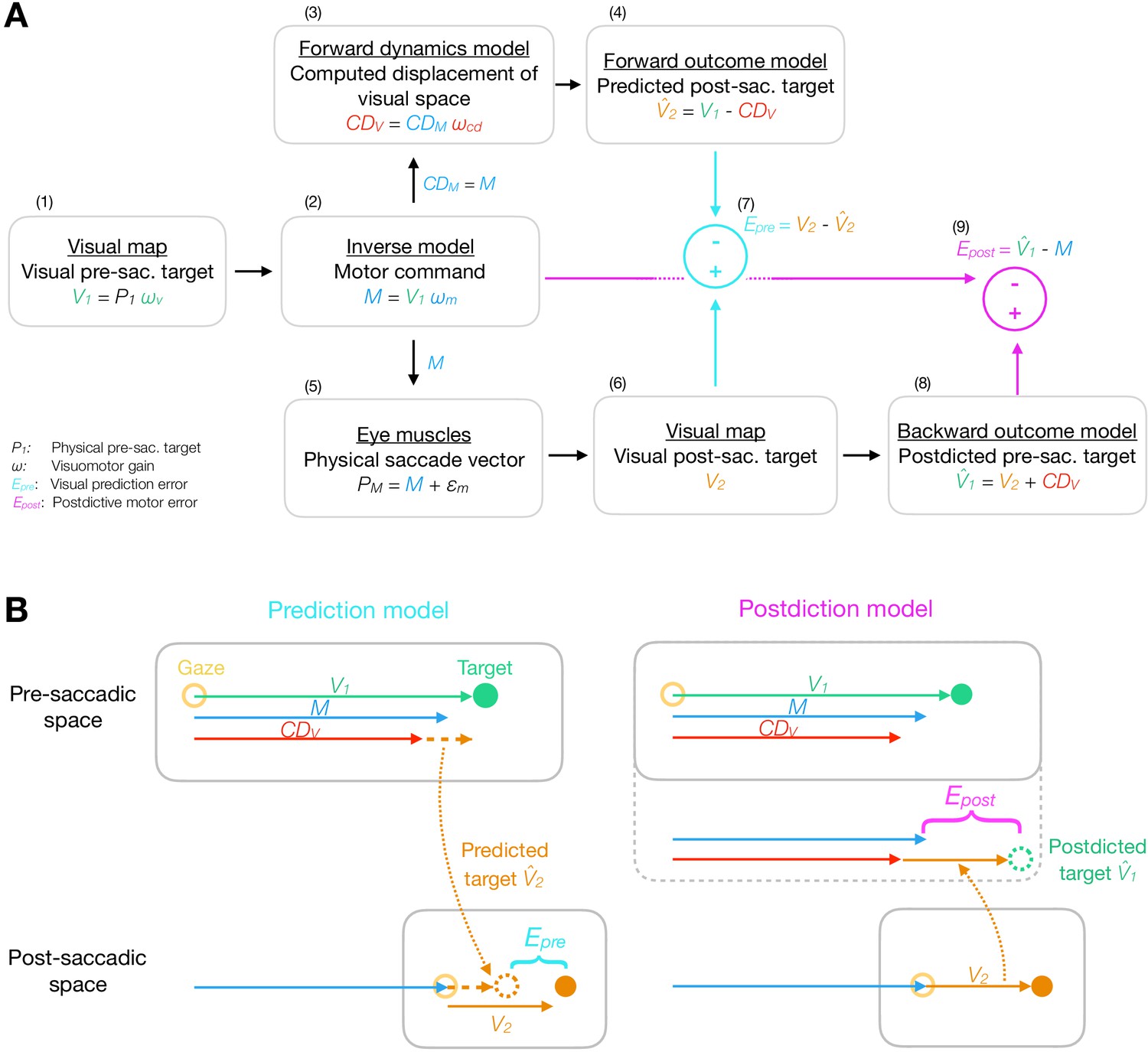
Model framework.
(A) The visual pre-saccadic target V1 (i.e. the perceived location of a physical target P1) is transformed into the motor command M. Before saccade execution, a forward dynamics model transforms a copy of the motor command into a computed displacement of visual space , a visual estimate of the saccade vector. Hence, the forward outcome model predicts the visual post-saccadic target to appear at position . After saccade execution, the visual post-saccadic target appears at position V2. According to prediction-based learning, the visuomotor system detects an error if the visual post-saccadic target deviates from its prediction (), experiencing a violation of spatial stability. According to postdiction-based learning, the visuomotor system assumes the world to remain stable during the saccade. Hence, a backward outcome model postdicts the visual post-saccadic target back to pre-saccadic space () in order to retroactively evaluate the motor command (). (B) Computation of visual prediction error and postdictive motor error . In prediction-based learning, the predicted visual error is derived from the visual pre-saccadic target V1 and the signal in pre-saccadic space () and is then compared to the actual visual error in post-saccadic space (). In postdiction-based learning, the visual error V2 is obtained in post-saccadic space and postdicted back to pre-saccadic space based on the signal (). It is then compared to the original motor command to calculate postdictive motor error ().
Figure 3
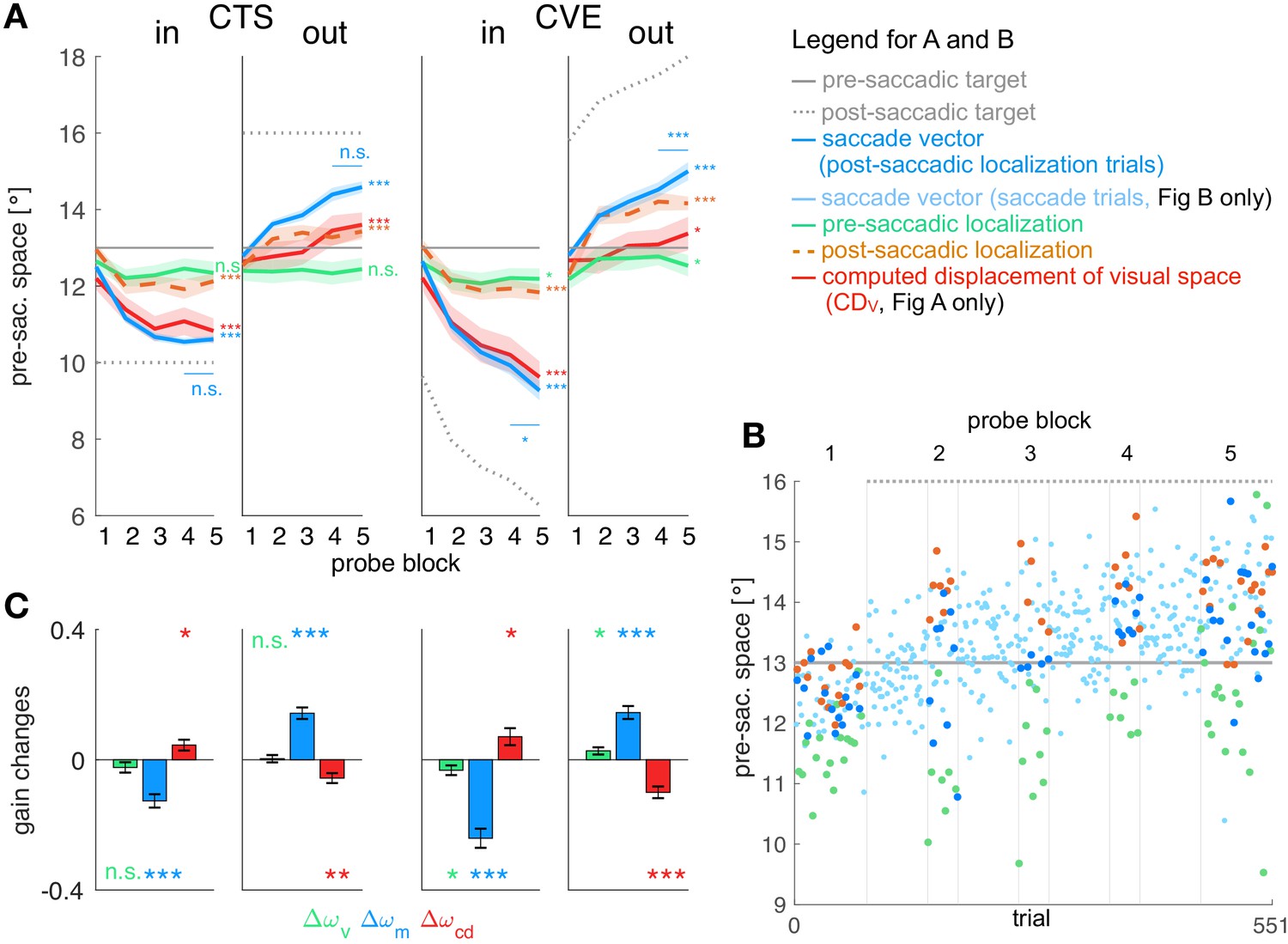
Experimental data and gain changes.
(A) Experimental data averaged across subjects. Each panel shows saccade vectors, pre- and post-saccadic localizations and of the five probe blocks for a specific learning condition. Error bars indicate standard error of the mean. Asterisks at the right edge of each panel indicate significant change from probe block 1 to 5 with ***p<0.001, **p<0.01, *p<0.05 and n.s. p≥0.05. Blue asterisks within the panel indicate significant change from probe block 4 to 5 showing that learning was completed at the end of the CTS conditions but still in progress at the end of the CVE conditions. (B) Experimental data of an example subject for the CTSout condition. Saccade vectors, pre- and post-saccadic localizations were measured within five probe blocks across learning. As saccade vectors needed to be related to post-saccadic localizations, only the saccade vectors of the post-saccadic localization trials (dark blue) were used for the analysis. (C) Gain changes from the first to the last trial for the four learning conditions, averaged across subjects. Asterisks indicate significant difference from zero with ***p<0.001, **p<0.01, *p<0.05 and n.s. p≥0.05.
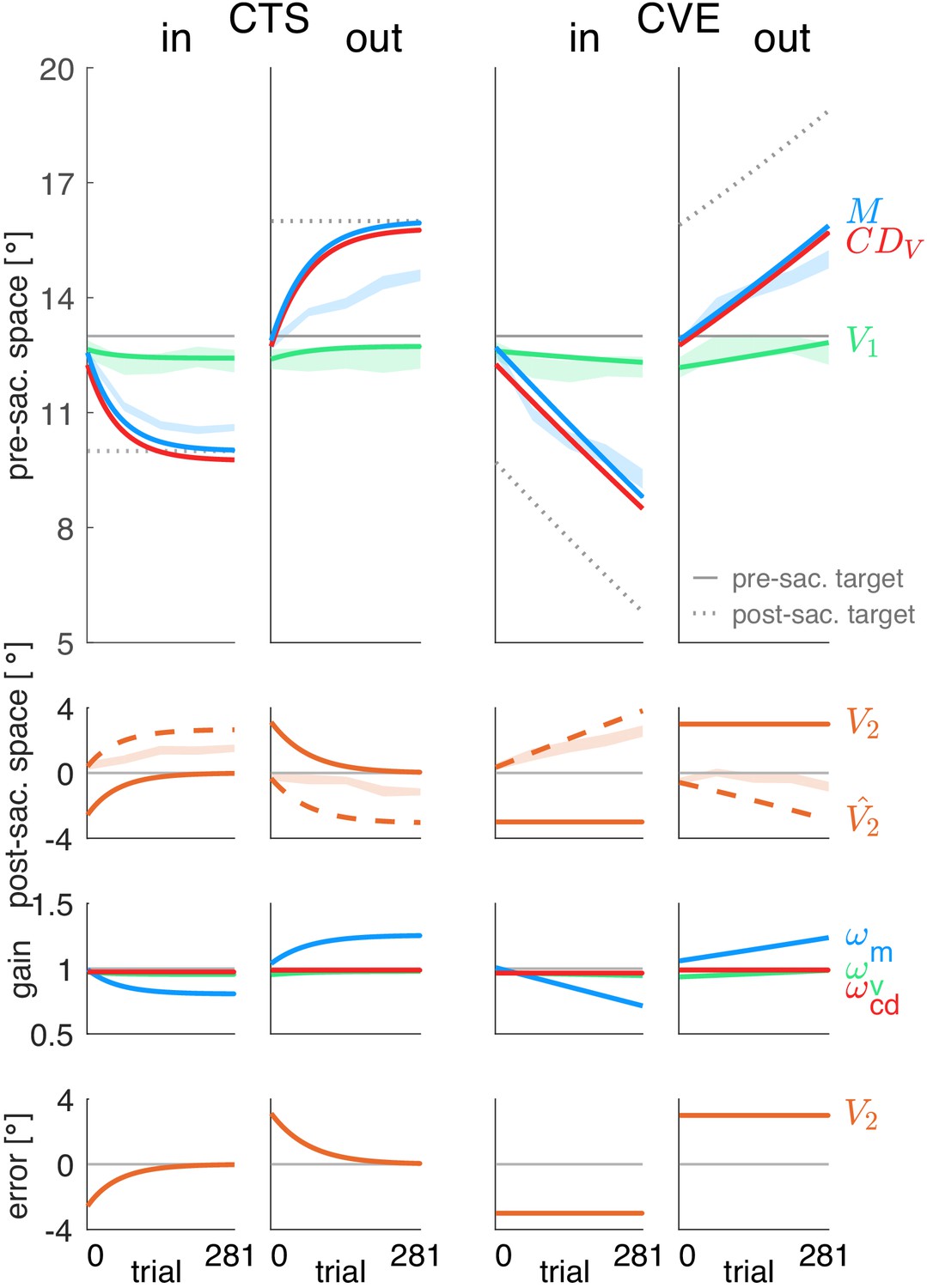
Figure 4
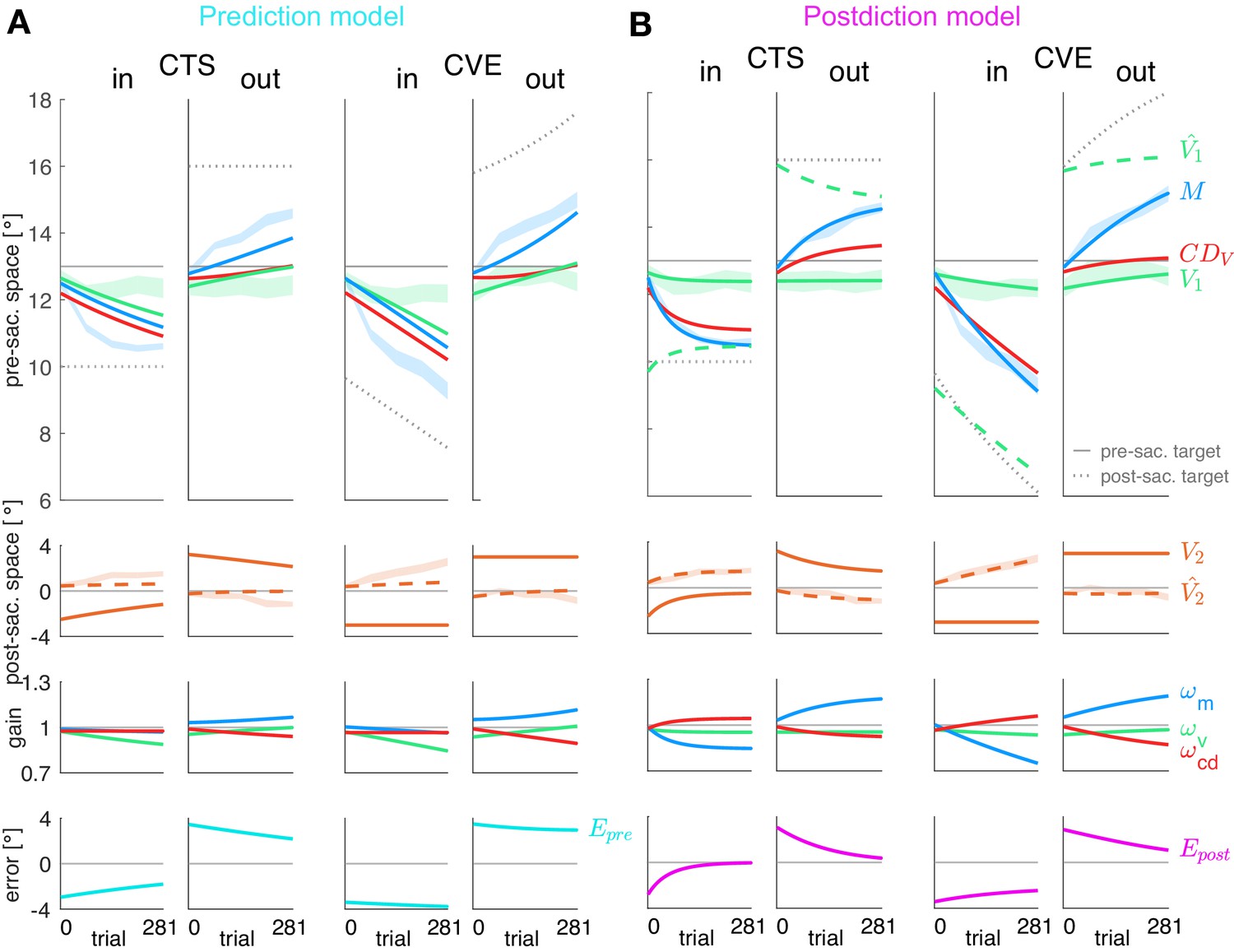
Prediction model fits and postdiction model fits to the experimental data.
Each column shows the fit for a specific learning condition. Fits are shown by lines. Data (subject means ± standard error) are shown by shaded areas. Please note that due to the model fit, the lines appear smooth compared to the mean over subjects represented by the lines in Figure 3A. First row: Visual pre-saccadic target V1 (fitted to pre-saccadic retinal localizations, green shade), motor command M (fitted to saccade vectors, blue shade), computed displacement of visual space , postdicted pre-saccadic target in the postdiction model. Second row: Predicted post-saccadic target (fitted to post-saccadic retinal localizations, orange shade), visual post-saccadic target V2. Third row: Visual gain , motor gain , CD gain . (A) Last row: Visual prediction error . To nullify , the model requires to learn in the opposite direction of M. As this is not in line with the data, the prediction model does not adequately fit the data. Fitted learning rates are: CTSin = (4.9*10−6; 5.0*10−5; 3.8*10−17), CVEin = (4.6*10−6; 5.0*10−5; 3.4*10−17), CTSout = (2.1*10−6; 5.0*10−5; 2.3*10−6), CVEout = (2.9*10−6; 5.0*10−5; 4.0*10−6). (B) Last row: Postdictive motor error . At the end of the CTS conditions, so that the system is appears to be converged to a steady state while at the end of the CVE conditions learning is still in progress. Fitted learning rates are: CTSin = (5.2*10−6; 3.5*10−5; 1.8*10−5), CVEin = (1.9*10−6; 1.3*10−5; 5.4*10−6), CTSout = (8.4*10−8; 1.5*10−5; 6.3*10−6), CVEout = (2.0*10−6; 9.9*10−6; 8.0*10−6).
Figure 5

Residual standard error and visuomotor steady states.
(A) Residual standard error of the prediction and the postdiction model fit (subject means ± standard error). (B) Baseline and baseline if no target step occurs (CTS with = 0, subject means ± standard error). The baseline error should be close to zero as the system is assumed to be in a steady state. (C) Final of the prediction model fit and final of the postdiction model fit (subject medians with 25% and 75% quantiles). The final error should be close to zero if the system converged to a new steady state. (D) Percentage of decline of the prediction model fit and decline of the postdiction model fit from the first trial (including target step) to the last trial (subject medians with 25% and 75% quantiles). Black asterisks indicate significant difference between prediction and postdiction model values, colored asterisks for baseline and final error indicate significant difference from zero. (E) Vector fields depict non-isolated fixed points for the baseline situation without target step and the four learning conditions (in the plane for simplicity). Subject median of the first trial (for baseline) and the last trial (for learning in the respective condition) and median from the respective learning conditions were chosen to draw the vector field. Subjects were at visuomotor steady state in the baseline and learned in the direction of the shifted fixed points during learning. (F) The error determines how much visual endpoint error (visual post-saccadic target eccentricity) is left in the baseline adapted steady state of the CTS conditions (subject means ± standard error). Please note that , not , is depicted for easier comparison to V2. Black asterisks indicate significant difference from zero with ***p<0.001, **p<0.01, *p<0.05 and n.s. p≥0.05.
Appendix 1—figure 1
Simulations of a model that minimizes visual error.
Each column shows the simulation for a specific learning condition. Simulations are shown by lines. Data (means ± standard error) are shown by shaded areas. First row: Visual pre-saccadic target V1 (and pre-saccadic retinal localization data, green shade), motor command (and saccade vector data, blue shade) and computed displacement of visual space . Second row: Predicted post-saccadic target (and post-saccadic retinal localization data, orange shade), visual post-saccadic target V2 (visual error). Third row: Visual gain , motor gain , CD gain . Last row: shows again the visual post-saccadic target V2 (visual error) that is the error signal to be nullified. To nullify V2, the model requires to learn until the saccade lands on the post-saccadic target. This is not in line with the data. Instead, learning converges at an earlier stage with a remaining, non-zero visual error V2. Hence, the visual error model cannot adequately explain learning. Please note that the CD gain stays stable as the visual error V2 does not depend on such that the gradient descent procedure produces zero learning of the CD gain.
Appendix 1—figure 2

Simulations of the postdiction model without plasticity of the CD gain (=0).
Each column shows the simulation for a specific learning condition. Simulations are shown by lines. Data (means ± standard error) are shown by shaded areas. First row: Visual pre-saccadic target V1 (and pre-saccadic retinal localization data, green shade), motor command (and saccade vector data, blue shade), computed displacement of visual space , postdicted pre-saccadic target . Second row: Predicted post-saccadic target (and post-saccadic retinal localization data, orange shade), visual post-saccadic target V2. Third row: Visual gain , motor gain , CD gain . Last row: Postdictive motor error . If the CD gain is not plastic and hence, stays at baseline level as shown here, almost correctly reflects the saccade vector during learning such that the post-saccadic target localization matches the pre-saccadic target localization. This can be seen in the predicted post-saccadic target position that, however, does not match the data (second row). Moreover, a non-plastic CD gain requires the saccade vector to adapt until the saccade lands on the post-saccadic target to nullify the postdictive motor error . Hence, without CD plasticity the model cannot adequately explain the data.
Appendix 1—figure 3
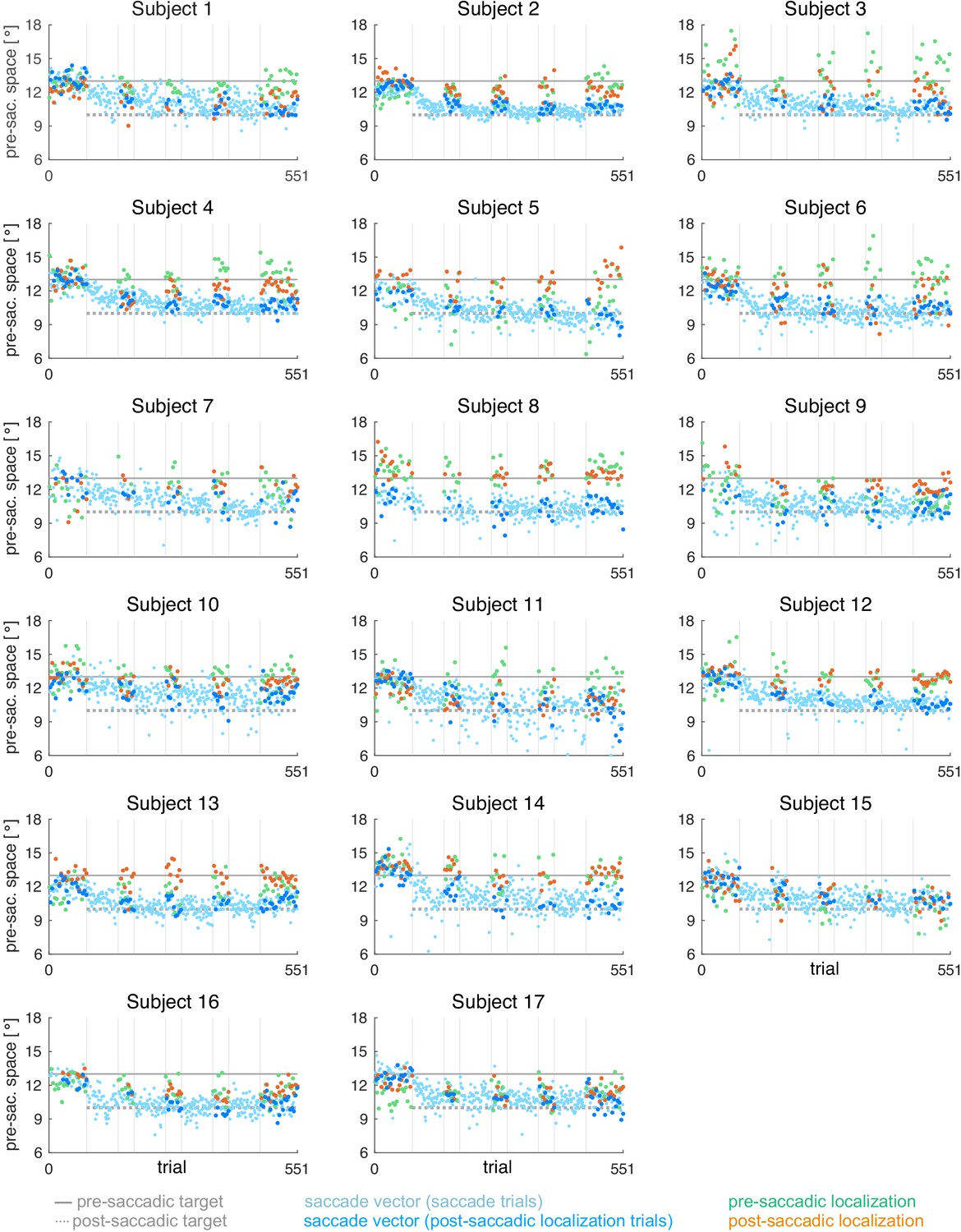
Individual subject data for the CTSin condition (subjects 1–17, = 17).
During the saccade, the target was shifted 3º inward (opposite to saccade direction).
Appendix 1—figure 4
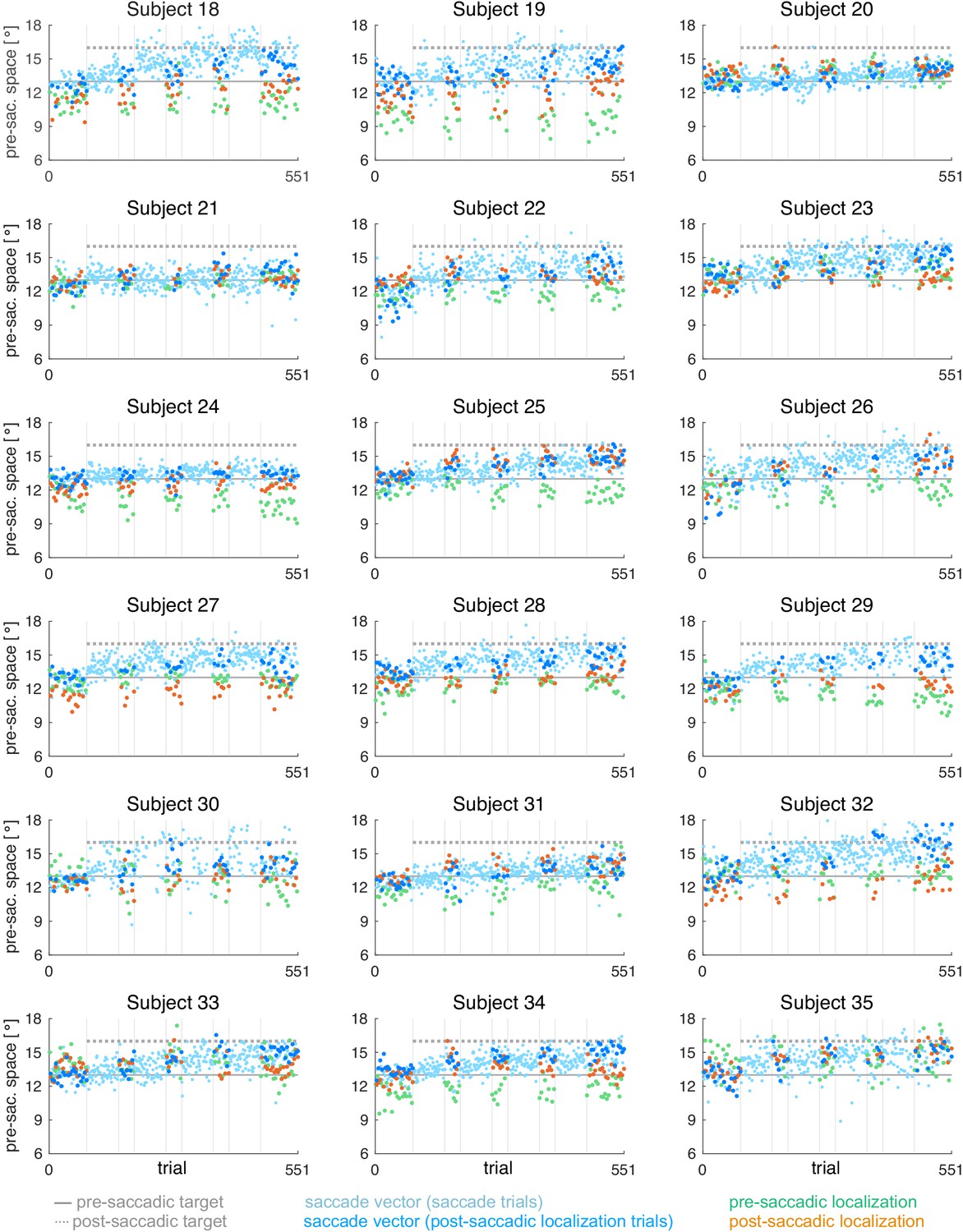
Individual subject data for the CTSout condition (subjects 18–35, = 18).
During the saccade, the target was shifted 3º outward (in saccade direction).
Appendix 1—figure 5
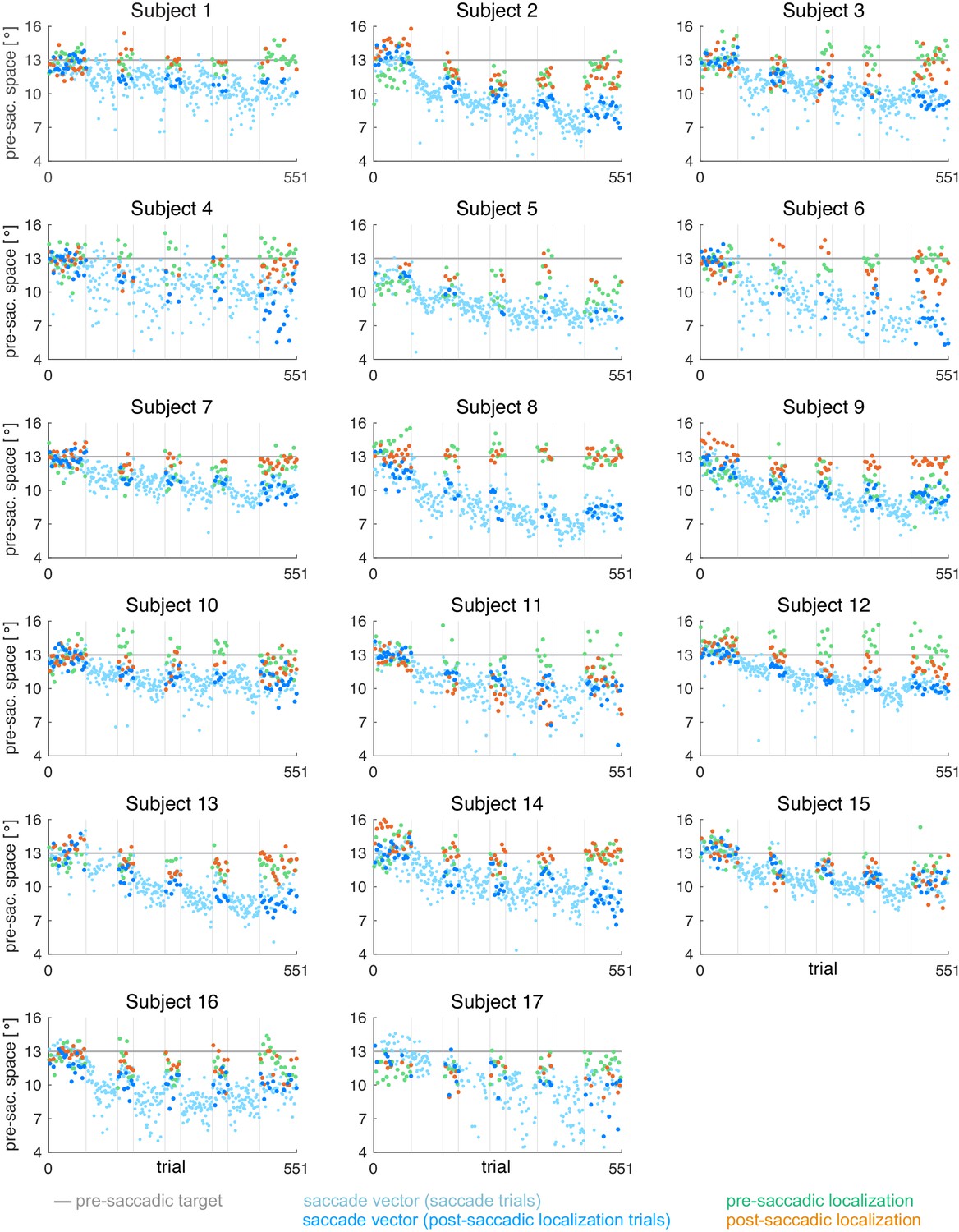
Individual subject data for the CVEin condition (subjects 1–17, = 17).
During the saccade, the target was shifted to the position that is 3º inward (opposite to saccade direction) of the post-saccadic gaze direction.
Appendix 1—figure 6

Individual subject data for the CVEout condition (subjects 18–35, = 18).
During the saccade, the target was shifted to the position that is 3º outward (in saccade direction) of the post-saccadic gaze direction.
Tables
Table 1
Analysis of the experimental data.
Here, we report mean and standard deviation of changes in saccade vector, pre- and post-saccadic localization from probe block 1 to 5. T-values are derived from two-sided t-tests against zero. F-values are derived from 2 × 2 mixed ANOVAs for saccade vector, pre- and post-saccadic localization changes (corrected for direction) with paradigm (CTS/CVE) as within-subject factor and direction (in/out) als between-subject factor. Changes in saccade vector were significant in all conditions but higher for inward than outward learning (within the CVE conditions, post-hoc t-test t33 = 3.68, p<0.001) and higher for CVE than CTS learning (within the inward conditions, post-hoc t-test t32 = 4.94, p<0.001, CVEin vs. CTSout t33 = −5.13, p<0.001, all other post-hoc tests p≥0.126, bonferroni-corrected significance level 0.008). Changes in post-saccadic localization were significant in all conditions but higher for CVE than CTS learning (within the outward conditions, post-hoc t-test t34 = −4.23, p<0.001, CVEout vs. CTSin t33 = −4.48, p<0.001, CVEout vs. CVEin t33 = −2.42, p=0.021, all other post-hoc tests p≥0.163, bonferroni-corrected significance level 0.008). Changes in pre-saccadic localization were small but significant in the CVE conditions.
| Pre-saccadic localization | Saccade vector | Post-saccadic localization | |
|---|---|---|---|
| CTSin | −0.31 ± 0.85°, = −1.48, p = 0.159 | −1.89 ± 0.61°, = −12.69, p < 0.001*** | −0.82 ± 0.65°, = −5.24, p < 0.001*** |
| CTSout | +0.04 ± 0.62°, = 0.30, p = 0.766 | +1.79 ± 0.71°, = 10.80, p < 0.001*** | +0.88 ± 0.67°, = 5.57, p < 0.001*** |
| CVEin | −0.42 ± 0.80°, = −2.17, p = 0.046* | −3.37 ± 1.08°, = −12.88, p < 0.001*** | −1.20 ± 0.87°, = −5.66, p < 0.001*** |
| CVEout | +0.35 ± 0.62°, = 2.44, p = 0.026* | +2.19 ± 0.80°, = 11.59, p < 0.001*** | +1.85 ± 0.70°, = 11.17, p < 0.001*** |
| paradigm | = 3.48, p = 0.071 | = 31.95, p < 0.001*** | = 24.60, p < 0.001*** |
| direction | = 0.56, p = 0.462 | = 8.24, p = 0.007** | = 2.94, p = 0.096 |
| interaction | = 0.76, p = 0.390 | = 10.75, p = 0.002** | = 4.75, p = 0.036* |
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Visuomotor learning from postdictive motor error
eLife 10:e64278.
https://doi.org/10.7554/eLife.64278




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}