Modelling the neural code in large populations of correlated neurons
- Department of Systems and Computational Biology, Albert Einstein College of Medicine, United States
- Institute for Ophthalmic Research, University of Tübingen, Germany
- Dominick P. Purpura Department of Neuroscience, Albert Einstein College of Medicine, United States
Figures
Figure 1
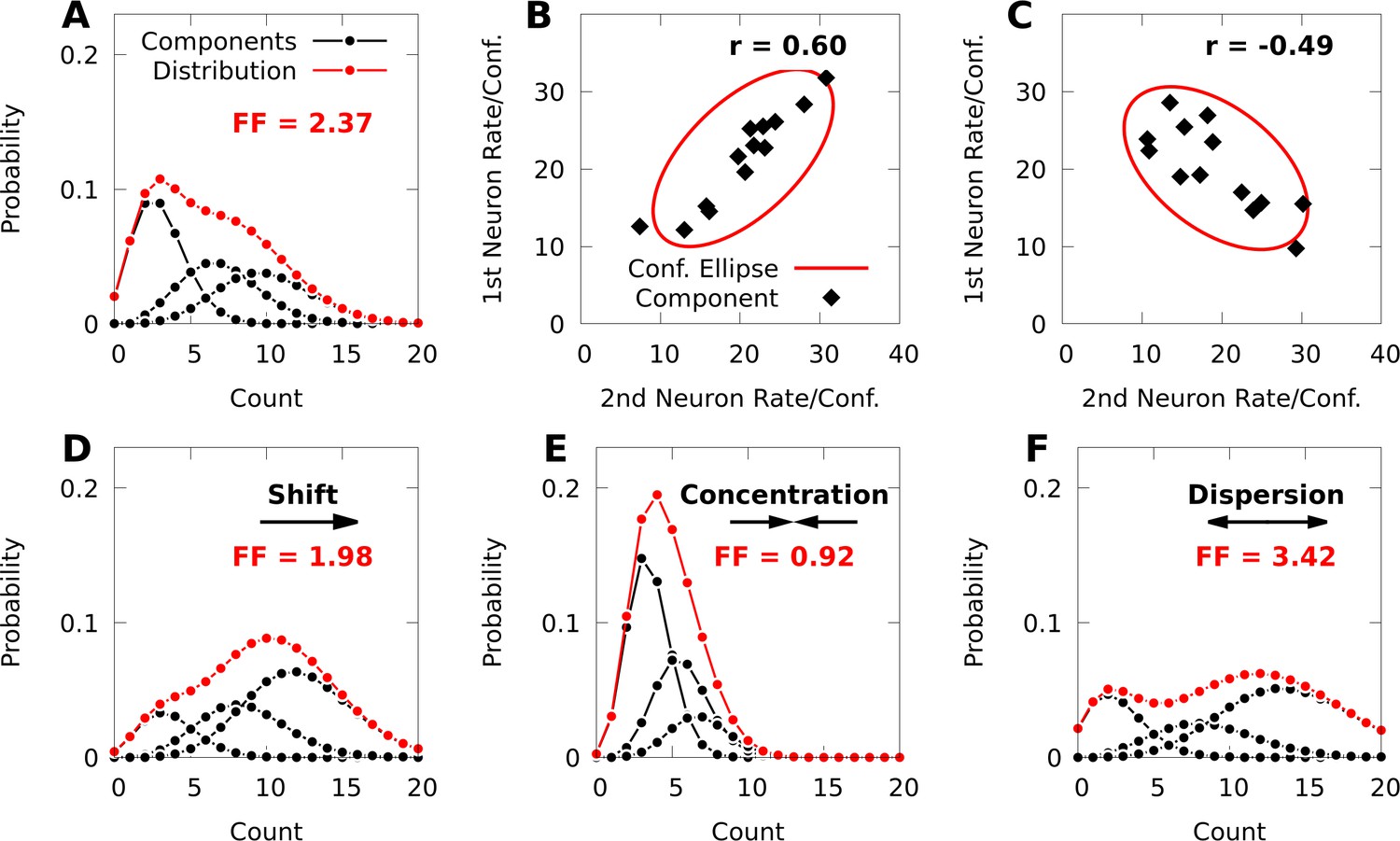
Poisson mixtures and Conway-Maxwell extensions exhibit spike-count correlations, and over- and under-disperson.
(A) A Poisson mixture distribution (red), defined as the weighted sum of three component Poisson distributions (black; scaled by their weights). FF denotes the Fano Factor (variance over mean) of the mixture. (B, C) The average spike-count (rate) of the first and second neurons for each of 13 components (black dots) of a bivariate IP mixture, and 68% confidence ellipses for the spike-count covariance of the mixture (red lines; see Equations 6 and 7). The spike-count correlation of each mixture is denoted by . (D) Same model as A, except we shift the distribution by increasing the baseline rate of the components. (E, F) Same model as A, except we use an additional baseline parameter based on Conway-Maxwell Poisson distributions to concentrate (E) or disperse (F) the mixture distribution and its components.
Figure 2
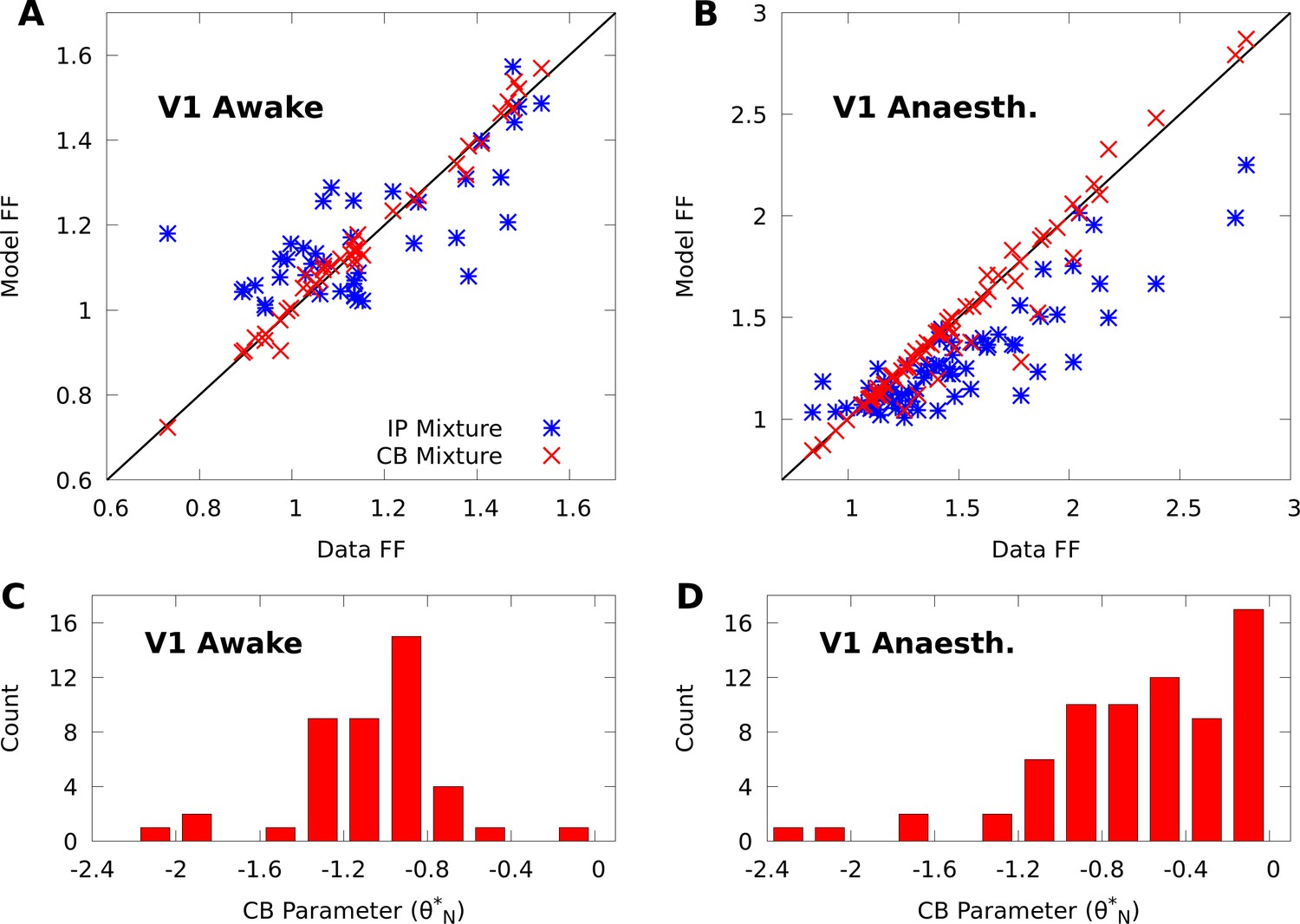
CoM-based parameters help Poisson mixtures capture individual variability in V1 responses to a single stimulus.
We compare Independent Poisson (IP) mixtures (Equation 1) and CoM-Based (CB) mixtures (Equation 2) on neural population responses to stimulus orientation in V1 of awake ( neurons and trials) and anaesthetized ( and ) macaques; both mixtures are defined with components for both data sets (see Materials and methods for training algorithms). A,B: Empirical Fano factors of the awake (A) and anaesthetized data (B), comparing IP (blue) and CB mixtures (red). C,D: Histogram of the CB parameters for the CB mixture fits to the awake (C) and anaesthetized (D) data. Values of denote under-dispersed mixture components, values denote over-dispersed components.
Figure 3
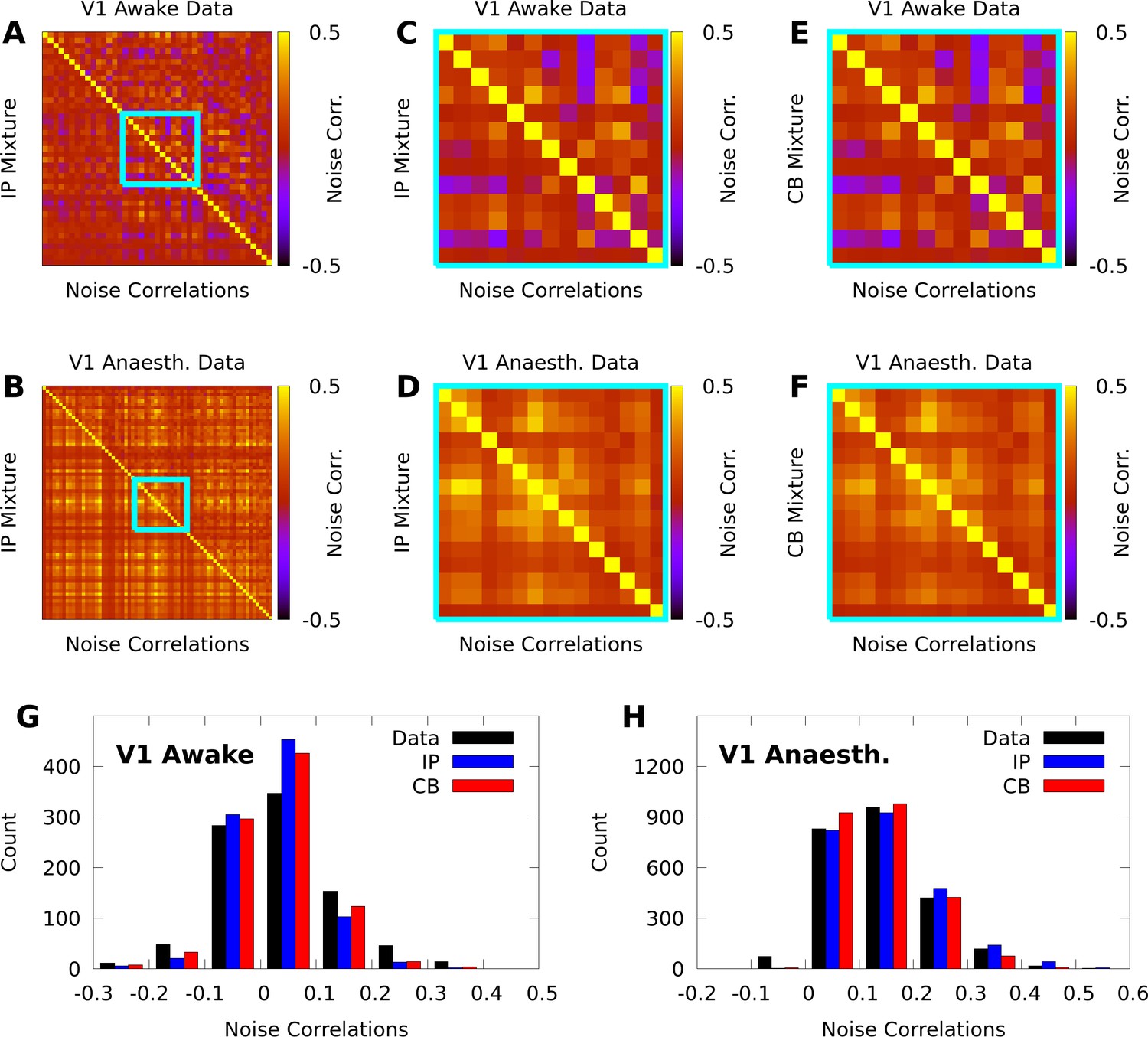
IP and CB mixtures effectively capture pairwise covariability in V1 responses to a single stimulus.
Here we analyze the pairwise statistics of the same models from Figure 2. (A, B) Empirical correlation matrix (upper right triangles) of awake (A) and anaesthetized data (B), compared to the correlation matrix of the corresponding IP mixtures (lower left triangles). (C, D) Noise correlations highlighted in A and B, respectively. (E, F) Highlighted noise correlations for CB mixture fit. (G,H) Histogram of empirical noise correlations, and model correlations from IP and CB mixtures.
Figure 4
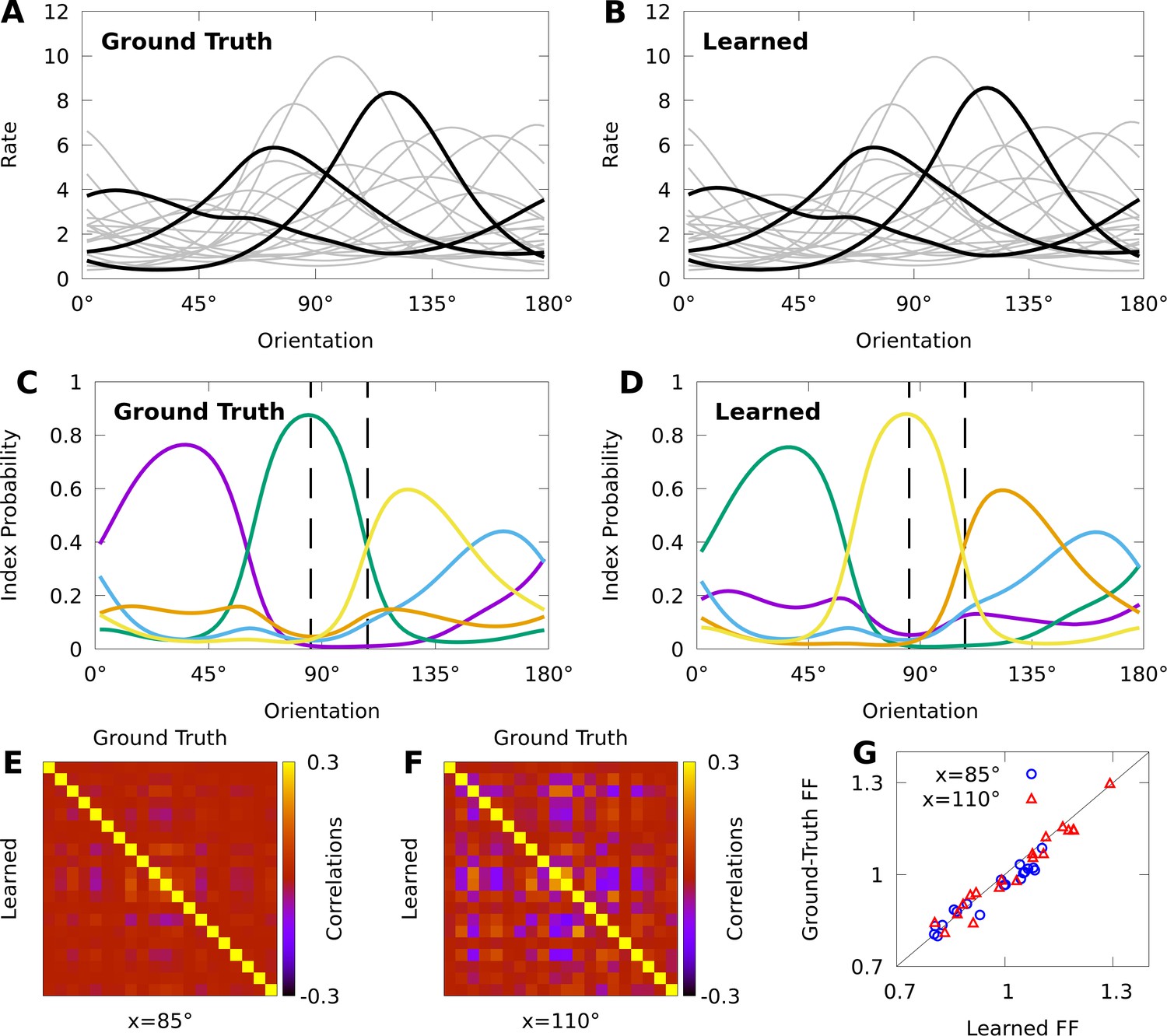
Expectation-maximization recovers a ground truth CoM-based, conditional mixture (CB-CM).
We compare a ground truth, CB-CM with 20 neurons, five mixture components, von Mises-tuned components, and randomized parameters to a learned CB-CM fit to 2000 samples from the ground truth CB-CM. A,B: Tuning curves of the ground-truth CB-CM (A) and learned CB-CM (B). Three tuning curves are highlighted for effect. C,D: The orientation-dependent index probabilities of the ground truth CB-CM (C) and learned CB-CM (D), where colour indicates component index. Dashed lines indicate example stimulus-orientations used in E, F, and G. (E, F) The correlation matrix of the ground truth CB-CM (upper right), compared to the correlation matrix of the learned CB-CM (lower left) at stimulus orientations (E) and (F). (G) The FFs of the ground-truth CB-CM compared to the learned CB-CM at orientations (blue circles) and (red triangles).
Figure 5

Finding the optimal number of parameters for CMs to model neural responses in macaque V1.
10-fold cross-validation of the information gain given awake V1 data (A) and anaesthetized V1 data (B), as a function of the number of model parameters, for multiple forms of CM: maximal CMs (green); minimal CMs with von Mises component tuning (blue); minimal CMs with discrete component tuning (purple); and for each case we consider either IP (dashed lines) or CB (solid lines) variants. Standard errors of the information gain are not depicted to avoid visual clutter, however they are approximately independent of the number of model parameters, and match the values indicated in Table 2.
Figure 6
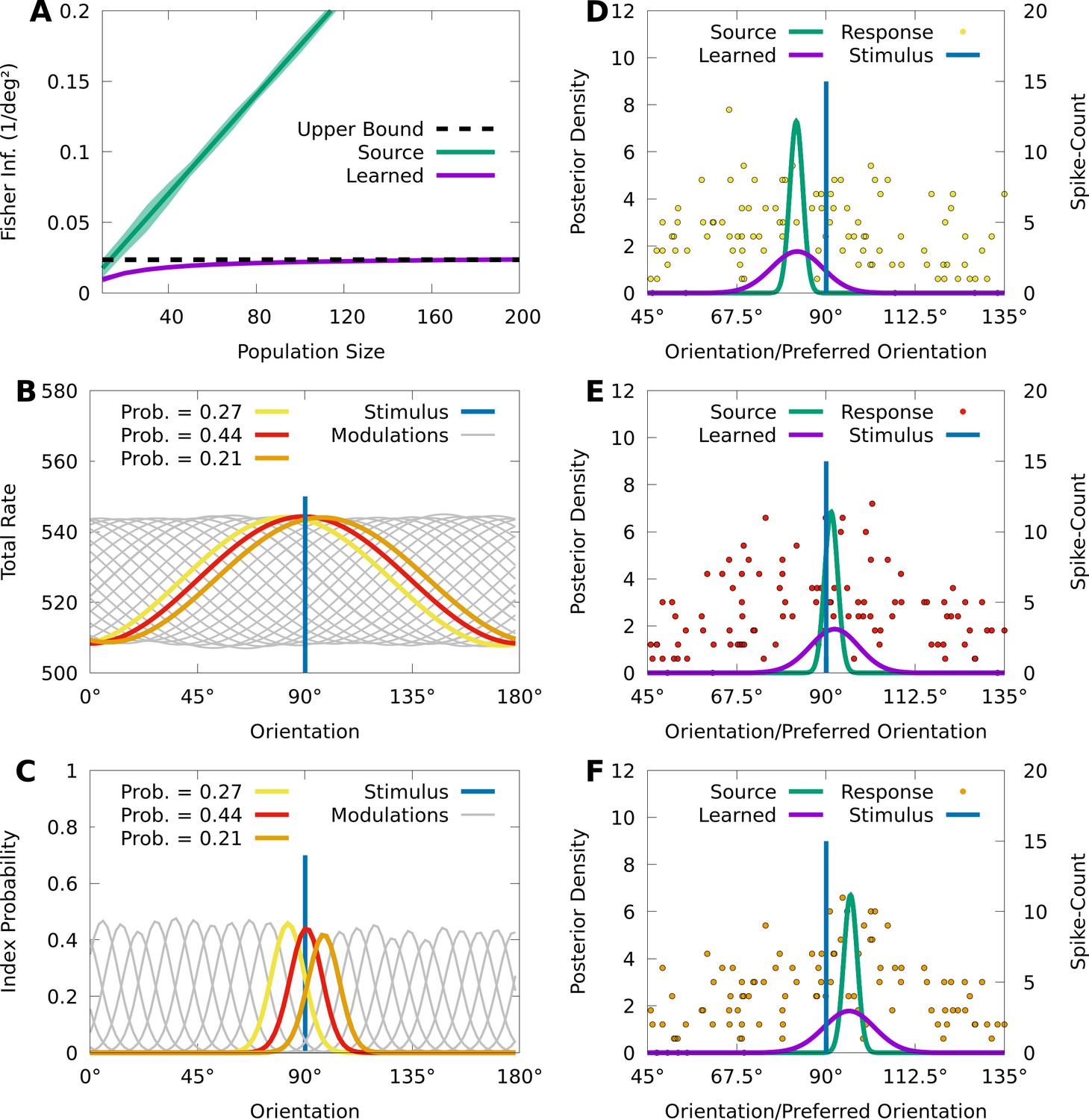
CMs can capture information-limiting correlations in data.
We consider a von Mises-tuned, independent Poisson source model (green) with neurons, and an information-limited, IP-CM (purple) with components, fit to 10,000 responses of the source-model to stimuli obscured by von Mises noise. In B-F we consider a stimulus-orientation (blue line). (A) The average (lines) and standard deviation (filled area) of the FI over orientations, for the source (green) and information-limited (purple) models, as a function of random subpopulations, starting with ten neurons, and gradually reintroducing missing neurons. Dashed black line indicates the theoretical upper bound. (B) The sum of the firing rates of the modulated IP-CM for all indices (lines) as a function of orientation, with three modulated IP-CMs highlighted (red, yellow, and orange lines) corresponding to the highlighted indices in C. (C) The index-probability curves (lines) of the IP-CM for indices and the intersection (red, yellow, and orange circles) of the stimulus with three curves (orange, yellow, and orange lines). (D-F) Three responses from the yellow (D; yellow points), red (E; red points), and orange modulated IP-CMs (F; orange points) indicated in C. For each response we plot the posterior based on the source model (green line) and the information-limited model (purple line).
Appendix 1—figure 1
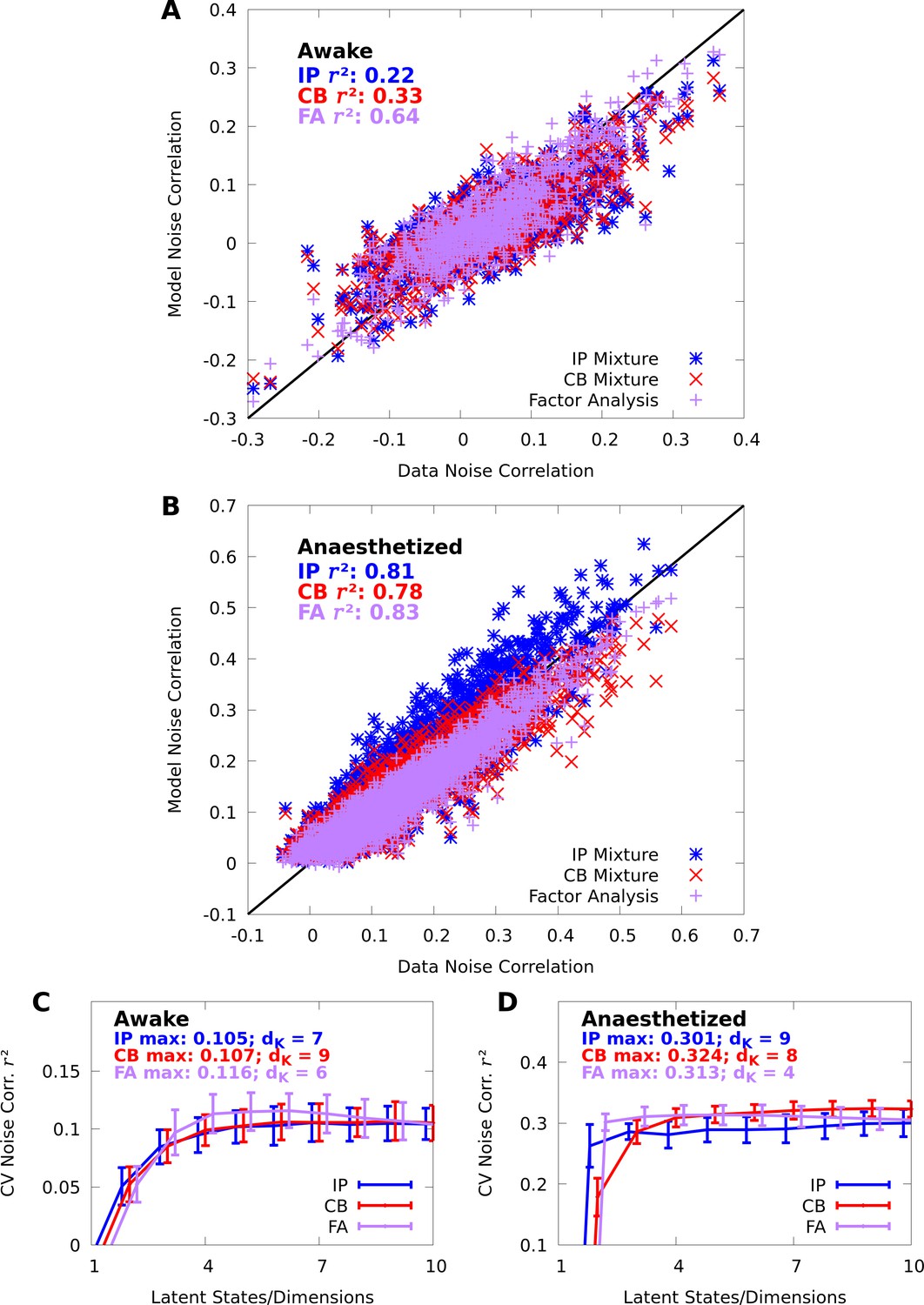
Mixture models capture spike-count correlations.
(A, B) Scatter plots of the data noise correlations versus the noise correlations modelled by IP (blue) and CB (red) mixtures, and FA (purple), in both the awake (A) and anaesthetized (B) datasets at orientation . Each point represent a pair of neurons ( and neurons in the awake and anaesthetized datasets, respectively). (C, D) We evaluate the noise correlation over all stimulus-orientations with 10-fold cross-validation. We plot the average (lines) and standard error (error bars) of the cross-validated noise correlation as a function of number of latent states/dimensions , in both the awake (C) and anaesthetized (D) datasets. We also indicate the peak performance achieved for each model, and requisite number of latent states/dimensions .
Appendix 1—figure 2
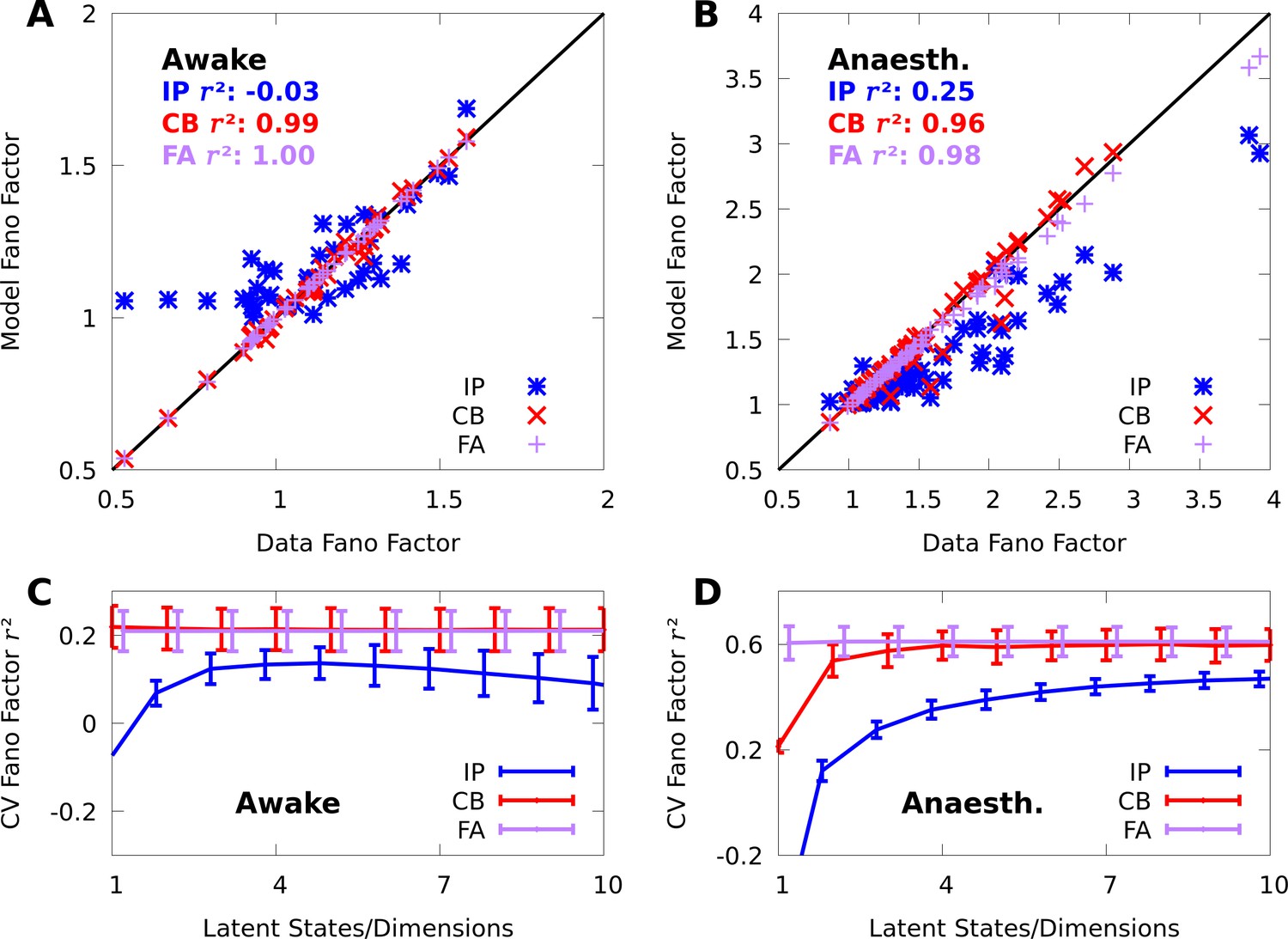
Mixture models capture spike-count Fano factors.
We repeat the analyses from Appendix References Figure 7 on Fano factors (FFs). (A, B) Scatter plots of the data FFs versus the FFs modelled by IP (blue) and CB mixtures (red), and FA (purple) in both the awake (A) and anaesthetized (B) datasets at orientation . (C, D) As a function of the number of latent states/dimensions, we plot the average (lines) and standard error (bars) of the cross-validated between the data and modelled Fano factors over all stimulus orientations, in both the awake (C) and anaesthetized (D) datasets.
Appendix 2—figure 1
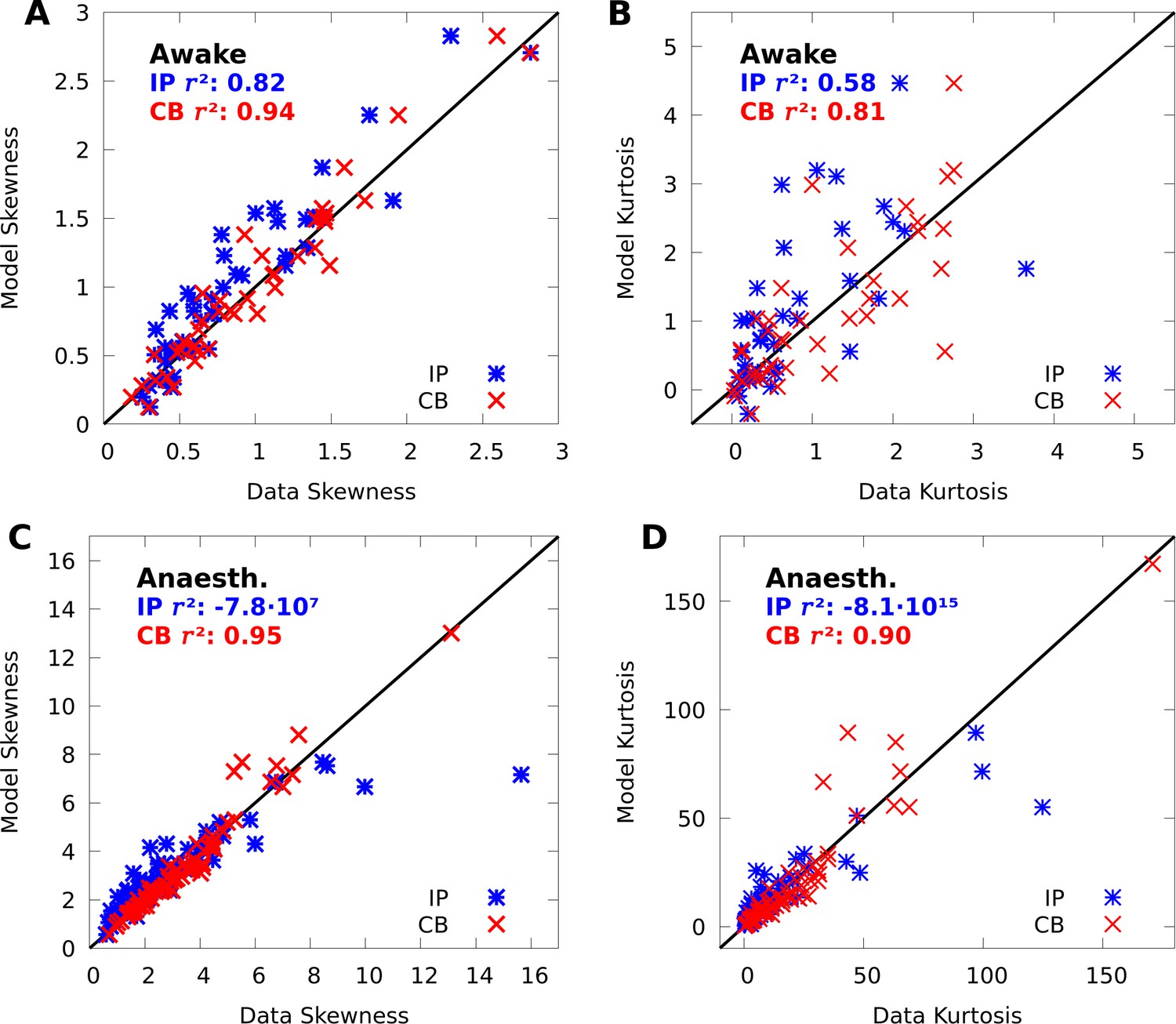
CoM-based mixtures capture data skewness and kurtosis.
(A, B) Scatter plots of the data skewness (A) and kurtosis (B) versus the skewness and kurtosis modelled by IP mixtures (blue) and CB mixtures (red). The skewness and kurtosis of 1 of 43 neurons modelled by the IP mixture were outside the bounds of each scatter plot. C,D: Same as A-B but on the anaesthetized data; the skewness of 11 of 43, and kurtosis of 12 of 43 neurons modelled by the IP mixture were outside the bounds of each scatter plot.
Appendix 3—figure 1

Sample complexity of discrete CMs.
10-fold cross-validation of discrete CMs with 3, 10, 20, and 40 components, on subsamples of 25%, 50%, 75%, and 100% of the awake and anaesthetized datasets, with and neurons, respectively. Left column: Cross-validated average log-likelihood of the models given test data (i.e. encoding performance). Right column: Cross-validated average log-posterior (i.e. decoding performance). Error bars represent standard error. In all panels, we added an offset on the abscissa for better visualization of the error bars.
Tables
Table 1
Parameter counts of CM models.
First row is number of parameters in IP models, second row is number of additional parameters in CB extensions of IP models, as a function of number of stimuli , neurons , and mixture components .
| Model parameter formulae | |||
|---|---|---|---|
| Maximal | Von mises | Discrete | |
| Num. Params | |||
| Add. CB Params | |||
Table 2
Conditional mixtures models of neural responses in macaque V1 capture significant information about higher-order statistics.
We apply 10-fold cross-validation to estimate the mean and standard error of the information gain (model log-likelihood -log-likelihood of a non-mixed, independent Poisson model in nats/trial) on held-out data, from either awake (sample size , from neurons, over orientations) or anaesthetized (, , ) macaque V1. We compare maximal CMs, minimal CMs with von Mises-tuned components, and minimal CMs with discrete-tuned components, and for each case we consider either IP or CB variants. For each variant, we indicate the number of CM components and the corresponding number of model parameters required to achieve peak information gain (cross-validated). For reference, the non-mixed, independent Poisson models use 129 and 210 parameters for the awake and anaesthetized data, respectively.
| Encoding performance | ||||||
|---|---|---|---|---|---|---|
| V1 awake data | V1 anaesthetized data | |||||
| CM Variant | Inf. Gain () | # Params. | Inf. Gain () | # Params. | ||
| Maximal IP | 5 | 1971 | 8 | 5103 | ||
| Maximal CB | 5 | 2358 | 7 | 5094 | ||
| Von Mises IP | 45 | 2065 | 40 | 2979 | ||
| Von Mises CB | 40 | 1888 | 35 | 2694 | ||
| Discrete IP | 40 | 2103 | 35 | 3044 | ||
| Discrete CB | 30 | 1706 | 30 | 2689 | ||
| Non-mixed IP | 0 | 1 | 129 | 0 | 1 | 210 |
Table 3
CMs support high-performance decoding of neural responses in macaque V1.
We apply 10-fold cross-validation to estimate the mean and standard error of the average log-posteriors on held-out data, from either awake or anaesthetized macaque V1. We compare discrete, minimal, CB-CM (CB-CM) and IP-CM (IP-CM); an independent Poisson model with discrete tuning (Non-mixed IP); a multiclass linear decoder (Linear); and a multiclass nonlinear decoder defined as an artificial neural network with two hidden layers (Artificial NN). The number of CM components was chosen to achieve peak information gain in Figure 5. The number of ANN hidden units was chosen based on peak cross-validation performance. In all cases we also indicate the number of model parameters required to achieve the indicated performance.
| Decoding performance | ||||
|---|---|---|---|---|
| V1 awake data | V1 anaesthetized data | |||
| Average Log-Post. | Num. Params. | Average Log-Post. | Num. Params. | |
| IP-CM | 2103 | 3044 | ||
| CB-CM | 1706 | 2689 | ||
| Non-mixed IP | 387 | 630 | ||
| Linear | 352 | 568 | ||
| Artificial NN | 527,108 | 408,008 | ||
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Modelling the neural code in large populations of correlated neurons
eLife 10:e64615.
https://doi.org/10.7554/eLife.64615




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}